MADFU: An Improved Malicious Application Detection Method Based on Features Uncertainty


Abstract
:1. Introduction
- MADFU uses the MCMC algorithm to calculate the uncertainty of the permission’s features in malicious detection. The results show that ignoring uncertainty can lead to false positives in the analysis.
- MADFU removes the uncertainty permissions and uses purified permissions to classify through machine learning.
- We used 2037 samples to verify the model. MADFU has good Accuracy for both known samples and new samples. Meanwhile, MADFU reduces memory consumption and classification times.
2. Background
2.1. Android Permission
2.2. MCMC
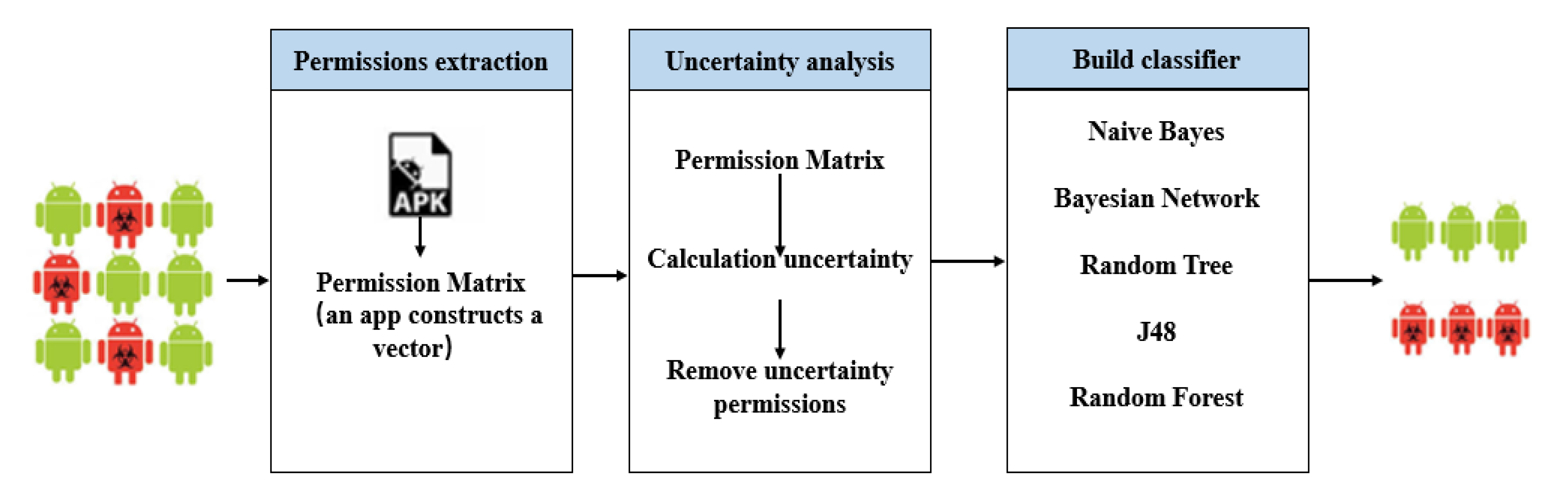
3. MADFU Model
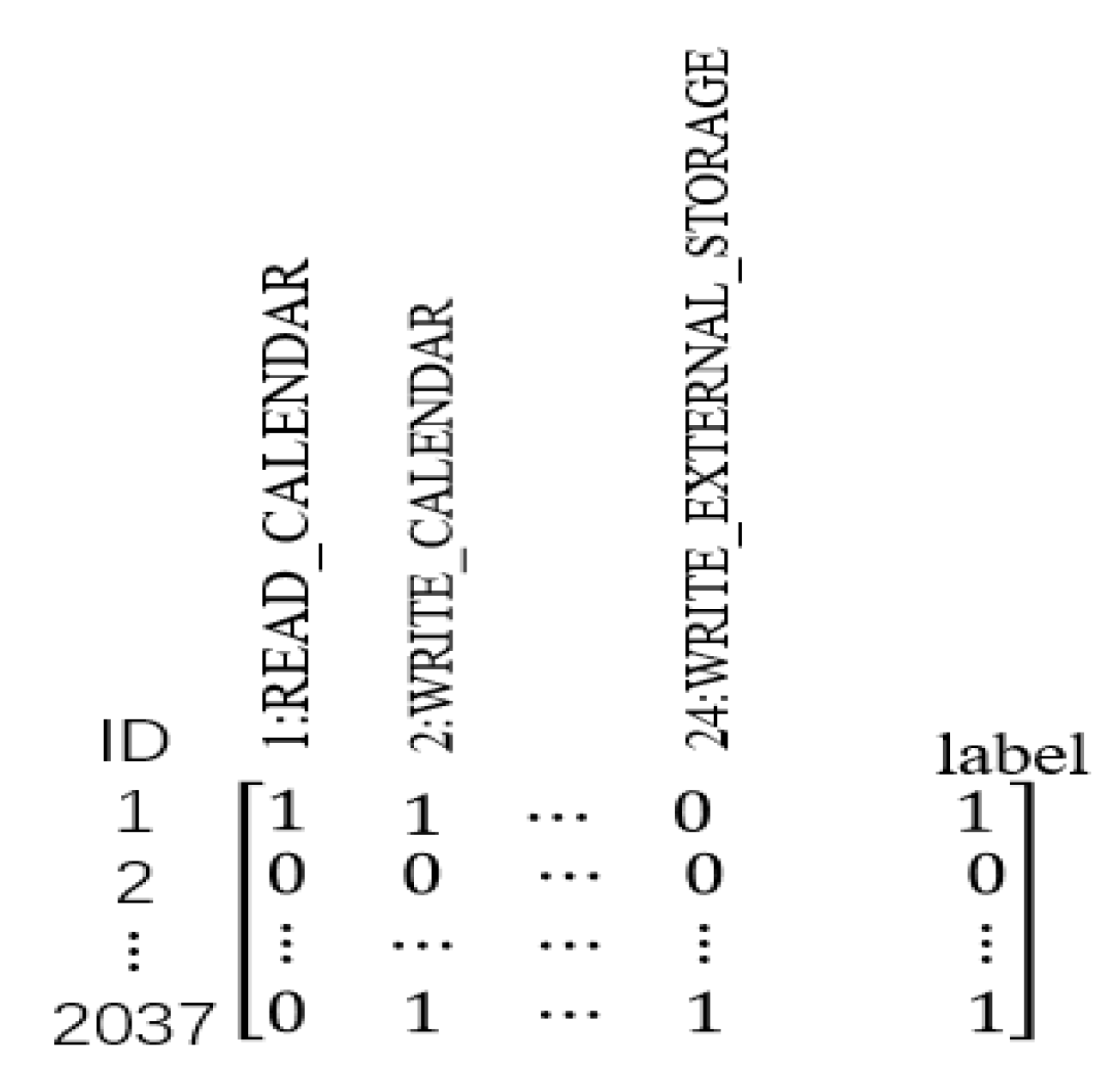
3.1. Permissions Extraction
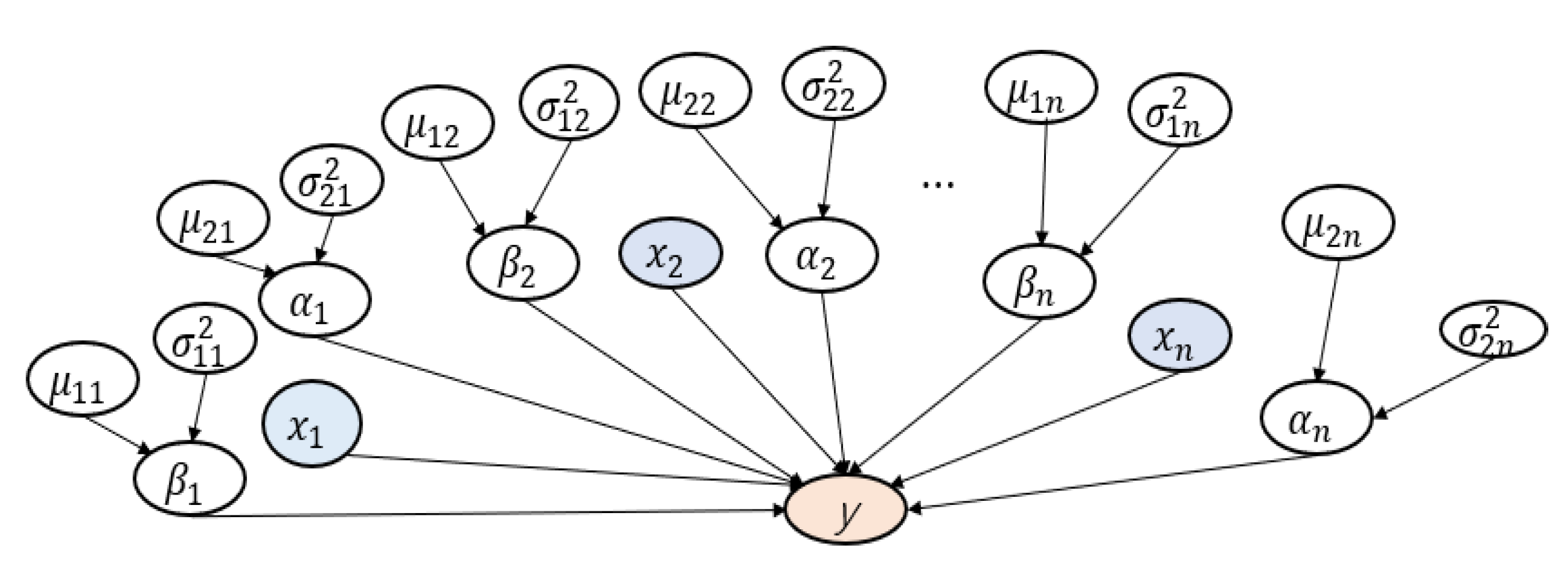
3.2. Uncertainty Analysis
| Algorithm 1 |
| 1: Input: 2: P (x): initial probability distribution; 3: Q: state transition matrix; the corresponding element is q(j|i) 4: Output: 5: X: sample sequence 6: Step1: Initialize the Markov chain state X_0=x_0 7: Step2: for time=0, 1, 2, …, do 8: X_t=x_t sampling y~q(x|x_t) 9: Sampling form uniform distribution: u~uniform [0,1] 10: if u<α(y│x_t)=min{(P(y)q(x_t│y))/(P(x_t)q(y|x_t)),1} then 11: x_(t+1)=y 12: else x_(t+1)=x_t 13: step3: return X |
3.3. Machine Learning Classification
4. Evaluation
4.1. Datasets
4.2. Experimental Methods
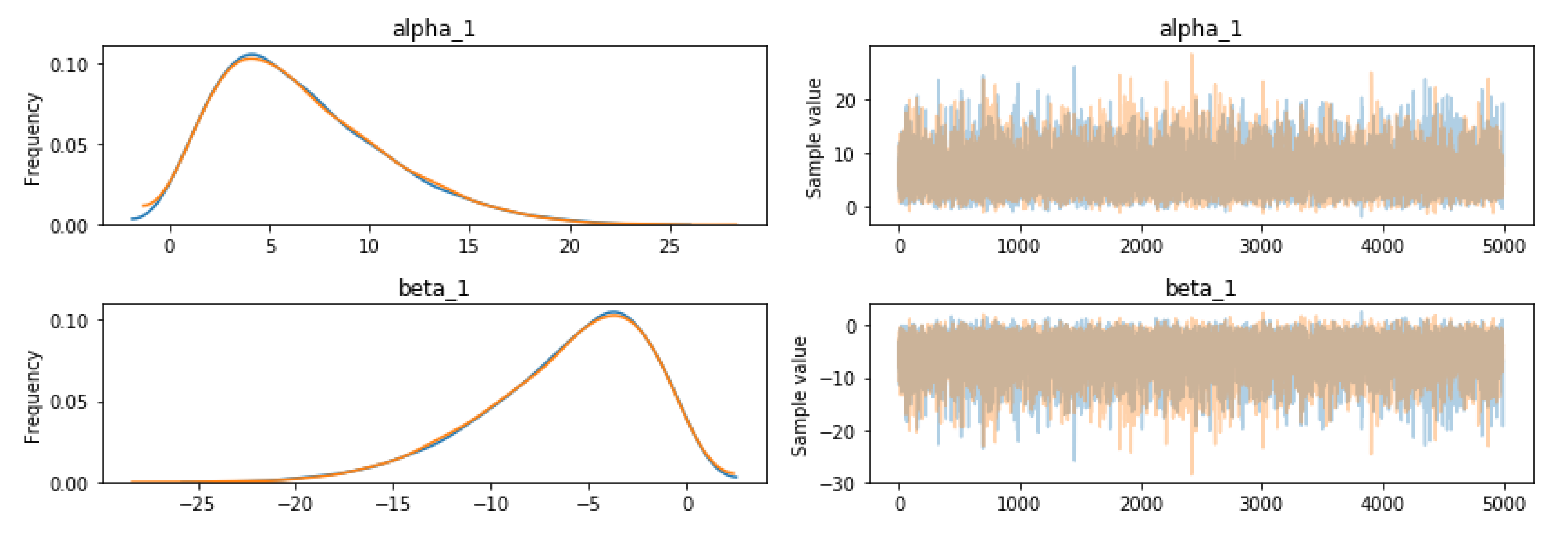
