Abstract
We present the truncated Lindley-G (TLG) model, a novel class of probability distributions with an additional shape parameter, by composing a unit distribution called the truncated Lindley distribution with a parent distribution function . The proposed model’s characteristics including critical points, moments, generating function, quantile function, mean deviations, and entropy are discussed. Also, we introduce a regression model based on the truncated Lindley–Weibull distribution considering two systematic components. The model parameters are estimated using the maximum likelihood method. In order to investigate the behavior of the estimators, some simulations are run for various parameter settings, censoring percentages, and sample sizes. Four real datasets are used to demonstrate the new model’s potential.
MSC:
62E10; 62F10; 60E05; 62P10; 62J02
1. Introduction
Suppose that G is a cumulative distribution function (cdf) that is defined on the real line, several papers have proposed composing a unit distribution with G (a parent cdf) to produce a new cdf. Eugene et al. (2002) [1] combined the cdf of the beta distribution with G to create the Beta-G model with cdf
where is the regularized incomplete beta function. Alexander et al. (2012) [2] and Nadarajah et al. (2014b) [3] generalized the Beta-G to the generalized-Beta-G and the modified-Beta-G. Cordeiro and Castro (2011) [4] developed the Kumaraswamy-G model by combining the Kumaraswamy cdf with the parent cdf G.
Based on a valid cdf, for , for any continuous distribution, we can construct a unit distribution as a truncated version of with a cdf (monotonically increasing with and ) given by
The truncated-G (TG) model is constructed by composing this truncated version of the cdf (or its associated survival function ) with a parent cdf G (or its associated survival function ) to give the parent distribution additional modeling ability and produce a new family of univariate distributions with cdfs (monotonically increasing with and ) given by
A list of TG models are given in Table 1.

Table 1.
Previous work on TG models.
In this paper, we generate a new family of continuous distributions using a truncated version of the Lindley distribution.
The new distribution is necessary and helpful because it provides an alternative option for failure time analysis. While there are already numerous existing distributions available for this purpose, having a new distribution adds to the range of choices researchers and analysts have when analyzing failure times. The existing distributions may not always adequately capture the characteristics or behavior of the data being analyzed. Different distributions have different assumptions and properties, and no single distribution can fit all scenarios perfectly. Therefore, having a new distribution can be beneficial in situations where none of the existing options are suitable or provide a good fit to the data. Additionally, the new distribution may offer advantages over existing ones in terms of interpretability, flexibility, or computational efficiency. It could introduce novel features or modeling capabilities that were previously unavailable with other distributions. This can lead to improved accuracy and reliability in failure time analysis.
In summary, while there are already many distributions available for failure time analysis, the introduction of a new distribution expands the options and possibilities for researchers, allowing them to choose the most appropriate model for their specific data and research objectives.
On the other hand, in several research areas (medical, engineering, biology, agronomy, etc.), the failure times are affected by explanatory variables. In this paper, we propose a regression model with censored observations, based on the truncated Lindley–Weibull distribution, which is a feasible alternative for modeling failure time data. Also, different simulation studies are presented to study the behavior of maximum likelihood estimation (MLE), as well as the residual analysis of the proposed regression model. The paper is structured as follows: Section 2 describes the unit truncated Lindley distribution which is the main component of the proposed new model. We discuss its properties, including moments, mode, quantile function (qf), mean deviations, and generating function. Section 3 discusses the proposed TLG model (linear representation, properties, shapes of the TLG, stochastic representation, truncated Lindley–Weibull (TLW) submodel and estimation of the parameters using the maximum likelihood method). In Section 4, we propose a regression model based on the TLW distribution and estimate its parameters using maximum likelihood. Also, we perform some simulation studies for the TLW regression model under different sample sizes and censoring proportions. The TLW regression model application is illustrated by examining four real datasets in Section 5. Finally, Section 6 summarizes the result and presents the conclusions.
2. The Unit Truncated Lindley Model
Lindley (1958) [16] first described the Lindley distribution as a lifetime distribution with one parameter. The probability density function (pdf) and the cdf are provided by
respectively. We suggest a new unit distribution, the unit truncated Lindley (UTL) distribution, based on the cdf of the Lindley distribution, which is a truncated form of with the cdf and pdf provided by
where .
The properties of the UTL model are given in Appendix A.
3. The Truncated Lindley- Model
The Truncated Lindley-G (TLG) model is constructed by applying the TG composition scheme (2) on the cdf of the UTL model given in Equation (4), i.e.,
That is, the cdf and pdf of the TLG model are given by
and
where .
The main reason for choosing the unit truncated form of the Lindley distribution is to add a new parameter to the parent distribution to generate a new distribution. The properties of the generated distribution will need further investigation, as they are, generally, different from those of the parent distribution.
Following the expansion , the TLG cdf (6) has a linear representation of the exponentiated-G (EG) cdf as
where (for ) is the EG cdf with power parameter j.
Differentiating (8) with respect to x, we obtain the linear representation of the TLG pdf as follows:
where , and are the EG densities with power parameters i and , respectively. On the basis of the linear representation (9), some TLG models’ properties are similar to the EG properties reported in several references, such as AL-Hussaini and Ehsanullah (2015) [17]. Henceforth, denotes that an rv has an EG distribution, with power parameter i and density .
3.1. Some Properties of the TLG Model
3.1.1. Critical Points
As , we have . Hence, the derivative of is
Using the identities and , the above identity is written as
Then, all critical points of satisfy , or equivalently,
Depending on the choice of the cdf G, the above equation can be reduced and its maximum (modes) and minimum points characterized. For an example where the function G is chosen to be the Weibull distribution, see Section 3.2.
3.1.2. Moments
Moments allow the examination of some of the distribution’s most significant features and characteristics. The kth raw moment (for ) of the TLG model is
where is the qf associated with the parent cdf G.
Furthermore, the kth raw moment can be expressed from (9) using the moments of the EG distribution as
3.1.3. Quantile Function
The qf is a highly desirable property in statistical distributions and is especially helpful in the computation of several values in statistical modeling and inferences. By inverting the cdf of the TLG distribution in (6), the qf for the TLG distribution can be expressed using the qf associated with the parent cdf G as
Therefore, follows the TLG distribution with pdf (7) if U is a uniform variate on the unit interval.
3.1.4. Mean Deviations
The following relationships can be used to describe, respectively, the mean deviations of X about the mean and the median M.
where is the kth incomplete moment of the rv that has an EG distribution with power parameter j (i.e., ).
3.1.5. Moment Generating Function
The mgf of can be expressed in an integral form as
Furthermore, it can be expressed using the mgf of the EG distribution as
where is the mgf of an rv that has an EG distribution with power parameter j ().
3.1.6. Entropy
Entropy measures the change in the uncertainty in physical systems. The Shannon and Rényi entropies are two well-known entropy measurements. Entropy values range from very small to very large, with larger values indicating greater data uncertainty. In this section, we derive the continuous Rényi and Shannon entropies of the TLG distribution. The Rényi entropy, where , of the TLG distribution is given by
It follows from the expansions and that
The Shannon entropy of the TLG distribution is given
using the expansion
we have
where is the Shannon entropy for the parent distribution. Since , then
3.2. Truncated Lindley–Weibull (TLW) Model
Consider the parent distribution is the Weibull distribution with shape parameter , and scale parameter , the cdf and pdf are given by
The cdf and pdf of the truncated Lindley–Weibull (TLW) model are given by
respectively, where is as in Equation (7). Note that
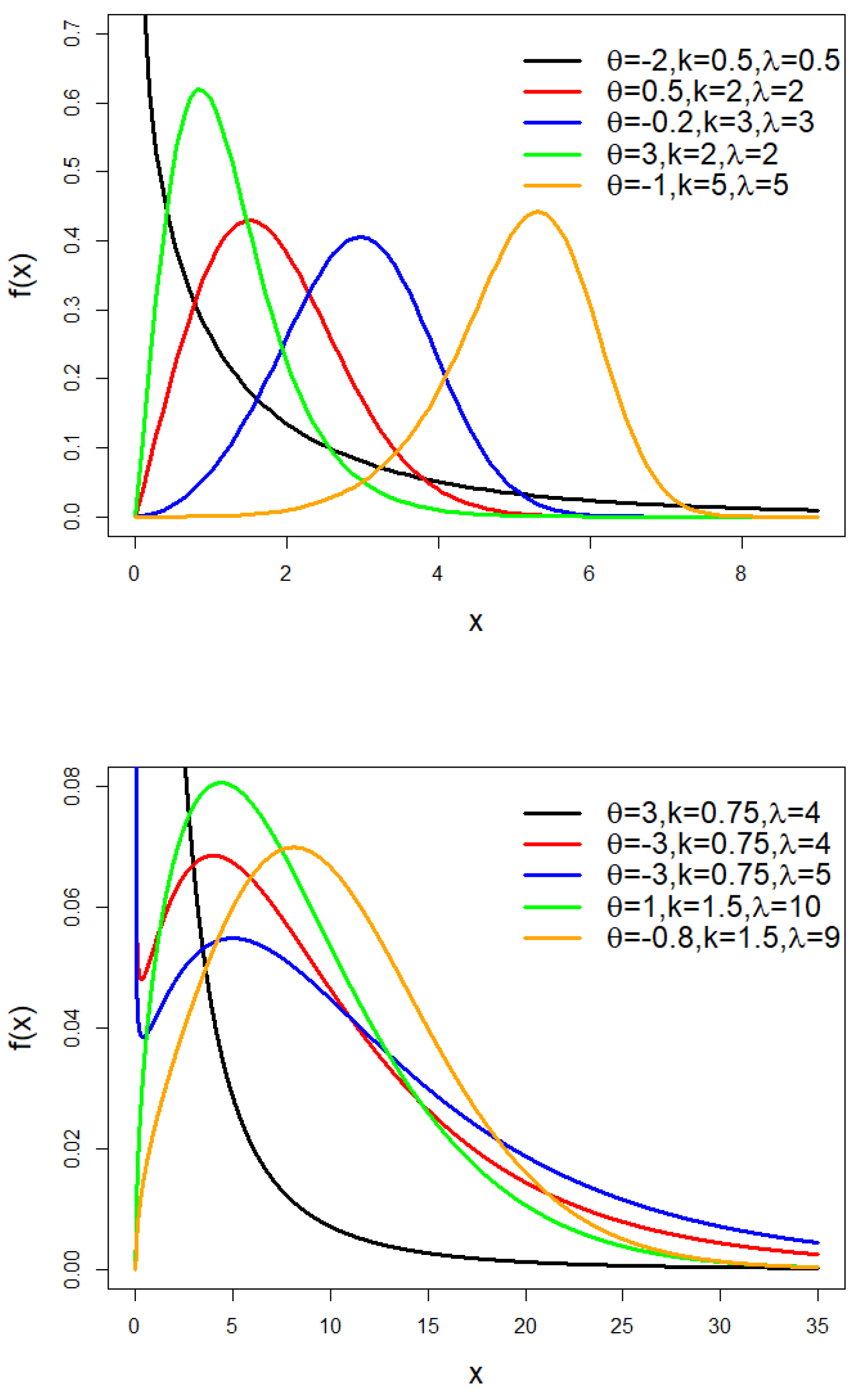
The TLW model’s pdf is shown in Figure 1 for various values of , and . Figure 1 illustrates how the TLW distribution’s density function is flexible and changes in shape depending on the parameter values.
