Abstract
Multi-focus image fusion is the process of combining focused regions of two or more images to obtain a single all-in-focus image. It is an important research area because a fused image is of high quality and contains more details than the source images. This makes it useful for numerous applications in image enhancement, remote sensing, object recognition, medical imaging, etc. This paper presents a novel multi-focus image fusion algorithm that proposes to group the local connected pixels with similar colors and patterns, usually referred to as superpixels, and use them to separate the focused and de-focused regions of an image. We note that these superpixels are more expressive than individual pixels, and they carry more distinctive statistical properties when compared with other superpixels. The statistical properties of superpixels are analyzed to categorize the pixels as focused or de-focused and to estimate a focus map. A spatial consistency constraint is ensured on the initial focus map to obtain a refined map, which is used in the fusion rule to obtain a single all-in-focus image. Qualitative and quantitative evaluations are performed to assess the performance of the proposed method on a benchmark multi-focus image fusion dataset. The results show that our method produces better quality fused images than existing image fusion techniques.
1. Introduction
Due to limited depth-of-field (DOF), it is not easy for cameras to capture an image that has all focused objects. Usually, in a camera captured image, the objects that lie in the range of the depth-of-field are sharp and the remaining objects tend to be blurred [1]. An additional cause of image blurring includes atmospheric scatter and spatial and temporal sensor integration [2]. Images that are partially focused are not enough for sound understanding and obtaining accurate results in different applications of computer vision such as object recognition and extraction [3], remote sensing and surveillance [4], image enhancement [5], medical imaging [6], etc. To resolve this issue, multi-focus image fusion algorithms are proposed in which a fused image of an extended depth-of-field is constructed by integrating the additional information of multiple images of the same scene.
In recent years, numerous multi-focus image fusion methods have been proposed. Some of them directly operate on image pixels and regions to obtain an all-in-focus image while others exploit the transform domains to achieve this task. The former methods are known as spatial domain based fusion methods, and the latter are categorized as transform domain based methods [7,8]. In transform domain based fusion, a fused image is regenerated from fused transform coefficients of the source images. The transform domain based fusion methods perform well for separating the discontinuities at edges, but do not give the representation for line and curve discontinuities [9]. They are computationally expensive techniques and may produce undesirable artifacts in fused image [10].
In spatial domain based fusion, the rules of fusion are applied to pixels or a region of input images directly without conversion to other representations to generate the fused image. Most spatial domain fusion algorithms operate at the pixel level, e.g., [11,12,13,14], and produce a fused image by weighting the corresponding pixels of source images. Some spatial domain based fusion techniques work at the region level, e.g., [15,16,17]. These methods compute focus measures for each region and construct a fused image by selecting a region with more clarity. The spatial domain based fusion algorithms provide high spatial resolution. However, the results might suffer from unwanted artifacts, e.g., the ghosting effect, which mainly occurs due to incorrect categorization of the pixels or regions as focused or de-focused. To overcome these problems, some techniques in the spatial domain use real values instead of binary values as focus measures and use the weighted averaging of pixel values to obtain the fused image [18,19].
In this paper, we propose a novel spatial domain based multi-focus image fusion algorithm. The proposed method is built on the idea of grouping the neighboring pixels with similar colors and patterns into larger pixels (also known as superpixels) to obtain an accurate decision map. We observe that such a grouping helps reduce the false categorization of pixels as focused and de-focused. The statistical properties of the computed superpixels are analyzed to distinguish the focused and de-focused pixels, generating the initial focus map, which is further processed to obtain a more accurate final decision map. Different tests performed to evaluate the performance of the proposed method reveal its effectiveness. A few of the sample fusion results achieved by the proposed method are shown in Figure 1.

Figure 1.
Results of the proposed algorithm on sample multi-focus images from the test dataset. (a) Source images with foreground focused, (b) source images with background focused, and (c) fused images using the proposed method.
The rest of this paper is organized as follows: A brief review of the literature on multi-focus image fusion is presented in Section 2. The proposed MIFalgorithm is presented in Section 3. The experimental evaluation through different qualitative and quantitative tools is carried out in Section 4. The performance of the proposed algorithm with different color distance models and the impact of other parameters is analyzed in Section 5. The conclusions are drawn in Section 6.
2. Background and Literature Review
The main step in any multi-focus image fusion algorithm is the detection of the focused region in the source multi-focus images to obtain a so-called decision map, also called the focus map. The source images are then fused to obtain an all-in-focus image. Based on the representation and working of the focus map estimation and fusion process, the existing MIF algorithms can be categorized into four groups: multi-scale transform based methods, feature space transform based methods, spatial domain based methods, and neural networks based methods [8,20].
The multi-scale transform based methods generally split the input images into a multi-scale domain and then fuse the transformed coefficients using some fusion rule. The all-in-focus image is generated from these fused coefficients [21]. Multi-scale transform methods have a wide of range of related techniques sequentially implemented in image fusion like pyramid decomposition [22], wavelet transform [23,24], curvelet transform (CVT) [25], and contourlet transform [26,27]. In the MIF algorithm presented in [28], the source images are split into approximation and detail coefficients at different levels, and the coefficients are fused by applying several fusion rules. Various level fused coefficients are merged to obtain the desired all-in-focus image. Sheng et al. [29] proposed a support value transform based method that uses a support vector machine to achieve the fused image. The discrete cosine transform has also been exploited for image fusion, e.g., [30,31]
The feature space transform based fusion has emerged as another popular mean for multi-focus image fusion [32]. These fusion methods estimate the focus map through a single scale feature space of source images. References [1,13,33,34] are a few examples of such MIF methods. The sparse representation based fusion method in [33] divides the input images into patches known as sparse coefficients using a dictionary. The coefficients are then combined, and the fused image is generated. The fusion method in [1] uses the feature space from a robust principal component analysis technique for decomposition, and local sparse features are used to compute the all-in-focus image. The higher order singular-value decomposition based method [34] picks informative patches from input images by estimating the activity level of each patch. This information helps to obtain the fused image. Another higher order singular-value decomposition based method was presented in [35]. Multi-focus image fusion with the dense scale-invariant feature transform method (DSIFT) [13] uses dense descriptors to calculate the activity level in the patches of source images to form an initial decision map. After refining and feature matching of the initial map, it is used to form the fused image.
In spatial domain based fusion methods, fused images are computed by processing the pixels of the input multi-focus images. Some methods operate at the pixel level, e.g., [11,14,36]; some are block based, e.g., [37,38,39]; and others are region based methods, such as [40,41,42]. Usually, pixel-by-pixel averaging of source images does not achieve plausible results as it may introduce different artifacts in the fuse image [13,43]. Therefore, the region based and block based spatial domain fusion methods have been introduced. In these methods, the input images are divided into blocks or segmented regions, and the sharpness of each block is calculated to form the focus map [44].
Image segmentation is a difficult task, so it is hard to maintain the quality of fused images obtained by region based methods. However, as an image block may contain both focused and defocused areas, the fused image computed by the block based method may exhibit anisotropic blur and misregistration. To resolve this problem, multi-scale image fusion methods have been introduced. The method in [45] is based on a multi-scale structure based focus measure. In this method, a binary-scale scheme is used, which calculates the weighted gradient of a focused region by applying small-scale focus measures. It proves helpful in reducing the anisotropic blur and misregistration with large-scale focus measures.
