1. Introduction
The link prediction problem has long been an active area of research, with applications ranging from friendship recommendation in social networks [
1,
2,
3] to finding missing interactions between proteins [
4,
5]. In this paper, we were interested in the latter. For general surveys in link prediction, we refer to [
6,
7,
8].
One particularly successful class of link prediction methods is those based on random walks [
5,
9,
10]. Random walk algorithms have been explored more generally throughout the field of network science, and many different applications exist. These include the ranking of web pages using PageRank [
11,
12], collaborative filtering [
13], and computer vision [
14]. Many random walk link prediction algorithms have also been studied [
5,
15]. These methods typically rely on discrete-time random walks.
In contrast, in this paper, we propose a class of link prediction methods based on continuous-time random walks. Moreover, the continuous-time setting allowed us to propose a new link prediction method using quantum walks, which closely resembles the classical method described here.
Continuous-time quantum walks, initially proposed in [
16], are the quantum analogues of continuous-time classical random walks, which describe the propagation of a particle over a discrete set of positions. Together with their discrete-time counterpart [
17], they have received much attention for their applications in quantum information processing [
18,
19], quantum computation [
20], and quantum transport [
21]. However, only a few recent methods have attempted to use quantum walks for link prediction, using their discrete-time [
22] and continuous-time [
23] variations. While the methods described here are
quantum-inspired, since they were implemented classically, we can foresee that these will be even more efficient if run on quantum devices. Continuous-time quantum walks have already been implemented on various physical platforms [
24], including optical setups [
25,
26,
27,
28,
29] and superconducting devices [
30,
31], and they can also be simulated on gate-based quantum computers [
32,
33].
In order to evaluate our proposed methods, we conducted experiments on several networks and found that both the classical and quantum walks outlined here are particularly good at finding missing links in protein–protein interaction (PPI) networks. Protein–protein interactions play a critical role in all cellular processes, ranging from cellular division to apoptosis. Elucidating and analysing PPIs is thus essential to understand the underlying mechanisms in biology and, eventually, to unveil the molecular roots of human disease [
34]. Indeed, this has been a major focus of research in recent years, providing a wealth of experimental data about protein associations [
35,
36]. Current PPI networks, called interactomes, have been constructed using a number of techniques, but despite the enormous advancement, the current coverage of PPIs is still rather poor (for example, it is estimated that only around 10% of interactions in humans are currently known [
37]). Additionally, despite considerable improvements in high-throughput (HTP) techniques, they are still prone to spurious errors and systematic biases, yielding a significant number of false positives and false negatives. This limitation impedes our ability to assess the true quality and coverage of the interactome.
Recently, a number of algorithms have been developed to predict protein–protein interactions. In a recent study by Kovács et al. [
4] (see also [
38,
39]), a novel PPI-specific link predictor was proposed. Their link predictor was biologically motivated by the so-called L3 principle, and it was shown to be superior to other general link predictors when applied to PPI data. The exceptional success of the L3 framework is rooted in its ability to capture the structural and evolutionary principles that drive PPIs. The results of Kovács and collaborators proved that, contrary to the current network paradigm, interacting proteins are not necessarily similar and similar proteins do not necessarily interact, questioning the traditional validation strategy based on the biological similarity of the predicted protein pairs.
However, the L3 link prediction method, considered the most-successful to date for PPIs, as well as most other existing link prediction methods are not without limitations. The most-common approaches cannot find interactions for self-interacting proteins or links between proteins that have long shortest paths between them. Given the low coverage of the current PPI databases, this can be a significant drawback. It is, therefore, highly desirable to complement the existing frameworks with methods relying on the exploration of the whole network, and consequently be able to predict edges whose corresponding nodes may be far away in the network. Thus, we propose novel quantum- and classical-random-walk-based link prediction methods that can potentially traverse the entire network and simultaneously predict self-edges.
2. Materials and Methods
Consider a network modelled by an undirected and unweighted graph
, where
V is the set of nodes of size
n and
E is the set of edges. We allowed for the existence of self-edges, so that for any node
i, the edge
may or may not be present in
E. The
adjacency matrix of
G is the
matrix defined by
The
graph Laplacian is defined as
, where
D is the
degree matrix defined by
.
The link prediction problem is to infer missing links in a network G, using only the information provided by the structure of G. Thus, a link prediction algorithm typically gives a ranking of all the non-edges (pairs of nodes that are not directly connected in G) based on some proposed scoring scheme.
We now present a rather general scoring scheme for ranking the non-edges of a graph based on state transition probabilities resulting from quantum and classical random walks; the precise details of the walks we employed are described in the next subsections. For now, it suffices to consider the notion of a probability transition matrix that evolves over time, denoted by
; for a graph
G, the probability of the walker being at node
v at time
t, given that it began at node
u, is thus
. For a fixed time
t, we define the score
between two non-adjacent nodes
i and
j at time
t to be
where
N(
v) denotes the set of nodes adjacent to
v (possibly including
v itself) and
is the degree of node
Equations (1) and (2) handle the cases of distinct nodes and self-edges, respectively. The scoring scheme in Equation (1) is based on the intuition that two nodes
i and
j should likely be connected if the walk is more likely to move from
i to
j than to other nodes. We also scale these probabilities by the node degrees so that high-degree nodes have a higher preference, similar to the preferential attachment link prediction method [
40,
41]. Further, Equation (2) claims that the properties of the walker in the neighbourhood of the node determines the likelihood of a self-edge. While the score in Equation (1) is superficially similar to the one proposed in [
5], the fact that we use continuous-time walks leads to several key differences: the continuous-time nature of our method allows for a wider range of time parameters
t to use; in the continuous-time setting, there is symmetry in the transition probabilities, i.e.,
for all nodes
finally, there is a close relationship in the implementation of classical and quantum walks in the continuous-time setting.