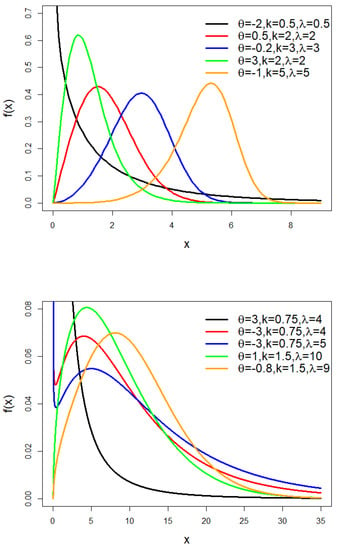
Figure 1.
The pdf of the TLW model.
3.2.1. Shapes of the TLW pdf
Considering G and g as given in (12), the Equation (10) of critical points is written as
As , the above identity becomes
Since and for each , the above identity is equivalently written as
where for and , we denote
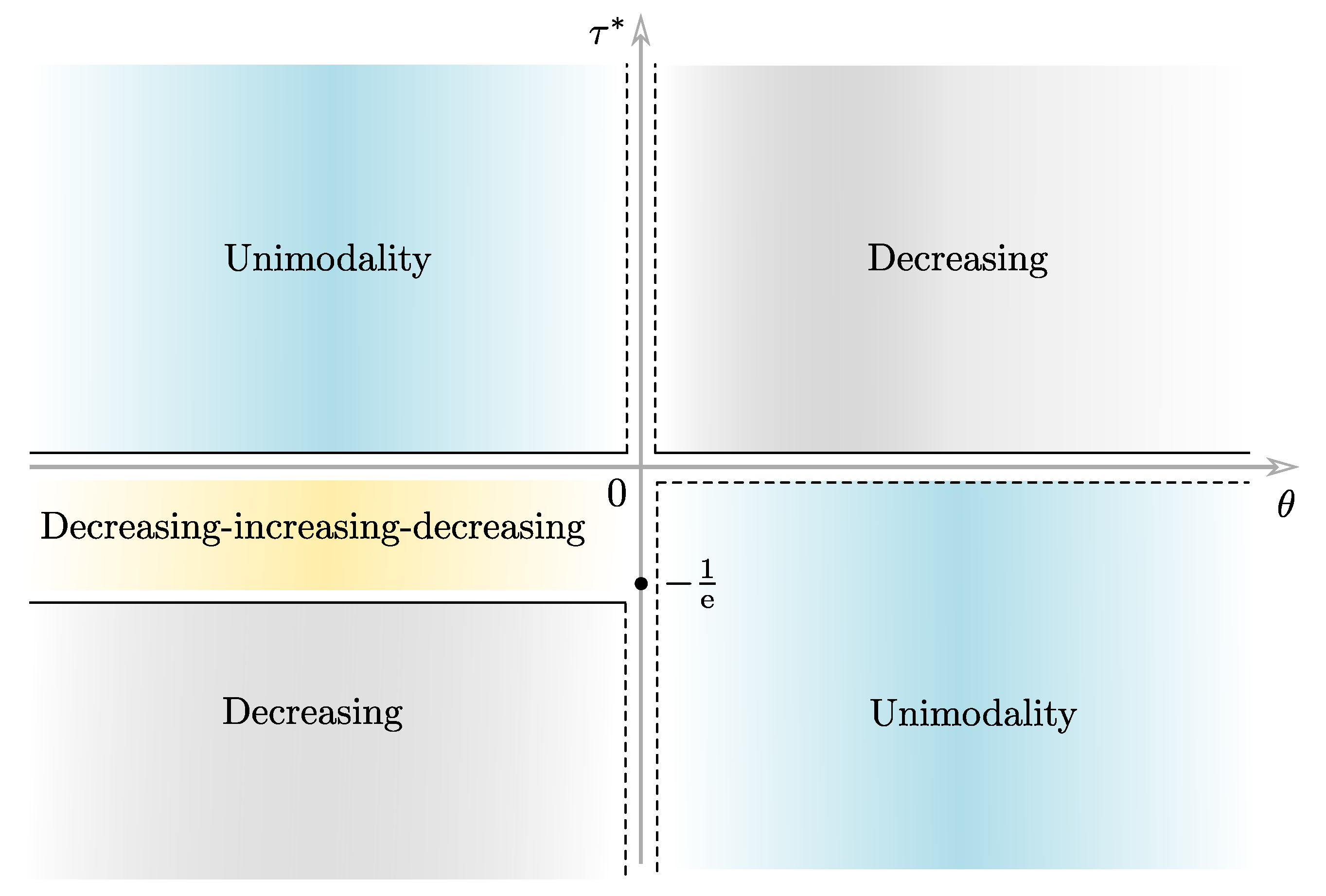
A simple calculation shows that the function is increasing (respectively, decreasing) when (respectively, ). Furthermore, notice that the function reaches the minimum value at . Using the graphs of the functions A and , and varying the parameters and , we can find the points of intersection of both graphs. Therefore, we can compactly classify the number of roots of Equation (16), as indicated in Table 2.
Table 2.
Number of roots of equation in (16) when varying the parameters and .
Based on Table 2, in what follows we divide our analysis into the following cases.
- 1
- If
- (a)
- (b)
- and , then . Following the same steps as in Item 1(a) we have that is unimodal.
- (c)
- 2
- If
- (a)
- and , then . Following the same steps as in Item 1(c) we have that is decreasing.
- (b)
- (c)
- and , then . Following the same steps as in Item 1(a) we have that is unimodal.
Table 3 summarizes the shapes of obtained in Items 1 and 2 above.
Table 3.
Shapes of TLW pdf when varying the parameters and .
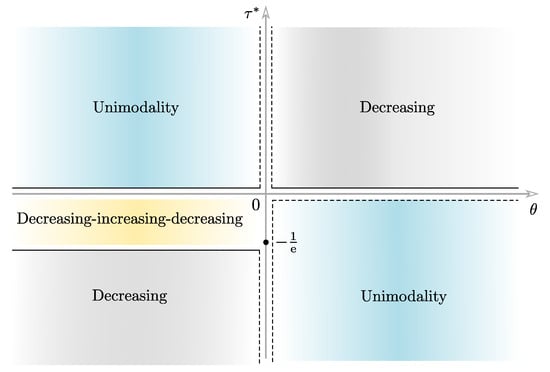
Figure 2.
Regions of the Cartesian plane where different forms of the TLW pdf occur.
3.2.2. Stochastic Representation
Let X and Y be two random variables with TLW and UTL distributions, respectively. As with , we obtain
Therefore, X has the stochastic representation
with being equality in distribution. In addition to generating random numbers, a stochastic representation is useful for determining moments, characteristic functions, quantiles, etc.
3.3. Maximum Likelihood Estimation
Let represent the observed values from the TLW model with the pdf given in (14). For the vector of parameters , the log-likelihood function is provided by
The following are the elements comprising the score vector
Traditionally, the MLEs of the three parameters can also be calculated by setting the preceding equations to zero and simultaneously solving them. Since it appears impossible to find a closed form estimator for , direct maximization of (17), as a multidimensional nonlinear unconstrained function, via a quasi-Newton optimization technique such as BFGS, SANN, Nelder–Mead, or CG might be appropriate for finding the maximum likelihood estimates of .
3.4. Monte Carlo Simulation
By generating n observations from the TLW distribution with varying parameter values, we conduct simulations to validate the performance of the MLEs of the TLW distribution parameters. The BFGS method from the R package is utilized to estimate the parameter values. The sample sizes considered are n = 20, 50, 100, 150, and 300, and the replicates number is N = 5000. The simulation results are evaluated using the mean absolute bias (MAB), the mean square error (MSE), and the average estimates (AEs), where for we have
The results in Table 4 and Table 5 show that the AEs tend to the true values and that the MABs and MSEs vanish as n increases, which reveals the asymptotic consistency of the MLEs of the TLW parameters.
Table 4.
