
An OpenCL-Based FPGA Accelerator for Faster R-CNN


Abstract
:1. Introduction
- We propose an OpenCL-based deep pipelined object detection hardware accelerator design, which can implement Faster R-CNN algorithms for different backbone networks (such as vgg16 [2], resnet50 [3]). To our knowledge, we are the first to systematically analyze and design a Faster R-CNN object detection accelerator.
- We perform hardware-aware algorithm optimizations on the Faster R-CNN network, including quantization, layer fusion, and a multi-batch RoIs detector. The cost of quantizing the network is a less than 1% accuracy loss and the multi-batch RoIs detector method can help the network to increases its speed by up to . This greatly improves the utilization of hardware resources and bandwidth, maximizing the performance gains of the final design.
- We introduce an end-to-end design space exploration flow for the proposed accelerator, which can comprehensively evaluate the performance and hardware resource utilization of the accelerator to fully exploit the potential of the accelerator.
- Experimental results show that the proposed accelerator design achieves a peak throughput of 846.9 GOP/s at a working frequency of 172 MHz. Compared with the state-of-the-art Faster R-CNN accelerator and the one-stage YOLO accelerator, our method achieves and inference throughput improvements, respectively.
2. Preliminaries
2.1. Review of the Faster R-CNN Algorithm
