Abstract
In this third and final paper of our series on the topic of portfolio optimization, we introduce a further generalized portfolio selection method called generalized entropic portfolio optimization (GEPO). GEPO extends discrete entropic portfolio optimization (DEPO) to include intervals of continuous returns, with direct application to a wide range of option strategies. This lays the groundwork for an adaptable optimization framework that can accommodate a wealth of option portfolios, including popular strategies such as covered calls, married puts, credit spreads, straddles, strangles, butterfly spreads, and even iron condors. These option strategies exhibit mixed returns: a combination of discrete and continuous returns with performance best measured by portfolio growth rate, making entropic portfolio optimization an ideal method for option portfolio selection. GEPO provides the mathematical tools to select efficient option portfolios based on their growth rate and relative entropy. We provide an example of GEPO applied to real market option portfolio selection and demonstrate how GEPO outperforms traditional Kelly criterion strategies.
1. Introduction
Our series on the topic of portfolio optimization has introduced novel entropy-based optimization problems that facilitate the selection of a variety of efficient portfolios. The return-entropy portfolio optimization (REPO) [1] allocates capital to an equity portfolio based on the expected return and Shannon entropy of portfolio returns. REPO was adapted to form the discrete entropic portfolio optimization (DEPO) [2] for application to portfolios comprised of assets with discrete distributed returns, like exotic instruments such as binary or digital options, or fixed-return options (FROs). In this paper we further extend DEPO to accommodate mixed returns with generalized entropic portfolio optimization (GEPO). GEPO can handle a combination of discrete and continuous returns, such as those exhibited by option strategies. Option strategies have expected return payoff functions that contain intervals of discrete returns and intervals of continuous returns.
The novel optimization methods introduced throughout our series on entropic portfolio optimization can be summarized as follows:
(1) Return-entropy portfolio optimization (REPO) [1]: for the selection of portfolios comprising continuous return assets, such as equities, indices, mutual funds, or other non-derivative financial products,
(2) Discrete entropic portfolio optimization (DEPO) [2]: for the selection of portfolios comprising strictly discrete return assets, such as binary options, digital options, fixed-return options (FRO), sports bets, or other betting wagers, and (3) Generalized entropic portfolio optimization (GEPO): for the selection of portfolios comprising assets with mixed returns (returns that can exhibit both continuous and discrete returns), like option strategies such as covered puts, married calls, credit spreads, straddles, long strangles, butterfly spreads, iron condors, and more. GEPO can handle portfolios that contain various types of options that are much more general than binary options. As seen in Section 2, these option strategies have a more generalized payoff function that include both continuous parts and discrete parts, and thus exist outside the scope of REPO or DEPO alone. GEPO can be thought of as combining the capabilities of both REPO and DEPO.
The applications of these new optimization methods can be illustrated by the following investor return payoff function diagrams:
Figure 1 represents the payoff function for an investor with a regular long position in a stock. For every dollar increase or decrease in the underlying stock price, a proportional increase or decrease is generated in investor return. This payoff function is continuous, since the underlying stock price and thus investor returns fall on the (non-negative) real line.
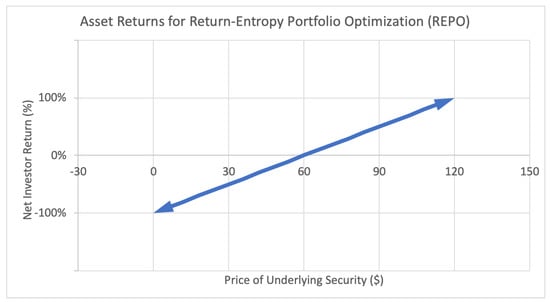
Figure 1.
Sample asset return payoff function for class of assets used in return-entropy portfolio optimization (REPO).
The second Figure 2 illustrates the payoff function for a binary option. This type of option generates a fixed positive return W if the underlying asset price lands above a certain threshold, in this case a strike price of $60, and generates a fixed negative return L otherwise. This payoff function is strictly discrete, since the only possible return states are and .
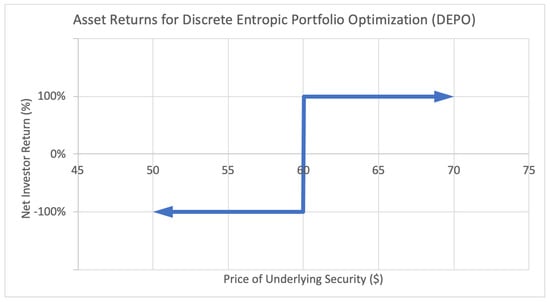
Figure 2.
Sample asset return payoff function for class of assets used in discrete entropic portfolio optimization (DEPO).
The latter Figure 3, the focal topic of this paper, is an example of a payoff function for a more complex option strategy called a bull put credit spread. This strategy involves buying and selling put options (an option to sell assets at an agreed upon price and date) in such a manner to limit one’s potential risk. The resulting payoff function covers a “spread” outside of which the option behaves just like a binary option—it generates a fixed positive return W if the underlying asset price lands above the upper bound, and generates a negative fixed return L if it lands below the lower bound. In between, if the price lands between the boundaries of the spread, the investor receives a partial return, proportional to the distance between the midpoint and the underlying price, as seen in the payoff function. These returns can be both discrete and continuous: , , and anything in between. These kind of option strategies are the main motivation behind this paper.
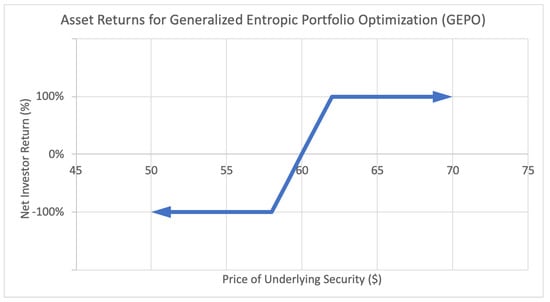
Figure 3.
