1. Introduction
Knowledge graphs (KGs) are collections of triples, such as Freebase [
1] and YAGO [
2]. Temporal KGs introduce a new dimension into static knowledge graphs [
3], i.e., a timestamp for each triple to form a quadruple. Although there are billions of triples in temporal KGs, they are still incomplete. These incomplete knowledge bases will lead to limitations in practical applications. Since temporal KGs involve the time dimension, the completion of temporal KGs can be divided into interpolation and forecasting. The former utilizes the facts of all timestamps to predict the triples at a particular moment; the latter employs historical facts to predict future triples. Due to the importance of temporal KG forecasting in event prediction, it has attracted growing attention recently. This paper mainly focuses on temporal KG forecasting.
Most current research on temporal KG completion focuses on interpolation [
4,
5,
6,
7,
8,
9,
10]. Recently, there have been attempts to investigate temporal KG forecasting [
3,
4,
7,
11,
12,
13]. According to the interpretability, research on temporal KG forecasting can be divided into two categories. One type is the black-box model, which designs an unexplainable scoring function for quadruples’ rationality. The other type is interpretable approaches. CyGNet [
11] utilizes one-hop repetitive facts to realize prediction. Its performance is limited by the lack of direct repetitive knowledge of historical moments. xERTR [
7], CluSTeR [
3], and TITer [
14] are all path-based temporal KG forecasting models. xERTR [
7] adopts the inference subgraphs to aggregate local information around the question. CluSTeR [
3] and TITer [
14] manipulate reinforcement learning for the path search and improve the performance through temporal reasoning.
Thus far, however, there has been little discussion on the following two aspects. Firstly, uniformly measuring the paths of different hops requires handling the same semantics equivalently at different hops. Current models utilize separate networks to evaluate paths at different hops. Although each hop’s network has the same architecture, each network acquires different parameters for better performance. Different parameters cause identical semantics to have different scores, so current models cannot truly compare multi-hop paths according to the same criteria. For example, xERTR [
7] simply gathers the scores of different paths for comparison, which is mainly based on training datasets. Secondly, although current models can provide reasoning paths, the comparison of paths operates in a black-box fashion. The interpretability of the current models means providing the reasoning paths, which is an essential property of path-based models. These models lack an explanation of the preference for various paths, i.e., they cannot provide the basis for path comparison.
In practice, forecasting based on path searching aims to find the appropriate multi-hop paths, the combination of whose relations is equivalent to the question’s relation. As we observe, reasoning based on multi-hop paths is akin to stepwise question answering. Inspired by stepwise question answering, this paper designs a new Interpretable Multi-Hop Reasoning (IMR) framework based on consistent basic models, which can uniformly integrate the paths of different hops and perform more interpretable reasoning.
The primary pathway of IMR can be as follows. IMR first transforms reasoning based on path searching into stepwise question answering based on basic KG embedding models [
1,
15,
16,
17,
18] and IRN [
19]. This framework calculates the unanswered parts of questions after each hop as the new question for the next hop during the stepwise question answering, which is named the remainder of questions in this paper. Moreover, IMR designs three indicators based on the unanswered parts of questions and the inferred tails: the query matching degree, answer completion level, and path confidence. The query matching degree, i.e., the matching degree between the reasoning tails and the original questions, measures the rationality of the new quadruples. The answer completion level, i.e., the matching degree between the relations of paths and that of the questions, measures the answer’s completeness. Path confidence, i.e., the difference between the same entities with different timestamps, measures the reliability of the reasoning paths. IMR achieves the unified scoring of multi-hop paths and better explainable reasoning simultaneously with these indicators’ combination.
The major contributions of this work are as follows. (1) A new Interpretable Multi-Hop Reasoning framework (IMR) is proposed in this paper, which provides a new framework for the specific design of forecasting models. Furthermore, IMR defines three indicators: the query matching degree, answer completion level, and path confidence. (2) Unlike other models that cannot measure the paths of different hops uniformly, IMR can measure the paths of different hops according to the same criteria and utilize multi-hop paths for inference. (3) IMR can provide reasoning paths similarly to other interpretable models and further explain the basis for path comparison. (4) Based on basic embedding models, IMR is instantiated as the specific model. Experiments on four benchmark datasets show that these instantiated models achieve state-of-the-art performance against previous models.
