
Estimation of the Covariance Matrix in Hierarchical Bayesian Spatio-Temporal Modeling via Dimension Expansion


Abstract
:1. Introduction
2. Hierarchical Bayesian Spatio-Temporal Modeling
- Step 1.
- Compute the hyperparameter values that maximize the marginal distribution using an empirical Bayesian approach (see (b) of Appendix A). The EM algorithm is used to obtain .
- Step 2.
- Obtain the predictive distributions of missing measurements as in (c) of Appendix A. Fill in the missing data by using the predictive distributions.
- Step 3.
- Obtain the estimate from the estimate of . In terms of , obtain the estimate of the covariance matrix by using a dimension expansion method given in Qin et al. [5] and the thin-plate spline method given in Wabba and Wendelberger (1980). The details are given in Section 4.1.
- Step 4.
- Estimate the hyperparameters and obtain the conditional predictive distribution (see Section 4.2).
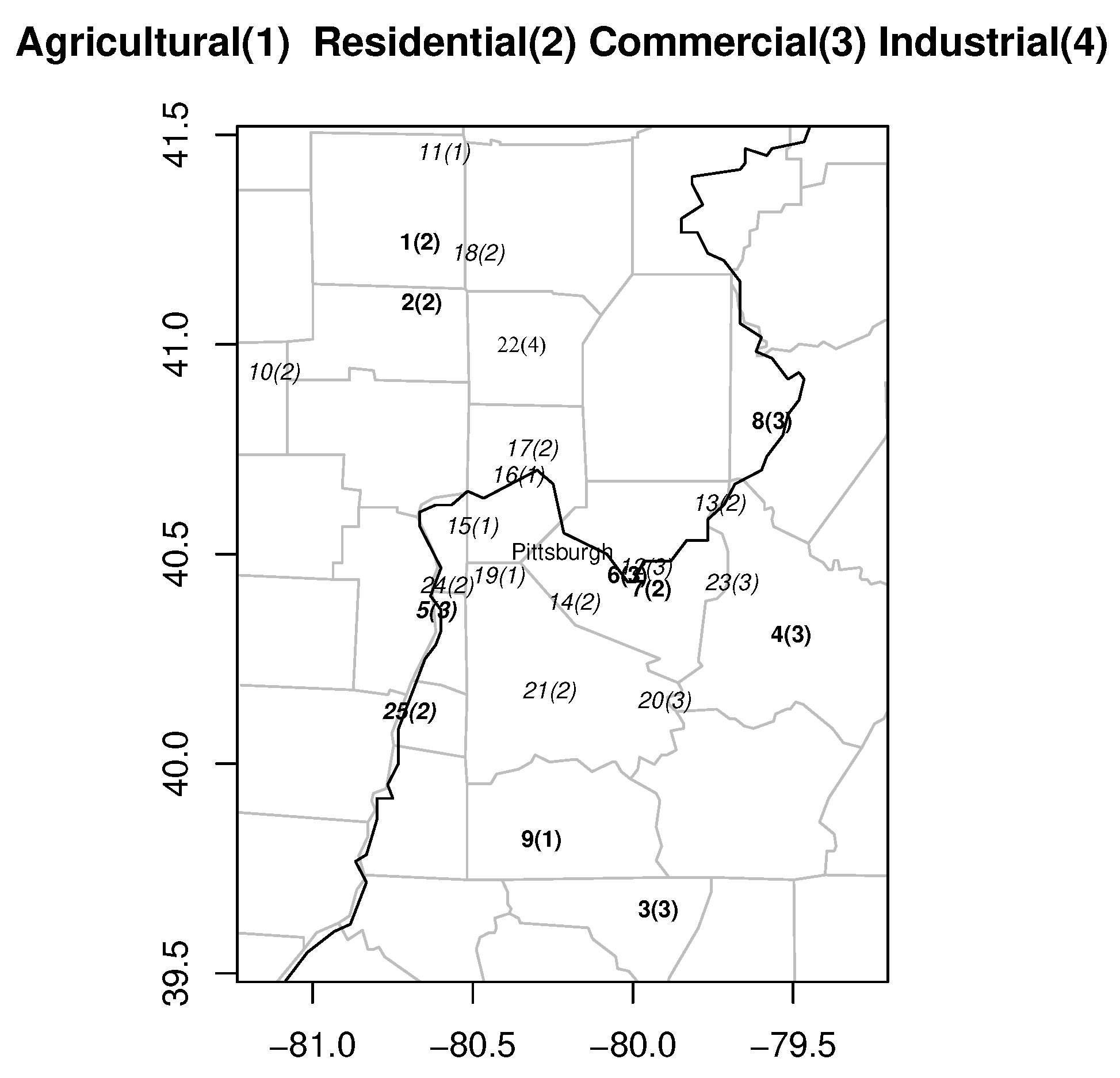
3. Ozone Concentrations from the Monitoring Stations in Pittsburgh Region
3.1. Filling in the Missing Measurements for Each Monitoring Station within the Period of Monitoring Blocks
3.2. Filling in the Missing Measurements in
- (i)
- Obtain a new data set from by filling in the 488 missing measurements at Stations 5 and 25 during the end of the time period by using the HBST modeling technique. N3.Miss in Table 1 displays the number of missing data in the data set , which shows that has a staircase data structure, as all of the missing data are located in the beginning of the time period.
