3. Design of Symmetric Three-Bit Uniform Quantizer for the Purpose of NN Weights Compression
For symmetrical data distributions, symmetrical quantizers with an even number of quantization steps are preferable [
14,
24,
25,
26,
27,
28,
29,
32,
34,
35,
38,
40]. Since it can be expected that most of the real data is asymmetrical, one could not conjecture that the preferable quantizer is also asymmetrical. For a better understanding of the quantization process, which accounts for the real but not necessarily symmetric data, in this section, we describe the symmetric three-bit uniform quantizer model that is designed for the Laplacian pdf. In the later sections, we describe its adjustment to the real data, i.e., to the weights of the pretrained NN. Since low-bit quantization can entail substantially diminishing in terms of SQNR, we describe the theoretical and experimental scenarios that target three-bit uniform quantization of pretrained FP32 weights of two NNs (MLP and CNN). As already mentioned, the weight distribution can closely fit some well-known pdfs, such as Laplacian pdf is [
2]. Accordingly, as in [
12,
13,
34,
38,
39,
40], we assume the Laplacian-like distribution for the experimental distribution of weights and the Laplacian pdf for the theoretical distribution of weights to estimate the performance of our three-bit UQ in question.
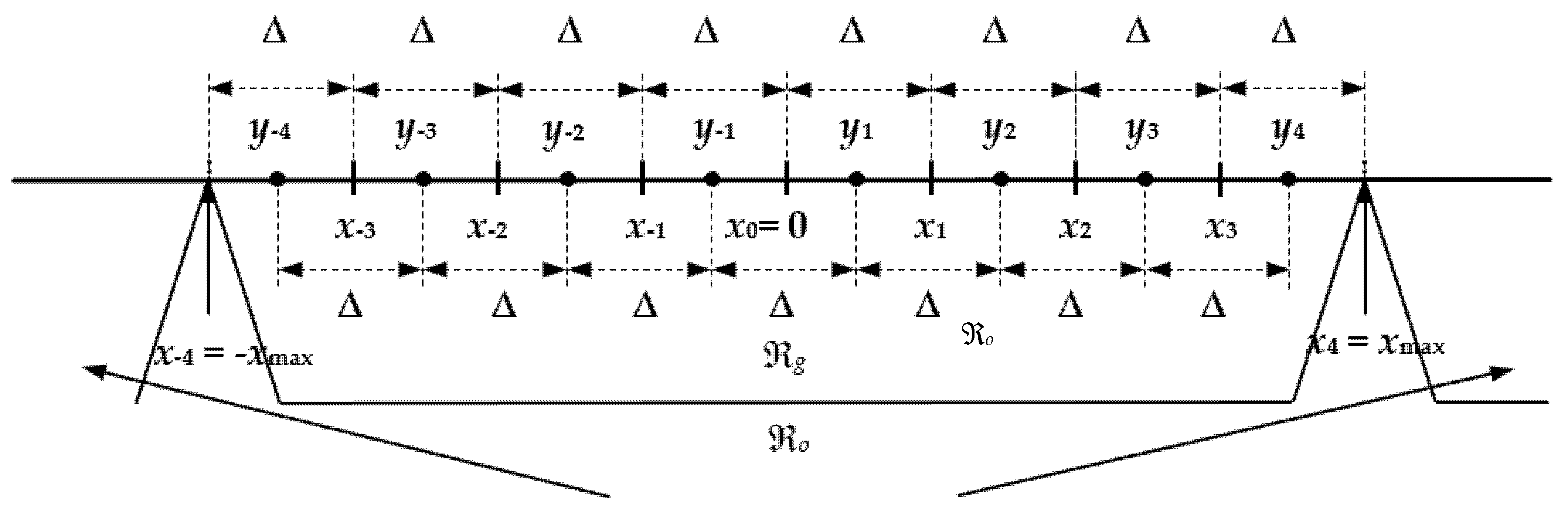
Firstly, we invoke the well-known preliminaries about uniform quantization and an
N-level symmetrical uniform quantizer
. During the quantization procedure, an input signal amplitude range is divided into a granular region ℜ
g and an overload region ℜ
o, separated by the support region threshold
xmax [
31]. For a given bit rate of
R = 3 bit/sample, with our symmetrical three-bit UQ, ℜ
g is partitioned into
N = 2
R = 8, equally spaced, nonoverlapped and bounded in width granular cells (see
Figure 1). The
ith granular cell of the three-bit UQ is defined as:
while
and
denote the granular cells in the negative and positive in amplitude regions, which are symmetrical. This symmetry also holds for the overload quantization cells, that is, for a pair of cells with unlimited widths in the overload region, ℜ
o, defined as:
The UQ model implies that the granular cells have equal widths (Δ), the output levels are the midpoints of the corresponding granular cells, and the code book
contains
N representation levels, denoted by
yi. In other words, by recalling the quantization procedure, the parameters of the symmetrical three-bit UQ can be calculated from:
- (a)
Δi = Δ = xmax/4, i ∊ {1, 2, 3, 4},
- (b)
−x−i = xi, xi = i·Δ = i·xmax/4, i ∊ {0, 1, 2, 3, 4},
- (c)
−y−i = yi, yi = (xi + xi−1)/2 = (2i − 1)·xmax/8, i ∊ {1, 2, 3, 4}.
The most common reason why it is convenient to deal with the zero-mean symmetric quantizer is that the codebook and the quantizer main parameter set can be halved since only the positive or the absolute values of the parameters should be stored. Recalling that
xmax =
x4 denotes the support region threshold of the three-bit UQ, one can conclude from rules (
a)–(
c) that
xmax completely determines the cell width Δ, the cell borders
xi,
i ∊ {0, 1, 2, 3, 4} and the representation levels (output levels)
yi,
i ∊ {1, 2, 3, 4} of the three-bit UQ (see
Figure 1). Accordingly, as we have already mentioned,
xmax is the key parameter of the uniform quantizer.
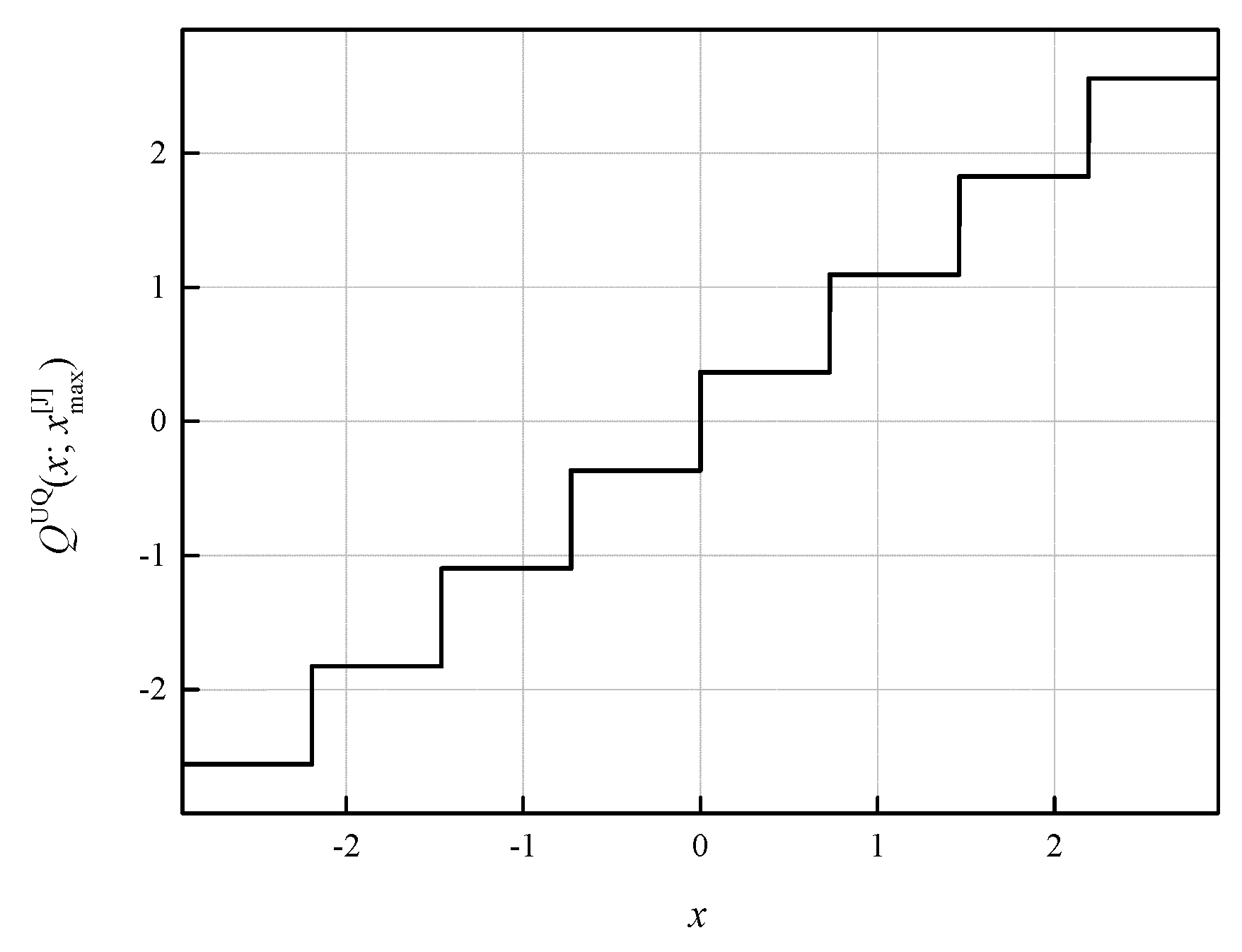
For the given
xmax, UQ is also well described by its transfer characteristic. The transfer characteristic of our symmetric three-bit UQ is given by:
where notation
N, indicating the number of quantization levels, is omitted due to the simplicity reasons. For
xmax =
xmax[J], it is illustrated on
Figure 2 and is denoted by
QUQ(
x;
xmax[J]), where the notation [J] comes from the name of the author of [
31]).
