
Federated Quantum Machine Learning



Abstract
:1. Introduction
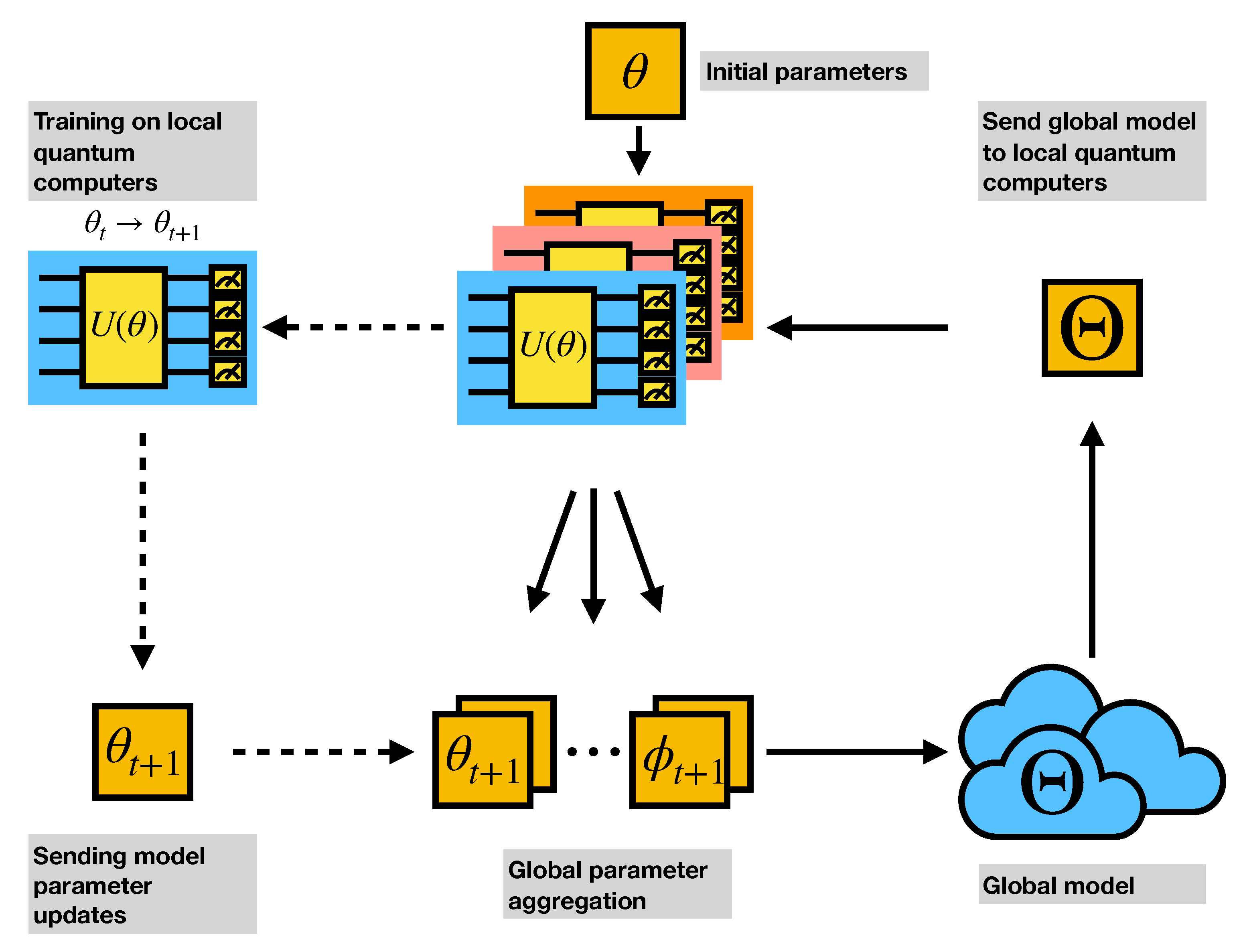
2. Federated Machine Learning
3. Variational Quantum Circuits
3.1. Quantum Encoder
3.2. Quantum Gradients
4. Hybrid Quantum-Classical Transfer Learning
5. Experiments and Results
- Central node C: Receive the uploaded circuit parameters from each local machine and aggregate them into a global parameter and distributes to all local machines.
- Training points are equally distributed to the local machines and the testing points are on the central node to evaluate the aggregated global model.
- Individual local machines : Each has a distinct part of the training data and will perform E epochs of the training locally with the batch size B.
