
Asymptotic Information-Theoretic Detection of Dynamical Organization in Complex Systems




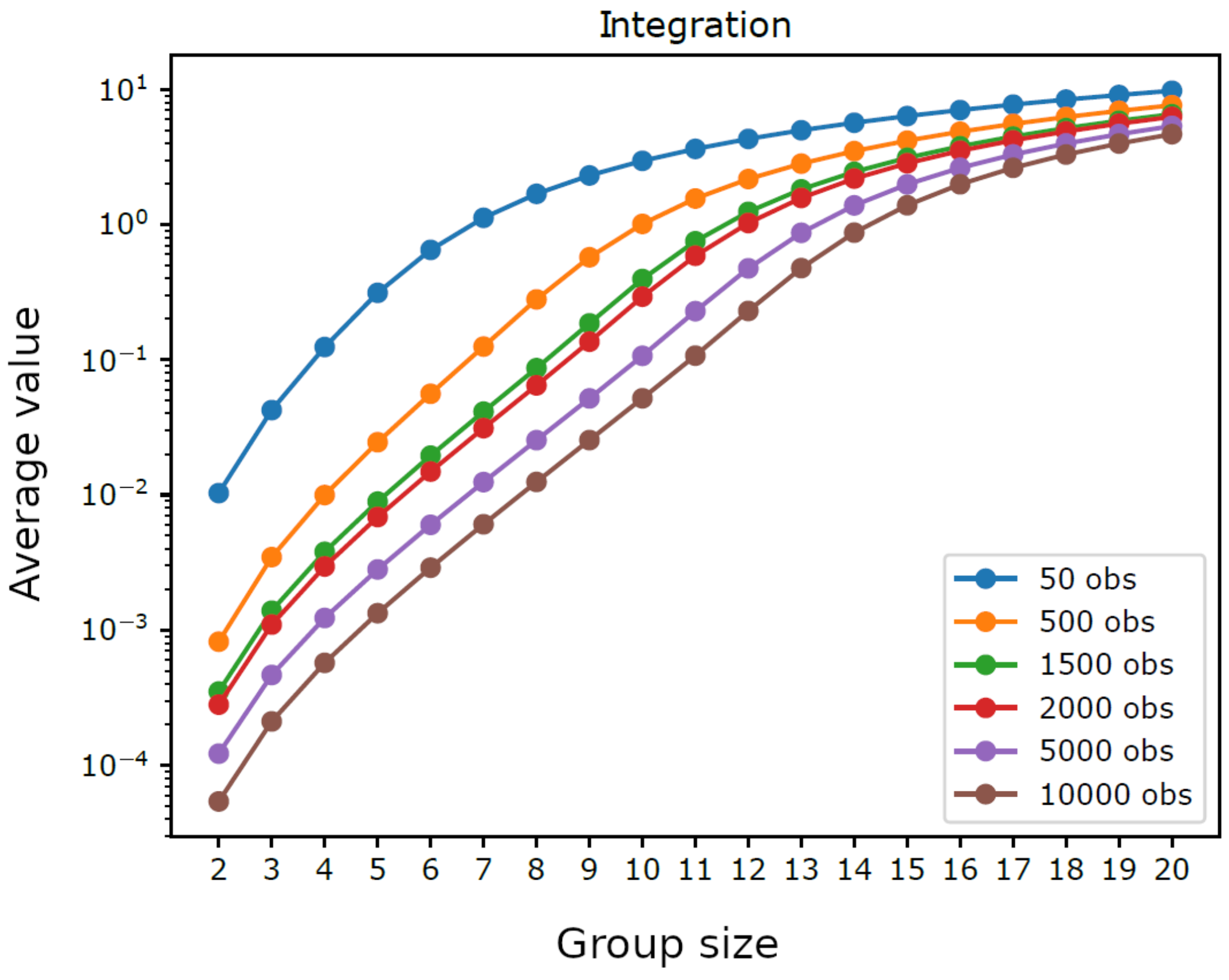{kind=link}
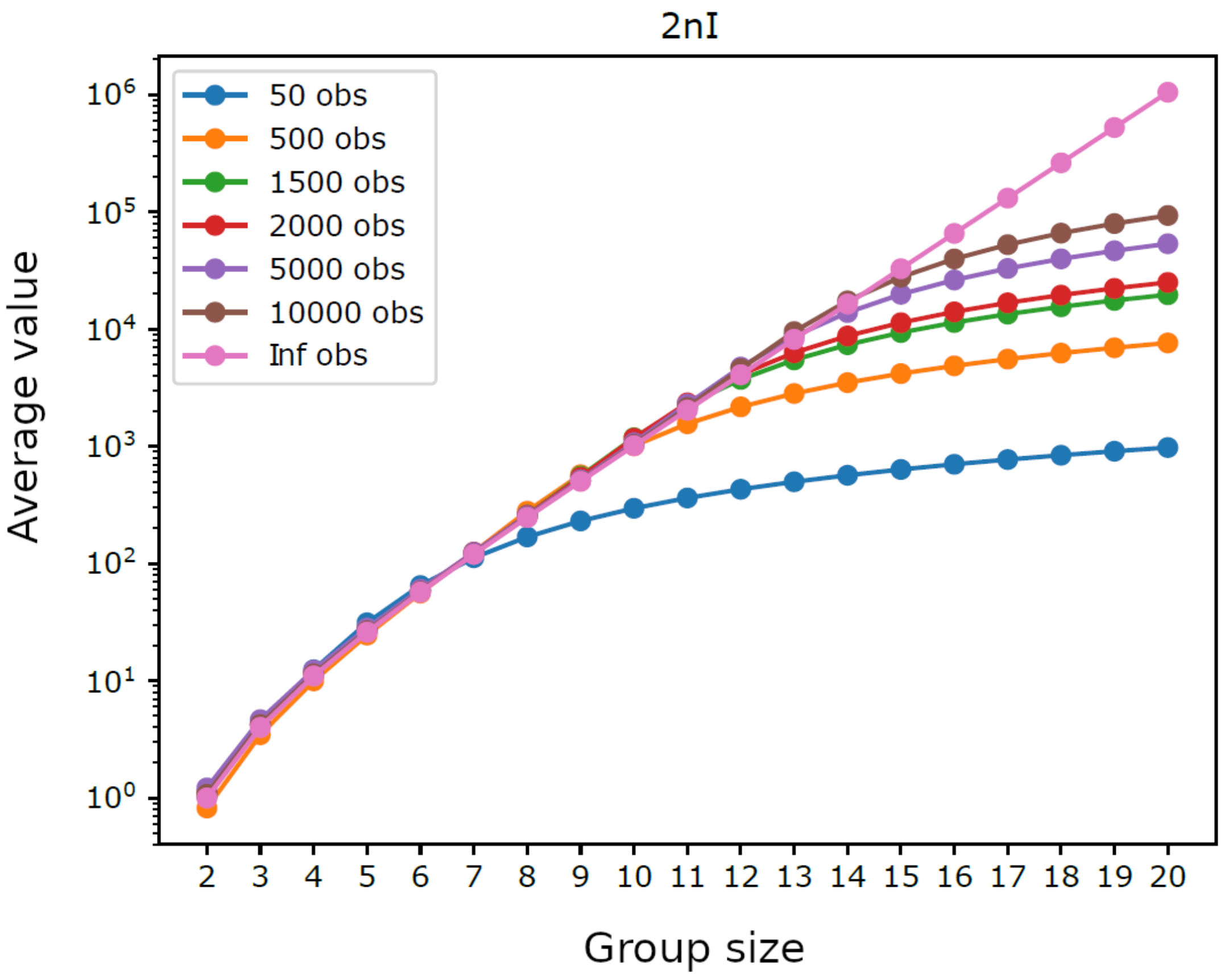{kind=link}
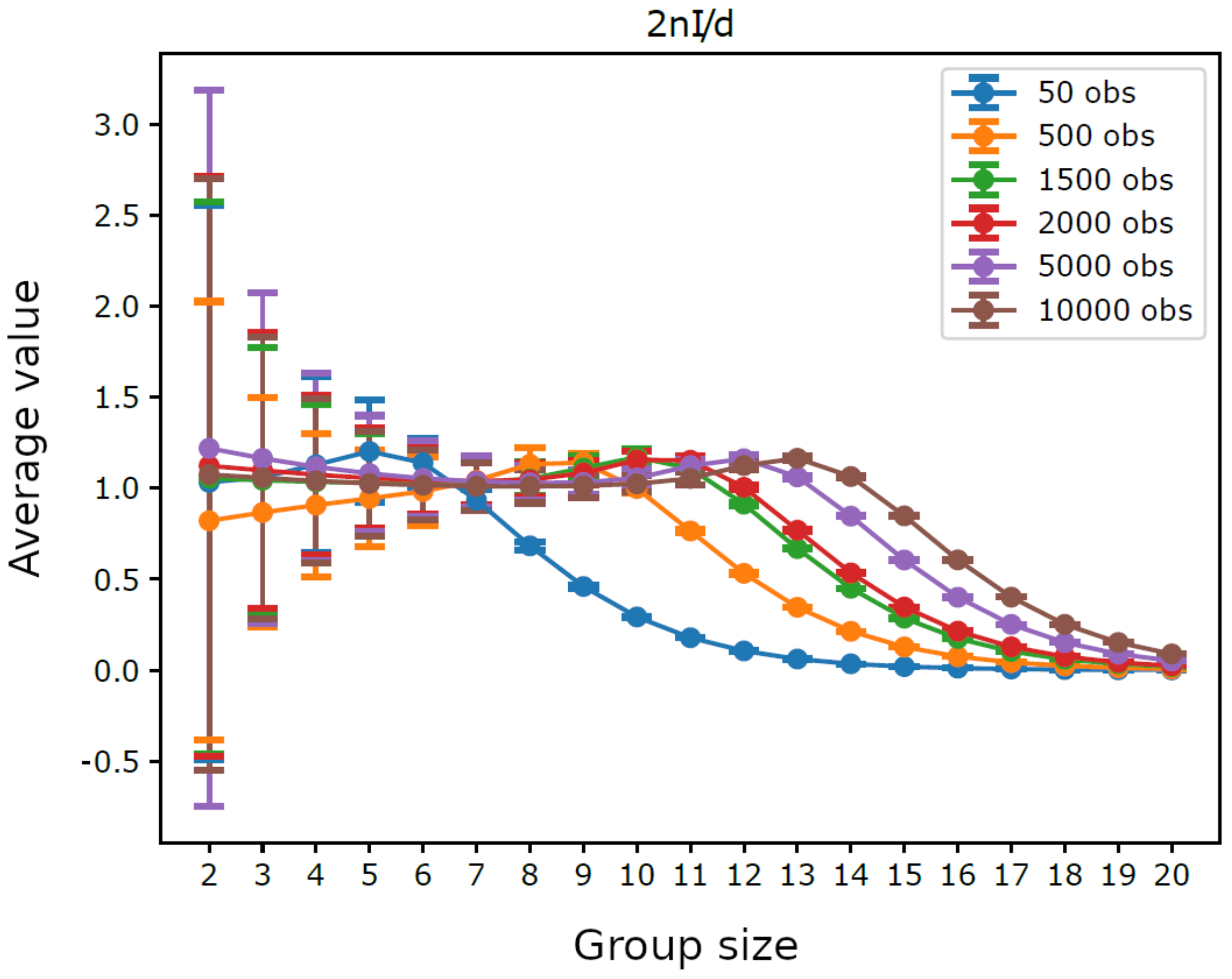{kind=link}
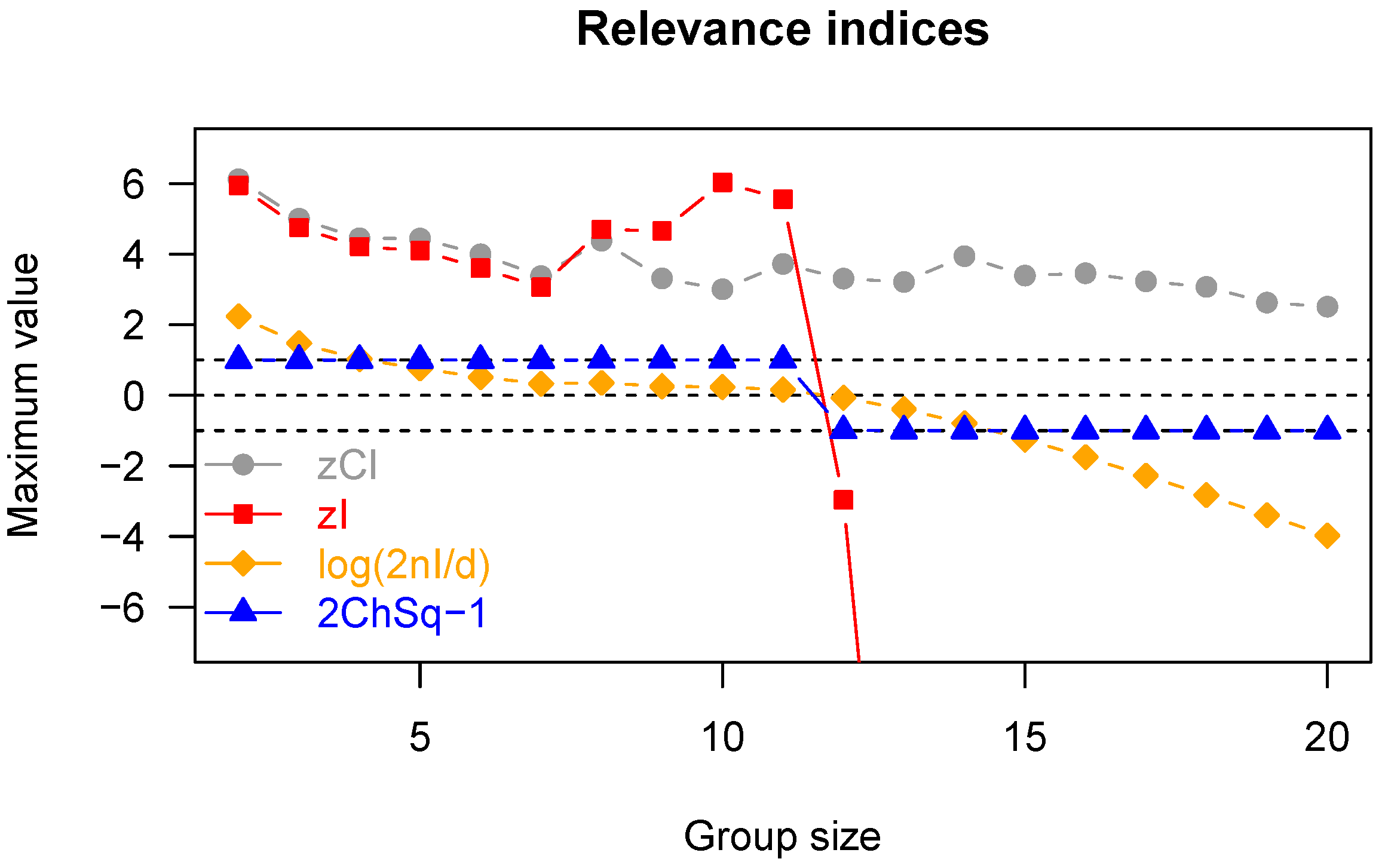{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
2. Methodological Background
2.1. Information-Theoretic Preliminaries
2.2. Cluster Index
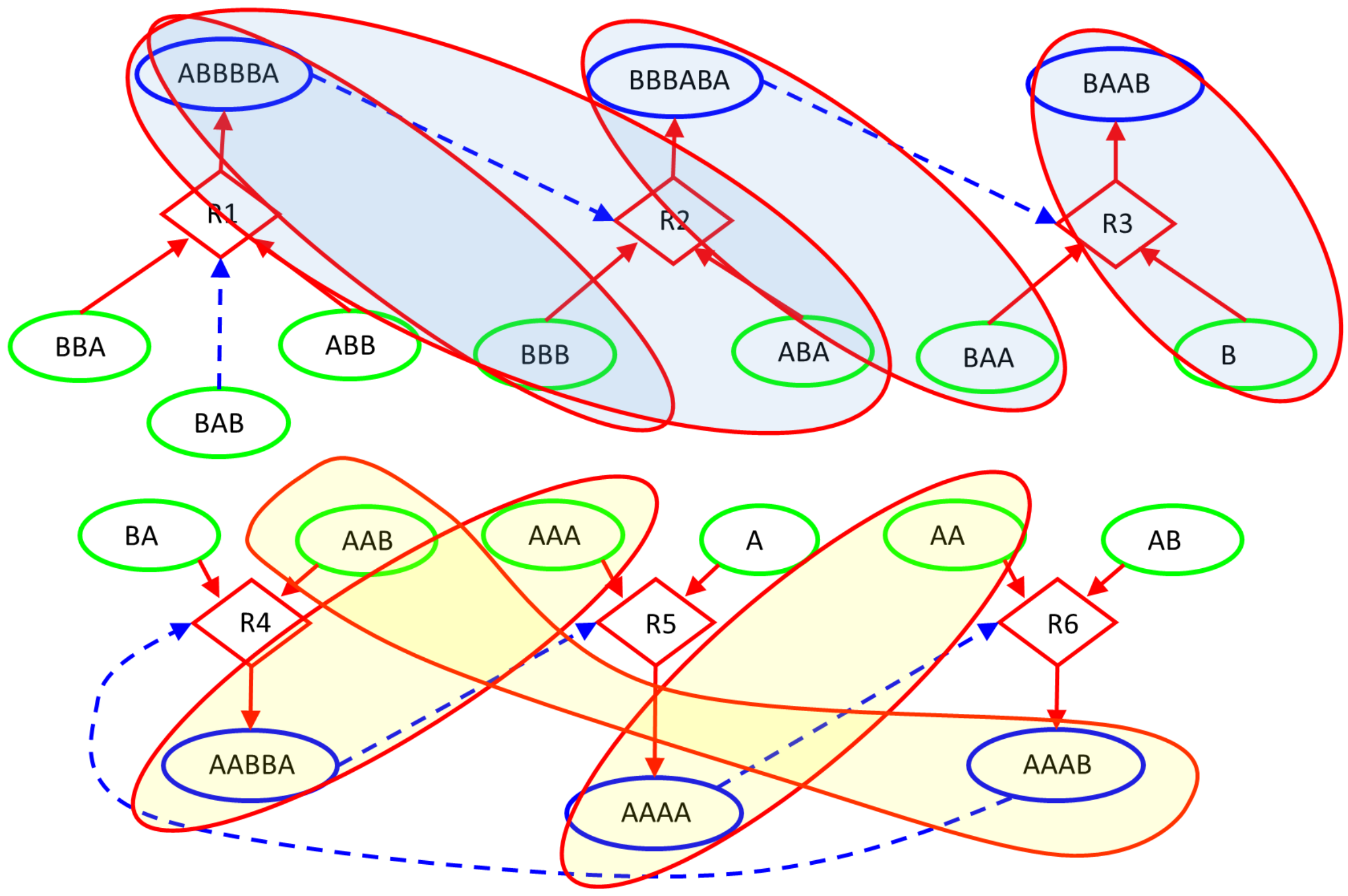
