
Driving Fatigue Detection with Three Non-Hair-Bearing EEG Channels and Modified Transformer Model

 ,
,
Abstract
:1. Introduction
2. Materials and Methods
2.1. Experimental Design
2.2. EEG Data Recording and Processing
2.3. Feature Extracting
2.4. Oneformer: Transformer for One-Dimensional Feature Vector
2.4.1. Self-Attention Sub-Block for Oneformer
2.4.2. Position-Wise Feed-Forward Network Sub-Block for Oneformer
2.4.3. Oneformer Block
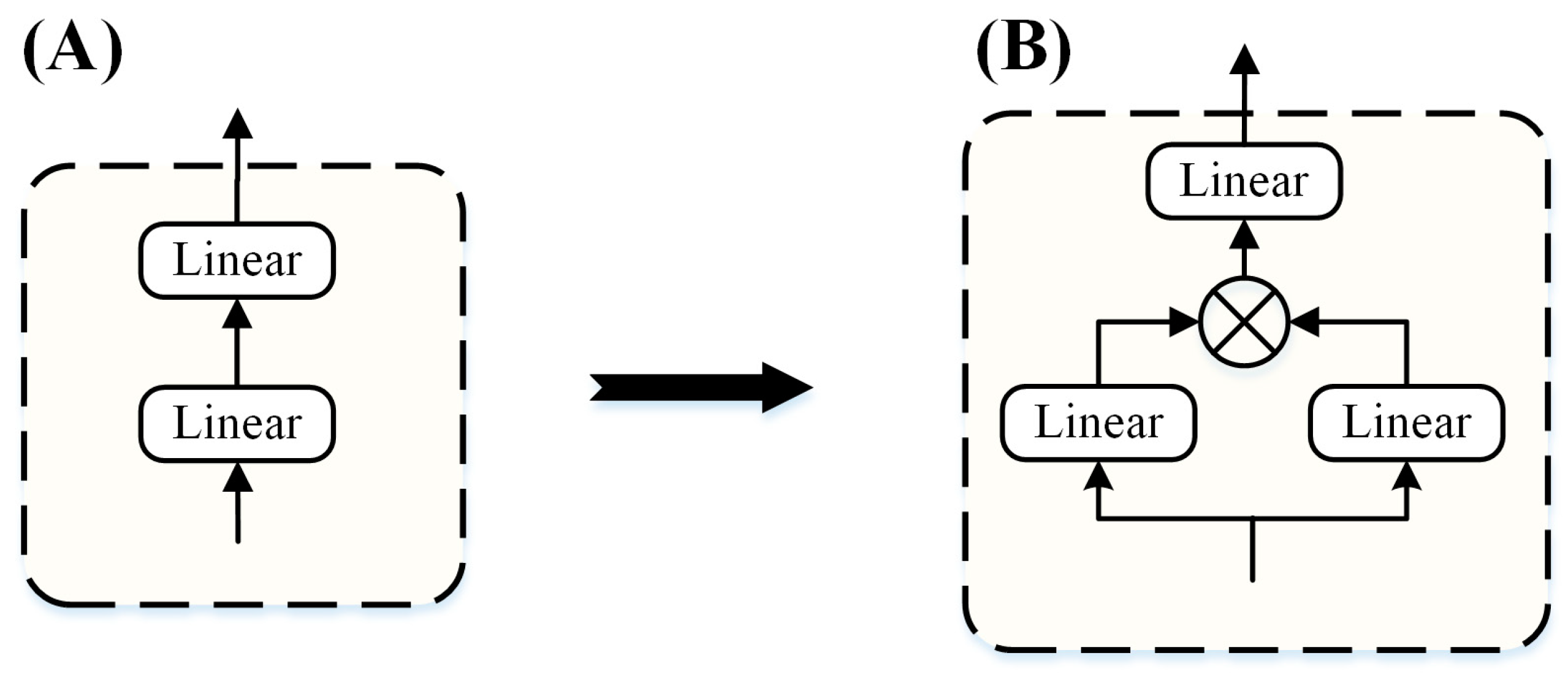
2.5. Gating Mechanism in Oneformer
2.5.1. GLU-FFN in Oneformer
2.5.2. GLU-Attention in Oneformer
2.6. GLU-Oneformer Parameters
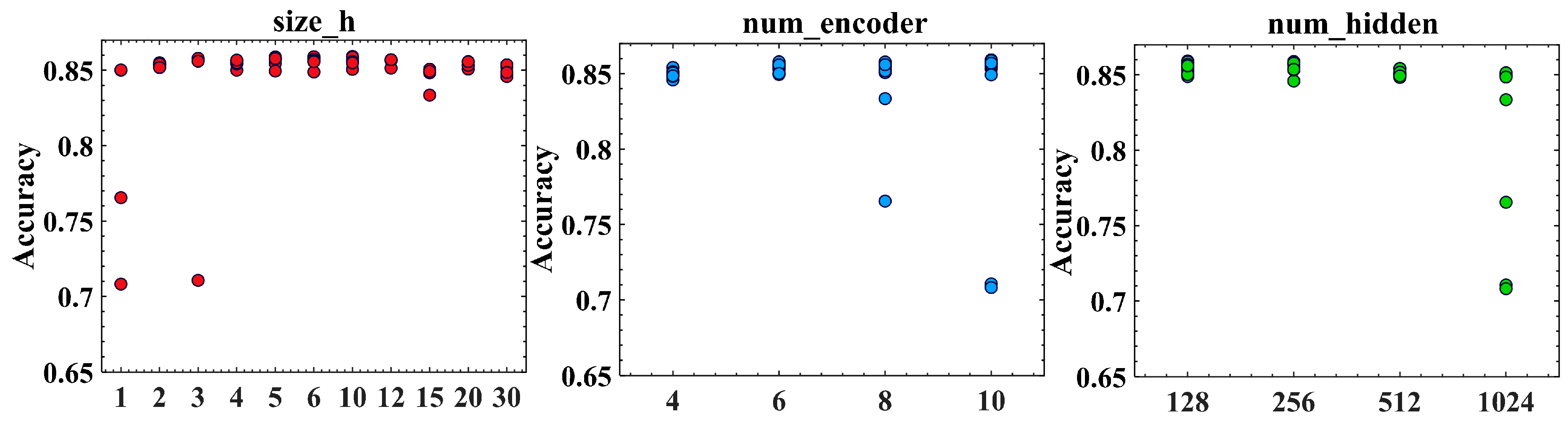
2.7. Oneformer Architecture Optimization
2.8. Machine Learning Classifiers
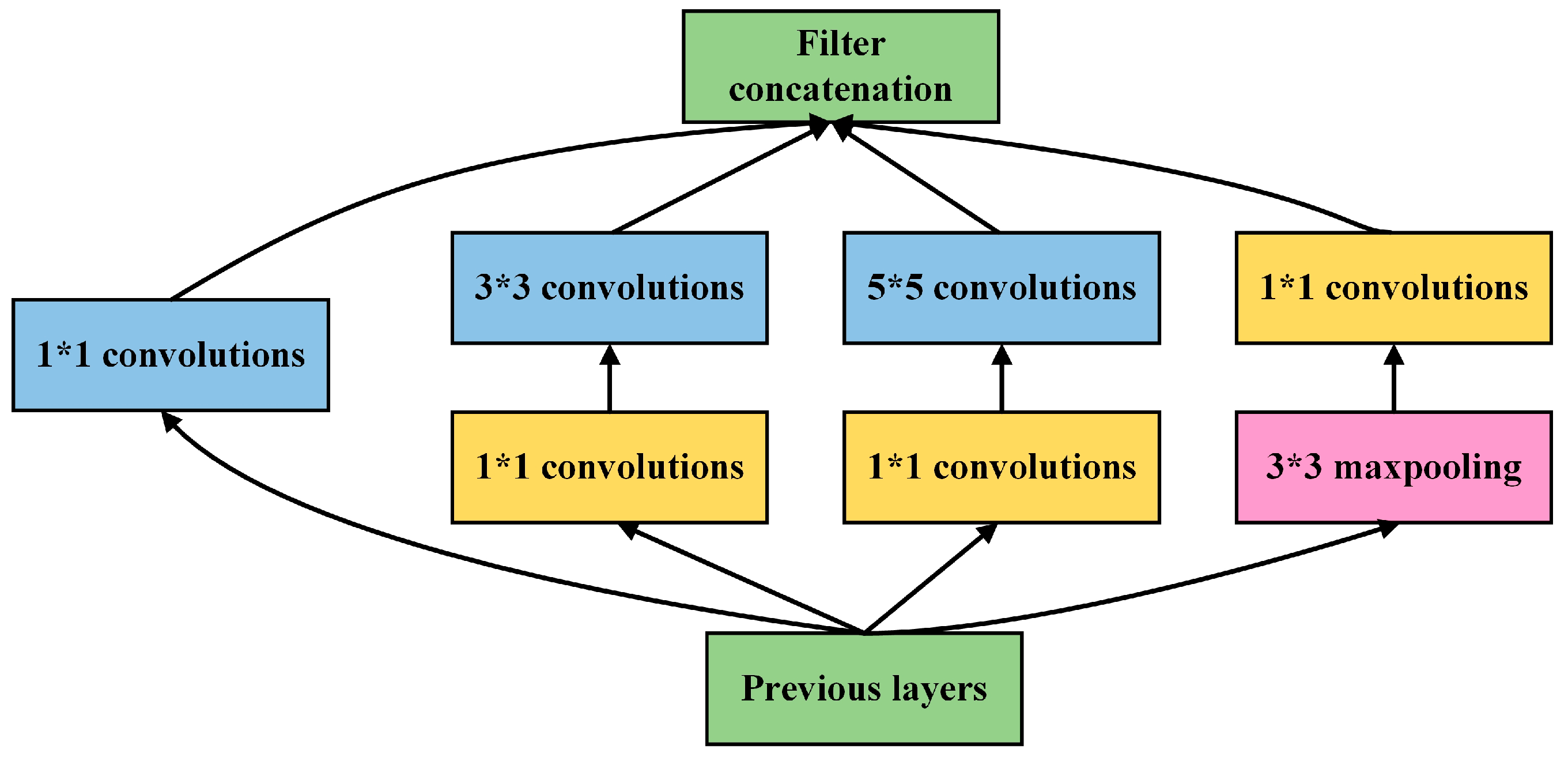
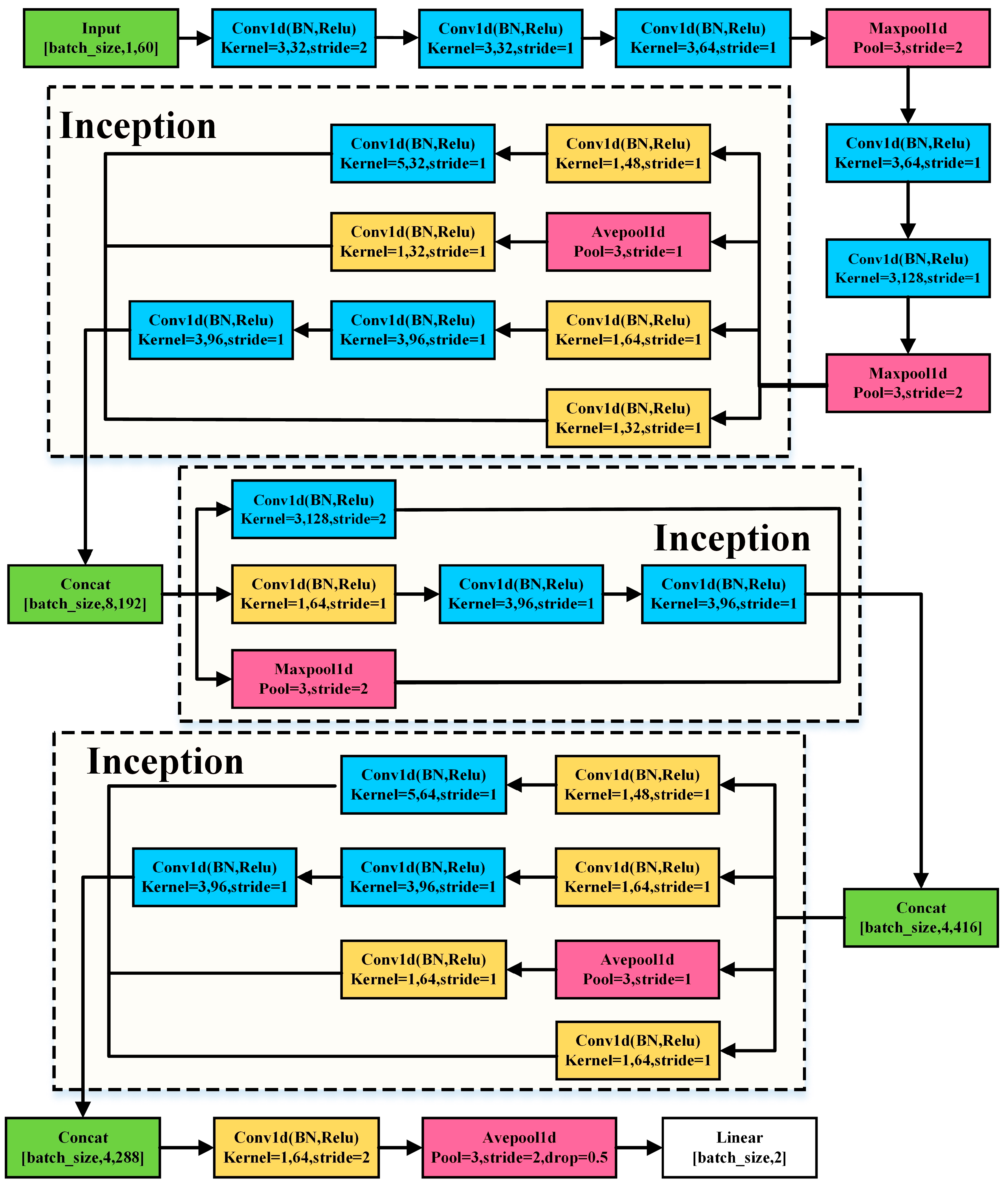
2.9. Deep Learning Classifiers
2.10. Evaluation Metrics for Classifiers
3. Results and Discussion
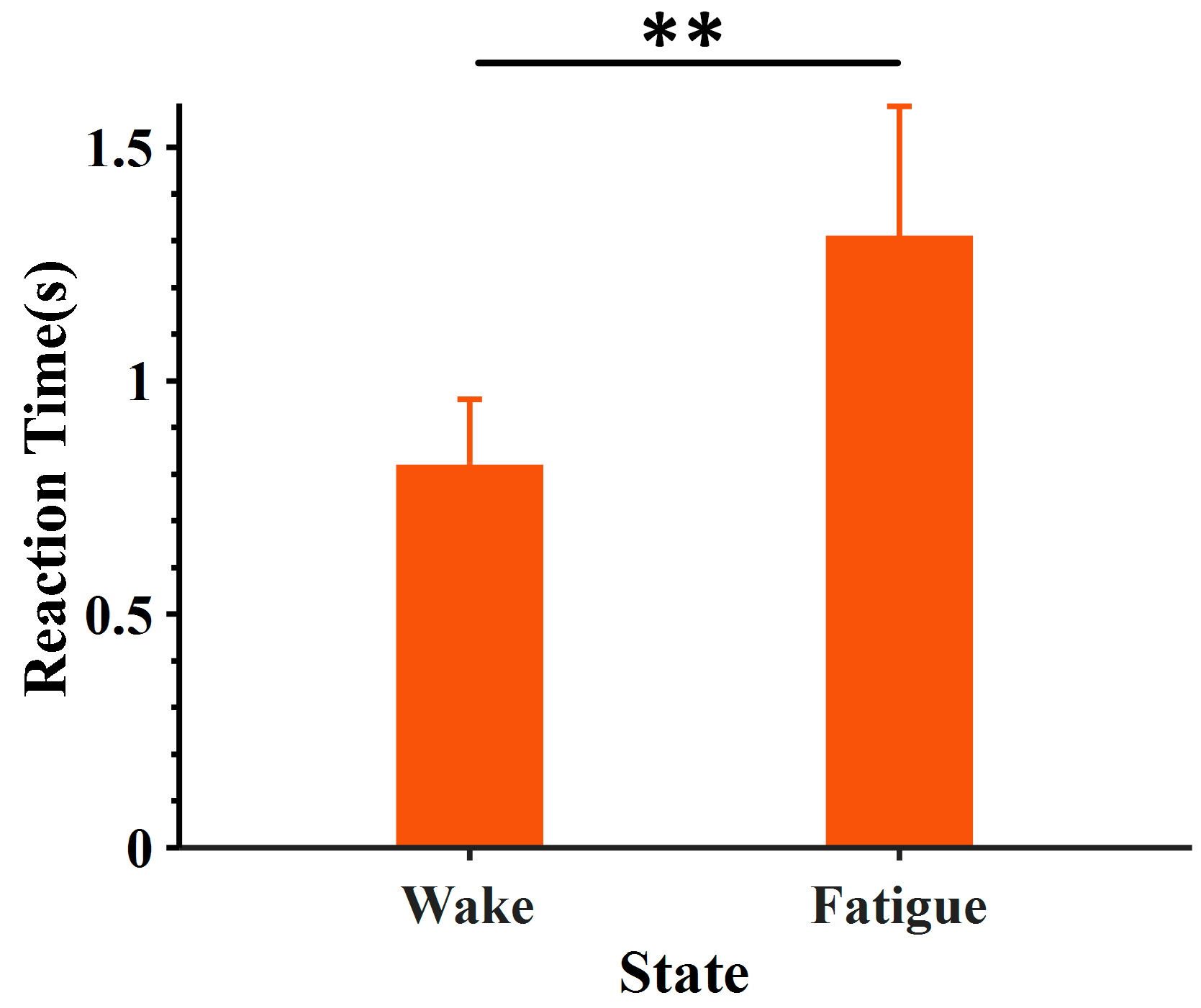
3.1. Driving Fatigue Determination with Behavioral Performance
3.2. Improvement with Lateralization Feature
3.3. Classification with Oneformer
3.4. Driving Fatigue Detection with GLU-Oneformer
3.5. Limitations
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Marcora, S.M.; Staiano, W.; Manning, V. Mental fatigue impairs physical performance in humans. J. Appl. Physiol. 2009, 106, 857–864. [Google Scholar] [CrossRef] [Green Version]
- Borghini, G.; Astolfi, L.; Vecchiato, G.; Mattia, D.; Babiloni, F. Measuring neurophysiological signals in aircraft pilots and car drivers for the assessment of mental workload, fatigue and drowsiness. Neurosci. Biobehav. Rev. 2014, 44, 58–75. [Google Scholar] [CrossRef] [PubMed]
- Han, C.; Sun, X.; Yang, Y.; Che, Y.; Qin, Y. Brain complex network characteristic analysis of fatigue during simulated driving based on electroencephalogram signals. Entropy 2019, 21, 353. [Google Scholar] [CrossRef] [Green Version]
- Singh, S. Critical Reasons for Crashes Investigated in the National Motor Vehicle Crash Causation Survey; National Center for Statistics and Analysis: Washington, DC, USA, 2015. [Google Scholar]
- Higgins, J.S.; Michael, J.; Austin, R.; Akerstedt, T.; Van Dongen, H.P.A.; Watson, N.; Czeisler, C.; Pack, A.I.; Rosekind, M.R. Asleep at the wheel-the road to addressing drowsy driving. Sleep 2017, 40, zsx001. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Taeho, H.; Miyoung, K.; Seunghyeok, H.; Kwang Suk, P. Driver drowsiness detection using the in-ear EEG. Annu. Int. Conf. 2016, 2016, 4646–4649. [Google Scholar] [CrossRef]
