1. Introduction
The Internet of Things (IoT) is a network framework merging the physical domain and the virtual domain through the Internet [
1]. IoT devices can collect information, process data, and interact with other connected members automatically. Security issues are major concerns persistent throughout the development of IoT. In IoT paradigms requiring device cooperation, a device may not have the capacity and integrity to complete most assignments and behave in the interest of most participants. Trust management is responsible for building and maintaining a profile of a device’s trustworthiness in a network to ensure that most devices are trustworthy. It is crucial for applications depending on the collaboration among IoT devices to guarantee user experience [
2]. In this section, readers can interpret trust as a particular level of the subjective probability with which an agent assesses that another agent or group of agents will perform a particular action [
3]. Trust mechanisms for issues in the traditional security field may not acclimatize well to IoT applications due to the following technical characteristics of IoT [
4]:
Popular IoT paradigms are heterogeneous, where devices have varying capabilities and communicate with various protocols. As a result, it is challenging to create a trust mechanism that can apply to different applications via easy adaptation.
IoT devices usually possess limited computing power and memory. A practical trust mechanism must balance the accuracy of trust estimations and algorithm complexity.
IoT devices are numerous and ubiquitous. A trust mechanism should be scalable to remain efficient when the number of devices grows in a network.
Mobile IoT devices such as smartphones and intelligent vehicles are dynamic, frequently joining and leaving networks. It complicates maintaining their profiles of trustworthiness for trust mechanisms.
Apart from these challenges, malicious devices can mislead evaluators into producing incorrect trust estimations by launching trust attacks. It should be a consideration for trust mechanisms [
5]. Roles played by contemporary devices are more and more complex. The social IoT is a paradigm of this trend, where researchers introduce the concept of human social networks to study relations automatically built among devices whose roles can shift between the requester and server [
6]. It may render trust attacks more attainable and profitable. For example, malicious attackers collude to exaggerate conspirators and slander other devices, aiming at the monopoly of service providers in a network. On the other hand, it facilitates communication among devices with different views, which is very helpful in locating trust attackers.
Researchers have proposed various trust mechanisms for different IoT networks, most of which adopt distributed architectures due to the quantity and ubiquity of IoT devices. Usually, a trust mechanism ultimately quantifies a device’s trustworthiness with a trust estimation derived from a data fusion process. Data fusion is responsible for utilizing a batch of descriptions or metrics of a device’s behavior with different times and sources to evaluate this device’s trustworthiness, as the core function of the trust mechanism. Bayesian inference or Dempster–Shafer theory [
7] are widely used approaches for data fusion, applicable to different networks such as sensor networks and ad hoc networks [
8,
9,
10,
11,
12,
13]. Supported by related statistics principles, the former can accomplish data fusion through simple computing. Analogous to human reasoning, the latter permits expressing the extent of uncertainty related to an event rather than entirely recognizing or denying its authenticity. This property is useful when acquired information about an event is temporarily scarce. They can work in conjunction: the former processes data gathered from direct observation and the latter processes data provided by other devices [
8,
10]. For similar reasons to why Dempster–Shafer theory is adopted, there is research choosing fuzzy logic [
14] or cloud theory [
15] for data fusion. It is also common to construct experience-based formulas for data fusion to let a trust mechanism designed for a particular application fully consider the characteristics peculiar to this application [
16,
17,
18,
19,
20]. For example, Chen et al. propose a trust mechanism for social IoT systems where data fusion produces three universal metrics related to the properties of a device’s performance in honesty, cooperativeness, and community interest. Further, they consist of an application-specific formula to compute a trust estimation [
16].
However, the above summarized technical characteristics of IoT bring the following common challenges that remain to be addressed for many existing trust mechanisms, regardless of whether their data fusion employs theoretical or empirical foundations. Firstly, A trust mechanism designed to solve specific trust problems of several applications is hard to suit other applications via adaptation, although it is feasible to propose a universal trust mechanism [
10]. Secondly, trust mechanisms employing distributed architectures and asking devices to share trust data cannot efficiently manage many devices due to their limited storage and communication capabilities. Thirdly, trust mechanisms often assume that devices can guarantee service quality, which does not apply to applications having inherent uncertainty. For example, interactions may occasionally fail due to noise interference in communication channels [
15].
