Abstract
Much research on adversarial attacks has proved that deep neural networks have certain security vulnerabilities. Among potential attacks, black-box adversarial attacks are considered the most realistic based on the the natural hidden nature of deep neural networks. Such attacks have become a critical academic emphasis in the current security field. However, current black-box attack methods still have shortcomings, resulting in incomplete utilization of query information. Our research, based on the newly proposed Simulator Attack, proves the correctness and usability of feature layer information in a simulator model obtained by meta-learning for the first time. Then, we propose an optimized Simulator Attack+ based on this discovery. Our optimization methods used in Simulator Attack+ include: (1) a feature attentional boosting module that uses the feature layer information of the simulator to enhance the attack and accelerate the generation of adversarial examples; (2) a linear self-adaptive simulator-predict interval mechanism that allows the simulator model to be fully fine-tuned in the early stage of the attack and dynamically adjusts the interval for querying the black-box model; and (3) an unsupervised clustering module to provide a warm-start for targeted attacks. Results from experiments on the CIFAR-10 and CIFAR-100 datasets clearly show that Simulator Attack+ can further reduce the number of consuming queries to improve query efficiency while maintaining the attack.
1. Introduction
With the recent development of deep neural networks (DNNs), people have increasingly realized that these network architectures are extremely vulnerable to attacks by adversarial perturbations [1,2,3]. By adding adversarial perturbations that humans cannot perceive to input images, DNNs [4] become unable to output correct feedback. Such a unique characteristic gives DNN robustness increasing research value. Based on how much internal network information DNNs provide, adversarial attacks are generally divided into two categories: white-box and black-box. The victim model of white-box attacks provides complete information for attackers, including the outputs of DNNs and all internal neural node gradient information [2,5]. This enables attackers to generate corresponding adversarial examples in a targeted manner. Nevertheless, such an attack background and condition do not satisfy the requirements of adversarial attacks in real environments. Thus, due to the harsh conditions of black-box attacks, with less available information, they have gradually become the recent mainstream research direction of adversarial attacks. In a black-box attack, the attacker can only obtain output information of input images from the target model, while the internal information remains hidden. Up to now, black-box adversarial attack methods proposed in academic circles have been mainly divided into three categories: query-based attacks, transfer-based attacks, and meta-learning-based attacks.
For attacks based on query, due to their high attack success rate, people have already made effort to study them under the circumstances that only the label or probability information of each input image can be obtained. Although there is still a problem in that the amount of information obtained by querying the model each time is relatively small, by using massive queries combined with a more accurate gradient estimation algorithm, attackers can still easily generate the required adversarial perturbations. In order to achieve better query results, researchers have begun to pay more attention to query efficiency problems. Various innovative methods for uncovering deeper hidden information [6,7,8,9] have emerged for increasing the query utilization rate. However, the considerable number of queries required still makes purposeful adversarial attacks detectable in real environment and signals the victim to take defensive actions.
For attacks based on model transfer, the original intention of this design was to decrease the ability of query attacks to be easily defended against. This type of black-box attack transfers part of the queries from the black-box model to the local agent model selected by the attacker in order to decrease the abnormal behavior of high-frequency queries to the black-box model [10,11,12,13,14]. Then, it uses existing white-box adversarial attack methods to generate black-box attack perturbations based on the transferred agent model. However, since the success of the attack completely depends on the similarity between the transferred local agent model and the black-box target model, the attack success rate of this method is extremely unstable. To minimize this difference between models as much as possible, a synthetic dataset training method [15,16,17] has been proposed, which cross-uses the training images and the output results of the black-box model to train the local agent model. This method also affects the black-box model’s initiation of defensive mechanisms [18,19,20]. When the training feedback of the local transferred model reaches the set threshold, the local agent model is considered a qualified imitator of the black-box target model and becomes the main target of subsequent queries. However, this type of black-box attack is still far from reaching the attack success rate of the aforementioned query-based attack.
For attacks based on meta-learning, the idea behind this type of attack is very novel. It optimizes and improves the shortages of query-based and transfer-based attacks. Meta-learning-based attacks use the characteristics of meta-learning and knowledge distillation to make the transferred simulator model more adaptable. This model can utilize a limited number of queries in a short time to imitate the target black-box model effectively and can quickly take on the task of acting as an accurate local agent model. As shown by Ma’s work [21], this method has the advantages of both keeping a high attack success rate and maintaining effective attack capabilities against black-box target models with defensive mechanism. However, such an attack still does not fully utilize the information of each query. For the simulator model object that is queried each time, Ma’s method [21] ignores internal information obtained by prior meta-learning and treats the model as a black-box during the entire attack process. Therefore, fully using the internal information in the simulator model, which consumes a great amount of training cost, is worthwhile for further research. As stated by Zhou et al. [22], the training and learning process of any model can be divided into two stages: feature representation ability learning and classification ability learning. Because the learning costs of the simulator model obtained by meta-learning are for various selected mainstream models, the feature representation ability and classification ability of these models to the training dataset have been mastered by the simulator model. When simulator attack begins, the simulator model used as a local agent model attempts to imitate the black-box target model, which has never been seen before. Referring to the transferability of a model [21], the feature representation ability of the initial simulator model is already especially similar to that of the black-box target model for the same dataset images. However, the gap between the simulator model and the black-box target model does exist in classification ability to a certain extent. Through feature extraction and visualization of the simulator model in the initial state and the model selected as the black-box target, we find that the feature attentional area of an image is almost the same between the two models. Furthermore, by output information extraction and visualization of the two models, we also observe that the initial simulator model and the black-box model have a large gap in classification ability through comparisons. Such results strongly prove the correctness and usability of the feature layer information of the simulator model.