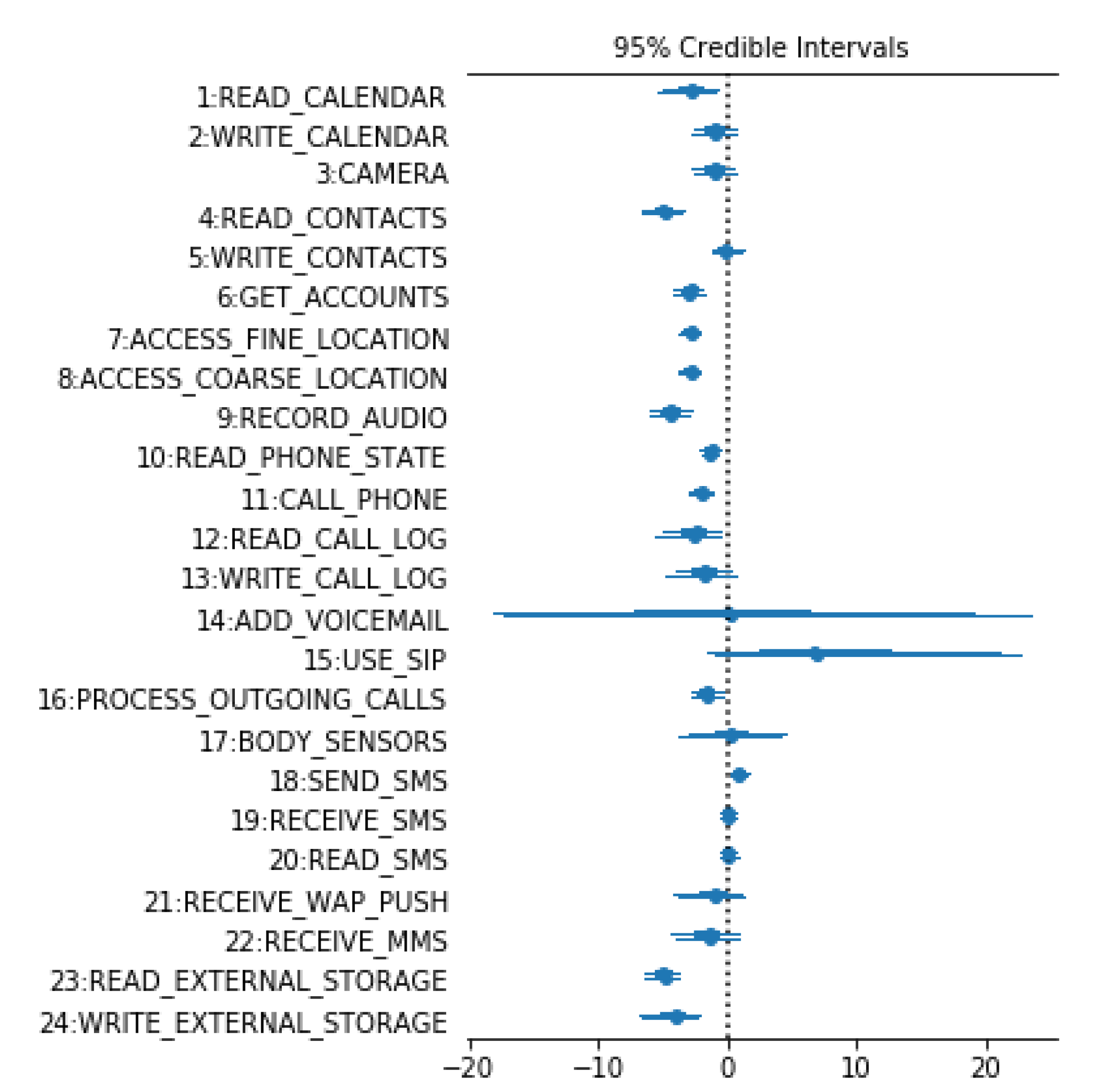
4.3. The Uncertainty of Permissions
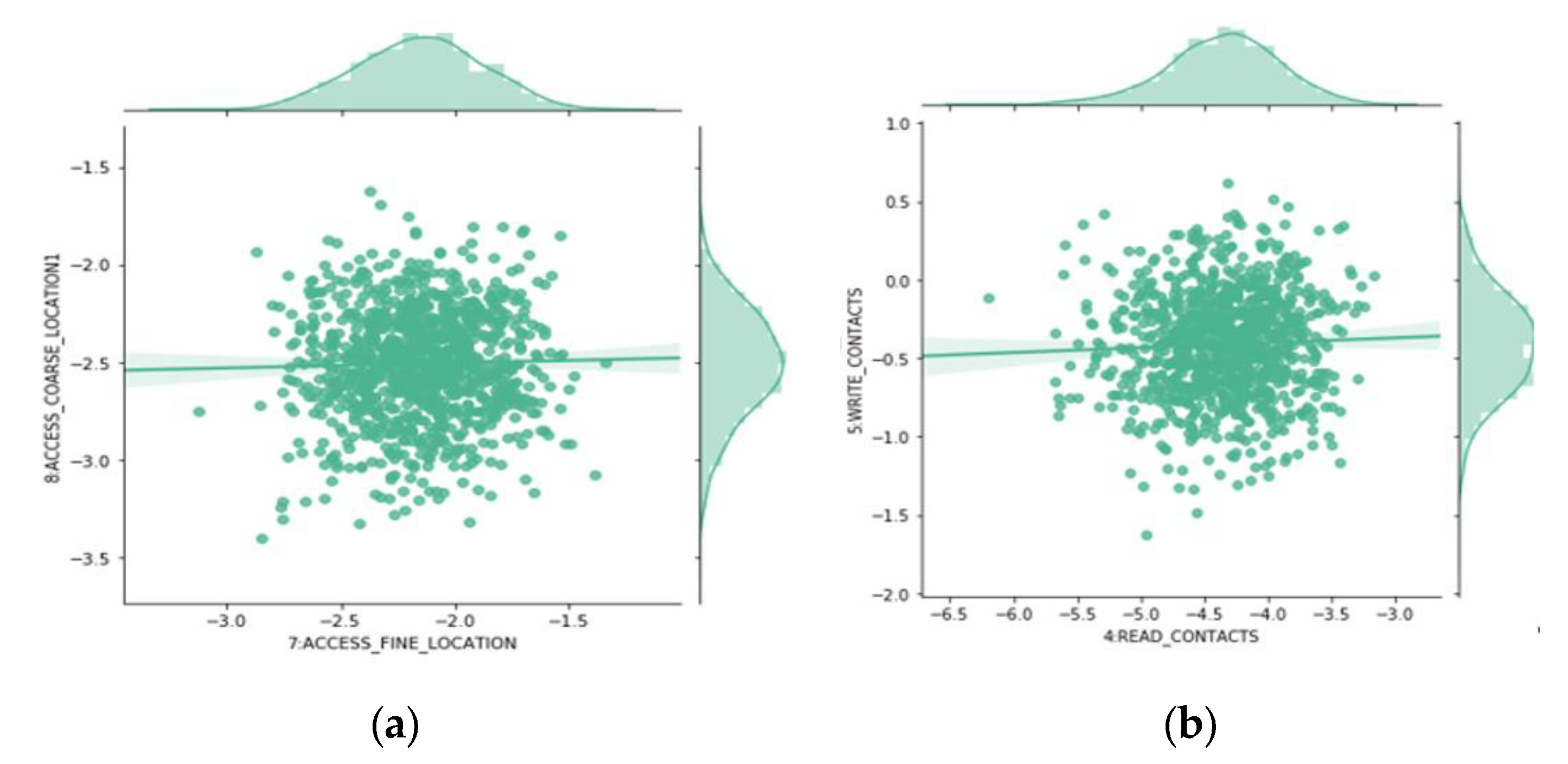
4.4. Joint Probabilities Analysis
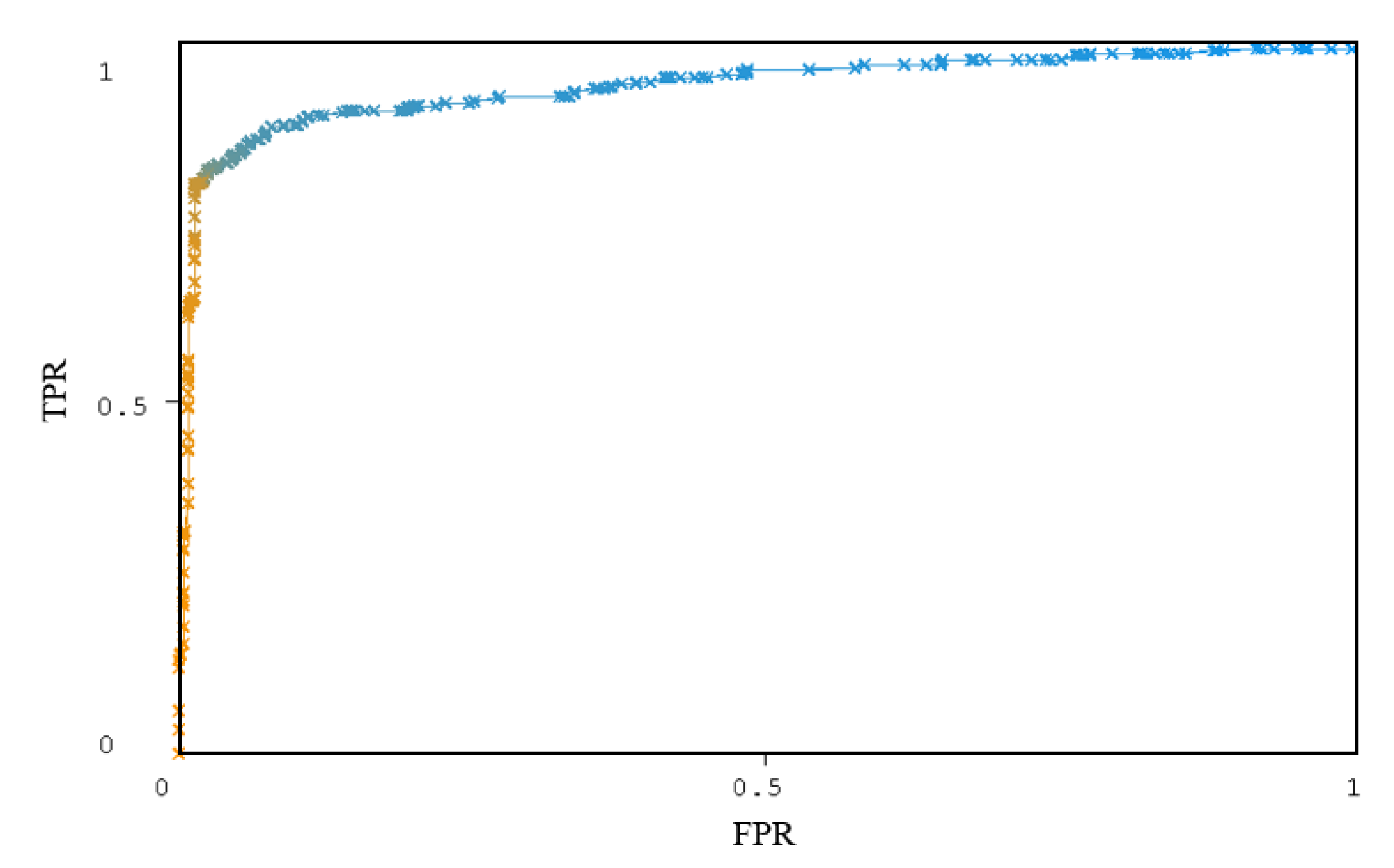
4.5. Performance of Detection
4.6. Compare with Other Approach
5. Discussion and Future Work
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Positive (Predicted) | Negative (Predicted) | |
|---|---|---|
| Positive (Actual) | TP (True Positive) | FN (False Negative) |
| Negative (Actual) | FP (False Positive) | TN (True Negative) |
Appendix B

References
- Wang, W.; Zhao, M.; Gao, Z.; Xu, G.; Xian, H.; Li, Y.; Zhang, X. Constructing features for detecting android malicious applications: Issues, taxonomy and directions. IEEE Access 2019, 7, 67602–67631. [Google Scholar] [CrossRef]
- Data of AppBrain. Available online: https://www.appbrain.com/stats/number-of-android-apps (accessed on 20 February 2019).
- 360 Internet Security Center. Available online: http://zt.360.cn/1101061855.php?dtid=1101061451&did=610100815 (accessed on 18 February 2019).
- Li, L.; Bissyand, T.F.; Papadakis, M.; Rasthofer, S.; Bartel, A.; Octeau, D.; Klein, J.; Traon, L. Static analysis of android apps: A systematic literature review. Inf. Softw. Technol. 2017, 88, 67–95. [Google Scholar] [CrossRef] [Green Version]
- Wang, W.; Wang, X.; Feng, D.; Liu, J.; Han, Z.; Zhang, X. Exploring permission-induced risk in Android applications for malicious application detection. IEEE Trans. Inf. Forensics Secur. 2014, 9, 1869–1882. [Google Scholar] [CrossRef] [Green Version]
