4.1. Datasets
Office-31 [
18]. It consists of three real-world image domains with 31 shared categories: Amazon (A), images are downloaded from Amazon online merchants; Webcam (W), images are obtained from low-resolution webcams; DSLR (D), images are obtained from a digital SLR camera with high-resolution. The total number of Office31 is 4652. Randomly select two domains as the source domain and the target domain, resulting in six cross-domain subtasks (A→W,
, D →A, W →A).
Office-Home [
46]. It consists of four significantly different data domains. These domains share 65 different categories from office and home scenes with a total number of 15,500. The four domains are: artistic images (denoted by Ar), which is an artistic depiction, such as sketches, paintings, and decorations of objects; clip art images (denoted by Cl), which constitute the image collection of clipart; product images (denoted by Pr), all its images have no background, similar to Amazon’s product images; real-world images (denoted by Rw) (all images are taken with a regular camera). This dataset has 12 adaptation sub-tasks; that is, Ar→Cl,
, Rw→Pr.
ImageCLEF-DA (
http://imageclef.org/2014/adaptation accessed on 1 November 2021) is a relatively small data set, which is the benchmark data set for ImageCLEF 2014 domain adaptation challenge. ImageCLEF-DA consists of three data domains, each of which shares 12 categories, and each category has 50 images. The three domains are from Caltech-256 (denoted by C), ImageNet ILSVRC 2012 (denoted by I), and Pascal VOC 2012 (denoted by P). Although the amount of data in each domain is very balanced, due to the small size of the domain, it is a relatively difficult dataset. There are six DA sub-tasks, that is, I→P,
, P→C.
VisDA2017 [
47] is a very challenging dataset first proposed in the 2017 Visual Domain Adaptation Challenge, which contains two very distinct domains: synthetic images—images are rendered from 3D models with different angles and lighting; and real images, which are composed of natural images. It has a total of more than 280 K images with 12 shared classes in training, validation, and test set. The 12 shared classes are plane, bicycle (shortened to bcyle), bus, car, horse, knife, motorcycle (shortened to mcyle), person, plant, and skateboards (shortened to sktbrd). We treat the synthetic image dataset and the real image dataset as the source and target domains, respectively.
4.2. Baselines and Experimental Setup
To demonstrate the benefits of our MRE, we employ it on the two most popular adversarial adaptation networks: DANN [
16] and CDAN [
17]. We compared MRE with other adversarial DA networks and several SOTA deep DA methods: ADDA [
20], which imposes an un-tied weight on the feature extractor and treated DANN as one of its special cases; JAN [
10], which aligns the joint distribution; MCD [
30], which does not explicitly use the discriminator, but apply two classifiers to implement adversarial training; MADA [
35], which applies multiple domain discriminator to align the class-conditional distribution; MDD [
48], which proposes a new and very effective distribution discrepancy measurement; BSP [
14], which tries to preserve discriminability by penalizing the largest singular value of feature; BNM [
39], which utilizes the F-norm and rank to improve feature discriminability and diversity; ALDA [
31], which is a adversarial-based DA method; GVB [
49], which applies the bridge to the generator and discriminator to progressively reduce the discrepancy across domains;
f-DAL [
27], which connects domain-adversarial learning with DA theory from the perspective of
f-divergence minimization; CGDM [
28], which, instead of directly manipulating the source and target domain features, minimizes their gradient difference; DWL [
36], which dynamically balances the weight between feature alignment and feature discriminability in adversarial learning; MetaAlign [
50], which regards distribution alignment and classification as the meta-train and meta-test tasks in a meta-learning scheme; and JUMBOT [
51], which combines mini-batch strategy with unbalanced optimal transport to yield robust performance.
The code was implemented with PyTorch. For Office31, Office-Home, and ImageCLEF datasets, ResNet50 [
15] pre-trained on ImageNet [
52] was used as the backbone. For dataset VisDA2017, the backbone network will be replaced by the ResNet101 [
15]. The network was trained by mini-batch stochastic gradient descent (SGD), and the momentum was set to 0.9. The learning rate schedule was the same as DANN [
16] and CDAN [
17]. Because both the domain discriminator and the classifier need to be trained from scratch, the learning rate was set to 10 times that of the backbone network. For data augmentation, some common operations, such as random flipping and random cropping, were employed. For Office31, Office-Home, and ImageCLEF datasets, the initial learning rate was 0.001. For the VisDA2017 dataset, the initial learning rate was 0.01. The batch size
N was 36 for all datasets. We maintained the hyper-parameters
and
as fixed. Our results are the average classification accuracy of three random experiments.