5.1. Cats vs. Dogs
5.2. CIFAR (Planes vs. Cars)
6. Discussion
6.1. Integration with Other Privacy-Preserving Protocols
6.2. Different Aggregation Method
6.3. Decentralization
6.4. Other Quantum Machine Learning Models
6.5. Potential Applications
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| VQC | Variational Quantum Circuit |
| QNN | Quantum Neural Network |
| QML | Quantum Machine Learning |
| FL | Federated Learning |
| NISQ | Noisy Intermediate Scale Quantum |
| DP | Differential Privacy |
| DLT | Distributed Ledger Technology |
References
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 12 June 2015; pp. 1–9. [Google Scholar]
- Voulodimos, A.; Doulamis, N.; Doulamis, A.; Protopapadakis, E. Deep Learning for Computer Vision: A Brief Review. Comput. Intell. Neurosci. 2018, 2018, 1–13. [Google Scholar] [CrossRef] [PubMed]
- Sutskever, I.; Vinyals, O.; Le, Q.V. Sequence to sequence learning with neural networks. Adv. Neural Inf. Process. Syst. 2014, 2, 3104–3112. [Google Scholar]
- Silver, D.; Huang, A.; Maddison, C.J.; Guez, A.; Sifre, L.; van den Driessche, G.; Schrittwieser, J.; Antonoglou, I.; Panneershelvam, V.; Lanctot, M.; et al. Mastering the game of Go with deep neural networks and tree search. Nature 2016, 529, 484–489. [Google Scholar] [CrossRef] [PubMed]
- Cross, A. The IBM Q experience and QISKit open-source quantum computing software. In Proceedings of the APS Meeting Abstracts, Los Angeles, CA, USA, 5–9 March 2018. [Google Scholar]
- Arute, F.; Arya, K.; Babbush, R.; Bacon, D.; Bardin, J.C.; Barends, R.; Biswas, R.; Boixo, S.; Brandao, F.G.; Buell, D.A.; et al. Quantum supremacy using a programmable superconducting processor. Nature 2019, 574, 505–510. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Grzesiak, N.; Blümel, R.; Wright, K.; Beck, K.M.; Pisenti, N.C.; Li, M.; Chaplin, V.; Amini, J.M.; Debnath, S.; Chen, J.S.; et al. Efficient arbitrary simultaneously entangling gates on a trapped-ion quantum computer. Nat. Commun. 2020, 11, 2963. [Google Scholar] [CrossRef]
- Lanting, T.; Przybysz, A.J.; Smirnov, A.Y.; Spedalieri, F.M.; Amin, M.H.; Berkley, A.J.; Harris, R.; Altomare, F.; Boixo, S.; Bunyk, P.; et al. Entanglement in a quantum annealing processor. Phys. Rev. X 2014, 4, 021041. [Google Scholar] [CrossRef] [Green Version]
- Harrow, A.W.; Montanaro, A. Quantum computational supremacy. Nature 2017, 549, 203–209. [Google Scholar] [CrossRef] [Green Version]
- Nielsen, M.A.; Chuang, I. Quantum Computation and Quantum Information. Am. J. Phys. 2002, 70. [Google Scholar] [CrossRef] [Green Version]
- Shor, P.W. Polynomial-time algorithms for prime factorization and discrete logarithms on a quantum computer. SIAM Rev. 1999, 41, 303–332. [Google Scholar] [CrossRef]
- Grover, L.K. Quantum mechanics helps in searching for a needle in a haystack. Phys. Rev. Lett. 1997, 79, 325. [Google Scholar] [CrossRef] [Green Version]
- Gottesman, D. Stabilizer codes and quantum error correction. arXiv 1997, arXiv:quant-ph/9705052. [Google Scholar]
- Gottesman, D. Theory of fault-tolerant quantum computation. Phys. Rev. A 1998, 57, 127. [Google Scholar] [CrossRef] [Green Version]
- Preskill, J. Quantum Computing in the NISQ era and beyond. Quantum 2018, 2, 79. [Google Scholar] [CrossRef]
- Peruzzo, A.; McClean, J.; Shadbolt, P.; Yung, M.H.; Zhou, X.Q.; Love, P.J.; Aspuru-Guzik, A.; O’brien, J.L. A variational eigenvalue solver on a photonic quantum processor. Nat. Commun. 2014, 5, 4213. [Google Scholar] [CrossRef] [Green Version]
- Cerezo, M.; Arrasmith, A.; Babbush, R.; Benjamin, S.C.; Endo, S.; Fujii, K.; McClean, J.R.; Mitarai, K.; Yuan, X.; Cincio, L.; et al. Variational Quantum Algorithms. arXiv 2020, arXiv:2012.09265. [Google Scholar]
