Abstract
This article delves into the complex world of quantum games in multi-agent settings, proposing a model wherein agents utilize gradient-based strategies to optimize local rewards. A learning model is introduced to focus on the learning efficacy of agents in various games and the impact of quantum circuit noise on the performance of the algorithm. The research uncovers a non-trivial relationship between quantum circuit noise and algorithm performance. While generally an increase in quantum noise leads to performance decline, we show that low noise can unexpectedly enhance performance in games with large numbers of agents under some specific circumstances. This insight not only bears theoretical interest, but also might have practical implications given the inherent limitations of contemporary noisy intermediate-scale quantum (NISQ) computers. The results presented in this paper offer new perspectives on quantum games and enrich our understanding of the interplay between multi-agent learning and quantum computation. Both challenges and opportunities are highlighted, suggesting promising directions for future research in the intersection of quantum computing, game theory and reinforcement learning.
1. Introduction
As the vanguard of computational theory and machine learning increasingly intersects with the intricacies of quantum mechanics, a profound shift in our understanding of complex systems is emerging. At this crossroads lies the study of quantum games and multi-agent learning, a field poised to revolutionize myriad sectors through the marriage of quantum computing, game theory and reinforcement learning. This research elucidates this profound transformation by delving into the intricate dynamics of quantum games involving multiple learning agents.
Game theory, a cornerstone of modern economics and numerous branches of social sciences, provides an insightful mathematical framework for analyzing strategic scenarios and deciphering decision-making complexities in interactive situations. The framework of game theory, first articulated by von Neumann and Morgenstern [1], has become a wide array of applications, from conflict resolution to artificial intelligence. However, when quantum effects are incorporated, an even more fascinating framework emerges, quantum game theory. Quantum games, a generalization of classical games [2,3], offer a richer strategy space and more diverse outcomes due to quantum superposition and entanglement, allowing significant advantages over their classical counterparts. Quantum effects facilitate novel strategic behaviors that enable players to coordinate their strategies in unprecedented ways. These benefits have not gone unnoticed and there have been successful experimental realizations of Quantum Games [4,5], further highlighting their potential.
It is critical to emphasize that Nash proved [6] that all classical games with a finite set of strategies have a Nash equilibrium. This equilibrium represents a collection of strategies, one for each player, in which no player can enhance their outcome by independently altering their strategy. This also extends to an -approximate Nash equilibrium, in which no player can improve their outcome by more than through a unilateral change of their strategy. Similarly, it has been demonstrated that a Nash equilibrium will always exist in any quantum game [7], despite the fact that the set of strategies is no longer finite. It has also been proven that finding Nash equilibria in classical games is PPAD-complete and that finding -approximate Nash equilibria in both classical and quantum games is also in PPAD [8]. This means that there are no efficient (polynomial) algorithms for solving these problems. As a result, there is significant interest in designing heuristic algorithms that can find equilibria in these scenarios.
Meanwhile, Multi-Agent Reinforcement Learning (MARL) is a field concerned with how autonomous agents can learn and adapt to their environment to optimize their collective behavior. MARL, paired with game theory, has driven advances in autonomous driving [9], drone field coverage [10] and smart grid optimization [11]. Simultaneously, quantum game theory has begun to produce rich applications, including communications, where it has been applied to address issues of spectrum scarcity [12] and congestion in data networks [13] and economics, with quantum market games [14] and monetary economics benefiting [15], heralding a new era of quantum-enhanced solutions.
Recent articles have ventured into Quantum Machine Learning [16] and Quantum Reinforcement Learning [17,18,19] and, more related to our work, Quantum Multi-Agent Reinforcement Learning using Simulated Quantum Annealing [20], Quantum Botzmann Machines [21] and Variational Quantum Circuits [22]. However, the focus predominantly remains on quantum agents interacting within a classical environment. Although these models are highly valuable and can achieve good generalization with limited training data [23], they do not consider the challenges and opportunities posed by quantum environments.
The present discussion deviates from this more common route, probing the behavior of classical agents within quantum games. There are precedents that examine classical multi-agent learning within quantum games. Ref. [24] presents the evolution of quantum agents in a two-dimensional lattice, emphasizing their advantage over classical agents. The study is restricted to scenarios with three to five agents due to the lattice structure, limiting on three quantum gates from the whole SU(2) space as strategies in the Prisoner’s Dilemma and two specific quantum strategies in the Parrondo Paradox. Refs. [25,26] further explore quantum games in a two-dimensional lattice with cellular automata interactions, analyzing the prisoners’ dilemma and Battle of the Sexes, respectively. These studies allow players to use the complete set of strategies within the SU(2) space, but focusing only on two-player games. Ref. [26] also provides an in-depth analysis of the Battle of the Sexes game with incomplete information, addressing the uncertainties players have about the intentions of others. Ref. [27] investigates multi-agent quantum games’ dynamics, studying the evolution of agents in the Prisoner’s Dilemma, Snowdrift and Stag-Hunt games on evolving random networks. The analysis highlights the transitions between strategies in multi-agent games on evolving networks, providing insights into strategy dominance in various game scenarios but limiting games to two-player scenarios and each agent’s strategy space to only four possible quantum strategies (C, D, H, Q) from the SU(2) space. Finally, ref. [28] introduces a novel method for learning and visualizing strategies in quantum games. The authors propose a decentralized learning algorithm for two players, unaware of the game’s payoff matrix and the actions and rewards of the competitors. The study explores the impact of entanglement and noise on various quantum games’ performance. The algorithm allows agents to learn from the complete SU(2) space, even allowing for mixed strategies. Our work differs from the previous ones since it presents a gradient-based (versus gradient-free methods) algorithm applicable to general-sum quantum games that involve any number of players, which can select quantum strategies from the complete SU(2) space.
The core of our study introduces an algorithm in which agents selfishly and independently utilize the Adam algorithm [29] to adjust their actions, a trio of continuous real values. This policy-based and gradient-descent approach provides flexibility by allowing agents to directly learn actions from rewards, ensures continuous policy improvements and results in locally optimized strategies. Our results reveal the remarkable efficacy of this algorithm across various game configurations, including games involving two to five players, which could also be extended to N players. The learning agents display proficient adaptation and, notably, are able to easily and methodically highlight when the performance of agents playing in quantum games surpasses that in their classical counterparts.
In addition to exploring the learning dynamics in quantum games, this work delves into the effects of quantum noise on algorithm performance. Contrary to the common belief that quantum noise is often regarded as a performance impediment [30], our analysis presents an intriguing finding: under certain conditions, a slight amount of quantum noise can actually improve performance. Such a counterintuitive phenomenon is particularly relevant in the era of Noisy Intermediate-Scale Quantum (NISQ) computers [31], where noise is considered a fundamental part of the system.
The findings of this work enhance our understanding of quantum game dynamics and open avenues for practical applications. The successful performance of the quantum game learning algorithm and its uncovering of the counterintuitive potential of quantum noise to enhance system performance provide meaningful contributions to quantum computing, strategic decision-making and machine learning. By enabling more accurate modeling of complex interactions and improved optimization strategies, this research brings us a step closer to realizing the vast potential of quantum computing in real-world scenarios.
The remainder of this paper is organized as follows. Section 2 provides a detailed discussion of quantum games and the proposed multi-agent learning model. Section 3 develops the application of the algorithm across various game configurations and compares its performance with classical games. Section 4 explores the intriguing effects of quantum noise on the algorithm’s performance. Finally, Section 5 provides a comprehensive analysis of the insights obtained from the study and its potential applications.
2. Description of the Model
2.1. Classical and Quantum Games
The goal of game theory is to analyze decision-making systems involving two or more players cooperating or not with each other. An important feature in games is that the reward one player receives depends not only on the strategy she chooses, but also on other player strategies. It is well known that a game is defined by three elements: players, strategies and rewards. This work is based on N players’ games with two pure strategies each. The rewards are defined by a -row (one for each combination of joint actions) payoff matrix where each row has N columns (one for each player), each column representing the reward for each player given a combination of the joint action. In Table 1, it is possible to observe a general representation of a two-player two-strategy payoff matrix where A0 and A1 are the strategies of player A; B0 and B1 are the strategies of player B; Ra1, Ra2, Ra3 and Ra4 are the rewards of player A; Rb1, Rb2, Rb3 and Rb4 are the rewards of player B. Consequently, a general payoff matrix for three and four players can be found in Table 2 and Table 3, respectively.

Table 1.
General payoff matrix for 2 players and 2 strategies.
Table 2.
General payoff matrix for 3 players and 2 strategies.
Table 3.
General payoff matrix for 4 players and 2 strategies.
The following N-player two-strategy games are considered throughout the article: the minority problem [32], which rewards agents who select a strategy that was selected by 50% of players or less. The platonia dilemma [33], which rewards a player if she chooses strategy 1 and all other agents choose 0. The unscrupulous dilemma [34], which is an N-player extension of the well-known prisoners’ dilemma. Finally, the volunteers’ dilemma [35], which is an N-player extension of the famous chicken game. All these games will be further expanded on in Section 3. A three-player payoff matrix of these games will be shown as an example even though they are all extendable to N players: the minority problem in Table 4, the platonia dilemma in Table 5, the unscrupulous dilemma in Table 6 and the volunteers’ dilemma in Table 7.
Table 4.
Minority game payoff matrix for 3 players.
Table 5.
Platonia dilemma payoff matrix for 3 players.
Table 6.
Unscrupulous dilemma payoff matrix for 3 players.
Table 7.
Volunteers’ dilemma payoff matrix for 3 players.
