
Exploring the Impact of Additive Shortcuts in Neural Networks via Information Bottleneck-like Dynamics: From ResNet to Transformer


Abstract
1. Introduction
1.1. Contributions
- Identification of distinct fitting and compression behaviors: We demonstrate that models with non-identity shortcuts (such as traditional ResNet architectures) follow the conventional two-phase training process, consisting of an initial fitting phase followed by a subsequent compression phase, similar to the behavior seen in traditional feed-forward networks [17].In contrast, models with identity shortcuts, such as Vision Transformers and MLP-Mixers, deviate from this pattern by skipping the initial fitting phase and moving directly into the compression phase. This deviation represents a significant challenge to traditional views of neural network optimization, where both fitting and compression are typically expected phases of training.
- Analysis of the mechanisms underlying the absence of a fitting phase: We conjecture that models with identity shortcuts are able to skip the fitting phase because the shortcut structure enables the model to propagate all necessary information for the classification task to deeper layers without the need for early-stage fitting.This conjecture is validated empirically by comparing Z-Y measures at initialization. These comparisons show that models with identity shortcuts retain sufficient information for the task even without requiring an explicit fitting phase, indicating that the network can bypass the typical initial training process.
- Analysis of the mechanisms driving compression: We also explore the mechanisms that drive compression in models with identity shortcuts. Through extensive empirical experiments, we identify two distinct mechanisms:
