Abstract
Matrix multiplication is important in various information-processing applications, including the computation of eigenvalues and eigenvectors, and in combinatorial optimization algorithms. Therefore, reducing the computation time of matrix products is essential to speed up scientific and practical calculations. Several approaches have been proposed to speed up this process, including GPUs, fast matrix multiplication libraries, custom hardware, and efficient approximate matrix multiplication (AMM) algorithms. However, research to date has yet to focus on accelerating AMMs for general matrices on GPUs, despite the potential of GPUs to perform fast and accurate matrix product calculations. In this paper, we propose a method for improving Monte Carlo AMMs. We also give an analytical solution for the optimal values of the hyperparameters in the proposed method. The proposed method improves the approximation of the matrix product without increasing the computation time compared to the conventional AMMs. It is also designed to work well with parallel operations on GPUs and can be incorporated into various algorithms. Finally, the proposed method is applied to a power method used for eigenvalue computation. We demonstrate that, on an NVIDIA A100 GPU, the computation time can be halved compared to the conventional power method using cuBLAS.
1. Introduction
Computing matrix products is a fundamental and essential operation in various information-processing tasks [1,2,3]. For example, one can obtain the largest eigenvalue and eigenvector of a positive definite matrix by repeating the following calculations:
In the power method, the computation of the matrix product is responsible for most of the computational burden. The same applies to optimization algorithms [4,5,6]. Therefore, it is crucial to reduce the computation time of matrix products to speed up various scientific and practical calculations.
A well-known method for accelerating matrix multiplication is to use GPUs. Other research has focused on implementing fast matrix multiplication libraries [7,8,9], designing custom hardware to accelerate specific classes of matrix multiplication [10,11,12], accelerating distributed matrix multiplication [13,14,15], designing exact and low-computation-order algorithms based on the divide-and-conquer method [16,17,18], and designing efficient approximate matrix multiplication (AMM) algorithms [19,20,21]. These areas are still active research fields. Recently, an AI-powered method that utilizes reinforcement learning to discover matrix arithmetic algorithms that are computationally less expensive than existing methods has been reported [22], building upon a previous study by Strassen [16].
For practical purposes, in some cases, the exact result of the matrix product may be optional. In this paper, we propose a method for such a case. It is known that when only an approximate result of the matrix product is required, the AMM methods can significantly reduce the computation time compared to other matrix acceleration approaches. MADDNESS, proposed in [20], provides high-speed approximate results. The paper demonstrated that MADDNESS, when executed on a CPU, can reduce the computation time by a factor of 100 compared to the exact matrix product while retaining sufficient computational accuracy to enable neural network inference. Allowing approximate calculations enables MADDNESS to achieve an overwhelming speed-up with other matrix optimization approaches. However, GPU computation can typically perform matrix products two orders of magnitude faster than CPU computation. Therefore, MADDNESS is practical for running neural networks in environments like the Internet of Things (IoT), where power consumption and installation space limitations make GPUs infeasible. On the other hand, if GPUs are available and there are no such limitations, obtaining the exact result by GPU computation rather than an approximate result by MADDNESS on a CPU is preferable.
A significant body of research proposing custom hardware exists to improve matrix multiplication performance. Hardware research often focuses on reducing energy consumption [23,24,25,26,27,28]. Existing hardware research has introduced various methods to reduce the energy consumption of artificial intelligence (AI) algorithms while maintaining acceptable accuracy. One approach involves approximate computing, which trades computational accuracy for improved energy efficiency. This strategy is particularly effective for AI algorithms that exhibit inherent error tolerance. Several papers have proposed using approximate multipliers, simplifying multiplication operations, and reducing energy consumption. Another approach involves using logarithmic multipliers, simplifying multiplication operations while sacrificing some degree of accuracy. This research significantly advances energy-efficient computing techniques tailored to AI algorithms, a central and pertinent topic within computer science. Our proposed method pertains to the approximate matrix multiplication algorithm and does not result in a reduction in the power consumption of a single FMA operation. However, it can potentially reduce the overall computation time of the application, thus making a valuable contribution to energy conservation.
To the best of our knowledge, no prior research other than the method for sparse matrices [29] has endeavored to accelerate approximate computations on GPUs, despite their capability for fast and precise computation of matrix products. Computations that can be efficiently accelerated by GPUs typically involve a large number of parallel executions of simple operations with regular memory access patterns. MADDNESS proposes an alternative approach to matrix multiplication by using hashing trees for table look-ups, which is considered unsuitable for GPU implementation. In addition, FD-AMM [30] incorporates the frequent direction algorithm [31] into AMM. However, the previous study [30] has reported that FD-AMM requires an SVD iteration to generate a sketch matrix whenever one of the multiplication matrices changes, resulting in longer computation times than existing methods. Thus, traditional AMM algorithms, which lack design considerations for parallel processing efficiency on GPUs, cannot guarantee the expected acceleration simply by implementing them on GPUs. Nevertheless, given that GPUs are already employed to expedite matrix products in numerous applications, it is also advantageous to leverage such devices for approximate calculations. Accordingly, we identified a known Monte Carlo AMM that can exploit the parallel computing capabilities of GPUs. Additionally, we devised an algorithm to enhance the approximation performance of this extant method while minimizing the increase in computational complexity. Our numerical experiments demonstrate that the proposed approach can expedite the computation of eigenvalues, which is crucial in both scientific and engineering domains.