2.2. OpenCL-Based Heterorgeneous Computing Platform Setup
3. System Design
3.1. Software and Hardware Architecture Co-Design Scheme
3.2. Hardware Architecture Design
3.2.1. Overall Architecture
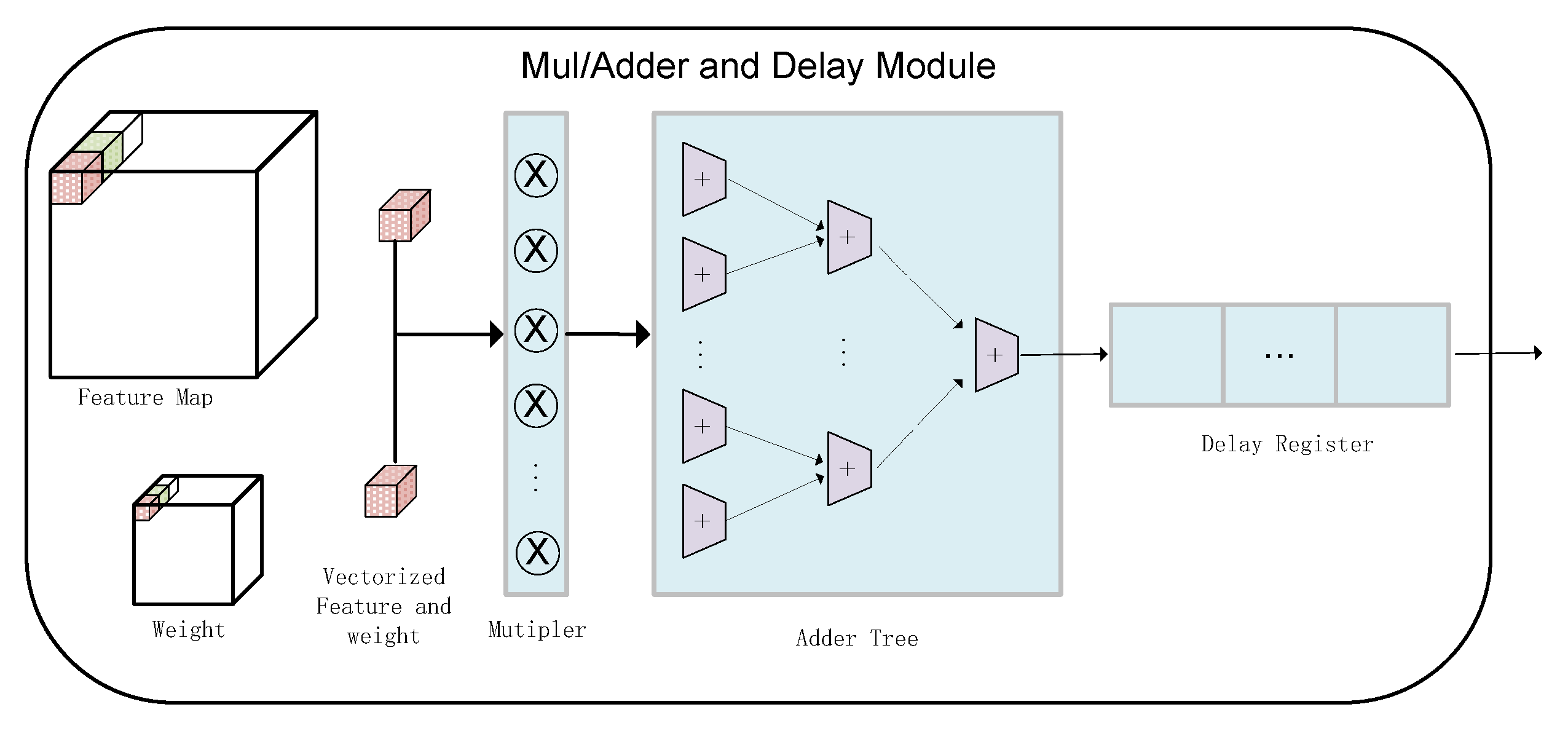
3.2.2. Convolution Kernel
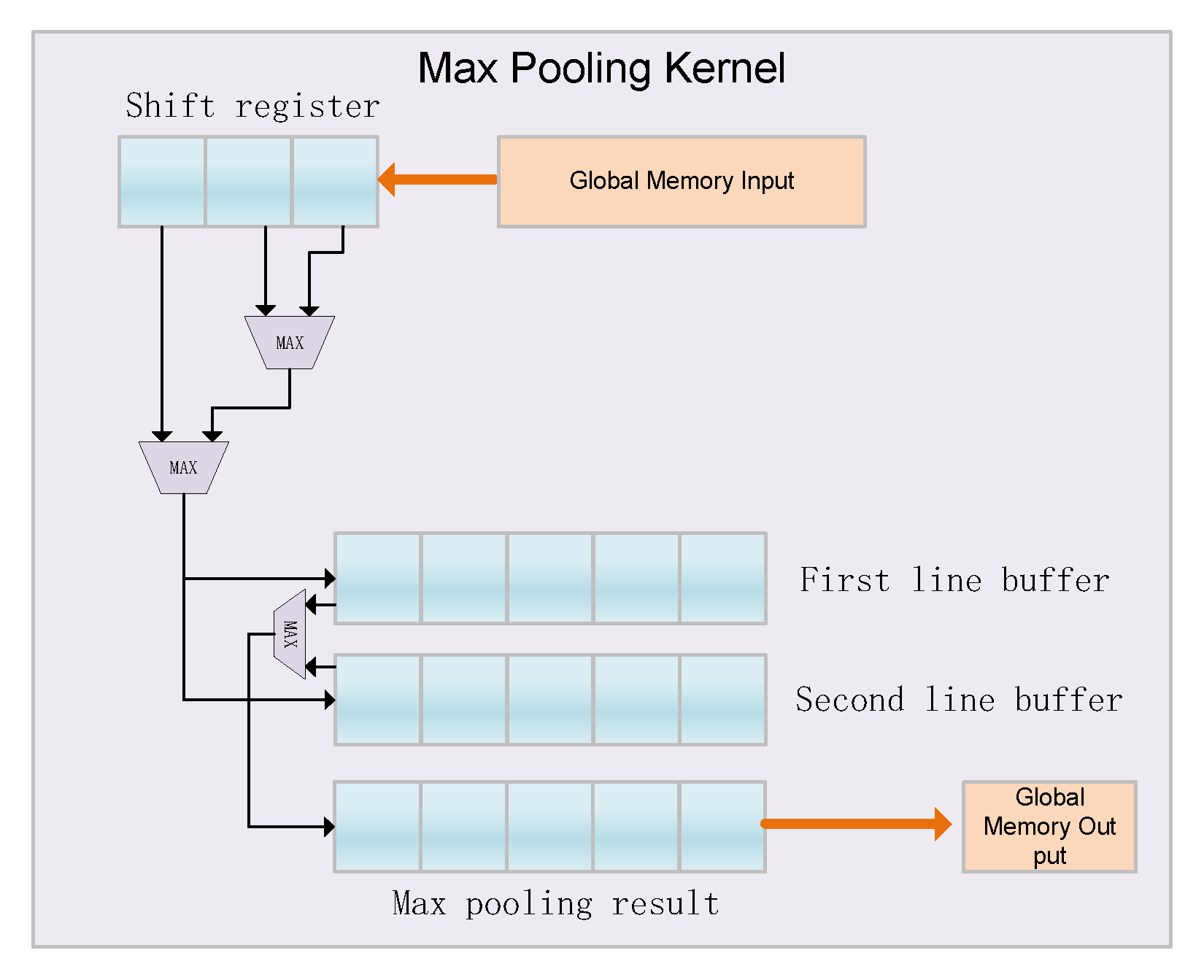
3.2.3. Max Pooling Kernel
3.2.4. RoI Pooling Kernel
3.2.5. MCR/MCW Kernel
3.2.6. Buffer Design
3.3. Hardware-Aware Algorithm-Level Optimization
3.3.1. Fixed-Point Quantization for Faster R-CNN
| Algorithm 1: Fixed-Point Quantization Algorithm Flow For Faster R-CNN |
 |
3.3.2. Layer Fusion
3.3.3. Multi-Batch RoIs Detector
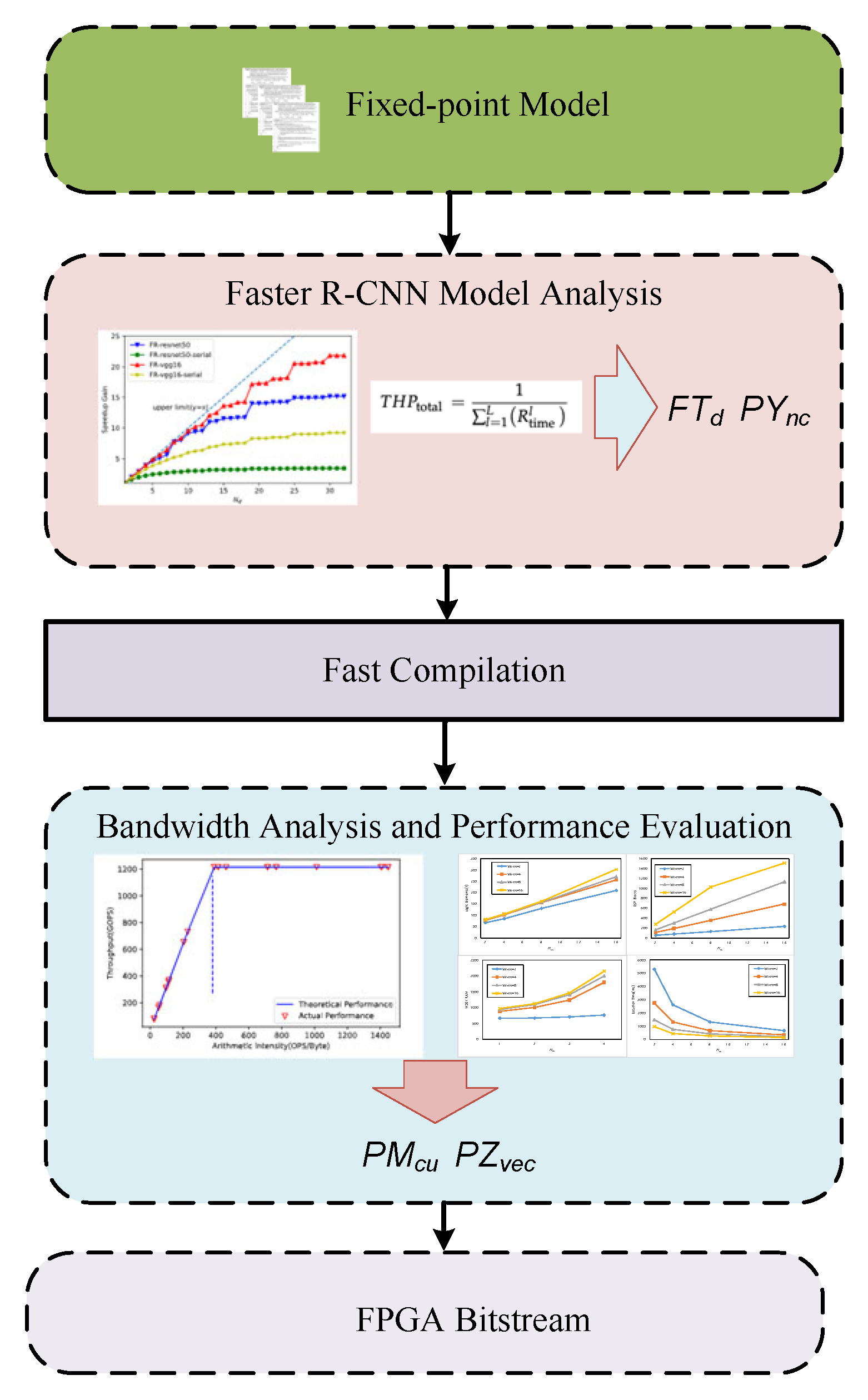
4. Performance Modeling
5. Results
5.1. Experimental Setup
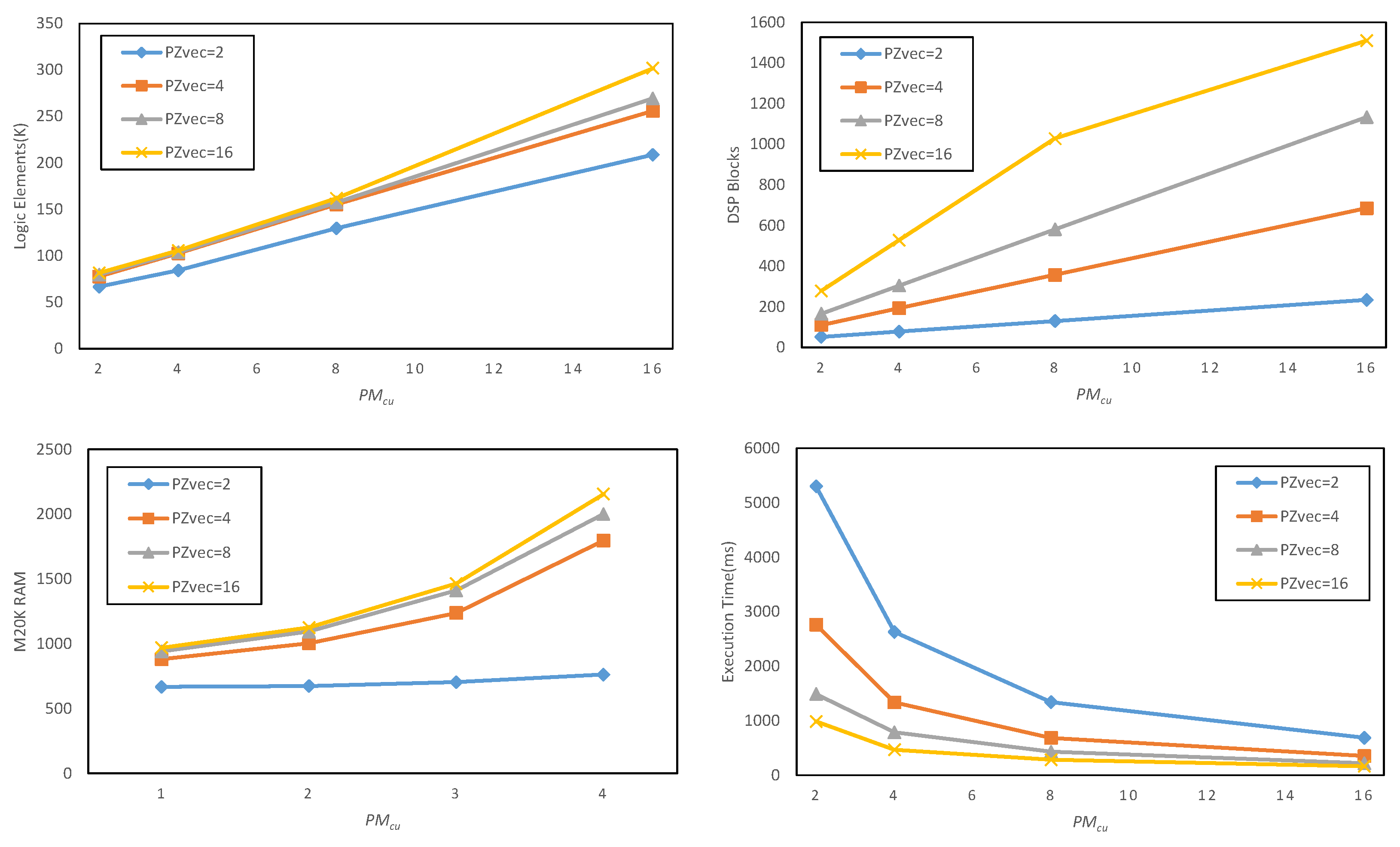
5.2. Design Space Exploration
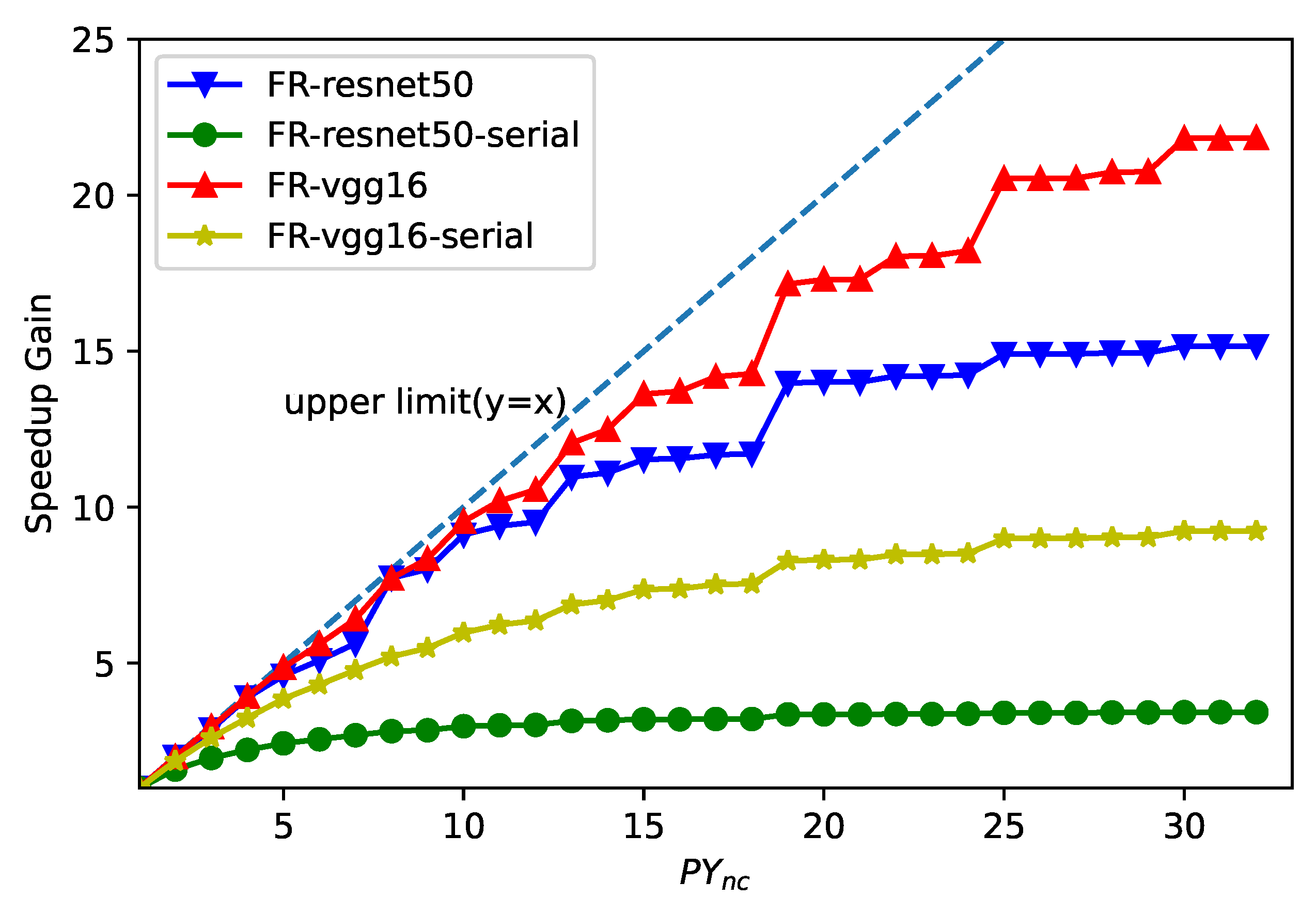
5.3. Comparison with Estimated Performance
5.4. Comparison with Start-of-the-Art
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on cOmputer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 91–99. [Google Scholar] [CrossRef] [PubMed]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and pAttern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Abdel-Hamid, O.; Mohamed, A.R.; Jiang, H.; Deng, L.; Penn, G.; Yu, D. Convolutional neural networks for speech recognition. IEEE/ACM Trans. Audio Speech Lang. Process. 2014, 22, 1533–1545. [Google Scholar] [CrossRef]