- Wang, F.; Wu, S.; Zhang, W.; Xu, Z.; Zhang, Y.; Chu, H. Multiple nonlinear features fusion based driving fatigue detection. Biomed. Signal Process. Control 2020, 62, 102075. [Google Scholar] [CrossRef]
- Wang, H.; Liu, X.; Li, J.; Xu, T.; Bezerianos, A.; Sun, Y.; Wan, F. Driving fatigue recognition with functional connectivity based on phase synchronization. IEEE Trans. Cogn. Dev. Syst. 2020, 13, 668–678. [Google Scholar] [CrossRef]
- Sun, Y.; Lim, J.; Meng, J.; Kwok, K.; Thakor, N.; Bezerianos, A. Discriminative analysis of brain functional connectivity patterns for mental fatigue classification. Ann. Biomed. Eng. 2014, 42, 2084–2094. [Google Scholar] [CrossRef]
- Qin, Y.; Hu, Z.; Chen, Y.; Liu, J.; Jiang, L.; Che, Y.; Han, C. Directed brain network analysis for fatigue driving based on EEG source signals. Entropy 2022, 24, 1093. [Google Scholar] [CrossRef] [PubMed]
- Sun, Y.; Lim, J.; Kwok, K.; Bezerianos, A. Functional cortical connectivity analysis of mental fatigue unmasks hemispheric asymmetry and changes in small-world networks. Brain Cogn. 2014, 85, 220–230. [Google Scholar] [CrossRef]
- Loch, F.; Hof Zum Berge, A.; Ferrauti, A.; Meyer, T.; Pfeiffer, M.; Kellmann, M. Acute effects of mental recovery strategies after a mentally fatiguing task. Front Psychol. 2020, 11, 558856. [Google Scholar] [CrossRef] [PubMed]
- Hu, J. Comparison of different features and classifiers for driver fatigue detection based on a single EEG channel. Comput. Math. Methods Med. 2017, 2017, 5109530. [Google Scholar] [CrossRef] [Green Version]
- Wang, P.; Min, J.; Hu, J. Ensemble classifier for driver’s fatigue detection based on a single EEG channel. IET Intell. Transp. Syst. 2018, 12, 1322–1328. [Google Scholar] [CrossRef]
- Wei, C.-S.; Wang, Y.-T.; Lin, C.-T.; Jung, T.-P. Toward drowsiness detection using non-hair-bearing EEG-based brain-computer interfaces. Ieee Trans. Neural Syst. Rehabil. Eng. 2018, 26, 400–406. [Google Scholar] [CrossRef] [PubMed]
- Tuncer, T.; Dogan, S.; Ertam, F.; Subasi, A. A dynamic center and multi threshold point based stable feature extraction network for driver fatigue detection utilizing EEG signals. Cogn. Neurodynamics 2021, 15, 223–237. [Google Scholar] [CrossRef] [PubMed]
- Wang, F.; Wu, S.; Ping, J.; Xu, Z.; Chu, H. EEG driving fatigue detection with PDC-based brain functional network. IEEE Sens. J. 2021, 21, 10811–10823. [Google Scholar] [CrossRef]
