
A Bayesian Approach to the Estimation of Parameters and Their Interdependencies in Environmental Modeling †



Abstract
:1. Introduction
2. Relation to Existing Work
3. Case Study: Modeling Chlorophyll Concentrations at Geesthacht Weir
3.1. General Background
3.2. Lagrangian Model Concept
3.3. Parameterizations Used in the Model
3.4. Parameters Selected for Calibration
4. Methods of Bayesian Analysis and Complexity Reduction
4.1. Bayesian Inference
4.2. Markov Chain Monte Carlo (MCMC)
4.3. Graphical Modeling
4.3.1. Gaussian Graphical Models (GGMs)
4.3.2. Bayesian Networks (BNs)
4.4. Gaussian Process Regression and Bayesian Global Optimization
4.5. Linear Dimension Reduction via Principal Components
4.6. Delayed Acceptance MCMC
4.7. Bayesian Hierarchical Models and Fractional Norms
4.8. Pre- and Postprocessing
5. Results
5.1. MCMC Sampling
5.2. Principal Component Analysis of Feasible Parameter Combinations
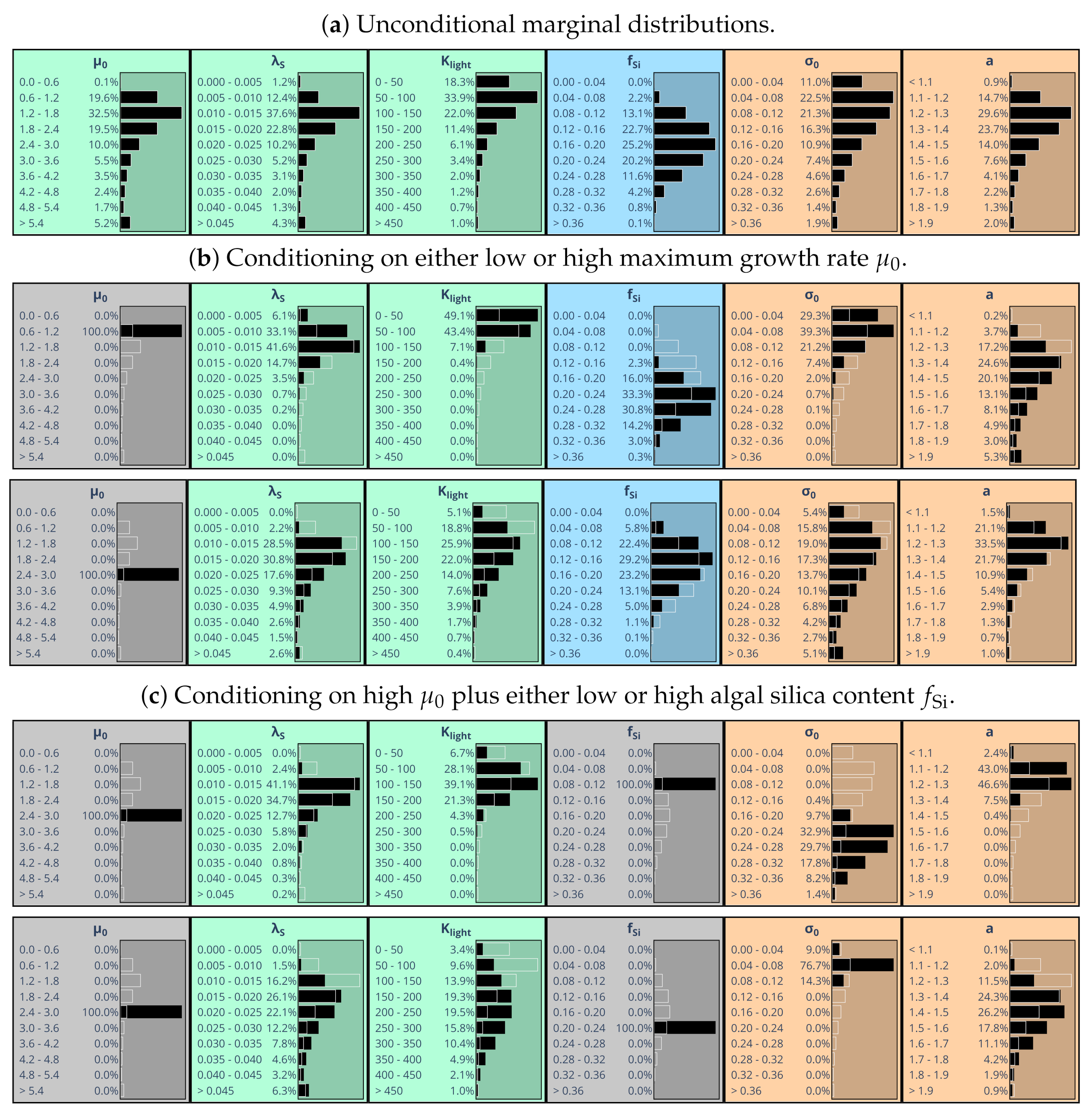
5.3. Exploring Conditional Marginal Distributions
5.4. Bayesian Network Assuming Simplified Parameter Interrelationships
5.5. Accelerated Sampling via Delayed Acceptance
- Construct a GP surrogate for the cost function on a space-filling sample sequence over the whole prior range.
