
The Residual ISI for Which the Convolutional Noise Probability Density Function Associated with the Blind Adaptive Deconvolution Problem Turns Approximately Gaussian


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. System Description
- The input sequence is a 16QAM source, which can be expressed as where and are ’s real and imaginary parts, respectively. 16QAM is a modulation that uses ± {1,3} levels for in-phase and quadrature components. and denotes the expectation of . The real and imaginary parts of are independent.
- The unidentified channel is a linear time-invariant filter that may not have a minimum phase and whose transfer function lacks “deep zeros,” or zeros that are sufficiently removed from the unit circle. The channel’s tap length is R.
- The filter is a tap-delay line.
- The channel noise is an additive Gaussian white noise.
3. The Residual ISI That Leads Approximately to a Gaussian pdf for the Convolutional Noise
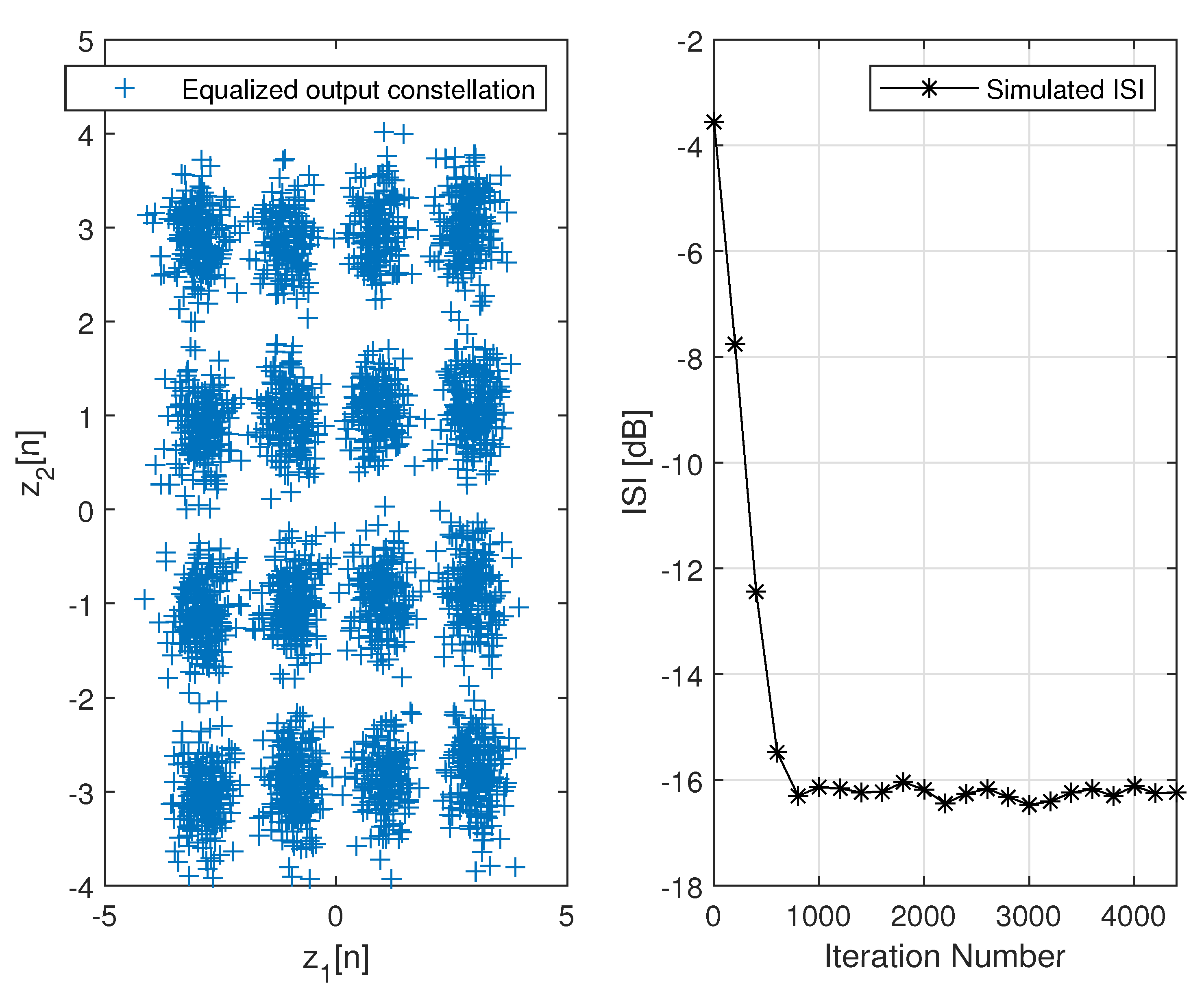
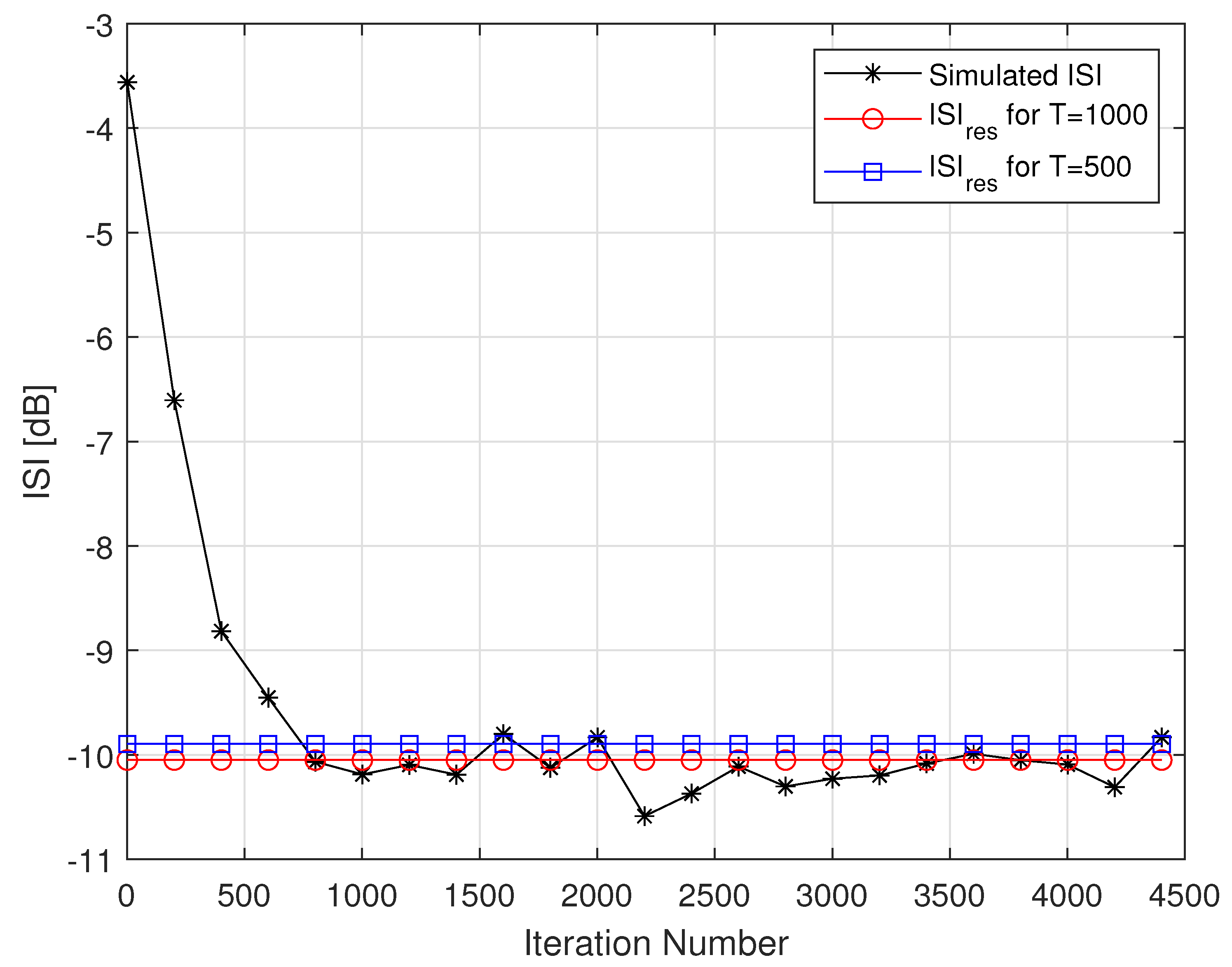
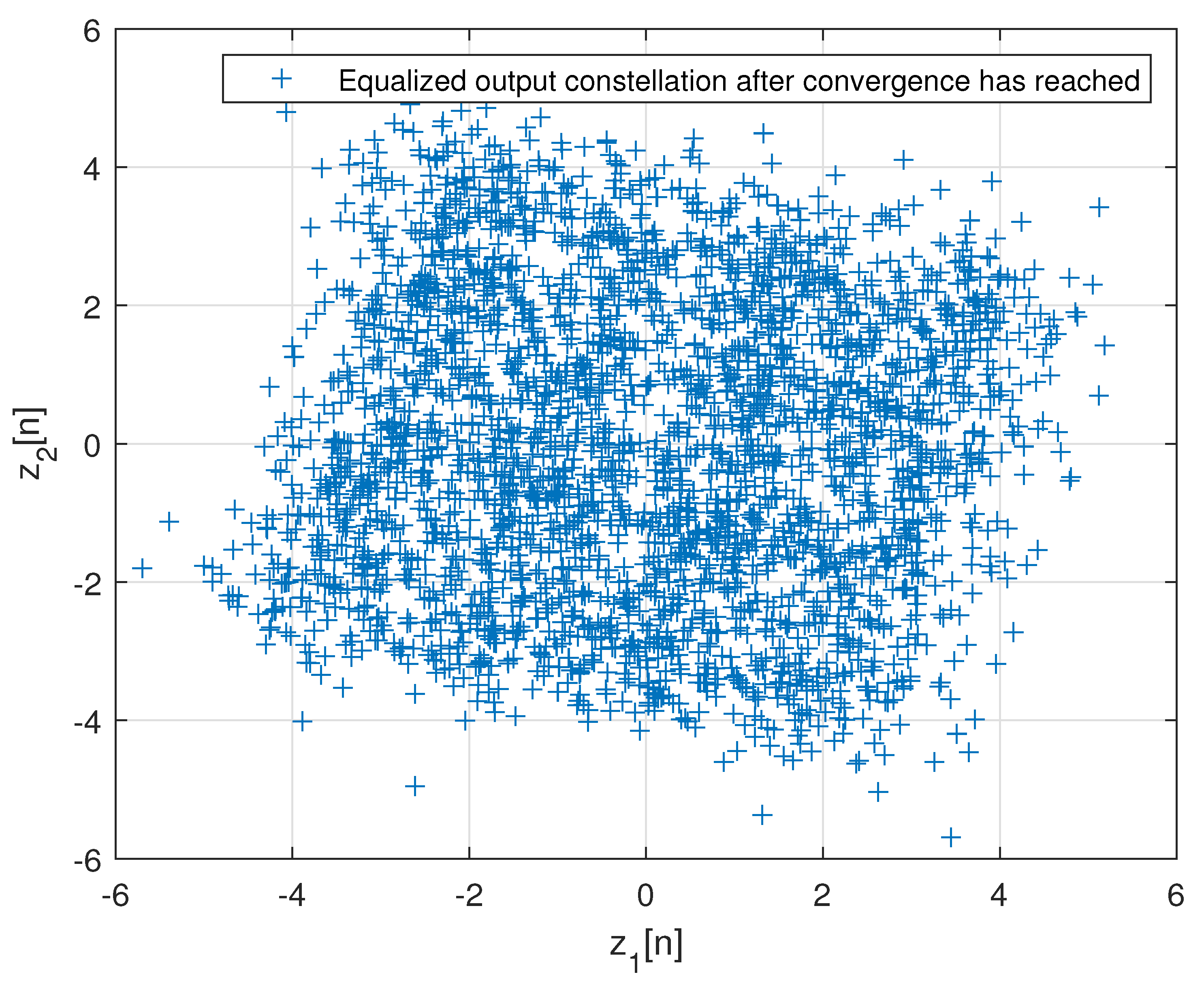
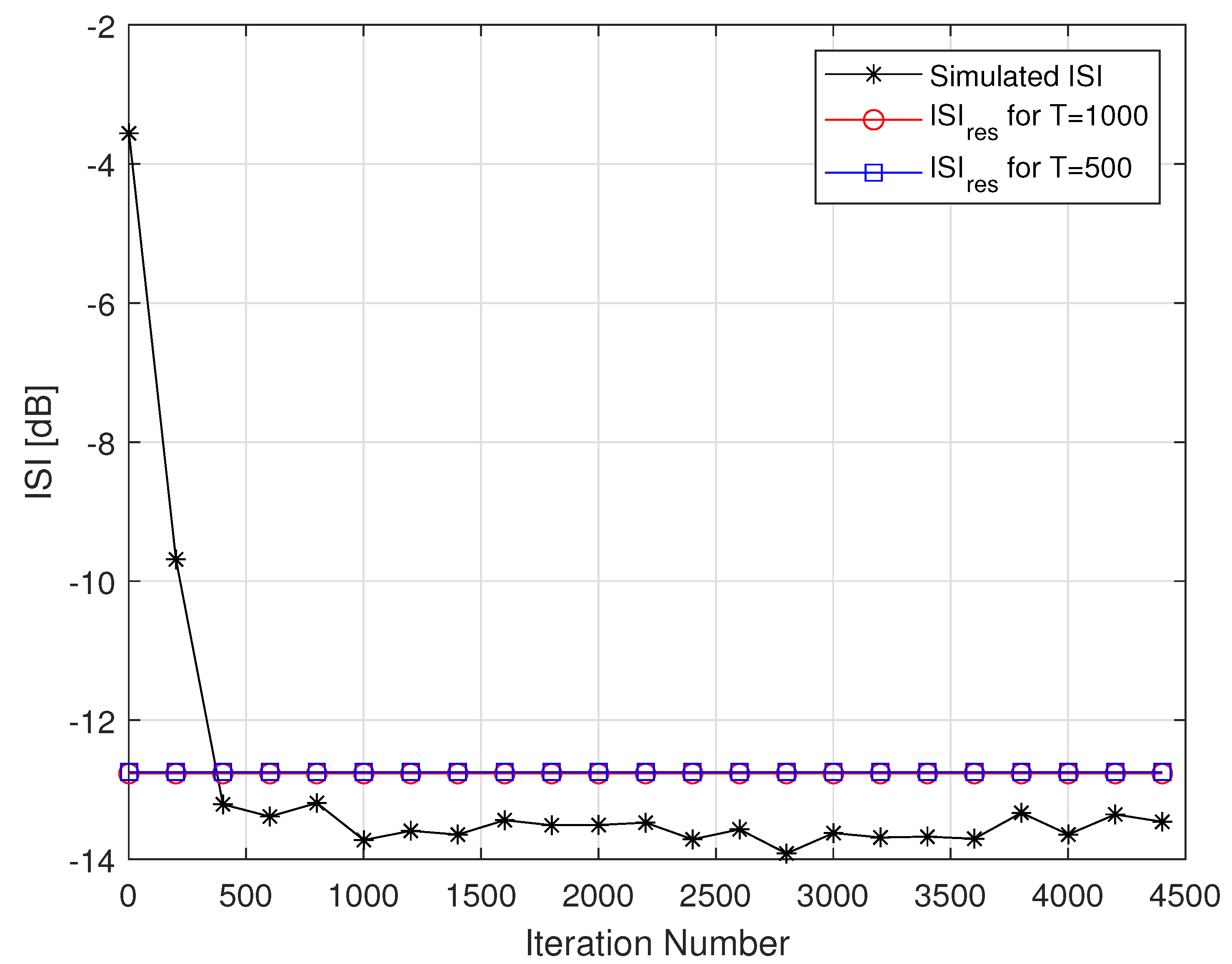
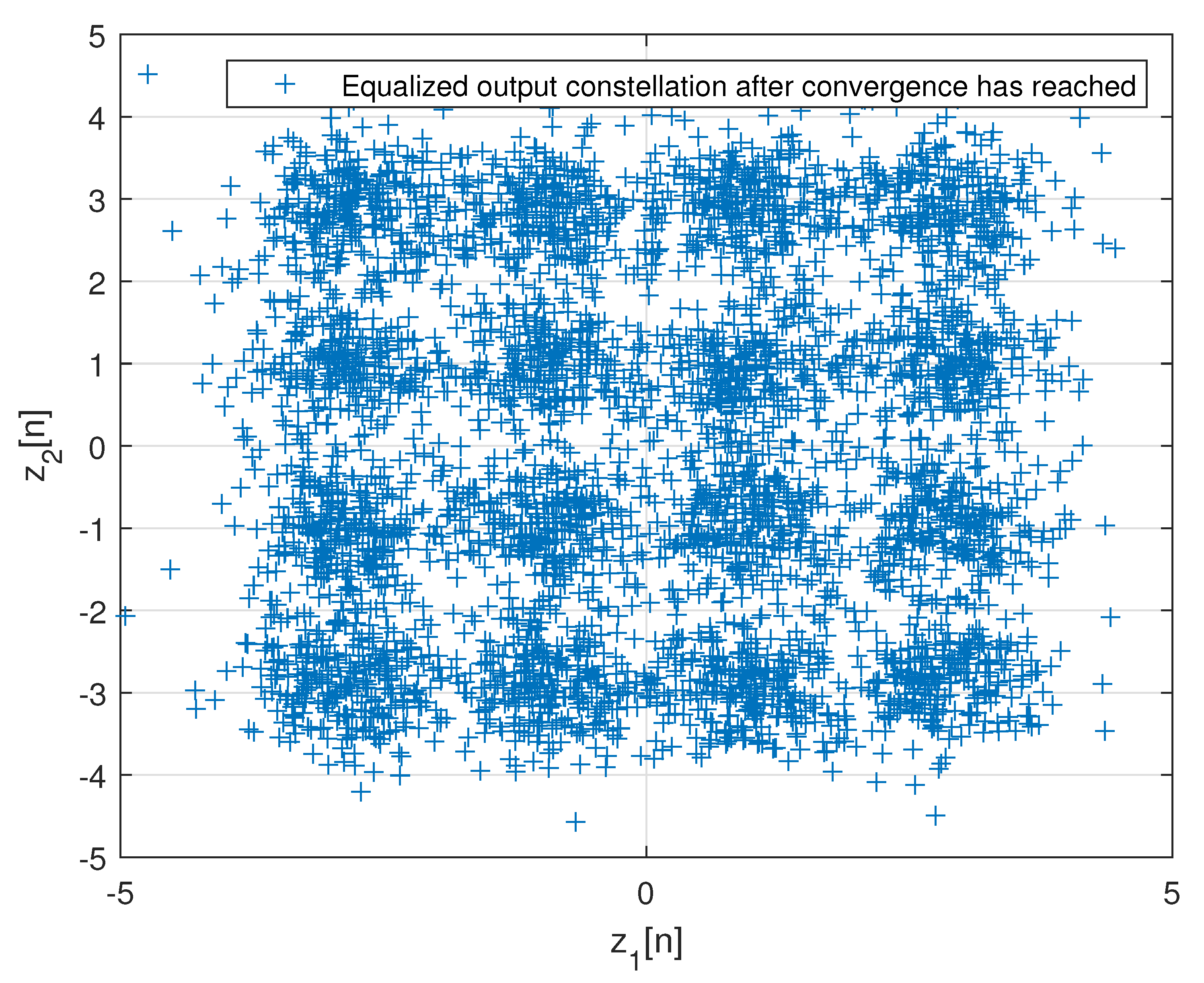
4. Simulation
5. Discussion
Funding
Data Availability Statement
Conflicts of Interest
References
- Pinchas, M.; Bobrovsky, B.Z. A Maximum Entropy approach for blind deconvolution. Signal Process. 2006, 86, 2913–2931. [Google Scholar] [CrossRef]
