1. Introduction
The mutual information between two random variables
X and
Y is often conveniently described using a diagram like this:

where the whole rectangle represents the entropy
of the joint variable
. This is, in general, less than the sum of
and
because
X and
Y are not independent. In this diagram, the purple and green regions together are intended to represent
, and the green and yellow regions are intended to represent
. The purple region on its own represents
: the entropy remaining, on average, when the value of
Y is known. In the same way, the yellow region represents
. Now, the mutual information is represented by the green section:

It is
or, by substitution,
Here, for illustrative purposes, mutual information is described relative to a specific example: the neural response of cells in the zebra finch auditory pathway to zebra finch songs. This is both an interesting neuroscientific example and an example which is typical of a broad set of neuroscience problems.
The zebra finch is a model animal used to study both auditory processing and learning; the male finch sings, and he has a single song which begins with a series of introductory notes, followed by two or three repetitions of the motif: a series of complex frequency stacks known as syllables, separated by pauses. Syllables are about 50 ms long, with songs lasting about two seconds. The songs have a very rich structure, and both male and female zebra finches can distinguish one zebra finch song from another.
Here, we use a data set consisting of spike trains recorded while the bird is listening to a set of songs, and we provide an estimate for the mutual information between the song identity and spike trains recorded from cells in the auditory pathway. This is an interesting and non-trivial problem. Generally, calculating mutual information is costly in terms of data because it requires the estimation of probabilities such as and . For this reason, some measure of correlation is often used when quantifying the relationship between two random variables. However, not all data types have a correlation: calculating the correlation assumes algebraic properties of the data that are not universal. As an example, calculating the correlation between X and Y requires the calculation of , which in turn assumes that it makes sense to multiply the x and y values. This is not the case for the typical neuroscience example considered here, where the set of outcomes for X is the song identities and that for Y is the spike trains. To circumvent this, spike trains are often replaced with something else, spike counts for example. However, this involves an implicit assumption about how information is coded. This is likely to be inappropriate in many cases. Indeed, the approach taken to calculating mutual information can involve making very strong assumptions about information coding, the very thing that is being studied.
The purpose of this review paper is to demonstrate a different approach: there is a metric-space version of the Kozachenko–Leonenko estimator [
1,
2] introduced in [
3,
4,
5] and inspired by [
6]. This approach has been tested on simulated data, for example in [
5], and this shows it to be promising. However, it is important to also test it on real data. Here, it is applied in the zebra finch example.
2. Materials and Methods
Let
be a data set. In our case, the
are the labels for songs in the set of stimuli, with each
;
is the number of different songs. For a given trial,
is the spiking response. This will be a point in “the space of spike trains”. What exactly is meant by the space of spike trains is less clear, but for our purposes here, the important point is that this can be regarded as a metric space, with a metric that gives a distance between any two spike trains; see [
7,
8], or, for a review, [
9].
Given the data, the mutual information is estimated by
where the particular choice of which conditional probability to use,
rather than
, has been made for later convenience. Thus, the problem of estimating mutual information is one of estimating the probability mass functions
and
at the data points in
. In our example, there is no challenge to estimating
, since each song is presented an equal number of times during the experiment
for all
and, in general
is known from the experiment design. However, estimating
and
is more difficult.
In a Kozachenko–Leonenko approach, this is performed by first noting that for a small volume
containing the point
,
with the estimate becoming more and more exact for smaller regions
. If the volume of
were reduced towards zero,
would be constant in the resulting tiny region. Here,
denotes the volume of
. Now, the integral
is just the probability mass contained in
and so it is approximated by the number of points in
that are in
:
It should be noted at this point that this approximation becomes more and more exact as
becomes bigger. Using the notation
this means
This formula provides an estimate for
provided that a strategy is given for choosing the small regions
around each point
. As will be seen, a similar formula can be derived for
, essentially by restricting the points to
:
where
is the number of points in
with label
and
is the total number of points with label
. In the example here,
. Once the probability mass functions are estimated, it is easy to estimate the mutual information. However, there is a problem: the estimates also require the volume of
. In general, a metric space does not have a volume measure. Furthermore while many everyday metric spaces also have coordinates providing a volume measure, this measure it not always appropriate since the coordinates are not related to the way the data are distributed. However, the space that the
’s belong to is not simply a metric space, it is also a space with a probability density,
. This provides a measure of volume:
In short, the volume of a region can be measured as the amount of probability mass it contains. This is useful because this quantity can in turn be estimated from data, as before, by counting points:
The problem with this, though, is that it gives a trivial estimate of the probability. Substituting back into the estimate for
, Equation (
8) gives
for all points
. This is not as surprising as it might at first seem. Probability density is a volume-measure dependent quantity; that is what is meant by calling it a density and is the reason that entropy is not well defined on continuous spaces. There is always a choice of coordinate that trivializes the density.
