Abstract
This study aims to unravel the resource allocation problem (RAP) by using a consensus-based distributed optimization algorithm under dynamic event-triggered (DET) strategies. Firstly, based on the multi-agent consensus approach, a novel one-to-all DET strategy is presented to solve the RAP. Secondly, the proposed one-to-all DET strategy is extended to a one-to-one DET strategy, where each agent transmits its state asynchronously to its neighbors. Furthermore, it is proven that the proposed two types of DET strategies do not have Zeno behavior. Finally, numerical simulations are provided to validate and illustrate the effectiveness of the theoretical results.
1. Introduction
With the development of network information technology and the era of artificial intelligence, multi-agent systems (MASs) have received extensive attention in view of their applications in the machining industry [1], synchronous generators [2], microservice-based cloud applications [3], USVs [4], and other fields. It is worth noting that consensus is one of the most fundamental and important problems in MASs, and there have been many studies about it [5,6,7,8]. In essence, the distributed optimization problem is that a group of agents achieve a goal by exchanging local information with neighbors and minimizing the sum of all the local cost functions. In contrast to conventional consensus, distributed optimization problems require both achieving consensus and solving optimization problems. Up to now, distributed optimization problems have already appeared widely in power systems [9], MPC and network flows [10], wireless ad hoc networks [11], etc.
Early distributed optimization problems were mainly solved by centralized optimization algorithms. The feature of a centralized optimization algorithm is that all agents have a central node that centrally stores all of the information to address the optimization problem [12,13]. However, centralized optimization algorithms are unsuitable for large-scale networks, because collecting information from all agents in the network requires a lot of communication and computational overhead, and there will be the single point of failure problem. Consequently, distributed optimization algorithms have emerged as the times require. In recent years, distributed optimization algorithms are divided into two main categories, i.e., discrete-time algorithms and continuous-time algorithms. More specifically, discrete-time distributed optimization algorithms have been utilized in the optimal solution of the saddle point dynamics problem [14], epidemic control resource allocation [15], and tactical production planning [16]. Additionally, many researchers have made substantial explorations of continuous-time distributed optimization algorithms recently. For instance, a continuous-time optimization model was developed in [17] for source-sink matching in carbon capture and storage systems. In [18], the application of a continuous-time optimization algorithm was investigated in power system load distribution, and the distributed continuous-time approximate projection protocol was proposed in [19] for solving the shortest distance optimization problem.
Many of the above optimization algorithms communicate in continuous time, which can lead to frequent algorithm updating and then cause unnecessary communication resource consumption, so it is necessary to solve the system’s resource problem. Therefore, applying event-triggered strategies to distributed optimization algorithms [20,21,22,23,24,25,26] is a feasible and promising scheme that can effectively reduce the energy waste of the system. Only when the designed event-triggered condition is satisfied, is the system allowed to communicate and update the protocol, which helps to reduce the cost and burden of communication and computing as well as the collection of gradient information. Primarily, for static event-triggered (SET) mechanisms, which include the constant trigger thresholds independent of time, it is theoretically difficult to rule out Zeno behavior. Furthermore, as the working time increases, the inter-event time intervals become larger, which results in more trigger actions and wasting the system’s resources. Furthermore, the event-triggered strategy has undergone a paradigm shift from the SET strategy to the dynamic event-triggered (DET), which introduces an auxiliary parameter for each agent to dynamically adjust its threshold. Moreover, in most cases, the DET strategy can well extend the average event intervals, thus further reducing the consumption of communication resources compared to SET communication. Therefore, the DET strategy has aroused much interest and it holds great applicability value, which was considered in [27,28,29,30,31,32,33]. An improved event-triggered strategy, independent of the initial conditions, was leveraged in [34] to solve the topology separation problems caused by critical communication link failures. In [35], the corresponding DET mechanism was presented for two cases based on nonlinear relative and absolute states coupling, and it was also proved that the continuous communication between agents can be effectively avoided. Under the DET strategy, each agent transmits information to all neighbors synchronously when its trigger condition is met, which is usually called the one-to-all DET strategy. Nevertheless, under the one-to-all DET strategy, it is unreasonable to ignore the possibility that each agent has different triggering sequences. Therefore, to overcome the limitation of the one-to-all DET strategy, it is essential to design a DET strategy that allows each agent to decide its own triggering sequences and transmit information asynchronously to its neighbors according to different event-triggered conditions designed for each of its neighbors, which is referred to as the one-to-one DET strategy. Under the one-to-one DET strategy, owing to its characteristics, an agent is not constrained by any synchronous execution of its neighbors’ transmission information, so it can adjust the information transmission more flexibly, especially in the case of cyber-attacks. In [36], under an adaptive DET strategy, the fully distributed observer-based strategy was developed, which guarantees asymptotic consensus and eliminates Zeno behavior.