- Pinchas, M. A New Efficient Expression for the Conditional Expectation of the Blind Adaptive Deconvolution Problem Valid for the Entire Range of Signal-to-Noise Ratio. Entropy 2019, 21, 72. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Shlisel, S.; Pinchas, M. Improved Approach for the Maximum Entropy Deconvolution Problem. Entropy 2021, 23, 547. [Google Scholar] [CrossRef] [PubMed]
- Freiman, A.; Pinchas, M. A Maximum Entropy inspired model for the convolutional noise PDF. Digit. Signal Process. 2015, 39, 35–49. [Google Scholar] [CrossRef]
- Rivlin, Y.; Pinchas, M. Edgeworth Expansion Based Model for the Convolutional Noise pdf. Math. Probl. Eng. 2014, 2014, 951927. [Google Scholar] [CrossRef]
- Pinchas, M. New Lagrange Multipliers for the Blind Adaptive Deconvolution Problem Applicable for the Noisy Case. Entropy 2016, 18, 65. [Google Scholar] [CrossRef] [Green Version]
- Shalvi, O.; Weinstein, E. New criteria for blind deconvolution of nonminimum phase systems (channels). IEEE Trans. Inf. Theory 1990, 36, 312–321. [Google Scholar] [CrossRef]
- Wiggins, R.A. Minimum entropy deconvolution. Geoexploration 1978, 16, 21–35. [Google Scholar] [CrossRef]
- Kazemi, N.; Sacchi, M.D. Sparse multichannel blind deconvolution. Geophysics 2014, 79, V143–V152. [Google Scholar] [CrossRef]
- Guitton, A.; Claerbout, J. Nonminimum phase deconvolution in the log domain: A sparse inversion approach. Geophysics 2015, 80, WD11–WD18. [Google Scholar] [CrossRef] [Green Version]
- Silva, M.T.M.; Arenas-Garcia, J. A Soft-Switching Blind Equalization Scheme via Convex Combination of Adaptive Filters. IEEE Trans. Signal Process. 2013, 61, 1171–1182. [Google Scholar] [CrossRef]