- Refine the sampling points near the posterior’s mode by Bayesian global optimization with the cost surrogate.
- Train a multi-output GP surrogate for the functional output on the refined sampling points.
- Use the function-valued surrogate for delayed acceptance in the MCMC run.
6. Discussion
6.1. The Case Study Example
6.2. MCMC in Relation to GLUE and BMC
6.3. Benefit from Using BNs
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Fedra, K.; van Straten, G.; Beck, M.B. Uncertainty and arbitrariness in ecosystems modelling: A lake modelling example. Ecol. Model. 1981, 13, 87–110. [Google Scholar] [CrossRef] [Green Version]
- Beck, M.B. Water quality modeling: A review of the analysis of uncertainty. Water Resour. Res. 1987, 23, 1393–1442. [Google Scholar] [CrossRef] [Green Version]
- Oreskes, N.; Shrader-Frechette, K.; Belitz, K. Verification, validation, and confirmation of numerical models in the earth sciences. Science 1994, 263, 641–646. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Spear, R.C. Large simulation models: Calibration, uniqueness and goodness of fit. Environ. Model. Software 1997, 12, 219–228. [Google Scholar] [CrossRef]
- Brun, R.; Reichert, P.; Künsch, H.R. Practical identifiability analysis of large environmental simulation models. Water Resour. Res. 2001, 37, 1015–1030. [Google Scholar] [CrossRef] [Green Version]
- Hesse, C.; Krysanova, V. Modeling climate and management change impacts on water quality and in-stream processes in the Elbe River basin. Water 2016, 8, 40. [Google Scholar] [CrossRef] [Green Version]
- MacKay, D.J.C. Information Theory, Inference and Learning Algorithms; Cambridge University Press: Cambridge, UK, 2003. [Google Scholar]
- Von der Linden, W.; Dose, V.; von Toussaint, U. Bayesian Probability Theory: Application in the Physical Sciences; Cambridge University Press: Cambridge, UK, 2014. [Google Scholar]
- Pearl, J. Probabilistic Reasoning in Intelligent Systems: Networks of Plausible Inference; Morgan Kaufmann Publishers: San Francisco, CA, USA, 1988; p. 552. [Google Scholar]
- Kjaerulff, U.B.; Madsen, A.L. Bayesian Networks and Influence Diagrams—A Guide to Construction and Analysis; Springer: New York, NY, USA, 2008. [Google Scholar]
- Pearl, J. Causality; Cambridge University Press: Cambridge, UK, 2000. [Google Scholar]
- Peters, J.; Janzing, D.; Schölkopf, B. Elements of Causal Inference—Foundations and Learning Algorithms; MIT Press: Cambridge, MA, USA, 2017. [Google Scholar]
- Christen, J.A.; Fox, C. Markov Chain Monte Carlo Using an Approximation. J. Comput. Graph. Stat. 2005, 14, 795–810. [Google Scholar] [CrossRef]
- Wiqvist, S.; Picchini, U.; Forman, J.L.; Lindorff-Larsen, K.; Boomsma, W. Accelerating Delayed-Acceptance Markov Chain Monte Carlo Algorithms. arXiv 2019, arXiv:1806.05982. [Google Scholar]
- Fedra, K. Mathematical modelling—A management tool for aquatic ecosystems? Helgol. Meeresunters 1980, 34, 221–235. [Google Scholar] [CrossRef] [Green Version]
- Wu, X.; Shirvan, K.; Kozlowski, T. Demonstration of the relationship between sensitivity and identifiability for inverse uncertainty quantification. J. Comput. Phys. 2019, 396, 12–30. [Google Scholar] [CrossRef] [Green Version]