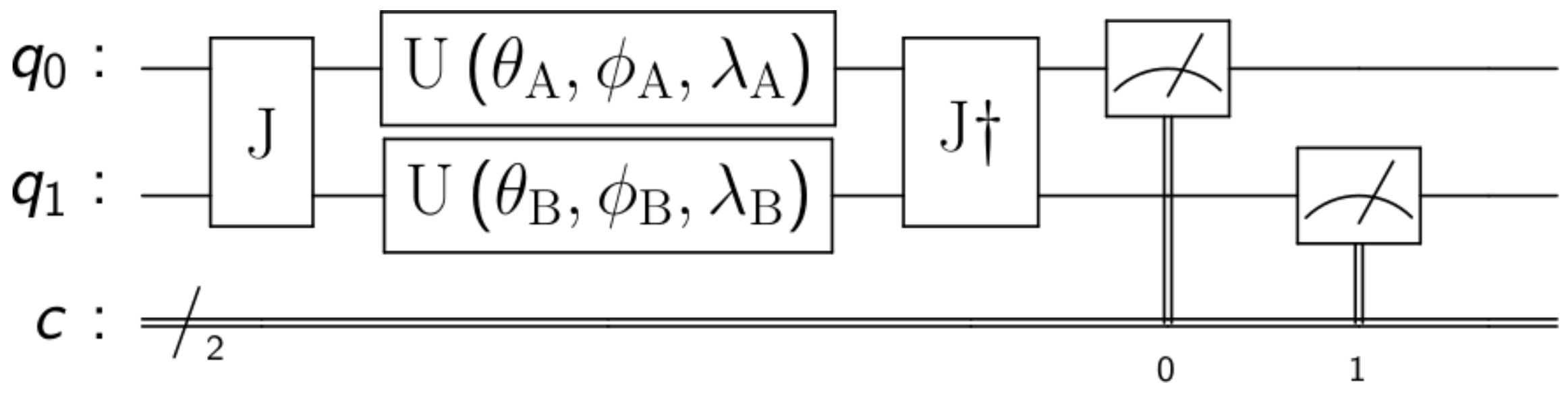
To model quantum games, we followed the EWL [2] protocol for two players and then extended it to N players in [3]. The first step involves assigning a quantum state to each of the possible strategies. In the case of two strategies, for example, in the prisoners’ dilemma, cooperate → and defect→. The second step is to create a quantum circuit where each player is assigned a qubit that starts in state . The third step is to create an entangled state between all players. This is done by applying the entangling operator , as seen in Figure 1 for N = 2 players, where is the identity matrix, the Pauli X-gate, N represents the number of players and a value that determines the amount of entanglement, being not entanglement at all (classical games) and maximum entanglement (fully quantum games).
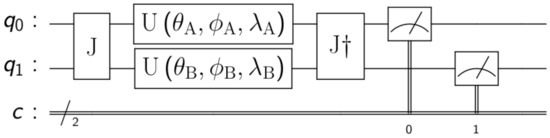
Figure 1.
EWL game model for 2 players. Where and are the initial quantum states of the players and c is a classical register where the qubit measurements are stored.
In the fourth step, every player chooses her most suitable strategy individually and independently. This is done by modifying the state of her own qubit locally. To do this, every player applies one or more one-qubit gates, modifying the state of her qubit. A general one-qubit gate [36] is a unitary matrix that can be represented as:
We can already highlight the fact that while classic players are limited to only two pure strategies (e.g., cooperate or defect), quantum players can choose among an infinite number of pure strategies, that is, any combination of real value for the three parameters , and . The fifth step is to apply the operator (J conjugate transpose) after the strategies of the players. Finally, the sixth step consists of measuring the state of the qubits to read the classical outputs of the circuit and, therefore, the final action of each player. The readouts are used as inputs of the pay-off matrix to determine the players’ rewards.
One last thing to add is the fact that we are going to replace the three-parameter general one-qubit gate with three one-parameter rotation one-qubit gates , with and . This is possible without losing generality since [36]. Having said that, the circuit from Figure 1 becomes the one from Figure 2.

Figure 2.
EWL game model for 2 players with rotation gates.
2.2. Learning Algorithm
In this section, the algorithm employed by the agents for learning optimal actions in the quantum games previously presented is elucidated. The algorithm operates on a decentralized basis, with each player solely attempting to maximize their own long-term reward. Although players do not share any information with their opponents about the game they are engaged in or the rewards they receive, they have to share their actions with other participants.
Before delving into the algorithmic description, it is important to define a few crucial concepts. First, each player’s strategy is represented as the matrix product of three parameter-dependent (actions) quantum rotation gates: . Second, the joint strategy of all players is represented as the Kronecker tensor product of all individual players’ actions. For the case of two players A and B, this is expressed as . This formalism allows the encapsulation of the collective strategies of players in the quantum game.
The output quantum state of the quantum circuit is then computed as . Lastly, the probability of each possible classical state being measured at the end of the quantum circuit is determined by the Born rule . This equation directly relates the actions of the players with the probabilistic outcomes of the quantum game. All these concepts are readily extensible to a general case involving N players.
All N-player games with two actions, as mentioned above, can be represented by a matrix of rows and N columns. Each row corresponds to a specific combination of actions chosen by the players, while each column represents the reward received by each player. This matrix representation serves as a succinct summary of all rewards assigned in the game for every possible combination of actions. As an illustrative example, a generic two-player game with two actions can be represented by the following matrix, where the pairs denote the reward combinations for player A and player B in response to their possible actions, respectively, .
Using the previously defined concepts, a reward vector can be computed. This is achieved by multiplying the output state probability vector by the game matrix. The mathematical representation of this operation is given by . In this calculation, the first row of the resulting vector represents the reward assigned to Player A: . This is a weighted sum of rewards for Player A, with weights corresponding to the probabilities of the respective states. Similarly, the second row corresponds to the reward for Player B: . Thus, the proposed framework allows for a clear determination of the expected rewards for each player given their actions.
It is now possible to outline the model-free policy-based algorithm employed by the players to update their strategies based on the rewards received in each iteration. Here, the term policy refers to a function used by the agent to select actions given the current reward received [37]. Every player starts with a randomly selected set of actions and utilizes the Adam algorithm [29], a prominent gradient-based optimization method in the machine learning domain, which adaptively adjusts the learning rates for the actions. However, before proceeding further, a critical aspect needs to be defined: the method by which each player calculates the gradient of the reward function with respect to its actions. The agent estimates the value of the gradient by recalculating its own reward but modifying one of their own actions by a small difference of . For instance, Player A, possessing information about the ongoing game and the actions taken by other players, can calculate the gradient with respect to each of their actions in the following manner:
Upon calculation of the gradients, the players’ actions could be directly adjusted in the direction of increasing rewards using stochastic gradient ascent (SGD) straightforwardly as in (2), where is the learning rate, that is, the speed at which a model adjusts to new feedback. Agents could also incorporate a moving average of the last gradients in order to take bigger steps on flatter areas and smaller steps in steeper areas, as in RMSProp.
However, the Adam algorithm surpasses vanilla SGD and RMSProp by offering adaptive learning rates that adjust for each action individually to navigate the reward function, employing moving averages (as RMSProp), but also incorporates the calculation of moment estimation. Although it needs additional computations, which are defined next:
where determines the step size at each iteration. is a very small number to prevent any division by zero. is used for the exponentially decaying average of past gradients. is used for the exponentially decaying average of past squared gradients. Finally, m is an estimate of the first moment (the mean) of the gradients and v is an estimate of the second moment (the uncentered variance) of the gradients. For further information on the Adam algorithm, please refer to the bibliography [29].
The gradient calculation method and the Adam algorithm both involve various hyperparameters. These values have been meticulously studied, resulting in the identification of an optimal set of values. These optimal values are adopted for the remainder of the article, ensuring consistency and optimal results in subsequent analyses and discussions.
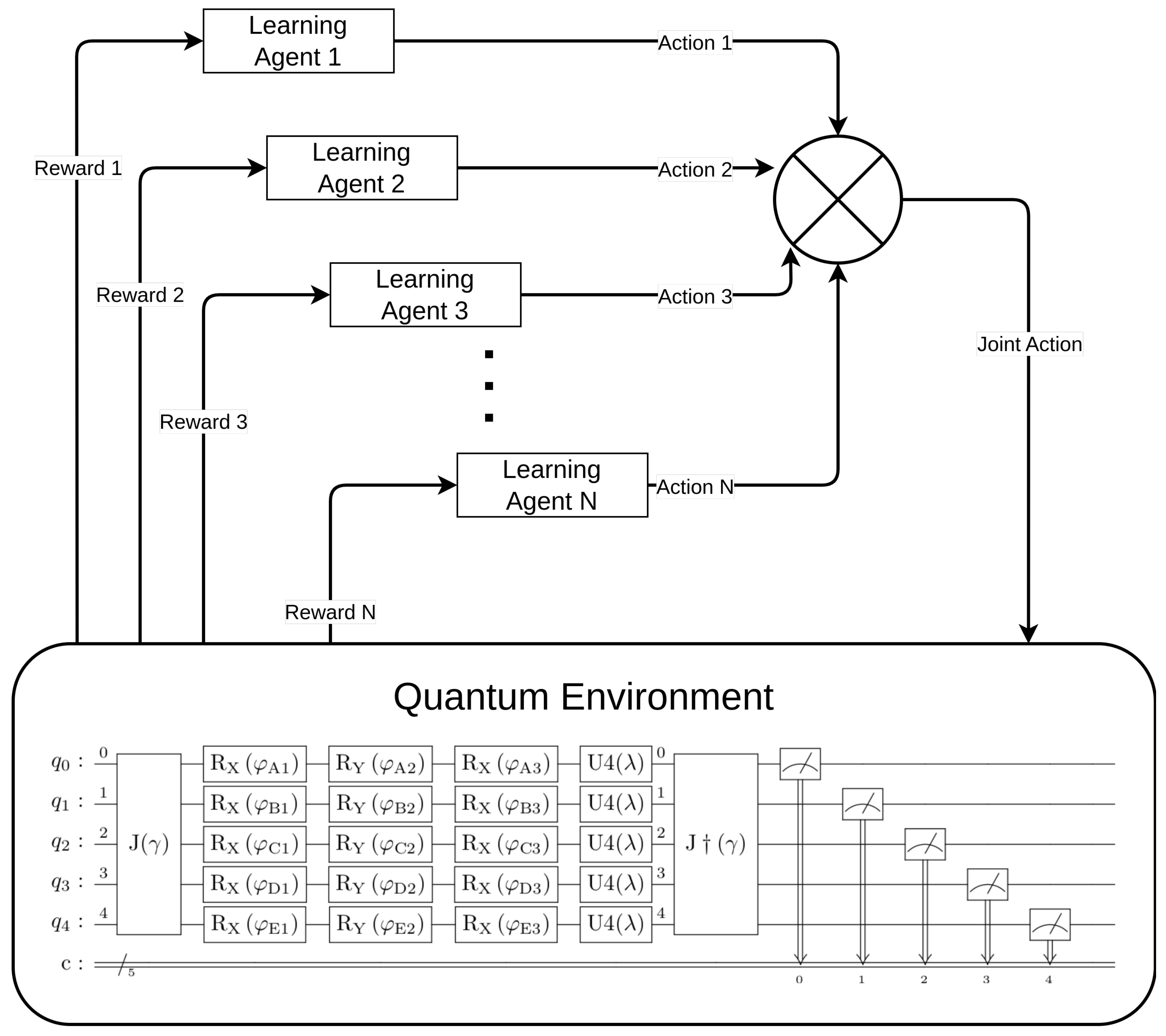
Finally, a block diagram depicting the comprehensive system that includes both the learning agents and the quantum game environment can be found in Figure 3.
