

Orders between Channels and Implications for Partial Information Decomposition

Abstract
:1. Introduction
2. Kolchinsky’s Axioms and Intersection Information
- (i)
- Monotonicity of mutual information w.r.t. T: .
- (ii)
- Reflexivity: for all .
- (iii)
- For any , , where is any variable taking a constant value with probability one, i.e., with a distribution that is a delta function or such that is a singleton.
- 1.
- Symmetry: is symmetric in the s.
- 2.
- Self-redundancy: .
- 3.
- Monotonicity: .
- 4.
- Equality for Monotonicity: If , then .
3. Channels and the Degradation/Blackwell Order
4. Other Orders and Corresponding II Measures
4.1. The “Less Noisy” Order
4.2. The “More Capable” Order
4.3. The “Degradation/Supermodularity” Order
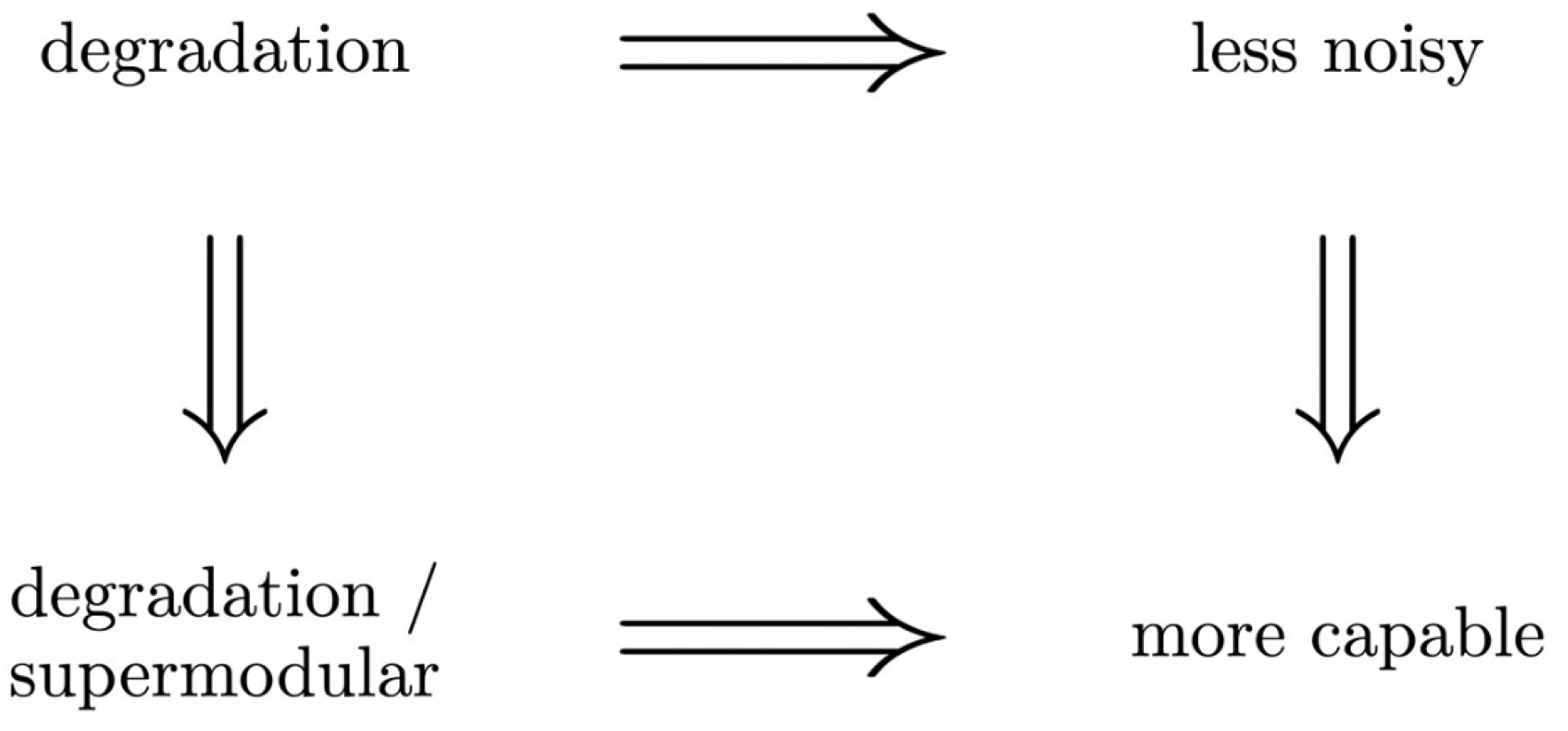
4.4. Relations between Orders
5. Optimization Problems
5.1. The “Less Noisy” Order
5.2. The “More Capable” Order
5.3. The “Degradation/Supermodularity” Order
6. Relation to Existing PID Measures
7. Conclusions and Future Work
- As a corollary of the previous result, the proposed measures satisfy the Williams–Beer axioms, and can be extended beyond two sources.
