
Facial Expression Recognition: One Attention-Modulated Contextual Spatial Information Network


Abstract
:1. Introduction
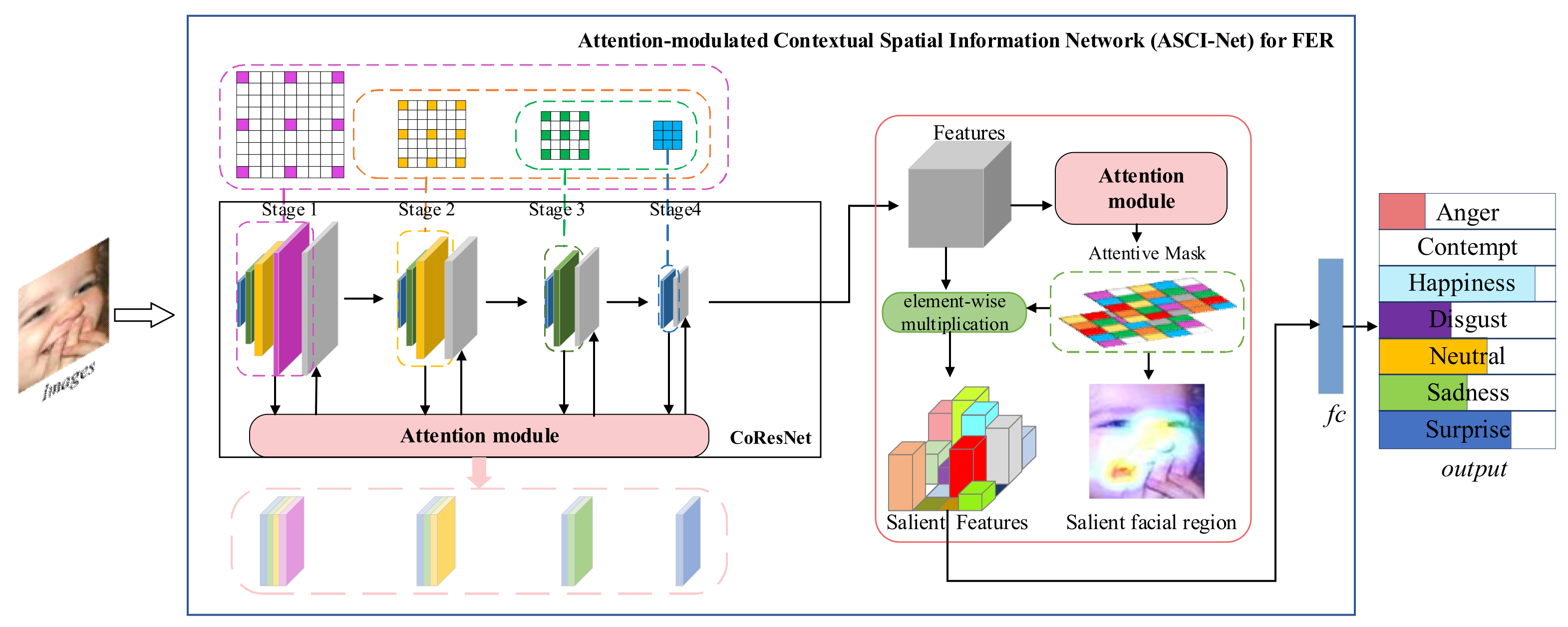
- Aiming at the in-the-wild FER task, we propose ACSI-Net. Different from some existing methods, ACSI-Net is able to focus on salient facial regions and automatically explore the intrinsic dependencies between subtle features of expression.
- To generate a holistic representation, a CoResNet is constructed for long-range dependent expression features extraction by supplying contextual convolution (CoConv) blocks in the main stages of the residual network (ResNet) to integrate spatial information of the face.
- The CA modules are adopted to adaptively modulate features, pushing the model to retain relevant information and weaken irrelevant ones. Extensive experiments conducted on two popular wild FER datasets (AffectNet and RAF_DB) demonstrate the effectiveness and competitiveness of our proposed model.