- Mitra, R.; Singh, S.; Mishra, A. Improved multi-stage clustering-based blind equalisation. IET Commun. 2011, 5, 1255–1261. [Google Scholar] [CrossRef] [Green Version]
- Gul, M.M.U.; Sheikh, S.A. Design and implementation of a blind adaptive equalizer using Frequency Domain Square Contour Algorithm. Digit. Signal Process. 2010, 20, 1697–1710. [Google Scholar]
- Sheikh, S.A.; Fan, P. New Blind Equalization techniques based on improved square contour algorithm. Digit. Signal Process. 2008, 18, 680–693. [Google Scholar] [CrossRef]
- Thaiupathump, T.; He, L.; Kassam, S.A. Square contour algorithm for blind equalization of QAM signals. Signal Process. 2006, 86, 3357–3370. [Google Scholar] [CrossRef]
- Sharma, V.; Raj, V.N. Convergence and performance analysis of Godard family and multimodulus algorithms for blind equalization. IEEE Trans. Signal Process. 2005, 53, 1520–1533. [Google Scholar] [CrossRef] [Green Version]
- Yuan, J.T.; Lin, T.C. Equalization and Carrier Phase Recovery of CMA and MMA in BlindAdaptive Receivers. IEEE Trans. Signal Process. 2010, 58, 3206–3217. [Google Scholar] [CrossRef]
- Yuan, J.T.; Tsai, K.D. Analysis of the multimodulus blind equalization algorithm in QAM communication systems. IEEE Trans. Commun. 2005, 53, 1427–1431. [Google Scholar] [CrossRef]
- Wu, H.C.; Wu, Y.; Principe, J.C.; Wang, X. Robust switching blind equalizer for wireless cognitive receivers. IEEE Trans. Wirel. Commun. 2008, 7, 1461–1465. [Google Scholar]
