1. Introduction
Data mining technology is an efficient tool for business. Early in 1993, Agrawal et al. [
1] proposed association rule mining for transaction databases to discover the intrinsic connection between different products and the shopping habits of customers. This technology makes sales prediction easier. By predicting what customers will buy in the next shopping basket and then recommending the products to them, retailers can improve their services and promote sales. We call such a technique market basket prediction, which is the basis of product recommendation systems.
Since Agrawal et al. proposed association rule mining, both data mining and recommendation systems have been developing rapidly. On the one hand, sequential patterns [
2], sequential rules [
3], coverage patterns [
4], temporal patterns [
5], subgraph patterns [
6] and periodic patterns [
7] have been proposed. Data mining, as an increasingly sophisticated technology, has been used for many domains, such as time series analysis [
8], medicine [
9] and image processing [
10]. On the other hand, recommendation systems include other kinds of implementation methods including pattern-based models, collaborative filtering [
11] and Markov chains [
12]. Advances in data mining technology make pattern-based models promising. There are many efficient and ready-made algorithms for pattern mining [
13], and they can be easily used to implement pattern-based recommendation systems.
A pattern reveals the relation between different products, which makes pattern-based models comprehensive. Among them, a sequential rule reveals the relation between the products in two consecutive transactions. This means that a customer bought a product at some time and will buy another product at a future time. For example, if a customer buys a computer, he or she will need a U-Disk or printer possibly when working on the computer. The higher the confidence of a sequential rule, the higher the possibility. A number of sophisticated and efficient sequential rule mining algorithms have been proposed, including RuleGen [
13], ERMiner [
14] and RuleGrowth [
3,
15]. Because all products have a limited service life, when a product is used out, we will buy another product again. Therefore, some products periodically appear in our market baskets. If we know the period of a periodic pattern, then we can predict when it will appear again. Some periodic pattern mining algorithms have been proposed, including SPP [
16], MPFPS [
17] and LPPM [
18]. The association rule reveals the relation between the products in a basket. This means that if a customer buys a product, he or she will buy another product at the same time. Some efficient algorithms such as TopKRules [
19] and TNR [
20] focus on association rule mining.
As described above, pattern-based models have the advantages of popularity and comprehensibility. However, existing pattern-based recommendation algorithms are insufficient to capture customers’ shopping habits. For example, Ref. [
21] focused on the association rule only, and the periodicity was neglected. Furthermore, the statistical characteristics inside a pattern, e.g., the distribution of periods of a periodic pattern, are also neglected. For example, by the current definition of periodic patterns [
22], when a periodic pattern is used to make a prediction, we can only predict that the pattern will reoccur between a time interval but the probability at an exact time.
In terms of the disadvantages of existing methods, our method leverages not only the association rule but also the sequential rule and periodic pattern for prediction at the same time. We call such a strategy pattern prediction. Furthermore, the frequency and tendency of a product will be considered the preference that customers have for this product and the evolution of preference, respectively, to make predictions, which we call preference prediction. Combining pattern prediction and preference prediction, we propose a new algorithm for market basket prediction, which we call (equential rule, eriodic pattern, ssociation rule, and reference).
In this paper, first, we present a new definition of periodic patterns and tendencies. Generally, if a product is bought periodically by a customer, then the period will be nearly equal to the service life of the product. However, service lives of a kind of product may differ from one another, leading to a fluctuation in the period. What type of pattern is a periodic pattern, which has a virtue to reveal the periodicity of product purchases that have not a fixed period? Obviously, if a pattern has periods that the fluctuation is too large compared to the average period, it will not be periodic. Taking the average period and standard deviation into account, the coefficient of variation, which is the specific value of the standard deviation and mean value, is used to measure the periodicity of patterns in our definition. The concept of tendency is based on the following considerations: if a product is more frequently bought in recent baskets than in early baskets of a customer, then the customer tends to be increasingly inclined to the product. Otherwise, if a product is more frequently bought in early baskets than recent ones, the customer tends to be increasingly estranged from the product. We use a new concept of tendency to reflect this fact.
