Abstract
We consider a binary classification problem for a test sequence to determine from which source the sequence is generated. The system classifies the test sequence based on empirically observed (training) sequences obtained from unknown sources and . We analyze the asymptotic fundamental limits of statistical classification for sources with multiple subclasses. We investigate the first- and second-order maximum error exponents under the constraint that the type-I error probability for all pairs of distributions decays exponentially fast and the type-II error probability is upper bounded by a small constant. In this paper, we first give a classifier which achieves the asymptotically maximum error exponent in the class of deterministic classifiers for sources with multiple subclasses, and then provide a characterization of the first-order error exponent. We next provide a characterization of the second-order error exponent in the case where only has multiple subclasses but does not. We generalize our results to classification in the case that and are a stationary and memoryless source and a mixed memoryless source with general mixture, respectively.
1. Introduction
1.1. Background
The problem of learning sources from training sequences and estimating the source from which a test sequence is generated is known as a classification problem. Recently, this problem has been actively studied in a field such as machine learning, and it is desirable to conduct studies that guarantee the performance of the system. In the field of information theory, studies have been conducted mainly to analyze the performance of optimal tests. When the number of sources is two, the binary classification problem can be regarded as a binary hypothesis testing problem, using training sequences. In the setting of binary hypothesis testing, it is assumed that the sources are known, but in real-world applications, the sources are not known in general. Therefore, it is of importance to consider the binary classification problem.
Hypothesis testing includes approaches such as the Bayesian test [1,2] and the Neyman–Pearson test [3,4,5]. In this paper, we take the latter approach to formulate the best asymptotic error exponent (the exponential part of an error probability).
There are a lot of studies related to the classification problem. We state important points, which are deeply connected to this study in some previous studies. Gutman [3] has shown that type-based (empirical distribution-based) tests asymptotically achieve the maximum type-II error exponent for stationary Markov sources, while the type-I error probability exponentially converges to zero as the length of a test sequence goes to infinity. Zhou et al. [5] derived second-order approximations of the maximum type-I error exponent for stationary and memoryless sources when the type-II error probability is upper bounded by a small constant. On the other hand, for the hypothesis testing problem, Han and Nomura [6] characterized a first-order maximum error exponent when each sequence is generated from a mixed memoryless source, which is a mixture of stationary and memoryless sources. In addition, they also characterized a second-order maximum error exponent in the case where one source is a stationary and memoryless source and the other source is a mixed memoryless source.
1.2. Contributions
In this paper, we investigate the binary classification problem for stationary memoryless sources with multiple subclasses. The class of sources with multiple subclasses is important in binary classification because there are many such settings in real-world applications. For example, newspaper articles with science headlines consist of topics of physics, chemistry, biology, etc. We assume that sources (subclasses) are characterized by a mixture with some unknown prior distribution (cf. Equation (2)), and the overall sources can be regarded as mixed memoryless sources [6]. The purpose of this paper is to characterize the first- and second-order maximum error exponents in a single-letter form (the term “single-letter form” means an expression which does not depend on lengths of sequences n or N (cf. the formulas for error exponents in Theorems 2–4)).
To this end, we generalize Gutman’s classifier [3], which was shown to be first- and second-order optimal for memoryless sources (with no multiple subclasses) in [5]. This classifier uses training sequences from one of the two sources, as in [3,4,5], making a type-based decision for a source (subclass) with the smallest skewed Jensen–Shannon divergence [7] among the subclasses. We show that this classifier asymptotically achieves the maximum type-II error exponent in the class of deterministic classifiers for a given pair of distributions when the type-I error probability decays exponentially fast for all pairs of distributions in Theorem 1. We also demonstrate that the structure of this classifier leads to a reversed and more relaxed relation; the maximization of the type-I error exponent when the type-II error probability is upper bounded by a small constant for sources with multiple subclasses in Theorem 2. In addition, using the Berry–Esseen theorem [8], we derive the second-order maximum error exponent in the case where only one of sources has subclasses in Theorem 3. Finally, the fact that the classifier uses the test sequence from one of two sources motivates us to consider a more general case; the first source is a source with no multiple subclasses, but the second source is given by a general mixture [6,9]. That is, the number of subclasses is not necessarily finite, and the prior distribution of subclasses may not be discrete (cf. Equation (75)). We give characterizations of the first- and second-order maximum error exponents in Theorem 4.
1.3. Related Work
Ziv [10] proposed a classifier based on empirical entropy and discussed the relationship between binary classification and universal source coding. Hsu and Wang [4] characterized the maximum error exponent with mismatched empirically observed statistics. In their achievability proof, a generalization of Gutman’s classifier is also used. Kelly et al. [11] investigated binary classification with large alphabets. Unnikrishnan and Huang [12] investigated the type-I error probability of binary classification using the analysis of weak convergence. Generalizing the binary classification problem, He et al. [13] discussed the binary distribution detection problem, in which a different generalization of Gutman’s classifier is also discussed.
There are also studies which take a Bayesian approach. Merhav and Ziv [1] analyzed the weighted sum of type-I and type-II error probabilities, and subsequently, Saito and Matsushima [2,14] gave a different result via the analysis for the Bayes code.