- Guo, K.; Zeng, S.; Yu, J.; Wang, Y.; Yang, H. [DL] A survey of FPGA-based neural network inference accelerators. ACM Trans. Reconfigurable Technol. Syst. (TRETS) 2019, 12, 1–26. [Google Scholar] [CrossRef]
- Zhang, C.; Li, P.; Sun, G.; Guan, Y.; Xiao, B.; Cong, J. Optimizing fpga-based accelerator design for deep convolutional neural networks. In Proceedings of the 2015 ACM/SIGDA International Symposium on fIeld-Programmable Gate Arrays, Monterey, CA, USA, 22–24 February 2015; pp. 161–170. [Google Scholar]
- Wang, D.; An, J.; Xu, K. PipeCNN: An OpenCL-based FPGA accelerator for large-scale convolution neuron networks. arXiv 2016, arXiv:1611.02450. [Google Scholar]
- Wang, D.; Xu, K.; Jia, Q.; Ghiasi, S. ABM-SpConv: A Novel Approach to FPGA-Based Acceleration of ConvolutionaI NeuraI Network Inference. In Proceedings of the 2019 56th ACM/IEEE Design Automation Conference (DAC), Las Vegas, NV, USA, 2–6 June 2019; pp. 1–6. [Google Scholar]
- Suda, N.; Chandra, V.; Dasika, G.; Mohanty, A.; Ma, Y.; Vrudhula, S.; Seo, J.S.; Cao, Y. Throughput-optimized OpenCL-based FPGA accelerator for large-scale convolutional neural networks. In Proceedings of the 2016 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, Monterey, CA, USA, 21–23 February 2016; pp. 16–25. [Google Scholar]
- Qiu, J.; Wang, J.; Yao, S.; Guo, K.; Li, B.; Zhou, E.; Yu, J.; Tang, T.; Xu, N.; Song, S.; et al. Going deeper with embedded fpga platform for convolutional neural network. In Proceedings of the 2016 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, Monterey, CA, USA, 21–23 February 2016; pp. 26–35. [Google Scholar]