Sample asset return payoff function for class of assets used in generalized entropic portfolio optimization (GEPO).
Traditional portfolio optimization methods, such as those employed by Markowitz mean-variance portfolio optimization (MVPO) [3], are not suited to handle the discretely distributed nature of option returns as these distributions cannot be described by mean and variance alone. So continuing with the use of relative entropy as the proxy for portfolio risk (as used in DEPO), GEPO is an optimization method containing an objective function that simultaneously maximizes the portfolio growth rate and minimizes the relative entropy of the portfolio with respect to the uniform distribution. In the case of option portfolios, GEPO selects a collection of options from a set of possible choices, for example a portfolio of credit spreads, in order to maximize the expected growth rate for a given level of relative entropy risk. By using the combinatorial generating functions to empirically calculate entropy, as done in REPO and DEPO, we are able to calculate the relative entropy risk of an option portfolio in GEPO by extending the scope to include both discrete and continuous returns. GEPO calculates the relative entropy over multiple return probability states, including return states with continuous returns. In terms of the expected return, the Kelly criterion provides valuable insights into maximizing the portfolio growth rate of an option portfolio. To that effect, we extend the Kelly criterion growth rate to include instances of both discrete and continuous returns. GEPO empowers investors to quantitatively select a portfolio of options based on their risk–reward tolerance.
The remainder of this paper is organized as follows. The following Section 1.1 gives a literature review of research on the topic of option portfolio optimization. Section 2 explains the technical details behind maximizing the portfolio growth rate by extending the Kelly criterion to generalized option strategies, with specific examples for several popular option strategies. Section 3 provides a brief review of information theory, Shannon entropy and Kullback–Leibler divergence, the foundation of entropic portfolio optimization. As the main feature of this paper, the GEPO problem is presented in Section 4. Finally, Section 5 demonstrates an example of GEPO selecting a portfolio of equity credit spreads chosen from the S&P100 composite index, and shows how GEPO outperformed the Kelly criterion and alternative Kelly criterion methods.
1.1. Literature Review
Option portfolio optimization is a considerably new topic of research, with the earliest found work beginning only this millennium. For a constant relative risk aversion investor, Liu (2003) [4] modeled the stochastic volatility to optimize a portfolio comprising one equity, a put option, and cash, deriving an analytic solution for the optimal allocation. Unfortunately for this method, a parametric model must be specified and the risk is mostly concentrated on just one option. Jones (2006) [5] exploited apparent mispricing of put options to derive an optimal portfolio of options using a general nonlinear latent factor model, but this model is overburdened by numerous required parameters. Eraker (2007) [6] modeled stochastic volatility parametrically, and then used the traditional mean-variance framework to optimize allocation between straddles, puts, and calls, yielding a closed-form solution for portfolio weights. Haugh (2007) [7] used duality and approximate dynamic programming (ADP) methods to facilitate high-dimensional American option pricing and portfolio optimization. Zymler (2011) [8] used robust portfolio optimization aimed to maximize the worst-case portfolio return for designing portfolios that include European-style options. This model trades off weak and strong guarantees on the worst-case portfolio return.
A moderate amount of research into option portfolio optimization has been conducted with respect to the use of value-at-risk (VaR) or conditional value-at-risk (CVaR) as a risk measure. See Alexander (2003, 2006) [9,10], Zymler (2013) [11], and Maasar (2016) [12]. As illustrated by Alexander, the VaR and CVaR minimization problems for derivative portfolios are typically ill-posed in the sense that there are many portfolios that have similar CVaR/VaR values to that of the optimal portfolio and slight perturbation of the data can lead to significantly different optimal solutions. Zymler notes that optimization problems involving VaR are often computationally intractable and require complete information about the return distribution of the portfolio assets, which is rarely available in practice. For these reasons, we conclude that VaR and CVaR methods are not ideal approaches to option strategy portfolio optimization.
Driessen (2013) [13] used generalized method of moments to maximize expected returns for a portfolio comprising a stock, an option strategy (puts and straddles), and cash. Constantinides (2013) [14] leverage-adjusted portfolios of either calls or puts by using the omega or lambda, known as the options’ elasticity. Fadugba (2014) [15] used a binomial model as a performance measure to price American and European options, and exploited mispricings to derive optimal portfolios. In a continuous time regime-switching market, Fu (2014) [16] introduced a functional operator to maximize the expected utility of the terminal wealth of a portfolio that contains an option, an underlying stock and a risk-free bond. Fatyanova (2017) [17] developed a constrained optimization problem for constructing an option portfolio that maximizes a certain payoff function. Faias (2017) [18] also noted that traditional portfolio optimization methods like mean-variance optimization are not suitable for option portfolios due to non-normality and difficulty estimating distribution of returns, then introduced a short-term view objective function used to optimize portfolios of European options mainly by exploiting mispricing between options. Zhao (2018) [19] used first- and second-order moments to model options returns and extended the Markowitz mean-variance framework to include option selection with much lower computational time than off-the-shelf solvers. Zeng (2018) [20] introduced a progressive hedging algorithm using reinforcement learning (Q-learning) for option portfolio optimization that was first of its kind to consider the exercise timings of an American option.
Almost all these alternative methods require some kind of parametric model assumption and are limited to the number of options composing the portfolio. GEPO is non-parametric and delivers well-diversified portfolios of many options with no limit. Additionally, all these methods misguidedly aim to maximize the portfolio expected returns, and besides the use of VaR and CVaR there has not yet been any suggestion for measuring or managing the risk of these option portfolios. GEPO not only minimizes the relative entropy risk of the portfolio, but also maximizes the proper metric for measuring the future performance of option returns: exponential growth rate.