1.4. Organization
The rest of this paper is organized as follows: In Section 2, we define the notation used in this paper and describe the details of the source and system model. Moreover, we state the problem setting, defining the first- and second-order maximum error exponents. In Section 3, we first give a classifier which achieves the asymptotically maximum error exponent in the class of deterministic classifiers for sources with multiple subclasses. Next, we characterize the first- and second-order maximum error exponents and the detailed proofs for the first-order representation. In Section 4, we generalize the obtained results to the classification of a mixed memoryless source with general mixture. In Section 5, we present numerical examples. Finally, in Section 6, we provide some concluding remarks and future work.
2. Problem Formulation
2.1. Notation
The set of non-negative real numbers is denoted by . Calligraphic stands for a finite alphabet. Upper-case X denotes a random variable taking values in , and lower-case denotes its realization. Throughout this paper, logarithms are of base e. For integers a and b such that denotes the set . The set of all probability distributions on a finite set is denoted as . Notation regarding the method of types [15] is as follows: Given a vector , the type is denoted as
The set of types formed from length-n sequences with alphabet is denoted as . The probability that n independent drawings from a probability distribution give is denoted by .
2.2. Source with Multiple Subclasses
Consider a source consisting of multiple subclasses. Each subclass is distributed according to a given probability (weight). Let be a family of probability distributions on a finite alphabet , where is a probability space with probability measure . That is, the probability of is given by
where the i-th subclass is a stationary and memoryless source. That is, for ,
(for notational simplicity, we denote both the multi-letter and single-letter probabilities by with a slight abuse of notation).
In view of (2), the sequence can be regarded as an output from a mixed memoryless source , and it is called a test sequence. Similarly, let be a family of probability distributions, where is a probability space with probability measure . For these mixed sources, if the sources are known, that is, the addressed problem is hypothesis testing, the first- and second-order error exponents were analyzed by Han and Nomura [6]. In this paper, we assume that the sources are unknown and training sequences are available to learn about the source. Sets of training sequences are denoted by and , where of length N is output from subclass j and for some fixed . Then, the joint probabilities of training sequences are, respectively,
We define the class of sources with multiple subclasses on a probability space with probability measure as
which means , where the set of weights is implicitly fixed. Similarly, we define the class of sources with multiple subclasses on a probability space with probability measure as
which means .
2.3. System Model
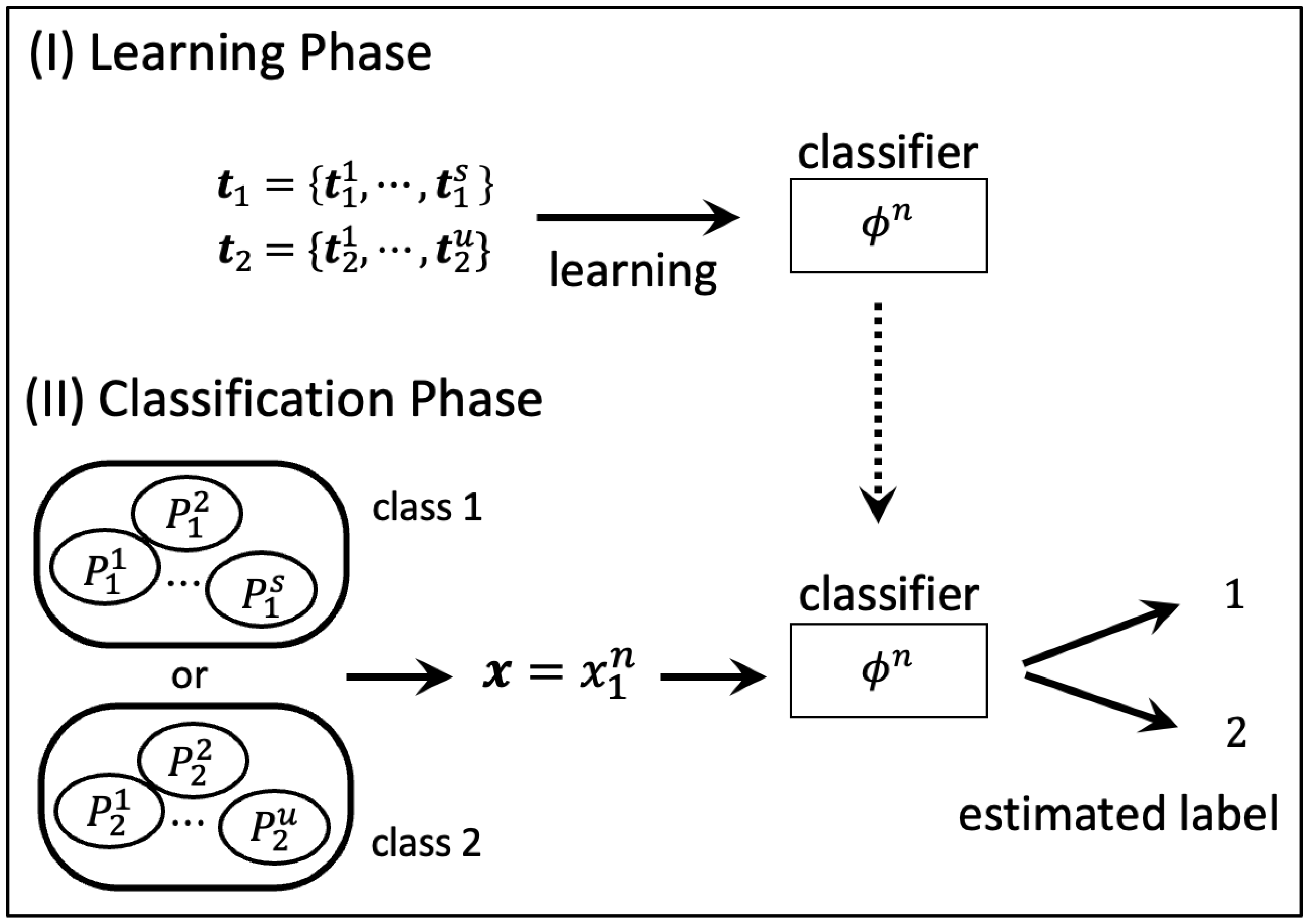
The binary classification problem assumed in this paper is shown in Figure 1. It consists of two phases: (I) learning phase and (II) classification phase. We explain the details of each phase.