- We demonstrate that if there is a degradation ordering between the sources, then the measures coincide in their decomposition. Conversely, if there is no degradation ordering (i.e., only a weaker ordering) between the source variables, the proposed measures lead to novel finer information decompositions that capture different finer information.
- We formulate the optimization problems that yield the proposed measures, and derive bounds by relating them to existing measures.
- Investigating conditions to verify whether two channels and satisfy .
- Kolchinsky [21] showed that when computing , it is sufficient to consider variables Q with a support size of at most , which is a consequence of the admissible region of being a polytope. The same is not the case with the less noisy or the more capable measures; hence, it is not clear whether it is sufficient to consider Q with the same support size, which could represent a direction for future research.
- Studying the conditions under which different intersection information measures are continuous.
- Implementing the introduced measures by addressing their corresponding optimization problems.
- Considering the usual PID framework, except that instead of decomposing , where H denotes the Shannon entropy, other mutual informations induced by different entropy measures could be considered, such as the guessing entropy [41] or the Tsallis entropy [42] (see the work of Américo et al. [23] for other core-concave entropies that may be decomposed under the introduced preorders, as these entropies are consistent with the introduced orders).
- Another line for future work might be to define measures of union information using the introduced preorders, as suggested by Kolchinsky [21], and to study their properties.
- As a more long-term research direction, it would be interesting to study how the approach taken in this paper can be extended to quantum information; the fact that partial quantum information can be negative might open up new possibilities or create novel difficulties [43].
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Williams, P.; Beer, R. Nonnegative decomposition of multivariate information. arXiv 2010, arXiv:1004.2515. [Google Scholar]
- Lizier, J.; Flecker, B.; Williams, P. Towards a synergy-based approach to measuring information modification. In Proceedings of the 2013 IEEE Symposium on Artificial Life (ALIFE), Singapore, 16–19 April 2013; pp. 43–51. [Google Scholar]
- Wibral, M.; Finn, C.; Wollstadt, P.; Lizier, J.; Priesemann, V. Quantifying information modification in developing neural networks via partial information decomposition. Entropy 2017, 19, 494. [Google Scholar] [CrossRef] [Green Version]
- Rauh, J. Secret sharing and shared information. Entropy 2017, 19, 601. [Google Scholar] [CrossRef] [Green Version]
- Vicente, R.; Wibral, M.; Lindner, M.; Pipa, G. Transfer entropy—A model-free measure of effective connectivity for the neurosciences. J. Comput. Neurosci. 2011, 30, 45–67. [Google Scholar] [CrossRef] [Green Version]
- Ince, R.; Van Rijsbergen, N.; Thut, G.; Rousselet, G.; Gross, J.; Panzeri, S.; Schyns, P. Tracing the flow of perceptual features in an algorithmic brain network. Sci. Rep. 2015, 5, 17681. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gates, A.; Rocha, L. Control of complex networks requires both structure and dynamics. Sci. Rep. 2016, 6, 24456. [Google Scholar] [CrossRef] [Green Version]
- Faber, S.; Timme, N.; Beggs, J.; Newman, E. Computation is concentrated in rich clubs of local cortical networks. Netw. Neurosci. 2019, 3, 384–404. [Google Scholar] [CrossRef]