- Vinod, P.; Zemmari, A.; Conti, M. A machine learning based approach to detect malicious Android apps using discriminant system calls. Future Gener. Comput. Syst. 2019, 94, 333–350. [Google Scholar] [CrossRef]
- Fan, M.; Liu, J.; Luo, X.; Chen, K.; Tian, Z.; Zheng, Q.; Liu, T. Android malware familial classification and representative sample selection via frequent subgraph analysis. IEEE Trans. Inf. Forensics Secur. 2018, 13, 1890–1905. [Google Scholar] [CrossRef]
- Cai, H.; Meng, N.; Ryder, B.G.; Yao, D. DroidCat: Effective Android malware detection and categorization via app-level profiling. IEEE Trans. Inf. Forensics Secur. 2019, 14, 1455–1470. [Google Scholar] [CrossRef]
- Martín, A.; Rodríguez-FerneEdez, V.; Camacho, D. CANDYMAN: Classifying Android malware families by modelling dynamic traces with Markov chains. Eng. Appl. Artif. Intell. 2018, 74, 121–133. [Google Scholar] [CrossRef]
- Saracino, A.; Sgandurra, D.; Dini, G.; Martinelli, F. MADAM: Effective and Efficient Behavior-based Android Malware Detection and Prevention. IEEE Trans. Dependable Secur. Comput. 2016, 15, 83–97. [Google Scholar] [CrossRef] [Green Version]
- Li, J.; Sun, L.; Yan, Q.; Li, Z.; Srisa-an, W.; Ye, H. Significant permission identification for Machine-learning-based android malware detection. IEEE Trans. Ind. Inform. 2018, 14, 3216–3225. [Google Scholar] [CrossRef]