Second, we propose probability models for pattern prediction. The sequential rule reveals the relation of two patterns belonging to two consecutive transactions. The former pattern is called the antecedent, and the latter the consequent. When a sequential rule is used for predicting the next basket, the time interval between antecedent and consequent is usually neglected. That is, the consequent will follow the antecedent with a given confidence, however, we do not know for sure at what time it occurs. In this paper, we learn the statistical model for the time interval of all sequential rules in the training data. In prediction, we use the statistical model to compute the probability of the occurrence of consequents at an exact time stamp. For periodic patterns, the statistical model is determined by the average period and standard deviation. After training, we obtain all sequential rules, periodic patterns and association rules, along with their statistical characteristics. Consequently, we can calculate the probability of all products in a customer’s next basket. Products that have a higher probability will have priority to be recommended. If the quantity of recommended products is insufficient, then we will make a preference prediction to select more products.
Preference prediction is based on this observation: if a product is more frequently bought by a customer, then we draw the conclusion that the customer has a preference for this product, and this product will have priority to be recommended. If some products have the same frequency, then the product with a higher tendency will be selected first in such a case.
Our contributions in this paper are summarized as follows:
- •
We present a new definition for periodic patterns and the tendency of patterns.
- •
We propose probability models for pattern prediction to predict the next basket.
- •
We design a new algorithm combining pattern prediction and preference prediction for next basket recommendation.
- •
Empirically, we show that our algorithm outperforms the baseline methods and state-of-the-art methods on three of four real-world transaction sequence datasets under the evaluation metrics of - and -.
The remainder of this paper is organized as follows:
Section 2 reviews the existing approaches.
Section 3 includes the preliminary. We introduce our prediction method in
Section 4. The implementation of our algorithm is described in
Section 5, and the experimental analysis is reported in
Section 6. Finally, we draw a conclusion in
Section 7.
2. Related Work
Implementation methods of recommendation systems can be categorized into sequential, general, pattern-based, and hybrid models. Sequential models [
23,
24], mostly relying on Markov chains, explore sequential transaction data by predicting the next purchase based on the last actions to capture sequential behavior. A major advantage of this model is its ability to capture sequential behavior to provide good recommendations. The general model [
25], in contrast, does not consider sequential behavior but makes recommendations based on customers’ whole purchase history. The key idea is collaborative filtering. The pattern-based model bases predictions on the frequent patterns that are extracted from the shopping records of all customers [
26]. Among them, the hybrid model combines the models mentioned above or other ideas, such as graph-based models [
27] and recurrent neural network models [
28,
29]. Since there are so many works devoted to recommendation systems, it is impossible to list all here. So, we only briefly review pattern-based approaches in the next paragraph.
Fu et al. [
30] first used an association rule for recommendation systems. Candidate items are listed for her in their order of support. Wang et al. [
31] proposed an association rule mining algorithm with maximal nonblank for recommendation. The weighted association rule mining algorithm based on
-
and its application procedure in personalization recommendation was given by Wang et al. [
32]. Ding et al. [
33,
34] proposed a method for personalized recommendation, which could decrease the number of association rules by merging different rules. Li et al. [
21,
35] proposed the notion of strongest association rules (
), and developed a matrix-based algorithm for mining
sets. As the subset of the entire association rule set, the
set includes many fewer rules with the special suitable form for personalized recommendation without information loss. Lazcorreta et al. [
26] applied a modified version of the well-known
data mining algorithm towards personalized recommendation. Najafabadi et al. [
36] applied the users’ implicit interaction records with items to efficiently process massive data by employing association rules mining. It captures the multiple purchases per transaction in association rules, rather than just counting total purchases made. Chen et al. [
37] mined simple association rules with a single item in consequent to avoid exponential pattern growth. The method proposed by Zhou et al. [
38] involved implementation of genetic network programming and ant colony optimization to solve the sequential rule mining problem for commercial recommendations in time-related transaction sequence databases. Maske et al. [
39] proposed a method describing how customer behavior predicted based on the customer purchase items by association rule mining algorithm Apriori.
