
Changing the Geometry of Representations: ?-Embeddings for NLP Tasks


Abstract
:1. Introduction
2. Word Embeddings Based on Conditional Models
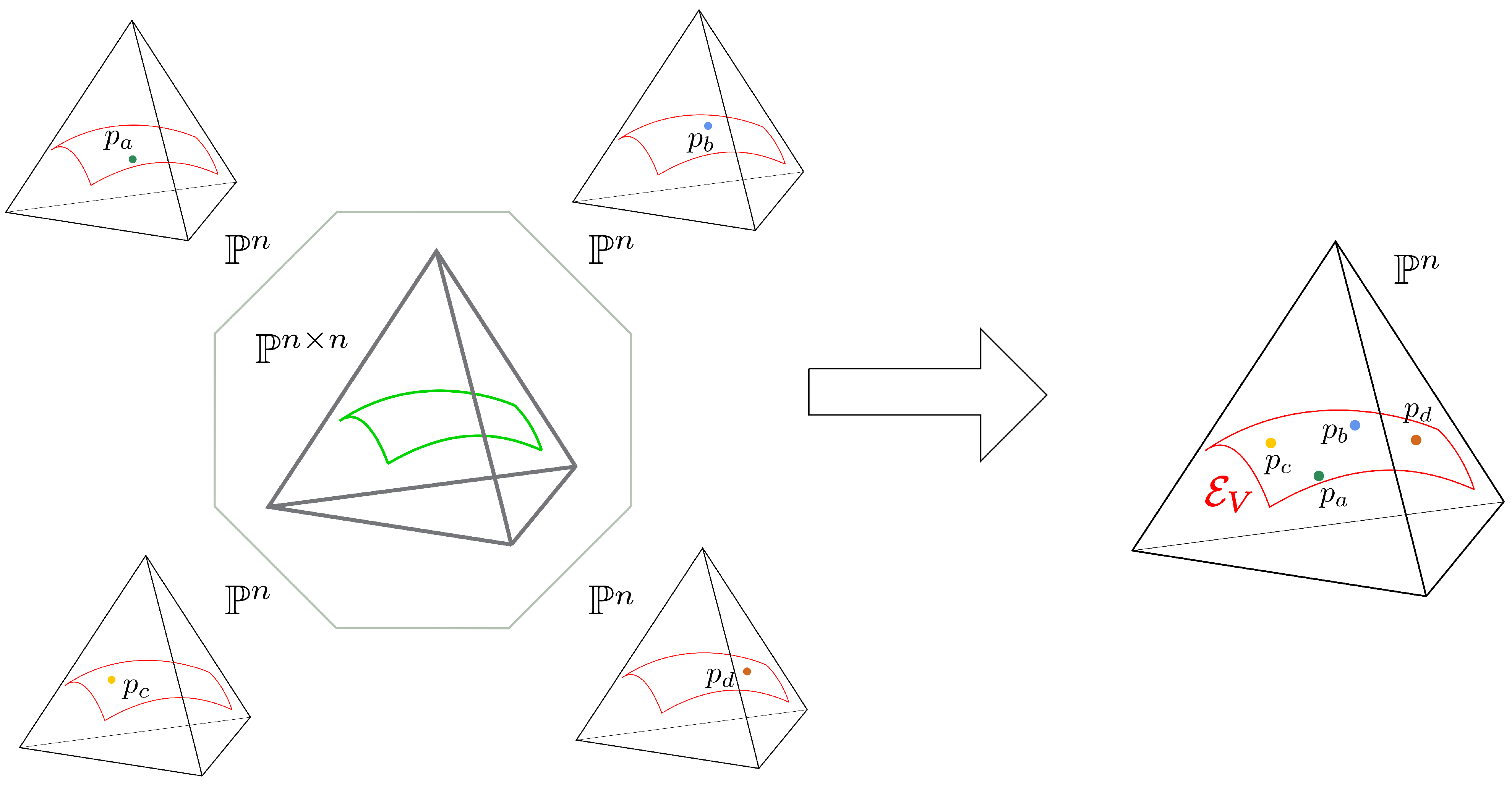
3. -Embeddings
| Algorithm 1:-embeddings. |
 |
Limit Embeddings
4. Experiments
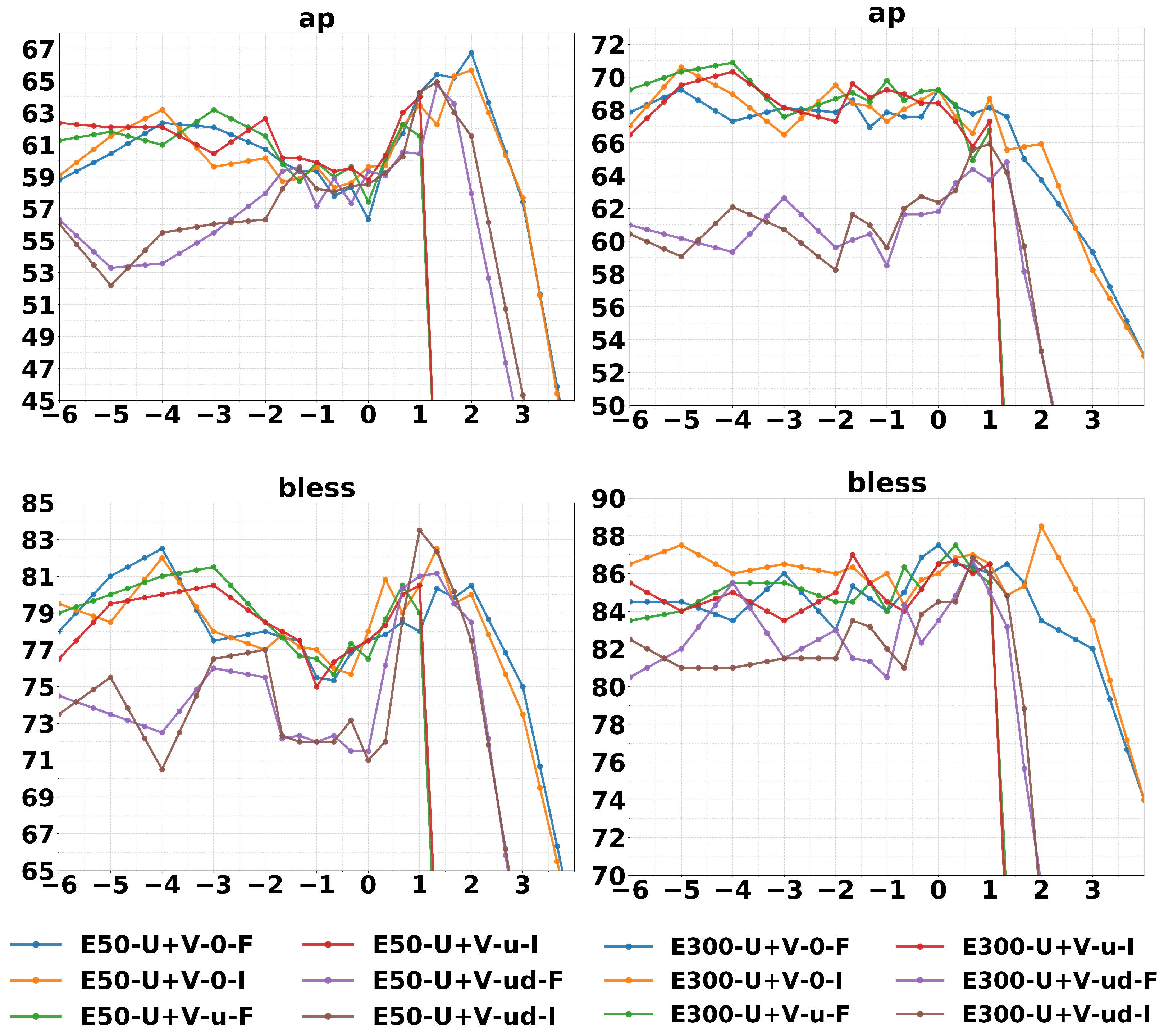
4.1. Similarities, Analogies, and Concept Categorization
4.2. Document Classification and Sentiment Analysis
4.3. Sentence Entailment
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning representations by back-propagating errors. Nature 1986, 323, 533–536. [Google Scholar] [CrossRef]
- Bengio, Y.; Ducharme, R.; Vincent, P.; Jauvin, C. A neural probabilistic language model. J. Mach. Learn. Res. 2003, 3, 1137–1155. [Google Scholar]
- Mikolov, T.; Karafiát, M.; Burget, L.; Cernocký, J.; Khudanpur, S. Recurrent neural network based language model. In Proceedings of the Annual Conference of the International Speech Communication Association, Chiba, Japan, 26–30 September 2010. [Google Scholar]
- Peters, M.E.; Neumann, M.; Iyyer, M.; Gardner, M.; Clark, C.; Lee, K.; Zettlemoyer, L. Deep contextualized word representations. In Proceedings of the North American Chapter of the Association for Computational Linguistics (NAACL), New Orleans, LA, USA, 1–6 June 2018. [Google Scholar]
- Radford, A.; Narasimhan, K.; Salimans, T.; Sutskever, I. Improving Language Understanding by Generative Pre-Training. Available online: https://www.cs.ubc.ca/~amuham01/LING530/papers/radford2018improving.pdf (accessed on 25 February 2021).