2. Maximum Exponential Growth Rate
2.1. The Kelly Criterion for Multiple Wagers
As previously presented in Mercurio et al. (2020) [2], we use the extension of the Kelly criterion (Kelly, 1956) [21] to n wagers. For events with success probabilities , let w represent the total percentage of bankroll to be wagered. For a portfolio that allocates the wager equally across among events, the growth rate coefficient G would be
Therefore, by denoting (this can be thought of as a blended probability of success), the Kelly criterion can be used here to identify the optimal size wager for maximum growth rate as .
2.2. Extension of the Kelly Criterion to Option Strategies
This section is a brief review of several most popular option strategies, with a summary of the details and motivation behind each. Additionally, we extend the Kelly criterion to find optimal growth rates of each option strategy. Further details and strategies can be found in the TMX Group Montreal Exchange guides and strategies documentation (2020) [22].
2.2.1. Covered Call
A covered call option strategy involves selling a call that is covered by an equivalent long stock position, providing a hedge on the stock. In exchange for upside potential, an investor can earn income on the premium. The motivation behind a covered call is to earn premium income. The maximum loss is limited to the initial stock purchase price slightly reduced by the premium income from sale of the call option. The maximum gain is limited, equal to the strike price less the initial stock purchase price, plus the premium income received. A sample expected payoff function for a covered call strategy is illustrated below in Figure 4.
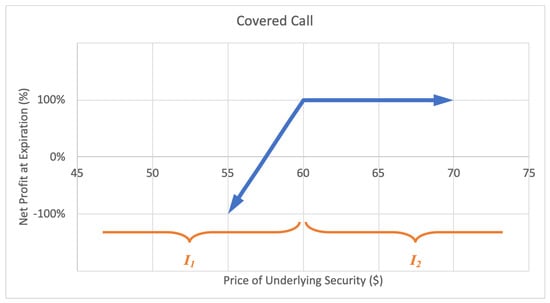
Figure 4.
Sample expected payoff function for a covered call strategy.
For the price of underlying security S and option return R, the growth rate for a covered call strategy becomes
where represents the probability , represents the probability with , and is the expected value of returns conditional on underlying price falling on interval , . Then G is maximized by differentiating with respect to w and setting equal to zero,
which implies a positive exists if and only if , for .
2.2.2. Married Put
A married put, or protective put option strategy involves adding a long-put position to a long stock position, forming a lower bound for the stock value. The investor profits as the stock price keeps rising. The motivation for a married put is to hedge against a temporary decrease in the stock price. The maximum loss is the stock purchase price less the strike price of the put plus the premium paid for the option. There is unlimited potential gain for a married put. A sample expected payoff function for a married put strategy is illustrated below in Figure 5.
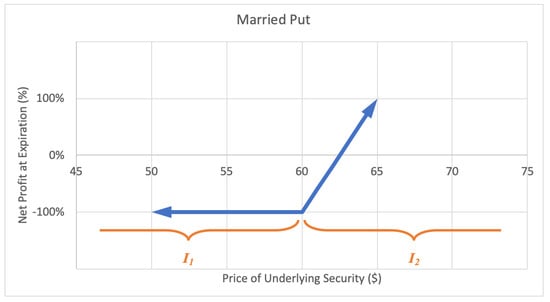
Figure 5.
Sample expected payoff function for a married put strategy.
For the price of underlying security S and option return R, the growth rate for a married put strategy becomes
where q represents the probability , represents the probability with , and is the expected value of returns conditional underlying price landing in interval , . Then G is maximized by differentiating with respect to w and setting equal to zero,
which implies a positive exists if and only if , for .
2.2.3. Credit Spread
A put credit spread, or bull put spread option strategy consists of a short-put option at a certain strike price and a long-put option at lower strike price. The investor profits with a rise in the underlying stock price. The motivations for a credit spread include to earn income with limited risk and to moderately profit from a rise in the stock price. The maximum loss is limited, equal to the net difference between the higher and lower strike prices less the net premium received. The maximum gain too is limited to the net premium received when putting on the position. A sample expected payoff function for a put credit spread strategy is illustrated below in Figure 6.
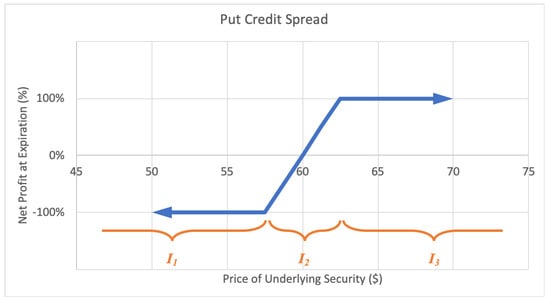
Figure 6.
Sample expected payoff function for a put credit spread strategy.
Alternatively, a call credit spread, or bear call spread option strategy consists of a short call option at a certain strike price and a long call option at a higher strike price. This way the investor profits with a decrease in the underlying stock price. The maximum loss is limited, equal to the net difference between the higher and lower strike prices less the net premium received. The maximum gain too is limited to the net premium received when calling on the position. A sample expected payoff function for a put credit spread strategy is illustrated below in Figure 7.
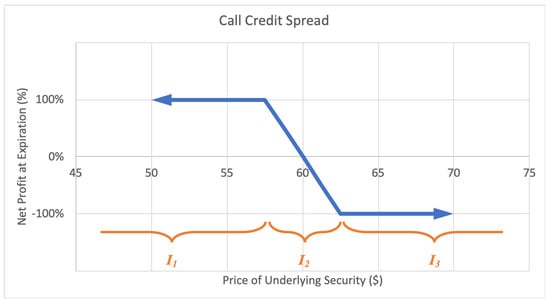
Figure 7.
