1. Introduction
1.1. Motivation
Finite mixture models are widely used for modeling data and finding latent clusters (see McLachlan and Peel [
1] and Fraley and Raftery [
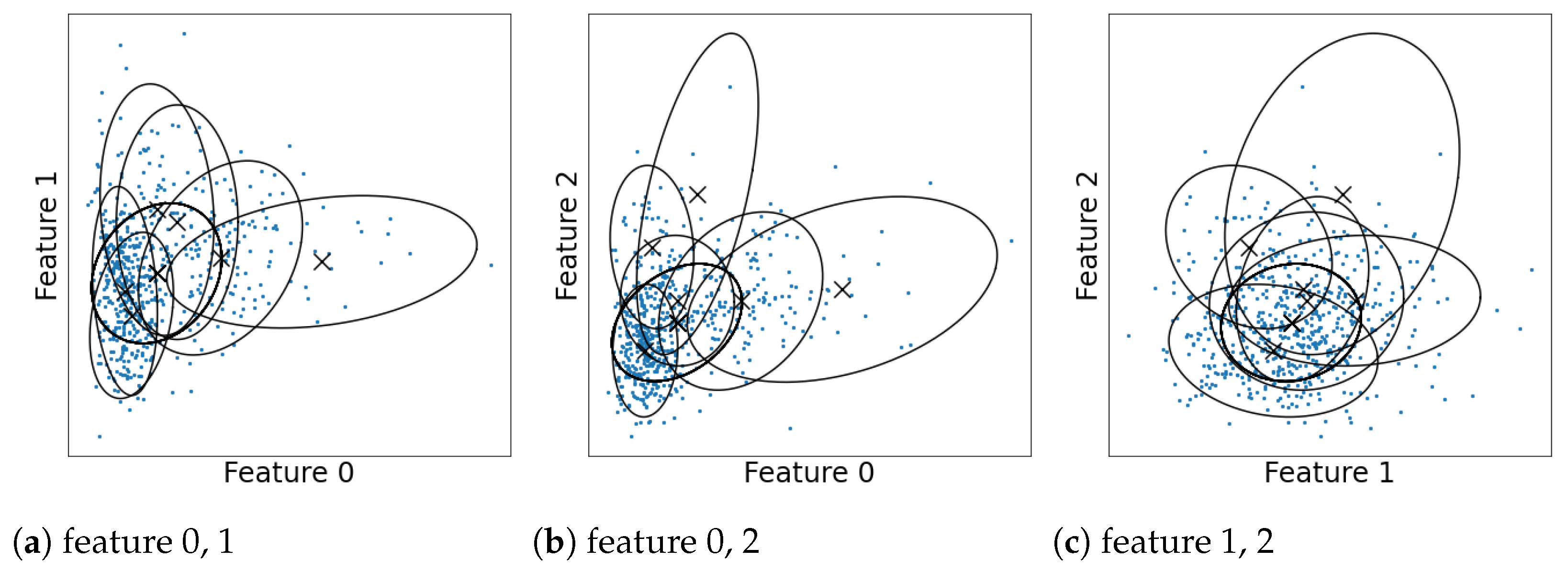
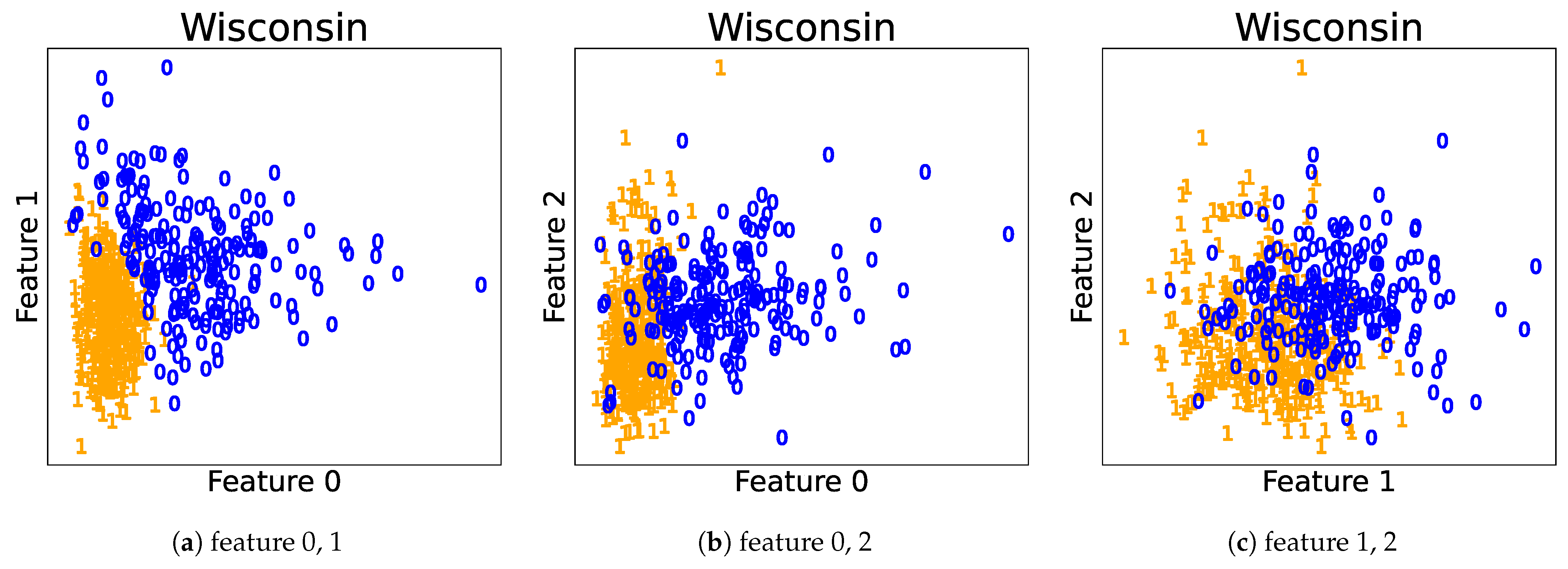
2] for overviews and references). When they are used for clustering, they are typically interpreted by regarding each component as a single cluster. However, the one-to-one correspondence between the clusters and mixture components does not hold when the components overlap. This is because the clustering structure then becomes more ambiguous and complex. Let us illustrate this using a Gaussian mixture model estimated for the Wisconsin breast cancer dataset in
Figure 1 (details of the dataset and estimation are discussed in
Section 8.2). A number of the components overlap with one another, which makes it difficult to estimate the shape of distribution or number of clusters. Therefore, we need an analysis of the overlaps to correctly interpret the models.