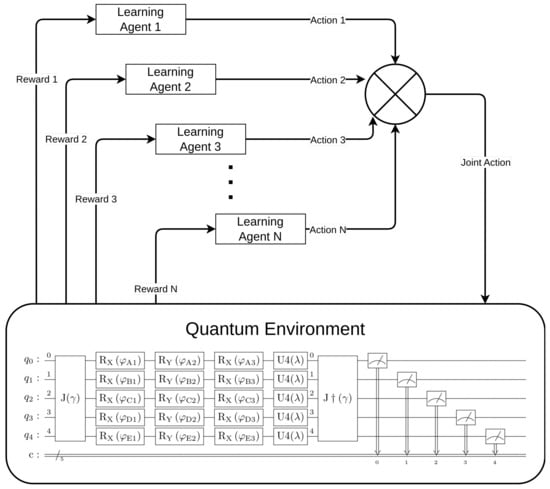
Figure 3.
Complete model of the system: agents learning + quantum environment.
3. Results
This section presents the results obtained from applying the previously described algorithm to the general-sum games mentioned earlier. Graphical representations of the rewards for each player over 1,000,000 iterations are provided for two scenarios:
- Games without entanglement, achieved with a value of in the operator J. This scenario corresponds to the classical version of the game.
- Games with entanglement, achieved with a value of in the operator J, which corresponds to the fully quantum version of the game.
The outcomes are presented in this way to verify the algorithm’s proper functionality—the classical scenario should behave as expected—and to compare the dynamics and performance of the players between the classical and quantum cases. This comparison can reveal any noteworthy shifts in behavior or strategy that emerge in the transition from a classical to a quantum framework.
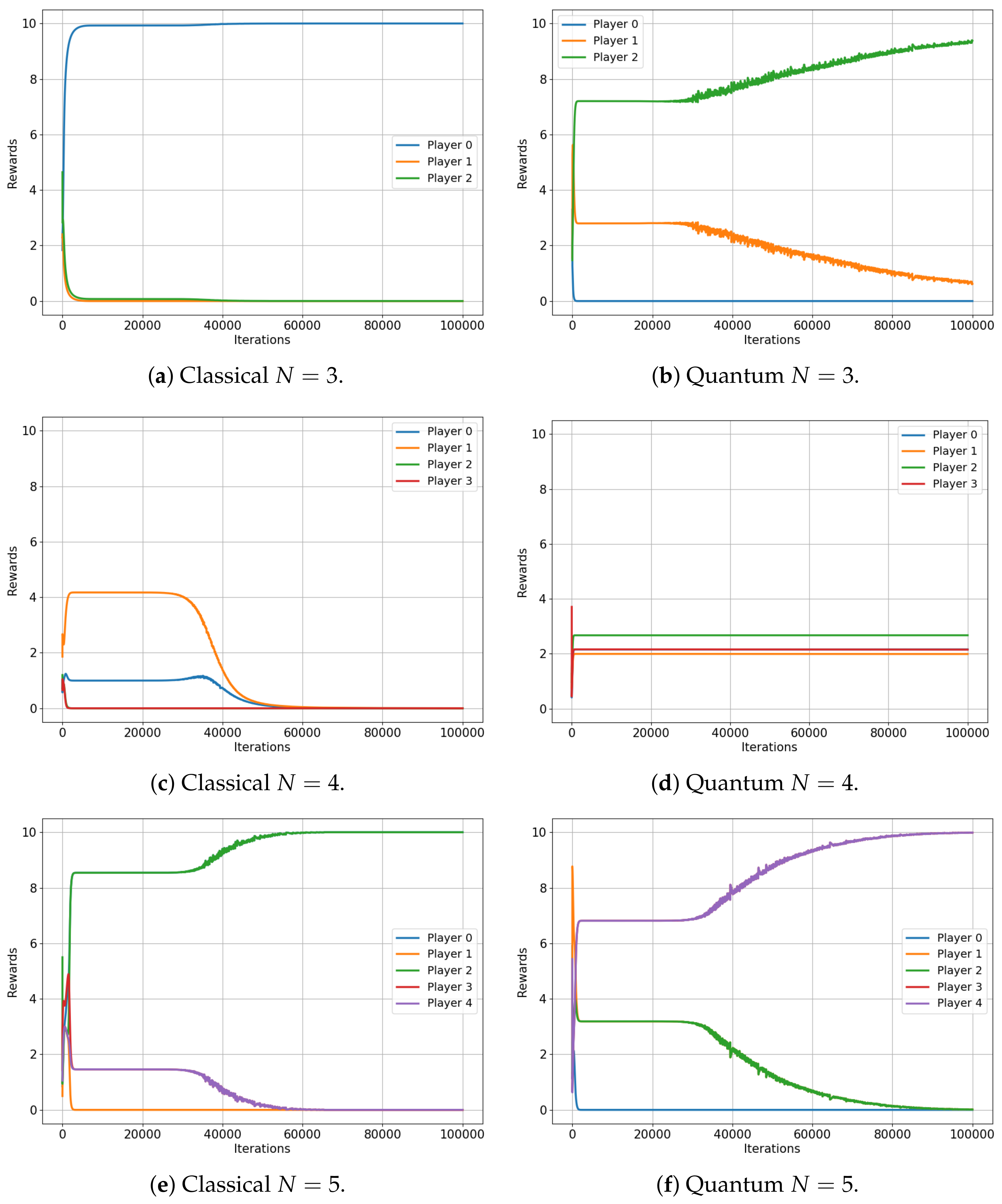
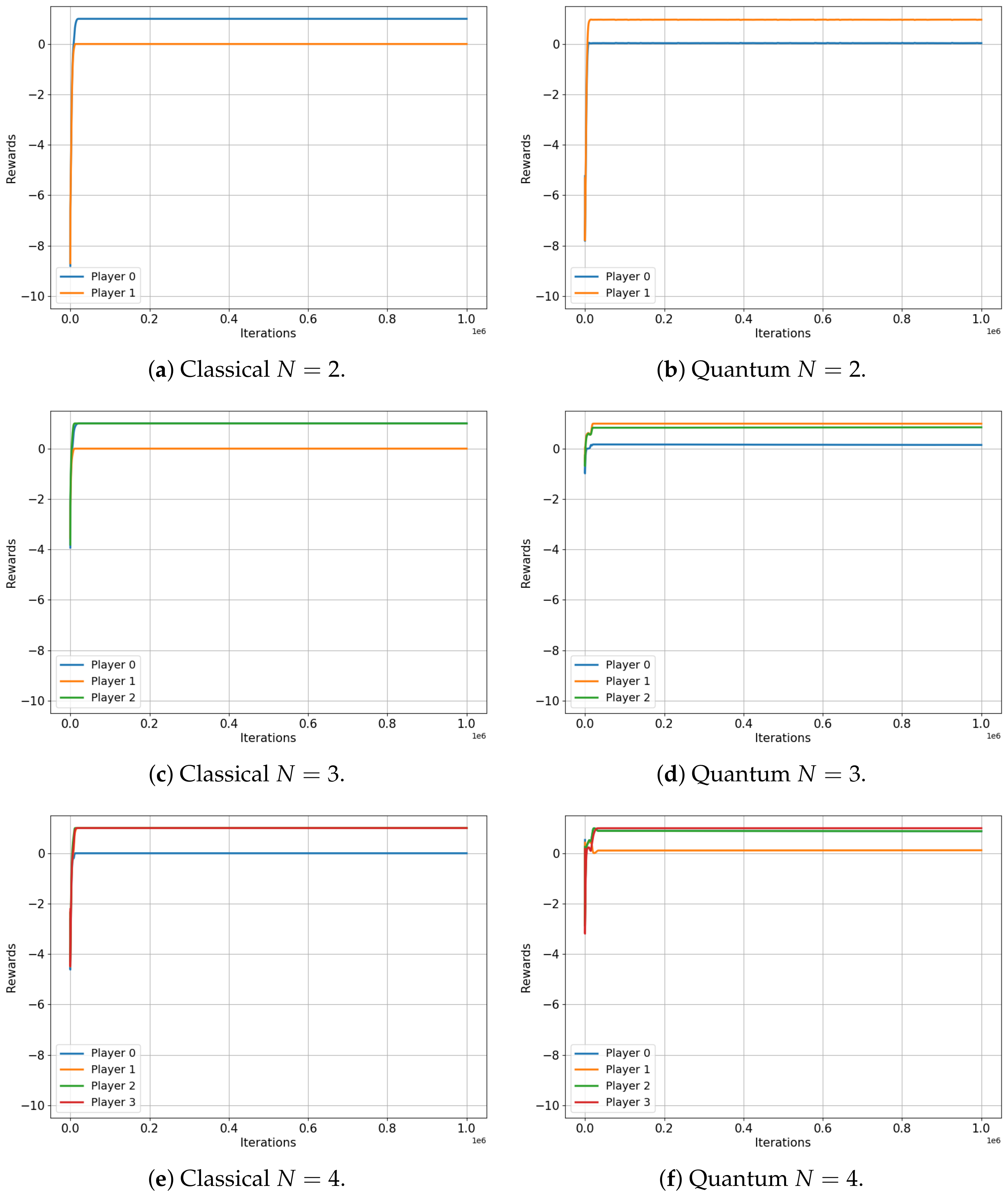
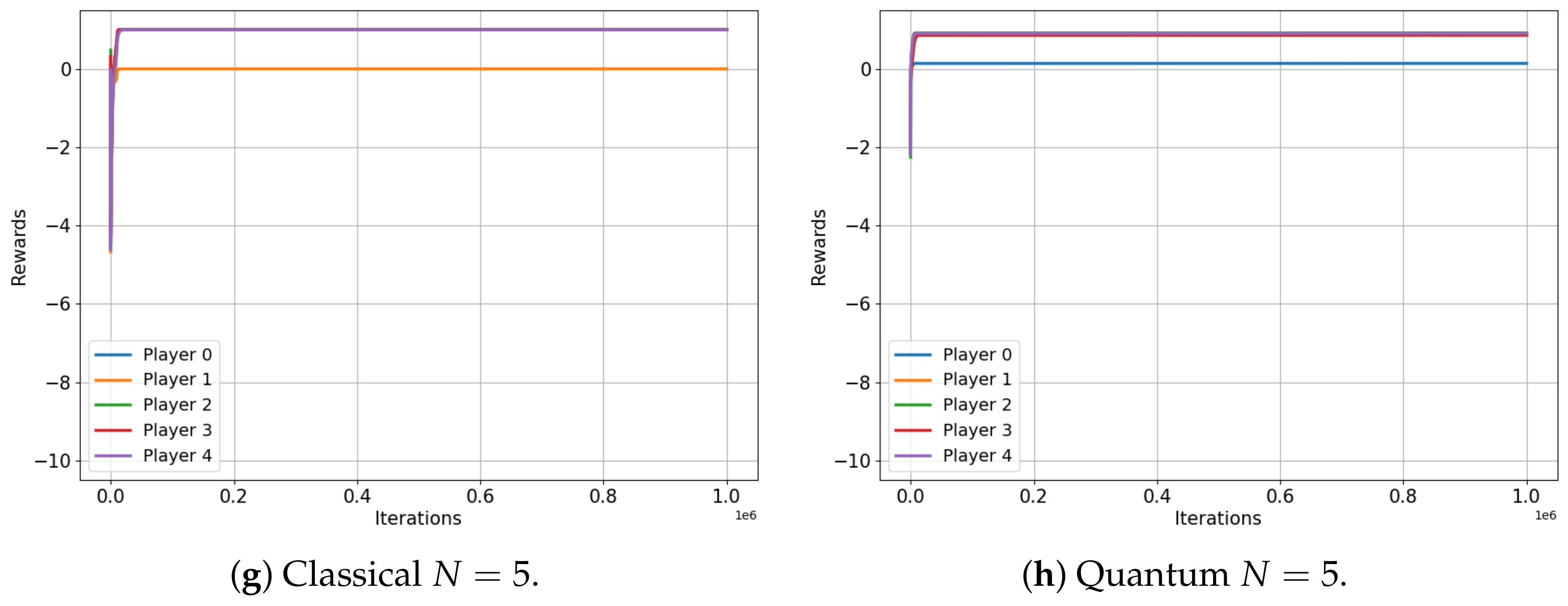
This analysis begins with the minority game. Figure 4 illustrates the evolution of the player rewards for both the classical (left) and quantum (right) cases, specifically for games that involve three, four and five players. Note that the minority game does not have a meaningful interpretation for a two-player scenario.
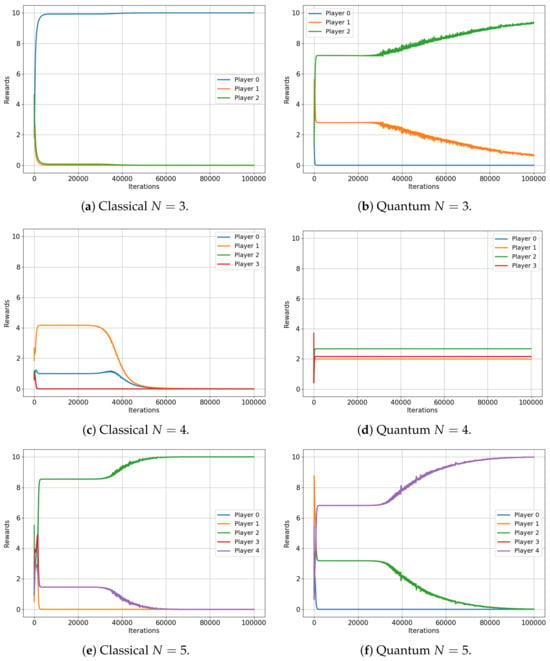
Figure 4.
Classical versus Quantum learning of Minority Games for 3, 4 and 5 players. (a): Average reward . (b): Average reward . (c): Average reward . (d): Average reward . (e): Average reward . (f): Average reward .