However, it is not the entropy that is being estimated here. It is the mutual information and this is well defined: its value does not change when the volume measure is changed. The mutual information uses more than one of the probability densities on the space; in addition to , it involves the conditional probabilities . Using the measure defined by does not make these conditional probability densities trivial. The idea behind the metric space estimator is to use to estimate volumes. This trivializes the estimates for , but it does allow us to estimate and use this to calculate an estimate of the mutual information.
In this way, the volume of
is estimated from the probability that a data point is in
, and this, in turn, is estimated by counting points. Thus, to fix the volume
, a number
h of data points is specified, and for each point, the
nearest data points are identified, giving
h points in all when the “seed point” is included. This is equivalent to expanding a ball around
until it has an estimated volume of
. This defines the small region
. The conditional probability is then estimated by counting how many points in
are points with label
, that is, are points in
. In fact, this just means counting how many of the
h points that have been identified are in
, or, put another way, it means counting how many of the
nearest points to the original seed point are from the same stimulus as the seed point. In summary, the small region consists of
h points. To estimate
, the number of points in the small region corresponding to label
is counted; this is referred to as
so
This is substituted into the formula for the density estimator, Equation (
6), to obtain
where, as before,
is the total number of trials for each song. It is assumed that each song is presented the same number of times. It would be easy to change this to allow for different numbers of trials for each song, but this assumption is maintained here for notational convenience. Substituting back into the formula for the estimated mutual information, Equation (
4) gives
The calculation of
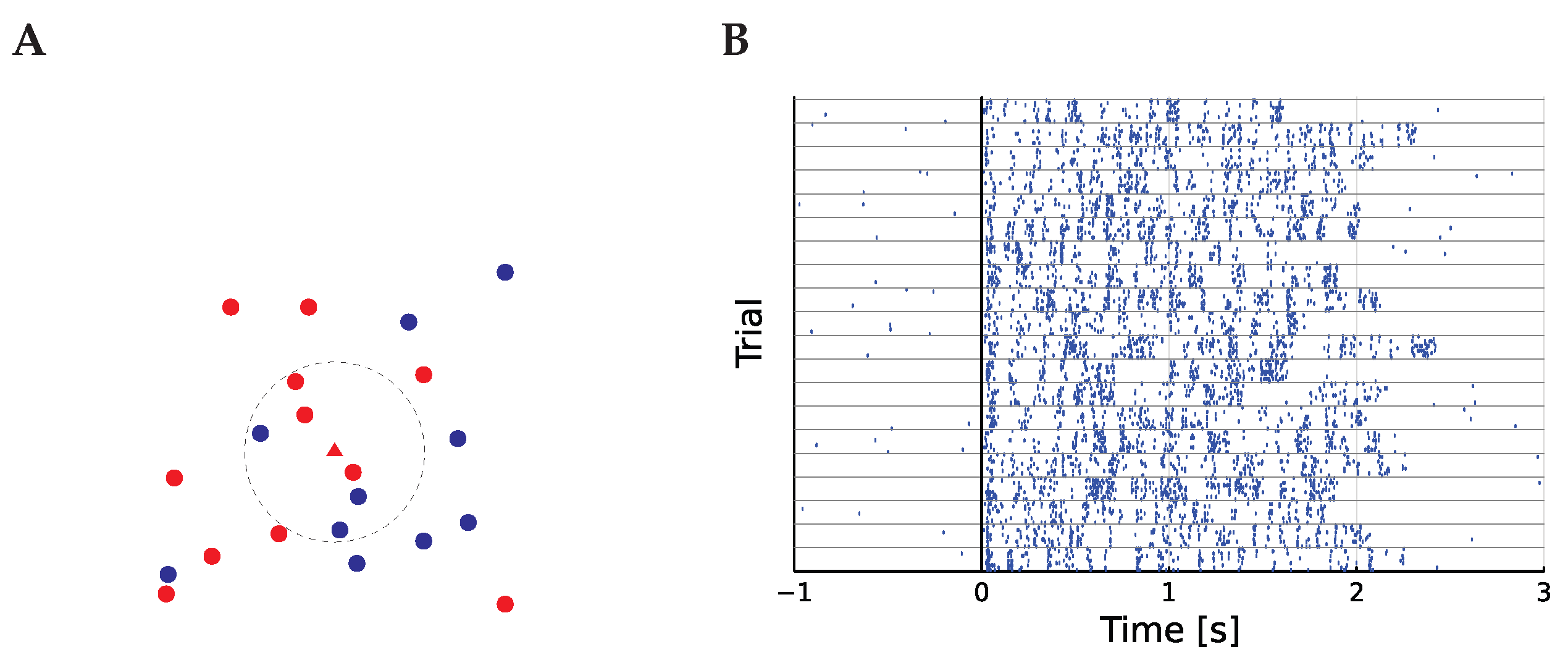
is illustrated in
Figure 1. The subscript zero has been added in order to preserve the unadorned
I for the information itself and
for the de-biased version of the estimator; this is discussed below.
This estimate is biased, and it gives a non-zero value even if
X and
Y are independent. This is a common problem with estimators of mutual information. One advantage of the Kozachenko–Leonenko estimator described here is that the bias at zero mutual information can be calculated exactly. Basically, for the estimator to give a value of zero