- Gupta, H.V.; Razavi, S. Revisiting the basis of sensitivity analysis for dynamical earth system models. Water Resour. Res. 2018, 54, 8692–8717. [Google Scholar] [CrossRef]
- Saltelli, A.; Chan, K.; Scott, E.M. Sensitivity Analysis; John Wiley & Sons: Chichester, UK, 2000. [Google Scholar]
- Sobol’, I.M. Sensitivity estimates for nonlinear mathematical models. Math. Modeling Comput. Exp. 1993, 1, 407–414. [Google Scholar]
- Sudret, B. Global sensitivity analysis using polynomial chaos expansions. Reliab. Eng. Syst. Safety 2008, 93, 964–979. [Google Scholar] [CrossRef]
- Wiener, N. The homogeneous chaos. Am. J. Math. 1938, 60, 897–936. [Google Scholar] [CrossRef]
- Beven, K.; Freer, J. Equifinality, data assimilation, and uncertainty estimation in mechanistic modelling of complex environmental sstems using the GLUE methodology. J. Hydrol. 2001, 249, 11–29. [Google Scholar] [CrossRef]
- Dilks, D.W.; Canale, R.P.; Meier, P.G. Development of Bayesian Monte Carlo techniques for water quality model uncertainty. Ecol. Model. 1992, 62, 149–162. [Google Scholar] [CrossRef] [Green Version]
- Vrugt, J.A.; ter Braak, C.J.F.; Gupta, H.V.; Robinson, B.A. Equifinality of formal (DREAM) and informal (GLUE) Bayesian approaches in hydrologic modeling? Stoch. Environ. Res. Risk Assess. 2008, 23, 1011–1026. [Google Scholar] [CrossRef] [Green Version]
- Camacho, R.A.; Martin, J.L.; McAnally, W.; Díaz-Ramirez, J.; Rodriguez, H.; Sucsy, P.; Zhang, S. A comparison of Bayesian methods for uncertainty amalysis in hydraulic and hydrodynamic modeling. J. Am. Water Resour. Assoc. 2015, 51, 1372–1393. [Google Scholar] [CrossRef]
- Ratto, M.; Tarantola, S.; Saltelli, A. Sensitivity analysis in model calibration: GSA-GLUE approach. Comput. Phys. Commun. 2001, 136, 212–224. [Google Scholar] [CrossRef]
- Callies, U.; Scharfe, M.; Ratto, M. Calibration and uncertainty analysis of a simple model of silica-limited diatom growth in the Elbe River. Ecol. Model. 2008, 213, 229–244. [Google Scholar] [CrossRef]
- Scharfe, M.; Callies, U.; Blöcker, G.; Petersen, W.; Schroeder, F. A simple Lagrangian model to simulate temporal variability of algae in the Elbe River. Ecol. Model. 2009, 220, 2173–2186. [Google Scholar] [CrossRef]
- Campbell, K.; McKay, M.D.; Williams, B.J. Sensitivity Analysis When Model Outputs Are Functions. Reliab. Eng. Syst. Saf. 2006, 91, 1468–1472. [Google Scholar] [CrossRef]
- Pratola, M.T.; Sain, S.R.; Bingham, D.; Wiltberger, M.; Rigler, E.J. Fast Sequential Computer Model Calibration of Large Nonstationary Spatial-Temporal Processes. Technometrics 2013, 55, 232–242. [Google Scholar] [CrossRef]
- Ranjan, P.; Thomas, M.; Teismann, H.; Mukhoti, S. Inverse Problem for a Time-Series Valued Computer Simulator via Scalarization. Open J. Stat. 2016, 6, 528–544. [Google Scholar] [CrossRef] [Green Version]
- Lebel, D.; Soize, C.; Fünfschilling, C.; Perrin, G. Statistical Inverse Identification for Nonlinear Train Dynamics Using a Surrogate Model in a Bayesian Framework. J. Sound Vib. 2019, 458, 158–176. [Google Scholar] [CrossRef] [Green Version]
- Perrin, G. Adaptive Calibration of a Computer Code with Time-Series Output. Reliab. Eng. Syst. Saf. 2020, 196, 106728. [Google Scholar] [CrossRef] [Green Version]