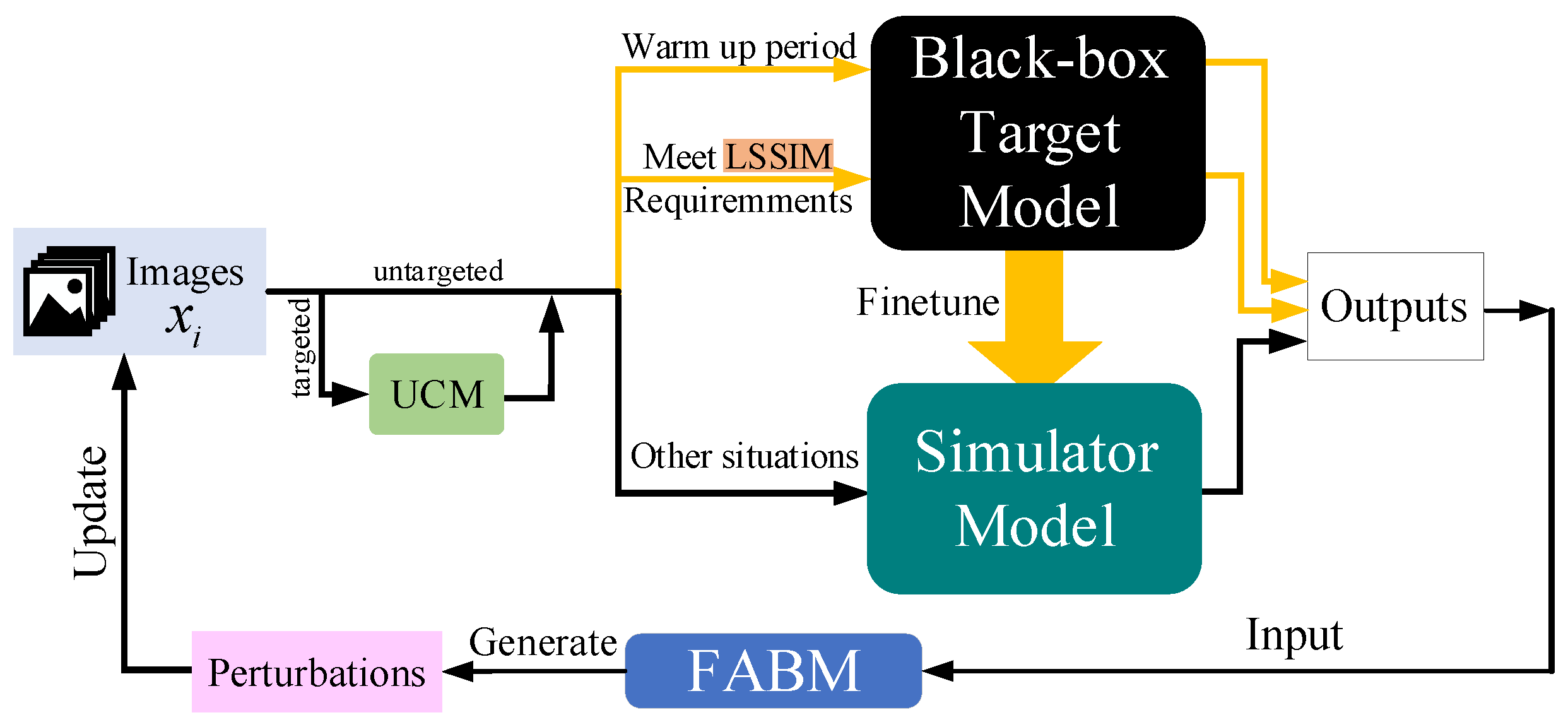
Based on this discovery, we make full use of the feature layer information of the simulator model and propose a feature attentional boosting module (FABM). This module strengthens the adversarial attack of perturbations, which is conducive to our attack framework to find suitable adversarial examples faster than the baseline. We add an unsupervised clustering module (UCM) and a linear self-adaptive simulator-predict interval mechanism (LSSIM) to the targeted attack to solve the cold start problem in attack situations requiring a large number of queries. Figure 1 below clearly presents the whole process of Simulator Attack+.
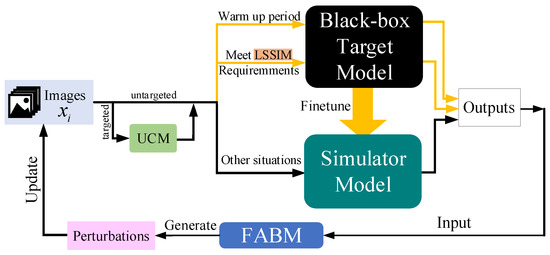
Figure 1.
Our Simulator Attack+ iteratively updates the attack images. These images query the black-box target model for finetuning the simulator model. LSSIM gives a dynamic interval for images to visit the black-box target model for adjustment. When the simulator model becomes similar enough to the black-box model, the simulator model receives the bulk of the queries. FABM takes both local and global information into consideration to boost the attack.
In this paper, for the purpose of comparing the performance of our attack framework with the baseline explicitly, we follow the settings of Ma et al. [21] to conduct adversarial attacks [8,9,23,24,25] against the same black-box target models using the CIFAR-10 [26] and CIFAR-100 [26] datasets. The experimental results show that, compared with the baseline [21], our framework achieves a certain degree of improvement in query information utilization while maintaining a high attack success rate.
The main contributions of this paper are summarized in the following points:
(1) We find and prove that the feature representation ability of the simulator model in black-box attacks based on meta-learning is correct and usable. The simulator model obtained through meta-learning can already represent the features and characteristics of an object in the image relatively correctly in the initial state. So the internal feature information of such a model can be used as a basis for generating and updating the perturbations that we require in the adversarial attack.
(2) Combined with the finding of (1), we analyze and optimize Ma’s Simulator Attack [21] and propose its improved version, Simulator Attack+. Our black-box attack framework makes specific adjustments to the three shortcomings of the baseline method by adding FABM, LSSIM, and UCM separately to solve the above mentioned problems:
- The correct feature layer information of the simulator model obtained by meta-learning is ignored in the baseline, whereas it is actually valuable for acquiring proper adversarial perturbations;
- Ma’s attack framework [21] has an imbalance in the imitation effect before and after the simulator model is fully fine-tuned;
- Adversarial perturbation changing only considers global adjustment without specialization enhancement.
(3) Conducting multi-group experiments on the CIFAR-10 and CIFAR-100 datasets, our well-designed meta-learning-based black-box attack framework greatly improves the utilization of query information compared with the original version, and also raises query efficiency to a certain extent while reducing the number of queries.
2. Related Works
In this section, we introduce some related work about present black-box adversarial attacks.
2.1. Attacks Based on Query
At present, query-based black-box adversarial attack studies follow two different directions to generate adversarial examples: score-based attacks and decision-based attacks. The former uses the probability of classification generated by the target black-box model in each query, while the latter depends on the label results of the target model outputs. Most score-based attack methods utilize specific gradient estimation calculations to find out the final adversarial perturbations. Zeroth-order optimization (ZOO) [6,27,28], inspired by derivative-free optimization (DFO) [29] and its improved versions [30], has been introduced to estimate the gradient of the target model directly for a relatively high attack success rate. However, this kind of black-box adversarial attack has to conduct a massive number of queries on the target model to collect enough information. Such information can be used to change specific pixels of an image in the attacking stage. This leads to the problem that such an attack can be easily defended against by the target model by rejecting or limiting queries in actual application scenes. In order to enhance query efficiency, strategies for focusing on the principal components of data [27], adaptive random estimation [30], involving prior gradients [9,31], active learning [32], approximating high-order gradients [33], and random search directions [34] and positions [35] have been applied. For decision-based attacks, researchers have put more focus on the use of label information [28,36] because in actual situations, classification labels are more common than score outputs. Although the information that can be obtained is sparse, query-based attacks still holds their place in black-box adversarial attack research. Several improved methods have been proposed, such as hard labeling with population-based optimization [37], an evolutionary attack algorithm [38], and a reverse boundary searching strategy [39].
2.2. Attacks Based on Transfer
Transfer-based attacks rely on the adversarial examples transferability theory [40]. While this type of attack can reduce the quantity of queries by consulting another designed model, the success rate is still tightly bound to the difference between the source model and the target model during the transformation period [10,12,13], which leads to the fact that such attacks may not perform well in some situations. Researchers have developed model-stealing attacks [30] and hyperparameter-stealing attacks [17] to reach higher attack success rates. For achieving a more accurate transferred model, model reconstruction [41], knockoff model [15], and local policy model [16] strategies have been published. Model reconstruction gives effective heuristic methods for reconstructing models from gradient information. A knockoff model applies queries fitting different distributions to enhance model performance. A local policy model builds the model on the basis of commonsense according to the usage of the target model and creates fake random training data for the policy model to learn decision boundaries more precisely. Nathan Inkawhich et al. [40] has pushed transfer-based attack further by using multi-layer perturbations on the basis of the extracted feature hierarchy. In this paper, we tend to train a super simulator model [21] by using the information generated from other popular recognition models to substitute for the target model. Once the simulator model has been adequately finetuned, it can perfectly imitate the black-box model, and then subsequent queries are sent to this imitator to avoid a large number of target model queries.