Moreover, the explanation of how parameters related to data fusion determine trust estimations is not detailed in many existing trust mechanism, leading to the undesirable dependency on operational experience with trial and error in the deployment phase. This problem is not unique to experience-based data fusion; it can also occur in theory-based data fusion. A trust mechanism with theory-based data fusion may require extra parameters beyond the underlying theories to provide special features. For example, to endow newer information more weight in data fusion, the trust mechanisms using Bayesian inference proposed in [
8,
10] utilize an aging factor and a penalty factor, respectively. Bayesian inference alone cannot provide this feature, where evidence collected in different periods is equivalent to being used to update the prior distribution. A poorly explicable parameter may limit a trust mechanism’s performance. For example, in [
16], the presented simulation indicates that the variation in the proposed trust mechanism’s estimations is not significant when altering the parameter related to external recommendations. Some research proposes cryptography-based reliable approaches that can protect the integrity and privacy of data for healthcare [
21] and vehicle [
22] applications. However, devices competent in quickly performing encryption and decryption operations, such as the cloud servers and intelligent vehicles in this research, are not generally deployed in the IoT field.
Finally, solutions to trust attacks are often absent in existing trust mechanisms. In this paper, trust attacks refer to the following attacks on service defined in [
5]: on-off attacks (OOAs), bad-mouthing attacks (BMAs), ballot-stuffing attacks (BSAs), discrimination attacks (DAs), self-promoting (SP) attacks, value imbalance exploitation (VIE), Sybil attacks (SAs), and newcomer attacks (NCAs). Although the following research gives analyses of how their data fusion mitigates influences from trust attacks or methods to identify trust attackers, there are several vulnerabilities: It may be accurate to assume that attackers are bad service providers for faulty devices [
8], but this assumption is no longer relevant for devices having more functions nowadays. The behavior of an attacker launching a DA may be different in front of two observers. Comparison-based methods against BMAs like the ones in [
13,
16,
23] may cause them to misjudge each other. The fluctuation in trust estimations alone cannot serve as an indication for trust attacks [
24] because they are not the only reason of this fluctuation. Moreover, there is a lack of discussion surrounding DAs, collusion among malicious devices, and the ability to launch multiple trust attacks.
Table 1 lists protection against trust attacks explicitly stated in the related literature on trust mechanisms.
Fog computing [
26] has been a popular technique for addressing IoT security issues [
4]. In recent research employing fog computing to design trust mechanism [
27,
28,
29], a fog node serving as a forwarder or analyzer receives data from and disseminates results to devices. There is research [
23,
24,
25,
30,
31,
32] aimed at building bidirectional trust between devices and fog nodes for the case where a device needs to choose a service provider from nearby fog nodes. A fog node can complete some challenging tasks for conventional techniques such as processing big data from numerous devices, managing mobile devices, and giving responses with low latency [
33]. Although fog computing is a handy tool for researchers, it cannot directly solve the three summarized problems, as they remain in this research.
Additionally, most trust mechanisms proposed in the literature derive a device’s trust estimation from two sources using direct information gathered during interactions with this device and indirect information about this device provided by other devices. Ganeriwal et al. proposed a structure consisting of two modules: the watchdog module and the reputation system module. The former receives data from a sensor during each interaction and outputs a metric of the credibility of these data using an outlier detection technique. The latter takes these metrics and external evaluations of this sensor to output a metric of whether this sensor is faulty to deliver incorrect data [
8]. This structure facilitates improvement in the trust mechanism’s adaptability: the watchdog module processes direct information, and the reputation system module processes indirect information. For example, in addition to outlier detection, the watchdog module can utilize a weighted summation-based method [
28] or machine learning to generate a metric.