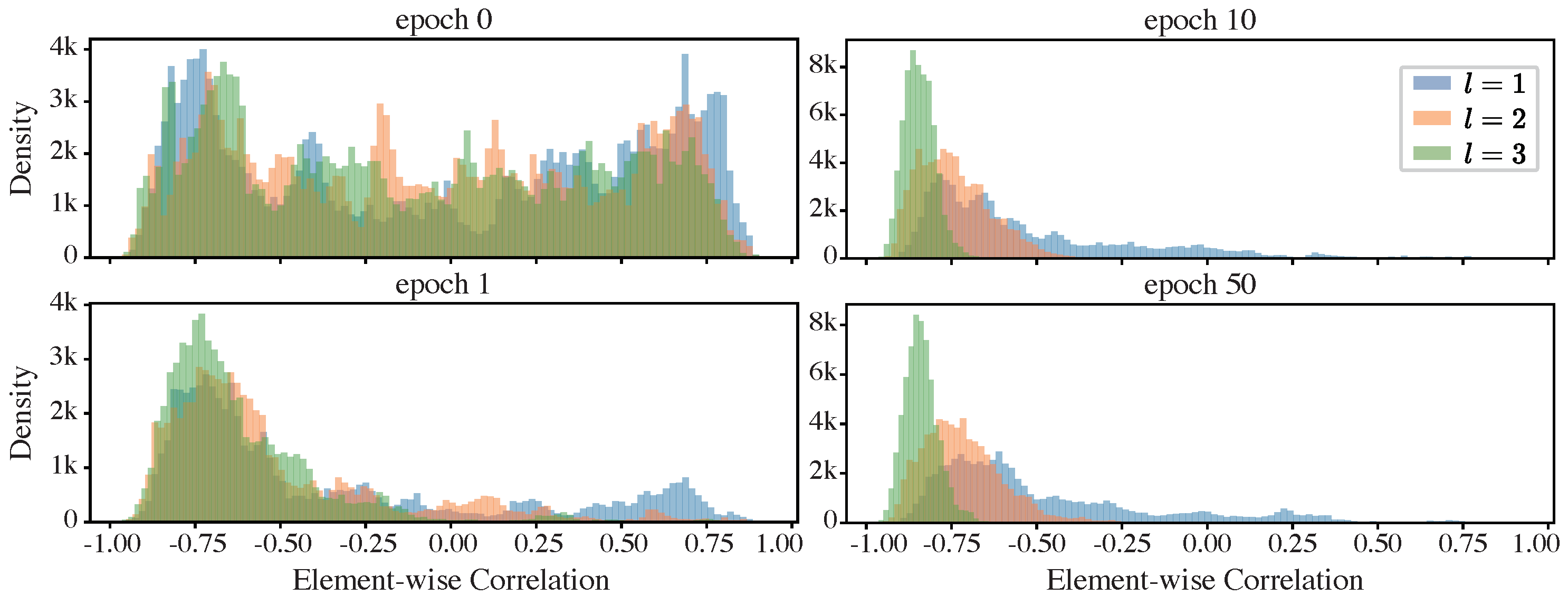
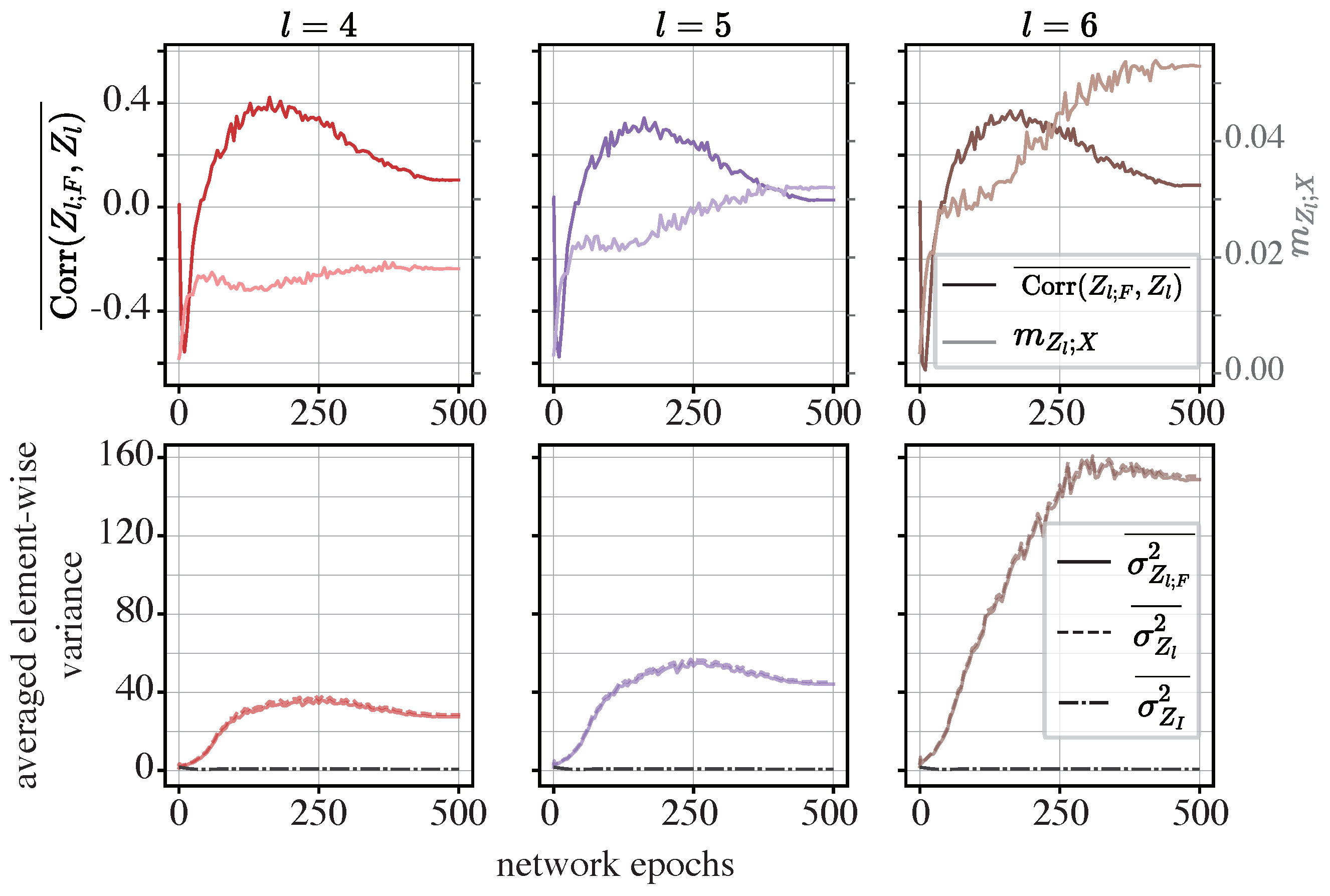
- In ResNet-like models with identity shortcuts, compression is caused by the canceling effect between the so-called functional and informative components (which we will define later) of the network’s representations.
- In Transformers and MLP-Mixers, compression occurs when the functional component of the network representations overwhelms the informative component, leading to a pronounced compression phase.
1.2. Organization of the Paper
- Section 1 provides an overview of the relevance of deep learning architectures and the importance of additive shortcut connections. It introduces the motivation behind studying the fitting and compression phases in these architectures.
- Section 2 discusses the Transformer architecture, state-of-the-art deep learning models, and shortcut structures in neural networks, with a focus on understanding their generalization and training dynamics.
- Section 3 introduces the Z-X and Z-Y measures adopted in this work, providing a background on their use to observe fitting and compression phases in neural networks.
- Section 4 presents empirical results comparing neural networks with and without shortcut connections, with a particular focus on ResNet, ViT, and MLP-Mixer models. The Z-X dynamics of models with identity and non-identity shortcuts are explored in detail.
- Section 5 analyzes the empirical findings, particularly the reasons why IS models skip the fitting phase and how they manage to compress effectively. This section further explores the interaction between the functional and informative components in network representations.
- Section 6 summarizes the key findings of the paper and outlines potential directions for future research.
