
A Quantum Model of Trust Calibration in Human–AI Interactions

 , , ,
, , , {kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
The Multi-Dimensional and Dynamic Nature of Trust
2. Modelling of Trust
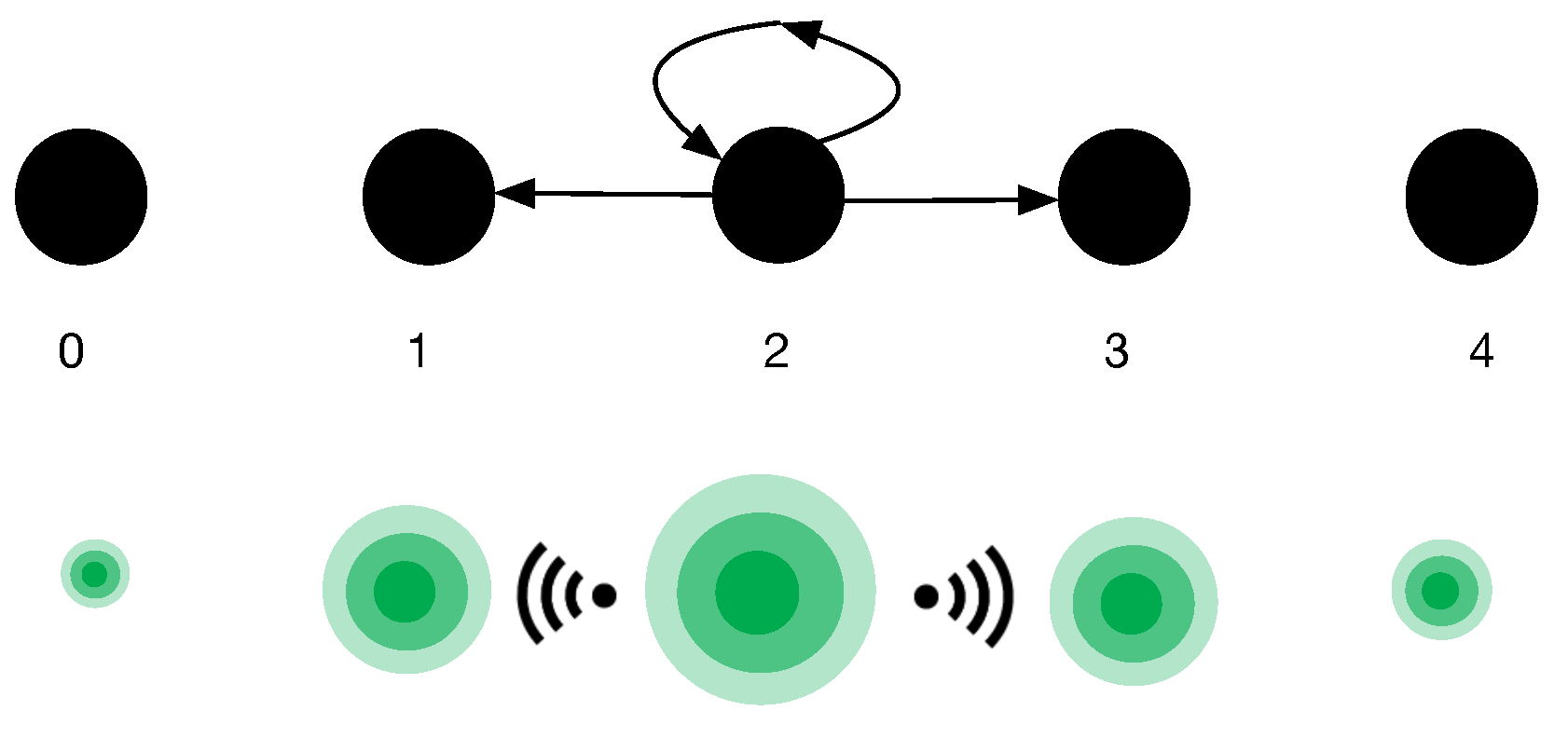
2.1. Markov Random Walk Model
2.2. Quantum Random Walk Model
3. A Wizard of Oz Human–AI Experiment
3.1. Participants
3.2. Materials
3.3. Experimental Protocol
3.4. Data Acquisition
3.5. Data Analysis
4. Results
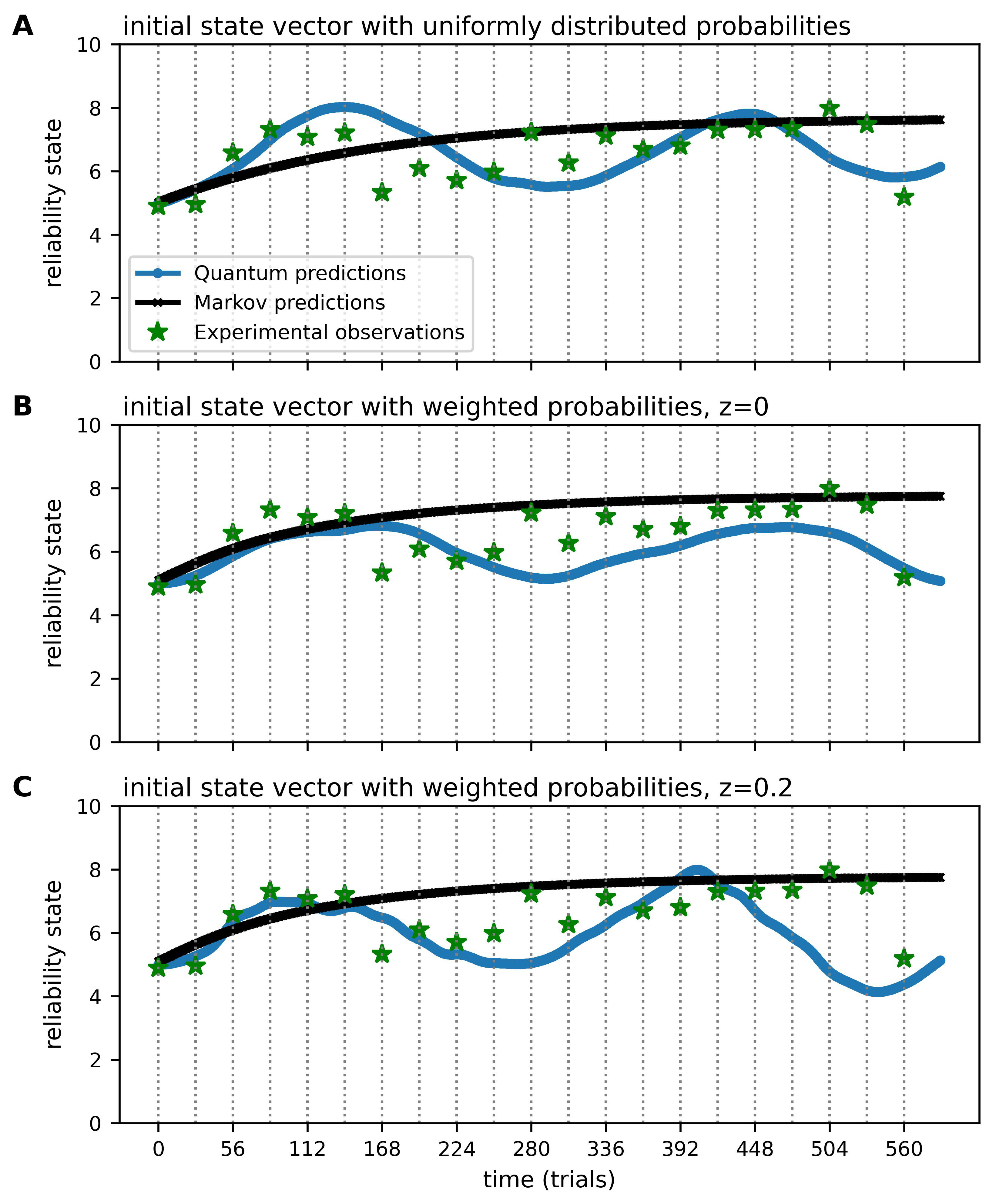
4.1. Markov and Quantum Models of Reliability Ratings
4.1.1. Definition of the Initial State Vectors
