
Mixed Mutual Transfer for Long-Tailed Image Classification
Abstract
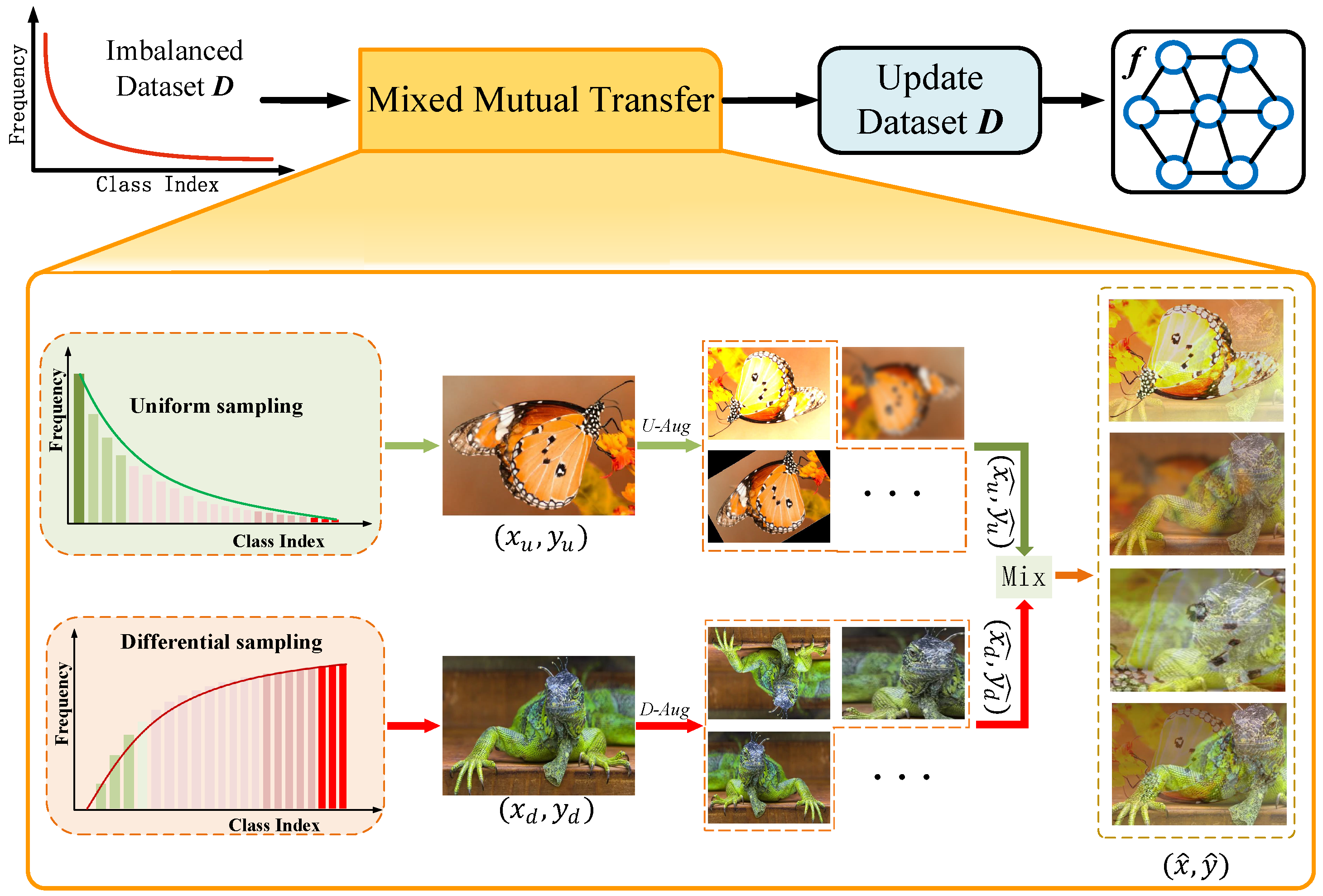
:1. Introduction
- We propose a novel transfer augmentation method, mixed mutual transfer, which enhances the performance of both minority and majority classes by maximizing the mutual information between head and tail classes.
- We propose a differential sampler that reverses the long-tailed distribution of the original dataset, reducing extreme imbalance and enhancing the classification of tail classes.