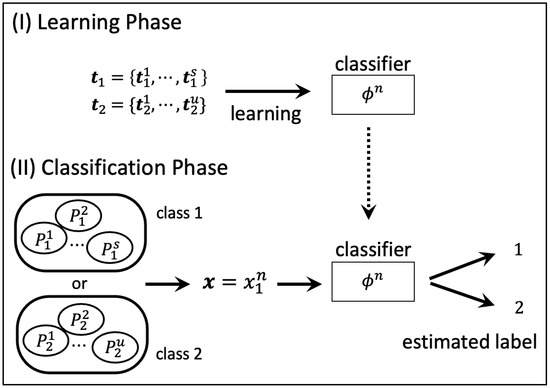
Figure 1.
System model.
(I) Learning phase: Determine the classifier by learning with the training sequences and generated from unknown source and , respectively.
(II) Classification phase: It represents the phase in which we judge whether the test sequence generated from or according to the classifier determined in (I).
2.4. Maximum Error Exponent
In this section, we define two error probabilities that arise in a binary classification problem and formulate the maximum error exponents. In the binary classification problem, a test is described as a partition of the space . The type-I and type-II error probabilities of a given test are denoted as and , respectively. That is,
Here, is the joint probability of training and testing sequences when the underlying parameter is , given by
We consider the problem of maximizing the type-I error exponent when the type-II error probability is upper bounded by a small constant . In this study, we characterize the following quantities (the first- and second-order maximum type-I error exponent).
Definition 1
(First-order maximum error exponent). For any pair of distributions and , we define
where the weights of are the sames as the weights of .
Definition 2
(Second-order maximum error exponent). For any pair of distributions and , we define
where the weights of are the sames as the weights of .
Remark 1.
In Definitions 1 and 2, we focus on universal tests that perform well for all pairs of distributions with respect to the type-I error probability, and at the same time, constrain the type-II error probability with respect to a particular pair of distributions. We obtain the same result when the weights of are not fixed.
3. Main Result
3.1. A Test to Achieve Maximum Error Exponent
The rule for estimating whether a test sequence generated from or is called a decision rule. One of the goals of the classification problem is to design an optimal decision rule which achieves a maximum error exponent based on training sequences. In this section, we present a decision rule that asymptotically achieves the maximum type-II error exponent for any pair of distributions when the type-I error exponent is lower bounded by a constant for all pairs of distributions (cf. Theorem 1).
To define a test that is asymptotically optimum, we define two generalizations of the Jensen–Shannon divergence. These generalizations are related to some variational definitions in [7,16]. For any pair of distributions and any number , let the generalized Jensen–Shannon divergence be
where denotes the Kullback–Leibler divergence for and defined as
The generalized Jensen–Shannon divergence corresponds to a skewed -Jensen–Shannon divergence for . Additionally, for , we define the minimized generalized Jensen–Shannon divergence by
Given a threshold (including ), the decision rule to achieve the maximum error exponent is given by
where , and is the set of determined to be class i by the test . By definition, the discriminant function , appearing on the right-hand side of (17), can also be expressed as
where . From (17) and (18), is a type-based test and implicitly depends on . In addition, this test uses training sequences asymmetrically; only sequence is used, but not (cf. refs. [3,4,5]).
Theorem 1.
For any given and any sequence of tests such that , the sequence of tests given by (17) satisfies for any pair of distributions ,
Proof.
Equation (19) is derived in Section 3.3.1. The proof of (20) follows from Corollary 1. Although there is a deviation between the exponents in Corollary 1 and for the test , the deviation vanishes asymptotically. □
Theorem 1 shows that the test can asymptotically achieve the maximum type-II error exponent among the tests for which the type-I error exponent is greater than or equal to . This test also has a reversed and more relaxed property; it achieves , the maximum type-I error exponent when the type-II error probability is upper bounded by a constant (see the achievability proof of Theorem 2 in Section 3.3.1).
3.2. First-Order Maximum Error Exponent
In this section, we characterize the first-order maximum error exponent in a single-letter form for sources with multiple subclasses.
Theorem 2.
For any pair of distributions , we have
It should be noted that depends on , but not on .
Proof.
The proof is provided in Section 3.3. □
Remark 2.
If and are singletons (that is, and ), Theorem 2 reduces to the following formula given by Zhou et al. [5]:
which means that does not depend on ϵ and the strong converse holds in this case, unlike in the case . On the other hand, for general and but in the spacial case of , formula (21) reduces to
3.3. Proof of Theorem 2
We divide the proof of Theorem 2 into two parts: the achievability (direct) part and the converse part.
3.3.1. Achievability Part
In the achievability proof, we use the type-based test given by (17). Fix any
Then, for any pair of distributions and for all pairs of distributions , we show
First, we prove (25). For preliminaries, we define the following sets used in the proof:
where is the projection of onto the space . To evaluate the probability of a source sequence being in , the following relationship holds from the method of types [15].