- Ye, B.; Qiu, T.; Bai, X.; Liu, P. Research on recognition method of driving fatigue state based on sample entropy and kernel principal component analysis. Entropy 2018, 20, 701. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Luo, H.; Qiu, T.; Liu, C.; Huang, P. Research on fatigue driving detection using forehead EEG based on adaptive multi-scale entropy. Biomed. Signal Process. Control 2019, 51, 50–58. [Google Scholar] [CrossRef]
- Gao, Z.; Li, S.; Cai, Q.; Dang, W.; Yang, Y.; Mu, C.; Hui, P. Relative wavelet entropy complex network for improving EEG-based fatigue driving classification. IEEE Trans. Instrum. Meas. 2018, 68, 2491–2497. [Google Scholar] [CrossRef]
- Gao, Z.; Li, Y.; Yang, Y.; Dong, N.; Yang, X.; Grebogi, C. A coincidence-filtering-based approach for CNNs in EEG-based recognition. IEEE Trans. Ind. Inform. 2019, 16, 7159–7167. [Google Scholar] [CrossRef]
- Gao, Z.; Wang, X.; Yang, Y.; Mu, C.; Cai, Q.; Dang, W.; Zuo, S. EEG-based spatio–temporal convolutional neural network for driver fatigue evaluation. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 2755–2763. [Google Scholar] [CrossRef]
- Li, J.; Liu, J.; Liu, P.; Qi, Y. Analysis of factors contributing to the severity of large truck crashes. Entropy 2020, 22, 1191. [Google Scholar] [CrossRef]
- Wang, H.; Xu, L.; Bezerianos, A.; Chen, C.; Zhang, Z. Linking attention-based multiscale CNN with dynamical GCN for driving fatigue detection. IEEE Trans. Instrum. Meas. 2020, 70, 2504811. [Google Scholar] [CrossRef]
- Delvigne, V.; Wannous, H.; Vandeborre, J.-P.; Ris, L.; Dutoit, T. Spatio-Temporal Analysis of Transformer based Architecture for Attention Estimation from EEG. arXiv 2022, arXiv:2204.07162. [Google Scholar]
- Beaton, A.A. The lateralized brain: The neuroscience and evolution of hemispheric asymmetries. Laterality 2019, 24, 255–258. [Google Scholar] [CrossRef]
- Galaburda, A.M.; LeMay, M.; Kemper, T.L.; Geschwind, N. Right-left asymmetries in the brain: Structural differences between the hemispheres may underlie cerebral dominance. Science 1978, 199, 852–856. [Google Scholar] [CrossRef] [PubMed]
- Rogers, L.J. Brain lateralization and cognitive capacity. Animals 2021, 11, 1996. [Google Scholar] [CrossRef]
- Pane, E.S.; Wibawa, A.D.; Purnomo, M.H. Improving the accuracy of EEG emotion recognition by combining valence lateralization and ensemble learning with tuning parameters. Cogn. Process. 2019, 20, 405–417. [Google Scholar] [CrossRef]
- Geschwind, N.; Levitsky, W. Human brain: Left-right asymmetries in temporal speech region. Science 1968, 161, 186–187. [Google Scholar] [CrossRef] [PubMed]