- Experimental results on the CIFAR100-LT, CIFAR10-LT, Tiny ImageNet-LT, and Food101-LT benchmarks demonstrate that our method outperforms the baseline (CE) by 6.12%, 8.73%, 4.27%, and 6.73%, respectively, with an imbalance ratio of 100.
2. Related Work
2.1. Tail-to-Tail Transfer Learning
2.2. Head-to-Tail Transfer Learning
2.3. Generalization Learning
2.4. Re-Weighting Methods
3. Proposed Method
3.1. From Vicinal Risk Minimization to MMT
| Algorithm 1 Training process of MMT |
|
3.2. Data Sampler
4. Experiments
4.1. Experimental Setup
- RS (Re-Sampling) [54]: Balancing the objective from different sampling probability for each sample.
- RW (Re-Weighting) [55]: Balancing the objective from different weights on the sample-wise loss.
- CB (Class-Balanced loss) [41]: A novel theoretical framework to measure data overlap by associating a small neighboring region with each sample rather than a single point with each sample.
- Focal loss [44]: It considers the imbalanced distribution of data and the distinguished complex sample. In detail, we replace the cross-entropy loss with focal loss in the experiment.
- LDAM [11]: A theoretically principled label-distribution-aware margin (LDAM) loss motivated by minimizing a margin-based generalization bound.
- BBN (Bilateral-Branch-Net) [14]: A unified Bilateral-Branch Network to take care of both representation learning and classifier learning simultaneously, where each branch performs its duty separately.
- BS (Balanced meta-Softmax) [56]: An elegant unbiased extension of Softmax to accommodate the label distribution shift between training and testing.
- Meta-weight-net [45]: A method capable of adaptively learning an explicit weighting function directly from data.
- IB (Influence-Balanced loss) [42]: A balancing training method to address problems in imbalanced data learning.
- Mixup [20]: Mixup is a classical data augmentation algorithm combining input data and corresponding labels.
- SMOTE (Synthetic Minority Oversampling Technique) [15]: Oversampling minority samples by interpolating between existing minority samples and their nearest minority neighbors.
- Remix (ECCV 2020) [21]: Remix assigns the label in favor of the minority class by providing a disproportionately higher weight to the minority class.
- M2m (Major-to-minor) [13]: A novel yet simple way to alleviate this issue is by augmenting less-frequent categories via translating samples (e.g., images) from more-frequent categories.
- CMO (Context-rich Minority Oversampling) [22]: A method pastes an image from a minority class onto rich-context images from a majority class, using them as background images.
- CUDA (CUrriculum of Data Augmentation) [57]: A method proper degree of augmentation be allocated for each class to mitigate class imbalance problems.
4.2. Main Results
4.2.1. Results on CIFAR-100-LT
4.2.2. Results on CIFAR-10-LT
4.2.3. Results on Tiny ImageNet-LT
4.2.4. Results on Food101-LT
4.3. Further Analysis
4.4. Ablation
4.4.1. Effect of the Dataset Update and Data Sampler in MMT
4.4.2. Effect of Fusion Strategy in MMT
4.4.3. Effect of Hyperparameter of Beta Distribution
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Liu, Z.; Miao, Z.; Zhan, X.; Wang, J.; Gong, B.; Yu, S.X. Large-scale long-tailed recognition in an open world. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 2537–2546. [Google Scholar]
- Gui, Q.; Zhou, H.; Guo, N.; Niu, B. A survey of class-imbalanced semi-supervised learning. Mach. Learn. 2024, 13, 5057–5086. [Google Scholar] [CrossRef]