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the North American Chapter of the Association for Computational Linguistics (NAACL), Minneapolis, MN, USA, 2–7 June 2019. [Google Scholar]
- Yang, Z.; Dai, Z.; Yang, Y.; Carbonell, J.G.; Salakhutdinov, R.; Le, Q.V. XLNet: Generalized Autoregressive Pretraining for Language Understanding. In Proceedings of the Advances in Neural Information Processing Systems (NeurIPS), Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. In Proceedings of the International Conference on Learning Representations, Scottsdale, AZ, USA, 2–4 May 2013. [Google Scholar]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed representations of words and phrases and their compositionality. In Proceedings of the Advances in Neural Information Processing Systems (NIPS), Harrahs and Harveys, Statelinec, NV, USA, 5–10 December 2013. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C. Glove: Global vectors for word representation. In Proceedings of the 2014 Conference on Empirical Methods In Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014. [Google Scholar]
- Levy, O.; Goldberg, Y. Neural Word Embedding as Implicit Matrix Factorization; NIPS: Quebec, QC, Canada, 2014; p. 9. [Google Scholar]
- Mikolov, T.; Yih, W.T.; Zweig, G. Linguistic Regularities in Continuous Space Word Representations; NAACL-HLT: Atlanta, GA, USA, 2013. [Google Scholar]
- Arora, S.; Li, Y.; Liang, Y.; Ma, T.; Risteski, A. Rand-walk: A latent variable model approach to word embeddings. arXiv 2016, arXiv:1502.03520. [Google Scholar]
- Mu, J.; Bhat, S.; Viswanath, P. All-But-the-Top: Simple and Effective Postprocessing for Word Representations. In Proceedings of the International Conference on Learning Representations (ICLR), Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Bullinaria, J.A.; Levy, J.P. Extracting semantic representations from word co-occurrence statistics: A computational study. Behav. Res. Methods 2007, 39, 510–526. [Google Scholar] [CrossRef] [Green Version]
- Bullinaria, J.A.; Levy, J.P. Extracting semantic representations from word co-occurrence statistics: Stop-lists, stemming, and SVD. Behav. Res. Methods 2012, 44, 890–907. [Google Scholar] [CrossRef] [PubMed]
- Levy, O.; Goldberg, Y.; Dagan, I. Improving Distributional Similarity with Lessons Learned from Word Embeddings. Trans. Assoc. Comput. Linguist. 2015, 3, 211–225. [Google Scholar] [CrossRef]
- Tsvetkov, Y.; Faruqui, M.; Ling, W.; Lample, G.; Dyer, C. Evaluation of Word Vector Representations by Subspace Alignment. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing (EMNLP), Lisbon, Portugal, 17–21 September 2015; pp. 2049–2054. [Google Scholar] [CrossRef] [Green Version]
- Schnabel, T.; Labutov, I.; Mimno, D.; Joachims, T. Evaluation methods for unsupervised word embeddings. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015; pp. 298–307. [Google Scholar] [CrossRef]
- Raunak, V. Simple and Effective Dimensionality Reduction for Word Embeddings. In Proceedings of the LLD Workshop—Advances in Neural Information Processing Systems (NIPS), Long Beach, CA, USA, 9 December 2017. [Google Scholar]
- Volpi, R.; Malagò, L. Natural Alpha Embeddings. arXiv 2019, arXiv:1912.02280. [Google Scholar]