- (ii)
- Put , , , , , , , , , , , , , , , , and . Fill in the remaining missing values in by executing Steps 1–2 of the HBST modeling procedure.
4. Model the Ozone Concentrations in the Pittsburgh Region
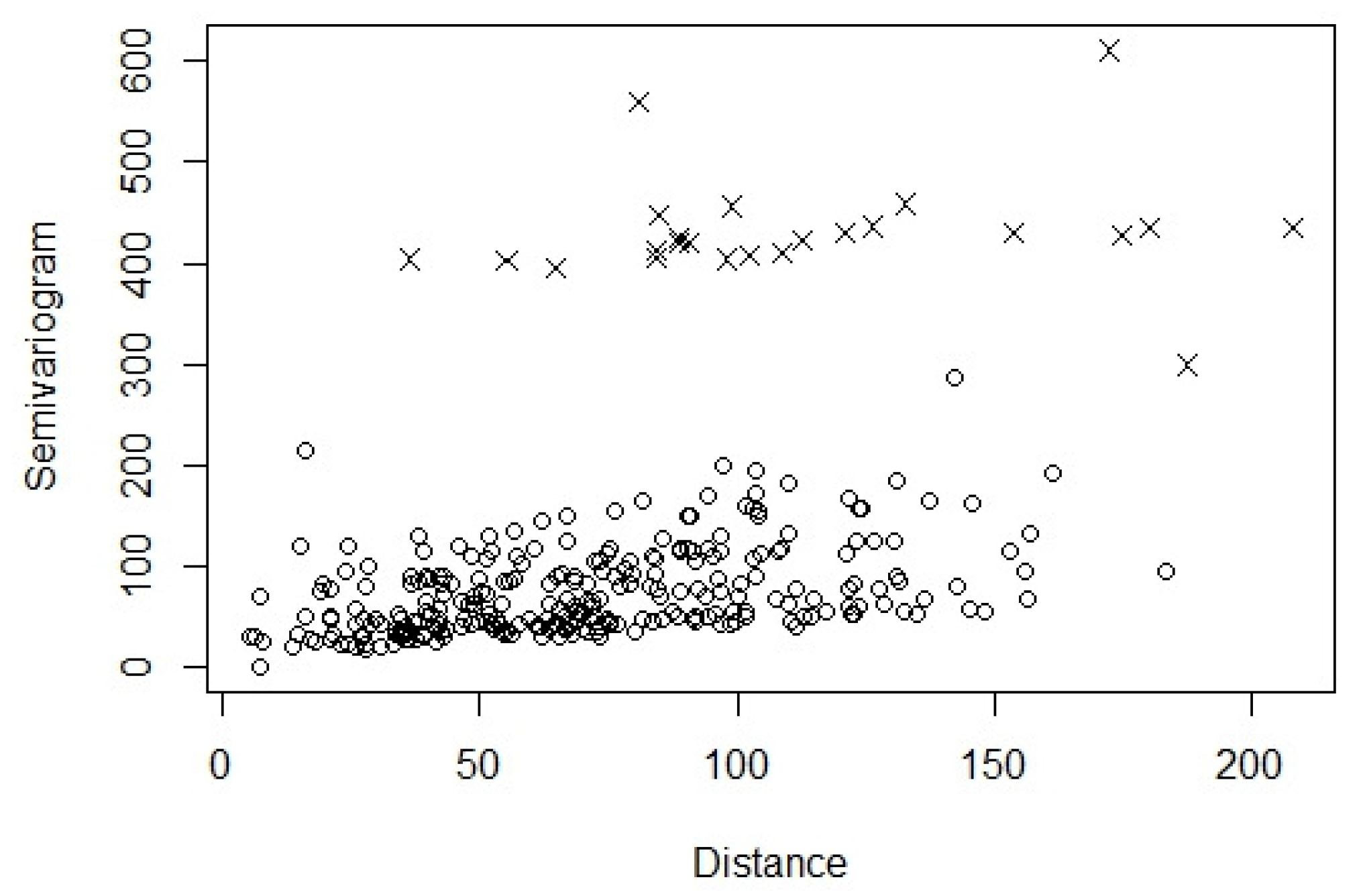
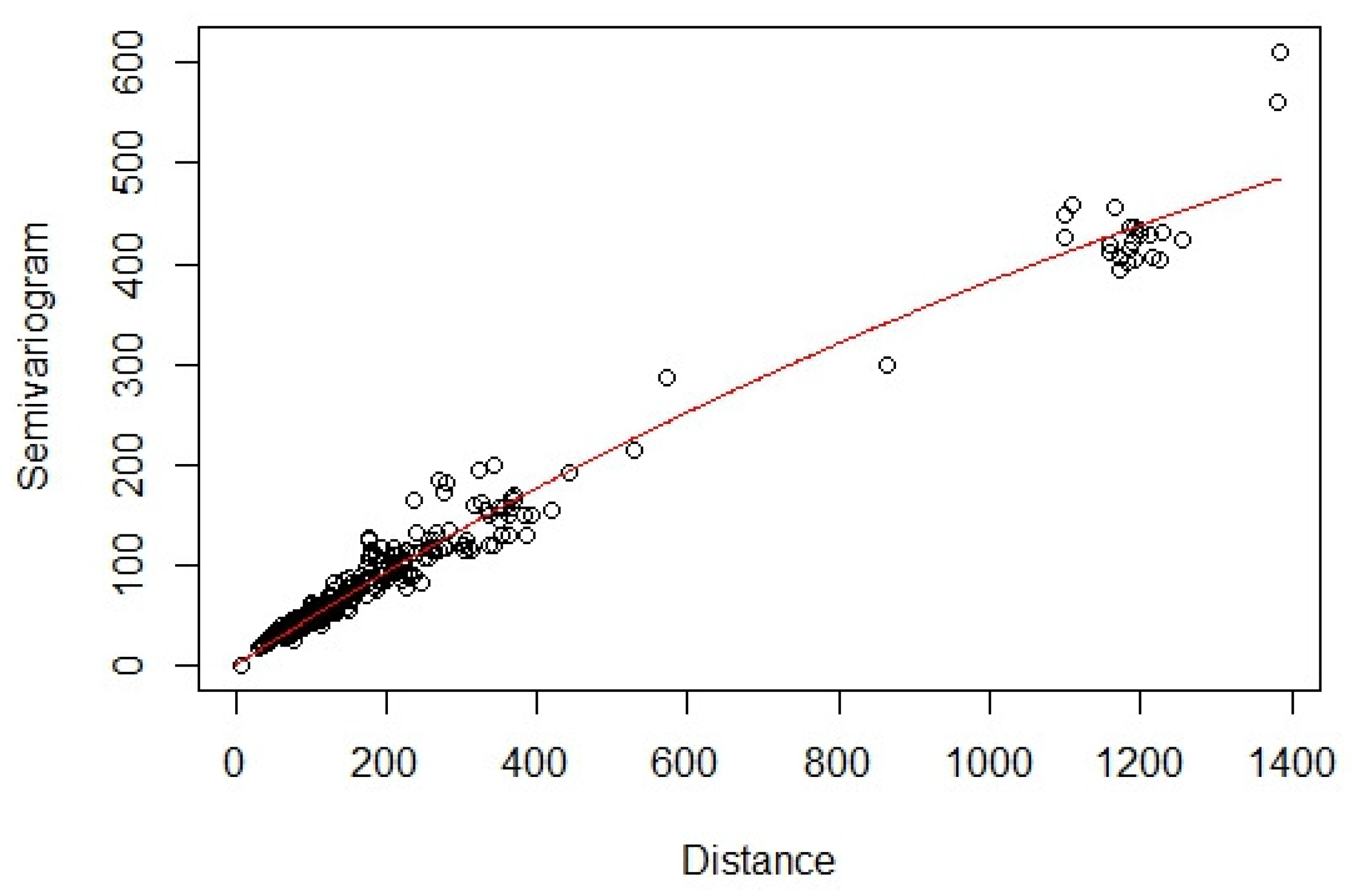
4.1. Estimation of the Covariance Matrix
- ,
- ,
4.2. Prediction of the Daily Ozone Concentrations at the Grid Points
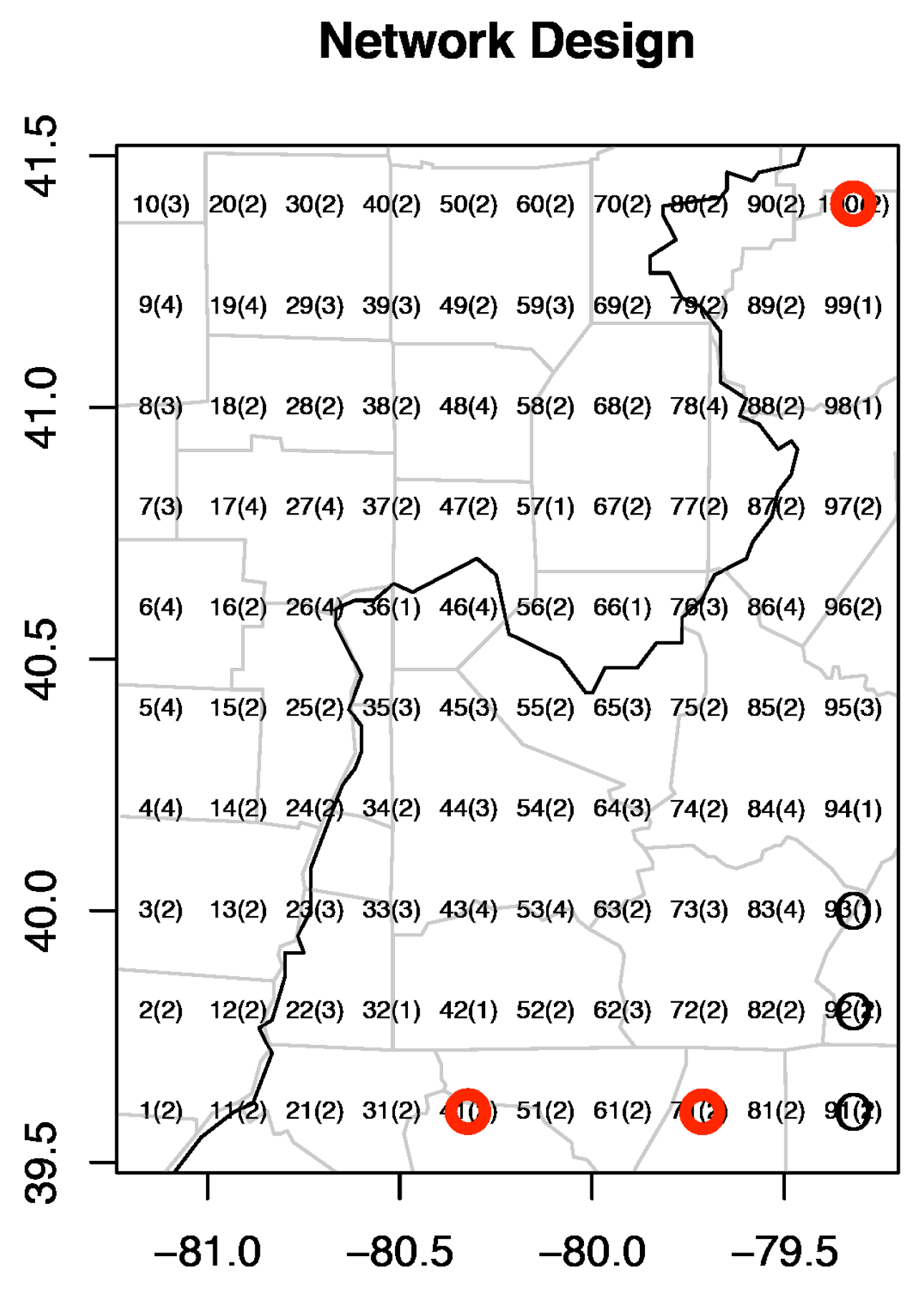
5. Environmental Network Extension
6. Model Evaluation
7. Conclusions
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. Hierarchical Bayesian Spatio-Temporal Modeling
References
- Wikle, C.K.; Berliner, L.M.; Cressie, N. Hierachichical Bayesian space-time models. Environ. Ecol. Stat. 1998, 5, 117–154. [Google Scholar] [CrossRef]
- Le, N.D.; Sun, W.; Zidek, J.V. Spatial prediction and temporal backcasting for environmental fields having monotone data patterns. Can. J. Stat. 2001, 29, 529–554. [Google Scholar] [CrossRef]
- Jin, B.; Wu, Y.; Chan, E. Hierarchical Bayesian spatial-temporal modeling of regional ozone concentrations and respecitve network design. J. Environ. Stat. 2012, 3, 1–32. [Google Scholar]