2.3. Attacks Based on Meta Learning
Model training from meta-learning has the ability to adapt to news conditions very quickly. Ma et al. [42] present MetaAdvDet with a double-network framework based on meta-learning that only requires a few queries to detect a new kind of adversarial attack. One part of this framework can learn from previous attacks, and another can do specific tasks to counter new attack methods. Du et al. [23] use meta-leaning, gradient estimation, and an auto-encoder network structure to train a meta attacker, then search for successful adversarial examples rapidly with this attacker model. Finetuning has also been inserted into this gray-box attack to improve query efficiency. Moreover, based on meta knowledge hidden in the meta-training set and meta-testing set, Ma et al. [21] then introduce a simulator model containing the features of several classic models as a substitute through meta-training and knowledge distillation. Such a simulator model structure can be defined differently by users and can also perform well when the black-box target model has some defense characteristics. Although Ma’s simulator has a rather good attack success rate for both targeted attack and untargeted attack and meets low-query demands well, the potential of simulator attacks can be pushed further by utilizing the feature layer information in a pre-trained simulator model inspired by adversarial example transferability factors study [40]. In order to strengthen adversarial attack, a random normal distribution strategy and momentum boosting strategy can be applied while generating adversarial examples against the target model. Further, for higher query efficiency, we also add an unsupervised clustering module in the simulator attacking period. In the warm-up stage, prior gradient clustering knowledge can be shared amongst all batch images, which can rapidly help part of the images finish attacking successfully. Then, we design a unique simulator-predict interval increasing mechanism to allow our simulator model to make sufficient preparation for coming queries.
3. Methods
To improve the query efficiency and decrease the total number of queries consumed, we propose FABM, LSSIM, and UCM and then attach these modules to our Simulator Attack+ framework. These attachments follow our discovery that similarity feature layer information between two models can help optimize the baseline method.
3.1. Feature Attentional Boosting Module
As a consensus, a meta simulator model trained from meta-learning can quickly imitate another model by finetuning itself and shares generality with other mainstream models. However, such a meta simulator model applied in Simulator Attack is treated the same as the black-box model. Its internal information is ignored during an attack. In order to find the usability of this information, we extract and visualize the feature layer of a simulator model (Figure 2). After comparing the feature attentional regions between the simulator model and the black-box target model, we find that the attentional areas of both models nearly overlap. Thus, we conclude that some of the feature layer information in the meta simulator model can be used in the black-box attack due to their similarity. However, Figure 3 also indicates that the classification ability varies between the initial simulator model and the black-box target model, and this classification ability is the key point that the simulator model needs to learn during the finetuning process.

Figure 2.
The feature layer and attentional region visualization of the first 9 images from the first batch input into the initial simulator model and the black-box model. The first line is the original images. The second line is the feature layer visualization of the initial meta simulator model. The third line is the feature attentional region of the initial meta simulator model. The fourth line is the feature layer visualization of the black-box target model (PyramidNet272). The last line is the feature attentional region of the black-box model.
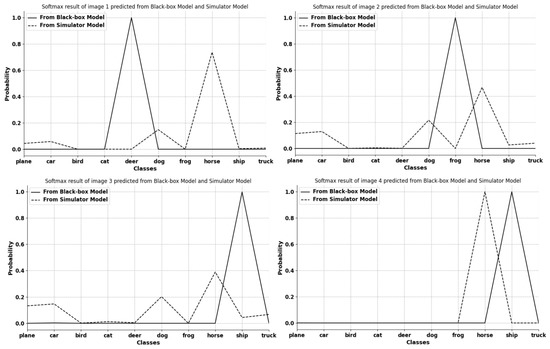
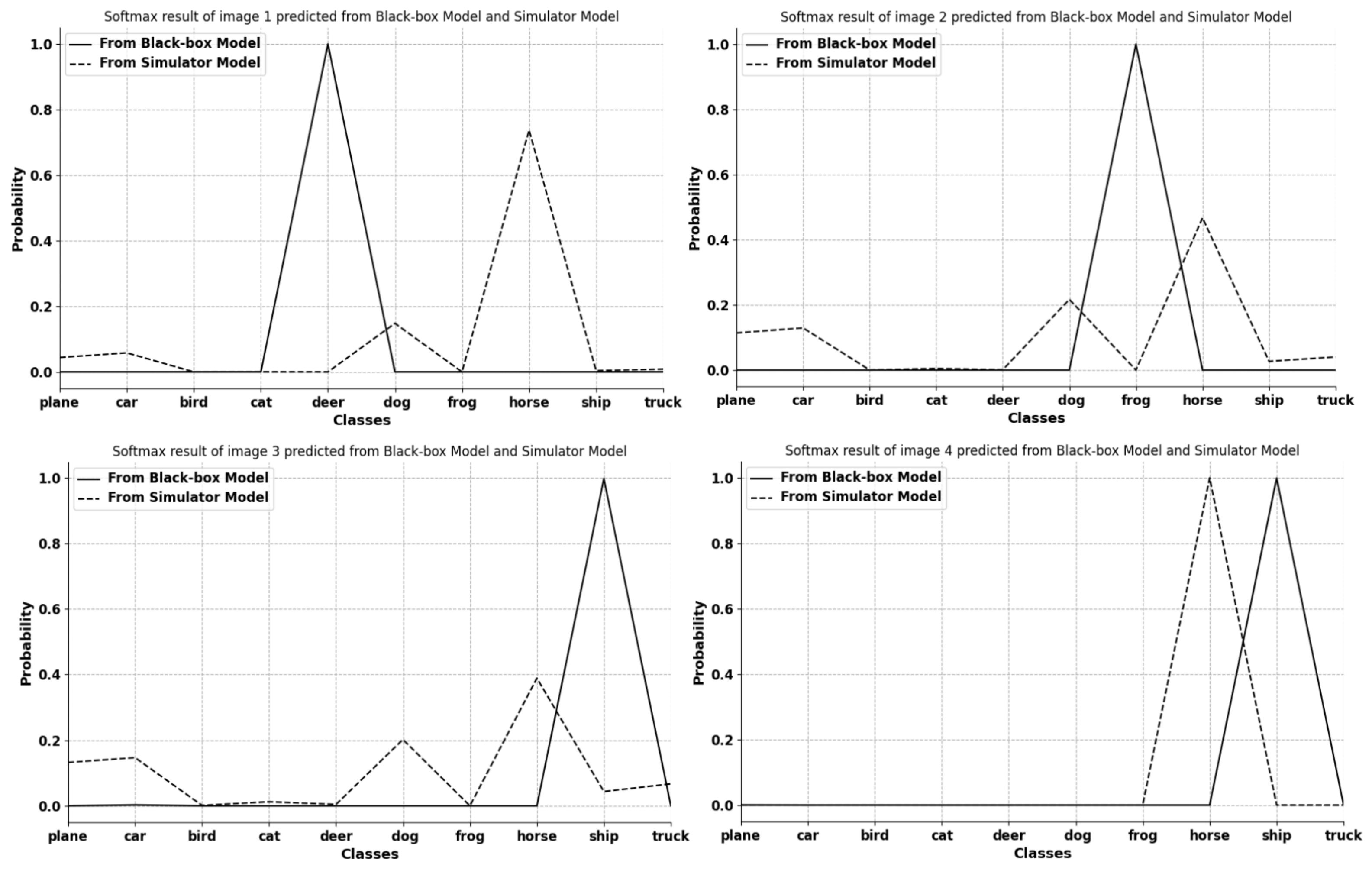
Figure 3.