- Bharti, K.; Cervera-Lierta, A.; Kyaw, T.H.; Haug, T.; Alperin-Lea, S.; Anand, A.; Degroote, M.; Heimonen, H.; Kottmann, J.S.; Menke, T.; et al. Noisy intermediate-scale quantum (NISQ) algorithms. arXiv 2021, arXiv:2101.08448. [Google Scholar]
- Mitarai, K.; Negoro, M.; Kitagawa, M.; Fujii, K. Quantum circuit learning. Phys. Rev. A 2018, 98, 032309. [Google Scholar] [CrossRef] [Green Version]
- Schuld, M.; Bocharov, A.; Svore, K.; Wiebe, N. Circuit-centric quantum classifiers. arXiv 2018, arXiv:1804.00633. [Google Scholar] [CrossRef] [Green Version]
- Farhi, E.; Neven, H. Classification with quantum neural networks on near term processors. arXiv 2018, arXiv:1802.06002. [Google Scholar]
- Benedetti, M.; Lloyd, E.; Sack, S.; Fiorentini, M. Parameterized quantum circuits as machine learning models. Quantum Sci. Technol. 2019, 4, 043001. [Google Scholar] [CrossRef] [Green Version]
- Mari, A.; Bromley, T.R.; Izaac, J.; Schuld, M.; Killoran, N. Transfer learning in hybrid classical-quantum neural networks. arXiv 2019, arXiv:1912.08278. [Google Scholar]
- Abohashima, Z.; Elhosen, M.; Houssein, E.H.; Mohamed, W.M. Classification with Quantum Machine Learning: A Survey. arXiv 2020, arXiv:2006.12270. [Google Scholar]
- Easom-McCaldin, P.; Bouridane, A.; Belatreche, A.; Jiang, R. Towards Building A Facial Identification System Using Quantum Machine Learning Techniques. arXiv 2020, arXiv:2008.12616. [Google Scholar]
- Sarma, A.; Chatterjee, R.; Gili, K.; Yu, T. Quantum Unsupervised and Supervised Learning on Superconducting Processors. arXiv 2019, arXiv:1909.04226. [Google Scholar]
- Chen, S.Y.C.; Huang, C.M.; Hsing, C.W.; Kao, Y.J. Hybrid quantum-classical classifier based on tensor network and variational quantum circuit. arXiv 2020, arXiv:2011.14651. [Google Scholar]
- Stein, S.A.; Baheri, B.; Tischio, R.M.; Chen, Y.; Mao, Y.; Guan, Q.; Li, A.; Fang, B. A Hybrid System for Learning Classical Data in Quantum States. arXiv 2020, arXiv:2012.00256. [Google Scholar]
- Chen, S.Y.C.; Yoo, S.; Fang, Y.L.L. Quantum Long Short-Term Memory. arXiv 2020, arXiv:2009.01783. [Google Scholar]
- Kyriienko, O.; Paine, A.E.; Elfving, V.E. Solving nonlinear differential equations with differentiable quantum circuits. arXiv 2020, arXiv:2011.10395. [Google Scholar]
- Dallaire-Demers, P.L.; Killoran, N. Quantum generative adversarial networks. Phys. Rev. A 2018, 98, 012324. [Google Scholar] [CrossRef] [Green Version]
- Li, J.; Topaloglu, R.; Ghosh, S. Quantum Generative Models for Small Molecule Drug Discovery. arXiv 2021, arXiv:2101.03438. [Google Scholar]
- Stein, S.A.; Baheri, B.; Tischio, R.M.; Mao, Y.; Guan, Q.; Li, A.; Fang, B.; Xu, S. QuGAN: A Generative Adversarial Network Through Quantum States. arXiv 2020, arXiv:2010.09036. [Google Scholar]
- Zoufal, C.; Lucchi, A.; Woerner, S. Quantum generative adversarial networks for learning and loading random distributions. NPJ Quantum Inf. 2019, 5, 103. [Google Scholar] [CrossRef] [Green Version]
- Situ, H.; He, Z.; Li, L.; Zheng, S. Quantum generative adversarial network for generating discrete data. arXiv 2018, arXiv:1807.01235. [Google Scholar]
- Nakaji, K.; Yamamoto, N. Quantum semi-supervised generative adversarial network for enhanced data classification. arXiv 2020, arXiv:2010.13727. [Google Scholar]
- Lloyd, S.; Schuld, M.; Ijaz, A.; Izaac, J.; Killoran, N. Quantum embeddings for machine learning. arXiv 2020, arXiv:2001.03622. [Google Scholar]
- Nghiem, N.A.; Chen, S.Y.C.; Wei, T.C. A Unified Classification Framework with Quantum Metric Learning. arXiv 2020, arXiv:2010.13186. [Google Scholar]