- Wang, W.; Zhao, M.; Wang, J. Effective android malware detection with a hybrid model based on deep autoencoder and convolutional neural network. J. Ambient Intell. Hum. Comput. 2019, 10, 3035–3043. [Google Scholar] [CrossRef]
- Wang, W.; Gao, Z.; Zhao, M.; Li, Y.; Liu, J.; Zhang, X. DroidEnsemble: Detecting Android malicious applications with ensemble of string and structural static features. IEEE Access 2018, 6, 31798–31807. [Google Scholar] [CrossRef]
- Kumar, R.; Xiaosong, Z.; Khan, R.U.; Kumar, J.; Ahad, I. Effective and explainable detection of Android malware based on machine learning algorithms. Proc. Int. Conf. Comput. Artif. Intell. 2018, 35–40. [Google Scholar] [CrossRef]
- Pirscoveanu, R.S.; Hansen, S.S.; Larsen, T.M.; Stevanovic, M.; Pedersen, J.M.; Czech, A. Analysis of malware behavior: Type classification using machine learning. In Proceedings of the 2015 International Conference on Cyber Situational Awareness, Data Analytics and Assessment (CyberSA), London, UK, 8–9 June 2015; pp. 1–7. [Google Scholar]
- Alzaylaee, M.K.; Yerima, S.Y.; Sezer, S. Emulator vs. real phone: Android malware detection using machine learning. In Proceedings of the 3rd ACM on International Workshop on Security and Privacy Analytics, New York, NY, USA, 24 March 2017; pp. 65–72. [Google Scholar]
- Xu, K.; Li, Y.; Deng, R.H. ICCDetector: ICC-based malware detection on Android. IEEE Trans. Inf. Forensics Secur. 2016, 11, 1252–1264. [Google Scholar] [CrossRef]