2. Related Work
3. The Proposed Method
3.1. CoResNet for Feature Extraction
3.2. CA Modules for Feature Refinement
4. Results and Discussion
4.1. Datasets
4.2. Implementation Details
4.3. Ablation Studies
4.3.1. Ablation Study of CoResNet
4.3.2. Ablation Study of CA
4.4. Quantitative Evaluation
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Jaiswal, S.; Nandi, G.C. Robust real-time emotion detection system using CNN architecture. Neural. Comput. Appl. 2020, 32, 11253–11262. [Google Scholar] [CrossRef]
- Zhao, X.; Zhu, J.; Luo, B.; Gao, Y. Survey on facial expression recognition: History, applications, and challenges. IEEE MultiMed. 2021, 28, 38–44. [Google Scholar] [CrossRef]
- Yan, Y.; Huang, Y.; Chen, S.; Shen, S.; Wang, H. Joint deep learning of facial expression synthesis and recognition. IEEE Trans. Multimed. 2019, 22, 2792–2807. [Google Scholar] [CrossRef] [Green Version]
- Mollahosseini, A.; Chan, D.; Mahoor, M.H. Going deeper in facial expression recognition using deep neural networks. In Proceedings of the IEEE 2016 Winter Conference on Applications of Computer Vision (WACV), New York, NY, USA, 7–9 March 2016; pp. 1–10. [Google Scholar]
- Shan, C.; Gong, S.; McOwan, P.W. Facial expression recognition based on local binary patterns: A comprehensive study. Image Vis. Comput. 2009, 27, 803–816. [Google Scholar] [CrossRef] [Green Version]
- Ng, P.C.; Henikoff, S. SIFT: Predicting amino acid changes that affect protein function. Nucleic Acids Res. 2003, 31, 3812–3814. [Google Scholar] [CrossRef] [Green Version]
- Navneet, D.; Bill, T. Histograms of oriented gradients for human detection. In Proceedings of the IEEE 2005 Computer Society Conference on Computer Vision and Pattern Recognition (CVPR 2005), San Diego, CA, USA, 20–26 June 2005; Volume 2, pp. 886–893. [Google Scholar]
- Kola, D.G.R.; Samayamantula, S.K. A novel approach for facial expression recognition using local binary pattern with adaptive window. Multimed. Tools Appl. 2021, 80, 2243–2262. [Google Scholar] [CrossRef]
- Moore, S.; Bowden, R. Local binary patterns for multi-view facial expression recognition. Comput. Vis. Image Underst. 2011, 115, 541–558. [Google Scholar] [CrossRef]
- Tan, X.; Triggs, B. Enhanced local texture feature sets for face recognition under difficult lighting conditions. IEEE Trans. Image Process. 2010, 19, 1635–1650. [Google Scholar] [CrossRef] [Green Version]
- Holder, R.P.; Tapamo, J.R. Improved gradient local ternary patterns for facial expression recognition. EURASIP J. Image Video 2017, 2017, 42. [Google Scholar] [CrossRef]
- Jabid, T.; Kabir, M.H.; Chae, O. Local directional pattern (LDP) for face recognition. In Proceedings of the 2010 Digest of Technical Papers International Conference on Consumer Electronics (ICCE), Las Vegas, NV, USA, 9–13 January 2010; pp. 329–330. [Google Scholar]
- Jabid, T.; Kabir, M.H.; Chae, O. Robust facial expression recognition based on local directional pattern. ETRI J. 2010, 32, 784–794. [Google Scholar] [CrossRef]
- Lokku, G.; Reddy, G.H.; Prasad, M.N. Optimized scale-invariant feature transform with local tri-directional patterns for facial expression recognition with deep learning model. Comput. J. 2021, 2–19. [Google Scholar] [CrossRef]
- Ryu, B.; Rivera, A.R.; Kim, J.; Chae, O. Local directional ternary pattern for facial expression recognition. IEEE Trans. Image Process. 2017, 26, 6006–6018. [Google Scholar] [CrossRef]
- Zheng, W.; Tang, H.; Lin, Z.; Huang, T.S. A novel approach to expression recognition from non-frontal face images. In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision (ICCV 2009), Kyoto, Japan, 29 September–2 October 2009; pp. 1901–1908. [Google Scholar]
- Zheng, W. Multi-view facial expression recognition based on group sparse reduced-rank regression. IEEE Trans. Affect. Comput. 2014, 5, 71–85. [Google Scholar] [CrossRef]