The results are indeed compelling, although a more specific description of the minority game is beneficial for our analysis. As framed in our environment, the minority game for N players provides each player with two options (0 and 1), while a reward of is conferred to the players who choose the minority option, which is defined as any selection made by fewer than 50% of the players [32].
Figure 4 shows that the average rewards for the game involving three and five players are nearly identical in both the classical and quantum cases ( and versus and , respectively), exactly as the classical and quantum Nash equilibria predicted in [3]. Not only are the values almost the same, but they also both converge to an optimal equilibrium state: in a three-player game, a single player is in the minority, while in a five-player game, two players constitute the minority. This optimal equilibrium denotes a state of balance where rewards are maximized, underscoring the algorithm’s successful implementation in both classical and quantum contexts.
However, for the four-player game, the classical case converges to a reward of for all players, while the quantum case does not. Players in the quantum game manage to learn a set of strategies, ensuring that each player wins with a probability , also as predicted in [3]. This results in each player receiving an average reward of roughly , demonstrating a clear advantage of quantum gameplay over the classical approach in this particular scenario.
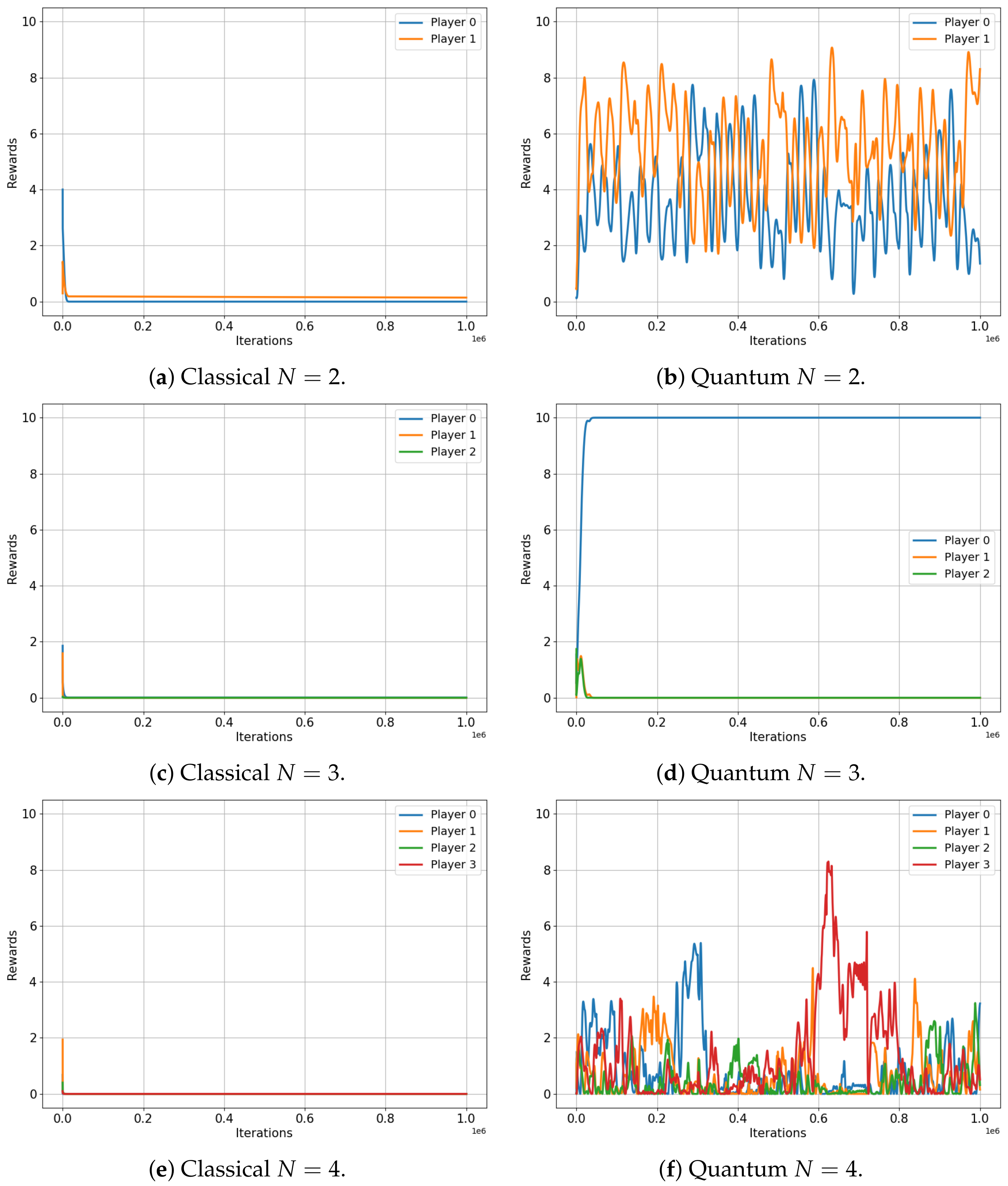
Let us now turn our attention to Figure 5, which depicts the evolution of player rewards in the Platonia game for both classical (left) and quantum (right) setups, for two, three, four and five players. In this game, a reward of is given only to a player who selects action 1 but only if all other players have chosen option 0, as depicted in Table 8.