Regardless of which type of walk is used, we must choose a value
t, representing the time duration of the walk. We start the walk at time
and let it run for a time
t, at which point we extract the scores for the target edges from the probability distributions. In the case of a continuous-time classical random walk, the expected time it takes for a random walker to leave a node
i is
This motivates the idea that the amount of time we let the walk run should be related to the degree distribution of the network. In our experiments, we tested a few small multiples of the value
, where
is the average node degree in the graph, and report the value yielding the best results (see the results in
Section 3).
2.1. Continuous-Time Random Walks
A continuous-time (classical) random walk (CRW) is a Markov process with state space
V characterised by an initial distribution
over the set of nodes and a rate matrix
Q that has null row sum
for all
j. Here, we considered edge-based random walks [
42] (as opposed to node-based), which are characterised by setting
, where
L is the Laplacian of the underlying graph. In this case, the evolution of the probability vector
is governed by the equation:
where
is the probability transition matrix, which has the elements
, where
i and
j are standard basis vectors.
Intuitively, the random walker operates as follows. Every edge of the graph is associated with an independent Poisson process with unit intensity. When the walker is at some node, it will remain there until one of the Poisson processes at an incident edge jumps, at which point, the walker follows that edge to the corresponding neighbour, and the process repeats. Note that this implies that, on average, a random walker will spend less time waiting at a higher-degree node than at a lower-degree node. Furthermore, this method will assign non-zero probabilities to all pairs of nodes in a connected component, due to the continuous-time nature of the walk.
2.2. Continuous-Time Quantum Walks
In contrast to a classical random walk, a quantum walk on a network evolves according to the laws of quantum physics. A major implication of this is that the trajectories of the walker across the network can interfere constructively or destructively. This interference causes the evolution of the quantum walker to sometimes be significantly different from the classical one [
17,
43].
A continuous-time quantum walk (QW) [
16] on a graph
G is defined by considering the Hilbert space
spanned by the orthonormal vectors
, corresponding to the
n nodes of the graph and the unitary transformation
This transformation implies that the state vector in
at a time
t after starting from initial time
is given by the evolution:
where
is the unitary evolution operator and
H is the Hamiltonian. In general, the Hamiltonian
H can be almost any Hermitian matrix related to
G as long as it describes the structure of the network [
19], but the most-common choices are the graph adjacency matrix
A or the Laplacian
L [
44]. We also note that, in the classical random walk, the rate matrix
Q is required to have a null row sum so that it is probability-conserving, and thus, the Laplacian
L is a valid choice. However, for quantum walks, no such restriction exists, and a wider range of walks can be considered by modifying the Hamiltonian, as long as it remains Hermitian [
45]. For example, the graph adjacency matrix can be used as a Hamiltonian, but not as a classical rate matrix since its rows do not sum to zero. In this paper, we used both the adjacency and Laplacian matrices as the Hamiltonians separately and, therefore, can compare different realisations of quantum walks for the link prediction task.
In order to obtain a probability transition matrix analogous to the one in Equation (3), we must take the square of the modulus of the entries of
. The entries of the probability transition matrix are given by
These transition probabilities can then be used to compute scores for non-edges as described in Equations (1) and (2) above. Note that, contrary to the classical case, where randomness comes from stochastic transitions between states, in the quantum walk, the state transitions are deterministically governed by the Schrödinger equation, and the randomness results from the measurement and collapse of the wave function.
Our motivation for the usage of continuous- rather than discrete-time walks is threefold: there is a close resemblance between the classical and quantum versions via the matrix exponential, which allows both methods to be easily compared; having a real, rather than an integer-valued hyperparameter
t allows for a wider range of results to be explored and also permits non-zero scores to be assigned to all pairs of non-neighbouring nodes within a connected component. We emphasise that the usage of continuous-time quantum walks for link prediction is a new direction of research, with very few studies conducted so far. The method proposed in [
23], in particular, appears to be competitive with some state-of-the-art link prediction methods in certain real networks. While some aspects of their algorithm are similar to the quantum version of our algorithm, the implementation details and calculation of the link prediction scores are very different. Moreover, their algorithm requires entanglement with an additional ancilla. While this would be feasible in a hypothetical implementation on a quantum computer, the typical sizes of relevant real networks are far beyond the capabilities of current and near-term quantum hardware. Simulations on classical computers are required, but the presence of the extra ancilla increases the complexity of the simulations.
2.3. Datasets and Metrics
We tested our link prediction methods on six different PPI networks. Four networks were
Homo sapiens (human) PPI networks: we used the physical, multi-validated interactions from v4.4.219 of BioGRID [
46], the high-quality binary and co-complex interactions from the HINT database [
47], the interactions proven by 2 or more pieces of experimental evidence from APID [
48,
49] (downloaded on 1 March 2023), and the experimentally validated interactions from the Integrated Interactions Database (IID) [
50], Version 2021-05. Furthermore, we also tested our methods on the interactions of the organism
Saccharomyces cerevisiae (yeast) from BioGRID and HINT just described.
Some statistics of these networks are listed below in
Table 1, and their degree distributions are shown in
Figure 1. We observed from these statistics that the networks have high clustering and that they are very sparse. Furthermore, the networks are approximately scale-free [
51], which is typical of biological networks. One distinguishing feature of PPI networks compared to most other complex networks is that they contain self-edges, which represent the ability of a protein to interact with itself.