- Zhao, K.; Zhang, D.; Su, X.; Li, W. Fest: A feature extraction and selection tool for Android malware detection. IEEE Symp. Comput. Commun. 2015, 714–720. [Google Scholar] [CrossRef]
- Li, D.; Wang, Z.; Li, L.; Wang, Z.; Wang, Y.; Xue, Y. FgDetector: Fine-Grained Android Malware Detection. In Proceedings of the 2017 IEEE Second International Conference on Data Science in Cyberspace (DSC), Shenzhen, China, 26–29 June 2017; pp. 311–318. [Google Scholar] [CrossRef]
- Mahmood, D. Entropy-based security risk measurement for Android mobile applications. Soft Comput. 2018, 23, 7303–7319. [Google Scholar] [CrossRef]
- Sarma, B.P.; Li, N.; Gates, C.; Potharaju, R.; Nita-Rotaru, C.; Molloy, I. Android permissions: A perspective combining risks and benefits. In Proceedings of the 17th ACM Symposium on Access Control Models and Technologies, New York, NY, USA, 3 June 2012; pp. 13–22. [Google Scholar]
- Peiravian, N.; Zhu, X. Machine learning for Android malware detection using permission and api calls. In Proceedings of the 2013 IEEE 25th International Conference on Tools with Artificial Intelligence, Washington, DC, USA, 4–6 November 2014; pp. 300–305. [Google Scholar]
- Su, D.; Wang, W.; Wang, X.; Liu, J. Anomadroid: Profiling Android applications’ behaviors for identifying unknown malapps. In Proceedings of the 2016 IEEE Trustcom/BigDataSE/ISPA, Tianjin, China, 23–26 August 2016; pp. 691–698. [Google Scholar]
