
Complex Embedding with Type Constraints for Link Prediction

Abstract
:1. Introduction
- A novel complex embedding model, named CHolE, was proposed to model relational learning with type constraints, which extended compositional representation HolE [17] to complex domain and injected the type information as modulus constraints into complex embeddings of entities and relations for improving link prediction. It was able to model the entities, relations and the relevant type constraints jointly and effectively utilize their type information for improving link prediction.
- A brand new compositional representation mechanism was developed to integrate the ontology-based information and instance information in KGs. This mechanism used the modulus and phase angles of complex vectors to form the type constraints and nonontological interactions between entities and combined them together with the complex circular correlation to capture multifaceted associations in relations.
- In the experiments, the proposed method outperformed state-of-the-art real-valued knowledge representation methods, including TransE [11], TransH [12], RESCAL [15], DistMult [14], HolE [17], and the classic complex embedding model ComplEx [16], on link prediction tasks. The experimental results on standard benchmark datasets showed that the impartment of type constraints obtained performance gains on link prediction.
2. Related Works
2.1. Translation-Based Models
2.2. Tensor Factorization-Based Models
2.3. Neural Network-Based Models
2.4. Methods with Type Information
2.5. Complex Embedding Methods
3. Preliminaries
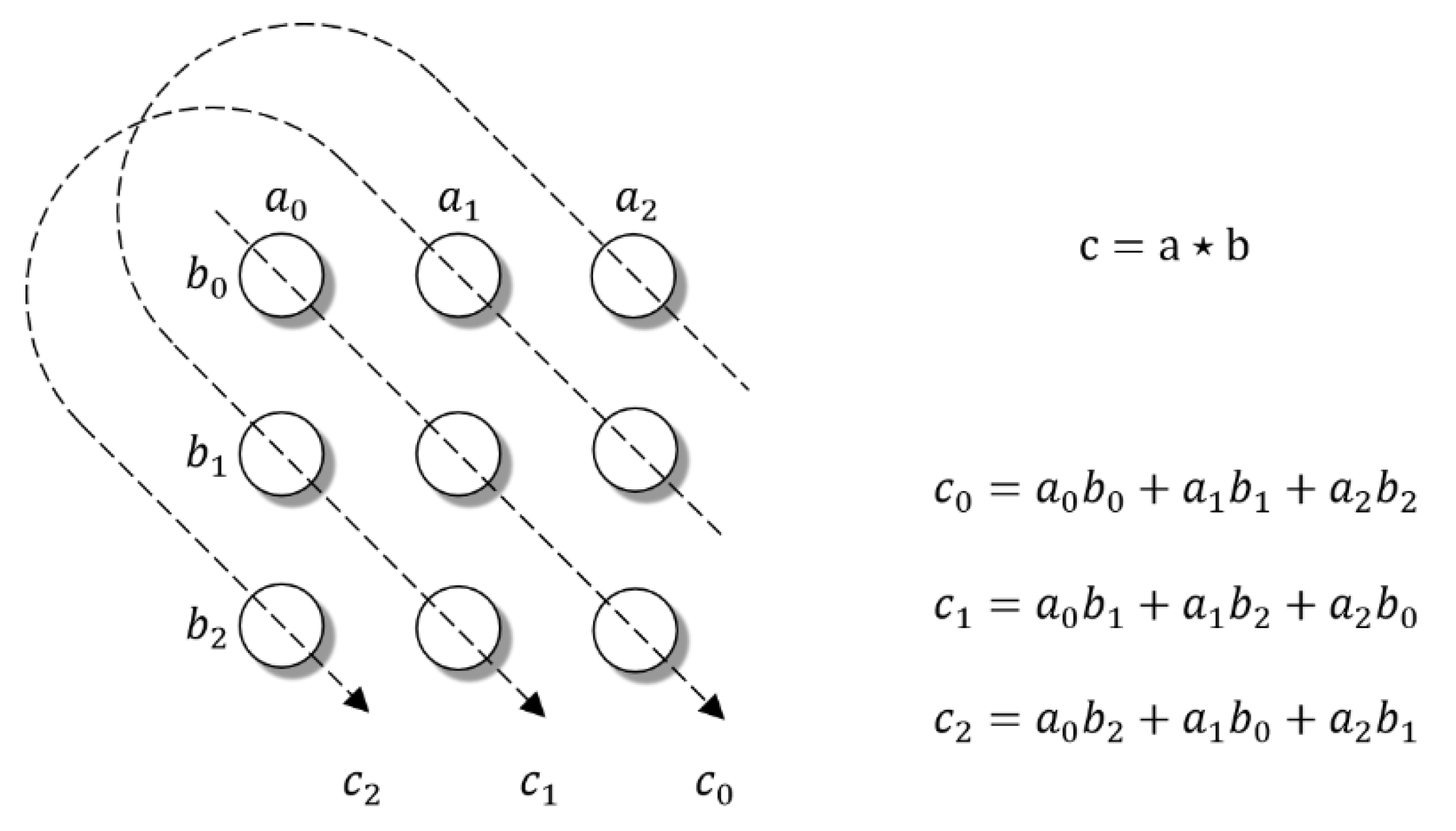
3.1. Complex Circular Correlation
3.1.1. HolE and Circular Correlation
3.1.2. Complex Circular Correlation
3.1.3. Mechanisms of Modulus Constraint and Phase Interaction
3.2. Problem Formulation
4. Methodology
4.1. Overview
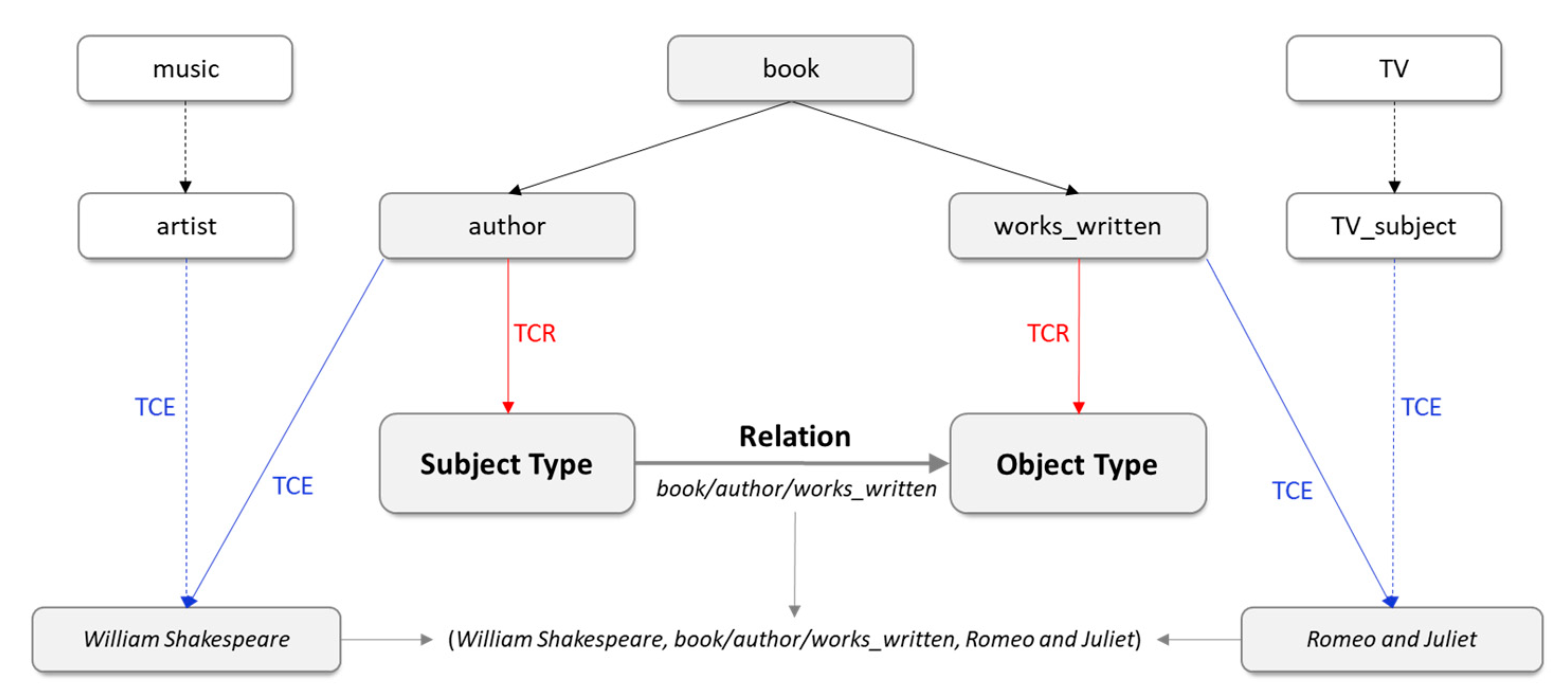
4.2. TCM
4.2.1. TCE Component
4.2.2. TCR Component
4.3. RLM
5. Experiments
5.1. Datasets
5.2. Experiment Settings
5.2.1. Baselines
5.2.2. Evaluation Protocol
5.2.3. Implementation Details
5.3. Results of Link Prediction
- CHolE outperformed baseline models on most of the metrics for link prediction on FB15K-571 and FB15K-237-TC. This condition demonstrated that the proposed complex embedding method was effective and promising, and the impartment of type constraints considerably improved the performance on link prediction.
- Compared with the original HolE [17], the experimental results of the “RL only” version of CHolE were higher on FB15K-237-TC, but most of the metrics, including MRR (Filtered), Hits@1, Hits@3, and Hits@10 were slightly lower than HolE [17], and the MRR (Raw) was flat on FB15K-571. This finding was partially because the complex circular correlation in CHolE led to more complicated and rigorous constraints with modulus and phase angles, which were more difficult to reach. However, with the introduction of type constraints, the entities