Average estimates from simulations of the TLW distribution.
Table 5.
MABs and MSEs from simulations of the TLW distribution.
Using Equation (11), for the Weibull distribution we have , implying that the qf of the TLW distribution is
The data are generated from
4. The TLW Regression Model with Censored Data and Two Systematic Components
Statistical analysis of lifetimes is an important topic used in different areas such as, for example, medicine, biology, epidemiology, engineering, among others. Failure time refers to the time until the occurrence of an event of interest, which may be death, the appearance of a tumor, the development of a disease, the breakdown of an electronic component, among other examples.
We relate the parameters and k to
covariates by the logarithm link function
respectively, where and denote the vectors of regression coefficients and .
The survival function of is given by
where
Equation (19) is referred to as the TLW parametric regression model. This regression model opens new possibilities for fitting many different types of data.
Consider a sample of n independent observations, where each random response is defined by , where are the censoring times and are the observed lifetimes. We assume non-informative censoring such that the observed lifetimes and censoring times are independent. Let F and C be the sets of individuals for which is the lifetime or censoring, respectively. The total log-likelihood function for reduces to
where r is the number of uncensored observations (failures) and . By maximizing the log-likelihood (20), the MLE of the vector of unknown parameters can be calculated. We use the R software to determine .
4.1. Residual Analysis
For the TLW regression model with censored observations, we present two types of residuals to evaluate deviations from the error assumptions and detect outliers. The deviance residuals have been used more frequently in the literature because they take into account the information of censored times. The TLW regression model can also use these residuals. A reliable method for detecting atypical observations and confirming that the fitted model is adequate is to plot the deviance residual against the observed times. It is possible to express the deviance residual as
where
is the martingale residual, means that the observation is uncensored, means that the observation is censored and
4.2. Simulation Study
To verify the accuracy of the MLEs of the TLW regression model, we carried out a simulation study for different censoring percentages and sample sizes , 300, and 500. For each sample size, we carried out N = 1000 replicates and considered the approximate censoring percentages: 0%, 10% and 30%. A covariate binomial is included from the following systematic components:
The inverse transformation method is used to obtain the lifetimes from the TLW distribution, and the censoring times are determined from a uniform distribution , where controls the censoring percentages. The true values used for generation are , , , , and .
The Results are checked for from MABs, MSEs, and AEs given in (18), where here . The simulation process is given by:
(i) Generate binomial ;
(ii) Calculate and ;
(iii) Generate TLW ;
(iv) Generate ;
(v) Calculate the survival times ;
(vi) If , then ; otherwise, , for , where is the censoring indicator.
(vii) Calculate AEs, biases, and MSEs.
Table 6 displays these values. It is verified that for all scenarios the averages of the estimates approach the true values of the parameters and the MABs and MSEs decrease as the sample size increases. These results illustrate that the estimates are consistent, even at higher censoring percentages.
Table 6.
Simulation results of TLW regression models for different censoring percentages (%) with true values: , , , , and .
5. Data Analysis
In order to demonstrate the superiority of the new distribution over some other models, we use two real datasets originating from different fields. We compare the fits of the TLW model to those of the parent Weibull model (W), the Kumarswamy–Weibull model (KW) from Cordeiro and Castro (2011) [4], the Weibull–Weibull model (WW) from Alzaatreh et al. [18], the Geometric–Poisson–Weibull model (GPW) from Nadarajah et al. (2013) [19], the Poisson–Weibull model (PW) from Ristic and Nadarajah (2013) [5] the beta-Weibull model (BW) from Eugene et al. (2002) [1], the Marshall–Olkin–Weibull model (MOW) from Marshall and Olkin (1997) [20] and the exponentiated generalized Weibull model (EGW) from Cordeiro et al. (2013) [21]. The cdfs of these models are provided in Appendix B. The parameter estimates are computed by maximizing (17) using the BFGS method available in the adequacy model package in the R software [22].
The considered models are compared according to a collection of statistics (AIC, CAIC, BIC, HQIC, minus maximum log-likelihood function ()) which assess the relative degree of fit of these models to a dataset.
