
Research on a Critical Link Discovery Method for Network Security Situational Awareness

Abstract
1. Introduction
- Our work introduces mapping entropy into the link importance assessment method for the first time, which effectively expands the domain of link importance assessments by fusing the topological information of links with neighborhood set information, thus increasing the assessment efficacy of relevant link discovery metrics.
- Based on the dependent mechanism of the multi-layer network model, this paper proposes a critical link discovery metric, multi-layer link mapping entropy (MDLE), which is more adaptable to the link assessment needs of multi-layer networks than the classical link discovery metrics and has more advantages in assessment accuracy and network damage effects.
2. Related Work
2.1. Critical Link Discovery
2.2. Type of Link
3. Materials and Methods
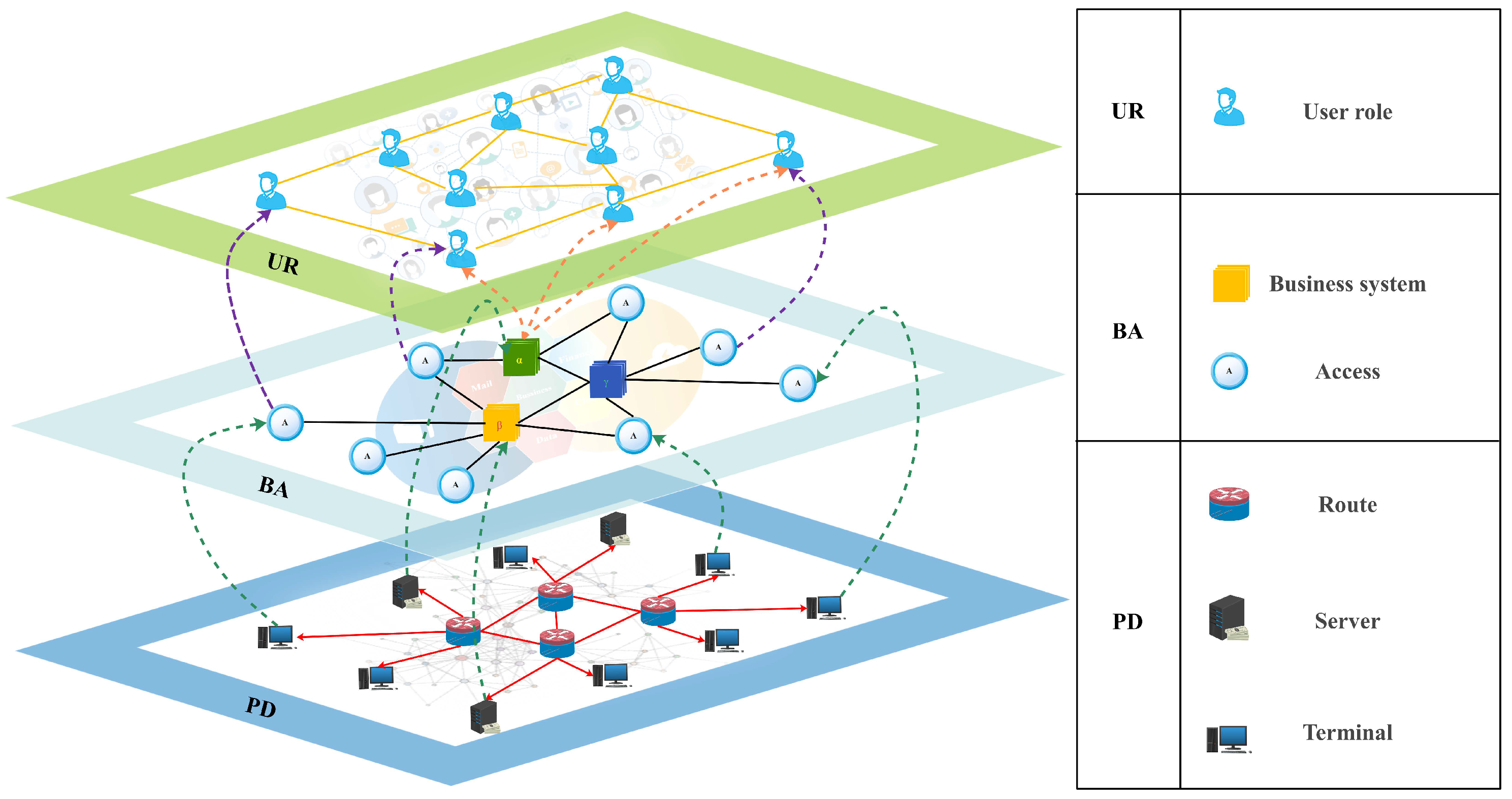
3.1. Network Model Definition
3.2. The Multi-Layer Network Model for Network Security Situational Awareness
3.2.1. Network Architecture Layering Perspective
3.2.2. Node Bearer Medium Perspective
3.2.3. Link Connection Type Perspective
4. Critical Link Discovery
4.1. Problem Analysis
- (a)
- The size of the links in the network will increase at a significant rate compared to the nodes, and even in sparse graphs, the number of links may be much larger than the nodes. It is much more difficult for the network to collect all the information on links than to collect information on nodes. Therefore, when conducting a critical link importance assessment, it should be centered around the local information of the links as much as possible.
- (b)
- During the discovery of a critical link, if many links have the same importance score, then it will not be possible to make a precise importance decision, so the importance assessment metrics for links need to have a high granularity for assessment.
- (c)
- Since the model has two types of links, “connected links” and “dependent links”, the contribution of the target link in both connected and dependent relationships should be considered to ensure the generalizability of the link identification methodology (both types can be evaluated using the same framework).
- (d)
- The critical links obtained according to the critical link identification method should have a certain status in the network structure and undertake important functional tasks, and will have a large impact on the network when the critical links are removed or fail.