Lemma 1.
Suppose that the sequence is sampled independently from the source . Then,
where denotes the set of types formed from length-n sequences with alphabet and .
Then, an upper bound on the type-II error probability of the test for all pairs of distributions can be evaluated as follows:
where (31) is derived from (4), (32) follows from Lemma 1 and (33) is derived in Appendix A. Minimizing exponents in (33) with respect to , we further obtain
where (34) is derived from (16) and (28), and (35) follows from Lemma 1.
Next, we demonstrate (26). For preliminaries, we define a new typical set and show some properties for the proof. For any given , define the following typical set:
By using [6, Lemma 22], for , , generated from memoryless sources , we have
For any given and any pair of distributions , we define information density as
Furthermore, for any pair of distributions , define the function , as the index of the subclass of , as follows:
Hereafter, we denote simply as when the first argument is clear from the context.
Lemma 2.
Assume that . For , , we have
Proof.
The proof is provided in Appendix B. □
Lemma 3
(Zhou et al. [5]). Assume that . For , , by applying the Taylor expansion to around , we have
where denotes the m-th symbol of sequence and denotes the m-th symbol of sequence .
Note that the probability is calculated by assuming that the test sequence is generated from (cf. Equation (11)). An upper bound on the type-II error probability can be evaluated as follows:
where Equation (43) follows from Equations (14), (38) and (40). By using Lemma 3, Equation (43) can be expanded as follows:
where Equation (44) is derived from Fatou’s lemma. It follows from (38) that
Here, Equation (14) can be also expressed as follows:
Therefore, by the weak law of large numbers, for any given ,
Thus, by (24), we can see that
3.3.2. Converse Part
For any pair of distributions and for all pairs of distributions , fix any test satisfying that
We show
We first give some lemmas, which are useful in the proof of the converse part.
Lemma 4.
Let be a test in which the decision rule depends only on . Then, for any given , we can construct a type-based test satisfying
for any pair of distributions .
Proof.
Lemma 4 can be proved in the same way as (Lemma 7 [5]), the proof of which is inspired by (Lemma 2 [3]). □
Remark 3.
As in the proof of (Lemma 2 [3]) and (Lemma 7 [5]), a type-based test specified in Lemma 4 is obtained by tailoring and satisfies Equations (54) and (55) for all . In other words, the construction of is universal, which is in the same spirit of (Lemma 2 [3]). This claim is slightly stronger than the one in (Lemma 7 [5]).
Lemma 5.
For any , any type-based test satisfying the condition that for all pairs of distributions ,
we have that for any pair of distributions
where with .
Proof.
The proof is provided in Appendix C. □
The type-based test specified in Lemma 4 satisfies Equations (54) and (55) for all . If we set in Lemma 4, and combine it with Lemma 5, we can derive the following relation:
Corollary 1.
For any given , any test satisfying the condition that for all pairs of distributions
we have that for any pair of distributions
Proof.
The proof is provided in Appendix D. □
3.4. Second-Order Maximum Error Exponent
In this section, we characterize the second-order maximum error exponent. For simplicity, we assume that only has subclasses, but does not (). First, from Theorem 2 with , the first-order maximum error exponent in this setting is characterized as follows: for any pair of distributions , we have
where in (21) is replaced by .
Next, we provide a characterization of the second-order maximum error exponent in Definition 2 with in the case where only has subclasses. By definition, if and if . Therefore, in the discussion of the second-order error exponent, we focus on the case .
Theorem 3.
For any pair of distributions and ,
where ,
which is the cumulative distribution function of the standard Gaussian distribution, and for any pair of distributions ,
where represents the variances with respect to .
Proof.
The proof is provided in Appendix E. □
Remark 4.
If is a singleton (), Theorem 3 reduces to for , which is the same result given by Zhou et al. [5].
Remark 5.
We can summarize the two terms on the right-hand side of (65) into the following single term called the canonical equation [6]:
We focus on the case . From Theorem 2, it holds that
and
Here, let us consider the following canonical equation for r
4. Generalization to Mixed Memoryless Sources with General Mixture
In this section, we consider the classification problem in the case where does not have subclasses and is given by a general mixture model. The general mixture model considered in this problem represents an extension of the source with multiple subclasses defined in Section 2.2. Since the decision rule that achieves the maximum error exponent can be operated using only one of the training sequences, we assume in this section that only the training sequence is available. Then, we provide a characterization of the maximum error exponents in a single-letter form under this setting. First, we define the source referred to as a mixed memoryless source with general mixture [6,9] as follows. Let be an arbitrary probability space with a general probability measure . Then, the probability of is given by
where is a stationary and memoryless source for each . That is, for
When a test sequence is output from , the probability distribution of the sequence takes the form of (75). Here, type-I and type-II error probabilities of a test are given by
Theorem 4.
(First-and second-order maximum error exponents) For any pair of distributions and , we have
and
Proof.
We can prove this theorem in the same way as Theorems 2 and 3. □
5. Numerical Calculation
5.1. First-Order Maximum Error Exponent
In this section, we present a numerical example to illustrate the first-order maximum type-I error exponent characterized in Theorem 2.