We also performed an application of the TLW regression model considering censored data. We compared different systematic components for the proposed new regression model and the Weibull regression model. In this part we use the RS algorithm in the gamlss package in the R software to maximize the log-likelihood function (20) and we use the AIC and global deviance (GD) statistics to select the most suitable models.
- Dataset I: Temperature Dataset
This dataset, reported by Barakat et al. (2014) [23], depicts the average July temperatures (C) for Neuenburg, Switzerland, between 1864 and 1993. The observations are as follows.
| 19.0 | 20.1 | 18.4 | 17.4 | 19.7 | 21.0 | 21.4 | 19.2 | 19.9 | 20.4 | 20.9 | 17.2 | 20.2 |
| 17.8 | 18.1 | 15.6 | 19.4 | 21.7 | 16.2 | 16.4 | 19.0 | 20.6 | 19.0 | 20.7 | 15.8 | 17.7 |
| 16.8 | 17.1 | 18.1 | 18.4 | 18.7 | 18.7 | 18.4 | 19.2 | 18.0 | 18.7 | 20.7 | 19.4 | 19.2 |
| 17.4 | 22.0 | 21.4 | 19.3 | 16.8 | 18.2 | 16.2 | 15.9 | 22.1 | 17.5 | 15.3 | 16.5 | 17.4 |
| 17.0 | 18.3 | 18.3 | 15.3 | 18.2 | 21.5 | 17.0 | 21.6 | 18.2 | 18.1 | 17.6 | 18.2 | 22.6 |
| 19.9 | 17.1 | 17.2 | 17.3 | 19.4 | 20.1 | 20.1 | 17.0 | 19.4 | 17.5 | 16.8 | 17.0 | 19.9 |
| 18.2 | 19.2 | 18.5 | 20.8 | 19.5 | 21.1 | 15.8 | 21.3 | 21.2 | 18.8 | 22.3 | 18.6 | 16.8 |
| 18.2 | 17.2 | 18.4 | 18.7 | 21.1 | 16.3 | 17.4 | 18.0 | 19.5 | 21.2 | 16.8 | 17.4 | 20.7 |
| 18.4 | 19.8 | 18.7 | 20.5 | 18.3 | 18.2 | 18.2 | 19.2 | 20.2 | 18.2 | 17.4 | 19.2 | 16.3 |
| 17.4 | 20.3 | 23.4 | 19.2 | 20.2 | 19.3 | 19.0 | 18.8 | 20.3 | 19.7 | 20.7 | 19.6 | 18.1 |
The MLEs and 95% CIs for the model parameters are shown in Table 7. Table 8 provides the competence of the considered models.
Table 7.
Estimates of TLW parameters for dataset I.
Table 8.
Competence of the models for the dataset.
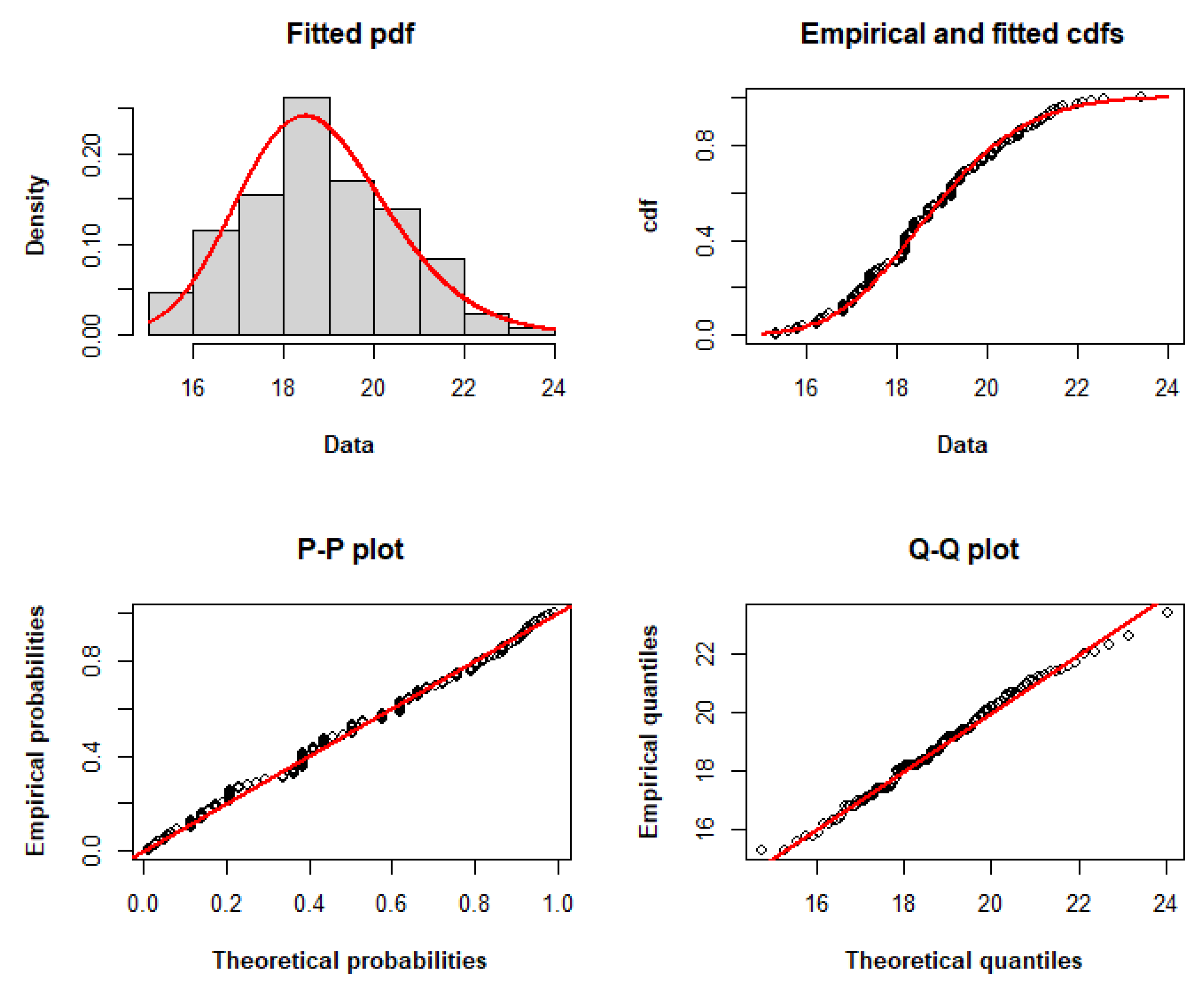
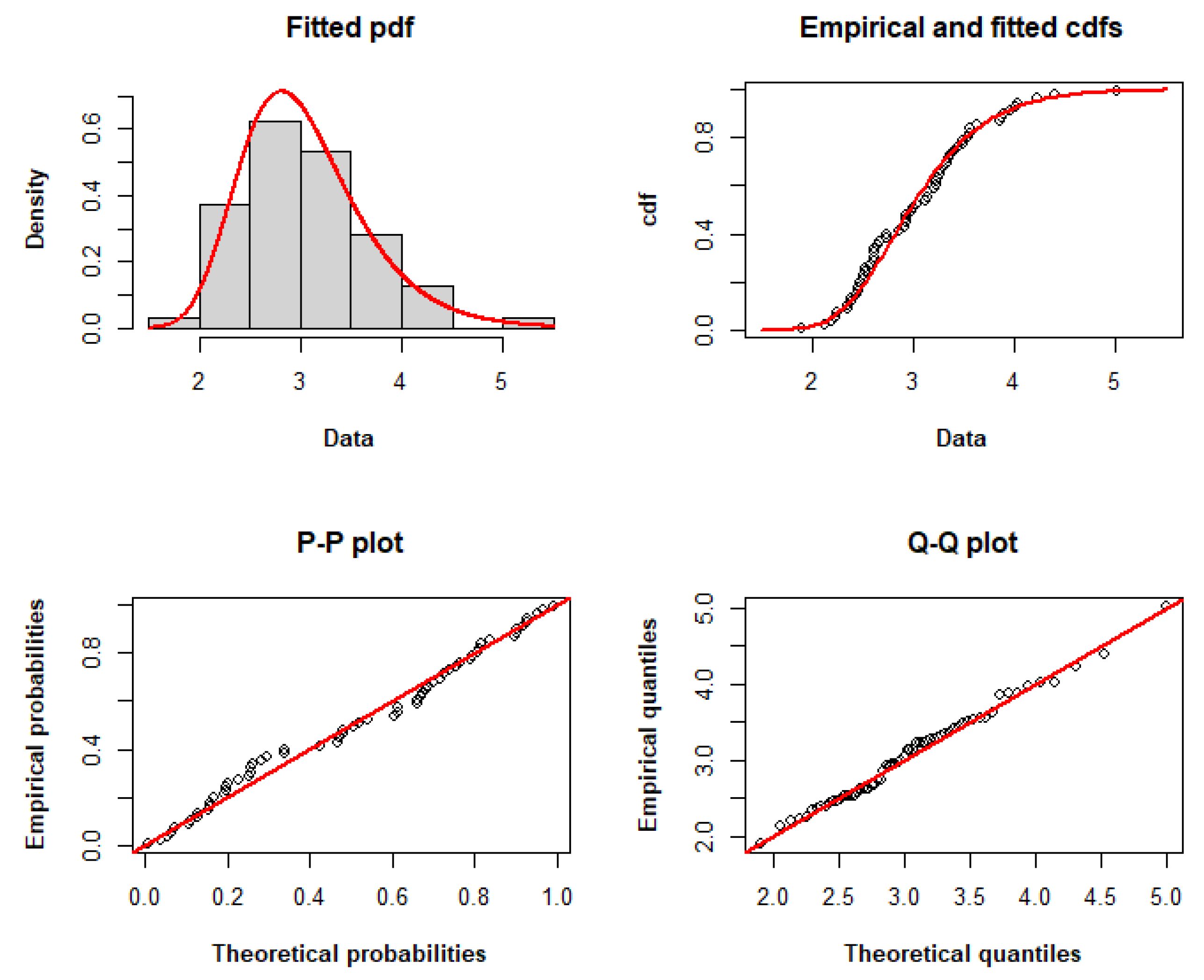
The TLW model fits the dataset with the lowest AIC, CAIC, BIC, HQIC, and minus log-likelihood among the other models, as determined by the adequacy statistics presented in Table 8. Therefore, it may be a viable option for modeling these data. Figure 3 compares the empirical and fitted distributions of the data, displaying the histogram and fitted pdf, the fitted and empirical cdfs, the P–P plot, and the Q–Q plot, respectively, to graphically explain the appropriateness of the TLW for modeling these data.
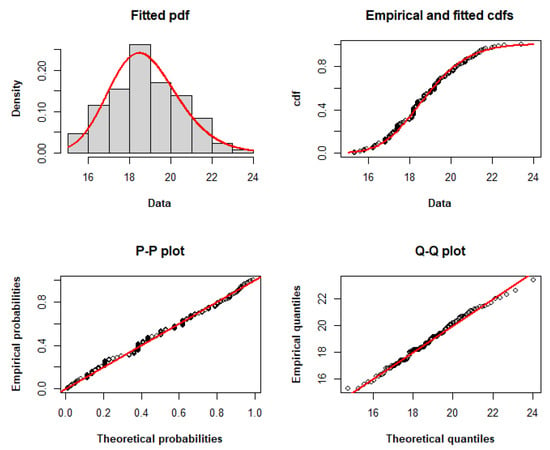
Figure 3.
Histogram and fitted pdf, empirical and fitted cdfs, and P–P and Q–Q plots of the TLW model fitted to dataset I.
- Dataset II: Breaking Stress of Carbon Fibers
The breaking stress of 64 single carbon fibers of gauge length 10 mm (Cheng and Traylor (1970) [24]). The observations are as follows.
| 1.901 | 2.132 | 2.203 | 2.228 | 2.257 | 2.35 | 2.361 | 2.396 | 2.397 | 2.4450 | 2.454 |
| 2.454 | 2.474 | 2.518 | 2.522 | 2.525 | 2.532 | 2.575 | 2.614 | 2.616 | 2.618 | 2.624 |
| 2.659 | 2.675 | 2.738 | 2.74 | 2.856 | 2.917 | 2.928 | 2.937 | 2.937 | 2.977 | 2.996 |
| 3.03 | 3.125 | 3.139 | 3.145 | 3.22 | 3.223 | 3.235 | 3.243 | 3.264 | 3.272 | 3.294 |
| 3.332 | 3.346 | 3.377 | 3.408 | 3.435 | 3.493 | 3.501 | 3.537 | 3.554 | 3.562 | 3.628 |
| 3.852 | 3.871 | 3.886 | 3.971 | 4.024 | 4.027 | 4.225 | 4.395 | 5.02 |
Table 9 displays the MLEs and 95% CIs for the model parameters, demonstrating the validity of the considered models. According to Table 10, the TLW model fits the dataset with the lowest AIC, CAIC, BIC, HQIC, and minus log-likelihood among the other models. Therefore, it may be a viable option for modeling these data. Figure 4 compares the empirical and fitted distributions of the data, displaying the histogram and fitted pdf, the fitted and empirical cdfs, the P–P plot and the Q–Q plot to graphically demonstrate the appropriateness of the TLW for modeling these data.
Table 9.
Estimates of TLW parameters for dataset II.
Table 10.
Competence of the models for dataset II.
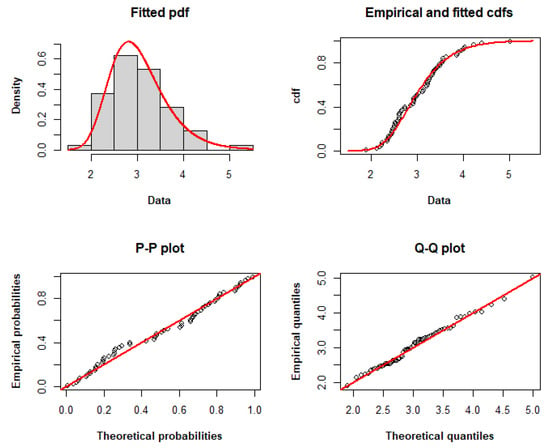
Figure 4.
Histogram and fitted pdf, empirical and fitted cdfs, and P–P and Q–Q plots of the TLW model fitted to dataset II.
- Dataset III: COVID-19
In this application we consider the regression model for censored data. This dataset refers to patients hospitalized with COVID-19. The disease is caused by the pathogen identified as a new coronavirus, denominated severe acute respiratory syndrome coronavirus-2 (SARS-CoV-2). The epidemiological data were tallied by the Health Information System of the Brazilian government, and are available at https://opendatasus.saude.gov.br/dataset/srag-2020 (accessed on 1 May 2023).
This study involved 195 patients hospitalized in the city of Campinas, state of São Paulo, in May 2020, with infection confirmed by RT-PCR and classified as SARS caused by COVID-19. The survival time consisted of the time in days from the date of first symptoms to the date of evolution of the case, either death (failure) or end of observation (censoring). The censoring percentage was 56.92% and the following variables were considered: :
- : observed time (in days);
- : censoring indicator ( censored, observed lifetime);
- : sex ( male, female);
- : age (in years).