Given these considerations, we proposed a Bayesian trust mechanism (BTM), which emphasizes researching the reputation system module. BTM does not rely on any specific IoT technique and takes simple input to address the challenge of heterogeneity, which requires two common assumptions to evaluate devices and to identify trust attackers by listening to feedback whose sources are diversified: first, devices frequently communicate with each other, and second, normal devices are in the majority. These are our contributions in detail:
This paper proposes a new trust estimation approach by adapting data structures and algorithms used in the beta reputation system (BRS). For e-commerce trust issues, BRS’s feedback integration feature combines Bayesian statistics and Jøsang’s belief model derived from Dempster–Shafer theory to let data fusion fully utilize feedback from different sources [
34]. It enables the BRS to produce more accurate trust estimations defined from a probabilistic perspective to quantify an IoT device’s trustworthiness. In contrast to previous research utilizing the two techniques, the data fusion of BTM enables the following novel and practical features: trust estimations that are universal, accurate, and resilient to trust attacks; efficient detection against various trust attacks; an option to combine fog computing as an optimization technique to address the challenges of scalability and dynamic; and a probability theory-explicable parameter setting.
Based on the above trust evaluation, this paper proposes an automatic forgetting algorithm that gives more weight to newer interaction results and feedback in the computing process of trust estimations. It ensures that an IoT device’s trust estimation reflects the device’s current status in time, retards OOAs, and expedites the elimination of adverse influences from trust attacks. In contrast to conventional forgetting algorithms, this algorithm can automatically adjust this weight to achieve good performance. These two contributions form the trust evaluation module of BTM, which is less restricted by the heterogeneity of IoT and balances the accuracy of trust estimations and algorithm complexity.
This paper proposes a tango algorithm capable of curbing BMAs by improving the processing of feedback in BTM as a precaution. Based on the trust evaluation module and hypothesis testing, this paper designs a trust attack detection mechanism that can identify BMAs, BSAs, DAs, and VIE to deal with high-intensity trust attacks. These two form the trust attack handling module of BTM.
This paper conducts a simulation to corroborate the performance of BTM, where it is simultaneously challenged by inherent uncertainty and considerable colluding attackers with composite attack capabilities composed of BMAs, BSAs, and DAs. The presented results indicate that BTM can ensure that evaluators generate relatively accurate trust estimations, gradually eliminate these attackers, and quickly restore the trust estimations of normal IoT devices. This performance is better than existing trust mechanisms.
For the convenience of notation reference during the reading of subsequent sections in this paper,
Table 2 lists all the notations used in BTM. (This paper continues to use the notation method in [
34]. When a superscript and a subscript appear simultaneously, the former indicates an evaluator, the latter indicates an evaluatee, and a second subscript indicates a position in a sequence. Sometimes, they are omitted for the sake of simplicity if there is no ambiguity).
2. Materials and Methods
In this section, we elaborate on how BTM functions in this sequence: its system model; its basic trust evaluation approach. Given two probabilistic definitions of trust and reputation, this approach lets the evaluator regard direct interaction results as evidence to perform Bayesian inference; its feedback integration mechanism, where Jøsang’s belief model enables the evaluator to utilize external evidence from other devices as feedback in Bayesian inference; its forgetting mechanism; and its trust attack-handling module.
2.1. System Model
In BTM, devices are not necessarily homogeneous. The watchdog module generates a boolean value representing whether the device feels satisfied with the server’s behavior during an interaction. Each device determines the design of this module according to its specific requirements. The reputation system module takes input from the watchdog module and feedback from other devices to produce trust estimations, including all algorithms proposed in this paper. BTM offers two feedback integration algorithms, providing two optional trust evaluation styles for the same network. Their trust estimations are virtually identical given the same input.
Figure 1 illustrates BTM’s architecture from the view of evaluator
i.
In the purely distributed style, each device is equipped with the two modules and undertakes trust management on behalf of itself. Furthermore, devices need to share local trust data to ensure the accuracy of trust estimations. If a device has accomplished at least one interaction with device i lately, it is a neighbor of device i. When device i initiates contact with device k, it initializes the trust data of device k based on its current knowledge. Then, it requests the trust data of device k from its all neighbors to perform feedback integration. There are two colluding malicious devices x and y trying to mislead device i into producing trust estimations in more favor of them by trust attacks. As a neighbor of devices i and k, device j satisfies device i’s request. Meanwhile, the two attackers always return fake trust data adverse to device k. Attacker x also discriminates against device k by ignoring requests or providing trouble service. BTM should help device i solve the confusion why devices k and x criticize each other, as both them are good neighbors.