- Chen, S.Y.C.; Yang, C.H.H.; Qi, J.; Chen, P.Y.; Ma, X.; Goan, H.S. Variational quantum circuits for deep reinforcement learning. IEEE Access 2020, 8, 141007–141024. [Google Scholar] [CrossRef]
- Lockwood, O.; Si, M. Reinforcement Learning with Quantum Variational Circuit. In Proceedings of the 16th AAAI Conference on Artificial Intelligence and Interactive Digital Entertainment, Worcester, MA, USA, 19–23 October 2020; pp. 245–251. [Google Scholar]
- Wu, S.; Jin, S.; Wen, D.; Wang, X. Quantum reinforcement learning in continuous action space. arXiv 2020, arXiv:2012.10711. [Google Scholar]
- Jerbi, S.; Trenkwalder, L.M.; Nautrup, H.P.; Briegel, H.J.; Dunjko, V. Quantum enhancements for deep reinforcement learning in large spaces. arXiv 2019, arXiv:1910.12760. [Google Scholar]
- CHEN, C.C.; SHIBA, K.; SOGABE, M.; SAKAMOTO, K.; SOGABE, T. Hybrid quantum-classical Ulam-von Neumann linear solver-based quantum dynamic programing algorithm. Proc. Annu. Conf. JSAI 2020, JSAI2020, 2K6ES203. [Google Scholar] [CrossRef]
- Bausch, J. Recurrent quantum neural networks. arXiv 2020, arXiv:2006.14619. [Google Scholar]
- Yang, C.H.H.; Qi, J.; Chen, S.Y.C.; Chen, P.Y.; Siniscalchi, S.M.; Ma, X.; Lee, C.H. Decentralizing Feature Extraction with Quantum Convolutional Neural Network for Automatic Speech Recognition. arXiv 2020, arXiv:2010.13309. [Google Scholar]
- Suzuki, K. Overview of deep learning in medical imaging. Radiol. Phys. Technol. 2017, 10, 257–273. [Google Scholar] [CrossRef] [PubMed]
- Lundervold, A.S.; Lundervold, A. An overview of deep learning in medical imaging focusing on MRI. Z. Med. Phys. 2019, 29, 102–127. [Google Scholar] [CrossRef] [PubMed]
- Deng, L.; Hinton, G.; Kingsbury, B. New types of deep neural network learning for speech recognition and related applications: An overview. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26–31 May 2013; pp. 8599–8603. [Google Scholar]
- Amodei, D.; Ananthanarayanan, S.; Anubhai, R.; Bai, J.; Battenberg, E.; Case, C.; Casper, J.; Catanzaro, B.; Cheng, Q.; Chen, G.; et al. Deep speech 2: End-to-end speech recognition in english and mandarin. In Proceedings of the International conference on machine learning, New York, NY, USA, 19–24 June 2016; pp. 173–182. [Google Scholar]
- Hannun, A.; Case, C.; Casper, J.; Catanzaro, B.; Diamos, G.; Elsen, E.; Prenger, R.; Satheesh, S.; Sengupta, S.; Coates, A.; et al. Deep speech: Scaling up end-to-end speech recognition. arXiv 2014, arXiv:1412.5567. [Google Scholar]
- McMahan, B.; Moore, E.; Ramage, D.; Hampson, S.; y Arcas, B.A. Communication-efficient learning of deep networks from decentralized data. In Proceedings of the 20th International Conference on Artificial Intelligence and Statistics, Fort Lauderdale, FL, USA, 9–11 May 2017; pp. 1273–1282. [Google Scholar]
- Shokri, R.; Shmatikov, V. Privacy-preserving deep learning. In Proceedings of the 22nd ACM SIGSAC conference on Computer and Communications Security, Denver, CO, USA, 12–16 October 2015; pp. 1310–1321. [Google Scholar]
- Kulkarni, V.; Kulkarni, M.; Pant, A. Survey of Personalization Techniques for Federated Learning. arXiv 2020, arXiv:2003.08673. [Google Scholar]
- Kairouz, P.; McMahan, H.B.; Avent, B.; Bellet, A.; Bennis, M.; Bhagoji, A.N.; Bonawitz, K.; Charles, Z.; Cormode, G.; Cummings, R.; et al. Advances and open problems in federated learning. arXiv 2019, arXiv:1912.04977. [Google Scholar]
- Lim, W.Y.B.; Luong, N.C.; Hoang, D.T.; Jiao, Y.; Liang, Y.C.; Yang, Q.; Niyato, D.; Miao, C. Federated learning in mobile edge networks: A comprehensive survey. IEEE Commun. Surv. Tutor. 2020, 22, 2031–2063. [Google Scholar] [CrossRef] [Green Version]
- Yang, Q.; Liu, Y.; Chen, T.; Tong, Y. Federated machine learning: Concept and applications. ACM Trans. Intell. Syst. Technol. (TIST) 2019, 10, 1–19. [Google Scholar] [CrossRef]