4.3. Results and Discussion
The results of Office-31 are displayed in
Table 1. Our MRE significantly outperforms all comparison methods on most DA sub-tasks and achieves the best average result. Compared with the two baselines (DANN [
16], CDAN [
17]), MRE achieved a significant performance improvement on all subtasks, especially on difficult sub-tasks, D→A and W→A, in which there were significantly fewer source samples than the target domain. MRE achieved a final average accuracy improvement of 4.8% and 2.1% for DANN and CDAN, respectively, which demonstrates that domain adaptation can benefit from integrating matrix rank embedding into adversarial training to enhance the discriminability and transferability. Compared with the current SOTA DA methods, MRE still achieved competitive results.
Table 2 is the results on the ImageCLEF-DA dataset. The performance of MRE on the two baselines is improved. In
Table 2, except for I→P and C→P, the accuracy of other sub-tasks are all over 90%, which shows that the sub-tasks are more challenging when P is the target domain. Nevertheless, our MRE achieved a significant improvement over the baseline in these two tasks. Compared with other methods, our MRE constitutes a relatively minor improvement since the images in ImageCLEF-DA are more visually similar, but the amount of data is very limited (600 for each domain), which may not be sufficient for training. Thus, the accuracies exhibited less room for improvement in all methods.
Table 3 shows the results of the Office-Home dataset. Compared with the two baselines, MRE achieved a significant performance improvement on all subtasks and achieved an average accuracy improvement of 9.0% and 5.9% for DANN [
16] and CDAN [
17], respectively. Compared with methods (BSP [
14], ALDA [
31], and BNM [
39]) that focus on improving feature discriminability, our method has a significant improvement in terms of average accuracy. Compared with the current SOTA methods (GVB-GD [
49], JUMBO [
51]), our MRE with the CDAN significantly outperformed the comparison methods on eight sub-tasks and got the best average result. Especially, MRE is superior to MetaAlign on both baseline methods. It is noted that our MRE shows significant improvements compared with other DA methods when the artistic images (Ar) serve as the target domain. Since images in Ar within the same class have large differences, sub-tasks with Ar as the target domain are more challenging. Our MRE method still yielded larger improvement on such difficult DA sub-tasks, which highlights the power of our MRE.
Results of VisDA-2017 are displayed in
Table 4. Compared with the two baselines DANN [
16] and CDAN [
17], MRE outperforms DANN (CDAN) in 9 (12) of 12 sub-tasks, and the average accuracy is improved by
and
, respectively. MRE provided the best performance in the final mean accuracy, surpassing the second-best (ALDA [
31]) by
. Notably, ALDA learns the discriminative target features by generating a confusion matrix and trains the model in a self-training manner, while our MRE enhances transferability and discriminability simultaneously. Furthermore, according to the accuracy of each category, a substantial improvement was generated in the truck category. Compared to the other methods, which only focus on improving transferability or discriminability, our method achieved the best results, demonstrating that improving transferability and discriminability are equally important in DA.
4.4. Effectiveness Verification Experiments
Ablation study: To verify the effectiveness of each component in the objective function of MRE, ablation study was performed on the Office-Home dataset; the results are presented in
Table 5. Our ablation study started with the very baseline method of DANN [
16], which only aligns the marginal distribution without category information. Thereafter, we conducted a comparison with CDAN [
17], which only aligns the class-conditional distribution of the data in the feature space. Subsequently, to investigate how the class-conditional distribution alignment in the label space aids in learning more transferable features, we removed the
loss in Equation (
9) from main minimax problem in Equation (
11), which was denoted as “MRE (w/o ld)”. To determine the effects of the proposed discriminative loss
in Equation (
6), we removed Equation (
6) from Equation (
11), which was denoted as “MRE (w/o dse)”.
Table 5 demonstrates that CDAN provided a significant improvement over DANN, indicating that the discriminated multimodal structure information is very important in DA. MRE (w/o ld) outperformed CDAN, indicating the efficacy of our proposed discriminative adversarial learning. MRE (w/o dse) also outperformed CDAN, thereby demonstrating the effectiveness of aligning features and class conditional distribution of labels. MRE significantly outperformed MRE (w/o dse) and MRE (w/o ld), confirming the efficacy of the proposed simultaneous improvement in the discriminability and transferability.