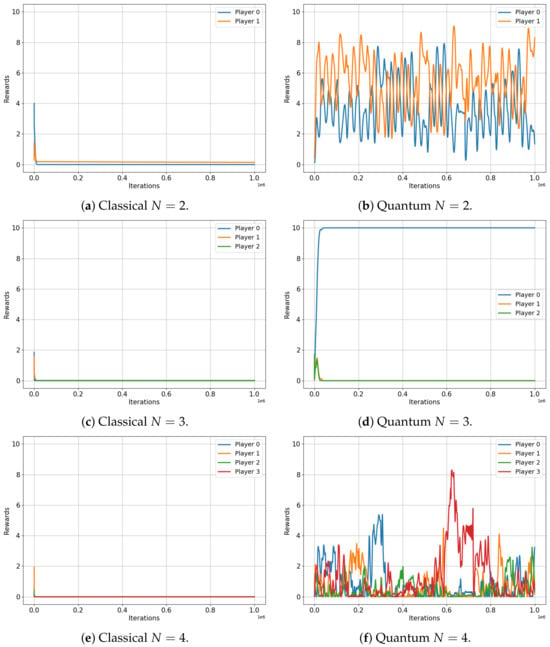
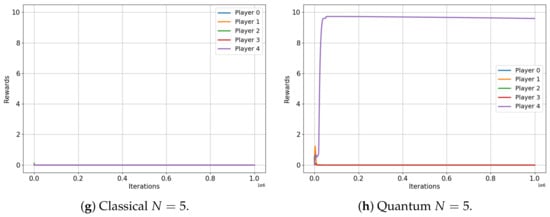
Figure 5.
Classical versus Quantum learning of Platonia Games for 2, 3, 4 and 5 players. (a) Total reward . (b) Total reward . (c) Total reward . (d) Total reward . (e) Total reward . (f) Total reward . (g) Total reward . (h) Total reward .
Table 8.
Payoff matrix for N-player Platonia Game.
The results of this game are certainly more striking. All players in the classical game converge (regardless of the number of players, N) to their Nash equilibrium, resulting in a total reward of for all players. Despite being predictable, this outcome resulted in the worst possible performance. In stark contrast, the quantum setup showcases the power of entanglement, as players consistently achieve significantly higher total reward, irrespective of the number of players involved (, , and ). This remarkable result highlights the effectiveness of the algorithm and the potential of quantum strategies in complex multiplayer games, which may offer advantages over their classical counterparts.
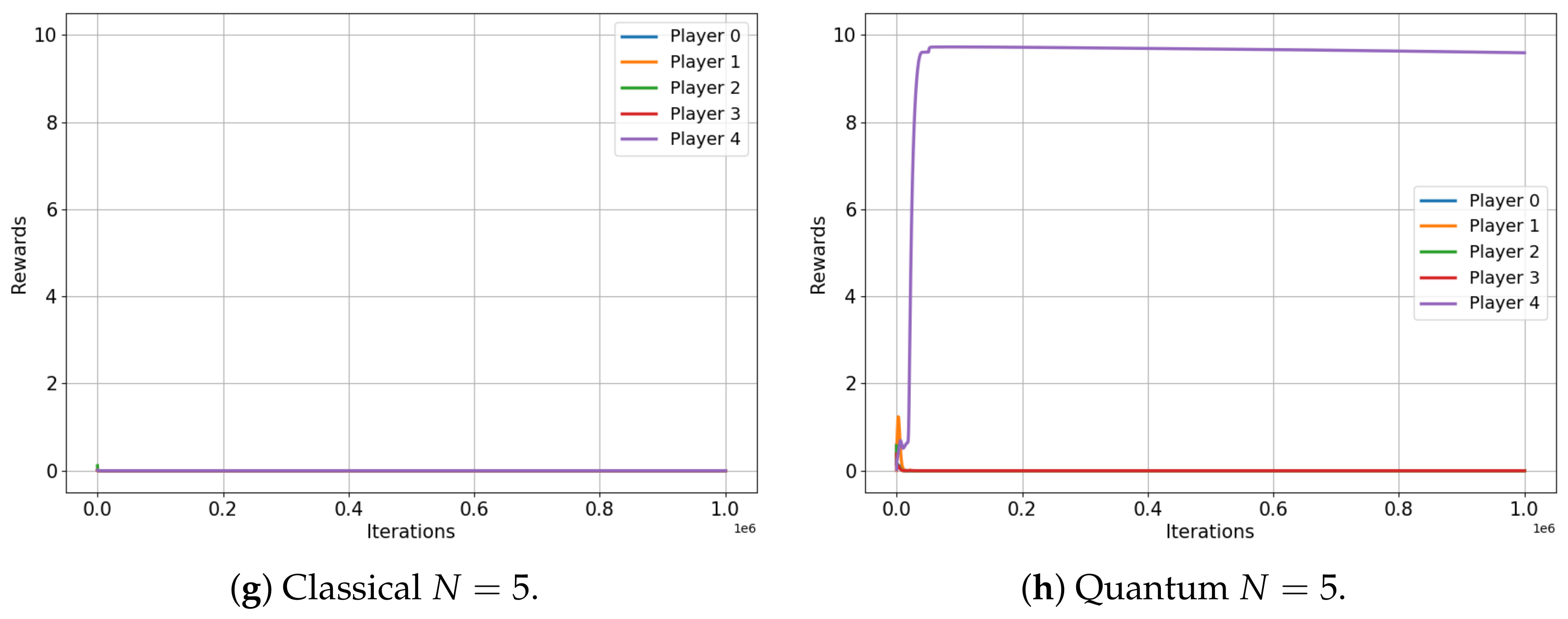
Figure 6 depicts the evolution of rewards for players in both the classical (left) and quantum (right) scenarios of the unscrupulous diners dilemma game. This game involves two, three, four and five players and it is an N-player extension of the well-known prisoners’ dilemma. The unscrupulous diners dilemma represents a situation where a group, agreeing to split the cost of a meal, must individually choose between a less expensive or a more expensive dish. While choosing the more expensive dish may seem advantageous to each individual, this collective decision ultimately leads to a less optimal overall financial outcome [34]. In Table 9, we present a payoff matrix for the two-player version of the unscrupulous diners game, which also serves as a representation of the renowned prisoners’ dilemma.
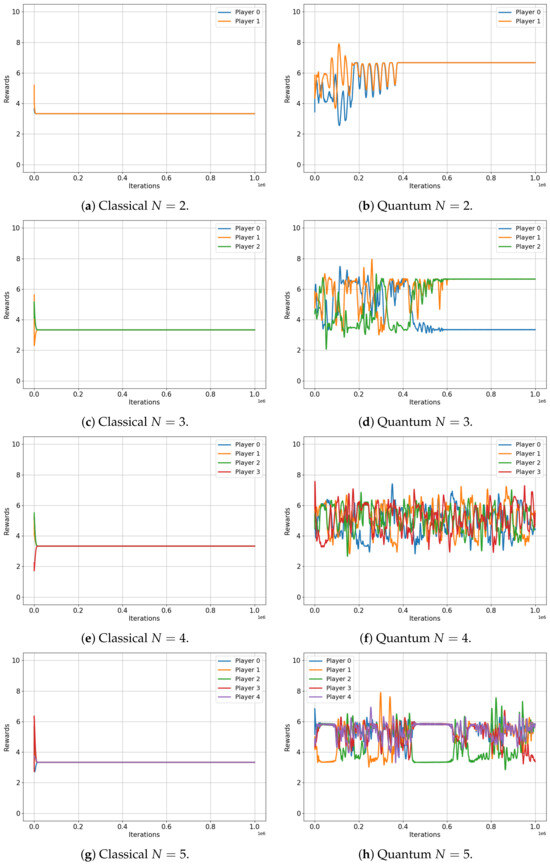
Figure 6.
Classical versus Quantum learning of Unscrupulous Games for 2, 3, 4 and 5 players. (a) Average reward (b) Average reward (c) Average reward (d) Average reward (e) Average reward (f) Average reward (g) Average reward (h) Average reward
Table 9.
Payoff matrix for 2-player Unscrupulous Game or Prisoners Dilemma.
As seen in Figure 6, the rewards of the classical players always (for every N) quickly converge to the value of . This value represents the expected classical Nash equilibrium and corresponds to the selfish action that yields the minimum reward when chosen by all players. However, the quantum case presents another encouraging contrast. In the case of two players, both rewards converge to a value of , corresponding to the ideal value associated with both players cooperating. On the other hand, for three, four and five players, the rewards of the quantum players do not completely converge; instead, they fluctuate around achieving the final values of . Although this value is not the highest possible, it is significantly greater than the obtained in the classical case.
