
Inference for Inverse Power Lomax Distribution with Progressive First-Failure Censoring


Abstract
:1. Introduction
2. Maximum Likelihood Estimation
Asymptotic Confidence Interval
3. Bayesian Estimation
3.1. Tierney–Kadane’s Approximation Method
3.2. The Highest Posterior Density Credible Interval
4. Simulation Study
- Step 1: Set the initial values of both group size and censoring scheme .
- Step 2: Generate independent observations that obey the uniform distribution .
- Step 3: Let , .
- Step 4: Set .
- Step 5: For given and , using inverse transformation , , we obtain the PFF censored sample from IPL distribution, where represents the inverse CDF in (2).
- When n increases but m and k are fixed, the MSEs of MLEs and Bayesian estimates of three parameters decrease. Therefore, we tend to get better estimation results with an increase in sample size.
- When m increases but n and k are fixed, the MSEs of MLEs and Bayesian estimates decrease. While when k increases but n and m are fixed, the MSEs of all estimates decrease in most of the cases.
- In the case of Bayesian estimates, there is little difference between the MSEs under SELF and GELF, and the estimation effect of GELF is slightly better than SELF in terms of MSE. While under GELF, there is no significant difference in MSEs among the three modes. The estimation effect seems better when q = 1.
- When n increases but m and k are fixed, the average length of asymptotic confidence and HPD credible intervals narrow down. While the average length of 95% asymptotic confidence and HPD credible intervals narrow down when the group size k increases.
- When m increases but n and k are fixed, the average length of 95% asymptotic confidence HPD credible intervals narrow down in most of the cases.
- The HPD credible intervals are better than asymptotic confidence intervals in respect of average length.
- For the CPs of interval for the unknown parameters, the HPD credible intervals are slightly better than asymptotic confidence intervals in almost all cases.
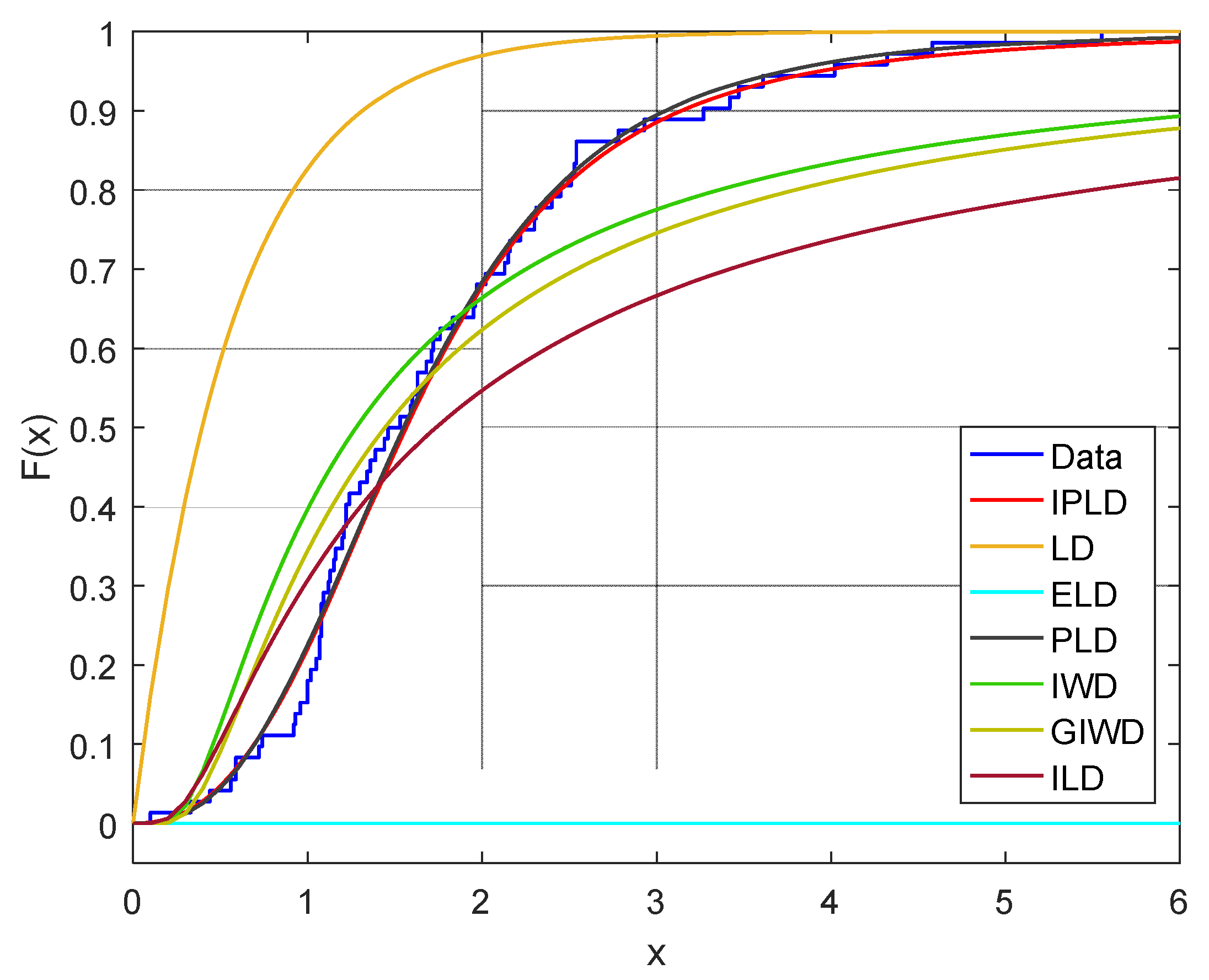
5. Real Data Analysis
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Balakrishnan, N.; Aggarwala, R. Progressive Censoring: Theory, Methods, and Applications; Birkhauser: Boston, MA, USA, 2000. [Google Scholar]
- Balakrishnan, N. Progressive censoring methodology: An appraisal. Test 2007, 16, 211–259. [Google Scholar] [CrossRef]
- Johnson, L.G. Theory and Technique of Variation Research; Elsevier Publishing Company: New York, NY, USA, 1964. [Google Scholar]
- Balasooriya, U.; Saw, S.L.C.; Gadag, V. Progressively censored reliability sampling plans for the weibull distribution. Technometrics 2000, 42, 160–167. [Google Scholar] [CrossRef]
- Wu, J.W.; Hung, W.L.; Tsai, C.H. Estimation of the parameters of the Gompertz distribution under the first failure censored sampling plan. Statistics 2003, 37, 517–525. [Google Scholar] [CrossRef]
- Wu, J.W.; Yu, H.Y. Statistical inference about the shape parameter of the Burr type XII distribution under the failure censored sampling plan. Appl. Math. Comput. 2005, 163, 443–482. [Google Scholar] [CrossRef]
- Wu, S.J.; Kus, C. On estimation based on progressive first failure censored sampling. Comput. Stat. Data. Anal. 2009, 53, 3659–3670. [Google Scholar] [CrossRef]