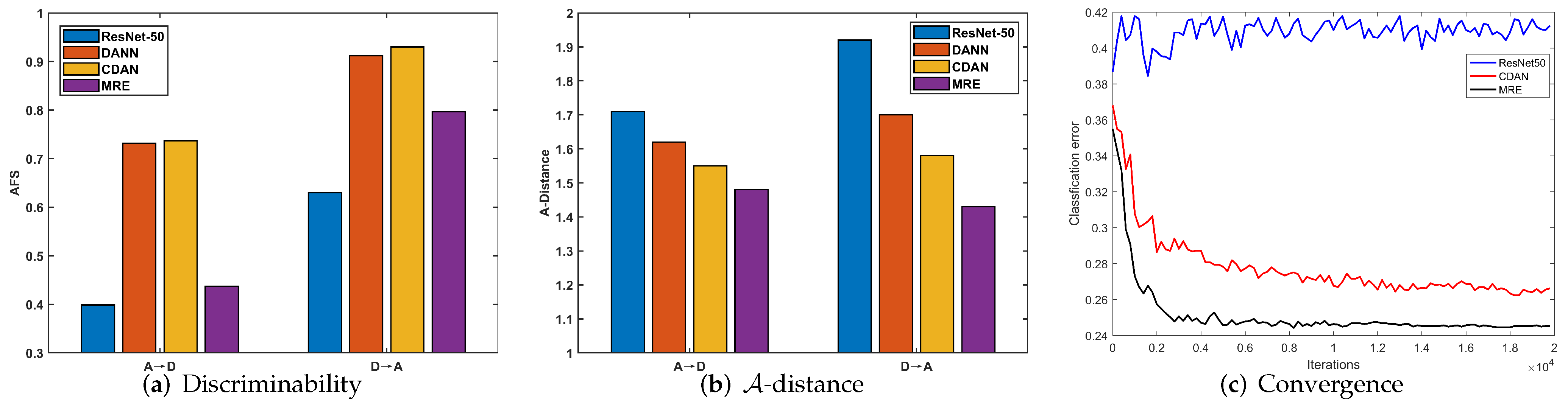
Discriminability: We investigated the discriminability of different methods by calculating the AFS [
19]. As mentioned previously, the AFS serves as an effective indicator of discriminability. A lower Fisher value indicates that the features are more discriminative. The results of sub-tasks A→D and D→A are presented in
Figure 3a. Comparing ResNet-50 with DANN and CDAN, although adversarial domain adaptation methods can enhance the transferability, as they achieve better performance in
Table 1, the discriminability of DANN and CDAN is reduced, while our MRE can not only significantly enhance the discriminability but also preserve transferability.
Distribution discrepancy: In DA, the cross-domain distribution discrepancy is commonly measured by
-distance [
3], which is calculated as
. We denote
as the test error of a classifier, which is trained to discriminate whether a feature vector
v comes from the source domain or the target domain, where
v is the feature extracted from a learned DA feature extractor. We compared our proposed MRE with ResNet-50 [
15], DANN [
16], and CDAN [
17] on the subtasks A→D and D→A in the Office31 dataset. As shown in
Figure 3b, the
-distances of DANN, MRE, and CDAN were smaller than that of ResNet-50, indicating that adversarial DA enables significantly reduce cross-domain distribution discrepancy. The
-distance of MRE is the smallest among DANN, CDAN, and MRE, indicating that the features extracted by our MRE show better transferability.
Convergence: To verify the convergence of ResNet-50 [
15], CDAN [
17], and our MRE, we conducted an experiment on the sub-task W→A in the Office31 dataset.
Figure 3c presents the result. The test error in
Figure 3c is equal to (1.0—accuracy). The value of ResNet-50 is the target domain test error by the network trained only with the source domain data. Because target domain data does not present in the training of ResNet50, the learned parameter is irrelevant to the target domain. As a result, its test error in the target domain fluctuates in a small range. Our MRE yielded faster convergence than CDAN.