were grouped into their relation-specific types with modulus to make the modulus constraint harder, and the greater possibility of phase matching was obtained. Most of the experimental results indicated that the full version (“TC + RL”) of CHolE performed better than HolE [17] on two datasets. In the FB15K-571 dataset, CHolE (TC+RL) obtained 0.019 higher MRR (Filtered), 2.2% higher Hits@1, 2.4% higher Hits@3 and 0.7% higher Hits@10. In the FB15K-237-TC dataset, the full version of CHolE obtained 0.061 higher MRR (Raw), 0.059 higher MRR (Filtered), 7% higher Hits@1, 5.8% higher Hits@3 and 5.7% higher Hits@10.
- Compared with the complex embedding ComplEx [16], the “RL only” version of CHolE obtained higher results on most metrics, and the “TC+RL” version made significant progress on two datasets. As seen in Table 3, CHolE(TC+RL) obtained 0.058 higher MRR (Filtered), 7.7% higher Hits@1, 6% higher Hits@3 and 1.7% higher Hits@10 on FB15K-571, and 0.08 higher MRR (Filtered), 9.1% higher Hits@1, 9.8% higher Hits@3 and 6% higher Hits@10 on FB15K-237-TC. We ascribed the improvement of the full version of CHolE to having utilized the modulus and phase angles to capture the semantic relatedness on ontology and instance view, respectively. By contrast, the ComplEx [16] extended DistMult [14] to complex space. It neither took full advantage of the modulus and phase angles of complex representational vectors nor integrated type constraints into relational interactions with them.