Since the ground truth of the considered PPI networks is of course unknown, we proceeded to test the algorithms using cross-validation. For each dataset, we randomly removed
of the edges in the original network, for
, and reserved these edges as positive test cases. All of the non-edges (including self-edges that are not present in the network) were used as negative testing data. These positive and negative edges were used to evaluate the methods, and the remaining
existing edges were used for running the models in question. In other words, after removing the
of the edges, the non-edges were ranked by sorting them in descending order according to their scores, and the edges with higher scores were deemed most likely to exist. This ranking was then compared to the evaluation set to see how well the positive test cases were ranked. This process was repeated 10 times for each
P, and the results of the accuracy metrics were averaged (see the results in
Section 3).
In order to compare the rankings of the edges of the methods under consideration, we used the areas under the precision–recall and receiver operator characteristic curves, two metrics that are typically used in link prediction and other binary classification problems. Hence, we define
where TP = true positive, FP = false positive, FN = false negative, and TN = true negative. In order to calculate each of these from the rankings, a threshold that serves as a cut-off rule has to be selected (the predictions above the thresholds are classified as positive and below it as negative). Our two metrics were calculated by varying this threshold trough the rankings. Firstly, we considered the area under the precision–recall curve (AuPR). Precision–recall curves plot the recall on the
x-axis against precision on the
y-axis. In order to reduce this curve to a single number, the area under the curve is used, and this also circumvents the problem of choosing an arbitrary score threshold at which to distinguish predicted positives from negatives. Note that the AuPR focuses only on performance relative to the positive class, an important consideration when the ratio of positive cases to negatives cases is small, as is the case in most networks and especially in PPI networks (these networks are extremely sparse; see
Table 1). As a secondary metric, we considered the area under the receiver operating characteristic curve (AuROC) [
52], which plots the false positive rate versus the recall. It can be interpreted as the probability that the classifier will rank a positive case, chosen uniformly at random from the positive set, higher than a negative one, chosen uniformly at random from the negative set [
53]. Thus, a random classifier has an AuROC equal to half and a perfect classifier has an AuROC equal to one. We emphasise that the AuPR is widely accepted as the preferred metric for link prediction, due to the large class imbalance mentioned above [
54,
55].
3. Results
In order to test our methods, we selected five other popular link prediction methods to compare against:
L3 relies on a weighted counting of paths of length three and was designed specifically to predict links in PPI networks [
4];
preferential attachment (PA) defines a score between two disconnected nodes by multiplying their degrees [
40,
41];
common neighbours (CN) is a straightforward heuristic that assigns a score to the node pair
defined by the number of neighbours that
u and
v have in common;
Adamic-Adar (AA) is an adaptation of the common neighbours idea, but adds more weight to less-connected neighbours [
1]; the
structural perturbation method (SPM) uses perturbations of the adjacency matrix of a graph in order to estimate its predictability [
56]. While the SPM has shown great success as a general link prediction method [
6,
57], it is yet to be tested extensively on PPI networks. For the SPM, we used
and averaged the results over 10 runs, as was performed in the original paper [
56].
The following tables show the average AuPR and AuROC values for the six different networks described in
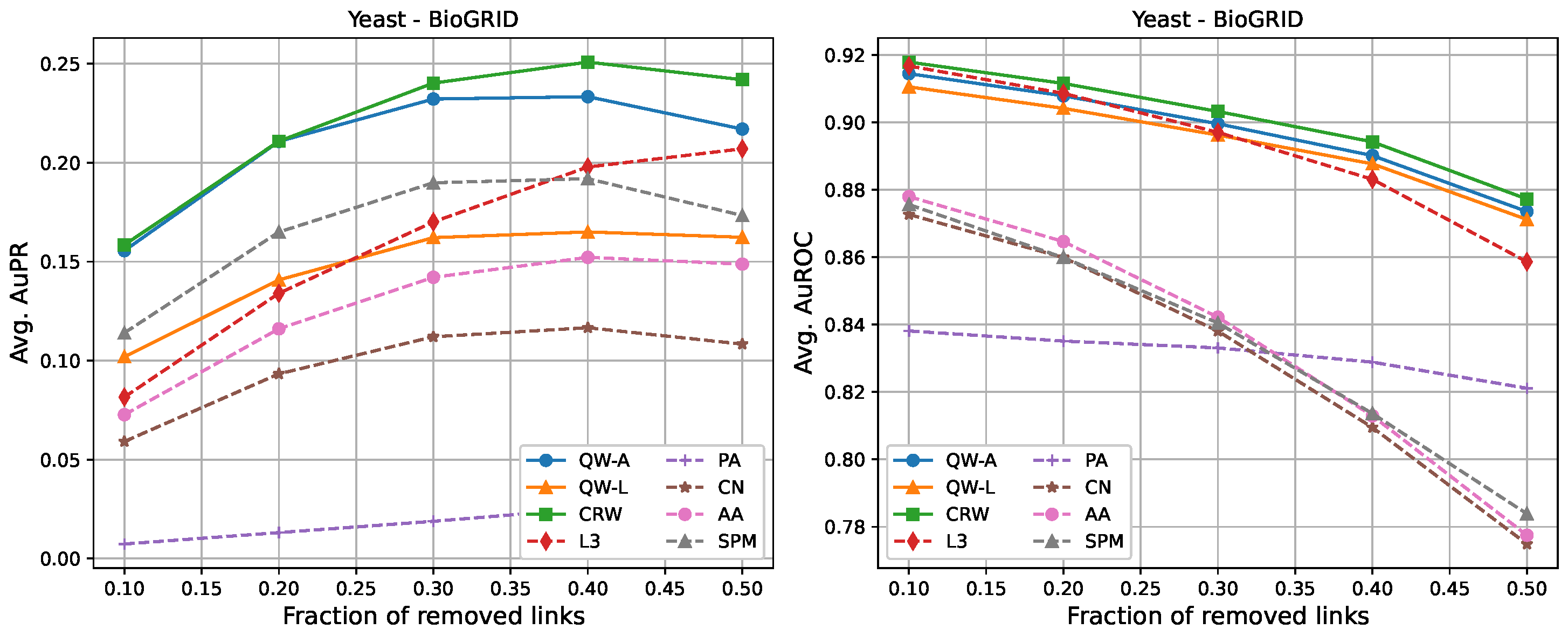
Section 2.3. Each value was averaged over 10 runs (10 randomly selected edge removals), and the highest value for each network is shown in bold. We compared three variations of our proposed methods, labelled as “QW-A”, “QW-L”, and “CRW”, referring to quantum walks using the network adjacency matrix as the Hamiltonian, quantum walks using the network Laplacian matrix as the Hamiltonian, and classical random walks, respectively.