- Zhang, F.; Gui, W. Parameter and reliability inferences of inverted exponentiated Half-Logistic distribution under the progressive first-Failure censoring. Mathematics 2020, 8, 708. [Google Scholar] [CrossRef]
- Bakoban, R.A.; Abd-Elmougod, G.A. MCMC in analysis of progressively first failure censored competing risks data for gompertz model. J. Comput. Theor. Nanosci. 2016, 13, 6662–6670. [Google Scholar] [CrossRef]
- Dube, M.; Krishna, H.; Garg, R. Generalized inverted exponential distribution under progressive first-failure censoring. J. Stat. Comput. Simul. 2016, 86, 1095–1114. [Google Scholar] [CrossRef]
- Singh, S.; Tripathi, Y.M. Reliability sampling plans for a lognormal distribution under progressive first-failure censoring with cost constraint. Stat. Pap. 2015, 56, 773–817. [Google Scholar] [CrossRef]
- Soliman, A.A.; Abou-Elheggag, N.A.; Ellah, A.H.A.; Modhesh, A.A. Bayesian and non-Bayesian inferences of the Burr-XII distribution for progressive first-failure censored data. Metron 2014, 70, 1–25. [Google Scholar] [CrossRef]
- Ahmadi, M.V.; Doostparast, M. Pareto analysis for the lifetime performance index of products on the basis of progressively first-failure-censored batches under balanced symmetric and asymmetric loss functions. J. Appl. Stat. 2018, 46, 1–32. [Google Scholar] [CrossRef]
- Amal, H.; Hani, S. On estimation of overlapping measures for exponential populations under progressive first failure censoring. Qual. Technol. Quant. Manag. 2019, 16, 560–574. [Google Scholar]
- Abd El-Monsef, M.M.E.; El-Latif Hassanein, W.A.A. Assessing the lifetime performance index for Kumaraswamy distribution under first-failure progressive censoring scheme for ball bearing revolutions. Qual. Reliab. Engng. Int. 2020, 36, 1086–1097. [Google Scholar] [CrossRef]
- Yu, J.; Gui, W.H.; Shan, Y.Q. Statistical inference on the Shannon entropy of inverse Weibull distribution under the progressive first-failure censoring. Entropy 2019, 21, 1209. [Google Scholar] [CrossRef] [Green Version]
- Panahi, H.; Morad, N. Estimation of the inverted exponentiated Rayleigh distribution based on adaptive Type II progressive hybrid censored sample. J. Comput. Appl. Math. 2020, 364, 112345. [Google Scholar] [CrossRef]
- Bantan, R.A.R.; Elgarhy, M.; Chesneau, C.; Jamal, F. Estimation of Entropy for Inverse Lomax Distribution under Multiple Censored Data. Entropy 2020, 22, 601. [Google Scholar] [CrossRef] [PubMed]
- Nassar, M.; Abo-Kasem, O.E. Estimation of the inverse Weibull parameters under adaptive type-II progressive hybrid censoring scheme. J. Comput. Appl. Math. 2017, 315, 228–239. [Google Scholar] [CrossRef]
- Lee, K.; Cho, Y. Bayesian and maximum likelihood estimations of the inverted exponentiated half logistic distribution under progressive Type II censoring. J. Appl. Stat. 2017, 44, 811–832. [Google Scholar] [CrossRef]
- Xu, R.; Gui, W.H. Entropy estimation of inverse Weibull distribution under adaptive Type-II progressive hybrid censoring schemes. Symmetry 2019, 11, 1463. [Google Scholar] [CrossRef] [Green Version]
- Bantan, R.A.R.; Jamal, F.; Chesneau, C.; Elgarhy, M. A New Power Topp–Leone Generated Family of Distributions with Applications. Entropy 2019, 21, 1177. [Google Scholar] [CrossRef] [Green Version]
- Hassan, A.S.; Abd-Allah, M. On the Inverse Power Lomax distribution. Ann. Data Sci. 2019, 6, 259–278. [Google Scholar] [CrossRef]