1.3. Notations
2. Related Work
2.1. The Transformer as a State-of-the-Art Deep Learning Architecture
Understanding Transformers
2.2. Exploring Shortcut Structures in Neural Networks
2.3. Methodologies for Understanding Neural Networks
2.3.1. Explainable Deep Learning
2.3.2. Generalization Bound Analysis
2.3.3. Information Bottlenecks and Network Dynamics Analysis
3. Recap: The Z-X Measure and the Z-Y Measure for Observing the Fitting and Compression Phases
3.1. The Z-X Measure and the Z-Y Measure
3.1.1. The Z-X Measure
3.1.2. The Z-Y Measure
3.2. Estimating the Z-X and Z-Y Measures
| Algorithm 1: Estimate the Z-X measure and the Z-Y measure with the validation set. |
 |
3.3. Z-X Dynamics and Z-Y Dynamics
3.4. The Fitting Phase and the Compression Phase
3.4.1. The Fitting Phase
3.4.2. The Compression Phase
4. The Fitting and Compression Phases in Models with Additive Shortcuts
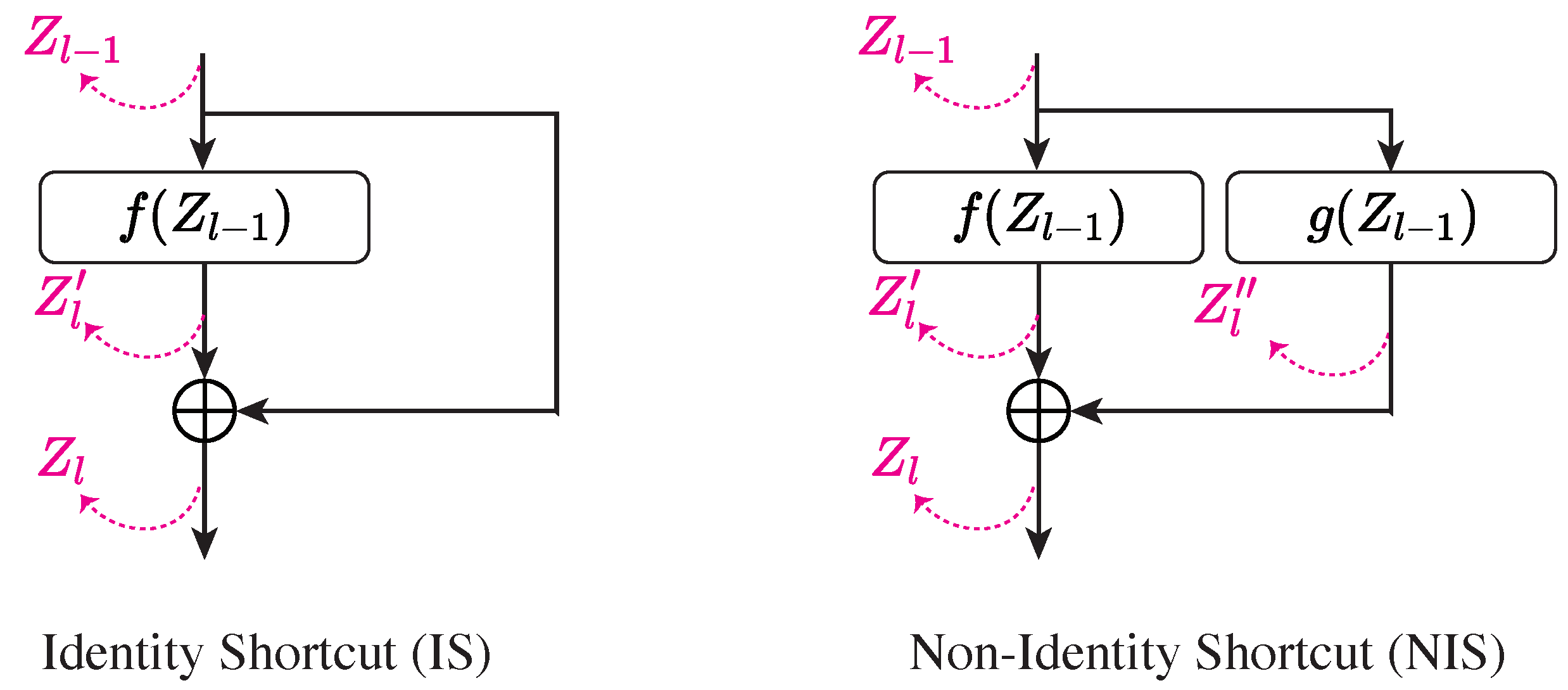
4.1. Identity Shortcuts and Non-Identity Shortcuts
- (NS) CNN: A VGG-like CNN serves as the control group with no shortcuts (NS).
- (NIS) ResCNN: A ResCNN model incorporating NISs, similar to ResNet [4].
- (IS) iResCNN: A modified ResCNN, incorporating ISs throughout.
