Abstract
In the era of the popularization of the Internet of Things (IOT), analyzing people’s daily life behavior through the data collected by devices is an important method to mine potential daily requirements. The network method is an important means to analyze the relationship between people’s daily behaviors, while the mainstream first-order network (FON) method ignores the high-order dependencies between daily behaviors. A higher-order dependency network (HON) can more accurately mine the requirements by considering higher-order dependencies. Firstly, our work adopts indoor daily behavior sequences obtained by video behavior detection, extracts higher-order dependency rules from behavior sequences, and rewires an HON. Secondly, an HON is used for the RandomWalk algorithm. On this basis, research on vital node identification and community detection is carried out. Finally, results on behavioral datasets show that, compared with FONs, HONs can significantly improve the accuracy of random walk, improve the identification of vital nodes, and we find that a node can belong to multiple communities. Our work improves the performance of user behavior analysis and thus benefits the mining of user requirements, which can be used to personalized recommendations and product improvements, and eventually achieve higher commercial profits.
1. Introduction
With the rapid popularization of the Internet of Things (IoT) and smart home, it has gradually become a mature way to collect user information through various sensors, cameras, and mobile phones to record users’ behavior data. User behavior analysis is of great significance to various business activities at present. According to the collected user behavior, the analysis results [1] can be applied to personalized recommendation services [2], product updates and improvements [3,4], and market demand research [5]. Accurate and reliable user behavior analysis results will be the key to achieve the above applications.
Typically, user behavior records are stored in the form of logs, which are processed to obtain time-stamped sequence data. Methods for analyzing sequence data include methods using machine learning [6,7,8] and methods using network analysis [9]. Machine learning methods mainly use models that support sequence data input, which can obtain higher accuracy but lack interpretability. Traditional network modeling and analysis methods are to build sequence data as an FON, and the edges of the network represent the relationship between nodes, which rely on the first-order Markov assumption, but the lack of higher-order dependency leads to lower accuracy. For user behavior analysis, it is necessary to have both high accuracy and interpretability to ensure the usability of the analysis results.
An HON is better able to mine historical information, and higher-order nodes are also able to show the sources of historical information [10]. An HON has higher accuracy improvement on sequence data with richer historical information and strong dependency [11], such as citation network data [12,13], trajectory data [14], etc. And there are also quite a few dependencies between user behaviors. Let us take an example; the case is shown in Figure 1.
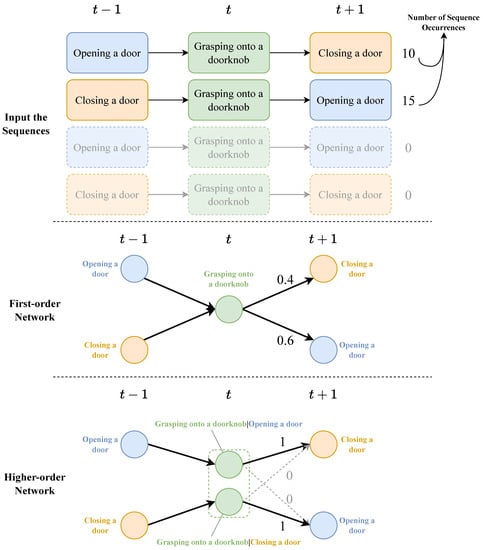
Figure 1.
The example considers two sequences consisting of three daily actions: opening a door, grasping onto a doorknob, and closing a door. The two sequences describe the actions of , t, and moments. The number after the sequence is the number of occurrences of the sequence.
In this case, an FON is constructed based on two kinds of sequences. The probabilities of transferring from grasping onto a doorknob node to closing a door and opening a door are 0.4 and 0.6, respectively. But, according to common sense, if you open a door before grasping onto a doorknob, you will not be able to open a door again, which means the action before grasping onto a doorknob will affect the transition probability distribution of subsequent actions. When building an HON, the grasping onto a doorknob node is split into two higher-order nodes, grasping onto a doorknob|opening a door and grasping onto a doorknob|closing a door. At this time, the network is split into two disconnected components. At this time, if opening a door before grasping onto a doorknob, the node status at the moment is higher-order node grasping onto a doorknob|opening a door, then the probability of closing a door in the next step is 1, and the probability of opening a door is 0, which is realistic. In HONs, due to the consideration of higher-order dependencies, some edges (the gray links in the case diagram) that exist in FONs will be removed. By removing these inaccurate edges, the accuracy of the random walk will be improved. Other random-walk-based algorithms will also benefit from it.
Therefore, considering the dependencies between user behaviors, in order to improve the accuracy of user behavior analysis and ensure interpretability, this paper will use an HON to model user behavior sequence data, and carry out random walk prediction, vital node identification, and community detection on the HON. The main contributions of this paper are as follows:
- We take the dataset Charades in the field of video behavior detection and the behavior label of each video in Charades [15] and CharadesEgo [16] as the dataset, and obtain the behavior sequence data through preprocessing data.
- We use the BuildHON+ algorithm to extract the higher-order dependency rules and build the HON of user behaviors.
- On this basis, we use RandomWalk, PageRank, and MapEquation algorithms to analyze the HON of user behavior, and compare the results in the FON, which shows the advantages of the HON over the FON.
The rest of the paper is organized as follows: Section 2 presents recent research related to behavior analysis and HONs. Section 3 introduces the first-order and higher-order Markov process. Section 4 introduces the HON and its construction methods. Section 5 conducts experiments for applying the HON to behavior data. Section 6 summarizes our work and discusses future directions. The structure of the paper is shown in Figure 2.
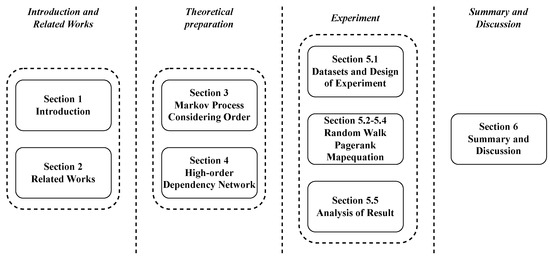
Figure 2.
The structure of the paper.
2. Related Works
Behavior analysis/valuation is a concept derived from psychology and medicine, which is used to predict and treat diseases [17]. Behavior analysis includes many applications and methods, some of which are carried out from the medical view [18], and some of which use data mining methods, including wavelet neural network [19] and recurrent neural network [20]. On the basis of various methods, behavior analysis is also widely used in other fields, such as abnormal behavior detection in Internet DNS servers [21], artificial intelligence training of automatic driving [22], and anomaly detection of user behavior [23]. Behavior analysis in the medical field is a process of causal inference, historical experience, and data analysis to detect potential diseases. This model is also applicable to requirement mining based on behavior analysis. Requirement mining based on behavior analysis is applied to the prediction of shared vehicle demand [24], intelligent prediction of medical demand [25], etc.
By reconstructing behavior sequence data into network, network science methods can be introduced into the study of behavior sequence data mining. Currently, most of the complex network modeling and reconstruction methods are based on traditional FONs [10,13]; however, in real life, higher-order interactions and higher-order dependencies are ubiquitous [26]. Collaboration among more than two authors of a paper [27], online social networks with group relationships among more than two people [28], etc., are all examples of higher-order interactions, which can generally be modeled as hypergraph or simplicial complex [29,30,31,32,33]. Networks that take these higher-order relationships into account are generally referred to as higher-order networks.
There are many kinds of high-order relationships between network nodes, and dependency relationship is one of them. Hypergraphs and simplicial complexes in common high-order networks are not suitable for describing dependencies. In order to describe higher-order dependencies on the network, the concept of a higher-order dependency network (HON) with memory nodes arises. The dynamics on a traditional FON are implicitly based on the first-order Markov assumption that the choice of the next target node depends only on the current node, but, in fact, all nodes before the current node may have an impact on the next transition [34].