4.2. Classical Critical Link Assessment Metrics
4.3. Critical Link Discovery Method Fusing the Link-Local Betweenness Mapping Entropy and the Link-Dependent Mechanism
4.3.1. Link-Local Betweenness Centrality
4.3.2. Link-Local Mapping Betweenness Entropy
4.3.3. Link-Dependent Mechanism
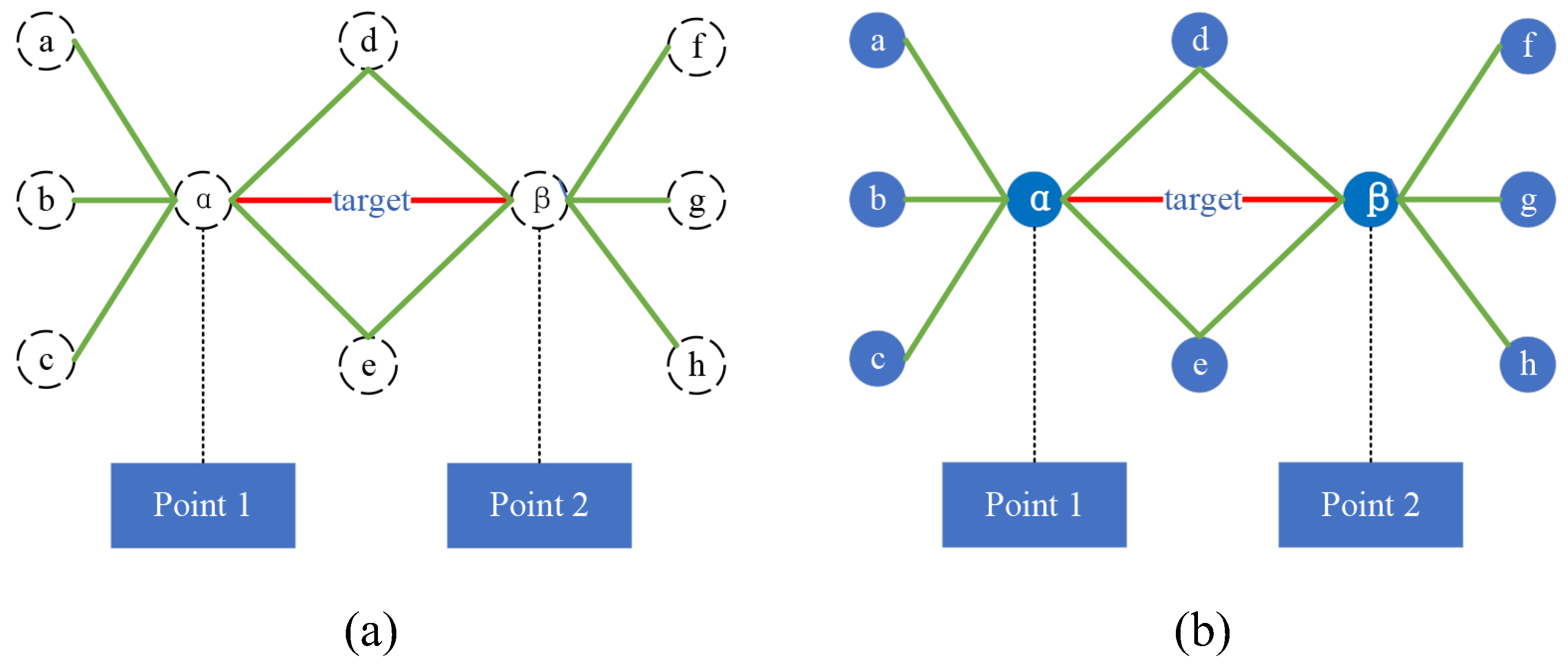
- (a)
- The analysis of “connected links”, whose two endpoints and are on an equal footing (Points), which carry out the connectivity function in the network, shows that they are substitutable and do not form a dependency with their neighboring links.
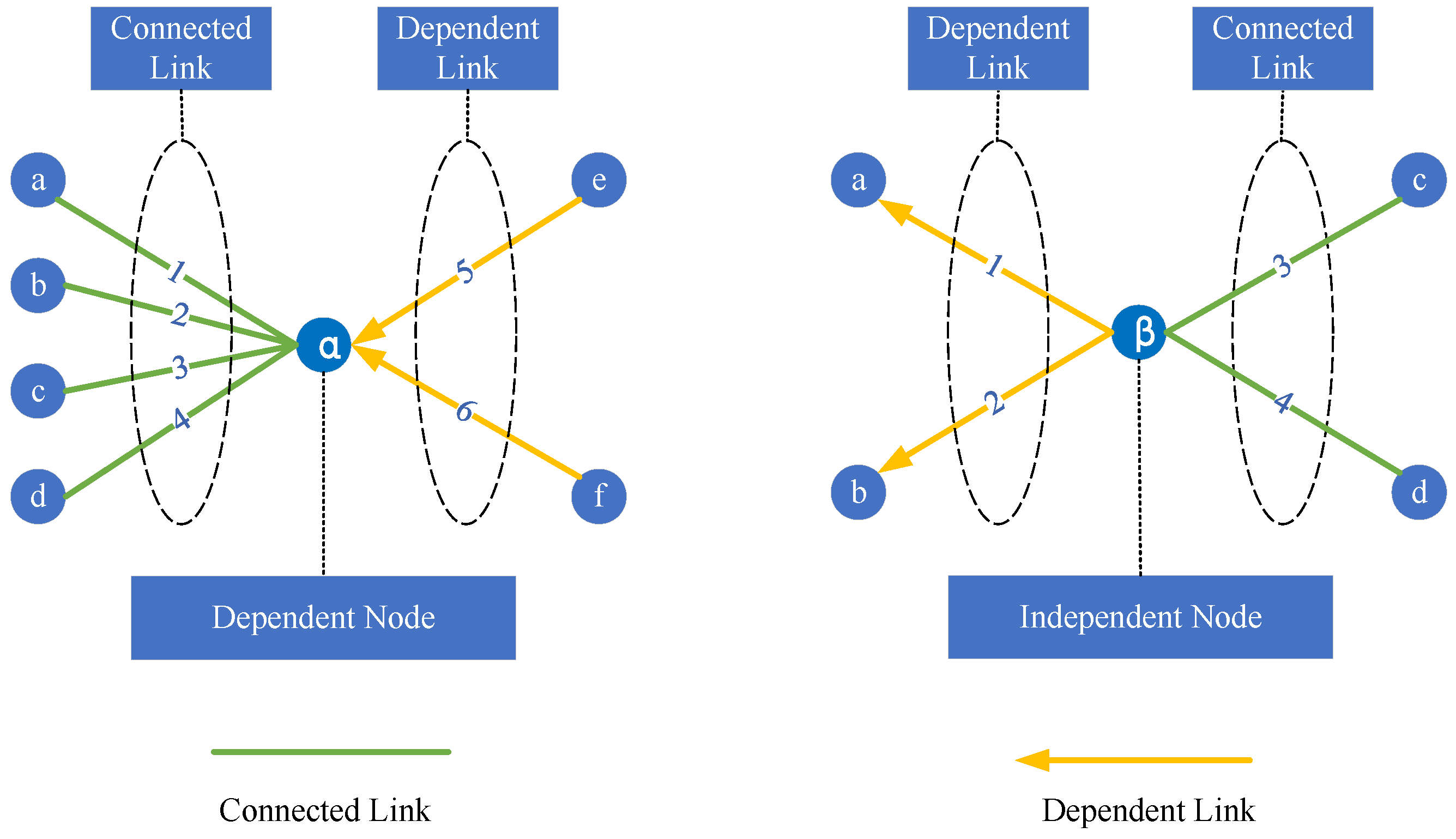
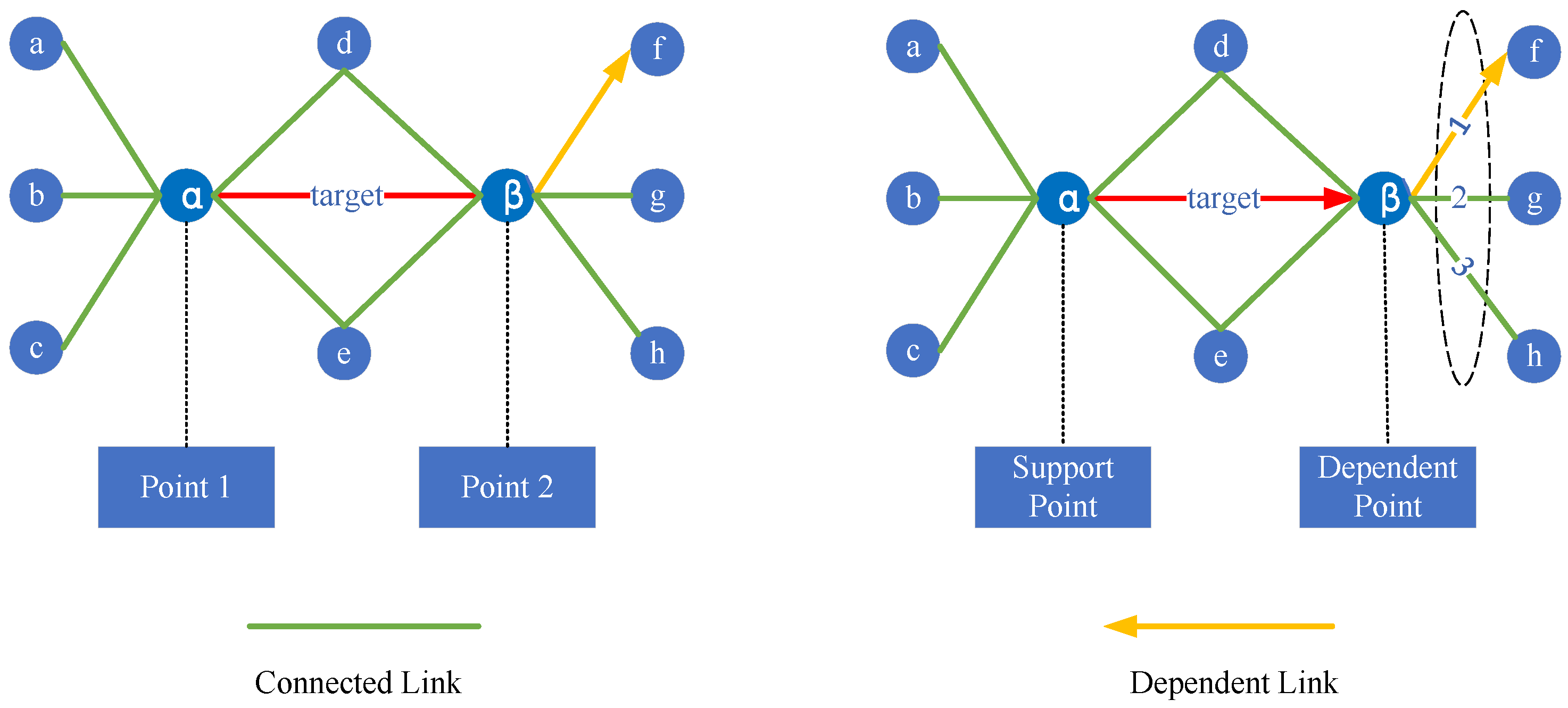
- (b)
- Analyzing the “dependent links”, its two endpoints and have different roles (support node and dependent node), and there is a dependent relationship between the source endpoint and the target endpoint . In other words, when the source endpoint fails or the link is broken, the target endpoint will also fail, and the other links also dependent on the target endpoint will also be broken. Therefore, from the perspective of node importance, the importance of the target endpoint needs to be transmitted to the source endpoint . Similarly, from the perspective of link importance, the importance of the target endpoint ’s neighboring links other than the homologous dependent links also needs to be transmitted to link .