Sample expected payoff function for a call credit spread strategy.
For the price of underlying security S and option return R, the growth rate for a credit spread strategy becomes
where p is the probability , represents the probability , q represents the probability , with , and is the expected value of returns conditional on underlying price landing in interval , . Then G is maximized by differentiating with respect to w and setting equal to zero,
by the quadratic formula, for .
2.2.4. Straddle
A straddle option strategy involves buying a call and buying a put with equal strike price and expiration date. The investor profits when the underlying stock price experiences a big move up or down. The motivation behind a straddle is to capitalize on correctly predicting a big price move or high volatility in the near future. The maximum loss for a straddle is limited to the premium paid for the call and put options. The potential gain is unlimited. A sample expected payoff function for a straddle strategy is illustrated below in Figure 8.
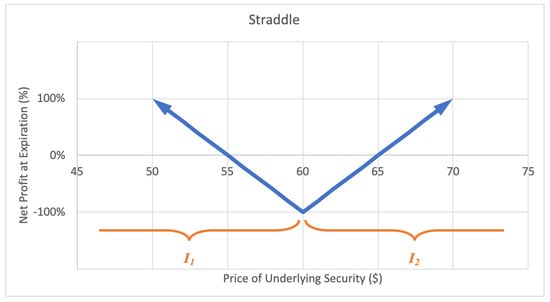
Figure 8.
Sample expected payoff function for a straddle strategy.
For the price of underlying security S and option return R, the growth rate for a straddle strategy becomes
where represents the probability , represents the probability , and expected values and , while . Then G is maximized by differentiating with respect to w and setting equal to zero,
which implies a positive exists if and only if the odds ratio , for .
2.2.5. Long Strangle
A long strangle option strategy involves buying an out-of-the-money call option and an out-of-the-money put option with the same expiration date. A strangle is similar to a straddle except a straddle has equal strike price whereas a strangle has a call option with higher strike price than the put option. The investor profits when there is a very big move up or down in the stock price. The motivation behind a long strangle is to capture a big move in the stock price over the term of the option. The maximum loss for a straddle is limited to the net premium paid for the call and put options. A sample expected payoff function for a long strangle strategy is illustrated below in Figure 9.
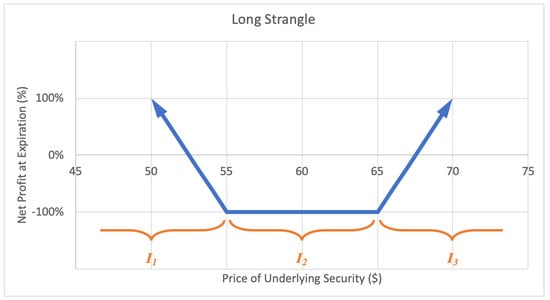
Figure 9.
Sample expected payoff function for a long strangle strategy.
For the price of underlying security S and option return R, the growth rate for a long strangle strategy becomes
where represents the probability , q represents the probability , and represents the probability , and expected values and , while . Then G is maximized by differentiating with respect to w and setting equal to zero,
by the quadratic formula, for .
2.2.6. Butterfly Spread
A butterfly spread, or long call butterfly option strategy consists of two short calls at a middle strike price and two long calls, one at the lower strike and one at the higher strike price, all with the same expiration date. The investor profits by correctly predicting the underlying stock price at expiration. The motivation behind a butterfly spread is to capitalize from predicting a target stock price at the options expiry date. The maximum loss for a butterfly spread is the short call strike price less the lower long call strike price less the net premium paid. The potential gain is unlimited. A sample expected payoff function for a butterfly spread strategy is illustrated below in Figure 10.
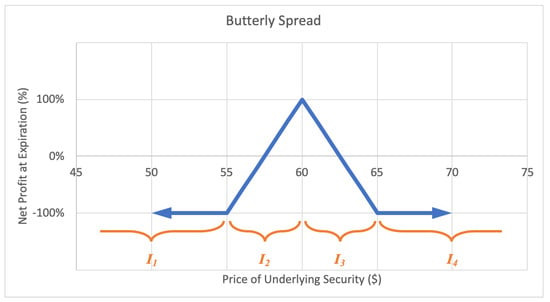
Figure 10.
Sample expected payoff function for a butterfly spread strategy.
For the price of underlying security S and option return R, the growth rate for a butterfly spread strategy becomes
where q represents the probability , represents the probability , represents the probability , and expected values and , while . Then G is maximized by differentiating with respect to w and setting equal to zero,
by the quadratic formula, for .
2.2.7. Iron Condor
An iron condor, or short condor option strategy involves selling one call and buying another call with a higher strike price, plus selling one put and buying another put with a lower strike price, with the current underlying price falling between the call and put strikes. The investor profits if the underlying stock price is between the call and put strikes at option expiration. The motivation behind an iron condor is when the investor foresees the stock trading in a narrow range over the life of the options. The maximum loss of an iron condor is the greater of the difference between high and low call strikes and high and low put strikes, less the net premium received. A sample expected payoff function for an iron condor strategy is illustrated below in Figure 11.
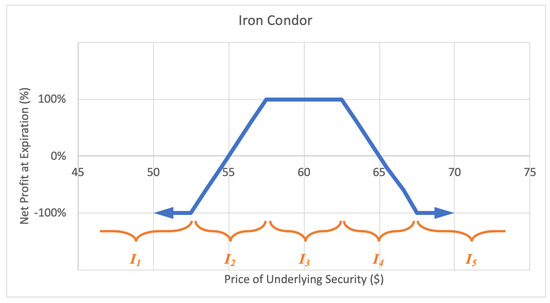
Figure 11.
