1. Introduction
Automatic building semantic segmentation in very high resolution (VHR) remote sensing images has proved use in a range of applications, including emergency management, urban planning, traffic evaluation, and mapping [
1,
2]. Segmentation is often used in computer vision [
3,
4] and industrial robots [
5,
6], but it has lately been used in remote sensing, which is important in a variety of applications such as environmental monitoring and danger identification [
7]. Building segmentation using distant sensing photos (VHR images) is often more challenging than segmenting objects from ordinary photographs. Many factors, however, influence and complicate the extraction of 2D buildings from VHR photos, including sizes, backdrop complexity (i.e., water, shadow, vegetation, bodies, and other physical elements), roof diversities, and other topological difficulties [
8]. For building extraction from two-dimensional and three-dimensional data, several techniques have been proposed, which include deep learning and traditional methods. In traditional methods, hand-crafted features, such as geometrical information and spectral/spatial information, are used [
8,
9]. In random field, clustering, and active contours, low-level features, such as color, texture, etc., are used [
10,
11]. However, they reduce representational ability and performance, and rely on an inefficient manual feature selection process.
Deep learning algorithms can extract high-level characteristics from 2D/3D data sets, harmonizing various absorption levels. As a result, deep learning dominates the field of building extraction [
12,
13]. A number of deep learning techniques have been developed for building extraction. The fully convolutional networks and the convolutional networks are often used as a foundation for newer image segmentation techniques [
14]. Deeplab-V3 [
15], VGG-16 [
16], ResNet [
17] and DensNet [
18] are some of the pre-trained deep convolutional neural networks that have been designed to identify images.
Features are taken and integrated for each of the aforementioned networks to provide efficient segmentation. Furthermore, for the semantic segmentation of large things, abstract characteristics and high levels are utilized, whereas natural features and low levels are appropriate for tiny items. Several supervised semantic segmentation techniques based on deep networks have also been developed.
In semantic segmentation, the suggested approach for producing a building segmentation image assigns a class name to every pixel. To achieve outstanding results, deep neural networks must be trained with a high number of pixel-level segmentation labels. The most major constraint of the segmentation challenge is the collecting of pixel-level information. It will take some extra time and money because it is a bit challenging. Many researchers have developed a variety of DCNN-based weakly supervised segmentation approaches to lower the degree of pixel-level annotations. Only a few annotations, such as bounding boxes, image-level labels, and scribbles, are used in these techniques.
Although the image level label is the most time consuming and simple of all of these weakly supervised methods, the semantic segmentation accuracy is still considerably inferior to strongly supervised results when only image-level labels are used. Box-level annotations produce results that are quite analogous to real pixel-level annotations. However, box annotations include the object bounds and trusted background regions, and therefore box-supervised training is not possible for distributing information. Spot and scribble weakly supervised learning, on the other hand, occupies a center ground between image-level and box-level supervision. With spots, a few pixel locations are provided, which should lead to a higher level of performance than with image annotations [
2,
4,
7,
19]. A few extra pixels of location data provided by spots are expected to improve performance, compared to box-level annotations [
18,
20]. Spot seeds are more vague and lack a defined boundary of objects; compared to scribble [
21], sparse spot seeds [
21] are more efficient for annotating images. Additionally, spots are easier to note “things” (for example, sky, grass, ocean waters, and so on) that have hazy and ill-defined boundaries. In this paper, the training images are fed into a superpixels algorithm in order to forecast a boundary map.