- Kundur, D.; Hatzinakos, D. A novel blind deconvolution scheme for image restoration using recursive filtering. IEEE Trans. Signal Process. 1998, 46, 375–390. [Google Scholar] [CrossRef]
- Likas, C.L.; Galatsanos, N.P. A variational approach for Bayesian blind image deconvolution. IEEE Trans. Signal Process. 2004, 52, 2222–2233. [Google Scholar] [CrossRef]
- Li, D.; Mersereau, R.M.; Simske, S. Blind Image Deconvolution Through Support Vector Regression. IEEE Trans. Neural Netw. 2007, 18, 931–935. [Google Scholar] [CrossRef] [PubMed]
- Amizic, B.; Spinoulas, L.; Molina, R.; Katsaggelos, A.K. Compressive Blind Image Deconvolution. IEEE Trans. Image Process. 2013, 22, 3994–4006. [Google Scholar] [CrossRef] [Green Version]
- Tzikas, D.G.; Likas, C.L.; Galatsanos, N.P. Variational Bayesian Sparse Kernel-Based Blind Image Deconvolution with Student’s-t Priors. IEEE Trans. Image Process. 2009, 18, 753–764. [Google Scholar] [CrossRef]
- Feng, C.; Chi, C. Performance of cumulant based inverse filters for blind deconvolution. IEEE Trans. Signal Process. 1999, 47, 1922–1935. [Google Scholar] [CrossRef]
- Abrar, S.; Nandi, A.S. Blind Equalization of Square-QAM Signals: A Multimodulus Approach. IEEE Trans. Commun. 2010, 58, 1674–1685. [Google Scholar] [CrossRef]
- Vanka, R.N.; Murty, S.B.; Mouli, B.C. Performance comparison of supervised and unsupervised/blind equalization algorithms for QAM transmitted constellations. In Proceedings of the 2014 International Conference on Signal Processing and Integrated Networks (SPIN), Noida, India, 20–21 February 2014. [Google Scholar]
