1. Introduction
The quantum search algorithm is one of the most significant quantum algorithms [
1]. Compared with classical search algorithms, quantum search algorithms exhibit quadratic speedup [
2,
3]. This demonstrates the superiority of quantum computing over classical computing. Grover proposed the first quantum search algorithm [
1,
4], which can find
M marked items from an unstructured database with
N items by querying only
times [
5,
6]. If the measurements are made after the optimal iterations, Grover’s algorithm will have a success rate
to find the marked items, where
and
is the number of optimal Grover iterations. If
, the maximum probability approaches 1, which means that the Grover’s algorithm usually has a high success rate if the dimension of the quantum database is very large.
There have been several important developments in the Grover’s algorithm. In some situations, such as structured search [
7], where the success rate is the product of the success rates of individual search, high success rate in each individual search is critical; especially, when dimensions are not so large, the standard Grover’s algorithm will not perform well. In order to solve this problem, some modified search algorithms have been proposed [
8,
9,
10,
11,
12]. The Grover–Long algorithm [
11], one of these improved algorithms, has been proved to be the simplest and most optimal [
13,
14]. This algorithm achieves 100% success rate, whereas Grover’s algorithm can only achieve 100% success rate when finding one out of four.
In both the original Grover and improved versions of Grover’s algorithm, one needs to know the exact number of marked states in advance. Therefore, if the exact number is not known, these algorithms can not determine when to stop [
15]. Spatial search [
16,
17,
18] is one of the methods to solve this problem. Fixed-point search algorithm is another method to solve this problem. By constructing the recursively searching operator, the ratio of marked state always amplifies after each search, the
fixed-point search algorithm of Grover [
19], for example. In this algorithm, each search approaches the marked states monotonously, but the cost of monotony is large in this algorithm, and the quadratic speedup of standard Grover’s algorithm is lost.
The Yoder–Low–Chung algorithm [
20] was proposed to improve the performance of fixed-point algorithms on wide ranges of
. It retains the quadratic speedup advantage of quantum search, and it achieves the fixed-point property at the same time. It also solves overcooking problem, but the success rate of which is not monotonically increasing as in the
algorithm. The error is bounded by a tunable parameter
over an ever-widening range of
, but the phases in each search step need to be calculated by solving a hype-trigonometric equation.
In this paper, we develop a robust quantum search algorithm, based on the Grover–Long algorithm, which overcomes the problem of not knowing the exact ratio in advance. This algorithm has the advantage of easiness in constructing the search operators, and also certain degrees of “fixed-point” properties. Namely, it enjoys a high success rate over a wide range of the ratio of . In our algorithm, we do not need to know the exact number of marked states, but rather an approximate number in the range of the ratio . The error of our algorithm is bounded by a parameter related to the . Specifically, searching operators in our algorithm are determined by the lower bound . After iterations, the probability of success is larger than , where is denoted as .
This paper is organized as follows. First of all, the Grover–Long algorithm is summarized. Secondly, the relationship between the success rate of Grover–Long algorithm and iterative steps is studied, and the relation between iteration number and success rate is given. Thirdly, we propose a robust search version of Grover–Long algorithm and show its high tolerance to the ratio
. The comparison is then made with the Yoder–Low–Chuang algorithm, standard Grover’s algorithm, and the Grover
fixed-point algorithm, respectively. Finally, we prove that our algorithm can find the target state with a success rate of more than
from an database, with only an estimate of
M, in the range between
, which can be carried out using the quantum counting algorithm [
21,
22].
2. Overview of Grover–Long Algorithm
The Grover–Long algorithm can extract
M marked items from an unstructured database with
N items by querying
times. First, from the given ratio
, parameter
can be calculated:
which is further used to determine the value of search steps
. The square brackets here represent the floor function. One can set the number of iteration as
Then, the phases in the search algorithm are calculated by
Next, the oracle operator can be expressed as
where
denotes as the superposition of
M marked states, and the phase shifting operator for the
state is
Finally, the Grover–Long operator in each iteration is
where
H is the Hadamard gate. After
steps of iterations, one can obtain the marked states with certainty by measurement. When
, we recover the original Grover’s algorithm, which usually does not find the marked states with certainly.