Visualization of 4 selected image softmax results from the first batch input into the initial simulator model and the black-box model. The x axis and y axis represent 10 different classes in CIFAR-10 [26] and probability values, respectively. The figure obviously shows that the classification results of the two models at the beginning are different. This indicates that the classification ability of the simulator model at this stage is not well prepared.
In the baseline, Ma et al. [21] only use random normal distribution noise as their step-size in the image changing process. This method has strong randomness in searching for proper adversarial perturbations. Furthermore, for how to change the adversarial images properly, Ma [21] merely provides a global direction for all pixels in an image to transform without optimizing specific areas or using any corrected feature information based on prior knowledge. To improve the usage of information from queries more rationally, we add an extra adversarial effect inspired by the attention mechanism to reduce the randomness as much as possible. At the same time, such additional adversarial perturbations can create extra radical attacks on attentional regions where both the meta simulator model and the black-box model focus. We give two different options of adversarial perturbation type: normal distribution boosting and momentum boosting. Normal distribution boosting follows the method of the baseline to search for the proper adversarial perturbation randomly by using a common distribution. Because the information supplied by black-box model outputs is so sparse, we have to use additional perturbations when they are random, as in Ma et al. [21], to enhance the adversarial effect on specific regions while reducing randomness of inappropriate values in significant positions. However, different from the baseline, we consider different concrete distributions that are smoother to highlight the attentional area and keep the original distribution working as previously. As Wu et al. [40] conclude, the local oscillation of a loss surface can be suppressed by the smoothing effect. Our smoother distribution reduces harmful effects to the utmost and makes valid emphasis of attentional regions. Equations (1) and (2) show how the feature attentional boosting module works compared to a random normal distribution:
where and refer to the attack image in the current attack step and previous attack step, respectively, represents the final adversarial perturbation in the current attack step, is the original adversarial perturbation the baseline creates, and is the additional adversarial perturbation belonging to another distribution we designed to strengthen the effect on the attentional region.
Momentum boosting replaces the original random normal distribution in attentional regions by an adversarial perturbation updating strategy based on momentum. This method takes both the descent direction achieved in the current attack step and all previous directions into consideration. By consulting these factors comprehensively, the additional adversarial perturbation emphasizes the adversarial effect in the attentional region and hastens the image-changing process. Equations (3) and (4) define the momentum boosting module in detail:
where is the final momentum boosting adversarial perturbation added via the original random normal process, and parameter controls the effect generated by the current adversarial perturbation direction and the average direction calculated from all previous adversarial perturbations; the value of should be set in the range from zero to one.
The whole feature attentional boosting module (FABM) only works after visiting the black-box target model. As the adversarial perturbation direction obtained by the black-box target model is definitely correct, using this direction on attentional regions helps the adversarial attack succeed faster. If this module works at every stage of the attack, the total number of queries will increase instead. When the simulator model has not been fine-tuned well, it may give wrong directions for attentional module guidance. This would cause the adversarial model to require more queries to attack successfully.
3.2. Linear Self-Adaptive Simulator-Predict Interval Mechanism
While the simulator model acquired from meta-learning can imitate any model by finetuning itself in limited steps, the simulator model in its initial state is not well-prepared for coming queries. It still has a weak ability to give similar outputs to those of the black-box target at the early period. This leads to the fact that the first several queries to the simulator model might misdirect the changing of adversarial perturbations due to the difference between the two models, as shown in Figure 3. Thus, the whole attack process may waste queries finding the right direction, which can make the query number reasonably large. To solve this problem, we design a linear self-adaptive simulator-predict interval mechanism (LISSIM) in our simulator attack. The mechanism is divided into two parts: a linear self-adaptive function guided by a gradually increasing parameter, and a threshold value to give a maximum to the simulator-predict interval. Equation (5) describes this mechanism in detail.
where is the final interval for every visit to the black-box target model, refers to the upper bound value of the interval for whole attack process, is the index of steps, and is the adaptive factor we designed to control the pace of interval increases.
By using this mechanism, our simulator will have plenty of time to adjust itself to be more similar to the black-box target model. At the same time, adversarial perturbations also have enough opportunities to move further along in the appropriate direction precisely by visiting the black-box model with a high frequency during the beginning.
3.3. Unsupervised Clustering Module
Based on the usability of simulator model internal feature information, we add an unsupervised clustering module (UCM) as warm boot at the beginning to accelerate the whole simulator attack process. This module helps other images in the same clustering group quickly find adversarial perturbations based on the prior knowledge of clustering centers. We select a low-dimension feature clustering algorithm in this module. For the clustering mechanism, we focus on the distance between features extracted from simulator models and specific processes.