6. Discussion
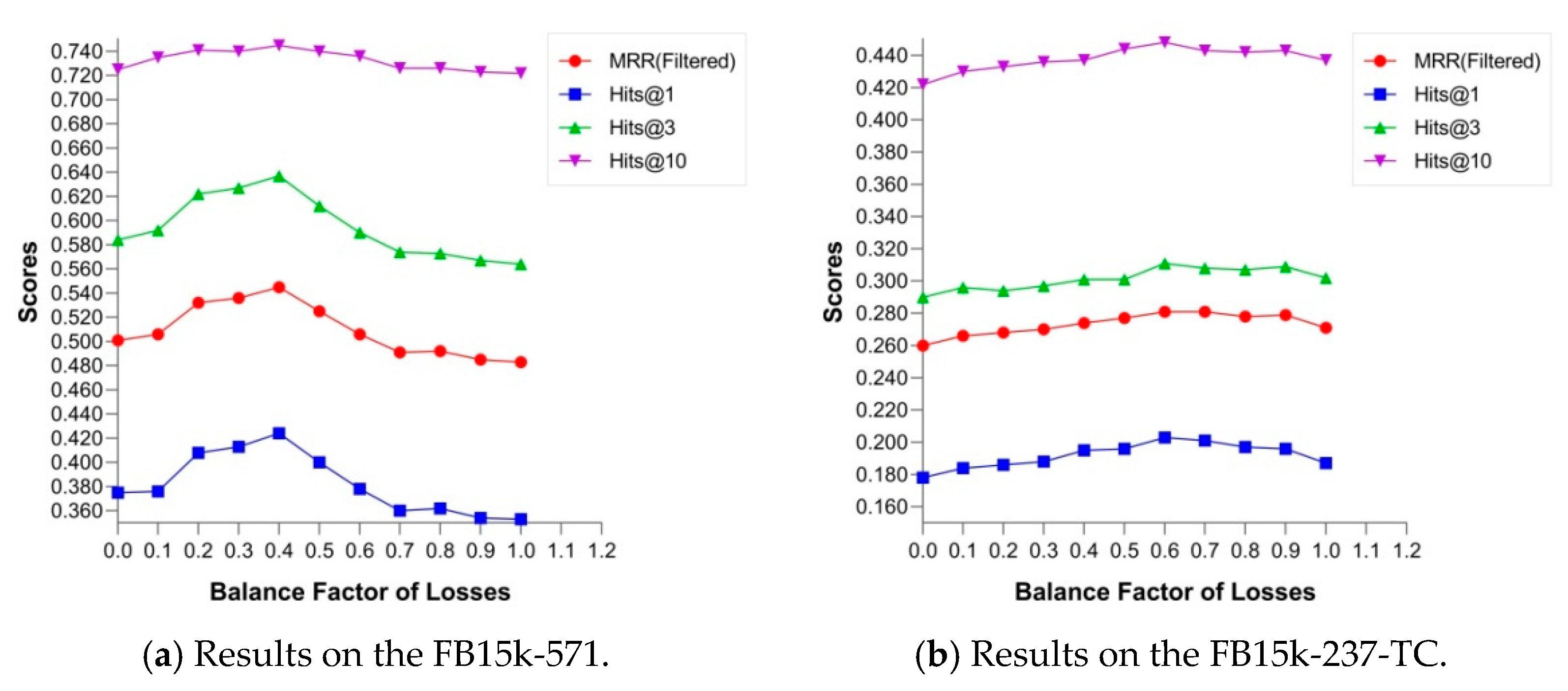
6.1. Balance Factor of Losses
6.2. Base of Type Radius
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Bollacker, K.; Evans, C.; Paritosh, P.; Sturge, T.; Taylor, J. Freebase: A collaboratively created graph database for structuring human knowledge. In Proceedings of the 2008 ACM SIGMOD International Conference on Management of Data, Vancouver, BC, Canada, 9–12 June 2008; pp. 1247–1250. [Google Scholar]
- Miller, G.A. WordNet: A lexical database for English. Commun. ACM 1995, 38, 39–41. [Google Scholar] [CrossRef]
- Suchanek, F.M.; Kasneci, G.; Weikum, G. Yago: A core of semantic knowledge. In Proceedings of the 16th International Conference on World Wide Web, Banff, AB, Canada, 8–12 May 2007; pp. 697–706. [Google Scholar]
- Choudhury, N.; Faisal, F.; Khushi, M. Mining Temporal Evolution of Knowledge Graphs and Genealogical Features for Literature-based Discovery Prediction. J. Informetr. 2020, 14, 101057. [Google Scholar] [CrossRef]
- Sitar-Tăut, D.-A.; Mican, D.; Buchmann, R.A. A knowledge-driven digital nudging approach to recommender systems built on a modified Onicescu method. Expert Syst. Appl. 2021, 181, 115170. [Google Scholar] [CrossRef]
- Xie, R.; Liu, Z.; Sun, M. Representation learning of knowledge graphs with hierarchical types. In Proceedings of the 25th International Joint Conference on Artificial Intelligence, Palo Alto, CA, USA, 9–15 July 2016; pp. 2965–2971. [Google Scholar]
- Zhang, M.; Geng, G.; Zeng, S.; Jia, H. Knowledge Graph Completion for the Chinese Text of Cultural Relics Based on Bidirectional Encoder Representations from Transformers with Entity-Type Information. Entropy 2020, 22, 1168. [Google Scholar] [CrossRef] [PubMed]
- Li, W.; Peng, R.; Li, Z. Knowledge Graph Completion by Jointly Learning Structural Features and Soft Logical Rules. IEEE Trans. Knowl. Data Eng. 2021, 8, 224. [Google Scholar] [CrossRef]
- Xiong, H.; Wang, S.; Tang, M.; Wang, L.; Lin, X. Knowledge Graph Question Answering with semantic oriented fusion model. Knowl. Based Syst. 2021, 221, 106954. [Google Scholar] [CrossRef]
- Lin, Y.; Xu, B.; Feng, J.; Lin, H.; Xu, K. Knowledge-enhanced recommendation using item embedding and path attention. Knowl. Based Syst. 2021, 233, 107484. [Google Scholar] [CrossRef]
- Bordes, A.; Usunier, N.; Garcia-Duran, A.; Weston, J.; Yakhnenko, O. Translating embeddings for modeling multi-relational data. Adv. Neural Inf. Process. Syst. 2013, 2, 2787–2795. [Google Scholar]
- Wang, Z.; Zhang, J.; Feng, J.; Chen, Z. Knowledge graph embedding by translating on hyperplanes. In Proceedings of the 28th AAAI Conference on Artificial Intelligence, Québec City, QC, Canada, 27–31 July 2014; pp. 1112–1119. [Google Scholar]