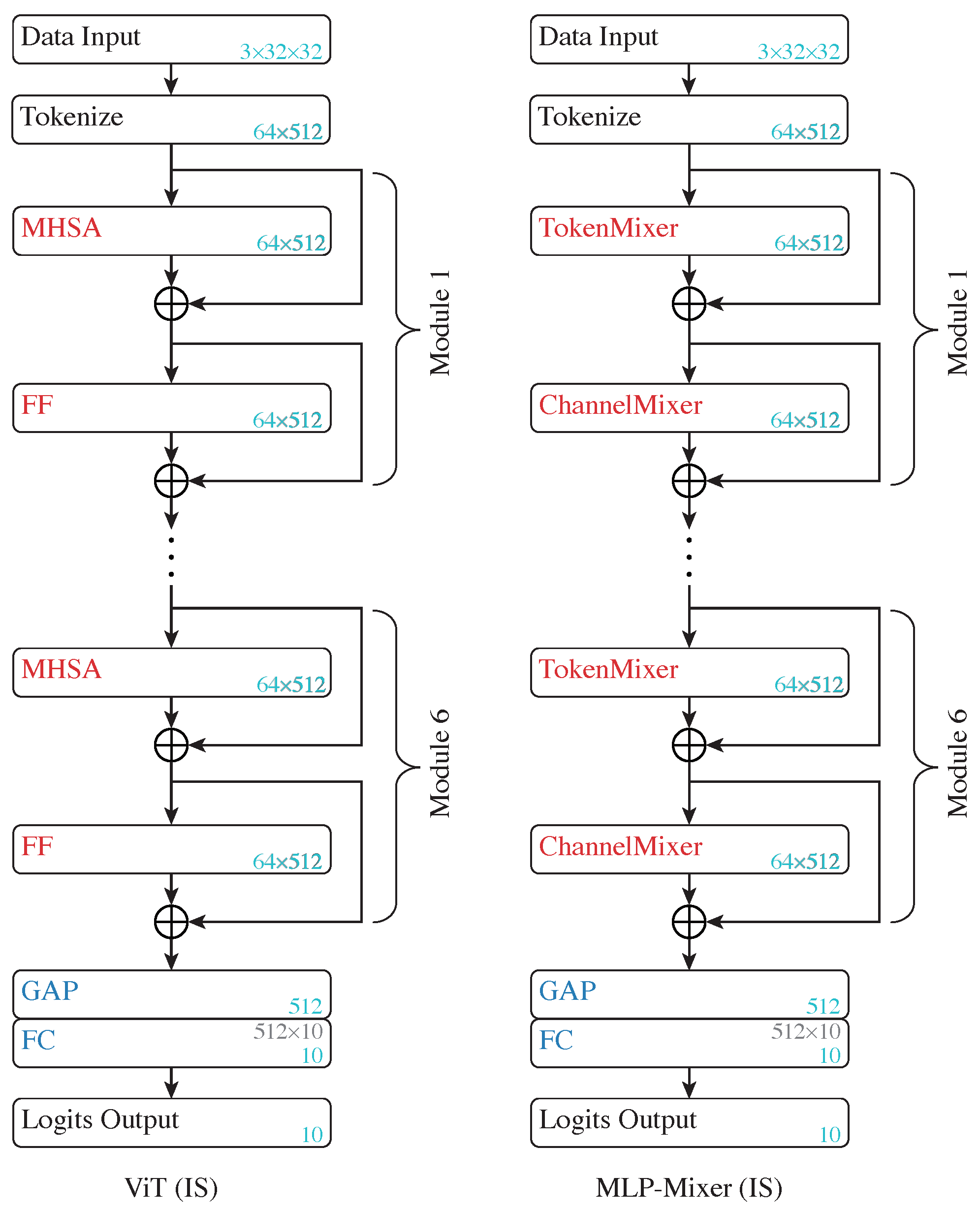
- (IS) Vision Transformer (ViT): A ViT model that uses ISs by design.
- (IS) MLP-Mixer: A MLP-Mixer model also with ISs by design.
4.2. The CNN and ResCNN
4.2.1. Setup
4.2.2. The Z-X Dynamics of the CNN and ResCNN
4.3. The iResCNN
4.3.1. Setup
4.3.2. The Z-X Dynamics of the iResCNN
4.4. ViTs and MLP-Mixers
4.4.1. Setup
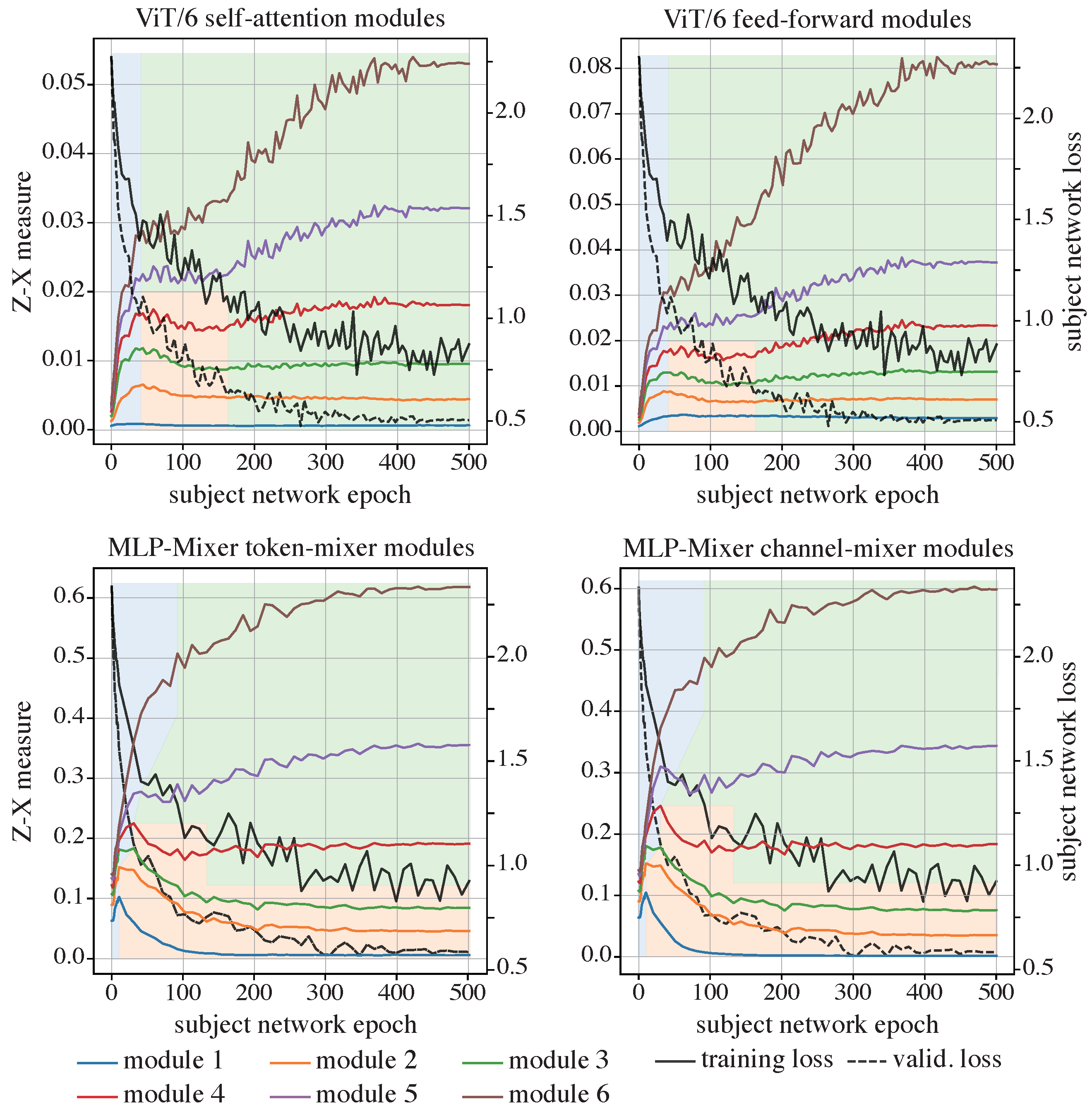
4.4.2. The Z-X Dynamics of the ViT and MLP-Mixer
5. Why Does the Behavior of IS-Based Models Differ from the Behavior of NIS-Based Models?
5.1. On the Absence of the Initial Fitting Phase
5.1.1. Estimating Z-Y Measures
5.1.2. Results
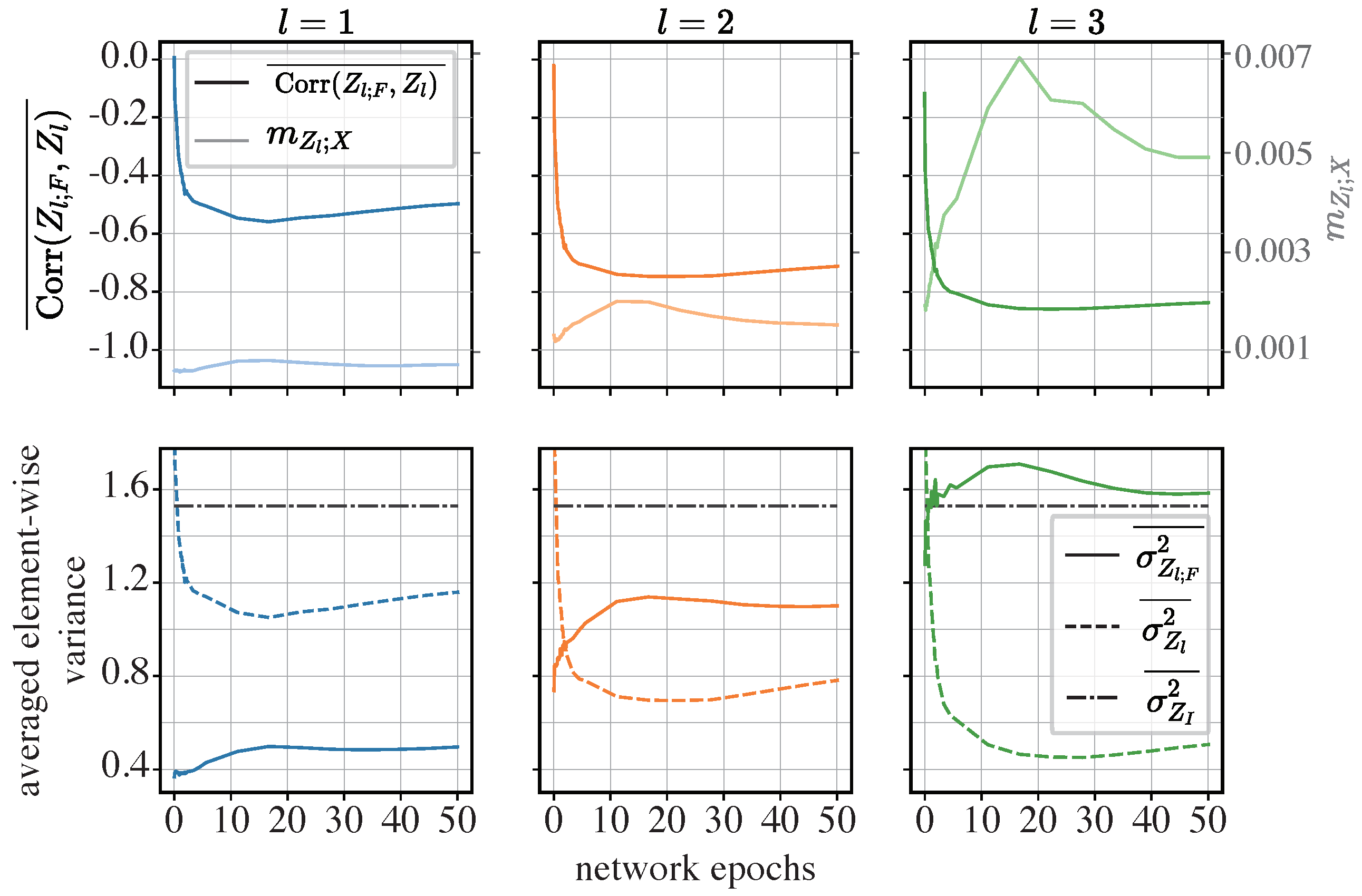
5.2. The Mechanisms Enabling Compression in Models with ISs
5.2.1. Methodology
5.2.2. Results and Analysis
6. Conclusions
6.1. Limitations and Future Work
- The dataset and task scope: This study uses a single dataset (CIFAR-10) and does not examine other data types or tasks, such as language or video processing, which may exhibit different IB dynamics. Testing these findings across larger and more diverse datasets, especially those with varied data types, is essential to determine the generality of these dynamics.
- Inductive bias in the ViT and MLP-Mixer: As noted in the comments, the ViT and MLP-Mixer models are known to have weaker inductive biases than convolutional models, making them less optimal for small datasets like CIFAR-10 when they are trained from scratch. While we trained the ViT and MLP-Mixer to competitive levels of 86.14% and 83.76% accuracy, respectively, these results are still lower than the benchmarks achieved by convolutional models like ResNet. This limitation highlights the need for testing on larger datasets or using pre-trained versions of these models to capture the shortcut path dynamics better.
- Shortcut configurations: This study focuses on additive shortcuts and does not explore alternative configurations, such as the concatenation shortcuts used in DenseNet or combinations of identity and non-identity shortcuts. Investigating these different shortcut designs may reveal additional dynamics that influence IB behavior in novel ways.
- Layer-specific analysis: The compression behavior in IS-based models appears to vary across layers, suggesting that layer-wise analysis could yield more precise insights into IB dynamics. Future studies could benefit from examining shortcut path dynamics at the layer-specific level to identify potential opportunities to fine-tune the shortcut configurations and improve performance.