- Karrasch, B.; Mehrens, M.; Rosenlöcher, Y.; Peters, K. The dynamics of phytoplankton bacteria and heterotrophic flagellates at two banks near Magdeburg in the River Elbe (Germany). Limnologica 2001, 31, 93–107. [Google Scholar] [CrossRef] [Green Version]
- De Ruyter van Steveninck, E.D.; Admiraal, W.; Breebaart, L.; Tubbing, G.M.J.; van Zanten, B. Plankton in the River Rhine: Structural and functional changes observed during downstream transport. J. Plankton Res. 1992, 14, 1351–1368. [Google Scholar] [CrossRef]
- Schöl, A.; Kirchesch, V.; Bergfeld, T.; Schöll, F.; Borchering, J.; Müller, D. Modelling the chlorophyll a content of the River Rhine—Interrelation between riverine algal production and population biomass of grazers, rotifers and the zebra mussel, Dreissena polymorpha. Internat. Rev. Hydrobiol. 2002, 87, 295–317. [Google Scholar] [CrossRef]
- Hardenbicker, P.; Weitere, M.; Ritz, S.; Schöll, F.; Fischer, H. Longitudinal plankton dynamics in the rivers Rhine and Elbe. River Res. Applic. 2016, 32, 1264–1278. [Google Scholar] [CrossRef]
- Waylett, A.J.; Hutchins, M.G.; Johnson, A.C.; Bowes, M.J.; Loewenthal, M. Physico-chemical factors alone cannot simulate phytoplankton behaviour in a lowland river. J. Hydrol. 2013, 497, 223–233. [Google Scholar] [CrossRef]
- Schroeder, F. Water quality in the Elbe estuary: Significance of different processes for the oxygen deficit at Hamburg. Env. Model. Assess. 1997, 2, 73–82. [Google Scholar] [CrossRef]
- Böhme, M.; Eidner, R.; Ockenfeld, K.; Guhr, H. Ergebnisse der fließzeitkonformen Elbe-Längsschnittbereisung 26.6.-7.7.2000. In Primärdaten. BfG-1309; Bundesanstalt für Gewässerkunde: Koblenz, Germany, 2002. [Google Scholar]
- Smith, E.L. Photosynthesis in relation to light and carbon dioxide. Proc. Natl. Acad. Sci. USA 1936, 22, 504–510. [Google Scholar] [CrossRef] [Green Version]
- Neal, R.M. Probabilistic Inference Using Markov Chain Monte Carlo Methods; Technical Report CRG-TR-93-1; Department of Computer Science, University of Toronto: Toronto, ON, Canada, 1993. [Google Scholar]
- Press, W.H.; Teukolsky, S.A.; Vetterling, W.T.; Flannery, B.P. Numerical Recipes 3rd Edition: The Art of Scientific Computing, 3rd ed.; Cambridge University Press: Cambridge, UK, 2007. [Google Scholar]
- Yustres, Á.; Asensio, L.; Alonso, J.; Navarro, V. A review of Markov Chain Monte Carlo and information theory tools for inverse problems in subsurface flow. Comput. Geosci. 2012, 16, 1–20. [Google Scholar] [CrossRef]
- Hastings, W.K. Monte Carlo sampling methods using Markov Chains and their applications. Biometrika 1970, 57, 97–109. [Google Scholar] [CrossRef]
- Freni, G.; Mannina, G. Bayesian approach for uncertainty quantification in water quality modelling: The influence of prior distribution. J. Hydrol. 2010, 392, 31–39. [Google Scholar] [CrossRef] [Green Version]
- Edwards, D. Introduction to Graphical Modelling; Springer: New York, NY, USA, 1995. [Google Scholar]
- Whittaker, J. Graphical Models in Applied Multivariate Statistics; John Wiley & Sons: Chichester, UK, 1990. [Google Scholar]
- Dempster, A.P. Covariance selection. Biometrics 1972, 28, 157–175. [Google Scholar] [CrossRef]
- Jordan, M.I. Graphical models. Stat. Sci. 2004, 19, 140–155. [Google Scholar] [CrossRef]