- Meena, H.K.; Joshi, S.D.; Sharma, K.K. Facial expression recognition using graph signal processing on HOG. IETE J. Res. 2021, 67, 667–673. [Google Scholar] [CrossRef]
- Wang, H.; Wei, S.; Fang, B. Facial expression recognition using iterative fusion of MO-HOG and deep features. J. Supercomput. 2020, 76, 3211–3221. [Google Scholar] [CrossRef]
- Jumani, S.Z.; Ali, F.; Guriro, S.; Kandhro, I.A.; Khan, A.; Zaidi, A. Facial expression recognition with histogram of oriented gradients using CNN. Indian J. Sci. Technol. 2019, 12, 1–8. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE 2016 Conference on Computer Vision and Pattern Recognition (CVPR 2016), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Zeiler, M.D.; Fergus, R. Visualizing and understanding convolutional networks. In Proceedings of the European Conference on Computer Vision (ECCV 2014), Zurich, Switzerland, 6–12 September 2014; Springer: Cham, Switzerland, 2014; Volume 6, pp. 818–833. [Google Scholar]
- Fasel, B. Robust face analysis using convolutional neural networks. In Proceedings of the 2002 International Conference on Pattern Recognition, Quebec City, QC, Canada, 11–15 August 2002; pp. 40–43. [Google Scholar]
- Fasel, B. Head-pose invariant facial expression recognition using convolutional neural networks. In Proceedings of the Fourth IEEE International Conference on Multimodal Interfaces (ICMI 2002), Pittsburgh, PA, USA, 14–16 October 2002; pp. 529–534. [Google Scholar]
- Matsugu, M.; Mori, K.; Mitari, Y.; Kaneda, Y. Subject independent facial expression recognition with robust face detection using a convolutional neural network. Neural Netw. 2003, 16, 555–559. [Google Scholar] [CrossRef]
- Li, Y.; Zeng, J.; Shan, S.; Chen, X. Patch-gated CNN for occlusion-aware facial expression recognition. In Proceedings of the 24th International Conference on Pattern Recognition (ICPR 2018), IEEE, Beijing, China, 20–24 August 2018; Springer: Cham, Switzerland, 2018; pp. 2209–2214. [Google Scholar]
- Li, S.; Deng, W.; Du, J.P. Reliable crowdsourcing and deep locality-preserving learning for expression recognition in the wild. In Proceedings of the IEEE 2017 Conference on Computer Vision and Pattern Recognition (CVPR 2017), Honolulu, HI, USA, 21–16 July 2017; pp. 2852–2861. [Google Scholar]
- Lian, Z.; Li, Y.; Tao, J.H.; Huang, J.; Niu, M.-Y. Expression analysis based on face regions in real-world conditions. Int. J. Autom. Comput. 2020, 17, 96–107. [Google Scholar] [CrossRef] [Green Version]
- Hua, W.; Dai, F.; Huang, L.; Xiong, J.; Gui, G. HERO: Human emotions recognition for realizing intelligent Internet of Things. IEEE Access 2019, 7, 24321–24332. [Google Scholar] [CrossRef]
- Zhao., S.; Cai, H.; Liu, H.; Zhang, J.; Chen, S. Feature Selection Mechanism in CNNs for Facial Expression Recognition. In Proceedings of the British Machine Vision Conference (BMVC 2018), Newcastle, UK, 2–6 September 2018; p. 317. [Google Scholar]
- Zhao, Z.; Liu, Q.; Wang, S. Learning deep global multi-scale and local attention features for facial expression recognition in the wild. IEEE Trans. Image Process. 2021, 30, 6544–6556. [Google Scholar] [CrossRef]
- Li, Y.; Lu, G.; Li, J.; Zhang, Z.; Zhang, D. Facial expression recognition in the wild using multi-level features and attention mechanisms. IEEE Trans. Affect. Comput. 2020, 32, 3178–3189. [Google Scholar] [CrossRef]
- Fan, X.; Jiang, M.; Shahid, A.R.; Yan, H. Hierarchical scale convolutional neural network for facial expression recognition. Cogn. Neurodyn. 2022, 1–12. [Google Scholar] [CrossRef]
- Liang, X.; Xu, L.; Zhang, W.; Liu, J.; Liu, Z. A convolution-transformer dual branch network for head-pose and occlusion facial expression recognition. Vis. Comput. 2022, 1–14. [Google Scholar] [CrossRef]