- Memory constraints and computational intensity: Due to the memory-intensive nature of the ViT and MLP-Mixer, our study required substantial memory resources to implement multiple estimations across layers, checkpoints, and measures (Z-X and Z-Y). Convolutional networks are comparatively more memory-efficient due to shared kernel use and pooling operations, which reduce the memory intensity. In contrast, ViTs’ tokenized representation and dense matrix multiplications increase the computational demands, making these models more challenging to study. Future work could explore memory-optimized methods for self-attention or alternative ways to handle large-scale estimations.
6.2. Summary
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- LeCun, Y.; Bengio, Y. Convolutional networks for images, speech, and time series. Handb. Brain Theory Neural Netw. 1995, 3361, 1995. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 84–90. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Vaswani, A. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 6000–6010. [Google Scholar]
- Grigorescu, S.; Trasnea, B.; Cocias, T.; Macesanu, G. A survey of deep learning techniques for autonomous driving. J. Field Robot. 2020, 37, 362–386. [Google Scholar] [CrossRef]
- Elsken, T.; Metzen, J.H.; Hutter, F. Neural architecture search: A survey. J. Mach. Learn. Res. 2019, 20, 1–21. [Google Scholar]
- Tan, M.; Le, Q.V. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. arXiv 2019, arXiv:1905.11946. [Google Scholar]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Hochreiter, S. Long Short-term Memory. In Neural Computation; MIT-Press: Cambridge, MA, USA, 1997. [Google Scholar]
- Dosovitskiy, A. An image is worth 16 × 16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Tolstikhin, I.O.; Houlsby, N.; Kolesnikov, A.; Beyer, L.; Zhai, X.; Unterthiner, T.; Yung, J.; Steiner, A.; Keysers, D.; Uszkoreit, J.; et al. Mlp-mixer: An all-mlp architecture for vision. Adv. Neural Inf. Process. Syst. 2021, 34, 24261–24272. [Google Scholar]
- Saxe, A.M.; Bansal, Y.; Dapello, J.; Advani, M.; Kolchinsky, A.; Tracey, B.D.; Cox, D.D. On the information bottleneck theory of deep learning. J. Stat. Mech. Theory Exp. 2019, 2019, 124020. [Google Scholar] [CrossRef]
- Tishby, N.; Pereira, F.C.; Bialek, W. The information bottleneck method. arXiv 2000, arXiv:physics/0004057. [Google Scholar]
- Tishby, N.; Zaslavsky, N. Deep learning and the information bottleneck principle. In Proceedings of the 2015 IEEE Information Theory Workshop (ITW), Jeju Island, Republic of Korea, 11–15 October 2015; pp. 1–5. [Google Scholar]
- Shwartz-Ziv, R.; Tishby, N. Opening the black box of deep neural networks via information. arXiv 2017, arXiv:1703.00810. [Google Scholar]
- Lyu, Z.; Aminian, G.; Rodrigues, M.R. On Neural Networks Fitting, Compression, and Generalization Behavior via Information-Bottleneck-like Approaches. Entropy 2023, 25, 1063. [Google Scholar] [CrossRef]