In recent years, many pixel based spatial domain methods have been proposed. These methods include image matting based [18] and guided filtering based [46] methods, which compute the fused image by extracting enough information from the source images and achieve high efficiency by preserving spatial consistency. The MIF method proposed in [18] focuses on obtaining all-in-one focus images from detected focused regions in multi-focus images by using morphological filtering and the image matting technique. In the guided filtering based method [46], two-scale image decomposition is done to produce focused images from the base layer and detail layer.
Some pixel based methods, such as [47,48,49], solve the maximum optimization problem by estimating a weight map. The algorithm in [47] has the benefit of a multi-spectral algorithm along with spatial domain methods. The combined activity estimation of high and low frequencies of source images is calculated, and a new smoothness term is introduced for the alignment of the solution to the boundaries of the defocused and focused pixel. In [48], multi-focus image fusion was proposed using edge and multi-matting models. A multi-focus image fusion algorithm based on random walks [49] analyzes the feature area locally and identifies nodes globally to compute connected graphs of random walks.
Multi-focus image fusion has also been achieved through deep neural networks in several ways; the majority of these techniques rely on the detection of the focused region [50]. In the fusion method presented in [50], features are extracted through a u-shaped network to obtain high- and low-level frequency texture information. It directly maps multi-focus images to fused images instead of detecting focused regions. The pulse coupled neural network (PCNN) is also explored for image fusion, e.g., [16]. In these methods, the source multi-focus images are decomposed into fixed-size blocks, and the image Laplacian of each block is computed to obtain the feature maps. These feature maps are used as the input of the PCNN as in [16].
Recently, deep learning has also been explored for efficient image fusion [51]. A number multi-focus image fusion techniques based on deep learning (DL) have been presented using convolutional neural networks (CNNs), such as in [52,53,54,55,56]. The method in [52] proposes a pixel-wise convolution neural network for image fusion, and the deep convolutional neural network (CNN) based method [54] uses the Siamese network for feature extraction and activity level measurement in source images to obtain a focus map. The CNN based MIF method presented in [53] also uses Siamese multi-scale feature extraction. In [55], a multi-level dense network was presented for fusing multi-focus images. It extracts shallow and dense features from images from a mixture of many distributions. The convolutional sparse representation (CSR) is used for multi-focus image fusion, e.g., [57,58,59]. The algorithm in [59] uses Taylor expansion and convolutional sparse representation for fusing multi-focus images. Morphological component analysis and convolutional sparse representation were used in [58] to obtain texture features using pre-learned dictionaries. The obtained sparse coefficients of the source images were merged, and a fused image was obtained. Generative adversarial networks (GANs) have also been exploited for increasing the depth of field, e.g., [60,61,62].
3. Proposed Method
We propose a spatial domain based multi-focus image fusion algorithm that builds on the idea that pixels in a small locality in an image are highly autocorrelated—having similar colors and textures—and thus can be merged into larger patches known as superpixels to improve the speed and quality of different tasks. These superpixels are more expressive than single pixels as they carry more distinctive statistical properties when compared with other superpixels. Moreover, we observe that they have a greater tendency to be distinguished as focused and out-of-focused compared to single pixels. We exploit this important characteristic to design a novel and efficient image fusion algorithm. The proposed method works in three steps. First, superpixels in the source multi-focus images are computed. Second, using the statistical properties of superpixels, they are categorized as focused and de-focused, from which initial focus maps are constructed. The initial focus map is refined using a spatial consistency constraint. Third, the refined focus map is used to obtain the fused image from source multi-focus images with the help of a fusion rule. A schematic diagram of the proposed method is shown in Figure 2. These steps are described in detail in the following sections.
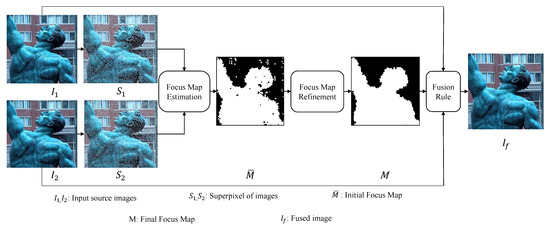
Figure 2.
Schematic diagram of the proposed multi-focus image fusion algorithm.
3.1. Superpixels Computation
Several algorithms have been proposed to obtain superpixels from an image, e.g., [63,64,65]. Like most existing superpixel algorithms, the proposed technique also uses pixel color and its spatial position in deciding their merging. Our method extends the simple linear iterative clustering (SLIC) algorithm [65], which uses k-means clustering to generate superpixels, to obtain superpixels better suited for image fusion. In particular, similar to [65], we divide the image pixels into k number of clusters based on their color and location. Superpixels are computed based on the mean color values of pixels. For an image with N pixels, the size of each superpixel is approximately pixels. Regular spaced grid pixels S are computed where . Every initial cluster center is then sampled based on S to produce equally sized superpixels. After the comparison, these centers are then moved forward to the lowest gradient position. Then, each pixel of the image is associated with the nearest cluster center through a distance measure . is computed considering the pixel spatial distance and the color difference .
The spatial distance of the pixel located at and a cluster center is computed using the Euclidean distance metric.
For color distance measure, unlike the method in [65], we use the CIEDE2000color difference model, which produces better superpixels for image fusion. We performed numerous experiments and tested different color distance models to evaluate their effectiveness for pixel focus detection, which favored the CIEDE2000 metric. It is a complicated, but accurate color distance measure [66]. In this model, the color difference between two pixels with color in the model () and () is computed as:
where is the difference in luminance components and and are computed from the chroma components .
with , and .
The weighting factor , , and in (2) are usually set to unity. , , and are the compensation of lightness, chroma, and hue. To keep the discussion simple, the complete details of the metric are not presented here, and they can be found in [66].
Finally, the two distance measures are combined as in [65] to obtain . It is the sum of the spatial distances (1) and color distances (2), which are normalized by gird interval S. The factor m in (3) is used to control the compactness of the superpixels.
Let and be two source multi-focus images. In the rest of the text, they are simply referred to as source images. Using the proposed algorithm, the superpixels in are computed, which are mapped to to divide into the corresponding set of superpixels. That is, the superpixels in are not computed; instead, the superpixel labels computed in are assumed for as well, and the values of their centers are updated with respect to . This helps to establish the correspondence between the superpixels in and . We recall that both images are complementary and represent the same scene, but with different focused regions. Therefore, the superpixel structure of the two images is kept the same so that the correspondence between them can be established. Figure 3 shows the superpixels computed using the proposed strategy on a sample multi-focus image pair (shown in Figure 1).

Figure 3.
Superpixel computation using the proposed strategy. (a) Superpixels of (foreground focused). (b) Superpixels of (background focused).