- Zeng, H.; Chen, R.; Zhang, C.; Prasanna, V. A framework for generating high throughput CNN implementations on FPGAs. In Proceedings of the 2018 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, Monterey, CA, USA, 25–27 February 2018; pp. 117–126. [Google Scholar]
- Zhao, R.; Niu, X.; Wu, Y.; Luk, W.; Liu, Q. Optimizing CNN-based object detection algorithms on embedded FPGA platforms. In Proceedings of the International Symposium on Applied Reconfigurable Computing. Springer, Delft, The Netherlands, 3–7 April 2017; pp. 255–267. [Google Scholar]
- Nakahara, H.; Yonekawa, H.; Fujii, T.; Sato, S. A lightweight YOLOv2: A binarized CNN with a parallel support vector regression for an FPGA. In Proceedings of the 2018 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, Monterey, CA, USA, 25–27 February 2018; pp. 31–40. [Google Scholar]
- Yu, J.; Guo, K.; Hu, Y.; Ning, X.; Qiu, J.; Mao, H.; Yao, S.; Tang, T.; Li, B.; Wang, Y.; et al. Real-time object detection towards high power efficiency. In Proceedings of the 2018 Design, Automation & Test in Europe Conference & Exhibition (DATE), Dresden, Germany, 19–23 March 2018; pp. 704–708. [Google Scholar]
- Xu, K.; Wang, X.; Liu, X.; Cao, C.; Li, H.; Peng, H.; Wang, D. A dedicated hardware accelerator for real-time acceleration of YOLOv2. J. -Real-Time Image Process. 2021, 18, 481–492. [Google Scholar] [CrossRef]