- Beyer, L.; Zhai, X.; Kolesnikov, A. Better plain ViT baselines for ImageNet-1k. arXiv 2022, arXiv:2205.01580. [Google Scholar]
- Li, Z.; Wallace, E.; Shen, S.; Lin, K.; Keutzer, K.; Klein, D.; Gonzalez, J. Train big, then compress: Rethinking model size for efficient training and inference of transformers. In Proceedings of the International Conference on Machine Learning, Virtual Event, 13–18 July 2020; pp. 5958–5968. [Google Scholar]
- Bai, Y.; Mei, J.; Yuille, A.L.; Xie, C. Are transformers more robust than cnns? Adv. Neural Inf. Process. Syst. 2021, 34, 26831–26843. [Google Scholar]
- Alammar, J. The Illustrated Transformer. 2024. Available online: https://jalammar.github.io/illustrated-transformer/ (accessed on 9 October 2024).
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 10–17 October 2021; pp. 10012–10022. [Google Scholar]
- Wu, K.; Peng, H.; Chen, M.; Fu, J.; Chao, H. Rethinking and improving relative position encoding for vision transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 10–17 October 2021; pp. 10033–10041. [Google Scholar]
- Kazemnejad, A.; Padhi, I.; Natesan Ramamurthy, K.; Das, P.; Reddy, S. The impact of positional encoding on length generalization in transformers. Adv. Neural Inf. Process. Syst. 2024, 36, 24892–24928. [Google Scholar]
- Ke, G.; He, D.; Liu, T.Y. Rethinking positional encoding in language pre-training. arXiv 2020, arXiv:2006.15595. [Google Scholar]
- Chen, P.C.; Tsai, H.; Bhojanapalli, S.; Chung, H.W.; Chang, Y.W.; Ferng, C.S. A simple and effective positional encoding for transformers. arXiv 2021, arXiv:2104.08698. [Google Scholar]
- Leem, S.; Seo, H. Attention Guided CAM: Visual Explanations of Vision Transformer Guided by Self-Attention. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 20–27 February 2024; Volume 38, pp. 2956–2964. [Google Scholar]
- Ma, J.; Bai, Y.; Zhong, B.; Zhang, W.; Yao, T.; Mei, T. Visualizing and understanding patch interactions in vision transformer. IEEE Trans. Neural Netw. Learn. Syst. 2023, 35, 13671–13680. [Google Scholar] [CrossRef]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Wang, P. Lucidrains/MLP-Mixer-Pytorch: An All-MLP Solution for Vision, from Google Ai. 2022. Available online: https://github.com/lucidrains/mlp-mixer-pytorch (accessed on 16 October 2023).
- Zeiler, M.D.; Fergus, R. Visualizing and understanding convolutional networks. In Proceedings of the Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Proceedings, Part I 13. Springer: Berlin/Heidelberg, Germany, 2014; pp. 818–833. [Google Scholar]