3.2. Focus Map Estimation
A superpixel carries various statistical properties, e.g., mean, standard deviation, variance, and kurtosis, which can be used to draw different characteristics of the superpixel. The standard deviation is considered to be an important and widely used index to measure information diversity and variability in an image [67,68]. It has been shown in different studies, e.g., [69], that the variance (or standard deviation) of the de-focused regions is generally less than the sharp regions. In the proposed method, we exploit this property to designate the superpixels as focused and de-focused. We calculate the standard deviation of each superpixel in the source images and use it to estimate the focus map. We found that the standard deviation of L channel serves as a better discriminant than the standard deviation computed over all three channels, i.e., l, a, and b. Therefore, for each superpixel, s, the standard deviation of the L values of its constituent pixels is computed.
where is the i-th superpixel in image , is the number of pixels in , and is the mean of the pixels in superpixel .
The standard deviation of each superpixel in , , is computed analogously. The standard deviations of the corresponding superpixels in and are compared, and the focus map is constructed. If is greater than , this means is focused in and the same region is de-focused in . In the focus map , the focus value of pixels corresponding to is set to one, and it is set to zero if . That is,
Figure 4 shows the focus map constructed from the superpixels shown in Figure 3 using Equation (5).

Figure 4.
Initial focus map generated using the proposed strategy for the images shown in Figure 3.
It is possible that in the initial focus map obtained through the proposed algorithm, a few superpixels are incorrectly categorized, as can be noted in Figure 4. Some focused superpixels are falsely marked as de-focused, and a few de-focused patches are incorrectly marked as focused. These false positives and false negatives should be resolved to obtain a high-quality fused image. To this end, a neighbor constraint technique is proposed. We observed from experiments that the incorrectly categorized superpixels usually appear as a single entity, and most of its neighbors are correctly identified. Based on this observation, we form a neighbor constraint rule to eliminate the false positives and negatives from the map. The rule examines each superpixel in the map, investigates all its neighboring superpixels, and assigns the category that most of its neighbors have. Specifically, it is marked as focused if more than half of its neighbors are marked as focused, and vice versa.
Figure 5 shows the results of the proposed refinement process. Figure 5a shows a source image with superpixels overlaid on it; two sample focused and de-focused regions magnified to ease the inspection are shown below it. Figure 5b shows the initial focus map; superpixels structures are also overlaid to highlight the details, and selected regions are also shown below this figure. The results of the refinement procedure are shown in Figure 5c. The results show that most incorrectly marked regions were successfully recovered by the proposed refinement strategy.

Figure 5.
Initial focus map refinement: (a) a sample multi-focus image with superpixels structures overlaid on it, (b) the obtained focus map, and (c) the refined focus map.
3.3. Fusion Rule
The final focus map M obtained after refinement is used to fuse the contents of the source images and to generate the all-in-focus image . The fusion rule simply takes the pixel value from if the focus map value is one and from otherwise. Figure 6 shows the fused image generated from the source images shown in Figure 3.

Figure 6.
Fusion results using the refined focus map: (a) first source image , (b) second source image , and (c) fused image .
4. Experiments and Results
In this section, we evaluate the performance of the proposed multi-focus image fusion method and compare it with the existing MIF techniques. The performance was assessed both qualitatively and quantitatively, and various analyses were also performed to evaluate the robustness of the proposed method. The experiments were performed on the recent widely used Lytro multi-focus dataset [43,70]. The dataset contains 20 color multi-focused image pairs, each of size . Sample image pairs from the dataset are shown in Figure 7.

Figure 7.
Sample multi-focus image pairs from the Lytro dataset.
4.1. Compared Methods
To evaluate the effectiveness of the proposed method, its performance was compared with existing well-known multi-focus image fusion (MIF) algorithms. In particular, nine representative methods were selected for the comparison. The discrete cosine harmonic wavelet transform (DCHWT) based method [24] reduces the fusion complexity by using the discrete cosine transform (DCT) and discrete harmonic wavelet coefficients. The wavelet based statistical sharpness measure (WSSM) [71] utilizes the spreading of the wavelet coefficient distribution as a sharpness measure and evaluates it by the adaptive Laplacian mixture model. The pulse coupled neural network (PCNN) method [26,72] uses the orientation information to obtain the fused image. The source images are decomposed into fixed-size blocks, and the image Laplacian of each block is computed to obtain feature maps that are used in PCNN for fusion. The DCTLP method [31] uses DCT coefficients and Laplacian pyramids to achieve fusion. The method presented in [73] uses Independent Component Analysis (ICA) and topographic independent component analysis bases for fusion.
In image fusion using luminance gradients (IFGD) [74], the highest gradients of each pixels’ locations of the source images are blended, and then, fused luminance is obtained by the reconstruction technique. In the nonsubsampled contourlet transform (NSCT) based MIF algorithm [27], NSCT decomposition is used to obtain the selection rules for sub-band coefficients. In the PCA method [75], the fused image is obtained using wavelets and principal component analysis (PCA). The CSR fusion algorithm [76] decomposes each source image into base and detail layers with the help of convolution sparse representation. It performs different fusion techniques on both layers and then merges the results. A deep convolutional neural network (CNN) based MIF method was presented in [54]. In particular, it uses the Siamese network for feature extraction and activity level measurement in source images.
4.2. Qualitative Performance Evaluation
The qualitative performance analysis was performed by analyzing the quality of fused images visually. For the visual inspection, we present the fusion results obtained by the compared methods and our algorithm. For comparison, “Swimmer” and “Cookie” image pairs are selected from the test dataset. The visual inspection is difficult to perform and generalize as each multi-focus image pair has different information about focused and de-focused regions. Nevertheless, it can certainly provide some insight into the quality of fused images obtained from different algorithms.
Figure 8 presents the fused images of the “Swimmer” image pair obtained by our algorithm and the compared methods. One can note that the results of the DCTLP method suffer from undesirable ringing artifacts: the fused image has lost most of the sharpness around the strong edges. Some blurred regions can be spotted in the results of the PCNN and NSCT methods. The fused image obtained by IFGD has lost some fine details due to extra brightness. The ghosting and ringing artifacts can be seen in the results of the PCA and NSCT algorithms as well. The ghosting artifact is also visible around the edges in the fused image produced by the ICA method. The fused images produced by WSSM, CNN, CSR, and our method are of good quality and are hard to visually differentiate. Similar observations can be made from the visual inspection of the results of ours and the compared methods on the “Cookie” image pair shown in Figure 9.

Figure 8.
Visual quality assessment of the fusion results achieved by the proposed and the compared methods on the “Swimmer” multi-focus image pair from the test dataset. WSSM, wavelet based statistical sharpness measure; PCNN, pulse coupled neural network; DCTLP, discrete cosine transform Laplacian pyramid; IFGD, image fusion using luminance gradients; CSR, convolutional sparse representation.

Figure 9.
Visual quality assessment of the fusion results achieved by the proposed and the compared methods on the “Cookie” multi-focus image pair from the test dataset.
The visual quality inspection shows that the results produced by our method are crisp and are free of ghosting and ringing artifacts. A qualitative analysis, however, is difficult to perform due to various reasons including viewing conditions, trained subjects, etc., and it is particularly laborious on large datasets. Therefore, to truly assess the performance of an algorithm, along with the visual inspection, an objective fusion quality assessment is necessary.
