
How to Effectively Collect and Process Network Data for Intrusion Detection?

 , , ,
, , ,
Abstract
:1. Introduction
Motivation, Methodology and Main Objectives
- To establish and verify an optimal set of flow-based features usable for network intrusion detection,
- To establish the minimal amount of labeled data necessary to train a machine-learning-based NIDS for effective deployment,
- To clear the path for anyone wishing to collect an NIDS dataset.
- Establishes a set of effective and usable flow-based features based on five recent benchmark datasets.
- Establishes a minimum amount of data that allows the training of an ML classifier in IDS.
- Validates the findings by training a set of different ML models and reports the results.
2. Related Works
3. Machine Learning over NetFlow Data
3.1. Collecting Data
3.2. Datasets
- UNSW-NB15 [39]—The dataset was created in 2015, with the IXIA PerfectStorm tool. Using this software, clean traffic and various types of network anomalies were generated. Approximately 100 GB of data stored as PCAP files was collected and thanks to the developers at The Cyber Range Lab of the Australian Centre for Cyber Security (ACCS), the collection has been made public as part of further research into improving network security. The structure of the collection originally contained 49 features and encompassed 2,218,761 samples of clean traffic, which is about 87.35% of the whole collection. The rest, i.e., 321,283 network frames, is made up of executed attacks.
- BoT-IoT [40]—Developers in Australia (ACCS) also created this dataset in 2018. In this case, a network flow taking place in a real network environment was recorded. This collection estimates about 69 GB of data in PCAP format and contains 42 features. The diversity of traffic in this collection is very uneven as it contains only 477 frames and there are 3,668,045 flows of the infected traffic. This results in normal traffic of only 0.01%.
- ToN-IoT [41]—this data collection is very similar to the BoT-IoT collection, as it also contains very many attacks and very little normal traffic. The collection comes from the IoT network, more precisely from service telemetry data, and was recorded in 2020. The number of infected frames equals 21,542,641 samples while normal traffic is only 796,380 flows. This represents a percentage of 96.44% for the infected samples and 3.56% for normal traffic, respectively.
- CSE-CIC-IDS2018 [42]—in 2018, another dataset made available through a collaboration between two organizations: Communications Security Establishment (CSE) and the Canadian Institute for Cybersecurity (CIC), was released. This is a very realistic set, as the scenario was designed using the infrastructure of five large organizations and server rooms. Normal traffic was generated by human users and several different machines were used to attack these networks. The whole collection contains 73 features and consists of a large amount of data amounting to 16,232,943 flows. The attacks in this collection represent 2,748,235 samples and the normal traffic represents 13,484,708 flows.
- UQ-NIDS [43]—a dataset that was created by combining the four previously presented datasets. It represents the advantages of shared datasets, where it is possible to combine multiple smaller datasets, which leads to a larger and more versatile NIDS dataset containing flows from multiple network configurations and different attack settings. This network dataset contains 11,994,893 flows, of which 9,208,048 (76.77%) are benign flows and 2,786,845 (23.23%) are attacks.