- Chattopadhyay, A.; Sarkar, A.; Howlader, P.; Balasubramanian, V.N. Grad-CAM++: Generalized Gradient-Based Visual Explanations for Deep Convolutional Networks. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2017; pp. 839–847. [Google Scholar]
- Selvaraju, R.R.; Das, A.; Vedantam, R.; Cogswell, M.; Parikh, D.; Batra, D. Grad-CAM: Visual Explanations from Deep Networks via Gradient-Based Localization. Int. J. Comput. Vis. 2016, 128, 336–359. [Google Scholar] [CrossRef]
- Xu, L.; Yan, X.; Ding, W.; Liu, Z. Attribution rollout: A new way to interpret visual transformer. J. Ambient. Intell. Humaniz. Comput. 2023, 14, 163–173. [Google Scholar] [CrossRef]
- Abnar, S.; Zuidema, W. Quantifying attention flow in transformers. arXiv 2020, arXiv:2005.00928. [Google Scholar]
- Vapnik, V.N.; Chervonenkis, A.Y. On the uniform convergence of relative frequencies of events to their probabilities. In Measures of Complexity: Festschrift for Alexey Chervonenkis; Springer: Berlin/Heidelberg, Germany, 2015; pp. 11–30. [Google Scholar]
- Waltz, D. A Theory of the Learnable. Commun. ACM 1984, 27, 1134–1142. [Google Scholar]
- Shalev-Shwartz, S.; Ben-David, S. Understanding Machine Learning: From Theory to Algorithms; Cambridge University Press: Cambridge, UK, 2014. [Google Scholar]
- Neyshabur, B.; Bhojanapalli, S.; McAllester, D.A.; Srebro, N. A PAC-Bayesian Approach to Spectrally-Normalized Margin Bounds for Neural Networks. arXiv 2017, arXiv:1707.09564. [Google Scholar]
- Li, H.; Xu, Z.; Taylor, G.; Studer, C.; Goldstein, T. Visualizing the loss landscape of neural nets. Adv. Neural Inf. Process. Syst. 2018, 31, 6391–6401. [Google Scholar]
- Alemi, A.A.; Fischer, I.; Dillon, J.V.; Murphy, K. Deep variational information bottleneck. arXiv 2016, arXiv:1612.00410. [Google Scholar]
- Polyanskiy, Y.; Wu, Y. Lecture notes on information theory. Lect. Notes ECE563 (UIUC) 2014, 6, 7. [Google Scholar]
- Goldfeld, Z.; van den Berg, E.; Greenewald, K.; Melnyk, I.; Nguyen, N.; Kingsbury, B.; Polyanskiy, Y. Estimating information flow in deep neural networks. arXiv 2018, arXiv:1810.05728. [Google Scholar]
- Darlow, L.N.; Storkey, A. What information does a ResNet compress? arXiv 2020, arXiv:2003.06254. [Google Scholar]
- Noshad, M.; Zeng, Y.; Hero, A.O. Scalable mutual information estimation using dependence graphs. In Proceedings of the ICASSP 2019–2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 2962–2966. [Google Scholar]
- Jónsson, H.; Cherubini, G.; Eleftheriou, E. Convergence behavior of DNNs with mutual-information-based regularization. Entropy 2020, 22, 727. [Google Scholar] [CrossRef] [PubMed]
- Kirsch, A.; Lyle, C.; Gal, Y. Scalable training with information bottleneck objectives. In Proceedings of the International Conference on Machine Learning (ICML): Workshop on Uncertainty and Robustness in Deep Learning, Virtual, 17–18 July 2020; pp. 17–18. [Google Scholar]
