
A UoI-Optimal Policy for Timely Status Updates with Resource Constraint


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
- In contrast to [27,30], we assumed that the context-aware weight is a first-order irreducible positive recurrent Markov process or independent and identically distributed (i.i.d.) over time. We formulated the updating problem as a CMDP problem and proved the single threshold structure of the UoI-optimal policy. We then derived the policy through LP with the threshold structure and discussed the conditions that the monitored process needs to satisfy for the threshold structure.
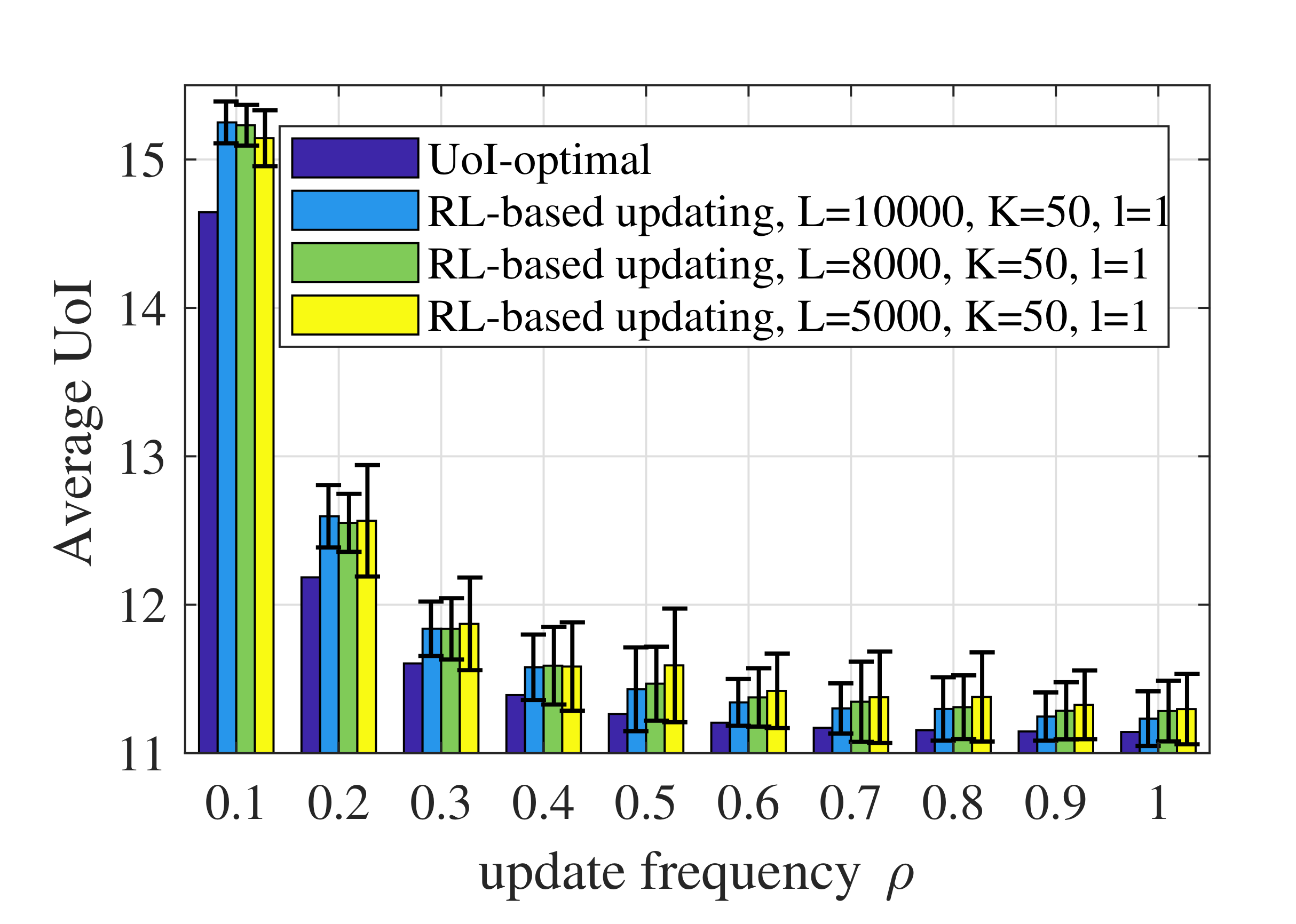
- When the distributions of the context-aware weight and the increment in estimation error were unknown, we used model-based RL method to learn the state transitions of the whole system and derive a near-optimal RL-based updating policy.