3.3. Feature Selection
- Filter methods,
- Wrapper methods,
- Embedded methods,
- Hybrid methods.
3.4. The Effect of Training Data Size on the Model
| Algorithm 1 The process of extracting and splitting a dataset. |
|
3.5. Classification Models
4. Experiments and Results
5. Discussion
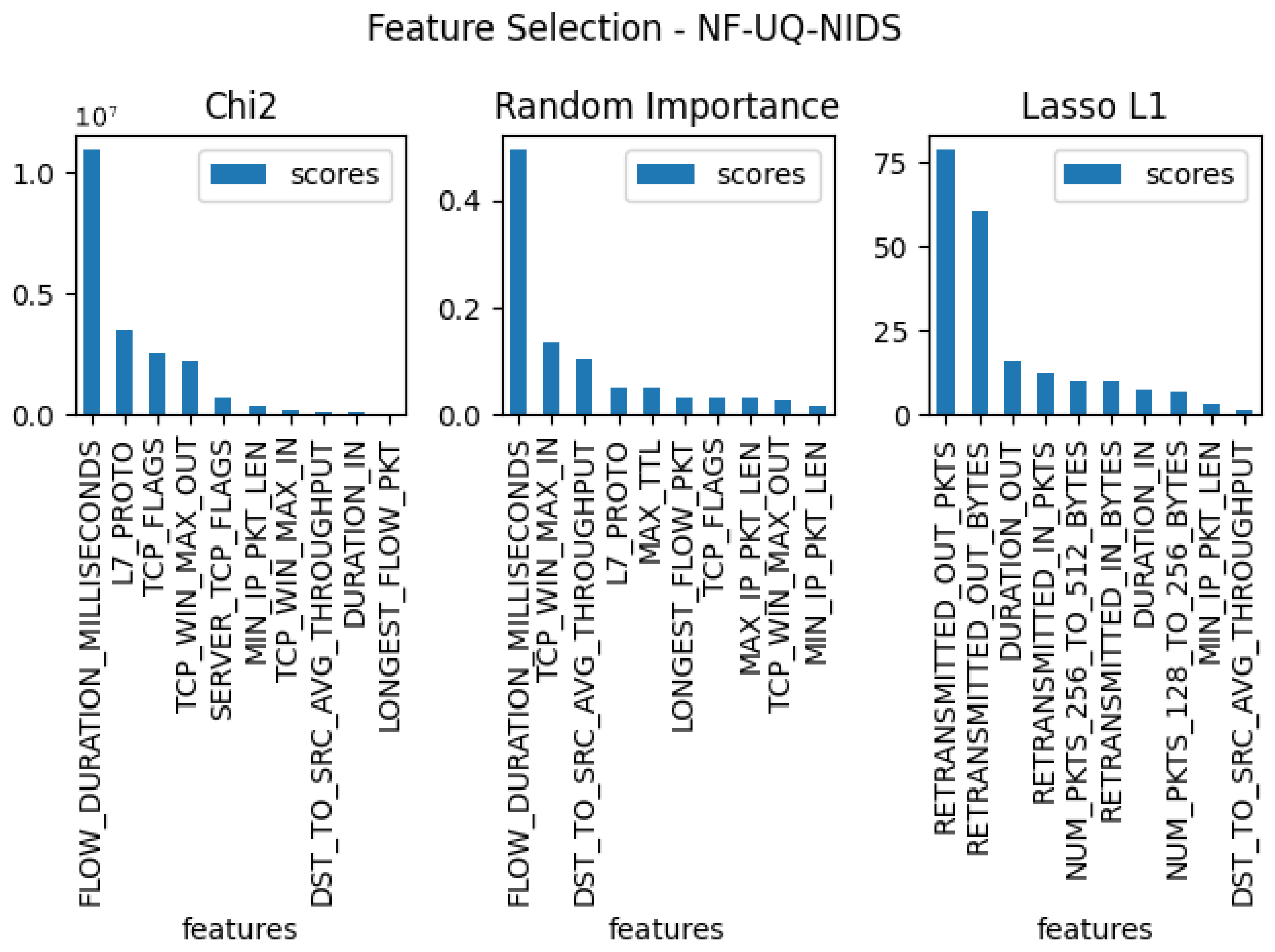
- FLOW_DURATION_MILLISECONDS
- TCP_WIN_MAX_IN
- DURATION_OUT
- MAX_TTL
- L7_PROTO
- SRC_TO_DST_AVG_THROUGHPUT
- SHORTEST_FLOW_PKT
- MIN_IP_PKT_LEN
- TCP_WIN_MAX_OUT
- OUT_BYTES
6. Conclusions and Threats to Validity
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Kaur, J.; Ramachandran, R. The Recent Trends in CyberSecurity: A Review. J. King Saud-Univ.-Comput. Inf. Sci. 2021. [Google Scholar] [CrossRef]
- Pawlicka, A.; Jaroszewska-Choras, D.; Choras, M.; Pawlicki, M. Guidelines for Stego/Malware Detection Tools: Achieving GDPR Compliance. IEEE Technol. Soc. Mag. 2020, 39, 60–70. [Google Scholar] [CrossRef]
- Mihailescu, M.E.; Mihai, D.; Carabas, M.; Komisarek, M.; Pawlicki, M.; Hołubowicz, W.; Kozik, R. The Proposition and Evaluation of the RoEduNet-SIMARGL2021 Network Intrusion Detection Dataset. Sensors 2021, 21, 4319. [Google Scholar] [CrossRef]
- Komisarek, M.; Pawlicki, M.; Kozik, R.; Choras, M. Machine Learning Based Approach to Anomaly and Cyberattack Detection in Streamed Network Traffic Data. J. Wirel. Mob. Netw. Ubiquitous Comput. Dependable Appl. 2021, 12, 3–19. [Google Scholar] [CrossRef]
- Komisarek, M.; Choras, M.; Kozik, R.; Pawlicki, M. Real-time stream processing tool for detecting suspicious network patterns using machine learning. In Proceedings of the ARES 2020: The 15th International Conference on Availability, Reliability and Security, Virtual Event, Ireland, 25–28 August 2020; Volkamer, M., Wressnegger, C., Eds.; ACM: New York, NY, USA, 2020; pp. 60:1–60:7. [Google Scholar] [CrossRef]
- Komisarek, M.; Pawlicki, M.; Kowalski, M.; Marzecki, A.; Kozik, R.; Choraś, M. Network Intrusion Detection in the Wild-the Orange use case in the SIMARGL project. In Proceedings of the 16th International Conference on Availability, Reliability and Security, Vienna, Austria, 17–20 August 2021; pp. 1–7. [Google Scholar]
- Szczepanski, M.; Komisarek, M.; Pawlicki, M.; Kozik, R.; Choraś, M. The Proposition of Balanced and Explainable Surrogate Method for Network Intrusion Detection in Streamed Real Difficult Data. In International Conference on Computational Collective Intelligence; Springer: Cham, Switzerland, 2021; pp. 241–252. [Google Scholar]
- Choraś, M.; Pawlicki, M. Intrusion detection approach based on optimised artificial neural network. Neurocomputing 2021, 452, 705–715. [Google Scholar] [CrossRef]
- Ring, M.; Wunderlich, S.; Scheuring, D.; Landes, D.; Hotho, A. A survey of network-based intrusion detection data sets. Comput. Secur. 2019, 86, 147–167. [Google Scholar] [CrossRef] [Green Version]
- Ghafir, I.; Prenosil, V.; Svoboda, J.; Hammoudeh, M. A Survey on Network Security Monitoring Systems. In Proceedings of the 2016 IEEE 4th International Conference on Future Internet of Things and Cloud Workshops (FiCloudW), Vienna, Austria, 22–24 August 2016; pp. 77–82. [Google Scholar]