4.1.2. Definition of the Markov Intensity and Quantum Hamiltonian Matrices
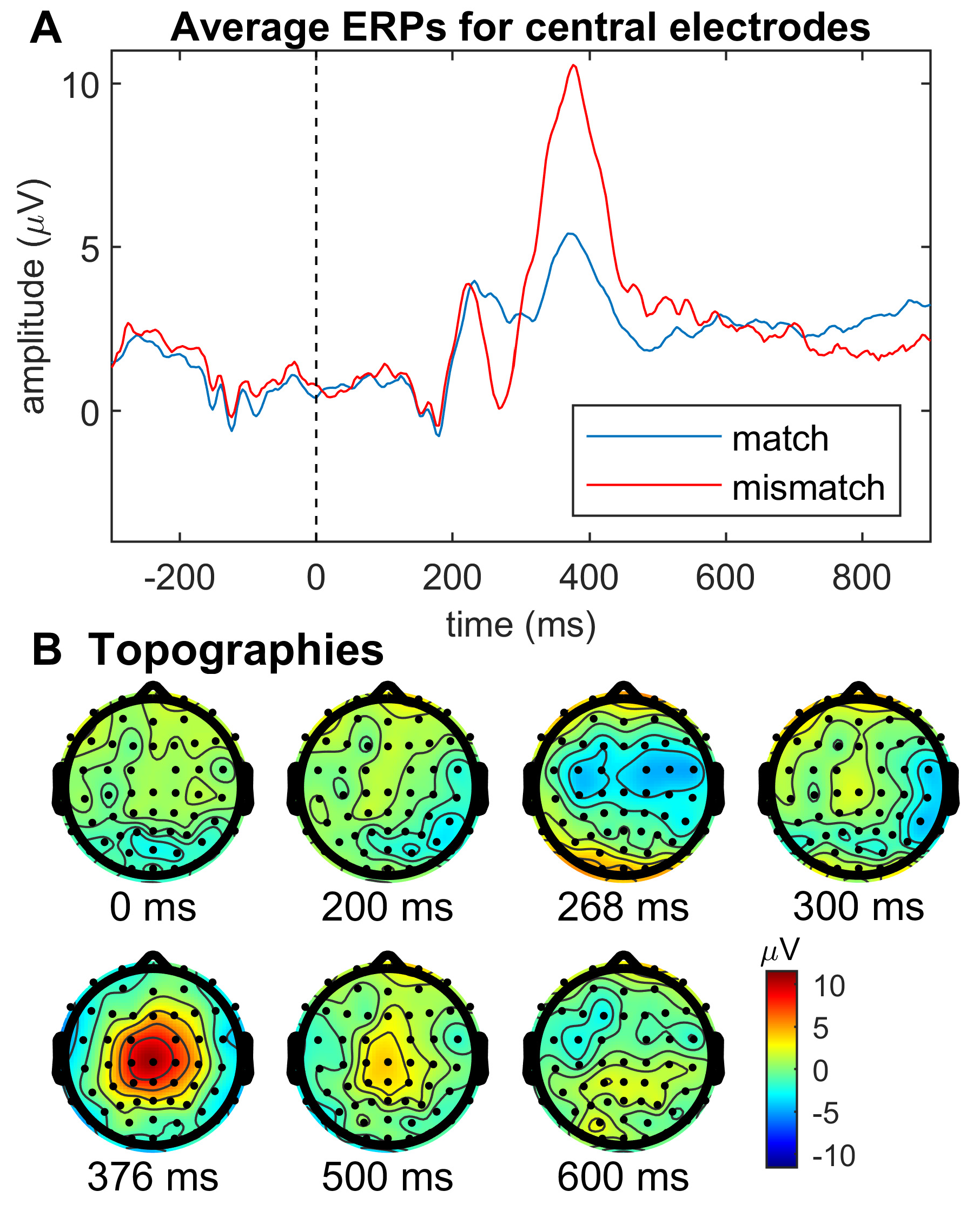
4.2. Event-Related Potentials
5. Discussion
5.1. Predictive Modelling of Reliability Ratings
5.2. Determinate vs. Indeterminate Trust
5.3. Potential Neural Correlate of Trust Perturbation
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Miller, T. Explanation in artificial intelligence: Insights from the social sciences. Artif. Intell. 2019, 267, 1–38. [Google Scholar] [CrossRef]
- Gulaiti, S.; Sousa, S.; Lamas, D. Modelling trust in human-like technologies. In Proceedings of the 9th Indian Conference on Human Computer Interaction, Bangalore, India, 16–18 December 2018; pp. 1–10. [Google Scholar]
- Gratch, J.; Friedland, P.; Knott, B. Recommendations for Research on Trust in Autonomy. In Proceedings of the Fifth International Workshop on Human-Agent Interaction Design and Models, New York, NY, USA, 9–11 July 2016. [Google Scholar]
- Friedland, P. AI Systems and Trust: Past, Present, and Future. Available online: https://assets.website-files.com/5f47f05cf743023a854e9982/5f887cadc4a86618cbd276dd_Peter_Friedland_RI%20Trust%20Meeting.pdf (accessed on 5 July 2022).