- Callies, U. Interaction structures analysed from water-quality data. Ecol. Model. 2005, 187, 475–490. [Google Scholar] [CrossRef]
- Callies, U.; Scharfe, M. Mean spring conditions at Helgoland Roads, North Sea: Graphical modeling of the influence of hydro-climatic forcing and Elbe River discharge. J. Sea Res. 2015, 101, 1–11. [Google Scholar] [CrossRef] [Green Version]
- Taeb, A.; Reager, J.T.; Turmon, M.; Chandrasekaran, V. A statistical graphical model of the California reservoir. Water Resour. Res. 2017, 53, 9721–9739. [Google Scholar] [CrossRef]
- Kullback, S. Information Theory and Statistics; Wiley: New York, NY, USA, 1959. [Google Scholar]
- O’Hagan, A. Curve Fitting and Optimal Design for Prediction. J. R. Stat. Soc. Ser. B 1978, 40, 1–24. [Google Scholar] [CrossRef]
- Bishop, C.M. Pattern Recognition and Machine Learning; Springer: New York, NY, USA, 2006. [Google Scholar]
- Rasmussen, C.E.; Williams, C.K.I. Gaussian Processes for Machine Learning; MIT Press: Cambridge, MA, USA, 2006. [Google Scholar] [CrossRef] [Green Version]
- Shahriari, B.; Swersky, K.; Wang, Z.; Adams, R.P.; de Freitas, N. Taking the Human Out of the Loop: A Review of Bayesian Optimization. Proc. IEEE 2016, 104, 148–175. [Google Scholar] [CrossRef] [Green Version]
- Osborne, M.A.; Garnett, R.; Roberts, S.J. Gaussian Processes for Global Optimization. In Proceedings of the International Conference on Learning and Intelligent Optimization, Trento, Italy, 14–18 January 2009. [Google Scholar]
- Preuss, R.; von Toussaint, U. Global Optimization Employing Gaussian Process-Based Bayesian Surrogates. Entropy 2018, 20, 201. [Google Scholar] [CrossRef]
- Newman, A.J. Model Reduction via the Karhunen-Loeve Expansion Part I: An Exposition; University of Maryland: College Park, MD, USA, 1996. [Google Scholar]
- Shang, H.L. A Survey of Functional Principal Component Analysis. AStA Adv. Stat. Anal. 2014, 98, 121–142. [Google Scholar] [CrossRef] [Green Version]
- Cadzow, J.A. Spectral Analysis. In Handbook of Digital Signal Processing; Elsevier: Amsterdam, Netherlands, 1987; pp. 701–740. [Google Scholar]
- Allenby, G.M.; Rossi, P.E.; McCulloch, R.E. Hierarchical Bayes Models: A Practitioners Guide; SSRN Scholarly Paper ID 655541; Social Science Research Network: Rochester, NY, USA, 2005. [Google Scholar] [CrossRef] [Green Version]
- Aggarwal, C.C.; Hinneburg, A.; Keim, D.A. On the Surprising Behavior of Distance Metrics in High Dimensional Space. In Database Theory — ICDT 2001; Lecture Notes in Computer Science; Van den Bussche, J., Vianu, V., Eds.; Springer: Berlin/Heidelberg, Germany, 2001; pp. 420–434. [Google Scholar] [CrossRef] [Green Version]
- Dose, V. Bayesian Estimate of the Newtonian Constant of Gravitation. Meas. Sci. Technol. 2006, 18, 176–182. [Google Scholar] [CrossRef]
- Flexer, A.; Schnitzer, D. Choosing Lp Norms in High-Dimensional Spaces Based on Hub Analysis. Neurocomputing 2015, 169, 281–287. [Google Scholar] [CrossRef] [Green Version]
- Albert, C.; Babin, R.; Hadwiger, M.; Hofmeister, R.; Kendler, M.; Khallaayoune, M.; Rath, K.; Rubino-Moyner, B.; RedMod Team. proFit: Probabilistic response model fitting with interactive tools. v0.4. 2021. Available online: https://doi.org/10.5281/zenodo.3580488 (accessed on 29 September 2021).