We address this issue from two aspects. In the first aspect, we consider merging mixture components to regard several components as one cluster. We repeatedly select the most overlapping pairs of components to merge them. In this procedure, it is important how the degree of overlap is measured. A number of criteria for measuring cluster overlaps have been proposed [
4,
5,
6], but they have not yet been compared theoretically. We give a theoretical framework for comparing merging criteria by defining three essential conditions that any method for merging clusters should satisfy. The more conditions any method satisfies, the better it is. From this viewpoint, we evaluate the existing criteria (entropy (Ent) [
4], directly estimated misclassification (DEMP) [
5] probability, mixture complexity (MC) [
7]). We also modify these existing criteria so that they can satisfy more essential conditions.
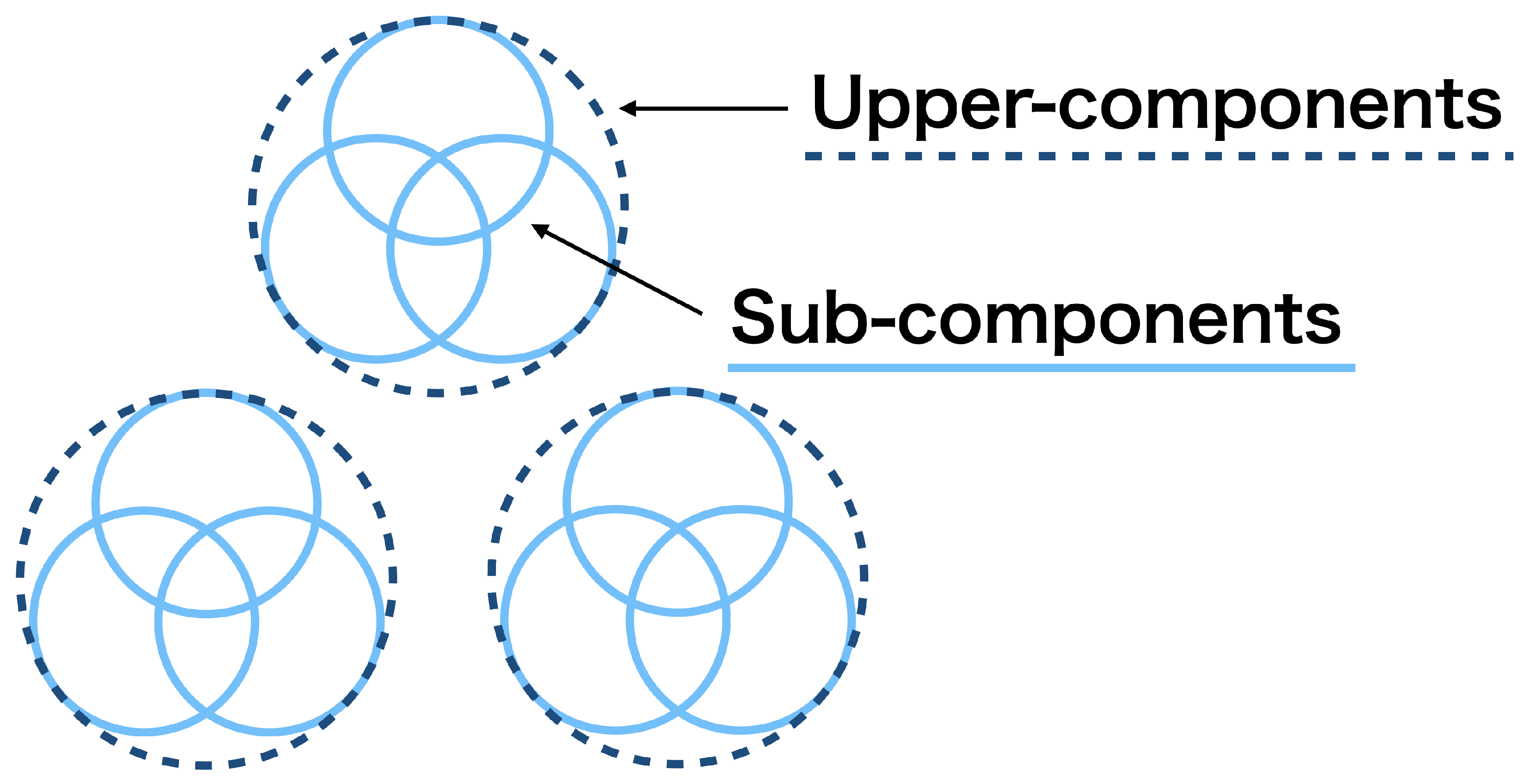
In the second aspect, we consider how to summarize the merging results quantitatively. After merging mixture components, we obtain two types of clustering structures; those among the upper-components and those among sub-components within each upper-component, as illustrated in
Figure 2. These structures might be still ambiguous because the upper-components are determined to be the different clusters, but they may overlap; the sub-components are determined to belong to the same cluster, but they may be scattered in the cluster. Therefore, we need to evaluate the degree to which the upper- and sub-components are discriminated as different clusters. We realize this using the notions of
mixture complexity (MC) [
7] and
normalized mixture complexity (NMC). They give real-valued quantification of the number of effective clusters and the degree of their separation, respectively. We therefore develop a novel method for cluster summarization.
Our hypotheses in this paper are summarized as follows:
Modifying merging criteria based on essential conditions can improve the ability to find cluster structures in the mixture model.
Cluster summarization based on MC and NMC effectively describes the clustering structures.
We empirically verify them by experiments, using artificial and real datasets.
1.2. Significance and Novelty of This Paper
The significance and novelty of this paper is summarized below.