3. Proposed Methodology
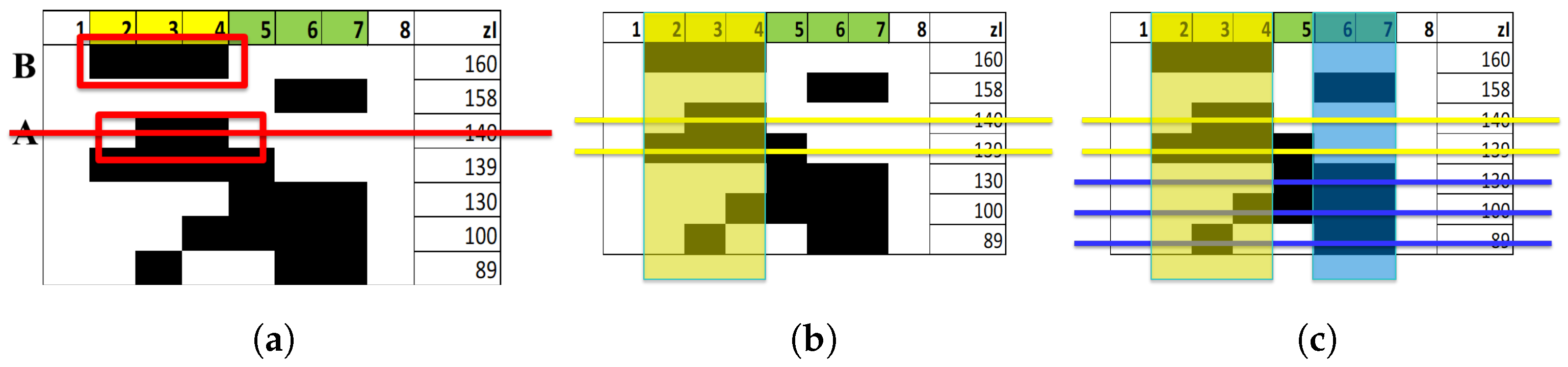
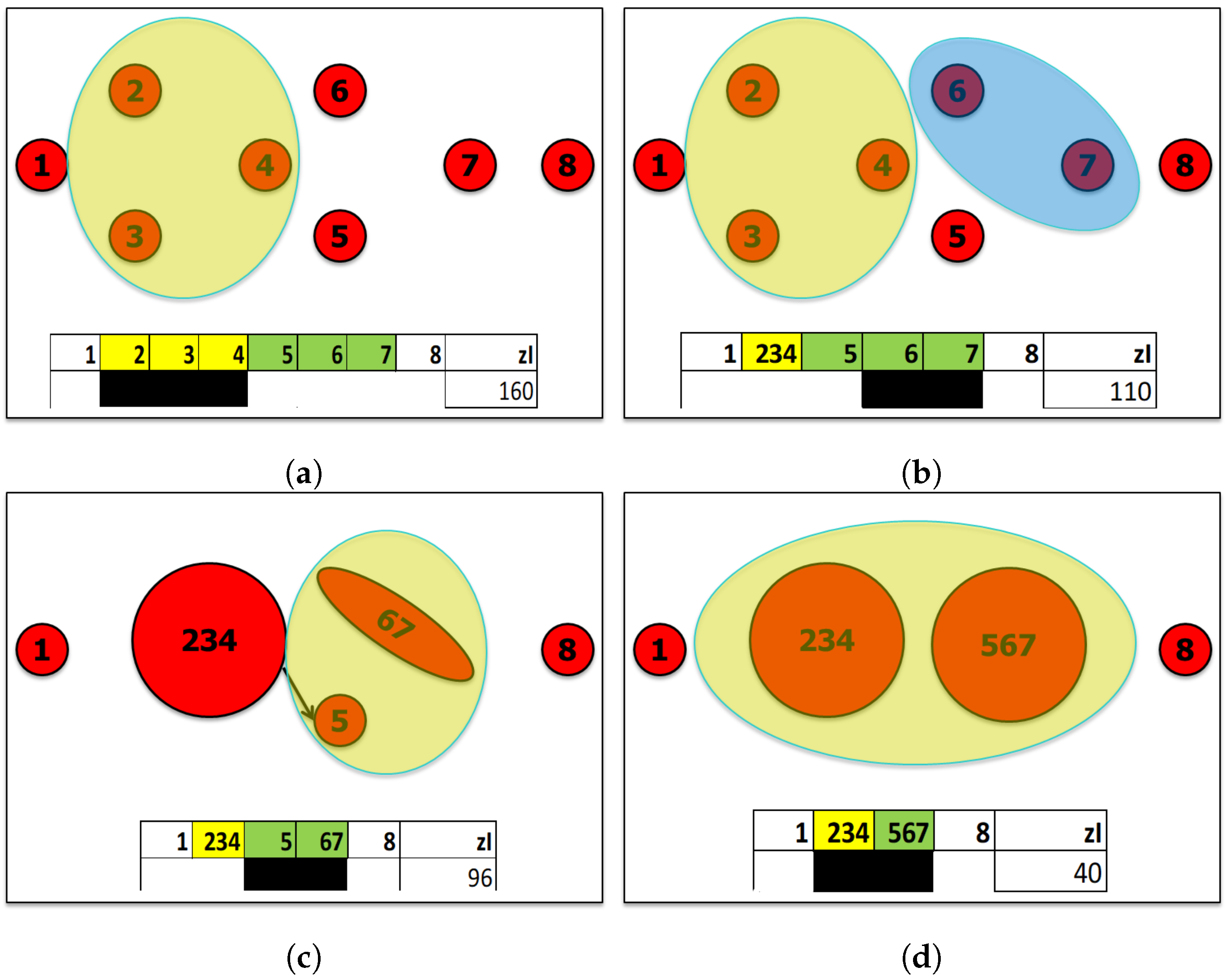
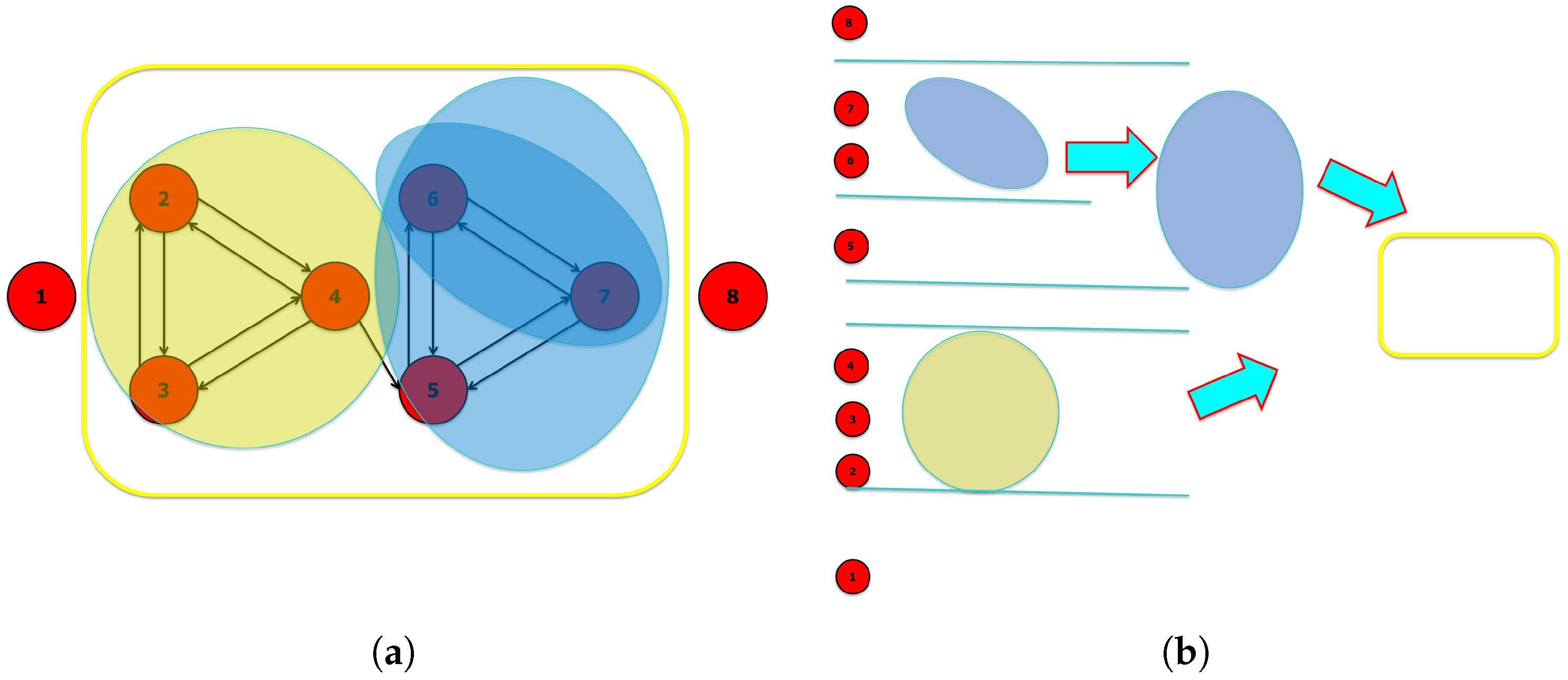
3.1. Searching for Relevant Subsets
3.1.1. Challenges
- (a)
- The cardinality of the set of all possible subsets of a set is gigantic. However, even beforehand the computational effort needed to deal with this amount of data, it is noteworthy that this wide set contains many groups included in others and a huge number of partially overlapping groups. All these situations require further analyses to assess their actual relevance or independence. Indeed, a high index value is not sufficient to characterize a relevant subset, because such a value might result from the presence of a smaller subset characterized by a higher coordination among variables. Conversely, a set having a high index value might reach an even higher value, if some other relevant variables are added to it.
- (b)
- It is burdensome to compute the averages of integration and mutual information on a suitable homogeneous system. Even though simulations from the homogeneous system are straightforward, they have to be repeated for all subsets of interest, which results in very long computing times. Furthermore, a specific homogeneous system has to be selected for the simulations, which introduces an unwelcome degree of arbitrariness in the analysis.