- Diggle, P.J.; Ribeiro, P.J., Jr. Model-Based Geostatistics; Springer: Berlin/Heidelberg, Germany, 2007. [Google Scholar]
- Qin, S.; Sun, B.; Wu, Y.; Fu, Y. Generalized least-squares in dimension expansion method for nonstationary processes. Environmetrics 2021, 32, e2684. [Google Scholar] [CrossRef]
- Cressie, N. Statistics for Spatial Data, Revised Edition; Wiley: New York, NY, USA, 2015. [Google Scholar]
- Xue, X.T.; Guy, B.; Xing, L.; Pierre, F.; Claire, G.; Philip, R. The Impact of High Altitude Aircraft on the Ozone Layer in the Stratosphere. J. Atmos. Chem. 1994, 18, 103–128. [Google Scholar]
- Bornn, L.; Shaddick, G.; Zidek, J.V. Modeling non-stationary processes through dimension expansion. J. Am. Stat. Assoc. 2012, 107, 281–289. [Google Scholar] [CrossRef] [Green Version]
- Journel, A.G.; Huijbregts, C.J. Mining Geostatistics; Academic: London, UK, 1978. [Google Scholar]
- Wabba, G.; Wendelberger, J. Some new mathematical methods for variational objective analysis using splines and cross-validation. Mon. Weather Rev. 1980, 108, 1122–1143. [Google Scholar] [CrossRef] [Green Version]