Previously, HONs have been applied to data mining of sequence data. Rosvall et al. [34] improved the accuracy of algorithms such as PageRank and MapEquation by considering fixed second-order dependency, thus enabling the accuracy of community detection, ranking, and dynamics to be improved, and this effect was validated on several datasets. Xu et al. [10] released the limitation of fixed second-order dependency and extended the dependency to propose BuildHON to build a variable-order network, which was used in mining global shipping data to verify the advantages of the algorithm in terms of accuracy, scalability, and compatibility. Saebi et al. [14] improved BuildHON in terms of computational efficiency and proposed BuildHON+, which explored the application to anomaly detection on taxi trajectory data and applied it to HON embedding in subsequent work [35]. In addition, there are other algorithms for building HONs, such as GrowHON [36], ReHON [12], and SF-HON [37].
Existing behavior analysis methods are mainly based on FONs and machine learning methods which are hard to interpret, and no research has yet introduced higher-order Markov processes into behavior analysis. Our work considers this for the first time and uses an HON on user behavior sequence data, thus taking into account the dependencies between user behaviors.
3. Markov Process Considering Order
The first-order Markov assumption only considers the current state, but as the order increases, the historical state is gradually taken into consideration. The order of the HON is essentially the same as the order of the higher-order Markov process. The HON integrates the historical information in the higher-order Markov process into the higher-order nodes. Therefore, the construction of high-order dependency networks is based on the theory of high-order Markov processes. This section describes the Markov process considering order, mainly to provide the evolution from the first-order to the higher-order Markov process. In addition, the calculation of the state transition probability of the high-order Markov process is also the basis for the construction of the link weights between nodes in the HON. Therefore, it is necessary to describe the high-order Markov process before constructing the HON.
3.1. First-Order Markov Process
In a complex system of stochastic processes, there exists a sequence of states . is a sequence of random variables that varies with time t. Each specific variable corresponds to a state in the system. With the flow of time, there is a transition between the states of the system, which can be described by the sequence of states , and the corresponding sequence of variables is . Typically, the probability of reaching state i at moment depends on all the previous states passed through, that is, the entire path history. It can be expressed as
However, with the advancement of the state transition process, the influence of the historical state farther from the current state on the prediction of the state transition probability at the next moment is significantly reduced, and retaining too much historical information will also cause a large amount of data redundancy and computing power waste. In many cases, the probability of transitioning to the next state depends only on the current state.
A process that satisfies the above conditions is called a Markov process. Strictly speaking, it is the first-order Markov process (M1) [34]. The above probabilities are called transition probabilities and reflect only one-step transitions. When the number of transition steps is k, the k-step transition probability is defined as
In the M1, a series of state nodes and edges form a network and the weight of edges represent the transition probability distribution between state nodes. Therefore, the transition probability from state i to state j is
We use to represent the weight of the edge from state i to state j. Based on the transition probability, and the probability at the previous state i, the probability of being in state j at the moment is
3.2. Higher-Order Markov Process
The M1 supports most research on complex networks, but there are still many defects. The biggest problem is the assumption that the next state depends only on the current state. This assumption reduces the complexity of the algorithm and the redundancy of the data well, but it is not applicable to all situations. In our work, the M1 loses a considerable part of historical information and cannot capture the dependencies. Therefore, more historical information and path dependency need to be added, which is the higher-order Markov process. First, we start with the second-order Markov process (M2) [34].
In an M2, the next state depends not only on the current state, but also on the previous state.
Therefore, it is not the current node that decides the probability of the next state, but the path formed by the current and previous nodes. When calculating the transition probability, instead of physical node, a memory node with historical path information will be used (we use the concepts of “physical node” and “memory node” in Rosvall’s work [34]). For example, for the path , it can be regarded as a directed edge formed by two memory nodes and in M2. The M2 dynamics can be regarded as being carried out on the network of memory nodes. On this network, the probability of state j transferring to state k is
The probability of being in state at time is
Therefore, in M2, the probability of being in state k at time is
Higher-order Markov processes are similar to second-order, in that the next state depends on the current state and several previous states. For an m-order Markov process, the transition probability of the next state satisfies
For the dependency of the higher-order Markov process in the network, it is not just a simple link composed of pairwise nodes, but a path containing multiple nodes. Then, corresponding to the path , recording the paths as , the probability of transferring from state k to state l is
The probability of being in memory node at moment is
The probability of being in state l at moment is
It is worth noting that there is a distinction between higher-order Markov processes and k-step transition. The k-step transition probability refers to the state probability of reaching a certain state after walking k steps from the current state, which can be applied to the first-order Markov process or the higher-order Markov process; while the higher-order Markov process reflects the degree of dependency on the historical state.
Table 1 shows the relationship between multistep transitions and higher-order Markov processes.

Table 1.
The relationship between higher-order Markov and multistep transition probability.
4. Higher-Order Dependency Network
4.1. Concept and Introduction
Different from the FON, the nodes of the HON reflect the dependencies between the nodes under the higher-order Markov processes. In the HON, nodes with higher-order dependencies will be constructed, which is similar to the higher-order Markov processes, so we introduce them in the previous section. The node of the HON is constructed from a path consisting of current and previous nodes.
Figure 3 shows the process of transforming an FON into an HON, and the name of each node is marked next to it. Among them, the node f in the original FON can generate a fourth-order node at most, and is a fourth-order node, indicating that the current node depends on the previous path . is a first-order node, which means that all the previous paths can become the conditions of this node. In other words, it does not depend on the previous path. and are second-order and third-order nodes.
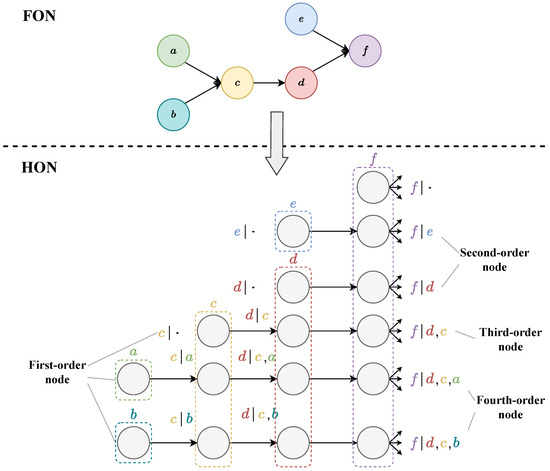
Figure 3.
Transform an FON to an HON.
In an HON, not all dependent paths of each node need to be taken into account unless the path appears a sufficient number of times to reduce redundancy. In the process of building an HON, the order of higher-order nodes usually does not need to reach the highest order, and the corresponding algorithm (BuildHON) [10] will determine the highest order required by a node, which will be introduced in the HON construction method in Section 4.2.
The transition probability in the previous higher-order Markov processes can be given in the form of higher-order nodes. Taking Equation (7) of the M2 as an example, it can be rewritten as follows:
Equation (13) represents the transition probability from higher-order node to first-order node k.
4.2. Construction of HON
This part refers to Xu’s [10] BuildHON algorithm consisting of two steps (rule extraction and network rewiring). We only give the general method and idea of building in our work without entering into too many details, as it is not our focus.
4.2.1. Rule Extraction
Before describing the method of rule extraction, first, we explain what the rules in our work are.
There are many methods of FON storage: adjacency list, adjacency matrix, and sparse matrix derived from the adjacency matrix. A sparse matrix is represented as a series of triples.
Each triplet is in the form of , which are the source node, target node, and the weight of the edge. Weight usually refers to the transition probability between nodes. We express the triplet in another form, for example, . The form of this inference rule expresses the same meaning as the triple, so the FON can actually be considered as a series of rules. Reversely, the FON can be formed with these rules.