2. Proposed Methods
2.1. Theory of Monte Carlo AMM
In this section, we present the theory behind the Monte Carlo method [32] used to compute the approximate matrix multiplication (AMM) of matrices and . We denote the lth column and row of a real matrix by and , respectively. The Frobenius norm of the matrix is denoted by , defined as the square root of the sum of the squares of all elements in the matrix. Furthermore, the Euclidean norm of vector is denoted as .
Algorithm 1 presents the pseudocode for the Monte Carlo AMM. It is a randomized algorithm that returns an approximate solution that is close to the exact solution with high probability. The expected square Frobenius error between and is evaluated using the following equation:
| Algorithm 1: Monte Carlo AMM [32] |
| Require: and , and |
| Ensure: such that is small |
| 1: |
| 2: Set such that |
| 3: for do |
| 4: Pick with |
| 5: |
| 6: end for |
It has been proven that this equation is minimized when the probability of sampling the lth column/row is set to its optimal value, defined as
In this case, the error is given by
The statement that and Equation (3) imply that Algorithm 1 with the optimal Monte Carlo sampling is designed to assign a higher probability to columns/rows with larger Frobenius norms during sampling and to compute their product as an approximate solution.
2.2. AMM with Preprocessing: Proposed Methods
A straightforward method to reduce the expected squared error is to increase the number of sampling iterations c. The error decreases inversely with the number of iterations. However, increasing c results in a longer computation time for the Monte Carlo AMM. Therefore, in this paper, we propose a method to reduce the expected squared error without significantly increasing the computation time by further exploiting the information used in the conventional AMM.
Let and be the mean of and , respectively. We define the following two matrices
where , , , , and is an l-dimensional vector whose elements are all one. These mean that we obtain and by subtracting a constant value from the ith column of and from the ith row of . Then,
The second, third, and fourth terms in Equation (6) can be computed using the matrix–vector and inner products instead of matrix–matrix products. By leveraging this fact, these terms can be accurately calculated with fewer computations for given matrices , , , and . Consequently, we utilize this approach to evaluate an AMM of matrices and instead of directly using and . Then, the expected error of this approximation relies solely on the error of . To simplify the notation, we define and . Notably, the matrices and are constant, and the crucial observation is that all column sums of and row sums of are equal to zero.
Algorithm 2 presents the pseudocode of our proposed method. The only differences between the proposed and conventional method lie in the second and third lines. The second line solely involves matrix–vector multiplication and inner product computation, which are less computationally intensive than matrix multiplication. Furthermore, the third line allows parallel execution for each pair of i and j. Consequently, the proposed method can be regarded as integrating the less computationally demanding preprocessing employed by the existing Monte Carlo AMM. This algorithm represents the calculation of an approximate solution to , as shown by the following calculation.
| Algorithm 2: Proposed method: Monte Carlo AMM with preprocessing |
| Require: and , and |
| Ensure: , such that is small |
| 1: |
| 2: , , |
| 3: for all and |
| 4: Set such that |
| 5: for do |
| 6: Pick with |
| 7: |
| 8: end for |
Equation (7) can be regarded as the case of in Equation (6). Remarkably, we can prove theoretically that the expected error by Algorithm 2 is equal to or less than the error by Algorithm 1. Considering the discussion on Equation (4), we see that the expected squared error for computing using Equation (6) and the combination of AMM with exact computations is proportional to
The expected squared error can be represented by . Hereafter, our objective is to establish the superior accuracy of the proposed method compared to the original Monte Carlo AMM. To achieve this, we aim to demonstrate that, through the presentation of several theorems, the global minimum of E occurs at .
Theorem 1.
Equation (8) is minimized at if all elements in are zero.
Proof.
Suppose that all elements of are zero for a certain i. Let be the vector, such that
For simplicity, we introduce the following notations.
Since we have , the following equalities hold.
In addition, we have
where denotes the Frobenius inner product.
We can easily see that holds for vectors and . Combining this equality, the Cauchy–Schwarz inequality, and the triangle inequality, we obtain
If all the elements in are identical, then according to the definitions of and , all elements in are also identical. Hence, applying Theorem 1, we can deduce that the value of yields the minimum value of E is 0, which implies . Combining this equation with Equation (8), we can obtain the values of , which minimize E by extracting the submatrices, respectively, after removing the ith column from and the ith row from .
Therefore, to minimize E, we can eliminate the ith column of and the ith row of if all of their elements are identical. Subsequently, we can minimize the error E using the resulting submatrix, which can be obtained by removing identical elements, as presented in Equation (8). Hereafter, we denote the standard deviation of the elements in and by and , respectively, with the assumption that and for all i.
Theorem 2.
The following equations hold for any i.
Proof.