would be required for every
i. In fact, while this is the expected value if
X and
Y are independent,
has a probability distribution which can be calculated as a sort of an urn problem. As detailed in [
10], performing this calculation gives the de-biased estimator:
where
, the bias, is
and
u is the probability for the hypergeometric distribution using the parameterization used by the distributions.jl Julia library.
Obviously, the estimator relies on the choice of smoothing parameter h. Recall that for a small h, the counting estimates for the number of points in the small region and for the volume of the small regions are noisy. For a large h, the assumption that the probability density is constant in the small region is poor. These two countervailing points of approximation affect and differently. It seems that a good strategy in picking h for real data is to maximize over h. This is the approach that will be adopted here.
As an example, we will use a data set recorded from zebra finches and made available on the Collaborative Research in Computational Neuroscience data sharing website [
11]. This data set contains a large number of recordings from neurons in different parts of the zebra finch auditory pathway. The original analysis of these data are described in [
12,
13]. The data set includes different auditory stimuli; here, though only the responses to zebra finch song are considered. There are 20 songs, so
, and each song is presented ten times,
, giving
. The zebra finch auditory pathway is complex and certainly does not follow a single track, but for our purposes, it looks like
where CN is the cochlear nuclei; MLd is the mesencephalicus lateralis pars dorsalis, analogous to mammalian inferior colliculus; OV is the nucleus ovoidalis; Field L is the primary auditory pallium, analogous to mammalian A1; and, finally, HVc is regarded as the locus of song recognition. The mapping of the auditory pathway and our current understanding of how to best associate features of this pathway to features of the mammalian brain is derived from, for example [
13,
14,
15,
16,
17].
In the data set, there are 49 cells from each of MLd and Field L, and here, the entropy is calculated for all 98 of these cells.
3. Results
Our interest in considering the mutual information for bird songs was to check whether the early part of the spike train was more informative about the song identity. It seemed possible that the amount of information later in the spike train would be less than in the earlier portion. This does not seem to be the case.