Therefore, the prerequisite for building an HON is to obtain all the rules, so the first step in building an HON is to extract rules. An HON can also be represented by a series of rules. As mentioned in Table 1, the one-step transition of a higher-order Markov process is a process from path to node; then, the source node of the higher-order rule can be expressed as a higher-order node, the target node is a first-order node, and the weight is the transition probability between nodes. It is worth noting that among the rules of an HON, there are also a large number of rules in which both the source node and the target node are first-order.
The brief steps of rule extraction are as follows:
- According to the given sequence, calculate the frequency of all subsequences more than the minimum support (MinSupport) from the second order to the highest order (MaxOrder).
- Starting from the second order, calculate the distribution frequency of the higher-order subsequence and the current subsequence.
- Compare whether the frequency distribution of the two sequences changes significantly, and accept the higher-order subsequence as a rule if there is a significant change; otherwise, use the current order subsequence as a rule.
The index used to compare the difference between two distributions is KL divergence, and the calculation method is
Among them, represents the probability distribution of the current order rule, and represents the probability distribution of the higher-order rule.
Define the threshold :
where is the order of and is the number of times the rule appears.
The higher-order sequence is grown from the lower-order sequence . Then, the number of occurrences of the higher-order sequence is . And because of , when the order increases, the denominator of the threshold decreases, the numerator increases, and the value also increases monotonically.
For , there is
As the order increases, the threshold also increases. Therefore, when , it means that the value of at this time is small, which also means that the distribution is more dispersed. Therefore, when , it can be considered that has a significant change on .
When the value of KL divergence is greater than the threshold , the distribution of higher-order rules is considered to be significantly different from that of lower-order rules, and the higher-order rules are accepted. The rule extraction process is shown in Figure 4.
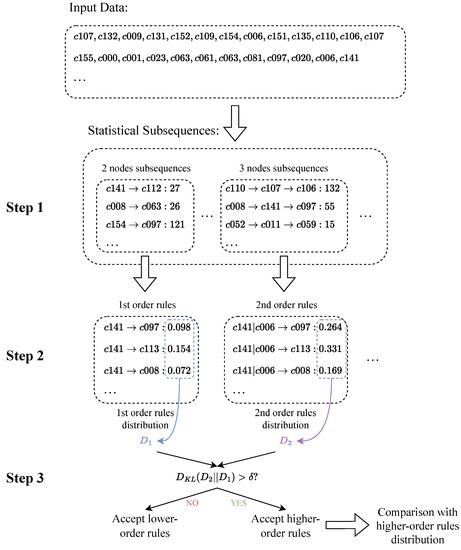
Figure 4.
Extract rules from sequence data.
4.2.2. Network Rewiring
After obtaining the rules, the steps to construct an HON are mainly:
- Convert all first-order rules to edges;
- Convert higher-order rules into edges and create corresponding higher-order nodes;
- Add incoming edges for higher-order nodes;
- The target nodes in the higher-order rules are all first-order, but if there are corresponding higher-order nodes generated by other rules at this time, the first-order target nodes can be merged into the higher-order nodes.
The network construction process is shown in Figure 5.
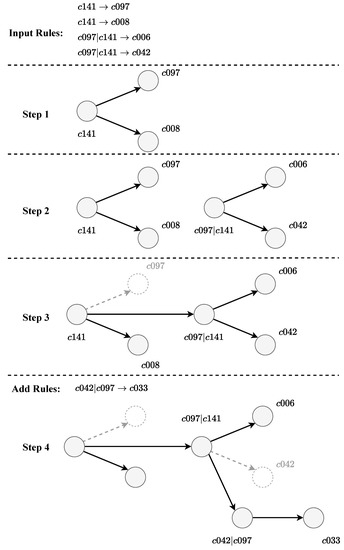
Figure 5.
Rewire network using rules.
5. Experiments
5.1. Datasets and Design of Experiments
The datasets used in this paper are the Charades [15] and CharadesEgo [16], which come from ECCV2016 and CVPR2018, respectively. The two datasets are basically consistent in data format, so we merge them together. The merged dataset contains behavior sequence data extracted from 17,708 videos (9848 from Charades and 7860 from CharadesEgo). Charades and CharadesEgo were originally datasets for behavior detection in the field of computer vision. The two datasets provide a large number of videos and video label data for training. It is worth mentioning that the data used in our work are the labels extracted from the videos, not the videos themselves.
The dataset contains 157 behaviors, which are referred to using numbers from c000-c157. The specific behaviors corresponding to each behavior can refer to the file “Charades_v1_classes.txt”, which can be downloaded from the dataset link provided at the end of the article.
In this paper, three experiments of random walk prediction, vital node identification, and community detection are carried out on an FON and an HON, respectively. The purpose of random walk prediction is to compare the pros and cons of the HON with the FON in terms of sequence prediction accuracy. The purpose of identifying vital nodes is to explore the impact of high-order dependencies on node importance changes and to explore the rules of their changes. The purpose of carrying out the community detection experiment is to highlight the fuzziness of the community division in the HON, and to give a more optimized community affiliation bias. Among the three experiments, random walk is the basic experiment, and the remaining key node identification and community detection experiments rely on the principle of random walk, so the improvement of random walk on the HON will also affect the results of the latter two experiments’ performance. The purpose and relationship of the three experiments are shown in Figure 6:
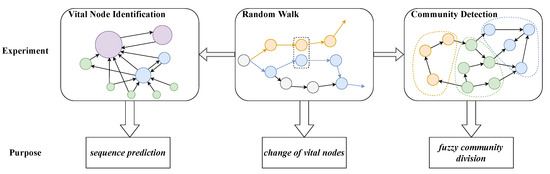
Figure 6.
Design and relationship of three experiments.
5.2. Data Preprocessing
5.2.1. Converting Videos to Sequence Data
In Charades and CharadesEgo, each video has an action field, which consists of behaviors extracted from the corresponding video; each behavior can be expressed as a triplet in the form of <number of behavior, start, and end >. For example: <c006, 21.80, 31.70> indicates a behavior starting at 21.80 s and ending at 31.70 s of the video. The number corresponds to the behavior description of “closing a door”.
However, in the original dataset, these behavior triplets are unordered. In order to construct a temporal behavior sequence, we sort these behavior triplets by start time. For a toy example: [<c137 0.30 9.00>, <c092 0.00 18.90>, <c152 3.50 31.00>] contains c137,c092,c152 three behaviors; the start time of these three behaviors are 0.30, 0.00, and 3.50, respectively. The toy example will be sorted into [c092,c137,c152] by start time, and now we obtain a temporal behavior sequence. The process for converting videos to sequence data is shown in Figure 7. Following this approach, we convert the 17,708 videos to 17,708 temporal behavior sequences which will be the input for the subsequent construction of the HON.
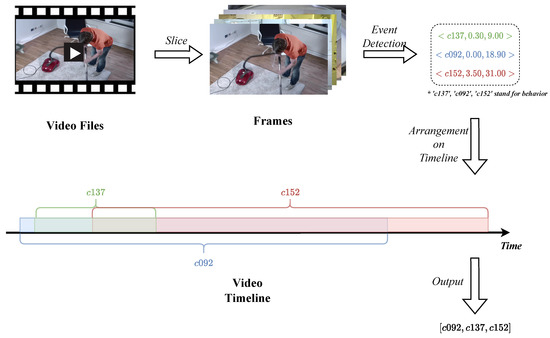
Figure 7.
Converting videos to behavior sequences.
5.2.2. Dividing Data by Scene
For each video, there is a main scene where the behavior occurs, which corresponds to the “scene” field in the dataset. To facilitate subsequent subscene analysis, the 17,708 temporal behavior sequences were split according to the “scene” field (15 main scenes and other scenes). The descriptive statistics are shown in Table 2.