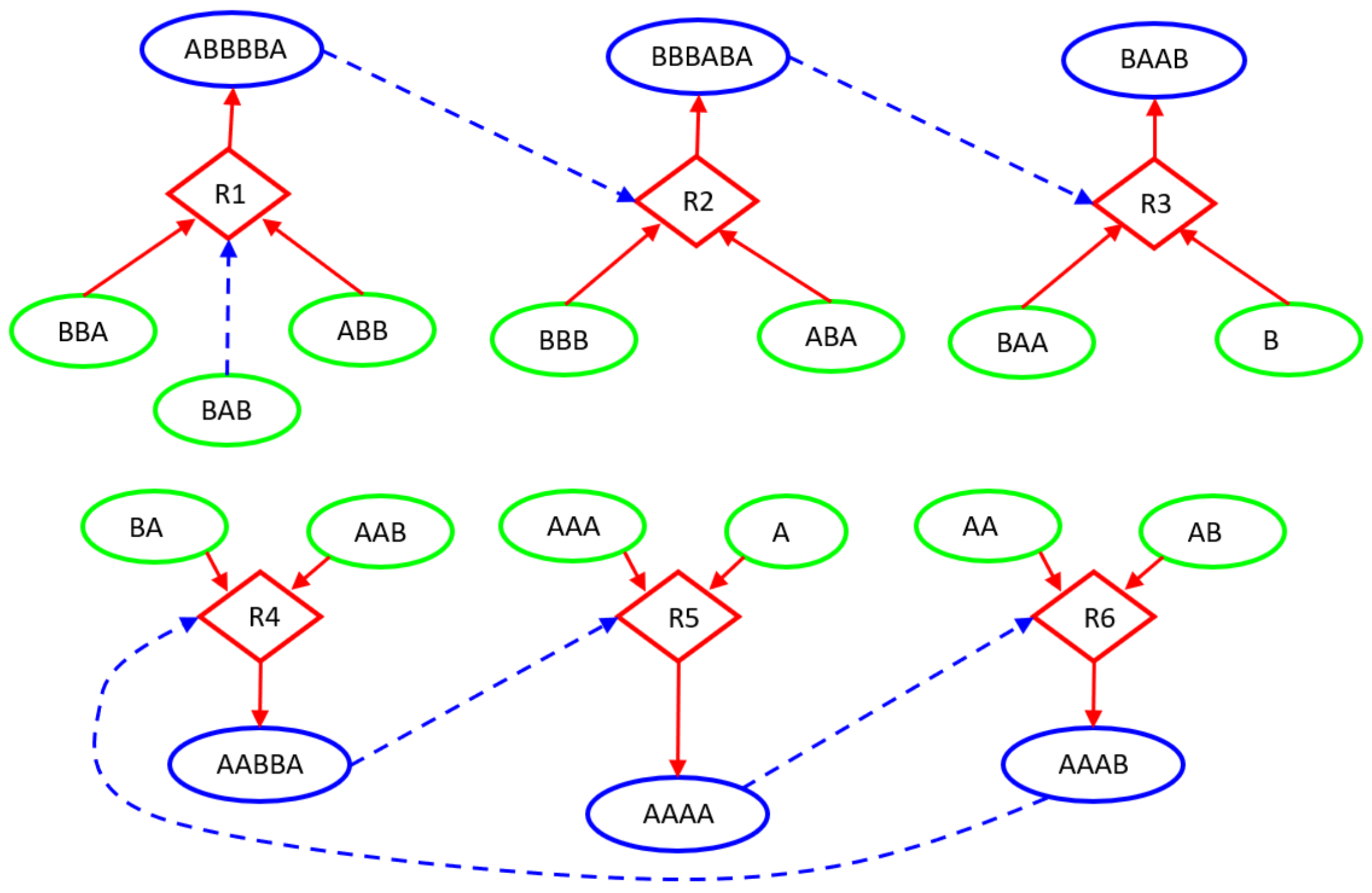
3.1.2. The Iterative Sieving Method
3.2. Asymptotic Null Distribution of the Empirical Integration
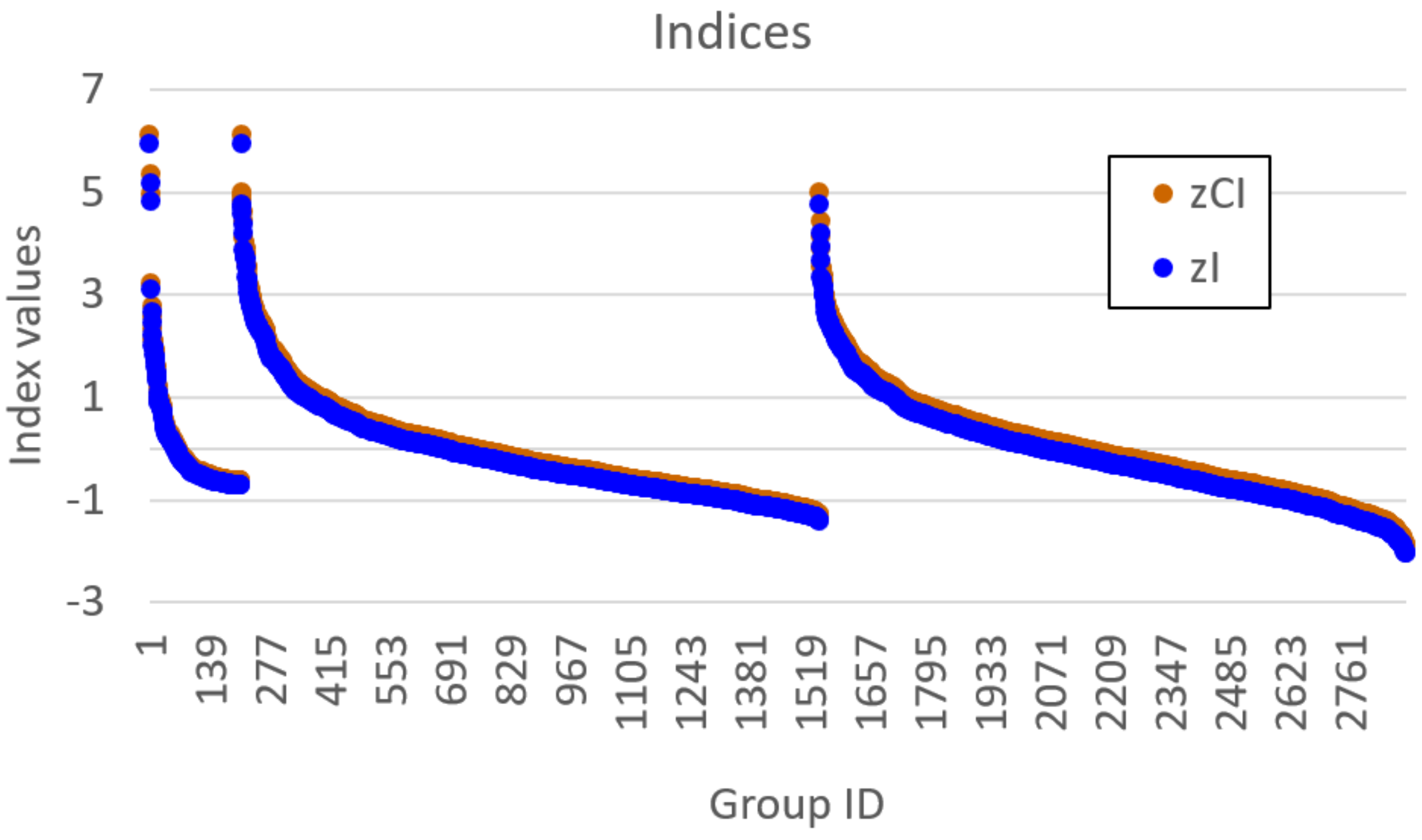
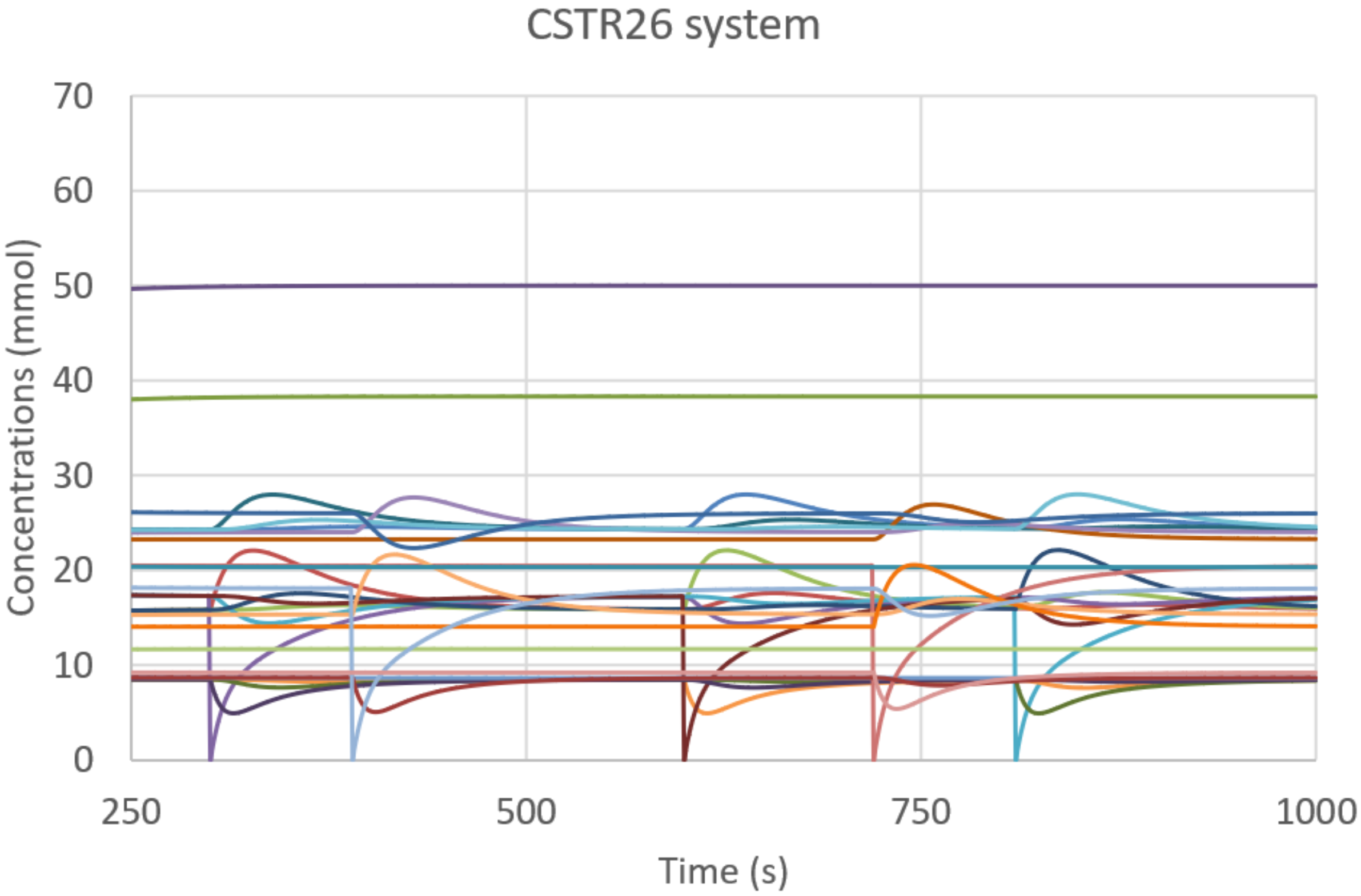
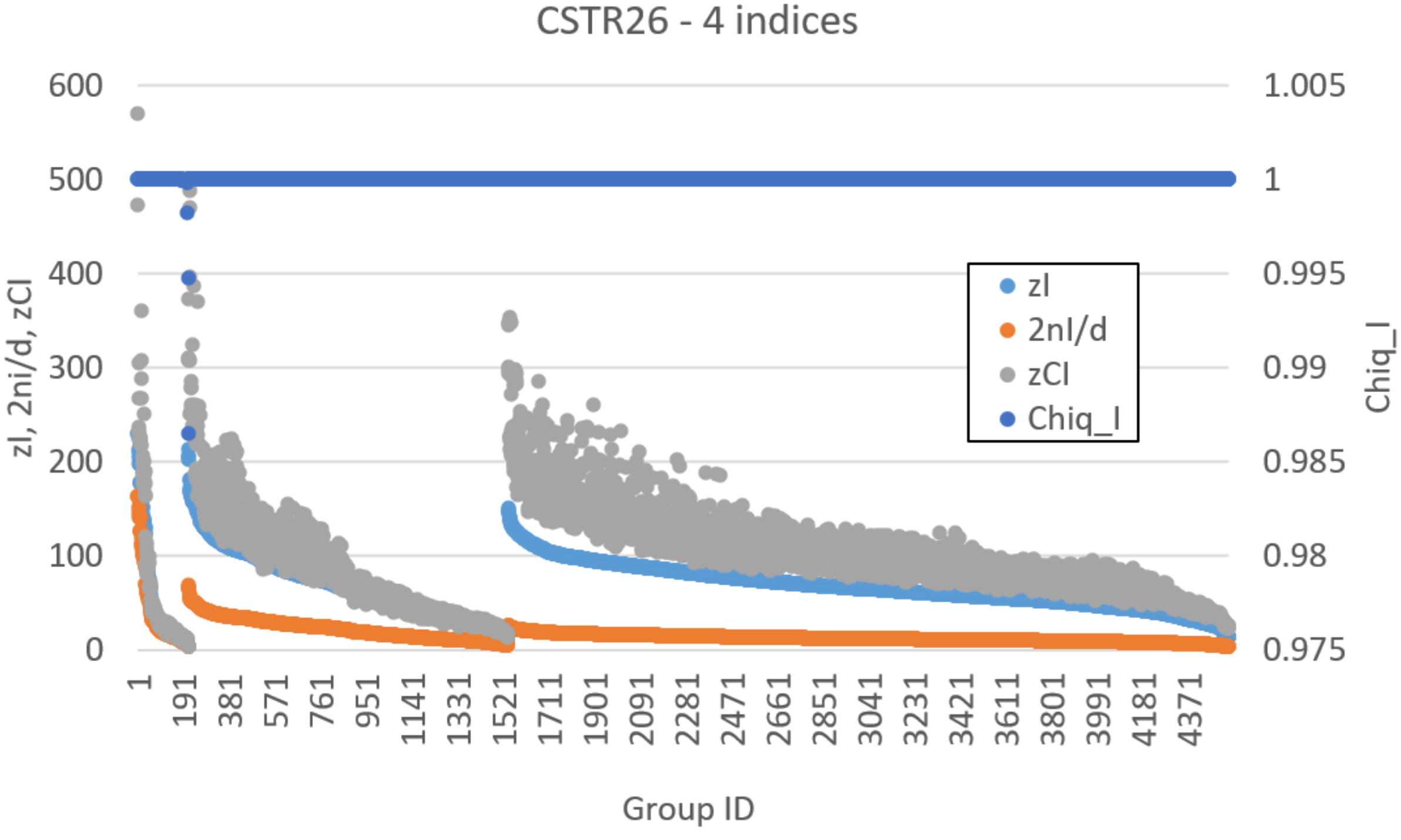
4. Results
4.1. Dynamically Homogeneous Systems
4.2. Dynamically Organized Systems
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A
Appendix A.1. The Sieving Method

| Algorithm A1 The Sieving Method |
|
Appendix A.2. The Iterative Sieving Method


References
- Lane, D.; Pumain, D.; van der Leeuw, S.E.; West, G. (Eds.) Complexity Perspectives in Innovation and Social Change; Springer: Dordrecht, The Netherlands, 2009. [Google Scholar]
- Haken, H. Synergetics: Introduction and Advanced Topics; Springer: Berlin, Germany, 2004. [Google Scholar]
- Emmeche, C.; Køppe, S.; Stjernfelt, F. Explaining emergence: Towards an ontology of levels. J. Gen. Philos. Sci. 1997, 28, 83–117. [Google Scholar] [CrossRef]
- Lane, D. Hierarchy, complexity, society. In Hierarchy in Natural and Social Sciences; Pumain, D., Ed.; Springer: Dordrecht, The Netherlands, 2006; pp. 81–119. [Google Scholar]
- Barabási, A.L. Network Science; Cambridge University Press: Cambridge, UK, 2016. [Google Scholar]
- Lewis, T.G. Network Science: Theory and Application; Wiley: Hoboken, NJ, USA, 2009. [Google Scholar]
- Fortunato, S. Community detection in graphs. Phys. Rep. 2010, 486, 75–174. [Google Scholar] [CrossRef]
- Scott, J.G. Social Network Analysis: A Handbook, 2nd ed.; SAGE: London, UK, 2000. [Google Scholar]
- Tononi, G.; McIntosh, A.R.; Russel, D.P.; Edelman, G.M. Functional clustering: Identifying strongly interactive brain regions in neuroimaging data. Neuroimage 1998, 7, 133–149. [Google Scholar] [CrossRef]
- Tononi, G.; Sporns, O.; Edelman, G.M. A measure for brain complexity: Relating functional segregation and integration in the nervous system. Proc. Natl. Acad. Sci. USA 1994, 91, 5033–5037. [Google Scholar] [CrossRef] [PubMed]
- Cover, T.M.; Thomas, A. Elements of Information Theory, 2nd ed.; Wiley: New York, NY, USA, 2006. [Google Scholar]
- Watanabe, S. Information theoretical analysis of multivariate correlation. IBM J. Res. Dev. 1960, 4, 66–82. [Google Scholar] [CrossRef]
- Nemenman, I.; Shafee, F.; Bialek, W. Entropy and inference, revisited. In Proceedings of the 14th International Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 3–8 December 2001; MIT Press: Cambridge, MA, USA, 2002; pp. 471–478. [Google Scholar]
- Hausser, J.; Strimmer, K. Entropy inference and the James-Stein estimator, with application to nonlinear gene association networks. J. Mach. Learn. Res. 2009, 10, 1469–1484. [Google Scholar]
- Archer, E.; Park, I.M.; Pillow, J.W. Bayesian and quasi-Bayesian estimators for mutual information from discrete data. Entropy 2013, 15, 1738–1755. [Google Scholar] [CrossRef]
- Miller, G.A.; Madow, W.G. On the Maximum Likelihood Estimate of the Shannon-Wiener Measure of Information; Technical Report 54-75; Air Force Cambridge Research Center: Dayton, OH, USA, 1954. [Google Scholar]
- Miller, G.A. Note on the bias of information estimates. In Information Theory in Psychology; Quastler, H., Ed.; Free Press: Glencoe, IL, USA, 1955; pp. 95–100. [Google Scholar]
