Figure 1.
Schematic diagram illustrating the variance in perturbations generated by various generative methods. The string represented beneath these perturbations denotes the secret data or the targeted class of the adversarial attack embedded within. D represents the decoder, responsible for decoding the secret data, while its output represents the decoded secret information. C denotes the target classification network, with its output indicating the classified prediction, and the red section highlights inaccuracies in the prediction.
Figure 1.
Schematic diagram illustrating the variance in perturbations generated by various generative methods. The string represented beneath these perturbations denotes the secret data or the targeted class of the adversarial attack embedded within. D represents the decoder, responsible for decoding the secret data, while its output represents the decoded secret information. C denotes the target classification network, with its output indicating the classified prediction, and the red section highlights inaccuracies in the prediction.
Figure 2.
The framework of HAG-NET: the encoder E receives the cover image ICO and the secret message MIN to generate encoded image IE; the decoder D recovers MIN from IE and outputs the decoded message MOUT; the attacker generates adversarial example IA. The adversarial discriminator A receives ICO or IA and IE to predict whether the input has been encoded; the target classifier C predicts the classification of IE. The loss function LE is the pixel-level difference between IE and ICO; the loss function LC is used to optimize the ability to resist attacks. The loss function LG provides adversarial loss for E. The loss function LD minimizes the difference between MIN and MOUT. The dashed line indicates that data are transferred according to the settings.
Figure 2.