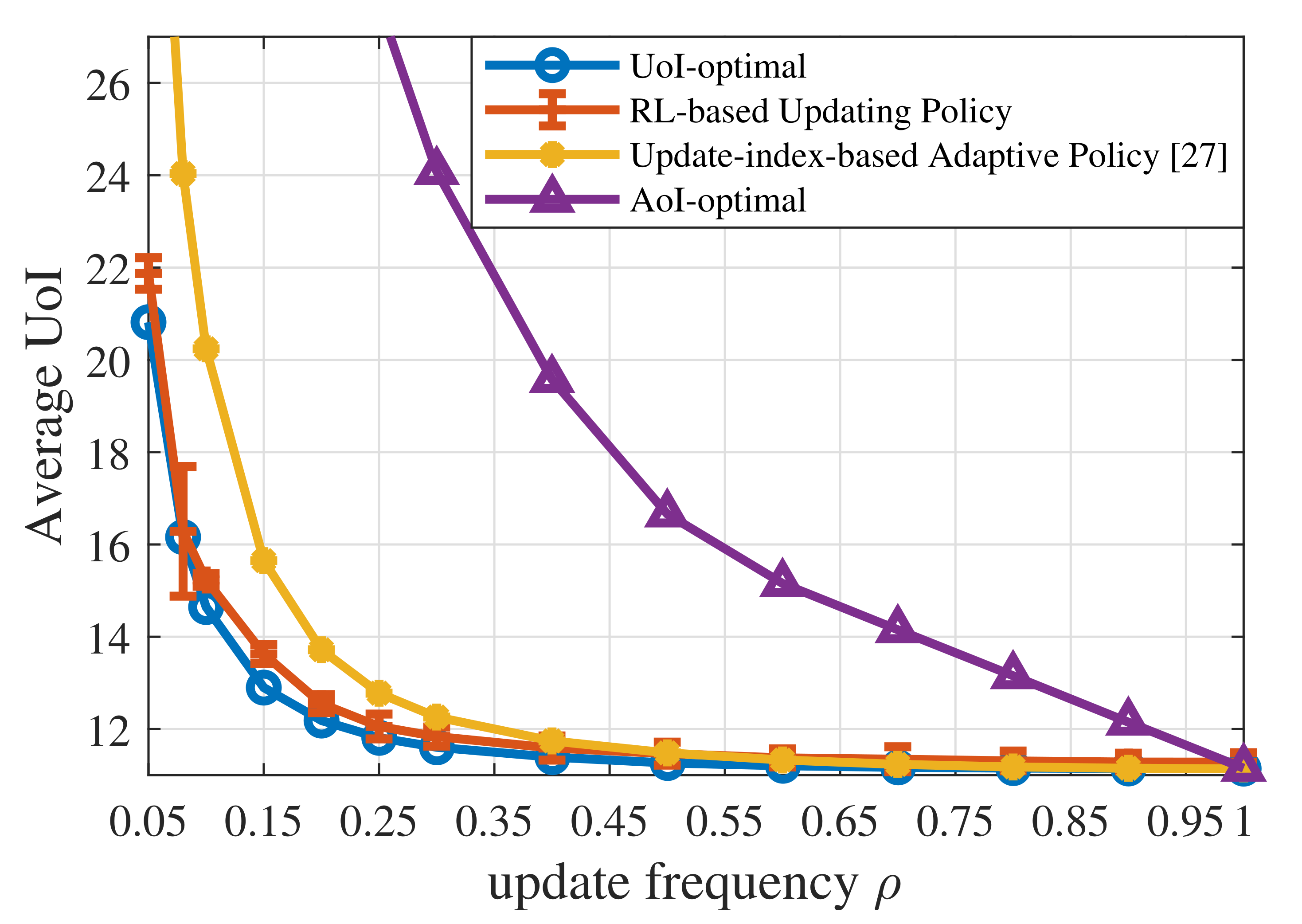
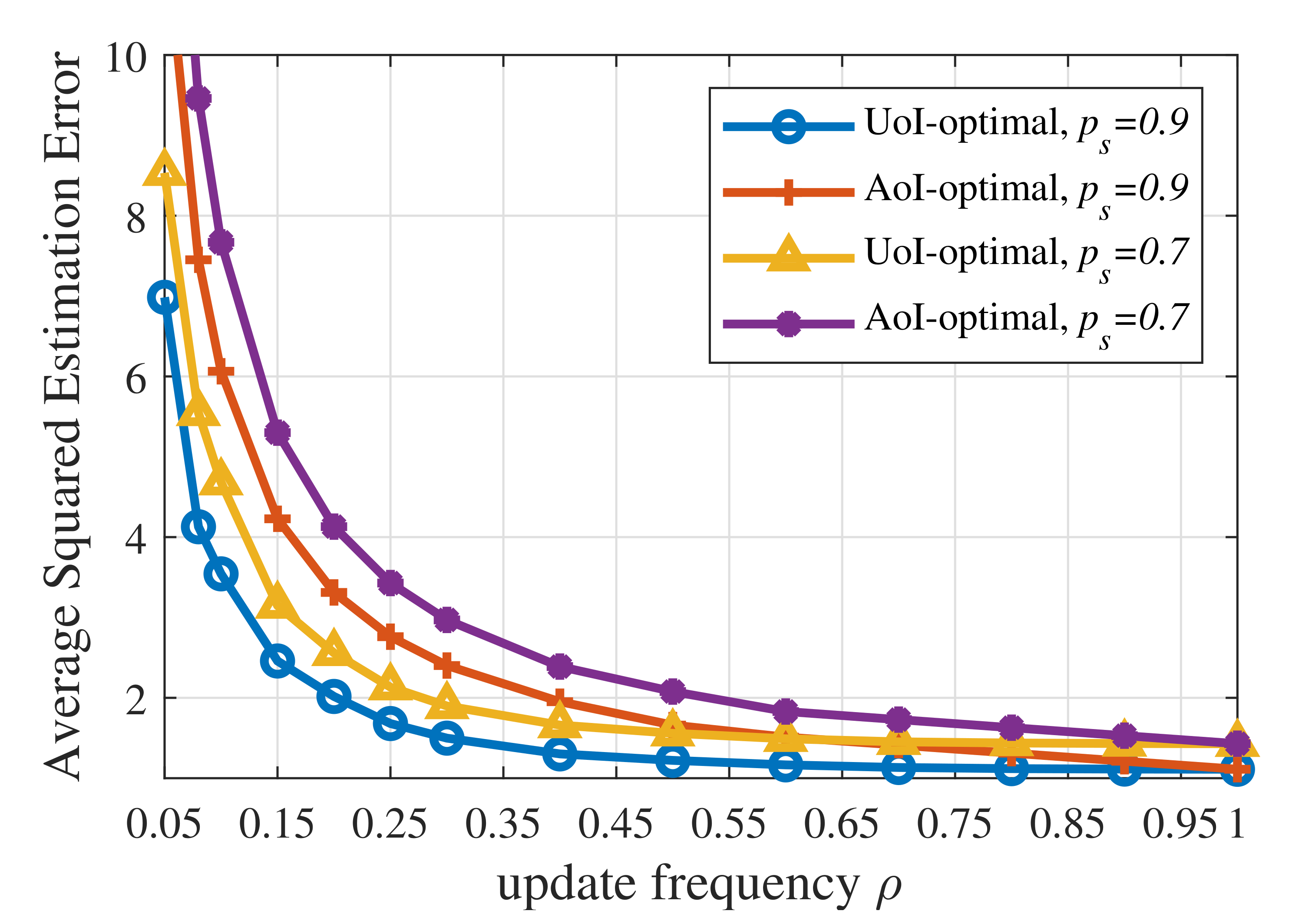
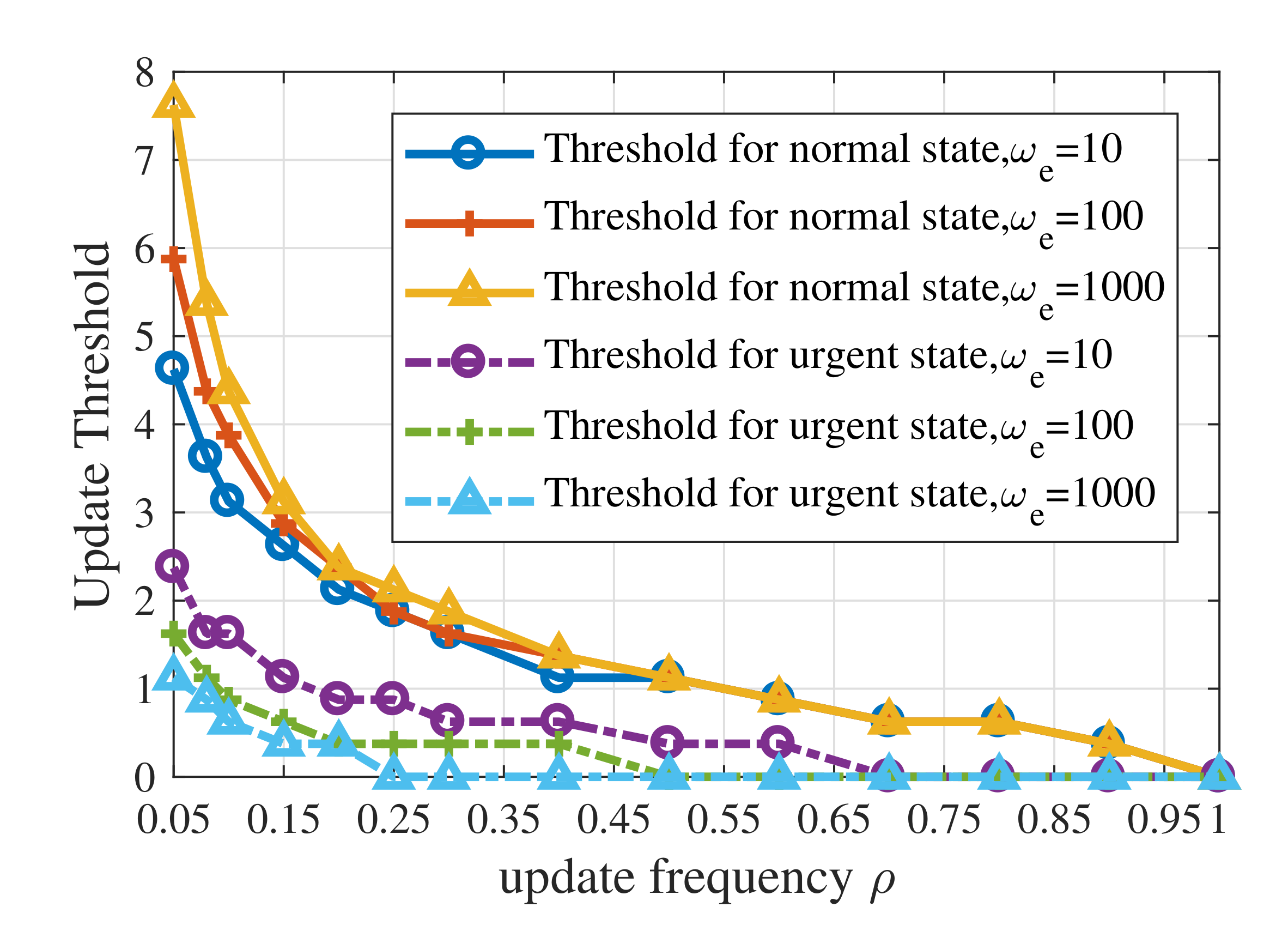
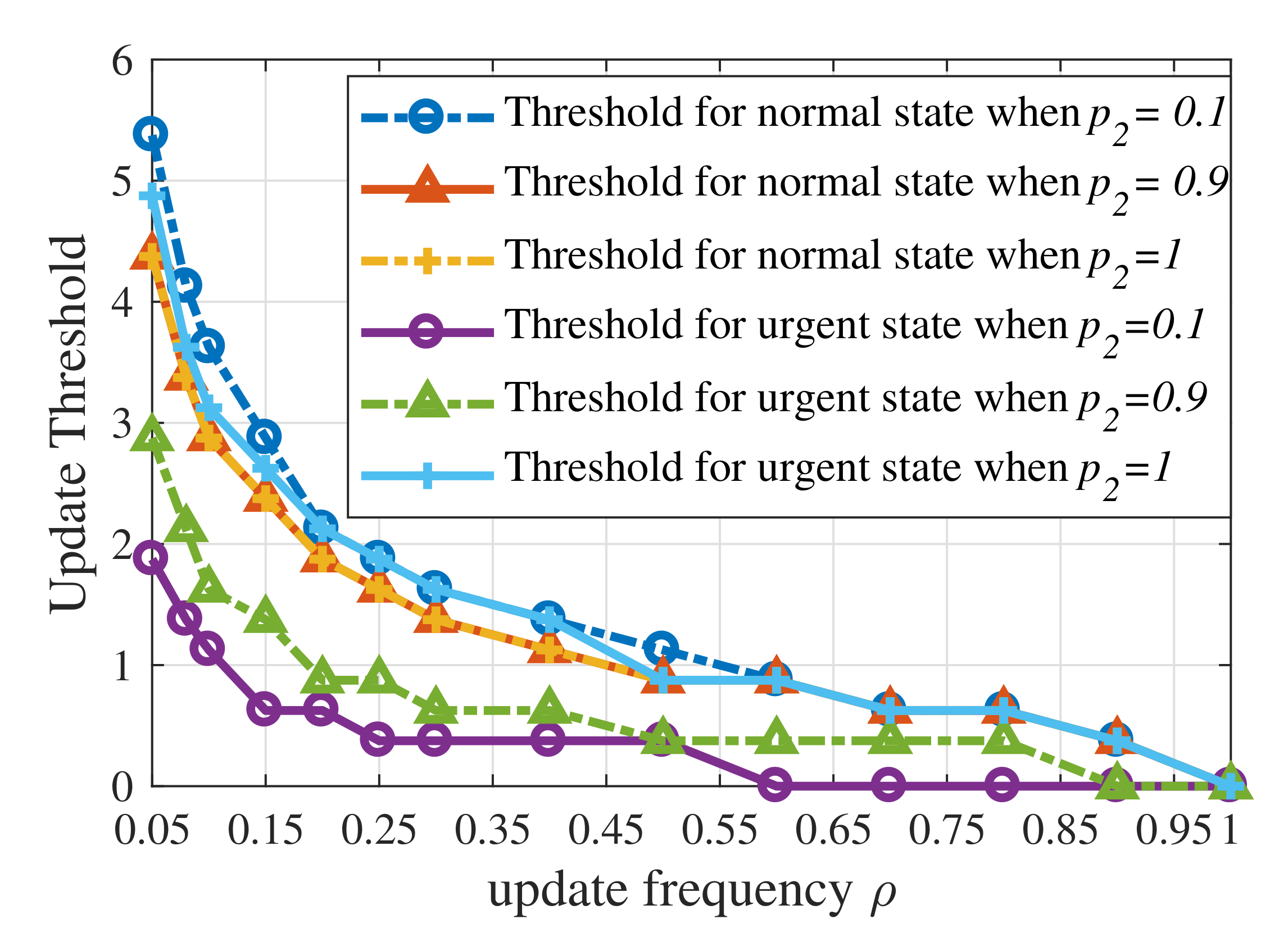
- Simulations were conducted to verify the theoretical analysis of the threshold structure and show the near-optimal performance of the RL-based updating policy. The results indicate that: (i) the update thresholds decrease when the maximum average update frequency becomes large; (ii) the update threshold for emergency can actually be larger than that for ordinary states when the probability of transferring from emergency to ordinary states tends to 1.
2. System Model and Problem Formulation
3. Scheduling with CMDP-Based Approach
3.1. Constrained Markov Decision Process Formulation
- State space: The state of the vehicle in slot t, denoted by , includes the current estimation error and the context-aware weight. Then, we discretize with the step size , i.e., the estimation error . For