4.3. Quantitative Performance Evaluation
The objective quality assessment of fused images is a tough task as the ground truth images of multi-focus images cannot be acquired. To objectively evaluate the performance of MIF algorithms, many metrics have been introduced, but none of them are certainly better than the others. Therefore, to evaluate the performance of fusion methods, it is desirable to use multiple metrics. These metrics evaluate the quality of the fused image with reference to the source multi-focus images. To perform an extensive objective performance evaluation of the proposed method and other competing techniques, we chose 12 fusion quality assessment metrics and computed the results over the whole dataset. These metrics assess the quality of a fused image using its different characteristics and modalities. Based on these characteristics, the metrics are generally grouped into four categories [8,77]: information theory based metrics, image structural similarity based metrics, image feature based metrics, and human perception based metrics. These metrics are summarized in Table 1.

Table 1.
Objective image fusion quality assessment metrics used in the performance evaluation.
- Information theory based metrics analyze the quality of the fused images by checking the amount of information transferred from the source images to the fused image. These metrics include: normalized mutual information [79], visual information fidelity [81], and the nonlinear correlation information entropy metric [80].
- Image feature based metrics calculate the quality of fused image by analyzing the transferred features from the source images to the fused image. Gradient based fusion performance metrics [82], [83], image fusion metric based on multiscale scheme [85], image fusion metric based on spatial frequency [84], and image fusion metric based on phase congruency [86,91] are examples of these metrics.
- Image structural similarity based metrics: The measurement of image similarity depends on the proof that the human visual system is profoundly adjusted to structural information, which is exploited in these metrics to assess the quality of a fused image. The loss of structural information is very important to estimate the image distortion. These metrics include Piella’s metric [87], Cvejie’s image fusion metric [88], and Yang’s image fusion metric [89].
- Human perception inspired fusion metrics, e.g., Chen Blum metric [90], measure the quality of fused images on the basis of the saliency map, which is generated by filtering and calculating the preservation of contrast.
The objective performance analysis of the proposed and the compared methods was carried out using all twelve metrics described in Table 1. Each metric’s scores was computed over the whole dataset using the implementation presented in [77], and the results were averaged to obtain an overall quality score. The comparison is presented in Table 2, and the best performing algorithm on each metric is marked in bold. The results show that for the widely used metric, our method performed the best, achieving the highest score . The proposed method outperformed all competing techniques in most metrics including , , , , , and . The performance of our method in the rest of the metrics was also appreciative, where it was the second or the third best algorithm. These statistics reveal that the proposed algorithm overall produces better quality fused images than most compared methods. Both qualitative and quantitative analyses reflect the effectiveness of the proposed method.
Table 2.
Objective performance evaluation of the proposed and the compared methods on the Lytro dataset. The best scores for each metric are highlighted in bold.
4.4. Computational Complexity
We also analyzed the computational complexity of the proposed and the compared methods. All MIF algorithms were executed over the whole dataset, and their average execution time was computed and is reported in Table 3. These times also include the file I/O time, if any, and were computed on an Intel® Core™ i7 GHz processor with 8 GB RAM and 64 bit operating system. The results show that the PCA algorithm is the fastest among all approaches; the proposed method takes an average seconds to generate a fused image. The main contributor to this time is the complex computation involved in estimating the superpixels and using the CIEDE2000 color distance model. An efficient implementation can help reduce its computational complexity.
Table 3.
Execution time (seconds) comparison of the proposed and the compared MIF algorithms.
4.5. Summary
The performance of the proposed MIF method was evaluated using different tools and techniques. To appreciate the performance of the proposed method, visual results achieved by the proposed and the compared MIF algorithms were presented in the preceding sections. From the visual inspection of the results presented in Figure 8 and Figure 9, we see that the results of most compared methods suffer from different impairments such as the ghosting effect, ringing artifacts, and blurry regions. In contrast, the results of the presented methods are crisp and free from these artifacts. The objective performance evaluation metrics confirm this. The advantages of the proposed method lie in its simplicity and ability to compute an accurate focus map. Unlike other competing methods that employ complex mechanisms to estimate the focus map and fusion strategies, the proposed method uses a simple fusion rule. We recall that the proposed MIF algorithm is built on the fact that the pixels in a small locality in an image are highly autocorrelated—having similar colors and textures. Based on this phenomenon, the pixels in the image are merged into larger patches, which provide the grounds for an accurate focus map, resulting in good fusion results. One limitation of the present proposed method is its inability to work with grayscale images. Since pixel color is an important clue in our focus map estimation method, its absence can degenerate its performance. However, extending it to grayscale images would certainly be an interesting investigation that we plan to carry out in the future.
5. Performance Analysis Using Different Color Distance Models and the Impact of other Parameters
In this section, we report different experiments and analyses that we performed to investigate the performance of the proposed image fusion algorithm. We performed three sets of experiments, first to evaluate the different color distance models for efficient superpixel estimation for fusion. The second set of experiments analyzed the impact of the number of superpixels on the performance of the proposed algorithm. In the third set of experiments, the contribution of color distance and spatial distance towards the overall distance measure was analyzed, and their impact on the performance of the proposed method was investigated.
5.1. Fusion Performance with Different Color Distance Models
We recall that determining the clusters to which the pixels are assigned to (Section 3.1) is decided using a distance measure Equation (3). is formed from the spatial distance and the color distance of the pixel and the cluster centers. The former measure Equation (1) is simple the Euclidean distance between the two coordinates, and the latter is the Euclidean distance between the lab colors of the two points Equation (2). We tested different color distance models to find the distance measure most suited for image fusion applications. In addition to the CIEDE2000 model (Section 3.1), the following color distance models are explored.
- Euclidean color distance in the RGB color space: The simplest and the most well-known way to compute the distance between two colors is using the Euclidean distance in the RGB color space. The distance between two pixel colors and is computed as,
- Color approximation distance (CAD): The perception of brightness by the human eye is non-linear, and for each color, non-linearity is not the same, as proven by different experiments [92,93,94]. Therefore, there have been many attempts to weight the RGB values to better fit human perception so that the color approximation would be more appropriate. The CAD between two colors and is computed as:where is the average of and ; , , and are the differences between the red, green, and blue channels of the two colors, respectively.
- CIEXYZ: The visualization of the RGB color space was not perfect because the color space of the human eye is greater than the experiment results of CIERGB, and an updated color difference model, CIEXYZ, was introduced by Commission Internationale de L’éclairage (CIE) [95]. It was mathematically designed to avoid the negative numbers known as tristimulus values. It consists of three parameters: non-negative cone response curve , luminance , and partially-equal to blue color .The normalized tristimulus values x, y, and z were calculated from X, Y, and Z as: where . The difference between the tristimulus values of two colors was then computed using the Euclidean distance formula.
- CIE76: In the CIE76 color distance model, the CIELAB color space was used as it is considered to be the most exact means of representing color [96]. The color difference between two colors and in the CIELAB color space is calculated by following formula:where , , and
- CIE94: The CIE94 color model retains the CIELAB color space, and it addressed the non-uniformities in CIE76 [97,98]. CIE94 was defined in the lightness, chroma, and hue (LCh) color space, and they are calculated from the Lab-coordinates.