An important aspect of our interest in the three-bit UQ design that dictates assumptions about parameters of the quantizer in question has emerged from the maximal SQNR or the minimal overall distortion, that is, in the case where
xmax has an optimal value. For a given bit rate of
R = 3 bit/sample, the MSE distortion of the three-bit UQ for a source density with infinite support can be expressed as a sum of the granular and the overload distortion from the granular and overload regions, respectively [
22,
24,
31,
35,
36]. To determine the total distortion of our three-bit UQ that is a sum of the granular and the overload distortion, denoted, respectively, by
DgUQ and
DoUQ, we begin with the basic definition of the distortion, given by [
31]:
Let us recall that the cell borders and representation levels are functions of
xmax. Accordingly, an inspection of Formulas (4) and (5) reveals that
xmax appears not only in the limits of integrals but also in integrands. Hereof, despite the simplicity of the UQ model, determining
xmax analytically to provide the minimal MSE distortion is still difficult or even impossible. The value of
xmax determined by Jayant [
31] is a result of numerical distortion optimization. Hui had analytically obtained the equation for
xmax of the symmetrical
N-level asymptotically optimal UQ that is designed for high bit rates and an input signal with the Laplacian pdf of zero mean and unit variance [
22], which, for
N = 2
R = 8, gives:
As we pointed out earlier, we assume the unrestricted Laplacian pdf of zero mean and variance
σ2 = 1 for the input data distribution in the theoretical analysis of our three-bit UQ:
First, to simplify our derivation, let us define that it holds that
x5 = ∞. In other words,
x5 denotes the upper limit of the integral in Equation (5). By introducing
x5, the total distortion of our symmetrical three-bit UQ can be rewritten as:
or shortly as:
For the assumed pdf given by Equation (7), we further derive:
Eventually, by substituting Equations (10)–(12) into Equation (9), we derive:
Similarly, as in numerous papers about quantization (for instance, in [
6,
9,
22,
23,
24,
25,
26,
27,
28,
29,
30,
32,
34,
35,
36,
38,
40]), we are interested in conducting an analysis for the variance-matched case, where the designed for and applied to variance of data being quantized match and commonly amount to 1. Therefore, we further assume
σ2 = 1 so that we end up with the following novel closed-form formula for the distortion of the symmetrical three-bit UQ when the input has the Laplacian pdf of zero mean and unit variance:
Let us finally define the theoretical SQNR as:
which will also be calculated for
σ2 = 1 and compared with the experimentally determined SQNR
exUQ.
4. Specification of Two NN Models and Post-Training Prerequisites
After we have defined the quantizer, we can proceed with the design and implementation of the two NN model architectures for the practical application of our three-bit UQ in post-training NN quantization. The first chosen NN model architecture is MLP and is fairly simple, consisting of three fully connected layers (see
Figure 3), as our goal is to analyze the impact of the quantizer design on the MLP model’s accuracy but not to achieve the highest possible accuracy on the dataset itself. Moreover, our goal is to provide a fair comparison with the results from [
34], where the same architecture was assumed. The second chosen NN model architecture is CNN, which contains one additional convolutional layer.
Both NN models have been trained on the MNIST dataset for handwritten digits recognition, consisting of 60,000 black and white images of handwritten digits from 0 to 9 [
41]. In particular, the MNIST dataset consists of 70,000 black and white images of handwritten digits, with pixel values in the range [0–255]. The dataset is split into 60,000 training and 10,000 testing sets, while all images have equal dimensions of 28 × 28 pixels [
41]. The images for MLP are being flattened into one-dimensional vectors of 784 (28 × 28) elements to match the shape accepted by our first NN, while for a proper CNN input, one additional dimension is being added to represent the channel. The last pre-processing step is normalizing the input into the range [0–1] by dividing every image sample with the highest possible value for black and white image amplitude of 255.
The MLP model consists of two hidden and one output layer, with three fully connected (dense) layers in total (see
Figure 3). Hidden layers consist of 512 nodes, while the output layer consists of 10 nodes, where every node estimates the probability that the MLP output is any digit from 0 to 9. Both hidden layers utilize ReLU activation and dropout regularization, which sets 20% of the outputs of hidden layers to 0 to prevent overfitting [
42]. In the output layer, the SoftMax activation is utilized, which outputs probabilities that the input belongs to any of 10 possible classes. Training and accuracy evaluation of our MLP model has been implemented in TensorFlow framework with Keras API, version 2.5.0 [
43].
The CNN model consists of one convolutional layer, followed by ReLU activation, max pooling and flatten layer, whose output is fed to the previously described MLP with two hidden FC layers and the output layer. The convolutional layer contains 16 filters with kernel size set to 3 × 3, while the max pooling layer utilizes a pooling window of size 2 × 2. The output of the pooling layer is further flattened into a one-dimensional vector for feeding it forward to the FC dense layer. The only difference between the previously described MLP and the dense layers utilized in CNN is in the dropout percentage, which is in the case of CNN set to 50%, to further prevent overfitting of the FC layers. Therefore, the CNN model consists of three hidden layers and the output layer with a total of 1,652,906 trainable parameters. The training is performed on the MNIST, in the same manner as for the MLP, with a total of 10 epochs, while the batch size is equal to 128 training samples.
Additional results are also provided in the paper for both specified models, MLP and CNN, trained on the Fashion-MNIST dataset [
44]. Fashion-MNIST is a dataset comprising of 28 × 28 grayscale images of 70,000 fashion products from 10 categories, with 7000 images per category [
44]. The training set has 60,000 images and the test set has 10,000 images. Fashion-MNIST shares the same image size, data format and the structure of training and testing splits with the MNIST. It has been highlighted in [
45] that although Fashion-MNIST dataset poses a more challenging classification task compared to MNIST dataset, the usage of MNIST dataset does not seem to be decreasing. Additionally, it has been pointed out at the fact that the reason MNIST dataset is still widely utilized comes from its size, allowing deep learning researchers to quickly check and prototype their algorithms.
For both NNs, training, accuracy analysis, and quantization have been implemented in the Python programming language [
46]. After training NN models, the corresponding (different) weights are stored as 32-bit floating points, which represents full precision in the TensorFlow framework. The MLP model achieves the accuracy of 98.1% on the MNIST validation set and 88.96% on the Fashion-MNIST validation set, obtained after 10 epochs of training. The CNN model achieves a higher accuracy of 98.89% on the MNIST validation set and 91.53%, obtained on the Fashion-MNIST validation set, also after 10 epochs of training.
The first NN model (MLP) consists of 669,706 parameters, which are all fed to our three-bit UQ after training. As mentioned, the second NN model (CNN) consists of 1,652,906 parameters, which are also all fed to our three-bit UQ after training in the CNN case. While compressing the model weights, we reduce the bit rate for every parameter from 32 to 3 bits per sample. Once we have obtained the quantized representations of the NN model weights, we can feed them back into the model and assess the QNN model performance when the post-training quantization is applied, and each of the NN weights is represented with only 3 bits. This holds for both NNs addressed in this paper.
In brief, to evaluate the performance of our three-bit UQ in practice, we have conducted an experimental training of two NN models, and we have stored the corresponding weights represented in FP32 format. As most machine learning frameworks store trained weights as 32-bit floating-point values, this bit rate is treated as baseline (full) precision. After the two training processes were complete, we accessed the stored weights, applied the quantization, and loaded the quantized weights into the corresponding models. As previously stated, by doing so, we can significantly reduce the amount of storage required for saving the QNN models. As in any lossy compression task, where the original input values cannot be restored after the compression/quantization is applied, an irreversible quantization error is introduced, which can have a negative impact on the accuracy of our models. However, by representing the weights of MLP and CNN by 3 bits per sample, we perform compression with a factor larger than 10 times. When performing compression of that amount, it is crucial to make the best use out of available resources, which in this case is our available bit rate.
Typically, when performing uniform quantization of nonuniform unrestricted sources, e.g., the Laplacian source, the choice of the support region width (ℜ
g width) is the most sensitive quantizer parameter, which can significantly impact the performance [
22,
23,
24,
25,
30,
31,
35]. We have already confirmed this premise for the bit rate of 2 bits per sample in [
34], where the support region choice is crucial not only for the performance of the quantizer alone but also for the QNN model’s accuracy due to only four representation levels being available. This imposed a question of whether the choice of ℜ
g will have an equally strong impact on SQNR and accuracy for the case of 3 bits per sample available, which will be discussed in the later sections. Let us highlight that to provide a fair comparison with the results from [
34], in this paper, the identical MLP architecture is assumed, and the identical weights (stored in FP32 format) are uniformly quantized by using one additional bit. Essentially, we evaluate and compare the performance of multiple three-bit UQ designs, where we also highlight a few significant cases of its design to provide a fair comparison with the results from [
34]. By doing so, we aim to determine the influence of the choice of the key parameter of the three-bit UQ on the performance of both quantizer and QNN models, whereas, compared to the analysis of the numerical results from [
34], the analysis presented in this paper is much wider. Moreover, unlike [
34], where the analysis has been only performed for MLP and MNIST datasets, in this paper, the analysis is additionally performed for a CNN model and the MNIST dataset. Eventually, in this paper, results are also provided for both specified models, MLP and CNN, trained on the Fashion-MNIST dataset [
44].
6. Numerical Results and Analysis
The performance analysis of our post-training quantization can be broadly observed in two aspects: the accuracy of the QNN models and the SQNR of the uniform quantizers implemented to perform the weight compression. Our main goal is to determine and isolate the impact of the choice of ℜ
g on the accuracy of the QNNs. Therefore, for the first NN model (MLP), we have conducted a detailed analysis of the statics of both the original and the uniformly quantized weights. For both NN architectures, MLP and CNN, which are trained on the MNIST dataset, we have determined the accuracies of the QNNs for various values of the key quantizer parameter for the bit rate of
R = 3 bit/sample. As previously mentioned, the full precision accuracy of our MLP on the MNIST validation dataset amounts to 98.1%, which is the benchmark accuracy used in the comparisons. The second point of reference is the accuracy of the QNN presented in [
34], where we have obtained accuracy up to 96.97% with the use of two-bit UQ for the quantization of identical weights with the identical MLP architecture. Let us highlight that we have shown in [
34] that an unsuitable choice of the support region can significantly degrade the accuracy (more than 3.5%), that is, the performance of the post-training two-bit uniform quantization for the assumed MLP model trained on MNIST. The second point of reference will give us insight into the differences in impact of ℜ
g on the QNN accuracy when using 1 bit per sample more for compression. The intuition is that for a larger bit rate of
R = 3 bit/sample, the influence of the support region of the quantizer will be smaller compared to the case presented in [
34], where only 2 bits have been used to represent the QNN weights. To confirm this premise, we have designed multiple three-bit UQs with different ℜ
g values and analyzed the accuracy accordingly, which will be presented later in this section.
Firstly, we have conducted multiple training procedures of the specified MLP on the MNIST dataset to confirm that in various training sequences, the weights converge to the values that belong to the same range while obtaining similar model accuracy for both MLP and quantized MLP models.
Table 1 shows the statistics of the trained weights and the performance of our MLP model without and with the application of quantization for four independent training procedures of the same MLP model on the MNIST dataset. One can observe that the weights fall into almost the same range of values for each training, with and without normalization. Additionally, the model achieves similar accuracy throughout various training procedures with small variations. Finally, the obtained SQNR values (for the case where the support region threshold is specified by (6)) are very close for different weight vectors, with dynamics of approximately 0.04 dB. We can conclude that the weight vector chosen in our analysis (the same weight vector as utilized in [
34]) can be considered a proper representation of any training sequence obtained with the same MLP architecture and that the results of post-training quantization are very close to each other for all of the observed cases.