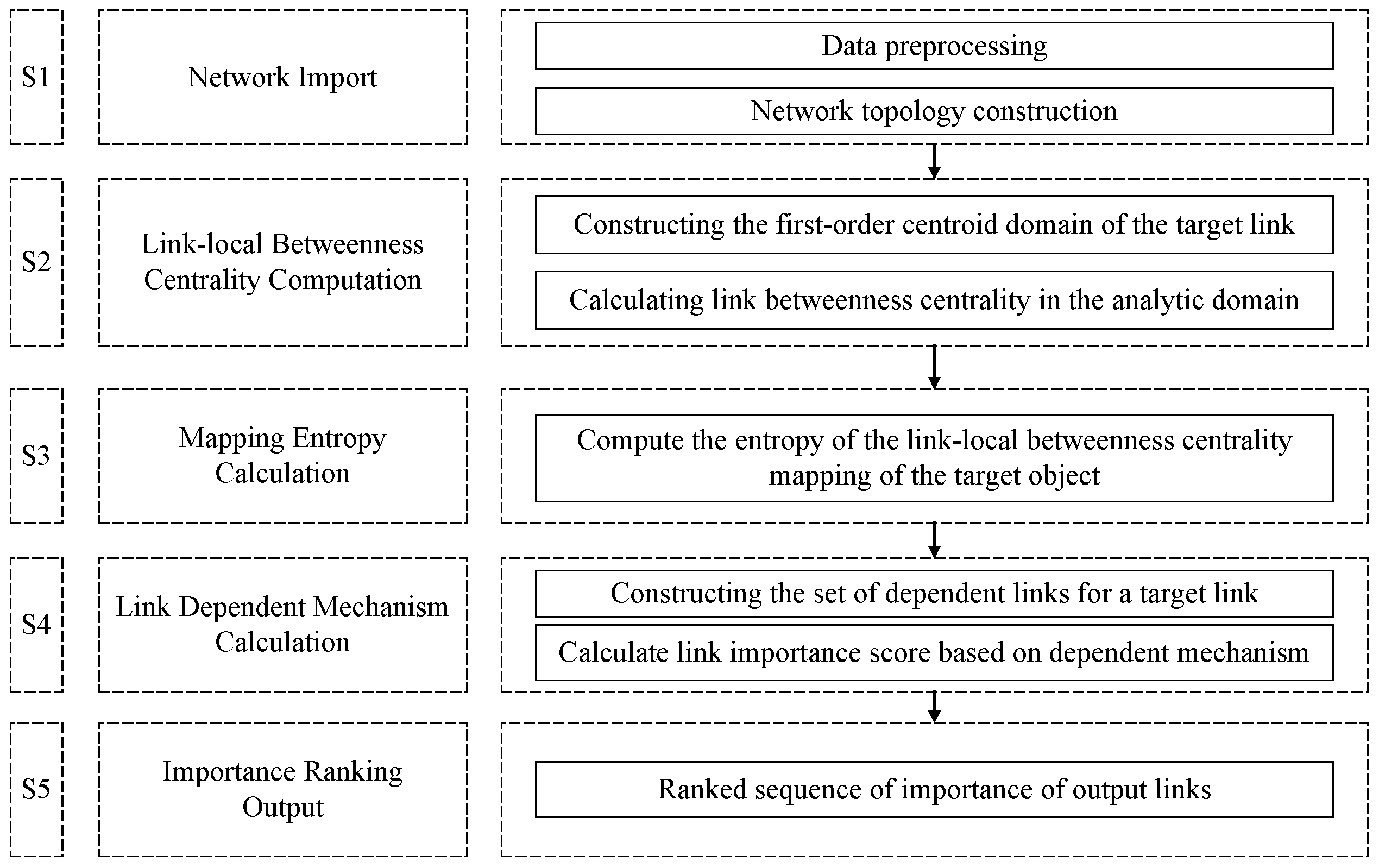
4.3.4. Critical Link Discovery Process
- S1: network input phase.
- S2: link-local betweenness computation phase.
- S3: mapping entropy calculation phase.
- S4: comprehensive link importance assessment phase.
- S5: sequence output phase.
5. Network Experiment and Result Analysis
5.1. Dataset and Experimental Setup
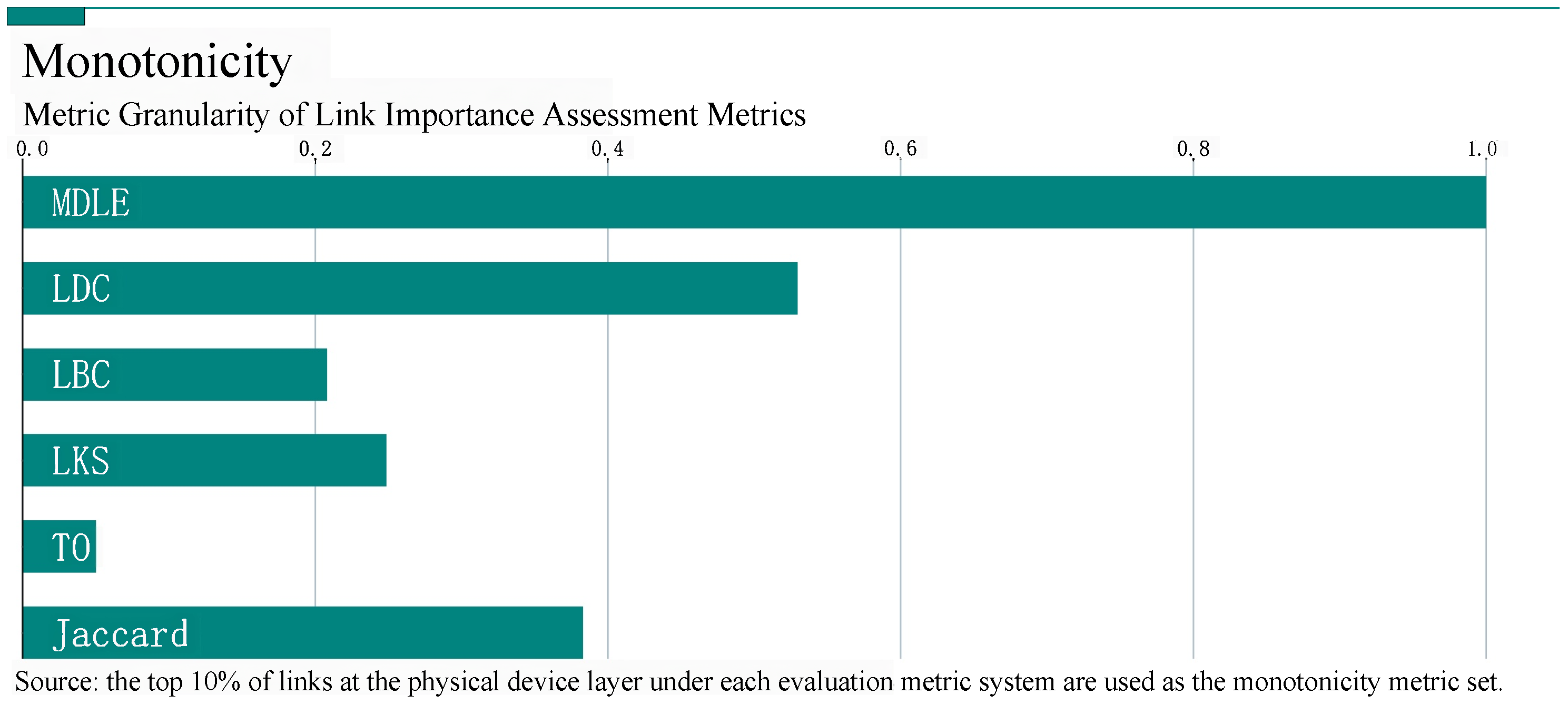
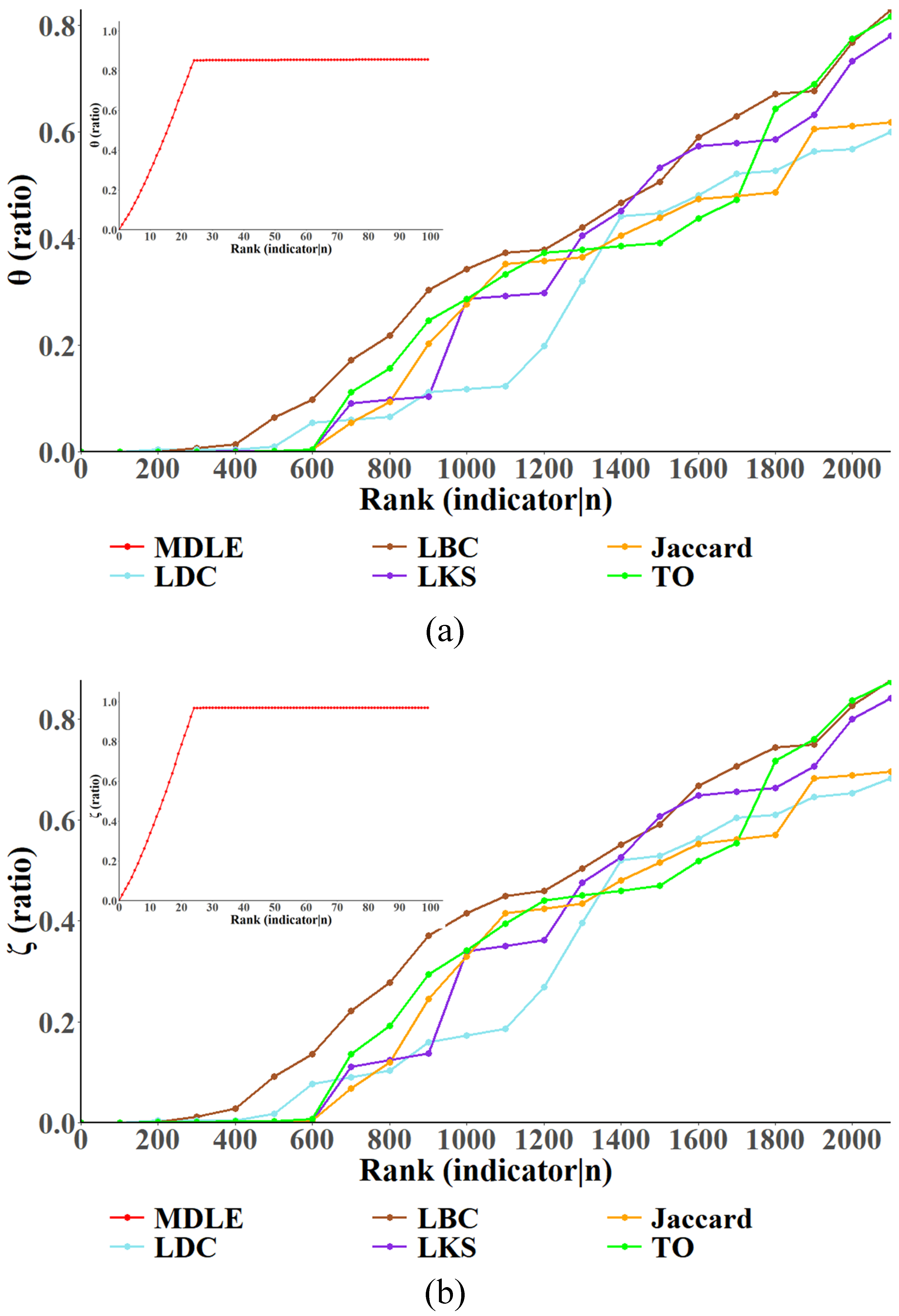
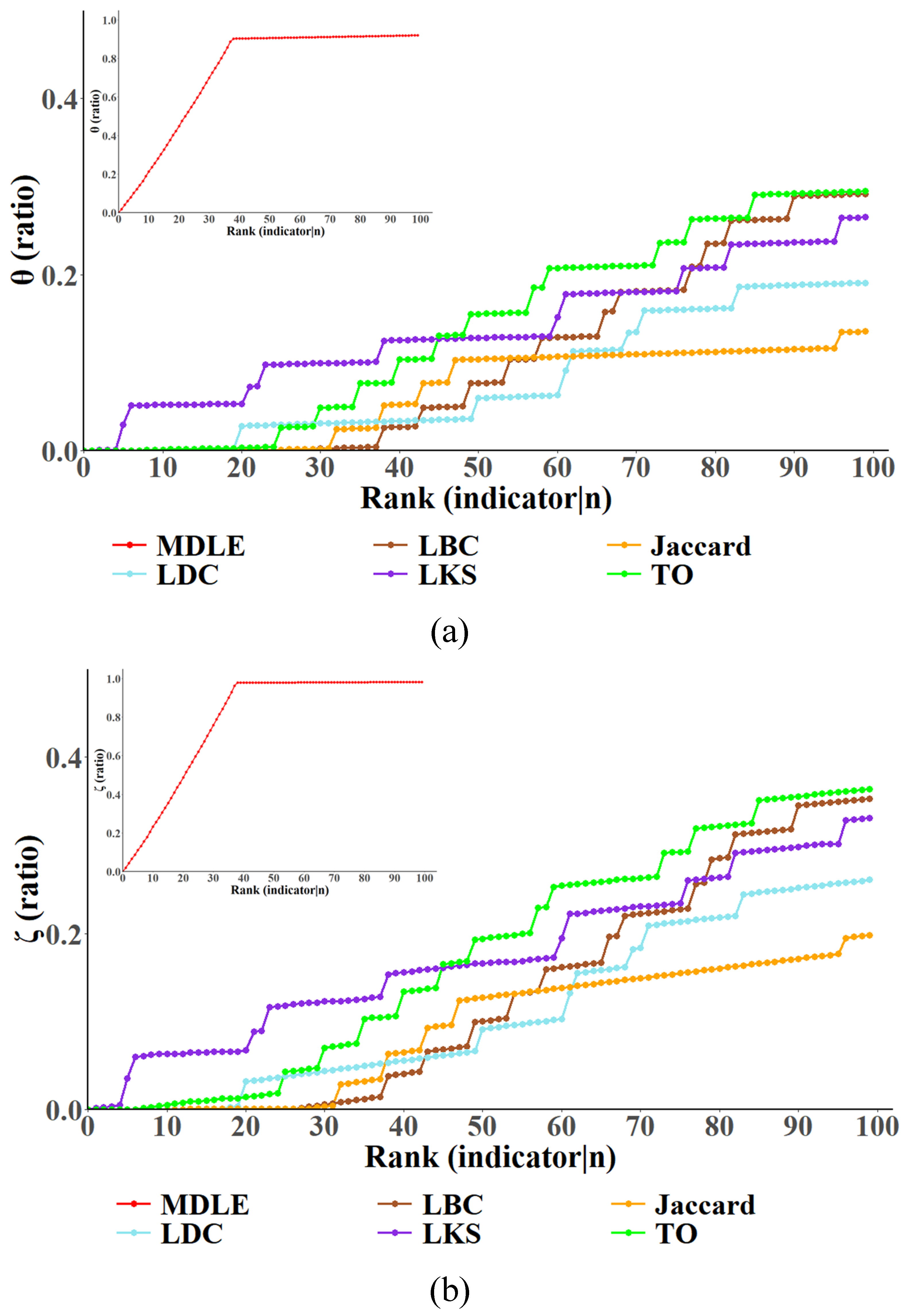
5.2. Link Importance Metric Ranking Monotonicity
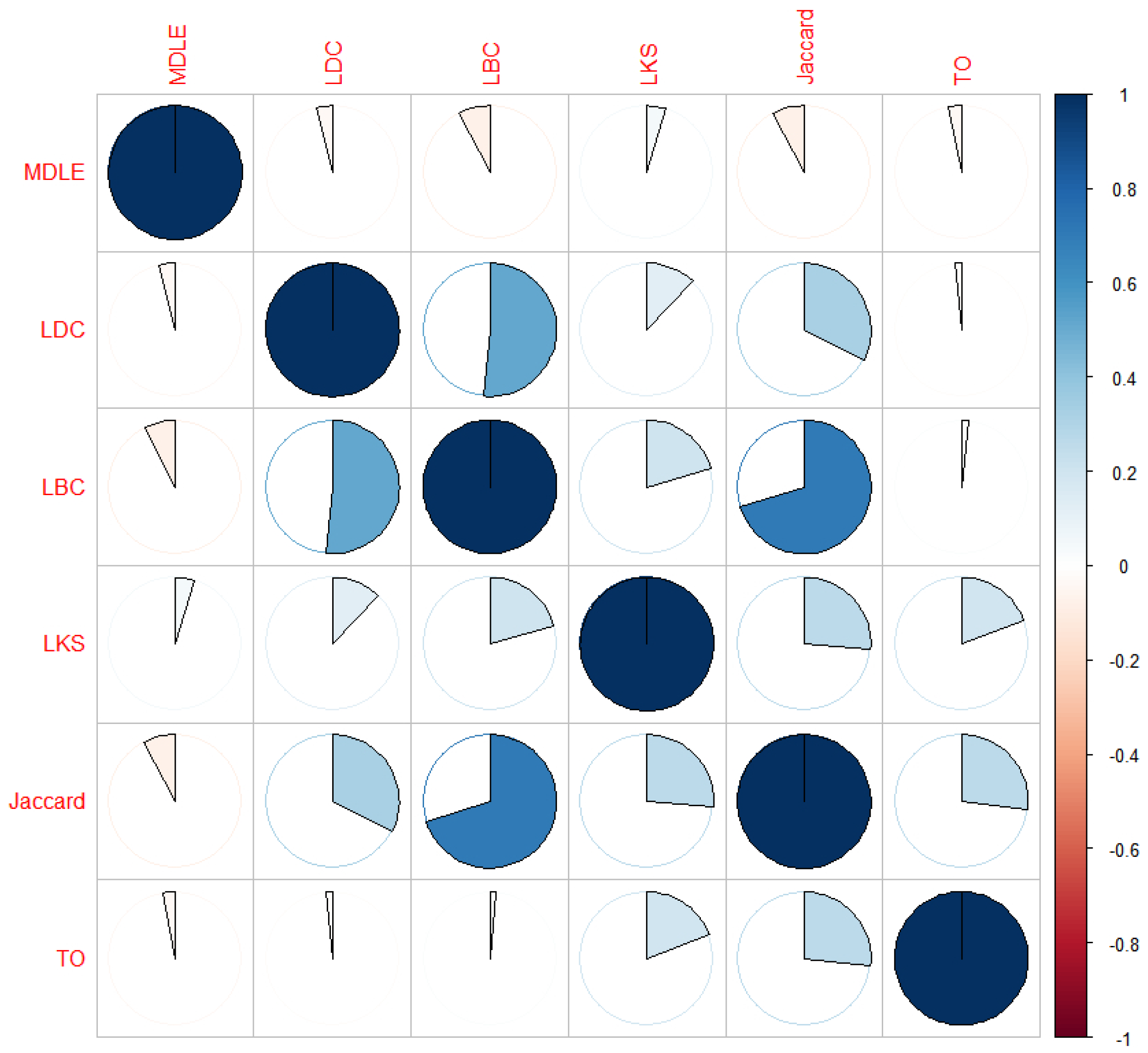
5.3. Link Importance Metric Correlation Analysis
5.4. Link-Removal-Based Network Destruction Simulation
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- Yin, J.; Zhang, C.; Xie, W.; Liang, G.; Zhang, L.; Gui, G. Anomaly traffic detection based on feature fluctuation for secure industrial internet of things. Peer-to-Peer Netw. Appl. 2023, 16, 1680–1695. [Google Scholar] [CrossRef] [PubMed]
- Sandosh, S.; Govindasamy, V.; Akila, G. Enhanced intrusion detection system via agent clustering and classification based on outlier detection. Peer-to-Peer Netw. Appl. 2020, 13, 1038–1045. [Google Scholar] [CrossRef]
- Fraunholz, D.; Zimmermann, M.; Schotten, H.D. An adaptive honeypot configuration, deployment and maintenance strategy. In Proceedings of the 2017 19th International Conference on Advanced Communication Technology (ICACT), PyeongChang, Republic of Korea, 19–22 February 2017; pp. 53–57. [Google Scholar]
- Shingate, P.P.; Trimbake, A.; Sawant, M.S.; Jagdhane, R.; Jadhav, H. Web vulnerability scanning framework. Int. J. Res. Appl. Sci. Eng. Technol. 2023, 11, IJRASET50797. [Google Scholar] [CrossRef]
- Xiu-zhen, C.; Qinghua, Z.; Xiaohong, G.; Chen-Guang, L. Quantitative hierarchical threat evaluation model for network security. J. Softw. 2006, 17, 885. [Google Scholar]
- Kong, D.; Li, H.; Dong, H. Research on network security situation assessment technology based on fuzzy evaluation method. J. Phys. Conf. Ser. 2021, 1883, 012108. [Google Scholar] [CrossRef]