- CMC l:c: The color difference CMC (Colour Measurement Committee of the Society of Dyes and Colourists of Great Britain) l:c is calculated in the LCh color space and has two parameters: lightness (l) and chroma (c). For the application, it allows the users based on the ratio of to weight the difference that is deemed appropriate.
- CIEDE2000: The CIE Delta E (CIEDE2000) color distance model was introduced by CIE and provides an improved method for the calculation of color differences. A detailed discussion is presented in Section 3.1.
The proposed algorithm with each of these distance measures was executed on the whole test dataset. The quality of the fused images was evaluated using all 12 fusion quality assessment metrics, and the average results are presented in Table 4. The best scores for each metric are highlighted in bold. The results show that most fusion quality assessment metrics rate the fusion results of the proposed method with the CIEDE2000 color distance model as the best. In these experiments, all other parameters were kept fixed. Moreover, we also computed the average execution time of the proposed method with each color distance model, and the results are reported in Table 4. One can note that CIEDE2000 takes the maximum time of seconds per image pair due to its complex computations. However, it produces better decision maps for fusion and therefore is preferred over other measures.
Table 4.
Comparison of different color distance models for the proposed multi-focus image fusion algorithm. The best values are in bold. Time (in seconds) is the average execution time of the proposed method with each color distance model. CAD, color approximation distance.
5.2. Impact of the Number of Superpixels on the Fusion Quality
The parameter that is important in the computation of superpixels is k (Section 3.1), the desired number of approximately equally-sized superpixels. For an image with N pixels, the size of each superpixel is approximately pixels. In this experiment, we analyzed the impact of the number of superpixels on the performance of the proposed algorithm. We computed the fusion results with the proposed method using different values of k, and the results were evaluated using all 12 objective fusion quality metrics to get a general indicator. In particular, we tested the performance with , . From the results shown in Figure 10, one can note that most metrics show negligible or no change in the quality of the fused images; therefore, the impact of k on the fusion performance of our method is negligible. However, using a larger value of k certainly increases the execution time of the method due to the extra computation needed in computing the superpixels and their subsequent steps. The average execution times for different k are reported in Table 5. In our method, was set as the default.
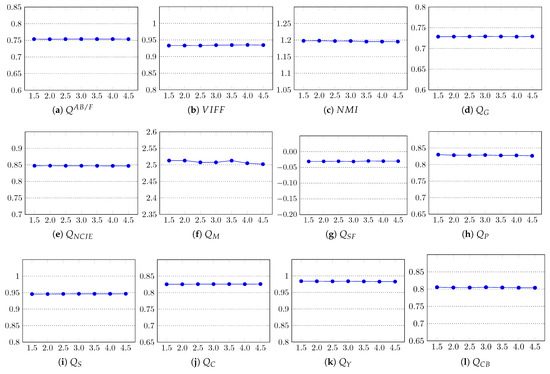
Figure 10.
Impact of the number of superpixels k on the fusion quality of the proposed method. In all graphs, the x-axis represents k and the y-axis the quality score. The x-axis labels are coded as .
Table 5.
Execution time of the proposed method with different numbers of superpixels k. Time (in seconds) is the average execution time. The best time is marked in bold.
5.3. Analysis of the Relative Contribution of Spatial and Color Distances
The parameter m in Equation (3) is used to control the compactness of the superpixels: it weights the relative information between the spatial and the color proximity. The recommended range of the value of m in the CIELAB color space is . We performed a set of experiments using different values of weighting factor m. We note that for small values of m, the shape and size of the superpixels become less regular and more tightly adhere to the image boundaries. For a large value of m, the superpixels are more compact, and spatial proximity becomes more important. The results of superpixel estimations with different values of m on a sample image are shown in Figure 11.

Figure 11.
Superpixels estimated with the proposed algorithm using (a) and (b) .
The fusion results were assessed using all 12 quality metrics, and their average scores are graphed in Figure 12. The results clearly show that m does not contribute to the quality enhancement of the fused image. Since for large values of m, the superpixels are more compact, the execution time of the method is reduced, as shown in Table 6. In the implementation of our method, the default value of m was set to 25.
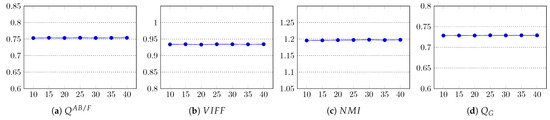
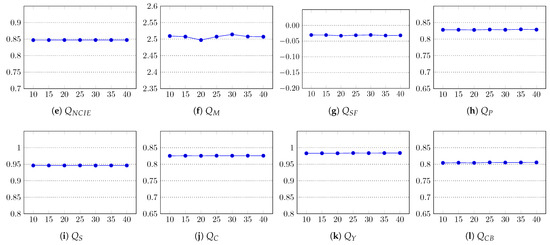
Figure 12.
Impact of the weight factor m on the fusion quality of the proposed method. In all graphs, the x-axis represents m and the y-axis the quality score.
Table 6.
Impact of weight factor m on execution time. Time (in seconds) is the average execution time of the proposed method with different values of m. The best values are in bold.
6. Conclusions
In this paper, a novel multi-focus image fusion technique is presented. The proposed technique merges similar pixels into larger groups termed superpixels. The spatial and color properties of the pixels are exploited to estimate the superpixels in the source multi-focus images. Moreover, different color distance models are tested to obtain high quality fused images. Different statistical properties of the computed superpixels are analyzed to categorize them as focused and de-focused, and based on this information, a focus map is generated. Moreover, the wrongly categorized superpixels are corrected by a spatial constraint rule. The qualitative and quantitative experiments worked out on a benchmark multi-focus image dataset reveal that our method produces better quality images than existing similar techniques. The source code of the proposed method is released publicly at the project website (http://www.di.unito.it/~farid/Research/SBF.html, accessed on 18 February 2021).
Author Contributions
Conceptualization, A.I., M.S.F., M.H.K. and M.G.; methodology, A.I., M.S.F. and M.H.K.; software, A.I., M.S.F. and M.H.K.; validation, A.I., M.S.F., M.H.K. and M.G.; investigation, A.I., M.S.F., M.H.K.; writing—original draft preparation, A.I., M.S.F., M.H.K. and M.G.; writing—review and editing, A.I., M.S.F., M.H.K., and M.G. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Data sharing not applicable.
Conflicts of Interest
The authors declare that they have no conflict of interest.