- Hofstede, R.; Celeda, P.; Trammell, B.; Drago, I.; Sadre, R.; Sperotto, A.; Pras, A. Flow Monitoring Explained: From Packet Capture to Data Analysis with NetFlow and IPFIX. IEEE Commun. Surv. Tutor. 2014, 16, 2037–2064. [Google Scholar] [CrossRef] [Green Version]
- Claise, B.; Bryant, S. Specification of the IP Flow Information Export (IPFIX) Protocol for the Exchange of IP Traffic Flow Information; Technical Report, RFC 5101; IETF: Wilmington, DE, USA, January 2008. [Google Scholar]
- Sharafaldin, I.; Lashkari, A.H.; Ghorbani, A.A. Toward generating a new intrusion detection dataset and intrusion traffic characterization. ICISSp 2018, 1, 108–116. [Google Scholar]
- Dhanabal, L.; Shantharajah, S. A study on NSL-KDD dataset for intrusion detection system based on classification algorithms. Int. J. Adv. Res. Comput. Commun. Eng. 2015, 4, 446–452. [Google Scholar]
- Subbaswamy, A.; Saria, S. From development to deployment: Dataset shift, causality, and shift-stable models in health AI. Biostatistics 2020, 21, 345–352. [Google Scholar] [CrossRef] [PubMed]
- Wang, R.Y.; Strong, D.M. Beyond Accuracy: What Data Quality Means to Data Consumers. J. Manag. Inf. Syst. 1996, 12, 5–33. [Google Scholar] [CrossRef]
- Cai, L.; Zhu, Y. The Challenges of Data Quality and Data Quality Assessment in the Big Data Era. Data Sci. J. 2015, 14, 2. [Google Scholar] [CrossRef]
- Demchenko, Y.; Membrey, P.; Grosso, P.; Laat, C. Addressing Big Data Issues in Scientific Data Infrastructure. In Proceedings of the 2013 International Conference on Collaboration Technologies and Systems (CTS), San Diego, CA, USA, 20–24 May 2013. [Google Scholar] [CrossRef] [Green Version]
- Becker, D.; King, T.D.; McMullen, B. Big data, big data quality problem. In Proceedings of the 2015 IEEE International Conference on Big Data (Big Data), 2015, Santa Clara, CA, USA, 29 October–1 November 2015; pp. 2644–2653. [Google Scholar] [CrossRef]
- Taleb, I.; Serhani, M.A.; Dssouli, R. Big Data Quality: A Survey. In Proceedings of the 2018 IEEE International Congress on Big Data (BigData Congress), San Francisco, CA, USA, 2–7 July 2018; pp. 166–173. [Google Scholar] [CrossRef]
- Althnian, A.; AlSaeed, D.; Al-Baity, H.; Samha, A.; Dris, A.B.; Alzakari, N.; Abou Elwafa, A.; Kurdi, H. Impact of Dataset Size on Classification Performance: An Empirical Evaluation in the Medical Domain. Appl. Sci. 2021, 11, 796. [Google Scholar] [CrossRef]
- Kozik, R.; Pawlicki, M.; Choraś, M. Cost-Sensitive Distributed Machine Learning for NetFlow-Based Botnet Activity Detection. Secur. Commun. Netw. 2018, 2018, 8753870. [Google Scholar] [CrossRef] [Green Version]
- Pawlicki, M.; Choraś, M.; Kozik, R.; Holubowicz, W. On the Impact of Network Data Balancing in Cybersecurity Applications. In International Conference on Computational Science; Springer: Cham, Switzerland, 2020; Volume 12140, pp. 196–210. [Google Scholar]
- Buczak, A.L.; Guven, E. A Survey of Data Mining and Machine Learning Methods for Cyber Security Intrusion Detection. IEEE Commun. Surv. Tutor. 2016, 18, 1153–1176. [Google Scholar] [CrossRef]
- Prusa, J.; Khoshgoftaar, T.M.; Seliya, N. The Effect of Dataset Size on Training Tweet Sentiment Classifiers. In Proceedings of the 2015 IEEE 14th International Conference on Machine Learning and Applications (ICMLA), Miami, FL, USA, 9–11 December 2015; pp. 96–102. [Google Scholar] [CrossRef]