- Arnold, B.C.; Press, S.J. Bayesian inference for Pareto populations. J. Econom. 1983, 21, 287–306. [Google Scholar] [CrossRef]
- Tierney, T.; Kadane, J.B. Accurate approximations for posterior moments and marginal densities. J. Am. Stat. Assoc. 1986, 81, 82–86. [Google Scholar] [CrossRef]
- Lindley, D.V. Approximate Bayes methods. Trabajos de Estadistica 1980, 31, 223–237. [Google Scholar] [CrossRef]
- Kundu, D.; Gupta, A.K. Bayes estimation for the Marshall–Olkin bivariate Weibull distribution. Comput. Statist. Data Anal. 2013, 57, 271–281. [Google Scholar] [CrossRef]
- Maurya, R.K.; Tripathi, Y.M.; Rastogi, M.K.; Asgharzadeh, A. Parameter estimation for a Burr XII distribution under progressive censoring. Am. J. Math. Manag. Sci. 2017, 36, 259–276. [Google Scholar] [CrossRef]
- Sultana, F.; Tripathi, Y.M.; Rastogi, M.K.; Wu, S.J. parameter estimation for the kumaraswamy distribution based on hybrid censoring. Am. J. Math. Manag. Sci. 2018, 37, 243–261. [Google Scholar] [CrossRef]
- Balakrishnan, N.; Sandhu, R.A. A simple simulation algorithm for generating progressively type-II generated samples. Am. Statist. 1995, 49, 229–230. [Google Scholar]
- Bjerkedal, T. Acquisition of resistance in guinea pigs infected with different doses of virulent tubercle bacilli. Am. J. Epidemiol. 1960, 72, 130–148. [Google Scholar] [CrossRef]
- Boumaraf, B.; Seddik-Ameur, N.; Barbu, V.S. Estimation of beta-pareto distribution based on several optimization methods. Mathematics 2020, 8, 1055. [Google Scholar] [CrossRef]

{kind=link}
| k | n | m | Censoring Scheme | ||||||
|---|---|---|---|---|---|---|---|---|---|
| EV | MSE | EV | MSE | EV | MSE | ||||
| 2 | 30 | 15 | (15, 0*14) | 1.6392 | 0.1327 | 0.8925 | 0.1084 | 0.5929 | 0.1061 |
| (0*6, 6, 5, 4, 0*6) | 1.6342 | 0.1359 | 0.8893 | 0.1106 | 0.5967 | 0.1146 | |||
| (0*14, 15) | 1.6415 | 0.1391 | 0.8843 | 0.1138 | 0.5974 | 0.1076 | |||
| 20 | (10, 0 *19) | 1.6240 | 0.1175 | 0.9188 | 0.0946 | 0.5818 | 0.0917 | ||
| (1, 0)*10 | 1.6392 | 0.1296 | 0.8893 | 0.1084 | 0.6029 | 0.1048 | |||
| (0*19, 10) | 1.6350 | 0.1371 | 0.9109 | 0.1033 | 0.5821 | 0.0942 | |||
| 30 | (0*30) | 1.5471 | 0.0721 | 0.9517 | 0.0655 | 0.5519 | 0.0697 | ||
| 50 | 25 | (25, 0*24) | 1.5861 | 0.0934 | 0.9217 | 0.0886 | 0.5759 | 0.0824 | |
| (0*8, 1, 3*8, 0*8) | 1.5932 | 0.0956 | 0.9159 | 0.0908 | 0.5763 | 0.0831 | |||
| (0*24, 25) | 1.5916 | 0.0940 | 0.9214 | 0.0894 | 0.5640 | 0.0828 | |||
| 30 | (20, 0*29) | 1.5735 | 0.0714 | 0.9497 | 0.0796 | 0.5631 | 0.0772 | ||
| (2, 0, 0)*10 | 1.5742 | 0.0756 | 0.9459 | 0.0875 | 0.5515 | 0.0810 | |||
| (0*29, 20) | 1.5769 | 0.0751 | 0.9353 | 0.0818 | 0.5541 | 0.0780 | |||
| 50 | (0*50) | 1.5328 | 0.0704 | 0.9738 | 0.0637 | 0.5468 | 0.0638 | ||
| 3 | 30 | 15 | (15, 0*14) | 1.6387 | 0.1316 | 0.9162 | 0.0928 | 0.5725 | 0.0955 |
| (0*6, 6, 5, 4, 0*6) | 1.6306 | 0.1353 | 0.9101 | 0.0934 | 0.5748 | 0.0994 | |||
| (0*14, 15) | 1.6354 | 0.1387 | 0.9018 | 0.0954 | 0.5732 | 0.1004 | |||
| 20 | (10, 0*19) | 1.6271 | 0.1047 | 0.9303 | 0.0832 | 0.5721 | 0.0829 | ||
| (1, 0)*10 | 1.6230 | 0.1212 | 0.9109 | 0.0944 | 05734 | 0.0904 | |||
| (0*19, 10) | 1.6245 | 0.1381 | 0.9235 | 0.0946 | 0.5745 | 0.0931 | |||
| 30 | (0*30) | 1.5466 | 0.0713 | 0.9636 | 0.0647 | 0.5516 | 0.0690 | ||
| 50 | 25 | (25, 0*24) | 1.5850 | 0.0936 | 0.9323 | 0.0782 | 0.5641 | 0.0784 | |
| (0*8, 1, 3*8, 0*8) | 1.5878 | 0.0965 | 0.9318 | 0.0795 | 0.5315 | 0.0791 | |||
