
A Foreground-Aware Framework for Local Face Attribute Transfer



Abstract
:1. Introduction
- Accurately and faithfully transferring the attribute from the reference headshot photography to the semantically-equivalent regions in the user’s own face photo;
- Avoid an unnatural and artificial transition between the foreground with the new attribute and the background with the original attribute to ensure the results resemble the photos directly taken by users, instead of a crude composition of some regions in the input and reference;
- Providing an interactive method for users to determine which regions are foreground and which are background.
- We introduce the semantic map of both the input and reference images for local face attribute transfer to produce a visually pleasing result using a semantically meaningful fashion. Equipped with the semantic map, we successfully achieve locally semantic-level attribute transfer (e.g., mouth-to-mouth), sufficiently improving the accuracy of the stylistic match.
- We add an additional background channel into our semantic map to indicate the background region required to be maintained the same as the input image. We also provide an effective initialization strategy and propose a novel term, a preservation term, to flexibly handle the particular demand that merely manipulates the attribute of the foreground region, while preserving the background region.
- We conduct extensive experiments to reveal the efficacy of our design, and demonstrate its advantages over other state-of-the-art methods.
2. State of the Art
2.1. Global Neural Style Transfer
2.2. Face Attribute Manipulation
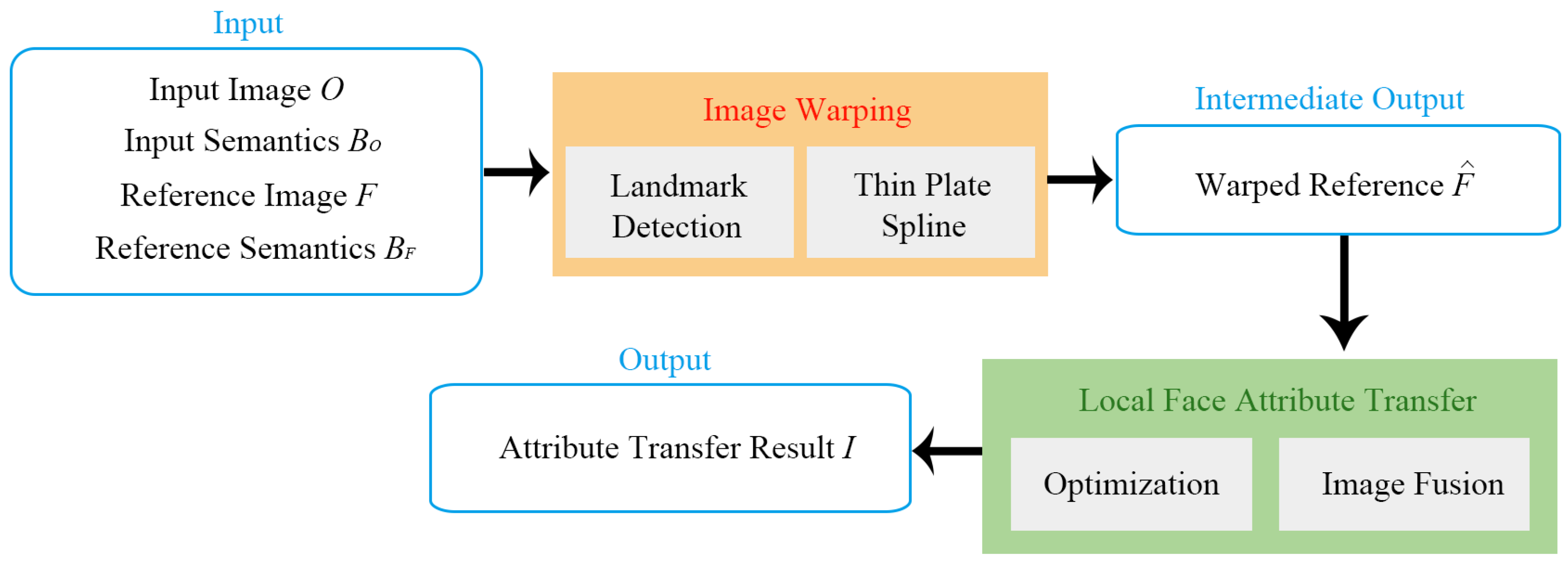
3. Methodology
3.1. Facial Landmark Detection
3.2. Thin Plate Spline
3.3. Image Fusion
3.4. Optimization
4. Experimental Validation
4.1. Evaluation Metrics
4.1.1. Inception Score
4.1.2. Fréchet Inception Distance
4.2. Comparison with Other State-of-the-Art Works
4.3. Flexibility Verification
4.4. Ablation Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Jing, Y.; Yang, Y.; Feng, Z.; Ye, J.; Yu, Y.; Song, M. Neural style transfer: A review. IEEE Trans. Vis. Comput. Graph. 2019, 26, 3365–3385. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Shih, Y.; Paris, S.; Barnes, C.; Freeman, W.T.; Durand, F. Style transfer for headshot portraits. TOG 2014, 33, 148:1–148:14. [Google Scholar] [CrossRef] [Green Version]
- Gatys, L.A.; Ecker, A.S.; Bethge, M. Image style transfer using convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2414–2423. [Google Scholar]
- Johnson, J.; Alahi, A.; Li, F.-F. Perceptual losses for real-time style transfer and super-resolution. In European Conference on Computer Vision; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer: Cham, Switzerland, 2016; pp. 694–711. [Google Scholar]
- Chen, D.; Yuan, L.; Liao, J.; Yu, N.; Hua, G. Stylebank: An explicit representation for neural image style transfer. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2770–2779. [Google Scholar]