- Han, S.; Kim, H. On the Optimal Size of Candidate Feature Set in Random forest. Appl. Sci. 2019, 9, 898. [Google Scholar] [CrossRef] [Green Version]
- Oujezsky, V.; Horvath, T. Traffic Similarity Observation Using a Genetic Algorithm and Clustering. Technologies 2018, 6, 103. [Google Scholar] [CrossRef] [Green Version]
- Vaarandi, R.; Pihelgas, M. NetFlow Based Framework for Identifying Anomalous End User Nodes. In Proceedings of the 15th International Conference on Cyber Warfare and Security: ICCWS 2020, Norfolk, VA, USA, 12–13 March 2020. [Google Scholar]
- Flanagan, K.; Fallon, E.; Connolly, P.; Awad, A. NetFlow Anomaly Detection Though Parallel Cluster Density Analysis in Continuous Time-Series. In Wired/Wireless Internet Communications; Koucheryavy, Y., Mamatas, L., Matta, I., Ometov, A., Papadimitriou, P., Eds.; Springer International Publishing: Cham, Switzerland, 2017; pp. 221–232. [Google Scholar]
- Mohamed, S.; Ejbali, R. Deep Learning with Moderate Architecture for Network Intrusion Detection System. In Intelligent Systems Design and Applications; Abraham, A., Piuri, V., Gandhi, N., Siarry, P., Kaklauskas, A., Madureira, A., Eds.; Springer International Publishing: Cham, Switzerland, 2021; pp. 774–783. [Google Scholar]
- Liu, W.; Duan, H.X.; Ren, P.; Li, X.; Wu, J.P. Wavelet based data mining and querying in network security databases. In Proceedings of the 2003 International Conference on Machine Learning and Cybernetics (IEEE Cat. No. 03EX693), Xi’an, China, 5 November 2003; Volume 1, pp. 178–182. [Google Scholar] [CrossRef]
- Siddiqui, S.; Khan, M.S.; Ferens, K. Multiscale Hebbian neural network for cyber threat detection. In Proceedings of the 2017 International Joint Conference on Neural Networks (IJCNN), Anchorage, AK, USA, 14–19 May 2017; pp. 1427–1434. [Google Scholar] [CrossRef]
- He, F.; Zhang, Y.; Liu, D.; Dong, Y.; Liu, C.; Wu, C. Mixed Wavelet-Based Neural Network Model for Cyber Security Situation Prediction Using MODWT and Hurst Exponent Analysis. In Network and System Security; Yan, Z., Molva, R., Mazurczyk, W., Kantola, R., Eds.; Springer International Publishing: Cham, Switzerland, 2017; pp. 99–111. [Google Scholar]
- Liu, H.; Lang, B. Machine Learning and Deep Learning Methods for Intrusion Detection Systems: A Survey. Appl. Sci. 2019, 9, 4396. [Google Scholar] [CrossRef] [Green Version]
- Fejrskov, M.; Pedersen, J.M.; Vasilomanolakis, E. Cyber-security research by ISPs: A NetFlow and DNS Anonymization Policy. In Proceedings of the 2020 International Conference on Cyber Security and Protection of Digital Services (Cyber Security), Dublin, Ireland, 15 June 2020; pp. 1–8. [Google Scholar] [CrossRef]
- Qureshi, S.; Menghwar, G.; Tunio, S.; Ullah, F.; Nazir, A.; Wajahat, A. Performance Analysis of Open Source Solution -ntop‖ for Active and Passive Packet Analysis Relating to Application and Transport Layer. Int. J. Adv. Comput. Sci. Appl. 2019, 10, 4. [Google Scholar] [CrossRef]
- Deri, L. nProbe: An Open Source NetFlow Probe for Gigabit Networks. In Proceedings of the TERENA Networking Conference 2003, Zagreb, Croatia, 19–22 May 2003. [Google Scholar]
- Sarhan, M.; Layeghy, S.; Moustafa, N.; Portmann, M. NetFlow Datasets for Machine Learning-based Network Intrusion Detection Systems. arXiv 2020, arXiv:2011.09144. Available online: https://arxiv.org/abs/2011.09144 (accessed on 14 September 2021).