So far, note that many distributed optimization algorithms have been leveraged to solve the resource allocation problem (RAP), such as in [37,38,39]. Therefore, it is necessary and significant to combine DET strategies to solve the RAP. Motivated by the above discussions, we further investigate distributed optimization algorithms with two novel synchronous and asynchronous DET strategies to address the RAP. The main contributions of this article are developed as follows.
- (1)
- This work combines the consensus idea and one-to-all DET strategy to design a new distributed optimization algorithm to solve RAP, in which the algorithm can keep the equality constraint constant. In addition, unlike the SET strategies of [40,41], the DET in this work has a lower trigger frequency, which means that the system resources can be saved.
- (2)
- In order to improve the flexibility and practicality of the algorithm, the one-to-all DET strategy is extended to a one-to-one DET strategy. Based on this strategy, a distributed optimization algorithm is developed to address the RAP.
- (3)
- The two types of proposed distributed optimization algorithms only use the information of the decision variable to avoid the communication among agents, which ingeniously reduces the resource consumption, while the algorithm in [42] needs to exchange information about the variables and . In addition, the introduced internal dynamic parameters in this work are not only effective in solving RAP, but also crucial in successfully excluding Zeno behavior.
The organization of the remaining parts of this paper is as follows. Some algebraic graph theory preliminaries, a basic definition and assumptions, and the optimization problem formulation are given in Section 2. In Section 3 and Section 4, distributed optimization algorithms under the proposed one-to-all and one-to-one DET strategies are presented to solve the RAP. Furthermore, the proof of the exclusion of Zeno behavior is included. In Section 5, numerical simulation results are given to illustrate the effectiveness of the proposed algorithms. Finally, we show our conclusions and future work direction in Section 6.
Notation 1.

The symbols appearing in this article are listed in Table 1.
Table 1.
Notation used in this paper.
2. Preliminaries
2.1. Algebraic Graph Theory
The topology among n nodes can be modeled as a graph consisting of a finite node set , a set of edges , and a weighted adjacency matrix , with if and otherwise. Given an edge , we refer to as a neighbor of , then, and can receive each other’s information. The set of is defined as , which does not contain self-edges . An undirected graph is connected if for any vertex , there exists a path that connects and . The Laplacian matrix is denoted by and . Furthermore, . The eigenvalue of is a non-decreasing order, i.e., .
2.2. Problem Statement
In the distributed RAP, we consider the MASs composed of n agents where each agent has a local quadratic convex cost function . The global objective function is denoted by . , where the cost coefficients , , and . Then, the RAP can be rewritten as the following optimization problem:
where is a decision variable vector. For convenience, only the case will be discussed, owing to the fact that when it can be solved similarly and completely by using the Kronecker product. and stand for the global cost function and the local cost function, respectively. represents the global resource constraint. In the economic dispatch problem of smart grids, denotes the output power of generator i, and D denotes the total power demand and equality constraint and is called the demand constraint.
This paper aims to design distributed DET strategies to solve RAP (1). Therefore, we need the following definition and assumptions before further analysis.
Definition 1.
The multi-agent consensus problem would be addressed as long as for any initial value of state ,
Assumption 1.
The communication topology is undirected and connected.
Assumption 2.
The local objective functions are quadratically continuously differentiable and strongly convex.
3. The One-to-All DET Strategy
In this section, we construct the one-to-all DET strategy, which allows each agent to transmit information synchronously. Moreover, a distributed optimization algorithm with the proposed DET is introduced and the consensus is derived, which solves the RAP (1).
For the one-to-all DET, the triggering time sequence is determined by The measurement error of each agent is defined as
Then, we propose the one-to-all DET triggering sequence as follows
where and , , are positive constants.
Remark 1.
If setting , the DET strategy reduces to the SET strategy. Then, the one-to-all SET triggering sequence is as follows
Consequently, the SET strategy is a special case of the DET strategy, and the DET strategy is a more general situation. In addition, due to the internal dynamic variables of the DET function, it is easier to exclude Zeno behavior than for SET.
Inspired by [43], we design an internal dynamic variable satisfying
where , and with , are positive constants.
Let and . The distributed optimization algorithm is designed as follows to solve the RAP (1):
where , is an auxiliary variable.
According to the distributed optimization algorithm (4), one obtains where the initial value satisfies
In addition, in matrix form can be described as
where , and .
Then, the distributed optimization problem is transformed into a multi-agent consensus, which implies when , , the RAP (1) is obtained for any agents. Then, is the final value of when it reaches consensus. The detailed procedure of the one-to-all DET strategy is given as Algorithm 1.
| Algorithm 1 Distributed optimization algorithm with the one-to-all DET strategy |
|
Remark 2.
For the quadratic original optimization problem with the equality constraint, based on the Lagrange multiplier method, we construct the Lagrangian function as . Then, under Assumption 2, , is the optimal solution, where is the optimal Lagrange multipliers if and only if , . Therefore, we need to let the Lagrange multiplier of each agent update so that all reach consensus at the value , which means that the optimization problem with equality constraint is transformed to a MASs consensus problem completely. Therefore, as long as the equation holds, the algorithm can achieve consensus and the optimization problem can be addressed.