2. Related Work
Static KG reasoning. Knowledge graph reasoning based on representation learning has been widely investigated by scholars. These approaches to reasoning can be categorized into geometric models [
1,
17,
20,
21,
22], tensor decomposition models [
15,
16,
18,
23], and deep learning models [
24,
25,
26]. In recent years, some scholars have attempted to introduce GCN into knowledge graph reasoning [
27], which can improve the performance of basic models. Some other scholars focus on multi-hop reasoning with symbolic inference rules learned from relation paths [
28,
29]. The above methods are all designed for static KGs, making it challenging to deal with temporal KG reasoning.
Temporal KG reasoning. Temporal KGs import the time dimension into static KGs, which makes the facts of a specific timestamp extremely sparse. The temporal KG reasoning task can be divided into two categories: reasoning about historical facts [
4,
5,
6,
7,
8,
30], i.e., interpolation on temporal KGs, and reasoning about future facts [
3,
4,
7,
11], i.e., forecasting on temporal KGs. The former predicts the missing facts of a specific historical moment based on the facts of all moments, and the latter predicts future events based only on the past facts. There are many studies on the task of temporal KG interpolation. However, these studies are all black-box models, which cannot explain predictions. Most of the proposed models for temporal KG forecasting are also black-box models. BoxTE [
31] utilizes BoxEmbedding for temporal KG forecasting, which is expressive and possesses an inductive capacity. Recently, xERTR [
7], CluSTer [
3], and TITer [
14] were shown to explain predictions to some extent. These models can provide the reasoning paths for the predictions. However, both models cannot truly handle multi-hop paths crossing the same criteria, which is more similar to the weighted combination. xERTR and TiTer combine the scores of paths with different hops by training weights. Experiments show that CluSTeR performs worse on paths with multiple hops than on paths with only one hop.
Most current temporal KG forecasting models are black-box models. Only some models can provide reasoning paths for prediction. Moreover, none of them can explain how path comparisons work and none of them can integrate paths of different hops uniformly.
3. Preliminaries
The task of temporal KG forecasting. Suppose that
,
, and
represent the entity set, predicate set, and timestamp set, respectively. The temporal KG is a collection of quadruples, which can be expressed as
denotes a quadruple;
and
represent the subject and object, respectively.
r represents the relation, and
t represents the time that the quadruple occurs. Suppose that facts happening before the selected time
can be expressed as
Temporal KG forecasting predicts future links based on past facts. This means that its foundation is the process of predicting based on a question and the previous facts , where denote the relation and timestamp of the question. Temporal KG forecasting involves ranking all entities of the specific moment and obtaining the preference for prediction.
Temporal KG forecasting based on paths. Knowledge graph embedding associates the entities
and relations
with vectors
. Different from static KGs, the entities in temporal KGs contain time information. The entity may contain different attributes at different moments. In order to better characterize the entity in temporal KGs, we associate each entity
e with a specific time label
, so the entity
e can be depicted as
and its embedding can be denoted as
. The set of quadruples directly associated with
, which can be defined as the 1-hop paths associated with
, can be expressed as
, where
. In this way,
can represent all associated quadruples. The set of entities directly associated with
in the path
, i.e., the 1-hop neighbors of
, can be denoted as
, where
. Given the question
, the forecasting task can be depicted as requesting the entity
based on path searching. For example, we search the path with
as the starting point:
where
denotes the relations of the
ith-hop. Thus, answers to the question may be
and the corresponding inference hop is
, respectively. Moreover,
denotes the remaining (or unanswered) subjects and relations of questions after the
ith-hop paths, which will be explained in
Section 4.3.2.
Uniformly measuring paths of different hops. Uniformly measuring paths of different hops requires models scoring paths of different hops according to the same criteria. For example, given question and the searched 1-hop path , the score obtained for the searched 1-hop path is f. If we find no path during the first hop, the original question is left to the second hop to solve. Thus, the remaining question (unanswered question) for the second hop is still . When the path searched at the second hop is also , the score for the searched path at the second hop should also be f. As is shown in this example, we should score identical semantics equivalently even under different hops. Moreover, the equal comparison of paths provides the basis for the interpretability of path comparison. This attribute constrains models to have an identical scoring mechanism at each hop, i.e., each hop’s separate networks for the models based on neural networks should have the same parameters. However, only IMR can meet the attribute.
Fact matching based on TransE. This paper is the first study of the design of interpretable evaluation indicators from the perspective of actual semantics. We instantiate IMR to better illustrate the design pathway and thus choose the basic embedding model TransE as the basis of IMR. In TransE, relations are represented as translations in the embedding space. If the triple
holds in static KGs, TransE [
1] assumes the following relationship.
where
and
, and
k denotes the dimension of each vector.