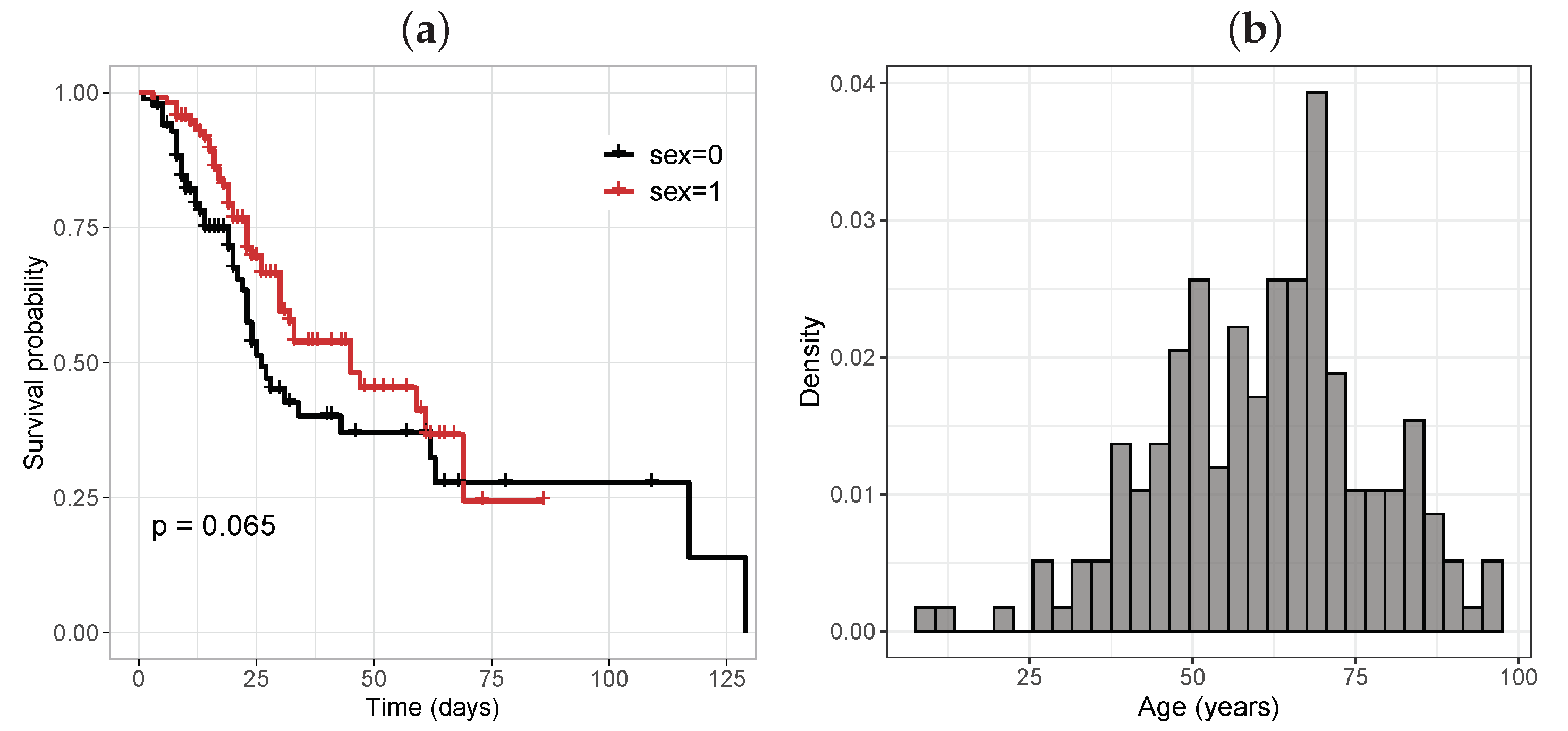
There were 110 male patients (56.41%), of whom 42 (38.18%) died, while of the 85 women (43.58%), there were 42 deaths (49.41%). Figure 5a presents the Kaplan–Meier survival curve broken down by sex. It can be seen that men had a higher risk of death. Figure 5b depicts the histogram of the ages, where the greatest frequency was in the category from 50 to 75 years old.
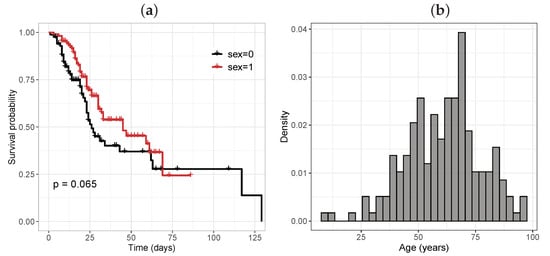
Figure 5.
(a) Kaplan–Meier survival curve for the sex variable ( male, female); (b) histogram of the age variable.
We compared the TLW regression model with the Weibull regression model based on the following systematic components:
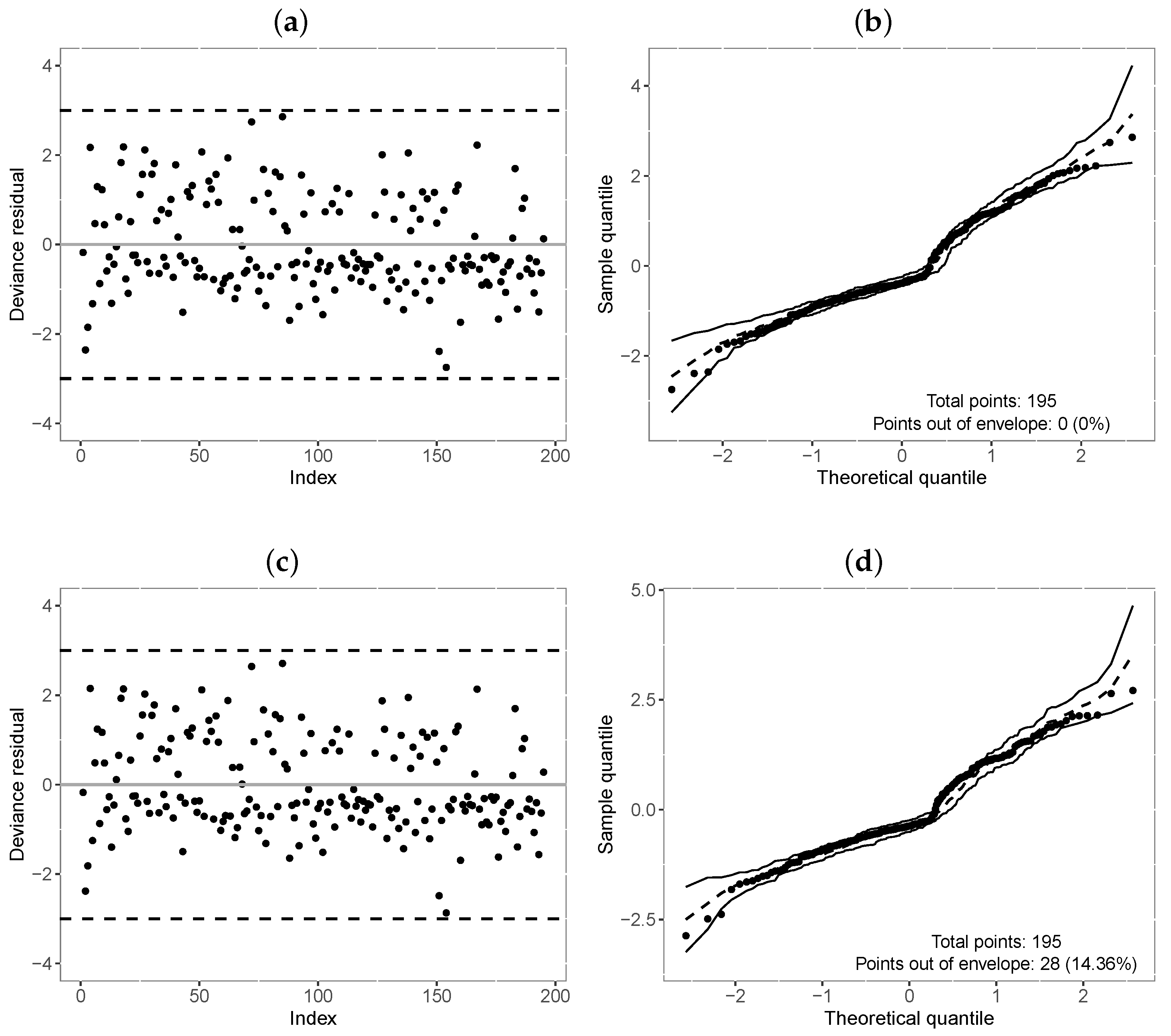
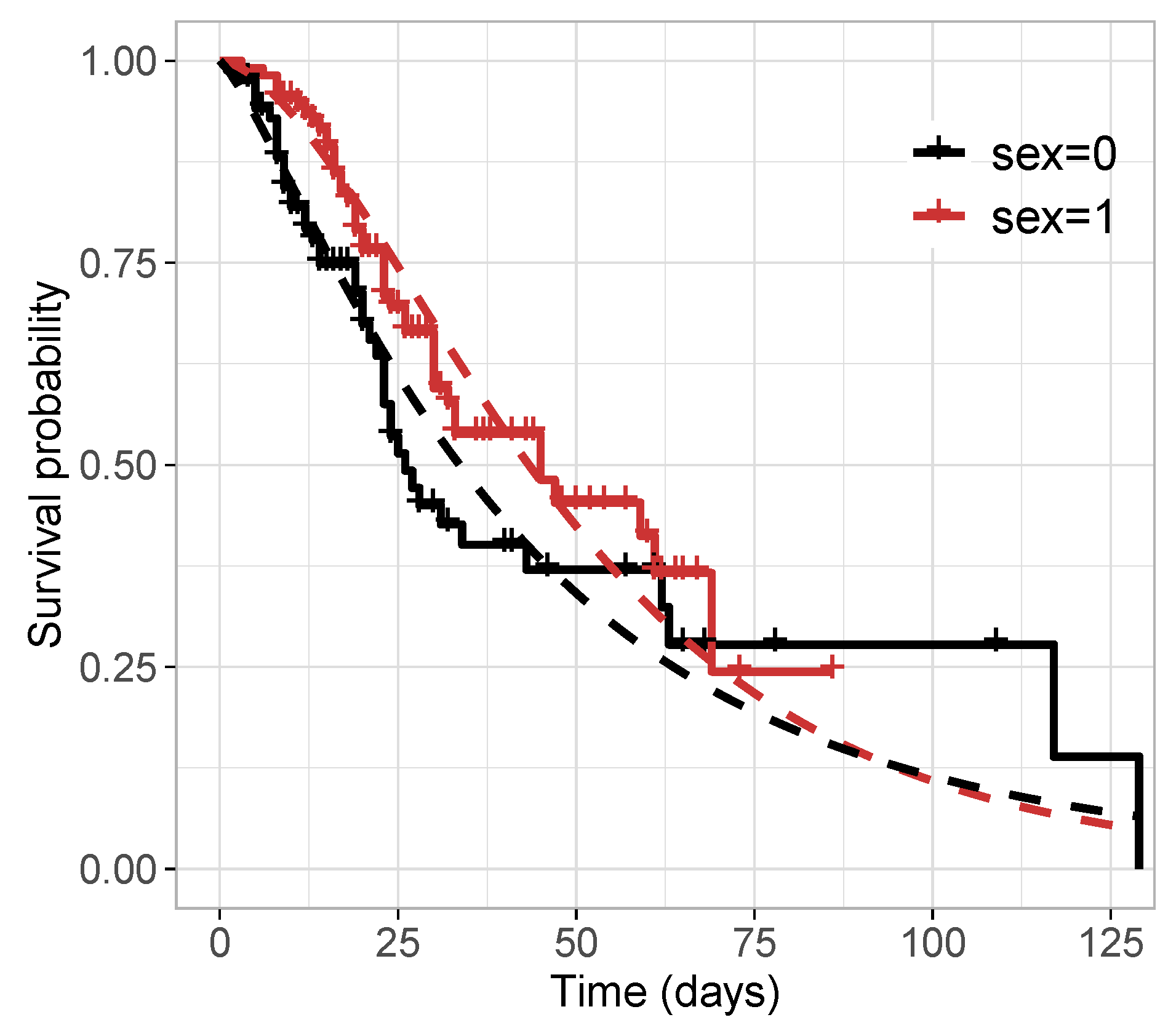
Table 11 reports the values of the selection criteria of the models, in which the -TLW model was superior to the others. We also compared this model with the -Weibull model by means of the residuals in Figure 6. In turn, Figure 6a,c illustrate the residuals versus the index of the observations, showing that both models have residuals with random behavior around zero, and no point is outside the interval . Nevertheless, Figure 6b,d indicate that the TLW model behaved better, with all the points within the simulated envelope, denoting its superiority. Finally, we illustrate the Kaplan–Meier curves and estimated survival curves in Figure 7 for the TLW model, showing that this model is able to capture the non-proportional curves of this dataset. The results of this model are shown in Table 12. Some conclusions can be obtained as follows.
Table 11.
AIC and GD values for TLW and Weibull regression models with different structures for COVID-19 data.
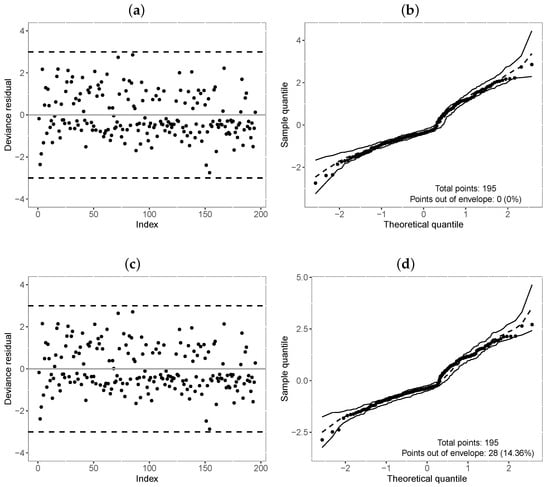
Figure 6.
Index plot and normal probability plot with envelope of the deviance residual from the fitted regressions model to the COVID-19 data. (a,b): -TLW; (c,d): -Weibull.