Let be the ith row and jth column element of matrix . For matrices and , we have the following equalities:
Using Equation (17), we can reformulate a term in Equation (8) as
Since the sum of each column of and each row of is zero, and are valid for any l. Applying this to the equality above, we have
Since the average of elements in is zero, we have , where denotes the ith element of vector . From this equality, we obtain
In the same way, we have
Substituting Equation (19), Equation (20), and Equation (21) into Equation (8), we obtain
Because we have , the following holds.
Thus,
In the same way, we have
By combining Equation (24) with Equation (25), we can derive Equation (16). □
Theorem 3.
The largest eigenvalue of is less than or equal to for any real nonzero matrix . The equality holds if the rank of is one.
Proof.
Let be the ith largest eigenvalue of . Since is positive semidefinite, all eigenvalues of are non-negative, and we have . Therefore, the largest eigenvalue of is less than or equal to .
The equality holds if and only if all eigenvalues other than the largest one are zero, which means that the rank of is one. Hereafter, we assume that the rank of is one. Let r be the rank of . We then have the singular value decomposition (SVD) of as , where , and . Because is an orthogonal matrix and is a diagonal matrix, holds. This is nothing but the SVD of , and it implies that the rank of is r as well. Since the rank of is one, we have ; thus, the rank of is one. □
Theorem 4.
The following equation holds for any combination of i and j.
Theorem 5.
The Hessian matrices of E, regarding and , and and , are positive semidefinite at .
Proof.
We define for simplicity. Then, we have
Moreover, the following equalities hold.
Substituting these equalities into Equation (24), we can simplify as
Since is equal to the square of the Euclidean length of , we have . Substituting this into Equation (31), we obtain
This equation implies that
For , we can simplify as
This equation implies that
Let be a diagonal and regular matrix . From Theorem 3, the largest eigenvalue of is less than or equal to Thus,
where is an identity matrix. Therefore, holds, which shows that is positive semidefinite at . In the same way, we can prove that is positive semidefinite at . □
Theorem 6.
The function E is locally optimal at .
Proof.
The Hessian matrix of E can be expressed as
Theorem 4 provides at . Furthermore, Theorem 5 claims that and are positive semidefinite at , which means is also positive semidefinite at . Based on the positive semidefinite property and Theorem 2, it is apparent that the point serves as a locally optimal solution for the minimization of E. □
The preceding discussion demonstrates that the point constitutes a local optimum of E. Hereafter, we establish that, in almost all cases, this point is a global optimum because E has only one local optimum, and, in other cases, the point is globally optimal as well because all local optima are connected.
Theorem 7.
Let be a rank-1 matrix and be a vector satisfying . The vector is the only eigenvector of . The matrix has an eigenvalue of 0, and only a scaled version of is its eigenvector.
Proof.
As holds, we have . Since is a rank-1 matrix, is a rank-1 matrix as well and has only one eigenvalue. Combining this and , we can see that is the unique eigenvector of . Moreover, based on the equality above, the matrix has an eigenvalue of 0, and only a scaled version of becomes its eigenvector. □
Theorem 8.
Let be a rank-1 matrix, and be a vector satisfying . Let be a regular and diagonal matrix. The vectors that satisfy are scaled versions of .
Proof.
Since is a rank-1 matrix and is regular, is a rank-1 matrix as well. Let be , and be a vector satisfying . Theorem 7 implies that has an eigenvalue of 0 and only a scaled version of becomes its eigenvector. Because holds, we have . Thus, a scaled version of is an eigenvector of corresponding to an eigenvalue of 0. Therefore, the following equality holds for any real value of c.
We can easily see that holds, and it implies that the matrix has the eigenvalue of 0 and only a scaled version of is one of its eigenvectors. Moreover, we have the following equalities:
Therefore, the matrix has an eigenvalue of 0, and a scaled version of is one of its eigenvectors.
Theorem 3 claims that is positive semidefinite, and it implies that is positive semidefinite as well. Thus, the vector satisfying is zero vector or a scaled version of the eigenvector corresponding to the eigenvalue of 0. Therefore, are scaled versions of . □
Theorem 9.
The function E is globally optimal at x = y = 0.
Proof.
Let be and be a diagonal and regular matrix
From Theorem 3, the largest eigenvalue of is less than or equal to
Thus, we have
In particular, "≻" holds if .
- (i)
- , or and is not a scaled version of a column vector of
Because the rank of is greater than 1, we have . Combining this inequality and Equation (42), we see that holds at only. Therefore, if is a local minimum of E, then holds and we have . Since a local minimum is limited to , it also becomes the global minimum.
- (ii)
- and is a scaled version of a column vector of
All rows of are dependent due to . As is a scaled version of a column vector of , we can express as by introducing a vector . By definition, is not always zero.
Substituting Equation (44) into Equation (42), we have
The right-hand side of Equation (46) is zero due to . Theorem 8 claims that the vectors satisfying are scaled versions of , where . The equality gives us , and it means . Thus,
must be satisfied with a certain real value of c, where . Solving this equation, we have . This means that if is a scaled version of vector then we have . Because can be , points satisfying have the same value of E at .