The framework of HAG-NET: the encoder E receives the cover image ICO and the secret message MIN to generate encoded image IE; the decoder D recovers MIN from IE and outputs the decoded message MOUT; the attacker generates adversarial example IA. The adversarial discriminator A receives ICO or IA and IE to predict whether the input has been encoded; the target classifier C predicts the classification of IE. The loss function LE is the pixel-level difference between IE and ICO; the loss function LC is used to optimize the ability to resist attacks. The loss function LG provides adversarial loss for E. The loss function LD minimizes the difference between MIN and MOUT. The dashed line indicates that data are transferred according to the settings.
Figure 3.
Schematic diagram of the skip connection of the secret message in middle layers, where secret message is MIN, cover image is ICO, and the expanded secret message will be the same size as ICO and the middle layers data.
Figure 3.
Schematic diagram of the skip connection of the secret message in middle layers, where secret message is MIN, cover image is ICO, and the expanded secret message will be the same size as ICO and the middle layers data.
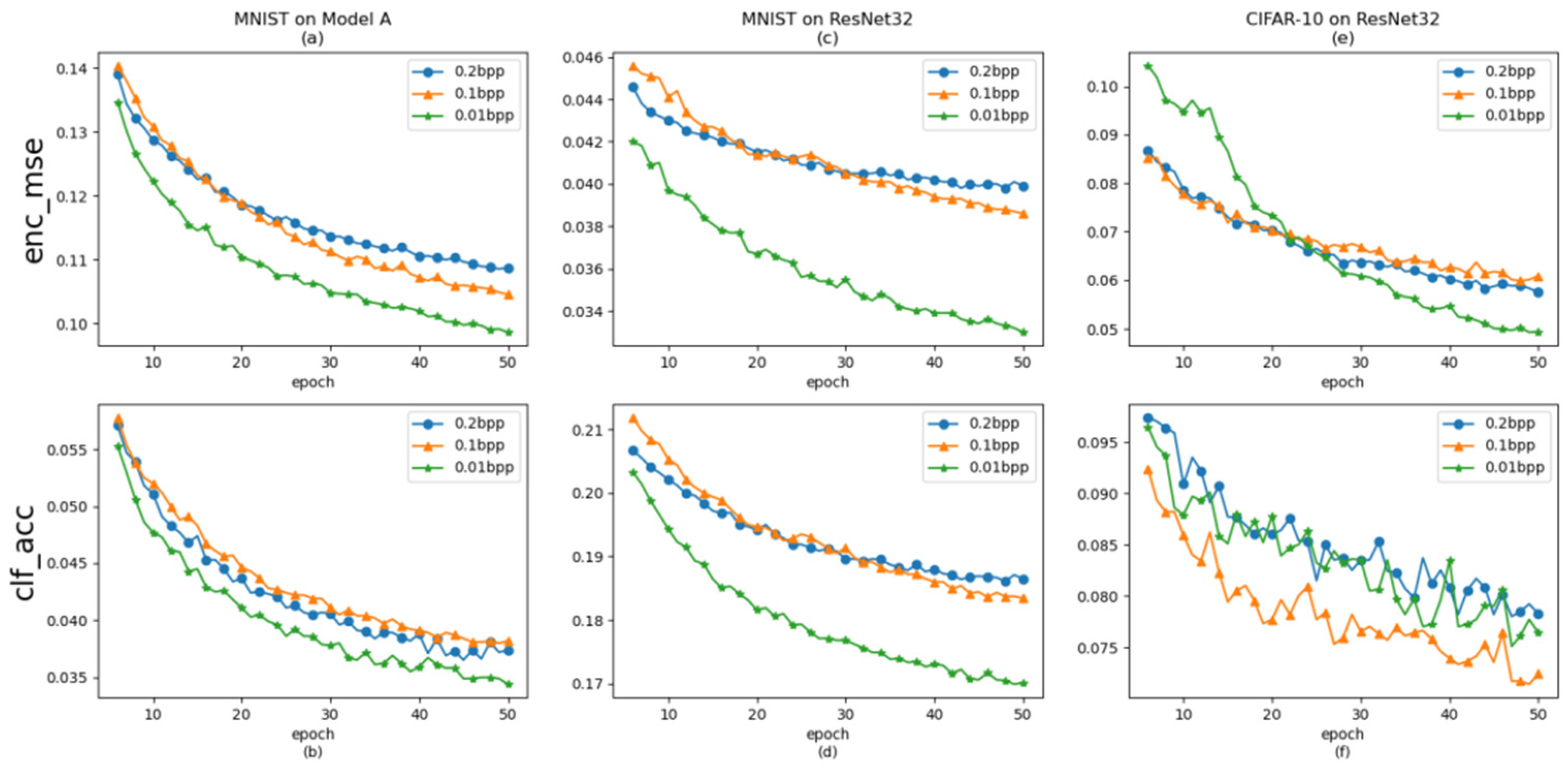
Figure 4.
Pre-training of HAG-NET under different experimental settings, where (a,b) show the curves of LE loss and the classification accuracy of target classification network Model A in MNIST dataset, (c,d) show the curves of LE loss and the classification accuracy of the target classification network ResNet32 in the MNIST dataset, (e,f) show curves of LE loss and the classification accuracy of the target classification network ResNet32 in the CIFAR-10 dataset.
Figure 4.
Pre-training of HAG-NET under different experimental settings, where (a,b) show the curves of LE loss and the classification accuracy of target classification network Model A in MNIST dataset, (c,d) show the curves of LE loss and the classification accuracy of the target classification network ResNet32 in the MNIST dataset, (e,f) show curves of LE loss and the classification accuracy of the target classification network ResNet32 in the CIFAR-10 dataset.
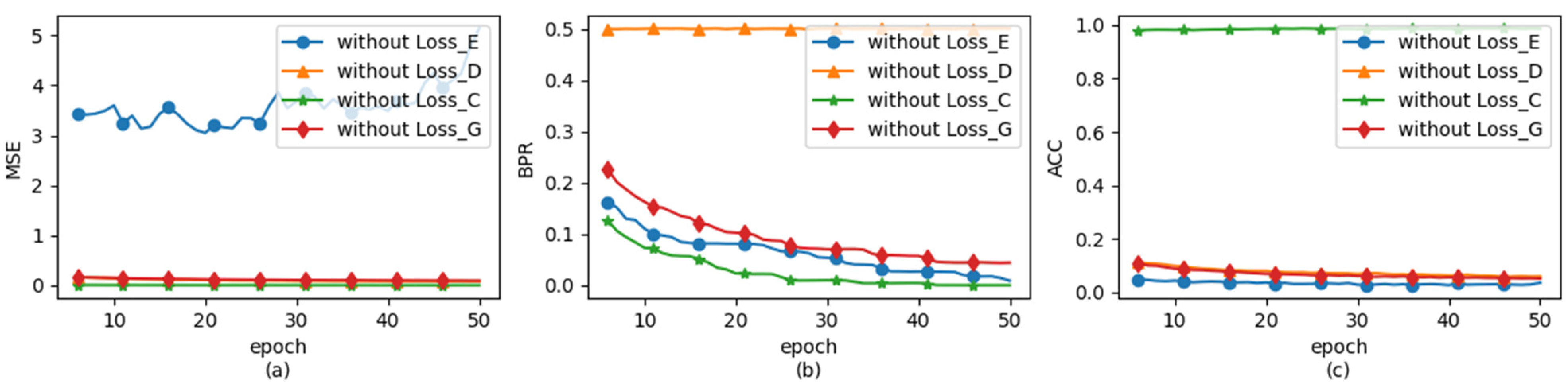
Figure 5.