For each quadruple
in temporal KGs, the relation
can also be taken as the translation from the subject
to the object
, i.e.,
. We suppose that when the distance
d of quadruples is smaller, the quadruple will be better matched. The distance of the quadruple
can be expressed as
The relations in KG embedding models indicate the translations between entities, whose specific design determines the complexity of the indicators designed by IMR. The design route of IMR originates from the perspective of reasoning from actual semantics, which is not limited to specific basic models. The consistent basic model of IMR-TransE is TransE, i.e., all IMR-TransE’s specific formulas are based on TransE, which will not be explained below. To limit the length of the paper, we move the details of IMR-TransE and IMR-ComplEx to
Appendix A.2.
4. IMR: Interpretable Multi-Hop Reasoning
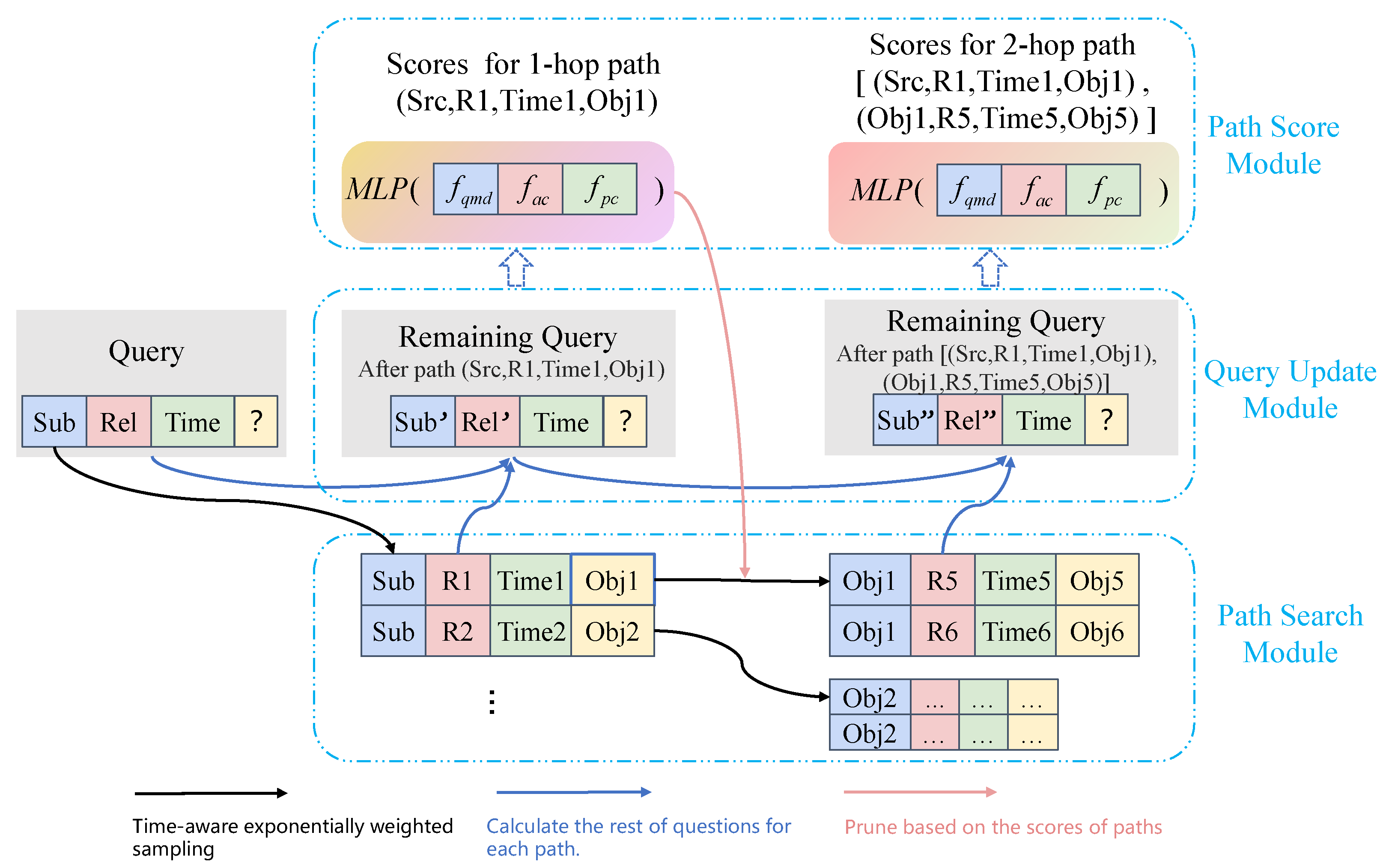
We introduce the Interpretable Multi-Hop Reasoning framework (IMR) in this section. We first provide an overview of IMR in
Section 4.1. IMR comprises three modules: the path searching module, query updating module, and path scoring module. The path searching module searches related paths hop by hop from the subjects of questions, involving path sampling and entity clipping, whose motivation and design are presented in
Section 4.2. The query updating module calculates the remaining questions hop-by-hop for each path, involving the update of the subject and relations, whose motivation and design are introduced in
Section 4.3. The path scoring module designs three indicators: the question matching degree, answer completion level, and path confidence. This module combines three indicators to evaluate each path, whose motivation and design are presented in
Section 4.4. We introduce training strategies and the regularizations on state continuity in
Section 4.5. IMR conducts uniform path comparisons based on consistent basic models. To better illustrate this framework, we also include the corresponding instance model (IMR-TransE) in
Section 4.3,
Section 4.4 and
Section 4.5. The detailed implementations of IMR-RotatE and IMR-ComplEx are included in
Appendix A.2.
4.1. Framework Overview
We notice that predicting unknown facts based on paths is akin to answering questions, i.e., the question can be answered directly via finding triples with an equal relation or gradually by utilizing the multi-hop equivalent paths. Inspired by this observation, we take the task of link prediction as stepwise question answering. IMR primarily consists of searching for paths hop by hop, updating the remaining questions for each path, and filtering the best answers based on three indicators: the question matching degree, answer completion level, and path confidence.
We show a toy example in
Figure 1. Given a question
and the previous facts
, the task of forecasting is predicting the missing object
. The steps of IMR are as follows.
Step 1: Starting from the subject
, we first acquire the associated quadruples