example, when , its value will be taken as . The smaller the step size , the smaller the performance degradation caused by discretization. In addition, the value set of the context-aware weight is denoted by . Then, the state space is thus countable but infinite.
- Action space: At each slot, the vehicle can take two actions, namely , where denotes the vehicle deciding to transmit updates in slot t and denotes the vehicle deciding to wait.
- Probability transfer function: After taking action U at state , the next state is denoted by . When the vehicle decides not to transmit or the transmission fails, the probability of the estimation error transferring from Q to is written as . Due to the discretization of the estimation error, the increment , where . In addition, , where is the CDF of increment . In addition, the probability of the context-aware weight transferring from to is written as . Based on the assumption that the context-aware weight is independent with the estimation error , then the probability of the state transferring from to given action U is:
- One-step cost: The cost caused by taking action U in state is:while the one-step updating penalty only depends on the chosen action:
3.2. Threshold Structure of the Optimal Policy
- When , then , for , we can derive that:
- When , there exists an increment , such that , and . Notice that and , then is a term in the summation , namely . Similarly, is a term in the summation . We further define , since , then .Furthermore, the probability of the estimation error transferring from to , i.e., equals , the probability of the estimation error transferring from to . Since , then . According to our assumption of the increment, we can prove that for any , . Then, we can derive:where .
- When , since , we only need to consider the case when , in this case . Therefore, is a term in the summation . Similarly, we can also prove that when .
- , ;
- .