HAG-NET provides line graphs illustrating the variations in different types of data when each component loss function is individually removed. Among these, (a) illustrates the changes in Mean Squared Error (MSE) between ASE and the carrier image under various conditions; (b) displays the variations in Bit Error Rate (BER) of decoded information; and (c) demonstrates the changes in accuracy of target classification network in recognizing ASE.
Figure 5.
HAG-NET provides line graphs illustrating the variations in different types of data when each component loss function is individually removed. Among these, (a) illustrates the changes in Mean Squared Error (MSE) between ASE and the carrier image under various conditions; (b) displays the variations in Bit Error Rate (BER) of decoded information; and (c) demonstrates the changes in accuracy of target classification network in recognizing ASE.
Figure 6.
The ASE of 0–4 target class in CIFAR-10 and the ASE of 5–9 target class in MNIST.
Figure 6.
The ASE of 0–4 target class in CIFAR-10 and the ASE of 5–9 target class in MNIST.
Figure 7.
(a) shows the ASE of that a dog image has been attacked into remaining nine classes, from top to bottom and left to right they are plane, car, bird, cat, deer, frog, horse, ship, and truck. (b) shows the corresponding adversarial embedded disturbance at the same location.
Figure 7.
(a) shows the ASE of that a dog image has been attacked into remaining nine classes, from top to bottom and left to right they are plane, car, bird, cat, deer, frog, horse, ship, and truck. (b) shows the corresponding adversarial embedded disturbance at the same location.
Table 1.
The network frameworks of ResNet32 and WRN34.
Table 1.
The network frameworks of ResNet32 and WRN34.
| ResNet 32 | WRN 34 |
|---|
| conv2d layer(kernel = 3, stride = 1, depth = 16) | conv2d layer(kernel = 3, stride = 1, depth = 16) |
| basic block layer1 = basic block(16) × 5 | basic block layer1 = basic block(16, 160) × 5 |
| (basic block(16,16): | (basic block: |
| conv2d layer(kernel = 3, stride = 1, depth = 16) | batch norm layer(eps = 0.00001, depth = 16) |
| batch norm layer(eps = 0.00001, depth = 16) | conv2d layer(kernel = 3, stride = 1, depth = 160) |
| conv2d layer(kernel = 3, stride = 1, depth = 16) | batch norm layer(eps = 0.00001, depth = 160) |
| batch norm layer(eps = 0.00001, depth = 16) | conv2d layer(kernel = 3, stride = 1, depth = 160) |
| shortcut) | shortcut:) |
| basic block layer2 = basic block(32) × 5 | basic block layer2 = basic block(160, 320) × 5 |
| basic block layer3 = basic block(64) × 5 | basic block layer3 = basic block(320, 640) × 5 |
| average pooling layer(kernel- = 6, stride = 1) | average pooling layer(kernel- = 6, stride = 1) |
| flatten layer | flatten layer |
| softmax classifier | softmax classifier |
Table 2.
A schematic diagram depicting the partial loss functions during the training process of HGA-NET is absent.
Table 3.
Runtimes of HAG-NET, FGSM, C&W, PGD, and HUGO.
Table 3.
Runtimes of HAG-NET, FGSM, C&W, PGD, and HUGO.
| | FGSM | C&W | PGD | HUGO | HAG-NET |
|---|
| Runtime | 0.06 s | >3 h | 0.7 s | 0.08 s | <0.01 s |
Table 4.
The attack success rate of target attacks by HAG-NET on each target classification networks in MNIST and CIFAR-10 datasets.
Table 4.