In the other methods, Cumby et al. [
40] proposed a predictor that embraces a user-centric vision by reformulating basket prediction as a classification problem. They build a distinct classifier for every customer and perform predictions by relying just on their personal data. Unfortunately, this approach assumes the independence of items purchased together. Wang et al. [
41] employed a two-layer structure to construct a hybrid representation over customers and items purchase history from last transactions: the first layer represents the transactions by aggregating item vectors from the last transactions, while the second layer realizes the hybrid representation by aggregating the customer’s vectors and the transactions representations. Guidotti et al. [
42,
43,
44] defined a new pattern named the Temporal Annotated Recurring Sequence (
), which seeks to simultaneously and adaptively capture the co-occurrence, sequentiality, periodicity and recurrence of the items in the transaction sequence. Jain et al. [
45] designed a business strategy prediction system for market basket analysis. Kraus et al. [
46] proposed similarity matching based on subsequential dynamic time warping as a novel predictor of market baskets, and leverage the Wasserstein distance for measuring the similarity among embedded purchase histories. Hu et al. [
47] presented a k-nearest neighbors (kNN) based method to directly capture two useful patterns: repeated purchase pattern and collaborative purchase pattern that associate with personalized item frequency. Faggioli et al. [
48] proposed an efficient solution to achieve the next basket recommendation, under a more general top-n recommendation framework by exploiting a set of collaborative filtering based techniques to capture customers’ shopping patterns and intentions.
3. Preliminary
Retailers usually preserve their customers’ shopping histories in a database that we call the transaction sequence database. A customer’s shopping history contains many transactions. Transaction, also called basket, usually contains ID, date, product list and quantity. All transactions of a customer are sorted according to date. This is called the transaction sequence, as
Table 1 shows. A transaction sequence database contains all customers’ transaction sequence, as
Table 2 shows.
Let be a set of n customers and be a set of m items or products in the market. The transaction sequence of customer c is denoted as , and , where , , denotes a transaction or basket. The terms transaction, basket and itemset will be used interchangeably, due to the fact that we are referring to an unordered set of items (or products). The size of sequence is denoted as , and . denotes the next basket that will be purchased by customer c at the next time. We use indexes set of baskets in transaction sequence rather than formal dates as timestamps to simplify the problem. The interval of two transactions is denoted as and defined as , where . The transaction sequence dataset consists of transaction sequences of n customers.
Problem 1. Assume a transaction sequence dataset, our aim is to predict the next basket for each customer according to their transaction sequence. Then, we will select k products to recommend to him or her. Formally, given dataset D, for all transaction sequenceandto predict, which contains a set of candidate items for recommendation. Letdenote the selected item set; then,contains k items selected fromto recommend to customer c.
Definition 1. (Frequent Itemset Pattern) Given an itemset p,, frequency threshold θ, and transaction sequence. If, we have, then we calla support for p. Letdenotes all supports of p, then. The absolute frequency of p is defined as, and the relative frequency is. If, then we call p a frequent itemset pattern and itemset pattern for short. If p contains only a single item, that is,, we call it a single item pattern.
Definition 2. (Association Rule) Given two itemset patternsandof a transaction sequence, confidence threshold η, if
- (1)
,
- (2)
is an itemset pattern, and
- (3)
,
thenis an association rule. Its frequency is denoted asand defined as. Its confidence is denoted asand defined as. We callthe antecedent, andthe consequent.
Definition 3. (Frequent Sequential Pattern) A sequenceis a subsequence of transaction sequence, denoted as, if and only if there exist k integerssuch that,andit holds that. We call this integer set an embedding of s in B, denoted as,.denotes the set of all embeddings of s in B. In transaction sequence dataset D, if, we calla support of s. The set of all supports of s is denoted asand. The absolute frequency of s is defined asand the relative frequency. Given a threshold θ for frequency, if, then s is a frequent sequential pattern, sequential pattern for short.
In this paper, the length of s is denoted as , and defined as . If a sequence s contains only an itemset p, that is, , , then it can be mapped into itemset p, and we have . If , viz. s has only a single itemset, and this itemset contains only a single item. We call it a single item pattern.
Definition 4. (Sequential Rule) Given two sequential patternsandof a transaction sequence dataset and confidence threshold η, if
- (1)
,
- (2)
(concatenates with) is a sequential pattern, and
- (3)
,
then we calla sequential rule. Its frequency, and confidence. We callthe antecedent, andthe consequent.
Property 1. Assume a sequential rule, where, then we have,...,, and,...,.
Proof. The proof comes from the anti-monotonicity of sequential patterns’ frequency. □
Definition 5. (Periodic Pattern) Let p be an itemset pattern of transaction sequence,. The occurrence list of p is denoted as, and defined as. Then, the period list of p in B is denoted as, and defined as. The coefficient of variation of p is denoted as, and, whereandare the standard deviation and mean, respectively. Given a threshold δ for the coefficient of variation, if, then p is a periodic itemset pattern or periodic pattern for short.