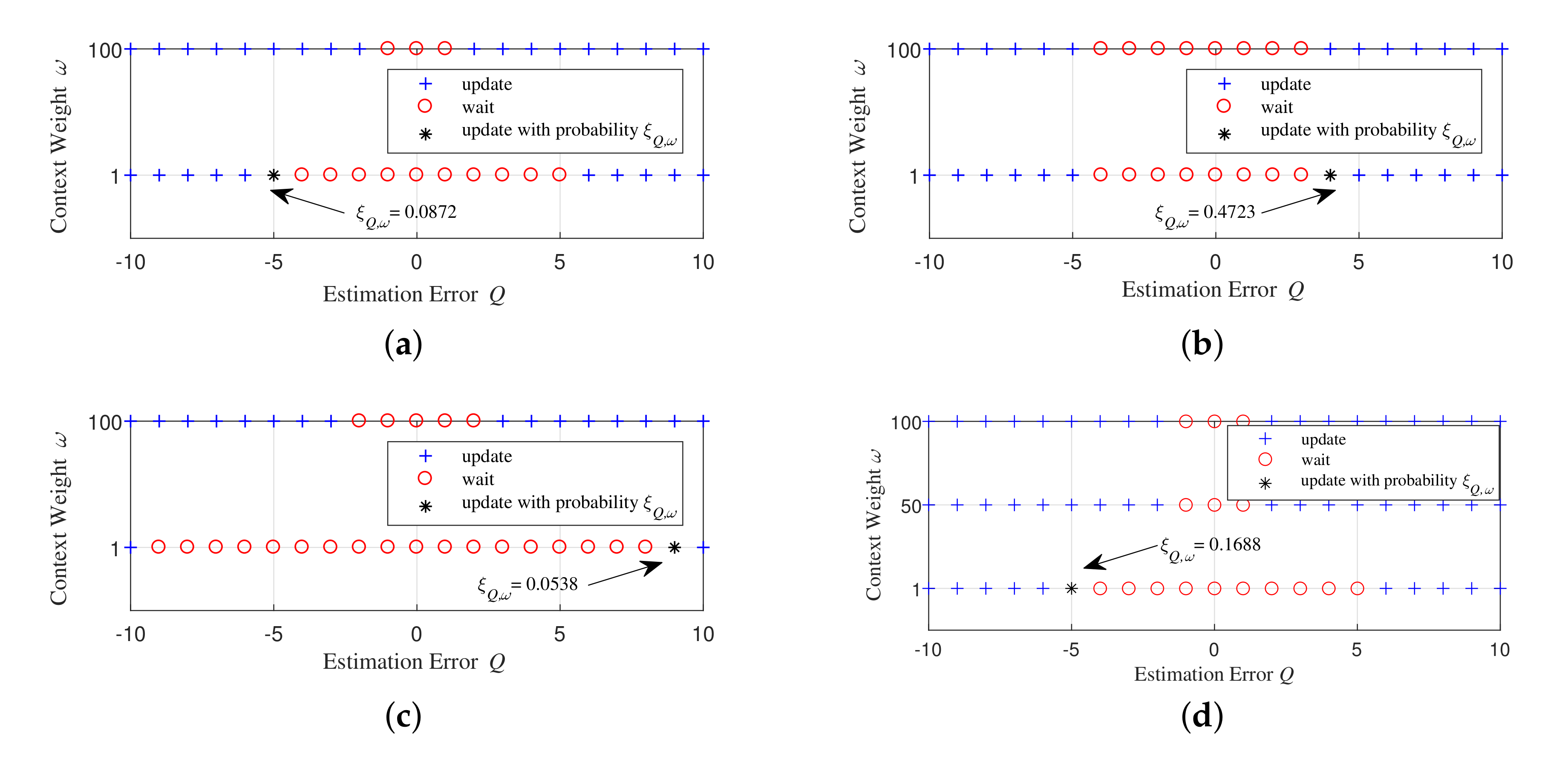
3.3. Numerical Solution of Optimal Strategy
4. Scheduling in Unknown Contexts
| Algorithm 1 RL-based Updating Policy |
Input:
Output: output the RL-based updating policy |
5. Simulation Results and Discussion
5.1. Simulation Setup
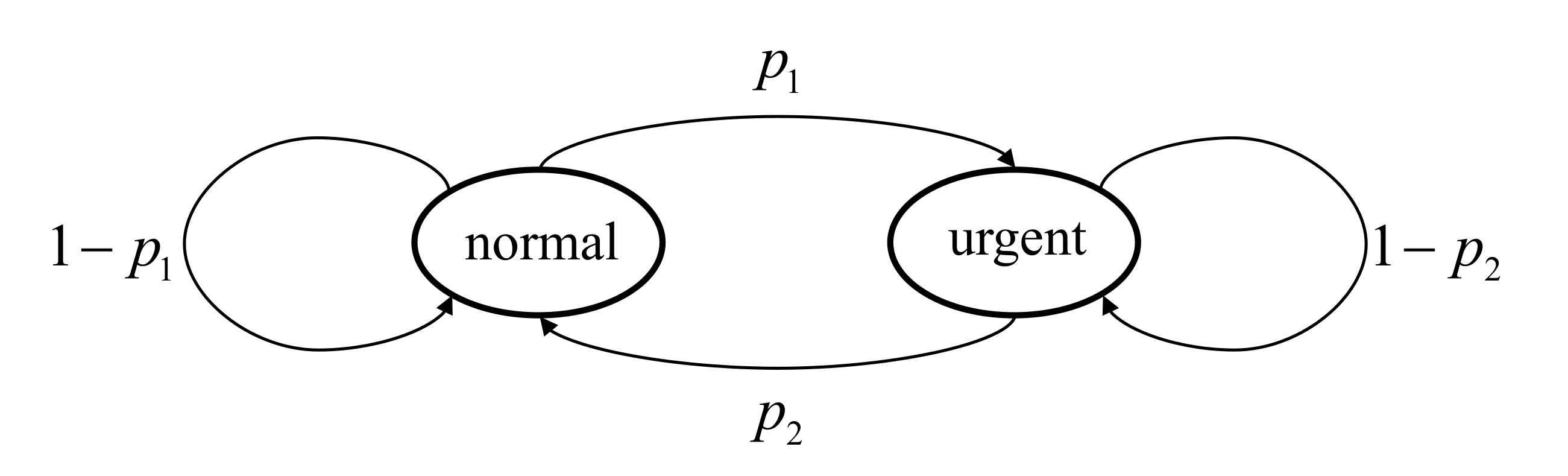
- The context-aware weight has the first-order Markov property. The state transition diagram of is shown in Figure 2 and is irreducible and positive recurrent. is the probability of the context-aware weight transferring from the normal state to the urgent state, while is the probability of the weight transferring from the urgent state to the normal state;
- The context-aware weight is i.i.d. over time. The probability of the weight being in the urgent state and the normal state are denoted by and , respectively.