Remark 3.
Algorithm (4) only uses the information of variable , which is beneficial to save communication resources in the case of limited bandwidth. Furthermore, let , from Assumption 1, i.e., , the proposed zero-initial-value distributed optimization algorithm, i.e., , satisfies the equality constraint at all times. The initial values of the algorithm are composed of the decision variable initial value and the auxiliary variable initial value . Then, we can prove that , and , because the equation holds. Therefore, when the equation is satisfied, the equality constraint holds as well at any time.
Theorem 1.
Under Assumptions 1 and 2, assume that , , then the RAP (1) is solved under the distributed optimization algorithm (4) and the DET strategies (2) and (3). Moreover, Zeno behavior is excluded.
Proof.
Construct the Lyapunov function of the following form
where □
The rest of the proof is the similar to Theorem 2.
4. The One-to-One DET Strategy
In this section, in consideration of the existence of asynchronous transmission needs, the one-to-one DET strategy is introduced, which has the unique characteristics that each agent transmits its information to all of its neighbors asynchronously, unlike the one-to-all DET strategy. Furthermore, based on the one-to-one DET strategy, a more flexible distributed optimization algorithm is similarly presented and the consensus is achieved, which also solves the RAP (1). Then, we prove that the Zeno behavior will not occur, which strongly ensures that the algorithm is implementable.
For the one-to-one DET strategy, the edge-dependent triggering time sequence is raised, i.e., , which essentially differs from the one-to-all case.
Corresponding to the one-to-one DET case, the measurement error is described as
Then, we propose the one-to-one DET triggering sequence as follows
where and , , are positive constants.
Remark 4.
Similarly, if setting , the DET strategy reduces to the SET strategy. Then, the one-to-one SET triggering sequence is as follows
Inspired by [43], we design an internal dynamic variable satisfying
where , and , are positive constants. In addition, , and thus .
Let . The distributed optimization algorithm is determined as follows to solve the RAP (1):
for . In addition, one obtains
where the initial value , , satisfies the equation The detailed one-to-one DET procedure is given as Algorithm 2.
Theorem 2.
Under Assumptions 1 and 2, if the parameters and in (5a,b) and (6) satisfy , , then the RAP (1) is solved under the distributed optimization algorithm (7) and the DET strategies (5a,b) and (6). Moreover, Zeno behavior is excluded.
| Algorithm 2 Distributed optimization algorithm with the one-to-one DET strategy |
|
Proof.
- (i)
- Define the following Lyapunov function:
where
From (8), we have
Note that
From Young’s inequality, one has
Substituting (10) and (11) into (9) yields
According to Formula (12), taking the derivative of the Lyapunov function can be derived as
Then, we can obtain from (5a,b) and (6) that
Since , , , one obtains . This implies that cannot increase and that and are bounded. In addition, , which leads to .
By LaSalle’s invariance principle in [44], one obtains , Thus, the RAP (1) is solved eventually.
- (ii)
- In this part, we prove that Zeno behavior does not occur by contradiction. Assume that the triggering sequence determined by (7) and (8) leads to Zeno behavior, which indicates that for any there exists a such that for any ,
Evidently,
For , , .
Then, for , from (8),
where and .
Therefore, for any ,
By the trigger conditions (5a,b) and (6), when ,
Noting
By using the comparison principle,
Combining (14) and (15), it has
Therefore,
For it is not difficult to see from (16) that , which is obviously contradictory to (13). Consequently, there is no Zeno behavior. □
Remark 5.
In contrast to the one-to-all DET strategy mentioned in Theorem 1, under the one-to-one DET strategy, the triggering sequences of each agent is different, which contributes to flexibly adjusting the transferred information to each of its neighbors . Furthermore, the remarkable feature of the one-to-one DET strategy is that each agent is allowed to design its own distinctive triggering instant which is immune to any synchronous executions and the requirements of or , , and so on. Therefore, in practice, one-to-one DET strategies potentially offer greater flexibility and efficiency in terms of adjusting the transmission of information, which is significant to designing a good DET strategy.
Remark 6.
The proposed algorithms (4) and (7) can effectively solve RAP, but both of them need to satisfy and , which means with initialization constraints. In our future research, we will consider eliminating state initialization.
5. Numerical Example
In this section, two numerical examples are provided to illustrate the effectiveness of the theoretical results. The proposed one-to-all and one-to-one DET strategies are applied to the RAP (1) in case 1 and case 2, respectively. Figure 1 depicts the connection topology, which satisfies Assumption 1. The chosen cost coefficients , , and of the quadratic cost function are listed in Table 2. The load demand D is assumed to be 145. Then, the initial values of are selected as , , , , and , .
Figure 1.
Connection topology.
Table 2.
Cost coefficients.