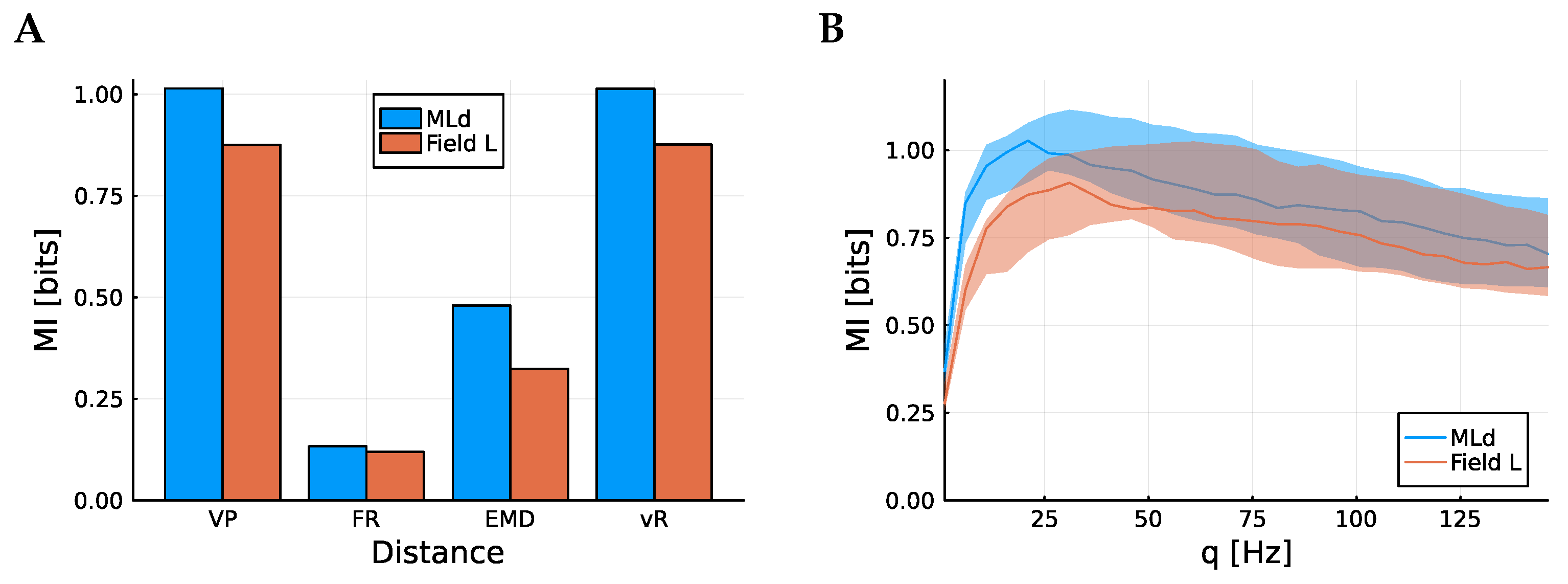
There are a number of spike train metrics than could be used. Although these differ markedly in the mechanics of how they calculate a distance, it does appear that the more successful among them are equally good at capturing the information content. In
Figure 2A, the total mutual information between song identity and spike train is plotted. Here, the Victor–Purpura (VP) metric [
7], the spike count, the Earth mover distance (EMD) [
18], and the van Rossum metric [
8] are considered. The Victor–Purpura metric and van Rossum metric both include a parameter which can be tuned, roughly corresponding to the precision of spike timing. Here, the optimal value for each case has been used, chosen to maximize the average information. These values are
Hz for the VP metric and
ms for the vR metric. The mutual information estimator uses the metric to order the points, and each small region contains the
points nearest the seed point so the estimator does not depend on the distances themselves, just the order. Indeed, the estimated mutual information is not very sensitive to the choice of
q or
. This is demonstrated in
Figure 2B, where the mutual information is calculated as a function of
q, the parameter for the VP metric.
The Victor–Purpura metric and van Rossum metric clearly have the highest mutual information and are very similar to each other. This indicates that the estimator is not sensitive to the choice of metric, provided the metric is one that can capture features of the spike timing as well as the overall rate. The spike count does a poor job, again indicating that there is information contained in spike timing as well as the firing rate. Similar results were seen in [
9,
19], though a different approach to evaluating the performance of the metrics was used there.
The cells from MLd have higher mutual information, on average, than the cells from Field L. Since Field L is further removed from the auditory nerve than MLd, this is to be expected from the information processing inequality. This inequality stipulates that away from the source of information, information can only be lost, not created.