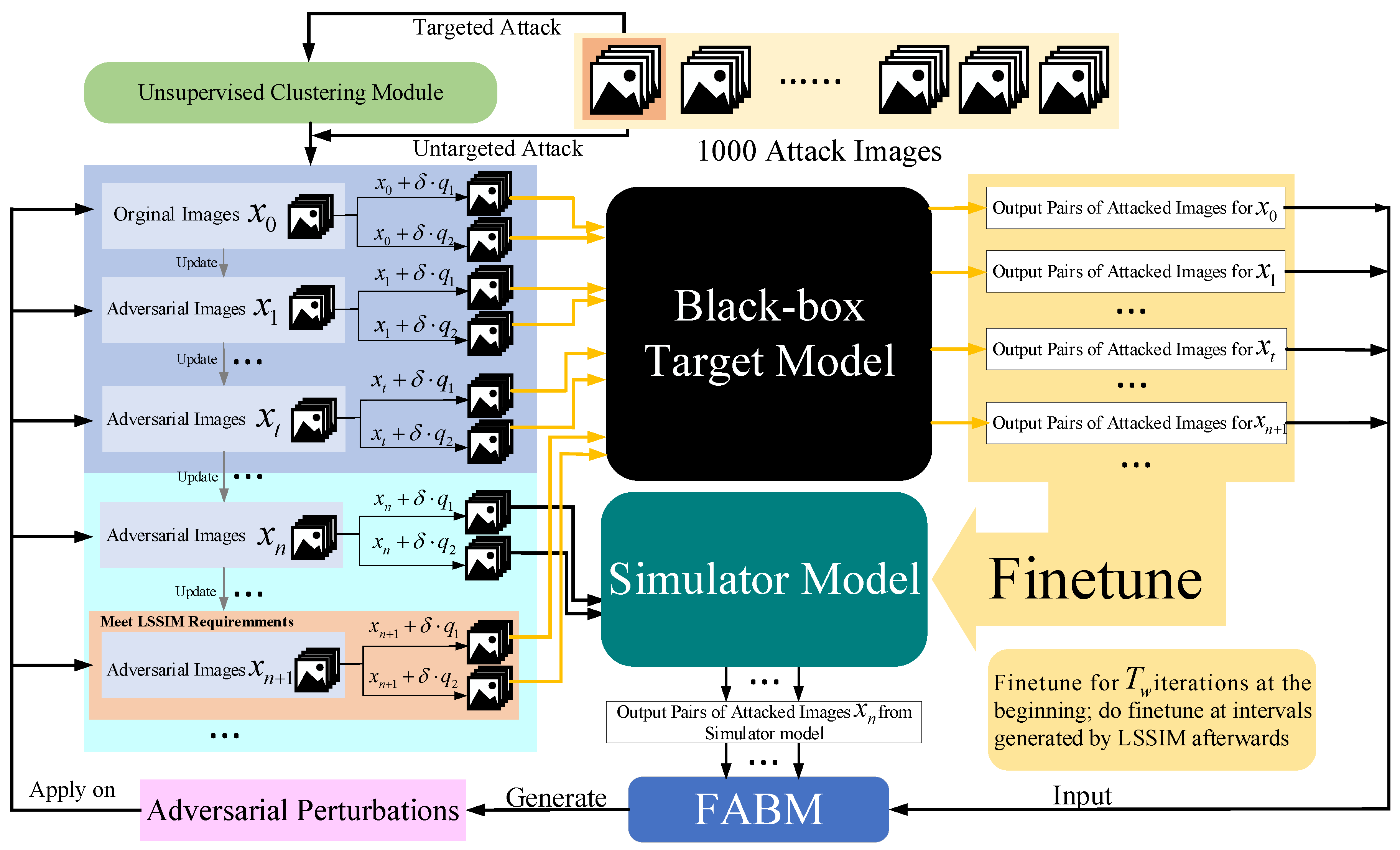
By applying an unsupervised clustering module to simulator attack, samples close to clustering centers rapidly finish their attack during the beginning of the attack process. Then we change the adversarial perturbation back to the initial state to achieve a cold boot for other unfinished images. Because these images are far from clustering centers, using prior knowledge will interference with their generating of correct adversarial perturbation. The whole process of Simulator Attack+ is exhibited in Figure 4. Firstly, the generation of adversarial perturbations relies on the estimation of image general gradient direction by adding noise and .
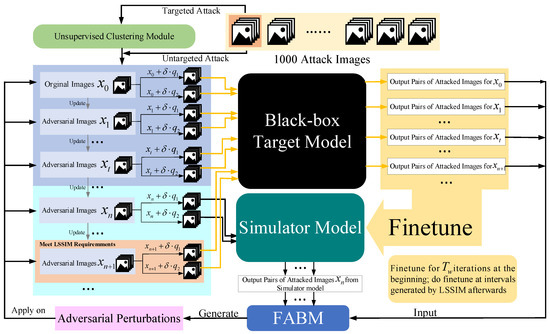
Figure 4.
Detailed process of Simulator Attack+.
If the attacker chooses to conduct a targeted attack, all the attack images are input into our unsupervised clustering module (UCM) to learn clustering center prior knowledge based on feature layer information. Otherwise, if the attacker chooses to conduct an untargeted attack, the attack images are immediately ready.
In the first steps, images visit the black-box target model to provide accurate information to finetune the pre-trained initial simulator model. Through this operation, our simulator model can gradually master the classification ability similar to that of the black-box target model and give precise results for any image input. When the step index meets the requirements of the interval value calculated by the linear self-adaptive simulator-predict interval mechanism (LSSIM), the attack images in the figure also visit the black-box target model in order to finetune the simulator model at a certain frequency. In the finetuning stage, influences making the simulator similar to the black-box target model. Further, other attack images such as query our finetuned simulator model for how to adjust the pixels.
The feature attentional boosting module (FABM) is utilized to enhance the adversarial effect of perturbations that are generated by the outputs of the two models. Such new perturbations are used to update the attack images from global and local perspectives in this iteration. Through constantly updating iterations, the attack images finally make the black-box target model unable to recognize them correctly. Additionally, the whole simulator attack is also shown in Algorithm 1.
4. Experiments
4.1. Experiment Settings
In this section, the parameter settings of the experiment and the setup of the model are described in detail.
4.1.1. Dataset and Target Models
Experiments in this paper are conducted on the CIFAR-10 [26], CIFAR-100 [26] datasets. CIFAR-10 consists of 60,000 32*32-pixel colored images from 10 classes. CIFAR-100 is composed of 100 classes of images with 600 images per class. For comparison with the work of Ma et al. [21], we also use 1000 randomly selected test images from validation sets of CIFAR-10 and CIFAR-100 for evaluating our improved attack method. For the black-box targets, we select the sames models as Ma et al. [21] and Yan et al. [43]: (1) PyramidNet+Shakedrop network with 272 layers (PyramidNet-272) [44,45] trained by AutoAugment [46]; (2) GDAS [47] generated by neural architecture search with DAG involved; (3) WRN-28 [48], which contains 28 layers and possesses a wide dimension; and (4) WRN-40 [48] with 40 layers.
| Algorithm 1 Simulator Attack+ under the condition |
Input: The input image , where D means the image dimension, the label of the image x with groundtruth, the pre-trained simulator model , the forward function of the black-box target model interface f, and the finetuning loss function . Parameters: Warm-up iteration steps t, the adaptive predict-interval of LSSIM , Bandits Attack parameter , noise exploration parameter , Bandits prior learning rate , image updating rate , the momentum factor of FABM, group numbers of unsupervised clustering results, the center beginning perturbations , of input images, attack type , project function , and image update function . Output: Adversarial image that meets the requirements of norm-set attack, as .
|
4.1.2. Method Setting
We follow the black-box attack process of Ma et al. [21]; we divide the whole attack into two parts: training the meta simulator and using the meta simulator to attack. In the training part, we first generate the meta-train set and meta-test set on query sequence data , also known as meta tasks obtained after querying other classic models. Then, ResNet-34 is selected as the backbone of the simulator model. We train the simulator to adjust its weights by the meta-train set and meta-test set ; each of them consists of 50 query pairs. During the attacking period, we give a 10-time fine-tuning operation as a warm up for the simulator attack. After that, the fine-tuning number reduces to a random number ranging from 3 to 5 in subsequent iterations. For an untargeted attack, the victim image may be changed randomly to a class it originally did not belong to. For a targeted attack, we give two options for attackers: random or incremental targeting. Random targeting is designed to give a random target set as , where is the total class number, and is the target class. Incremental targeting sets the target class as . For evaluating the simulator attack together with the condition of conducted query number, we introduce attack success rate and average and median values of queries. Here, the whole black-box attack process has been conducted on an NVIDIA RTX 3090 GPU. On our platform, the average time required for an untargeted attack on four selected target victim models is around 10 h, and that of a targeted attack is around 72 h.
4.1.3. Pre-Trained Networks
The models we select for the meta-learning of the simulator do not contain the black-box models, so we can completely show the performance of our attack method under the hardest condition. For CIFAR-10 and CIFAR-100 datasets, we choose 14 different networks as the meta-learning materials, including AlexNet, DenseNet, PreResNet, ResNeXt, etc., and their other versions. Identical to the attack evaluation logic of Ma et al. [21], we conduct attacks against defensive black-box models. However, the simulator for defensive targets is retrained without considering ResNet networks because such targets apply ResNet-50 as their backbone. If we use the same simulator model as the normal version during the experiment, it may cause inaccuracy in the end and may be incomparable to the work of Ma et al. [21].
