Abstract
In this paper, a kernel-free quadratic surface support vector regression with non-negative constraints (NQSSVR) is proposed for the regression problem. The task of the NQSSVR is to find a quadratic function as a regression function. By utilizing the quadratic surface kernel-free technique, the model avoids the difficulty of choosing the kernel function and corresponding parameters, and has interpretability to a certain extent. In fact, data may have a priori information that the value of the response variable will increase as the explanatory variable grows in a non-negative interval. Moreover, in order to ensure that the regression function is monotonically increasing on the non-negative interval, the non-negative constraints with respect to the regression coefficients are introduced to construct the optimization problem of NQSSVR. And the regression function obtained by NQSSVR matches this a priori information, which has been proven in the theoretical analysis. In addition, the existence and uniqueness of the solution to the primal problem and dual problem of NQSSVR, and the relationship between them are addressed. Experimental results on two artificial datasets and seven benchmark datasets validate the feasibility and effectiveness of our approach. Finally, the effectiveness of our method is verified by real examples in air quality.
1. Introduction
For regression problems, sometimes there is a priori information, such as the response variable increasing as the explanatory variable increases. It is more natural to expect that the the air quality will decrease when the pollution gas concentration increases. However, the model sometimes obtains regression coefficients that do not match this a priori information, which can reduce the credibility and prediction accuracy of the model. Therefore, to solve this problem, we restrict the range of values of the regression coefficients to ensure the soundness of the model.
At present, several types of constraints have been utilized, including non-negative constraints [1,2,3,4], monotonicity constraints [5,6,7,8], smoothing constraints [9,10,11], etc. Powell et al. [12] proposed a Bayesian hierarchical model for estimating constraints conditional random fields to analyze the relationship between air pollution and health. Moreover, non-negative constraints have been applied to various problems. The non-negative least squares problem (NNLS) was introduced by Lawson [13]. Chen et al. [14] presented non-negative distributed regression as an effective method specifically designed for analyzing data in wireless sensor networks. Shekkizhar et al. [15,16] proposed non-negative kernel regression to handle graph construction from data and dictionary learning. Additionally, Chapel et al. [17] proposed non-negative penalized linear regression to address the challenge of unbalanced optimal transport.
Due to its excellent generalization ability, support vector regression (SVR) [18] has been widely used in various fields, such as the financial industry [19,20] and construction industry [21,22]. However, the selection of appropriate kernel functions and their corresponding parameters can be time-consuming during experiments, prompting researchers to explore kernel-free regression models. Su proposed the non-negative constraints SVR (NNSVR) for analyzing air quality data, which is only suitable for regression problems since it cannot use kernel functions. Based on the idea of quadratic kernel-free support vector machine (QSSVC) [23], Gao et al. [24] proposed a kernel-free fuzzy reduced quadratic surface -support vector machine for Alzheimer’s disease classification. Zhou et al. [25] proposed a kernel-free QSSVC. For the regression problem, Ye et al. [26,27] proposed two kernel-free nonlinear regression models, quadratic surface kernel-free least squares SVR (QLSSVR) and -kernel-free soft QSSVR (-SQSSVR), respectively. Zhai et al. [28] proposed a linear twin quadratic surface support vector regression. Zheng et al. [29] developed a hybrid QSSVR and applied it to stock indices and price forecasting. These advancements have attracted significant attention from the research community seeking more efficient approaches in regression analysis without relying on kernel functions.
In this paper, a kernel-free quadratic surface support vector regression with non-negative constraints (NQSSVR) is proposed, which incorporates the idea of a kernel-free technique and non-negative constraints. The main contributions are summarized as follows.
- NQSSVR is proposed by utilizing the kernel-free technique, which avoids the complexity of choosing the kernel functions and their parameters, and has interpretability to some extent. In fact, the task of NQSSVR is to find a quadratic regression function to fit the data, so it can achieve better generalization ability than other linear regression methods.
- The non-negative constraints with respect to the regression coefficients are added to construct the optimization problem of NQSSVR, which can obtain a monotonically increasing regression function with explanatory variables on a non-negative interval. In some cases, the value of the response variable grows as the explanatory variable grows. For example, when exploring the air quality examples, the air quality index will increase as the concentration of gases in the air increases.
- Both the primal and dual problems can be solved, since our method does not involve kernel functions. In the theoretical analysis, the existence and uniqueness of solutions to the primal and dual problems, as well as their interconnections, are analyzed. In addition, the properties of regression function on the domain of definition are given.