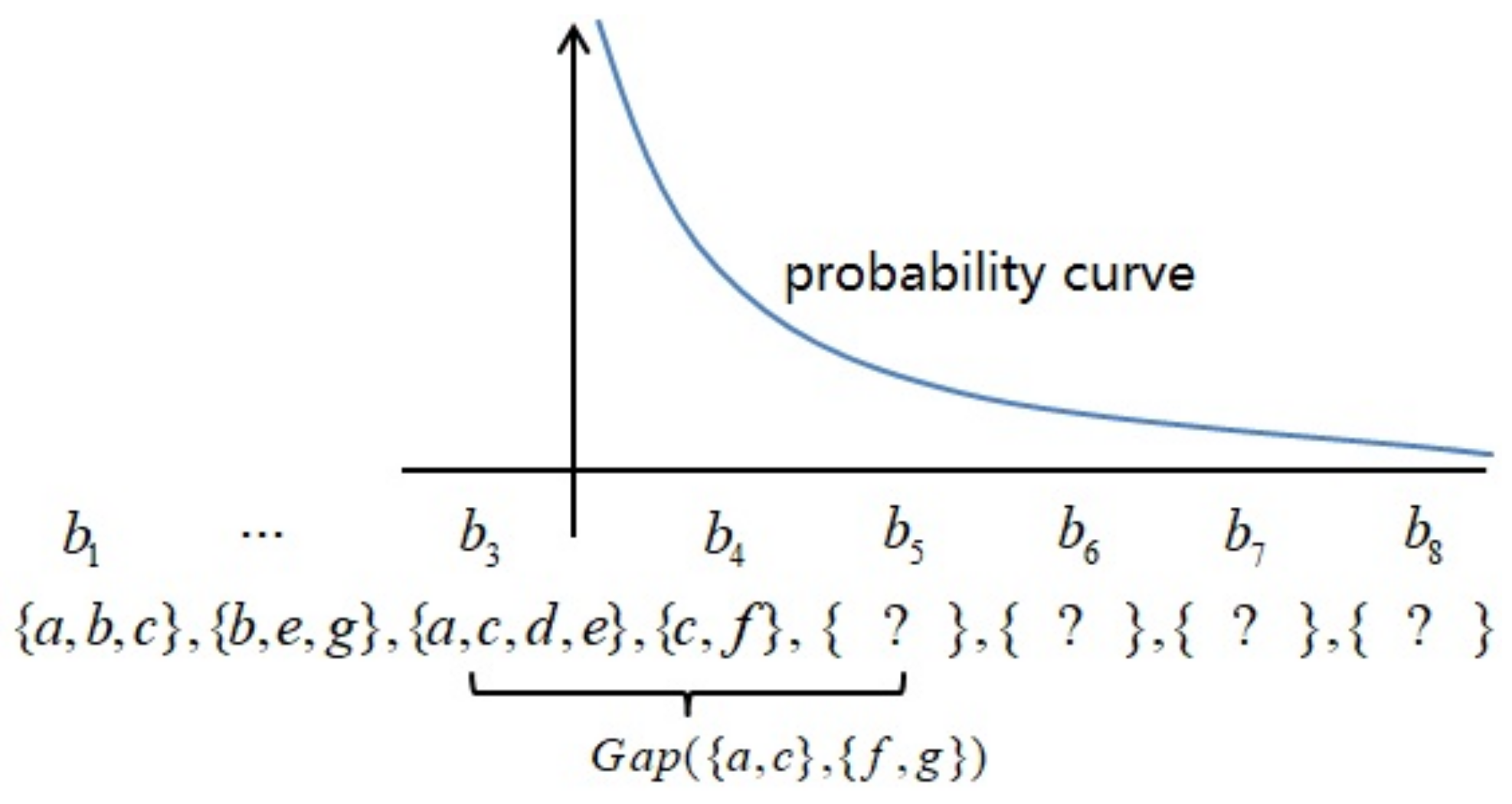
Definition 6. (Gap of Two Itemsets) Given two itemsetsandof transaction sequence B. Ifand, then the gap ofandin B is defined as; otherwise,.
Definition 7. (Gap of Two Subsequences) Given two subsequencesandof transaction sequence B. Ifand, then the gap ofandin B is defined as; otherwise,.