- Volpi, R.; Malagò, L. Natural Alpha Embeddings. Inf. Geom. 2021, in press. [Google Scholar]
- Amari, S.I.; Nagaoka, H. Methods of Information Geometry; American Mathematical Society: Cambridge, MA, USA, 2000. [Google Scholar]
- Amari, S.I. Information Geometry and Its Applications; Applied Mathematical Sciences; Springer: Tokyo, Japan, 2016; Volume 194. [Google Scholar]
- Fonarev, A.; Grinchuk, O.; Gusev, G.; Serdyukov, P.; Oseledets, I. Riemannian Optimization for Skip-Gram Negative Sampling. In Proceedings of the Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Vancouver, BC, Canada, 30 July–4 August 2017; pp. 2028–2036. [Google Scholar]
- Jawanpuria, P.; Balgovind, A.; Kunchukuttan, A.; Mishra, B. Learning Multilingual Word Embeddings in Latent Metric Space: A Geometric Approach. Trans. Assoc. Comput. Linguist. 2019, 7, 107–120. [Google Scholar] [CrossRef]
- Nickel, M.; Kiela, D. Poincaré embeddings for learning hierarchical representations. In Proceedings of the Advances in Neural Information Processing Systems (NIPS), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Tifrea, A.; Becigneul, G.; Ganea, O.E. Poincaré GloVe: Hyperbolic Word Embeddings. In Proceedings of the International Conference on Learning Representations (ICLR), New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Meng, Y.; Huang, J.; Wang, G.; Zhang, C.; Zhuang, H.; Kaplan, L.; Han, J. Spherical text embedding. In Proceedings of the Advances in Neural Information Processing Systems (NeurIPS), Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]
- Volpi, R.; Malago, L. Evaluating Natural Alpha Embeddings on Intrinsic and Extrinsic Tasks. In Proceedings of the 5th Workshop on Representation Learning for NLP-Association for Computational Linguistics (ACL), 9 July 2020. Online. [Google Scholar]
- Amari, S.I. Differential-Geometrical Methods in Statistics; Lecture Notes in Statistics; Springer: New York, NY, USA, 1985; Volume 28. [Google Scholar]
- Amari, S.I.; Cichocki, A. Information geometry of divergence functions. Bull. Pol. Acad. Sci. Tech. Sci. 2010, 58, 183–195. [Google Scholar] [CrossRef] [Green Version]
- Free eBooks—Project Gutenberg. Available online: https://www.gutenberg.org (accessed on 1 September 2019).
- Zhu, Y.; Kiros, R.; Zemel, R.; Salakhutdinov, R.; Urtasun, R.; Torralba, A.; Fidler, S. Aligning books and movies: Towards story-like visual explanations by watching movies and reading books. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 7–13. [Google Scholar]
- Aligning Books and Movie: Towards Story-like Visual Explanations by Watching Movies and Reading Books. Available online: https://yknzhu.wixsite.com/mbweb (accessed on 3 September 2019).
- Kobayashi, S. Homemade BookCorpus. Available online: https://github.com/soskek/bookcorpus (accessed on 13 September 2019).
- WikiExtractor. Available online: https://github.com/attardi/wikiextractor (accessed on 8 October 2017).
- Pennington, J.; Socher, R.; Manning, C. GloVe Project Page. Available online: https://nlp.stanford.edu/projects/glove/ (accessed on 26 October 2017).
- word2vec Google Code Archive. Available online: https://code.google.com/archive/p/word2vec/ (accessed on 19 October 2017).