A numerical example of the first-order maximum error exponent is given by calculating the right-hand side of (64) for the following settings. We assume that . We fix the set of probabilities and weights
and
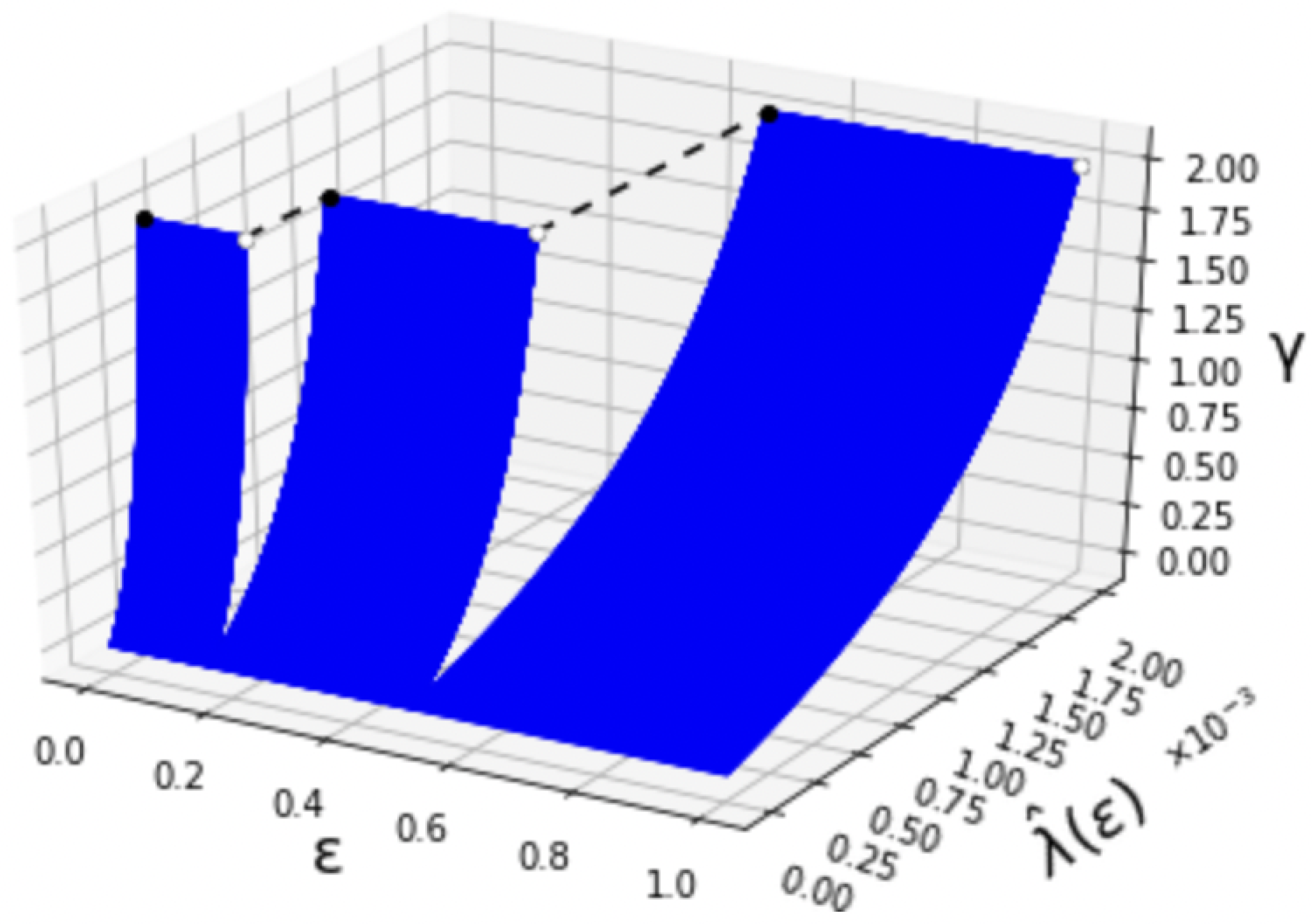
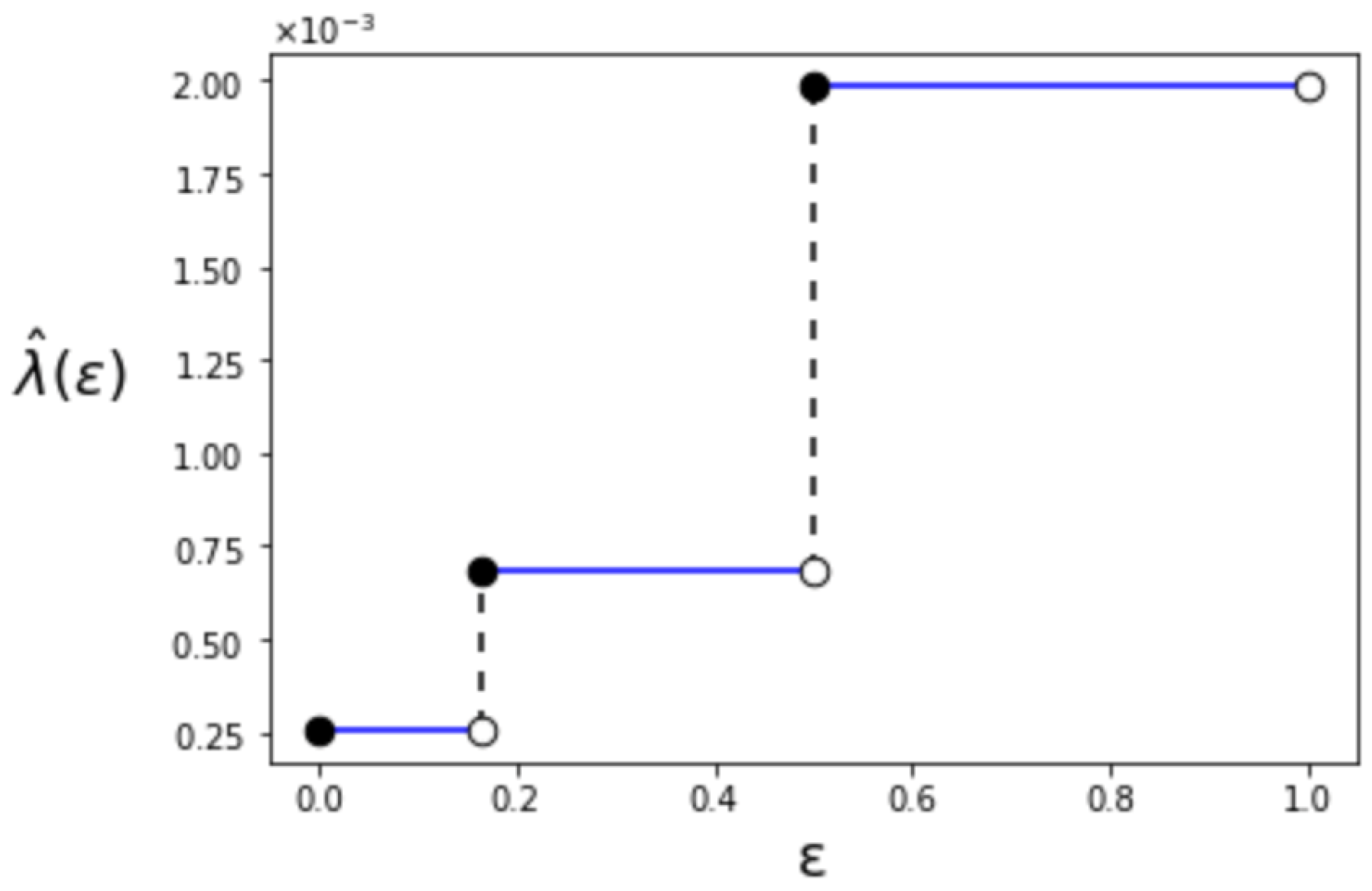
where denotes the Bernoulli distribution. The relation among , and is shown in Figure 2. Additionally, for , the behavior of is depicted in Figure 3. When becomes larger, the value of also increases like a step function. The step increases when and . We can