- Ding, C.; Wang, S.; Liu, N.; Xu, K.; Wang, Y.; Liang, Y. REQ-YOLO: A resource-aware, efficient quantization framework for object detection on FPGAs. In Proceedings of the 2019 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, Seaside, CA, USA, 24–26 February 2019; pp. 33–42. [Google Scholar]
- Wang, Z.; Xu, K.; Wu, S.; Liu, L.; Liu, L.; Wang, D. Sparse-YOLO: Hardware/Software co-design of an FPGA accelerator for YOLOv2. IEEE Access 2020, 8, 116569–116585. [Google Scholar] [CrossRef]
- Yu, L.; Zhu, J.; Zhao, Q.; Wang, Z. An Efficient YOLO Algorithm with an Attention Mechanism for Vision-Based Defect Inspection Deployed on FPGA. Micromachines 2022, 13, 1058. [Google Scholar] [CrossRef] [PubMed]
- Pestana, D.; Miranda, P.R.; Lopes, J.D.; Duarte, R.P.; Véstias, M.P.; Neto, H.C.; De Sousa, J.T. A full featured configurable accelerator for object detection with YOLO. IEEE Access 2021, 9, 75864–75877. [Google Scholar] [CrossRef]
- Xu, X.; Liu, B. FCLNN: A flexible framework for fast CNN prototyping on FPGA with OpenCL and caffe. In Proceedings of the 2018 International Conference on Field-Programmable Technology (FPT), Naha, Okinawa, Japan, 10–14 December 2018; pp. 238–241. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Uijlings, J.R.; Van De Sande, K.E.; Gevers, T.; Smeulders, A.W. Selective search for object recognition. Int. J. Comput. Vis. 2013, 104, 154–171. [Google Scholar] [CrossRef]