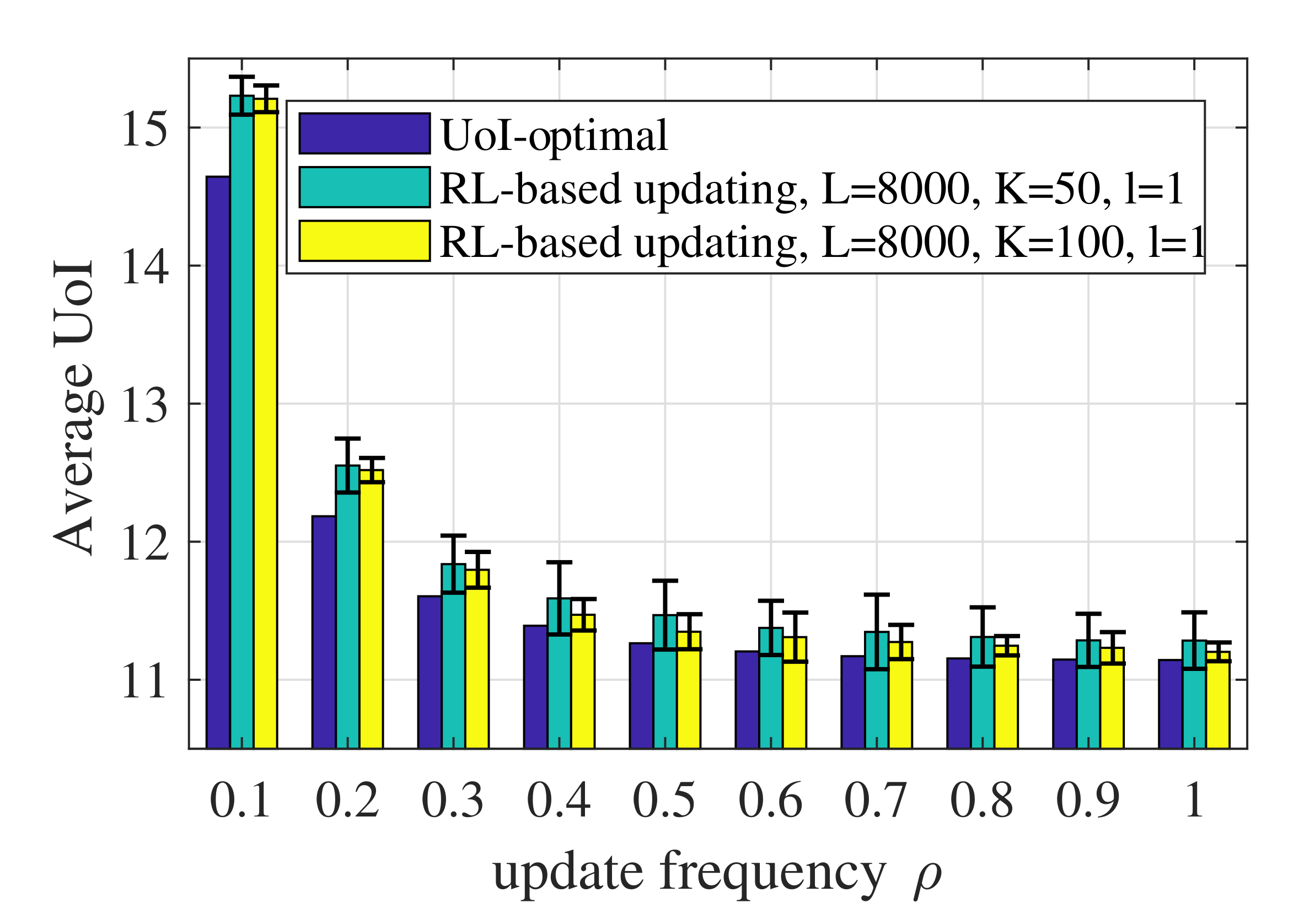
5.2. Numerical Results
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| AoI | Age of Information |
| AoII | Age of Incorrect Information |
| AoS | Age of Synchronization |
| CDF | Cumulative Distribution Function |
| CMDP | Constrained Markov Decision Process |
| CoUD | Cost of Update Delay |
| i.i.d. | Independent and Identically Distributed |
| IoT | Internet of Things |
| LP | Linear Programming |
| Probability Density Function | |
| RL | Reinforcement Learning |
| UoI | Urgency of Information |
| URLLC | Ultra-Reliable Low-Latency Communication |
| VR | Virtual Reality |
| V2X | Vehicle to Everything |
Appendix A. Proof of Theorem 1
- Assumption A1: In this problem, is the UoI at state s, namely . is 1 if the vehicle chooses to transmit its status and is 0 otherwise, namely . Therefore, Assumption A1 holds, for any , the number of states with is finite.
- Assumption A2: Due to the current high-level wireless communication technology, we reasonably assumed that the successful transmission probability is relatively close to 1. Based on the assumptions mentioned above, the Markov chain of context-aware weight obviously satisfies Assumption A2. Define the probability of the context-aware weight transferring from to in k steps for the first time as . Then, we consider the policy for all , namely this policy chooses to transmit in all the states.Since the evolution of the context-aware weight is independent with the evolution of the estimation error and the updating policy. Therefore, we first focused on the estimation error, which can be formulated as a one-dimensional irreducible Markov chain with state space . We denote the set of states which can transfer to state Q in a single step by . The probability of the estimation error transferring from state Q to state at the k-th step without an arrival to state is defined as . Obviously, . Then, the probability of the first passage from state to 0 taking steps is , where is the probability that the increment in estimation error is . Therefore, the expected time of the first passage from to 0 is finite.For state , the estimation error will stay in this state in the next step with a probability of and will first return to state in the second transition with a probability smaller than . Then, starting from state , the estimation error will first return to state in the -th () step will be smaller than . Therefore, we can prove that state is a positive recurrent state, and is a positive recurrent class of the induced Markov chain of the estimation error. Furthermore, for any states in , the expected time of the first passage from the state in to state under is finite and the probability of the states in not getting to state in k steps is smaller than .Define the probability of state Q transferring to state in k steps for the first time as . Then, the probability of state transferring to state in k steps for the first time is . Since and , then . Therefore, the set of states is a positive recurrent class. Similarly, we can prove that satisfies Assumption A2. Finally, , .
- Assumption A3: Define , . Consider the policy for all states , notably that this policy chooses not to transmit in any states. Similarly, we first focus on the Markov chain of estimation error. Starting from state Q, the probability of transferring to state in -th steps for the first time is smaller than . Then, the expected time of the first passage from state Q to state under policy is finite. Similarly, since the Markov chain of context-aware weight is irreducible positive recurrent and independent with the updating policy, we can therefore prove that the expected time of the first passage from state to state under policy is finite.