- Jacovi, A.; Marasović, A.; Miller, T.; Goldberg, Y. Formalizing trust in artificial intelligence: Prerequisites, causes and goals of human trust in AI. In Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency, Virtual, 3–10 March 2021; pp. 624–635. [Google Scholar]
- Gratch, J.; Hill, S.; Morency, L.P.; Pynadath, D.; Traum, D. Exploring the implications of virtual human research for human–robot teams. In Proceedings of the Virtual, Augmented and Mixed Reality: 7th International Conference, VAMR 2015, Held as Part of HCI International 2015, Los Angeles, CA, USA, 2–7 August 2015; Proceedings 7. Springer: Berlin/Heidelberg, Germany, 2015; pp. 186–196. [Google Scholar]
- Busemeyer, J.R.; Bruza, P.D. Quantum Models of Cognition and Decision; Cambridge University Press: Cambridge, UK, 2012. [Google Scholar]
- Mayer, R.C.; Davis, J.H.; Schoorman, F.D. An integrative model of organizational trust. Acad. Manag. Rev. 1995, 20, 709–734. [Google Scholar] [CrossRef]
- Lee, J.D.; See, K.A. Trust in automation: Designing for appropriate reliance. Hum. Factors 2004, 46, 50–80. [Google Scholar] [CrossRef] [PubMed]
- Hoff, K.A.; Bashir, M. Trust in automation: Integrating empirical evidence on factors that influence trust. Hum. Factors 2015, 57, 407–434. [Google Scholar] [CrossRef] [PubMed]
- Riek, L.D. Wizard of oz studies in hri: A systematic review and new reporting guidelines. J. Hum.-Robot Interact. 2012, 1, 119–136. [Google Scholar] [CrossRef]
- Kohn, S.C.; de Visser, E.J.; Wiese, E.; Lee, Y.C.; Shaw, T.H. Measurement of trust in automation: A narrative review and reference guide. Front. Psychol. 2021, 12, 604977. [Google Scholar] [CrossRef] [PubMed]
- Nightingale, S.J.; Farid, H. AI-synthesized faces are indistinguishable from real faces and more trustworthy. Proc. Natl. Acad. Sci. USA 2022, 119, e2120481119. [Google Scholar] [CrossRef]
- Peirce, J.; Gray, J.R.; Simpson, S.; MacAskill, M.; Höchenberger, R.; Sogo, H.; Kastman, E.; Lindeløv, J.K. PsychoPy2: Experiments in behavior made easy. Behav. Res. Methods 2019, 51, 195–203. [Google Scholar] [CrossRef]
- Oostenveld, R.; Praamstra, P. The five percent electrode system for high-resolution EEG and ERP measurements. Clin. Neurophysiol. 2001, 112, 713–719. [Google Scholar] [CrossRef]
- Delorme, A.; Makeig, S. EEGLAB: An open source toolbox for analysis of single-trial EEG dynamics including independent component analysis. J. Neurosci. Methods 2004, 134, 9–21. [Google Scholar] [CrossRef] [PubMed]
- Bigdely-Shamlo, N.; Mullen, T.; Kothe, C.; Su, K.M.; Robbins, K.A. The PREP pipeline: Standardized preprocessing for large-scale EEG analysis. Front. Neuroinform. 2015, 9, 16. [Google Scholar] [CrossRef] [PubMed]
- Mullen, T. NITRC CleanLine. 2012. Available online: https://www.nitrc.org/projects/cleanline (accessed on 31 July 2023).