Once we have established that the chosen weights represent a good specimen for any training sequence of a given MLP architecture, we can proceed with the QNN accuracy evaluation.
Table 2 presents SQNR of the three-bit UQ and QNN model accuracy, obtained for multiple choices of ℜ
g for the bit rate of
R = 3 bit/sample and the specified MLP trained on MNIST dataset. Along with the experimentally obtained SQNR values (calculated by using Equations (18) and (19)), we have determined theoretical SQNR by using Equations (14) and (15), for each ℜ
g choice to evaluate differences between the theoretical and experimental SQNR values. Choices 1 and 2 depend on the statistics of the normalized NN model weights, specifically on the minimum and maximum weight value (
wmin and
wmax), while in Choice 3 and 4, ℜ
g is specified with the well-known optimal and asymptotically optimal values for the assumed bit rates, as given in [
22,
31]. In addition,
Table 3 presents SQNR and the QNN model’s accuracy obtained with the application of two-bit UQ, where ℜ
g is defined following the same principles as in
Table 2 and the identical weights of the MLP model (trained on MNIST dataset) are quantized [
34]. Specifically, Choice 1 of ℜ
g in
Table 2 matches Case 1 in
Table 3, etc.
Table 3 is provided for comparison purposes to help us make conclusions about the different impacts that the choice of ℜ
g has on the SQNR and QNN model’s accuracy for a specified MLP and different bit rates. It has been highlighted in [
47] that Choice 2, that is, Case 2, is a popular choice for the quantizer design, which, as one can notice from
Table 3, is not the most suitable choice in terms of accuracy and SQNR. In the following, we first analyze the results obtained for the MLP and the three-bit UQ presented in
Table 2, with a reference to the two-bit uniform quantization model presented in [
34].
Choice 1 defines ℜ
g of the UQ in the range [−
wmax,
wmax], meaning that ℜ
g is symmetrically designed according to the absolute value of the maximum weight sample. In our case with the MLP, it holds |
wmax| =
wmax (
wmax ≥ 0), so we have simplified our notation. From
Table 2 and
Table 3, one can notice that with the so-defined ℜ
g, 99.988% of the normalized weight samples are within ℜ
g. Choice 2 defines ℜ
g in the range [
wmin, −
wmin], meaning that our quantizer is symmetrically designed according to the absolute value of the minimum normalized weight sample, |
wmin|. In our case, it holds |
wmin| = −
wmin (
wmin ≤ 0). ℜ
g defined in Choice 2 includes all of the normalized weight samples, meaning that none of the samples fall into the overload region of the quantizer. From
Table 2, one can notice that although SQNR for Choices 1 and 2 differ to a great extent, the QNN model’s accuracy is identical. In contrast, one can notice from
Table 3 that with two-bit UQ, the QNN model exhibits significant performance variations in both SQNR and model accuracy, where both are dominantly determined by the choice of ℜ
g. Similar is the case with Choices 3 and 4, where
xmax[H] and
xmax[J] take relatively close values. Although SQNR obtained for Choices 3 and 4, presented in