| (0*24,25) | 1.5901 | 0.0972 | 0.9305 | 0.0899 | 0.5419 | 0.0815 | |||
| 30 | (20, 0*29) | 1.5714 | 0.0732 | 0.9588 | 0.0665 | 0.5501 | 0.0692 | ||
| (2, 0, 0)*10 | 1.5731 | 0.0767 | 0.9585 | 0.0687 | 0.5581 | 0.0711 | |||
| (0*29, 20) | 1.5762 | 0.0794 | 1.0480 | 0.0856 | 0.5534 | 0.0766 | |||
| 50 | (0*50) | 1.5218 | 0.0659 | 0.9743 | 0.0632 | 0.5427 | 0.0633 | ||
| k | n | m | Censoring Scheme | ||||||
|---|---|---|---|---|---|---|---|---|---|
| EV | MSE | EV | MSE | EV | MSE | ||||
| 2 | 30 | 15 | (15, 0*14) | 1.5993 | 0.1166 | 0.9163 | 0.0986 | 0.5701 | 0.1019 |
| (0*6, 6, 5, 4, 0*6) | 1.5977 | 0.1187 | 0.9200 | 0.0936 | 0.5684 | 0.0982 | |||
| (0*14, 15) | 1.5968 | 0.1098 | 1.0769 | 0.0942 | 0.5675 | 0.0951 | |||
| 20 | (10, 0*19) | 1.5887 | 0.0990 | 0.9287 | 0.0860 | 0.5793 | 0.0878 | ||
| (1, 0)*10 | 1.5847 | 0.0948 | 0.9334 | 0.0841 | 0.5682 | 0.0865 | |||
| (0*19, 10) | 1.5822 | 0.0908 | 0.9523 | 0.0759 | 0.5579 | 0.0769 | |||
| 30 | (0*30) | 1.5412 | 0.0703 | 0.9589 | 0.0712 | 0.5463 | 0.0753 | ||
| 50 | 25 | (25, 0*24) | 1.5582 | 0.0928 | 0.9309 | 0.0854 | 0.5586 | 0.0824 | |
| (0*8, 1, 3*8, 0*8) | 1.5647 | 0.0910 | 1.0642 | 0.0819 | 0.5579 | 0.0821 | |||
| (0*24, 25) | 1.5630 | 0.0904 | 0.9397 | 0.0810 | 0.5565 | 0.0802 | |||
| 30 | (20, 0*29) | 1.5582 | 0.0793 | 0.9518 | 0.0746 | 0.5490 | 0.0774 | ||
| (2, 0, 0)*10 | 1.5451 | 0.0758 | 0.9546 | 0.0728 | 0.5446 | 0.0727 | |||
| (0*29, 20) | 1.5432 | 0.0726 | 0.9567 | 0.0724 | 0.5472 | 0.0715 | |||
| 50 | (0*50) | 1.5307 | 0.0701 | 0.9643 | 0.0704 | 0.5437 | 0.0738 | ||
| 3 | 30 | 15 | (15, 0*14) | 1.5871 | 0.1132 | 0.9274 | 0.0932 | 0.5893 | 0.0906 |
| (0*6, 6, 5, 4, 0*6) | 1.5834 | 0.1124 | 0.9286 | 0.0915 | 0.5648 | 0.0874 | |||
| (0*14,15) | 1.5823 | 0.1052 | 0.9351 | 0.0913 | 0.5658 | 0.0857 | |||
| 20 | (10, 0*19) | 1.5775 | 0.0987 | 0.9487 | 0.0783 | 0.5522 | 0.0795 | ||
| (1, 0)*10 | 1.5744 | 0.0943 | 0.9451 | 0.0780 | 0.5489 | 0.0778 | |||
| (0*19,10) | 1.5716 | 0.0891 | 0.9488 | 0.0743 | 0.5533 | 0.0766 | |||
| 30 | (0*30) | 1.5401 | 0.0701 | 0.9591 | 0.0709 | 0.5430 | 0.0742 | ||
| 50 | 25 | (25, 0*24) | 1.5435 | 0.0922 | 0.9491 | 0.0817 | 0.5527 | 0.0763 | |
| (0*8, 1, 3*8, 0*8) | 1.5682 | 0.0906 | 0.9524 | 0.0745 | 0.5518 | 0.0751 | |||
| (0*24,25) | 1.5479 | 0.0897 | 0.9569 | 0.0737 | 0.5576 | 0.0744 | |||
| 30 | (20, 0*29) | 1.5474 | 0.0762 | 1.0380 | 0.0678 | 0.5443 | 0.0742 | ||
| (2,0,0)*10 | 1.5446 | 0.0754 | 0.9680 | 0.0665 | 0.5563 | 0.0620 | |||
| (0*29,20) | 1.5419 | 0.0719 | 0.9682 | 0.0689 | 0.5541 | 0.0687 | |||
| 50 | (0*50) | 1.5209 | 0.0643 | 0.9688 | 0.0702 | 0.5413 | 0.0730 | ||
| k | n | m | Censoring Scheme | ||||||
|---|---|---|---|---|---|---|---|---|---|
| EV | MSE | EV | MSE | EV | MSE | ||||
| 2 | 30 | 15 | (15, 0*14) | 1.5985 | 0.1165 | 0.9170 | 0.0986 | 0.5673 | 0.1004 |
| (0*6, 6, 5, 4, 0*6) | 1.5965 | 0.1183 | 0.9213 | 0.0935 | 0.5640 | 0.0976 | |||
| (0*14,15) | 1.5951 | 0.1095 | 1.0761 | 0.0940 | 0.5621 | 0.0950 | |||
| 20 | (10, 0*19) | 1.5872 | 0.0988 | 0.9294 | 0.0858 | 0.5779 | 0.0871 | ||
| (1, 0)*10 | 1.5841 | 0.0941 | 0.9346 | 0.0840 | 0.5677 | 0.0859 | |||
| (0*19,10) | 1.5818 | 0.0902 | 0.9529 | 0.0761 | 0.5548 | 0.0757 | |||
| 30 | (0*30) | 1.5407 | 0.0701 | 0.9593 | 0.0710 | 0.5458 | 0.0751 | ||
| 50 | 25 | (25, 0*24) | 1.5573 | 0.0923 | 0.9327 | 0.0852 | 0.5580 | 0.0822 | |