We show that if is a scaled version of vector . Substituting into Equation (32), we have
We also obtain the following equality for by applying into Equation (34).
Summarizing Equations (48), (49), and the equality , we can simplify as follows:
The assumption on and definition of attain for all i. Thus, we have
The discussion regarding the positive semidefiniteness of Equation (36) also demonstrates that the first term on the right-hand side of Equation (50) is positive semidefinite. Therefore, holds if is a scaled version of vector .
Through the discussion on the conditions under which must satisfy in the local solution of E when is a constant vector, the following revelations emerge:
- If is a local solution, it must be a scaled version of vector .
- All local solutions are continuous and have the same value of E.
- holds if is a scaled version of vector .
In other words, the set of local solutions is globally minimal, and also becomes a global minimum.
Both discussions (i) and (ii) yield the conclusion that is valid when E is minimized under the condition of a constant . Similar observations can be made regarding investigating the conditions for in the local solution of E. Hence, the function E attains global optimality at . □
3. Results
3.1. Assessing the Accuracy of Approximate Matrix Multiplications
We evaluate the approximation performance of the proposed method for matrix multiplication. First, we set the size of the matrices to . Then, we randomly determine each element of the matrices independently of a uniform distribution between 0 and 1.
Figure 1A evaluates the speedup ratio of the computation time and the approximation performance obtained by applying the conventional and proposed methods for AMM. The horizontal axis compares the computation time of the approximate calculation with that of the exact matrix product calculation. In the experiments of this chapter, we implemented the CUDA program for AMM using CUDA 12.0, which was executed on an NVIDIA A100 GPU. The exact matrix product was computed using an API incorporated into cuBLAS (NVIDIA’s official matrix library). The numerical precision was set to a single-precision floating point. The vertical axis in this figure represents the median relative accuracy between an approximate matrix and the exact solution , calculated by executing each method 100 times. The relative accuracy is defined as
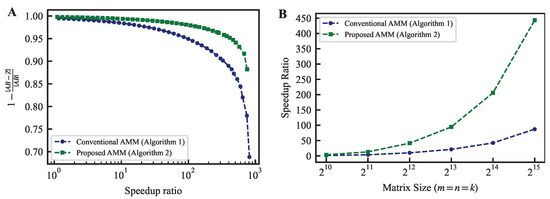
Figure 1.
(A) The trade-off between the speedup ratio and Frobenius norm error when calculating AMM using the conventional and proposed methods. The matrices are of size , with elements randomly generated from a uniform distribution between 0 and 1. The speedup ratio is the ratio of the time taken to calculate the matrix product precisely using cuBLAS on a GPU to the time taken to execute AMM. (B) Comparison of speedup ratios for achieving a relative accuracy of 0.95. It is clear that as the matrix size increases, the difference in speedup rate increases.
Figure 1A demonstrates that the proposed method achieves higher acceleration while maintaining relative accuracy. For instance, at a relative accuracy of 0.95, the acceleration rate is 87.2 times faster for the conventional method and 443.2 times faster for the proposed method. Although the relative accuracy required depends on the application, the proposed method outperforms the traditional method at all levels of relative accuracy.
Figure 1B displays a graph showing the speedup ratio trend achieving a relative accuracy of 0.95 when the matrix size is changed from to . This demonstrates that the proposed method can achieve higher speedup ratios than the conventional method regardless of the matrix size. Furthermore, the difference in the speedup ratio expands as the matrix size increases. If the matrix size is small, the exact product does not generally become the bottleneck of the entire calculation. The approximate product is required mainly for large-scale computations. The property of the proposed method (that the advantage becomes more pronounced as the matrix size increases) is desirable.
3.2. Application to a Practical Problem: Computing Eigenvalues and Eigenvectors
Next, we evaluate the performance of the proposed methodology in practical applications. We focus on the computation of eigenvalues, particularly the largest eigenvalue. Several algorithms have been proposed for computing the largest eigenvalue, including power iteration, inverse power iteration [33], accelerated stochastic power iteration [34], and the LOBPCG method [35]. This paper applies the proposed AMM to the power iteration, which forms the backbone of many existing techniques.
We assume for simplicity that the matrix is symmetric. Then, all eigenvalues of are real. See Algorithm 3. For any square matrix , let be an eigenvalue of . Then, has an eigenvalue of . Therefore, we substitute with in Algorithm 3.
| Algorithm 3: Power method |
| Require: , : m-dimensional randomized unit vector. |
| Ensure: : the eigenvalue of with the largest absolute value |
| 1: for while not converged do |
| 2: |
| 3: |
| 4: |
| 5: end for |
| 6: Return |
In this case, the second line is expressed as , and we apply the proposed AMM to this step. From Equation (7), we have
We execute the calculation of in Equation (53) using Algorithm 2. By incorporating this AMM into Algorithm 3, we obtain Algorithm 4, a power iteration algorithm that utilizes the approximation. The fourth to eighth lines of Algorithm 4 correspond to the Monte Carlo AMM with the proposed method.