1.2.1. Proposal of Theoretical Framework for Evaluating Merging Criteria
We give a theoretical framework for evaluating merging methods by defining the essential conditions. They are necessary conditions that any merging criterion should satisfy: (1) the criterion should take the best value when the components are entirely overlapped, (2) it should take the worst value when the components are entirely separated, and (3) it should be invariant with respect to the scale of the weights. We empirically confirm that the more essential conditions any merging method satisfies, the better the clustering structure obtained in terms of larger interdistances and smaller intradistances.
1.2.2. Proposal of Quantitative Clustering Summarization
We propose a method for quantitatively summarizing clustering results based on MC and NMC. MC is an extended concept of the number of clusters into a real number from the viewpoint of information theory [
7]. It quantifies the diversity among the components, considering their overlap and weight bias. NMC is defined by normalizing MC to remove the effects of weight bias. It quantifies the degree of the scatter of the components based only on their overlap. Furthermore, MC and NMC have desirable properties for clustering summarization: they are scale invariant and can quantify overlaps among more than two components. We empirically demonstrate that our MC-based method effectively summarizes the clustering structures. We therefore give a novel quantification of clustering structures.
2. Related Work on Finite Mixture Models and Model-Based Clustering
In this section, we present related work on finite mixture models and model-based clustering in four parts: roles of overlap, model, optimization, and visualization. The overlap has a particular impact on the construction of models.
2.1. Roles of Overlap
There has been widespread discussion about the roles of overlap in finite mixture models. One argues that the overlap is emerged to represent various distributions. While this flexibility is beneficial for modeling the data, various issues arise in applying them to clustering. For example, McLachlan and Peel [
1] pointed out that some skew clusters required more than one Gaussian component to be represented. Moreover, Biernacki et al. [
8] pointed out that the number of mixture components selected for estimating densities was typically more than that of clusters because of overlapping. Model selection methods based on clustering (complete) likelihood, such as the integrated complete likelihood (ICL) [
8], the normalized maximum likelihood (NML) [
9,
10], and the decomposed normalized maximum likelihood (DNML) [
11,
12], have been proposed to obtain less-overlapping mixtures so that one component corresponds to one cluster. However, they have problems in that they need to define the shape of the clusters in advance. This leads to a trade-off between shape flexibility and component overlap in model-based clustering.
Others argue that the overlap represents that the data belong to more than one cluster. For example, in clustering documents by their topics, the data may have several topics. Such issues have been widely discussed in the field of overlapping clustering. For example, Banerjee et al. [
13] extended the mixture model to allow the data to belong to multiple clusters based on membership matrices. Fu and Banerjee [
14] considered the product of cluster distributions to represent multiple memberships of the data. Xu et al. [
15] proposed methods for describing more complex memberships by calculating correlation weights between the data and the cluster. While these methods allow complex relationships between the data and the clusters, cluster shapes become simple.
The overlap is also used for measuring the complexity of clustering structures in the concept of MC [
7]. It is a non-integer valued quantity, which implies the uncertainty of determining the number of clusters. MC was introduced in the scenario of change detection in [
7]. This paper gives a new application scenario of MC in the context of quantifying clustering structures. Moreover, this paper also newly introduces NMC as a variant of MC, which turns out to be most effective in this context.
2.2. Model
We discuss the issue of constructing models achieving both flexible cluster shapes and interpretability. Allowing each cluster to have complex shapes is a solution to tackle this. For example, mixtures of non-normal distributions have been proposed for this purpose, as reviewed by Lee and McLachlan [
16]. Modeling each cluster as a finite mixture model, called the mixture of mixture model or multi-layer mixture model, has been considered in this regard. Various methods have been proposed to estimate such mixture models based on maximum likelihood estimation [
17,
18] and Bayesian estimation [
19,
20]. However, additional parameters are required for assigning sub-components to upper-clusters in many cases because changes of assignment do not change the overall distribution. Merging mixture components [
4,
5,
6] is an alternative way of the composition of mixture models using single-layer estimations. In this approach, the criteria to measure the degree of component overlap have to be identified. Although various concepts have been developed to measure the degree of overlap, such as entropy [
5], misclassification rate [
4,
6], and unimodality [
4], they have not been satisfactorily compared yet.
2.3. Optimization
Merging components has also been discussed in the scenario of optimizing parameters in the mixture models. Ueda et al. [
21] proposed splitting and merging mixture components to obtain better estimations, and Minagawa et al. [
22] revised their methods to search the models with higher likelihoods. Zhao et al. [
23] considered randomly swapping the mixture components during optimization, which allows a more flexible search than splitting and merging components. Because these methods aim only to optimize the models, there remains the problem of interpreting them.
We also refer to the agglomerative hierarchical clustering as a similar approach to merging components. Our methods are similar to the Bayesian hierarchical clustering methods [
24,
25] in that the number of merging is automatically decided. However, our approaches can not only create clusters, but also evaluate their shape and closeness under the assumption that the mixture models are given.
2.4. Visualization
Methods of interpreting clustering structures have been studied along with visualization methods. Visualizing the values of criteria with a dendrogram is useful for understanding cluster structures among sub-components [
6]. Class-preserved projections [
26] and parametric embedding [
27] were proposed for visualizing structures among upper-clusters by reducing data dimension. We present a method to interpret both structures uniformly based on the MC and NMC.
3. Merging Mixture Components
We assume that data
and a finite mixture model are given. The probability distribution of the model
f is written as follows:
where
K denotes the number of components,
denote the mixture proportions of each component summing up to one, and
denote the probability distributions. We assume that the data
are independently sampled from
f. The random variable
X following
f is called an
observed variable, because it can be observed as a data point. We also define the
latent variable as the index of the component from which
X originated. The pair
is called a
complete variable. The distribution of the latent variable
and the conditional distribution of the observed variable
can be given by the following:
In the case that f is not known, we will replace f by its estimation under the assumption that is so close to f that can be approximately regarded as samples from .
We discuss identifying cluster structures in
and
f by merging mixture components as described below. First, we define a criterion function denoted as
which measures the degree of overlap or closeness between two components. For simplicity, we change the sign of the original definitions as needed so that
takes smaller values as the components are closer. Then, we choose the closest two components that minimize the criterion and merge them. By repeating the merging process several times, we finally obtain clusters. We show the pseudo-code and computational complexity of this procedure in
Appendix A.