Sample expected payoff function for an iron condor strategy.
For the price of underlying security S and option return R, the growth rate for an iron condor strategy becomes
where q represents the probability , represents the probability , p represents the probability , represents the probability , and expected values and , while . Then G is maximized by differentiating with respect to w and setting equal to zero,
if and only if (reflective symmetry for expected values), by the quadratic formula.
3. Minimum Relative Entropy
For the purposes of GEPO, the risk of an option portfolio is defined here as the relative entropy of portfolio returns, with respect to the uniform distribution. In order to calculate the relative entropy, we first must calculate the Shannon entropy.
3.1. Shannon Entropy
As a quick review of information theory (Shannon, 1948) [23,24], the Shannon entropy of a random variable represents the amount of randomness inherent to that variable. For a discrete random variable X with probability mass function that can take on possible values , the Shannon entropy H is the average amount of information produced by X, defined as
For n discrete random variables respectively with states, the joint entropy of is given by
This can be calculated empirically given a set of historical data by using the method introduced in REPO [1]. For the case of options returns, many strategies have more than just two (binary) states. Generally there can be up to four total states: positive discrete returns (), negative discrete returns (), continuous returns positively correlated with underlying price, and continuous returns negatively correlated with underlying price.
3.2. Kullback–Leibler Divergence
Kullback and Leibler (1951) [25,26] introduced the Kullback–Leibler divergence which measures the directed divergence between two probability distributions. For discrete probability distributions P and Q, the Kullback–Leibler divergence between P and Q, also known as the relative entropy of P with respect to Q, is given by
As shown in our previous paper (2020) [2], relative entropy qualifies as a convex risk measure based on the relative entropy principle. We once again use this quantity as the discriminatory risk measure for option portfolio optimization. For m total possible states, we will use the m-state discrete uniform distribution as the reference distribution and measure from there the distance to the distribution of portfolio returns. Thus, for Shannon entropy , the risk of an option strategy portfolio is measured by the relative entropy of with respect to the uniform distribution ,
Using the same combinatorial technique employed for REPO [1] and DEPO [2], the Shannon entropy of option portfolio returns can be estimated empirically via probability generating functions. For a collection of n discrete return assets over time period , let denote the cross-sectional n-dimensional vector of outcomes across one observational row of data, and let them be uniquely represented by the collection of ’s such that . Then the empirical Shannon entropy of option portfolio returns can be expressed as
for kth-derivative at of generating function
Therefore, the risk of an option portfolio is given by the relative entropy of portfolio returns , estimated empirically as
for m-state discrete uniform distribution .
4. Option Portfolio Selection Based on Growth Rate and Relative Entropy
4.1. Generalized Entropic Portfolio Optimization (GEPO)
The new generalized entropic portfolio optimization (GEPO) problem uses a multi-objective function that minimizes estimated relative entropy and maximizes expected growth rate. Using this optimization, investors can make portfolio selections based on a chosen risk tolerance. The highest risk portfolio solely maximizes the expected portfolio growth rate, equivalent to the Kelly criterion method. The lowest risk portfolio minimizes the portfolio relative entropy, the most diversified portfolio allocating capital to all n options equally. Somewhere in between lies a user’s optimal portfolio of choice. For the case of option strategies the returns can be both discrete and continuous in nature. For example, credit spread returns can be either for a success, for a failure, or somewhere in between and on a continuous scale for partial returns which we will denote by 0. Thus, we would have discrete return outcomes u such that . This leads to the generalized entropic portfolio optimization problem. Consider n potential option strategy contracts. Let be the number of probability states in the single-asset option strategy. For the generalized option strategy, returns can exhibit at most four general unique probability states: some continuous return on a positively sloped leg (with mean ), and some continuous return on a negatively sloped leg (with mean ), therefore . Let the up-to-four probability states be represented respectively by for event , and let represent the percentage of portfolio funds to be allocated on option i, with the total allocation summing to . Let denote the cross-sectional n-dimensional vector of outcomes across one observational row of data. Over T data points this leads to m historical unique vectors for such that each is unique, with m bounded by either T or the maximum number of possible combinations , so . Basically, the collection of ’s is a unique representation of the ’s with no duplicates. Let us also denote as the number of chosen options in the portfolio, where is the indicator function for the event . Then the GEPO problem is defined as the following optimization program, generalized for different kinds of option strategies,
for the m-state uniform distribution and kth-derivative at of probability generating function
The last constraint in the optimization problem stems from the fact that joint entropy measures randomness strictly based on the inclusion or exclusion of a random variable. The joint entropy value does not change upon changes to non-zero percentages of asset allocation, so any non-zero weight contributes the corresponding marginal entropy from asset i, regardless of the magnitude of . For this reason every asset included in the portfolio is assigned an equal weighting of .
4.2. Risk-Adjusted Performance
Here we will use the risk-adjusted ratio for comparing growth rates of gambling portfolios introduced in our previous paper (Mercurio et al., 2020) [2], called the Growth Rate Over UNiform Divergence (GROUND) ratio. This ratio measures the expected growth rate of a portfolio, adjusted by its risk level—relative entropy with respect to the uniform distribution. Let be the m-state discrete uniform distribution. Then for chosen portfolio and minimum risk portfolio existing in the m-state event space, the GROUND ratio is defined as
where is the growth rate of the chosen portfolio with weighting , is the growth rate of the minimum risk portfolio with weighting , is the relative entropy of the chosen portfolio with respect to , is the relative entropy of the minimum risk portfolio with respect to , and is the Shannon entropy.