| Algorithm 4: Power method with the proposed Monte Carlo AMM |
| Require: : symmetric positive-semidefinite matrix, : m-dimensional randomized unit vector, |
| Ensure: : the largest absolute eigenvalue of |
| 1: , |
| 2: Set , such that |
| 3: for while not converged do |
| 4: |
| 5: for do |
| 6: Pick with |
| 7: |
| 8: end for |
| 9: |
| 10: |
| 11: end for |
| 12: Return |
In this section, we assess the performance of the proposed methodology by employing the principal component analysis (PCA) [36] as a representative example, which serves as one of the applications for computing eigenvalues. The PCA is a method employed to examine and reduce the dimensionality of the dataset. It involves identifying the principal components and linear combinations of the original features that effectively capture the most substantial variations within the data. The eigenvalues and eigenvectors of a covariance matrix hold a pivotal role in PCA. When presented with a dataset comprising p features, the initial step in PCA involves the computation of the covariance matrix. This matrix assumes a symmetric structure with dimensions of p-by-p, where each element denotes the covariance between two specific features. The quest for the most dominant principal components is tantamount to identifying the largest eigenvector within the covariance matrix. Hence, within this section, we focus on image analysis, an area in which PCA finds frequent application. Specifically, we have obtained the largest eigenvalues and corresponding eigenvectors from a matrix with a size of , which is acquired via the eigenface algorithm [37] on the LFW dataset [38].
Figure 2A illustrates the variation in convergence over time when CUDA programs of the power method (PM) are run on an NVIDIA A100 GPU. Both figures share a common horizontal axis representing the computation time.
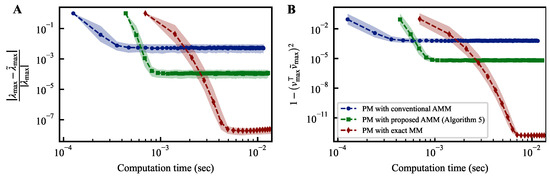
Figure 2.
Temporal convergence curves of power methods. The differences between the estimated largest eigenvalue and its corresponding eigenvector at each iteration of the power method from their respective true values, denoted as and , are plotted on the vertical axis of each figure.
The vertical axis in Figure 2A represents the relative error between the largest and estimated eigenvalue during iterations. In contrast, the vertical axis in Figure 2B represents the deviation between the eigenvector corresponding to the largest eigenvalue and the estimated eigenvector during iterations. Incorporating the proposed AMM into the power method requires the execution of the first line of Algorithm 4, resulting in a longer duration until the completion of the initial iteration compared to the conventional method incorporating AMM in the power method. However, since this computation only needs to be performed once, its impact on the overall computation time is limited. Compared to the power method with the conventional AMM, the method with the proposed AMM demonstrates favorable convergence in both indicators. The power method with the proposed AMM cannot achieve the same level of convergence as the one employing exact matrix multiplication. This is because the expected variance from the AMM breaks the condition revealed in previous studies on the noisy power method [39].
To solve this problem, we propose a variance reduction method that performs exact matrix multiplication under some criteria. When obtaining the approximate matrix product of the matrices and , if is known, we can compute the approximate solution and provide as an approximate solution. As mentioned in Section 2, the expected error will decrease if the Frobenius norm of is small. The estimated eigenvector converges gradually through the power method. Therefore, computing the exact matrix product only sometimes and minimizing the expected error of the AMM are expected to be effective. Based on this motivation, we present Algorithm 5. It uses the proposed AMM while performing exact matrix multiplication only for the steps that satisfy the given conditions.
| Algorithm 5: Variance reduction power method with the proposed Monte Carlo AMM |
| Require: : symmetric positive-semidefinite matrix, : m-dimensional randomized unit vector, |
| Ensure: : the largest absolute eigenvalue of |
| 1: , , , |
| 2: Set , such that |
| 3: for while not converged do |
| 4: if criteria are met then |
| 5: |
| 6: for do |
| 7: Pick with |
| 8: |
| 9: end for |
| 10: else |
| 11: , , |
| 12: end if |
| 13: |
| 14: |
| 15: end for |
| 16: Return |
Various conditions can be considered for performing exact matrix multiplication. For instance, we can employ a static strategy where an exact computation is performed every few steps. Alternatively, a dynamic strategy is also promising, where convergence stagnation due to approximation errors is detected, and an exact computation is executed. In this section, we adopt a hybrid approach that combines an AMM with the exact computation based on this dynamic strategy. To assess the convergence of eigenvector calculations, we adopt the following rules:
- 1.
- If the dot product between the current and previous vectors of exceeds a threshold value , then we execute the exact matrix product at the next step.
- 2.
- Even if the initial condition is met, the subsequent calculation employs an AMM if the exact matrix multiplication was previously executed.