4. Essential Conditions
In this section, we propose three
essential conditions that the criteria should satisfy, so that the criteria can be compared in terms of the conditions. To establish the conditions, we restrict the criteria to those that can be calculated from the posterior probability of the latent variables
defined as follows:
where
k is the index of the component. After merging the components
i and
j, the posterior probability can be easily updated as follows:
Note that some other merging methods reestimate the distribution of the merged components as a single component [
4]. We do not consider these in this study because they lack the benefit that the merged components can have complex shapes.
For later use, we define
and
as the best and worst values that the criteria can take:
where
is a set of
real values in
that satisfies
for all
n.
We formulate the three conditions. They provide natural and minimum conditions on the behaviors in the extreme cases that the components are entirely overlapped or separated and on the scale invariance of the criteria. The conditions for the moderate cases that the components partially overlap should be investigated in further studies.
First, we define the condition that a criterion should take the best value when the two components entirely overlap. It is formally defined as follows.
Definition 1. If a criterion satisfies thatthen, we say that it satisfies the condition BO (best in entirely overlap).
Next, we define the condition that the criterion should take the worst value when the two components are entirely separated.
Definition 2. We consider that the sequence of the models satisfies the following:as . We define as the criterion value based on . Then, if (1) implies thatwe say that it satisfies the condition WS (worst in entirely separate).
Note that this definition is written using limits in case that the distribution of the components has support in the entire space, such as the Gaussian distributions.
Finally, we define the condition that the value of the criterion should be invariant with the scale of mixture proportions.
Definition 3. We consider that the components i and j are isolated from the other components, i.e., the sequence of the models satisfies the following:for all and n as . In addition, we consider another sequence of the mixture model with different scales on the mixture proportions of the components i and j, i.e., holds for some . We define as the criterion value based on . Then, we say that the criterion satisfies the condition SI (Scale invariance)
if for any a, the following holds:
5. Modifying Merging Methods
In this section, we introduce the existing merging criteria and propose new criteria by modifying them so that they can satisfy more essential conditions.
5.1. Entropy-Based Criterion
First, we introduce the
entropy-based criterion (Ent) proposed by Baudry et al. [
5]. It selects the components that reduce the entropy of the latent variable the most. This criterion, denoted as
, is formulated as follows:
where
.
However, it violates the conditions BO and SI. Therefore, we propose to modify it in two regards. First, we correct the scale of the weights to make
satisfy SI. We propose a new criterion
defined as follows:
where
. This satisfies the condition SI.
Next, we propose removing the effects of the weight biases to make
satisfy BO. We further introduce a new criterion
defined as follows:
This satisfies all conditions: BO, WS, and SI.
5.2. Directly Estimated Misclassification Probabilities
Second, we introduce the criterion named directly estimated misclassification probabilities (DEMP) [
4]. It selects the components with the highest misclassification probabilities. The criterion is formulated as follows:
where
However, this violates the condition BO when
is not
i or
j for some
n. Therefore, we modify it by restricting the choice of the latent variable to component
i or
j. We define
as follows:
and define
by replacing
with
in the definition of
. Then, this satisfies all essential conditions.
5.3. Mixture Complexity
Finally, we propose a new criterion based on mixture complexity (MC) [
7]. MC is an extended concept of (the logarithm of) the number of clusters into a real value considering the overlap and bias among the components. It is defined based on information theory, and formulated as follows:
where
denotes the weights of the data
,
denotes their sum, and
is redefined as
. Examples of MC for mixtures of two components are shown in
Figure 3. In them, the exponential of the MCs take values between 1 and 2, according to the uncertainty in the number of clusters induced by the overlap or weight bias between the components.
We first propose a new merging criterion
to select the components whose MCs are the smallest. It is defined as follows:
However, this does not satisfy the condition WS because of the effects of the weight biases. Therefore, we modify it by removing the biases to propose a new criterion, which we call the
normalized mixture complexity (NMC)
. The criterion is defined as follows:
It satisfies all conditions BO, WS, and SI. Note that it is equivalent to because .
We summarize the relationships between the criteria and the essential conditions in
Table 1. The modification led to the fulfillment of many conditions.
6. Stopping Condition
We also propose a new stopping condition based on NMC. First, we calculate the NMC for the (unmerged) mixture model
f defined as follows:
Since it represents the average degree of separation in the components of f, it can be used for the stopping condition for merging. Then, before merging components i and j, we compare to . If , then the merging algorithm halts without merging components i and j. Otherwise, the algorithm merges components i and j and continues further.
Note that this stopping criterion can be applied when a criterion other than is used. In this case, we use the criterion to search the two closest components and use NMC to decide whether to merge them.
7. Clustering Summarization
In this section, we propose methods to quantitatively explain the merging results, using the MC and NMC.
We consider that a mixture model with
K-component is merged into
L upper- components. We define the sets
that partition
as the sets of the indices that are contained in each upper-component. Then, the MC and NMC among the upper-components, denoted as
and
, respectively, can be calculated as follows:
where
denotes the weight of the upper-component
l calculated as follows:
For each
l, the MC and NMC in the sub-components within the upper-component
l, written as
and
, respectively, can be calculated as follows:
where
denotes the relative weight of the sub-component
calculated as
NMC is undefined if the denominator is 0.
MC and NMC quantify the degree to which the components are regarded as clusters in different ways: larger values indicate that the components definitely look like different clusters. MC quantifies this by measuring (the logarithm of) the number of clusters continuously, considering the ambiguity induced by the overlap and weight bias among the components. It takes a value between 0 and the logarithm of the number of the components. In contrast, NMC measures the scattering of the components based only on their overlap. It takes a value between 0 and 1. They have also the desirable properties that they are scale invariant and can quantify overlaps among more than two components.
Therefore, we propose the summarization of clustering structures by listing , , component weights, , and in a table, which we call the clustering summarization. The clustering summarization is useful for evaluating the confidence level of the clustering results.