- Li, X.; Li, X.; Zhao, Z. Combining deep learning with rough set analysis: A model of cyberspace situational awareness. In Proceedings of the 2016 6th International Conference on Electronics Information and Emergency Communication (ICEIEC), Beijing, China, 17–19 June 2016; pp. 182–185. [Google Scholar]
- Zhenghu, G. A rough set analysis model of network situation assessment. Comput. Eng. Sci. 2012, 34, 1. [Google Scholar]
- Zhang, Y.; Lu, Y.; Yang, G.; Hou, D.; Luo, Z. An internet-oriented multilayer network model characterization and robustness analysis method. Entropy 2022, 24, 1147. [Google Scholar] [CrossRef] [PubMed]
- Moresco, M.; De S, A.; Costa, Y.M.G.; Senger, L.J.; Hochuli, A.G. Combining multi-layer features for plant species classification in a Siamese network. In Proceedings of the 2022 IEEE International Conference on Systems, Man, and Cybernetics (SMC), Prague, Czech Republic, 9–12 October 2022; pp. 2446–2451. [Google Scholar]
- Zhang, L.; Chen, G.; An, J.; Tian, L. A global optimal resource scheduling algorithm in multi-layer optical networks. J. Opt. Commun. 2023. [Google Scholar] [CrossRef]
- Zhang, Y.; Lu, Y.; Yang, G.; Luo, Z. Research on the identification of internet critical nodes based on multilayer network modeling. Secur. Commun. Netw. 2022, 2022, 1–17. [Google Scholar] [CrossRef]
- Freeman, L.C. Centrality in social networks conceptual clarification. Soc. Netw. 1978, 1, 215–239. [Google Scholar] [CrossRef]
- Hong-Zhong, D. Evaluation method for node importance based on node contraction in complex networks. Syst. Eng. Theory Pract. 2006, 11, 79–83. [Google Scholar]
- Sabidussi, G. The centrality index of a graph. Psychometrika 1966, 31, 581–603. [Google Scholar] [CrossRef]
- Lin, Z.; Zhang, Y.; Gong, Q.; Chen, Y.; Oksanen, A.; Ding, A.Y. Structural hole theory in social network analysis: A review. IEEE Trans. Comput. Soc. Syst. 2021, 9, 724–739. [Google Scholar] [CrossRef]