In the core style, a common device only has a watchdog module and directly submits its input as evaluations of other devices to a neighbor equipped with the two modules. It is responsible for the whole network’s trust management and disseminates trust estimations as the sole evaluator. This evaluator is elected by devices or designated by managers beforehand. The device can send an evaluation after an interaction or merge multiple evaluations into one before reporting to this evaluator. The evaluator periodically checks whether each device functions well by demanding service or self-check reports. This process is not necessary if it can receive adequate evaluations from neighbors that can guarantee their service quality because of a property of BTM’s feedback integration.
An application selects the better style according to its conditions. The main difference between the two styles is the scalability determinant: it hinges on the storage and communications abilities of most devices on average in the former, while it mainly depends on the storage and computing abilities of the sole evaluator in the latter. It is easier to strengthen this evaluator merely when wanting to accommodate more devices. Moreover, if devices merge evaluations and keep the frequency of interactions, the sole evaluator can invoke no more feedback integration algorithms than the purely distributed style. Given these considerations and that the research of elections among devices is not involved, we adopt the core style and assume that the sole evaluator is a fog node. The fog node is flexible to deploy and has more resources than devices to execute algorithms. Typically managed by a large organization such as a company, it is also more reliable [
26].
BTM forbids a device from sending an evaluation of itself, which precludes SP attacks. BTM is expected to accurately and efficiently distinguish malicious devices that can use the following modeled trust attacks in combination:
OOAs, attackers periodically suspend attacks to avoid being noticed;
BMAs, attackers always send negative evaluations after interactions;
BSAs, attackers always send positive evaluations after interactions;
DAs, attackers treat other devices with a discriminatory attitude, providing victims with nothing or terrible service;
VIE, attackers always send evaluations contrary to reality after interactions.
2.2. Trust Evaluation Based on Direct Observation
Since direct observation is the most fundamental approach to trust evaluation, our study starts with an abstraction of the definition of trust given in
Section 1 from the perspective of probability theory to introduce Bayesian statistics to process results from direct interactions. In BTM, a trust value quantifies a device’s trustworthiness, derived from a reputation vector storing digested information from all previous interactions. Bayesian statistics enables initializing reputation vectors freely and updating them iteratively.
Given that device
j accomplishes an assigned task with a probability
, we define device
i’s trust in device
j as its estimation of the probability of satisfying service from device
j in the next interaction. It is desirable for device
i that
approximates
. In daily life, building trust by synthesizing what people have said and done in the past is deemed reasonable. In this kind of reputation-based trust model, reputation can be regarded as a random variable that is a function of previous behavior, and trust is a function of reputation. The two steps can be formulized as follows:
where
represents the behavior of device
j observed by device
i in the
nth interaction, described by a random variable or a group of random variables. Updating the reputation given a new behavior is more convenient than updating the trust because the reputation can serve as a data structure containing digested information, and the trust’s form can be more intelligible for people.
Traditionally, a device can qualitatively describe the other side’s behavior in each interaction with a Boolean value. Such a value can serve as an instance of a random variable abiding by a binomial distribution
, where
represents an independent trial’s success rate unknown to this device. In Bayesian statistics, a device can refer to acquired subjective knowledge to estimate a parameter with a few samples called evidence and to update the result iteratively. For
,
’s prior distribution is a beta distribution:
where
and
are hyperparameters set beforehand according to the domain knowledge of
. The denominator is a beta function denoted by
. Note that the
is identical to
, where
is uniformly distributed over
. It is a reasonable prior distribution when the knowledge of
is scarce. Given evidence,
including
r successful attempts and
s unsuccessful attempts. The posterior distribution is obtained using Bayes’ theorem, characterized by a conditional probability density function:
Equation (
3) is the prior distribution in the next estimation too. Rather than a posterior distribution giving all probabilities of an unknown parameter’s values, it is more common to output the expected value of this distribution in Bayesian parameter estimation. The expected value of (
2) is
.