Table 2.
Descriptive statistics of subdatasets divided by scenes.
5.2.3. Network Construction
Based on the behavior sequence data, we constructed two networks, FON and HON. We added a table with basic information about the generated FON and HON. The basic attribute characteristics of the two networks are added to Table 3.
Table 3.
Network descriptive statistics.

Figure 8.
Demonstration of the FON constructed from behavioral data.
Figure 9.
Demonstration of the HON constructed from behavioral data.
5.3. Performance of Random Walk on FON and HON
5.3.1. Introduction of Experiment
Based on the temporal behavior sequences above, we constructed an FON and an HON, and conducted random walk on the two networks, respectively. The experimental results illustrate that the HON significantly improves the accuracy of random walk compared with the FON.
The detailed steps are shown in Figure 10. First, we divided the sequences satisfying certain length requirements into a training part and a test part. After that, we constructed the FON and the HON, respectively, and conducted random walk on the two graphs, respectively. Finally, we calculated the accuracy of random walk on both networks, and we found that the HON achieved an absolutely correct prediction compared to 33% from the FON. In short, the HON improved the accuracy of random walk by revealing more implied information.
where i is the step of random walk, denotes the accuracy of i-step random walk in the HON, and denotes the accuracy of i-step random walk in the FON. is the logarithm of ratio of to . We can obtain the value of and by dividing the number of correct prediction by the number of test path (note that when the number of steps is greater than 1, correct prediction counts only if all steps are correctly predicted).
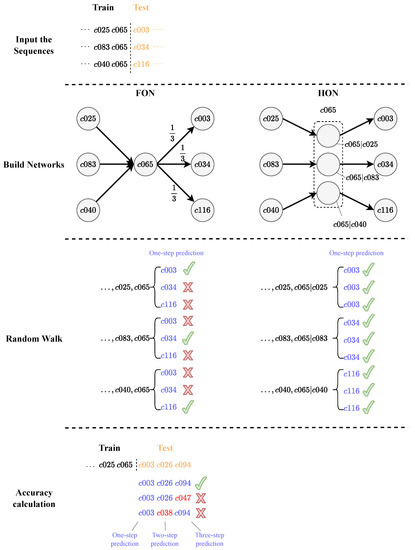
Figure 10.
Random walk and accuracy on the FON and the HON.
5.3.2. Results without Division of Scenes
An FON and an HON were constructed based on the training part of the temporal behavior sequences without dividing the scenes. Then, based on the constructed networks, we performed random walk 1000 times to predict 1 step, 2 steps, and 3 steps of each temporal behavior sequence, and the prediction was correct only if the prediction was consistent with the test part. The proportions of correct predictions in 1000 random walks for 1 step, 2 steps, and 3 steps are shown in the first bar of Figure 11.
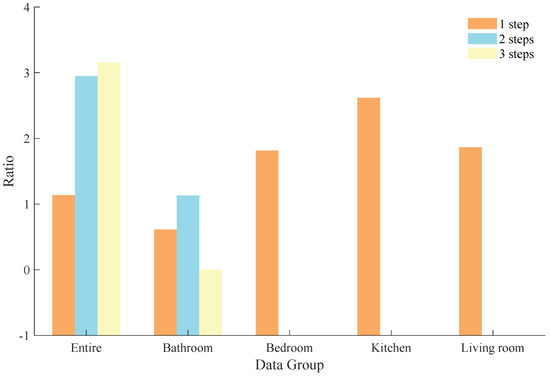
Figure 11.
Comparison of prediction accuracy between FON and HON. The bars that are not shown represent infinite value (2-step and 3-step accuracy in Bedroom, Kitchen, and Living Room).
From the experimental results, we can see that the HON can significantly improve the accuracy of the random walk, and the accuracy improvement is more obvious as prediction step increases. When performing one-step prediction, the FON only considers one node before the test part, and performs a random walk based on the probability distribution of outflow from that node, which will inevitably ignore path dependencies of beyond 1 step. In the HON, these ignored path dependencies are taken into consideration, and, thus, it improves the accuracy of random walk. On the other hand, the path dependency effect of higher order is accumulated in each step, so the improvement of accuracy of the HON compared to the FON is more obvious when multistep prediction is performed.
5.3.3. Results with Division of Scenes
In order to discuss the accuracy of the random walk algorithm under different scenes, we divided the entire dataset into 15 scenes (to ensure sufficient training data, we finally selected 4 scenes with more than 1000 sequences of behaviors for the experiment), and conducted random walk experiments on each scene separately. The results of the experiments are shown in Figure 11.
One-step accuracy under the FON is significantly lower than that of the HON in the Bedroom, Kitchen, and Living Room scenes. As the number of prediction steps increases to 2 or 3, the accuracy of the FON is reduced to 0. The reason for accuracy improvement on the HON compared to the FON in these three scenes is also higher-order dependencies between the temporal behavior sequences.
We note that the bars corresponding to two-step and three-step prediction in the Bedroom, Kitchen, and Living Room scenes are not shown. The reason is that accuracy based on the FON in these scenes is 0, which leads to a infinite ratio. The correct prediction of the random walk is based on the fact that the last few behavior nodes of the training part and the test part together form a pattern, and such a pattern needs to be included in the rule. This premise is easily satisfied in one-step prediction; however, when the number of prediction steps is increased to two or three steps, the premise becomes hard to satisfy.
Another noteworthy phenomenon is that in the Bathroom scene, there is no difference in the three-step accuracy between the FON and the HON, unlike the one-step and two-step experiments. We first found that in the Bathroom scene, the one-step prediction accuracy of the HON was 4.0936 times that of the FON, and the two-step prediction accuracy was 13.4664 times, both of which were lower compared to the other scenes, which could prove that higher-order dependencies between behaviors in the Bathroom scene were weaker than other scenes. In addition, unlike the other three scenes, the highest order of the HON constructed in the Bathroom scene is only 2-order, i.e., there is no 3-order dependency in this subdataset, which means the HON does not have a significant advantage over the FON when performing the three-step prediction, and finally means that the three-step prediction accuracy of the FON and the HON is very close.
5.3.4. Analysis of Results
The above results show that the accuracy of random walk prediction is significantly improved regardless of whether the scenes are divided or not. In the process of HON reconstruction, the large number of higher-order rules generated shows that there are more higher-order dependencies among the behavior sequences. This indicates that there are dependencies in the occurrence of user behaviors, and the requirements linked to the relevant behaviors are equally dependent and traceable. The accuracy of random walk in the HON is significantly higher than that of the FON, which indicates that higher-order dependencies play a greater role in the prediction of behaviors. Therefore, the accuracy improvement in higher-order networks may be more significant when using path prediction algorithms derived from random walk methods. In the behavioral analysis, the accuracy improvement of behavioral sequence prediction brought about by the HON will be more accurate in predicting and mining requirements, thus providing more accurate personalized recommendations. In the intelligent home scenario, relying on IoT, accurate behavioral prediction and requirements mining can also provide better quality of life services.
5.4. Performance of PageRank on FON and HON
5.4.1. Introduction of Experiment
Based on the constructed behavior network, we can use the PageRank algorithm to identify high-frequency behaviors of indoor life. The PageRank algorithm is based on random walk, and the HON also significantly changes the results of the PageRank algorithm [38] by improving the accuracy of random walk.
We adopted a weighted PageRank algorithm with random jump. And for node v, its score at time is given by
where the score of node v at time consists of two parts, one from random jump and the other from neighbors to node v, and the proportion of the two parts is adjusted by parameter (in our work, ). When is small, there will be greater probability for the walker to jump from the current node. Otherwise, the probability for the walker to jump will be smaller. In Formula (19), denotes the score of node v at time , and denotes the score of node u at time t, where there is an edge from node u to node v, i.e., . N denotes the number of nodes of the network. is the sum of weights of edges starting from node u, in which is the sum of weights of edges from node u to node v.