4.1.4. Compared Methods
We follow Ma’s selection in his simulator attack and choose NES [8], Bandits [9], Meta Attack [23], RGF [24], P-RGF [25], and Simulator Attack [21] as our compared attack methods, with Simulator Attack as our baseline. We extend Ma’s criteria of these attack methods and his compared experiment results to the CIFAR-10 and CIFAR-100 datasets. We give a limit of queries of 10,000 in both untargeted and targeted attacks, and set the same values in the same experiment group: 4.6 in the norm attack, and 8/255 in the norm attack. In the meta-learning stage, we set the default learning rate of the inner loop update as 0.01 and of the outer ones as 0.001. In the simulator-attacking stage, the default values of the image learning rate are 0.1 and 1/255 for norm and norm attacks, respectively. Furthermore, the prior learning rates of Bandit attacks, also known as OCO learning rates, are 0.1 for norm attack and 1.0 for norm attack. For simulator predict interval, we give 5 as the standard. In the fine-tuning section, the length of the fine-tuning queue is 10, and we present 10 black-box queries as the warm-up for the whole framework. The detailed information of the default parameters for Simulator Attack+ are shown in Table 1.

Table 1.
Default parameter settings of Simulator Attack+.
4.2. Ablation Study
4.2.1. Ablation Study for Feature Attentional Boosting Module
We first compare our two methods in FABM and decide to use the momentum boosting module in the final version of our Simulator Attack+. Then, we conduct a group of experiments for our opinion by only adding FABM and adjusting the weight values of the current direction and the average direction. The range of current direction weight value is set from 0.9 to 1. Table 2 and Table 3 show results.
Table 2.
Experiments using only momentum boosting module (FABM) on CIFAR-100, untargeted attack, and norm.
Table 3.
Experiments only using momentum boosting module (FABM) on CIFAR-10 against different defensive models.
4.2.2. Ablation Study for Linear Self-Adaptive Simulator-Predict Interval Mechanism
Table 4 clearly shows the results of experiments with Simulator Attack with different parameters of only the LSSIM module added. This module can provide considerable positive influence under proper parameter pairs when conducting targeted attacks, as such attacks use large numbers of queries.
Table 4.
Experiments using only linear self-adaptive simulator-predict interval mechanism module (LSSIM) on CIFAR-100, targeted attack, and norm.
4.2.3. Ablation Study for Unsupervised Clustering Module
We conduct a targeted attack within the norm on CIFAR-10 to test the enhancement effect of our unsupervised clustering module (UCM). Table 5 shows the results compared with the baseline [21]. As the time that this attack takes is very long, we only choose one round to show the improvement.
Table 5.
Experiments using only unsupervised clustering module (UCM) on CIFAR-10, targeted attack, and norm.
4.3. Comparisons with Existing Methods
In this section, we conduct comparison experiments with our baseline Simulator Attack and other existing black-box adversarial methods. Then, we give an analysis of the results we achieve. At last, we present our tables and figures of these experiment results.
4.3.1. Comparisons with Attacks on Normal Victim Models
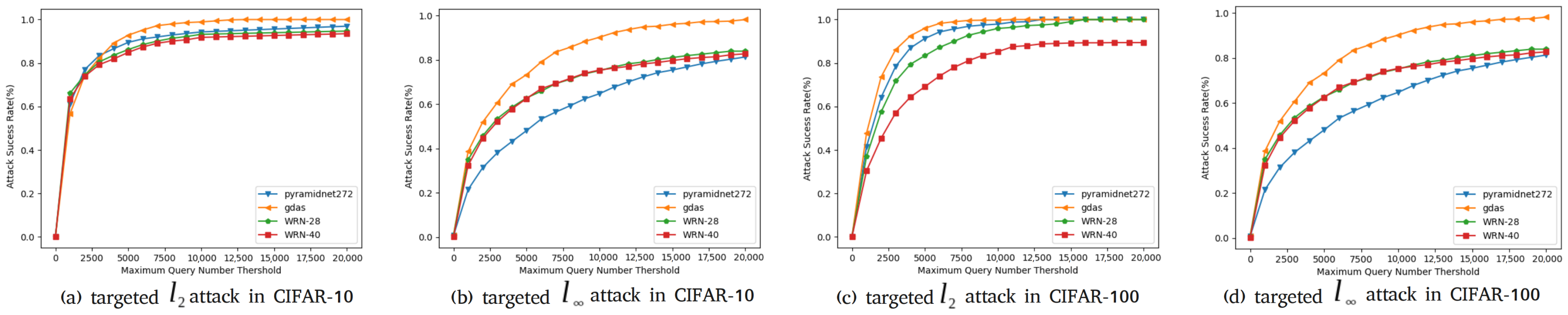
In this part, we compare our method with our baseline Simulator Attack [21] and other classic black-box adversarial attack methods on normal victim classification models mentioned before. The models are designed without considering defensive mechanisms. Experiments are conducted on the target models we mention in Section 4.1. We show the results of these experiments on CIFAR-10 and CIFAR-100 datasets in Table 6 and Table 7. We found a decline in the success rate of attacks, mainly concentrated on targeted attacks on the CIFAR-10 and CIFAR-100 datasets. To demonstrate the effectiveness of our proposed method, Simulator Attack+, we set the maximum queries from 10,000 to 20,000, named Simulator Attack ++, and calculate the average queries when the attack success rates are close to the comparison method. To further inspect the attack success rates with different maximum numbers of queries, as shown in Figure 5 and Figure 6, we perform targeted attacks on CIFAR-10 and CIFAR-100 datasets by limiting the different maximum queries of each adversarial example.
Table 6.
Experimental results of untargeted attacks on CIFAR-10 and CIFAR-100 datasets with a maximum of 10,000 queries.
Table 7.
Experimental results of targeted attacks on CIFAR-10 and CIFAR-100 datasets with a maximum of up to 20,000 queries.
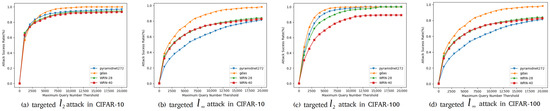
Figure 5.
Attack success rates at different maximum query limits.

Figure 6.
Average queries per successful image at different desired success rates.
4.3.2. Comparisons with Attacks on Normal Defensive Victim Models
The results of attacks on defensive models are presented in Table 4. The defensive victim models are the same as those selected by Ma et al. [21] and include ComDefend (CD) [49], Prototype conformity loss (PCL) [50], Feature Distillation (FD) [51], and Adv Train [4]. ComDefend and Feature Distillation share a similar strategy of denoising the input images at the beginning. This operation makes sure that the images fed into the target model are their clean version. Prototype conformity loss represents a kind of loss function that is usually applied to divide the classes according to the information generated from their feature layers. For fair comparison, our PCL defensive model here is similar to Ma’s research, in that it is not trained adversarially in these experiments. Adv Train uses a min–max optimization framework to conduct adversarial training, which makes models gain strong and robust features and defensive performance. Table 8 exhibits the results of our attack against defensive models.
Table 8.