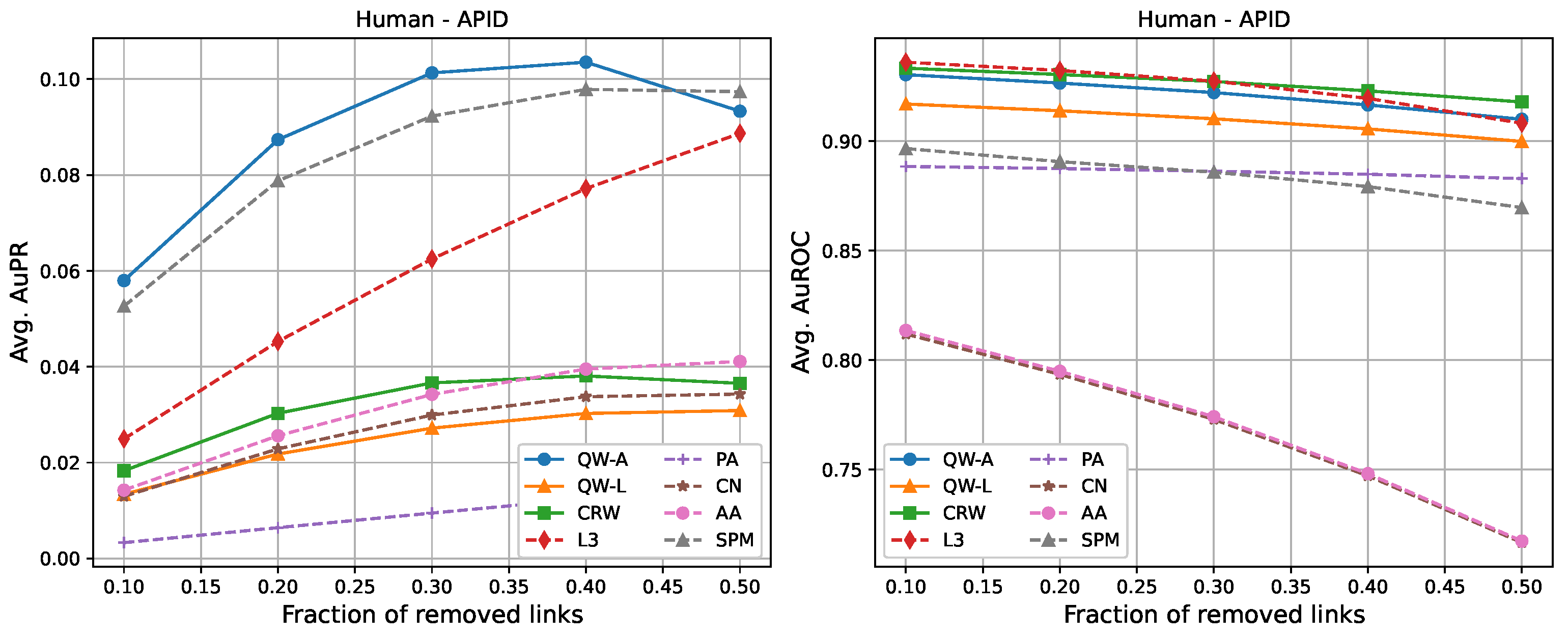
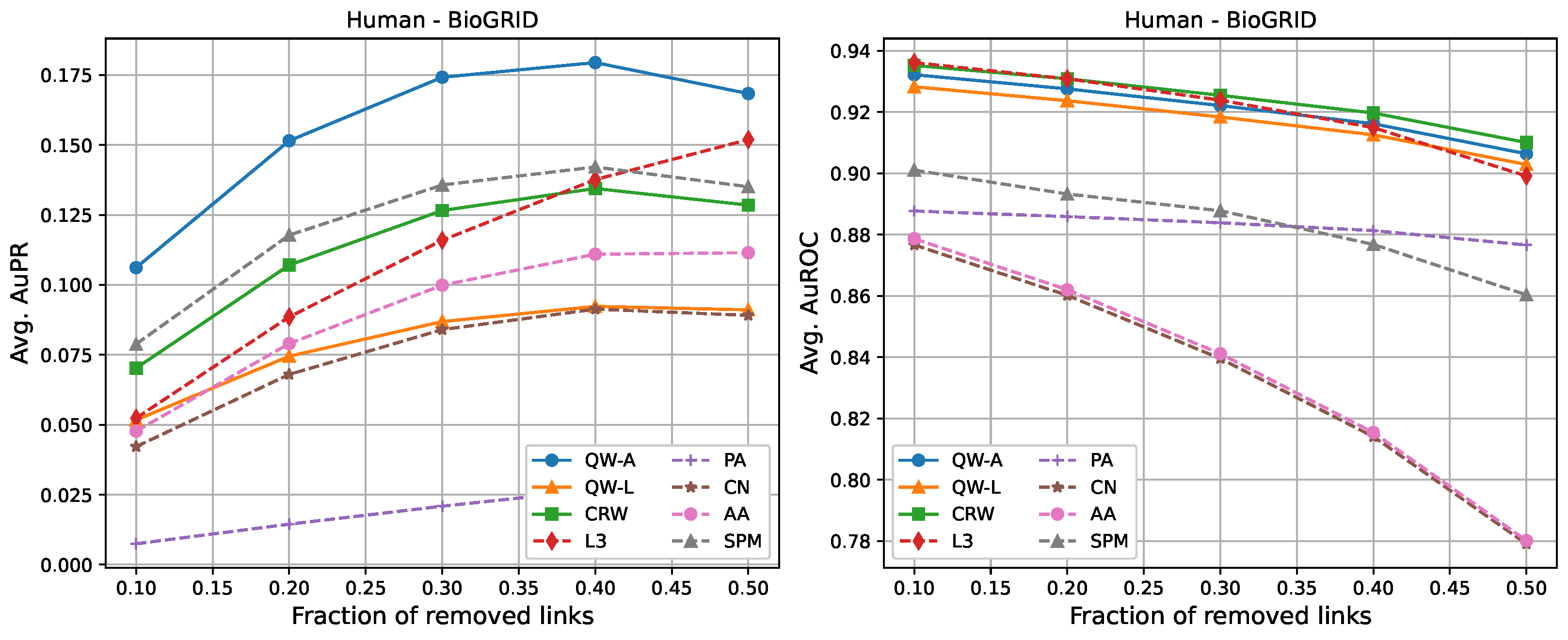
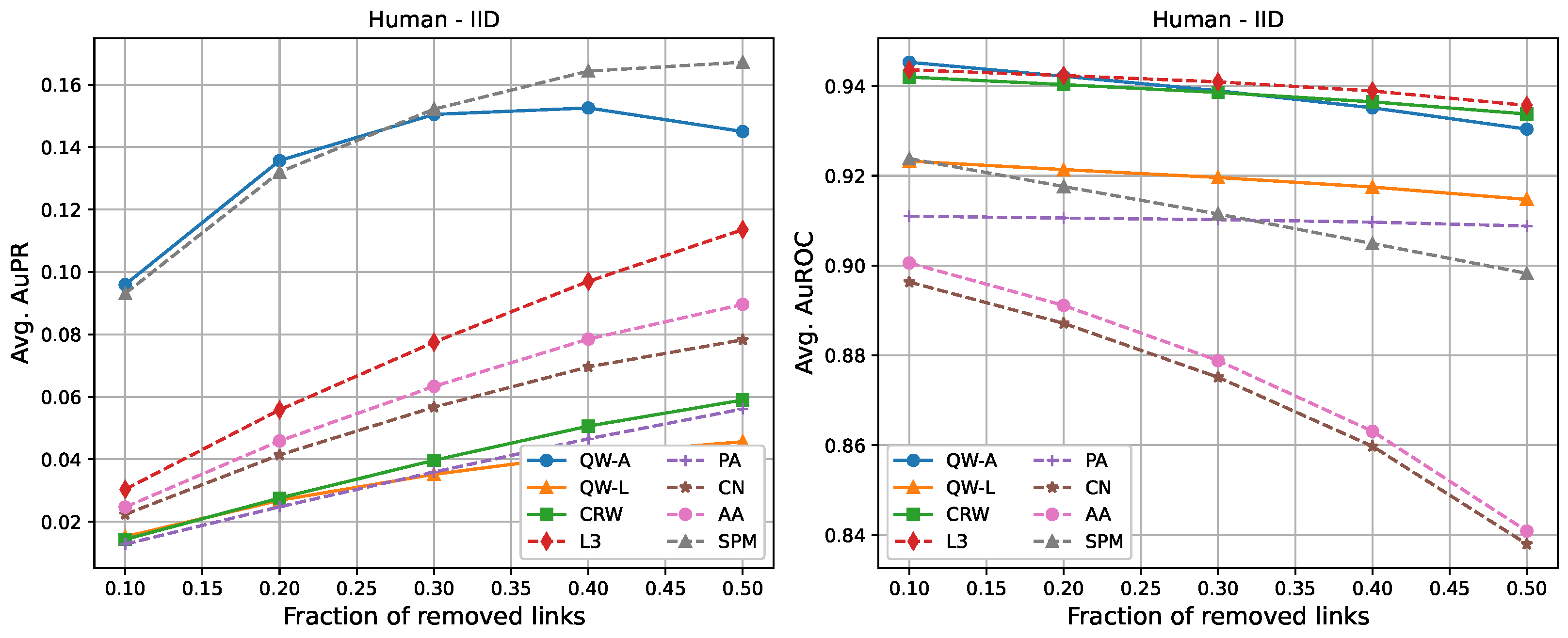
For completeness, in
Figure 2,
Figure 3,
Figure 4,
Figure 5,
Figure 6 and
Figure 7, we also include plots showing the relationship of the area under the precision–recall curve and area under the ROC curve as a function of the edge removal fraction.
In terms of area under the precision–recall curve (AuPR), the quantum walk with the adjacency Hamiltonian (QW-A) showed the best results overall. When 10% of the edges were removed, the QW-A had a higher average AuPR than all other benchmarked methods. This also held when 50% of the edges were removed, except in three cases. For the secondary metric, AuROC, the three best methods appeared to be QW, CRW, and L3; while L3 had the highest AuROC in half of the networks at the 10% removal level by a small margin, CRW had the highest AuROC at the 50% level in all but one network.