References
- Wan, T.; Zhu, C.; Qin, Z. Multifocus image fusion based on robust principal component analysis. Pattern Recognit. Lett. 2013, 34, 1001–1008. [Google Scholar] [CrossRef]
- Campbell, J.B.; Wynne, R.H. Introduction to Remote Sensing; Guilford Press: New York, NY, USA, 2011. [Google Scholar]
- Ardeshir Goshtasby, A.; Nikolov, S. Guest editorial: Image fusion: Advances in the state of the art. Inf. Fusion 2007, 8, 114–118. [Google Scholar] [CrossRef]
- Wang, X.; Bai, S.; Li, Z.; Sui, Y.; Tao, J. The PAN and MS image fusion algorithm based on adaptive guided filtering and gradient information regulation. Inf. Sci. 2021, 545, 381–402. [Google Scholar] [CrossRef]
- Xu, Y.; Yang, C.; Sun, B.; Yan, X.; Chen, M. A novel multi-scale fusion framework for detail-preserving low-light image enhancement. Inf. Sci. 2021, 548, 378–397. [Google Scholar] [CrossRef]
- Du, J.; Li, W.; Tan, H. Three-layer medical image fusion with tensor based features. Inf. Sci. 2020, 525, 93–108. [Google Scholar] [CrossRef]
- Li, S.; Yang, B.; Hu, J. Performance comparison of different multi-resolution transforms for image fusion. Inf. Fusion 2011, 12, 74–84. [Google Scholar] [CrossRef]
- Zafar, R.; Farid, M.S.; Khan, M.H. Multi-Focus Image Fusion: Algorithms, Evaluation, and a Library. J. Imaging 2020, 6, 60. [Google Scholar] [CrossRef]
- Saha, A.; Bhatnagar, G.; Wu, Q.J. Mutual spectral residual approach for multifocus image fusion. Digit. Signal Process. 2013, 23, 1121–1135. [Google Scholar] [CrossRef]
- Goshtasby, A.A.; Nikolov, S. Image fusion: advances in the state of the art. Inf. Fusion 2007, 2, 114–118. [Google Scholar] [CrossRef]
- Li, S.; Kwok, J.T.; Wang, Y. Multifocus image fusion using artificial neural networks. Pattern Recognit. Lett. 2002, 23, 985–997. [Google Scholar] [CrossRef]
- Eltoukhy, H.A.; Kavusi, S. Computationally efficient algorithm for multifocus image reconstruction. In Proceedings of the Sensors and Camera Systems for Scientific, Industrial, and Digital Photography Applications IV, Santa Clara, CA, USA, 20–24 January 2003; Volume 5017, pp. 332–341. [Google Scholar]
- Liu, Y.; Liu, S.; Wang, Z. Multi-focus image fusion with dense SIFT. Inf. Fusion 2015, 23, 139–155. [Google Scholar] [CrossRef]
- Li, S.; Kang, X.; Fang, L.; Hu, J.; Yin, H. Pixel-level image fusion: A survey of the state of the art. Inf. Fusion 2017, 33, 100–112. [Google Scholar] [CrossRef]
- Li, S.; Kwok, J.Y.; Tsang, I.H.; Wang, Y. Fusing images with different focuses using support vector machines. IEEE Trans. Neural Netw. 2004, 15, 1555–1561. [Google Scholar] [CrossRef]
- Huang, W.; Jing, Z. Multi-focus image fusion using pulse coupled neural network. Pattern Recognit. Lett. 2007, 28, 1123–1132. [Google Scholar] [CrossRef]
- Agrawal, D.; Singhai, J. Multifocus image fusion using modified pulse coupled neural network for improved image quality. IET Image Process. 2010, 4, 443–451. [Google Scholar] [CrossRef]
- Li, S.; Kang, X.; Hu, J.; Yang, B. Image matting for fusion of multi-focus images in dynamic scenes. Inf. Fusion 2013, 14, 147–162. [Google Scholar] [CrossRef]
- Kumar, B.S. Image fusion based on pixel significance using cross bilateral filter. Signal Image Video Process. 2015, 9, 1193–1204. [Google Scholar] [CrossRef]
- Liu, Y.; Wang, L.; Cheng, J.; Li, C.; Chen, X. Multi-focus image fusion: A Survey of the state of the art. Inf. Sci. 2020, 64, 71–91. [Google Scholar] [CrossRef]
- Piella, G. A general framework for multiresolution image fusion: From pixels to regions. Inf. Fusion 2003, 4, 259–280. [Google Scholar] [CrossRef]
- Petrovic, V.; Xydeas, C.S. Gradient based multiresolution image fusion. IEEE Trans. Image Process. 2004, 13, 228–237. [Google Scholar] [CrossRef]
- Li, H.; Manjunath, B.; Mitra, S.K. Multisensor image fusion using the wavelet transform. Graph Model Image Proc. 1995, 57, 235–245. [Google Scholar] [CrossRef]
- Kumar, B.S. Multifocus and multispectral image fusion based on pixel significance using discrete cosine harmonic wavelet transform. Signal Image Video Process. 2013, 7, 1125–1143. [Google Scholar] [CrossRef]
- Nencini, F.; Garzelli, A.; Baronti, S.; Alparone, L. Remote sensing image fusion using the curvelet transform. Inf. Fusion 2007, 8, 143–156. [Google Scholar] [CrossRef]
- Xiao-Bo, Q.; Jing-Wen, Y.; Hong-Zhi, X.; Zi-Qian, Z. Image fusion algorithm based on spatial frequency-motivated pulse coupled neural networks in nonsubsampled contourlet transform domain. Acta Autom. Sin. 2008, 34, 1508–1514. [Google Scholar]
- Zhang, Q.; Guo, B.L. Multifocus image fusion using the nonsubsampled contourlet transform. Signal Process. 2009, 89, 1334–1346. [Google Scholar] [CrossRef]
- Bavirisetti, D.P.; Dhuli, R. Multi-focus image fusion using multi-scale image decomposition and saliency detection. Ain Shams Eng. J. 2018, 9, 1103–1117. [Google Scholar] [CrossRef]
- Zheng, S.; Shi, W.Z.; Liu, J.; Zhu, G.X.; Tian, J.W. Multisource image fusion method using support value transform. IEEE Trans. Image Process. 2007, 16, 1831–1839. [Google Scholar] [CrossRef]
- Haghighat, M.B.A.; Aghagolzadeh, A.; Seyedarabi, H. Multi-focus image fusion for visual sensor networks in DCT domain. Comput. Electr. Eng. 2011, 37, 789–797. [Google Scholar] [CrossRef]
- Naidu, V.; Elias, B. A novel image fusion technique using DCT based Laplacian pyramid. Int. J. Invent. Eng. Sci. 2013, 5, 2319–9598. [Google Scholar]
- Bai, X.; Liu, M.; Chen, Z.; Wang, P.; Zhang, Y. Morphology and active contour model for multi-focus image fusion. In Proceedings of the International Conference on Digital Image Computing: Techniques and Applications (DICTA), Adelaide, SA, Australia, 23–25 November 2015; pp. 1–6. [Google Scholar]
- Yang, B.; Li, S. Multifocus image fusion and restoration with sparse representation. IEEE Trans. Instrum. Meas. 2009, 59, 884–892. [Google Scholar] [CrossRef]
- Liang, J.; He, Y.; Liu, D.; Zeng, X. Image fusion using higher order singular value decomposition. IEEE Trans. Image Process. 2012, 21, 2898–2909. [Google Scholar] [CrossRef]
- Luo, X.; Zhang, Z.; Zhang, C.; Wu, X. Multi-focus image fusion using HOSVD and edge intensity. J. Vis. Commun. Image Represent. 2017, 45, 46–61. [Google Scholar] [CrossRef]
- Zhang, X.; Li, X.; Liu, Z.; Feng, Y. Multi-focus image fusion using image-partition based focus detection. Signal Process. 2014, 102, 64–76. [Google Scholar] [CrossRef]
- Li, S.; Kwok, J.T.; Wang, Y. Combination of images with diverse focuses using the spatial frequency. Inf. Fusion 2001, 2, 169–176. [Google Scholar] [CrossRef]