- Finkelstein, L.; Gabrilovich, E.; Matias, Y.; Rivlin, E.; Solan, Z.; Wolfman, G.; Ruppin, E. Placing search in context: The concept revisited. In Proceedings of the 10th International Conference on World Wide Web, Hong Kong, China, 1–5 May 2001; pp. 406–414. [Google Scholar]
- Miller, G.A.; Charles, W.G. Contextual correlates of semantic similarity. Lang. Cogn. Process. 1991, 6, 1–28. [Google Scholar] [CrossRef]
- Rubenstein, H.; Goodenough, J.B. Contextual correlates of synonymy. Commun. ACM 1965, 8, 627–633. [Google Scholar] [CrossRef]
- Huang, E.H.; Socher, R.; Manning, C.D.; Ng, A.Y. Improving word representations via global context and multiple word prototypes. In Proceedings of the 50th Annual Meeting of the Association for Computational Linguistics: Long Papers—Volume 1, Jeju, Korea, 8–14 July 2012. [Google Scholar]
- Bruni, E.; Tran, N.K.; Baroni, M. Multimodal distributional semantics. J. Artif. Intell. Res. 2014, 49, 1–47. [Google Scholar] [CrossRef] [Green Version]
- Radinsky, K.; Agichtein, E.; Gabrilovich, E.; Markovitch, S. A word at a time: Computing word relatedness using temporal semantic analysis. In Proceedings of the 20th International Conference on World Wide Web, Hyderabad, India, 28 March–1 April 2011; pp. 337–346. [Google Scholar]
- Luong, M.T.; Socher, R.; Manning, C.D. Better word representations with recursive neural networks for morphology. In Proceedings of the Seventeenth Conference on Computational Natural Language Learning, Sofia, Bulgaria, 8–9 August 2013; pp. 104–113. [Google Scholar]
- Hill, F.; Reichart, R.; Korhonen, A. Simlex-999: Evaluating semantic models with (genuine) similarity estimation. Comput. Linguist. 2015, 41, 665–695. [Google Scholar] [CrossRef]
- Baroni, M.; Dinu, G.; Kruszewski, G. Don’t count, predict! a systematic comparison of context-counting vs. context-predicting semantic vectors. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics (ACL) (Volume 1: Long Papers), Baltimore, MD, USA, 22–27 June 2014; pp. 238–247. [Google Scholar]
- Almuhareb, A. Attributes in Lexical Acquisition. Ph.D. Thesis, University of Essex, Colchester, UK, 2006. [Google Scholar]
- Baroni, M.; Lenci, A. How we BLESSed distributional semantic evaluation. In Proceedings of the GEMS 2011 Workshop on GEometrical Models of Natural Language Semantics, Edinburgh, UK, July 2011; pp. 1–10. Available online: https://www.aclweb.org/anthology/W11-2501/ (accessed on 26 February 2021).
- Banerjee, A.; Dhillon, I.S.; Ghosh, J.; Sra, S. Clustering on the unit hypersphere using von Mises-Fisher distributions. J. Mach. Learn. Res. 2005, 6, 1345–1382. [Google Scholar]
- Laska, J.; Straub, D.; Sahloul, H. Spherecluster. Available online: https://github.com/jasonlaska/spherecluster (accessed on 4 December 2019).
- Wang, B.; Wang, A.; Chen, F.; Wang, Y.; Kuo, C.C.J. Evaluating word embedding models: Methods and experimental results. APSIPA Trans. Signal Inf. Process. 2019, 8, e19. [Google Scholar] [CrossRef] [Green Version]
- Lang, K. Newsweeder: Learning to filter netnews. In Machine Learning Proceedings 1995; Elsevier: Amsterdam, The Netherlands, 1995; pp. 331–339. [Google Scholar]
- Maas, A.L.; Daly, R.E.; Pham, P.T.; Huang, D.; Ng, A.Y.; Potts, C. Learning word vectors for sentiment analysis. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies—Volume 1, Portland, OR, USA, 19–24 June 2011; pp. 142–150. [Google Scholar]
- Bowman, S.R.; Angeli, G.; Potts, C.; Manning, C.D. A large annotated corpus for learning natural language inference. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing (EMNLP), Lisbon, Portugal, 17–21 September 2015. [Google Scholar]
- Parikh, A.P.; Täckström, O.; Das, D.; Uszkoreit, J. A decomposable attention model for natural language inference. In Proceedings of the Empirical Methods in Natural Language Processing, Austin, TX, USA, 1–5 November 2016. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Paszke, A.; Gross, S.; Chintala, S.; Chanan, G.; Yang, E.; DeVito, Z.; Lin, Z.; Desmaison, A.; Antiga, L.; Lerer, A. Automatic Differentiation in PyTorch. In Proceedings of the NIPS Autodiff Workshop, Long Beach, CA, USA, 8 December 2017; 2017. [Google Scholar]
- Kim, Y. Available online: https://github.com/harvardnlp/decomp-attn (accessed on 23 October 2017).