- Gu, M.; Sun, S.; Liu, Y. Dynamical sampling with langevin normalization flows. Entropy 2019, 21, 1096. [Google Scholar] [CrossRef] [Green Version]
- Livingstone, S.; Girolami, M. Information-geometric Markov chain Monte Carlo methods using diffusions. Entropy 2014, 16, 3074–3102. [Google Scholar] [CrossRef]
- Hock, K.; Earle, K. Markov chain Monte Carlo used in parameter inference of magnetic resonance spectra. Entropy 2016, 18, 57. [Google Scholar] [CrossRef] [Green Version]
- Li, Q.; Newton, K. Diffusion equation-assisted Markov chain Monte Carlo methods for the inverse radiative transfer equation. Entropy 2019, 21, 291. [Google Scholar] [CrossRef] [Green Version]
- Brooks, S.; Gelman, A.; Jones, G.; Meng, X. Handbook of Markov Chain Monte Carlo; CRC Press: Boca Raton, FL, USA, 2011. [Google Scholar]
- Mneimneh, S.; Ahmed, S.A. Gibbs/MCMC Sampling for Multiple RNA Interaction with Sub-optimal Solutions. In Algorithms for Computational Biology; Springer: Cham, Switzerland, 2016. [Google Scholar]
- Boland, A.; Friel, N.; Maire, F. Efficient MCMC for Gibbs Random Fields using pre-computation. Electron. J. Stats. 2017, 12, 1–23. [Google Scholar] [CrossRef]
- Hill, S.D.; Spall, J.C. Stationarity and convergence of the metropolis-hastings algorithm: Insights into theoretical aspects. IEEE Control Syst. 2019, 39, 56–67. [Google Scholar] [CrossRef]