Experimental results of untargeted attacks on CIFAR-10, CIFAR-100, and TinyImageNet datasets against different defensive models with a maximum of 10,000 queries. In this table, ComDefend, Feature Distillation, and Prototype Conformity Loss are referred to as CD, FD, and PCL, respectively.
4.3.3. Experimental Figure and Analysis
The three principal indicators of Table 6, Table 7 and Table 8, respectively, are attack success rate, average query number, and median query number. In order to compare the performance of our Simulator Attack+ with the baseline [21] and normal models under different conditions, we set and norm attack limits separately and maximum queries as 10,000. The results in the tables evidently show that: (1) our Simulator Attack+ method can easily obtain a reduction ranging from 5% to 10% in the average and median values of query times compared to the baseline Simulator Attack and other attacks; (2) our attack framework keeps the values of attack success rate in both types of attack closed enough to that of the original version; (3) our Simulator Attack+ also performs well when attacking black-box models with defensive mechanism.
5. Conclusions
In this study, we first discover the feature layer similarity of simulator models based on meta-learning. Then we propose an improved black-box attack framework, Simulator Attack+. UCM, FABM, and LSSIM are attached to our attack, which takes more information into consideration when searching for proper adversarial perturbations than the baseline by Ma et al. [21]. UCM in targeted attack can utilize prior gradient knowledge to accelerate the attack process. FABM can boost the perturbations in attentional regions. LSSIM helps the simulator model have a warm-start. At last, the experiment results clearly show that our Simulator Attack+ framework can use fewer queries to attack black-box target models efficiently while maintaining a relatively high attack success rate.
Author Contributions
Conceptualization, Z.C.; methodology, Z.C.; software, Z.C.; data curation, J.D., Y.S. and S.L.; Writing—Original draft preparation, J.D.; Supervision, F.W.; Editing Investigation, F.W.; Visualization, C.Z.; Writing- Reviewing and Editing, J.S.; Ideas, formulation or evolution of overarching research goals and aims, Y.J. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the National Key R&D Program of China (2018AAA0103300, 2018AAA0103302), Natural Science Foundation of Jiangsu Province (Higher Education Institutions) (BK20170900, 19KJB520046, and 20KJA520001), Innovative and Entrepreneurial talents projects of Jiangsu Province, Jiangsu Planned Projects for Postdoctoral Research Funds (No. 2019K024), Six talent peak projects in Jiangsu Province (JY02), Postgraduate Research & Practice Innovation Program of Jiangsu Province (KYCX19_0921, KYCX19_0906), Open Research Project of Zhejiang Lab (2021KF0AB05), and NUPT DingShan Scholar Project and NUPTSF (NY219132).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Conflicts of Interest
All authors disclosed no relevant relationships.
References
- Biggio, B.; Corona, I.; Maiorca, D.; Nelson, B. Evasion attacks against machine learning at test time. In Machine Learning and Knowledge Discovery in Databases; Springer: Berlin/Heidelberg, Germany, 2013; pp. 387–402. [Google Scholar]
- Goodfellow, I.J.; Shlens, J.; Szegedy, C. Explaining and Harnessing Adversarial Examples. arXiv 2014, arXiv:1412.6572. [Google Scholar]
- Szegedy, C.; Zaremba, W.; Sutskever, I.; Bruna, J.; Erhan, D.; Goodfellow, I.; Fergus, R. Intriguing properties of neural networks. arXiv 2014, arXiv:1312.6199. [Google Scholar]
- Madry, A.; Makelov, A.; Schmidt, L.; Tsipras, D.; Vladu, A. Towards deep learning models resistant to adversarial attacks. Stat 2017, 1050, 9. [Google Scholar]
- Carlini, N.; Wagner, D. Towards evaluating the robustness of neural networks. In Proceedings of the 2017 IEEE Symposium on Security and Privacy, San Jose, CA, USA, 22–26 May 2017; pp. 39–57. [Google Scholar]
- Chen, P.Y.; Zhang, H.; Sharma, Y.; Yi, J.; Hsieh, C.J. Zoo: Zeroth order optimization based black-box attacks to deep neural networks without training substitute models. In Proceedings of the 10th ACM Workshop on Artificial Intelligence and Security, Dallas, TX, USA, 3 November 2017; pp. 15–26. [Google Scholar]
- Tu, C.C.; Ting, P.; Chen, P.Y.; Liu, S.; Cheng, S.M. AutoZOOM: Autoencoder-Based Zeroth Order Optimization Method for Attacking Black-Box Neural Networks. In Proceedings of the AAAI Conference on Artificial Intelligence, Atlanta, Georgia, 8–12 October 2019; Volume 33, pp. 742–749. [Google Scholar]
- Ilyas, A.; Engstrom, L.; Athalye, A.; Lin, J. Black-box adversarial attacks with limited queries and information. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 2137–2146. [Google Scholar]
- Ilyas, A.; Engstrom, L.; Madry, A. Prior convictions: Black-box adversarial attacks with bandits and priors. arXiv 2018, arXiv:1807.07978. [Google Scholar]
- Liu, Y.; Chen, X.; Liu, C.; Song, D. Delving into Transferable Adversarial Examples and Black-box Attacks. arXiv 2016, arXiv:1611.02770. [Google Scholar]
- Oh, S.J.; Schiele, B.; Fritz, M. Towards Reverse-Engineering Black-Box Neural Networks; Springer: Cham, Switzerland, 2019; pp. 121–144. [Google Scholar]
- Demontis, A.; Melis, M.; Pintor, M.; Jagielski, M.; Biggio, B.; Oprea, A.; Nita-Rotaru, C.; Roli, F. Why do adversarial attacks transfer? explaining transferability of evasion and poisoning attacks. In Proceedings of the 28th USENIX Security Symposium (USENIX Security 19), Santa Clara, CA, USA, 14–16 August 2019; pp. 321–338. [Google Scholar]
- Huang, Q.; Katsman, I.; He, H.; Gu, Z.; Belongie, S.; Lim, S.N. Enhancing adversarial example transferability with an intermediate level attack. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 4733–4742. [Google Scholar]
- Chen, S.; He, Z.; Sun, C.; Yang, J.; Huang, X. Universal Adversarial Attack on Attention and the Resulting Dataset DAmageNet. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 2188–2197. [Google Scholar] [CrossRef]
- Orekondy, T.; Schiele, B.; Fritz, M. Knockoff nets: Stealing functionality of black-box models. In Proceedings of the Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4954–4963. [Google Scholar]
- Papernot, N.; McDaniel, P.; Goodfellow, I.; Jha, S.; Celik, Z.B.; Swami, A. Practical black-box attacks against machine learning. In Proceedings of the 2017 ACM on Asia Conference on Computer and Communications Security, Abu Dhabi, United Arab Emirates, 2–6 April 2017; pp. 506–519. [Google Scholar]
- Tramr, F.; Zhang, F.; Juels, A.; Reiter, M.K.; Ristenpart, T. Stealing machine learning models via prediction APIs. In Proceedings of the 25th USENIX security symposium (USENIX Security 16), Austin, TX, USA, 10–12 August 2016; pp. 601–618. [Google Scholar]