The quantum search algorithm can be described using the SO(3) picture [
11,
23] instead of SU(2). In this picture, the quantum search operator in Equation (
6) corresponds to a rotation in three-dimensional space with the following matrix form
where the entries of the matrix
are calculated in [
11]. The states are rotated along the
axis
with an angle
In this picture, the state vector
is represented as
where
and
,
,
are the unit vector along the
x,
y,
z axis. The initial state
and the marked state
are represented by
Each search step is a rotation of
toward
. The SO(3) description of the Grover–Long algorithm is pictured as a circle in
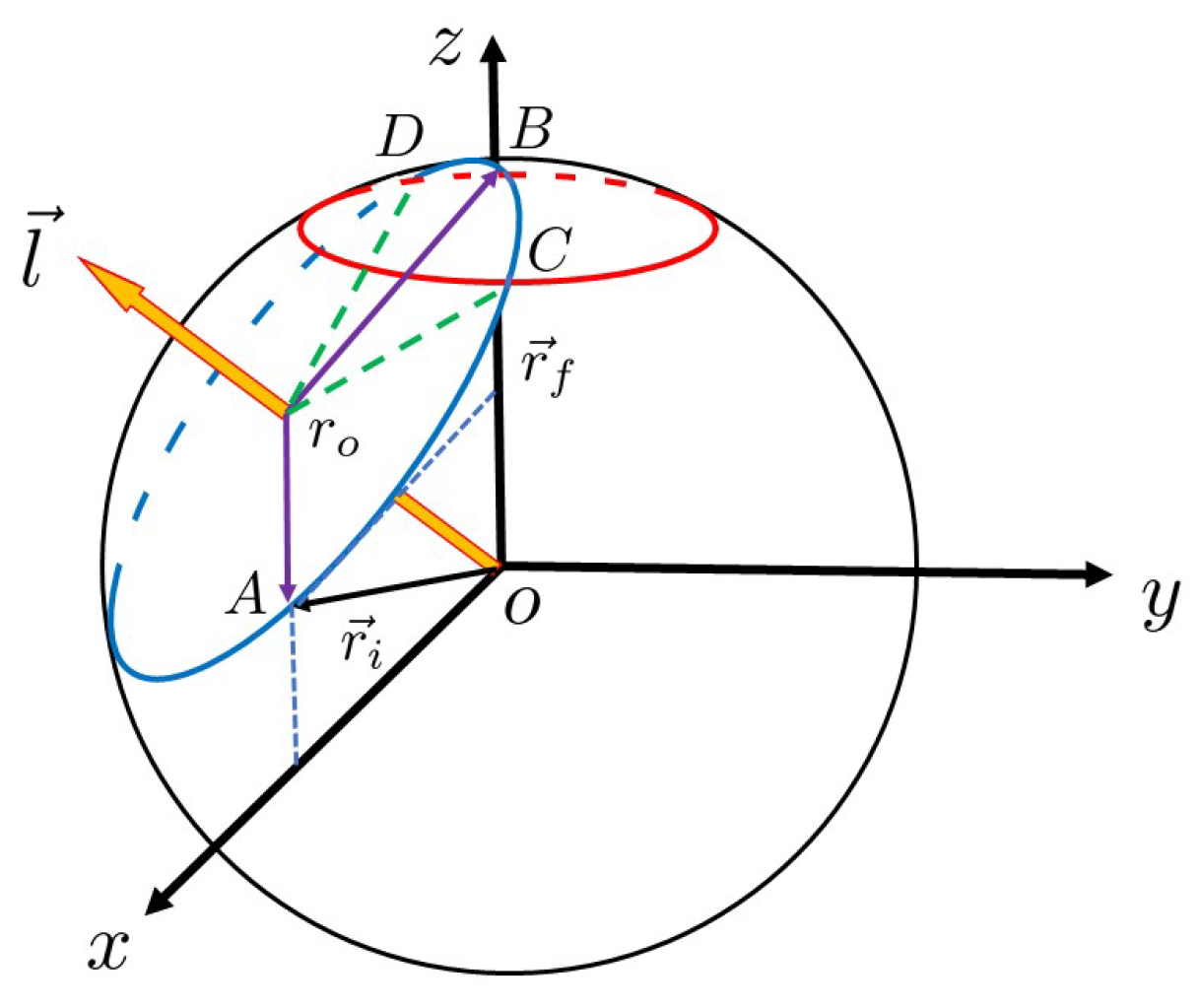
Figure 1.