- Numerical experiments on artificial datasets demonstrate the visualization results of the regression function obtained by our NQSSVR. The results on benchmark datasets show that the comprehensive performance of the method is relatively better than that of linear-SVR and NNSVR. In addition, more importantly, by exploring the practical application of air quality, it can be shown that our method is more applicable than QLSSVR and -SQSSVR.
The paper is structured as follows. Section 2 introduces a brief introduction to the -SQSSVR model, and some definitions and notations. In Section 3, we construct the primal and dual problems for NQSSVR and analyze the corresponding properties. Section 4 presents the results of numerical experiments conducted on datasets. Finally, Section 5 provides conclusions from this study.
2. Background
In this section, we give the related definitions and notations, and review the -SQSSVR model.
2.1. Definition and Notations
The following mathematical notations are utilized in this paper. Lowercase bold and uppercase bold represent vectors and matrices, respectively. is the identity matrix of any size, is the set of m-dimensional symmetric matrices, is the set of dimensional matrices. Next, define the operators as follows.
Definition 1.
For any symmetry matrix , its half-vectorization operator can be defined as follows:
Definition 2.
For any vector , define the following quadratic operator:
Definition 3.
For a vector , define the vector-to-matrix operator as follows:
2.2. -SQSSVR
Given the training set
where , , . The task of -SQSSVR is to seek the quadratic regression function
where , , and . To obtain the regression function (5), the optimization problem is established as follows:
where is a penalty parameter, and is the slack vector. The optimization problem (6)–(9) is a quadratic programming problem, so it can be solved directly. In addition, this model uses the quadratic surface kernel-free technique, which avoids the difficulty of choosing the kernel function and the corresponding parameters.
3. Kernel-Free QSSVR with Non-Negative Constraints (NQSSVR)
In this section, we establish the primal and dual problems of the kernel-free QSSVR with the non-negative constraints (NQSSVR). The properties of primal and dual problems are discussed, and the properties of the regression function with non-negative constraints are proved.
3.1. Primal Problem
Given the training set T (4), to find the regression function (5), the following optimization problem is formulated
where , , . mean that each component of and is greater than or equal to zero. is the penalty parameter, and is a slack vector.
In the above optimization problem (10)–(14), we impose constraints on the regression coefficients, namely . Restricting the range of values of regression coefficients can help us to obtain regression functions that are more consistent with a priori information. In addition, the optimization problem does not involve kernel functions, which can avoid the complicated process of kernel functions, and its parameters selection further reduced computation time.
According to Definitions 1–3, the primal optimization problem (10)–(14) is simplified to the following form:
where , , , , , , . means that each component of is greater than or equal to to zero. The matrix is positive semidefinite matrix, since .
3.2. Dual Model
Next, the Lagrange multiplier vectors , , and are introduced to the optimization problem (15)–(19). The Lagrange function can be expressed as follows:
The Karush–Kuhn–Tuchker (KKT) conditions for problems (15)–(19) are given as follows:
According to the Equation (21),
By substituting (21)–(30) into (20), the dual problem of the optimization problem (15)–(19) is formulated as
where and are vectors, and is the penalty parameter. Since the proposed model does not involve kernel functions, both the primal and dual problems can be solved directly. Solving the primal problem saves the cost of computing the inverse matrix. In particular, when the input dimension is large, solving the dual problem is more convenient.
3.3. Some Theoretical Analysis
In this subsection, the theoretical properties of the primal and dual problems, as well as the regression function after adding the non-negative constraints, are analyzed into properties.
Theorem 1.
Proof.
Suppose and are the two optimal solutions of the primal problem. There exists such that the following equation holds:
Clearly, is also an optimal solution to the optimization problem (15)–(19), so the following inequalities hold:
Multiplying inequality (37) by and inequality (38) by , then summing them up yields
By simplifying the Formula (39), we obtain
Then, we have
Since the matrix is a positive definite matrix and , inequality (41) holds if and only if . □
Theorem 2.
For the training set T (4) and , if the matrix is positive definite, the optimal solution = of the dual problem (32)–(35) exists and is unique, and the optimal solution of the primal problem (15)–(19) can be expressed as
or
Proof.
By the (21) equation in the KKT condition, we have
If there exists components, and . such that or , or , by the complementary slackness conditions, , we have
or
□
Next, the properties of the regression function (5) after adding non-negative constraints with respect to the regression coefficients are analyzed. The domain is defined as follows:
Theorem 3.