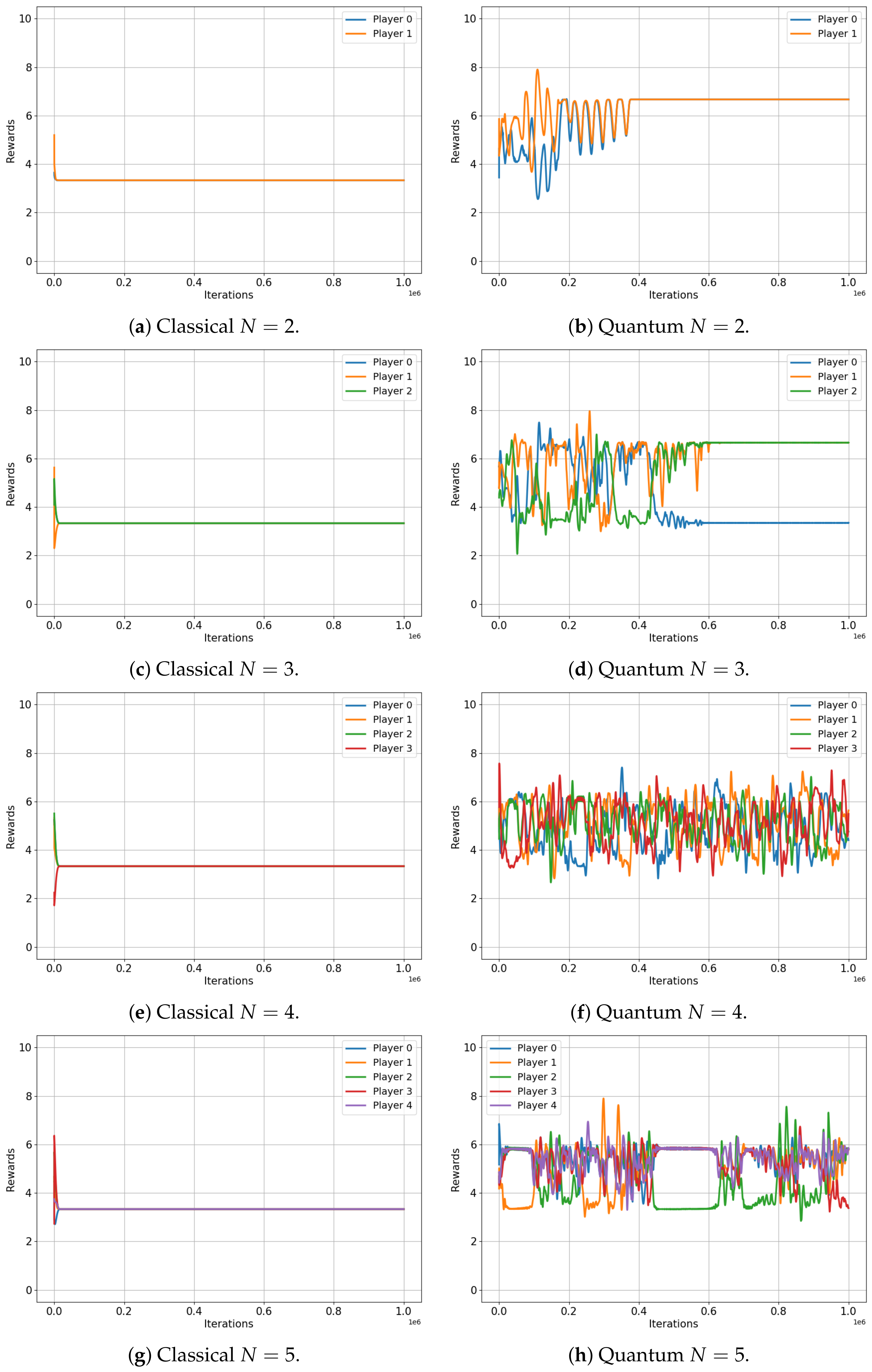
Finally, we focus on the volunteer game, as depicted in Figure 7. The volunteer game is an N-player extension of the chicken game, embodying scenarios where an entire group benefits from an individual’s minor sacrifice, but all suffer if no one acts [35]. The payoff matrix for the two-player volunteer dilemma game is illustrated in Table 10, representing at the same time the famous chicken game.
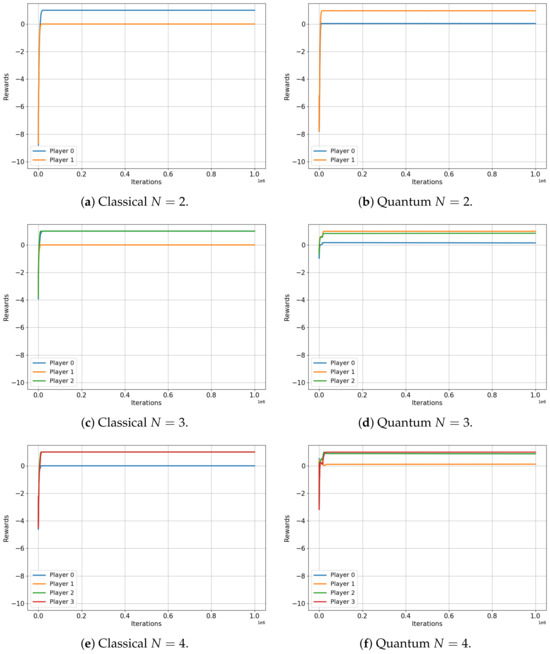
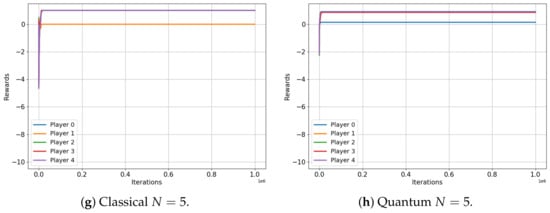
Figure 7.
Classical versus Classical learning of Volunteer Games for 2, 3, 4 and 5 players. (a) Average reward (b) Average reward (c) Average reward (d) Average reward (e) Average reward (f) Average reward (g) Average reward (h) Average reward
Table 10.
Payoff matrix for 2-player Volunteer Dilemma or Chicken Game.
In this final scenario, we observe that the behaviors of both the classical and quantum cases are nearly identical for every N. Rewards consistently converge to the expected value of the classical Nash equilibrium in both setups. This outcome thereby confirms that quantum advantages may not always be present and that our proposed algorithm is a valuable tool for efficiently and systematically verifying these behaviors.
All the computer code required to reproduce the results reported in this section can be found in the Github repository shared in the “Supplementary Materials” section.
4. Noise Effects
This chapter examines how the inherent noise in quantum computers might affect the performance of the learning algorithm. This analysis is a first step towards understanding the practical implications of deploying such algorithms in real-world quantum computational environments, where noise is an unavoidable factor.
In Section 3, we assumed that, after the application of operator J, all players could apply their gates to their qubits in an ideal channel, without any type of noise affecting the vulnerability of the quantum system. Given the difficulty of meeting such a condition, it becomes necessary to undertake a modeling approach to take into account this situation accurately.
The noise model chosen for our study is the depolarizing channel, primarily because it effectively models both bit-flip and phase-flip errors. While the depolarizing channel captures the essential features of numerous real-world noise processes, it is a simplified model. In order to represent all the nuances of noise in some specific quantum devices, further fine-tuning is needed. The state of the quantum system of one qubit after this noise is , with being the density matrix of the quantum state before the noise is applied. The way to model this (Figure 8) is by adding a fourth gate after ; this gate will be selected randomly following the probabilities:
.

Figure 8.
A comprehensive model of the EWL protocol for two players, incorporating both the entanglement factor and the effects of depolarizing channel noise.
Figure 8.
A comprehensive model of the EWL protocol for two players, incorporating both the entanglement factor and the effects of depolarizing channel noise.

This means that the quantum state in each channel will remain intact with probability and will be modified with probability . To modify the quantum state of the channel, the X, Y or Z gates will be applied with the same probability.
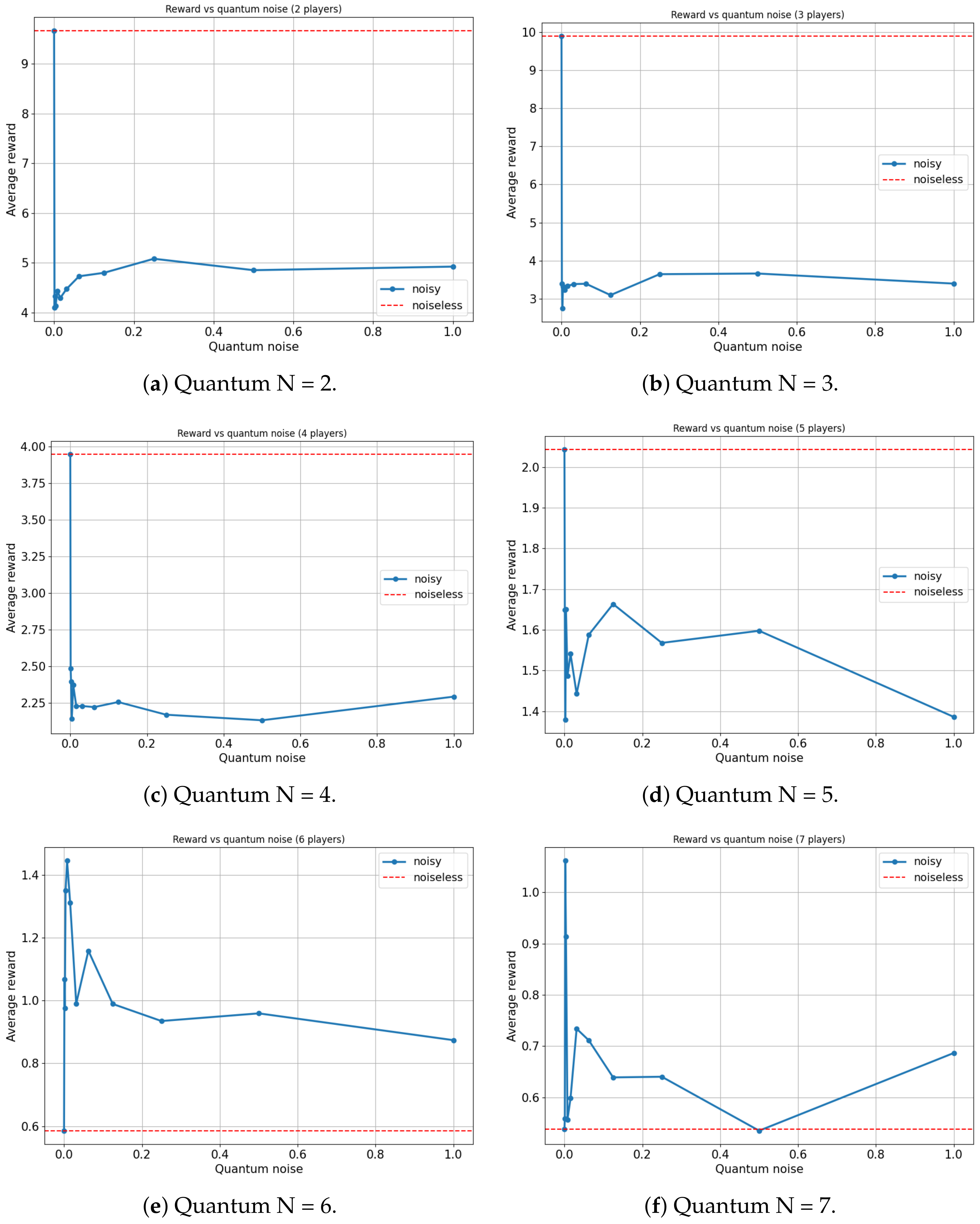
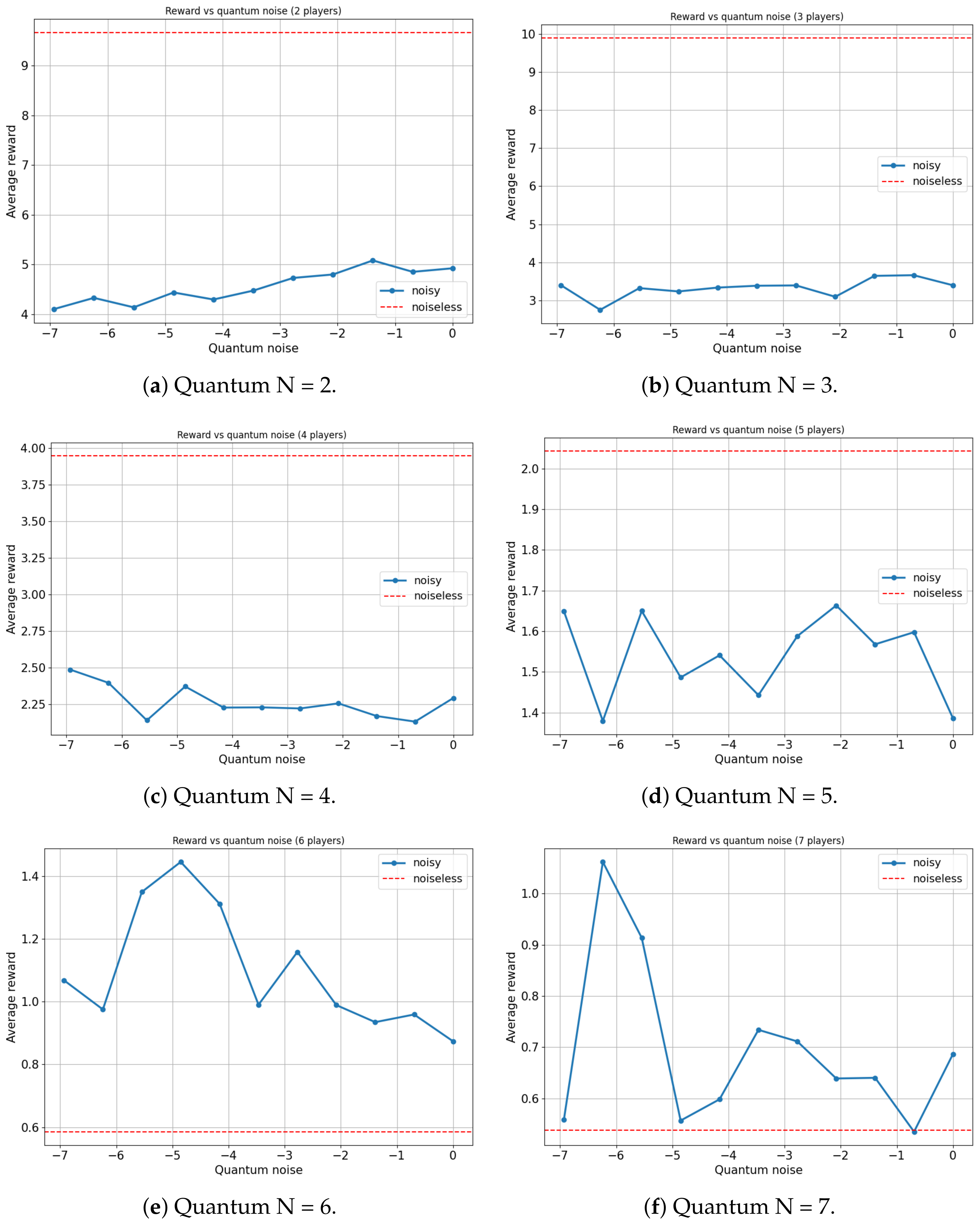
For this analysis, our focus will be on the Platonia game in its quantum variant (), as this game manifests the most significant advantage when contrasting classical and quantum models. Figure 9 and Figure 10 illustrate the variation in the average reward of players as a function of the quantum noise ( and , respectively, and the red dotted line represents the noiseless system, ) inherent in the quantum circuit of the EWL model for two, three, four, five, six and seven players.