- Li, Y.; Wang, N.; Liu, J.; Hou, X. Demystifying neural style transfer. arXiv 2017, arXiv:1701.01036. [Google Scholar]
- Li, Y.; Fang, C.; Yang, J.; Wang, Z.; Lu, X.; Yang, M. Universal style transfer via feature transforms. In Proceedings of the NIPS, Long Beach, CA, USA, 4–9 December 2017; pp. 386–396. [Google Scholar]
- Sheng, L.; Lin, Z.; Shao, J.; Wang, X. Avatar-net: Multi-scale zero-shot style transfer by feature decoration. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 8242–8250. [Google Scholar]
- Shen, F.; Yan, S.; Zeng, G. Neural style transfer via meta networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 8061–8069. [Google Scholar]
- Huang, H.; Wang, H.; Luo, W.; Ma, L.; Jiang, W.; Zhu, X.; Li, Z.; Liu, W. Real-time neural style transfer for videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 7044–7052. [Google Scholar]
- Luan, F.; Paris, S.; Shechtman, E.; Bala, K. Deep photo style transfer. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6997–7005. [Google Scholar]
- Raskar, R.; Tan, K.; Feris, R.S.; Yu, J.; Turk, M.A. Non-photorealistic camera: Depth edge detection and stylized rendering using multi-flash imaging. TOG 2004, 23, 679–688. [Google Scholar] [CrossRef]
- Liu, X.; Cheng, M.; Lai, Y.; Rosin, P.L. Depth-aware neural style transfer. In Proceedings of the NPAR, Los Angeles, CA, USA, 29–30 July 2017; pp. 4:1–4:10. [Google Scholar]
- Hertzmann, A.; Jacobs, C.E.; Oliver, N.; Curless, B.; Salesin, D. Image analogies. In Proceedings of the SIGGRAPH, Los Angeles, CA, USA, 12–17 July 2001; pp. 327–340. [Google Scholar]
- Men, Y.; Lian, Z.; Tang, Y.; Xiao, J. A common framework for interactive texture transfer. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 6353–6362. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the ICLR, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Gu, S.; Chen, C.; Liao, J.; Yuan, L. Arbitrary style transfer with deep feature reshuffle. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 8222–8231. [Google Scholar]
- Chang, H.; Lu, J.; Yu, F.; Finkelstein, A. Pairedcyclegan: Asymmetric style transfer for applying and removing makeup. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 40–48. [Google Scholar]
- Choi, Y.; Choi, M.; Kim, M.; Ha, J.; Kim, S.; Choo, J. Stargan: Unified generative adversarial networks for multi-domain image-to-image translation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 8789–8797. [Google Scholar]
- Cao, K.; Liao, J.; Yuan, L. CariGANs: Unpaired photo-to-caricature translation. TOG 2018, 37, 244:1–244:14. [Google Scholar] [CrossRef] [Green Version]
- Kemelmacher-Shlizerman, I.; Suwajanakorn, S.; Seitz, S.M. Illumination-aware age progression. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014; pp. 3334–3341. [Google Scholar]