Case 1. One-to-all DET
First, consider the one-to-all DET based on Theorem 1. Given the scalars , , , , , , , , , , , , , , , , , , , , , , , , Figure 2 shows that converges to , which essentially guarantees that all agents reach asymptotic consensus. Then, from Figure 3, converges to the optimal values. Figure 4 shows the triggering instants of the one-to-all DET strategy. In addition, the equality constraint can be obtained from Figure 5.
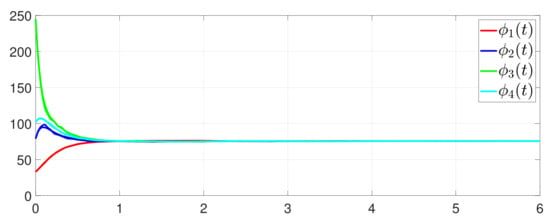
Figure 2.
Trajectory of .
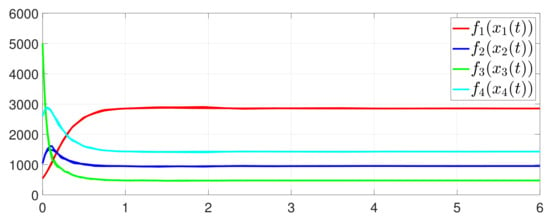
Figure 3.
State evolution of .
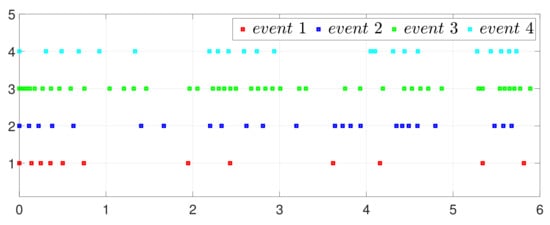
Figure 4.
Event triggering instants under one-to-all DET.
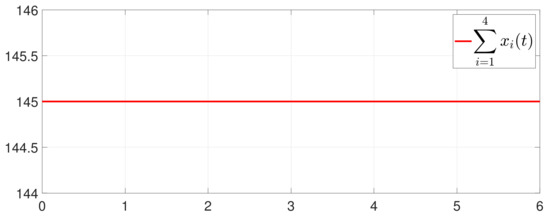
Figure 5.
Trajectory of .
Furthermore, the equality constraint can be obtained from Figure 6. The trajectories of are shown in Figure 7. Moreover, Figure 8 shows the minimum value of , where is the optimal solution of the RAP (1). Figure 9 exhibits the trajectory of the dynamic variable .
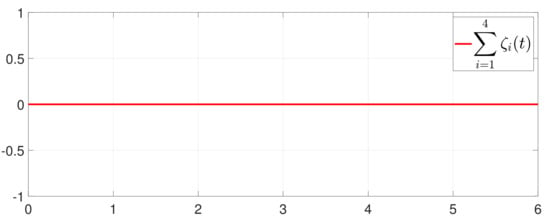
Figure 6.
Trajectory of .
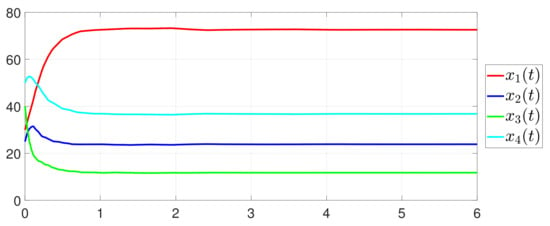
Figure 7.
State evolution of .
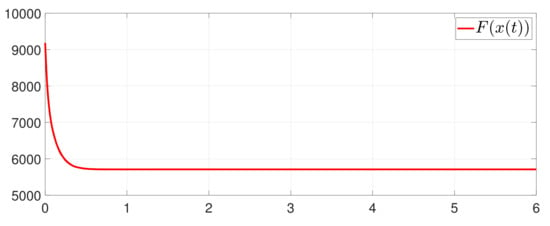
Figure 8.
State evolution of .
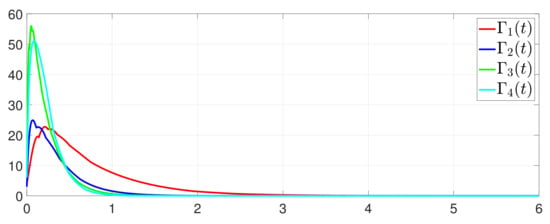
Figure 9.
State evolution of .
Case 2. One-to-one DET
Consider the one-to-one DET based on Theorem 2. Different from case 1, given , Figure 10 shows that converges to , which also implies that consensus is indeed achieved. Then, as seen in Figure 11, converges to the minimum value. Figure 12 shows the triggering instants of the one-to-one DET strategy. In addition, the equation constraint is guaranteed from Figure 13.