- Seo, Y.M.; Park, K.B. Uncertainty analysis for parameters of probability distribution in rainfall frequency analysis by bayesian MCMC and metropolis hastings algorithm. J. Environ. Sci. Int. 2011, 20, 329–340. [Google Scholar] [CrossRef]
- Vrugt, J.A.; Gupta, H.V.; Bouten, W.; Sorooshian, S. A shuffled complex evolution metropolis algorithm for optimization and uncertainty assessment of hydrologic model parameters. Water Resour. Res. 2003, 39, 1–11. [Google Scholar] [CrossRef] [Green Version]
- Xu, T.; White, L.; Hui, D.; Luo, Y. Probabilistic inversion of a terrestrial ecosystem model: Analysis of uncertainty in parameter estimation and model prediction. Glob. Biogeochem. Cycles 2006, 20, 27–36. [Google Scholar] [CrossRef]
- The Drebin Dataset. Available online: https://www.sec.tu-bs.de/~danarp/drebin/ (accessed on 2 February 2020).
- Cui, Z.; Zhang, M.; Chen, Y. Deep embedding logistic regression. In Proceedings of the 2018 IEEE International Conference on Big Knowledge (ICBK), Singapore, 17–18 November 2018; pp. 176–183. [Google Scholar]
- Virscan. Available online: http://www.virscan.org/ (accessed on 10 February 2020).
- Virustotal. Available online: https://www.virustotal.com/ (accessed on 10 February 2020).
- Theano · PyPI. Available online: https://pypi.org/project/Theano/ (accessed on 12 February 2020).
- Pymc3 · PyPI. Available online: https://pypi.org/project/pymc3/ (accessed on 12 February 2020).







| Classifier | False Positive Rate (FPR) | Accuracy | F-Measure | Area under Curve (AUC) |