Proof.
The function can be written as
It only remains to justification that this holds for the k-th component of , the quadratic function containing can be expressed as
Taking the derivative of the above equation yields
On the domain , the function monotonically non-decreasing is equivalent to being non-negative at the right end of the above equation, so it is a necessary and sufficient condition to prove that the latter holds as follows:
Sufficiency is obvious, and we only need to prove necessity. Supposing and taking , then we obtain the following:
The above relation is contrary to the known conditions. Supposing the existence of with all other components being zero. Obviously, when the is sufficiently large, the following formula holds:
This is a contradict. Similarly, it can be shown that Theorem 3 holds. □
4. Numerical Experiments
To verify the validity of our proposed NQSSVR model, we compare it with other methods, including linear SVR (lin-SVR), SVR with Gaussian kernel (rbf-SVR), and polynomial kernel (poly-SVR), and linear SVR with non-negative constraints (NNSVR), as well as QLSSVR and -SQSSVR. The primal and dual problems of the NQSSVR method are denoted as NQSSVR(p) and NQSSVR(d), respectively. The above experiments are tested on 2 artificial datasets, 7 UCI [30] datasets, and AQCI datasets. All numerical experiments in this section are conducted on a computer equipped with a 2.50GHz (i7-9700) CPU and 8G RAM using MatlabR2016(a).
To validate the fitting performances of various methods, the following four evaluation criteria are introduced as shown in Table 1. Without loss of generality, let and be the predicted and mean values, respectively. The penalty parameters C and -insensitive parameter, as well as the Gaussian kernel parameter , are selected from , while the polynomial kernel parameter p is selected from . All methods are selected through 5-fold cross-validation to obtain the optimal parameters.

Table 1.
Evaluation criteria.
4.1. Artificial Datasets
The 2 artificial datasets are conducted to validate the performance of the NQSSVR model.
Example 1.
The data points are indicated by magenta “o”, the red solid line indicates the target function, and the blue dashed line indicates the regression function obtained by the kernel function method. The green dashed line and the black solid line indicate NQSSVR(p), and NQSSVR(d), respectively. The regression functions obtained by NQSSVR and different kernel functions are shown in Figure 1. From Figure 1, it can be seen that NQSSVR yields an approximately linear regression function as well as the other three methods. The regression coefficients obtained by solving the primal and dual problems of our proposed method are and , respectively. So, NQSSVR can handle linear regression problem.

Figure 1.
The visualization results on Example 1.
Example 2.
The fitting results of an artificial dataset are shown in Figure 2. The data points are denoted by “·”. Figure 2a,b present the regression surfaces obtained from the primal and dual problems, respectively. On this dataset, the regression coefficients obtained by our method are , , , and , , . From Figure 2 and the regression coefficients, the quadratic surface fitted by our method can be matched to the actual distribution of the data.
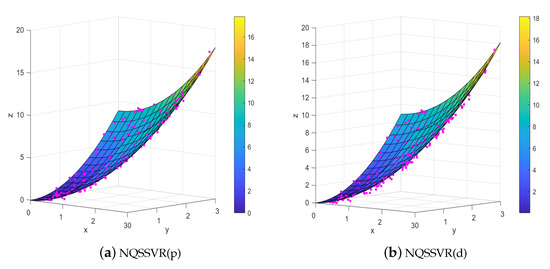
Figure 2.
The visualization results on Example 2.
Table 2 shows the results of the our proposed model and SVR with kernel functions on the two datasets mentioned above. When considering the linear regression problems, it is evident that the five models yield n similar outcomes. However, when addressing the non-linear data, our method demonstrates superior performance compared to the other three methods, as evidenced by the smaller average values of RMSE and MAE. Moreover, the difference in values between our method and the optimal result is minimal. Notably, the T2 values reveal that our method exhibits faster computation times than SVR with kernel function. This advantage comes from the fact that it does not contain a kernel function, thus eliminating the need for kernel parameter selection.
Table 2.
Experimental results on artificial datasets.
For example 2, the influence of the parameter on the accuracy of our proposed method is analyzed. As can be seen by Figure 3, the penalty parameters C and insensitive loss parameter have a greater impact on the accuracy of the NQSSVR model. So, reasonable parameters can improve the accuracy of the model. In the next experiments, we choose the optimal parameters for the model within the defined parameter range.