Definition 8. (Tendency) Given an itemset p of transaction sequence B, we callthe tendency of itemset p in transaction sequence B.
Example 1. For the transaction sequence given inTable 1, the support of itemsetis, frequency,,,, periods list,. InTable 2, the frequency of sequenceis, the frequency of sequenceis, and the frequency of sequenceis. We have... The frequencies of itemsetsandin transaction sequenceareand, respectively. The occurrence list of itemsetin transaction sequenceis, tendency. 4. Framework
Our method includes pattern prediction and preference prediction. In pattern prediction, first, all sequential rules, periodic patterns and association rules are found together with their statistical characteristics. Then, probability models are built based on their statistical characteristics. Afterward, we use the probability models to calculate the probability of all products in the next basket for a customer. The products that have a higher probability will be selected preferentially to recommend to him or her. If
k products have been selected, then continue to the prediction of the next customer; otherwise, make preference predictions. In preference prediction, the product that is more frequent in the individual shopping records will be selected first. If some products have the same frequency, then the product that has a higher tendency will be selected. Until all
k products are selected, we continue to predict the next customer. See Algorithm 1. We introduce the probability list
to preserve the probability of all items in
, viz.
.
| Algorithm 1: SPAP. |
![Entropy 23 01430 i001]() |
4.1. Sequential Rule Prediction
4.1.1. Probability Model of Sequential Rule
Sequential rules reveal the relation between products in two consecutive transactions. This means that a customer bought a product at some time, and he or she will buy another product at a future time. However, the sequential rule defined by the previous section has a limitation to use for the next basket prediction. For example, given sequential rule . If event occurs, then it will lead to event occurring at a confidence of , and the confidence is considered as the probability here, that is, . However, we did not know for sure at what time event occurs, and did not know the probability of event occurring at an exact time after event occurred. To address this limitation, we build a probability model for time intervals of the sequential rule. The time interval of a sequential rule, i.e., the time interval between event and event , is a random variable and represented by X here, . Generally, the larger the time interval, the lower the relevance of and , and vice versa. We suppose that the probability model nearly follows an exponential distribution with a parameter of .
Example 2. For a transaction sequence dataset showed inTable 2, let,and, we have,. If we set,, and we have, thenis a sequential rule. The time interval betweenandisin, whereand. In a similar way,,,,,. Note that in sequence, we haveand, leadingto be multiple-valued. According to Definition 6, we have. Consequently, we obtain a probability model foras,and, respectively. 4.1.2. Principle of Sequential Rule Prediction
Given transaction sequence , sequential rule , and its probability distribution of time intervals between and . Suppose the consequent contains only a single itemset, that is, (Since if , then we can break it down into several sequential rules, which have a consequent containing only a single itemset, according to Property 1). If , then . Otherwise, , where . Since sequential rule means that , then . Suppose denote the event . In a similar way, denote the event . If event occurs, then , . In a similar way, if event occurs, then , . Since , we obtain the probability of , .
First, the time variable is continuous in general. However, in our case, we use the index of baskets as the timestamp, so the time variable is discretized. The probability of an exact value of the time variable is the probability within a unit interval over this value. Second, if an item is contained in the consequents of several sequential rules, then it will be predicted several times. In such a case, we update its probability as the maximal value. See Algorithm 2.
| Algorithm 2: SequentialRulePrediction. |
![Entropy 23 01430 i002]() |
Continue with the Example 2 Let
; we predict the probability of all products in
. In Example 2, we obtain a sequential rule
and its probability model.
,
. If
, then
. We have
from the probability distribution. Finally, we have
, as
Figure 1 shows.
4.2. Periodic Pattern Prediction
4.2.1. Probability Model of Periodic Pattern
Periodic events intrinsically reoccur with a fixed period. However, in the real world, the period is influenced by different factors, leading to a fluctuation in the period. In this case, we only have an average value for periods. As we all know, the smaller the fluctuation, the better. So, we compare the fluctuation with the average period. If the fluctuation is too large compared to the average period, we do not define it as a periodic event. The coefficient of variation, which is the specific value of the standard deviation and mean value, is suitable for periodicity measure, since standard deviation is a good measure for fluctuation. The service life of a product is no exception. If a product is bought periodically by a customer, then the period will be nearly equal to the service life of the product. However, service lives of a kind of products may differ from one another, leading to a fluctuation in the period.