Table 2, and the matching Cases 3 and 4 from
Table 3 has stable, close values, this is not the case for the QNN model’s accuracy (see
Table 3).
By analyzing the QNN model accuracies presented in
Table 2, we can observe that the accuracy dynamics, defined as the difference between the highest and lowest obtained accuracy, amounts to 0.2%. On the other hand, by performing the same analysis for the case of implementing two-bit UQ, we can calculate that QNN accuracy dynamics amounts to 2.39%. Moreover, by comparing the SQNR values obtained for the three-bit UQ presented in
Table 2 for Choices 2 and 4, we can observe a high dynamic range of SQNR values with the difference between Choices 2 and 4 amounting to 6.3146 dB, while the difference in the QNN model’s accuracy for these choices of ℜ
g amounts to just 0.2%. This further indicates that a large difference in SQNR of the three-bit UQ does not necessarily result in a large difference in the accuracy of the QNN, as had been found for the two-bit UQ in [
34]. The maximum theoretical and experimental SQNR is obtained for Choice 4, where ℜ
g is defined optimally by
xmax[J], while the maximum QNN model accuracy is obtained in Choices 1 and 2 (see bolded values). We can conclude that the choice of ℜ
g dominantly determines the QNN model’s accuracy in the case of a very low bit rate of 2 bits per sample, where we have only four available representation levels. By doubling the number of representation levels to eight for a bit rate of
R = 3 bit/sample, it turns out that the impact of the ℜ
g on QNN model’s accuracy significantly reduces. This statement will be inspected later in this section by observing the QNN model’s accuracy in a wider range of ℜ
g choices for both MLP and CNN models.
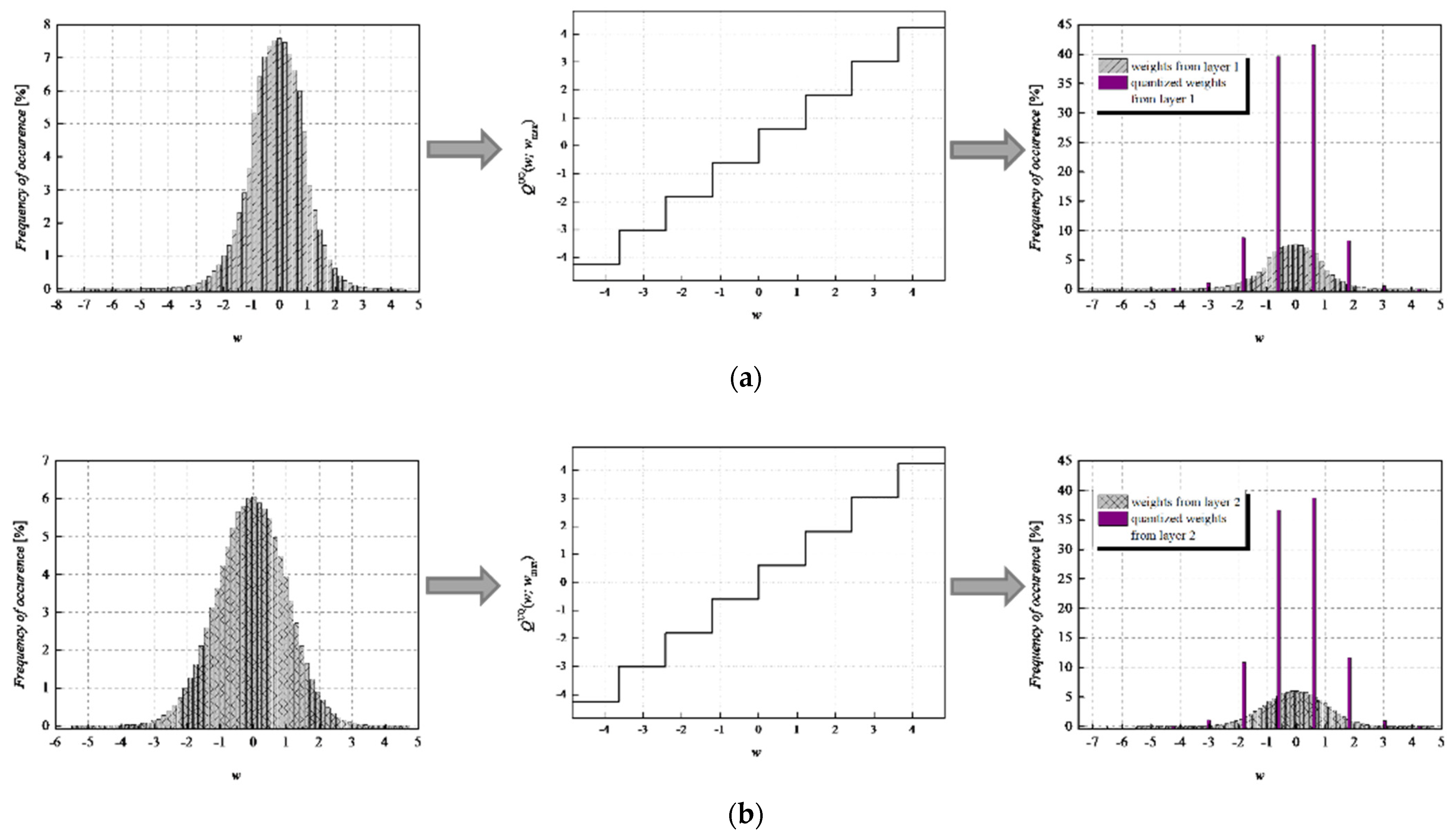
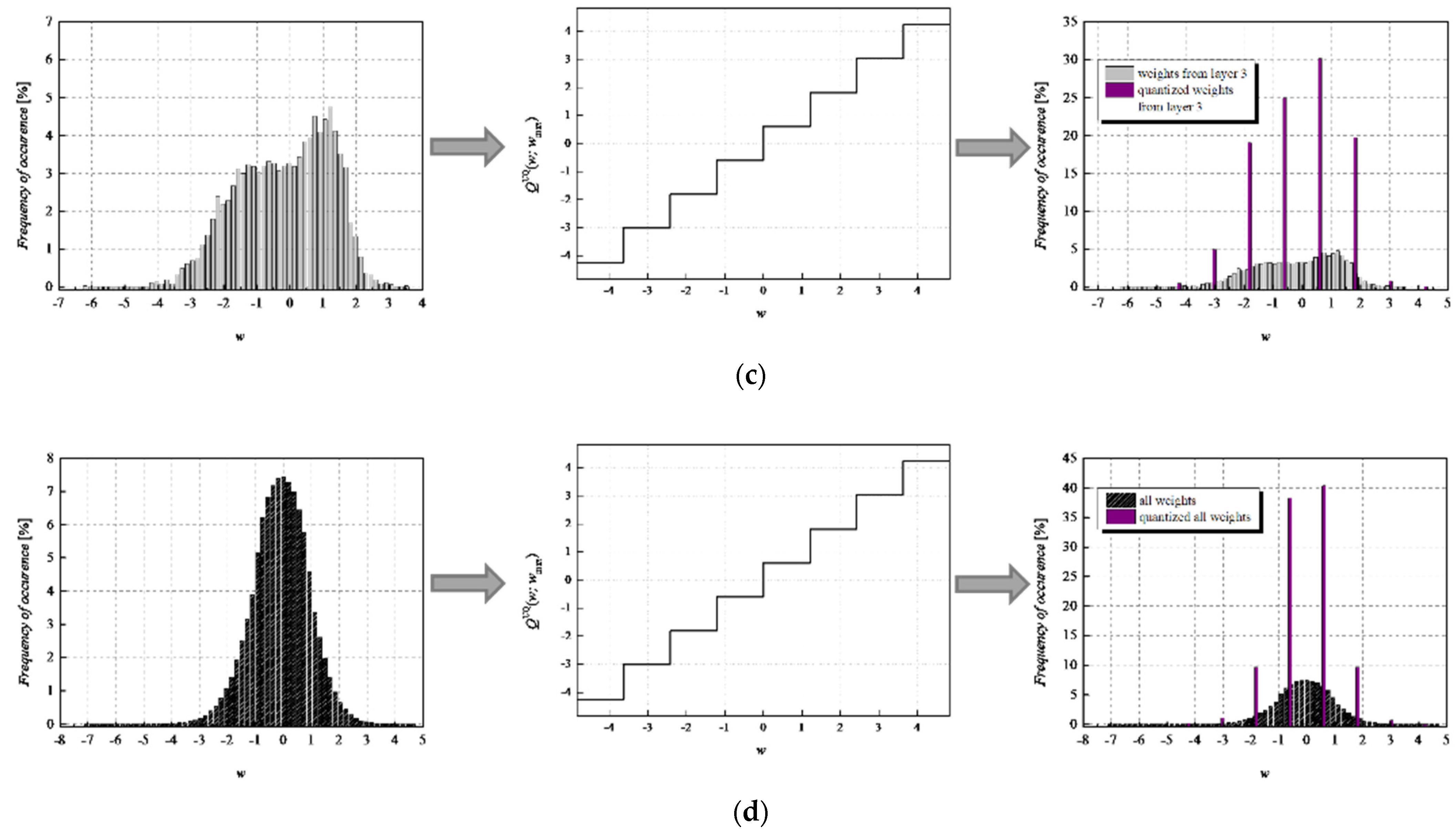
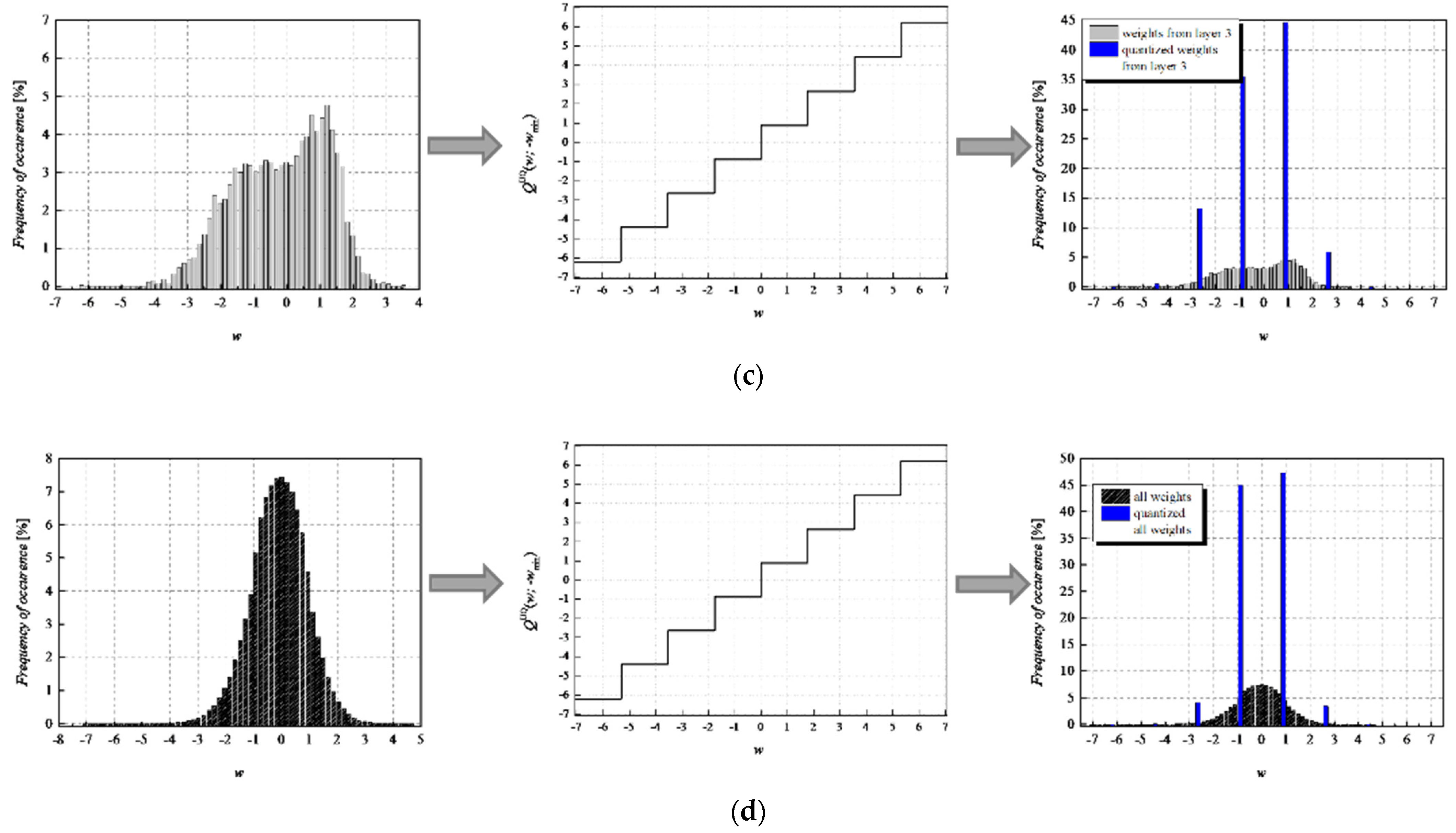
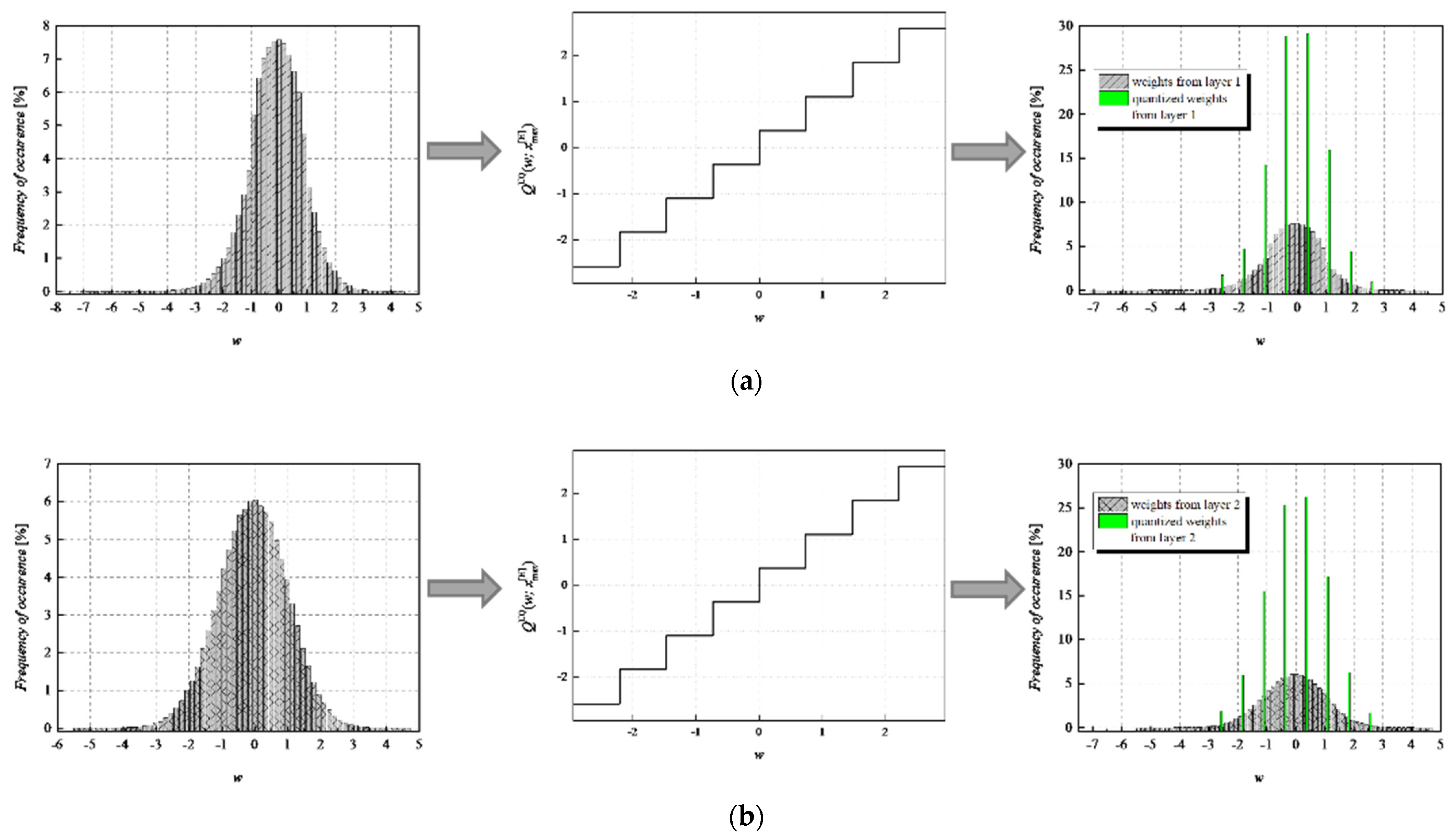
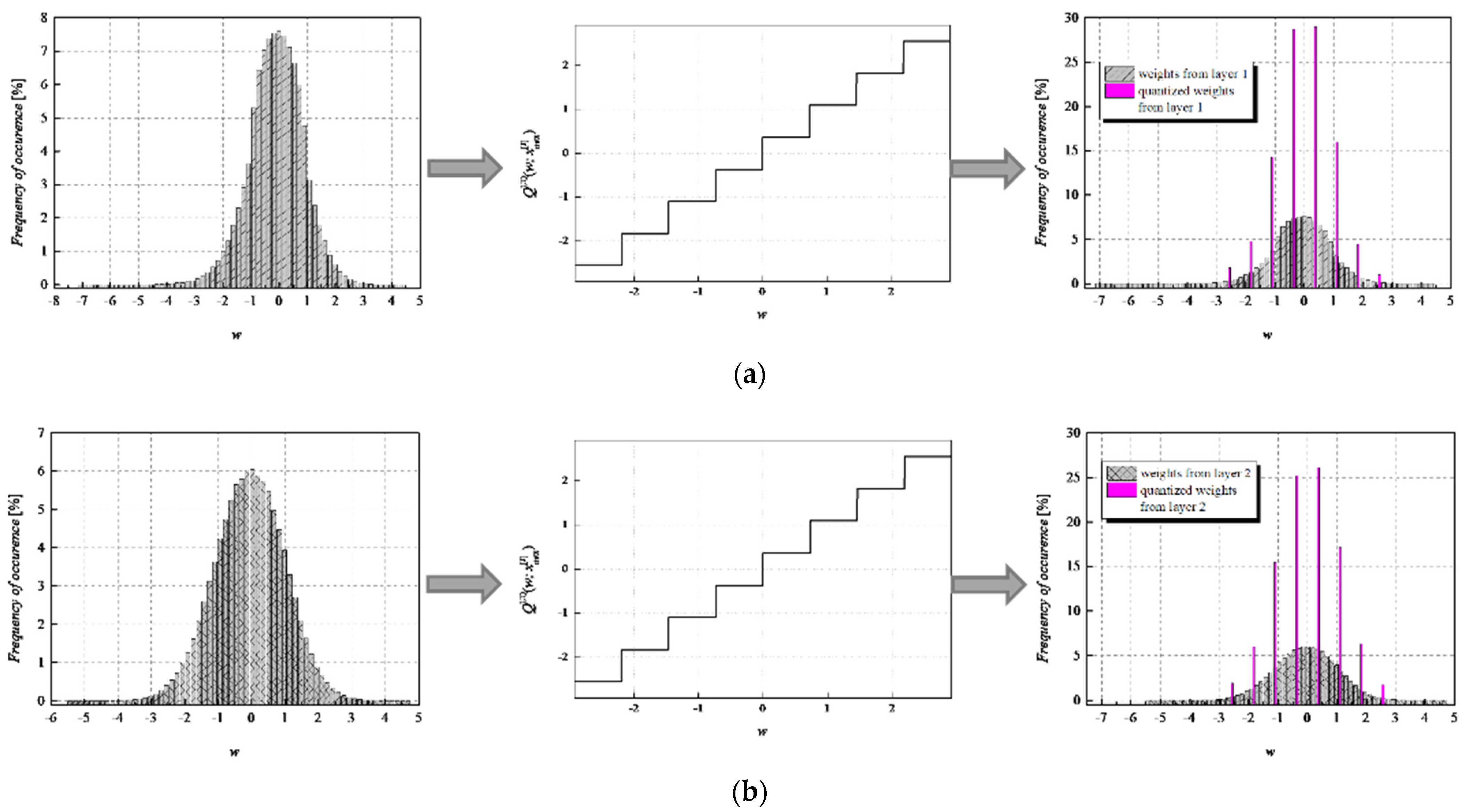
To achieve a high-quality compressed signal, it is of great significance to exploit the full potential of the available bit rate. To inspect the distribution of the normalized weights among different representation levels of the three-bit UQ, we have extracted histograms of normalized weights of individual layers, as well as the joint histogram of all normalized weights of the MLP (trained on MNIST dataset) before and after compression/quantization (see
Figure 4,
Figure 5,
Figure 6 and
Figure 7). At first glance, by comparing Choices 1 and 2 with Choices 3 and 4, one can notice that in the first two choices, we dominantly utilize only four of the eight available representation levels of UQ, which is especially noticeable on the histogram presenting all normalized weights of QNN model for Choice 2. This leads us to the conclusion that in Choices 1 and 2, we utilize unnecessary wide ℜ
g, which explains the lower SQNR values obtained for the first two choices, especially in Choice 2, where ℜ
g ranges [−7.063787, 7.063787]. At the same time, a wider ℜ
g positively contributes to the QNN model’s accuracy, which is higher for the first two observed choices compared to Choices 3 and 4.