- Li, T.; Sahu, A.K.; Talwalkar, A.; Smith, V. Federated learning: Challenges, methods, and future directions. IEEE Signal Process. Mag. 2020, 37, 50–60. [Google Scholar] [CrossRef]
- Li, Q.; Wen, Z.; He, B. Federated learning systems: Vision, hype and reality for data privacy and protection. arXiv 2019, arXiv:1907.09693. [Google Scholar]
- Wang, X.; Han, Y.; Leung, V.C.; Niyato, D.; Yan, X.; Chen, X. Convergence of edge computing and deep learning: A comprehensive survey. IEEE Commun. Surv. Tutor. 2020, 22, 869–904. [Google Scholar] [CrossRef] [Green Version]
- Semwal, T.; Mulay, A.; Agrawal, A.M. FedPerf: A Practitioners’ Guide to Performance of Federated Learning Algorithms. In Proceedings of the 34th Conference on Neural Information Processing Systems (NeurIPS 2020), Vancouver, BC, Canada, 7–11 December 2020. [Google Scholar]
- Sim, S.; Johnson, P.D.; Aspuru-Guzik, A. Expressibility and Entangling Capability of Parameterized Quantum Circuits for Hybrid Quantum-Classical Algorithms. Adv. Quantum Technol. 2019, 2, 1900070. [Google Scholar] [CrossRef] [Green Version]
- Du, Y.; Hsieh, M.H.; Liu, T.; Tao, D. The expressive power of parameterized quantum circuits. arXiv 2018, arXiv:1810.11922. [Google Scholar]
- Abbas, A.; Sutter, D.; Zoufal, C.; Lucchi, A.; Figalli, A.; Woerner, S. The power of quantum neural networks. arXiv 2020, arXiv:2011.00027. [Google Scholar]
- Chen, S.Y.C.; Wei, T.C.; Zhang, C.; Yu, H.; Yoo, S. Quantum Convolutional Neural Networks for High Energy Physics Data Analysis. arXiv 2020, arXiv:2012.12177. [Google Scholar]
- Chen, S.Y.C.; Wei, T.C.; Zhang, C.; Yu, H.; Yoo, S. Hybrid Quantum-Classical Graph Convolutional Network. arXiv 2021, arXiv:2101.06189. [Google Scholar]
- Sierra-Sosa, D.; Arcila-Moreno, J.; Garcia-Zapirain, B.; Castillo-Olea, C.; Elmaghraby, A. Dementia Prediction Applying Variational Quantum Classifier. arXiv 2020, arXiv:2007.08653. [Google Scholar]
- Wu, S.L.; Chan, J.; Guan, W.; Sun, S.; Wang, A.; Zhou, C.; Livny, M.; Carminati, F.; Di Meglio, A.; Li, A.C.; et al. Application of Quantum Machine Learning using the Quantum Variational Classifier Method to High Energy Physics Analysis at the LHC on IBM Quantum Computer Simulator and Hardware with 10 qubits. arXiv 2020, arXiv:2012.11560. [Google Scholar]
- Jerbi, S.; Gyurik, C.; Marshall, S.; Briegel, H.J.; Dunjko, V. Variational quantum policies for reinforcement learning. arXiv 2021, arXiv:2103.05577. [Google Scholar]
- Takaki, Y.; Mitarai, K.; Negoro, M.; Fujii, K.; Kitagawa, M. Learning temporal data with variational quantum recurrent neural network. arXiv 2020, arXiv:2012.11242. [Google Scholar]
- Schuld, M.; Petruccione, F. Information Encoding. In Supervised Learning with Quantum Computers; Springer International Publishing: Cham, Switzerland, 2018; pp. 139–171. [Google Scholar] [CrossRef]
- Schuld, M.; Bergholm, V.; Gogolin, C.; Izaac, J.; Killoran, N. Evaluating analytic gradients on quantum hardware. Phys. Rev. A 2019, 99, 032331. [Google Scholar] [CrossRef] [Green Version]
- Bergholm, V.; Izaac, J.; Schuld, M.; Gogolin, C.; Blank, C.; McKiernan, K.; Killoran, N. Pennylane: Automatic differentiation of hybrid quantum-classical computations. arXiv 2018, arXiv:1811.04968. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. Pytorch: An imperative style, high-performance deep learning library. arXiv 2019, arXiv:1912.01703. [Google Scholar]
- Suzuki, Y.; Kawase, Y.; Masumura, Y.; Hiraga, Y.; Nakadai, M.; Chen, J.; Nakanishi, K.M.; Mitarai, K.; Imai, R.; Tamiya, S.; et al. Qulacs: A fast and versatile quantum circuit simulator for research purpose. arXiv 2020, arXiv:2011.13524. [Google Scholar]