also confirm that is right-continuous in . This is due to the limit that the superior of the type-II error probability is constrained in Definition 1.
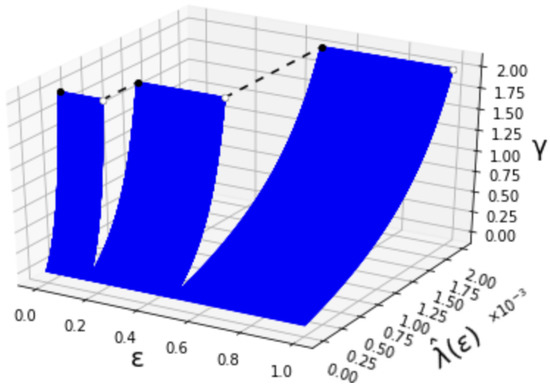
Figure 2.
The first-order maximum type-I error exponent ().
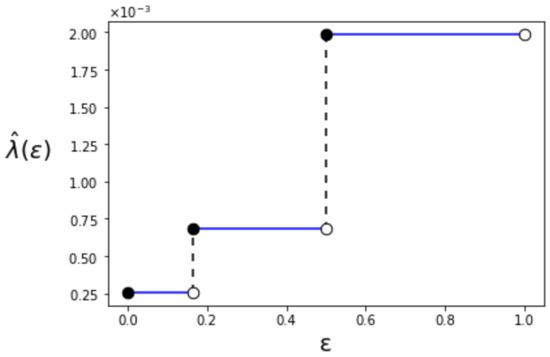
Figure 3.
The first-order maximum type-I error exponent ().
5.2. Second-Order Maximum Error Exponent
As in the previous subsection, we present a numerical example to illustrate the second-order maximum type-I error exponent characterized in Theorem 3.