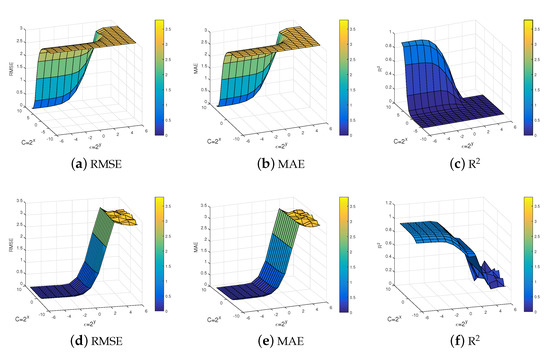
Figure 3.
Effect of parameters on method performance NQSSVR.
Next, the average test time is compared for NQSSVR(p), NQSSVR(d), rbf-SVR, and poly-SVR. Since lin-SVR is only applicable to linear regression, no comparison is made here. The CPU running time of the above four methods in different dimensions and data points is shown in Table 3. Where the input dimensions m of data point are 2, 4, 8, and 16 and the number n of data points is 200, 400, 600, 800, and 1000, respectively. It is noteworthy that the time variation of NQSSVR(p) remains small as the number of data points increases for the same input dimension, outperforming both the rbf-SVR and poly-SVR methods. Moreover, when the number of data points is consistent, NQSSVR(p) exhibits shorter average test time costs compared to rbf-SVR and poly-SVR. Furthermore, as the input dimension of data points increases, the average test time for the dual problem is found to be shorter than that for the primal problem.
Table 3.
Experimental results on the benchmark datasets.
4.2. Benchmark Datasets
In this section, to further validate the reliability of the proposed method, the NQSSVR model is compared with the lin-SVR, poly-SVR, rbf-SVR, NNSVR, QLSSVR, and -SQSSVR models on seven benchmark datasets. Details of all datasets are listed in Table 4. All datasets are normalized before conducting data experiments, and are divided into training datasets, test datasets and a validation datasets in a ratio of 3:1:1. All methods are compared on evaluation criteria: MAE, RMSE, T1, T2. The top two relatively better results are highlighted in bold. All results were repeated 5 times and their mean values are calculated.
Table 4.
Details of the benchmark datasets.
Table 5 lists the regression results of the eight methods on the seven datasets. In terms of the evaluation criteria RMSE and MAE, it can be seen that NQSSVR is significantly better than lin-SVR and NNSVR. For most of the datasets, the NQSSVR model outperforms QLSSVR and -SQSSVR, and is not significantly different from rbf-SVR and poly-SVR. In terms of time, our method is second only to QLSSVR and outperforms other methods.
Table 5.
Experimental results on the datasets.
To compare the performances of our proposed method and other six methods, the Friedman test and post hoc test are employed. Initially, the Friedman test is conducted with the null hypothesis states that all methods have the same performances. Furthermore, we can calculate the Friedman statistics for each evaluation criterion using the following formula.
where N and K are, respectively, the numbers of datasets and methods, is the average rank of the i-th method.
According to the Formula (59), the Friedman statistics corresponding to the three criteria are 12.2124, 13.8361 and 35.1600, respectively. Next, for = 0.05, the critical value of Friedman statistic is calculated to be . Since the Friedman statistic on each regression criteria is greater than , so we reject the null hypothesis. That is, these 8 methods have significantly different performances on the 3 evaluation criteria. To further compare the difference of each method, we proceed with a post hoc test. Specifically, if the difference of average ranks for two methods is larger than the critical difference (), then their performances are considered to be significantly different. Where the value can be calculated by the Formula (60)
For , we know . Thus, we obtain by the Formula (60).
Figure 4 visually displays the results of Friedman test and Nemenyi post hoc test on three regression evaluation criteria, respectively. Where the average ranks of each method for three criteria are marked along an axis. The axis is turned so that the lowest (best) ranks is to the right of each criterion. Groups of methods that are not significantly different are linked by a red line. Statistically, the performance of NQSSVR (p) is not significantly different from rbf-SVR and poly-SVR in terms of RMSE, MAE. And our method ranks better than both the kernel-free quadratic surface and lin-SVR models on RMSE, MAE. In terms of time, our model ranks third and fourth, outperforming the SVR with kernel functions and -SQSSVR. In general, the comprehensive performance of our method is similar to rbf-SVR and poly-SVR, and completely superior to lin-SVR and NNSVR.