3. Relationship between the Success Rate and Searching Iterations
During each search step of the Grover–Long algorithm, state
rotates toward
, which is described geometrically in
Figure 1. In other words, this process is point
A moving to point
B on the blue circle
. In this picture, the probability of finding the marked state is
[
11], where
is the
Z component of point
A. Thus, if one wants to find a marked state with a probability greater than
, point
A of the segment
must rotate into the arc
, where point
C and point
D are the intersections of the circle
and the red error circle:
. If we can calculate the arc length
, then we obtain a reasonable number of iterations.
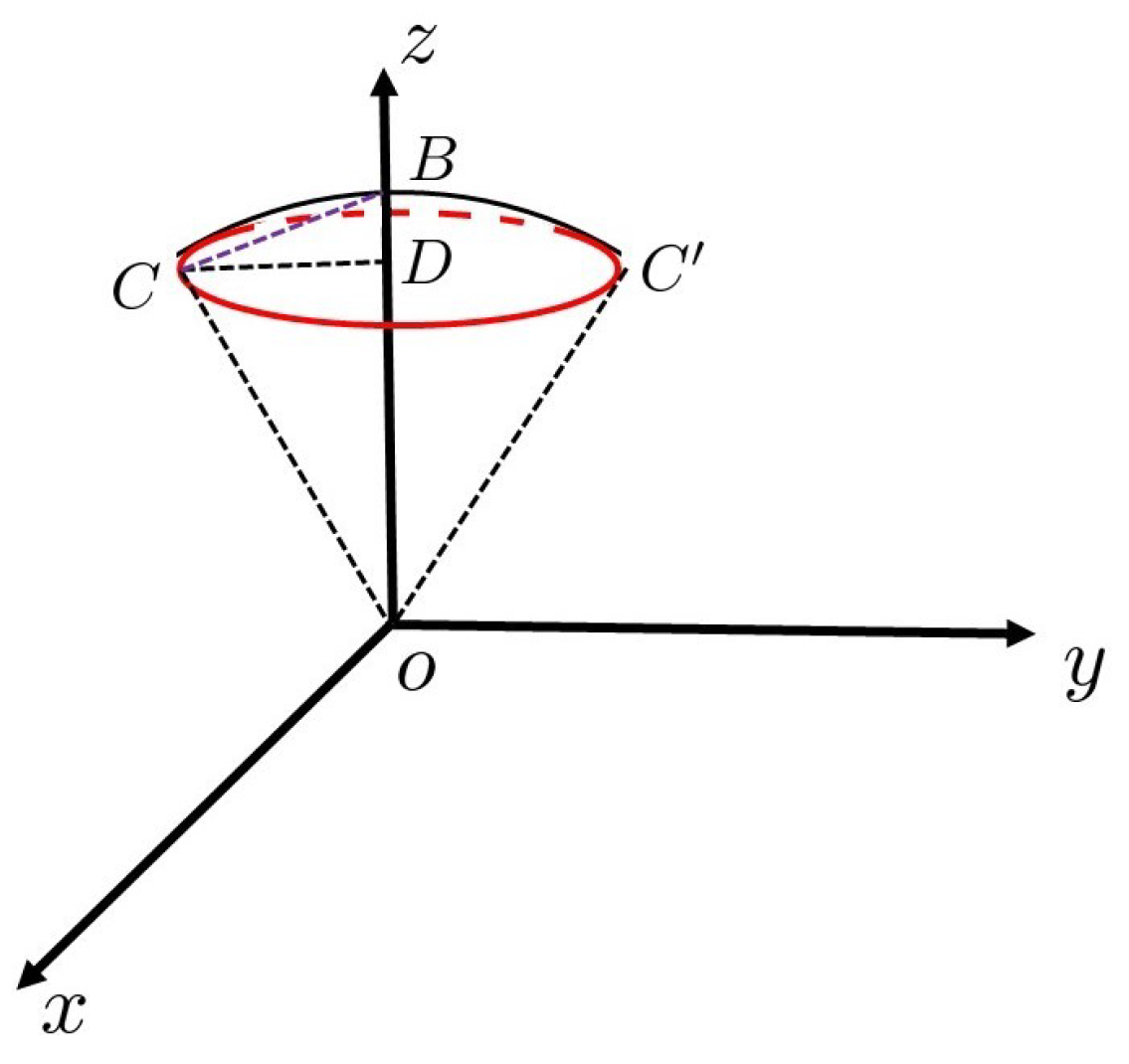
For this reason, we focus on the spherical cone, which consists of the unit sphere and the red circle. It is shown in
Figure 2. The segment
in
Figure 2 is a segment from point
to point
C on the red error circle. In
Figure 2,
,
,
. The following relationship holds:
The half length of arc
is approximated to
.