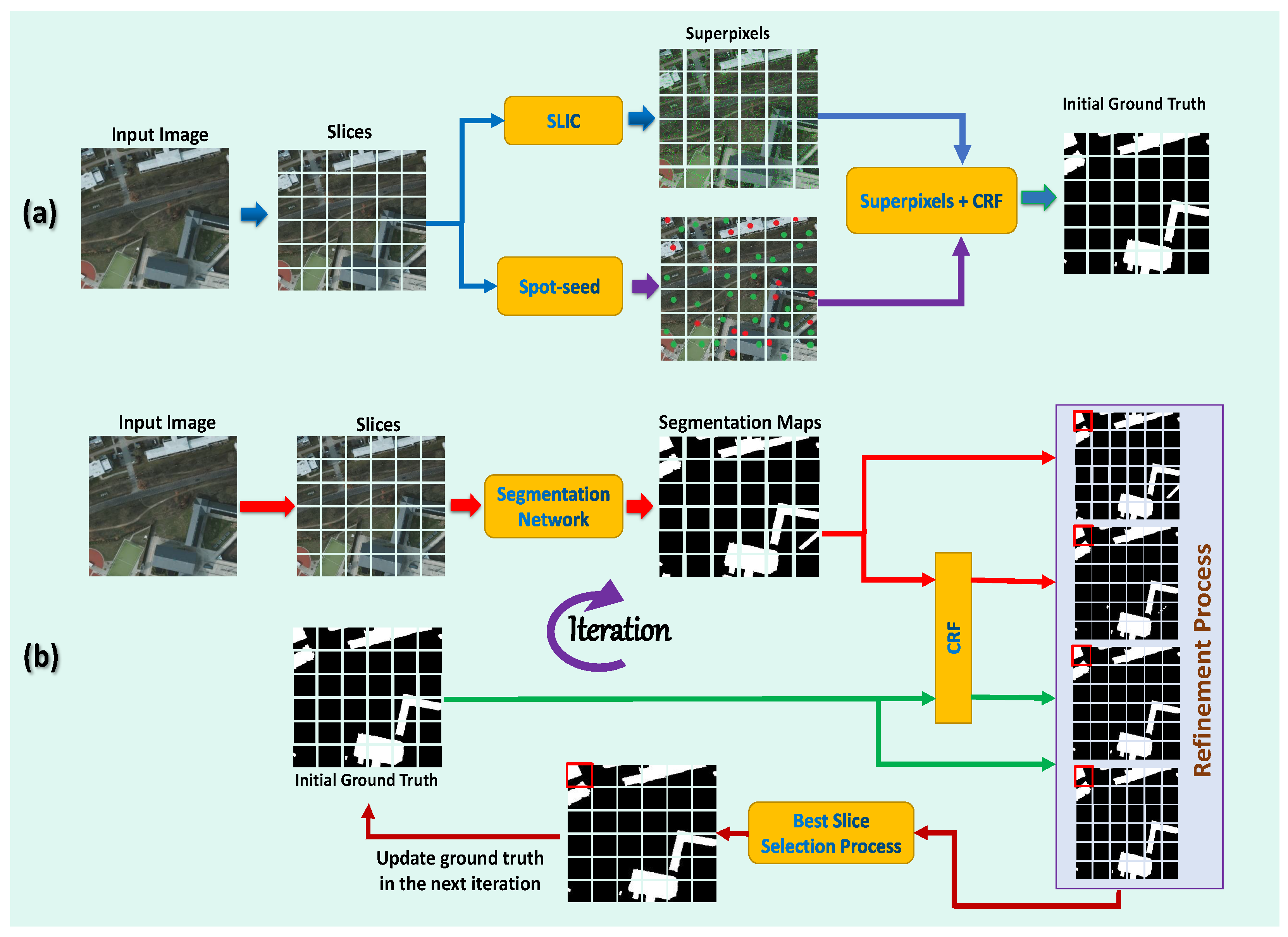
The information from spot seeds is then propagated from spot seeds to unmarked regions, using a graphical model (superpixels-CRF) developed over superpixel regions to create the first pixel-level annotations, which can accommodate more boundaries and capture exact local structure while maintaining object shape. After that, the segmentation network is used to train and prophesy segmentation maps using the initial pixel-level annotations. The proposed refining technique is then used for segmentation masks in order to obtain precise and complete annotations at the pixel level, which are subsequently used to start training again the segmentation network. These steps are repeated continuously to provide high-quality annotations at the pixel level and to train a more accurate segmentation network. Our proposed method, as shown in
Figure 1, enables more exact pixel-level annotations than earlier annotations, which improves the segmentation performance. The proposed method is known as the “spots supervised iteration framework (SSIF)” for weakly supervised building semantic segmentation in very high resolution (VHR images). Compared to previous fully supervised works, the proposed framework achieves comparable results while significantly reducing the annotation workload. To the best of our knowledge, this study is the first work to use spot annotations for weakly supervised building semantic segmentation. Our contributions to this work can be summarized as follows.
We release novel spot annotation datasets for building semantic segmentation.
We propose a method for generating high-quality pixel-level annotations using spot annotations and a graphical model based on superpixel segmentation.
A novel iterative training framework is proposed in our work. The performance can be improved by refining the pixel level annotation and iteratively optimizing the segmentation network.