According to Definition 5, we define periodic patterns based on the coefficient of variation. If a pattern has a higher coefficient of variation, which means that the standard deviation is too large compared to the mean value, the pattern is not periodic. Otherwise, we classify it as a periodic pattern. Given a periodic pattern, if it occurs at some time, then it is more likely to reoccur after an average period of time. The probability at a time closer to the time after an average period later has a higher value; otherwise, it has a lower value. We suppose that the probability model of periods follows a normal distribution and has two parameters:
and
, as
Figure 2 shows.
4.2.2. Principle of Periodic Pattern Prediction
Given transaction sequence , and a periodic pattern p of B, the prediction of the probability of is analogous to the sequential rule prediction.
4.3. Association Rule Prediction
Given an association rule , if itemset pattern , then itemset pattern with a probability of . If , then , and .
After sequential rule prediction and periodic pattern prediction, we obtain a set of candidate products with their probability in . At the same time, we define the probability of as . Therefore, we get the probability of as . See Algorithm 3.
After pattern prediction, if a product has not been predicted, then it will have a default probability value of zero and is not included in
to be recommended in the pattern prediction stage. Therefore, we obtain a set of candidate products along with their probabilities in the next basket
. In
, a product with a higher probability will have priority to be recommended to customers. If
, that is, the number of candidate items is less than
k in
, then we will make a preference prediction to continue to select products to recommend until we get all
k products.
| Algorithm 3: AssociationRulePrediction. |
![Entropy 23 01430 i003]() |
4.4. Preference Prediction
In pattern prediction, we selected a set of products to recommend to a customer. If the number of selected products is less than k, then we continue to select based on preference prediction.
In preference prediction, if a product is more frequently bought by a customer, then we conclude that the customer has a preference for this product. However, the preference will evolve over time. The purchase distribution of a product over a shopping history will indicate a change in preference. If a product is more frequently bought in the recent baskets than the earlier ones of a customer, then the customer is more and more inclined toward the product; otherwise, if a product is more frequently bought in earlier baskets than recent ones, then the customer tends to be increasingly estranged from the product. According to Definition 8, tendency reflects such a fact. The preference prediction is based on the frequency and tendency of a product in customers’ shopping histories. We first select the products that are more frequent to recommend. If some products have the same frequency, then the product that has a higher tendency is prioritized.
4.5. A Comprehensive Example
For the transaction sequence given in
Table 1, itemset
has an occurrence list of
and a period list of
. By calculating, we get
and
,
. If we set
and
, then
p is a periodic pattern and its period follows
. Now let us predict
and select 5 products to recommend, viz.
. Suppose we have a sequential rule of Example 2 and an association rule of
at the same time. First, in sequential rule prediction, we have
,
. Second, we use periodic pattern
to predict. As
,
. If
, then
. We have
from the probability model. Merging
into
, we get
. Third, the association rule is used to predict. By definition, we have
, then
. Finally, the products are selected in the order of
. However, there are not enough products to recommend. Thus, we will have a preference prediction.
In preference prediction, all products that are in the individual shopping history, excluding selected products, are sorted by frequency. We have , , and . Because the frequencies of items a and b are the same, their tendencies are calculated. Item a has an occurrence list of , and item b has . We get and , and select a. Finally, all 5 products are selected.
4.6. Relation of Two Prediction Strategies
In pattern prediction, we must set a value to the frequency threshold, confidence threshold and threshold for the coefficient of variation in pattern mining. These parameters determine the weight of pattern prediction and preference prediction.
The confidence threshold parameter is set for sequential rule mining and association rule mining. A higher value of the confidence threshold is set, and fewer sequential rules and association rules are found. The threshold parameter for the coefficient of variation is set for periodic pattern mining. If it has a lower value, then fewer periodic patterns are found. The frequency threshold parameter is set for all three types of patterns. If a higher value is set, then fewer patterns are found. There is no parameter for preference prediction.
In general, if we have a higher value on the frequency threshold and confidence threshold and a lower value on the threshold for the coefficient of variation, then we will select fewer products in pattern prediction. Preference prediction will have a higher weight on the selected result, and pattern prediction will have the opposite effect. Conversely, preference prediction will have a lower weight on the selected result.