- Luce, R.D. The theory of selective information and some of its behavioral applications. In Developments in Mathematical Psychology; Luce, R.D., Ed.; Free Press: Glencoe, IL, USA, 1960; pp. 5–119. [Google Scholar]
- Villani, M.; Roli, A.; Filisetti, A.; Fiorucci, M.; Poli, I.; Serra, R. The search for candidate relevant subsets of variables in complex systems. Artif. Life 2015, 21, 412–431. [Google Scholar] [CrossRef] [PubMed]
- Roli, A.; Villani, M.; Caprari, R.; Serra, R. Identifying critical states through the relevance index. Entropy 2017, 19, 73. [Google Scholar] [CrossRef]
- Roli, A.; Villani, M.; Filisetti, A.; Serra, R. Dynamical criticality: Overview and open questions. J. Syst. Sci. Complex. 2018, 31, 647–663. [Google Scholar] [CrossRef]
- Villani, M.; Sani, L.; Pecori, R.; Amoretti, M.; Roli, A.; Mordonini, M.; Serra, R.; Cagnoni, S. An iterative information-theoretic approach to the detection of structures in complex systems. Complexity 2018, 2018, 3687839. [Google Scholar] [CrossRef]
- Filisetti, A.; Villani, M.; Roli, A.; Fiorucci, M.; Poli, I.; Serra, R. On some properties of information theoretical measures for the study of complex systems. In Advances in Artificial Life and Evolutionary Computation, Proceedings of the WIVACE 2014, Vietri sul Mare (SA), Italy, 14–15 May 2014; Pizzuti, C., Spezzano, G., Eds.; Springer: Berlin/Heidelberg, Germany, 2014; pp. 140–150. [Google Scholar]
- Filisetti, A.; Villani, M.; Roli, A.; Fiorucci, M.; Serra, R. Exploring the organisation of complex systems through the dynamical interactions among their relevant subsets. In Proceedings of the European Conference on Artificial Life 2015, York, UK, 20–24 July 2015; Andrews, P., Caves, L., Doursat, R., Hickinbotham, S., Polack, F., Stepney, S., Tim, T., Jon, T., Eds.; MIT Press: Cambridge, MA, USA, 2015; pp. 286–293. [Google Scholar]
- Sani, L.; Amoretti, M.; Vicari, E.; Mordonini, M.; Pecori, R.; Roli, A.; Villani, M.; Cagnoni, S.; Serra, R. Efficient search of relevant structures in complex systems. In AI*IA 2016 Advances in Artificial Intelligence; Adorni, G., Cagnoni, S., Gori, M., Maratea, M., Eds.; Springer: Cham, Switzerland, 2016; pp. 35–48. [Google Scholar]
- Silvestri, G.; Sani, L.; Amoretti, M.; Pecori, R.; Vicari, E.; Mordonini, M.; Cagnoni, S. Searching Relevant Variable Subsets in Complex Systems Using K-Means PSO. In Artificial Life and Evolutionary Computation, Proceedings of the WIVACE 2017, Venice, Italy, 19–21 September 2017; Pelillo, M., Poli, I., Roli, A., Serra, R., Slanzi, D., Villani, M., Eds.; Springer: Cham, Switzerland, 2018; pp. 308–321. [Google Scholar]
- Vicari, E.; Amoretti, M.; Sani, L.; Mordonini, M.; Pecori, R.; Roli, A.; Villani, M.; Cagnoni, S.; Serra, R. GPU-based parallel search of relevant variable sets in complex systems. In Advances in Artificial Life, Evolutionary Computation, and Systems Chemistry, Proceedings of the WIVACE 2016, Fisciano, Italy, 4–6 October 2016; Rossi, F., Piotto, S., Concilio, S., Eds.; Springer: Cham, Switzerland, 2017; pp. 14–25. [Google Scholar]
- Held, L.; Sabanés Bové, D. Applied Statistical Inference; Springer: Berlin, Germany, 2014. [Google Scholar]
- Wilks, S.S. The large-sample distribution of the likelihood ratio for testing composite hypotheses. Ann. Math. Stat. 1938, 9, 60–62. [Google Scholar] [CrossRef]