- Girvan, M.; Newman, M.E.J. Community structure in social and biological networks. Proc. Natl. Acad. Sci. USA 2001, 99, 7821–7826. [Google Scholar] [CrossRef] [PubMed]
- Yu, G.; Shi, H. A tsp algorithm based on link degree. J. Phys. Conf. Ser. 2020, 1682, 012040. [Google Scholar] [CrossRef]
- Sun, S.; Liu, X.; Wang, L.; Xia, C. New link attack strategies of complex networks based on k-core decomposition. IEEE Trans. Circuits Syst. II Express Briefs 2020, 67, 3157–3161. [Google Scholar] [CrossRef]
- Chen, C.-Y.; Zhao, Y.; Qin, H.; Meng, X.; Gao, J. Robustness of interdependent scale-free networks based on link addition strategies. Phys. A Stat. Mech. Appl. 2022, 604, 127851. [Google Scholar] [CrossRef]
- Onnela, J.-P.; Saramaki, J.; Hyvonen, J.; Szabo, G.; Lazer, D.M.J.; Kaski, K.K.; Kertesz, J.; Barabasi, A.-L. Structure and tie strengths in mobile communication networks. Proc. Natl. Acad. Sci. USA 2007, 104, 7332–7336. [Google Scholar] [CrossRef]
- Masahiro, K.; Kazumi, S.; Hiroshi, M. Blocking Links to Minimize Contamination Spread in a Social Network. ACM Trans. Knowl. Discov. Data 2009, 3, 1–23. [Google Scholar]
- Kazumi, S.; Masahiro, K.; Kouzou, O.; Hiroshi, M. Detecting Critical Links in Complex Network to Maintain Information Flow/Reachability. In Proceedings of the 14th Pacific Rim International Conference on Artificial Intelligence, Phuket, Thailand, 22–26 August 2016; Volume 9810, pp. 419–432. [Google Scholar] [CrossRef]
- Kazumi, S.; Kouzou, O.; Masahiro, K.; Hiroshi, M. Accurate and efficient detection of critical links in network to minimize information loss. J. Intell. Inf. Syst. 2018, 51, 235–255. [Google Scholar] [CrossRef]
- Kazumi, S.; Takayasu, F.; Kouzou, O.; Masahiro, K.; Hiroshi, M. Efficient computation of target-oriented link criticalness centrality in uncertain graphs. Intell. Data Anal. 2021, 25, 1323–1343. [Google Scholar] [CrossRef]