, namely 1-hop paths. We temporally bias the neighborhood sampling using an exponential distribution for the neighbors [
7]. The distribution negatively correlates with the time difference between node
and its neighbor
. Then, we calculate the remaining questions (the remaining subject
and the remaining relation
) for each sampled path. Finally, IMR scores 1-hop paths based on three indicators, which is discussed in
Section 4.4.
Step 2: To prevent the path searching from exploding, the model samples the tails of 1-hop paths for the 2-hop path searching. As shown by the pink arrow in
Figure 1, the tails of 1-hop paths are clipped according to the scores of 1-hop paths. For the 2-hop paths searched from the clipped tails, IMR samples the paths negatively correlated with time distances. Then, IMR calculates the remaining questions for each 2-hop path (the remaining subject
and the remaining relation
) and scores the 2-hop paths based on three indicators.
Step 3: Rank the scores of 1-hop and 2-hop paths to obtain the preference answer.
4.2. Path Searching Module
Inspired by the observation that reasoning based on multi-hop paths is akin to stepwise question answering, this module searches related paths hop by hop from the subjects of questions.
Path sampling. For the path searching from the starting subject
, the number of triples in
may be very large. To prevent the path searching from exploding, we sample a subset of the paths. In fact, the attributes of entities in temporal KGs may change over time. Consider the observation that when
is closer to
, the attributes of
should be more similar to those of
. We also verify the correlation between attributes and the time distance in
Appendix A.6. Therefore, we are more prone to sample nodes whose time is closer to
. In this paper, we employ time-aware exponentially weighted sampling in xERTR [
7]. xERTR temporally biases the neighborhood sampling using an exponential distribution of temporal distance.
Entity pruning. The search for next-hop paths is based on the tails of previous-hop paths, so the number of paths is increased by the exponent of dimensions. To avoid the explosion of next-hop path searching, this paper proposes to select the top-K entities for the next-hop search based on the sorted scores of the previous hops.
4.3. Query Updating Module
Given a question , there may be a few relations directly equivalent to in the temporal KGs for the task of link prediction. More questions need to go through multi-hop paths to infer the outcome. In question answering, a complex question can be decomposed into multiple sub-questions, with one sub-question answered at each step. Thus, inference based on the multi-hop path is equivalent to answering complex questions step by step. Moreover, we need to remove the part resolved to focus on the remaining questions. IMR proposes to update the question according to the last hop and focus on finding the unsolved parts. The query updating module mainly calculates the remaining questions, i.e., the unanswered questions.