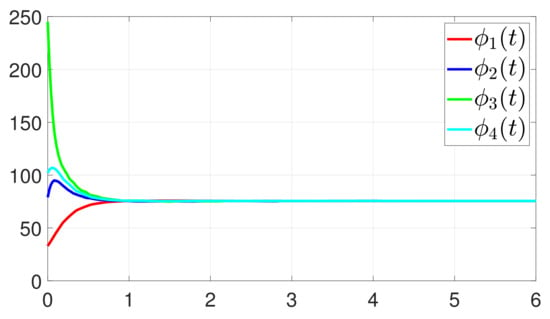
Figure 10.
Trajectory of .
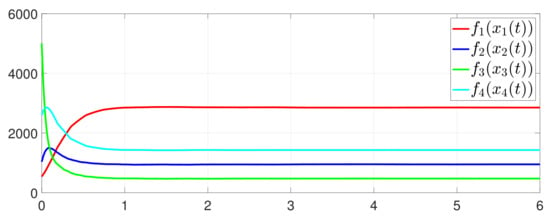
Figure 11.
State evolution of .
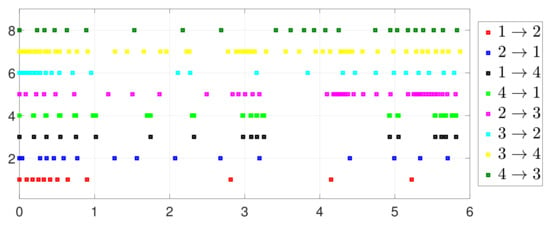
Figure 12.
Event triggering instants under one-to-one DET.
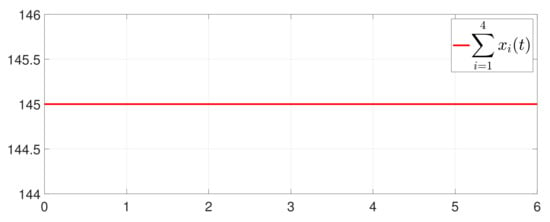
Figure 13.
Trajectory of .
Besides, the equation constraint is guaranteed from Figure 14. The motion trajectory of is shown in Figure 15. Furthermore, Figure 16 depicts the minimum value of , where is the optimal solution of the RAP (1). Figure 17 shows that converges to 0 and always holds.
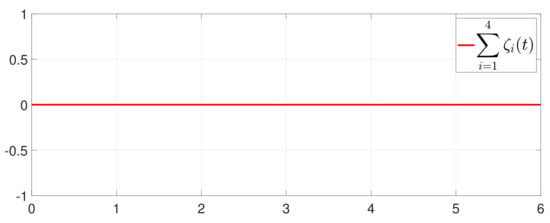
Figure 14.
Trajectory of .
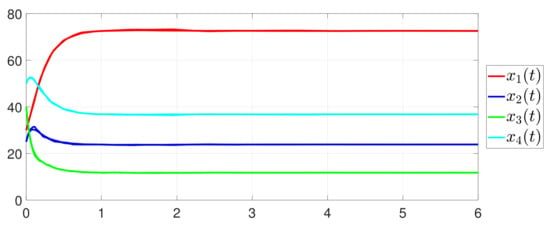
Figure 15.
State evolution of .
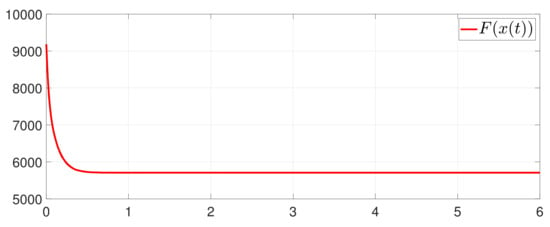
Figure 16.
State evolution of .
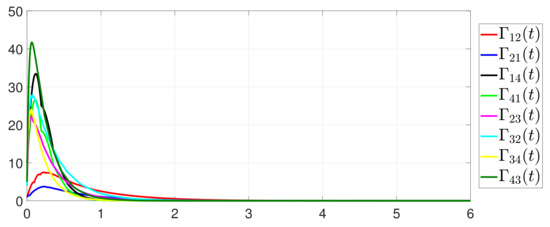
Figure 17.
State evolution of .
Case 3. DET vs. SET
By letting and in (2) and (5), one has the one-to-all SET and one-to-one SET versions (2b) and (5b). Then, the one-to-all DET and SET strategies are compared in Figure 18 and Figure 19. Moreover, the one-to-one DET strategy and the corresponding SET strategy are compared in Figure 20 and Figure 21. Since in (2) and in (5), the DET strategies are likely to have fewer triggering times, as compared with the SET strategies, which are also displayed in Figure 18, Figure 19, Figure 20 and Figure 21 and Table 3 and Table 4, which means that DET is beneficial for saving system resources with a slower update frequency.
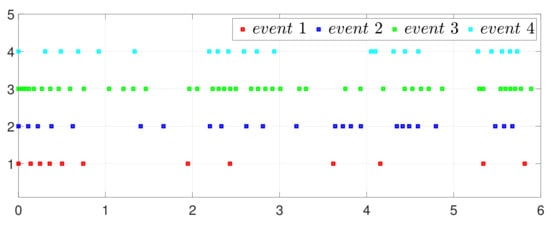
Figure 18.