- De Schotten, M.T.; Bizzi, A.; Dell’Acqua, F.; Allin, M.; Walshe, M.; Murray, R.; Williams, S.C.; Murphy, D.G.; Catani, M. Atlasing location, asymmetry and inter-subject variability of white matter tracts in the human brain with MR diffusion tractography. Neuroimage 2011, 54, 49–59. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar] [CrossRef]
- Qu, W.; Wang, Z.; Hong, H.; Chi, Z.; Feng, D.D.; Grunstein, R.; Gordon, C. A residual based attention model for eeg based sleep staging. IEEE J. Biomed. Health Inform. 2020, 24, 2833–2843. [Google Scholar] [CrossRef]
- Wu, D.; Zhang, J.; Zhao, Q. Multimodal fused emotion recognition about expression-EEG interaction and collaboration using deep learning. IEEE Access 2020, 8, 133180–133189. [Google Scholar] [CrossRef]
- Eldele, E.; Chen, Z.; Liu, C.; Wu, M.; Kwoh, C.-K.; Li, X.; Guan, C. An attention-based deep learning approach for sleep stage classification with single-channel eeg. IEEE Trans. Neural Syst. Rehabil. Eng. 2021, 29, 809–818. [Google Scholar] [CrossRef]
- Liu, X.; Li, G.; Wang, S.; Wan, F.; Sun, Y.; Wang, H.; Bezerianos, A.; Li, C.; Sun, Y. Toward practical driving fatigue detection using three frontal EEG channels: A proof-of-concept study. Physiol. Meas. 2021, 42, 044003. [Google Scholar] [CrossRef]
- Delorme, A.; Makeig, S. EEGLAB: An open source toolbox for analysis of single-trial EEG dynamics including independent component analysis. J. Neurosci. Methods 2004, 134, 9–21. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sun, Y.; Li, J.; Suckling, J.; Feng, L. Asymmetry of hemispheric network topology reveals dissociable processes between functional and structural brain connectome in community-living elders. Front. Aging Neurosci. 2017, 9, 361. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ba, J.L.; Kiros, J.R.; Hinton, G.E. Layer normalization. arXiv 2016, arXiv:1607.06450. [Google Scholar]
- Shafiq, M.; Gu, Z. Deep Residual Learning for Image Recognition: A Survey. Appl. Sci. 2022, 12, 8972. [Google Scholar] [CrossRef]
- Aharoni, R.; Johnson, M.; Firat, O. Massively multilingual neural machine translation. arXiv 2019, arXiv:1903.00089. [Google Scholar]
- Raganato, A.; Tiedemann, J. An analysis of encoder representations in transformer-based machine translation. In Proceedings of the 2018 EMNLP Workshop BlackboxNLP: Analyzing and Interpreting Neural Networks for NLP, Brussels, Belgium, 1 November 2018. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language models are unsupervised multitask learners. OpenAI Blog 2019, 1, 9. [Google Scholar]