- Lee, T.; Edwards, B.; Molloy, I.; Su, D. Defending against neural network model stealing attacks using deceptive perturbations. In Proceedings of the 2019 IEEE Security and Privacy Workshops, San Francisco, CA, USA, 19–23 May 2019; pp. 43–49. [Google Scholar]
- Orekondy, T.; Schiele, B.; Fritz, M. Prediction Poisoning: Towards Defenses Against DNN Model Stealing Attacks. arXiv 2019, arXiv:1906.10908. [Google Scholar]
- Xu, Y.; Ghamisi, P. Universal Adversarial Examples in Remote Sensing: Methodology and Benchmark. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–15. [Google Scholar] [CrossRef]
- Ma, C.; Chen, L.; Yong, J.H. Simulating unknown target models for query-efficient black-box attacks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 11835–11844. [Google Scholar]
- Zhou, B.; Cui, Q.; Wei, X.S.; Chen, Z.M. Bbn: Bilateral-branch network with cumulative learning for long-tailed visual recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 9719–9728. [Google Scholar]
- Du, J.; Zhang, H.; Zhou, J.T.; Yang, Y.; Feng, J. Query-efficient Meta Attack to Deep Neural Networks. arXiv 2020, arXiv:1906.02398. [Google Scholar]
- Nesterov, Y.; Spokoiny, V. Random gradient-free minimization of convex functions. Found. Comput. Math. 2017, 17, 527–566. [Google Scholar] [CrossRef]
- Cheng, S.; Dong, Y.; Pang, T.; Su, H.; Zhu, J. Improving black-box adversarial attacks with a transfer-based prior. Adv. Neural Inf. Process. Syst. 2019, 32, 10934–10944. [Google Scholar]
- Krizhevsky, A.; Hinton, G. Learning Multiple Layers of Features from Tiny Images; University of Toronto: Toronto, ON, USA, 2009. [Google Scholar]
- Bhagoji, A.N.; He, W.; Li, B.; Song, D. Practical black-box attacks on deep neural networks using efficient query mechanisms. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 154–169. [Google Scholar]
- Cheng, M.; Le, T.; Chen, P.Y.; Zhang, H.; Yi, J.; Hsieh, C.J. Query-Efficient Hard-label Black-box Attack: An Optimization-based Approach. arXiv 2019, arXiv:1807.04457. [Google Scholar]
- Brendel, W.; Rauber, J.; Bethge, M. Decision-Based Adversarial Attacks: Reliable Attacks Against Black-Box Machine Learning Models. arXiv 2018, arXiv:1712.04248. [Google Scholar]
- Wang, B.; Gong, N.Z. Stealing hyperparameters in machine learning. In Proceedings of the 2018 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 20–24 May 2018; pp. 36–52. [Google Scholar]
- Ma, C.; Cheng, S.; Chen, L.; Zhu, J.; Yong, J. Switching Transferable Gradient Directions for Query-Efficient Black-Box Adversarial Attacks. arXiv 2020, arXiv:2009.07191. [Google Scholar]
- Pengcheng, L.; Yi, J.; Zhang, L. Query-efficient black-box attack by active learning. In Proceedings of the 2018 IEEE International Conference on Data Mining (ICDM), Singapore, 17–20 November 2018; pp. 1200–1205. [Google Scholar]
- Papernot, N.; McDaniel, P.; Goodfellow, I. Transferability in machine learning: From phenomena to black-box attacks using adversarial samples. arXiv 2016, arXiv:1605.07277. [Google Scholar]
- Guo, C.; Gardner, J.; You, Y.; Wilson, A.G.; Weinberger, K. Simple black-box adversarial attacks. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; pp. 2484–2493. [Google Scholar]
- Andriushchenko, M.; Croce, F.; Flammarion, N.; Hein, M. Square attack: A query-efficient black-box adversarial attack via random search. In Computer Vision—ECCV 2020; Springer: Cham, Switzerland, 2020; pp. 484–501. [Google Scholar]
- Chen, J.; Jordan, M.I.; Wainwright, M.J. Hopskipjumpattack: A query-efficient decision-based attack. In Proceedings of the 2020 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 18–21 May 2020; pp. 1277–1294. [Google Scholar]
- Yang, J.; Jiang, Y.; Huang, X.; Ni, B.; Zhao, C. Learning black-box attackers with transferable priors and query feedback. Adv. Neural Inf. Process. Syst. 2020, 33, 12288–12299. [Google Scholar]
- Inkawhich, N.; Liang, K.; Wang, B.; Inkawhich, M.; Carin, L.; Chen, Y. Perturbing across the feature hierarchy to improve standard and strict blackbox attack transferability. Adv. Neural Inf. Process. Syst. 2020, 33, 20791–20801. [Google Scholar]
- Dong, Y.; Su, H.; Wu, B.; Li, Z.; Liu, W.; Zhang, T.; Zhu, J. Efficient decision-based black-box adversarial attacks on face recognition. In Proceedings of the Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 7714–7722. [Google Scholar]
- Wu, L.; Zhu, Z.; Tai, C. Understanding and enhancing the transferability of adversarial examples. arXiv 2018, arXiv:1802.09707. [Google Scholar]
- Milli, S.; Schmidt, L.; Dragan, A.D.; Hardt, M. Model reconstruction from model explanations. In Proceedings of the Conference on Fairness, Accountability, and Transparency, Atlanta, GA, USA, 29–31 January 2019; pp. 1–9. [Google Scholar]
- Ma, C.; Zhao, C.; Shi, H.; Chen, L.; Yong, J.; Zeng, D. Metaadvdet: Towards robust detection of evolving adversarial attacks. In Proceedings of the 27th ACM International Conference on Multimedia, Nice, France, 21–25 October 2019; pp. 692–701. [Google Scholar]
- Guo, Y.; Yan, Z.; Zhang, C. Subspace attack: Exploiting promising subspaces for query-efficient black-box attacks. Adv. Neural Inf. Process. Syst. 2019, 32, 3825–3834. [Google Scholar]
- Han, D.; Kim, J.; Kim, J. Deep pyramidal residual networks. In Proceedings of the Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5927–5935. [Google Scholar]
- Yamada, Y.; Iwamura, M.; Akiba, T.; Kise, K. Shakedrop regularization for deep residual learning. IEEE Access 2019, 7, 186126–186136. [Google Scholar] [CrossRef]
- Cubuk, E.D.; Zoph, B.; Mane, D.; Vasudevan, V.; Le, Q.V. Autoaugment: Learning augmentation strategies from data. In Proceedings of the Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 113–123. [Google Scholar]
- Dong, X.; Yang, Y. Searching for a robust neural architecture in four gpu hours. In Proceedings of the Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 1761–1770. [Google Scholar]
- Zagoruyko, S.; Komodakis, N. Wide Residual Networks. arXiv 2016, arXiv:1605.07146. [Google Scholar]
- Jia, X.; Wei, X.; Cao, X.; Foroosh, H. Comdefend: An efficient image compression model to defend adversarial examples. In Proceedings of the of Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 6084–6092. [Google Scholar]
- Mustafa, A.; Khan, S.; Hayat, M.; Goecke, R.; Shen, J.; Shao, L. Adversarial defense by restricting the hidden space of deep neural networks. In Proceedings of the Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3385–3394. [Google Scholar]
- Liu, Z.; Liu, Q.; Liu, T.; Xu, N.; Lin, X.; Wang, Y.; Wen, W. Feature distillation: Dnn-oriented jpeg compression against adversarial examples. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 860–868. [Google Scholar]


Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).