- Matthews, A.G.G.; van der Wilk, M.; Nickson, T.; Fujii, K.; Boukouvalas, A.; León-Villagrá, P.; Ghahramani, Z.; Hensman, J. GPflow: A Gaussian process library using TensorFlow. J. Mach. Learn. Res. 2017, 18, 1–6. [Google Scholar]
- Van der Wilk, M.; Dutordoir, V.; John, S.T.; Artemev, A.; Adam, V.; Hensman, J. A framework for interdomain and multioutput Gaussian processes. arXiv 2020, arXiv:2003.01115. [Google Scholar]
- GPy. GPy: A Gaussian Process Framework in Python, Since 2012. Available online: https://gpy.readthedocs.io/en/deploy/ (accessed on 29 September 2021).
- Von Toussaint, U. Bayesian inference in physics. Rev. Mod. Phys. 2011, 83, 943–999. [Google Scholar] [CrossRef] [Green Version]
- Gelman, A.; Rubin, D.B. Inference from iterative simulation using multiple sequences. Stat. Sci. 1992, 7, 457–472. [Google Scholar] [CrossRef]
- Fraedrich, K.; Ziehmann, C.; Sielmann, F. Estimates of spatial degrees of freedom. J. Climate 1995, 8, 361–369. [Google Scholar] [CrossRef] [Green Version]
- Von Storch, H.; Zwiers, F.W. Statistical Analysis in Climate Research; Cambridge University Press: Cambridge, UK, 1999. [Google Scholar]
- Cowell, R.G.; Dawid, A.P.; Lauritzen, S.L.; Spiegelhalter, D.J. Probabilistic Networks and Expert Systems; Springer: New York, NY, USA, 1999. [Google Scholar]
- Hedgpeth, J.W. Models and muddles. Helgoländer Wiss. Meeresunters. 1977, 30, 92–104. [Google Scholar] [CrossRef] [Green Version]
- Hornberger, G.M.; Spear, R.C. Eutrophication in Peel Inlet—I. The problem-defining behavior and a mathematical model for the phosphorus scenario. Water Res. 1980, 14, 29–42. [Google Scholar] [CrossRef]
- Humphries, R.B.; Hornberger, G.M.; Spear, R.C.; McComb, A.J. Eutrophication in Peel Inlet—III. A model for the nitrogen scenario and a retrospective look at the preliminary analysis. Water Res. 1984, 18, 389–395. [Google Scholar] [CrossRef]
- Van Straten, G. Maximum likelihood estimation of parameters and uncertainty in phytoplankton models. In Uncertainty and Forecasting of Water Quality; Beck, M.B., van Straten, G., Eds.; Springer: Berlin/Heidelberg, Germany, 1983; pp. 157–171. [Google Scholar]
- Hornberger, G.M. An approach to the preliminar analysis of environmental systems. J. Environ. Mgmt. 1981, 12, 7–18. [Google Scholar]
- Spear, R.C.; Hornberger, G.M. Eutrophication in Peel Inlet—II. Identification of critical uncertainties via generalized sensitivity analysis. Water Res. 1980, 14, 43–49. [Google Scholar] [CrossRef]
- Beven, K.; Binley, A.M. The future of distributed models: Model calibration and uncertainty prediction. Hydrol. Process. 1992, 6, 279–298. [Google Scholar] [CrossRef]
- Tan, J.; Cao, J.; Cui, Y.; Duan, Q.; Gong, W. Comparison of the generalized likelihood uncertainty estimation and Markov Chain Monte Carlo methods for uncertainty analysis of the ORYZA_V3 model. Agron. J. 2019, 111, 555–564. [Google Scholar] [CrossRef]