- James, R.; Ayala, B.; Zakirov, B.; Crutchfield, J. Modes of information flow. arXiv 2018, arXiv:1808.06723. [Google Scholar]
- Arellano-Valle, R.; Contreras-Reyes, J.; Genton, M. Shannon Entropy and Mutual Information for Multivariate Skew-Elliptical Distributions. Scand. J. Stat. 2013, 40, 42–62. [Google Scholar] [CrossRef]
- Cover, T. Elements of Information Theory; John Wiley & Sons: Hoboken, NJ, USA, 1999. [Google Scholar]
- Gutknecht, A.; Wibral, M.; Makkeh, A. Bits and pieces: Understanding information decomposition from part-whole relationships and formal logic. Proc. R. Soc. A 2021, 477, 20210110. [Google Scholar] [CrossRef]
- Harder, M.; Salge, C.; Polani, D. Bivariate measure of redundant information. Phys. Rev. E 2013, 87, 012130. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bertschinger, N.; Rauh, J.; Olbrich, E.; Jost, J.; Ay, N. Quantifying unique information. Entropy 2014, 16, 2161–2183. [Google Scholar] [CrossRef] [Green Version]
- Griffith, V.; Koch, C. Quantifying synergistic mutual information. In Guided Self-Organization: Inception; Springer: Berlin/Heidelberg, Germany, 2014; pp. 159–190. [Google Scholar]
- James, R.; Emenheiser, J.; Crutchfield, J. Unique information via dependency constraints. J. Phys. A Math. Theor. 2018, 52, 014002. [Google Scholar] [CrossRef] [Green Version]
- Chicharro, D.; Panzeri, S. Synergy and redundancy in dual decompositions of mutual information gain and information loss. Entropy 2017, 19, 71. [Google Scholar] [CrossRef] [Green Version]
- Bertschinger, N.; Rauh, J.; Olbrich, E.; Jost, J. Shared information—New insights and problems in decomposing information in complex systems. In Proceedings of the European Conference on Complex Systems 2012, Brussels, Belgium, 2–7 September 2012; Springer: Berlin/Heidelberg, Germany, 2013; pp. 251–269. [Google Scholar]
- Rauh, J.; Banerjee, P.; Olbrich, E.; Jost, J.; Bertschinger, N.; Wolpert, D. Coarse-graining and the Blackwell order. Entropy 2017, 19, 527. [Google Scholar] [CrossRef] [Green Version]
- Ince, R. Measuring multivariate redundant information with pointwise common change in surprisal. Entropy 2017, 19, 318. [Google Scholar] [CrossRef] [Green Version]
- Kolchinsky, A. A Novel Approach to the Partial Information Decomposition. Entropy 2022, 24, 403. [Google Scholar] [CrossRef]
- Korner, J.; Marton, K. Comparison of two noisy channels. In Topics in Information Theory; Csiszr, I., Elias, P., Eds.; North-Holland Pub. Co.: Amsterdam, The Netherlands, 1977; pp. 411–423. [Google Scholar]
- Américo, A.; Khouzani, A.; Malacaria, P. Channel-Supermodular Entropies: Order Theory and an Application to Query Anonymization. Entropy 2021, 24, 39. [Google Scholar] [CrossRef]
- Cohen, J.; Kempermann, J.; Zbaganu, G. Comparisons of Stochastic Matrices with Applications in Information Theory, Statistics, Economics and Population; Springer Science & Business Media: Berlin/Heidelberg, Germany, 1998. [Google Scholar]
- Blackwell, D. Equivalent comparisons of experiments. Ann. Math. Stat. 1953, 24, 265–272. [Google Scholar] [CrossRef]
- Makur, A.; Polyanskiy, Y. Less noisy domination by symmetric channels. In Proceedings of the 2017 IEEE International Symposium on Information Theory (ISIT), Aachen, Germany, 25–30 June 2017; pp. 2463–2467. [Google Scholar]
- Csiszár, I.; Körner, J. Information Theory: Coding Theorems for Discrete Memoryless Systems; Cambridge University Press: Cambridge, UK, 2011. [Google Scholar]
- Wyner, A. The wire-tap channel. Bell Syst. Tech. J. 1975, 54, 1355–1387. [Google Scholar] [CrossRef]
- Bassi, G.; Piantanida, P.; Shamai, S. The secret key capacity of a class of noisy channels with correlated sources. Entropy 2019, 21, 732. [Google Scholar] [CrossRef] [Green Version]