- Wei, T.; Liu, Q.Y.; Shi, J.X.; Tu, W.W.; Guo, L.Z. Transfer and share: Semi-supervised learning from long-tailed data. Mach. Learn. 2024, 113, 1725–1742. [Google Scholar] [CrossRef]
- Zhang, Y.; Kang, B.; Hooi, B.; Yan, S.; Feng, J. Deep Long-Tailed Learning: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 45, 10795–10816. [Google Scholar] [CrossRef] [PubMed]
- Oksuz, K.; Cam, B.C.; Kalkan, S.; Akbas, E. Imbalance Problems in Object Detection: A Review. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 43, 3388–3415. [Google Scholar] [CrossRef] [PubMed]
- Branco, P.; Torgo, L.; Ribeiro, R.P. A survey of predictive modeling on imbalanced domains. ACM Comput. Surv. (CSUR) 2016, 49, 1–50. [Google Scholar] [CrossRef]
- Ren, M.; Zeng, W.; Yang, B.; Urtasun, R. Learning to Reweight Examples for Robust Deep Learning. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018. [Google Scholar]
- Wang, Y.X.; Ramanan, D.; Hebert, M. Learning to Model the Tail. In Proceedings of the Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Dong, Q.; Gong, S.; Zhu, X. Imbalanced Deep Learning by Minority Class Incremental Rectification. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 41, 1367–1381. [Google Scholar] [CrossRef] [PubMed]
- Yang, L.; Jiang, H.; Song, Q.; Guo, J. A survey on long-tailed visual recognition. Int. J. Comput. Vis. 2022, 130, 1837–1872. [Google Scholar] [CrossRef]
- Cao, K.; Wei, C.; Gaidon, A.; Arechiga, N.; Ma, T. Learning imbalanced datasets with label-distribution-aware margin loss. In Proceedings of the Annual Conference on Neural Information Processing Systems 2019, NeurIPS 2019, Vancouver, BC, Canada, 8–14 December 2019; Volume 32. [Google Scholar]
- Cui, Y.; Song, Y.; Sun, C.; Howard, A.; Belongie, S. Large scale fine-grained categorization and domain-specific transfer learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4109–4118. [Google Scholar]
- Kim, J.; Jeong, J.; Shin, J. M2m: Imbalanced classification via major-to-minor translation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 13896–13905. [Google Scholar]
- Zhou, B.; Cui, Q.; Wei, X.S.; Chen, Z.M. Bbn: Bilateral-branch network with cumulative learning for long-tailed visual recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 9719–9728. [Google Scholar]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic minority over-sampling technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- He, H.; Bai, Y.; Garcia, E.A.; Li, S. ADASYN: Adaptive synthetic sampling approach for imbalanced learning. In Proceedings of the 2008 IEEE International Joint Conference on Neural Networks (IEEE World Congress on Computational Intelligence), Hong Kong, China, 1–6 June 2008; pp. 1322–1328. [Google Scholar]
- Han, H.; Wang, W.Y.; Mao, B.H. Borderline-SMOTE: A new over-sampling method in imbalanced data sets learning. In Proceedings of the Advances in Intelligent Computing: International Conference on Intelligent Computing, ICIC 2005, Hefei, China, 23–26 August 2005; pp. 878–887. [Google Scholar]
- Mullick, S.S.; Datta, S.; Das, S. Generative adversarial minority oversampling. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1695–1704. [Google Scholar]
- Meng, Z.; Gu, X.; Shen, Q.; Tavares, A.; Pinto, S.; Xu, H. H2T-FAST: Head-to-Tail Feature Augmentation by Style Transfer for Long-Tailed Recognition. In Proceedings of the Frontiers in Artificial Intelligence and Applications, Beijing, China, 14–16 April 2023; IOS Press: Clifton, VA, USA, 2023. [Google Scholar] [CrossRef]