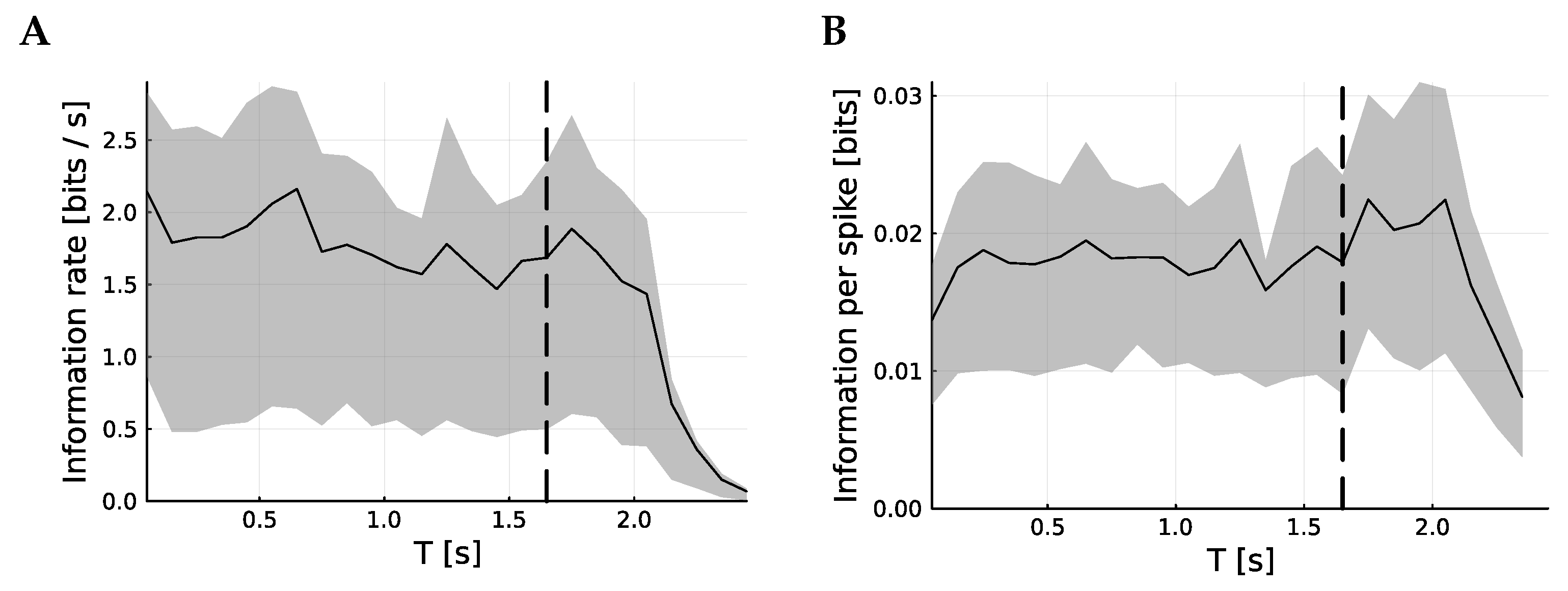
In
Figure 3, the information content of the spike trains as a function of time is considered. To achieve this, the spike trains are sliced into 100 ms slices and the information is calculated for each slice. The songs have variable lengths, so the mutual information becomes harder to interpret after the end of the shortest song, marked by a dashed line. Nonetheless, it is clear that the rate of information and the information per spike are largely unchanged through the song.


{kind=link}
{kind=link}
{kind=link}
 where the whole rectangle represents the entropy of the joint variable . This is, in general, less than the sum of and because X and Y are not independent. In this diagram, the purple and green regions together are intended to represent , and the green and yellow regions are intended to represent . The purple region on its own represents : the entropy remaining, on average, when the value of Y is known. In the same way, the yellow region represents . Now, the mutual information is represented by the green section:
where the whole rectangle represents the entropy of the joint variable . This is, in general, less than the sum of and because X and Y are not independent. In this diagram, the purple and green regions together are intended to represent , and the green and yellow regions are intended to represent . The purple region on its own represents : the entropy remaining, on average, when the value of Y is known. In the same way, the yellow region represents . Now, the mutual information is represented by the green section:


