


Survey of Reinforcement-Learning-Based MAC Protocols for Wireless Ad Hoc Networks with a MAC Reference Model



Abstract
:1. Introduction
- We describe how to use RL to classify observations into positive/negative types, and how to integrate it with different MAC components, to make a better decision.
- We review different RL algorithms used in various MAC components.
- We summarize open research issues and future directions in this field.
2. Review of Related Survey Articles
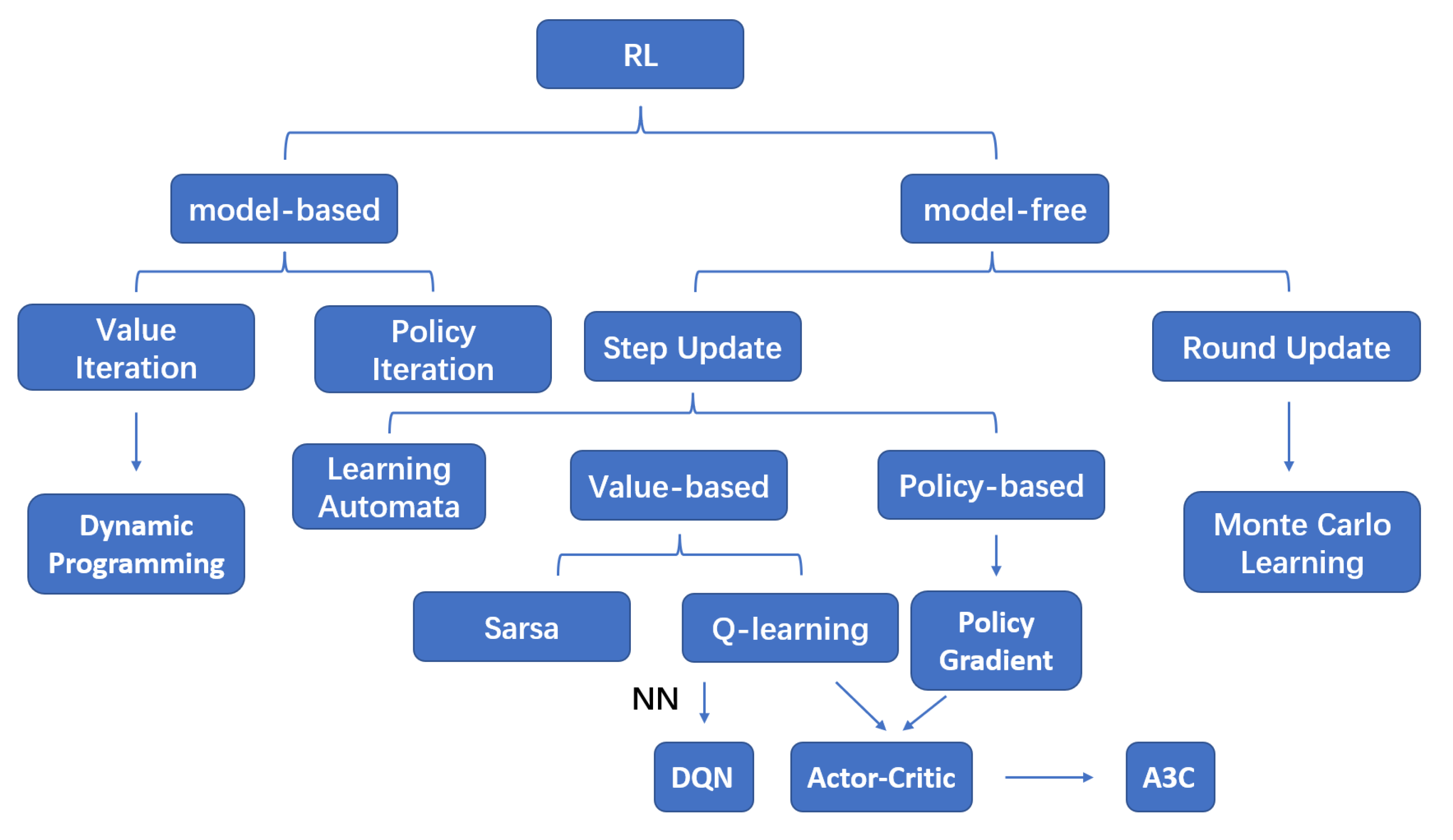
3. RL Algorithms
3.1. Machine Learning Framework
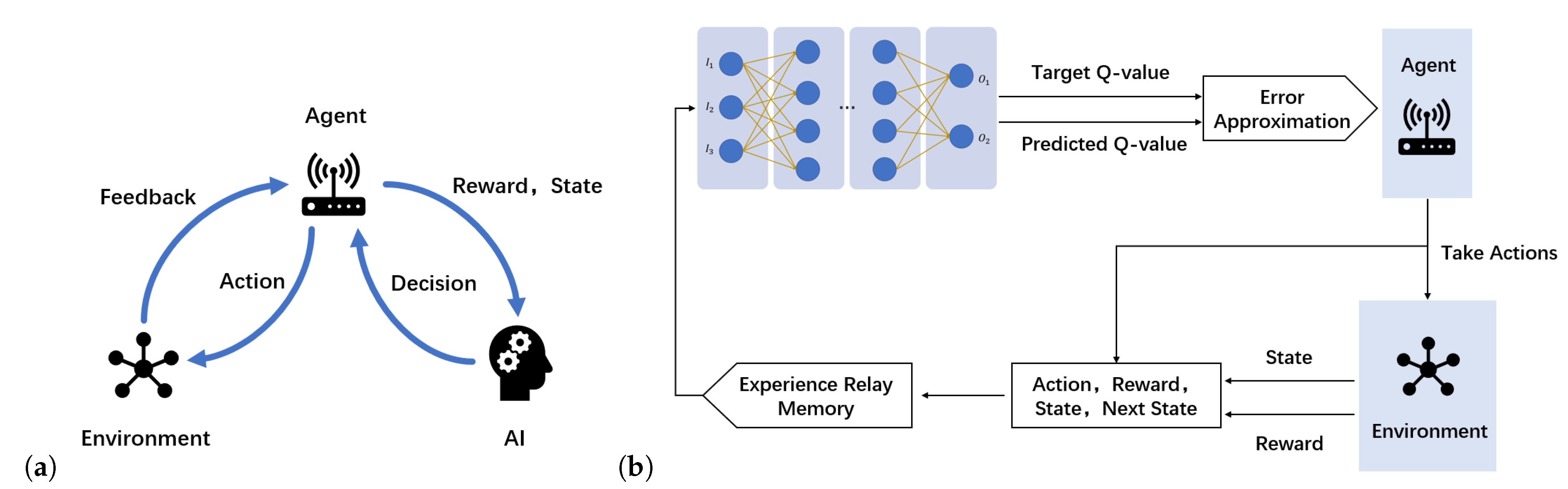
3.2. Reinforcement Learning
3.3. From RL to DRL
3.4. Optimal Design with RL
- Interaction with the environment: Due to node mobility, the network topology is constantly changing so that protocols are also required to be dynamically and automatically configured to achieve better network performance. RL can interact with the environment and feed back network changes to the protocol in time.
- Self-learning and self-correction: The characteristics of self-learning and interaction with the surroundings make systems adapt to the frequent changes of the network in time. Thus, the optimal scheme should be more adaptive, highly scalable and energy-efficient.
- Model without prior training: WNs are generated at any time and easy to construct; they do not need to be supported by preexisting networks. Compared with other learning schemes using trained models, RL schemes train the model by interacting with the networks in real time to make the trained model more suitable for the current environment.
4. Application of Reinforcement Learning for MAC Protocols
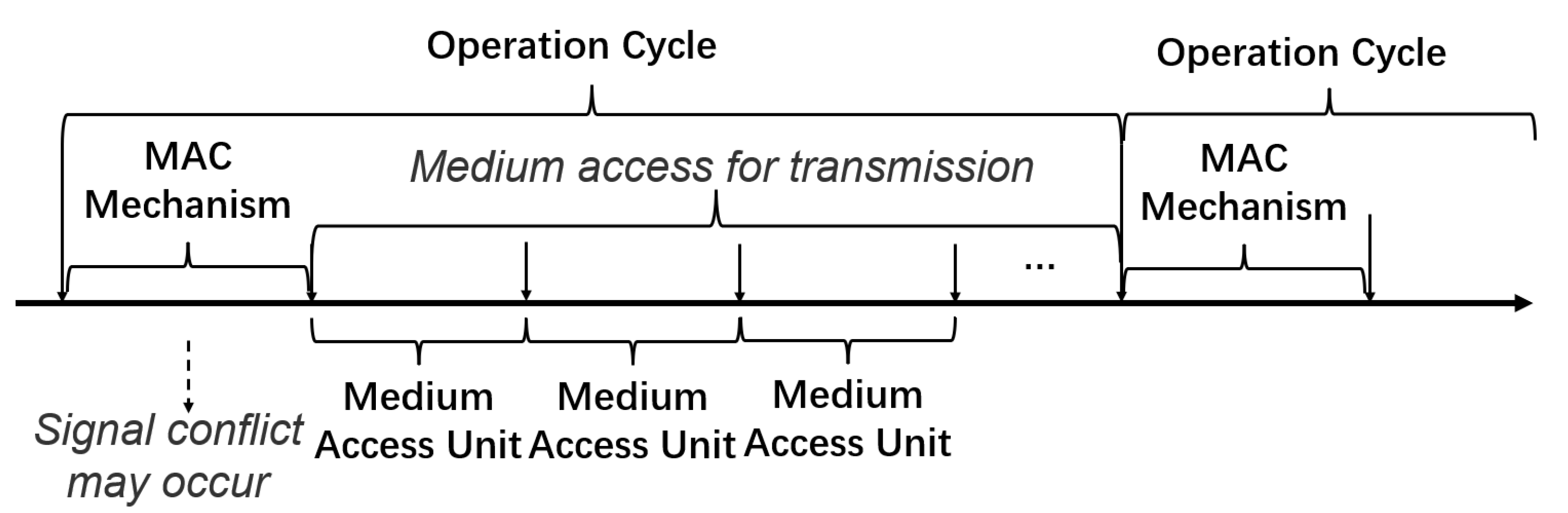
4.1. Operation Cycle
4.2. Medium Access Unit
4.3. MAC Mechanism
4.3.1. Backoff
4.3.2. Scheduling
4.3.3. Other MAC Mechanisms
4.4. Summary
5. Open Research Issues
5.1. Operation Cycle
5.2. Medium Access Unit
5.3. MAC Mechanism
5.4. Other Issues
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Kou, K.; Lei, L.; Zhang, L.; Cai, S.; Shen, G. Intelligent Selection: A Neural Network-Based MAC Protocol-Selection Mechanism for Wireless Ad hoc Networks. In Proceedings of the IEEE 19th International Conference on Communication Technology (ICCT), Xián, China, 16–19 October 2019; pp. 424–429. [Google Scholar]
- Toh, C.K. Wireless ATM and Ad-Hoc Networks: Protocols and Architectures; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2012. [Google Scholar]
- Hu, X.; Liu, S.; Chen, R.; Wang, W.; Wang, C. A Deep Reinforcement Learning-Based Framework for Dynamic Resource Allocation in Multibeam Satellite Systems. IEEE Commun. Lett. 2018, 22, 1612–1615. [Google Scholar] [CrossRef]
- Tilwari, V.; Bani-Bakr, A.; Qamar, F.; Hindia, M.N.; Jayakody, D.N.K.; Hassan, R. Mobility and queue length aware routing approach for network stability and load balancing in MANET. In Proceedings of the 2021 International Conference on Electrical Engineering and Informatics (ICEEI), Kuala Terengganu, Malaysia, 12–13 October 2021; pp. 1–5. [Google Scholar]
- Abbas, T.; Qamar, F.; Hindia, M.N.; Hassan, R.; Ahmed, I.; Aslam, M.I. Performance analysis of ad hoc on-demand distance vector routing protocol for MANET. In Proceedings of the 2020 IEEE Student Conference on Research and Development (SCOReD), Johor, Malaysia, 27–29 September 2020; pp. 194–199. [Google Scholar]
- Ahmadi, H.; Bouallegue, R. Exploiting machine learning strategies and RSSI for localization in wireless sensor networks: A survey. In Proceedings of the 13th International Wireless Communications and Mobile Computing Conference (IWCMC), Valencia, Spain, 26–30 June 2017; pp. 1150–1154. [Google Scholar]
- Bangotra, D.K.; Singh, Y.; Selwal, A. Machine Learning in Wireless Sensor Networks: Challenges and Opportunities. In Proceedings of the Fifth International Conference on Parallel, Distributed and Grid Computing, Solan, India, 20–22 December 2018. [Google Scholar]
- Mastronarde, N.; Modares, J.; Wu, C.; Chakareski, J. Reinforcement Learning for Energy-Efficient Delay-Sensitive CSMA/CA Scheduling. In Proceedings of the IEEE Global Communications Conference (GLOBECOM), Washington, DC, USA, 4–8 December 2016; pp. 1–7. [Google Scholar]
- Khamukhin, A.A.; Bertoldo, S. Spectral analysis of forest fire noise for early detection using wireless sensor networks. In Proceedings of the International Siberian Conference on Control and Communications (SIBCON), Moscow, Russia, 12–14 May 2016; pp. 1–4. [Google Scholar]
- Lu, J.; Huang, D.D. A slotted CSMA based reinforcement learning approach for extending the lifetime of underwater acoustic wireless sensor networks. Comput. Commun. 2013, 36, 1094–1099. [Google Scholar]
- Alhassan, I.B.; Mitchell, P.D. Packet flow based reinforcement learning MAC protocol for underwater acoustic sensor networks. Sensors 2021, 21, 2284. [Google Scholar] [CrossRef] [PubMed]
- Gazi, F.; Ahmed, N.; Misra, S.; Wei, W. Reinforcement Learning-Based MAC Protocol for Underwater Multimedia Sensor Networks. ACM Trans. Sens. Netw. (TOSN) 2022. [Google Scholar] [CrossRef]
- Kassab, R.; Destounis, A.; Tsilimantos, D.; Debbah, M. Multi-agent deep stochastic policy gradient for event based dynamic spectrum access. In Proceedings of the 2020 IEEE 31st Annual International Symposium on Personal, Indoor and Mobile Radio Communications, London, UK, 31 August–3 September 2020; pp. 1–6. [Google Scholar]
- Zhu, J.; Song, Y.; Jiang, D.; Song, H. A new deep-Q-learning-based transmission scheduling mechanism for the cognitive Internet of Things. IEEE Internet Things J. 2017, 5, 2375–2385. [Google Scholar] [CrossRef]
- Tang, F.; Mao, B.; Fadlullah, Z.M.; Kato, N. On a novel deep-learning-based intelligent partially overlapping channel assignment in SDN-IoT. IEEE Commun. Mag. 2018, 56, 80–86. [Google Scholar] [CrossRef]
- Jiang, N.; Deng, Y.; Nallanathan, A.; Chambers, J.A. Reinforcement learning for real-time optimization in NB-IoT networks. IEEE J. Sel. Areas Commun. 2019, 37, 1424–1440. [Google Scholar] [CrossRef] [Green Version]
- Ye, H.; Li, G.Y.; Juang, B.H.F. Deep Reinforcement Learning Based Resource Allocation for V2V Communications. IEEE Trans. Veh. Technol. 2019, 68, 3163–3173. [Google Scholar] [CrossRef] [Green Version]
- Chen, M.; Saad, W.; Yin, C. Liquid state machine learning for resource and cache management in LTE-U unmanned aerial vehicle (UAV) networks. IEEE Trans. Wirel. Commun. 2019, 18, 1504–1517. [Google Scholar] [CrossRef] [Green Version]
- Chen, M.; Wang, T.; Ota, K.; Dong, M.; Zhao, M.; Liu, A. Intelligent resource allocation management for vehicles network: An A3C learning approach. Comput. Commun. 2020, 151, 485–494. [Google Scholar] [CrossRef]
- Hoel, C.J.; Driggs-Campbell, K.; Wolff, K.; Laine, L.; Kochenderfer, M.J. Combining planning and deep reinforcement learning in tactical decision making for autonomous driving. IEEE Trans. Intell. Veh. 2019, 5, 294–305. [Google Scholar] [CrossRef]
- Daknou, E.; Tabbane, N.; Thaalbi, M. A MAC multi-channel scheme based on learning-automata for clustered VANETs. In Proceedings of the 2018 IEEE 32nd International Conference on Advanced Information Networking and Applications (AINA), Krakow, Poland, 16–18 May 2018; pp. 71–78. [Google Scholar]
- Shah, A.S.; Ilhan, H.; Tureli, U. Designing and Analysis of IEEE 802.11 MAC for UAVs Ad Hoc Networks. In Proceedings of the 2019 IEEE 10th Annual Ubiquitous Computing, Electronics & Mobile Communication Conference (UEMCON), New York, NY, USA, 10–12 October 2019; pp. 934–939. [Google Scholar]
- Zheng, Z.; Sangaiah, A.K.; Wang, T. Adaptive Communication Protocols in Flying Ad Hoc Network. IEEE Commun. Mag. 2018, 56, 136–142. [Google Scholar] [CrossRef]
- Rezwan, S.; Choi, W. A survey on applications of reinforcement learning in flying ad-hoc networks. Electronics 2021, 10, 449. [Google Scholar] [CrossRef]
- Karabulut, M.A.; Shah, A.S.; Ilhan, H. A Novel MIMO-OFDM Based MAC Protocol for VANETs. IEEE Trans. Intell. Transp. Syst. 2022, 23, 20255–20267. [Google Scholar] [CrossRef]
- Ding, H.; Zhao, F.; Tian, J.; Li, D.; Zhang, H. A deep reinforcement learning for user association and power control in heterogeneous networks. Ad Hoc Netw. 2020, 102, 102069. [Google Scholar] [CrossRef]
- Zhao, N.; Liang, Y.C.; Niyato, D.; Pei, Y.; Wu, M.; Jiang, Y. Deep Reinforcement Learning for User Association and Resource Allocation in Heterogeneous Cellular Networks. IEEE Trans. Wirel. Commun. 2019, 18, 5141–5152. [Google Scholar] [CrossRef]
- Yu, Y.; Wang, T.; Liew, S.C. Deep-Reinforcement Learning Multiple Access for Heterogeneous Wireless Networks. IEEE J. Sel. Areas Commun. 2019, 37, 1277–1290. [Google Scholar] [CrossRef] [Green Version]
- Zhang, L.; Tan, J.; Liang, Y.C.; Feng, G.; Niyato, D. Deep reinforcement learning-based modulation and coding scheme selection in cognitive heterogeneous networks. IEEE Trans. Wirel. Commun. 2019, 18, 3281–3294. [Google Scholar] [CrossRef] [Green Version]
- Shah, A.S.; Qasim, A.N.; Karabulut, M.A.; Ilhan, H.; Islam, M.B. Survey and performance evaluation of multiple access schemes for next-generation wireless communication systems. IEEE Access 2021, 9, 113428–113442. [Google Scholar] [CrossRef]
- Shah, A.S. A Survey From 1G to 5G Including the Advent of 6G: Architectures, Multiple Access Techniques, and Emerging Technologies. In Proceedings of the 2022 IEEE 12th Annual Computing and Communication Workshop and Conference (CCWC), Virtual, 26–29 January 2022; pp. 1117–1123. [Google Scholar]
- Tang, F.; Mao, B.; Kawamoto, Y.; Kato, N. Survey on Machine Learning for Intelligent End-to-End Communication Toward 6G: From Network Access, Routing to Traffic Control and Streaming Adaption. IEEE Commun. Surv. Tutor. 2021, 23, 1578–1598. [Google Scholar] [CrossRef]
- Kakalou, I.; Papadimitriou, G.I.; Nicopolitidis, P.; Sarigiannidis, P.G.; Obaidat, M.S. A Reinforcement learning-based cognitive MAC protocol. In Proceedings of the IEEE International Conference on Communications (ICC), London, UK, 8–12 June 2015; pp. 5608–5613. [Google Scholar]
- Nisioti, E.; Thomos, N. Robust Coordinated Reinforcement Learning for MAC Design in Sensor Networks. IEEE J. Sel. Areas Commun. 2019, 37, 2211–2224. [Google Scholar] [CrossRef]
- Deshpande, Y.; Ayan, O.; Kellerer, W. Improving AoI via Learning-based Distributed MAC in Wireless Networks. arXiv 2022, arXiv:2202.09222. [Google Scholar]
- Yang, H.; Zhong, W.D.; Chen, C.; Alphones, A.; Xie, X. Deep-reinforcement-learning-based energy-efficient resource management for social and cognitive internet of things. IEEE Internet Things J. 2020, 7, 5677–5689. [Google Scholar] [CrossRef]
- Moon, S.; Ahn, S.; Son, K.; Park, J.; Yi, Y. Neuro-DCF: Design of Wireless MAC via Multi-Agent Reinforcement Learning Approach. In Proceedings of the Twenty-Second International Symposium on Theory, Algorithmic Foundations, and Protocol Design for Mobile Networks and Mobile Computing, Seoul, Republic of Korea, 26–29 July 2021; pp. 141–150. [Google Scholar] [CrossRef]
