



Lossless and Near-Lossless Compression Algorithms for Remotely Sensed Hyperspectral Images


Abstract
:1. Introduction
- A novel lossless compression technique of remotely sensed hyperspectral images is proposed by employing our recent method of seed generation based on bit manipulation techniques [39]. Four variations are employed in our experiments using the Corpus dataset of HSIs. Our performance results yield an enhancement in data reduction that reaches 29.89% when comparing the corresponding geometric mean value with that obtained by the state-of-the-art -raster method [40].
- A novel near-lossless compression of HSIs is also proposed by incorporating our published quadrature-based square rooting method [39]. A data reduction that varies from 38.90% to 39.73% is realized with a maximum relative error of 0.33 and a maximum absolute error of only 30. Since hyperspectral images with high entropies are hard to losslessly compress due to their reduced correlation, this approach can be applied with a small to negligible impact on the accuracy of the decompressed data.
2. Related Work
3. Lossless Compression
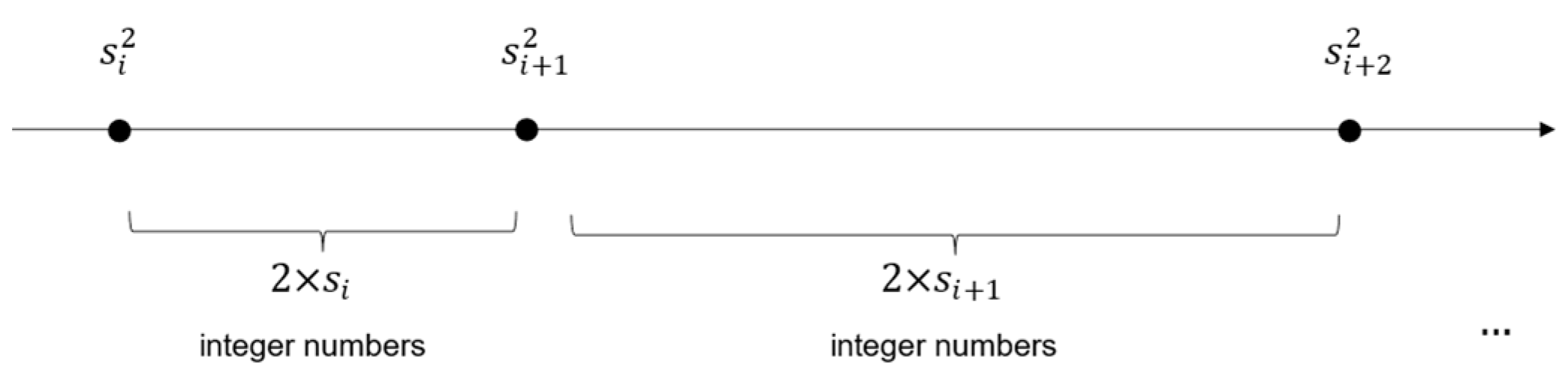
3.1. Computation of the Integral Part
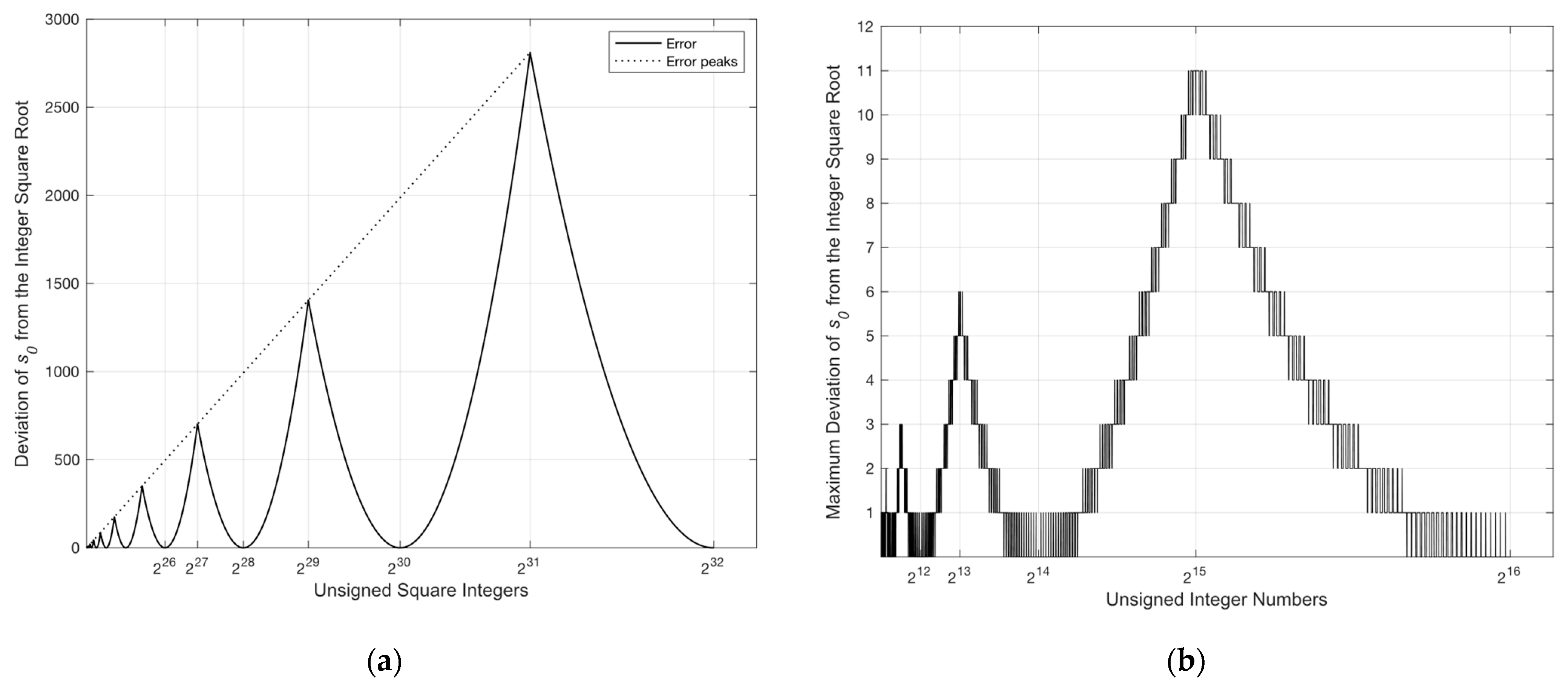
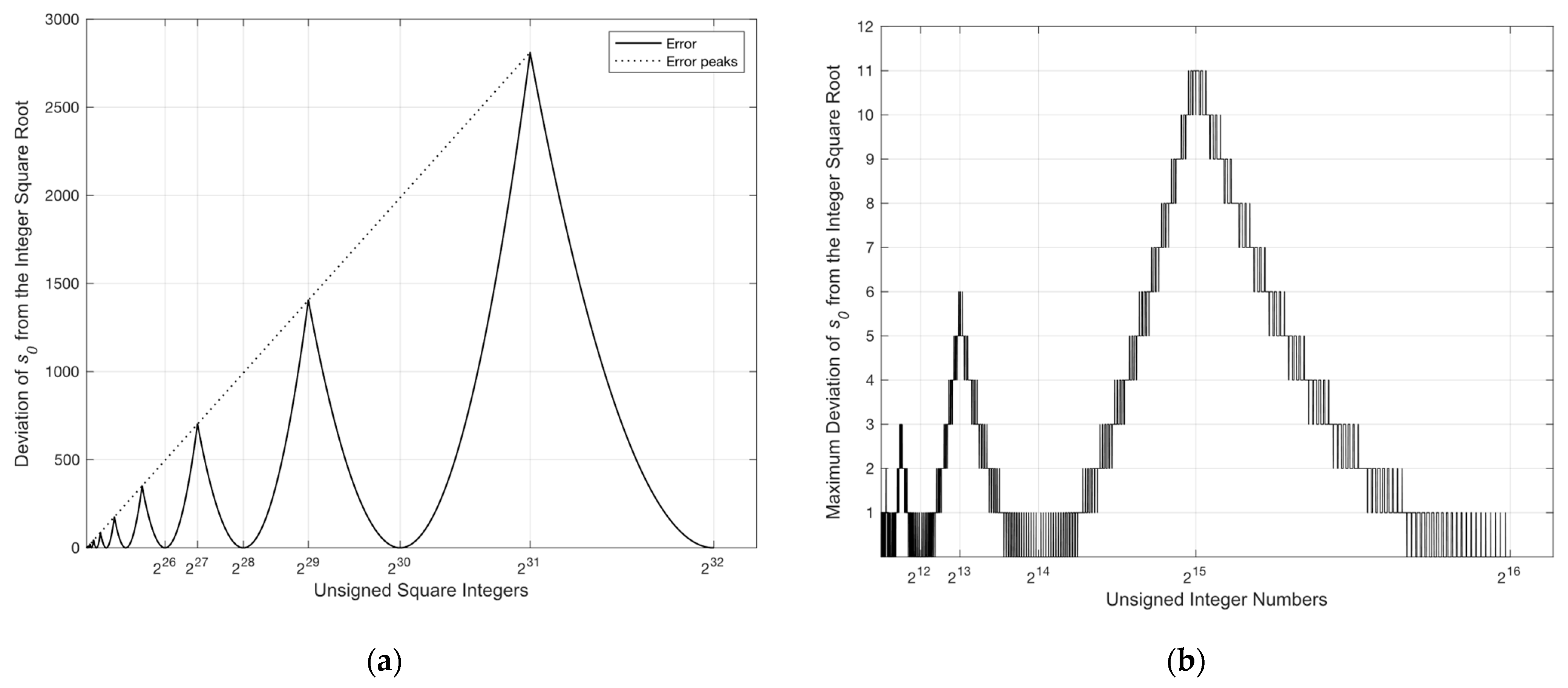
3.1.1. Error Compensation
| Algorithm 1. . |
| Input: Output: Initialization: While ) Do End Do |
3.1.2. Error Avoidance
3.2. Computation of the Fractional Part
3.3. Preprocessing
3.4. Postprocessing
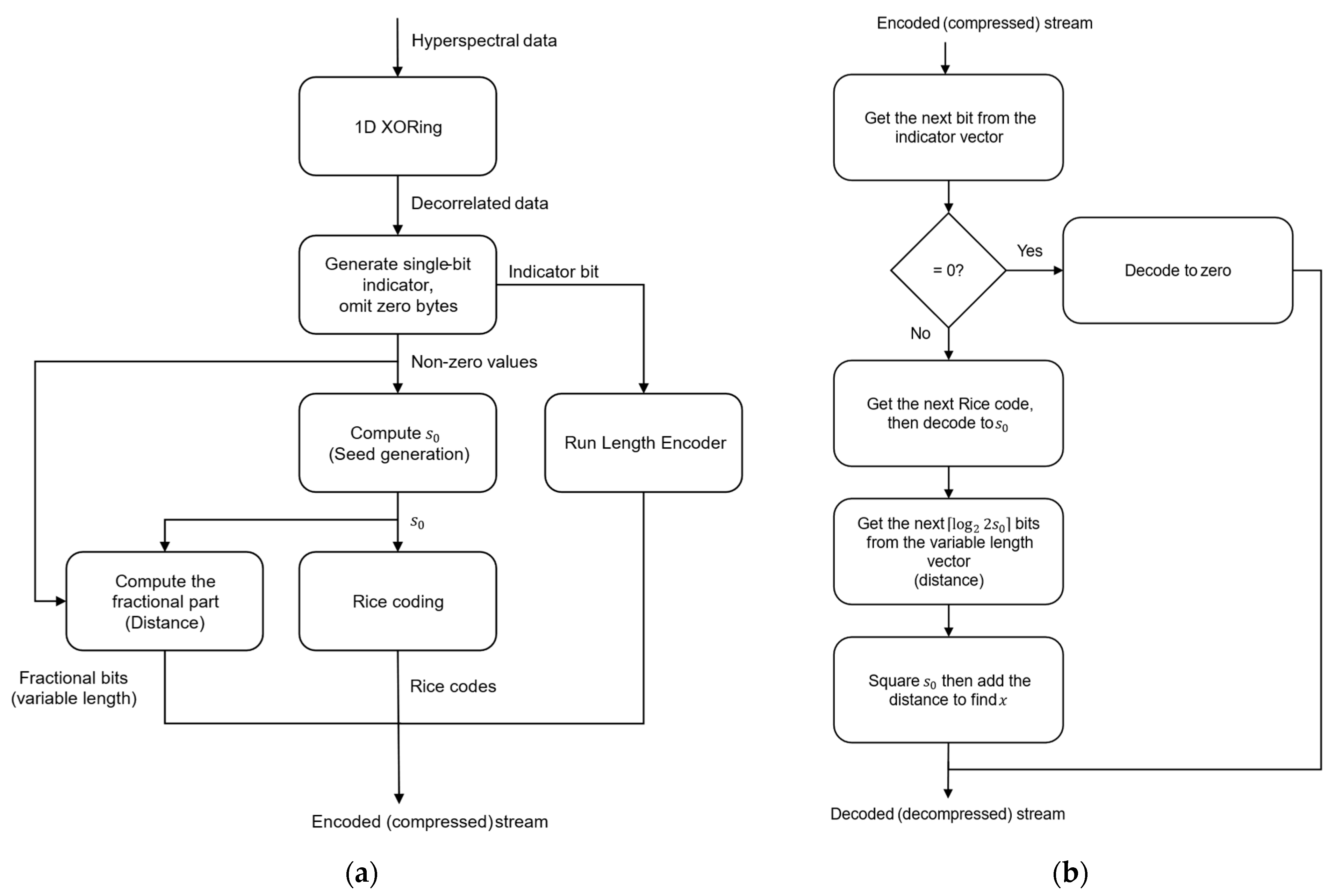