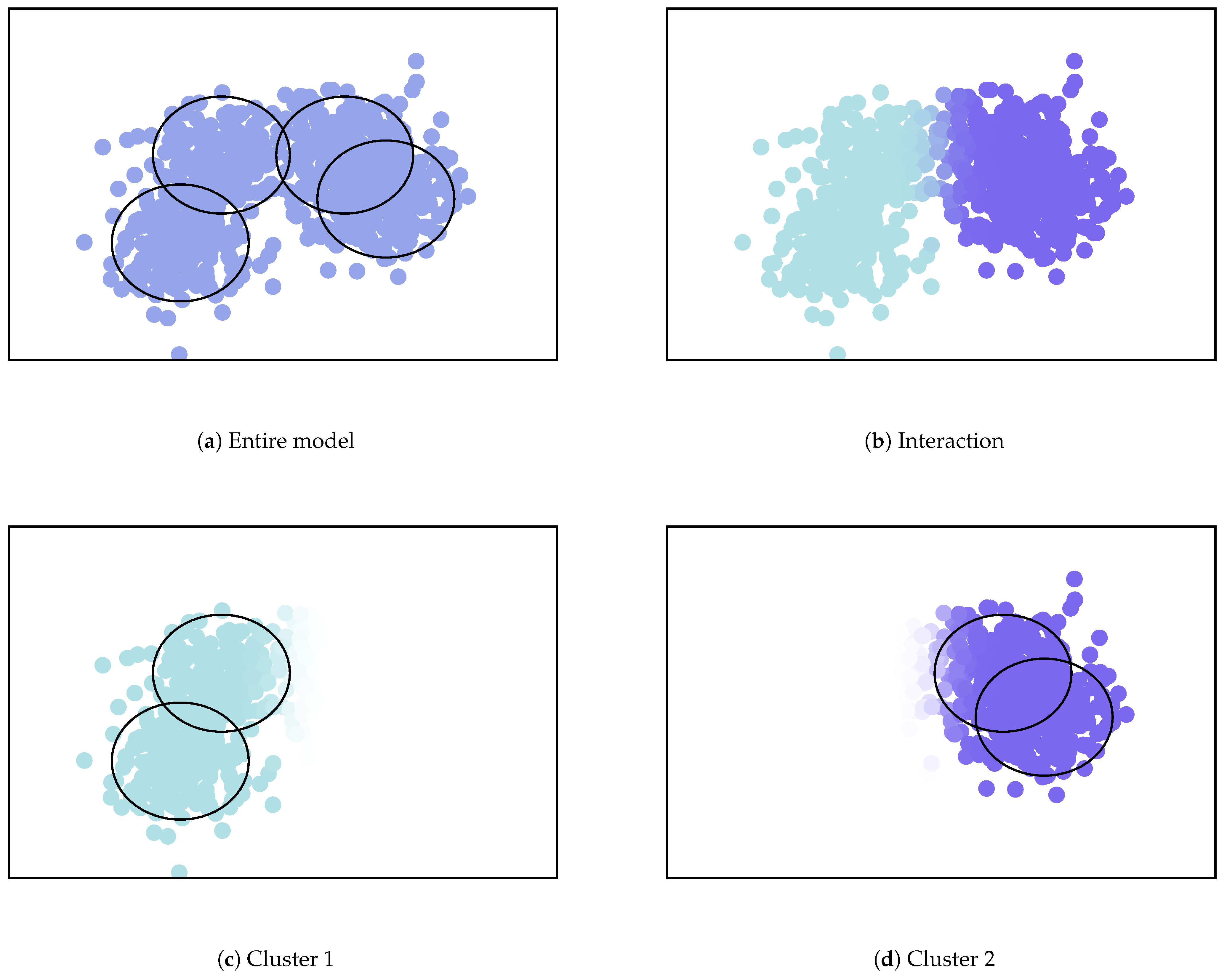
We show an example of the clustering summarization using the mixture model illustrated in
Figure 4. In this example, there are four Gaussian components as illustrated in
Figure 4a, and two merged clusters on the left and right sides as illustrated in
Figure 4b–d. The clustering summarization is presented in
Table 2. For the upper-components, the exponential of MC is almost two, and the NMC is almost one. This indicates that two upper-components can be definitely regarded as different clusters. For both sub-components, the exponential of MC is larger than one. This indicates that they have more complex shapes than a single component. Moreover, the structures within Component 1 are more complex than those in 2, because the MC and NMC are larger.
8. Experiments
In this section, we present the experimental results to demonstrate the effectiveness of merging the mixture components and modifying the criteria.
8.1. Analysis of Artificial Dataset
To reveal the differences among the criteria, we conducted experiments with artificially generated Gaussian mixture models. First, we randomly created a two-dimensional Gaussian mixture model
as follows:
where
denotes the Dirichlet distribution, and
denotes the uniform distribution from
m to
M. Then, we sampled 5000 points
from
f, and ran the merging algorithms without stopping conditions. The algorithms were evaluated using the (maximum) intra-cluster distance
and (minimum) inter-cluster distance
defined as follows:
where
denote the centers of the components defined as
The clustering structure is said to be
better, as
is smaller and
is larger. Both distances are measured with several
K and compared among the algorithms with different criteria. Although we may obtain better results for these metrics by using them as merging criteria in a similar way as used in hierarchical clustering [
28,
29], we used them only for comparison rather than optimizing them.
The experiments were performed 100 times by randomly generating
f and the data. Accordingly, the ranking of the criteria was calculated for each distance.
Table 3 presents the average rank of each criterion. As seen from the table, the modifications of the criteria improved the rank. In addition, DEMP2 and NMC, satisfying all essential conditions, were always in the top three. These results indicate the effectiveness of the essential conditions.