- Chou, P.Y.; Chen, W.Y.; Wang, C.Y.; Hwang, R.H.; Chen, W.T. Deep Reinforcement Learning for MEC Streaming with Joint User Association and Resource Management. In Proceedings of the ICC 2020—2020 IEEE International Conference on Communications (ICC), Dublin, Ireland, 7–11 June 2020; pp. 1–7. [Google Scholar] [CrossRef]
- Dutta, H.; Biswas, S. Distributed Reinforcement Learning for scalable wireless medium access in IoTs and sensor networks. Comput. Netw. 2022, 202, 108662. [Google Scholar] [CrossRef]
- Wang, S.; Liu, H.; Gomes, P.H.; Krishnamachari, B. Deep reinforcement learning for dynamic multichannel access in wireless networks. IEEE Trans. Cogn. Commun. Netw. 2018, 4, 257–265. [Google Scholar] [CrossRef] [Green Version]
- Li, W.; Zhou, F.; Chowdhury, K.R.; Meleis, W. QTCP: Adaptive congestion control with reinforcement learning. IEEE Trans. Netw. Sci. Eng. 2018, 6, 445–458. [Google Scholar] [CrossRef]
- Zafaruddin, S.M.; Bistritz, I.; Leshem, A.; Niyato, D. Distributed learning for channel allocation over a shared spectrum. IEEE J. Sel. Areas Commun. 2019, 37, 2337–2349. [Google Scholar] [CrossRef] [Green Version]
- Bao, S.; Fujii, T. Q-learning Based p-pesistent CSMA MAC Protcol for Secondary User of Cognitive Radio Networks. In Proceedings of the Third International Conference on Intelligent Networking and Collaborative Systems, Fukuoka, Japan, 30 November–2 December 2011; pp. 336–337. [Google Scholar]
- Nguyen, T.T.; Oh, H. SCSMA: A Smart CSMA/CA Using Blind Learning for Wireless Sensor Networks. IEEE Trans. Ind. Electron. 2020, 67, 10981–10988. [Google Scholar] [CrossRef]
- Nisioti, E.; Thomos, N. Fast Q-learning for Improved Finite Length Performance of Irregular Repetition Slotted ALOHA. IEEE Trans. Cogn. Commun. Netw. 2020, 6, 844–857. [Google Scholar] [CrossRef]
- Liu, Y.; Liu, H.; Fang, H.; Li, P.; Yu, C.; Zhang, H. Enhancement Objective Q-learning MAC for Emergency Transmission. In Proceedings of the 6th International Symposium on Electromagnetic Compatibility (ISEMC), Milan, Italy, 23–27 June 2019; pp. 1–5. [Google Scholar]
- Klaine, P.V.; Imran, M.A.; Onireti, O.; Souza, R.D. A Survey of Machine Learning Techniques Applied to Self-Organizing Cellular Networks. IEEE Commun. Surv. Tutor. 2017, 19, 2392–2431. [Google Scholar] [CrossRef]
- Li, Z.; Guo, C. Multi-agent deep reinforcement learning based spectrum allocation for D2D underlay communications. IEEE Trans. Veh. Technol. 2019, 69, 1828–1840. [Google Scholar] [CrossRef] [Green Version]
- Nakashima, K.; Kamiya, S.; Ohtsu, K.; Yamamoto, K.; Nishio, T.; Morikura, M. Deep reinforcement learning-based channel allocation for wireless lans with graph convolutional networks. IEEE Access 2020, 8, 31823–31834. [Google Scholar] [CrossRef]
- Chen, S.; Chen, J.; Chen, J. A deep reinforcement learning based network management system in smart identifier network. In Proceedings of the 2020 4th International Conference on Digital Signal Processing, Chengdu, China, 19–21 June 2020; pp. 268–273. [Google Scholar]
- Tang, F.; Mao, B.; Fadlullah, Z.M.; Liu, J.; Kato, N. ST-DeLTA: A novel spatial-temporal value network aided deep learning based intelligent network traffic control system. IEEE Trans. Sustain. Comput. 2019, 5, 568–580. [Google Scholar] [CrossRef]
- Mao, Q.; Hu, F.; Hao, Q. Deep Learning for Intelligent Wireless Networks: A Comprehensive Survey. IEEE Commun. Surv. Tutor. 2018, 20, 2595–2621. [Google Scholar] [CrossRef]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Patterson, J.; Gibson, A. Deep Learning: A Practitioner’s Approach; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2017. [Google Scholar]
- Jiang, S. State-of-the-Art Medium Access Control (MAC) Protocols for Underwater Acoustic Networks: A Survey Based on a MAC Reference Model. IEEE Commun. Surv. Tutor. 2017, 20, 96–131. [Google Scholar] [CrossRef]