| (0*8, 1, 3*8, 0*8) | 1.5640 | 0.0907 | 1.0651 | 0.0815 | 0.5558 | 0.0814 | |||
| (0*24, 25) | 1.5625 | 0.0901 | 0.9427 | 0.0805 | 0.5549 | 0.0801 | |||
| 30 | (20, 0*29) | 1.5572 | 0.0790 | 0.9536 | 0.0741 | 0.5487 | 0.0772 | ||
| (2, 0, 0)*10 | 1.5441 | 0.0752 | 0.9551 | 0.0723 | 0.5438 | 0.0724 | |||
| (0*29, 20) | 1.5428 | 0.0723 | 0.9574 | 0.0720 | 0.5469 | 0.0711 | |||
| 50 | (0*50) | 1.5278 | 0.0696 | 0.9650 | 0.0702 | 0.5430 | 0.0736 | ||
| 3 | 30 | 15 | (15, 0*14) | 1.5863 | 0.1128 | 0.9289 | 0.0930 | 0.5887 | 0.0904 |
| (0*6, 6, 5, 4, 0*6) | 1.5825 | 0.1120 | 0.9294 | 0.0914 | 0.5632 | 0.0869 | |||
| (0*14, 15) | 1.5812 | 0.1048 | 0.9378 | 0.0911 | 0.5652 | 0.0857 | |||
| 20 | (10, 0*19) | 1.5763 | 0.0981 | 0.9490 | 0.0782 | 0.5516 | 0.0794 | ||
| (1, 0)*10 | 1.5739 | 0.0939 | 0.9459 | 0.0778 | 0.5478 | 0.0773 | |||
| (0*19, 10) | 1.5710 | 0.0882 | 0.9492 | 0.0740 | 0.5527 | 0.0764 | |||
| 30 | (0*30) | 1.5352 | 0.0693 | 0.9598 | 0.0707 | 0.5428 | 0.0740 | ||
| 50 | 25 | (25, 0*24) | 1.5426 | 0.0917 | 0.9521 | 0.0813 | 0.5515 | 0.0761 | |
| (0*8, 1, 3*8, 0*8) | 1.5620 | 0.0901 | 0.9534 | 0.0741 | 0.5505 | 0.0748 | |||
| (0*24,25) | 1.5468 | 0.0892 | 0.9578 | 0.0735 | 0.5570 | 0.0744 | |||
| 30 | (20, 0*29) | 1.5461 | 0.0759 | 1.0387 | 0.0677 | 0.5437 | 0.0740 | ||
| (2, 0, 0)*10 | 1.5438 | 0.0751 | 0.9689 | 0.0663 | 0.5556 | 0.0619 | |||
| (0*29, 20) | 1.5401 | 0.0712 | 0.9680 | 0.0685 | 0.5532 | 0.0683 | |||
| 50 | (0*50) | 1.5209 | 0.0640 | 0.9694 | 0.0701 | 0.5410 | 0.0729 | ||
| k | n | m | Censoring Scheme | ||||||
|---|---|---|---|---|---|---|---|---|---|
| EV | MSE | EV | MSE | EV | MSE | ||||
| 2 | 30 | 15 | (15, 0*14) | 1.5974 | 0.1163 | 0.9271 | 0.0964 | 0.5658 | 0.1003 |
| (0*6, 6, 5, 4, 0*6) | 1.5948 | 0.1181 | 0.9264 | 0.0935 | 0.5634 | 0.0974 | |||
| (0*14, 15) | 1.5950 | 0.1095 | 1.0741 | 0.0938 | 0.5617 | 0.0931 | |||
| 20 | (10, 0*19) | 1.4254 | 0.0982 | 0.9303 | 0.0853 | 0.5717 | 0.0869 | ||
| (1, 0)*10 | 1.4269 | 0.0940 | 0.9366 | 0.0840 | 0.5665 | 0.0854 | |||
| (0*19, 10) | 1.4287 | 0.0901 | 0.9529 | 0.0760 | 0.5538 | 0.0751 | |||
| 30 | (0*30) | 1.5421 | 0.0703 | 0.9602 | 0.0705 | 0.5421 | 0.0750 | ||
| 50 | 25 | (25, 0*24) | 1.5564 | 0.0921 | 0.9341 | 0.0852 | 0.5568 | 0.0820 | |
| (0*8, 1, 3*8, 0*8) | 1.5636 | 0.0905 | 1.0649 | 0.0812 | 0.5561 | 0.0814 | |||
| (0*24, 25) | 1.5609 | 0.0899 | 0.9446 | 0.0804 | 0.5540 | 0.0796 | |||
| 30 | (20, 0*29) | 1.5572 | 0.0790 | 0.9537 | 0.0740 | 0.5482 | 0.0771 | ||
| (2, 0, 0)*10 | 1.5438 | 0.0750 | 0.9542 | 0.0721 | 0.5434 | 0.0724 | |||
| (0*29, 20) | 1.5419 | 0.0720 | 0.9556 | 0.0719 | 0.5468 | 0.0710 | |||
| 50 | (0*50) | 1.5267 | 0.0695 | 0.9657 | 0.0701 | 0.5432 | 0.0736 | ||
| 3 | 30 | 15 | (15, 0*14) | 1.5856 | 0.1124 | 0.9313 | 0.0927 | 0.5849 | 0.0902 |
| (0*6, 6, 5, 4, 0*6) | 1.5816 | 0.1118 | 0.9345 | 0.0912 | 0.5621 | 0.0863 | |||
| (0*14,15) | 1.5803 | 0.1042 | 0.9397 | 0.0910 | 0.5638 | 0.0853 | |||
| 20 | (10, 0*19) | 1.5758 | 0.0980 | 0.9490 | 0.0782 | 0.5516 | 0.0794 | ||
| (1, 0)*10 | 1.5727 | 0.0935 | 0.9459 | 0.0778 | 0.5478 | 0.0773 | |||
| (0*19,10) | 1.5704 | 0.0880 | 0.9492 | 0.0740 | 0.5527 | 0.0764 | |||
| 30 | (0*30) | 1.5348 | 0.0691 | 0.9598 | 0.0707 | 0.5428 | 0.0740 | ||
| 50 | 25 | (25, 0*24) | 1.5417 | 0.0912 | 0.9521 | 0.0813 | 0.5515 | 0.0761 | |
| (0*8, 1, 3*8, 0*8) | 1.5607 | 0.0897 | 0.9534 | 0.0741 | 0.5505 | 0.0748 | |||