- Ram Babu, T.; Kumar, P.R. Blind Channel Equalization Using CMA Algorithm. In Proceedings of the 2009 International Conference on Advances in Recent Technologies in Communication and Computing (ARTCom 09), Kottayam, India, 27–28 October 2009. [Google Scholar]
- Qin, Q.; Huahua, L.; Tingyao, J. A new study on VCMA-based blind equalization for underwater acoustic communications. In Proceedings of the 2013 International Conference on Mechatronic Sciences, Electric Engineering and Computer (MEC), Shengyang, China, 20–22 December 2013. [Google Scholar]
- Wang, J.; Huang, H.; Zhang, C.; Guan, J. A Study of the Blind Equalization in the Underwater Communication. In Proceedings of the WRI Global Congress on Intelligent Systems, GCIS ’09, Xiamen, China, 19–21 May 2009. [Google Scholar]
- Miranda, M.D.; Silva, M.T.M.; Nascimento, V.H. Avoiding Divergence in the Shalvi Weinstein Algorithm. IEEE Trans. Signal Process. 2008, 56, 5403–5413. [Google Scholar] [CrossRef]
- Samarasinghe, P.D.; Kennedy, R.A. Minimum Kurtosis CMA Deconvolution for Blind Image Restoration. In Proceedings of the 4th International Conference on Information and Automation for Sustainability (ICIAFS 2008), Colombo, Sri Lanka, 12–14 December 2008. [Google Scholar]
- Zhao, L.; Li, H. Application of the Sato blind deconvolution algorithm for correction of the gravimeter signal distortion. In Proceedings of the 2013 Third International Conference on Instrumentation, Measurement, Computer, Communication and Control, Shenyang, China, 21–23 September 2013; pp. 1413–1417. [Google Scholar]