- Aslantas, V.; Kurban, R. Fusion of multi-focus images using differential evolution algorithm. Expert Syst. Appl. 2010, 37, 8861–8870. [Google Scholar] [CrossRef]
- Siddique, A.; Xiao, B.; Li, W.; Nawaz, Q.; Hamid, I. Multi-Focus Image Fusion Using Block-Wise Color-Principal Component Analysis. In Proceedings of the IEEE 3rd International Conference on Image, Vision and Computing (ICIVC), Chongqing, China, 27–29 June 2018; pp. 458–462. [Google Scholar]
- Li, M.; Cai, W.; Tan, Z. A region based multi-sensor image fusion scheme using pulse-coupled neural network. Pattern Recognit. Lett. 2006, 27, 1948–1956. [Google Scholar] [CrossRef]
- Li, S.; Yang, B. Multifocus image fusion using region segmentation and spatial frequency. Image Vis. Comput. 2008, 26, 971–979. [Google Scholar] [CrossRef]
- Lewis, J.J.; O’Callaghan, R.J.; Nikolov, S.G.; Bull, D.R.; Canagarajah, N. Pixel-and region based image fusion with complex wavelets. Inf. Fusion 2007, 8, 119–130. [Google Scholar] [CrossRef]
- Nejati, M.; Samavi, S.; Shirani, S. Multi-focus image fusion using dictionary based sparse representation. Inf. Fusion 2015, 25, 72–84. [Google Scholar] [CrossRef]
- Huang, W.; Jing, Z. Evaluation of focus measures in multi-focus image fusion. Pattern Recognit. Lett. 2007, 28, 493–500. [Google Scholar] [CrossRef]
- Zhou, Z.; Li, S.; Wang, B. Multi-scale weighted gradient based fusion for multi-focus images. Inf. Fusion 2014, 20, 60–72. [Google Scholar] [CrossRef]
- Li, S.; Kang, X.; Hu, J. Image fusion with guided filtering. IEEE Trans. Image Process. 2013, 22, 2864–2875. [Google Scholar]
- Bouzos, O.; Andreadis, I.; Mitianoudis, N. Conditional random field model for robust multi-focus image fusion. IEEE Trans. Image Process. 2019, 28, 5636–5648. [Google Scholar] [CrossRef] [PubMed]
- Chen, Y.; Guan, J.; Cham, W.K. Robust multi-focus image fusion using edge model and multi-matting. IEEE Trans. Image Process. 2017, 27, 1526–1541. [Google Scholar] [CrossRef]
- Hua, K.L.; Wang, H.C.; Rusdi, A.H.; Jiang, S.Y. A novel multi-focus image fusion algorithm based on random walks. J. Vis. Commun. Image Represent. 2014, 25, 951–962. [Google Scholar] [CrossRef]
- Li, H.; Nie, R.; Cao, J.; Guo, X.; Zhou, D.; He, K. Multi-Focus Image Fusion Using U-Shaped Networks With a Hybrid Objective. IEEE Sens. J. 2019, 19, 9755–9765. [Google Scholar] [CrossRef]
- Liu, Y.; Chen, X.; Wang, Z.; Wang, Z.J.; Ward, R.K.; Wang, X. Deep learning for pixel-level image fusion: Recent advances and future prospects. Inf. Fusion 2018, 42, 158–173. [Google Scholar] [CrossRef]
- Tang, H.; Xiao, B.; Li, W.; Wang, G. Pixel convolutional neural network for multi-focus image fusion. Inf. Sci. 2018, 433–434, 125–141. [Google Scholar] [CrossRef]
- Mustafa, H.T.; Yang, J.; Zareapoor, M. Multi-scale convolutional neural network for multi-focus image fusion. Image Vis. Comput. 2019, 85, 26–35. [Google Scholar] [CrossRef]
- Liu, Y.; Chen, X.; Peng, H.; Wang, Z. Multi-focus image fusion with a deep convolutional neural network. Inf. Fusion 2017, 36, 191–207. [Google Scholar] [CrossRef]
- Mustafa, H.T.; Zareapoor, M.; Yang, J. MLDNet: Multi-level dense network for multi-focus image fusion. Signal Process. Image Commun. 2020, 85, 115864. [Google Scholar] [CrossRef]
- Wang, C.; Zhao, Z.; Ren, Q.; Xu, Y.; Yu, Y. A novel multi-focus image fusion by combining simplified very deep convolutional networks and patch based sequential reconstruction strategy. Appl. Soft Comput. 2020, 91, 106253. [Google Scholar] [CrossRef]
- Liu, Y.; Chen, X.; Ward, R.K.; Wang, Z.J. Medical Image Fusion via Convolutional Sparsity Based Morphological Component Analysis. IEEE Signal Process. Lett. 2019, 26, 485–489. [Google Scholar] [CrossRef]
- Zhang, C. Multi-focus Image Fusion Based on Convolutional Sparse Representation with Mask Simulation. In Advances in 3D Image and Graphics Representation, Analysis, Computing and Information Technology; Kountchev, R., Patnaik, S., Shi, J., Favorskaya, M.N., Eds.; Springer: Singapore, 2020; pp. 159–168. [Google Scholar]
- Xing, C.; Wang, M.; Dong, C.; Duan, C.; Wang, Z. Using Taylor Expansion and Convolutional Sparse Representation for Image Fusion. Neurocomputing 2020, 402, 437–455. [Google Scholar] [CrossRef]
- Zhang, H.; Le, Z.; Shao, Z.; Xu, H.; Ma, J. MFF-GAN: An unsupervised generative adversarial network with adaptive and gradient joint constraints for multi-focus image fusion. Inf. Fusion 2021, 66, 40–53. [Google Scholar] [CrossRef]
- Huang, J.; Le, Z.; Ma, Y.; Mei, X.; Fan, F. A generative adversarial network with adaptive constraints for multi-focus image fusion. Neural Comput. Appl. 2020, 32, 15119–15129. [Google Scholar] [CrossRef]
- Murugan, A.; Arumugam, G.; Gobinath, D. Multi-Focus Image Fusion Using Conditional Generative Adversarial Networks. In Intelligent Computing and Applications; Dash, S.S., Das, S., Panigrahi, B.K., Eds.; Springer: Singapore, 2021; pp. 559–566. [Google Scholar]
- Veksler, O.; Boykov, Y.; Mehrani, P. Superpixels and Supervoxels in an Energy Optimization Framework. In Computer Vision—ECCV 2010, Proceedings of the Europion Conference on Computer Vision (ECCV 2010), Heraklion, Crete, Greece, 5–11 September 2010; Daniilidis, K., Maragos, P., Paragios, N., Eds.; Springer: Berlin/Heidelberg, Germany, 2010; pp. 211–224. [Google Scholar]
- Levinshtein, A.; Stere, A.; Kutulakos, K.N.; Fleet, D.J.; Dickinson, S.J.; Siddiqi, K. TurboPixels: Fast Superpixels Using Geometric Flows. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 31, 2290–2297. [Google Scholar] [CrossRef]
- Achanta, R.; Shaji, A.; Smith, K.; Lucchi, A.; Fua, P.; Süsstrunk, S. SLIC Superpixels Compared to State-of-the-Art Superpixel Methods. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 2274–2282. [Google Scholar] [CrossRef] [PubMed]
- Sharma, G.; Wu, W.; Dalal, E.N. The CIEDE2000 color-difference formula: Implementation notes, supplementary test data, and mathematical observations. Color Res. Appl. 2005, 30, 21–30. [Google Scholar] [CrossRef]
- Kumar, V.; Gupta, P. Importance of statistical measures in digital image processing. Int. J. Emerg. Technol. Adv. Eng. 2012, 2, 56–62. [Google Scholar]
- Wang, W.; Chang, F. A Multi-focus Image Fusion Method Based on Laplacian Pyramid. J. Comput. 2011, 6, 2559–2566. [Google Scholar] [CrossRef]
- Farid, M.S.; Mahmood, A.; Al-Maadeed, S.A. Multi-focus image fusion using Content Adaptive Blurring. Inf. Fusion 2019, 45, 96–112. [Google Scholar] [CrossRef]
- Lytro Multi-Focus Dataset. Available online: http://mansournejati.ece.iut.ac.ir/content/lytro-multi-focus-dataset (accessed on 31 October 2019).