The embedding of entities is first introduced in this subsection, followed by the query updating module of IMR-TransE.
4.3.1. Entity Representation
The attributes contained in the entities may change over time. This paper divides the entity embeddings of each timestamp into a static representation and dynamic representation.
Here, the vector
denotes the static embedding, which captures time-invariant features and global dependencies over the temporal KGs. The vector
represents the dynamic embedding for each entity that changes over time.
denotes the operation of concatenation and
denotes the multilayer perceptron (MLP).
denotes the activation function. We provide more details about
and
in
Appendix A.3.
4.3.2. Question Updating
Each path contains a different set of relations. After each hop, the question needs to discard the processed semantic, i.e., to obtain the remaining subject and relation of the question.
Question updating for IMR-TransE. As shown in
Figure 1, the subject and relation of the question after the
i-th hop path are updated based on Equation (
5) as follows.
where the embedding
and
represent the remaining subject and relation of the question after the
i-hop path, respectively. Moreover,
,
and
denotes the relation of
i-th hop path and
i is the number of hops for each path.
4.4. Path Scoring Module
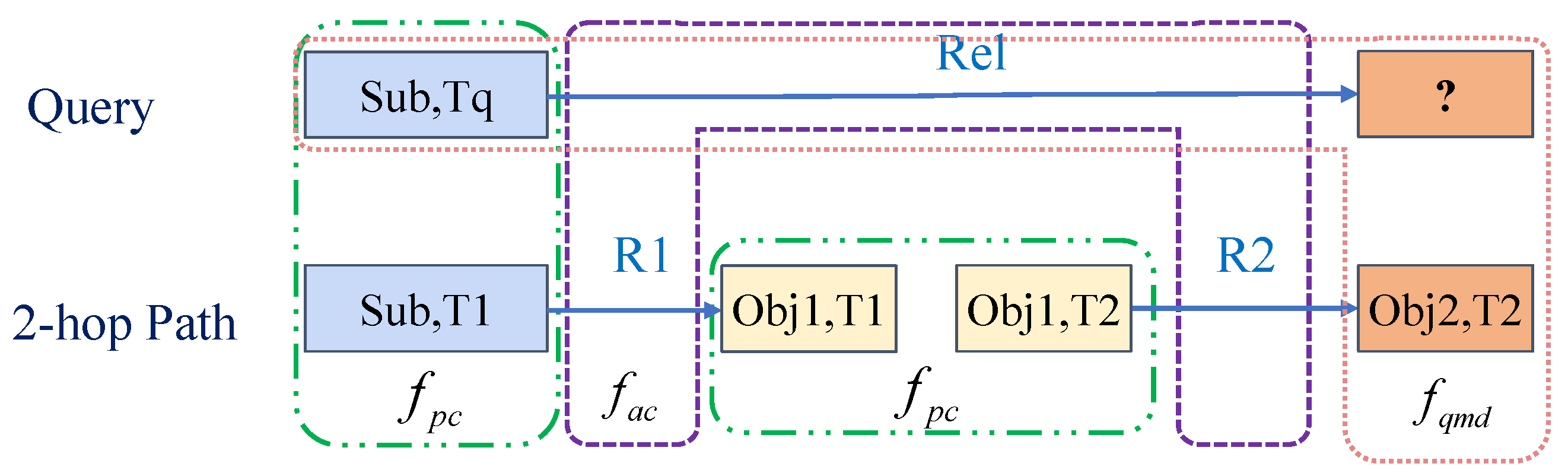
For the question (Sub, Rel, ?, Tq), we search the 2-hop path (Sub, R1, Obj1, T1),(Obj1, R2, Obj2, T2). The pink box indicates that the original question and the tail of the path are combined as a quadruple to measure the rationality of searched tails, i.e., the question matching degree . The purple box represents the comparison between the question’s relation and the path relations to measure the semantic equivalence between the question and the path, i.e., the answer completion level . These green boxes compare the attributes of the same entities with different timestamps to measure the reliability of the search path, i.e., the path confidence .