Event under one-to-all DET (2a).
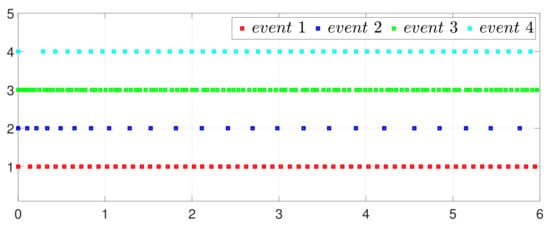
Figure 19.
Event under one-to-all SET (2b).
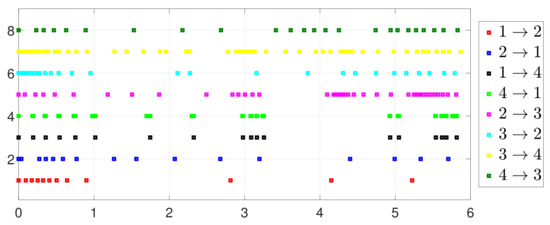
Figure 20.
Event under one-to-one DET (5a).
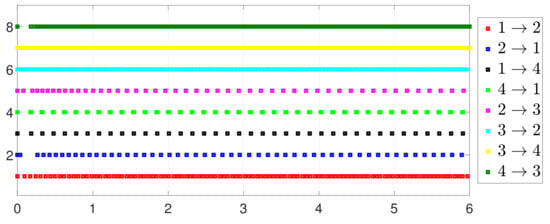
Figure 21.
Event under one-to-one SET (5b).
Table 3.
One-to-all DET performance comparison with SET.
Table 4.
One-to-one DET performance comparison with SET.
6. Conclusions
In this paper, two novel DET strategies are combined to design distributed optimization algorithms to solve the RAP; they have fewer trigger times compared to SET strategies. Furthermore, the designed distributed optimization algorithms require only the state information of the agent itself and do not require information exchange with neighboring nodes, which saves on the communication energy of the system. Furthermore, the internal dynamic variables and not only solve the RAP, but also play an important role in eliminating the Zeno behavior. In the future, we will combine DET strategies to study optimization problems with equality and inequality constraints under directed graphs.
Author Contributions
Conceptualization, F.G. and S.C.; methodology, F.G. and X.C.; software, M.Y.; validation, M.Y. and F.G.; formal analysis, F.G. and X.C.; investigation, F.G.; resources, F.G.; data curation, F.G. and S.C.; writing—original draft preparation, M.Y.; writing—review and editing, F.G. and M.Y.; visualization, M.Y.; supervision, H.J.; project administration, S.C.; funding acquisition, X.C. and H.J. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported in part by the National Natural Science Foundation of China (Grant no. 62163035), in part by the China Postdoctoral Science Foundation under Grant 2021M690400, in part by the Special Project for Local Science and Technology Development Guided by the Central Government under Grant ZYYD2022A05, in part by the Xinjiang Key Laboratory of Applied Mathematics under Grant XJDX1401, in part by Tianshan Talent Program (Grant No. 2022TSYCLJ0004), and in part by the National Undergraduate Training Program for Innovation and Entrepreneurship (no. 202210755077).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| MASs | Multi-agent systems |
| SET | Static event-triggered |
| DET | Dynamic event-triggered |
| RAP | Resource allocation problem |
References
- Yahouni, Z.; Ladj, A.; Belkadi, F.; Meski, O.; Ritou, M. A smart reporting framework as an application of multi-agent system in machining industry. Int. J. Comput. Integr. Manuf. 2021, 34, 470–486. [Google Scholar] [CrossRef]
- Sharifi, A.; Sharafian, A.; Ai, Q. Adaptive MLP neural network controller for consensus tracking of multi-agent systems with application to synchronous generators. Expert Syst. Appl. 2021, 184, 115460. [Google Scholar] [CrossRef]
- Liu, Z.; Yu, H.; Fan, G.; Chen, L. Reliability modelling and optimization for microservice-based cloud application using multi-agent system. IET Commun. 2022, 16, 1182–1199. [Google Scholar] [CrossRef]
- Males, L.; Sumic, D.; Rosic, M. Applications of multi-agent systems in unmanned surface vessels. Electronics 2022, 11, 3182. [Google Scholar] [CrossRef]
- Qin, J.; Ma, Q.; Shi, Y.; Wang, L. Recent advances in consensus of multi-agent systems: A brief survey. IEEE Trans. Ind. Electron. 2016, 64, 4972–4983. [Google Scholar] [CrossRef]
- Amirkhani, A.; Barshooi, A. Consensus in multi-agent systems: A review. Artif. Intell. Rev. 2021, 55, 3897–3935. [Google Scholar] [CrossRef]
- Yu, W.; Zhou, L.; Yu, X.; Lu, J.; Lu, R. Consensus in multi-agent systems with second-order dynamics and sampled data. IEEE Trans. Ind. Inform. 2012, 9, 2137–2146. [Google Scholar] [CrossRef]
- Xie, Y.; Lin, Z. Global optimal consensus for multi-agent systems with bounded controls. Syst. Control Lett. 2017, 102, 104–111. [Google Scholar] [CrossRef]