- Blanz, V.; Basso, C.; Poggio, T.A.; Vetter, T. Reanimating faces in images and video. Comput. Graph. Forum 2003, 22, 641–650. [Google Scholar] [CrossRef]
- Wang, Y.; Zhang, L.; Liu, Z.; Hua, G.; Wen, Z.; Zhang, Z.; Samaras, D. Face relighting from a single image under arbitrary unknown lighting conditions. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 31, 1968–1984. [Google Scholar] [CrossRef] [PubMed]
- Yang, F.; Wang, J.; Shechtman, E.; Bourdev, L.D.; Metaxas, D.N. Expression flow for 3D-aware face component transfer. TOG 2011, 30, 60. [Google Scholar] [CrossRef]
- Korshunova, I.; Shi, W.; Dambre, J.; Theis, L. Fast face-swap using convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 3697–3705. [Google Scholar]
- Isola, P.; Zhu, J.; Zhou, T.; Efros, A.A. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5967–5976. [Google Scholar]
- Zhu, J.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the ICCV, Venice, Italy, 22–29 October 2017; pp. 2242–2251. [Google Scholar]
- Yi, Z.; Zhang, H.R.; Tan, P.; Gong, M. Dualgan: Unsupervised dual learning for image-to-image translation. In Proceedings of the ICCV, Venice, Italy, 22–29 October 2017; pp. 2868–2876. [Google Scholar]
- Kim, T.; Cha, M.; Kim, H.; Lee, J.K.; Kim, J. Learning to discover cross-domain relations with generative adversarial networks. In Proceedings of the ICML, Sydney, NSW, Australia, 6–11 August 2017; pp. 1857–1865. [Google Scholar]
- Choi, Y.; Uh, Y.; Yoo, J.; Ha, J. Stargan v2: Diverse image synthesis for multiple domains. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 8185–8194. [Google Scholar]
- Hui, L.; Li, X.; Chen, J.; He, H.; Yang, J. Unsupervised multi-domain image translation with domain-specific encoders/decoders. In Proceedings of the ICPR, Beijing, China, 20–24 August 2018; pp. 2044–2049. [Google Scholar]
- Liu, M.; Huang, X.; Mallya, A.; Karras, T.; Aila, T.; Lehtinen, J.; Kautz, J. Few-shot unsupervised image-to-image translation. In Proceedings of the ICCV, Seoul, Korea, 27 October–2 November 2019; pp. 10550–10559. [Google Scholar]
- Chen, Y.; Lin, H.; Shu, M.; Li, R.; Tao, X.; Shen, X.; Ye, Y.; Jia, J. Facelet-bank for fast portrait manipulation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 3541–3549. [Google Scholar]
- Chen, Y.; Shen, X.; Lin, Z.; Lu, X.; Pao, I.; Jia, J. Semantic component decomposition for face attribute manipulation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 9859–9867. [Google Scholar]
- Sabour, S.; Frosst, N.; Hinton, G.E. Dynamic routing between capsules. In Proceedings of the NIPS, Long Beach, CA, USA, 4–9 December 2017; pp. 3856–3866. [Google Scholar]
- Breitenstein, M.D.; Küttel, D.; Weise, T.; Gool, L.V.; Pfister, H. Real-time face pose estimation from single range images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Anchorage, AK, USA, 24–26 June 2008. [Google Scholar]
- Zhu, X.; Ramanan, D. Face detection, pose estimation, and landmark localization in the wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012; pp. 2879–2886. [Google Scholar]