| (0*24, 25) | 1.5457 | 0.0889 | 0.9578 | 0.0735 | 0.5570 | 0.0744 | |||
| 30 | (20, 0*29) | 1.5457 | 0.0754 | 1.0387 | 0.0677 | 0.5437 | 0.0740 | ||
| (2, 0, 0)*10 | 1.5427 | 0.0749 | 0.9689 | 0.0663 | 0.5456 | 0.0615 | |||
| (0*29, 20) | 1.5376 | 0.0707 | 0.9680 | 0.0685 | 0.5432 | 0.06831 | |||
| 50 | (0*50) | 1.5203 | 0.0636 | 0.9663 | 0.0697 | 0.5249 | 0.0721 | ||
| k | n | m | Censoring Scheme | ||||||
|---|---|---|---|---|---|---|---|---|---|
| EV | MSE | EV | MSE | EV | MSE | ||||
| 2 | 30 | 15 | (15, 0*14) | 1.5971 | 0.1162 | 0.9268 | 0.0962 | 0.5651 | 0.1002 |
| (0*6, 6, 5, 4, 0*6) | 1.5929 | 0.1178 | 0.9281 | 0.0934 | 0.5604 | 0.0972 | |||
| (0*14, 15) | 1.5938 | 0.1090 | 1.0732 | 0.0929 | 0.5597 | 0.0934 | |||
| 20 | (10, 0*19) | 1.4342 | 0.0980 | 0.9379 | 0.0850 | 0.5703 | 0.0867 | ||
| (1, 0)*10 | 1.4381 | 0.0932 | 0.9398 | 0.0831 | 0.5657 | 0.0850 | |||
| (0*19, 10) | 1.4379 | 0.0895 | 0.9563 | 0.0759 | 0.5516 | 0.0750 | |||
| 30 | (0*30) | 1.5412 | 0.0702 | 0.9638 | 0.0702 | 0.5419 | 0.0748 | ||
| 50 | 25 | (25, 0*24) | 1.5547 | 0.0918 | 0.9386 | 0.0850 | 0.5545 | 0.0818 | |
| (0*8, 1, 3*8, 0*8) | 1.5624 | 0.0904 | 1.0627 | 0.0810 | 0.5549 | 0.0811 | |||
| (0*24, 25) | 1.5601 | 0.0896 | 0.9458 | 0.0802 | 0.5527 | 0.0792 | |||
| 30 | (20, 0*29) | 1.5553 | 0.0787 | 0.9549 | 0.0738 | 0.5458 | 0.0768 | ||
| (2, 0, 0)*10 | 1.5431 | 0.0749 | 0.9538 | 0.0720 | 0.5428 | 0.0722 | |||
| (0*29, 20) | 1.5416 | 0.0719 | 0.9552 | 0.0720 | 0.5467 | 0.0706 | |||
| 50 | (0*50) | 1.5264 | 0.0695 | 0.9671 | 0.0700 | 0.5428 | 0.0734 | ||
| 3 | 30 | 15 | (15, 0*14) | 1.5827 | 0.1117 | 0.9348 | 0.0924 | 0.5827 | 0.0901 |
| (0*6, 6, 5, 4, 0*6) | 1.5801 | 0.1116 | 0.9431 | 0.0910 | 0.5618 | 0.0861 | |||
| (0*14, 15) | 1.5801 | 0.1042 | 0.9416 | 0.0907 | 0.5626 | 0.0850 | |||
| 20 | (10, 0*19) | 1.5736 | 0.0978 | 0.9512 | 0.0778 | 0.5510 | 0.0792 | ||
| (1, 0)*10 | 1.5727 | 0.0935 | 0.9459 | 0.0778 | 0.5478 | 0.0773 | |||
| (0*19,10) | 1.5701 | 0.0880 | 0.9531 | 0.0739 | 0.5520 | 0.0764 | |||
| 30 | (0*30) | 1.5327 | 0.0690 | 0.9632 | 0.0705 | 0.5423 | 0.0739 | ||
| 50 | 25 | (25, 0*24) | 1.5410 | 0.0910 | 0.9536 | 0.0811 | 0.5501 | 0.0760 | |
| (0*8, 1, 3*8, 0*8) | 1.5601 | 0.0897 | 0.9528 | 0.0740 | 0.5497 | 0.0743 | |||
| (0*24, 25) | 1.5426 | 0.0883 | 0.9590 | 0.0733 | 0.5537 | 0.0742 | |||
| 30 | (20, 0*29) | 1.5419 | 0.0752 | 1.0378 | 0.0674 | 0.5432 | 0.0740 | ||
| (2, 0, 0)*10 | 1.5412 | 0.0746 | 0.9697 | 0.0661 | 0.5447 | 0.0612 | |||
| (0*29, 20) | 1.5354 | 0.0705 | 0.9694 | 0.0683 | 0.5420 | 0.0631 | |||
| 50 | (0*50) | 1.5202 | 0.0635 | 0.9768 | 0.0694 | 0.5238 | 0.0718 | ||
| k | n | m | Censoring Scheme | ||||||
|---|---|---|---|---|---|---|---|---|---|
| AL | CP | AL | CP | AL | CP | ||||
| 2 | 30 | 15 | (15, 0*14) | 2.1359 | 0.945 | 1.6560 | 0.944 | 1.2398 | 0.948 |
| (0*6, 6, 5, 4, 0*6) | 2.0936 | 0.943 | 1.6849 | 0.942 | 1.2356 | 0.947 | |||
| (0*14, 15) | 2.0528 | 0.943 | 1.7936 | 0.951 | 1.2125 | 0.945 | |||
| 20 | (10, 0*19) | 1.9267 | 0.946 | 1.5312 | 0.949 | 1.1243 | 0.950 | ||
| (1, 0)*10 | 1.9587 | 0.948 | 1.7287 | 0.952 | 1.1183 | 0.951 | |||
| (0*19, 10) | 1.8942 | 0.943 | 1.5242 | 0.946 | 1.1146 | 0.949 | |||
| 30 | (0*30) | 1.9051 | 0.953 | 1.5351 | 0.952 | 1.1048 | 0.955 | ||
| 50 | 25 | (25, 0*24) | 1.8797 | 0.955 | 1.5617 | 0.948 | 1.1118 | 0.953 | |