5. An Option Portfolio Selection Example with GEPO
5.1. Data
In this example, actual put and call option data is presented for 20 randomly selected equities from the S&P100 composite index using the Wharton Research Data Services (WRDS) from the Wharton School of the University of Pennsylvania, found at wrds-www.wharton.upenn.edu. Prices, volumes, expiration dates, and other essential option data is compiled from June 2012 to January 2018 (June 2012 is the earliest month available that contains data for all listed securities). Included in this data are the Greek parameters for options, which are described in detail in the Equity Options Reference Manual from TMX Group Montreal Exchange guides and strategies documentation (2020) [22]. The of each option, from the Greek parameters for options, effectively represents an estimated probability of landing in-the-money at expiry, and this parameter serves as the estimated success rates for the portfolio optimization here. For the purposes of this paper, we are only concerned with closest to, but not less than 50%, to ensure every possible option yields a slight edge. Using these data archives, we are able to build historical weekly bull put spread and bear call spread options by selecting the buy-sell pairs that most closely resemble a 1:1 odds wager for each expiration date, creating 287 unique data points for each equity. Weekly credit spread outcomes versus historical strike prices are recorded and computed as follows,
where is the expiration price for the underlying equity in question, is the strike price for the sold option, is the strike price for the bought option, and is the midpoint of the two strike prices. The result is a value between and inclusive, on the continuous line, where positive 1 is awarded for an expiration price above the upper strike, for an expiration price below the lower strike, and partial continuous returns between and for spreads expiring in the middle interval in between strike prices from the credit spread payoff function diagrams in Figure 6 and Figure 7. Using this historical data, we are able to empirically calculate the estimated relative entropy of each option. The selected credit spread options and their respective outcomes against strikes over June 2012 to January 2018 are presented below in Table 1.

Table 1.
Mean outcome, average state probabilities and estimated relative entropy (in trits) of select equity credit spread options from July 2012 to January 2018.
Over the following calendar year 2018, there are 52 weekly equity option expiration periods, and estimated success probabilities for each option are defined as follows. For put options, the negative represents the probability of landing in-the-money for bought puts, and represents landing out-the-money for sold puts. For call options, the represents landing in-the-money for bought calls, and represents landing out-the-money for sold calls. The historical results summarized in Table 1 are used to evaluate the estimated relative entropy risk of each option, as well as the combined estimated relative entropy of the composite portfolio. The emulation here shows how GEPO performs against leading Kelly criterion methods for picking a portfolio of options for each week throughout 2018.
For illustrative purposes, let us examine this method applied to the second week, with option expiration dates 12 January 2018. Table 2 lists the details of the selected group of equity credit spreads built of the appropriate option pairs.
Table 2.
Selected equity credit spreads on 12 January 2018, with their respective spread intervals, deltas and state projections.
GEPO determines which collection of credit spreads to select and what percentage of portfolio funds to allocate to each, in order to build the optimal risk–reward credit spread portfolio.
Each potential portfolio has an expected growth rate, given the projections, and an estimated relative entropy with respect to the uniform distribution. The historical data contains data points for each option, so the maximum joint entropy that can possibly be exhibited is , i.e., uniform distribution with possible probability states. Therefore, a portfolio has an estimated relative entropy of
for joint entropy .
5.2. Efficient Frontier and Portfolio Selection
In the portfolio selection problem, the efficient frontier refers to the set of the optimal portfolios that yield the greatest expected return for a defined level of risk, or equivalently the least risk of a defined level of expected return (the dual problem). The efficient frontier illustrates the risk-return trade-off for a given set of optimal portfolios. Here we show the analogous efficient frontier for portfolios with discrete returns, comparing the expected growth rates and risk levels (estimated relative entropy) of each efficient portfolio. For the same week of 12 January 2018, Figure 12 below plots the potential portfolios and their respective expected growth rates against their inherent risk profile, the estimated relative entropy with respect to the uniform distribution Uniform(T) to historical joint outcomes of the portfolio.
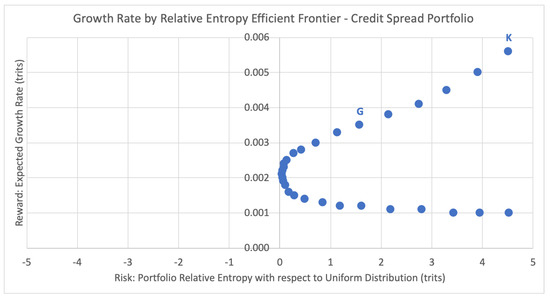
Figure 12.
Growth rate by relative entropy efficient frontier.
For the current season emulation, the Kelly criterion strategy chooses the portfolio that maximizes the expected growth rate. For week 2 this leads to the top right-most data point K = (4.5206, 0.0056), with estimated relative entropy of 4.5206 and expected growth rate of 0.0056. This portfolio consists of just one equity credit spread from Table 2: bull put spread on IBM, consisting of buying a put with strike 150 and selling a put with strike 152.5, betting on IBM to expire above 152.5 with a 50.5% probability of success, 31.2% probability of loss, and 18.3% of a partial return. According to our extended Kelly criterion conditions from Section 2.2, the optimal bet size here is 12%, and thus the chosen portfolio for week 2 is 12% of portfolio funds on [150, 152.5] < IBM, shown below in Table 3. This strategy disregards any concept of risk associated with the expected portfolio growth rate of .
Table 3.
The Kelly criterion portfolio of options with percent allocation for expiration week 2, 12 January 2018.