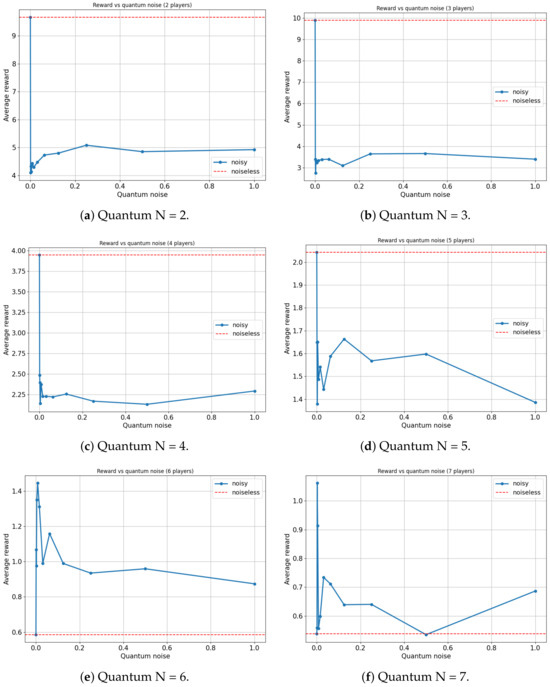
Figure 9.
Average reward of N-player Platonia Game versus Quantum noise plotted as (for ). (a) Maximum average reward = 9.882 for quantum noise for = 0. (b) Maximum average reward = 9.971 for quantum noise for = 0. (c) Maximum average reward = 4.319 for quantum noise for = 0. (d) Maximum average reward = 6.451 for quantum noise for = 0. (e) Maximum average reward = 2.221 for quantum noise for = 0.0078125. (f) Maximum average reward = 1.686 for quantum noise for = 0.00390625.
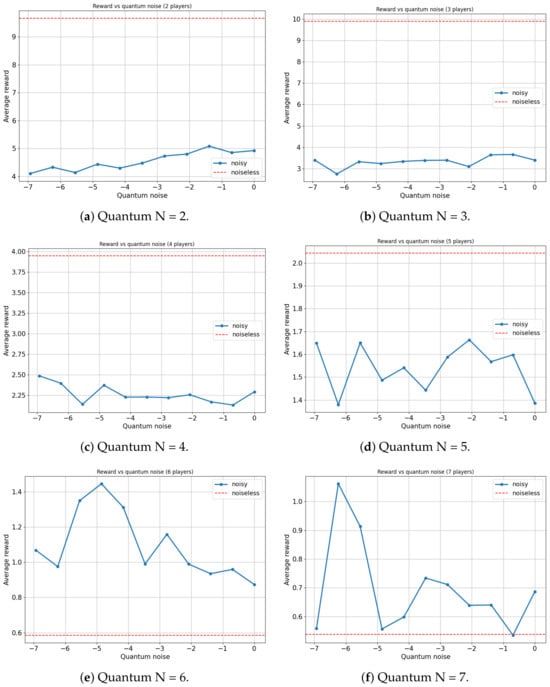
Figure 10.
Average reward of N-player Platonia Game versus Quantum noise plotted as (for ). (a) Maximum average reward = 9.882 for quantum noise for = 0. (b) Maximum average reward = 9.971 for quantum noise for = 0. (c) Maximum average reward = 4.319 for quantum noise for = 0. (d) Maximum average reward = 6.451 for quantum noise for = 0. (e) Maximum average reward = 2.221 for quantum noise for = 0.0078125. (f) Maximum average reward = 1.686 for quantum noise for = 0.00390625.
On the one hand, for the scenarios involving two, three, four and five players, an expected outcome is observed: as the noise in the quantum circuit increases, the performance of the players deteriorates. This is anticipated since the feedback received from the players to update their strategies, using the proposed algorithm, contains progressively more noise as increases. Consequently, the learning efficacy of the players decreases with increasing , leading to a decrease in their overall performance. All players achieve a maximum average reward when , with the ideal case of no noise.
On the other hand, a particular behavior is observed when the number of agents in the quantum game rises to six and seven players. It appears that a slight degree of noise in the quantum circuit is advantageous for the algorithm in terms of maximizing the players’ average reward. In both instances, games involving six and seven players yield the highest average reward for a non-zero value of ( and , respectively).
It is important to note that there could be a trivial case in which the performance of the players improves in a non-decreasing manner as the amount of noise in the quantum circuit increases. That is, in several games, a player acting entirely at random (maximum noise) achieves a higher reward than a rational player (zero noise). However, such behavior would not be particularly noteworthy. For example, this is observed in the classic prisoners’ dilemma (Table 9), where rational behavior converges on a reward of , while completely random behavior yields a reward of . In our study, a small amount of noise is beneficial, but excessive noise remains disadvantageous. This nontrivial behavior is relevant since any non-isolated quantum system will have intrinsic noise that could potentially be harnessed. This is particularly noteworthy in the present context, where all contemporary quantum computers inevitably possess a significant level of noise. Our quantum noise model is very general and does not represent any particular type of quantum device made of different material. Therefore, discovering applications where such noise can be leveraged to enhance system performance is of utmost relevance.
A plausible explanation for this phenomenon might stem from the fact that when the number of players increases, the reward function becomes more complex and, if the algorithm operates in a noiseless setup, it can become trapped in local maxima. However, a minuscule amount of noise in the quantum circuits might suffice to remove the system from these local maxima, allowing exploration of other actions with higher rewards. Importantly, the noise level needs to be low enough to not harm the overall learning process and therefore the performance of the system.