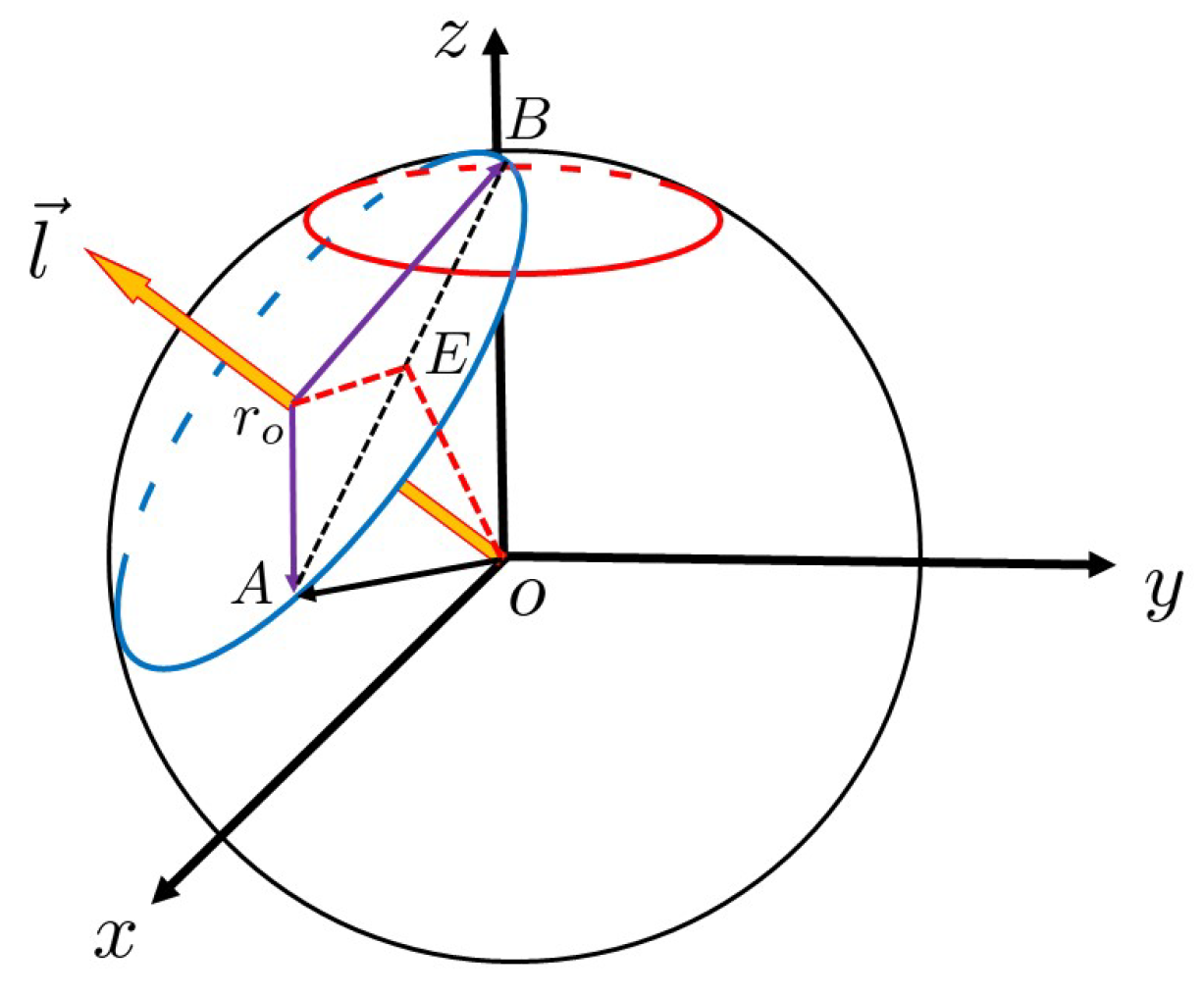
Next, we find the radius of the blue circle
. As shown in
Figure 3, point
E is the middle of the segment
.