- Wilks, S.S. The likelihood test of independence in contingency tables. Ann. Math. Stat. 1935, 6, 190–196. [Google Scholar] [CrossRef]
- Villani, M.; Campioli, D.; Damiani, C.; Roli, A.; Filisetti, A.; Serra, R. Dynamical regimes in non-ergodic random Boolean networks. Nat. Comput. 2017, 16, 353–363. [Google Scholar] [CrossRef]
- Villani, M.; Sani, L.; Amoretti, M.; Vicari, E.; Pecori, R.; Mordonini, M.; Cagnoni, S.; Serra, R. A Relevance Index Method to Infer Global Properties of Biological Networks. In Artificial Life and Evolutionary Computation, Proceedings of the WIVACE 2017, Venice, Italy, 19–21 September 2017; Pelillo, M., Poli, I., Roli, A., Serra, R., Slanzi, D., Villani, M., Eds.; Springer: Cham, Switzerland, 2018; pp. 129–141. [Google Scholar]
- Sani, L.; D’Addese, G.; Graudenzi, A.; Villani, M. The detection of dynamical organization in cancer evolution models. In Advances in Artificial Life and Evolutionary Computation, Proceedings of the WIVACE 2019, Rende, Italy, 18–20 September 2019; Pizzuti, C., Spezzano, G., Eds.; Springer: Cham, Switzerland, 2020; pp. 49–61. [Google Scholar]
- Righi, R.; Roli, A.; Russo, M.; Serra, R.; Villani, M. New paths for the application of DCI in social sciences: Theoretical issues regarding an empirical analysis. In Advances in Artificial Life, Evolutionary Computation, and Systems Chemistry, Proceedings of the WIVACE 2016, Fisciano, Italy, 4–6 October 2016; Rossi, F., Piotto, S., Concilio, S., Eds.; Springer: Berlin/Heidelberg, Germany, 2017; pp. 42–52. [Google Scholar]
- Villani, M.; Filisetti, A.; Benedettini, S.; Roli, A.; Lane, D.; Serra, R. The detection of intermediate-level emergent structures and patterns. In Advances in Artificial Life, Proceedings of the ECAL 2013, Sicily, Italy, 2–6 September 2013; Liò, P., Miglino, O., Nicosia, G., Nolfi, S., Pavone, M., Eds.; MIT Press: Boston, MA, USA, 2013; pp. 372–378. [Google Scholar]
- Dyson, F.J. Origins of Life; Cambridge Univesity Press: Cambridge, UK, 1985. [Google Scholar]
- Eigen, M.; Schuster, P. A principle of natural self-organization. Naturwissenschaften 1977, 64, 541–565. [Google Scholar] [CrossRef] [PubMed]
- Eigen, M.; Schuster, P. The hypercycle. Naturwissenschaften 1978, 65, 7–41. [Google Scholar] [CrossRef]
- Filisetti, A.; Serra, R.; Carletti, T.; Villani, M.; Poli, I. Non-linear protocell models: Synchronization and chaos. Eur. Phys. J. B 2010, 77, 249–256. [Google Scholar] [CrossRef]
- Jain, S.; Krishna, S. Autocatalytic sets and the growth of complexity in an evolutionary model. Phys. Rev. Lett. 1998, 81, 5684–5687. [Google Scholar] [CrossRef]
- Kauffman, S.A. The Origins of Order; Oxford University Press: Oxford, UK, 1993. [Google Scholar]
- Ruiz-Mirazo, K.; Briones, C.; de la Escosura, A. Prebiotic systems chemistry: New perspectives for the origins of life. Chem. Rev. 2014, 114, 285–366. [Google Scholar] [CrossRef]
- Solé, R.V.; Munteanu, A.; Rodriguez-Caso, C.; Macía, J. Synthetic protocell biology: From reproduction to computation. Philos. Trans. R. Soc. B Biol. Sci. 2007, 362, 1727–1739. [Google Scholar] [CrossRef]
- Hordijk, W.; Hein, J.; Steel, M. Autocatalytic sets and the origin of life. Entropy 2010, 12, 1733–1742. [Google Scholar] [CrossRef]