- Wasserman, S.; Faust, K. Social Network Analysis: Methods and Applications; Cambridge University Press: Cambridge, UK, 1994. [Google Scholar]
- Newman, M.E.J. Networks: An Introduction; Oxford University Press: Oxford, UK, 2010. [Google Scholar]
- Holme, P.; Saramaki, J. Temporal networks. Phys. Rep. 2012, 519, 97–125. [Google Scholar] [CrossRef]
- Mikko, K.; Alex, A.; Marc, B.; James, P.G.; Yamir, M.; Mason, A.P. Multilayer networks. J. Complex Netw. 2014, 2, 203–271. [Google Scholar] [CrossRef]
- Buldyrev, S.V.; Parshani, R.; Paul, G.; Stanley, H.E.; Havlin, S. Catastrophic cascade of failures in interdependent networks. Nature 2010, 464, 1025–1028. [Google Scholar] [CrossRef]
- Liu, R.; Mao, G.; Zhang, N. Research of chemical elements and chemical bonds from the view of complex network. Found. Chem. 2018, 21, 193–206. [Google Scholar] [CrossRef]
- Nie, T.; Guo, Z.; Zhao, K.; Lu, Z. Using mapping entropy to identify node centrality in complex networks. Phys. A-Stat. Mech. Its Appl. 2016, 453, 290–297. [Google Scholar] [CrossRef]
- Zhang, Y. Available online: https://github.com/multilayer-go/muti-layer-network (accessed on 5 December 2023).
- Bae, J.; Kim, S. Identifying and ranking influential spreaders in complex networks by neighborhood coreness. Phys. A: Stat. Mech. Appl. 2014, 395, 549–559. [Google Scholar] [CrossRef]
- Pearson product-moment correlation coefficient. In The SAGE Encyclopedia of Research Design; SAGE: Thousand Oaks, CA, USA, 2022.
- Li, Z.; Zeng, J.; Chen, Y.; Liang, Z. Attackg: Constructing technique knowledge graph from cyber threat intelligence reports. In Proceedings of the European Symposium on Research in Computer Security, Copenhagen, Denmark, 26–30 September 2022. [Google Scholar]
- Taylor, R.; Kardas, M.; Cucurull, G.; Scialom, T.; Hartshorn, A.S.; Saravia, E.; Poulton, A.; Kerkez, V.; Stojnic, R. Galactica: A large language model for science. arXiv 2022, arXiv:2211.09085v1. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Connection Type | Point 1 | Point 2 | Pos | Description |