In
Figure 3,
,
, and
. In
and
:
Thus, the number of iterations on the arc length
is
where ⌈⌉ denotes ceil function. Therefore, after several iterations with a number in
, the success rate in
will be achieved.
We show the relationship between
and the minimum number of queries for a given success rate in
Figure 4, which means that if the desired rate of success is not high, the number of queries is correspondingly reduced.
4. Robust Quantum Search with Uncertain Number of Targets
Now, consider the situation where the ratio is not known. Our goal is to find the marked state with high success. Here, we propose a robust search version of the Grover–Long algorithm. In our algorithm, the error is bounded by a parameter over . In fact, our algorithm degenerates to the original Grover–Long algorithm if . We proceed our algorithm as follows. The initial state is prepared to the superposition state . Then, we find out the target state with success probability higher than , in which the overlap is nonzero ( is the phase difference between and ) and . We provide the oracle operator which will flip the ancilla qubit if it matches the target state, that is, for and for , while are orthogonal to . Next, we prove how to extract by querying times with the successful probability higher than . This algorithm is shown as follows.
Suppose there is a database without exact
but, rather, its upper and lower bounds are denoted as
. If we plug the lower bound
as the “overlap” into the Grover–Long algorithm, we will obtain
then
which obeys Equation (
2), that
. Thus,
can be chosen as the number of iterations in Grover–Long algorithm, but when plugging
J and
into Equation (
3), we will not obtain the right matching phase. Thus, we will not obtain the right rotation angle
in Equation (
9) for each iteration along the axis
in Equation (
10). Instead, we will obtain