4. Discussion
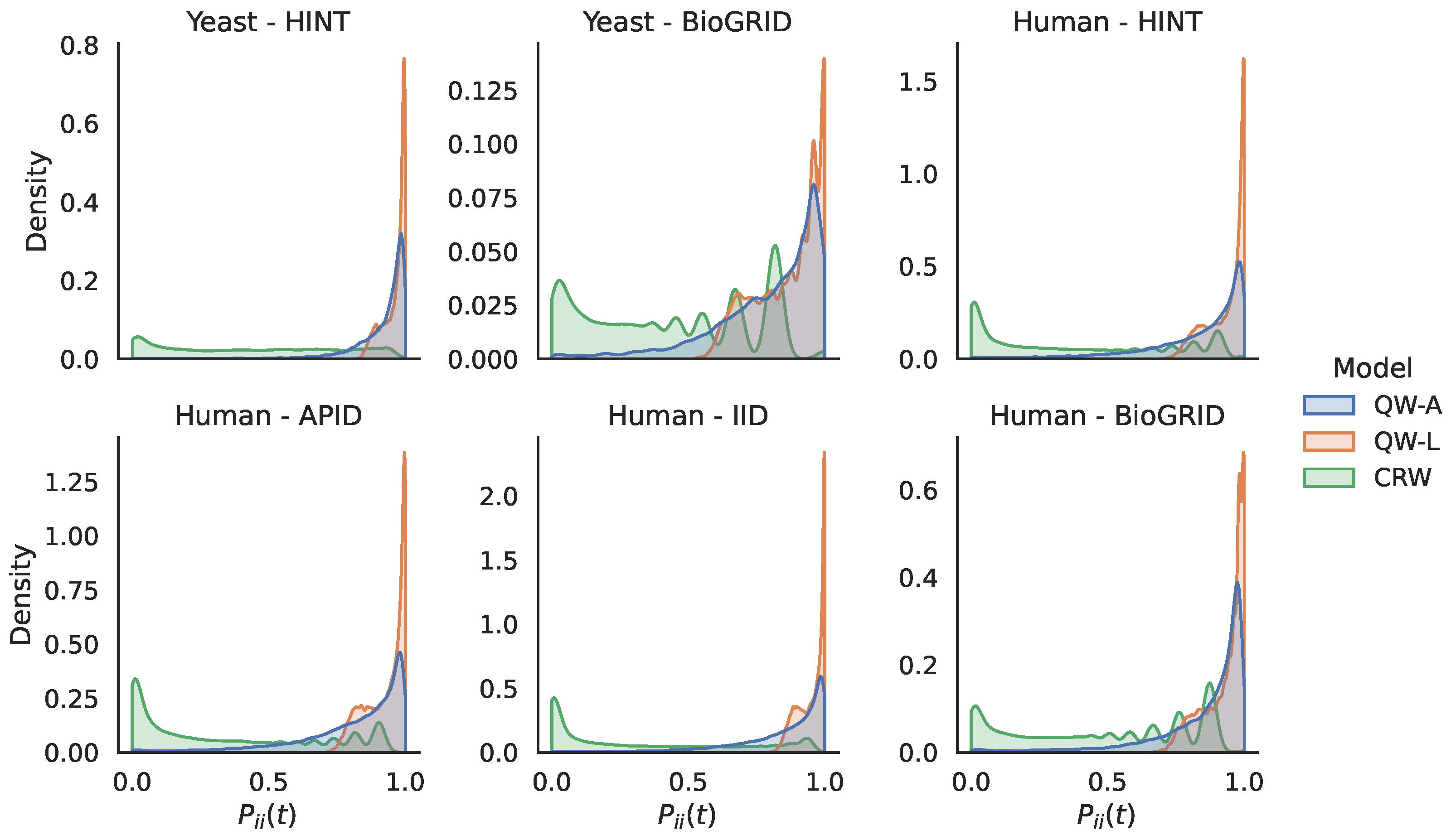
The experimental results in the previous section showed that our methods performed well on a variety of PPI networks. In particular, we saw that our quantum walk with the adjacency Hamiltonian method yielded the best overall performance of all algorithms tested with respect to the area under the precision–recall curve. Furthermore, the adjacency Hamiltonian always beat the Laplacian as the better choice when comparing the results of quantum walks. One possible explanation for this is that the inclusion of node degrees on the diagonal of the Hamiltonian for the Laplacian matrix caused walkers to remain at nodes for longer periods of time, thus preventing them from adequately exploring the rest of the network. In order to explore this further, in
Figure 8, we show the distribution of the return probabilities
over all nodes
i for the various networks studied. Indeed, we see that the QW-L had a large spike close to 1.0 for all of the networks, indicating that the majority of nodes were never departed from when using the Laplacian Hamiltonian. In order to verify that this claim holds for other values of
t, in
Figure 9, we compare the return probabilities, averaged over all nodes, for various values of
We see that the QW-L always had the largest average return probability, while the QW-A had an average return probability that was less than the QW-L, but larger than the CRW.
Comparing the QW-A to the CRW,
Table 2 and
Table 3 above show that the former had a higher area under the precision–recall curve for all networks, except the Yeast-BioGRID network. One interesting property of this network is that it has the highest proportion of self-edges (826 self-interacting proteins out of 4186 proteins; see
Table 1) of all the networks considered. In order to test the hypothesis that the CRW performs better when the proportion of self-edges is high, we repeated our experiments on the Yeast-BioGRID network, but this time did not use any self-edges for scoring. We found that the change in AuPR was negligible and that the CRW still had a slightly higher AuPR than the QW-A. Therefore, we do not believe that the high proportion of self-edges plays a significant role in explaining the better performance of the CRW for this network.