- Moustafa, N.; Slay, J. UNSW-NB15: A comprehensive data set for network intrusion detection systems (UNSW-NB15 network data set). In Proceedings of the 2015 Military Communications and Information Systems Conference (MilCIS), Canberra, Australia, 10–12 November 2015; pp. 1–6. [Google Scholar] [CrossRef]
- Koroniotis, N.; Moustafa, N.; Sitnikova, E.; Turnbull, B. Towards the development of realistic botnet dataset in the Internet of Things for network forensic analytics: Bot-IoT dataset. Future Gener. Comput. Syst. 2019, 100, 779–796. [Google Scholar] [CrossRef] [Green Version]
- Alsaedi, A.; Moustafa, N.; Tari, Z.; Mahmood, A.; Anwar, A. TON_IoT Telemetry Dataset: A New Generation Dataset of IoT and IIoT for Data-Driven Intrusion Detection Systems. IEEE Access 2020, 8, 165130–165150. [Google Scholar] [CrossRef]
- Sharafaldin, I.; Habibi Lashkari, A.; Ghorbani, A.A. Toward Generating a New Intrusion Detection Dataset and Intrusion Traffic Characterization. In Proceedings of the 4th International Conference on Information Systems Security and Privacy-ICISSP, INSTICC, Funchal, Portugal, 22–24 January 2018; SciTePress: Setúbal, Portugal, 2018; pp. 108–116. [Google Scholar] [CrossRef]
- Sarhan, M.; Layeghy, S.; Portmann, M. Towards a Standard Feature Set for Network Intrusion Detection System Datasets. arXiv 2021, arXiv:cs.NI/2101.11315. [Google Scholar] [CrossRef]
- Honest, N. A survey on Feature Selection Techniques. GIS Sci. J. 2020, 7, 353–358. [Google Scholar]
- Khalid, S.; Khalil, T.; Nasreen, S. A survey of feature selection and feature extraction techniques in machine learning. In Proceedings of the 2014 Science and Information Conference, London, UK, 27–29 August 2014; pp. 372–378. [Google Scholar] [CrossRef]
- Ferreira, A.J.; Figueiredo, M.A. Efficient feature selection filters for high-dimensional data. Pattern Recognit. Lett. 2012, 33, 1794–1804. [Google Scholar] [CrossRef] [Green Version]
- Jović, A.; Brkić, K.; Bogunović, N. A review of feature selection methods with applications. In Proceedings of the 2015 38th International Convention on Information and Communication Technology, Electronics and Microelectronics (MIPRO), Opatija, Croatia, 25–29 May 2015; pp. 1200–1205. [Google Scholar] [CrossRef]
- Mostert, W.; Malan, K.M.; Engelbrecht, A.P. A Feature Selection Algorithm Performance Metric for Comparative Analysis. Algorithms 2021, 14, 100. [Google Scholar] [CrossRef]
- Potdar, K.; Pardawala, T.; Pai, C. A Comparative Study of Categorical Variable Encoding Techniques for Neural Network Classifiers. Int. J. Comput. Appl. 2017, 175, 7–9. [Google Scholar] [CrossRef]
- Hancock, J.T.; Khoshgoftaar, T.M. Survey on categorical data for neural networks. J. Big Data 2020, 7, 28. [Google Scholar] [CrossRef] [Green Version]
- Muthukrishnan, R.; Rohini, R. LASSO: A feature selection technique in predictive modeling for machine learning. In Proceedings of the 2016 IEEE International Conference on Advances in Computer Applications (ICACA), Coimbatore, India, 24 October 2016; pp. 18–20. [Google Scholar] [CrossRef]
- Osman, H.; Ghafari, M.; Nierstrasz, O. Automatic Feature Selection by Regularization to Improve Bug Prediction Accuracy. In Proceedings of the 2017 IEEE Workshop on Machine Learning Techniques for Software Quality Evaluation (MaLTeSQuE), Klagenfurt, Austria, 21 February 2017. [Google Scholar] [CrossRef]