Given (
1), BTM represents device
j’s reputation at device
i as
and represents
as
, where
and
. Because a greater
or
brings about less variation in the trust when
r or
s changes, device
i can increase
and
if it has confidence in its knowledge of device
j. As the evaluator should set
and
during the initialization of reputations, BTM does not suggest any operation on
r and
s without evidence-based reasons.
Note that the feedback integration and forgetting mechanisms introduced in the following content do not change the fact that a trust is a parameter estimation in nature, on which BTM relies to handle the heterogeneity and inherent uncertainty. The presented simulation will confirm that inherent uncertainty cannot mislead evaluators into misjudging normal devices even if meeting trust attacks. In the following content, trust values and reputation vectors in BTM are abbreviated to trusts and reputations.
2.3. Feedback Integration
Feedback integration enables updating reputations using external evidence contained in evaluations from other devices to expedite the acquisition of accurate trusts. It also retards DAs by synthesizing evaluations of a device from diversified views. Derived from the combination of Jøsang’s belief model with Bayesian statistics and formulized with group theory, BTM’s feedback integration can serve as a more accurate extension of BRS [
34]. As illustrated in
Section 2.1, BTM includes two feedback integration algorithms, providing two trust evaluation styles producing virtually identical trusts. The answer to which better hinges on applications. We also compare these algorithms with their counterpart in BRS. Note that BTM does not adopt the common practice that computes a global trust estimation by weight-summing direct and indirect trust estimations like [
10,
28]. In BTM, when an evaluator receives a piece of feedback, it directly digests this feedback’s influence on a device’s trust into this device’s reputation.
2.3.1. Derivation of Feedback Integration
An evaluation’s effect should be proportional to the source’s trustworthiness, which is practicable by circulating the opinion defined in Jøsang’s belief model. Device
i’s opinion about device
j is
, where
and
.
is the probability of a statement from device
j being true in device
i’s view, and
is the probability of this statement being false. The sum of
and
is not bound to be in unity, and
expresses device
i’s uncertainty of this statement. In other words, they are belief, disbelief, and uncertainty. Device
j sends
as its evaluation of device
k to device
i. Device
i processes
using an operation called belief discounting [
34] that
This process can be represented as a binary operation upon the opinion set
that
.
is a monoid with an identity element
.
On the other hand, the updating of reputations using evidence can be represented as a binary operation upon a subset of the reputation set
, where
and
are constants. Given two reputations
,
‘.’ denotes fetching a scalar in a vector.
is a commutative monoid. Its commutativity ensures no exception when simply adding positive and negative cases to merge evidence. In BTM,
is determined by
with a function from
to
defined in (
6). It is a bijection, and the inverse function is (
7). Algorithm 1 describes how device
i integrates
as an evaluation using these two equations. Equation (
8) directly gives the result of the brief discounting. This algorithm precludes SP attacks because a sender cannot provide an evaluation of itself. Note that input parameters’ original values change when altering them in BTM’s algorithms.
| Algorithm 1: Feedback integration. |
Input: , , - 1
- 2
- 3
|
Note that
suffers more discounting when the subjective parameters related to device
j increase. Moreover, when
and
to let
be comparable with
,
is the only way to exempt
from discounting:
Algorithm 1 is suitable for the purely distributed style, where devices should periodically share their reputation data for the sake of feedback integration. Evaluator i prepares two reputations for device j: one only comprises evidence from interactions, while the other synthesizes both direct and discounted external evidence. The former is the base for the latter and is provided for other devices as the evaluation of device j. The latter is the base for and discounting evaluations from device j. Note that when evaluator i has integrated an old , it needs to compute the latter reputation from scratch if it wants to update with a newer .