|---|---|---|---|---|
| NB | 0.083 | 91.5% | 88.3% | 0.83 |
| BN | 0.088 | 91.1% | 90.3% | 0.901 |
| J48 | 0.012 | 95.5% | 94.7% | 0.944 |
| RT | 0.081 | 91.8% | 91.4% | 0.89 |
| RF | 0.47 | 69.5% | 44.5% | 0.451 |
| Datasets Number | Method | FPR | Accuracy | F-Measure |
|---|---|---|---|---|
| 1145 (589 begin/556 malicious) | 24 Dangerous Permissions | 0.057 | 88.7% | 87.5% |
| MADFU | 0.012 | 95.5% | 94.7% | |
| 892 (469 begin/423 malicious) | MADFU | 0.056 | 92.7% | 91.3% |
| Method | Accuracy | F-Measure | Learning and Classification Times(s) |
|---|---|---|---|
| SIGPID | 94.6% | 91.6% | 4.5 |
| Chi-Square | 93.1% | 91.2% | 3.1 |
| MADFU | 95.5% | 94.7% | 3 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yuan, H.; Tang, Y. MADFU: An Improved Malicious Application Detection Method Based on Features Uncertainty. Entropy 2020, 22, 792. https://doi.org/10.3390/e22070792
Yuan H, Tang Y. MADFU: An Improved Malicious Application Detection Method Based on Features Uncertainty. Entropy. 2020; 22(7):792. https://doi.org/10.3390/e22070792
Chicago/Turabian StyleYuan, Hongli, and Yongchuan Tang. 2020. "MADFU: An Improved Malicious Application Detection Method Based on Features Uncertainty" Entropy 22, no. 7: 792. https://doi.org/10.3390/e22070792
APA StyleYuan, H., & Tang, Y. (2020). MADFU: An Improved Malicious Application Detection Method Based on Features Uncertainty. Entropy, 22(7), 792. https://doi.org/10.3390/e22070792