- Strobl, C.; Boulesteix, A.L.; Zeileis, A.; Hothorn, T. Bias in random forest variable importance measures: Illustrations, sources and a solution. BMC Bioinform. 2007, 8, 25. [Google Scholar] [CrossRef] [Green Version]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Nguyen, T.T.; Huang, J.Z.; Nguyen, T.T. Unbiased Feature Selection in Learning Random Forests for High-Dimensional Data. Sci. World J. 2015, 2015, 471371. [Google Scholar] [CrossRef] [PubMed]
- Suryakanthi, T. Evaluating the Impact of GINI Index and Information Gain on Classification using Decision Tree Classifier Algorithm. Int. J. Adv. Comput. Sci. Appl. 2020, 11, 612–619. [Google Scholar] [CrossRef]
- Nihan, S. Karl Pearsons chi-square tests. Educ. Res. Rev. 2020, 15, 575–580. [Google Scholar] [CrossRef]
- Hossin, M.; Sulaiman, M.N. A Review on Evaluation Metrics for Data Classification Evaluations. Int. J. Data Min. Knowl. Manag. Process 2015, 5, 1–11. [Google Scholar] [CrossRef]
- Fatourechi, M.; Ward, R.K.; Mason, S.G.; Huggins, J.; Schlögl, A.; Birch, G.E. Comparison of Evaluation Metrics in Classification Applications with Imbalanced Datasets. In Proceedings of the 2008 Seventh International Conference on Machine Learning and Applications, San Diego, CA, USA, 11–13 December 2008; pp. 777–782. [Google Scholar] [CrossRef]
- Brodersen, K.H.; Ong, C.S.; Stephan, K.E.; Buhmann, J.M. The Balanced Accuracy and Its Posterior Distribution. In Proceedings of the 2010 20th International Conference on Pattern Recognition, Istanbul, Turkey, 23–26 August 2010; pp. 3121–3124. [Google Scholar] [CrossRef]
- Chicco, D.; Jurman, G. The advantages of the Matthews correlation coefficient (MCC) over F1 score and accuracy in binary classification evaluation. BMC Genom. 2020, 21, 6. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Primartha, R.; Adhi Tama, B. Anomaly detection using random forest: A performance revisited. In Proceedings of the 2017 International Conference on Data and Software Engineering (ICoDSE), Palembang, Indonesia, 1–2 November 2017; pp. 1–6. [Google Scholar] [CrossRef]
- Huč, A.; Šalej, J.; Trebar, M. Analysis of Machine Learning Algorithms for Anomaly Detection on Edge Devices. Sensors 2021, 21, 4946. [Google Scholar] [CrossRef]
- Biswas, P.; Samanta, T. Anomaly detection using ensemble random forest in wireless sensor network. Int. J. Inf. Technol. 2021, 13, 2043–2052. [Google Scholar] [CrossRef]
- Seifert, S. Application of random forest based approaches to surface-enhanced Raman scattering data. Sci. Rep. 2020, 10, 5436. [Google Scholar] [CrossRef]
- Gulati, P.; Sharma, A.; Gupta, M. Theoretical Study of Decision Tree Algorithms to Identify Pivotal Factors for Performance Improvement: A Review. Int. J. Comput. Appl. 2016, 141, 19–25. [Google Scholar] [CrossRef]
- Yang, N.; Li, T.; Song, J. Construction of Decision Trees based Entropy and Rough Sets under Tolerance Relation. In International Journal of Computational Intelligence Systems; Atlantis Press: Paris, France, 2007. [Google Scholar] [CrossRef] [Green Version]