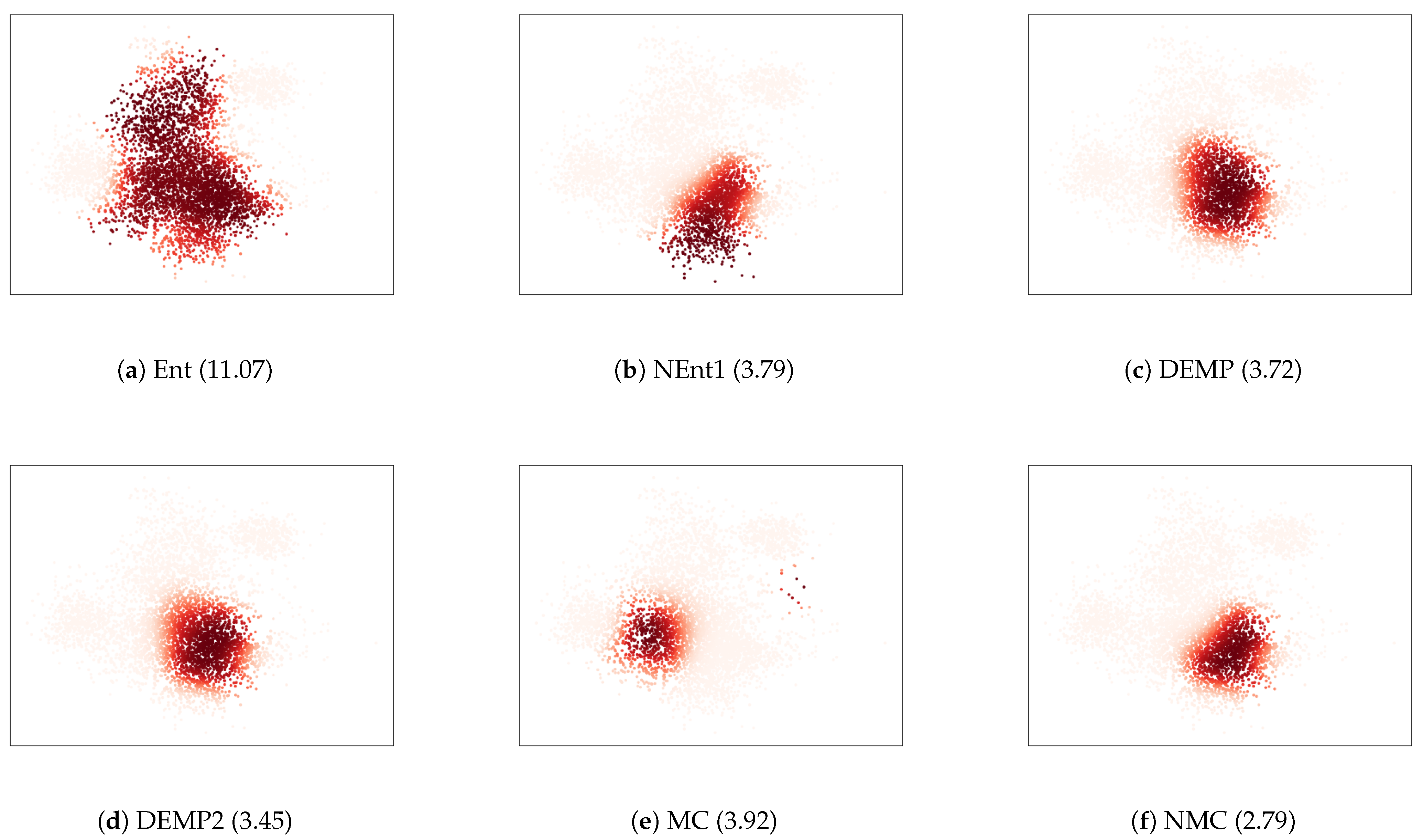
To further investigate the relationships between the essential conditions and resulting cluster structures, we illustrated the cluster obtained in a trial where the intra-cluster distance was the largest in
Figure 5. For the criterion Ent, one cluster continued to grow. This is because Ent lacks the condition SI, and is advantageous for larger clusters. For the criterion NEnt1, the growth of the larger clusters was mitigated by adding the condition SI to Ent. Nevertheless, the intra-cluster distances were still large because NEnt lacked the condition BO. It tended to create unnecessarily large clusters because it tended to merge larger and more distant components rather than smaller and closer components. The criterion NMC improved such a disadvantage by adding the condition BO to NEnt1. For the criterion MC, distant components were merged, as the condition WS was not satisfied. NMC overcame this by adding the condition WS to MC. The differences between DEMP and DEMP2 were unclear in
Figure 5c,d, and both criteria elucidated the cluster structure well because they satisfied relatively many conditions. We conclude that the essential conditions are effective for obtaining better cluster structures.
8.2. Analysis of Real Dataset
We discuss the results of applying the merging algorithms and clustering summarization to eight types of real datasets with true cluster labels. The details of the datasets and processing are described in
Appendix B.
8.2.1. Evaluation of Clustering Using True Labels
First, we compared the clustering performance of the merging algorithms by measuring similarity between estimated and true cluster labels. Formally, given the dataset
and the true labels
, we first estimated the clustering structures using
without seeing
, and obtained the estimated labels
. We define
and
as the number of the true and estimated clusters. Then, we evaluated the similarity between
and
using the adjusted Rand index (ARI) [
30] and F-measure. ARI takes values between -1 and 1, and F-measure takes values between 0 and 1. Their larger value corresponds to better clustering. Both indices can be applied when the number of true and estimated clusters is different.
To run the merging algorithms, the mixture models should be estimated first. In our experiments, we estimated them by the variational Bayes Gaussian mixture model with
[
31] implemented in the Scikit-learn package [
32]; we adopted this, as it exhibited good performance in our experiments. We used the prior distributions of the mixture proportions as the Dirichlet distributions with
, and we set the other parameters for prior distributions as the default values in the package. For each dataset, we fitted the algorithm ten times with different initializations and used the best one.
We compared the merging algorithms with three types of model-based clustering algorithms based on the Gaussian mixture model, which are summarized in
Table 4. First, we estimated the number of components, using BIC [
33]. It selects a suitable model for describing the densities, and the mixture components tend to overlap. Nevertheless, it has been widely used for clustering by regarding each component as a cluster. Second, we estimated the number of clusters using DNML [
11,
12]. It selects a model whose components can be regarded as clusters by considering the description length of the latent and observed variables. Finally, we estimated the clusters as the mixture of Gaussian mixture models implemented by Malsiher-Walli et al, [
20]. By fixing two integers
K and
L,
K Gaussian mixture models were estimated with
L components. The number of clusters was automatically adjusted by shrinking the redundant clusters. As in the original paper, we set
(and some specific parameters in the paper) for the DLB dataset and
for the other datasets.