- Jaynes, E.T. Information Theory and Statistical Mechanics, Statistical Physics, 3rd ed.; Ford, K.W., Ed.; Benjamin: New York, NY, USA, 1963. [Google Scholar]
- Le, N.D.; Zidek, J.V. Statistical Analysis of Environmental Space-Time Processes; Springer: New York, NY, USA, 2006. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ID | Class | Lon | Lat | N1.Miss | N2.Miss | N3.Miss | ID | Class | Lon | Lat | N1.Miss | N2.Miss | N3.Miss |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | −40.24 | 80.66 | 855 | 854 | 854 | 14 | 2 | −40.38 | 80.18 | 22 | 0 | 0 |
| 2 | 2 | −41.09 | 80.65 | 610 | 610 | 610 | 15 | 1 | −40.56 | 80.50 | 13 | 0 | 0 |
| 3 | 3 | −39.64 | 79.92 | 618 | 610 | 610 | 16 | 1 | −40.68 | 80.35 | 11 | 0 | 0 |
| 4 | 3 | −40.30 | 79.50 | 488 | 488 | 488 | 17 | 2 | −40.74 | 80.31 | 4 | 0 | 0 |
| 5 | 3 | −40.36 | 80.61 | 858 | 854 | 366 | 18 | 2 | −41.21 | 80.48 | 5 | 0 | 0 |
| 6 | 3 | −40.44 | 80.01 | 370 | 366 | 366 | 19 | 1 | −40.44 | 80.42 | 16 | 0 | 0 |
| 7 | 2 | −40.41 | 79.94 | 370 | 366 | 366 | 20 | 3 | −40.14 | 79.90 | 3 | 0 | 0 |
| 8 | 3 | −40.81 | 79.56 | 328 | 318 | 318 | 21 | 2 | −40.17 | 80.26 | 1 | 0 | 0 |