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A. Language models are few-shot learners. Adv. Neural Inf. Process. Syst. 2020, 33, 1877–1901. [Google Scholar]
- Du, N.; Huang, Y.; Dai, A.M.; Tong, S.; Lepikhin, D.; Xu, Y.; Krikun, M.; Zhou, Y.; Yu, A.W.; Firat, O. Glam: Efficient scaling of language models with mixture-of-experts. arXiv 2021, arXiv:2112.06905. [Google Scholar]
- Thoppilan, R.; De Freitas, D.; Hall, J.; Shazeer, N.; Kulshreshtha, A.; Cheng, H.-T.; Jin, A.; Bos, T.; Baker, L.; Du, Y. Lamda: Language models for dialog applications. arXiv 2022, arXiv:2201.08239. [Google Scholar]
- Dauphin, Y.N.; Fan, A.; Auli, M.; Grangier, D. Language modeling with gated convolutional networks. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 933–941. [Google Scholar]
- Shazeer, N. Glu variants improve transformer. arXiv 2020, arXiv:2002.05202. [Google Scholar]
- Shahriari, B.; Swersky, K.; Wang, Z.; Adams, R.P.; de Freitas, N. Taking the human out of the loop: A review of bayesian optimization. Proc. IEEE 2016, 104, 148–175. [Google Scholar] [CrossRef] [Green Version]
- Bergstra, J.; Yamins, D.; Cox, D.D. Hyperopt: A python library for optimizing the hyperparameters of machine learning algorithms. In Proceedings of the 12th Python in Science Conference, Austin, TX, USA, 24–29 June 2013; p. 20. [Google Scholar]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Cover, T.; Hart, P. Nearest neighbor pattern classification. IEEE Trans. Inf. Theory 1967, 13, 21–27. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Doniec, R.J.; Siecinski, S.; Duraj, K.M.; Piaseczna, N.J.; Mocny-Pachonska, K.; Tkacz, E.J. Recognition of Drivers’ Activity Based on 1D Convolutional Neural Network. Electronics 2020, 9, 2002. [Google Scholar] [CrossRef]
- Wang, J.; Shi, J.; Xu, Y.; Zhong, H.; Li, G.; Tian, J.; Xu, W.; Gao, Z.; Jiang, Y.; Jiao, W. A New Strategy for Mental Fatigue Detection Based on Deep Learning and Respiratory Signal. In Proceedings of the 11th International Conference on Computer Engineering and Networks, Belgrade, Serbia, 9–11 July 2022; pp. 543–552. [Google Scholar]
- Zuo, X.; Zhang, C.; Cong, F.Y.; Zhao, J.; Hamalainen, T. Driver Distraction Detection Using Bidirectional Long Short-Term Network Based on Multiscale Entropy of EEG. IEEE Trans. Intell. Transp. Syst. 2022, 23, 19309–19322. [Google Scholar] [CrossRef]