- Fiori, S. Blind deconvolution by a Newton method on the non-unitary hypersphere. Int. J. Adapt. Control Signal Process. 2013, 7, 488–518. [Google Scholar] [CrossRef]
- Shevach, R.; Pinchas, M. A Closed-form approximated expression for the residual ISI obtained by blind adaptive equalizers applicable for the non-square QAM constellation input and noisy case. In Proceedings of the International Conference on Pervasive and Embedded Computing and Communication Systems (PECCS), Angers, France, 11–13 February 2015; pp. 217–223. [Google Scholar]
- Abrar, S.; Ali, A.; Zerguine, A.; Nandi, A.K. Tracking Performance of Two Constant Modulus Equalizers. IEEE Commun. Lett. 2013, 17, 830–833. [Google Scholar] [CrossRef]
- Azim, A.W.; Abrar, S.; Zerguine, A.; Nandi, A.K. Steady-state performance of multimodulus blind equalizers. Signal Process. 2015, 108, 509–520. [Google Scholar] [CrossRef] [Green Version]
- Azim, A.W.; Abrar, S.; Zerguine, A.; Nandi, A.K. Performance analysis of a family of adaptive blind equalization algorithms for square-QAM. Digit. Signal Process. 2016, 48, 163–177. [Google Scholar] [CrossRef] [Green Version]
- Johnson, R.C.; Schniter, P.; Endres, T.J.; Behm, J.D.; Brown, D.R.; Casas, R.A. Blind Equalization Using the Constant Modulus Criterion: A Review. Proc. IEEE 1998, 86, 1927–1950. [Google Scholar] [CrossRef] [Green Version]
- Pinchas, M.; Bobrovsky, B.Z. A Novel HOS Approach for Blind Channel Equalization. IEEE Wirel. Commun. J. 2007, 6, 875–886. [Google Scholar] [CrossRef]