| 9 | 1 | −39.81 | 80.28 | 278 | 244 | 244 | 22 | 4 | −40.99 | 80.34 | 0 | 0 | 0 |
| 10 | 2 | −40.93 | 81.12 | 12 | 0 | 0 | 23 | 3 | −40.42 | 79.69 | 5 | 0 | 0 |
| 11 | 1 | −41.45 | 80.59 | 1 | 0 | 0 | 24 | 2 | −40.42 | 80.58 | 5 | 0 | 0 |
| 12 | 3 | −40.46 | 79.96 | 2 | 0 | 0 | 25 | 2 | −40.12 | 80.69 | 488 | 488 | 0 |
| 13 | 2 | −40.61 | 79.73 | 8 | 0 | 0 |
| ID | Our Method | Jin et al. (2012) [3] | ID | Our Method | Jin et al. (2012) [3] |
|---|---|---|---|---|---|
| 1 | 0.0789 (0.0627) | 0.8134 (0.0682) | 13 | 0.1145 (0.1096 ) | 0.2003 (0.1769) |
| 2 | 0.1206 (0.1356) | 0.1221 (0.1121) | 14 | 0.1361 (0.1732) | 0.2211 ( 0.2283) |
| 3 | 0.8517 (0.8517) | 0.1572 ( 0.1572) | 15 | 0.1911 (0.2052) | - |
| 4 | 0.1756 (0.1693) | - | 16 | 0.1189 (0.1179) | 0.1285 (0.1161) |
| 5 | 0.1575 (0.1731) | 0.1986 (0.1855) | 17 | 0.1496 (0.1594 ) | 0.1669 (0.1727) |
| 6 | 0.1336 (0.1513) | 0.1477 (0.1667 ) | 18 | 0.1253 (0.1154 ) | 0.1256 (0.1372) |
| 7 | 0.1265 (0.1563 ) | 0.1456 (0.1732) | 19 | 0.1369 (0.1272) | 0.1026 ( 0.0994) |
| 8 | 0.0968 (0.0804) | 0.1135 (0.1023) | 20 | 0.1603 (0.1598) | 0.1310 (0.1134) |