We evaluate the path searching from three perspectives. First, the searched tails should match the original question, which means that the correct tails searched by paths and the question should satisfy the consistent basic embedding model. Secondly, the ideal path should be the search for equivalent semantics for relations, not merely the search for the correct tails. It is necessary to ensure the correctness of semantic equivalence, i.e., the path is semantically equivalent to the relation of the question. Finally, considering the particularity of the temporal KGs, the attributes of the same entity may change over time. The current sampling strategy for path searching is to sample adjacent timestamp triples of the same entity. When the attribute value of the entity changes significantly over time, it is inappropriate to perform this sampling strategy for the next hop. We need to ensure that the same entity with different timestamps has similar properties in the same path. In this way, three indicators have been developed by IMR to measure the rationality of the reasoning path, respectively: the question matching degree, answer completion level, and path confidence. Although the current methods, such as models based on reinforcement learning, can have complicated designs, the score functions simply belong to a type of question matching degree. We provide a detailed analysis of the correlation between IMR and reinforcement-learning-based models in
Appendix A.5.
4.4.1. Question Matching Degree
For the tails found by path searching, we need to measure the matching degree between the tails and the question, the question matching degree. In fact, the scoring function applied by some traditional reinforcement learning methods is a type of question matching degree. As shown in the yellow box in
Figure 2, for the entity
searched by the paths with
i hops, we combine the entity
and the question
into a new quadruple
.
Question matching degree for IMR-TransE. Question matching degree
in IMR-TransE calculates the distance of the constructed quadruple based on TransE [
1]. The better the entity matches the question, the smaller the distance of quadruples will be. The calculation of
for
ith-hop path is as follows.
where the
p-norm of a complex vector
V is defined as
. We use the L1-norm for all indicators in the following.
4.4.2. Answer Completion Level
Among the paths to the right tails, some paths are not related to the semantics of the question. Although these paths can infer the tail, these paths are invalid due to being unrelated to the question in semantics. Therefore, IMR designs an index to measure the semantic relevance between the path and the question. Answer completion level indicates whether the combination of path relations can reflect the relation of the question in semantics. IMR takes the remaining relations of the question as the answer completion level, which is calculated based on the distance between the relations of paths and the relation . The fewer the relations of a question that remain, the more complete the answer given by the combination of path relations.
Answer completion level for IMR-TransE. The calculation of
for
ith-hop path in IMR-TransE is as follows.
4.4.3. Path Confidence
Path searching is the process of searching for the next-hop paths based on the tail of the previous hop. When searching for a path, the current sampling strategy is to sample adjacent timestamp triples of the same entity. There are deviations between the same entities with different timestamps in temporal KGs. The premise of this sampling strategy is that only when entities have similar attributes under different timestamps, the path searching is valid. When the entity’s attributes change significantly over time, performing an effective next path search is inappropriate. The reasoning path is more reliable when the deviations between entities are smaller. IMR designs path confidence , i.e., the error between the subject of the updated question and the tails of the path with i hops.
Path confidence for IMR-TransE. The calculation of
for
ith-hop path in IMR-TransE is as follows.
where
represents the remaining subject of the question updated by paths of the length
i, and
represents the tail reasoned by the
i-hop paths.
4.4.4. Combination of Scores
IMR merges indicators with positive weights to obtain the final score of each path, i.e., , where .
Entity aggregation for IMR. Considering that the searched paths may lead to entities with different timestamps, IMR adopts specific aggregation for searched entities. First, entities with the same timestamp may be inferred by different paths, so IMR needs to combine the scores of entities with unique timestamps. Considering that only one path matches the question best, IMR employs max aggregation to various paths reaching the same entities with the same timestamp. Moreover, specific paths may infer the same entity with different timestamps. IMR performs average aggregation on the scores of entities with different timestamps. Finally, IMR obtains the score of each entity at the question timestamp.
4.5. Learning
We utilize binary cross-entropy as the loss function, which is defined as
where
represents the set of entities reasoned by selected paths.
represents the binary label that indicates whether it is the answer for
q and
Q represents the training set.
denotes the score obtained by
Section 4.4.4 for each path. We jointly learn the embeddings and other model parameters by end-to-end training.
Regularization. For the same entity with different timestamps, the closer its time distance is, the closer its dynamic embedding is [
32]. IMR proposes the regularization on continuity for the dynamic vectors of entities.
The specific regularization for IMR is as follows.
where
denotes the dynamic embedding of the
k-th entity at the
j-th timestamp.
denotes the dynamic embedding of the previous and later timestamp against
, respectively.
denotes the
p norm of the vectors and we take
p as 1 in this paper.







{kind=link}
{kind=link}
{kind=link}
{kind=link}