First, we construct the FON and the HON separately. Then, the PageRank algorithm is applied to calculate the score of each node separately. In the HON, the score of the higher-order node is the score for the entity node, i.e., the sum of all state nodes, which is shown in Figure 12.
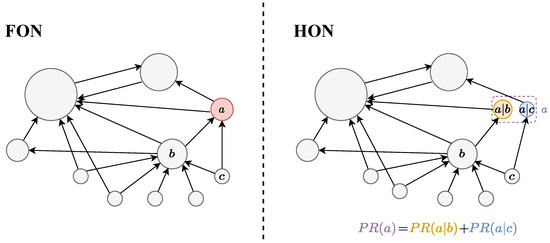
Figure 12.
PageRank score calculation on the FON and HON.
5.4.2. Results of Experiment
The nodes are ranked on the FON and the HON without dividing the scenes. The probability of random jumping in the PageRank algorithm is set to 0.15, the convergence criteria is set to , and the maximum number of iterations is 1000. And Table 4 shows the top three behaviors with large score change (score change = HON score of node – FON score of node).
Table 4.
Top 3 positive and negative score change of nodes.
Table 4 lists the three behavior nodes with the largest positive change and negative change in score. The three behavior nodes with the largest increase in score during the change from FON to HON are c156, c061, and c065, and the nodes with the largest decrease in score are c151, c152, and c033.
Each node name represents a behavior; the three nodes with the highest score increases were someone is eating something(c156) (0.015798 to 0.034973), holding some food(c061) (0.022992 to 0.040868), and eating a sandwich(c065) (0.007647 to 0.020194). The three nodes with the most decreasing scores are someone is going from standing to sitting(c137) (0.013632 to 0.00861), someone is smiling(c125) (0.022617 to 0.015149), and holding a towel(c038) (0.02568 to 0.017065).
5.4.3. Analysis of Results
In Table 4, we rank the top three discrepancies, in terms of weight, for the node with the most increased score (c156) and the node with the most decreased score (c151).
In Figure 13, we show the change of inflow and outflow from the FON to the HON for node c156 and node c151, respectively. The height of the bars indicates the sum of weight, which is given by
where node b can be node c156 or c151. is the set of nodes before node b, i.e., there is an edge from node a to node b. And is the set of nodes after node b, i.e., there is an edge from node b to node c. We sum the weight of edges flowing in node b in HON, and minus the sum in FON, then obtain the height of the bar named “in”. The height of can be obtained in the same way except that should be a negative value.
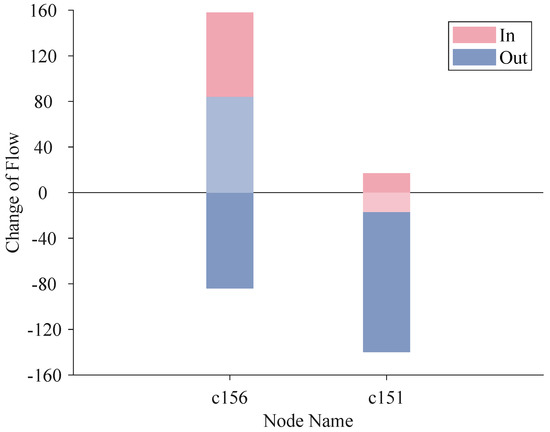
Figure 13.
Flow change of node c156 and c151.
From FON to HON, the scores of nodes change a lot and we take a close look at node c156 and node c151 which are the nodes that gain the most and lose the most, respectively. The inflow of node c156 increases by 158 units, and its outflow increases by 84 units, which results in a 74-unit net inflow, and we fold the bar of outflow increment onto the bar of inflow increment to show the net inflow prominently. For node c151, by folding a inflow increment of 17 units into a outflow increment of 140 units, we obtain a 123-unit net outflow.
In Figure 14, we present a marginal histogram to analyze the difference of score for the FON and the HON. For every node, its coordinate on the y-axis indicates the score in the HON, and coordinate on the x-axis indicates the score in the FON. The nodes on the curve in royal blue satisfy “”, which means that their coordinates on the x-axis are equal to those on the y-axis. The red curve is the fitted curve of scatters. We find that the fitted curve deviates far from the curve “”. The slope of the fitted curve is larger than 1 and it has a negative bias. This means that the nodes with a low score in the FON will obtain an even lower score in the HON, and nodes with a high score will obtain a higher score in the HON. In other words, when we rank nodes with the PageRank algorithm in the process of changing from the FON to the HON, the strong become stronger and the weak become weaker. A word of caution: this phenomenon does not occur on every node as it is statistical. In the upper and right part of Figure 14, we show the normal distributions of scores in the FON and the HON. It is obvious that the distribution curve of the HON is flatter than that of the FON, which reveals a more significant distinction between nodes with low score and nodes with high score in the process of changing from the FON to the HON, in accordance with the phenomenon indicated by the fitted curve.
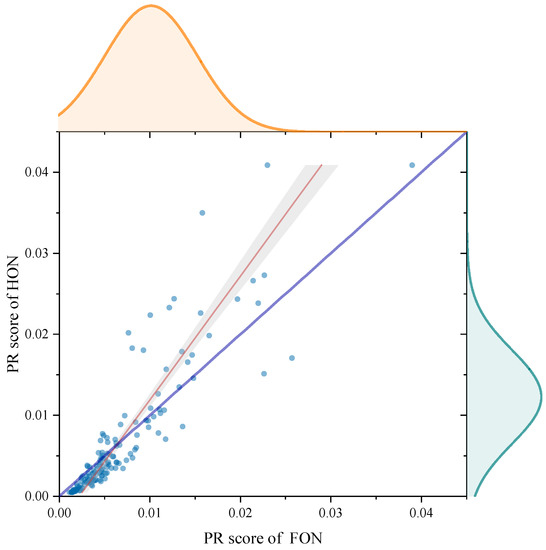
Figure 14.
PageRank score analysis in the FON and the HON.
5.4.4. Comparison of Different Vital Node Identification Algorithms
We continued to use LeaderRank [39], Hits [40], and Eigenvector Centrality [41], three vital node identification algorithms applied to the FON and the HON. The maximum number of iterations of the above algorithm is 1000, and the tolerance is 0.00005. The five nodes with the highest score among the FON and the HON for each algorithm are listed in Table 5.
Table 5.
Ranking of top 5 nodes under different vital node identification algorithms.
The three new algorithms were applied to the HON and the FON, respectively, and the five behaviors with the highest scores are listed in the table. From the comparison of performance on the two networks, the difference between Hits on the FON and the HON is the largest, and the behavior of the top five has changed greatly, while the performance difference of Eigenvector Centrality on different networks is the smallest. From the comparison between algorithms, the performance of PageRank, Eigenvector Centrality, and LeaderRank on the FON is similar, while the performance of Hits is quite different from the first three algorithms. On the HON, the differences between the four algorithms generally become larger.
For the behavior sequence network in this paper, it is not possible to judge the performance of different algorithms, but different algorithms show different evaluation characteristics. However, after comparative experiments, we found that for node importance evaluation on the FON, the performance difference between different algorithms is relatively small; while on the HON, the difference is relatively large. This shows that the complexity of the HON amplifies the difference between nodes of importance. The identification of vital nodes through multiple algorithms can also increase the credibility of some nodes with high scores (such as c154 and c151).
5.5. Performance of Infomap on FON and HON
5.5.1. Introduction of Experiment
Infomap is an algorithm for community detection based on random walk, and it has been used in overlap community detection [42,43]. Infomap combines community detection and information coding. The main idea of Infomap is that a good division of communities has a short code of sequence sampled from a network.