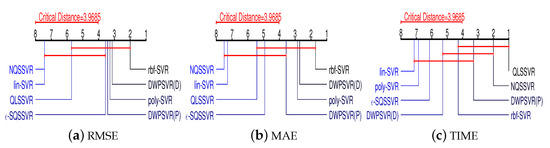
Figure 4.
The results of Friedman test and Nemenyi post hoc test.
4.3. Air Quality Composite Index Dataset (AQCI)
This section uses two AQCI datasets, the monthly AQCI dataset and the daily AQCI dataset. These two datasets containing 18 data points and 841 data points, respectively. Each data point has six input features including nitrogen dioxide (), sulfur dioxide (), PM2.5, ozone (), carbon monoxide (CO), PM10, respectively. And the output response is AQCI. Our method is compared with QLSSVR, -SQSSVR and NNSVR.
In Figure 5, the value of AQCI has a tendency to increase as the values of the remaining five input features increase, except for the feature. Therefore, the regression function we obtain should be monotonically increasing on the monthly AQCI dataset.
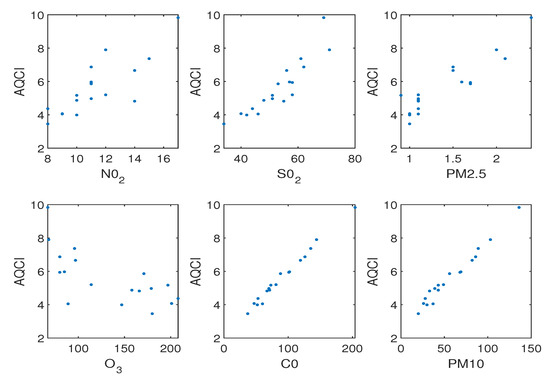
Figure 5.
The relationship between six features and AQCI on monthly AQCI dataset.
Table 6 shows the experimental results of our NQSSVR and the other three methods on these two datasets. The accuracy of our model is better than that of QLSSVR and -SQSSVR on the datasets because our NQSSVR imposes non-negative constraints with respect to the regression coefficients. In addition, our model has greater accuracy than the NNSVR model. Because NNSVR can only obtain a linear regression function, but NQSSVR can obtain a quadratic regression function.
Table 6.
Results on the AQCI datasets.
To investigate the effect of adding non-negative constraints on the accuracy of the regression function, we compare the regression coefficients and obtained by NQSSVR(p) with those obtained using the other three methods. Since NNSVR is a linear model, it has only linear term coefficients and does not involve nonlinear term coefficients . The regression coefficients obtained by the four methods are small, and for comparison purposes, we enlarge the and by a factor of 100 and 10, respectively, before drawing the figure. When the regression coefficient is negative, the color of the color block is closer to blue.
We want to obtain a regression function that is monotonically increasing, by Theorem 3 it is equivalent to the non-negative constraints with respect to regression coefficients. From the Figure 6 and Figure 7, we can see that -SQSSVR and QLSSVR obtained and contain negative numbers, so the regression functions obtained do not match the a priori information. However, our model yields regression coefficients that all match the a priori information. Therefore, adding non-negative constraints can improve the accuracy and reasonableness of the model. Since our method can obtain a quadratic regression function, it is therefore more accurate than the linear regression function obtained by NNSVR.
Figure 6.
-matrices.
Figure 7.
-vectors.
Figure 8 show the effect of the parameters on the performance of our model. Here we have chosen three evaluation criteria, including RMSE, MAE, and . Figure 8a–c displays the experimental results obtained for the dual problem, while Figure 8d–f presents the experimental results for the primal problem. It can be observed that the effect of the parameters on our proposed model remains significant. It is worth noting that our model receives -insensitive parameter influence more and is not very sensitive to the change of penalty parameter C.
Figure 8.
Effect of parameters on method performance NQSSVR.