Alternatively, GEPO chooses the optimal portfolio based on the risk–reward trade-off. For each of the weeks 1 to 52, portfolio selection is performed according to the following GEPO problem with , and (using logarithm base 3 here since we are dealing with three outcome states: 1, 0, and ),
for Uniform(T) distribution as the target distribution, and for the kth-derivative at of probability generating function with T data points,
Although the Kelly criterion places the entire wager on the option (or options) with the greatest expected growth rate, GEPO diversifies the portfolio by distributing the percent allocation across multiple options according to the appropriate risk profile. For week 2, GEPO selects data point D = (1.5845, 0.0035), with estimated relative entropy of 1.5845 and expected growth rate of 0.0035. This corresponds to the optimal portfolio of the six credit spreads listed below in Table 4, with a total portfolio allocation of 9% (compared to the 12% allocated by the Kelly criterion).
Table 4.
GEPO portfolio of options with percent allocation for expiration week 2, 12 January 2018.
Looking at the portfolio efficiency via the risk-adjusted GROUND ratio, the GEPO portfolio has a GROUND ratio of , more than twice as efficient as the Kelly criterion portfolio at .
The actual expiration prices that follow for week 2 are IBM at 163.14 (win), AIG at 60.97 (94% partial loss), MCD at 173.57 (win), ORCL at 49.51 (win), FB at 179.37 (win), and MRK at 58.66 (loss), for a total return of 3.2% in week 2. Therefore, the Kelly criterion strategy experiences a gain of 12% of portfolio balance in week 2, while the competing GEPO strategy gains 3.2%.
5.3. Comparison to the Kelly Criterion Over Time
We demonstrate here the performance of GEPO versus the Kelly and Kelly variant strategies over the entire 2018 calendar year, executing option strategies at weekly intervals. Methods in the previous Section 5.2 are repeated week by week over the course of 52 weeks. The Kelly criterion strategy allocates the optimal investment size each week on the option (or options) that yield the greatest expected growth rate. Half Kelly is the same strategy but uses the fractional Kelly variant by allocating only half the Kelly criterion weighting on the same options. GEPO optimal risk strategy employs the GEPO algorithm each week to select the portfolio with the greatest growth rate subject to the main constraint that the portfolio has an estimated relative entropy of no greater than 2. Each strategy begins the year with $10,000 and the total results are shown below in Figure 13.
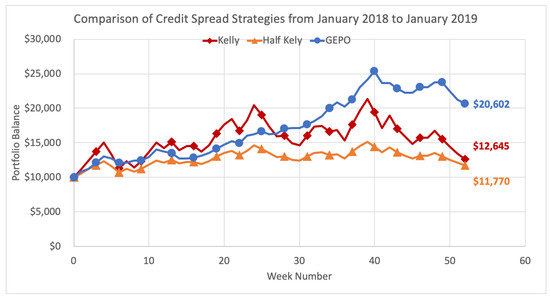
Figure 13.
Comparison of Credit Spread Strategies from January 2018 to January 2020.
With consistent, sustainable returns, GEPO ultimately outperforms both the Kelly and half Kelly methods over the 52-week period, and more than doubles the initial investment by the end of the year. As the Kelly strategies experiences gross variability with the see-saw pattern returns, the diversification strategy of GEPO holds strong and consistently returns profits month after month. The main purpose of GEPO is to mitigate risk of inaccurate predictions, and goal is well accomplished. In the end, GEPO finishes the year at a profit of $10,062, more than 100% ROI, while the Kelly criterion gives up most gains and only retains $2645 (26.45%) profit, with half Kelly finishing up $1770 (17.7%).
6. Conclusions
Presented here is a new entropy-based combinatorial approach to option strategy portfolio selection called generalized entropic portfolio optimization (GEPO). GEPO is the most general method of the entropic portfolio optimizations introduced in our research series. We extend the notorious Kelly criterion to accommodate multiple assets and mixed returns, with direct application to option strategies. Using the convex risk measure relative entropy, GEPO presents a robust method for evaluating risk of option strategy portfolios and gives the mathematical tools to make data-driven portfolio selection decisions to mitigate risk. GEPO is robust, non-parametric, and indifferent to non-normality, asymmetry and small sample size data, making it an ideal approach to the option strategy portfolio selection problem. We show how GEPO comfortably outperforms leading Kelly criterion strategies in choosing optimal portfolios of equity credit spreads over 2018, both absolutely and in terms of risk-adjusted performance via the GROUND ratio. GEPO has a wide range of applications including option strategies such as covered calls, married puts, credit spreads, straddles, strangles, butterfly spreads, iron condors, and more.
7. Materials and Methods
Equity option data sourced from OptionsMetrics (www.optionmetrics.com), provided by Wharton Research Data Services (WRDS) from the Wharton School of the University of Pennsylvania, found at wrds-www.wharton.upenn.edu.
Data and R code (R version 3.5.1) used for the portfolio selection example demonstrated in this paper can be accessed from the following DropBox sharing links, Data: https://www.dropbox.com/s/nd6lowuz5ngpjuf/SP1002018.csv?dl=0, Code: https://www.dropbox.com/s/1v51xhako1jqkjh/SP1002018-GEPO.R?dl=0.
Author Contributions
Conceptualization, P.J.M., Y.W. and H.X.; Data curation, P.J.M.; Formal analysis, P.J.M.; Investigation, P.J.M.; Methodology, P.J.M.; Project administration, Y.W. and H.X.; Resources, P.J.M.; Software, P.J.M.; Supervision, Y.W. and H.X.; Validation, P.J.M., Y.W. and H.X.; Visualization, P.J.M.; Writing—original draft, P.J.M.; Writing—review & editing, P.J.M., Y.W. and H.X. All authors have read and agreed to the published version of the manuscript.