Firstly, we sampled a sequence consisting of nodes (just like in PageRank; there is also a probability to jump from the current node when sampling nodes). After that, we clustered nodes based on double-layer coding to make the sequence as short as possible. The main idea of double-layer coding is to number every community and also number every node in the same community. To achieve this, we can identify every node in network uniquely in the form of “community number + node number”.
For a scheme of encoding,
where all nodes are divided into m communities . A community including nodes is given by
When sampling a node by random walk on a network with n nodes, with probability of jump from the current node, the probability of visiting node is given by
where node has an edge to , i.e., is one of the nodes in neighbors .
For each sequence sampled from a network, its length of code is equal to length of community number plus length of node number. The expected value of length of sequence code is given by
is the average length of code for sequence sampled, in which is the average length of code for communities and is the average length of nodes inside communities. The probability of jumping from the -th node to the k-th node in sequence across two communities is given by
And the probability of transferring from the -th node to the k-th node in sequence inside a community is given by
Then, we tried sending every node to communities nearby and we saved the change in which the length of code for sequence sampled declined fastest. We repeated the program until the length of code became stable.
Compared with network detection on FONs, HONs are able to split a single node into multiple higher-order nodes, which can be divided into multiple communities, and finally the higher-order nodes representing the same original node are merged to obtain the community detection results under the HON. The calculation method of the original node’s PageRank score is shown in Figure 15.
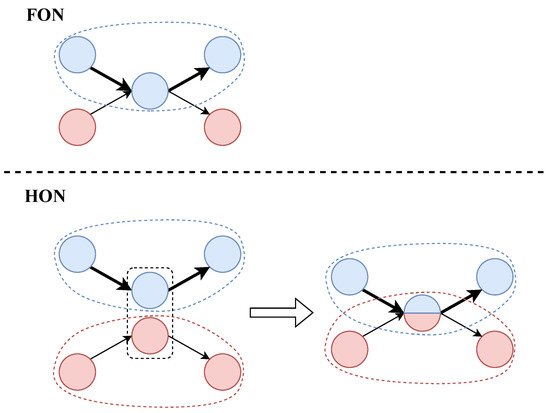
Figure 15.
Community detection in the FON and the HON.
The result of community detection is to define the affiliation relationship of nodes to communities. In a behavior network, a community may refer to a collection of behaviors that occur in succession. In the community detection in an FON, a behavior belongs to only one community, which means it is included in a single behavior set. But many behaviors appear in more than one behavior set. For example, two behavior sets { making a sandwich, holding a sandwich, eating a sandwich } and { taking a sandwich from somewhere, holding a sandwich, putting a sandwich somewhere } both have the behavior of holding a sandwich. In the community division based on an FON, this behavior can only belong to one community, but this is unreasonable. On an HON, this behavior can belong to multiple communities at the same time, that is, a collection of behaviors. Therefore, the significance of using an HON for community division is to divide behavior sets more accurately, so as to better analyze behavior rules.
5.5.2. Results without Division of Scenes
The FON contains 157 nodes and the HON contains 438 nodes (157 nodes after merging), and community detection is conducted on the FON and the HON, respectively. The final results are obtained in Table 6.
Table 6.
Result comparison of community detection.
The number of communities is 17 in FON, and the number of communities in HON is 26. The average community sizes are 9.24 and 16.85 nodes, respectively. A interesting phenomenon emerges on the HON regarding the number of communities which the nodes belong to. About one-fifth of the nodes in HON are divided into multiple communities, in which half of the multi-community nodes are the member of two communities, and the other half of the multi-community nodes are contained in three or more communities, with the node c059 even belonging to eight communities. In contrast, the node c119 belongs to only one community. We filter out the higher-order dependency rules in which node c059 and node c119 are the source nodes, and find that there are 24 second-order rules starting from c059 and only 2 second-order rules starting from c119. The phenomenon indicates that nodes with more higher-order dependency rules are more likely to be divided into multiple communities. It is worth noting that for a node with higher-order dependencies, it is not necessarily divided into multiple communities, because the higher-order nodes may be divided into the same community, which does not increase the number of communities the original node belongs to.
5.5.3. Results with Division of Scenes
We construct an FON and an HON for four scenes, Bathroom, Bedroom, Kitchen, and Living Room, and conduct community detection separately. Table 7 reports the results of community detection in the four scenes.
Table 7.
Results of community detection of divided scenes.
Table 7 shows the results of the community detection after dividing scenes. To analyze the relationship between higher-order dependency rules and community detection, the number and percentage of higher-order dependency rules in the four scenes are also listed in the table. It is worth noting that when community detection is conducted on the HON, higher-order nodes are used.
In Bathroom, there is no significant difference in all indicators between the FON and the HON, which means that the network in the Bathroom scene does not have a significant higher-order dependency effect. Higher-order dependency rules account for 13.04% of all rules. In contrast, in the scenes of Bedroom, Kitchen, and Living Room, there are more communities in the HON than in the FON, and the community assignment is also greatly increased. In these three scenes, the proportion of higher-order rules is about 25% (much higher than the Bathroom scene).
We further verify that the proportion of higher-order dependency rules will affect the community detection results of the HON. On the one hand, the increase in the proportion of higher-order dependency rules will significantly increase the number of communities and community assignments. On the other hand, the increase in the proportion of higher-order dependency rules may also make the community smaller. Generally speaking, the increase of the proportion of higher-order dependency rules will make the community division more detailed, which is manifested in the increase of the number of communities and the decrease of community size.
5.5.4. Analysis of Results
The community detection results for HON indicate that the higher-order nodes of one original node may belong to different communities. In behavior analysis, some behaviors may form a behavior groups, and behaviors in the same group have stronger dependencies and often occur in a certain event together. In an FON, each node belongs to only one community, while a behavior may occur in many events in real life. For example, the action c059 (sitting in a chair), which belongs to a number of communities, can occur in multiple life events, such as a meal in restaurants, relaxing in the living room, or reading in a study. The community detection for an HON allows nodes to be contained in more communities and thus more accurately assigns behaviors to a group.
5.5.5. Comparison of Different Community Detection Algorithms
We continued to add Louvian [44] and Greedy Modularity [45,46], two experiments on community detection algorithms applied to directed graphs, and compared their performance in the FON and the HON. In addition to the original Infomap algorithm, the situation of the three algorithms to divide the community is shown in Table 8.
Table 8.
Results of different community detection algorithms.
Judging from the comparison of performance on the two networks, the three algorithms all divide more communities in the HON, and the size of a single community is also larger. And due to the characteristics of the HON, a node can also belong to more communities, so the community assignment of the three algorithms in the HON is also higher. Judging from the characteristics of the three algorithms, the performance of Louvian is different from the other two algorithms. The community size on the HON is smaller than that on the FON, and the community assignment of the HON is also significantly higher than the other two algorithms. Because the Louvian algorithm divides more communities, the community size is generally small, but the community assignment increases significantly. The Greedy Modularity algorithm has a small number of divided communities, so the size of each community is also greatly increased.
For the behavior sequence network in this paper, we cannot judge the performance of different community detection algorithms. However, from the experiments of the three algorithms on the two networks, there are still some common features. Due to the increase in the number of nodes in the HON, various algorithms can divide more communities, but community size generally decreases. In the HON, the product of community assignment and number of nodes, which is fixed, is proportional to the product of community size and number of communities. Through the comparison of various algorithms, the characteristic differences between the HON and the FON in community detection are further highlighted.
5.6. Summary and Analysis of Experimental Results
Based on the above three experiments, we study the difference between the HON and the FON on some classic network tasks. The results of three experiments demonstrate some properties of the HON compared to the FON:
- Higher-order dependencies cause the network to have more accurate state transitions, and all network algorithms based on state transition will benefit.