- Pion-Tonachini, L.; Kreutz-Delgado, K.; Makeig, S. ICLabel: An automated electroencephalographic independent component classifier, dataset, and website. NeuroImage 2019, 198, 181–197. [Google Scholar] [CrossRef]
- Chang, C.Y.; Hsu, S.H.; Pion-Tonachini, L.; Jung, T.P. Evaluation of artifact subspace reconstruction for automatic artifact components removal in multi-channel EEG recordings. IEEE Trans. Biomed. Eng. 2019, 67, 1114–1121. [Google Scholar] [CrossRef] [PubMed]
- Lopez-Calderon, J.; Luck, S.J. ERPLAB: An open-source toolbox for the analysis of event-related potentials. Front. Hum. Neurosci. 2014, 8, 213. [Google Scholar] [CrossRef]
- Griffiths, T.L.; Chater, N.; Kemp, C.; Perfors, A.; Tenenbaum, J.B. Probabilistic models of cognition: Exploring representations and inductive biases. Trends Cogn. Sci. 2010, 14, 357–364. [Google Scholar] [CrossRef] [PubMed]
- Pothos, E.M.; Busemeyer, J.R. Quantum cognition. Annu. Rev. Psychol. 2022, 73, 749–778. [Google Scholar] [CrossRef] [PubMed]
- Kvam, P.D.; Pleskac, T.J.; Yu, S.; Busemeyer, J.R. Interference effects of choice on confidence: Quantum characteristics of evidence accumulation. Proc. Natl. Acad. Sci. USA 2015, 112, 10645–10650. [Google Scholar] [CrossRef] [PubMed]
- Kvam, P.D.; Busemeyer, J.R.; Pleskac, T.J. Temporal oscillations in preference strength provide evidence for an open system model of constructed preference. Sci. Rep. 2021, 11, 8169. [Google Scholar] [CrossRef]
- Rosner, A.; Basieva, I.; Barque-Duran, A.; Glöckner, A.; von Helversen, B.; Khrennikov, A.; Pothos, E.M. Ambivalence in decision making: An eye tracking study. Cogn. Psychol. 2022, 134, 101464. [Google Scholar] [CrossRef]
- Busemeyer, J.; Zhang, Q.; Balakrishnan, S.; Wang, Z. Application of quantum—Markov open system models to human cognition and decision. Entropy 2020, 22, 990. [Google Scholar] [CrossRef]
- Bruza, P.D.; Fell, L.; Hoyte, P.; Dehdashti, S.; Obeid, A.; Gibson, A.; Moreira, C. Contextuality and context-sensitivity in probabilistic models of cognition. Cogn. Psychol. 2023, 140, 101529. [Google Scholar] [CrossRef] [PubMed]
- Polich, J. Neuropsychology of P300. In Oxford Handbook of Event-Related Potential Components; Luck, S.J., Kappenman, E.S., Eds.; Oxford University Press: New York, NY, USA, 2012; pp. 159–188. [Google Scholar]
- Luck, S.J. An Introduction to the Event-Related Potential Technique; MIT Press: Cambridge, MA, USA, 2014. [Google Scholar]
- Manzano, D. A short introduction to the Lindblad master equation. Aip Adv. 2020, 10, 025106. [Google Scholar] [CrossRef]

Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Roeder, L.; Hoyte, P.; van der Meer, J.; Fell, L.; Johnston, P.; Kerr, G.; Bruza, P. A Quantum Model of Trust Calibration in Human–AI Interactions. Entropy 2023, 25, 1362. https://doi.org/10.3390/e25091362
Roeder L, Hoyte P, van der Meer J, Fell L, Johnston P, Kerr G, Bruza P. A Quantum Model of Trust Calibration in Human–AI Interactions. Entropy. 2023; 25(9):1362. https://doi.org/10.3390/e25091362
Chicago/Turabian StyleRoeder, Luisa, Pamela Hoyte, Johan van der Meer, Lauren Fell, Patrick Johnston, Graham Kerr, and Peter Bruza. 2023. "A Quantum Model of Trust Calibration in Human–AI Interactions" Entropy 25, no. 9: 1362. https://doi.org/10.3390/e25091362
APA StyleRoeder, L., Hoyte, P., van der Meer, J., Fell, L., Johnston, P., Kerr, G., & Bruza, P. (2023). A Quantum Model of Trust Calibration in Human–AI Interactions. Entropy, 25(9), 1362. https://doi.org/10.3390/e25091362