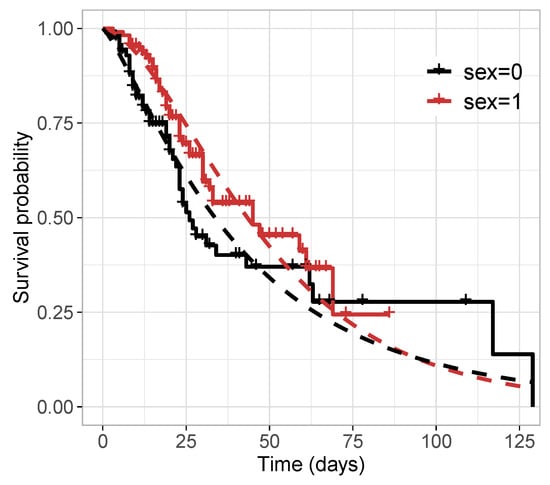
Figure 7.
Kaplan–Meier survival curve and estimated survival functions from the -TLW by sex.
Table 12.
MLEs, SEs, and p-values for the -TLW regression fitted to COVID-19 data.
Interpretations for :
- A significant difference exists between men and women in relation to survival time (men have shorter survival). Various other studies have also indicated significant differences between the sexes (see [25,26]);
- The survival time declines with advancing age. This result corroborates the findings of several studies that have indicated that older age is a predictor of higher mortality caused by COVID-19 (see [27,28,29]).
Interpretations for k:
- A significant difference exists between men and women with regard to the variability in the survival time;
- In relation to age, the variability in survival time increased with older age of the patients.
- Dataset IV: Post-harvested
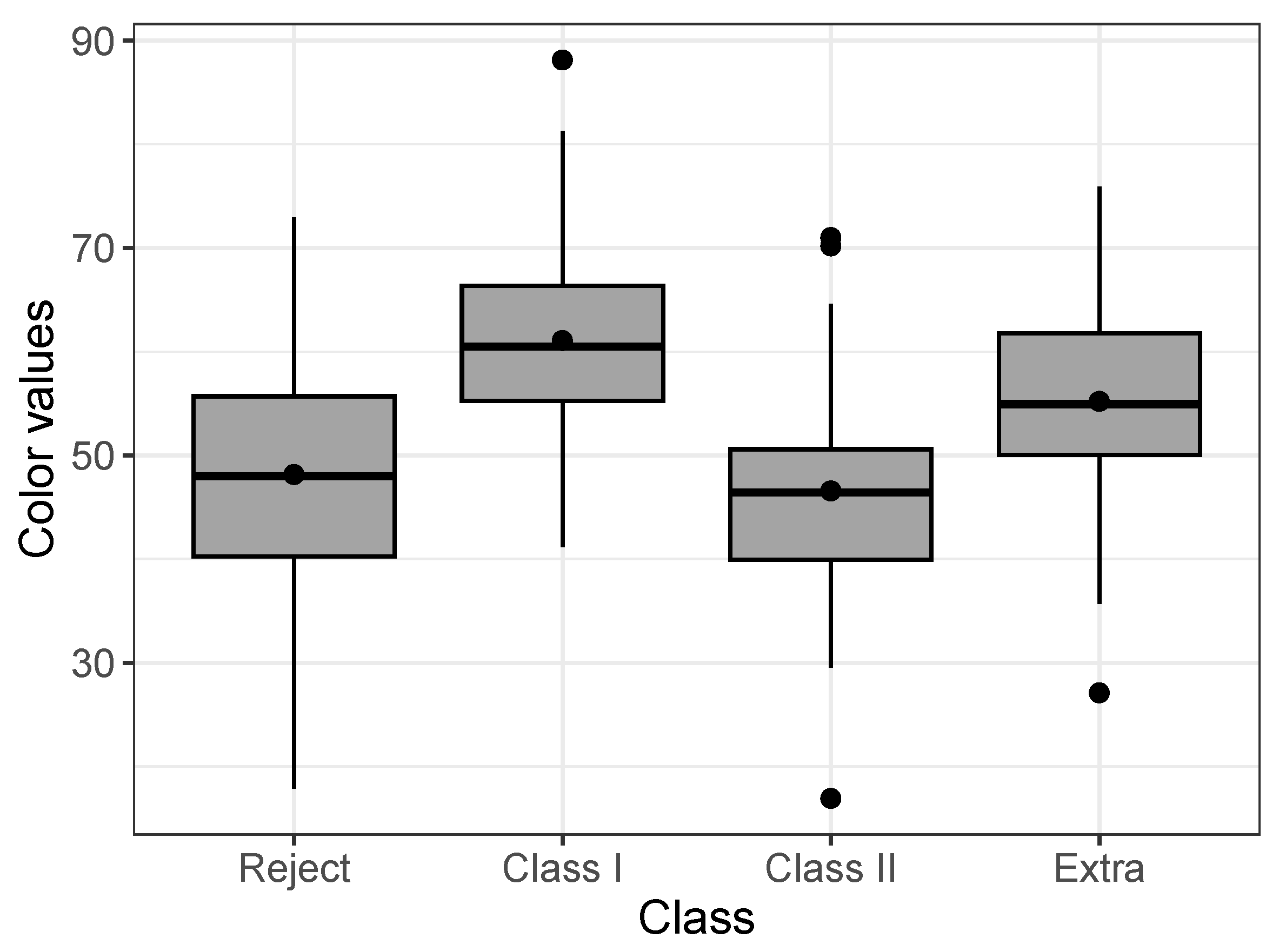
In this application, we consider the regression model for uncensored data. These data refer to Musa acuminata banana species from a banana plantation in the Philippines. A total of banana tiers were chosen randomly, in which the numerical values of the RGB colors (red, green, and blue) were obtained from images taken by hardware of four banana classes, extra class, class I, class II, and reject, where the classes contain 65, 49, 30, and 50 samples, respectively. The dataset is available in the repository: https://data.mendeley.com/datasets/zk3tkxndjw/2 (accessed on 20 May 2023) and more details can be seen in [30]. Each banana tier sample was captured with a white background in six different views: front, back, left, right, top, and bottom views. Here, we consider the values of B in front view. Figure 8 displays a boxplot by class, it is possible to observe differences between the colors according to the class.