- Tian, J.; Chen, L. Adaptive multi-focus image fusion using a wavelet based statistical sharpness measure. Signal Process. 2012, 92, 2137–2146. [Google Scholar] [CrossRef]
- Qu, X.; Hu, C.; Yan, J. Image fusion algorithm based on orientation information motivated pulse coupled neural networks. In Proceedings of the 7th World Congress on Intelligent Control and Automation, Chongqing, China, 25–27 June 2008; pp. 2437–2441. [Google Scholar]
- Mitianoudis, N.; Stathaki, T. Pixel-based and region-based image fusion schemes using ICA bases. Inf. Fusion 2007, 8, 131–142. [Google Scholar] [CrossRef]
- Paul, S.; Sevcenco, I.S.; Agathoklis, P. Multi-exposure and multi-focus image fusion in gradient domain. J. Circuits Syst. Comput. 2016, 25, 1650123. [Google Scholar] [CrossRef]
- Naidu, V.; Raol, J.R. Pixel-level image fusion using wavelets and principal component analysis. Def. Sci. J. 2008, 58, 338–352. [Google Scholar] [CrossRef]
- Liu, Y.; Chen, X.; Ward, R.K.; Wang, Z.J. Image fusion with convolutional sparse representation. IEEE Signal Process. Lett. 2016, 23, 1882–1886. [Google Scholar] [CrossRef]
- Liu, Z.; Blasch, E.; Xue, Z.; Zhao, J.; Laganiere, R.; Wu, W. Objective Assessment of Multiresolution Image Fusion Algorithms for Context Enhancement in Night Vision: A Comparative Study. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 94–109. [Google Scholar] [CrossRef]
- Qu, G.; Zhang, D.; Yan, P. Information measure for performance of image fusion. Electron. Lett. 2002, 38, 313–315. [Google Scholar] [CrossRef]
- Hossny, M.; Nahavandi, S.; Creighton, D. Comments on’Information measure for performance of image fusion’. Electron. Lett. 2008, 44, 1066–1067. [Google Scholar] [CrossRef]
- Wang, Q.; Shen, Y.; Jin, J. 19—Performance evaluation of image fusion techniques. In Image Fusion; Stathaki, T., Ed.; Academic Press: Oxford, UK, 2008; pp. 469–492. [Google Scholar]
- Han, Y.; Cai, Y.; Cao, Y.; Xu, X. A new image fusion performance metric based on visual information fidelity. Inf. Fusion 2013, 14, 127–135. [Google Scholar] [CrossRef]
- Xydeas, C.S.; Petrovic, V. Objective image fusion performance measure. Electron. Lett. 2000, 36, 308–309. [Google Scholar] [CrossRef]
- Xydeas, C.S.; Petrovic, V. Objective pixel-level image fusion performance measure. Int. Soc. Opt. Photonics 2000, 4051, 89–98. [Google Scholar]
- Zheng, Y.; Essock, E.A.; Hansen, B.C.; Haun, A.M. A new metric based on extended spatial frequency and its application to DWT based fusion algorithms. Inf. Fusion 2007, 8, 177–192. [Google Scholar] [CrossRef]
- Wang, P.W.; Liu, B. A novel image fusion metric based on multi-scale analysis. In Proceedings of the 2008 9th International Conference on Signal Processing, Beijing, China, 26–29 October 2008; pp. 965–968. [Google Scholar]
- Liu, Z.; Forsyth, D.S.; Laganière, R. A feature based metric for the quantitative evaluation of pixel-level image fusion. Comput. Vis. Image Underst. 2008, 109, 56–68. [Google Scholar] [CrossRef]
- Piella, G.; Heijmans, H. A new quality metric for image fusion. In Proceedings of the 2003 International Conference on Image Processing (Cat. No.03CH37429), Barcelona, Spain, 14–17 September 2003. [Google Scholar]
- Cvejic, N.; Loza, A.; Bull, D.; Canagarajah, N. A similarity metric for assessment of image fusion algorithms. Int. J. Signal Process. 2005, 2, 178–182. [Google Scholar]
- Yang, C.; Zhang, J.Q.; Wang, X.R.; Liu, X. A novel similarity based quality metric for image fusion. Inf. Fusion 2008, 9, 156–160. [Google Scholar] [CrossRef]
- Chen, Y.; Blum, R.S. A new automated quality assessment algorithm for image fusion. Image Vis. Comput. 2009, 27, 1421–1432. [Google Scholar] [CrossRef]
- Zhao, J.; Laganiere, R.; Liu, Z. Performance assessment of combinative pixel-level image fusion based on an absolute feature measurement. Int. J. Innov. Comput. Inf. Control. 2007, 3, 1433–1447. [Google Scholar]
- Industrial Colour-Difference Evaluation. Available online: http://cie.co.at/publications/industrial-colour-difference-evaluation (accessed on 1 January 2021).
- Colour Metric. Available online: www.compuphase.com/cmetric.htm (accessed on 15 October 2020).
- Kuehni, R.G. Industrial color difference: Progress and problems. Color Res. Appl. 1990, 15, 261–265. [Google Scholar] [CrossRef]
- Smith, T.; Guild, J. The C.I.E. colorimetric standards and their use. Trans. Opt. Soc. 1931, 33, 73–134. [Google Scholar] [CrossRef]
- Sharma, G.; Bala, R. Digital Color Imaging Handbook; CRC press: Boca Raton, FL, USA, 2017. [Google Scholar]
- Melgosa, M. CIE94, History, Use, and Performance. In Encyclopedia of Color Science and Technology; Springer: New York, NY, USA, 2014; pp. 1–5. [Google Scholar]
- McDonald, R.; Smith, K.J. CIE94-a new colour-difference formula. J. Soc. Dye. Colour. 1995, 111, 376–379. [Google Scholar] [CrossRef]













Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).