- Elson, J.; Douceur, J.J.; Howell, J.; Saul, J. Asirra: A CAPTCHA that Exploits Interest-Aligned Manual Image Categorization. In Proceedings of the 14th ACM Conference on Computer and Communications Security (CCS), Alexandria, VA, USA, 29 October–2 November 2007. [Google Scholar]
- Krizhevsky, A. Learning Multiple Layers of Features from Tiny Images; Technical Report; CiteSeerX Publishing: Princeton, NJ, USA, 2009. [Google Scholar]
- Dwork, C.; Roth, A. The algorithmic foundations of differential privacy. Found. Trends Theor. Comput. Sci. 2014, 9, 211–407. [Google Scholar] [CrossRef]
- Fredrikson, M.; Jha, S.; Ristenpart, T. Model inversion attacks that exploit confidence information and basic countermeasures. In Proceedings of the 22nd ACM SIGSAC Conference on Computer and Communications Security, Denver, CO, USA, 12–16 October 2015; pp. 1322–1333. [Google Scholar]
- Shokri, R.; Stronati, M.; Song, C.; Shmatikov, V. Membership inference attacks against machine learning models. In Proceedings of the 2017 IEEE Symposium on Security and Privacy (SP), San Jose, CA, USA, 25 May 2017; pp. 3–18. [Google Scholar]
- Abadi, M.; Chu, A.; Goodfellow, I.; McMahan, H.B.; Mironov, I.; Talwar, K.; Zhang, L. Deep learning with differential privacy. In Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security, Vienna, Austria, 24–28 October 2016; pp. 308–318. [Google Scholar]
- Goryczka, S.; Xiong, L.; Sunderam, V. Secure multiparty aggregation with differential privacy: A comparative study. In Proceedings of the Joint EDBT/ICDT 2013 Workshops, Genoa, Italy, 18–22 March 2013; pp. 155–163. [Google Scholar]
- Li, W.; Lu, S.; Deng, D.L. Quantum Private Distributed Learning Through Blind Quantum Computing. arXiv 2021, arXiv:2103.08403. [Google Scholar]
- Pillutla, K.; Kakade, S.M.; Harchaoui, Z. Robust aggregation for federated learning. arXiv 2019, arXiv:1912.13445. [Google Scholar]
- Ang, F.; Chen, L.; Zhao, N.; Chen, Y.; Wang, W.; Yu, F.R. Robust federated learning with noisy communication. IEEE Trans. Commun. 2020, 68, 3452–3464. [Google Scholar] [CrossRef] [Green Version]
- Savazzi, S.; Nicoli, M.; Rampa, V. Federated learning with cooperating devices: A consensus approach for massive IoT networks. IEEE Internet Things J. 2020, 7, 4641–4654. [Google Scholar] [CrossRef] [Green Version]
- Wittkopp, T.; Acker, A. Decentralized Federated Learning Preserves Model and Data Privacy. arXiv 2021, arXiv:2102.00880. [Google Scholar]
- Pokhrel, S.R.; Choi, J. A decentralized federated learning approach for connected autonomous vehicles. In Proceedings of the 2020 IEEE Wireless Communications and Networking Conference Workshops (WCNCW), Seoul, Korea, 25–28 May 2020; pp. 1–6. [Google Scholar]
- Bonawitz, K.; Eichner, H.; Grieskamp, W.; Huba, D.; Ingerman, A.; Ivanov, V.; Kiddon, C.; Konečnỳ, J.; Mazzocchi, S.; McMahan, H.B.; et al. Towards federated learning at scale: System design. arXiv 2019, arXiv:1902.01046. [Google Scholar]
- Xiao, Y.; Ye, Y.; Huang, S.; Hao, L.; Ma, Z.; Xiao, M.; Mumtaz, S. Fully Decentralized Federated Learning Based Beamforming Design for UAV Communications. arXiv 2020, arXiv:2007.13614. [Google Scholar]
- Lalitha, A.; Shekhar, S.; Javidi, T.; Koushanfar, F. Fully decentralized federated learning. In Proceedings of the Third workshop on Bayesian Deep Learning (NeurIPS), Montreal, QC, Canada, 7 December 2018. [Google Scholar]
- Lu, S.; Zhang, Y.; Wang, Y. Decentralized federated learning for electronic health records. In Proceedings of the 2020 54th Annual Conference on Information Sciences and Systems (CISS), Princeton, NJ, USA, 18–20 March 2020; pp. 1–5. [Google Scholar]