According to experimental results on three public datasets, the proposed framework achieves a marked improvement in the building’s segmentation quality while reducing human labeling efforts.
The following chapters are organized as follows.
Section 2 reviews related work in skin lesion segmentation.
Section 3 elaborates on the mechanisms used in our framework.
Section 4 demonstrates the experiment setting, results, analysis, etc. Finally, we conclude in
Section 5.
3. The Proposed Method
This section introduces the training strategy for extracting buildings from VHR images using weakly supervised semantic segmentation, as well as the proposed framework in detail. The components of the proposed framework are first described. Second, we show how the initial ground truth annotations are made. Finally, we show how we may iteratively update the initial ground truth annotations using the refinement process and train the segmentation network.
Figure 2 shows the main steps of the proposed method.
3.1. The Proposed Framework’s Architecture
A set of pixels with a category label is called an annotated spot seed with a category. The spot seeds are provided in a sparse manner, which is in contrast to the requirements of pixel-level semantic segmentation, which requires the identification of dense, internal, and integral regions in order to perform pixel-level inference. As a solution to this problem, we employ spot seeds to drive a superpixels-CRF model through superpixels segmentation, resulting in high-quality ground truths. Then, using the high-quality ground facts as supervision, the segmentation network is trained, and the anticipated segmentation masks are generated. The proposed refining approach is then applied to segmentation masks, resulting in more precise and full ground truths for retraining the segmentation network. These steps are repeated iteratively to obtain high-quality ground facts and improve the segmentation network.
3.2. Generating High-Quality Initial Ground Truths
The semantic segmentation criteria are not met because the spot seeds are too sparse, but they do offer position information for a few pixels of an object. With the aim of identifying the high-quality ground-truth value, a superpixels-CRF model is built over superpixels segmentation, which can propagate information from spot seeds to unmarked regions. We propose that these regions could potentially retain object contour, catch the deep local structure, and outperform spot seeds, which may include many little bits in the object segment but are not located on area bounds. We find that ground truth annotations obtained during the training stage with the proposed method will speed up network learning and provide more precise segmentation masks than spot seeds.
3.3. Spot-Seeds Guided Superpixels-CRF Model for Object Region Supplement
The superpixels-CRF model was utilized to disseminate data from spot seeds to unknown regions. To accomplish this, we create a network based on the superpixels segmentation. A vertex in the graph represents a region, and an edge in the graph represents the similarity between two regions. The proper segment image is denoted as
I, and the
is set of non-overlapping regions, which satisfies the condition
and
. Moreover, spots of an input image are
, where
is the pixels of spot in category
i and
is the spot’s category label (supposing that there are
L categories and
for background). The region
is used for a category label
. Additionally, in order to determine the final label and minimize the energy, a graph-cut optimization framework [
34] is used to find the final label, which minimizes the energy,
where
is a unary term that includes the region
determined by the spot seed, and
and is a pairwise term that connects two regions,
and
. The following is the definition of the unary term:
According to the first condition in this equation, when a region overlaps with a spot seed , the cost is zero when this region is allocated to the label . On the contrary, when the region does not overlap with any spot having the same probability, , denotes the number of spot labels on this image. This exclusive information is helpful in reducing false-positive predictions.
In this model,
, the pairwise term, indicates the similarity between two regions. Furthermore, it is seen as a simple look of similarity to its bordering regions. After that, we construct the histograms of the color and texter region
. The color histogram
on area
is based on the
Lab color space and is divided into 30 bins uniformly. The texture histogram
and a bank of 38 filters [
35], including the Gaussian and Laplacian of Gaussian filters, edges and bar filters with three scales and six orientations, convolve the image. All bins are concatenated and standardized in color/texture histograms. If background pixels are near object spots and have a similar appearance to the object spots, or if background pixels are classified as object areas, object spots should be kept far away from them. This may have an impact on the segmentation quality. As a result, the pairwise term
can be defined as follows:
where
is 1 if the condition is met and 0 otherwise, and similarity is defined as
The color similarity and texture similarity are defined as
where
is the color histogram built on the CIE Lab color space, and
is the texture histogram. In our experiment, we set empirically
and
. The definition implies that if the appearance of contiguous regions belonging to different labels is similar, the expenses will be higher. However, the labeling problem in Equation (
1) is an NP-hard problem to solve. The expansion and swap moves technique [
34], which determines the shortest cut for a given graphical model, can be used to solve it.