- Gamal, A. The capacity of a class of broadcast channels. IEEE Trans. Inf. Theory 1979, 25, 166–169. [Google Scholar] [CrossRef]
- Clark, D.; Hunt, S.; Malacaria, P. Quantitative information flow, relations and polymorphic types. J. Log. Comput. 2005, 15, 181–199. [Google Scholar] [CrossRef]
- Griffith, V.; Chong, E.; James, R.; Ellison, C.; Crutchfield, J. Intersection information based on common randomness. Entropy 2014, 16, 1985–2000. [Google Scholar] [CrossRef] [Green Version]
- Barrett, A. Exploration of synergistic and redundant information sharing in static and dynamical Gaussian systems. Phys. Rev. E 2015, 91, 052802. [Google Scholar] [CrossRef] [Green Version]
- DeWeese, M.; Meister, M. How to measure the information gained from one symbol. Netw. Comput. Neural Syst. 1999, 10, 325. [Google Scholar] [CrossRef]
- Rauh, J.; Banerjee, P.; Olbrich, E.; Jost, J.; Bertschinger, N. On extractable shared information. Entropy 2017, 19, 328. [Google Scholar] [CrossRef] [Green Version]
- Rauh, J.; Bertschinger, N.; Olbrich, E.; Jost, J. Reconsidering unique information: Towards a multivariate information decomposition. In Proceedings of the 2014 IEEE International Symposium on Information Theory, Honolulu, HI, USA, 29 June–4 July 2014; pp. 2232–2236. [Google Scholar]
- Gács, P.; Körner, J. Common information is far less than mutual information. Probl. Control Inf. Theory 1973, 2, 149–162. [Google Scholar]
- Griffith, V.; Ho, T. Quantifying redundant information in predicting a target random variable. Entropy 2015, 17, 4644–4653. [Google Scholar] [CrossRef] [Green Version]
- Finn, C.; Lizier, J. Pointwise Partial Information Decomposition Using the Specificity and Ambiguity Lattices. Entropy 2018, 20, 297. [Google Scholar] [CrossRef] [Green Version]
- James, R.; Ellison, C.; Crutchfield, J. “dit”: A Python package for discrete information theory. J. Open Source Softw. 2018, 3, 738. [Google Scholar] [CrossRef]
- Massey, J. Guessing and entropy. In Proceedings of the 1994 IEEE International Symposium on Information Theory, Trondheim, Norway, 27 June–1 July 1994; p. 204. [Google Scholar]
- Tsallis, C. Possible generalization of Boltzmann-Gibbs statistics. J. Stat. Phys. 1988, 52, 479–487. [Google Scholar] [CrossRef]
- Horodecki, M.; Oppenheim, J.; Winter, A. Partial quantum information. Nature 2005, 436, 673–676. [Google Scholar] [CrossRef] [PubMed] [Green Version]

{kind=link}
| T | |||
|---|---|---|---|
| (0, 0) | 0 | 0 | |
| (0, 1) | 0 | 1 | |
| (1, 0) | 1 | 0 | |
| (1, 1) | 1 | 1 |
| Target | ||||||
|---|---|---|---|---|---|---|
| 0 | 0.311 | 0.311 | 0.311 | 0.311 | 0.311 | |
| 0 | 0.5 | 0.5 | 0.5 | 0.5 | 0.5 | |
| 0 | 0 | 0 | 0 | 0 | 0 | |
| 0 | 0 | 0 | 0 | 0 | 1 |
| 0 | 0.002 | 0.004 | * | 0.004 | 0.004 | 0.004 | 0.002 | 0.003 | 0.047 | 0.003 | 0.004 | 0 |
| 0 | 0 | 0.322 | 0.322 | 0.322 | 0.193 | 0 | 0 | 0.058 | 0 | 0 | 0 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gomes, A.F.C.; Figueiredo, M.A.T. Orders between Channels and Implications for Partial Information Decomposition. Entropy 2023, 25, 975. https://doi.org/10.3390/e25070975
Gomes AFC, Figueiredo MAT. Orders between Channels and Implications for Partial Information Decomposition. Entropy. 2023; 25(7):975. https://doi.org/10.3390/e25070975
Chicago/Turabian StyleGomes, André F. C., and Mário A. T. Figueiredo. 2023. "Orders between Channels and Implications for Partial Information Decomposition" Entropy 25, no. 7: 975. https://doi.org/10.3390/e25070975
APA StyleGomes, A. F. C., & Figueiredo, M. A. T. (2023). Orders between Channels and Implications for Partial Information Decomposition. Entropy, 25(7), 975. https://doi.org/10.3390/e25070975