| (0*8, 1, 3*8, 0*8) | 1.8415 | 0.952 | 1.5425 | 0.945 | 1.0581 | 0.952 | |||
| (0*24, 25) | 1.8344 | 0.951 | 1.2889 | 0.946 | 1.0024 | 0.951 | |||
| 30 | (20, 0*29) | 1.6577 | 0.958 | 1.1018 | 0.951 | 0.9189 | 0.952 | ||
| (2, 0, 0)*10 | 1.6134 | 0.956 | 1.5134 | 0.957 | 0.9664 | 0.959 | |||
| (0*29, 20) | 1.5581 | 0.953 | 1.1980 | 0.954 | 0.8893 | 0.955 | |||
| 50 | (0*50) | 1.5128 | 0.957 | 1.4651 | 0.959 | 0.9246 | 0.957 | ||
| 3 | 30 | 15 | (15, 0*14) | 1.7536 | 0.948 | 1.1076 | 0.947 | 1.0056 | 0.948 |
| (0*6, 6, 5, 4, 0*6) | 1.7625 | 0.945 | 1.0431 | 0.945 | 0.9834 | 0.947 | |||
| (0*14, 15) | 1.7560 | 0.942 | 1.6560 | 0.954 | 0.9062 | 0.945 | |||
| 20 | (10, 0*19) | 1.5921 | 0.951 | 0.9611 | 0.949 | 0.8753 | 0.950 | ||
| (1, 0)*10 | 1.6313 | 0.953 | 0.9661 | 0.954 | 0.8766 | 0.951 | |||
| (0*19, 10) | 1.5442 | 0.952 | 1.3442 | 0.956 | 0.8043 | 0.949 | |||
| 30 | (0*30) | 1.5956 | 0.955 | 1.5247 | 0.959 | 0.8016 | 0.956 | ||
| 50 | 25 | (25, 0*24) | 1.5068 | 0.956 | 0.9455 | 0.951 | 0.7643 | 0.953 | |
| (0*8, 1, 3*8, 0*8) | 1.5082 | 0.954 | 0.8636 | 0.948 | 0.7743 | 0.952 | |||
| (0*24, 25) | 1.4889 | 0.952 | 1.2728 | 0.947 | 0.7169 | 0.951 | |||
| 30 | (20, 0*29) | 1.4786 | 0.960 | 0.9245 | 0.951 | 0.6731 | 0.952 | ||
| (2, 0, 0)*10 | 1.4391 | 0.957 | 0.8545 | 0.957 | 0.6817 | 0.957 | |||
| (0*29, 20) | 1.3980 | 0.954 | 1.1273 | 0.959 | 0.6290 | 0.955 | |||
| 50 | (0*50) | 1.3879 | 0.961 | 1.1348 | 0.958 | 0.6203 | 0.959 | ||
| k | n | m | Censoring Scheme | ||||||
|---|---|---|---|---|---|---|---|---|---|
| AL | CP | AL | CP | AL | CP | ||||
| 2 | 30 | 15 | (15, 0*14) | 1.9507 | 0.946 | 1.3070 | 0.951 | 1.1772 | 0.951 |
| (0*6, 6, 5, 4, 0*6) | 1.9249 | 0.945 | 1.3122 | 0.951 | 1.1803 | 0.952 | |||
| (0*14, 15) | 1.8799 | 0.944 | 1.2852 | 0.950 | 1.1423 | 0.948 | |||
| 20 | (10, 0*19) | 1.7347 | 0.9 51 | 1.1515 | 0.952 | 1.0889 | 0.952 | ||
| (1, 0)*10 | 1.7034 | 0.948 | 1.2790 | 0.955 | 1.0766 | 0.953 | |||
| (0*19, 10) | 1.6723 | 0.949 | 1.1328 | 0.951 | 1.0496 | 0.956 | |||
| 30 | (0*30) | 1.6549 | 0.958 | 1.1258 | 0.954 | 1.0467 | 0.956 | ||
| 50 | 25 | (25, 0*24) | 1.5696 | 0.956 | 1.0608 | 0.951 | 0.9954 | 0.953 | |
| (0*8, 1, 3*8, 0*8) | 1.5726 | 0.954 | 1.1023 | 0.949 | 0.9831 | 0.954 | |||
| (0*24, 25) | 1.4319 | 0.958 | 1.0281 | 0.947 | 0.9068 | 0.952 | |||
| 30 | (20, 0*29) | 1.3533 | 0.961 | 0.9863 | 0.952 | 0.8466 | 0.954 | ||
| (2, 0, 0)*10 | 1.4284 | 0.962 | 1.0047 | 0.959 | 0.8629 | 0.960 | |||
| (0*29, 20) | 1.2657 | 0.956 | 0.9678 | 0.955 | 0.8223 | 0.956 | |||
| 50 | (0*50) | 1.2657 | 0.959 | 0.9789 | 0.960 | 0.8341 | 0.960 | ||
| 3 | 30 | 15 | (15, 0*14) | 1.4718 | 0.951 | 0.9802 | 0.948 | 0.8865 | 0.950 |
| (0*6, 6, 5, 4, 0*6) | 1.4972 | 0.953 | 0.9927 | 0.950 | 0.9472 | 0.951 | |||
| (0*14, 15) | 1.3936 | 0.949 | 0.9172 | 0.954 | 0.8474 | 0.949 | |||
| 20 | (10, 0*19) | 1.3215 | 0.953 | 0.9064 | 0.951 | 0.7753 | 0.952 | ||
| (1, 0)*10 | 1.3459 | 0.956 | 0.8943 | 0.956 | 0.8202 | 0.953 | |||
| (0*19, 10) | 1.2881 | 0.952 | 0.8298 | 0.957 | 0.7546 | 0.956 | |||
| 30 | (0*30) | 1.3552 | 0.957 | 0.8762 | 0.961 | 0.7813 | 0.961 | ||
| 50 | 25 | (25, 0*24) | 1.1733 | 0.959 | 0.8194 | 0.954 | 0.7656 | 0.958 | |
| (0*8, 1, 3*8, 0*8) | 1.2339 | 0.957 | 0.8166 | 0.950 | 0.7388 | 0.953 | |||
| (0*24, 25) | 1.1756 | 0.961 | 0.7711 | 0.953 | 0.6823 | 0.952 | |||
| 30 | (20, 0*29) | 1.0191 | 0.961 | 0.6264 | 0.953 | 0.6643 | 0.954 | ||