- Higher-order dependencies can change the importance of nodes in the network, which can eliminate some errors caused by inappropriate first-order connections.
- Higher-order dependency changes the membership of nodes to communities, which is different from the single membership of nodes and communities in the FON. After considering higher-order dependency, nodes have multiple membership.
Applying higher-order dependencies to daily behavior networks brings improvements in the analysis of daily behavior. Firstly, the prediction of future behavior through random walks on the network is more accurate. Secondly, the change in the value of node importance reduces the importance of some intermediary behaviors and increases the importance of scene-specific behaviors, so it helps to identify key behaviors exclusive to some scenarios and reduces the effect of some recurring behaviors. Thirdly, multiple communities to which the behavior belongs makes it possible to effectively detect behaviors that occur in multiple scenarios when the community is classified as a scene.
6. Summary and Discussion
We carried out a series of experiments on behavior sequences on an HON, which basically confirmed our previous conjecture. That is to say, there are higher-order dependencies between daily life behaviors that can help to perform better on various tasks, such as identification of vital nodes and community detection of behaviors, which are based on the improvement of random walk accuracy.
The improvement of random walk accuracy is significant. There are a mass of algorithms based on random walk whose accuracy will grow significantly, for example, DeepWalk [47], node2vec [48], and so on. We can predict behavior more accurately and provide support for more accurate requirement mining and personalized recommendation. The improvement of accuracy of vital node identification can help us find out the key behaviors with high frequency, which can be used to generate more practical user behavior guidelines. The diversity of community detection shows that a behavior (especially at the intersection) belonging to only one community in an FON can be divided into multiple communities in an HON, which will reveal that the behavior is related to multiple scenes.
It is worth mentioning that the random walk algorithm used in our work for predicting behavior is not an efficient prediction algorithm. Although the accuracy in the HON is substantially better than that in the FON, the absolute value of the accuracy in the HON is still quite low (less than 10% in one-step prediction). Therefore, more efficient prediction methods can be considered in subsequent studies. In addition, the study in this paper uses sequence data without timescale, and only the order of the behaviors is considered without considering the time, which will result in the loss of more detailed information. In subsequent studies, we can try a temporal network on the tasks. The method used in this article can be promoted in many fields, such as software development process and supply chain management.
Author Contributions
Conceptualization, L.Q. and C.G.; methodology, L.Q. and C.G.; software, C.G.; validation, C.G. and L.Q.; formal analysis, C.G. and L.Q.; investigation, L.Q. and C.G.; resources, L.Q.; data curation, C.G. and L.Q.; writing—original draft preparation, L.Q. and C.G.; writing—review and editing, Y.D., X.X. and Y.T.; visualization, L.Q.; supervision, Y.D., X.X. and Y.T.; project administration, Y.D. and Y.T.; funding acquisition, Y.D. and Y.T. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the National Natural Science Foundation of China (NNSFC) under Grants 71901214, 72204028.
Institutional Review Board Statement
This article does not involve ethical research and does not require ethical approval.
Data Availability Statement
The common dataset used in this study can be obtained from https://prior.allenai.org/projects/charades and https://prior.allenai.org/projects/charades-ego (all accessed on 14 June 2023).
Acknowledgments
We thank the Editor and the reviewers for their valuable comments and detailed suggestions to improve the paper. Further, we also acknowledge the partial support by the National Science Foundation of China under grant No. 71901214.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Luo, X.; Wang, J.; Shen, Q.; Wang, J. User Behavior Analysis Based on User Interest by Web Log Mining. In Proceedings of the 2017 27th International Telecommunication Networks And Applications Conference (ITNAC), Melbourne, VIC, Australia, 22–24 November 2017; pp. 486–490. [Google Scholar]
- Qinglong, L.; Cui, S.; Shin, B.; JaeKyeong, K. A Study of Deep Learning-based Personalized Recommendation Service for Solving Online Hotel Review and Rating Mismatch Problem. Inf. Syst. Rev. 2021, 23, 51–75. [Google Scholar]
- Liao, S.H.; Chen, Y.N.; Tseng, Y.Y. Mining demand chain knowledge of life insurance market for new product development. Expert Syst. Appl. 2009, 36, 9422–9437. [Google Scholar] [CrossRef]
- Gaku, R. Demand forecasting procedure for short life-cycle products with an actual food processing enterprise. Int. J. Comput. Intell. Syst. 2014, 7, 85–92. [Google Scholar] [CrossRef]
- Park, S.; Han, S.; Son, Y. Demand power forecasting with data mining method in smart grid. In Proceedings of the 2017 IEEE Innovative Smart Grid Technologies—Asia: Smart Grid for Smart Community, ISGT-Asia 2017, Auckland, New Zealand, 4–7 December 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Yang, A.; Zhang, W.; Wang, J.; Yang, K.; Han, Y.; Zhang, L. Review on the Application of Machine Learning Algorithms in the Sequence Data Mining of DNA. Front. Bioeng. Biotechnol. 2020, 8, 1032. [Google Scholar] [CrossRef] [PubMed]
- Qu, J.; Wu, S.; Zhang, J. Flight Delay Propagation Prediction Based on Deep Learning. Mathematics 2023, 11, 494. [Google Scholar] [CrossRef]
- Xiang, X.; Zhou, J. An Excess Entropy Approach to Classify Long-Term and Short-Term Memory Stationary Time Series. Mathematics 2023, 11, 2448. [Google Scholar] [CrossRef]
- Zhang, Z.L.; Liu, Z.C.; Tian, M.F. Network Behavior Analysis Based on Association Rules. In Proceedings of the International Conference on Automation, Mechanical and Electrical Engineering (AMEE 2015), Phuket, Thailand, 26–27 July 2015; pp. 1066–1072. [Google Scholar]
- Xu, J.; Wickramarathne, T.L.; Chawla, N.V. Representing higher-order dependencies in networks. Sci. Adv. 2016, 2, e1600028. [Google Scholar] [CrossRef]
- Aguirre-Guerrero, D.; Bernal-Jaquez, R. A Methodology for the Analysis of Collaboration Networks with Higher-Order Interactions. Mathematics 2023, 11, 2265. [Google Scholar] [CrossRef]
- Li, X.; Zhao, C.; Hu, Z.; Yu, C.; Duan, X. Revealing the character of journals in higher-order citation networks. Scientometrics 2022, 127, 6315–6338. [Google Scholar] [CrossRef]
- Lambiotte, R.; Rosvall, M.; Scholtes, I. From networks to optimal higher-order models of complex systems. Nat. Phys. 2019, 15, 313–320. [Google Scholar] [CrossRef]