5. Conclusions
For the regression problem, a novel kernel-free quadratic surface support vector regression with non-negative constraints (NQSSVR) is proposed by utilizing the kernel-free technique and introducing the non-negative constraints with respect to regression coefficients. Specifically, by using a quadratic surface to fit the data, the regression function is nonlinear and does not involve kernel functions, so the model is unnecessary to select kernel functions and corresponding parameters, and the obtained regression function has better interpretability. Moreover, adding non-negative constraints with respect to regression coefficients to the model ensures that the obtained regression function conforms to the monotonic non-decreasing characteristics on non-negative interval. In fact, when exploring air quality examples, there is a prior information that air quality indicators will increase with the increase in all gas concentrations in the atmosphere. Fortunately, we have proven that the quadratic regression function obtained by NQSSVR is monotonically non-decreasing on the non-negative interval if and only if the non-negative constraints with respect to the regression coefficients hold true. The results of numerical experiments on the two artificial datasets, seven benchmark datasets and air quality datasets demonstrate that our method is feasible and effective.
In this paper, we impose a non-negative restriction on the regression coefficients based on prior information. In the subsequent optimization problems, we can add different restrictions to the values of the regression coefficients based on the prior information. For example, part of the regression coefficients are restricted to non-negative intervals and part of the regression coefficients are unrestricted.
Author Contributions
Methodology, D.W. and Z.Y.; Software, D.W.; Writing—original draft, D.W.; Writing—review & editing, Z.Y. and J.Y.; Supervision, Z.Y., J.Y. and X.Y.; Funding acquisition, Z.Y. All authors have read and agreed to the published version of the manuscript.
Funding
This work is supported by the National Natural Science Foundation of China (No. 12061071).
Data Availability Statement
All of the benchmark datasets used in our numerical experiments are from the UCI Machine Learning Repository, which are available at https://archive.ics.uci.edu/ml/351index.php (the above datasets accessed on 18 August 2021).
Acknowledgments
The authors would like to thank the editor and referees for their valuable comments and suggestions, which helped us to improve the results of this paper.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Zhou, L.; Harrach, B.; Seo, J.K. Monotonicity-based electrical impedance tomography for lung imaging. Inverse Probl. 2018, 34, 045005. [Google Scholar] [CrossRef]
- Chatterjee, S.; Guntuboyina, A.; Sen, B. On matrix estimation under monotonicity constraints. Bernoulli 2018, 24, 1072–1100. [Google Scholar] [CrossRef]
- Wang, J.; Qian, Y.; Li, F.; Liang, J.; Ding, W. Fusing fuzzy monotonic Decision Trees. IEEE Trans. Fuzzy Syst. 2019, 28, 887–900. [Google Scholar] [CrossRef]
- Henderson, N.C.; Varadhan, R. Damped anderson acceleration with restarts and monotonicity control for accelerating em and em-like algorithms. J. Comput. Graph. Stat. 2019, 28, 834–846. [Google Scholar] [CrossRef]
- Bro, R.; Sidiropoulos, N.D. Least squares algorithms under unimodality and non-negativity constraints. J. Chemom. J. Chemom. Soc. 1998, 12, 223–247. [Google Scholar] [CrossRef]
- Luo, X.; Zhou, M.C.; Li, S.; Hu, L.; Shang, M. Non-negativity constrained missing data estimation for high-dimensional and sparse matrices from industrial applications. IEEE Trans. Cybern. 2019, 50, 1844–1855. [Google Scholar] [CrossRef]
- Theodosiadou, O.; Tsaklidis, G. State space modeling with non-negativity constraints using quadratic forms. Mathematics 2019, 9, 1905. [Google Scholar] [CrossRef]
- Haase, V.; Hahn, K.; Schndube, H.; Stierstorfer, K.; Maier, A.; Noo, F. Impact of the non-negativity constraint in model-based iterative reconstruction from CT data. Med. Phys. 2019, 46, 835–854. [Google Scholar] [CrossRef] [PubMed]