The angle difference
between
and
is
The total rotation angle difference is
The angle
is the overcooked angle
or arc
, shown in
Figure 2. We define this overcook as
:
We then reduce the number of iterations in order to improve the success rate. The relation between the number of iterations and the error is given by Equation (
16). Thus, the reduced number of iterations is
which drives the final state into the interval of arc
instead of
, so the success rate of the final search is greater than
.
The flowchart of our Algorithm 1 is listed as follows:
| Algorithm 1 Robust quantum search with uncertain number of targets. |
for a given database, just know the lower bound and upper bound of , ().
BeginCalculate Calculate Calculate Calculate Calculate Obtain the search operator: Implement the search operator Q on the initial state for times. Make measurement of the final state and one will find out the marked state with the probability greater than .
End |
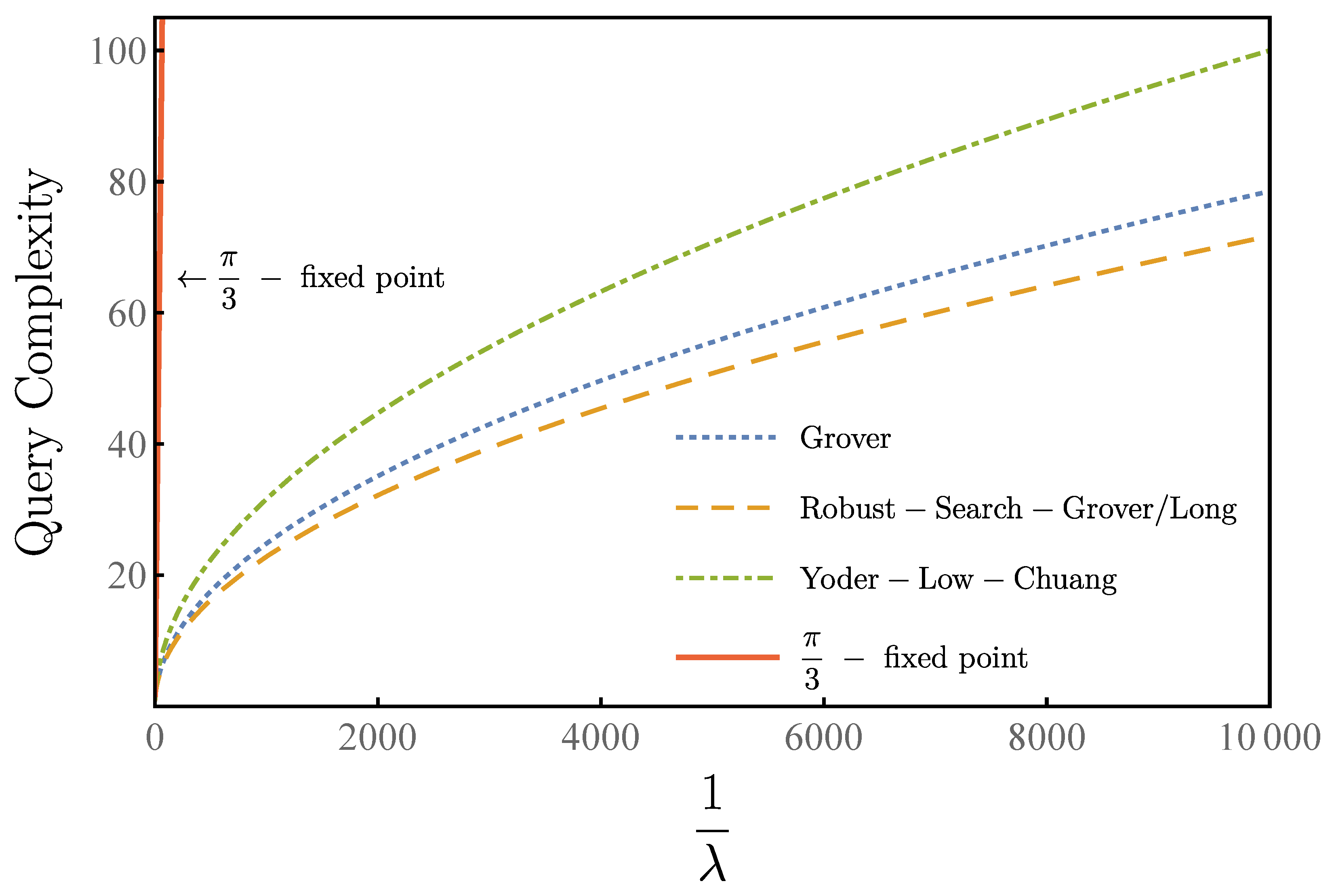
Compared with other algorithms, our algorithm maintains quadratic speedup. As shown in
Figure 5, our algorithm and Yoder–Low–Chuang algorithm have the same query complexity
as the standard Grover’s algorithm. Under the condition of output success rate greater than
, our algorithm makes eight queries while the Yoder–Low–Chuang algorithm makes 10 queries and the
-algorithm makes 160 queries for
. For
, our algorithm makes 46 queries while the Yoder–Low–Chuang algorithm makes 64 queries and the
-algorithm makes 6437 queries. For
10,000, our algorithm makes 72 queries while the Yoder–Low–Chuang algorithm makes 100 queries and the
-algorithm makes 16,094 queries. Both our algorithm and the Yoder–Low–Chuang algorithm have the same query complexity
as the standard Grover’s algorithm, while the query complexity of
-algorithm is scaled as
.