- Chung, J.; Gulcehre, C.; Cho, K.; Bengio, Y. Empirical evaluation of gated recurrent neural networks on sequence modeling. arXiv 2014, arXiv:1412.3555. [Google Scholar]
- Tng, S.S.; Le, N.Q.K.; Yeh, H.-Y.; Chua, M.C.H. Improved Prediction Model of Protein Lysine Crotonylation Sites Using Bidirectional Recurrent Neural Networks. J. Proteome Res. 2022, 21, 265–273. [Google Scholar] [CrossRef]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- Boksem, M.A.; Meijman, T.F.; Lorist, M.M. Mental fatigue, motivation and action monitoring. Biol. Psychol. 2006, 72, 123–132. [Google Scholar] [CrossRef]
- Coull, J.T.; Frackowiak, R.S.; Frith, C.D. Monitoring for target objects: Activation of right frontal and parietal cortices with increasing time on task. Neuropsychologia 1998, 36, 1325–1334. [Google Scholar] [CrossRef]
- Sturm, W.; De Simone, A.; Krause, B.; Specht, K.; Hesselmann, V.; Radermacher, I.; Herzog, H.; Tellmann, L.; Müller-Gärtner, H.-W.; Willmes, K. Functional anatomy of intrinsic alertness: Evidencefor a fronto-parietal-thalamic-brainstem network in theright hemisphere. Neuropsychologia 1999, 37, 797–805. [Google Scholar] [CrossRef]
- Dragoi, E.-N.; Dafinescu, V. Parameter control and hybridization techniques in differential evolution: A survey. Artif. Intell. Rev. 2016, 45, 447–470. [Google Scholar] [CrossRef]
- He, F.; Ye, Q. A bearing fault diagnosis method based on wavelet packet tansform and convolutional neural network optimized by simulated annealing algorithm. Sensors 2022, 22, 1410. [Google Scholar] [CrossRef]
- Mei, J.; Wang, P.; Han, Y.; Cai, Z.; Peng, Q.; Xue, F. Prediction of stress corrosion crack growth rate of ni-base alloy 600 based on TPE-XGBoost algorithm. Rare Met. Mater. Eng. 2021, 50, 2399–2408. [Google Scholar]
- Chai, R.; Tran, Y.; Craig, A.; Ling, S.H.; Nguyen, H.T. Enhancing accuracy of mental fatigue classification using advanced computational intelligence in an electroencephalography system. Annu. Int. Conf. 2014, 2014, 1338–1341. [Google Scholar] [CrossRef]
- Arik, S.Ö.; Pfister, T. Tabnet: Attentive interpretable tabular learning. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 2–9 February 2021; pp. 6679–6687. [Google Scholar]
- Shwartz-Ziv, R.; Armon, A. Tabular data: Deep learning is not all you need. Inf. Fusion 2022, 81, 84–90. [Google Scholar] [CrossRef]
- Rahaman, N.; Baratin, A.; Arpit, D.; Draxler, F.; Lin, M.; Hamprecht, F.; Bengio, Y.; Courville, A. On the spectral bias of neural networks. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; pp. 5301–5310. [Google Scholar]