- Zhang, H.; Zhou, R. The analysis and optimization of decision tree based on ID3 algorithm. In Proceedings of the 2017 9th International Conference on Modelling, Identification and Control (ICMIC), Kunming, China, 10–12 July 2017; pp. 924–928. [Google Scholar] [CrossRef]
- Mazini, M.; Shirazi, B.; Mahdavi, I. Anomaly network-based intrusion detection system using a reliable hybrid artificial bee colony and AdaBoost algorithms. J. King Saud Univ.-Comput. Inf. Sci. 2019, 31, 541–553. [Google Scholar] [CrossRef]
- Yuan, Y.; Kaklamanos, G.; Hogrefe, D. A Novel Semi-Supervised Adaboost Technique for Network Anomaly Detection. In Proceedings of the 19th ACM International Conference on Modeling, Analysis and Simulation of Wireless and Mobile Systems, Malta, 13–17 November 2016; pp. 111–114. [Google Scholar] [CrossRef]
- Li, W.; Li, Q. Using Naive Bayes with AdaBoost to Enhance Network Anomaly Intrusion Detection. In Proceedings of the 2010 Third International Conference on Intelligent Networks and Intelligent Systems, Shenyang, China, 1–3 November 2010; pp. 486–489. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Wibawa, A.; Kurniawan, A.; Murti, D.; Adiperkasa, R.P.; Putra, S.; Kurniawan, S.; Nugraha, Y. Naïve Bayes Classifier for Journal Quartile Classification. Int. J. Recent Contrib. Eng. Sci. IT (IJES) 2019, 7, 91. [Google Scholar] [CrossRef]
- Szczepański, M.; Choraś, M.; Pawlicki, M.; Kozik, R. Achieving explainability of intrusion detection system by hybrid oracle-explainer approach. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020; pp. 1–8. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature | Description |
|---|---|
| IPV4_SRC_ADDR | IPv4 source address |
| IPV4_DST_ADDR | IPv4 destination address |
| L4_SRC_PORT | IPv4 source port number |
| L4_DST_PORT | IPv4 destination port number |
| PROTOCOL | IP protocol identifier byte |
| L7_PROTO | Layer 7 protocol (numeric) |
| IN_BYTES | Incoming number of bytes |
| OUT_BYTES | Outgoing number of bytes |
| IN_PKTS | Incoming number of packets |
| OUT_PKTS | Outgoing number of packets |
| FLOW_DURATION_MILLISECONDS | Flow duration in milliseconds |
| TCP_FLAGS | Cumulative of all TCP flags |
| CLIENT_TCP_FLAGS | Cumulative of all client TCP flags |
| SERVER_TCP_FLAGS | Cumulative of all server TCP flags |
| DURATION_IN | Client to Server stream duration (msec) |
| DURATION_OUT | Client to Server stream duration (msec) |
| MIN_TTL | Min flow TTL |
| MAX_TTL | Max flow TTL |
| LONGEST_FLOW_PKT | Longest packet (bytes) of the flow |
| SHORTEST_FLOW_PKT | Shortest packet (bytes) of the flow |
| MIN_IP_PKT_LEN | Len of the smallest flow IP packet observed |
| MAX_IP_PKT_LEN | Len of the largest flow IP packet observed |
| SRC_TO_DST_SECOND_BYTES | Src to dst Bytes/sec |
| DST_TO_SRC_SECOND_BYTES | Dst to src Bytes/sec |
| RETRANSMITTED_IN_BYTES | No. of r-d TCP flow bytes (src->dst) |
| RETRANSMITTED_IN_PKTS | No. of r-d TCP flow packets (src->dst) |
| RETRANSMITTED_OUT_BYTES | No. of r-d TCP flow bytes (dst->src) |
| RETRANSMITTED_OUT_PKTS | No. of r-d TCP flow packets (dst->src) |
| SRC_TO_DST_AVG_THROUGHPUT | Src to dst average thpt (bps) |
| DST_TO_SRC_AVG_THROUGHPUT | Dst to src average thpt (bps) |
| NUM_PKTS_UP_TO_128_BYTES | Packets whose IP size ≤ 128 |
| NUM_PKTS_128_TO_256_BYTES | Packets whose IP size > 128 and ≤256 |
| NUM_PKTS_256_TO_512_BYTES | Packets whose IP size > 256 and ≤512 |