- Zhang, C.; Patras, P.; Haddadi, H. Deep Learning in Mobile and Wireless Networking: A Survey. IEEE Commun. Surv. Tutor. 2019, 21, 2224–2287. [Google Scholar] [CrossRef] [Green Version]
- Zuriatunadhirah binti Zubir, N.; Ramli, A.F.; Basarudin, H. Optimization of wireless sensor networks MAC protocols using machine learning; a survey. In Proceedings of the 2017 International Conference on Engineering Technology and Technopreneurship (ICE2T), Kuala Lumpur, Malaysia, 18–20 September 2017; pp. 1–5. [Google Scholar] [CrossRef]
- Kherbache, M.; Sobirov, O.; Maimour, M.; Rondeau, E.; Benyahia, A. Reinforcement Learning TDMA-Based MAC Scheduling in the Industrial Internet of Things: A Survey. IFAC-PapersOnLine 2022, 55, 83–88. [Google Scholar] [CrossRef]
- Kulin, M.; Kazaz, T.; De Poorter, E.; Moerman, I. A Survey on Machine Learning-Based Performance Improvement of Wireless Networks: PHY, MAC and Network Layer. Electronics 2021, 10, 318. [Google Scholar] [CrossRef]
- Sun, Y.; Peng, M.; Zhou, Y.; Huang, Y.; Mao, S. Application of Machine Learning in Wireless Networks: Key Techniques and Open Issues. IEEE Commun. Surv. Tutor. 2019, 21, 3072–3108. [Google Scholar] [CrossRef]
- Cao, X.; Yang, B.; Huang, C.; Yuen, C.; Di Renzo, M.; Han, Z.; Niyato, D.; Poor, H.V.; Hanzo, L. AI-Assisted MAC for Reconfigurable Intelligent-Surface-Aided Wireless Networks: Challenges and Opportunities. IEEE Commun. Mag. 2021, 59, 21–27. [Google Scholar] [CrossRef]
- Sharma, H.; Haque, A.; Blaabjerg, F. Machine Learning in Wireless Sensor Networks for Smart Cities: A Survey. Electronics 2021, 10, 1012. [Google Scholar] [CrossRef]
- Bithas, P.S.; Michailidis, E.T.; Nomikos, N.; Vouyioukas, D.; Kanatas, A.G. A Survey on Machine-Learning Techniques for UAV-Based Communications. Sensors 2019, 19, 5170. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Winston, P.H. Artificial Intelligence; Addison-Wesley Longman Publishing Co., Inc.: Upper Saddle River, NJ, USA, 1992. [Google Scholar]
- Xiong, Z.; Zhang, Y.; Niyato, D.; Deng, R.; Wang, P.; Wang, L.C. Deep Reinforcement Learning for Mobile 5G and Beyond: Fundamentals, Applications, and Challenges. IEEE Veh. Technol. Mag. 2019, 14, 44–52. [Google Scholar] [CrossRef]
- Watkins, C.; Dayan, P. Technical Note: Q-learning. Mach. Learn. 1992, 8, 279–292. [Google Scholar] [CrossRef]
- Beletsioti, G.A.; Papadimitriou, G.I.; Nicopolitidis, P.; Varvarigos, E.; Mavridopoulos, S. A Learning-Automata-Based Congestion-Aware Scheme for Energy-Efficient Elastic Optical Networks. IEEE Access 2020, 8, 101978–101992. [Google Scholar] [CrossRef]
- Narendra, K.S.; Thathachar, M.A.L. Learning Automata—A Survey. IEEE Trans. Syst. Man Cybern. 1974, SMC-4, 323–334. [Google Scholar] [CrossRef] [Green Version]
- Li, Y. Deep Reinforcement Learning: An Overview. arXiv 2017, arXiv:1701.07274. [Google Scholar]
- Khan, Z.A.; Samad, A. A Study of Machine Learning in Wireless Sensor Network. Int. J. Comput. Netw. Appl. 2017, 4, 105–112. [Google Scholar] [CrossRef]
- De Rango, F.; Cordeschi, N.; Ritacco, F. Applying Q-learning approach to CSMA Scheme to dynamically tune the contention probability. In Proceedings of the 2021 IEEE 18th Annual Consumer Communications Networking Conference (CCNC), Las Vegas, NV, USA, 9–12 January 2021; pp. 1–4. [Google Scholar] [CrossRef]
- Lee, D.J.; Deng, Y.; Choi, Y.J. Back-off Improvement By Using Q-learning in IEEE 802.11p Vehicular Network. In Proceedings of the 2020 International Conference on Information and Communication Technology Convergence (ICTC), Jeju Island, Republic of Korea, 21–23 October 2020; pp. 1819–1821. [Google Scholar] [CrossRef]