By observing the histograms of Choices 3 and 4, one can notice that all representation levels of the three-bit UQ take enough values to be clearly noticeably on the QNN histogram, implying that during the quantization process, we exploit the full potential of the three-bit UQ. Moreover, this can be confirmed by comparing the histogram envelope of all normalized weights before and after quantization. One can notice that in Choices 3 and 4, the envelope of the histogram of the quantized normalized weights follows the envelope of the histogram of all normalized weights before quantization to a great extent. This shows us that the distribution of the quantized normalized weights follows the distribution of the normalized weights. Additionally, by analyzing the normalized weights in different NN model layers, we can see that level 3 has the highest deviation from the Laplacian distribution, having a distribution that is closer to the uniform one. As the uniform quantizer is optimal for the uniform distribution, by making a suitable choice of ℜg, the benefits of the UQ model can be significantly exploited for this layer. Histograms offer us another interesting insight that lies in a small asymmetry of the QNN model normalized weights. This phenomenon is a consequence of the fact that the percentage of non-negative weights after normalization is 50.79%, meaning that it is higher by 1.58% than the percentage of negative weight values after normalization. This leads to a righthand side shift of the samples during quantization, which can be observed in individual and joint histograms of normalized weights before and after quantization. The asymmetry is largest at layer 2, where the percentage of positive weight samples after normalization amounts to 51.3649%, meaning that it is higher by 2.7298% than the percentage of negative weight values after normalization. As a result, we have the highest level of asymmetry after quantization at layer 2.
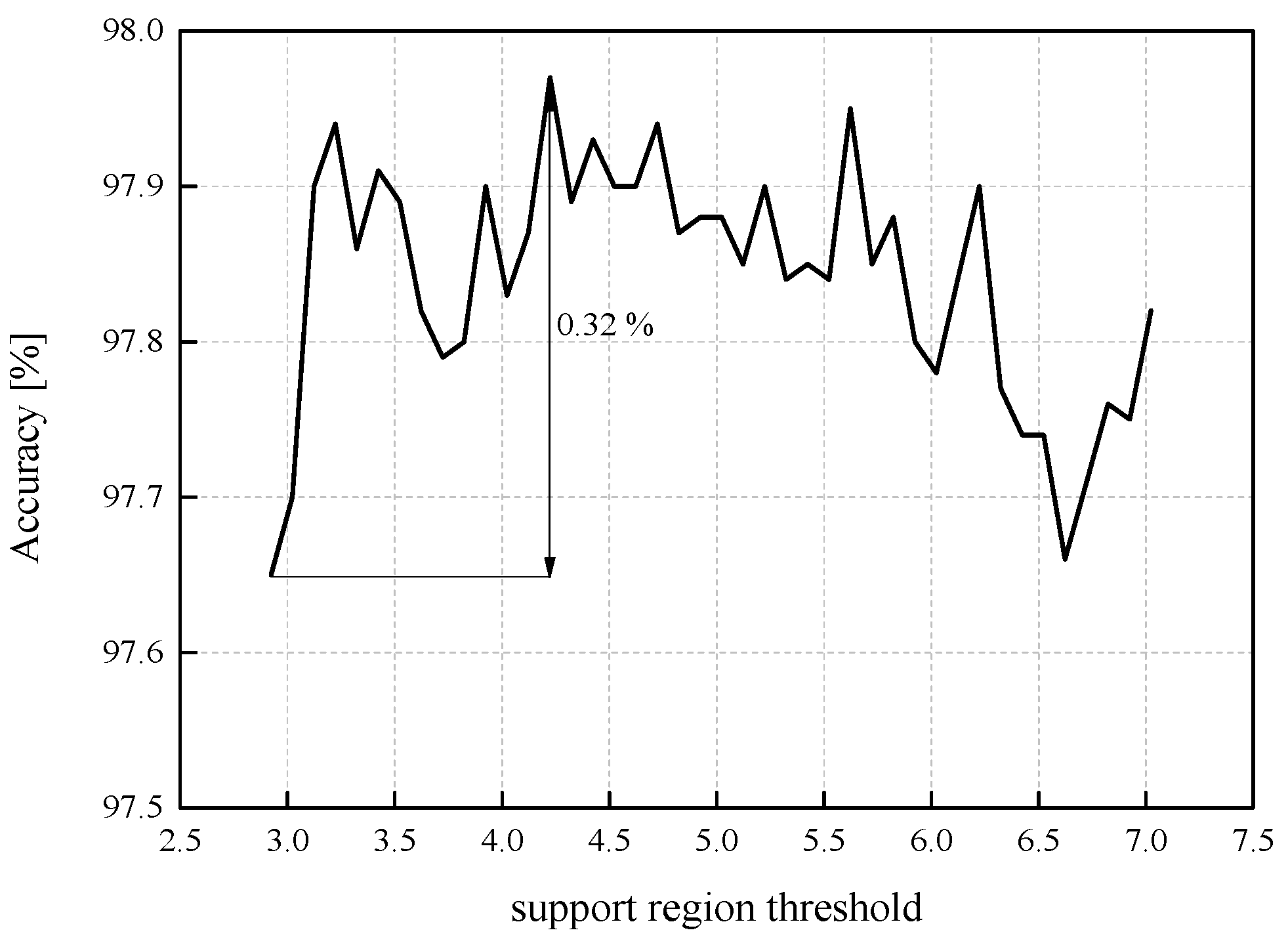
So far, we have confirmed that in all four observed choices of ℜ
g, our first QNN model achieves a stable performance in terms of accuracy, with a deviation of approximately 0.2%. To further inspect the influence that
wsupp has on the QNN model’s accuracy, we have determined the QNN model’s accuracy for
wsupp values in the range from
xmax[J] = 2.9236 to |
xmin| = 7.063787, with a step size of 0.1 (see
Figure 8). The highest obtained accuracy in the observed range amounts to 97.97%, while the lowest value is 97.65%, that is, the accuracy dynamics amounts to 0.32%. Therefore, we have once more confirmed that for a bit rate of
R = 3 bit/sample, the impact of the ℜ
g choice on the QNN model’s accuracy significantly reduces compared to the case where the identical weights of MLP, stored in FP32 format, are uniformly quantized with the bit rate of 2 bit/sample. It should be mentioned out that accuracy dynamics presented in
Figure 8 has been determined in a wide but carefully chosen range of the observed values of
wsupp, which we heuristically specified.