3.4. Network Training
To create segmentation masks, we use VGG16 [
16] as our backbone network. As shown in
Figure 1, we train the prediction network using initial ground truths. A discussion is held in
Section 5 to explore the effectiveness of using VGG16 [
16] compared to the other networks as the backbone. The cross-entropy loss is the loss function that promotes the prediction to match the real-world regions:
where
is a collection of pixels in the supervision that are labeled with class
c. To begin, we employ a VGG16-net [
16] that is pre-trained on the ImageNet dataset [
21]. Empirically, we select a learning rate of
as our starting point. It takes an average of 50 epochs to converge. Stochastic gradient descent (SGD) with mini batch is used for the training classification and segmentation network. We set
as the dropout rate,
as the momentum,
as the weight decay, and 12 as the batch size. After one iteration, we predict on the training dataset using the model with the lowest loss, and then refine the new predicted result using fully connected CRF [
20]. The whole process iterates several times until the network finally converges. Our implementation is based on a NVIDIA GeForce TITAIN GPU with 12 GB memory.
3.5. The Proposed Refinement Process
Although the initial ground truth annotations are improved in accuracy, they are still distant from the true pixel-level annotations. The segmentation results obtained by training the segmentation network with initial ground truth annotations as supervision can be improved further. As a result, we introduce a refinement method in order to obtain more precise ground truth annotations. The original input image is denoted by the letter
I, and the associated initial ground truth annotation is denoted by the letter
. We use the trained model to generate segmentation maps after the initial complete training of the segmentation network is converged. We denote the predicted segmentation map as
. In addition, we thoroughly couple the CRF operation to the initial ground truth annotations, as well as the projected segmentation maps. The segmentation maps that emerge are referred to as
, and
, respectively. According to Algorithm 1, we update the training samples as well as their related ground truth annotations for the following iteration. The CRF operation is denoted by
, and
signifies the updated ground truth annotation, which is then utilized as the segmentation ground truth for the next iterative training. The average pixelwise absolute difference between two segmentation maps (i.e.,
and
) is defined as
, which is determined as follows:
the width and height of the segmentation map are
w and
h, respectively. We evaluate the mean
between each pair of initial ground truth annotations
after each training round. For the predicted segmentation map
, when the mean
falls below a certain level or the total number of training rounds exceeds 5, the halting criteria are defined as the CRF output of the current segmentation map annotation
, and the CRF output of the predicted segmentation map
. We empirically set the thresholds,
and
to 15 and 40, respectively, during the annotation updating process, and we set the mean
for the training stop criteria at
. The quality of segmentation maps is discussed in
Section 5, with and without the proposed refinement process in order to demonstrate the influence of refined segmentation maps in terms of accuracy.
![Entropy 24 00741 i001]()
4. Experimental Results and Analysis
The effectiveness of the proposed method for building footprint segmentation is discussed in this section. The classification and segmentation network are trained and evaluated using Tensorflow on GPU (TITAIN). The goal of this framework is to bridge the gap between weakly and fully supervised semantic segmentation algorithms for building footprint segmentation. As a result, this gap remains an important measure of the effectiveness of weakly supervised semantic segmentation algorithms.
ISPRS Potsdam Challenge Dataset (Potsdam) Dataset: The ISPRS two-dimensional semantic label contest (Potsdam) is a standard dataset with accurate images, including 38 high-resolution actual orthophoto tiles chosen from a sizable TOP mosaic, which can be downloaded from the general website (
https://www2.isprs.org/commissions/comm2/wg4/ (accessed on 7 May 2022 )). To increase the visibility of the small details, we adopt a tile that contains pixels size of
and a 5 cm resolution. The ground truth consists of 6 of the highest mutual land cover classes. For instance, buildings, invincible superficies, cars, plants, low vegetation, and clutter/background.
WHU Building Dataset: The WHU building dataset contains aerial and satellite subsets, as well as photos and labels for each, which can be downloaded from the general website (
http://gpcv.whu.edu.cn/data/ (accessed on 7 May 2022)). For comparison with the proposed approach, we used an aerial subset that was widely used in previous studies. The data have 8189 images with 30 cm ground resolution and cover a
area
in Christchurch, New Zealand. Each image is
and comprises three bands with pixels that correspond to red (R), green (G), and blue (B) wavelengths. The dataset broken into three sets: training (4736 images), validation (1036 images), and testing (2416 images). There are buildings, including 130,500, 14,500, and 42,000 tiles for the training, validation, and test datasets, respectively.