- Chen, Y.W.; Kao, K.C. Study of Contention Window Adjustment for CSMA/CA by Using Machine Learning. In Proceedings of the 2021 22nd Asia-Pacific Network Operations and Management Symposium (APNOMS), Tainan, Taiwan, 8–10 September 2021; pp. 206–209. [Google Scholar] [CrossRef]
- Kim, T.W.; Hwang, G.H. Performance Enhancement of CSMA/CA MAC Protocol Based on Reinforcement Learning. J. Inf. Commun. Converg. Eng. 2021, 19, 1–7. [Google Scholar]
- Ali, R.; Shahin, N.; Zikria, Y.B.; Kim, B.S.; Kim, S.W. Deep reinforcement learning paradigm for performance optimization of channel observation–based MAC protocols in dense WLANs. IEEE Access 2018, 7, 3500–3511. [Google Scholar] [CrossRef]
- Lee, S.; Chung, S.H. Unslotted CSMA/CA mechanism with reinforcement learning of Wi-SUN MAC layer. In Proceedings of the 2022 Thirteenth International Conference on Ubiquitous and Future Networks (ICUFN), Barcelona, Spain, 5–8 July 2022; pp. 202–204. [Google Scholar] [CrossRef]
- Barbosa, P.F.C.; Silva, B.A.d.; Zanchettin, C.; de Moraes, R.M. Energy Consumption Optimization for CSMA/CA Protocol Employing Machine Learning. In Proceedings of the 2020 IEEE 91st Vehicular Technology Conference (VTC2020-Spring), Antwerp, Belgium, 25–28 May 2020; pp. 1–5. [Google Scholar] [CrossRef]
- Zhao, Y.; Hu, J.; Yang, K.; Cui, S. Deep Reinforcement Learning Aided Intelligent Access Control in Energy Harvesting Based WLAN. IEEE Trans. Veh. Technol. 2020, 69, 14078–14082. [Google Scholar] [CrossRef]
- Bayat-Yeganeh, H.; Shah-Mansouri, V.; Kebriaei, H. A multi-state Q-learning based CSMA MAC protocol for wireless networks. Wirel. Netw. 2018, 24, 1251–1264. [Google Scholar] [CrossRef]
- Aboubakar, M.; Roux, P.; Kellil, M.; Bouabdallah, A. An Efficient and Adaptive Configuration of IEEE 802.15.4 MAC for Communication Delay Optimisation. In Proceedings of the 2020 11th International Conference on Network of the Future (NoF), Bordeaux, France, 12–14 October 2020; pp. 1–7. [Google Scholar] [CrossRef]
- Cho, S. Rate adaptation with Q-learning in CSMA/CA wireless networks. J. Inf. Process. Syst. 2020, 16, 1048–1063. [Google Scholar]
- Cho, S. Reinforcement Learning for Rate Adaptation in CSMA/CA Wireless Networks. In Advances in Computer Science and Ubiquitous Computing; Springer: Berlin/Heidelberg, Germany, 2021; pp. 175–181. [Google Scholar]
- Zhang, M.; de Alfaro, L.; Garcia-Luna-Aceves, J. Using reinforcement learning in slotted aloha for ad-hoc networks. In Proceedings of the 23rd International ACM Conference on Modeling, Analysis and Simulation of Wireless and Mobile Systems, Alicante, Spain, 16–20 November 2020; pp. 245–252. [Google Scholar]
- Zhang, L.; Yin, H.; Zhou, Z.; Roy, S.; Sun, Y. Enhancing WiFi Multiple Access Performance with Federated Deep Reinforcement Learning. In Proceedings of the 2020 IEEE 92nd Vehicular Technology Conference (VTC2020-Fall), Virtual, 18 November–16 December 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Mennes, R.; Claeys, M.; De Figueiredo, F.A.P.; Jabandžić, I.; Moerman, I.; Latré, S. Deep Learning-Based Spectrum Prediction Collision Avoidance for Hybrid Wireless Environments. IEEE Access 2019, 7, 45818–45830. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| References | Networking Schemes | Learning Model | Survey Contents | |||
|---|---|---|---|---|---|---|
| RL | DL | DRL | Other | |||
| [56] (2019) | Cellular, ad hoc, cognitive radio networks (CRNs), IoT | ✓ | ✓ | The crossovers between DL models and mobile/wireless networking | ||
| [57] (2017) | WSNs, IoT | ✓ | ✓ | ML algorithms for WSNs. | ||
| [58] (2022) | TDMA, IoT | ✓ | ✓ | RL-based schemes for TDMA-based MAC protocols. | ||