- Lin, Y.; Liu, Z.; Sun, M.; Liu, Y.; Zhu, X. Learning entity and relation embeddings for knowledge graph completion. In Proceedings of the 29th AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015; pp. 2181–2187. [Google Scholar]
- Yang, B.; Yih, W.-T.; He, X.; Gao, J.; Deng, L. Embedding entities and relations for learning and inference in knowledge bases. In Proceedings of the 2015 International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015; pp. 1–12. [Google Scholar]
- Nickel, M.; Tresp, V.; Kriegel, H.P. A three-way model for collective learning on multi-relational data. In Proceedings of the 28th International Conference on International Conference on Machine Learning, Bellevue, WA, USA, 28 June–2 July 2011; pp. 809–816. [Google Scholar]
- Trouillon, T.; Welbl, J.; Riedel, S.; Gaussier, É.; Bouchard, G. Complex embeddings for simple link prediction. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016; pp. 2071–2080. [Google Scholar]
- Nickel, M.; Rosasco, L.; Poggio, T. Holographic Embeddings of Knowledge Graphs. In Proceedings of the 30th AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; pp. 1955–1961. [Google Scholar]
- Lv, X.; Hou, L.; Li, J.; Liu, Z. Differentiating concepts and instances for knowledge graph embedding. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 1971–1979. [Google Scholar]
- Hao, J.; Chen, M.; Yu, W.; Sun, Y.; Wang, W. Universal representation learning of knowledge bases by jointly embedding instances and ontological concepts. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 1709–1719. [Google Scholar]
- Xiao, H.; Huang, M.; Zhu, X. From One Point to A Manifold: Knowledge Graph Embedding for Precise Link Prediction. In Proceedings of the 25th International Joint Conference on Artificial Intelligence, Palo Alto, CA, USA, 9–15 July 2016; pp. 1315–1321. [Google Scholar]
- Sun, Z.; Deng, Z.H.; Nie, J.Y.; Tang, J. RotatE: Knowledge Graph Embedding by Relational Rotation in Complex Space. In Proceedings of the International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019; pp. 1–18. [Google Scholar]
- Dai, Y.; Wang, S.; Xiong, N.; Guo, W. A Survey on Knowledge Graph Embedding: Approaches, Applications and Benchmarks. Electronics 2020, 9, 750. [Google Scholar] [CrossRef]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Ji, G.; He, S.; Xu, L.; Liu, K.; Zhao, J. Knowledge graph embedding via dynamic mapping matrix. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing, Beijing, China, 26–31 July 2015; pp. 687–696. [Google Scholar]
- Brigham, E.O.; Brigham, E.O. The Fast Fourier Transform and Its Applications; Pearson: Upper Saddle River, NJ, USA, 1988; Volume 448. [Google Scholar]