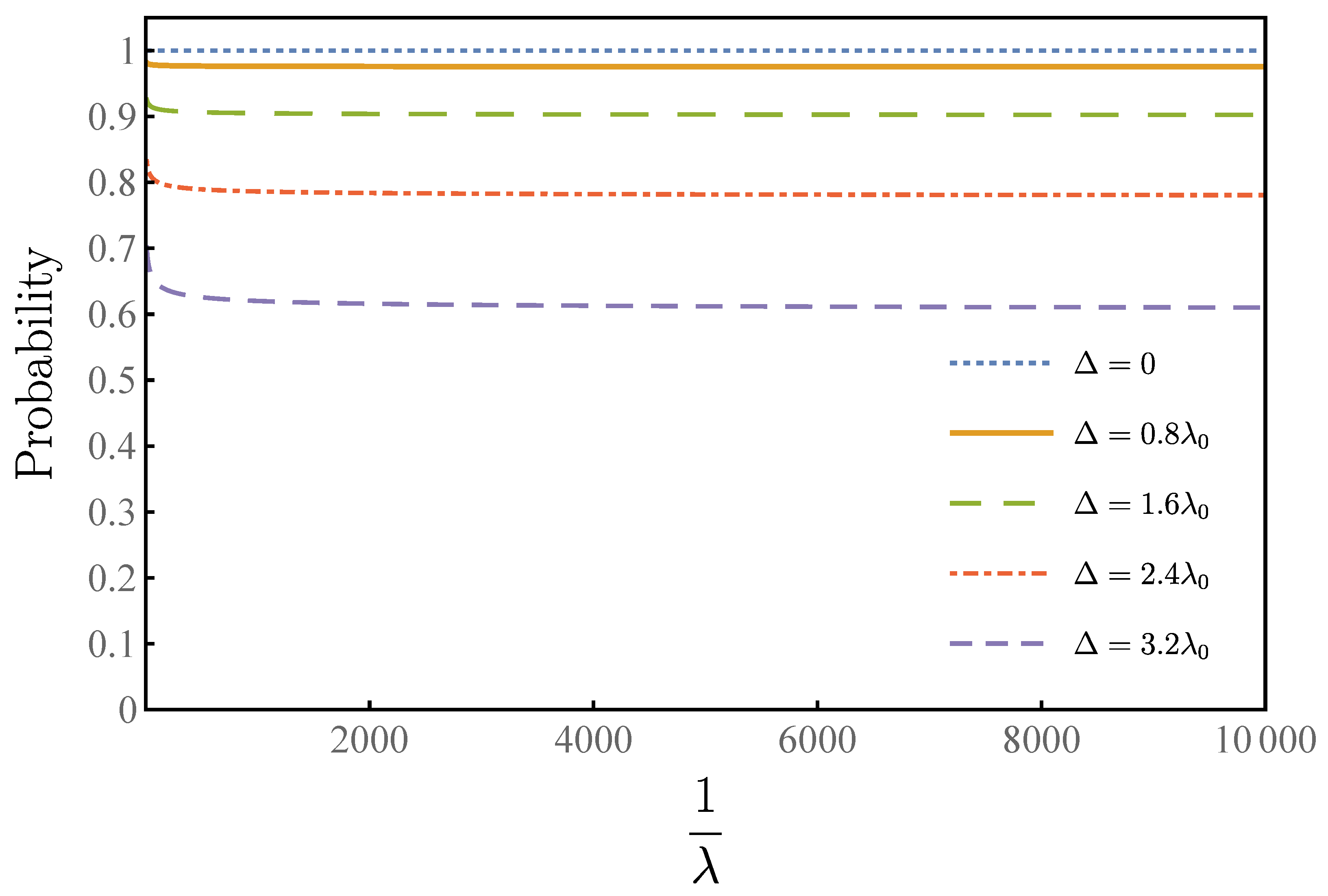
5. Discussions
In our algorithm, the infimum bound of the success rate is described by Equation (
24). The infimum bound of the success rate is related to
. In
Figure 6, we show the relationship between the lower success rate and the overlap rate at different uncertainty
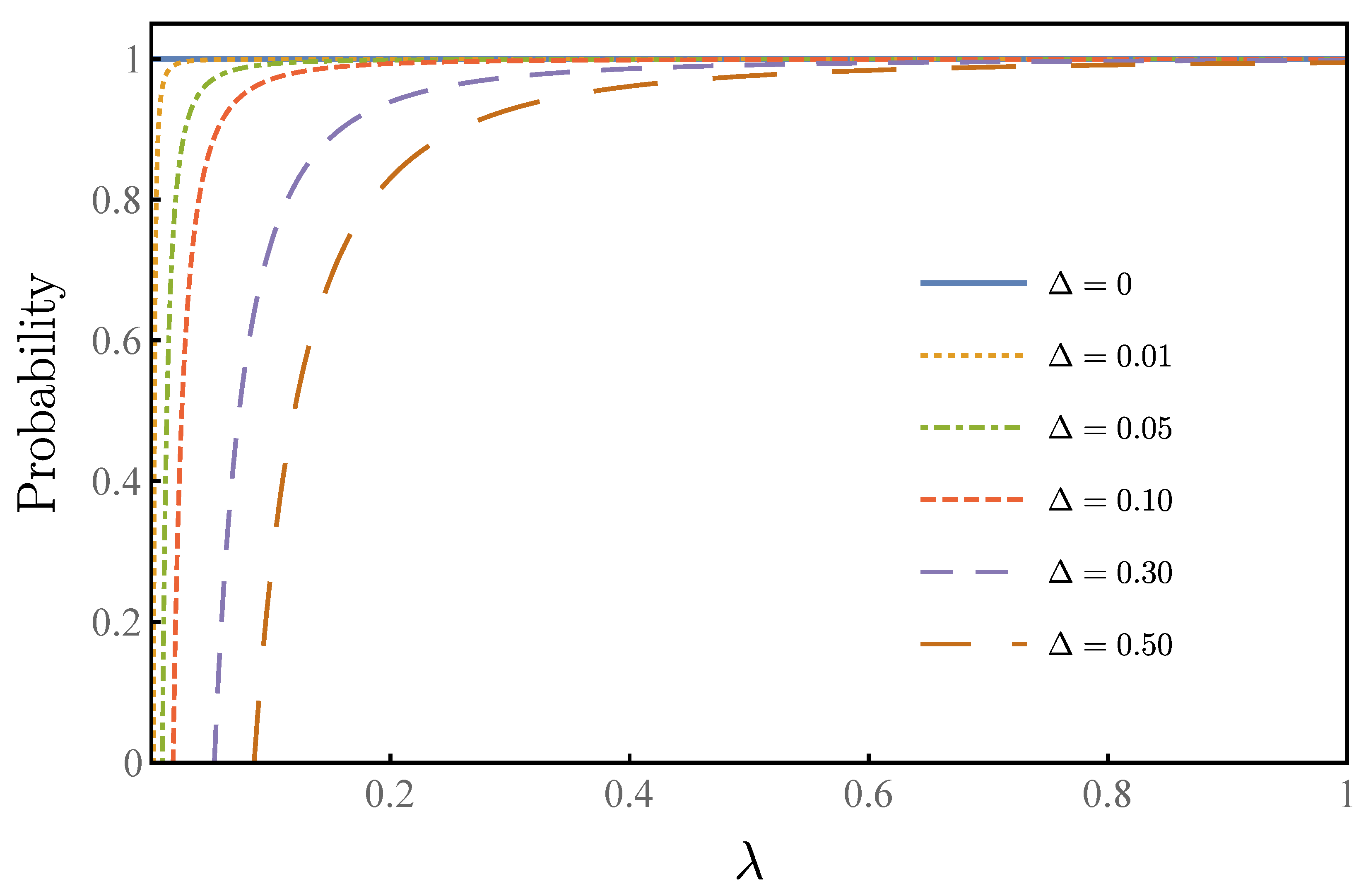
. When the uncertainty is zero,
success rate will be achieved every time, and our algorithm degrades to the standard Grover–Long algorithm. The curve increases sharply with the increase of
, and the success rate is above
when the uncertainty is double
. When the uncertainty is the same order as
, one can still achieve a high success rate, as high as
.
Therefore, our algorithm has a high tolerance to the uncertainty of the ratio
. In order to see the performance of the robustness of our algorithm clearly, especially when the overlap
is small, we provide
Figure 7, which shows the relationship between probability and
. By taking
to infinity, one can see that when
equals zero, our algorithm degrades to the original Grover–Long algorithm. For
equals to
, the success rate of our algorithm exceeds
, and our algorithm has a success rate of more than
when
equals
, and a
success rate when
equals
. Even if
equals 3.2
, our algorithm still has success rates above 60%.
In the worst-case scenario, one knows nothing about the rate
. Then, one has to run the quantum counting algorithm to estimate
M, which will have an uncertainty
. Our algorithm works well in this case, with a success rate above
and keeping the total
query complexity as in Grover’s algorithms. After running the quantum counting algorithm, one obtains the ratio with uncertainty, that is
. Thus,
. Plugging this value into Equation (
24), the result shows that the success rate of this algorithm is higher than
.
Our algorithm can be used as a subroutine in any case where amplitude amplification [
8] or Grover search are used [
24,
25,
26,
27].
In summary, we propose a robust quantum search algorithm with both the advantage of simple search operators, and high success rate over a wide range of
values. Therefore, it provides many potential applications [
28,
29,
30,
31,
32] in future quantum computing.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}