| [59] (2021) | IoT, mobile big data, CRNs, WSNs | ✓ | ✓ | ✓ | RL-based schemes for WNs of three layers: PHY, MAC and network. | |
| [31] (2022) | 1G to 6G | ✓ | Multiple access schemes for next-generation wireless. | |||
| [32] (2021) | WNs | ✓ | ✓ | ✓ | ML-based methods for ensuring end-to-end QoS and QoE. | |
| [60] (2019) | Cellular, WNs | ✓ | ✓ | ML-based schemes for network access, routing for traffic control and streaming adaption in WSNs. | ||
| [61] (2021) | RIS-aided WNs | ✓ | AI-assisted MAC for RIS-aided WNs. | |||
| [62] (2021) | WSN, IoT | ✓ | ✓ | RL-based methods in WSNs for smart city applications. | ||
| [63] (2019) | UAV, WNs | ✓ | ML framework for UAV-based communications. | |||
| This paper | WSNs, IoT, cellular, ad hoc, CRNs, USNs, HetNet, UANs | ✓ | ✓ | ✓ | RL/DRL-based MAC protocols for WNs with a MAC reference model. | |
| Protocols (References) | MAC Components | Network | Algorithm | Data Used for Learning | Performance |
|---|---|---|---|---|---|
| eOQ-MAC [46] (2019) | Superframe (OC) | WNs | Q-learning | Packet loss rate, emergency time slot, throughput | Lowered packet loss rate for emergency data transmission. |
| UA-Slotted CSMA [10] (2013) | Slot (MAU) | UA-WSNs | Q-learning | Lifetime, channel status, energy consumption, bandwidth | Minimized power consumption and extended the life of the network. |
| RL-IRSA [45] (2020) | MAC frame, slot (MAU) | CRNs | Q-learning | Convergence time, channel status, throughput | Significantly reduced convergence time with optimized degree distributions for small frame sizes. |
| DLMA [28] (2019) | Slot (MAU) | HetNet | DRL | Convergence time, throughput | Maximized the total throughput with faster learning speed. |
| Q-CSMA [71] (2021) | Slot (MAU), scheduling (MM) | WNs | Q-learning | Channel status, packet loss rate, delay | Reduced the number of collisions and packet delay. |
| Protocols (References) | MAC Components | Network | Algorithm | Data Used for Learning | Performance |
|---|---|---|---|---|---|
| Distributed rate adaptive CSMA/CA [8] (2016) | Backoff (MM) | WNs | Q-learning | Channel status, CW, energy consumption | Enabled users to reduce energy consumption based on their latency-limited needs with faster convergence. |
| Backoff Improvement [72] (2020) | Backoff (MM) | Vehicular networks | Q-learning | Channel status, transmission success rate | Had a more efficient data exchange process and ensured fairness. |
| CW adjustment scheme [73] (2021) | Backoff (MM) | WNs | Q-learning, supervised learning | CW, throughput | Effectively reduced the collision and improved the system throughput. |
| Performance enhancement CSMA [74] (2021) | Backoff, Scheduling (MM) | WNs | Reinforcement learning | Channel status, energy consumption, traffic load | Had a stable throughput. |
| Channel-observation-based MAC [75] (2018) | Backoff, scheduling (MM) | Dense WLANs | DRL | CW, throughput, channel status | Efficiently predicted the future channel state. |
| QUC [76] (2022) | Backoff (MM) | Wireless smart utility networks | Q-learning | Throughput, delay | The performance of the MAC layer was improved by 20%. |
| Neuro-DCF [37] (2021) | Backoff (MM), Slot(MAU) | WNs | DRL + GNN | Throughput, delay, channel utilization | Reduced the end-to-end delay while preserving optimal utility. |
| AEH-CSMA/CA [78] (2020) | Backoff (MM) (2020) | IoTs | Deep Q-learning | Throughput, CW, energy | Ensured a high throughput and low energy supply. |
| Protocols (References) | MAC Components | Network | Algorithm | Data Used for Learning | Performance |
|---|---|---|---|---|---|
| MCC-MAC [33] (2015) | Scheduling (MM) | CRNs | Q-learning + LA | Network traffic, channel status | Avoided the conflict between SUs and PUs. |