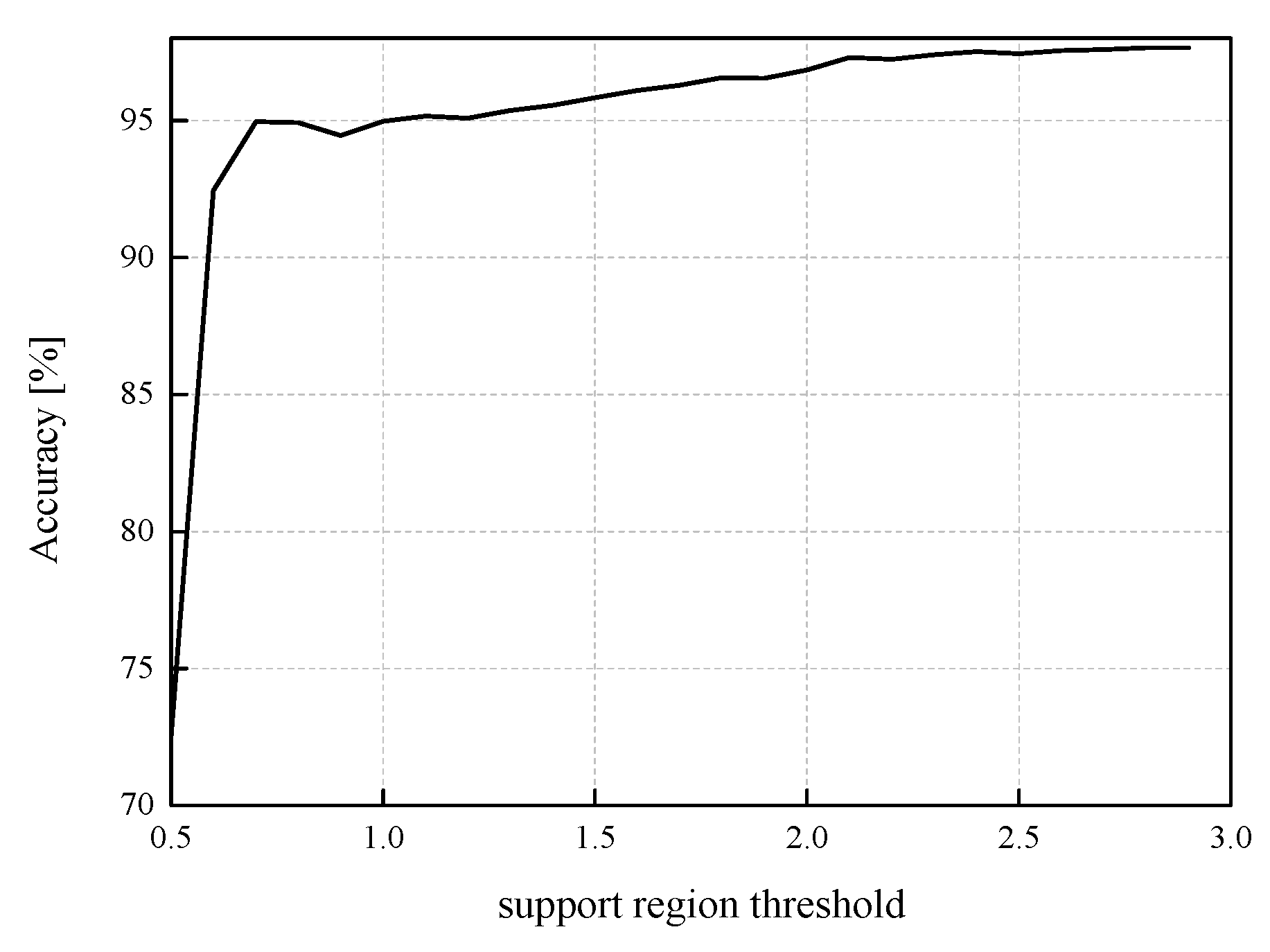
In this paper, we also present a range of unfavorable ℜ
g choices for MLP, i.e., the first NN model observed (see
Figure 9). If the support region threshold values range from 0.5 to
xmax[J] = 2.9236 and change with a step size of 0.1, the QNN’s accuracy varies from 72.51% to 97.65%. As this presents very high dynamic values, we can conclude that all four choices presented in
Table 2 have been carefully made according to the nature of our input data. In addition, it is noticeable that after passing the value of 2.5, the accuracy is persistently above 97% due to a small impact of different ℜ
g choices on the QNN model’s accuracy if
wsupp is chosen from a proper intuitively expected range, that is when it holds
wsupp ≥ 2.5.
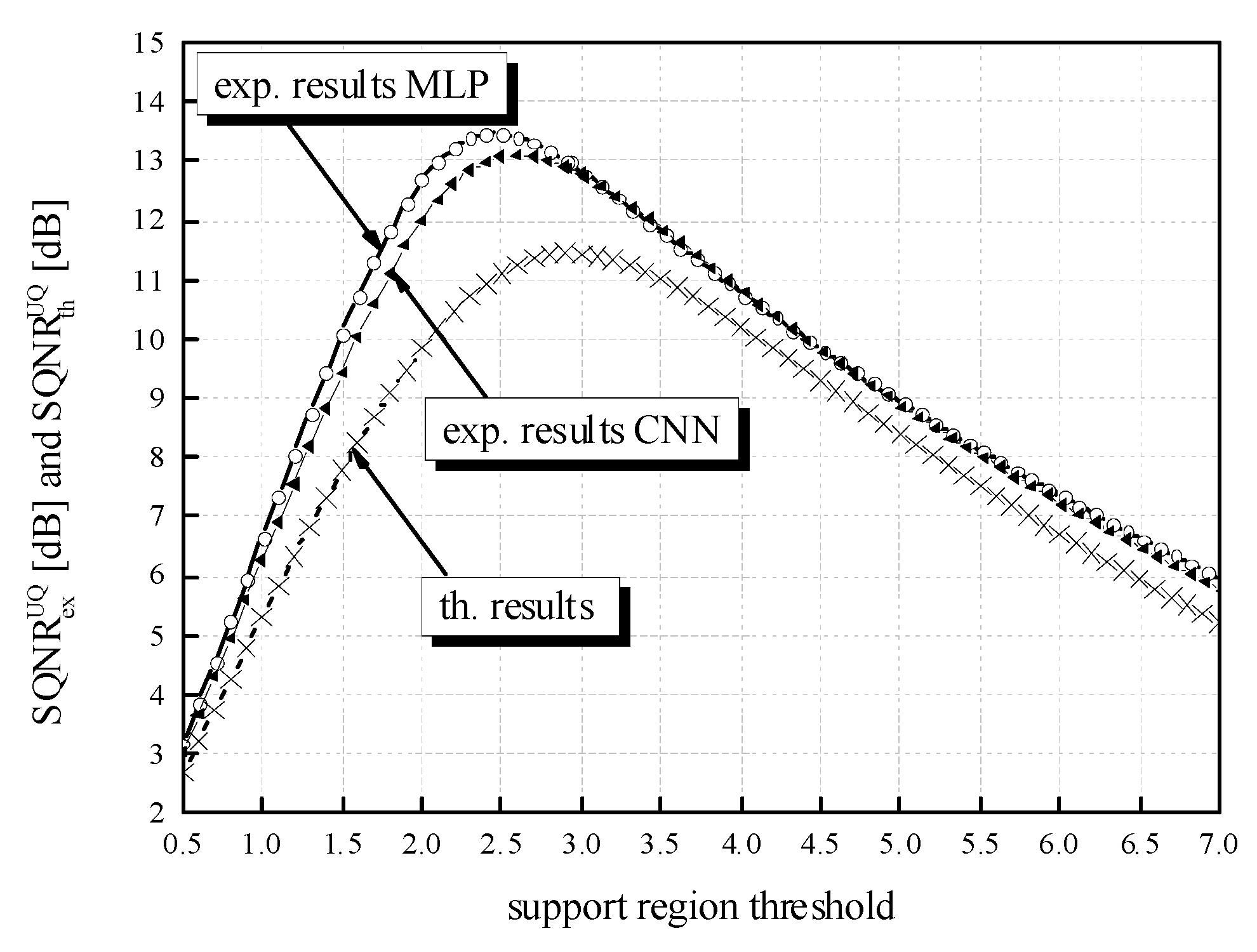
While the QNN model’s accuracy is the main point of reference observed in the experiments, the SQNR of the three-bit UQ takes a significant place in our analysis. Similar to the evaluation of the QNN model’s accuracy dynamics, we can observe the impact that the choice of ℜ
g has on the performance of the three-bit UQ.
Table 2 already showed that for a bit rate of
R = 3 bit/sample, SQNR values have much higher dynamics compared to the QNN model’s accuracy. To inspect the impact of
wsupp choice on the SQNR in a wider range of values, we have calculated the theoretical and experimental SQNR of the three-bit UQ in the
wsupp range of [0.5, 7.063787]. In addition, to compare experimentally determined values for the two different NN models specified in the paper, MLP and CNN, in
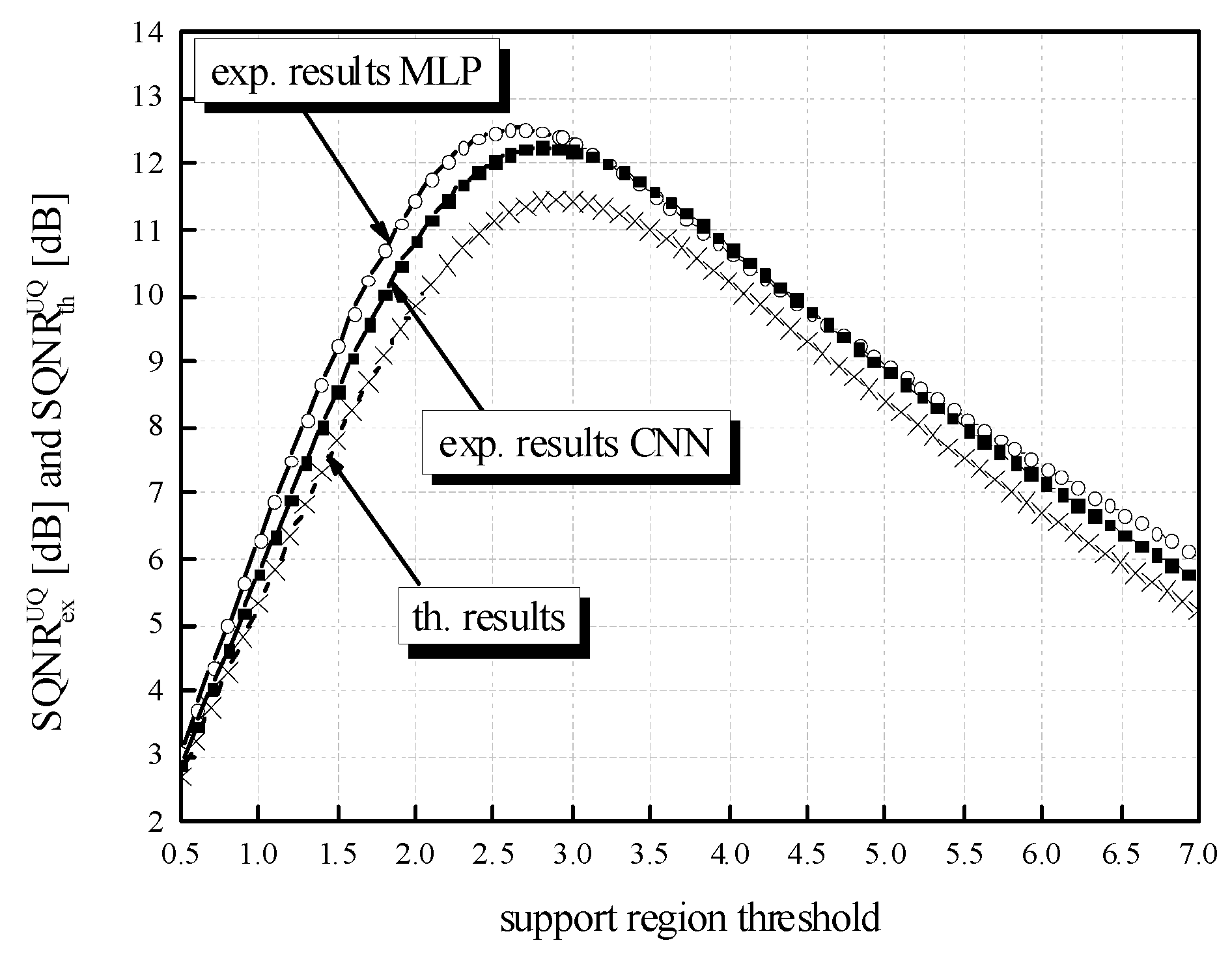
Figure 10, we provide additional experimental results for the CNN model. If we set
wsupp between
xmax[J] = 2.9236 and |
xmin| = 7.063787 with the step size of 0.1 and calculate the SQNR in 42 points, the dynamics of the experimentally calculated SQNR for the MLP is 12.9766 dB − 5.9005 dB = 7.0761 dB, which is considered to be a very large value. For the values of
wsupp in the range between 0.5 and
xmax[J] = 2.9236 with the step size of 0.1, the dynamics of SQNR for the same MLP case is 13.47669 dB − 3.18492 dB = 10.2918 dB. It is obvious that the choice of
wsupp has a large influence on the obtained SQNR of the three-bit UQ. Slightly smaller but also large dynamics of the experimentally calculated SQNR can be perceived for the CNN case. In addition,
Figure 10 depicts the difference in theoretically and experimentally obtained SQNR values. One can notice from
Figure 10 that the theoretical SQNR curve decreases after passing the theoretically optimal value of
xmax[J] = 2.9236. In contrast, the experimentally optimal value of
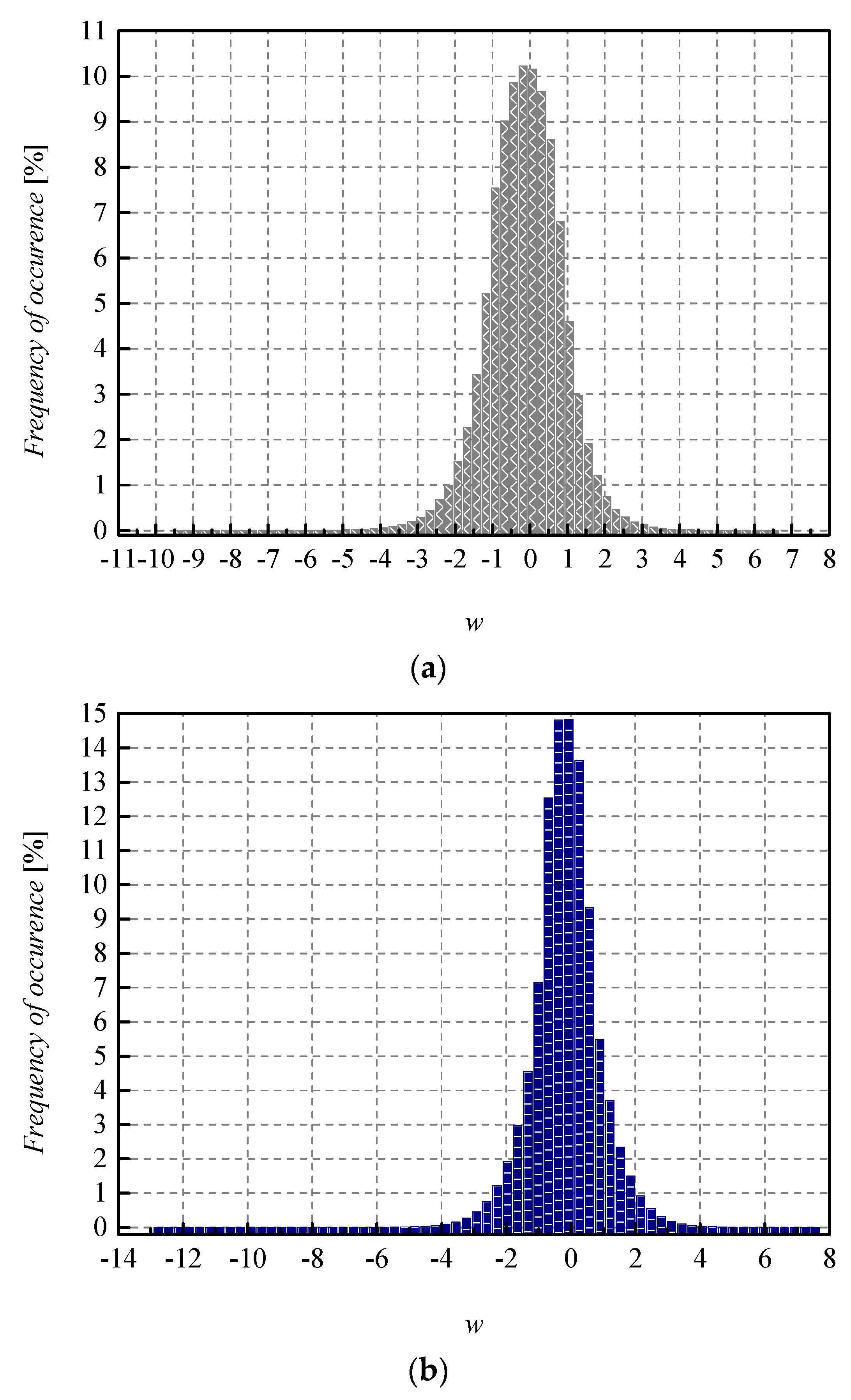
wsupp is lower compared to the theoretical one. This is a consequence of lower amplitude dynamics of real normalized weights (see
Figure 11) used in the experimental analysis compared to the theoretically assumed ones. The maximum of experimentally obtained SQNR values in the case of MLP amounts to 13.47669 dB for the support region threshold equal to 2.5, while the experimentally obtained QNN model accuracy for this ℜ
g choice is 97.43%, which is not the maximum obtained accuracy in the experiment. The maximum of experimentally obtained SQNR value in the CNN case amounts to 13.10203 dB, for the support region threshold equal to 2.6, while the experimentally obtained QNN model accuracy for this ℜ