- Li, B. Available online: https://github.com/libowen2121/SNLI-decomposable-attention (accessed on 11 November 2018).







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | ws353 | mc | rg | scws | ws353s | ws353r | Men | mturk287 | rw | simlex999 | All | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| enwiki | LE-U+V-ud-F (our) | 63.5 | 75.6 | 60.1 | ||||||||
| GloVe WG5-U+V | 65.1 | 73.8 | 77.6 | 62.2 | 71.3 | 60.7 | 65.7 | 51.5 | 41.0 | 61.3 | ||
| GloVe U | 60.2 | 69.3 | 69.8 | 58.3 | 67.1 | 56.4 | 69.2 | 67.2 | 47.1 | 31.4 | 53.6 | |
| GloVe U+V | 63.8 | 74.5 | 75.2 | 58.7 | 69.5 | 60.9 | 71.6 | 45.5 | 32.2 | 55.1 | ||
| Word2Vec U | 64.7 | 73.5 | 78.4 | 63.6 | 73.7 | 56.1 | 72.9 | 65.4 | 47.3 | 34.5 | 59.1 | |
| Word2Vec U+V | 66.1 | 75.3 | 76.1 | 75.2 | 57.3 | 72.5 | 63.8 | 46.1 | 33.4 | 58.7 | ||
| geb | LE-U+V-ud-F (our) | 62.4 | ||||||||||
| GloVe WG5-U+V | 65.1 | 73.8 | 77.9 | 61.8 | 71.3 | 60.7 | 77.2 | 65.7 | 53.2 | 40.6 | 60.4 | |
| GloVe U | 61.3 | 73.0 | 76.3 | 58.7 | 68.6 | 54.0 | 68.7 | 48.9 | 30.6 | 51.9 | ||
| GloVe U+V | 64.9 | 77.4 | 79.9 | 59.1 | 71.5 | 58.8 | 71.4 | 48.5 | 32.5 | 53.7 | ||
| Word2Vec U | 65.5 | 77.8 | 74.7 | 62.6 | 73.2 | 58.5 | 73.1 | 67.5 | 48.3 | 32.9 | 59.0 | |
| Word2Vec U+V | 69.4 | 77.4 | 78.2 | 63.5 | 76.0 | 62.5 | 73.9 | 65.3 | 49.0 | 32.9 | 59.6 | |
| GloVe PSM 6B [10] | 65.8 | 72.7 | 77.8 | 53.9 | - | - | - | - | 38.1 | - | - | |
| Word2Vec BDK [48] | 73 | - | 83 | - | 78 | 68 | 80 | - | - | - | - | |
| GloVe LGD win5 [17] | - | - | - | - | 74.5 | 61.7 | 74.6 | 63.1 | 41.6 | 38.9 | - | |
| GloVe LGD win10 [17] | - | - | - | - | 74.6 | 64.3 | 75.4 | 61.6 | 26.6 | 37.5 | - | |
| Poincaré GloVe 100D [28] | 62.3 | 80.5 | 76.0 | - | - | - | - | - | 42.8 | 31.8 | - | |
| JoSE 100D [29] | 73.9 | - | - | - | - | - | 74.8 | - | - | 33.9 | - | |
| Method | Sem | Syn | Tot | |
|---|---|---|---|---|
| enwiki | E-U+V-0-I (our) | 67.33 (−∞) | ||
| GloVe WG5-U+V | 79.4 | 72.6 | ||
| GloVe U | 77.8 | 62.1 | 68.9 | |
| GloVe U+V | 80.9 | 63.4 | 70.9 | |
| Word2Vec U | 74.58 | 54.96 | 63.39 | |
| Word2Vec U+V | 75.44 | 55.03 | 63.81 | |
| geb | E-U+V-0-I (our) | |||
| GloVe WG5-U+V | 78.7 | 65.2 | 70.7 | |
| GloVe U | 75.7 | 66.8 | 70.4 | |
| GloVe U+V | 80.0 | 68.5 | 73.2 | |
| Word2Vec U | 71.20 | 52.62 | 60.15 | |
| Word2Vec U+V | 71.59 | 51.88 | 59.87 | |
| GloVe PSM 1.6B [10] | 80.8 | 61.5 | 70.3 | |
| GloVe PSM 6B [10] | 77.4 | 67.0 | 71.7 | |
| Word2Vec BDK [48] | 80.0 | 68.5 | 73.2 | |