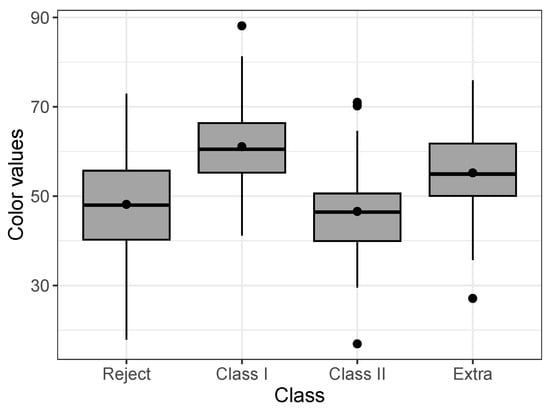
Figure 8.
Boxplot of colors by class for the Post-harvested dataset.
The variables considered are :
- : color value;
- : banana class (factor with four levels, defined by three variable dummies ).
We verified the relationship between colors and classes from the TLW and Weibull models according to the following systematic components:
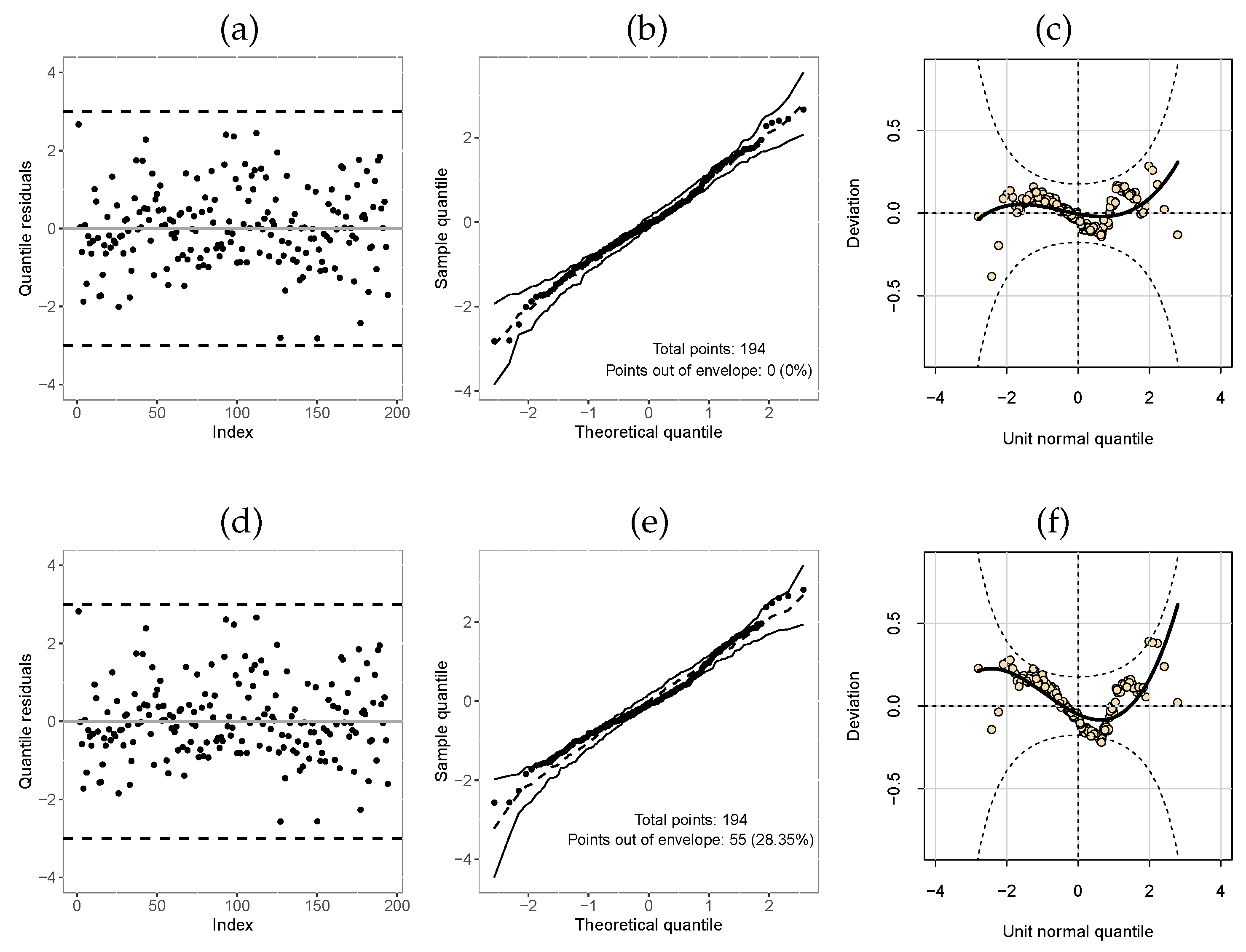
Table 13 displays the AIC and GD values for these fitted models, in which it can be seen that the -TLW model obtained the lowest values, being able to be chosen as the best model. In addition, we compare the -TLW and the -Weibull from the quantile residues (Figure 9). These plots agree with the results of Table 13, there is a high percentage of points outside the confidence band of the Weibull model (Figure 9e) and many deviations also from the confidence band worm plot confidence (Figure 9f).
Table 13.
AIC and GD values for TLW and Weibull regression models with different structures for the Post-harvested dataset.
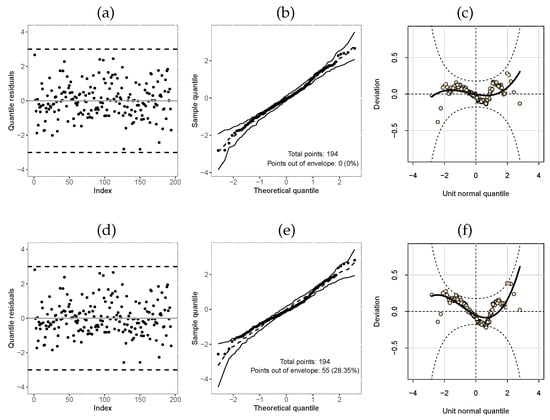
Figure 9.
Index plot, normal probability plot with envelope, and worm plot of the quantile residuals from the regression models fitted to the Post-harvested dataset: (a–c): -TLW; (d–f): -Weibull.
Finally, Table 14 presents MLEs, SEs, and p-values of the model -TLW, in which classes I, II, and extra are compared with the rejected class. We can obtain the following conclusions: there is a significant difference between the color of class 1 and the rejects. Its effect is positive, that is, it presented higher color values. Class II and the extra class do not present a significant difference with the rejected class. The extra class and class I’s colors affect the shape of the distribution compared to the reject class’s color.
Table 14.
MLEs, SEs, and p-values for the -TLW regression fitted to the Post-harvested dataset.
6. Conclusions
In this study, we propose a new class of distributions called the truncated Lindley-G (TLG) distribution with application to the truncated Lindley–Weibull (TLW) distribution with three parameters. Several structural properties of the TLG distribution, including an expansion of the density function, critical points, explicit expressions of the ordinary and incomplete moments, mean deviation, generating function, entropy, and quantile function, are discussed. The parameters of the model are estimated using the maximum likelihood technique. We fitted the TLW model to two sets of data to demonstrate the effectiveness of the proposed distribution. In comparison to the Kumarswamy–Weibull, Weibull–Weibull, Geometric–Poisson–Weibull, Poisson–Weibull, beta-Weibull, Marshall–Olkin–Weibull, and exponentiated generalized Weibull distributions, the proposed model had a better fit on four datasets. However, the goodness-of-fit measures for our model were not drastically better than the comparison models that are currently used in statistical analyses. Based on this new distribution, we propose a TLW regression model with two systematic components very suitable for modeling censored and uncensored data. Several simulation studies are performed for different parameter settings, sample sizes, and censoring percentages. We anticipate the further application of the proposed model in disciplines such as engineering, survival and lifetime data, and economics.
Author Contributions
Conceptualization, M.H., G.M.R., E.M.M.O., R.V. and H.E.; methodology, M.H., G.M.R., E.M.M.O., R.V. and H.E; software, M.H., G.M.R., E.M.M.O., R.V. and H.E.; investigation, M.H., G.M.R., E.M.M.O., R.V. and H.E.; writing—original draft preparation, M.H. and H.E.; writing—review and editing, M.H. and E.M.M.O. All authors have read and agreed to the published version of the manuscript.