g choice amount to 98.27%, which is also not the maximum obtained accuracy in the experiment for the CNN case. One can notice the higher amplitude dynamics of weights for the CNN case compared to the MLP case (see
Figure 11). For that reason, the maximum of experimentally obtained SQNR values in the CNN case is shifted right in
Figure 10. Moreover, one can notice that the theoretically determined SQNR curve is below both experimentally determined SQNR curves. The reason is that in the experimental analysis, the weights originating from the Laplacian-like distribution being quantized are from the limited set of possible values [−7.063787, 4.8371024] for the MLP model and from [−8.372064, 6.469376] for the CNN model. In the theoretical analysis, the quantization of values from an infinite set of values from the Laplacian source is assumed causing an increase in the amount of distortion, that is, the decrease in the theoretical SQNR value. Due to a similar reason (a wider amplitude dynamics of weights in the CNN case compared to the MLP case), the experimentally obtained SQNR is lower in the CNN case in comparison to the MLP case.
When compared to Case 1 of two-bit UQ presented in [
34], our three-bit UQ in the comparable case (Choice 1 for the MLP model) achieves a higher accuracy on the MNIST validation dataset by a significant 0.88%. Let us anticipate here that the QNN analysis with UQ should be limited to the cases of bit rate equal to 2 and 3 bits per sample, as it is expected that further increase in the bit rate will not contribute to the significant increase in the QNN model’s accuracy. In other words, we have shown that with the observed three-bit UQ, the accuracy of QNN amounting up to 97.97% can be achieved, meaning that by applying the described post-training quantization procedure to the MLP model trained on the MNIST dataset, the accuracy degradation of only 98.1% − 97.97% = 0.13% can be achieved compared to baseline MLP model stored in FP32 format.
In the following, we analyze the performance of the three-bit UQ in CNN model compression and the impact of various support region threshold values on both SQNR and post-training quantization accuracy. The observed cases and methodologies are the same as previously applied in MLP analysis. In particular, four specific choices of ℜ
g have been observed, and for each choice, we have calculated SQNR and the accuracy of CNN model when three-bit uniform post-training quantization is applied (see
Table 4).
One can notice that the CNN model’s accuracy is relatively stable, especially considering very high wmin and wmax values, compared to Choices 3 and 4. Moreover, the full precision of the CNN is expectedly higher when compared to the MLP, achieving accuracy of 98.89% on the MNIST validation set. Unlike the accuracy, the SQNR performance of the three-bit UQ differs a lot, which is a result of high absolute wmin and wmax values that are very far from the optimal value. Nevertheless, as the fluctuation of the accuracy is smaller than 1%, (98.56% − 97.64% = 0.92%) for such different Choices of ℜg, this confirms that the observations made for MLP regarding the influence of ℜg on the QNN performance are similar for the case of CNN.