2.3.2. Incremental Feedback Integration
With the above practice, the device’s storage and communication abilities for saving and sharing reputations on average determine the max member number of BTM. Adapted from Algorithm 1 according to
, Algorithm 2 concentrates all trust management tasks in a network to a sole evaluator. Imposing minimal trust management burdens on common devices and not requiring sending an evaluation’s duplicates to different receivers, Algorithm 2 can extend BTM’s scalability simply by strengthening the sole evaluator. Moreover, it can update a reputation iteratively with new evaluations rather than from scratch and can endow the evaluator with a global view to estimate devices and to detect trust attacks. Algorithm 2 applies to applications where cooperative devices have differential performance, such as smart home applications managing smart appliances using a smartphone or wireless router. Even if composed of homogeneous or dynamic devices like intelligent vehicles, applications can also adopt Algorithm 2 with the help of fog nodes [
14,
33].
from the device substitutes as the evaluation in Algorithm 2, which is the increment of . That is, restricting and to be constants, evidence is gathered from recent interactions with a device and sent out since the last sending evaluation. and are fixed to unities in common devices because they are not deeply involved in the details of generating trusts anymore. Evaluator i cannot know and directly using . Therefore, they are saved in a vector where . The function discounts , where is replaced by two. Note that is a direct observation result in device j while an evaluation needs to be discounted in fog node i. In BTM, is called direct evidence in the former case and feedback in the latter case.
Additionally, (
9) is the equation for integrating positive feedback in BRS:
To enable the free initialization of a device’s reputation even if without evidence, BTM separates
and
from
r and
s when representing this reputation and alters the mapping from reputations to opinions, resulting in the difference between (
8) and (
9). In the elementary form of providing feedback in BRS, the sender evaluates an agent’s performance in a transaction with a pair
where
and
w is a weight for normalization. The evaluator discounts this pair using (
9) [
34]. However,
is a concave function of
. But, evaluator
i cannot directly know the
related to all previous transactions with this pair. The sender should add the pair of the new transaction to the pair of previous transactions and send this sum as the evaluation. Note that as the evaluation to be integrated in Algorithm 1,