Funding
This research received funding from Deanship of Scientific Research at King Khalid University through General Research Project under grant number GRP/206/44, Coordenação de Aperfeiçoamento de Pessoal de Nível Superior–Brasil (CAPES) and Conselho Nacional de Desenvolvimento Científico e Tecnológico—Brasil (CNPq).
Institutional Review Board Statement
Not applicable.
Data Availability Statement
Stated in the text.
Acknowledgments
The authors extend their appreciation to the Deanship of Scientific Research at King Khalid University for funding this work through a General Research Project under grant number GRP/206/44. Also, this study was financed in part by the Coordenação de Aperfeiçoamento de Pessoal de Nível Superior, Brasil (CAPES) and Conselho Nacional de Desenvolvimento Científico e Tecnológico, Brasil (CNPq).
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A
The UTL model has the following properties:
- (1)
- MomentsThe UTL distribution’s kth raw moment () is given bywhere . Using integration by parts, can be calculated recursively byandThe first three moments areThe kth incomplete moment of X is given bywhere . Using integration by parts, can be calculated recursively byand
- (2)
- ModeThe mode of the UTL distribution is
- (3)
- Quantile FunctionTherefore The UTL distribution’s qf iswhere is the Lambert function satisfying for (see Corless et al. [31] for the definition and properties of the Lambert function).Therefore, the median of the UTL distribution is simply , that is,
- (4)
- Mean DeviationsThe UTL distribution’s mean deviation about the mean is given byand the mean deviation about the median M iswhere is the kth incomplete moment.
- (5)
- Moment Generating FunctionThe UTL distribution’s moment generating function (mgf) can be expressed as
Appendix B
- -
- The cdf of the Kumaraswamy-G model is given by
- -
- The cdf of the Weibull-G model is given by
- -
- The cdf of the Geometric-Poisson-G model is given by
- -
- The cdf of the Poisson-G model is given by
- -
- The cdf of the Beta-G model is given bywhere is the regularized incomplete beta function, and is the beta function.
- -
- The cdf of the Marshall–Olkin-G model is given by
- -
- The cdf of the exponentiated generalized-G model is given by
References
- Eugene, N.; Lee, C.; Famoye, F. Beta-Normal Distribution and Its Applications. Commun. Stat.-Theory Methods 2002, 31, 497–512. [Google Scholar] [CrossRef]
- Alexander, C.; Cordeiro, G.M.; Ortega, E.M.M.; Sarabia, J.M. Generalized Beta-Generated Distributions. Comput. Stat. Data Anal. 2012, 56, 1880–1897. [Google Scholar] [CrossRef]
- Nadarajah, S.; Teimouri, M.; Shih, S.H. Modified Beta Distributions. Sankhya B 2014, 76, 19–48. [Google Scholar] [CrossRef]
- Cordeiro, G.M.; de Castro, M. A New Family of Generalized Distributions. J. Stat. Comput. Simul. 2011, 81, 883–898. [Google Scholar] [CrossRef]
- Ristic, M.M.; Nadarajah, S. A New Lifetime Distribution. J. Stat. Comput. Simul. 2013, 84, 135–150. [Google Scholar] [CrossRef]
- Nadarajah, S.; Nassiri, V.; Mohammadpour, A. Truncated-Exponential Skew-Symmetric Distributions. Stat. A J. Theor. Appl. Stat. 2014, 48, 872–895. [Google Scholar] [CrossRef]
- Abid, A.H.; Abdulrazak, R.K. [0,1] Truncated Frèchet-G Generator of Distributions. Appl. Math. 2017, 7, 51–66. [Google Scholar] [CrossRef]
- Bantan, R.A.; Jamal, F.; Chesneau, C.; Elgarhy, M. Truncated Inverted Kumaraswamy Generated Family of Distributions with Applications. Entropy 2019, 21, 1089. [Google Scholar] [CrossRef]
- Aldahlan, M.A. Type II Truncated Fréchet Generated Family of Distributions. Int. J. Math. Its Appl. 2019, 7, 221–228. Available online: https://ijmaa.in/index.php/ijmaa/article/view/285 (accessed on 15 September 2022).
- Almarashi, A.M.; Elgarhy, M.; Jamal, F.; Chesneau, C. The Exponentiated Truncated Inverse Weibull Generated Family of Distributions with Applications. Symmetry 2020, 12, 650. [Google Scholar] [CrossRef]
- Jamal, F.; Bakouch, H.; Nasir, M.A. A Truncated General-G class of Distributions with Application to Truncated Burr G family. REVSTAT-Stat. J. 2021, 19, 513–530. [Google Scholar] [CrossRef]
- Almarashi, A.M.; Jamal, F.; Chesneau, C.; Elgarhy, M. A New Truncated Muth Generated Family of Distributions with Applications. Complexity 2021, 21, 1–4. [Google Scholar] [CrossRef]
- ZeinEldin, R.A.; Chesneau, C.; Jamal, F.; Elgarhy, M.; Almarashi, A.M.; Al-Marzouki, S. Generalized Truncated Fréchet Generated Family Distributions and their Applications. Comput. Model. Eng. Sci. 2021, 126, 791–819. [Google Scholar] [CrossRef]
- Algarni, A.; Almarashi, A.M.; Jamal, F.; Chesneau, C.; Elgarhy, M. Truncated Inverse Lomax Generated Family of Distributions with Applications to Biomedical Data. J. Med. Imaging Health Inform. 2021, 11, 2425–2439. [Google Scholar] [CrossRef]
- Bantan, R.A.; Chesneau, C.; Jamal, F.; Elbatal, I.; Elgarhy, M. The Truncated Burr X-G Family of Distributions: Properties and Applications to Actuarial and Financial Data. Entropy 2021, 23, 1088. [Google Scholar] [CrossRef]
- Lindley, D.V. Fiducial Distributions and Bayes’ Theorem. J. R. Stat. Soc. 1958, 20, 102–107. Available online: https://www.jstor.org/stable/2983909 (accessed on 12 August 2020). [CrossRef]
- AL-Hussaini, E.K.; Ahsanullah, M. Exponentiated Distributions “Part of the book series: Atlantis Studies in Probability and Statistics”; ATLANTISSPS; Atlantis Press: Paris, France, 2015. [Google Scholar]
- Alzaatreh, A.; Lee, C.; Famoye, F. A New Method for Generating Families of Continuous Distributions. Metron 2013, 71, 63–79. [Google Scholar] [CrossRef]
- Nadarajah, S.; Cancho, V.G.; Ortega, E.M.M. The Geometric Exponential Poisson Distribution. Stat. Methods Appl. 2013, 22, 355–380. [Google Scholar] [CrossRef]
- Marshall, A.W.; Olkin, I. A New Method for Adding a Parameter to a Family of Distributions with Application to the Exponential and Weibull Families. Biometrika 1997, 84, 641–652. Available online: https://www.jstor.org/stable/2337585 (accessed on 3 April 2010). [CrossRef]
- Cordeiro, G.M.; Ortega, E.M.M.; da Cunha, D.C.C. The Exponentiated Generalized Class of Distributions. J. Data Sci. 2013, 11, 1–27. [Google Scholar] [CrossRef]
- Team RC. R: A language and Environment for Statistical Computing; R Foundation for Statistical Computing, Vienna, Austria. 2022. Available online: https://www.r-project.org/ (accessed on 24 June 2022).
- Barakat, H.; Nigm, E.; Aldallal, R. Exact Prediction Intervals for Future Current Records and Record Range from any Continuous Distribution. SORT-Stat. Oper. Res. Trans. 2014, 38, 251–270. Available online: https://raco.cat/index.php/SORT/article/view/284044 (accessed on 5 March 2017).
- Cheng, R.C.; Traylor, L. Characterization of Material Strength Properties Using Probabilistic Mixture Models. WIT Trans. Model. Simul. 1970, 31, 553–560. [Google Scholar]
- Albitar, O.; Ballouze, R.; Ooi, J.P.; Ghadzi, S.M.S. Risk factors for mortality among COVID-19 patients. Diabetes Res. Clin. Pract. 2020, 166, 1–5. [Google Scholar] [CrossRef] [PubMed]
- Liu, Y.; Du, X.; Chen, J.; Jin, Y.; Peng, L.; Wang, H.H.; Zhao, Y. Neutrophil-to-lymphocyte ratio as an independent risk factor for mortality in hospitalized patients with COVID-19. J. Infect. 2020, 81, 6–12. [Google Scholar] [CrossRef] [PubMed]
- Giacomelli, A.; Ridolfo, A.L.; Milazzo, L.; Oreni, L.; Bernacchia, D.; Siano, M.; Galli, M. 30-day mortality in patients hospitalized with COVID-19 during the first wave of the Italian epidemic: A prospective cohort study. Pharmacol. Res. 2020, 158, 104931. [Google Scholar] [CrossRef]
- Atlam, M.; Torkey, H.; El-Fishawy, N.; Salem, H. Coronavirus disease 2019 (COVID-19): Survival analysis using deep learning and Cox regression model. Pattern Anal. Appl. 2021, 24, 993–1005. [Google Scholar] [CrossRef] [PubMed]
- Rodrigues, G.M.; Ortega, E.M.; Cordeiro, G.M.; Vila, R. An extended Weibull regression for censored data: Application for COVID-19 in campinas, Brazil. Mathematics 2022, 10, 3644. [Google Scholar] [CrossRef]
- Piedad, E.; Caladcad, J.A. Post-harvested Musa acuminata Banana Tiers Dataset. Data Brief 2023, 46, 108856. [Google Scholar] [CrossRef]
- Corless, R.M.; Gonnet, G.H.; Hare, D.E.G.; Jeffrey, D.J.; Knuth, D.E. On the Lambert W function. Adv. Comput. Math. 1996, 5, 329–359. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).