- Zhang, H.; Cisse, M.; Dauphin, Y.N.; Lopez-Paz, D. mixup: Beyond Empirical Risk Minimization. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Chou, H.P.; Chang, S.C.; Pan, J.Y.; Wei, W.; Juan, D.C. Remix: Rebalanced mixup. In Proceedings of the Computer Vision–ECCV 2020 Workshops, Glasgow, UK, 23–28 August 2020; pp. 95–110. [Google Scholar]
- Park, S.; Hong, Y.; Heo, B.; Yun, S.; Choi, J.Y. The majority can help the minority: Context-rich minority oversampling for long-tailed classification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 6887–6896. [Google Scholar]
- Haixiang, G.; Yijing, L.; Shang, J.; Mingyun, G.; Yuanyue, H.; Bing, G. Learning from class-imbalanced data: Review of methods and applications. Expert Syst. Appl. 2017, 73, 220–239. [Google Scholar] [CrossRef]
- Janowczyk, A.; Madabhushi, A. Deep learning for digital pathology image analysis: A comprehensive tutorial with selected use cases. J. Pathol. Inform. 2016, 7, 29. [Google Scholar] [CrossRef] [PubMed]
- Ling, C.X.; Li, C. Data mining for direct marketing: Problems and solutions. Kdd 1998, 98, 73–79. [Google Scholar]
- Bunkhumpornpat, C.; Sinapiromsaran, K.; Lursinsap, C. Safe-level-smote: Safe-level-synthetic minority over-sampling technique for handling the class imbalanced problem. In Proceedings of the Advances in Knowledge Discovery and Data Mining: 13th Pacific-Asia Conference, Bangkok, Thailand, 27–30 April 2009; pp. 475–482. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Proceedings of the Advances in Neural Information Processing Systems 27: Annual Conference on Neural Information Processing Systems 2014, Montreal, QC, Canada, 8–13 December 2014; Volume 27. [Google Scholar]
- Bau, D.; Zhu, J.Y.; Wulff, J.; Peebles, W.; Strobelt, H.; Zhou, B.; Torralba, A. Seeing what a gan cannot generate. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 4502–4511. [Google Scholar]
- Zhang, Y.; Wei, X.S.; Zhou, B.; Wu, J. Bag of tricks for long-tailed visual recognition with deep convolutional neural networks. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 11–15 October 2021; Volume 35, pp. 3447–3455. [Google Scholar]
- Li, S.; Gong, K.; Liu, C.H.; Wang, Y.; Qiao, F.; Cheng, X. Metasaug: Meta semantic augmentation for long-tailed visual recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021; pp. 5212–5221. [Google Scholar]
- Chu, P.; Bian, X.; Liu, S.; Ling, H. Feature space augmentation for long-tailed data. In Proceedings of the Computer Vision–ECCV 2020, Glasgow, UK, 23–28 August 2020; pp. 694–710. [Google Scholar]
- Kozerawski, J.; Fragoso, V.; Karianakis, N.; Mittal, G.; Turk, M.; Chen, M. Blt: Balancing long-tailed datasets with adversarially-perturbed images. In Proceedings of the Asian Conference on Computer Vision 2020, Kyoto, Japan, 30 November–4 December 2020. [Google Scholar]
- Yun, S.; Han, D.; Oh, S.J.; Chun, S.; Choe, J.; Yoo, Y. Cutmix: Regularization strategy to train strong classifiers with localizable features. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6023–6032. [Google Scholar]
- Chen, J.; Ding, L.; Yang, Y.; Xiang, Y. Active diversification of head-class features in bilateral-expert models for enhanced tail-class optimization in long-tailed classification. Eng. Appl. Artif. Intell. 2023, 126, 106982. [Google Scholar] [CrossRef]