- Assumption A4: For the Markov chain of the estimation error, any state will return to state if a successful transmission occurs. For the policy without transmission, namely , state still exists in only one positive recurrent class. For each positive recurrent class containing state , we can prove that there is only one positive recurrent class. Since the Markov chain of the context-aware weight is irreducible positive recurrent, we can similarly prove Assumption A4.
- Assumption A5: The policy that updates the status with a probability of satisfies Assumption A5. Here, is a small positive number. Under this policy, and .
References
- Talak, R.; Karaman, S.; Modiano, E. Speed limits in autonomous vehicular networks due to communication constraints. In Proceedings of the 2016 IEEE 55th Conference on Decision and Control (CDC), Las Vegas, NV, USA, 12–14 December 2016; pp. 4998–5003. [Google Scholar]
- Hou, I.H.; Naghsh, N.Z.; Paul, S.; Hu, Y.C.; Eryilmaz, A. Predictive Scheduling for Virtual Reality. In Proceedings of the IEEE INFOCOM 2020-IEEE Conference on Computer Communications, Toronto, ON, Canada, 6–9 July 2020; pp. 1349–1358. [Google Scholar]
- Kaul, S.; Yates, R.; Gruteser, M. Real-time status: How often should one update? In Proceedings of the 2012 Proceedings IEEE INFOCOM, Orlando, FL, USA, 25–30 March 2012; pp. 2731–2735. [Google Scholar]
- Sun, Y.; Polyanskiy, Y.; Uysal-Biyikoglu, E. Remote estimation of the Wiener process over a channel with random delay. In Proceedings of the 2017 IEEE International Symposium on Information Theory (ISIT), Aachen, Germany, 25–30 June 2017; pp. 321–325. [Google Scholar]
- Sun, Y.; Polyanskiy, Y.; Uysal, E. Sampling of the wiener process for remote estimation over a channel with random delay. IEEE Trans. Inf. Theory 2019, 66, 1118–1135. [Google Scholar] [CrossRef]
- Jiang, Z.; Zhou, S. Status from a random field: How densely should one update? In Proceedings of the 2019 IEEE International Symposium on Information Theory (ISIT), Paris, France, 7–12 July 2019; pp. 1037–1041. [Google Scholar]
- Bedewy, A.M.; Sun, Y.; Singh, R.; Shroff, N.B. Optimizing information freshness using low-power status updates via sleep-wake scheduling. In Proceedings of the Twenty-First International Symposium on Theory, Algorithmic Foundations, and Protocol Design for Mobile Networks and Mobile Computing, New York, NY, USA, 11–14 October 2020; pp. 51–60. [Google Scholar]
- Ceran, E.T.; Gündüz, D.; György, A. Average age of information with hybrid ARQ under a resource constraint. IEEE Trans. Wirel. Commun. 2019, 18, 1900–1913. [Google Scholar] [CrossRef] [Green Version]
- Sun, J.; Jiang, Z.; Krishnamachari, B.; Zhou, S.; Niu, Z. Closed-form Whittle’s index-enabled random access for timely status update. IEEE Trans. Commun. 2019, 68, 1538–1551. [Google Scholar] [CrossRef]
- Yates, R.D.; Kaul, S.K. Status updates over unreliable multiaccess channels. In Proceedings of the 2017 IEEE International Symposium on Information Theory (ISIT), Aachen, Germany, 25–30 June 2017; pp. 331–335. [Google Scholar]
- Sun, J.; Wang, L.; Jiang, Z.; Zhou, S.; Niu, Z. Age-Optimal Scheduling for Heterogeneous Traffic with Timely Throughput Constraints. IEEE J. Sel. Areas Commun. 2021, 39, 1485–1498. [Google Scholar] [CrossRef]
- Tang, H.; Wang, J.; Song, L.; Song, J. Minimizing age of information with power constraints: Multi-user opportunistic scheduling in multi-state time-varying channels. IEEE J. Sel. Areas Commun. 2020, 38, 854–868. [Google Scholar] [CrossRef] [Green Version]
- Abdel-Aziz, M.K.; Samarakoon, S.; Liu, C.F.; Bennis, M.; Saad, W. Optimized age of information tail for ultra-reliable low-latency communications in vehicular networks. IEEE Trans. Commun. 2019, 68, 1911–1924. [Google Scholar] [CrossRef] [Green Version]
- Devassy, R.; Durisi, G.; Ferrante, G.C.; Simeone, O.; Uysal-Biyikoglu, E. Delay and peak-age violation probability in short-packet transmissions. In Proceedings of the 2018 IEEE International Symposium on Information Theory (ISIT), Vail, CO, USA, 17–22 June 2018; pp. 2471–2475. [Google Scholar]
- Inoue, Y.; Masuyama, H.; Takine, T.; Tanaka, T. A general formula for the stationary distribution of the age of information and its application to single-server queues. IEEE Trans. Inf. Theory 2019, 65, 8305–8324. [Google Scholar] [CrossRef] [Green Version]
- Sun, Y.; Uysal-Biyikoglu, E.; Yates, R.D.; Koksal, C.E.; Shroff, N.B. Update or wait: How to keep your data fresh. IEEE Trans. Inf. Theory 2017, 63, 7492–7508. [Google Scholar] [CrossRef]
- Zheng, X.; Zhou, S.; Jiang, Z.; Niu, Z. Closed-form analysis of non-linear age of information in status updates with an energy harvesting transmitter. IEEE Trans. Wirel. Commun. 2019, 18, 4129–4142. [Google Scholar] [CrossRef] [Green Version]
- Kosta, A.; Pappas, N.; Ephremides, A.; Angelakis, V. Non-linear age of information in a discrete time queue: Stationary distribution and average performance analysis. In Proceedings of the ICC 2020—2020 IEEE International Conference on Communications (ICC), Dublin, Ireland, 7–11 June 2020; pp. 1–6. [Google Scholar]