- Khronos OpenCL Working Group. The OpenCL Specification Version 1.1. 2011. Available online: http://www.khronos.org/registry/cl/specs/opencl-1.1.pdf (accessed on 20 September 2022).
- Gysel, P.; Pimentel, J.; Motamedi, M.; Ghiasi, S. Ristretto: A framework for empirical study of resource-efficient inference in convolutional neural networks. IEEE Trans. Neural Networks Learn. Syst. 2018, 29, 5784–5789. [Google Scholar] [CrossRef] [PubMed]
- Rastegari, M.; Ordonez, V.; Redmon, J.; Farhadi, A. Xnor-net: Imagenet classification using binary convolutional neural networks. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2016; Springer: New York, NY, USA, 2016; pp. 525–542. [Google Scholar]
- Liu, Z.; Wu, B.; Luo, W.; Yang, X.; Liu, W.; Cheng, K.T. Bi-real net: Enhancing the performance of 1-bit cnns with improved representational capability and advanced training algorithm. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 722–737. [Google Scholar]
- Leng, C.; Dou, Z.; Li, H.; Zhu, S.; Jin, R. Extremely low bit neural network: Squeeze the last bit out with admm. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Everingham, M.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes (voc) challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef] [Green Version]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Number of Region Proposal | Resolution | # Param | # Operation | mAP |