- Krizhevsky, A.; Hinton, G. Learning Multiple Layers of Features from Tiny Images. 2009. Available online: https://xueshu.baidu.com/usercenter/paper/show?paperid=c55665fb879e98e130fce77052d4c8e8 (accessed on 29 October 2024).
- LeCun, Y.; Cortes, C.; Burges, C. MNIST handwritten digit database. ATT Labs 2010, 2. Available online: http://yann.lecun.com/exdb/mnist (accessed on 29 October 2024).
- Loshchilov, I.; Hutter, F. Sgdr: Stochastic gradient descent with warm restarts. arXiv 2016, arXiv:1608.03983. [Google Scholar]
- Carratino, L.; Ciss’e, M.; Jenatton, R.; Vert, J.P. On Mixup Regularization. J. Mach. Learn. Res. 2020, 23, 325:1–325:31. [Google Scholar]
- Yun, S.; Han, D.; Oh, S.J.; Chun, S.; Choe, J.; Yoo, Y.J. CutMix: Regularization Strategy to Train Strong Classifiers with Localizable Features. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6022–6031. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- Kentaro, Y. Kentaroy47/Vision-Transformers-CIFAR10: Let’s Train Vision Transformers (VIT) for CIFAR 10! 2023. Available online: https://github.com/kentaroy47/vision-transformers-cifar10 (accessed on 16 October 2023).
- Dumoulin, V.; Visin, F. A guide to convolution arithmetic for deep learning. arXiv 2016, arXiv:1603.07285. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| CNN | ResCNN | iResCNN | ViT | MLP-Mixer | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 1.082 | 1.049 | 1.393 | 0.479 | 0.571 | ||||||
| 1.354 | +0.272 | 1.252 | +0.203 | 1.376 | −0.017 | 0.326 | −0.153 | 0.446 | −0.125 | |
| 1.470 | +0.388 | 1.313 | +0.264 | 1.380 | −0.013 | 0.328 | −0.151 | 0.448 | −0.123 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lyu, Z.; Rodrigues, M.R.D. Exploring the Impact of Additive Shortcuts in Neural Networks via Information Bottleneck-like Dynamics: From ResNet to Transformer. Entropy 2024, 26, 974. https://doi.org/10.3390/e26110974
Lyu Z, Rodrigues MRD. Exploring the Impact of Additive Shortcuts in Neural Networks via Information Bottleneck-like Dynamics: From ResNet to Transformer. Entropy. 2024; 26(11):974. https://doi.org/10.3390/e26110974
Chicago/Turabian StyleLyu, Zhaoyan, and Miguel R. D. Rodrigues. 2024. "Exploring the Impact of Additive Shortcuts in Neural Networks via Information Bottleneck-like Dynamics: From ResNet to Transformer" Entropy 26, no. 11: 974. https://doi.org/10.3390/e26110974
APA StyleLyu, Z., & Rodrigues, M. R. D. (2024). Exploring the Impact of Additive Shortcuts in Neural Networks via Information Bottleneck-like Dynamics: From ResNet to Transformer. Entropy, 26(11), 974. https://doi.org/10.3390/e26110974