- Nakamoto, S. Bitcoin: A peer-to-peer electronic cash system. Bitcoin. Org 2008, 4. [Google Scholar] [CrossRef]
- Zyskind, G.; Nathan, O. Decentralizing privacy: Using blockchain to protect personal data. In Proceedings of the 2015 IEEE Security and Privacy Workshops, San Jose, CA, USA, 21–22 May 2015; pp. 180–184. [Google Scholar]
- Cai, W.; Wang, Z.; Ernst, J.B.; Hong, Z.; Feng, C.; Leung, V.C. Decentralized applications: The blockchain-empowered software system. IEEE Access 2018, 6, 53019–53033. [Google Scholar] [CrossRef]
- Pandl, K.D.; Thiebes, S.; Schmidt-Kraepelin, M.; Sunyaev, A. On the convergence of artificial intelligence and distributed ledger technology: A scoping review and future research agenda. IEEE Access 2020, 8, 57075–57095. [Google Scholar] [CrossRef]
- Qu, Y.; Gao, L.; Luan, T.H.; Xiang, Y.; Yu, S.; Li, B.; Zheng, G. Decentralized privacy using blockchain-enabled federated learning in fog computing. IEEE Internet Things J. 2020, 7, 5171–5183. [Google Scholar] [CrossRef]
- Ramanan, P.; Nakayama, K. Baffle: Blockchain based aggregator free federated learning. In Proceedings of the 2020 IEEE International Conference on Blockchain (Blockchain), Rhodes Island, Greece, 2–6 November 2020; pp. 72–81. [Google Scholar]
- Awan, S.; Li, F.; Luo, B.; Liu, M. Poster: A reliable and accountable privacy-preserving federated learning framework using the blockchain. In Proceedings of the 2019 ACM SIGSAC Conference on Computer and Communications Security, London, UK, 11–15 November 2019; pp. 2561–2563. [Google Scholar]
- Qu, Y.; Pokhrel, S.R.; Garg, S.; Gao, L.; Xiang, Y. A blockchained federated learning framework for cognitive computing in industry 4.0 networks. IEEE Trans. Ind. Inf. 2020, 17, 2964–2973. [Google Scholar] [CrossRef]
- Zhao, Y.; Zhao, J.; Jiang, L.; Tan, R.; Niyato, D.; Li, Z.; Lyu, L.; Liu, Y. Privacy-preserving blockchain-based federated learning for IoT devices. IEEE Internet Things J. 2020, 8, 1817–1829. [Google Scholar] [CrossRef]
- Bao, X.; Su, C.; Xiong, Y.; Huang, W.; Hu, Y. Flchain: A blockchain for auditable federated learning with trust and incentive. In Proceedings of the 2019 5th International Conference on Big Data Computing and Communications (BIGCOM), QingDao, China, 9–11 August 2019; pp. 151–159. [Google Scholar]
- Kim, H.; Park, J.; Bennis, M.; Kim, S.L. Blockchained on-device federated learning. IEEE Commun. Lett. 2019, 24, 1279–1283. [Google Scholar] [CrossRef] [Green Version]
- Liu, Y.; Ai, Z.; Sun, S.; Zhang, S.; Liu, Z.; Yu, H. Fedcoin: A peer-to-peer payment system for federated learning. In Federated Learning; Springer: Berlin/Heidelberg, Germany, 2020; pp. 125–138. [Google Scholar]
- Roy, A.G.; Siddiqui, S.; Pölsterl, S.; Navab, N.; Wachinger, C. Braintorrent: A peer-to-peer environment for decentralized federated learning. arXiv 2019, arXiv:1905.06731. [Google Scholar]
- Lalitha, A.; Kilinc, O.C.; Javidi, T.; Koushanfar, F. Peer-to-peer federated learning on graphs. arXiv 2019, arXiv:1901.11173. [Google Scholar]
- Hegedűs, I.; Berta, Á.; Kocsis, L.; Benczúr, A.A.; Jelasity, M. Robust decentralized low-rank matrix decomposition. ACM Trans. Intell. Syst. Technol. (TIST) 2016, 7, 1–24. [Google Scholar] [CrossRef]
- Ormándi, R.; Hegedűs, I.; Jelasity, M. Gossip learning with linear models on fully distributed data. Concurr. Comput. Pract. Exp. 2013, 25, 556–571. [Google Scholar] [CrossRef] [Green Version]
- Hegedűs, I.; Danner, G.; Jelasity, M. Gossip learning as a decentralized alternative to federated learning. In IFIP International Conference on Distributed Applications and Interoperable Systems; Springer: Berlin/Heidelberg, Germany, 2019; pp. 74–90. [Google Scholar]