- Li, L.; Xia, J.; Xu, C.Y.; Singh, V.P. Evaluation o the subjective factors of the GLUE method and comparison with the normal Bayesian method in uncertainty assessment of hydrological models. J. Hydrol. 2010, 390, 210–221. [Google Scholar] [CrossRef]
- Spear, R.C.; Grieb, T.M.; Shang, N. Parameter uncertainty and interaction in complex environmental models. Water Resour. Res. 1994, 30, 3159–3169. [Google Scholar] [CrossRef]
- Mulder, C.; Hendriks, A.J. Half-saturation constants in functional responses. Glob. Ecol. Conserv. 2014, 2, 161–169. [Google Scholar] [CrossRef] [Green Version]
- Reichert, P.; Omlin, M. On the usefulness of overparameterized ecological models. Ecol. Model. 1997, 95, 289–299. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| a | ||||||
|---|---|---|---|---|---|---|
| Equation (4) | Equation (5) | Equation (6) | Equation (2) | Equation (8) | ||
| : | 3.5 | 0.05 | 500 | 0.4 | 2.0 | 2.0 |
| d | W/m | mg Si/mg C | d | - | ||
| a | Color in Figure 3 | Cost/Prior | ||||||
|---|---|---|---|---|---|---|---|---|
| W/m | mg Si/mg C | - | d | d | ||||
| Minimum cost function | 0.0118 | 41.9 | 0.168 | 1.25 | 1.19 | 0.150 | black | 14.2/4.8 |
| Max. chlorophyll a on 11 May | 0.0054 | 216 | 0.145 | 1.34 | 1.89 | 0.156 | green | 23.6/6.6 |
| Max. chlorophyll a on 10 July | 0.0172 | 2.8 | 0.214 | 1.50 | 0.62 | 0.026 | brown | 26.2/4.8 |
| Min. chlorophyll a on 31 July | 0.0081 | 29.8 | 0.296 | 2.82 | 0.71 | 0.011 | red | 25.7/5.9 |
| 0.11 | −0.21 | −0.10 | 0.69 | 0.10 | ||
| 0.11 | −0.07 | 0.08 | 0.62 | −0.02 | ||
| −0.23 | −0.07 | 0.74 | −0.50 | −0.94 | ||
| 0.01 | −0.04 | 0.74 | −0.29 | −0.88 | ||
| 0.69 | 0.62 | −0.50 | −0.26 | 0.37 | ||
| 0.10 | 0.06 | −0.94 | −0.88 | 0.40 | ||
| −0.69 | 0.05 | −0.03 | 0.83 | −0.12 | ||
| −0.65 | 0.14 | 0.11 | 0.84 | −0.01 | ||
| 0 | 0.20 | −0.54 | −0.30 | −0.89 | ||
| 0 | 0 | −0.46 | −0.12 | −0.79 | ||
| 0.82 | 0.83 | −0.25 | 0 | −0.08 | ||
| −0.13 | 0 | −0.87 | −0.77 | 0 | ||
| log( | log( | log(a) | log() | log() | ||
|---|---|---|---|---|---|---|
| : | 74% | 72% | 94% | 84% | 89% | 96% |
| : | 73% | 69% | 93% | 83% | 87% | 96% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Albert, C.G.; Callies, U.; von Toussaint, U. A Bayesian Approach to the Estimation of Parameters and Their Interdependencies in Environmental Modeling. Entropy 2022, 24, 231. https://doi.org/10.3390/e24020231
Albert CG, Callies U, von Toussaint U. A Bayesian Approach to the Estimation of Parameters and Their Interdependencies in Environmental Modeling. Entropy. 2022; 24(2):231. https://doi.org/10.3390/e24020231
Chicago/Turabian StyleAlbert, Christopher G., Ulrich Callies, and Udo von Toussaint. 2022. "A Bayesian Approach to the Estimation of Parameters and Their Interdependencies in Environmental Modeling" Entropy 24, no. 2: 231. https://doi.org/10.3390/e24020231
APA StyleAlbert, C. G., Callies, U., & von Toussaint, U. (2022). A Bayesian Approach to the Estimation of Parameters and Their Interdependencies in Environmental Modeling. Entropy, 24(2), 231. https://doi.org/10.3390/e24020231