The experimental results are presented in Figure 3. We set the number of samplings c to 512. We executed each method 1000 times while changing random seeds. In this figure, the markers represent the median, while the shaded region represents the interquartile range from the first to the third quartiles. The top row corresponds to , while the bottom row corresponds to . The left panel depicts the relative error between the true largest eigenvalue and the estimated largest eigenvalue . The right panel illustrates the discrepancy between the eigenvectors corresponding to the largest eigenvalue, denoted as , and the estimated eigenvectors denoted as . The threshold is a hyperparameter, and it is not clear how to determine an appropriate value for it. Therefore, the method should exhibit stable convergence for various threshold values. For , the power method with the conventional AMM fails to converge. In contrast, the power method with the proposed AMM demonstrates convergence performance comparable to the power method employing exact matrix multiplication while achieving a reduced computation time. When the threshold is changed to , the steps involving exact matrix multiplication increase. Consequently, even the power method with the conventional AMM exhibits good convergence. However, the increased frequency of exact matrix multiplications requires more computation time than the power method with the proposed AMM. Thus, the power method with the proposed AMM demonstrates more robust convergence than the one utilizing only exact matrix multiplication. Moreover, it is faster than the power method using only exact matrix multiplication. For instance, when , the computation time until reaching is reduced by about 40%.
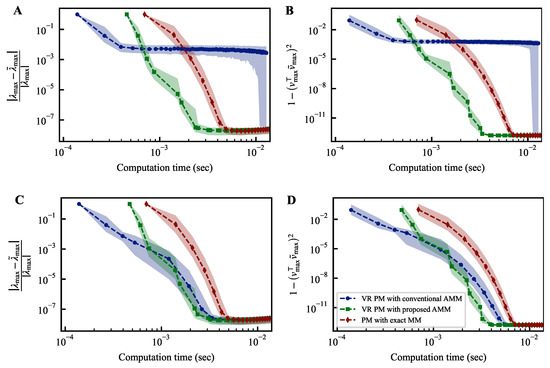
Figure 3.
Temporal convergence curves of variance reduction power methods. The differences between the estimated largest eigenvalue and its corresponding eigenvector at each iteration of the power method from their respective true values, denoted as and , are plotted on the vertical axis of each figure. The top row (A,B) corresponds to , while the bottom row (C,D) corresponds to . The notation is a parameter representing the threshold for switching between exact and approximate matrix products in power methods; the details of which are described in the main text.
4. Discussion
One of the challenges of the proposed method is that its effectiveness diminishes when the elements of matrix ’s columns, representing , and the elements of matrix ’s rows, representing , are close to zero. In practical applications and datasets, matrices often exhibit element distributions with specific tendencies or possess the property of being positive semidefinite, thereby deviating from the scenarios where the proposed method is less effective. However, there are cases in specific applications where these conditions apply, requiring alternative methods to improve the approximation accuracy of the matrices.
In this paper, we applied AMM to the simple power method and computed the largest eigenvalue. By incorporating QR decomposition into the iterations of the power method, we can obtain the first several singular eigenvectors [39]. Furthermore, by extending the application of AMM to other variants of the power method discussed in this paper, we anticipate accelerating the computation of various eigenvalue calculations. As mentioned in the previous section, some prior studies on the noisy power method analyze the convergence behavior when noise is introduced in each iteration of the power method. Although we determined the threshold in this paper, it is possible to analytically or dynamically adjust based on such prior research. This remains a challenge for future investigation.
Besides the power method, least square minimization can also be considered among the applications of AMM. Previous research has explored accelerating the analysis of large-scale single nucleotide polymorphisms by utilizing approximate calculations to reduce computational complexity, as the use of pseudo-inverse matrices for obtaining approximate solutions incur high computational costs [19]. By applying our proposed concept to randomized numerical linear algebra (RandNLA), including these applications, there is potential to achieve faster computations and obtain higher-quality approximate solutions. Therefore, applying our method to various scientific and technological computations will be important.
Author Contributions
Conceptualization, T.O., A.R., T.M., and M.N.; methodology, T.O.; software, T.O.; writing—original draft preparation, T.O.; writing—review and editing, A.R., T.M., and M.N.; visualization, T.O.; supervision, M.N.; project administration, M.N.; funding acquisition, M.N. All authors have read and agreed to the published version of the manuscript.
Funding
This study was supported in part by the CREST project (JPMJCR17N2) funded by the Japan Science and Technology Agency, Grants-in-Aid for Scientific Research (JP20H00233), and Transformative Research Areas (A) (JP22H05197) funded by the Japan Society for the Promotion of Science. A.R. was funded by the Japan Society for the Promotion of Science as an International Research Fellow.
Data Availability Statement
Readers can download the programs used in Section 3.1 and Section 3.2 from https://github.com/Takuya-Okuyama/AMM_with_preprocessing (accessed on 24 July 2023) and https://github.com/Takuya-Okuyama/eigenvalueComputation_by_AMM (accessed on 24 July 2023), respectively.
Acknowledgments
We would like to thank Nicolas Chauvet for useful discussions in the early stages of this work.
Conflicts of Interest
The authors declare that there are no conflicts of interest regarding the publication of this paper.