- Nedi, A.; Liu, J. Distributed optimization for control. Annu. Rev. Control. Robot. Auton. Syst. 2018, 1, 77–103. [Google Scholar] [CrossRef]
- Mota, J.F.C.; Xavier, J.M.F.; Aguiar, P.M.Q.; Puschel, A. Distributed optimization with local domains: Applications in MPC and network flows. IEEE Trans. Autom. Control 2014, 60, 2004–2009. [Google Scholar] [CrossRef]
- Tychogiorgos, G.; Gkelias, A.; Leung, K. A non-convex distributed optimization framework and its application to wireless ad-hoc networks. IEEE Trans. Wirel. Commun. 2013, 12, 4286–4296. [Google Scholar] [CrossRef]
- Hasegawa, M.; Hirai, H.; Nagano, K.; Harada, H.; Aihara, K. Optimization for centralized and decentralized cognitive radio networks. Proc. IEEE 2014, 102, 574–584. [Google Scholar] [CrossRef]
- Jumpasri, N.; Pinsuntia, K.; Woranetsuttikul, K.; Nilsakorn, T.; Khan-ngern, W. Comparison of distributed and centralized control for partial shading in PV parallel based on particle swarm optimization algorithm. In Proceedings of the 2014 International Electrical Engineering Congress (iEECON), Chonburi, Thailand, 19–21 March 2014; pp. 1–4. [Google Scholar]
- Gharesifard, B.; Cortes, J. Distributed continuous-time convex optimization on weight-balanced digraphs. IEEE Trans. Autom. Control 2014, 59, 781–786. [Google Scholar] [CrossRef]
- Ramírez-Llanos, E.; Martinez, S. Distributed discrete-time optimization algorithms with applications to resource allocation in epidemics control. Optim. Control Appl. Methods 2018, 39, 160–180. [Google Scholar] [CrossRef]
- Díaz-Madroñero, M.; Mula, J.; Peidro, D. A review of discrete-time optimization models for tactical production planning. Int. J. Prod. Res. 2014, 52, 5171–5205. [Google Scholar] [CrossRef]
- Tan, R.R.; Aviso, K.B.; Bandyopadhyay, S.; Ng, D.K.S. Continuous-time optimization model for source-sink matching in carbon capture and storage systems. Ind. Eng. Chem. Res. 2012, 51, 10015–10020. [Google Scholar] [CrossRef]
- Yi, P.; Hong, Y.; Liu, F. Distributed gradient algorithm for constrained optimization with application to load sharing in power systems. Syst. Control Lett. 2015, 83, 45–52. [Google Scholar] [CrossRef]
- Lou, Y.; Hong, Y.; Wang, S. Distributed continuous-time approximate projection protocols for shortest distance optimization problems. Automatica 2016, 69, 289–297. [Google Scholar] [CrossRef]
- Chen, G.; Yao, D.; Zhou, Q.; Li, H.; Lu, R. Distributed event-triggered formation control of USVs with prescribed performance. J. Syst. Sci. Complex. 2022, 35, 820–838. [Google Scholar] [CrossRef]
- Zhang, L.; Che, W.W.; Deng, C.; Wu, Z.G. Prescribed performance control for multiagent systems via fuzzy adaptive event-triggered strategy. IEEE Trans. Fuzzy Syst. 2022, 30, 5078–5090. [Google Scholar] [CrossRef]
- Wang, X.; Zhou, Y.; Huang, T.; Chakrabarti, P. Event-triggered adaptive fault-tolerant control for a class of nonlinear multiagent systems with sensor and actuator faults. IEEE Trans. Circuits Syst. I Regul. Pap. 2022, 69, 4203–4214. [Google Scholar] [CrossRef]
- Ge, C.; Liu, X.; Liu, Y.; Hua, C. Event-triggered exponential synchronization of the switched neural networks with frequent asynchronism. IEEE Trans. Neural Netw. Learn. Syst. 2022, 2162–2388. [Google Scholar] [CrossRef] [PubMed]
- Wang, J.; Yan, Y.; Ma, C.; Liu, Z.; Ma, K.; Chen, L. Fuzzy adaptive event-triggered finite-time constraint control for output-feedback uncertain nonlinear systems. Fuzzy Sets Syst. 2022, 443, 236–257. [Google Scholar] [CrossRef]
- Li, M.; Long, Y.; Li, T.; Chen, C.L.P. Consensus of linear multi-agent systems by distributed event-triggered strategy with designable minimum inter-event time. Inf. Sci. 2022, 609, 644–659. [Google Scholar] [CrossRef]
- Zhang, S.; Che, W.; Deng, C. Observer-based event-triggered control for linear MASs under a directed graph and DoS attacks. J. Control Decis. 2022, 9, 384–396. [Google Scholar] [CrossRef]