- Hordijk, W.; Steel, M. Detecting autocatalytic, self-sustaining sets in chemical reaction systems. J. Theor. Biol. 2004, 227, 451–461. [Google Scholar] [CrossRef]
- Filisetti, A.; Villani, M.; Damiani, C.; Graudenzi, A.; Roli, A.; Hordijk, W.; Serra, R. On RAF sets and autocatalytic cycles in random reaction networks. In Advances in Artificial Life and Evolutionary Computation, Proceedings of the WIVACE 2014, Vietri sul Mare, Italy, 14–15 May 2014; Pizzuti, C., Spezzano, G., Eds.; Springer: Cham, Switzerland, 2014; pp. 113–126. [Google Scholar]
- Hordijk, W.; Steel, M. A formal model of autocatalytic sets emerging in an RNA replicator system. J. Syst. Chem. 2013, 4, 3. [Google Scholar] [CrossRef]
- Vasas, V.; Fernando, C.; Santos, M.; Kauffman, S.A.; Szathmáry, E. Evolution before genes. Biol. Direct 2012, 7, 1. [Google Scholar] [CrossRef] [PubMed]
- Serra, R.; Villani, M. Modelling Protocells: The Emergent Synchronization of Reproduction and Molecular Replication; Springer: Dordrecht, The Netherlands, 2017. [Google Scholar]
- Perry, R.; Green, D. Perry’s Chemical Engineer’s Handbook, 8th ed.; Mc-Graw Hill: New York, NY, USA, 2007. [Google Scholar]
- Farmer, J.D.; Kauffman, S.A.; Packard, N.H. Autocatalytic replication of polymers. Phys. D Nonlinear Phenom. 1986, 22, 50–67. [Google Scholar] [CrossRef]
- Filisetti, A.; Graudenzi, A.; Serra, R.; Villani, M.; De Lucrezia, D.; Füchslin, R.M.; Kauffman, S.A.; Packard, N.; Poli, I. A stochastic model of the emergence of autocatalytic cycles. J. Syst. Chem. 2011, 2, 2. [Google Scholar] [CrossRef]
- Filisetti, A.; Graudenzi, A.; Serra, R.; Villani, M.; Füchslin, R.M.; Packard, N.; Kauffman, S.A.; Poli, I. A stochastic model of autocatalytic reaction networks. Theory Biosci. 2012, 131, 85–93. [Google Scholar] [CrossRef] [PubMed]
- Kauffman, S.A. At Home in the Universe; Oxford University Press: Oxford, UK, 1995. [Google Scholar]
- Serra, R.; Villani, M. Sustainable growth and synchronization in protocell models. Life 2019, 9, 68. [Google Scholar] [CrossRef]
- Arkin, A.; Shen, P.; Ross, J. A test case of correlation metric construction of a reaction pathway from measurements. Science 1997, 277, 1275–1279. [Google Scholar] [CrossRef]
- Amigó, J.M.; Balogh, S.G.; Hernández, S. A brief review of generalized entropies. Entropy 2018, 20, 813. [Google Scholar] [CrossRef]










Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
D’Addese, G.; Sani, L.; La Rocca, L.; Serra, R.; Villani, M. Asymptotic Information-Theoretic Detection of Dynamical Organization in Complex Systems. Entropy 2021, 23, 398. https://doi.org/10.3390/e23040398
D’Addese G, Sani L, La Rocca L, Serra R, Villani M. Asymptotic Information-Theoretic Detection of Dynamical Organization in Complex Systems. Entropy. 2021; 23(4):398. https://doi.org/10.3390/e23040398
Chicago/Turabian StyleD’Addese, Gianluca, Laura Sani, Luca La Rocca, Roberto Serra, and Marco Villani. 2021. "Asymptotic Information-Theoretic Detection of Dynamical Organization in Complex Systems" Entropy 23, no. 4: 398. https://doi.org/10.3390/e23040398
APA StyleD’Addese, G., Sani, L., La Rocca, L., Serra, R., & Villani, M. (2021). Asymptotic Information-Theoretic Detection of Dynamical Organization in Complex Systems. Entropy, 23(4), 398. https://doi.org/10.3390/e23040398