| (2, 0, 0)*10 | 1.0989 | 0.958 | 0.6845 | 0.959 | 0.6743 | 0.959 | |||
| (0*29, 20) | 0.9535 | 0.956 | 0.6620 | 0.960 | 0.6619 | 0.961 | |||
| 50 | (0*50) | 0.9672 | 0.963 | 0.6798 | 0.963 | 0.6597 | 0.959 | ||
| Distribution | MLEs | AIC | CAIC | BIC | HQIC | K-S |
|---|---|---|---|---|---|---|
| IPLD | 193.0546 | 193.3983 | 199.8854 | 195.7738 | 0.0743 | |
| LD | 230.5347 | 230.7038 | 235.0892 | 232.3482 | 0.6904 | |
| ELD | 194.5692 | 194.9124 | 201.3987 | 197.2882 | 0.0941 | |
| PLD | 193.0753 | 193.4182 | 199.9052 | 195.7943 | 0.0782 | |
| IWD | 240.3324 | 240.5014 | 244.8854 | 242.1453 | 0.1968 | |
| GIWD | 242.3318 | 242.6753 | 249.1618 | 245.0512 | 0.1973 | |
| ILD | 242.8217 | 242.9958 | 247.3747 | 244.6346 | 0.9986 |
| Censoring Scheme | Progressive First-Failure Censored Sample |
|---|---|
| = (10, 0*25) | 0.1, 1.2, 1.22, 1.24, 1.4, 1.34, 1.39, 1.46, 1.59, 1.63, 1.68, 1.72, 1.83, 1.97, 2.02, 2.15, 2.22, 2.31, 2.45, 2.53, 2.54, 2.78, 2.93, 3.42, 3.61, 4.02. |
| = (0*11, 3,4,3, 0*12) | 0.1, 0.44, 0.59, 0.74, 0.93, 1, 1.05, 1.07, 1.08, 1.12, 1.15, 1.2, 1.22, 1.39, 1.72, 2.15, 2.22, 2.31, 2.45, 2.53, 2.54, 2.78, 2.93, 3.42, 3.61, 4.02. |
| = (0*25, 10) | 0.1, 0.44, 0.59, 0.74, 0.93, 1, 1.05, 1.07, 1.08, 1.12, 1.15, 1.2, 1.22, 1.24, 1.4, 1.34, 1.39, 1.46, 1.59, 1.63, 1.68, 1.72, 1.83, 1.97, 2.02, 2.15 |
| MLEs | Censoring Schemes | BEs (Squared Loss) | Censoring Schemes | ||||
|---|---|---|---|---|---|---|---|
| CS1 | CS2 | CS3 | CS1 | CS2 | CS3 | ||
| 0.8245 | 0.4263 | 0.5248 | 0.8168 | 0.4375 | 0.5357 | ||
| 0.1982 | 0.0721 | 0.1156 | 0.1893 | 0.0786 | 0.1274 | ||
| 4.1089 | 2.3716 | 2.4823 | 4.1025 | 2.3785 | 2.4969 | ||
| BEs Entropy Loss | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| Censoring Schemes | Censoring Schemes | Censoring Schemes | |||||||
| CS1 | CS2 | CS3 | CS1 | CS2 | CS3 | CS1 | CS2 | CS3 | |
| 0.8472 | 0.4236 | 0.5318 | 0.8147 | 0.4380 | 0.5366 | 0.8025 | 0.4453 | 0.5354 | |
| 0.1927 | 0.0735 | 0.1298 | 0.1894 | 0.0792 | 0.1289 | 0.1823 | 0.0786 | 0.1274 | |
| 4.1354 | 2.3692 | 2.4987 | 4.1016 | 2.3775 | 2.4977 | 4.1025 | 2.3785 | 2.4969 | |
| Parameter | ACIs | Parameter | HPDCIs | ||||
|---|---|---|---|---|---|---|---|
| CS1 | CS2 | CS3 | CS1 | CS2 | CS3 | ||
| (0.2426, 2.4109) | (0.1917, 1.5328) | (0.1879, 2.1357) | (0.2426, 2.4103) | (0.1931, 1.5319) | (0.1884, 2.1352) | ||
| (0.0943, 1.8561) | (0.0257, 1.3771) | (0.0876,1.7457) | (0.0950, 1.8546) | (0.0265, 1.3762) | (0.0882,1.7451) | ||
| (0.8465,5.8102) | (0.5413, 3.1485) | (0.6874, 3.5438) | (0.8479, 5.8068) | (0.5620, 3.1424) | (0.6892, 3.5416) | ||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shi, X.; Shi, Y. Inference for Inverse Power Lomax Distribution with Progressive First-Failure Censoring. Entropy 2021, 23, 1099. https://doi.org/10.3390/e23091099
Shi X, Shi Y. Inference for Inverse Power Lomax Distribution with Progressive First-Failure Censoring. Entropy. 2021; 23(9):1099. https://doi.org/10.3390/e23091099
Chicago/Turabian StyleShi, Xiaolin, and Yimin Shi. 2021. "Inference for Inverse Power Lomax Distribution with Progressive First-Failure Censoring" Entropy 23, no. 9: 1099. https://doi.org/10.3390/e23091099
APA StyleShi, X., & Shi, Y. (2021). Inference for Inverse Power Lomax Distribution with Progressive First-Failure Censoring. Entropy, 23(9), 1099. https://doi.org/10.3390/e23091099