- Bulat, A.; Tzimiropoulos, G. Binarized convolutional landmark localizers for human pose estimation and face alignment with limited resources. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 3726–3734. [Google Scholar]
- Choi, D.; Song, B.C. Facial micro-expression recognition using two-dimensional landmark feature maps. IEEE Access 2020, 8, 121549–121563. [Google Scholar] [CrossRef]
- Kim, J.H.; Poulose, A.; Han, D.S. The extensive usage of the facial image threshing machine for facial emotion recognition performance. Sensors 2021, 21, 2026. [Google Scholar] [CrossRef] [PubMed]
- Kumar, A.; Marks, T.K.; Mou, W.; Wang, Y.; Jones, M.; Cherian, A.; Koike-Akino, T.; Liu, X.; Feng, C. LUVLi face alignment: Estimating landmarks’ location, uncertainty, and visibility likelihood. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 8233–8243. [Google Scholar]
- Kazemi, V.; Sullivan, J. One millisecond face alignment with an ensemble of regression trees. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014; pp. 1867–1874. [Google Scholar]
- Bookstein, F.L. Principal warps: Thin-plate splines and the decomposition of deformations. IEEE Trans. Pattern Anal. Mach. Intell. 1989, 11, 567–585. [Google Scholar] [CrossRef] [Green Version]
- Salimans, T.; Goodfellow, I.; Zaremba, W.; Cheung, V.; Radford, A.; Chen, X.; Chen, X. Improved techniques for training GANs. In Proceedings of the NIPS, Barcelona, Spain, 5–10 December 2016; pp. 2226–2234. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Heusel, M.; Ramsauer, H.; Unterthiner, T.; Nessler, B.; Hochreiter, S. GANs trained by a two time-scale update rule converge to a local nash equilibrium. In Proceedings of the NIPS, Long Beach, CA, USA, 4–9 December 2017; pp. 6626–6637. [Google Scholar]
- Smith, B.M.; Zhang, L.; Brandt, J.; Lin, Z.; Yang, J. Exemplar-based face parsing. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Portland, OR, USA, 23–28 June 2013; pp. 3484–3491. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | NST | BN | WCT | AvatarNet | DPST | Ours | |
|---|---|---|---|---|---|---|---|
| LULC | |||||||
| IS↑ | 3.10 | 3.02 | 3.16 | 3.19 | 3.76 | 3.81 | |
| FID↓ | 112.24 | 108.46 | 98.87 | 103.52 | 86.52 | 80.31 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fu, Y.; Ma, J.; Guo, X. A Foreground-Aware Framework for Local Face Attribute Transfer. Entropy 2021, 23, 615. https://doi.org/10.3390/e23050615
Fu Y, Ma J, Guo X. A Foreground-Aware Framework for Local Face Attribute Transfer. Entropy. 2021; 23(5):615. https://doi.org/10.3390/e23050615
Chicago/Turabian StyleFu, Yuanbin, Jiayi Ma, and Xiaojie Guo. 2021. "A Foreground-Aware Framework for Local Face Attribute Transfer" Entropy 23, no. 5: 615. https://doi.org/10.3390/e23050615
APA StyleFu, Y., Ma, J., & Guo, X. (2021). A Foreground-Aware Framework for Local Face Attribute Transfer. Entropy, 23(5), 615. https://doi.org/10.3390/e23050615