includes all evidence of previous interactions between devices
j and
k. This concavity provides some resistance against BMAs and BSAs, as
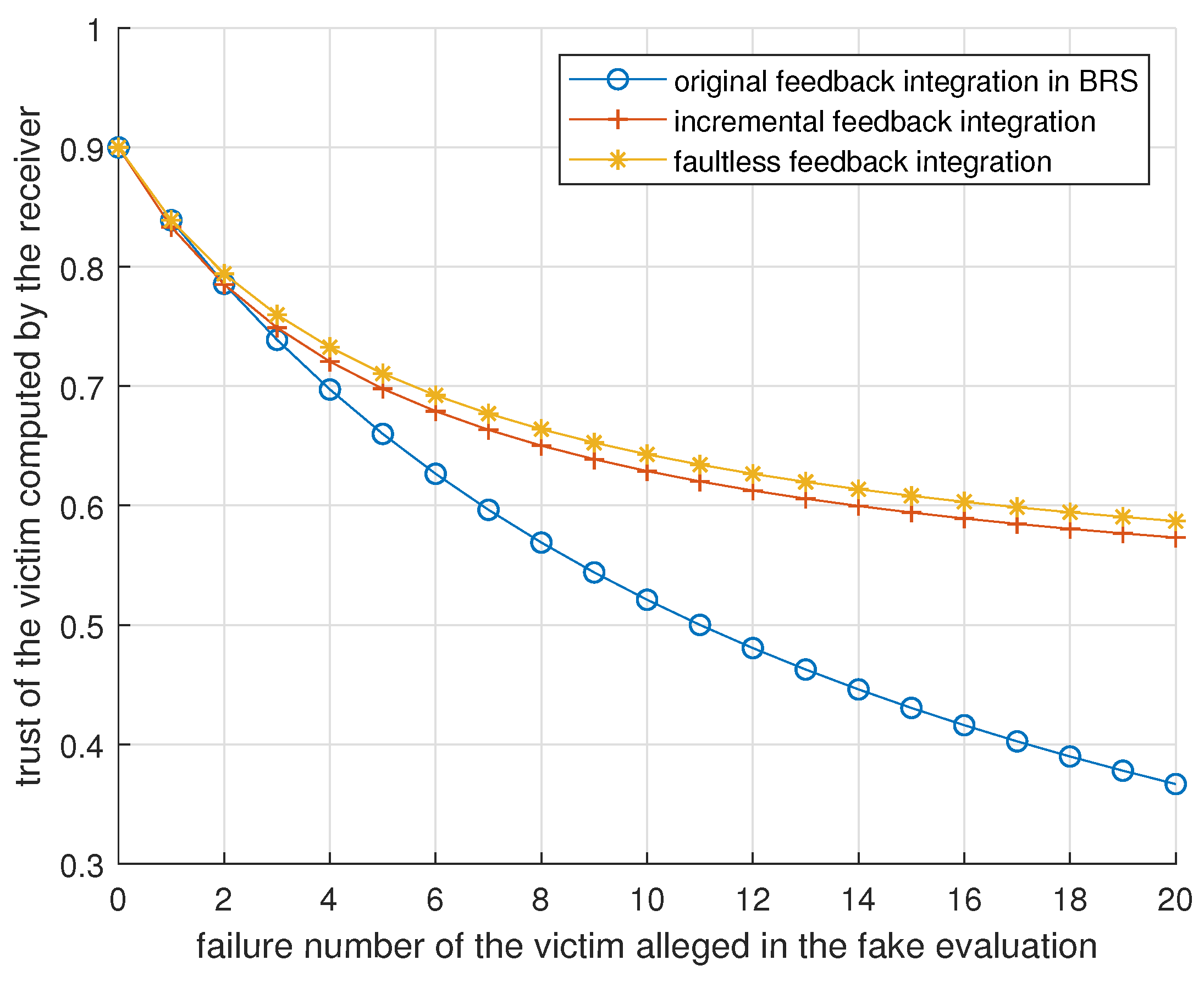
Figure 2 shows, where
,
, and
at the outset.
increases by 1, and device
j sends
and
to device
i per round. The following sections assume that
initially and that there is a fog node running Algorithm 2.
| Algorithm 2: Incremental feedback integration. |
 |
2.4. Forgetting Algorithm
In
Section 2.3, integrating direct evidence and discounted feedback in any order will lead to the same reputation since
is commutative. However, a device does not necessarily behave smoothly; it may break down due to fatal defects or shift to the attack mode due to an OOA. A forgetting algorithm lets newer collected data carry more weight in trust evaluations to ensure that a device’s trust estimation reflects its latest status in time. If the target value
after the
nth interaction is derived from a statistic of the
nth interaction
and previous statistics, a common forgetting form like the one used in BRS [
16,
28,
34] is
which uses a forgetting factor
.
As the first example of utilizing the separated subjective and objective parameters in reputations, we proposed Algorithm 3, which can achieve the same forgetting by automatically adjusting these parameters. Its idea is that given and embodying subjective information related to the trust, evaluator i stores direct evidence of device j over a queue containing n evidence at most. The smaller the evidence’s subscript is, the older it is. The oldest evidence is then discarded and becomes the experience to update and when new evidence arrives in a full queue. Evaluator i also merges discounted feedback into the element at the queue’s rear. Using a single queue containing the two kinds of evidence can reduce the algorithm’s complexity and memory space with negligible deviations.
In Algorithm 3,
lets the oldest element quit
and gives its value to
.
’s capacity
varies with circumstances. A larger
reduces the standard deviation of trusts but requires more memory space. The evaluator saves feedback in two double-dimensional arrays represented by two matrices
M and
N.
denotes the element of the
jth row
kth column of
M. Given the two matrices,
and
, indexes and serial numbers start with zero. The for-loop updates elements where device
j is an evaluation sender in
and
because
brings
an upper bound. Without this operation, the evaluation’s effect will indefinitely decline with the analysis of the concavity of (
8) in
Section 2.3.
v is a random variable abiding by
, used to choose which matrix to update because the order of the arrival of feedback is not recorded.