- Zhu, Z.; Xing, H.; Xu, Y. Easy balanced mixing for long-tailed data. Knowl.-Based Syst. 2022, 248, 108816. [Google Scholar] [CrossRef]
- Zhang, S.; Chen, C.; Hu, X.; Peng, S. Balanced knowledge distillation for long-tailed learning. Neurocomputing 2023, 527, 36–46. [Google Scholar] [CrossRef]
- Wang, L.; Zhou, J.; Li, Z.; Zhao, X.; Wu, C.; Xu, M. Adversarial MixUp with implicit semantic preservation for semi-supervised hyperspectral image classification. Signal Process. 2023, 211, 109116. [Google Scholar] [CrossRef]
- Zhong, Z.; Cui, J.; Liu, S.; Jia, J. Improving calibration for long-tailed recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 16489–16498. [Google Scholar]
- Yang, C.; An, Z.; Zhou, H.; Cai, L.; Zhi, X.; Wu, J.; Xu, Y.; Zhang, Q. Mixskd: Self-knowledge distillation from mixup for image recognition. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; pp. 534–551. [Google Scholar]
- Yang, C.; An, Z.; Zhou, H.; Zhuang, F.; Xu, Y.; Zhang, Q. Online knowledge distillation via mutual contrastive learning for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 10212–10227. [Google Scholar] [CrossRef] [PubMed]
- Cui, Y.; Jia, M.; Lin, T.Y.; Song, Y.; Belongie, S. Class-balanced loss based on effective number of samples. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 9268–9277. [Google Scholar]
- Park, S.; Lim, J.; Jeon, Y.; Choi, J.Y. Influence-balanced loss for imbalanced visual classification. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 735–744. [Google Scholar]
- Zhang, S.; Li, Z.; Yan, S.; He, X.; Sun, J. Distribution alignment: A unified framework for long-tail visual recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 2361–2370. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Shu, J.; Xie, Q.; Yi, L.; Zhao, Q.; Zhou, S.; Xu, Z.; Meng, D. Meta-weight-net: Learning an explicit mapping for sample weighting. Adv. Neural Inf. Processing Syst. 2019, 32, 1919–1930. [Google Scholar]
- Chapelle, O.; Weston, J.; Bottou, L.; Vapnik, V. Vicinal risk minimization. Adv. Neural Inf. Processing Syst. 2000, 13, 416–422. [Google Scholar]
- Cubuk, E.D.; Zoph, B.; Shlens, J.; Le, Q.V. Randaugment: Practical automated data augmentation with a reduced search space. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 702–703. [Google Scholar]
- Müller, S.G.; Hutter, F. TrivialAugment: Tuning-free yet state-of-the-art data augmentation, 2021 IEEE. In Proceedings of the CVF International Conference on Computer Vision, ICCV, Montreal, QC, Canada, 11–17 October 2021; pp. 10–17. [Google Scholar]
- Verma, V.; Lamb, A.; Beckham, C.; Najafi, A.; Mitliagkas, I.; Lopez-Paz, D.; Bengio, Y. Manifold mixup: Better representations by interpolating hidden states. In Proceedings of the International Conference on Machine Learning, Beach, CA, USA, 9–15 June 2019; pp. 6438–6447. [Google Scholar]
- Venkataramanan, S.; Kijak, E.; Amsaleg, L.; Avrithis, Y. Alignmixup: Improving representations by interpolating aligned features. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 19174–19183. [Google Scholar]
- Le, Y.; Yang, X. Tiny imagenet visual recognition challenge. CS 231N 2015, 7, 3. [Google Scholar]
- Bossard, L.; Guillaumin, M.; Van Gool, L. Food-101 – Mining Discriminative Components with Random Forests. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014. [Google Scholar]
- Yue, C.; Long, M.; Wang, J.; Han, Z.; Wen, Q. Deep quantization network for efficient image retrieval. In Proceedings of the 13th AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; pp. 3457–3463. [Google Scholar]