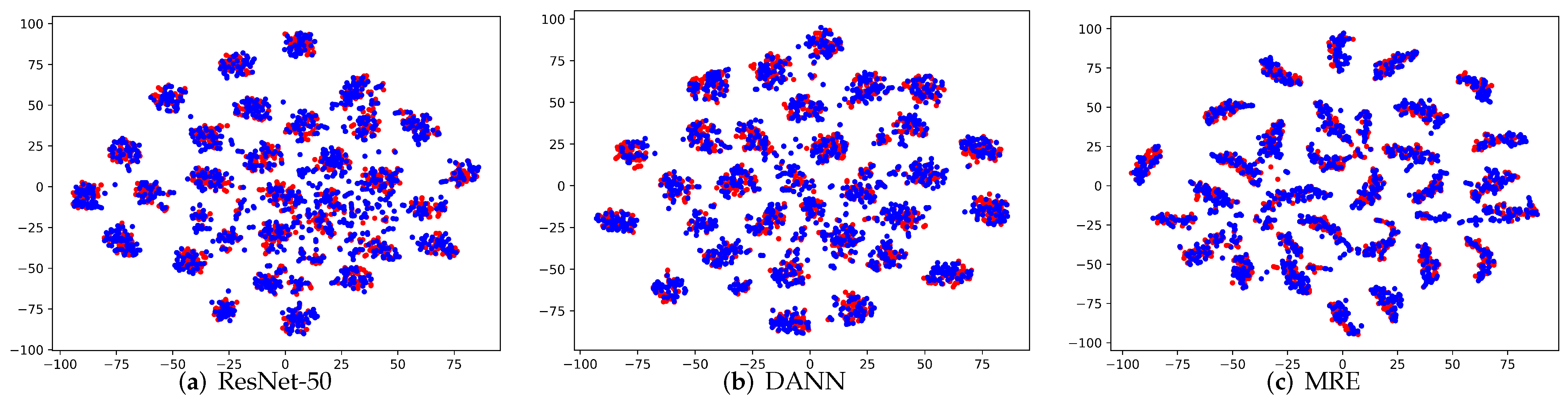
Visualization: To verify the clustering and separation characteristic of the extracted features, we apply the commonly used t-SNE [
53] to visualize the activations from different feature extractors. We conducted an experiment on the subtask A→D and compared our MRE method with ResNet-50 and DANN. As can be seen from the results in
Figure 4a–c, for the ResNet-50, there is a considerable proportion of the features are not aligned, the intra-class distance is relatively large, and the inter-class distance is relatively small. Comparing DANN with ResNet-50, the source domain and target features of DANN are better aligned, but its intra-class distance is still large. In MRE, the features were well aligned and exhibited better intra-class clustering and inter-class separation. This demonstrates the effectiveness of our MRE in aligning the class-conditional distributions in both feature and label space, and in learning a more discriminated target model.
Hyper-parameter analysis: There are three hyper-parameters—
,
, and the threshold
—where
is used to select target samples with higher confidence.
and
are two trade-off parameters, which are used to control the discriminative subspace embedding loss and the class-conditional label distribution loss, respectively. A case study on dataset Office-31 was conducted to investigate the sensitivity of
,
, and
. For each parameter, a set of reasonable values was selected to form a discrete candidate set, for
{0.85, 0.90, 0.95, 0.97, 0.99}, for
{0.01, 0.05, 0.1, 0,2, 0.5}, and for
{0.001, 0.005, 0.01, 0.05, 0.1}. The results are presented in
Table 6. When the value of
is greater than 0.9,
is insensitive. We fix
. For
and
, our MRE achieves the best result with
and
. From the results, as long as the parameters are within the feasible range, our MRE is robust to different settings. One can tune the hyper-parameter by IWCA [
54] for different applications.
Runtime comparison: We conduct experiments on sub-task of A→W in Office-31 dataset to compare the runtime. All experiments were run on the same machine (Linux version 4.15.0-20-generic, Ubuntu 7.3.0-16ubuntu3, python version = 1.3.1, CUDA version = 10.0.130, GPU = Tesla V100-PCIE-32GB). The batch size of all experiments is set to 36. CDAN is our baseline network.
Table 7 reports the total runtime required for each algorithm to train 20,000 iterations. In
Table 7, “MRE(w/o
)” means MRE without the
loss and “MRE(w/o
)” means MRE without the discriminative loss
. Compared to the baseline CDAN, our method has only a slight increase in computational cost. Our objective function contains four matrix nuclear-norm operators, which are calculated as the sum of matrix singular-values. Singular value decomposition (SVD) is very time-consuming in traditional machine learning. However, our calculation of SVD is based on mini-batches. Meanwhile, we calculate the SVD in label space, which has much lower dimensions compared to the feature space. Therefore, our method is computationally effective.







{kind=link}
{kind=link}
{kind=link}
{kind=link}