5. Conclusions
This research has probed the intricate dynamics of quantum games involving multiple agents, shedding light on the complex relationships between quantum noise, system performance and learning efficacy. It has been shown that gradient-based strategies in a multi-agent setting present intriguing characteristics when quantum mechanics are taken into account.
The proposed quantum learning algorithm has shown robust performance across various game configurations. Furthermore, the investigation of quantum noise effects uncovered a unique behavior that might have far-reaching implications. As expected, increased noise caused player performance in games involving fewer participants to deteriorate. However, strikingly, a slight amount of noise appeared advantageous in games with six and seven players, seemingly facilitating escape from local maxima and enabling exploration of more rewarding actions. This discovery stimulates discussion on the potential leverage of system noise, a common challenge in contemporary quantum computers, to enhance performance.
The insights from this study hold substantial implications for the real-world application of quantum computing. For example, in economic and financial models where strategic interaction and learning play critical roles, the exploitation of quantum effects could lead to more realistic and accurate predictions. In machine learning and artificial intelligence, quantum enhancements might allow for more efficient solution exploration and optimization. Finally, in communication networks, the principles of quantum games could enable the development of more robust quantum-enhanced communication systems.
The exploration of quantum games with multi-agent learning in this research has only scratched the surface. There is a wealth of complex dynamics and fascinating phenomena to be explored in this burgeoning field. Further research is anticipated to elucidate these exciting frontiers, advancing our understanding of quantum games and their potential applications.
Supplementary Materials
All the computer code required to reproduce the results reported in the whole article can be found in the following Github repository (accessed on 14 October 2023): https://github.com/agustinsilva447/QMARL/blob/main/paper_2/gqmarl.py.
Author Contributions
Conceptualization, A.S.; methodology, A.S., O.G.Z. and C.M.A.; software, A.S.; validation, O.G.Z. and C.M.A.; formal analysis, A.S.; investigation, A.S.; resources, O.G.Z.; data curation, A.S.; writing—original draft preparation, A.S.; writing—review and editing, O.G.Z. and C.M.A.; visualization, A.S.; supervision, O.G.Z.; project administration, C.M.A.; funding acquisition, C.M.A. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Von Neumann, J.; Morgenstern, O. Theory of Games and Economic Behavior, 2nd rev. ed.; Princeton University Press: Princeton, NJ, USA, 1947. [Google Scholar]
- Eisert, J.; Wilkens, M.; Lewenstein, M. Quantum games and quantum strategies. Phys. Rev. Lett. 1999, 83, 3077. [Google Scholar] [CrossRef]
- Benjamin, S.C.; Hayden, P.M. Multiplayer quantum games. Phys. Rev. A 2001, 64, 030301. [Google Scholar] [CrossRef]
- Du, J.; Li, H.; Xu, X.; Shi, M.; Wu, J.; Zhou, X.; Han, R. Experimental realization of quantum games on a quantum computer. Phys. Rev. Lett. 2002, 88, 137902. [Google Scholar] [CrossRef]
- Altepeter, J.; Hall, M.; Medic, M.; Patel, M.; Meyer, D.; Kumar, P. Experimental realization of a multi-player quantum game. In Nonlinear Optics: Materials, Fundamentals and Applications; Optica Publishing Group: Washington, DC, USA, 2009; p. PDNTuA2. [Google Scholar]
- Nash, J.F., Jr. Equilibrium points in n-person games. Proc. Natl. Acad. Sci. USA 1950, 36, 48–49. [Google Scholar] [CrossRef] [PubMed]
- Khan, F.S.; Solmeyer, N.; Balu, R.; Humble, T.S. Quantum games: A review of the history, current state and interpretation. Quantum Inf. Process. 2018, 17, 309. [Google Scholar] [CrossRef]
- Bostanci, J.; Watrous, J. Quantum game theory and the complexity of approximating quantum Nash equilibria. Quantum 2022, 6, 882. [Google Scholar] [CrossRef]
- Shalev-Shwartz, S.; Shammah, S.; Shashua, A. Safe, multi-agent, reinforcement learning for autonomous driving. arXiv 2016, arXiv:1610.03295. [Google Scholar]
- Pham, H.X.; La, H.M.; Feil-Seifer, D.; Nefian, A. Cooperative and distributed reinforcement learning of drones for field coverage. arXiv 2018, arXiv:1803.07250. [Google Scholar]
- Roesch, M.; Linder, C.; Zimmermann, R.; Rudolf, A.; Hohmann, A.; Reinhart, G. Smart grid for industry using multi-agent reinforcement learning. Appl. Sci. 2020, 10, 6900. [Google Scholar]
- Zabaleta, O.G.; Barrangú, J.P.; Arizmendi, C.M. Quantum game application to spectrum scarcity problems. Phys. A Stat. Mech. Its Appl. 2017, 466, 455–461. [Google Scholar] [CrossRef]
- Silva, A.; Zabaleta, O.G.; Arizmendi, C.M. Mitigation of Routing Congestion on Data Networks: A Quantum Game Theory Approach. Quantum Rep. 2022, 4, 135–147. [Google Scholar] [CrossRef]
- Piotrowski, E.W.; Sładkowski, J. Quantum market games. Phys. A Stat. Mech. Its Appl. 2002, 312, 208–216. [Google Scholar] [CrossRef]
- Samadi, A.H.; Montakhab, A.; Marzban, H.; Owjimehr, S. Quantum Barro–Gordon game in monetary economics. Phys. A Stat. Mech. Its Appl. 2018, 489, 94–101. [Google Scholar] [CrossRef]
- Qi, J.; Yang, C.H.H.; Chen, P.Y.; Hsieh, M.H. Theoretical error performance analysis for variational quantum circuit based functional regression. npj Quantum Inf. 2023, 9, 4. [Google Scholar] [CrossRef]
- Dunjko, V.; Taylor, J.M.; Briegel, H.J. Advances in quantum reinforcement learning. In Proceedings of the 2017 IEEE International Conference on Systems, Man and Cybernetics (SMC), Banff, AB, Canada, 5–8 October 2017; pp. 282–287. [Google Scholar]
- Chen, S.Y.C.; Yang, C.H.H.; Qi, J.; Chen, P.Y.; Ma, X.; Goan, H.S. Variational quantum circuits for deep reinforcement learning. IEEE Access 2020, 8, 141007–141024. [Google Scholar] [CrossRef]
- Skolik, A.; Jerbi, S.; Dunjko, V. Quantum agents in the gym: A variational quantum algorithm for deep q-learning. Quantum 2022, 6, 720. [Google Scholar] [CrossRef]
- Neumann, N.M.; de Heer, P.B.; Chiscop, I.; Phillipson, F. Multi-agent reinforcement learning using simulated quantum annealing. In Proceedings of the Computational Science–ICCS 2020: 20th International Conference, Amsterdam, The Netherlands, 3–5 June 2020; pp. 562–575. [Google Scholar]
- Müller, T.; Roch, C.; Schmid, K.; Altmann, P. Towards Multi-Agent Reinforcement Learning using Quantum Boltzmann Machines. arXiv 2021, arXiv:2109.10900. [Google Scholar]
- Yun, W.J.; Kwak, Y.; Kim, J.P.; Cho, H.; Jung, S.; Park, J.; Kim, J. Quantum multi-agent reinforcement learning via variational quantum circuit design. In Proceedings of the 2022 IEEE 42nd International Conference on Distributed Computing Systems (ICDCS), Bologna, Italy, 10–13 July 2022. [Google Scholar]
- Caro, M.C.; Huang, H.Y.; Cerezo, M.; Sharma, K.; Sornborger, A.; Cincio, L.; Coles, P.J. Generalization in quantum machine learning from few training data. Nat. Commun. 2022, 13, 4919. [Google Scholar] [CrossRef]
- Miszczak, J.A.; Pawela, Ł.; Sładkowski, J. General model for an entanglement-enhanced composed quantum game on a two-dimensional lattice. Fluct. Noise Lett. 2014, 13, 1450012. [Google Scholar] [CrossRef]
- Alonso-Sanz, R. Variable entangling in a quantum prisoner’s dilemma cellular automaton. Quantum Inf. Process. 2015, 14, 147–164. [Google Scholar] [CrossRef]
- Alonso-Sanz, R. A cellular automaton implementation of a quantum battle of the sexes game with imperfect information. Quantum Inf. Process. 2015, 14, 3639–3659. [Google Scholar] [CrossRef]
- Pawela, Ł. Quantum games on evolving random networks. Phys. A Stat. Mech. Its Appl. 2016, 458, 179–188. [Google Scholar] [CrossRef]
- Silva, A.; Zabaleta, O.G.; Arizmendi, C.M. Learning Mixed Strategies in Quantum Games with Imperfect Information. Quantum Rep. 2022, 4, 462–475. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Johnson, N.F. Playing a quantum game with a corrupted source. Phys. Rev. A 2001, 63, 020302. [Google Scholar] [CrossRef]
- Preskill, J. Quantum computing in the NISQ era and beyond. Quantum 2018, 2, 79. [Google Scholar] [CrossRef]
- Challet, D.; Marsili, M.; Zhang, Y.C. Minority Games: Interacting Agents in Financial Markets; OUP: Oxford, UK, 2004. [Google Scholar]
- Hofstadter, D.R. Metamagical Themas: Questing for the Essence of Mind and Pattern; Hachette UK: London, UK, 2008. [Google Scholar]
- Glance, N.S.; Huberman, B.A. The dynamics of social dilemmas. Sci. Am. 1994, 270, 76–81. [Google Scholar] [CrossRef]
- Diekmann, A. Volunteer’s dilemma. J. Confl. Resolut. 1985, 29, 605–610. [Google Scholar] [CrossRef]
- Nielsen, M.A.; Chuang, I.L. Quantum Computation and Quantum Information: 10th Anniversary Edition; Cambridge University Press: Cambridge, UK, 2010. [Google Scholar] [CrossRef]
- Albrecht, S.V.; Christianos, F.; Schäfer, L. Multi-Agent Reinforcement Learning: Foundations and Modern Approaches; MIT Press: Cambridge, MA, USA, 2023; Pre-print, non-final version. [Google Scholar]

Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).