6. Experiment
To evaluate the performance of our algorithm, experiments were conducted on four read-world datasets. First, we assessed the influences of parameters on the weight of pattern prediction and preference prediction. Second, we compared our algorithm with those of the baseline methods and state-of-the-art methods in the evaluation metrics of - and -. The experiments were conducted on a computer with an Intel Core I7-8550U 1.8 GHz processor and 8 GB of RAM, running Windows 10 (64-bit version). The is implemented in Java.
6.1. Datasets
- •
Ta-Feng is a dataset of a physical market, covering food, stationery and furniture, with a total of 23,812 different items in China. It contains 817,741 transactions made by 32,266 customers over 4 months.
- •
The Dunnhumby (Dunnh for short) dataset contains household level transactions over two years from a group of 2500 households who are frequent shoppers at a retailer.
- •
The X5-Retail-Hero (X5RH for short) dataset contains 183,258 transactions made by 9305 customers over 4 months and a total of 27,766 distinct items.
- •
The T-Mall dataset records four months of online transactions of an online e-commerce website. It contains 4298 transactions belonging to 884 users and 9531 distinct brands considered as items.
In preprocessing these datasets, we remove customers who have fewer than 10 baskets for Ta-Feng, Dunnh and T-Mall, and remove customers who have fewer than 21 baskets for X5RH. For simplicity, we adopt the index of the basket in sequence as the time unit rather than the real date.
Table 3 shows the details of these datasets used in our experiment.
6.2. Evaluate Metrics - and -
Following Guidotti et al. [
44], first, we sort the transactions by the timestamps for each customer. Then, we split the dataset into training set and testing set. Testing set contains the latest transaction of all customers for model evaluation. Training set contains the remainder of the transactions of all customers for model training. This is known as
-
-
strategy. The product set that customer
c actually buys is denoted as
. The product set recommended to customer
c is denoted as
. The metrics we use for evaluation,
-
and
-
, are defined as
where
is an indicator function. The
-
is reported by the average value of all customers.
Furthermore, to evaluate the contribution of two prediction strategies, we introduce a new measure:
. Let
denote all the items selected in pattern prediction for all customers, and
denote all the items selected in preference prediction for all customers. The number of all items selected to recommend to all customers is
, and we have
. The weights of pattern prediction and preference prediction are denoted as
and
, respectively, and defined as
due to the complementation of
and
, we report
only. A higher value of
means that more items are selected in pattern prediction, and vice versa. In the remainder of this paper, we use
to replace
. Note that if the number of all distinct products customer
c has bought is less than
k, then we cannot select a set of products including more than or equal to
k items to recommend to him or her, that is,
, leading to
, where
.
6.3. Influence of Parameters
Our algorithm is composed of two prediction strategies. We obtain the best performance only on the right proportion of weight on pattern prediction and preference prediction. There are four parameters in pattern prediction: relative frequency threshold and confidence threshold for sequential rule mining and association rule mining, threshold for coefficient of variation and absolute frequency threshold for periodic pattern mining. All of these parameters have an influence on the weight of these two prediction strategies. In this subsection, we will evaluate the influences of these parameters. k is set to the average basket size of each dataset. The values for the remainder of the parameters are preset to be , , and for Ta-Feng, , , and for Dunnh, , , and for X5RH, and , , and for T-Mall.
First, we test the parameter of relative frequency threshold
, and the results are shown in
Figure 4. We can see that when
rises, the total number of distinct rules, including sequential rules and association rules, and
decrease in all cases of the four datasets.
is always lower than 0.5, which means that preference prediction plays a dominant role. For the Ta-Feng dataset, when
has a value less than 0.16, both
-
and
-
remain unchanged and achieve the optimal values, and the situation is the same on the Dunnh dataset when
is greater than 0.75. Both
-
and
-
are constant on the X5RH dataset when
is greater than
. For the T-Mall dataset, when
is near to 0.11, both
-
and
-
achieve the optimal values.
Figure 5 shows the influences of different values for threshold
. As
rises, the number of rules and
decrease on all four datasets. Both
-
and
-
achieve the optimal values on the Ta-Feng dataset when
is less than 0.38, achieve the optimal values on the Dunnh when
is greater than 0.9 and achieve the optimal values on the T-Mall dataset when
is equal to 0.5, respectively. When
is greater than 0.8,
-
or
-
achieves the optimal value on the X5RH dataset.