- Mitchell, B.R. The Spatial Inductive Bias of Deep Learning; Johns Hopkins University: Baltimore, MD, USA, 2017. [Google Scholar]
- Borisov, V.; Leemann, T.; Seßler, K.; Haug, J.; Pawelczyk, M.; Kasneci, G. Deep neural networks and tabular data: A survey. arXiv 2021, arXiv:2110.01889. [Google Scholar]
- Grinsztajn, L.; Oyallon, E.; Varoquaux, G. Why do tree-based models still outperform deep learning on typical tabular data? In Proceedings of the Thirty-Sixth Conference on Neural Information Processing Systems Datasets and Benchmarks Track, Virtual, 29 November–1 December 2022. [Google Scholar]
- Ishii, A.; Tanaka, M.; Watanabe, Y. The Neural Mechanisms Underlying the Decision to Rest in the Presence of Fatigue: A Magnetoencephalography Study. PLoS ONE 2014, 9, e109740. [Google Scholar] [CrossRef] [PubMed]
- Gaggioni, G.; Ly, J.Q.M.; Chellappa, S.L.; Coppieters ‘t Wallant, D.; Rosanova, M.; Sarasso, S.; Luxen, A.; Salmon, E.; Middleton, B.; Massimini, M.; et al. Human fronto-parietal response scattering subserves vigilance at night. NeuroImage 2018, 175, 354–364. [Google Scholar] [CrossRef]
- Mu, Z.; Hu, J.; Yin, J. Driving fatigue detecting based on EEG signals of forehead area. Int. J. Pattern Recognit. Artif. Intell. 2017, 31, 1750011. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| PSD | Entropy | FC | Lateralization | |
|---|---|---|---|---|
| Features | α/β, θ/β, (α + θ)/β, (α + θ)/(β + ) | ApEn | MI | [X(R) − X(L)]/ [X(R) + X(L)] |
| Numbers | 4 × 3 | 4 × 3 | 4 × 3 | (4 + 4) × 3 |
| Variables | Choice |
|---|---|
| size_h | [1,2,3,4,5,10,12,15,20,30] |
| num_encoder | [4,6,8,10] |
| num_hidden | [128,256,512,1024] |
| Variables | Choice |
|---|---|
| num_layers | [1,2,3,4] |
| num_hidden | [50,100,150,200] |
| Models | Accuracy (%) (Mean ± SD) | Precision (%) (Mean ± SD) | Recall (%) (Mean ± SD) | F1 (%) (Mean ± SD) |
|---|---|---|---|---|
| KNN | 79.47 ± 0.19 | 81.56 ± 0.21 | 78.28 ± 0.20 | 79.88 ± 0.20 |
| SVM | 82.10 ± 0.23 | 82.22 ± 0.25 | 82.03 ± 0.24 | 82.04 ± 0.25 |
| RF | 76.70 ± 0.23 | 76.74 ± 0.24 | 76.63 ± 0.26 | 76.74 ± 0.24 |
| N | dffn | h | k | Accuracy | Precision | Recall | F1-Score | |
|---|---|---|---|---|---|---|---|---|
| Base | 6 | 256 | 6 | 10 | 85.42% | 83.64% | 83.27% | 83.45% |
| (A) | 1 | 60 | 85.02% | 83.08% | 83.23% | 83.10% | ||
| 2 | 30 | 85.38% | 83.51% | 83.22% | 83.42% | |||
| 3 | 20 | 85.36% | 83.43% | 83.27% | 83.36% | |||
| 4 | 15 | 85.35% | 83.38% | 83.30% | 83.33% | |||