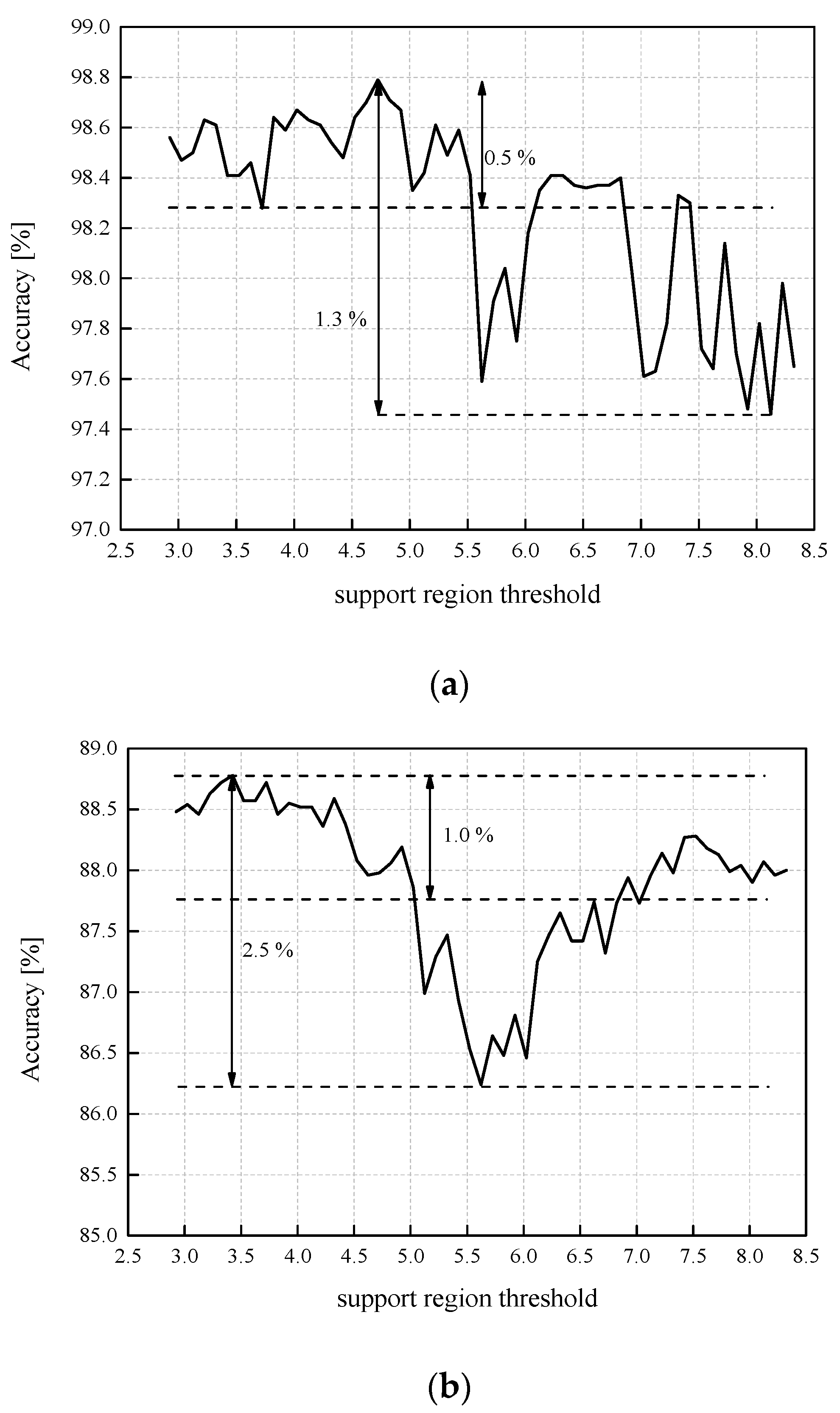
By analyzing the QNN model accuracies presented in
Figure 12a for the CNN case, we can observe that the accuracy dynamics, defined as the difference between the highest and lowest obtained accuracy in a very wide range of values selected for the support region threshold (wider than in the MLP case), amounts to 1.3%. On the other hand, by performing the rough analysis based only on the results from
Table 3, for the case of implementing two-bit UQ, we can calculate that QNN accuracy dynamics is higher and amounts to 2.39%. At first glance, by comparing the values of SQNR
exUQ for MLP and of SQNR
exUQ for CNN, for all four choices (see
Table 2 and
Table 4), one can notice that they have quite similar values for Choices 3 and 4. That is, one can notice that it holds SQNR
exUQ(MLP- Choices 3 and 4) ≈ SQNR
exUQ(CNN—Choices 3 and 4). However, for Choices 1 and 2, it is expected that SQNR
exUQ (MLP—Choices 1 and 2) > SQNR
exUQ (CNN- Choices 1 and 2) due to the higher amplitude dynamics of weights of the CNN model trained on the MNIST dataset compared to the one for the MLP model. Further, by analyzing the percentage of samples belonging to the ℜ
g for the CNN and MLP cases, one can notice that these percentages are quite similar for Choices 1 and 2 (see
Table 2 and
Table 4—within ℜ
g (%) (MLP—Choices 1 and 2) ≈ Within ℜ
g (%) (CNN- Choices 1 and 2). Moreover, it can be noticed that within ℜ
g (%) (MLP—Choices 3 and 4) > within ℜ
g (%) (CNN—Choices 3 and 4). In other words, the percentage of weights within ℜ
g (%) for MLP and Choices 3 and 4 is greater by approximately 0.25%.
Since we have almost the same accuracies: Accuracy (%) (MLP—Choice 3) ≈ Accuracy (%) (MLP—Choice 4) and Accuracy (%) (CNN—Choice 3) ≈ Accuracy (%) (CNN—Choices 4), one can observe almost the same difference in accuracy of 0.9% in favor of CNN for Choices 3 and 4, which has been intuitively expected. In addition, it is also reasonable to analyze the results shown in
Figure 12a for a somewhat narrower range of ℜ
g. More precisely, if we analyze the results up to
wmax = 6.469376 (Choice 1 within ℜ
g (%) is 99.9999% of the weights), a somewhat smaller value representing the accuracy dynamics can be determined. From both analyses conducted for the CNN model, trained on the MNIST dataset, and quantized by using three-bit UQ, one can conclude that a fairly stable accuracy can be achieved regardless of the ℜ
g choice, which is not the case with the post-training two-bit uniform quantization reported for the MLP case in [
34].
In this paper, results are also provided for both specified NN models, MLP and CNN, trained on the Fashion-MNIST dataset [
44].
Table 5 and
Table 6 present SQNR and the QNN model accuracy obtained with the application of different three-bit UQ designs for MLP and CNN trained on the Fashion-MNIST dataset, where ℜ
g is defined following the same principles as in previous tables.
Let us first highlight again that the MLP model achieves an accuracy of 98.1% on the MNIST validation set and 88.96% on the Fashion-MNIST validation set, where weights are represented in the FP32 format. Compared to MLP, the CNN model achieves a higher accuracy of 98.89% on the MNIST validation set, as well as a higher accuracy of 91.53% obtained on the Fashion-MNIST validation set, with weights also represented in the FP32 format. The highest obtained QNN accuracy for the observed ℜ
g ranges in
Table 5 amounts to 88.48% for Choice 4, while the lowest value for Choice 2 is 87.12%. Moreover, the accuracy dynamics for the results presented in
Table 5 amounts to 1.36%. For Choice 4, we can calculate that the degradation of the accuracy due to the application of the three-bit UQ amounts to 88.96% −88.48% = 0.48%. In
Table 6, the highest obtained accuracy amounts to 88.02% for Choice 3 (degradation due to the applied three-bit UQ amounts to 91.53% − 88.02% = 3. 52%), while the lowest value, also for Choice 2, is 84.90%. The accuracy dynamics for the results presented in
Table 6 amounts to 4.12%. It has been highlighted in [
47] that Choice 2 is a popular choice for the quantizer design, which, as one can notice from
Table 5 and
Table 6, is not the most suitable choice in terms of accuracy and SQNR, especially when the amplitude dynamics of the weights being quantized is relatively large.
In order to inspect further the influence of the ℜ
g choice on both, the accuracy and SQNR, for a wide range of
wsupp values and for both NN models (MLP and CNN) trained on Fashion-MNIST dataset, we can analyze results presented in
Figure 12b,c. For
wsupp having a relatively wide range of values, the accuracy dynamics presented in
Figure 12b,c amount to 2.5% and 5.5%, for MLP and CNN, respectively. This indicates that in the case where the specified MLP and CNN are trained on Fashion-MNIST dataset, more careful choice of ℜ
g should be performed. In addition, results presented in
Figure 12b,c indicate that there is a number of choices for ℜ
g that can result in the degradation of accuracy due to the application of the three-bit UQ up to 1% compared to the case with the highest identified accuracy. Eventually, we can highlight that the highest accuracies for the observed Fashion-MNIST dataset and MLP and CNN models are achieved for
wsupp = 3.42 and
wsupp = 3.52, respectively. These highest accuracies amount to 88.78% and 89.54% for MLP and CNN models (for Fashion-MNIST dataset), respectively. In other words, with the observed three-bit UQ, and with the selection of
wsupp = 3.42 and
wsupp = 3.52 for the corresponding cases (MLP and CNN), the accuracy degradation of 88.96% − 88.78% = 0.18% and 91.53% − 89.54% ≈ 2% is achieved. We can derive additional conclusions by analyzing theoretical and experimental SQNR values for MLP and CNN (both trained on Fashion-MNIST dataset) determined for a wide range of
wsupp values assumed in three-bit post-training uniform quantization (see
Figure 13).
From the SQNR aspect, the results presented in
Table 5 and
Table 6 show that, as expected, the highest values in both cases of interest (MLP and CNN) are achieved for Choice 4. As already highlighted, the theoretical SQNR curve decreases after passing the theoretically optimal value of 2.9236. Additionally, as previously concluded for the MLP and CNN trained on the MNIST dataset, in the observed cases with MLP and CNN trained on the Fashion-MNIST dataset, this theoretically optimal value of
wsupp differs from
wsupp = 2.7 and
wsupp = 2.8, at which the maximum of the experimentally determined SQNR value of 12.5374 dB and 12.2462 dB are achieved for MLP and CNN case, respectively. Similarly, as we have explained for the MNIST dataset and MLP and CNN, we can here explain that these differences are the consequence of lower amplitude dynamics of real normalized weights (see
Figure 14) used in the experimental analysis compared to the theoretically assumed ones. For
wsupp = 2.7, the QNN model’s accuracy for MLP trained on the Fashion-MNIST dataset amounts to 88.54%, which is not the maximum obtained accuracy in the experiment. A similar conclusion can be derived for the CNN trained on the Fashion-MNIST dataset, where for
wsupp = 2.8, we have determined that the QNN model’s accuracy is 87.73%. Therefore, we can conclude that for both NN models (MLP and CNN) and for both datasets (MNIST and Fashion-MNIST), it is not of utmost importance to determine the optimal value of the support region threshold, as it is the case in classical quantization, in order to fit into some predefined range of accuracy degradation that can be considered acceptable.
As with the MNIST dataset, in the case of using the Fashion-MNIST dataset, one can notice the higher amplitude dynamics of weights for the CNN case compared to the MLP case (see
Figure 14). For that reason, the maximum of experimentally obtained SQNR values in the CNN case is shifted right in
Figure 13. Moreover, one can notice that the theoretically determined SQNR curve is below both experimentally determined SQNR curves, where the reasons for these differences are similar to those explained for the MNIST dataset.
In summary, the experimental analysis confirmed that for the case of R = 3 bit/sample, different choices of ℜg do not have an equally high impact on the QNN model’s accuracy as is the case when the bit rate is equal to 2 bits per sample. Moreover, it has been shown that if the support region threshold takes value from a properly defined wide range, for both specified NN models, MLP and CNN trained on MNIST dataset, the performance of QNNs is quite stable for various choices of ℜg, and the accuracy of QNNs are greatly preserved in comparison to the corresponding baseline NN models. Eventually, we have concluded that for both NN models (MLP and CNN) and for both datasets (MNIST and Fashion-MNIST), it is not of utmost importance to determine the optimal value of the support region threshold, as it is the case in classical quantization, in order to fit into some predefined range of accuracy degradation that can be considered acceptable.
























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}