- Japkowicz, N. The class imbalance problem: Significance and strategies. In Proceedings of the International Conference on Artificial Intelligence, Breckenridge, CO, USA, 14–17 April 2000; Volume 56, pp. 111–117. [Google Scholar]
- Huang, C.; Li, Y.; Loy, C.C.; Tang, X. Learning deep representation for imbalanced classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 5375–5384. [Google Scholar]
- Ren, J.; Sheng, S.; Yu, C.; Ma, X.; Zhao, H.; Yi, S.; Li, H. Balanced meta-softmax for long-tailed visual recognition. Adv. Neural Inf. Process. Syst. 2020, 33, 4175–4186. [Google Scholar]
- Ahn, S.; Ko, J.; Yun, S.Y. CUDA: Curriculum of Data Augmentation for Long-tailed Recognition. In Proceedings of the Eleventh International Conference on Learning Representations, Kigali, Rwanda, 1–5 May 2023. [Google Scholar]


{kind=link}
{kind=link}
| Dataset | Training Samples | Categories | Image Size | Testing Samples | Imbalance Ratio (IF) |
|---|---|---|---|---|---|
| CIFAR-10 | 60,000 | 10 | 10,000 | {10, 50, 100} | |
| CIFAR-100 | 60,000 | 100 | 10,000 | {10, 50, 100} | |
| Tiny ImageNet | 100,000 | 200 | 10,000 | {10, 50, 100} | |
| Food 101 | 101,000 | 101 | 10,000 | {10, 50, 100} |
| IF = 100 | IF = 50 | IF = 10 | |
|---|---|---|---|
| Baseline (CE) | 38.65 | 44.75 | 56.73 |
| RS [54] † | 31.60 | - | 54.80 |
| RW [55] † | 31.10 | - | 56.00 |
| Focal loss [44] ‡ | 38.41 | 44.32 | 55.78 |
| SMOTE [15] † | 34.00 | - | 49.40 |
| CB (CVPR 2019) [41] | 38.45 | 43.27 | 56.82 |
| DRW (NeurlPS 2019) [11] | 41.02 | 46.74 | 57.65 |
| Balanced meta-Softmax (NeurlPS 2020) [56] | 41.87 | 46.59 | 57.79 |
| LDAM + DRW (NeurlPS 2019) [11] | 42.43 | 46.92 | 57.22 |
| IB (NeurlPS 2021) [42] ‡ | 42.14 | 46.22 | 57.13 |
| Meta-weight Net(2019) [45] * | 42.09 | 46.74 | 58.46 |
| BBN (CVPR 2020) [14] | 40.62 | 44.32 | 58.61 |
| Remix (ECCV 2020) [21] | 41.94 | - | 59.36 |
| M2m (CVPR 2020) [13] † | 42.90 | - | 58.20 |
| CMO (CVPR 2022) [22] | 41.57 | 47.83 | 59.54 |
| CUDA (ICLR 2023) [57] | 40.55 | 45.12 | 58.35 |
| MMT | 44.77 | 49.24 | 61.34 |
| IF = 100 | IF = 50 | IF = 10 | |
|---|---|---|---|
| Baseline (CE) | 39.07 | 42.59 | 55.38 |
| CB [41] | 39.05 | 42.61 | 55.43 |
| DRW [11] | 41.16 | 46.09 | 57.97 |
| LDAM + DRW [11] | 41.85 | 46.74 | 55.64 |
| Balanced meta-Softmax [56] | 42.72 | 46.91 | 56.87 |
| BBN [14] | 40.68 | 44.72 | 56.32 |
| CMO [22] | 40.91 | 46.75 | 58.40 |
| MMT | 43.04 | 47.93 | 60.18 |
| IF = 100 | IF =50 | IF = 10 | |
|---|---|---|---|
| Baseline (CE) | 70.86 | 76.53 | 86.59 |
| RS [54] † | 70.40 | - | 85.70 |
| RW [55] † | 72.80 | - | 86.60 |
| Focal loss [44] ‡ | 70.38 | 76.71 | 86.66 |
| SMOTE [15] † | 71.50 | - | 85.70 |
| CB [41] | 72.08 | 76.59 | 86.76 |
| DRW [11] | 75.58 | 80.30 | 87.53 |
| LDAM + DRW [11] | 77.70 | 81.57 | 87.78 |
| Balanced meta-Softmax [56] | 77.10 | 81.20 | 88.23 |
| IB [42] ‡ | 78.26 | 81.70 | 88.25 |
| Meta-weight Net [45] * | 75.21 | 80.06 | 87.84 |
| BBN [14] | 78.26 | 81.20 | 87.54 |
| Remix [21] | 75.36 | - | 88.15 |
| M2m [13] † | 78.30 | - | 87.90 |
| CMO [22] | 74.00 | 80.51 | 88.87 |
| CUDA [57] | 74.83 | 77.87 | 86.57 |
| MMT | 79.59 | 83.30 | 90.21 |
| IF = 100 | IF = 50 | IF = 10 | |
|---|---|---|---|
| Baseline (CE) | 70.71 | 76.27 | 86.36 |
| Class-Balanced loss [41] | 71.17 | 75.83 | 85.61 |
| DRW [11] | 76.65 | 79.94 | 87.53 |
| LDAM + DRW [11] | 76.91 | 81.69 | 87.78 |