The threshold for the coefficient of variation
is set for periodic pattern mining. A higher value for
will lead to a larger number of periodic patterns, as
Figure 6 shows. At the same time, a larger number of periodic patterns results in a higher
on all four datasets. When
is less than 0.4,
-
or
-
achieves the optimal value on the Ta-Feng dataset. Both
-
and
-
remain unchanged and achieve the optimal values on the Dunnh dataset when
is greater than
, and the situation is the same on the X5RH and T-Mall datasets when
is greater than
.
Finally, we test the absolute frequency threshold
for periodic pattern mining. As shown in
Figure 7, when
rises, the number of periodic patterns and
decrease on all four datasets. Both
-
and
-
remain unchanged and achieve the optimal values on the Ta-Feng dataset when
is greater than 11, and the situation is the same on the Dunnh dataset when
is greater than 27. In the case of X5RH, when
is equal to 7, both
-
and
-
achieve the optimal values. For the T-Mall dataset,
-
and
-
achieve their optimal values when
is equal to 10 and 5, respectively.
6.4. Comparison with Baseline Methods and State-of-the-Art Methods
In this subsection, we report the comparisons of our method with baseline methods, including , , and ; and state-of-the-art methods, including , , and .
- •
predicts the top-k most frequent items with respect to their appearance, i.e., the number of times that they are purchased, in a customer’s purchasing history .
- •
[
40] makes the prediction based on the last purchase
and on a Markov chain calculated on
.
- •
[
40]: Due to space limitations, we do not discuss here. See [
40] for more details.
- •
(Non-negative Matrix Factorization) [
51] is a collaborative filtering method that applies a non-negative matrix factorization to the customers-items matrix. The matrix is constructed from the purchase history of all customers.
- •
(Hierarchical Representation Model) [
41] employs a two-layer structure to construct a hybrid representation over customers and items purchase history
B from last transactions: the first layer represents the transactions by aggregating item vectors from the last transactions, while the second layer realizes the hybrid representation by aggregating the user’s vectors and the transactions representations.
- •
[
44] is a new pattern-based method proposed by Guidotti et al. [
44] that seeks to simultaneously capture the co-occurrence, sequentiality, periodicity and recurrence of the items in basket sequences.
- •
- •
[
48] (
https://github.com/MayloIFERR/RACF (Accessed data: 19 October 2021)) denotes User Popularity-based Collaborative Filtering. The model considers a user-based collaborative approach that relies on similar users to find new items that can be of interest to the target user.
Figure 8 shows the results of
-
, we can see that our
algorithm has the best
-
on the Ta-Feng dataset when
k is less than 14, and closes to
on the Dunnh and X5RH datasets.
Figure 9 shows the results of
-
,
outperforms the other algorithms on the Ta-Feng dataset, and closes to
on the Dunnh and X5RH datasets.
We noticed that all algorithms, except , exhibit poor performance for - when k is too higher or lower than the average basket size. The most obvious finding is on T-Mall dataset, which has the smallest average basket size. Because - is relevant to the size of recommended basket . A higher value for k means we will select more products to recommend, leading to a large size for and a lower value for ; otherwise, we have a lower value for . However, when the value of k increases, it results in a higher possibility of being hit, and - rises naturally. Only k has a value nearer to the average basket size, and we have a fairer comparison.
As described above, almost all algorithms exhibited their best performance when
k was set as a value of the average basket size.
Table 4 lists the performance results in which
k has a value of the average basket size,
,
,
and
for Ta-Feng, Dunnh, X5RH and T-Mall, respectively.
has the best performances on the T-Mall dataset. However, our
algorithm outperforms other algorithms on the Ta-Feng, Dunnh and X5RH datasets.
Patterns have a virtue of reflecting customers’ shopping habits. Due to the fact that people visit physical stores more regularly than online stores, our pattern-based model
achieves the best performances on physical store datasets Ta-Feng, Dunnh and X5RH.
Table 5 lists the improvements of
compared with
on the Ta-Feng, Dunnh and X5RH datasets; and compared with
on the T-Mall dataset.
6.5. Running Time
All of these algorithms have a running time ranging from several seconds to several hours.
is always the fast one [
44]. In this subsection, we compare the running time (training time and prediction time) of our algorithm with
. Both of them are implemented in Java. The results are shown in
Table 6. Source code for
,
,
,
,
,
and
are implemented in Python, so we do not report their running times here. We terminate the processe of
on the Dunnh dataset when it runs over two days.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}