We estimated the models ten times and compared the average score among the methods. The average number of clusters are listed in
Table 5, and F-measure and ARI are listed in
Table 6 and
Table 7.
Two clusters that achieved the best score and that were obtained by the heuristics proposed in
Section 6 are described. The best scores of the merging algorithms exceeded those of all other methods for six out of eight datasets. In particular, the merging methods satisfying many essential conditions, such as DEMP, DEMP2, and NMC, obtained high scores with a smaller number of clusters. Therefore, it can be said that the merging algorithms with more essential conditions are effective for elucidating the clustering structures. Moreover, the scores with NMC-based stopping conditions exceeded those of all other methods for four out of eight datasets.
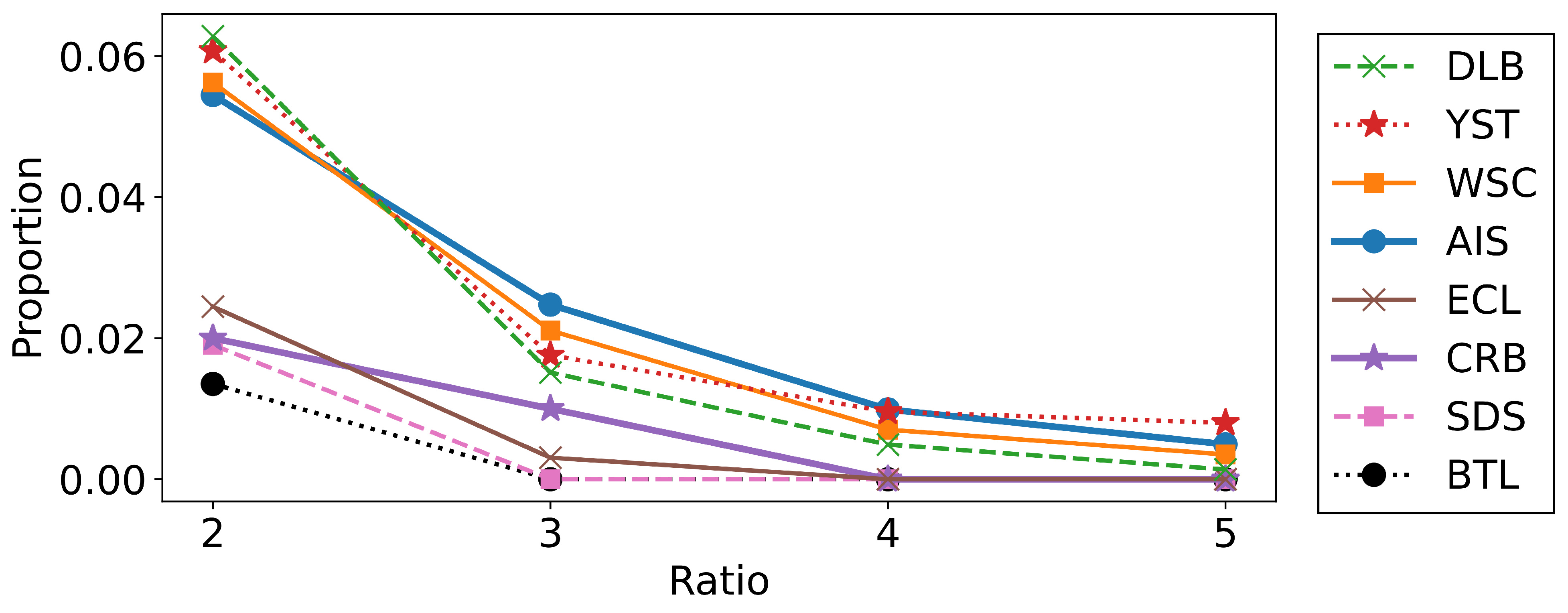
To further investigate the relationships between the performances of the algorithms and the shapes of the datasets, we estimated the proportion of outliers based on the
k-nearest neighbor distances
. We calculated the ratio of the 5-nearest neighbor distance
and its average
for each data point, and we plotted the proportions for which the ratio exceeded 2.0, 3.0, 4.0, and 5.0 in
Figure 6. As seen from the figure, the datasets where the merging methods did not work well, such as AIS, DLB, WSC, and YST, contained relatively many outliers. This is reasonable because the merging algorithms do not aim to merge distant clusters. We can conclude that the merging methods are particularly effective when the datasets have fewer outliers or when we want to find the aggregated clusters.
8.2.2. Results of Clustering Summarization
Next, we analyzed the results of the merging methods using the clustering summarization proposed in
Section 7. As examples, we show one result obtained using the NMC and NMC-based stopping conditions for the Flea beetles and Wisconsin breast cancer datasets. The clustering results are summarized in
Table 8 and
Table 9, respectively. For the upper-components in Flea beetles dataset, the exponential of
was close to 3.0, and
was close to 1.0; we see that the effective number of clusters was around three, and the clusters were well-separated. Components 2 and 3 were unmerged, and the exponentials of MC and NMC of Component 1 were close to 1.0 and 0.0, respectively. This indicates that each cluster can be represented by almost a single Gaussian distribution. Furthermore, the (exponentials of) MC and the NMC of the upper-components in the Wisconsin cancer dataset were 1.66 and 0.763, respectively. It can be expected that the situation was a partial overlap of the two clusters. For Components 1 and 2, NMCs were relatively large. This shows that partially separated components are needed to describe each component. MC of Component 2 was smaller than that of Component 1. Then, it is expected that Component 2 had simpler shapes than Component 1; however, the former seemed to have small components that might be outliers because NMC was larger. Plots of the predicted clusters are illustrated for the Flea beetles and Wisconsin breast cancer datasets in
Figure 7 and
Figure 8, respectively. We observe that the predictions described previously match to the actual plots. Therefore, we can reveal significant information about the clustering structures by observing the clustering summarizations.