As explained in
Section 2.3, the evaluator prepares two kinds of reputations for a device in the purely distributed style. Therefore, The evaluator also maintains the two queues of these reputations and updates them simultaneously in Algorithm 3. Moreover, when the evaluator sends out a reputation as an evaluation, it can append the corresponding queue to this reputation. Then, the receiver merges this queue into its one. In this way, the sender and the receiver can forget the same evidence at about the same time.
This algorithm automatically sets the evidence’s weight: The initial values of
and
are
and
,
.
when
quits. Then,
quits, resulting in
. That is, the forgetting factors of the first and second rounds are
and
, respectively. By mathematical induction,
| Algorithm 3: Forgetting algorithm. |
 |
2.5. Module against Trust Attacks
Algorithms 2 and 3 cannot guarantee the accuracy of trusts in the face of trust attacks. In this section, we analyze the ability and limitation of BTM’s feedback integration against trust attacks first to clarify the aims of BTM’s trust attack handling module. This module consists of a tango algorithm that can curb BMAs by adapting Algorithm 2 and a hypothesis testing-based trust attack detection mechanism against BMAs, DAs, BSAs, and VIE.
2.5.1. Influences of Trust Attacks and Tango Algorithm
For DAs, Algorithm 2 synthesizes feedback from different perspectives to render it unprofitable. For BMAs and BSAs, a reckless attacker sends a lot of fake feedback in a short time, which is inefficient due to the concavity of (
8), illustrated in
Figure 2. A patient attacker sends fake evaluations with an inconspicuous frequency for long-term interests, which works because Algorithm 2 does not check the authenticity of feedback.
Applying the principle that it takes two to tango to curb BMAs, Algorithm 4 is an adaptation of Algorithm 2. It divides blame between two sides when processing negative feedback, where the side having higher trust is given more
to criticize the other side. Assuming most interactions between normal device success, Algorithm 4 renders BMAs lose–lose with
time-complexity extra computing to make an independent BMA attacker’s trust continuously decline. Algorithm 1 can be adapted with the same idea as Algorithm 4.
| Algorithm 4: Tango algorithm. |
 |
2.5.2. Trust Attack Detection
Algorithm 4 mitigates trust attacks when normal devices are in the majority to tolerate some malicious devices. We propose a trust attack detection mechanism to identify attackers for harsher circumstances, which works in parallel with Algorithm 4 because the latter can filter subjects for the former.
BTM saves feedback in
M and
N for feedback integration. They also correspond to directed graphs in graph theory. If device
j sends criticism of device
k, there is an edge from node
j to node
k whose weight is
. DAs and BMAs can cause abnormal in-degree and out-degree in
N, respectively. BSAs can cause an abnormal out-degree in
M. It is an outlier detection problem and has universal solutions [
35]. For example, The local outlier factor (LOF) algorithm [
36] can check the degrees of
n nodes with
time complexity.
BTM uses a new approach quicker than LOF to detect these anomalies. With BTM’s feedback integration, a device’s trust is a parameter estimation hard to manipulate using trust attacks. If
and
, device
j reports that device
k succeeds
m times and fails
n times in recent interactions. Hypothesis testing can check its authenticity, whose idea is that a small probability event is unlikely to happen in a single trial. Using a
p-value method, the null hypothesis is that device
j honestly sends feedback, the test statistics are
and
, the corresponding p-value denoted by
is:
If the null hypothesis is true, should not be less than a significance level like 0.05 denoted by . In Algorithm 5, against BMAs, BSAs, and VIE, if , evaluator i calculates along the jth row. is for patient attackers, which can tolerate a frequency of rejected null hypothesis no more than . is very tiny for reckless attackers. This algorithm can check a single node with time complexity. Note that Algorithm 3 makes hover around .
The DA detection algorithm (Algorithm 6) is obtained by adapting Algorithm 5 via calculating
along a column and deleting
. Although the purely distributed style does not need
M and
N for feedback integration, it can introduce the two matrices to use Algorithm 5, whose updating is simple: when device
i receives
from device
j, it changes the elements of the
jth row
kth column in
and
to
.
| Algorithm 5: Detection against BMAs, BSAs, and VIE. |
 |
| Algorithm 6: Detection against DAs. |
 |




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}