- Bordes, A.; Glorot, X.; Weston, J.; Bengio, Y. A semantic matching energy function for learning with multi-relational data. Mach. Learn. 2014, 94, 233–259. [Google Scholar] [CrossRef] [Green Version]
- Socher, R.; Chen, D.; Manning, C.D.; Ng, A. Reasoning with neural tensor networks for knowledge base completion. Adv. Neural Inf. Process. Syst. 2013, 1, 926–934. [Google Scholar]
- Nguyen, D.Q.; Nguyen, T.D.; Nguyen, D.Q.; Phung, D. A Novel Embedding Model for Knowledge Base Completion Based on Convolutional Neural Network. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, New Orleans, LA, USA, 1–6 June 2018; Volume 2, pp. 327–333. [Google Scholar]
- Schlichtkrull, M.; Kipf, T.N.; Bloem, P.; Van Den Berg, R.; Titov, I.; Welling, M. Modeling relational data with graph convolutional networks. In Proceedings of the European Semantic Web Conference, Anissaras, Greece, 3–7 June 2018; pp. 593–607. [Google Scholar]
- Zhang, Z.; Li, Z.; Liu, H.; Xiong, N.N. Multi-scale Dynamic Convolutional Network for Knowledge Graph Embedding. IEEE Trans. Knowl. Data Eng. 2020, 3, 5952. [Google Scholar] [CrossRef]
- Zeb, A.; Haq, A.U.; Chen, J.; Lei, Z.; Zhang, D. Learning hyperbolic attention-based embeddings for link prediction in knowledge graphs. Knowl. Based Syst. 2021, 229, 107369. [Google Scholar] [CrossRef]
- Zhang, S.; Tay, Y.; Yao, L.; Liu, Q. Quaternion knowledge graph embeddings. In Proceedings of the 33th International Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; pp. 2731–2741. [Google Scholar]
- Gao, L.; Zhu, H.; Zhuo, H.H.; Xu, J. Dual Quaternion Embeddings for Link Prediction. Appl. Sci. 2021, 11, 5572. [Google Scholar] [CrossRef]
- Plate, T.A. Holographic reduced representations. IEEE Trans. Neural Netw. 1995, 6, 623–641. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Toutanova, K.; Chen, D.; Pantel, P.; Poon, H.; Choudhury, P.; Gamon, M. Representing text for joint embedding of text and knowledge bases. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–22 September 2015; pp. 1499–1509. [Google Scholar]
- Robbins, H.; Monro, S. A stochastic approximation method. Herbert Robbins Sel. Pap. 1985, 22, 102–109. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Glorot, X.; Bengio, Y. Understanding the difficulty of training deep feedforward neural networks. In Proceedings of the 13rd International Conference on Artificial Intelligence and Statistics, Chia Laguna Resort, Sardinia, Italy, 13–15 May 2010; pp. 249–256. [Google Scholar]
- Wang, Z.; Li, L.; Zeng, D. A Re-Ranking Framework for Knowledge Graph Completion. In Proceedings of the 2020 International Joint Conference on Neural Networks, Glasgow, Scotland, UK, 8–14 July 2020; pp. 1–8. [Google Scholar]