| NUM_PKTS_512_TO_1024_BYTES | Packets whose IP size > 512 and ≤1024 |
| NUM_PKTS_1024_TO_1514_BYTES | Packets whose IP size > 1024 and ≤1514 |
| TCP_WIN_MAX_IN | Max TCP Window (src-dst) |
| TCP_WIN_MAX_OUT | Max TCP Window (dst-src) |
| ICMP_TYPE | ICMP Type * 256 + ICMP code |
| ICMP_IPV4_TYPE | ICMP Type |
| DNS_QUERY_ID | DNS query transaction Id |
| DNS_QUERY_TYPE | DNS query type (e.g., 1 = A, 2 = NS.) |
| DNS_TTL_ANSWER | TTL of the first A record (if any) |
| FTP_COMMAND_RET_CODE | FTP client command return code |
| Model | Parameter | Value |
|---|---|---|
| Random Forest | n_estimators | 200 |
| max_features | auto | |
| max_depth | 8 | |
| criterion | entropy | |
| AdaBoost | n_estimators | 230 |
| learning_rate | 0.05 | |
| Naïve BAYES | var_smoothing | |
| ANN | epochs | 16 |
| batch size | 20 | |
| loss function | categorical_crossentropy |
| Dataset | ACC | Precision | Recall | F1 | BCC | MCC | AUC_ROC |
|---|---|---|---|---|---|---|---|
| Random Forest | |||||||
| UNSW-NB15 | 1 | 1 | 1 | 1 | 0.9858 | 0.9653 | 0.9653 |
| BoT-IoT | 1 | 1 | 1 | 1 | 0.9989 | 0.9970 | 0.9989 |
| CSE-CIC-IDS | 1 | 1 | 1 | 1 | 0.9828 | 0.9800 | 0.9828 |
| UQ-NIDS | 0.98 | 0.98 | 0.98 | 0.98 | 0.9837 | 0.9557 | 0.9837 |
| ToN-IoT | 1 | 1 | 1 | 1 | 0.9962 | 0.9933 | 0.9962 |
| ADABOOST | |||||||
| UNSW-NB15 | 1 | 1 | 0.95 | 0.97 | 0.9943 | 0.9406 | 0.9943 |
| BoT-IoT | 1 | 1 | 1 | 1 | 0.9828 | 0.9800 | 0.9828 |
| CSE-CIC-IDS | 0.99 | 0.99 | 0.99 | 0.99 | 0.9666 | 0.9574 | 0.9666 |
| UQ-NIDS | 0.95 | 0.95 | 0.95 | 0.95 | 0.9540 | 0.8928 | 0.9540 |
| ToN-IoT | 0.94 | 0.94 | 0.94 | 0.94 | 0.9321 | 0.8690 | 0.9321 |
| Naïve BAYES | |||||||
| UNSW-NB15 | 0.98 | 0.98 | 0.98 | 0.98 | 0.8706 | 0.7902 | 0.8706 |
| BoT-IoT | 0.94 | 0.99 | 0.94 | 0.97 | 0.6275 | 0.0667 | 0.6275 |
| CSE-CIC-IDS | 0.94 | 0.94 | 0.94 | 0.94 | 0.8869 | 0.7303 | 0.8869 |
| UQ-NIDS | 0.82 | 0.86 | 0.82 | 0.83 | 0.8524 | 0.6644 | 0.8524 |
| ToN-IoT | 0.64 | 0.72 | 0.64 | 0.64 | 0.6807 | 0.3538 | 0.6807 |
| ANN | |||||||
| UNSW-NB15 | 1 | 1 | 1 | 1 | 0.9930 | 0.9164 | 0.9930 |
| BoT-IoT | 1 | 1 | 1 | 1 | 0.9034 | 0.8653 | 0.9034 |
| CSE-CIC-IDS | 0.99 | 0.99 | 0.99 | 0.99 | 0.9791 | 0.9755 | 0.9791 |
| UQ-NIDS | 0.97 | 0.97 | 0.97 | 0.97 | 0.9701 | 0.9290 | 0.9701 |
| ToN-IoT | 0.98 | 0.98 | 0.98 | 0.98 | 0.9681 | 0.9461 | 0.9681 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Komisarek, M.; Pawlicki, M.; Kozik, R.; Hołubowicz, W.; Choraś, M. How to Effectively Collect and Process Network Data for Intrusion Detection? Entropy 2021, 23, 1532. https://doi.org/10.3390/e23111532
Komisarek M, Pawlicki M, Kozik R, Hołubowicz W, Choraś M. How to Effectively Collect and Process Network Data for Intrusion Detection? Entropy. 2021; 23(11):1532. https://doi.org/10.3390/e23111532
Chicago/Turabian StyleKomisarek, Mikołaj, Marek Pawlicki, Rafał Kozik, Witold Hołubowicz, and Michał Choraś. 2021. "How to Effectively Collect and Process Network Data for Intrusion Detection?" Entropy 23, no. 11: 1532. https://doi.org/10.3390/e23111532
APA StyleKomisarek, M., Pawlicki, M., Kozik, R., Hołubowicz, W., & Choraś, M. (2021). How to Effectively Collect and Process Network Data for Intrusion Detection? Entropy, 23(11), 1532. https://doi.org/10.3390/e23111532