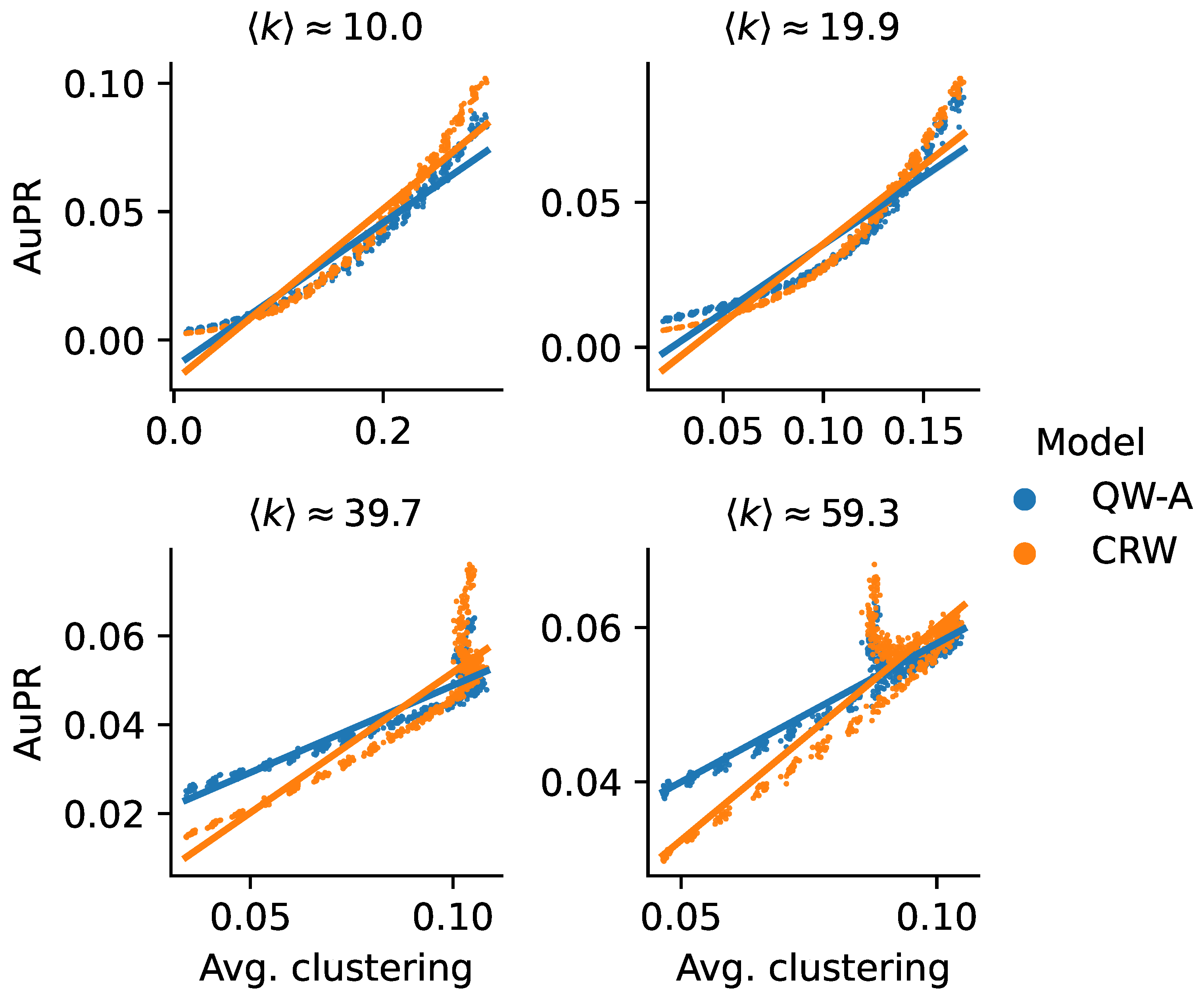
Another possible explanation for the higher AuPR of the CRW on the Yeast-BioGRID network may be due to its relatively high clustering compared to the other networks. In order to test this hypothesis, we used a theoretical model to generate scale-free networks with tunable average clusterings [
58]. Using this model, we generated scale-free networks with a variety of average clusterings while holding the average degree constant, up to minor random fluctuations. We then used these networks to run the QW-A and CRW using the same cross-validation method described above, with half the edges being removed for testing, in order to compare their performance. In
Figure 10, we see that, in all four cases, there was indeed a trend confirming that the QW-A has a better performance when clustering is low, while CRW performs better when clustering is higher. While these theoretically generated networks may not be accurate models of true PPI networks, the effect of clustering on classical and quantum walks remains an interesting topic for future research.
Finally, we mention a few points about the computational complexity of our algorithm and its implementation. The bottleneck of our algorithm, in either the classical or quantum case, is the computation of the matrix exponential appearing in Equations (3) and (5), which is a very well-studied problem with a long history [
59]. Our experiments were performed using the “matrix_exp” function in PyTorch [
60], which is an implementation of the Taylor polynomial approximation algorithm described in [
61]. The problem was thus reduced to a constant number of matrix multiplications, another well-studied problem that can be solved more quickly than the naive
method, for example with Strassen’s algorithm or its variations [
62]. It is also worth noting that, in this implementation of matrix exponentiation, and many others, the norm of the matrix being exponentiated has an impact on running time, so that using a small
t, as tends to be the case in our algorithm, may help in this regard.