8.2.3. Relationships between Clustering Summarization and Clustering Quality
Finally, we confirmed that MC and NMC in the sub-components were also related to the quality of classification. To confirm this, we conducted additional experiments discussed below. First, we ran the merging algorithms until
without the stopping conditions. Then, for every merged clusters created at
, we counted the number of data points classified into them. We define
as the number of points with true labels
k classified into the merged cluster
C. Then, we evaluated the quality of the cluster
C using the entropy calculated as follows:
where the cluster
C for
were omitted. This takes values between 0 and
. Smaller values are preferred, because
becomes small when most of the points within the component share the same cluster label. We calculated the MC/NMC and
within the clusters for all datasets and merging algorithms, and we plotted the relationships between them in
Figure 9. Note that the unmerged clusters were omitted because the NMC could not be defined. From the figure, it is evident that both MC and NMC had positive correlations with
. The correlation coefficients were 0.794 and 0.637 for MC and NMC, respectively. This observation is useful in applications. If the obtained cluster has smaller MC and NMC, then we can confirm that it contains only one group. Otherwise, we need to assume that it contains more than one group. Therefore, we conclude that MC and NMC indicate the confidence level of the cluster structures.
9. Discussion
To improve the interpretability of the mixture models with overlap, we have established novel methodologies to merge the components and summarize the results.
For merging mixture components, we proposed essential conditions that the merging criteria should satisfy. Although there have been studies creating some rules in the clustering approach [
34,
35], they have not been applied to clustering by merging components. The proposed essential conditions for merging criteria contributed to comparing and modifying existing criteria. The limitation of our conditions is that they only provide the necessary conditions for extreme cases, where the components are entirely overlapped or separated. The conditions for the moderate cases that the components partially overlap should be investigated in further studies.
We also proposed a novel methodology to interpret the merging results based on clustering summarization. While previous studies [
6,
26,
27] have focused on interpreting the structures among sub-components or upper-clusters only, our methods can quantify both structures uniformly based on the MC and NMC. They represented the overview of the structures in the mixture models by evaluating how much the components were distinguished based on the degree of overlap and weight bias.
We verified the effectiveness of our methods, using artificial and real datasets. In the artificial data experiments, we confirmed that the intra- and inter-cluster distances were improved corresponding to the modification of the criteria. Further, by observing the clusters with maximum intra-cluster distance, we found that the essential conditions were helpful to prevent the clusters from merging distant components or growing too much. In the real data experiments, we confirmed that the best scores of the proposed methods were better than the comparison methods for many datasets, and the scores obtained using the stopping condition were also better for the datasets containing relatively smaller outliers. In addition, we confirmed that the clustering summary was helpful to interpret the merging results. It was related to the shape of the clusters, weight biases, and the existence of the outliers. Further, we found that the MC and NMC within the components were also related to the quality of the classification. Therefore, the clustering summary also represented the confidence level of the cluster structures.
10. Conclusions
We have established the framework of theoretically interpreting overlapping mixture models by merging the components and summarizing merging results. First, we proposed three essential conditions for evaluating cluster-merging methods. They declared necessary properties that the merging criterion should satisfy. In this framework, we considered Ent, DEMP, and MC and their modifications to investigate whether they satisfied the essential conditions. The stopping condition based on NMC was also proposed.
Moreover, we proposed the clustering summarization based on MC and NMC. They quantify how overlapped the clusters are, how biased the clustering structure is, and how scattered the components are in a respective cluster. We can conduct this analysis from higher level clusters to lower level components to give a comprehensive survey of the global clustering structure. We then quantitatively explained the shape of the clusters, weight biases, and existence of the outliers.
In the experiments, we empirically demonstrated that the modification of the merging criteria improved the ability to find better clustering structures. We also investigated the merging order for each criterion and found that the essential conditions were helpful to prevent the clusters from merging distant components or growing too much. Further, we confirmed, using the real dataset, that the clustering summary revealed varied information in the clustering structure, such as the shape of the clusters, weight biases, the existence of the outliers, and even the confidence level of the cluster structures. We believe that this methodology gives a new view of the interpretability/explainability for model-based clustering.
We have studied how to interpret the overlapping mixture models after they were estimated. It remains for future study to apply merging criteria even in the phase of estimating mixture models.




{kind=link}
{kind=link}
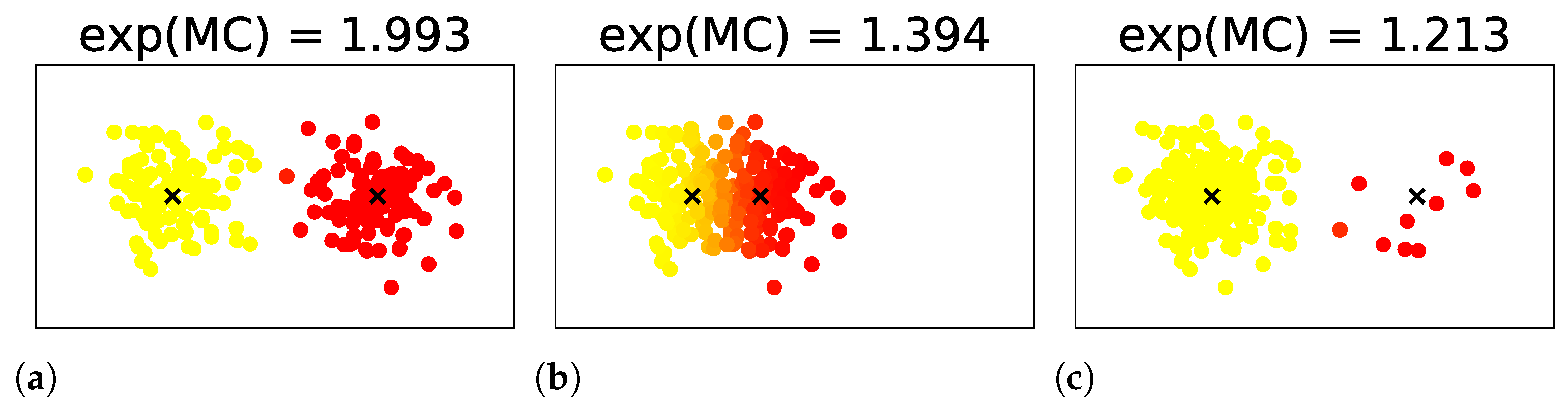{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}