- Haykin, S. Adaptive filter theory. In Blind Deconvolution; Haykin, S., Ed.; Prentice-Hall: Englewood Cliffs, NJ, USA, 1991; Chapter 20. [Google Scholar]
- Bellini, S. Bussgang techniques for blind equalization. IEEE Glob. Telecommun. Conf. Rec. 1986, 3, 1634–1640. [Google Scholar]
- Bellini, S. Blind Equalization. Alta Frequenza 1988, 57, 445–450. [Google Scholar]
- Godfrey, R.; Rocca, F. Zero memory non-linear deconvolution. Geophys. Prospect. 1981, 29, 189–228. [Google Scholar] [CrossRef]
- Jumarie, G. Nonlinear filtering. A weighted mean squares approach and a Bayesian one via the Maximum Entropy principle. Signal Process. 1990, 21, 323–338. [Google Scholar] [CrossRef]
- Papulis, A. Probability, Random Variables, and Stochastic Processes, 2nd ed.; International Edition; McGraw-Hill: New York, NY, USA, 1984; p. 536, Chapter 15. [Google Scholar]
- Assaf, S.A.; Zirkle, L.D. Approximate analysis of nonlinear stochastic systems. Int. J. Control 1976, 23, 477–492. [Google Scholar] [CrossRef] [Green Version]
- Bover, D.C.C. Moment equation methods for nonlinear stochastic systems. J. Math. Anal. Appl. 1978, 65, 306–320. [Google Scholar] [CrossRef] [Green Version]
- Armando Domínguez-Molina, J.; González-farías, G.; Rodríguez-Dagnino, R.M. A Practical Procedure to Estimate the Shape Parameter in the Generalized Gaussian Distribution. Universidad de Guanajuato, ITESM Campus Monterrey. 2003. Available online: http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.329.2835 (accessed on 28 March 2021).