| Poincaré GloVe 100D [28] | 66.4 | 60.9 | 63.4 | |
| Dataset | Method | Max Purity | Avg Purity |
|---|---|---|---|
| AP | E-U+V-u-F ( = −4) | 66.2 ± 2.1 | |
| GloVe U+V | 64.3 | 61.4 ± 2.5 | |
| Word2Vec U+V | 63.5 | 61.0 ± 1.6 | |
| GloVe [53] | 61.4 | - | |
| Word2Vec [53] | 68.2 | - | |
| Word2Vec BDK [48] | - | ||
| BLESS | E-U+V-ud-I ( = 1.1) | 83.5 ± 2.6 | |
| GloVe U+V | 86.0 | 83.4 ± 2.5 | |
| Word2Vec U+V | 80.0 | 77.3 ± 2.5 | |
| GloVe [53] | 82.0 | - | |
| Word2Vec [53] | 81.0 | - |
| Method | 20 Newsgroups | |
|---|---|---|
| AUC | acc | |
| Word2Vec U+V | 95.66 | 63.17 |
| GloVe U+V | 96.34 | 65.06 |
| E-U+V-0-F | 96.76 () | 65.86 () |
| E-U+V-u-F | () | () |
| E-U+V-ud-F | () | 65.24 () |
| LE-U+V-0-F | 96.65 (t3-w) | 64.47 (t1) |
| LE-U+V-u-F | 96.65 (t3-w) | 64.54 (t1) |
| LE-U+V-ud-F | 96.38 (t5-w) | 64.76 (t3-w) |
| Method | IMDB Reviews | |
|---|---|---|
| acc lin | acc BiLSTM | |
| Word2Vec U+V | 82.84 | 87.61 |
| GloVe U+V | 83.76 | 88.00 |
| E-U+V-0-F | 83.58 () | 88.12 () |
| E-U+V-u-F | 83.72 () | 88.56 () |
| E-U+V-ud-F | 84.23 () | 88.48 () |
| LE-U+V-0-F | 84.00 (t1) | 88.36 (t1) |
| LE-U+V-u-F | (t1) | (t1) |
| LE-U+V-ud-F | 84.00 (t3-w) | 88.49 (t3-w) |
| Method | No Projection | Projection |
|---|---|---|
| GloVe U+V Word2Vec U+V | 83.2 76.1 | 83.4 81.7 |
| E-U+V-0-I | 83.6 () | 84.2 () |
| E-U+V-0-F | 84.1 () | 84.2 () |
| E-U+V-u-I | 84.0 () | 84.0 () |
| E-U+V-u-F | ||
| E-U+V-ud-I | 83.8 () | 84.0 () |
| E-U+V-ud-F | 84.1 () | |
| GloVe U Word2Vec U | 83.7 74.6 | 84.1 76.1 |
| E-U-0-I | 83.7 () | 84.1 () |
| E-U-0-F | ||
| E-U-u-I | 83.5 () | 84.0 () |
| E-U-u-F | 83.9 () | 84.2 () |
| E-U-ud-I | 82.8 () | 84.0 () |
| E-U-ud-F | 83.1 () | 84.0 () |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Volpi, R.; Thakur, U.; Malagò, L. Changing the Geometry of Representations: ?-Embeddings for NLP Tasks. Entropy 2021, 23, 287. https://doi.org/10.3390/e23030287
Volpi R, Thakur U, Malagò L. Changing the Geometry of Representations: ?-Embeddings for NLP Tasks. Entropy. 2021; 23(3):287. https://doi.org/10.3390/e23030287
Chicago/Turabian StyleVolpi, Riccardo, Uddhipan Thakur, and Luigi Malagò. 2021. "Changing the Geometry of Representations: ?-Embeddings for NLP Tasks" Entropy 23, no. 3: 287. https://doi.org/10.3390/e23030287
APA StyleVolpi, R., Thakur, U., & Malagò, L. (2021). Changing the Geometry of Representations: ?-Embeddings for NLP Tasks. Entropy, 23(3), 287. https://doi.org/10.3390/e23030287