Vaihingen Dataset: The Vaihingen dataset is a public dataset for the ISPRS (2D) semantic labeling challenge dataset, which can be downloaded from the general website (
http://www2.isprs.org/commissions/comm3/wg4/semantic-labeling.html/ (accessed on 7 May 2022)). The Vaihingen dataset includes 33 spectral orthoimages with annotated images. Each image has a resolution of
m and an average size of
pixels. These date were also chosen because the buildings have different shapes and sizes; the diversity of the elements that make up the roofs of the buildings; and also because there are similarities with the other components of the images.
4.1. Dataset Preprocessing
On the Potsdam and Vaihingen datasets, due to the limited GPU memory and the necessity for more samples in training, the images with the average size of (6000 × 6000) are divided into minimal patches of (256 × 256). Finally, we obtain training (18,122 images), validation (10,874 images), and testing (7249 images) for the Potsdam dataset, and training (4059 images), validation (2435 images), and testing (1624 images) for the Vaihingen dataset. We keep the original image size of
pixels in the WHU dataset and resize them to
.
Table 1 summarizes the characteristics of each dataset after preprocessing.
4.2. Evaluation
In this study, for the task evaluation, we employ pixel-based measures instead of object-based measures. The pixel-based technique works on the number of pixels in elicited buildings and determines the number of building while providing a quick and accurate estimate. The
F1 score, lastly (MIOU) is used to measure the quantitative efficiency in the pixel-based evaluation. Hence, the
F1 score can be computed as
where,
where
,
, and
are true positive, false positive, and false negative, respectively. These values can be calculated by the pixel-based confusion matrices per tile, or an accumulated confusion matrix. IoU is an average value of the intersection of the prediction and ground truth regions over their union, as follows. Then, the MIoU can be computed by averaging the
IoU of all classes.
4.3. Comparison with Other Methods on ISPRS Potsdam Challenge Dataset (Potsdam) Dataset
We compared the proposed weakly supervised method to other state-of-the-art fully supervised building footprint segmentation methods. The performance of building footprint segmentation is compared in
Table 2, which shows that, while the proposed method’s various indicators are lower than other recently fully supervised and weakly supervised building footprint segmentation methods on the Potsdam dataset, the gap between the indicators is not big. Compared with these methods, the proposed method gives comparable results on most indications and greatly reduce the workload of annotation, demonstrating the effectiveness of the proposed method.
Figure 3 shows the obtained results on the Potsdam dataset. The four approaches, as well as the Deeplab-V3 [
15] MFRN [
36] and DAN [
14], are built and tested on the same empirical datasets (RGB images) used in the ISPRS 2D semantic-labeling contest (Potsdam). Nevertheless, several lower-level features of the Deeplab-V3 [
15] and MFRN [
36] networks have been overused, leading to over-segmentation due to limited spatial consideration; the fusion unit turns the produced fragmentary and minor buildings for five validity images. The boxes in red as indicated in
Figure 3 exhibit the improvement gained after applying the proposed method. These results emphasize that the proposed method achieves comparable results. Moreover, the proposed method achieves remarkable performance in building extractions from the VHR images, despite a few false classified buildings (refer to the highlighted boxes in
Figure 3.
4.4. Comparison with Other Methods on WHU Building Dataset
On WHU buildings dataset, we compare the obtained outcomes against FastFCN [
39] and Deeplab-V3 [
15] to describe the proposed method’s efficiency. The improvement obtained after using the proposed method is shown in red boxes in
Figure 4. These findings demonstrate that the proposed method produces comparable outcomes also on the test images from the WHU dataset. The numerical performance indexes of several models are illustrated in
Table 3. On all the four metrics, our proposed method produces comparable results compared to fully supervised and weakly supervised building footprint segmentation methods.
4.5. Comparison with Other Methods on Vaihingen Dataset
To investigate our model’s robustness and cross-dataset performance, we employ the Vaihingen dataset. As shown in
Table 4, the proposed weakly supervised model performs well compared to the fully supervised methods, as shown in
Figure 5. This demonstrates that the proposed framework has comparable accuracy and non-destructive segmentation ability, as well as good overall pixel-level segmentation performance. Furthermore, other methods are based on the concept of fully supervised learning and require a large number of manual annotation labels. The proposed weakly supervised framework not only reduces human efforts significantly, but it also outperforms some previous weakly supervised works in terms of some indicators.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}