- Wu, X.; Mao, B.; Wu, X.; Lu, J. Dynamic event-triggered leader-follower consensus control for multiagent systems. SIAM J. Control Optim. 2022, 60, 189–209. [Google Scholar] [CrossRef]
- Han, F.; Lao, X.; Li, J.; Wang, M.; Dong, H. Dynamic event-triggered protocol-based distributed secondary control for islanded microgrids. Int. J. Electr. Power Energy Syst. 2022, 137, 107723. [Google Scholar] [CrossRef]
- Liu, K.; Ji, Z. Dynamic event-triggered consensus of general linear multi-agent systems with adaptive strategy. IEEE Trans. Circuits Syst. II Express Briefs 2022, 69, 3440–3444. [Google Scholar] [CrossRef]
- Hu, S.; Qiu, J.; Chen, X.; Zhao, F.; Jiang, X. Dynamic event-triggered control for leader-following consensus of multiagent systems with the estimator. IET Control Theory Appl. 2022, 16, 475–484. [Google Scholar] [CrossRef]
- Liang, D.; Dong, Y. Robust cooperative output regulation of linear uncertain multi-agent systems by distributed event-triggered dynamic feedback control. Neurocomputing 2022, 483, 1–9. [Google Scholar] [CrossRef]
- Xin, C.; Li, Y.; Niu, B. Event-Triggered Adaptive Fuzzy Finite Time Control of Fractional-Order Non-Strict Feedback Nonlinear Systems. J. Syst. Sci. Complex. 2022, 35, 2166–2180. [Google Scholar] [CrossRef]
- Liu, P.; Xiao, F.; Wei, B. Event-Triggered Control for Multi-Agent Systems: Event Mechanisms for Information Transmission and Controller Update. J. Syst. Sci. Complex. 2022, 35, 953–972. [Google Scholar] [CrossRef]
- Xing, L.; Xu, Q.; Wen, C.; Mishra, Y.C.Y.; Ledwich, G.; Song, Y. Robust event-triggered dynamic average consensus against communication link failures with application to battery control. IEEE Trans. Control Netw. Syst. 2020, 7, 1559–1570. [Google Scholar] [CrossRef]
- Xu, Y.; Sun, J.; Wang, G.; Wu, Z.G. Dynamic triggering mechanisms for distributed adaptive synchronization control and its application to circuit systems. IEEE Trans. Circuits Syst. I Regul. Pap. 2021, 68, 2246–2256. [Google Scholar] [CrossRef]
- Xu, W.; He, W.; Ho, D.W.C.; Kurths, J. Fully distributed observer-based consensus protocol: Adaptive dynamic event-triggered schemes. Automatica 2022, 139, 110188. [Google Scholar] [CrossRef]
- Wang, X.; Hong, Y.; Sun, X.; Liu, K. Distributed optimization for resource allocation problems under large delays. IEEE Trans. Ind. Electron. 2019, 66, 9448–9457. [Google Scholar] [CrossRef]
- Deng, Z.; Chen, T. Distributed algorithm design for constrained resource allocation problems with high-order multi-agent systems. Automatica 2022, 144, 110492. [Google Scholar] [CrossRef]
- Li, L.; Zhou, Z.; Sun, S.; Wei, M. Distributed optimization of enhanced intercell interference coordination and resource allocation in heterogeneous networks. Int. J. Commun. Syst. 2019, 32, e3915. [Google Scholar] [CrossRef]
- Weng, S.; Yue, D.; Dou, C. Event-triggered mechanism based distributed optimal frequency regulation of power grid. IET Control Theory Appl. 2019, 13, 2994–3005. [Google Scholar] [CrossRef]
- Hu, W.; Liu, L.; Feng, G. Consensus of linear multi-agent systems by distributed event-triggered strategy. IEEE Trans. Cybern. 2016, 46, 148–157. [Google Scholar] [CrossRef]
- Dai, H.; Jia, J.; Yan, L.; Fang, X.; Chen, W. Distributed fixed-time optimization in economic dispatch over directed networks. IEEE Trans. Ind. Inform. 2021, 17, 3011–3019. [Google Scholar] [CrossRef]
- Hu, W.; Yang, C.; Huang, T.; Gui, W. A distributed dynamic event-triggered control approach to consensus of linear multiagent systems with directed networks. IEEE Trans. Cybern. 2020, 50, 869–874. [Google Scholar] [CrossRef] [PubMed]
- Lygeros, J.; Johansson, K.H.; Simic, S.N.; Zhang, J.; Sastry, S.S. Dynamical properties of hybrid automata. IEEE Trans. Autom. Control 2003, 48, 2–17. [Google Scholar] [CrossRef]





















Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).