References
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning representations by back-propagating errors. Nature 1986, 323, 533–536. [Google Scholar] [CrossRef]
- Sarle, W. Neural Networks and Statistical Models. In Proceedings of the 19th Annual SAS Users Group International Conference, Dallas, TX, USA, 10–13 April 1994; pp. 1538–1550. [Google Scholar]
- Lee, D.D.; Seung, H.S. Learning the parts of objects by non-negative matrix factorization. Nature 1999, 401, 788–791. [Google Scholar] [CrossRef]
- Okuyama, T.; Sonobe, T.; Kawarabayashi, K.; Yamaoka, M. Binary optimization by momentum annealing. Phys. Rev. E 2019, 100, 012111. [Google Scholar] [CrossRef] [PubMed]
- Bottou, L. On-Line Learning and Stochastic Approximations. In On-Line Learning in Neural Networks; Cambridge University Press: Cambridge, MA, USA, 1999; pp. 9–42. [Google Scholar]
- Wright, S.J. Primal-Dual Interior-Point Methods; SIAM: Philadelphia, PA, USA, 1997. [Google Scholar]
- Altschul, S.F.; Gish, W.; Miller, W.; Myers, E.W.; Lipman, D.J. Basic local alignment search tool. J. Mol. Biol. 1990, 215, 403–410. [Google Scholar] [CrossRef] [PubMed]
- Sanderson, C.; Curtin, R. Armadillo: A template-based C++ library for linear algebra. J. Open Source Softw. 2016, 1, 26. [Google Scholar] [CrossRef]
- Paszke, A.; Gross, S.; Chintala, S.; Chanan, G.; Yang, E.; DeVito, Z.; Lin, Z.; Desmaison, A.; Antiga, L.; Lerer, A. Automatic Differentiation in PyTorch. In Proceedings of the NIPS 2017 Workshop on Autodiff, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Jouppi, N.P.; Young, C.; Patil, N.; Patterson, D.; Agrawal, G.; Bajwa, R.; Bates, S.; Bhatia, S.; Boden, N.; Borchers, A.; et al. In-Datacenter Performance Analysis of a Tensor Processing Unit. SIGARCH Comput. Archit. News 2017, 45, 1–12. [Google Scholar] [CrossRef]
- Zhang, Z.; Wang, H.; Han, S.; Dally, W.J. SpArch: Efficient Architecture for Sparse Matrix Multiplication. In Proceedings of the 2020 IEEE International Symposium on High Performance Computer Architecture (HPCA), San Diego, CA, USA, 22–26 February 2020; pp. 261–274. [Google Scholar] [CrossRef]
- Zhou, H.; Dong, J.; Cheng, J.; Dong, W.; Huang, C.; Shen, Y.; Zhang, Q.; Gu, M.; Qian, C.; Chen, H.; et al. Photonic matrix multiplication lights up photonic accelerator and beyond. Light. Sci. Appl. 2022, 11, 30. [Google Scholar] [CrossRef]
- Yu, Q.; Maddah-Ali, M.A.; Avestimehr, A.S. Straggler Mitigation in Distributed Matrix Multiplication: Fundamental Limits and Optimal Coding. In Proceedings of the 2018 IEEE International Symposium on Information Theory (ISIT), Vail, CO, USA, 17–22 June 2018; pp. 2022–2026. [Google Scholar] [CrossRef]
- Aliasgari, M.; Simeone, O.; Kliewer, J. Private and Secure Distributed Matrix Multiplication With Flexible Communication Load. IEEE Trans. Inf. Forensics Secur. 2020, 15, 2722–2734. [Google Scholar] [CrossRef]
- Nissim, R.; Schwartz, O. Accelerating Distributed Matrix Multiplication with 4-Dimensional Polynomial Codes. In Proceedings of the SIAM Conference on Applied and Computational Discrete Algorithms (ACDA23), Seattle, WA, USA, 31 May–2 June 2023; pp. 134–146. [Google Scholar] [CrossRef]
- Strassen, V. Gaussian elimination is not optimal. Numer. Math. 1969, 13, 354–356. [Google Scholar] [CrossRef]
- Li, J.; Ranka, S.; Sahni, S. Strassen’s Matrix Multiplication on GPUs. In Proceedings of the 2011 IEEE 17th International Conference on Parallel and Distributed Systems, Tainan, Taiwan, 7–9 December 2011; pp. 157–164. [Google Scholar] [CrossRef]
- Winograd, S. On multiplication of 2 × 2 matrices. Linear Algebra Its Appl. 1971, 4, 381–388. [Google Scholar] [CrossRef]
- Drineas, P.; Mahoney, M.W. RandNLA: Randomized Numerical Linear Algebra. Commun. ACM 2016, 59, 80–90. [Google Scholar] [CrossRef]
- Blalock, D.; Guttag, J. Multiplying Matrices Without Multiplying. In Proceedings of the 38th International Conference on Machine Learning, Virtual Event, 18–24 July 2021; Meila, M., Zhang, T., Eds.; PMLR: La Jolla, CA, USA, 2021; Volume 139, pp. 992–1004. [Google Scholar]