A numerical example of the second-order maximum error exponent is given by calculating the right-hand side of (65) for the following settings. We assume that , . We fix and the set of probabilities and weights
and
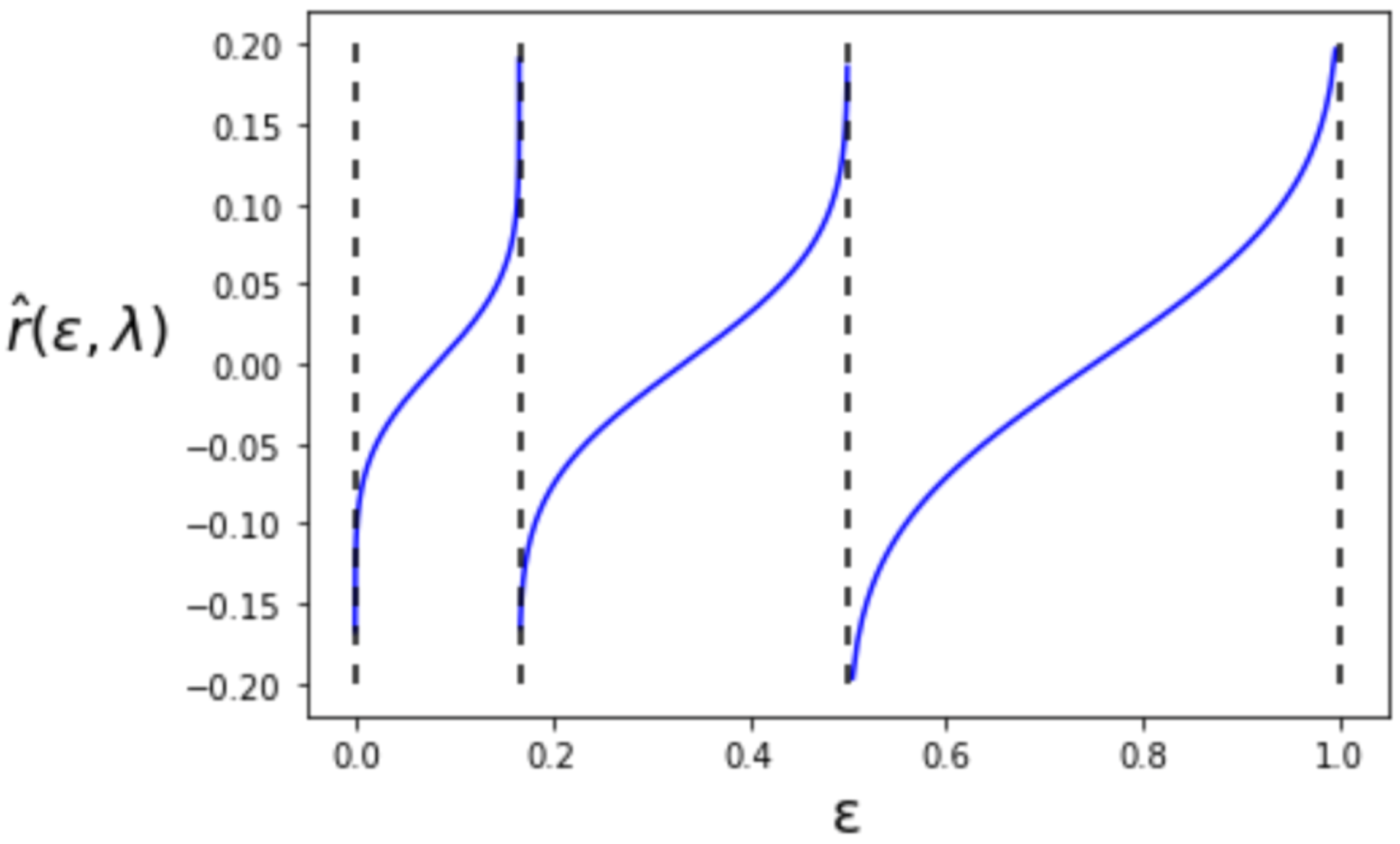
where is the same as the setting in the previous subsection. The behavior of is shown in Figure 4. The value of takes the inverse of the cumulative distribution function of the standard Gaussian for each interval of such that , and . In contrast to the first-order , is no longer right continuous in .
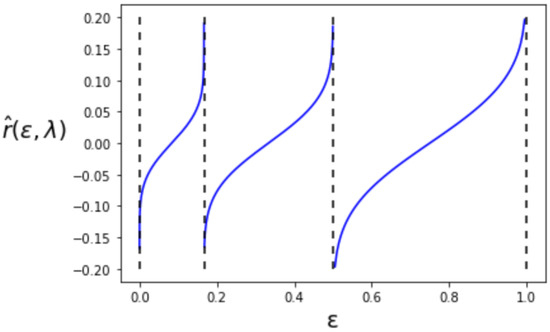
Figure 4.
The second-order maximum type-I error exponent .
6. Conclusions
For binary classification of sources with multiple subclasses, we characterized the first- and second-order maximum error exponents. First, we revealed the first-order maximum error exponent in the case where and are sources with multiple subclasses. In order to derive this representation, we gave a classifier which achieves the asymptotically maximum error exponent in the class of deterministic classifiers for sources with multiple subclasses.
Next, we showed the second-order maximum error exponent in the case where only one of sources has subclasses. The most important key technique to derive the second-order maximum error exponent is to apply the Berry–Esseen theorem [8] instead of the weak law of large numbers. One may wonder whether we can also derive the second-order approximation in the case where is also a source with multiple subclasses. To this end, we need to evaluate Lemma 2 more rigorously. This is future work.
In addition, for binary classification using only a training sequence generated from in the case where does not have subclasses and is given by a general mixture model, we generalized the analysis for the first- and second-order error exponents. From these results, we revealed the asymptotic performance limits of statistical classification for sources with multiple subclasses.
In this paper, we considered a binary classification problem, but in practice, multiclass classification is of importance. In the case where each class is a memoryless source (without multiple subclasses), the first- and second-order maximum error exponents were analyzed in [5]. Extending the obtained results to multiclass classification for sources with multiple subclasses is also a subject of future studies.
Author Contributions
Author H.K. contributed to the conceptualization of the research goals and aims, the visualization, the formal analysis of the results, and the review and editing. Author H.Y. contributed to the conceptualization of the ideas, the validation of the results, and the supervision. All authors have read and agreed to the published version of the manuscript.
Funding
This research was supported in part by JSPS KAKENHI Grant Numbers JP20K04462 and JP18H01438.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A
Appendix B
Proof of Lemma 2).
Applying the Taylor expansion to around for any , we obtain
Therefore by (14) for any , ,
holds, and the convergence is uniform in . Since for any , was given in the form
we obtain
□
Appendix C
Proof of Lemma 5.