- Kong, X.; Chen, X.; Hovy, E. Decompressing knowledge graph representations for link prediction. arXiv 2014, arXiv:1911.04053. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbols | Descriptions | Symbols | Descriptions |
|---|---|---|---|
| KG | knowledge graph | rTCR | TCR relation |
| E | entity set | S | triple set |
| C | type (concept) set | SI | general triple set |
| R | relation set | STC | type constraint triple set |
| RI | instance-level relation set | STCE | TCE triple set |
| RTC | type constraint relation set | STCE | TCR triple set |
| rTCE | TCE (instanceOf) relation |
| Dataset | FB15K-571 | FB15K-237-TC |
|---|---|---|
| #Entity * | 14,951 | 14,541 |
| #Type | 571 | 542 |
| #General (Instance-level) Relation | 1345 | 237 |
| #General Relation Triple | 592,213 | 310,116 |
| #TCE (instanceOf Relation) Triple | 123,842 | 121,287 |
| #TCR Triple | 1345 | 237 |
| #Train (General Relation Triple) | 483,142 | 272,115 |
| #Valid (General Relation Triple) | 50,000 | 17,535 |
| #Test (General Relation Triple) | 59,071 | 20,466 |
| Dataset | FB15K-571 | FB15K-237-TC | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Metrics | MRR | Hits@N | MRR | Hits@N | ||||||
| Setting | Raw | Filter | N = 1 | N = 3 | N = 10 | Raw | Filter | N = 1 | N = 3 | N = 10 |
| TransE | 0.417 | 0.150 | 0.314 | 0.476 | 0.144 | 0.233 | 0.147 | 0.263 | 0.398 | |
| TransH | 0.495 | 0.284 | 0.535 | 0.641 | 0.136 | 0.041 | 0.160 | 0.331 | ||
| RESCAL | 0.189 | 0.354 | 0.235 | 0.409 | 0.587 | 0.255 | 0.185 | 0.278 | 0.397 | |
| DistMult | 0.350 | 0.577 | 0.100 | 0.191 | 0.106 | 0.207 | 0.376 | |||
| HolE | 0.232 | 0.524 | 0.402 | 0.613 | 0.739 | 0.124 | 0.222 | 0.133 | 0.253 | 0.391 |
| ComplEx | 0.223 | 0.485 | 0.347 | 0.577 | 0.729 | 0.109 | 0.201 | 0.112 | 0.213 | 0.388 |
| CHolE (RL only) | 0.232 | 0.510 | 0.387 | 0.601 | 0.725 | 0.158 | 0.260 | 0.178 | 0.290 | 0.422 |
| CHolE (TC+RL) | 0.231 | 0.543 | 0.424 | 0.637 | 0.746 | 0.185 | 0.281 | 0.203 | 0.311 | 0.448 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, X.; Wang, Z.; Zhang, Z. Complex Embedding with Type Constraints for Link Prediction. Entropy 2022, 24, 330. https://doi.org/10.3390/e24030330
Li X, Wang Z, Zhang Z. Complex Embedding with Type Constraints for Link Prediction. Entropy. 2022; 24(3):330. https://doi.org/10.3390/e24030330
Chicago/Turabian StyleLi, Xiaohui, Zhiliang Wang, and Zhaohui Zhang. 2022. "Complex Embedding with Type Constraints for Link Prediction" Entropy 24, no. 3: 330. https://doi.org/10.3390/e24030330
APA StyleLi, X., Wang, Z., & Zhang, Z. (2022). Complex Embedding with Type Constraints for Link Prediction. Entropy, 24(3), 330. https://doi.org/10.3390/e24030330