| 9 | 0.1497 (0.1104) | 0.1619 (0.1208) | 21 | 0.1351 (0.1154) | 0.1274 (0.1123) |
| 10 | 0.1589 (0.1796 ) | - | 23 | 0.1617 (0.1858) | - |
| 11 | 0.6913 (0.6455) | - | 24 | 0.1286 (0.1051) | - |
| 12 | 0.1406 (0.1409) | 0.1265( 0.1416) | 25 | 0.1583 (0.1701) | 0.1722 ( 0.1675) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, B.; Wu, Y. Estimation of the Covariance Matrix in Hierarchical Bayesian Spatio-Temporal Modeling via Dimension Expansion. Entropy 2022, 24, 492. https://doi.org/10.3390/e24040492
Sun B, Wu Y. Estimation of the Covariance Matrix in Hierarchical Bayesian Spatio-Temporal Modeling via Dimension Expansion. Entropy. 2022; 24(4):492. https://doi.org/10.3390/e24040492
Chicago/Turabian StyleSun, Bin, and Yuehua Wu. 2022. "Estimation of the Covariance Matrix in Hierarchical Bayesian Spatio-Temporal Modeling via Dimension Expansion" Entropy 24, no. 4: 492. https://doi.org/10.3390/e24040492
APA StyleSun, B., & Wu, Y. (2022). Estimation of the Covariance Matrix in Hierarchical Bayesian Spatio-Temporal Modeling via Dimension Expansion. Entropy, 24(4), 492. https://doi.org/10.3390/e24040492