- González-Farías, G.; Domínguez-Molina, J.A.; Rodríguez-Dagnino, R.M. Efficiency of the Approximated Shape Parameter Estimator in the Generalized Gaussian Distribution. IEEE Trans. Veh. Technol. 2009, 8, 4214–4223. [Google Scholar] [CrossRef]
- Orszag, S.A.; Bender, C.M. Advanced Mathematical Methods for Scientist Engineers International Series in Pure and Applied Mathematics; McDraw-Hill: New York, NY, USA, 1978; Chapter 6. [Google Scholar]
- Godard, D.N. Self recovering equalization and carrier tracking in two-dimenional data communication system. IEEE Trans. Comm. 1980, 28, 1867–1875. [Google Scholar] [CrossRef] [Green Version]
- Pinchas, M. Two Blind Adaptive Equalizers Connected in Series for Equalization Performance Improvement. J. Signal Inf. Process. 2013, 4, 64–71. [Google Scholar] [CrossRef] [Green Version]
- Pinchas, M. The tap-length associated with the blind adaptive equalization/deconvolution problem. In Proceedings of the 1st International Electronic Conference—Futuristic Applications on Electronics, Basel, Switzerland, 1–30 November 2020. [Google Scholar] [CrossRef]
- Oh, K.N.; Chin, Y.O. Modified constant modulus algorithm: Blind equalization and carrier phase recovery algorithm. In Proceedings of the IEEE International Conference on Communications ICC ’95, Seattle, WA, USA, 18–22 June 1995; Volume 1, pp. 498–502. [Google Scholar]
- Yang, J.; Werner, J.-J.; Dumont, G.A. The multimodulus blind equalization and its generalized algorithms. IEEE J. Sel. Areas Commun. 2002, 20, 997–1015. [Google Scholar] [CrossRef]
- Tadmor, S.; Carmi, S.; Pinchas, M. A Novel Dual Mode Decision Directed Multimodulus Algorithm (DM-DD-MMA) for Blind Adaptive Equalization. In Proceedings of the 11th International Conference on Electronics, Coommunications and Networks (CECNet), Beijing, China, 18–21 November 2021. [Google Scholar]
- Pinchas, M. A Closed Approximated Formed Expression for the Achievable Residual Intersymbol Interference Obtained by Blind Equalizers. Signal Process. J. 2010, 90, 1940–1962. [Google Scholar] [CrossRef]
- Spiegel, M.R. Mathematical Handbook of Formulas and Tables, SCHAUM’S Outline Series; Mcgraw-Hill: New York, NY, USA, 1968. [Google Scholar]

Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pinchas, M. The Residual ISI for Which the Convolutional Noise Probability Density Function Associated with the Blind Adaptive Deconvolution Problem Turns Approximately Gaussian. Entropy 2022, 24, 989. https://doi.org/10.3390/e24070989
Pinchas M. The Residual ISI for Which the Convolutional Noise Probability Density Function Associated with the Blind Adaptive Deconvolution Problem Turns Approximately Gaussian. Entropy. 2022; 24(7):989. https://doi.org/10.3390/e24070989
Chicago/Turabian StylePinchas, Monika. 2022. "The Residual ISI for Which the Convolutional Noise Probability Density Function Associated with the Blind Adaptive Deconvolution Problem Turns Approximately Gaussian" Entropy 24, no. 7: 989. https://doi.org/10.3390/e24070989