- Yamashita, S.; Yagi, Y.; Okuwaki, R.; Shimizu, K.; Agata, R.; Fukahata, Y. Potency density tensor inversion of complex body waveforms with time-adaptive smoothing constraint. Geophys. J. Int. 2022, 231, 91–107. [Google Scholar] [CrossRef]
- Wang, J.; Deng, Y.; Wang, R.; Ma, P.; Lin, H. A small-baseline InSAR inversion algorithm combining a smoothing constraint and L1-norm minimization. IEEE Geosci. Remote Sens. Lett. 2019, 16, 1061–1065. [Google Scholar] [CrossRef]
- Mammen, E.; Marron, J.S.; Turlach, B.A.; Wand, M.P. A general projection framework for constraints smoothing. Stat. Sci. 2001, 16, 232–248. [Google Scholar] [CrossRef]
- Powell, H.; Lee, D.; Bowman, A. Estimating constraints concentration–response functions between air pollution and health. Environmetrics 2012, 23, 228–237. [Google Scholar] [CrossRef]
- Lawson, C.L.; Hanson, R.J. Solving Least Squares Problems; Society for Industrial and Applied Mathematics: Philadelphia, PA, USA, 1995. [Google Scholar]
- Chen, J.; Richard, C.; Honeine, P.; Bermudez, J.C.M. Non-negative distributed regression for data inference in wireless sensor networks. In Proceedings of the 2010 Conference Record of the Forty Fourth Asilomar Conference on Signals, Systems and Computers, Pacific Grove, CA, USA, 7–10 November 2010; pp. 451–455. [Google Scholar]
- Shekkizhar, S.; Ortega, A. Graph construction from data by non-negative kernel regression. In Proceedings of the ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 3892–3896. [Google Scholar]
- Shekkizhar, S.; Ortega, A. NNK-Means: Dictionary learning using non-negative kernel regression. arXiv 2021, arXiv:2110.08212. [Google Scholar]
- Chapel, L.; Flamary, R.; Wu, H.; Févotte, C.; Gasso, G. Unbalanced optimal transport through non-negative penalized linear regression. Adv. Neural Inf. Process. Syst. 2021, 34, 23270–23282. [Google Scholar]
- Drucker, H.; Burges, C.J.; Kaufman, L.; Smola, A.; Vapnik, V. Support vector regression machines. Adv. Neural Inf. Process. Syst. 1996, 9, 779–784. [Google Scholar]
- Fauzi, A. Stock price prediction using support vector machine in the second Wave of COVID-19 pandemic. Insearch Inf. Syst. Res. J. 2021, 1, 58–62. [Google Scholar] [CrossRef]
- Huang, S.; Cai, N.; Pacheco, P.P.; Narrandes, S.; Wang, Y.; Xu, W. Applications of support vector machine (SVM) learning in cancer genomics. Cancer Genom. Proteom. 2018, 15, 41–51. [Google Scholar]
- Zhong, H.; Wang, J.; Jia, H.; Mu, Y.; Lv, S. Vector field-based support vector regression for building energy consumption prediction. Appl. Energy 2019, 242, 403–414. [Google Scholar] [CrossRef]
- Guo, H.; Nguyen, H.; Bui, X.N.; Armaghani, D.J. A new technique to predict fly-rock in bench blasting based on an ensemble of support vector regression and GLMNET. Eng. Comput. 2021, 37, 421–435. [Google Scholar] [CrossRef]
- Dagher, I. Quadratic kernel-free non-linear support vector machine. J. Glob. Optim. 2008, 41, 15–30. [Google Scholar] [CrossRef]
- Gao, Z.; Wang, Y.; Huang, M.; Luo, J.; Tang, S. A kernel-free fuzzy reduced quadratic surface ν-support vector machine with applications. Appl. Soft Comput. 2022, 127, 109390. [Google Scholar] [CrossRef]
- Zhou, J.; Tian, Y.; Luo, J.; Zhai, Q. Novel non-Kernel quadratic surface support vector machines based on optimal margin distribution. Soft Comput. 2022, 26, 9215–9227. [Google Scholar] [CrossRef]
- Ye, J.Y.; Yang, Z.X.; Li, Z.L. Quadratic hyper-surface kernel-free least squares support vector regression. Intell. Data Anal. 2021, 25, 265–281. [Google Scholar] [CrossRef]
- Ye, J.Y.; Yang, Z.X.; Ma, M.P.; Wang, Y.L.; Yang, X.M. ϵ-Kernel-free soft quadratic surface support vector regression. Inf. Sci. 2022, 594, 177–199. [Google Scholar] [CrossRef]
- Zhai, Q.; Tian, Y.; Zhou, J. Linear twin quadratic surface support vector regression. Math. Probl. Eng. 2020, 2020, 3238129. [Google Scholar] [CrossRef]
- Zheng, L.J.; Tian, Y.; Luo, J.; Hong, T. A novel hybrid method based on kernel-free support vector regression for stock indices and price forecasting. J. Oper. Res. Soc. 2023, 74, 690–702. [Google Scholar] [CrossRef]
- Dua, D.; Graff, C. UCI Machine Learning Repository. 2017. Available online: https://archive.ics.uci.edu/ml/index.php (accessed on 18 August 2021).








Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).