| p-persistent CSMA [43] (2011) | Scheduling (MM) | CRNs | Q-learning | Throughput, channel utilization | Had good robustness and the SU efficiently utilized the available channel at the expense of an extra delay of the PU. |
| Optimal parameters for IEEE 802.15.4 [80] (2020) | Scheduling (MM) | WNs | Supervised learning | MAC parameters, delay, channel status | Increased the dynamic adaptability of nodes. |
| ALOHA-QUPAF [11] (2021) | Scheduling (MM) | UA-WSNs | Modified Q-learning | Throughput, channel status | Isolated the receiving slot from the transmitting slot to avoid collisions. |
| RL-MAC [12] (2022) | Scheduling (MM) | UA-WSNs | Q-learning | Channel traffic, energy consumption | Improved throughput with limited energy. |
| Improved ALOHA-QT [35] (2022) | Scheduling (MM) | WNs | RL + PT | Throughput, AoI, energy consumption | Adapted to the changing number of active agents with less energy. |
| Rate adaptation scheme [81] (2020) | Scheduling (MM) | WNs | Q-learning | MCS channel utilization, bandwidth | Obtained better network throughput. |
| Improved p-persistent CSMA [79] (2018) | Scheduling (MM) | WNs | Multi-state Q-learning | Channel status | Investigated the application of multistate RL algorithm. |
| Protocols (References) | MAC Components | Network | Algorithm | Data Used for Learning | Performance |
|---|---|---|---|---|---|
| SCSMA [44] (2020) | Messaging (MM) | WSNs | Blind learning [44] | SDN, throughput, channel status | Improved throughput, reduced energy consumption and could avoid hidden terminal problems. |
| Distributed ALOHA [39] (2022) | Prioritization (MM) | IoTs | Q-learning | Throughput, channel status | Maintained maximum throughput under dynamic topology loads. |
| ALOHA-dQT [83] (2020) | Messaging (MM) | WNs | Reinforcement learning | Channel history, throughput | Achieved a high channel utilization. |
| PPMAC [23] (2018) | Messaging (MM) | FANET | Q-learning | Channel status, position information | Provided an intelligent and highly adaptive communication solution. |
| SPCA [85] (2019) | Messaging (MM) | WSNs | DRL | Spectrograms of TDMA, channel utilization | Reduced the number of collisions with efficient channel utilization. |
| MAC Components | Open Research Issues |
|---|---|
| Operation cycle | Variable large frames and superframes Smart frame allocation algorithms |
| Medium access unit | Channel allocation in multichannel Adaptively adjust the guard slot |
| MAC mechanism | Optimize MMs’ parameters Choose MMs reasonably |
| Other issues | Network prediction standardization and model accuracy Resource allocation and task scheduling Systematical cross-layer design Fully consider the features of UANs |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zheng, Z.; Jiang, S.; Feng, R.; Ge, L.; Gu, C. Survey of Reinforcement-Learning-Based MAC Protocols for Wireless Ad Hoc Networks with a MAC Reference Model. Entropy 2023, 25, 101. https://doi.org/10.3390/e25010101
Zheng Z, Jiang S, Feng R, Ge L, Gu C. Survey of Reinforcement-Learning-Based MAC Protocols for Wireless Ad Hoc Networks with a MAC Reference Model. Entropy. 2023; 25(1):101. https://doi.org/10.3390/e25010101
Chicago/Turabian StyleZheng, Zhichao, Shengming Jiang, Ruoyu Feng, Lige Ge, and Chongchong Gu. 2023. "Survey of Reinforcement-Learning-Based MAC Protocols for Wireless Ad Hoc Networks with a MAC Reference Model" Entropy 25, no. 1: 101. https://doi.org/10.3390/e25010101
APA StyleZheng, Z., Jiang, S., Feng, R., Ge, L., & Gu, C. (2023). Survey of Reinforcement-Learning-Based MAC Protocols for Wireless Ad Hoc Networks with a MAC Reference Model. Entropy, 25(1), 101. https://doi.org/10.3390/e25010101