|---|---|---|---|---|---|
| Yolo [6] | - | 448 × 448 | 146.2 MB | 40.3 G | 63.4% |
| Yolov2 [25] | - | 4808 × 480 | 50.6 MB | 39.1 G | 77.8% |
| Yolov2 Tiny [25] | - | 4168 × 416 | 27.1 MB | 29.4 G | 57.2% |
| Faster-R-CNN(vgg16) [4] | 300 | 8008 × 600 | 137.1 MB | 271.7 G | 69.9% |
| Faster-R-CNN(resnet50) [4] | 300 | 8008 × 600 | 236 MB | 215.6 G | 73.7% |
| Model | float32 mAP | FP8 mAP | # Param | # Param Quantized |
|---|---|---|---|---|
| Faster-RCNN-vgg16 | 69.0% | 68.3% | 137.1 MB | 34.3 MB |
| Faster-RCNN-resnet50 | 73.7% | 73.4% | 236 MB | 59 MB |
| Implementation | Resolution | Precision | Target Device | Logic Usage | DSP Usage | RAM Usage | Clock | Latency (ms) | Throughput (GOP/s) | Accuracy (mAP) | Power(W) |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Faster R-CNN (vgg16) [16] | - | 32(float) | Xilinx ZC706 | - | - | - | 200 MHz | 875 | - | - | 1.167 |
| Faster R-CNN [18] | - | 8(fixed) | Zynq 7045 | - | - | - | - | 680 | 86.8 | 66 | 3 |
| YOLOv1 [18] | 416 × 416 | 8(fixed) | Xilinx KU115 | - | - | - | - | 65 | 461.5 | 62 | 13 |
| Lightweight YOLOv2 [17] | 224 × 224 | 1-16(fixed) | Zynq MPSoC | - | - | - | 300 MHz | 24.5 | 408.1 | 67.6 | 4.5 |
| OpenCL-YOLOv2 [19] | 416 × 416 | 8(fixed) | Arria-10 GX1150 | 34% | 72% | 68% | 200 MHz | 53 | 566 | 76 | 26 |
| FCLCNN [24] | 416 × 416 | 16(fixed) | Arria-10 GX1150 | 50% | 98% | 88% | 278 MHz | 53.8 | 557.6 | 76.08 | 45 |