- Wang, Z.; Zeng, F.; Liu, S.; Zeng, B. OAENet: Oriented attention ensemble for accurate facial expression recognition. Pattern Recognit. 2021, 112, 107694. [Google Scholar] [CrossRef]
- Rifai, S.; Bengio, Y.; Courville, A.; Vincent, P.; Mirza, M. Disentangling factors of variation for facial expression recognition. In Proceedings of the European Conference on Computer Vision (ECCV 2012), Florence, Italy, 7–13 October 2012; Springer: Berlin/Heidelberg, Germany, 2012; pp. 808–822. [Google Scholar]
- Liu, M.; Li, S.; Shan, S.; Chen, X. Au-aware deep networks for facial expression recognition. In Proceedings of the 10th IEEE International Conference and Workshops on Automatic Face and Gesture Recognition (FG 2013), Shanghai, China, 22–26 April 2013; pp. 1–6. [Google Scholar]
- Xie, S.; Hu, H.; Wu, Y. Deep multi-path convolutional neural network joint with salient region attention for facial expression recognition. Pattern Recognit. 2019, 92, 177–191. [Google Scholar] [CrossRef]
- Gera, D.; Balasubramanian, S. Landmark guidance independent spatio-channel attention and complementary context information based facial expression recognition. Pattern Recognit. Lett. 2021, 145, 58–66. [Google Scholar] [CrossRef]
- Sun, W.; Zhao, H.; Jin, Z. A visual attention based ROI detection method for facial expression recognition. Neurocomputing 2018, 296, 12–22. [Google Scholar] [CrossRef]
- Zhu, K.; Du, Z.; Li, W.; Huang, D.; Wang, Y.; Chen, L. Discriminative attention-based convolutional neural network for 3D facial expression recognition. In Proceedings of the 14th IEEE International Conference on Automatic Face and Gesture Recognition (FG 2019), Lille, France, 14–18 May 2019; pp. 1–8. [Google Scholar]
- Zhang, F.; Zhang, T.; Mao, Q.; Duan, L.; Xu, C. Facial expression recognition in the wild: A cycle-consistent adversarial attention transfer approach. In Proceedings of the 26th ACM International Conference on Multimedia, New York, NY, USA, 19–23 April 2018; pp. 126–135. [Google Scholar]
- Marrero Fernandez, P.D.; Guerrero Pena, F.A.; Ren, T.; Cunha, A. Feratt: Facial expression recognition with attention net. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2019), Long Beach, CA, USA, 15–21 June 2019. [Google Scholar]
- Albright, T.D.; Stoner, G.R. Contextual influences on visual processing. Annu. Rev. Neurosci. 2002, 25, 339–379. [Google Scholar] [CrossRef] [Green Version]
- Gilbert, C.D.; Wiesel, T.N. The influence of contextual stimuli on the orientation selectivity of cells in primary visual cortex of the cat. Vis. Res. 1990, 30, 1689–1701. [Google Scholar] [CrossRef]
- Zipser, K.; Lamme, V.A.F.; Schiller, P.H. Contextual modulation in primary visual cortex. J. Neurosci. 1996, 16, 7376–7389. [Google Scholar] [CrossRef] [Green Version]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate attention for efficient mobile network design. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2021), Online, 19–25 June 2021; pp. 13713–13722. [Google Scholar]
- Duta, I.C.; Georgescu, M.I.; Ionescu, R.T. Contextual Convolutional Neural Networks. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV 2021), Montreal, QC, Canada, 11–17 October 2021; pp. 403–412. [Google Scholar]
- Mollahosseini, A.; Hasani, B.; Mahoor, M.H. Affectnet: A database for facial expression, valence, and arousal computing in the wild. IEEE Trans. Affect. Comput. 2017, 10, 18–31. [Google Scholar] [CrossRef] [Green Version]
- Li, S.; Deng, W. Reliable crowdsourcing and deep locality-preserving learning for unconstrained facial expression recognition. IEEE Trans. Image Process. 2018, 28, 356–370. [Google Scholar] [CrossRef] [PubMed]
- Farzaneh, A.H.; Qi, X. Facial expression recognition in the wild via deep attentive center loss. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Online, 5–9 January 2021; pp. 2402–2411. [Google Scholar]