Funding
This research was partially supported by the Natural Sciences and Engineering Research Council (NSERC) of Canada.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| ADP | Approximate dynamic programming |
| AIG | American International Group |
| DEPO | Discrete entropic portfolio optimization |
| FB | Facebook Inc. |
| GEPO | Generalized entropic portfolio optimization |
| IBM | International Business Machines |
| KL | Kullback–Leibler |
| MCD | McDonald’s Corp |
| MRK | Merck & Co. |
| ORCL | Oracle Corp |
| REPO | Return-entropy portfolio optimization |
| WRDS | Wharton Research Data Services |
References
- Mercurio, P.; Wu, Y.; Xie, H. An Entropy-Based Approach to Portfolio Optimization. Entropy 2020, 22, 332. [Google Scholar] [CrossRef]
- Mercurio, P.; Wu, Y.; Xie, H. Portfolio Optimization for Binary Options Based on Relative Entropy. Entropy 2020, 22, 752. [Google Scholar] [CrossRef]
- Markowitz, H. Portfolio Selection. J. Financ. 1952, 7, 77–91. [Google Scholar]
- Liu, J.; Pan, J. Dynamic Derivative Strategies. J. Financ. Econ. 2003, 69, 401–430. [Google Scholar] [CrossRef]
- Jones, C. A Nonlinear Factor Analysis of S&P 500 Index Option Returns. J. Financ. 2006, 61, 2325–2363. [Google Scholar]
- Eraker, B. The Performance of Model Based Option Trading Strategies. Rev. Deriv. Res. 2007, 16, 1–23. [Google Scholar] [CrossRef]
- Haugh, M.; Kogan, L. Duality Theory and Approximate Dynamic Programming for Pricing American Options and Portfolio Optimization. Handb. Oper. Res. Manag. Sci. 2007, 15, 925–948. [Google Scholar]
- Zymler, S.; Rustem, B.; Kuhn, D. Robust Portfolio Optimization with Derivative Insurance Guarantees. Eur. J. Oper. Res. 2011, 210, 410–424. [Google Scholar] [CrossRef]
- Alexander, S.; Coleman, T.; Li, Y. Derivative Portfolio Hedging Based on CVaR. 2003. Available online: http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.702.6360&rep=rep1&type=pdf (accessed on 1 July 2020).
- Alexander, S.; Coleman, T.; Li, Y. Minimizing CVaR and VaR for a Portfolio of Derivatives. J. Bank. Financ. 2006, 30, 583–605. [Google Scholar] [CrossRef]
- Zymler, S.; Rustem, B.; Kuhn, D. Worst-Case Value-at-Risk of Non-Linear Portfolios. Manag. Sci. 2013, 59, 172–188. [Google Scholar] [CrossRef]
- Maasar, M.; Roman, D.; Date, P. Portfolio Optimisation Using Risky Assets with Options as Derivative Insurance. In Proceedings of the 5th Student Conference on Operational Research (SCOR 2016), Nottingham, UK, 8–10 April 2016; Volume 50, pp. 1–17. [Google Scholar]
- Driessen, J.; Maenhout, P. The World Price of Volatility and Jump Risk. J. Bank. Financ. 2013, 37, 518–536. [Google Scholar] [CrossRef]
- Constantinides, G.; Jackwerth, J.; Savov, A. The Puzzle of Index Option Returns. Rev. Asset Pricing Stud. 2013, 3, 229–257. [Google Scholar] [CrossRef]
- Fadugba, S. Performance Measure of Binomial Model for Pricing American and European Options. Appl. Comput. Math. 2014, 3, 18–30. [Google Scholar]
- Fu, J.; Wei, J.; Yang, H. Portfolio Optimization in a Regime-Switching Market with Derivatives. Eur. J. Oper. Res. 2014, 233, 184–192. [Google Scholar] [CrossRef]
- Fatyanova, M.; Semenov, M. Model for Constructing an Options Portfolio with a Certain Payoff Function. In Proceedings of the 3rd International Conference on Information Technology and Nanotechnology, Samara, Russia, 25–27 April 2017; Volume 3, pp. 254–262. [Google Scholar]
- Faias, J.; Santa-Clara, P. Optimal Option Portfolio Strategies: Deepening the Puzzle of Index Option Mispricing. J. Financ. Quant. Anal. 2017, 52, 277–303. [Google Scholar] [CrossRef]
- Zhao, L.; Palomar, D. A Markowitz Portfolio Approach to Options Trading. IEEE Trans. Signal Process. 2018, 66, 4223–4238. [Google Scholar] [CrossRef]
- Zeng, Y.; Klabjan, D. Portfolio Optimization for American Options. J. Comput. Financ. 2018, 22, 37–64. [Google Scholar] [CrossRef]
- Kelly, J. A New Interpretation of Information Rate. Bell Syst. Tech. J. 1956, 35, 917–926. [Google Scholar] [CrossRef]
- TMX Group. Montréal Exchange: Guides and Strategies. 2020. Available online: https://m-x.ca/educ_guides_strat_en.php (accessed on 1 March 2020).
- Shannon, C. A Mathematical Theory of Communication: Part 1. Bell Syst. Tech. J. 1948, 27, 379–423. [Google Scholar] [CrossRef]
- Shannon, C. A Mathematical Theory of Communication: Part 2. Bell Syst. Tech. J. 1948, 27, 623–656. [Google Scholar] [CrossRef]
- Kullback, S.; Leibler, R. On Information and Sufficiency. Ann. Math. Stat. 1951, 22, 79–86. [Google Scholar] [CrossRef]
- Kullback, S. Information Theory and Statistics; John Wiley and Sons: New York, NY, USA, 1959. [Google Scholar]













© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).