| Proposed Faster R-CNN(resnet50) | 800 × 600 | 8(fixed) | Arria-10 GX1150 | 71% | 99% | 72% | 172 MHz | 153.6 | 719 | 73.4 | 26 |
| Proposed Faster R-CNN(vgg16) | 800 × 600 | 8(fixed) | Arria-10 GX1150 | 71% | 99% | 72% | 172 MHz | 248.7 | 864.9 | 68.3 | 26 |
| Implementation | Resolution | Precision | Target Device | Latency (ms) | Throughput (GOP/s) | Accuracy (mAP) | Power Efficiency (GOP/s/W) |
|---|---|---|---|---|---|---|---|
| Faster R-CNN GPU basline [4] | 800 × 600 | 32(float) | Nvidia K40 | 198 | 1372.2 | 69.9 | 5.83 |
| Proposed Faster R-CNN(resnet50) | 800 × 600 | 8(fixed) | Arria-10 GX1150 | 153.6 | 719 | 73.4 | 27.7 |
| Proposed Faster R-CNN(vgg16) | 800 × 600 | 8(fixed) | Arria-10 GX1150 | 248.7 | 864.9 | 68.3 | 33.3 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
An, J.; Zhang, D.; Xu, K.; Wang, D. An OpenCL-Based FPGA Accelerator for Faster R-CNN. Entropy 2022, 24, 1346. https://doi.org/10.3390/e24101346
An J, Zhang D, Xu K, Wang D. An OpenCL-Based FPGA Accelerator for Faster R-CNN. Entropy. 2022; 24(10):1346. https://doi.org/10.3390/e24101346
Chicago/Turabian StyleAn, Jianjing, Dezheng Zhang, Ke Xu, and Dong Wang. 2022. "An OpenCL-Based FPGA Accelerator for Faster R-CNN" Entropy 24, no. 10: 1346. https://doi.org/10.3390/e24101346
APA StyleAn, J., Zhang, D., Xu, K., & Wang, D. (2022). An OpenCL-Based FPGA Accelerator for Faster R-CNN. Entropy, 24(10), 1346. https://doi.org/10.3390/e24101346