In order to compare the running times of the link prediction methods studied here, each method was implemented in python 3.10 and vectorised where possible. The methods were then run on the six networks described in
Section 2.3, without removing any edges. The experiments were carried out on a setup consisting of 16 cores and 112 GB of RAM. The results of the running times are shown in
Table 4. In general, L3, PA, CN, and AA had the fastest running times, but had low AuPR when compared to the QW-A and SPM (
Figure 2,
Figure 3,
Figure 4,
Figure 5,
Figure 6 and
Figure 7, left). Of the general link prediction methods, the SPM typically had the highest AuPR, but it is computationally demanding due to the need to calculate the eigenvectors and eigenvalues of the perturbed adjacency matrix many times. The QW-A is indeed the most-promising of the methods considered, since its runtime was several times faster than the SPM, while outperforming the SPM in every case, except two, in which case, the QW-A had the higher AuROC (
Figure 2 and
Figure 5 and
Table 5 and
Table 6).
5. Conclusions
Although experimental methods have greatly improved in the past ten years, most interactomes remain far from being complete. It is, therefore, important to discover new computational methods for inferring interactions from incomplete datasets. We described a class of algorithms based on continuous-time walks that rank among the best link prediction methods tested on PPI networks.
Furthermore, the continuous-time quantum walks described here are among the first successful quantum-inspired link prediction methods. Although we found that using the reciprocal of the average degree provided a good time length for which to run the walks, many further options can still be explored: using cross-validation to choose a more optimal value or using times that depend on the walker’s location are immediate candidates. Another open direction of research involves the choice of the Hamiltonian. Our experimental results demonstrated a strong sensitivity on the Hamiltonian used for controlling the quantum walks. While the adjacency matrix yielded better results than the Laplacian on the networks we tested, it would be beneficial to understand why this is the case. This also indicates the potential for improvement if better Hamiltonians can be found for the purpose of link prediction. Further investigations in this direction may yield better methods and insights into both networks being studied and the quantum walks being employed.

 and
and 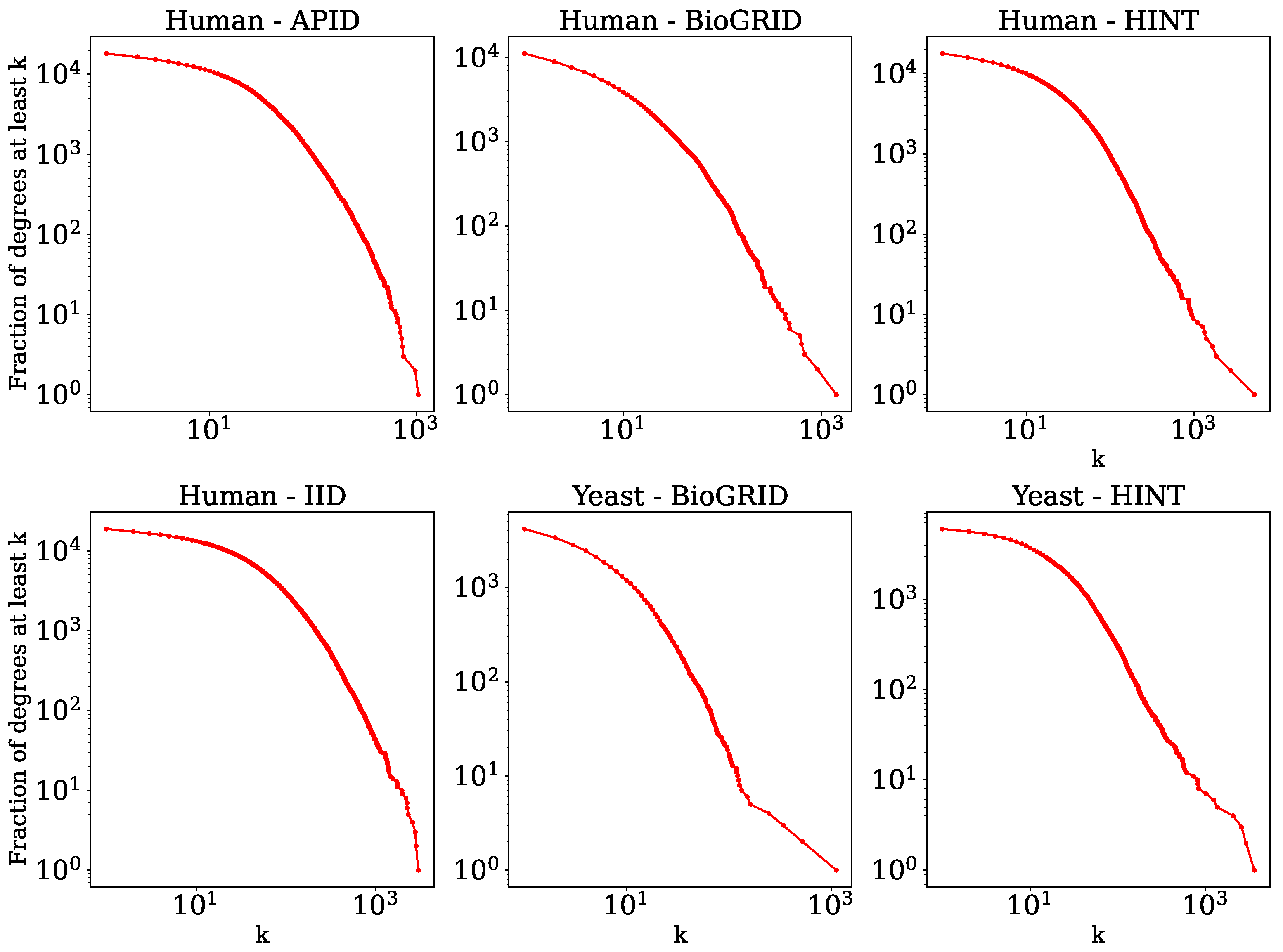




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}