| Connected Link | route | route | intra | Communication relationship between routers |
| business | business | intra | Business linkages or calling relationships between business systems | |
| business | access | intra | Access relationships between access nodes and business systems | |
| access | user | inter | Associations for user accounts logging in from access nodes | |
| user | user | intra | Social relationships or business connections between user roles | |
| Connection Type | Support Point | Dependent Point | Pos | Description |
| Dependent Link | route | server | intra | Server is dependent on the communication support provided by the router |
| route | terminal | intra | Terminal is dependent on the communication support provided by the router | |
| server | business | inter | Business system is dependent on the environment provided by server | |
| terminal | access | inter | Access node is entity mappings of a terminal in the business access relationship | |
| business | user | inter | User roles are groups of accounts that belong to the business system |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, G.; Zhang, Y.; Lu, Y.; Xie, Y.; Yu, J. Research on a Critical Link Discovery Method for Network Security Situational Awareness. Entropy 2024, 26, 315. https://doi.org/10.3390/e26040315
Yang G, Zhang Y, Lu Y, Xie Y, Yu J. Research on a Critical Link Discovery Method for Network Security Situational Awareness. Entropy. 2024; 26(4):315. https://doi.org/10.3390/e26040315
Chicago/Turabian StyleYang, Guozheng, Yongheng Zhang, Yuliang Lu, Yi Xie, and Jiayi Yu. 2024. "Research on a Critical Link Discovery Method for Network Security Situational Awareness" Entropy 26, no. 4: 315. https://doi.org/10.3390/e26040315
APA StyleYang, G., Zhang, Y., Lu, Y., Xie, Y., & Yu, J. (2024). Research on a Critical Link Discovery Method for Network Security Situational Awareness. Entropy, 26(4), 315. https://doi.org/10.3390/e26040315