- Hegedűs, I.; Danner, G.; Jelasity, M. Decentralized recommendation based on matrix factorization: A comparison of gossip and federated learning. In Joint European Conference on Machine Learning and Knowledge Discovery in Databases; Springer: Berlin/Heidelberg, Germany, 2019; pp. 317–332. [Google Scholar]
- Hegedűs, I.; Danner, G.; Jelasity, M. Decentralized learning works: An empirical comparison of gossip learning and federated learning. J. Parallel Distrib. Comput. 2021, 148, 109–124. [Google Scholar] [CrossRef]
- Hu, C.; Jiang, J.; Wang, Z. Decentralized federated learning: A segmented gossip approach. arXiv 2019, arXiv:1908.07782. [Google Scholar]
- Sergeev, A.; Balso, M.D. Horovod: Fast and easy distributed deep learning in TensorFlow. arXiv 2018, arXiv:1802.05799. [Google Scholar]
- Chen, S.Y.C.; Huang, C.M.; Hsing, C.W.; Kao, Y.J. An end-to-end trainable hybrid classical-quantum classifier. arXiv 2021, arXiv:2102.02416. [Google Scholar]
- Cong, I.; Choi, S.; Lukin, M.D. Quantum convolutional neural networks. Nat. Phys. 2019, 15, 1273–1278. [Google Scholar] [CrossRef] [Green Version]
- Li, Y.; Zhou, R.G.; Xu, R.; Luo, J.; Hu, W. A quantum deep convolutional neural network for image recognition. Quantum Sci. Technol. 2020, 5, 044003. [Google Scholar] [CrossRef]
- Oh, S.; Choi, J.; Kim, J. A Tutorial on Quantum Convolutional Neural Networks (QCNN). arXiv 2020, arXiv:2009.09423. [Google Scholar]
- Kerenidis, I.; Landman, J.; Prakash, A. Quantum algorithms for deep convolutional neural networks. arXiv 2019, arXiv:1911.01117. [Google Scholar]
- Liu, J.; Lim, K.H.; Wood, K.L.; Huang, W.; Guo, C.; Huang, H.L. Hybrid Quantum-Classical Convolutional Neural Networks. arXiv 2019, arXiv:1911.02998. [Google Scholar]
- Qi, J.; Yang, C.H.H.; Tejedor, J. Submodular rank aggregation on score-based permutations for distributed automatic speech recognition. In Proceedings of the ICASSP 2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 3517–3521. [Google Scholar]
- Egger, D.J.; Gambella, C.; Marecek, J.; McFaddin, S.; Mevissen, M.; Raymond, R.; Simonetto, A.; Woerner, S.; Yndurain, E. Quantum computing for Finance: state of the art and future prospects. IEEE Trans. Quantum Eng. 2020, 1, 3101724. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Linear | ReLU | Dropout (p = 0.5) | Linear | ReLU | Dropout (p = 0.5) | Linear | |
|---|---|---|---|---|---|---|---|
| Input | 25,088 | 4096 | 4096 | ||||
| Output | 4096 | 4096 | 4 | ||||
| Training Loss | Testing Loss | Testing Accuracy | |
|---|---|---|---|
| Federated Training (1 local epoch) | 0.3506 | 0.3519 | 98.7% |
| Federated Training (2 local epochs) | 0.3405 | 0.3408 | 98.6% |
| Federated Training (4 local epochs) | 0.3304 | 0.3413 | 98.6% |
| Non-Federated Training | 0.3360 | 0.3369 | 98.75% |
| Training Loss | Testing Loss | Testing Accuracy | |
|---|---|---|---|
| Federated Training (1 local epoch) | 0.4029 | 0.4133 | 93.40% |
| Federated Training (2 local epochs) | 0.4760 | 0.4056 | 94.05% |
| Federated Training (4 local epochs) | 0.4090 | 0.3934 | 93.45% |
| Non-Federated Training | 0.4190 | 0.4016 | 93.65% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, S.Y.-C.; Yoo, S. Federated Quantum Machine Learning. Entropy 2021, 23, 460. https://doi.org/10.3390/e23040460
Chen SY-C, Yoo S. Federated Quantum Machine Learning. Entropy. 2021; 23(4):460. https://doi.org/10.3390/e23040460
Chicago/Turabian StyleChen, Samuel Yen-Chi, and Shinjae Yoo. 2021. "Federated Quantum Machine Learning" Entropy 23, no. 4: 460. https://doi.org/10.3390/e23040460
APA StyleChen, S. Y.-C., & Yoo, S. (2021). Federated Quantum Machine Learning. Entropy, 23(4), 460. https://doi.org/10.3390/e23040460