| 5 | 12 | 85.41% | 83.49% | 83.17% | 83.32% | |||
| 10 | 6 | 85.38% | 83.59% | 83.06% | 83.28% | |||
| 12 | 5 | 85.41% | 83.65% | 83.14% | 83.38% | |||
| 15 | 4 | 85.33% | 83.31% | 83.23% | 83.41% | |||
| 20 | 3 | 85.27% | 83.36% | 83.03% | 83.28% | |||
| 30 | 2 | 85.19% | 83.43% | 82.92% | 83.17% | |||
| (B) | 128 | 85.38% | 83.58% | 83.30% | 83.43% | |||
| 512 | 85.40% | 83.62% | 83.16% | 83.43% | ||||
| 1024 | 85.07% | 83.16% | 82.87% | 83.00% | ||||
| (C) | 4 | 85.24% | 83.28% | 83.45% | 83.35% | |||
| 8 | 85.46% | 83.67% | 83.64% | 83.49% | ||||
| 10 | 85.62% | 83.72% | 83.73% | 83.71% | ||||
| Best | 10 | 512 | 6 | 10 | 85.65% | 83.78% | 83.77% | 83.77% |
| TPE | 10 | 128 | 10 | 6 | 85.92% | 84.11% | 84.12% | 83.88% |
| Model | Accuracy (%) (Mean ± SD) | Precision (%) (Mean ± SD) | Recall (%) (Mean ± SD) | F1 (%) (Mean ± SD) |
|---|---|---|---|---|
| 1D CNN [55] | 73.86 ± 0.97 | 72.93 ± 1.19 | 74.10 ± 1.31 | 73.56 ± 0.75 |
| LSTM [56] | 71.74 ± 1.15 | 71.28 ± 1.34 | 70.83 ± 1.36 | 69.81 ± 1.12 |
| BiLSTM [57] | 72.19 ± 1.03 | 71.62 ± 1.11 | 71.68 ± 1.22 | 71.73 ± 0.93 |
| GRU [58] | 73.02 ± 1.28 | 72.89 ± 1.27 | 72.31 ± 1.29 | 72.43 ± 1.07 |
| BiGRU [59] | 73.74 ± 1.12 | 73.53 ± 1.18 | 73.81 ± 1.38 | 73.92 ± 0.99 |
| 1D Inception | 76.83 ± 1.08 | 75.57 ± 1.23 | 75.73 ± 1.25 | 75.37 ± 0.94 |
| GLU-Attention | 86.43 ± 0.59 | 84.61 ± 1.06 | 84.22 ± 1.53 | 84.32 ± 0.79 |
| GLU-FFN | 86.57 ± 0.59 | 84.75 ± 1.03 | 84.39 ± 1.27 | 84.56 ± 0.75 |
| GLU-Oneformer | 86.97 ± 0.43 | 85.08 ± 0.09 | 85.44 ± 1.13 | 85.23 ± 0.67 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, J.; Xu, Y.; Tian, J.; Li, H.; Jiao, W.; Sun, Y.; Li, G. Driving Fatigue Detection with Three Non-Hair-Bearing EEG Channels and Modified Transformer Model. Entropy 2022, 24, 1715. https://doi.org/10.3390/e24121715
Wang J, Xu Y, Tian J, Li H, Jiao W, Sun Y, Li G. Driving Fatigue Detection with Three Non-Hair-Bearing EEG Channels and Modified Transformer Model. Entropy. 2022; 24(12):1715. https://doi.org/10.3390/e24121715
Chicago/Turabian StyleWang, Jie, Yanting Xu, Jinghong Tian, Huayun Li, Weidong Jiao, Yu Sun, and Gang Li. 2022. "Driving Fatigue Detection with Three Non-Hair-Bearing EEG Channels and Modified Transformer Model" Entropy 24, no. 12: 1715. https://doi.org/10.3390/e24121715
APA StyleWang, J., Xu, Y., Tian, J., Li, H., Jiao, W., Sun, Y., & Li, G. (2022). Driving Fatigue Detection with Three Non-Hair-Bearing EEG Channels and Modified Transformer Model. Entropy, 24(12), 1715. https://doi.org/10.3390/e24121715