Using (30) on the right-hand side of (A7), we obtain
where . Taking the negative logarithm of both sides and divide by n in (A8), we have
Since is arbitrary in (A9), we can set the i-th subclass as and the other as , . Furthermore, we set . Then we obtain
Therefore by (18), (A10) implies that is constrained in
and for any pair of distributions , we obtain
□
Appendix D
Appendix E
Proof of Theorem 3.
We divide the proof of Theorem 3 into two parts: the achievability (direct) part and the converse part. First, for preliminaries, we define the following quantity used in the proof: For ,
Next, we give a lemma that is important in the proof of Theorem 3. □
Lemma A1
(The Berry–Esseen theorem [8]). Let be independent with
Then for any , it holds that
Appendix E.1. Achievability Part
In the achievability proof, we use the following test :
where in (17) is now because the first source is assumed to be a stationary and memoryless source. Fix any
Then, for any pair of distributions and for all pairs of distributions , we show
The test defined by (A23) is the same as the test defined by (17) with replacing with and s with 1, and so (A25) can be derived from the argument in Section 3.3.1. Therefore, we will prove only (A26). We use the set defined by (37). An upper bound on the type-II error probability of the test , defined by (A23), for any pair of distributions can be evaluated as follows:
where (A27) follows from Lemma 3 and the proof of (A28) is provided in Appendix F.
where (A29) and the last inequality are derived from Lemma A1 and Fatou’s lemma, respectively. Here,
Therefore,
Thus, by (A24), we can see that
Appendix E.2. Converse Part
For any pair of distributions and for all pairs of distributions , fix any test satisfying that
We show
To prove (A36), we use Corollary 1 with replacing with . A lower bound on the type-II error probability of the test for any pair of distributions can be evaluated as follows:
where (A37) and (38) follow from Lemma 3 and Lemma A1, respectively. The last inequality is due to Fatou’s lemma. Here,
Therefore,
□
References
- Merhav, N.; Ziv, J. A Bayesian approach for classification of Markov sources. IEEE Trans. Inf. Theory 1991, 37, 1067–1071. [Google Scholar] [CrossRef]
- Saito, S.; Matsushima, T. Evaluation of error probability of classification based on the analysis of the Bayes code. In Proceedings of the 2020 IEEE International Symposium on Information Theory (ISIT), Los Angeles, CA, USA, 21–26 June 2020; pp. 21–26. [Google Scholar]
- Gutman, M. Asymptotically optimal classification for multiple tests with empirically observed statistics. IEEE Trans. Inf. Theory 1989, 35, 401–408. [Google Scholar] [CrossRef]
- Hsu, H.-W.; Wang, I.-H. On binary statistical classification from mismatched empirically observed statistics. In Proceedings of the 2020 IEEE International Symposium on Information Theory (ISIT), Los Angeles, CA, USA, 21–26 June 2020; pp. 2538–3533. [Google Scholar]
- Zhou, L.; Tan, V.Y.F.; Motani, M. Second-order asymptotically optimal statistical classification. Inf. Inference J. IMA 2020, 9, 81–111. [Google Scholar]
- Han, T.S.; Nomura, R. First- and second-order hypothesis testing for mixed memoryless sources. Entropy 2018, 20, 174. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lin, J. Divergence measures based on the Shannon entropy. IEEE Trans. Inf. Theory 1991, 37, 145–151. [Google Scholar] [CrossRef] [Green Version]
- Polyanskiy, Y.; Poor, H.V.; Verdú, S. Channel coding rate in the finite blocklength regime. IEEE Trans. Inf. Theory 2010, 56, 2307–2359. [Google Scholar] [CrossRef]
- Yagi, H.; Han, T.S.; Nomura, R. First- and second-order coding theorems for mixed memoryless channels with general mixture. IEEE Trans. Inf. Theory 2016, 62, 4395–4412. [Google Scholar] [CrossRef]
- Ziv, J. On classification with empirically observed statistics and universal data compression. IEEE Trans. Inf. Theory 1988, 34, 278–286. [Google Scholar] [CrossRef]
- Kelly, B.G.; Wagner, A.B.; Tularak, T.; Viswanath, P. Classification of homogeneous data with large alphabets. IEEE Trans. Inf. Theory 2013, 59, 782–795. [Google Scholar] [CrossRef] [Green Version]
- Unnikrishnan, J.; Huang, D. Weak convergence analysis of asymptotically optimal hypothesis tests. IEEE Trans. Inf. Theory 2016, 62, 4285–4299. [Google Scholar] [CrossRef]
- He, H.; Zhou, L.; Tan, V.Y.F. Distributed detection with empirically observed statistics. IEEE Trans. Inf. Theory 2020, 66, 4349–4367. [Google Scholar] [CrossRef]
- Saito, S.; Matsushima, T. Evaluation of error probability of classification based on the analysis of the Bayes code: Extension and example. In Proceedings of the 2021 IEEE International Symposium on Information Theory (ISIT), Melbourne, VIC, Australia, 12–20 July 2021; pp. 1445–1450. [Google Scholar]
- Csiszár, I. The method of types. IEEE Trans. Inf. Theory 1998, 44, 2505–2523. [Google Scholar] [CrossRef] [Green Version]
- Nielsen, F. On a variational definition for the Jensen-Shannon symmetrization of distances based on the information radius. Entropy 2021, 23, 464. [Google Scholar] [CrossRef] [PubMed]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).