- Kosta, A.; Pappas, N.; Ephremides, A.; Angelakis, V. The cost of delay in status updates and their value: Non-linear ageing. IEEE Trans. Commun. 2020, 68, 4905–4918. [Google Scholar] [CrossRef] [Green Version]
- Zhong, J.; Yates, R.D.; Soljanin, E. Two freshness metrics for local cache refresh. In Proceedings of the 2018 IEEE International Symposium on Information Theory (ISIT), Vail, CO, USA, 17–22 June 2018; pp. 1924–1928. [Google Scholar]
- Maatouk, A.; Kriouile, S.; Assaad, M.; Ephremides, A. The age of incorrect information: A new performance metric for status updates. IEEE/ACM Trans. Netw. 2020, 28, 2215–2228. [Google Scholar] [CrossRef]
- Kadota, I.; Sinha, A.; Uysal-Biyikoglu, E.; Singh, R.; Modiano, E. Scheduling policies for minimizing age of information in broadcast wireless networks. IEEE/ACM Trans. Netw. 2018, 26, 2637–2650. [Google Scholar] [CrossRef] [Green Version]
- Song, J.; Gunduz, D.; Choi, W. Optimal scheduling policy for minimizing age of information with a relay. arXiv 2020, arXiv:2009.02716. [Google Scholar]
- Sun, Y.; Cyr, B. Information aging through queues: A mutual information perspective. In Proceedings of the 2018 IEEE 19th International Workshop on Signal Processing Advances in Wireless Communications (SPAWC), Kalamata, Greece, 25–28 June 2018; pp. 1–5. [Google Scholar]
- Kam, C.; Kompella, S.; Nguyen, G.D.; Wieselthier, J.E.; Ephremides, A. Towards an effective age of information: Remote estimation of a markov source. In Proceedings of the IEEE INFOCOM 2018—IEEE Conference on Computer Communications Workshops (INFOCOM WKSHPS), Honolulu, HI, USA, 15–19 April 2018; pp. 367–372. [Google Scholar]
- Zheng, X.; Zhou, S.; Niu, Z. Context-aware information lapse for timely status updates in remote control systems. In Proceedings of the 2019 IEEE Global Communications Conference (GLOBECOM), Waikoloa, HI, USA, 9–13 December 2019; pp. 1–6. [Google Scholar]
- Zheng, X.; Zhou, S.; Niu, Z. Beyond age: Urgency of information for timeliness guarantee in status update systems. In Proceedings of the 2020 2nd IEEE 6G Wireless Summit (6G SUMMIT), Levi, Finland, 17–20 March 2020; pp. 1–5. [Google Scholar]
- Zheng, X.; Zhou, S.; Niu, Z. Urgency of Information for Context-Aware Timely Status Updates in Remote Control Systems. IEEE Trans. Wirel. Commun. 2020, 19, 7237–7250. [Google Scholar] [CrossRef]
- Ioannidis, S.; Chaintreau, A.; Massoulié, L. Optimal and scalable distribution of content updates over a mobile social network. In Proceedings of the IEEE INFOCOM 2009, Rio de Janeiro, Brazil, 19–25 April 2009; pp. 1422–1430. [Google Scholar]
- Wang, L.; Sun, J.; Zhou, S.; Niu, Z. Timely Status Update Based on Urgency of Information with Statistical Context. In Proceedings of the 2020 32nd IEEE International Teletraffic Congress (ITC 32), Osaka, Japan, 22–24 September 2020; pp. 90–96. [Google Scholar]
- Nayyar, A.; Başar, T.; Teneketzis, D.; Veeravalli, V.V. Optimal strategies for communication and remote estimation with an energy harvesting sensor. IEEE Trans. Autom. Control 2013, 58, 2246–2260. [Google Scholar] [CrossRef] [Green Version]
- Cika, A.; Badiu, M.A.; Coon, J.P. Quantifying link stability in Ad Hoc wireless networks subject to Ornstein-Uhlenbeck mobility. In Proceedings of the ICC 2019—2019 IEEE International Conference on Communications (ICC), Shanghai, China, 20–24 May 2019; pp. 1–6. [Google Scholar]
- Sennott, L.I. Constrained average cost Markov decision chains. Probab. Eng. Inf. Sci. 1993, 7, 69–83. [Google Scholar] [CrossRef]
- Bertsekas, D.P. Dynamic Programming and Optimal Control; Athena Scientific: Belmont, MA, USA, 2000. [Google Scholar]
- Sennott, L.I. Average cost optimal stationary policies in infinite state Markov decision processes with unbounded costs. Oper. Res. 1989, 37, 626–633. [Google Scholar] [CrossRef]
- Liu, B.; Xie, Q.; Modiano, E. Rl-qn: A reinforcement learning framework for optimal control of queueing systems. arXiv 2020, arXiv:2011.07401. [Google Scholar]
- Chen, X.; Liao, X.; Bidokhti, S.S. Real-time Sampling and Estimation on Random Access Channels: Age of Information and Beyond. arXiv 2020, arXiv:2007.03652. [Google Scholar]









Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, L.; Sun, J.; Sun, Y.; Zhou, S.; Niu, Z. A UoI-Optimal Policy for Timely Status Updates with Resource Constraint. Entropy 2021, 23, 1084. https://doi.org/10.3390/e23081084
Wang L, Sun J, Sun Y, Zhou S, Niu Z. A UoI-Optimal Policy for Timely Status Updates with Resource Constraint. Entropy. 2021; 23(8):1084. https://doi.org/10.3390/e23081084
Chicago/Turabian StyleWang, Lehan, Jingzhou Sun, Yuxuan Sun, Sheng Zhou, and Zhisheng Niu. 2021. "A UoI-Optimal Policy for Timely Status Updates with Resource Constraint" Entropy 23, no. 8: 1084. https://doi.org/10.3390/e23081084
APA StyleWang, L., Sun, J., Sun, Y., Zhou, S., & Niu, Z. (2021). A UoI-Optimal Policy for Timely Status Updates with Resource Constraint. Entropy, 23(8), 1084. https://doi.org/10.3390/e23081084