- Francis, D.P.; Raimond, K. A Practical Streaming Approximate Matrix Multiplication Algorithm. J. King Saud Univ. Comput. Inf. Sci. 2022, 34, 1455–1465. [Google Scholar] [CrossRef]
- Fawzi, A.; Balog, M.; Huang, A.; Hubert, T.; Romera-Paredes, B.; Barekatain, M.; Novikov, A.; Ruiz, F.J.R.; Schrittwieser, J.; Swirszcz, G.; et al. Discovering faster matrix multiplication algorithms with reinforcement learning. Nature 2022, 610, 47–53. [Google Scholar] [CrossRef] [PubMed]
- Lee, K.J.; Lee, J.; Choi, S.; Yoo, H.J. The Development of Silicon for AI: Different Design Approaches. IEEE Trans. Circuits Syst. Regul. Pap. 2020, 67, 4719–4732. [Google Scholar] [CrossRef]
- Pilipović, R.; Risojević, V.; Božič, J.; Bulić, P.; Lotrič, U. An Approximate GEMM Unit for Energy-Efficient Object Detection. Sensors 2021, 21, 4195. [Google Scholar] [CrossRef] [PubMed]
- Kim, M.S.; Barrio, A.A.D.; Oliveira, L.T.; Hermida, R.; Bagherzadeh, N. Efficient Mitchell’s Approximate Log Multipliers for Convolutional Neural Networks. IEEE Trans. Comput. 2019, 68, 660–675. [Google Scholar] [CrossRef]
- Ansari, M.S.; Cockburn, B.F.; Han, J. An Improved Logarithmic Multiplier for Energy-Efficient Neural Computing. IEEE Trans. Comput. 2021, 70, 614–625. [Google Scholar] [CrossRef]
- Pilipović, R.; Bulić, P.; Lotrič, U. A Two-Stage Operand Trimming Approximate Logarithmic Multiplier. IEEE Trans. Circuits Syst. Regul. Pap. 2021, 68, 2535–2545. [Google Scholar] [CrossRef]
- Kim, M.S.; Del Barrio, A.A.; Kim, H.; Bagherzadeh, N. The Effects of Approximate Multiplication on Convolutional Neural Networks. IEEE Trans. Emerg. Top. Comput. 2022, 10, 904–916. [Google Scholar] [CrossRef]
- Liu, X.; Liu, Y.; Yang, H.; Dun, M.; Yin, B.; Luan, Z.; Qian, D. Accelerating approximate matrix multiplication for near-sparse matrices on GPUs. J. Supercomput. 2022, 78, 11464–11491. [Google Scholar] [CrossRef]
- Ye, Q.; Luo, L.; Zhang, Z. Frequent Direction Algorithms for Approximate Matrix Multiplication with Applications in CCA. In Proceedings of the Twenty-Fifth International Joint Conference on Artificial Intelligence, New York, NY, USA, 9–15 July 2016; AAAI Press: Atlanta, GA, USA, 2016; pp. 2301–2307. [Google Scholar]
- Ghashami, M.; Liberty, E.; Phillips, J.M.; Woodruff, D.P. Frequent Directions: Simple and Deterministic Matrix Sketching. SIAM J. Comput. 2016, 45, 1762–1792. [Google Scholar] [CrossRef]
- Drineas, P.; Kannan, R.; Mahoney, M.W. Fast Monte Carlo Algorithms for Matrices I: Approximating Matrix Multiplication. SIAM J. Comput. 2006, 36, 132–157. [Google Scholar] [CrossRef]
- Serre, D. Matrices; Springer: New York, NY, USA, 2010. [Google Scholar] [CrossRef]
- Xu, P.; He, B.; De Sa, C.; Mitliagkas, I.; Re, C. Accelerated stochastic power iteration. In Proceedings of the International Conference on Artificial Intelligence and Statistics, Lanzarote, Canary Islands, 9–11 April 2018; pp. 58–67. [Google Scholar]
- Knyazev, A.V. Toward the Optimal Preconditioned Eigensolver: Locally Optimal Block Preconditioned Conjugate Gradient Method. SIAM J. Sci. Comput. 2001, 23, 517–541. [Google Scholar] [CrossRef]
- Jolliffe, I.T. Principal Component Analysis, 2nd ed; Springer Series in Statistics; Springer: New York, NY, USA, 2002. [Google Scholar]
- Turk, M.; Pentland, A. Face recognition using eigenfaces. In Proceedings of the 1991 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Maui, HI, USA, 3–6 June 1999; pp. 586–591. [Google Scholar] [CrossRef]
- Huang, G.B.; Jain, V.; Learned-Miller, E. Unsupervised Joint Alignment of Complex Images. In Proceedings of the ICCV, Rio de Janeiro, Brazil, 14–20 October 2007. [Google Scholar]
- Hardt, M.; Price, E. The Noisy Power Method: A Meta Algorithm with Applications. In Proceedings of the 27th International Conference on Neural Information Processing Systems—Volume 2; NIPS’14. MIT Press: Cambridge, MA, USA, 2014; pp. 2861–2869. [Google Scholar]



Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).