The attack success rate of target attacks by HAG-NET on each target classification networks in MNIST and CIFAR-10 datasets.
| | MNIST | CIFAR-10 |
|---|
| Target Class | Model A | Model B | ResNet32 | WRN34 |
|---|
| Class 0 | 98.58% | 99.69% | 98.88% | 98.98% |
| Class 1 | 99.04% | 98.32% | 99.68% | 99.38% |
| Class 2 | 99.25% | 98.80% | 99.16% | 99.36% |
| Class 3 | 99.88% | 98.65% | 99.50% | 99.16% |
| Class 4 | 98.79% | 99.00% | 98.40% | 99.30% |
| Class 5 | 99.40% | 99.72% | 99.48% | 99.10% |
| Class 6 | 99.21% | 99.42% | 98.88% | 99.32% |
| Class 7 | 99.65% | 99.33% | 98.91% | 99.35% |
| Class 8 | 98.98% | 99.17% | 98.76% | 98.83% |
| Class 9 | 99.83% | 99.04% | 98.65% | 98.85% |
| Average | 99.26% | 99.11% | 99.03% | 99.16% |
Table 5.
The average attack success rate of ADV-GAN, AI-GAN, and HAG-NET to target attack Model A, Model B, ResNet32, and WRN34 on MNIST and CIFAR-10 datasets.
Table 5.
The average attack success rate of ADV-GAN, AI-GAN, and HAG-NET to target attack Model A, Model B, ResNet32, and WRN34 on MNIST and CIFAR-10 datasets.
| | MNIST | CIFAR-10 |
|---|
| Methods | Model A | Model B | ResNet32 | WRN34 |
|---|
| ADV-GAN | 97.90% | 98.30% | 99.30% | 94.70% |
| AI-GAN | 99.14% | 98.50% | 95.39% | 95.84% |
| HAG-NET | 99.26% | 99.11% | 99.03% | 99.16% |
Table 6.
The success rates of different adversarial attack methods against a target classifier with defense mechanisms.
Table 6.
The success rates of different adversarial attack methods against a target classifier with defense mechanisms.
| | MNIST | CIFAR-10 |
|---|
| | Model A | Model B | ResNet32 | WRN34 |
|---|
| Methods | Adv. | Ens. | Iter.Adv | Adv. | Ens. | Iter.Adv | Adv. | Ens. | Iter.Adv | Adv. | Ens. | Iter.Adv |
|---|
| PGD | 20.59 | 11.45 | 11.08 | 10.67 | 10.34 | 9.90 | 9.22 | 10.06 | 11.41 | 8.09 | 9.92 | 9.87 |
| Adv-GAN | 8.00 | 6.30 | 5.60 | 18.70 | 13.50 | 12.60 | 10.19 | 8.96 | 9.30 | 9.86 | 9.07 | 8.99 |
| AI-GAN | 23.85 | 12.17 | 10.90 | 20.94 | 10.73 | 13.12 | 9.85 | 12.48 | 9.57 | 10.17 | 11.32 | 9.91 |
| HAG-NET(A) | 15.37 | 10.65 | 7.16 | 15.49 | 10.02 | 13.03 | 10.78 | 12.02 | 10.99 | 9.64 | 10.00 | 10.33 |
| HAG-NET(B) | 19.60% | 11.88 | 11.56 | 19.91 | 11.30 | 15.23 | 10.30 | 11.45 | 12.10 | 10.05 | 12.17 | 11.16 |
Table 7.
BRE differences between HAG-NET and other data hiding methods under different capacity settings.
Table 7.
BRE differences between HAG-NET and other data hiding methods under different capacity settings.
| Method | BPP | BER | BPP | BER | BPP | BER |
|---|
| HUGO | 0.010 | 0 | 0.100 | 0 | 0.200 | 0 |
| WOW | 0.010 | 0 | 0.100 | 0 | 0.200 | 0 |
| HiDDeN | 0.011 | <10−5 | 0.101 | <10−5 | 0.203 | <10−5 |
| ADV-EMB | 0.011 | <10−5 | 0.101 | <10−5 | 0.203 | <10−3 |
| HAG-NET | 0.011 | <10−5 | 0.101 | <10−5 | 0.203 | <10−3 |
Table 8.
The difference of MSE and information entropy value between HAG-NET and others.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}