| BBN [14] | 77.43 | 81.08 | 87.52 |
| Balanced meta-Softmax [56] | 77.17 | 81.16 | 87.56 |
| CMO [22] | 73.41 | 79.01 | 86.69 |
| MMT | 76.95 | 82.13 | 89.18 |
| MMT + Cutmix | 78.95 | 83.29 | 89.90 |
| ResNet-32 | ResNet-20 | |||||
|---|---|---|---|---|---|---|
| IF = 100 | IF = 50 | IF = 10 | IF = 100 | IF = 50 | IF = 10 | |
| Baseline (CE) | 25.31 | 27.80 | 35.95 | 23.40 | 26.66 | 33.27 |
| CB [41] | 25.89 | 28.11 | 35.95 | 23.82 | 26.70 | 34.05 |
| BBN [14] | 25.83 | 29.17 | 36.81 | 25.43 | 27.35 | 35.34 |
| LDAM + DRW [11] | 28.31 | 30.59 | 35.35 | 26.98 | 30.18 | 33.76 |
| CMO [22] | 24.32 | 27.07 | 34.13 | 22.62 | 24.47 | 31.89 |
| MMT | 29.58 | 32.97 | 39.30 | 28.55 | 31.54 | 37.25 |
| IF = 100 | IF = 50 | IF = 10 | |
|---|---|---|---|
| Baseline(CE) | 45.36 | 51.54 | 71.66 |
| BBN [14] | 47.76 | 54.29 | 73.50 |
| CMO [22] | 48.08 | 57.26 | 73.97 |
| MMT | 52.09 | 59.39 | 74.90 |
| All | Head | Med | Tail | |
|---|---|---|---|---|
| Baseline (CE) | 38.44 | 65.09 | 37.37 | 8.60 |
| Mixup [20] | 39.54 | 71.00 | 40.90 | 4.90 |
| CMO [22] | 41.92 | 69.54 | 40.03 | 11.90 |
| CUDA [57] | 40.55 | 69.00 | 39.23 | 8.90 |
| MMT | 44.77 | 71.57 | 45.49 | 12.67 |
| Methods | Training (m/epoch) | Testing (s/epoch) | Acc (%) |
|---|---|---|---|
| Baseline (CE) | 0.06 | 0.65 | 38.65 |
| Mixup [20] | 0.07 | 0.67 | 39.54 |
| CMO [22] | 0.08 | 0.67 | 41.57 |
| CUDA [57] | 0.09 | 0.68 | 40.55 |
| MMT | 0.14 | 0.66 | 44.77 |
| Class | Plane | Car | Bird | Cat | Deer | Dog | Frog | Horse | Ship | Truck |
|---|---|---|---|---|---|---|---|---|---|---|
| Training samples | 5000 | 3237 | 2096 | 1357 | 878 | 568 | 368 | 238 | 154 | 100 |
| Baseline (CE) | 96.20 | 97.70 | 87.20 | 78.00 | 80.80 | 65.20 | 78.80 | 64.90 | 59.20 | 57.10 |
| Focal Loss [44] | 91.60 | 95.10 | 73.10 | 59.20 | 67.80 | 67.20 | 84.20 | 77.30 | 83.90 | 61.80 |
| CB [41] | 92.90 | 96.30 | 79.20 | 75.10 | 82.40 | 69.90 | 75.00 | 69.10 | 73.60 | 66.80 |
| LDAM [11] | 96.90 | 98.50 | 82.90 | 74.70 | 82.80 | 69.00 | 78.50 | 69.90 | 65.30 | 66.00 |
| MMT | 96.40 | 98.90 | 91.70 | 82.40 | 86.40 | 74.60 | 86.10 | 77.50 | 73.20 | 65.50 |
| CIFAR-100-LT | CIFAR-10-LT | |||||
|---|---|---|---|---|---|---|
| IF = 100 | IF = 50 | IF = 10 | IF = 100 | IF = 50 | IF = 10 | |
| Mixup [20] | 39.54 | 44.99 | 58.02 | 73.06 | 77.82 | 87.10 |
| MMT w/o differential sampler | 43.35 | 49.18 | 61.29 | 77.10 | 81.44 | 89.88 |
| MMT | 44.77 | 49.24 | 61.34 | 79.59 | 83.30 | 90.21 |
| All | Head | Medium | Tail | |
|---|---|---|---|---|
| Baseline (CE) | 70.86 | 65.09 | 37.37 | 8.60 |
| MMTtail | 77.45 | 69.31 | 45.63 | 12.57 |
| MMTtail-beta | 77.80 | 69.74 | 44.40 | 12.80 |
| MMT | 79.59 | 71.57 | 45.49 | 12.67 |
| IF = 100 | IF = 50 | IF = 10 | |
|---|---|---|---|
| 0.1 | 78.15 | 82.06 | 90.08 |
| 0.2 | 79.59 | 83.30 | 90.21 |
| 0.5 | 78.57 | 83.34 | 90.30 |
| 0.7 | 78.17 | 82.56 | 89.99 |
| 1.0 | 77.81 | 83.24 | 89.93 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ren, N.; Li, X.; Wu, Y.; Fu, Y. Mixed Mutual Transfer for Long-Tailed Image Classification. Entropy 2024, 26, 839. https://doi.org/10.3390/e26100839
Ren N, Li X, Wu Y, Fu Y. Mixed Mutual Transfer for Long-Tailed Image Classification. Entropy. 2024; 26(10):839. https://doi.org/10.3390/e26100839
Chicago/Turabian StyleRen, Ning, Xiaosong Li, Yanxia Wu, and Yan Fu. 2024. "Mixed Mutual Transfer for Long-Tailed Image Classification" Entropy 26, no. 10: 839. https://doi.org/10.3390/e26100839