- Saebi, M.; Xu, J.; Kaplan, L.M.; Ribeiro, B.; Chawla, N.V. Efficient modeling of higher-order dependencies in networks: From algorithm to application for anomaly detection. EPJ Data Sci. 2020, 9, 15. [Google Scholar] [CrossRef]
- Sigurdsson, G.A.; Varol, G.; Wang, X.; Farhadi, A.; Laptev, I.; Gupta, A. Hollywood in homes: Crowdsourcing data collection for activity understanding. In Proceedings of the Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics), Amsterdam, The Netherlands, 11–14 October 2016; Volume 9905, pp. 510–526. [Google Scholar] [CrossRef]
- Sigurdsson, G.A.; Gupta, A.; Schmid, C.; Farhadi, A.; Alahari, K. Actor and Observer: Joint Modeling of First and Third-Person Videos. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7396–7404. [Google Scholar] [CrossRef]
- Sweis, B.M.; Nestler, E.J. Pushing the boundaries of behavioral analysis could aid psychiatric drug discovery. PLoS Biol. 2022, 20, e3001904. [Google Scholar] [CrossRef] [PubMed]
- Finn, E.S.; Bandettini, P.A. Movie-watching outperforms rest for functional connectivity-based prediction of behavior. NeuroImage 2021, 235, 117963. [Google Scholar] [CrossRef] [PubMed]
- Chen, H.; Zhang, A.; Hu, S. Behavior prediction for Ochotona curzoniae based on wavelet neural network. In Proceedings of the Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics), Lanzhou, China, 2–5 August 2016; Volume 9772, pp. 105–116. [Google Scholar] [CrossRef]
- Vargis, T.R.; Ghiasvand, S. Assessing Anonymized System Logs Usefulness for Behavioral Analysis in RNN Models. arXiv 2022, arXiv:2212.01101. [Google Scholar]
- Park, J.; Jang, R.; Mohaisen, M.; Mohaisen, D. A Large-Scale Behavioral Analysis of the Open DNS Resolvers on the Internet. IEEE ACM Trans. Netw. 2022, 30, 76–89. [Google Scholar] [CrossRef]
- Malik, M.; Nandal, R.; Dalal, S.; Maan, U.; Le, D.N. An efficient driver behavioral pattern analysis based on fuzzy logical feature selection and classification in big data analysis. J. Intell. Fuzzy Syst. 2022, 43, 3283–3292. [Google Scholar] [CrossRef]
- Choi, S.; Kim, C.; Kang, Y.S.; Youm, S. Human behavioral pattern analysis-based anomaly detection system in residential space. J. Supercomput. 2021, 77, 9248–9265. [Google Scholar] [CrossRef]
- Brandizzi, N.; Russo, S.; Galati, G.; Napoli, C. Addressing Vehicle Sharing through Behavioral Analysis: A Solution to User Clustering Using Recency-Frequency-Monetary and Vehicle Relocation Based on Neighborhood Splits. Information 2022, 13, 511. [Google Scholar] [CrossRef]
- Tiwari, A.; Dhiman, V.; Iesa, M.A.; Alsarhan, H.; Mehbodniya, A.; Shabaz, M. Patient Behavioral Analysis with Smart Healthcare and IoT. Behav. Neurol. 2021, 2021, 4028761. [Google Scholar] [CrossRef]
- Torres, L.; Blevins, A.S.; Bassett, D.; Eliassi-Rad, T. The why, how, and when of representations for complex systems. SIAM Rev. 2021, 63, 435–485. [Google Scholar] [CrossRef]
- Gebhart, T.; Funk, R.J. The Emergence of Higher-Order Structure in Scientific and Technological Knowledge Networks. arXiv 2020, arXiv:2009.13620. [Google Scholar] [CrossRef]
- Chavan, N.; Potika, K. Higher-order Link Prediction Using Triangle Embeddings. In Proceedings of the 2020 IEEE International Conference on Big Data, Big Data 2020, Atlanta, GA, USA, 10–13 December 2020; pp. 4535–4544. [Google Scholar] [CrossRef]
- Battiston, F.; Cencetti, G.; Iacopini, I.; Latora, V.; Lucas, M.; Patania, A.; Young, J.G.; Petri, G. Networks beyond pairwise interactions: Structure and dynamics. Phys. Rep. 2020, 874, 1–92. [Google Scholar] [CrossRef]
- Young, J.G.; Petri, G.; Peixoto, T.P. Hypergraph reconstruction from network data. Commun. Phys. 2021, 4, 135. [Google Scholar] [CrossRef]
- Iacopini, I.; Petri, G.; Barrat, A.; Latora, V. Simplicial models of social contagion. Nat. Commun. 2019, 10, 2485. [Google Scholar] [CrossRef]
- Vasilyeva, E.; Romance, M.; Samoylenko, I.; Kovalenko, K.; Musatov, D.; Raigorodskii, A.M.; Boccaletti, S. Distances in Higher-Order Networks and the Metric Structure of Hypergraphs. Entropy 2023, 25, 923. [Google Scholar] [CrossRef]
- Zhang, C.; Lei, Y.; Shen, X.; Li, Q.; Yao, H.; Cheng, D.; Xie, Y.; Yu, W. Fragility Induced by Interdependency of Complex Networks and Their Higher-Order Networks. Entropy 2023, 25, 22. [Google Scholar] [CrossRef] [PubMed]
- Rosvall, M.; Esquivel, A.V.; Lancichinetti, A.; West, J.D.; Lambiotte, R. Memory in network flows and its effects on spreading dynamics and community detection. Nat. Commun. 2014, 5, 4630. [Google Scholar] [CrossRef] [PubMed]
- Saebi, M.; Ciampaglia, G.L.; Kaplan, L.M.; Chawla, N.V. HONEM: Learning Embedding for Higher Order Networks. Big Data 2020, 8, 255–269. [Google Scholar] [CrossRef] [PubMed]
- Krieg, S.J.; Kogge, P.M.; Chawla, N.V. GrowHON: A scalable algorithm for growing Higher-order networks of sequences. In Complex Networks & Their Applications IX: Volume 2, Proceedings of the Ninth International Conference on Complex Networks and Their Applications Complex Networks 2020, Madrid, Spain, 1–3 December 2020; Springer: Cham, Switzerland, 2021; pp. 485–496. [Google Scholar]
- Saebi, M.; Xu, J.; Curasi, S.R.; Grey, E.K.; Chawla, N.V.; Lodge, D.M. Network analysis of ballast-mediated species transfer reveals important introduction and dispersal patterns in the Arctic. Sci. Rep. 2020, 10, 19558. [Google Scholar] [CrossRef] [PubMed]
- Page, L.; Brin, S. The PageRank Citation Ranking: Bringing Order to the Web. Stanf. Digit. Libr. Work. Pap. 1998, 98, 161–172. [Google Scholar] [CrossRef]
- Lü, L.; Zhang, Y.C.; Yeung, C.H.; Zhou, T. Leaders in social networks, the delicious case. PLoS ONE 2011, 6, e21202. [Google Scholar] [CrossRef] [PubMed]
- Kleinberg, J.M. Authoritative sources in a hyperlinked environment. J. ACM 1999, 46, 604–632. [Google Scholar] [CrossRef]
- Solá, L.; Romance, M.; Criado, R.; Flores, J.; García del Amo, A.; Boccaletti, S. Eigenvector centrality of nodes in multiplex networks. Chaos 2013, 23, 33131. [Google Scholar] [CrossRef] [PubMed]
- Leicht, E.A.; Newman, M.E. Community structure in directed networks. Phys. Rev. Lett. 2008, 100, 118703. [Google Scholar] [CrossRef]
- Rosvall, M.; Axelsson, D.; Bergstrom, C.T. The map equation. Eur. Phys. J. Spec. Top. 2009, 178, 13–23. [Google Scholar] [CrossRef]
- Blondel, V.D.; Guillaume, J.L.; Lambiotte, R.; Lefebvre, E. Fast unfolding of communities in large networks. J. Stat. Mech. Theory Exp. 2008, 2008, 10008. [Google Scholar] [CrossRef]
- Newman, M.E. Fast algorithm for detecting community structure in networks. Phys. Rev. E Stat. Phys. Plasmas Fluids Relat. Interdiscip. Top. 2004, 69, 5. [Google Scholar] [CrossRef]
- Newman, M.E. Modularity and community structure in networks. Proc. Natl. Acad. Sci. USA 2006, 103, 8577–8582. [Google Scholar] [CrossRef]
- Perozzi, B.; Al-Rfou, R.; Skiena, S. DeepWalk: Online learning of social representations. In Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 24–27 August 2014; pp. 701–710. [Google Scholar] [CrossRef]
- Grover, A.; Leskovec, J. Node2vec: Scalable feature learning for networks. In Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 855–864. [Google Scholar] [CrossRef]















Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).