- Guo, Y.; Zhang, L.; Hu, Y.; He, X.; Gao, J. Ms-celeb-1m: A dataset and benchmark for large-scale face recognition. In Proceedings of the European Conference on Computer Vision (ECCV 2016), Amsterdam, The Netherlands, 8–6 October 2016; Springer: Cham, Switzerland, 2016; pp. 87–102. [Google Scholar]
- Husnain, M.; Missen, M.M.S.; Mumtaz, S.; Luqman, M.M.; Coustaty, M.; Ogier, J.-M. Visualization of high-dimensional data by pairwise fusion matrices using t-SNE. Symmetry 2019, 11, 107. [Google Scholar] [CrossRef] [Green Version]
- Chen, Y.; Wang, J.; Chen, S.; Shi, Z.; Cai, J. Facial motion prior networks for facial expression recognition. In Proceedings of the IEEE 2019 Visual Communications and Image Processing (VCIP 2019), Sydney, Australia, 1–4 December 2019; pp. 1–4. [Google Scholar]
- Chefer, H.; Gur, S.; Wolf, L. Transformer interpretability beyond attention visualization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2021), Online, 19–25 June 2021; pp. 782–791. [Google Scholar]
- Xue, F.; Wang, Q.; Guo, G. Transfer: Learning relation-aware facial expression representations with transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV 2021), Montreal, QC, Canada, 11–17 October 2021; pp. 3601–3610. [Google Scholar]
- Hung, S.C.Y.; Lee, J.H.; Wan, T.S.T.; Chen, C.-H.; Chan, Y.-M. Increasingly packing multiple facial-informatics modules in a unified deep-learning model via lifelong learning. In Proceedings of the 2019 on International Conference on Multimedia Retrieval (ICMR 2019), Ottawa, ON, Canada, 10–13 June 2019; pp. 339–343. [Google Scholar]
- Li, Y.; Lu, Y.; Li, J.; Lu, G. Separate loss for basic and compound facial expression recognition in the wild. In Proceedings of the 11th Asian Conference on Machine Learning (ACML 2019), PMLR, Nagoya, Japan, 17–19 November 2019; pp. 897–911. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Stage | Input Size | Level | CoConv |
|---|---|---|---|
| 1 | |||
| 2 | |||
| 3 | |||
| 4 |
| Dataset | Affectnet-7 | RAF_DB | ||
|---|---|---|---|---|
| Train | Test | Train | Test | |
| Anger | 24,882 | 500 | 705 | 162 |
| Disgust | 3803 | 500 | 717 | 160 |
| Fear | 6378 | 500 | 281 | 74 |
| Happy | 134,415 | 500 | 4772 | 1185 |
| Sad | 25,459 | 500 | 1982 | 478 |
| Surprise | 14,090 | 500 | 1290 | 329 |
| Normal | 74,874 | 500 | 2524 | 680 |
| Total | 283,901 | 3500 | 12,271 | 3068 |
| Model | Params | GFLOPs | Time/s | Accuracy (%) | |
|---|---|---|---|---|---|
| RAF-DB | AffectNet-7 | ||||
| ResNet | 11.69 | 1.82 | 1.32 | 85.88 | 63.82 |
| CoResNet | 11.69 | 1.82 | 1.32 | 86.86 | 65.83 |
| Model | Params | GFLOPs | Time/s | Accuracy (%) | |
|---|---|---|---|---|---|
| RAF-DB | AffectNet-7 | ||||
| CoResNet | 11.69 | 1.82 | 1.32 | 86.29 | 64.38 |
| CoResNet_CA-a | 11.72 | 1.82 | 1.33 | 86.45 | 65.16 |
| CoResNet_CA-b | 11.75 | 1.82 | 1.35 | 86.52 | 65.60 |
| ACSI-Net | 11.78 | 1.82 | 1.38 | 86.86 | 65.83 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, X.; Zhu, C.; Zhou, F. Facial Expression Recognition: One Attention-Modulated Contextual Spatial Information Network. Entropy 2022, 24, 882. https://doi.org/10.3390/e24070882
Li X, Zhu C, Zhou F. Facial Expression Recognition: One Attention-Modulated Contextual Spatial Information Network. Entropy. 2022; 24(7):882. https://doi.org/10.3390/e24070882
Chicago/Turabian StyleLi, Xue, Chunhua Zhu, and Fei Zhou. 2022. "Facial Expression Recognition: One Attention-Modulated Contextual Spatial Information Network" Entropy 24, no. 7: 882. https://doi.org/10.3390/e24070882
APA StyleLi, X., Zhu, C., & Zhou, F. (2022). Facial Expression Recognition: One Attention-Modulated Contextual Spatial Information Network. Entropy, 24(7), 882. https://doi.org/10.3390/e24070882