3.5. Lossless Encoder/Decoder
| Algorithm 2. Pseudocode for the compressor part of the proposed lossless compression. |
| Input: // hyperspectral data Outputs: vecRice, // a vector that stores the calculated seed values. vecFrac, // a vector that stores the calculated fractions. vecRLE, // a vector that holds the counts of consecutive runs of zero and nonzero values. vecUnary. // a vector that holds the variable unary codes corresponding to the number of bits of each count. Initializations: . , // initialize the first nonzero value with 0. , // counts the number of consecutive runs. , // to calculate the required number of bits for each run. , // the required number of bits for each run. . For all Do 1. Preprocessing // perform exclusive-or operation. If Then 2. Calculation of the integral part ) 3. Calculation of the fractional part // The fraction encoded as the distance between the xored value and the squared value of the seed If Then Else End If ) Else End If 4. Run length encoding of If Then If Then 1 End If Else ) ) End If End Do If done Then ) ) End If |
| Algorithm 3. Pseudocode for the decompressor part of the proposed lossless compression. |
| Inputs: vecRice, vecFrac, vecRLE, vecUnary. Output: // reconstructed hyperspectral data. Initializations: the number of bits derived from the next unary code in vecUnary. bits from vecRLE. For all in vecRLE Do While Do If Then Else get the next rice code from vecRice. ) If Then the value of the next unary code from vecFrac Else bits from vecFrac. End If End Do End Do |
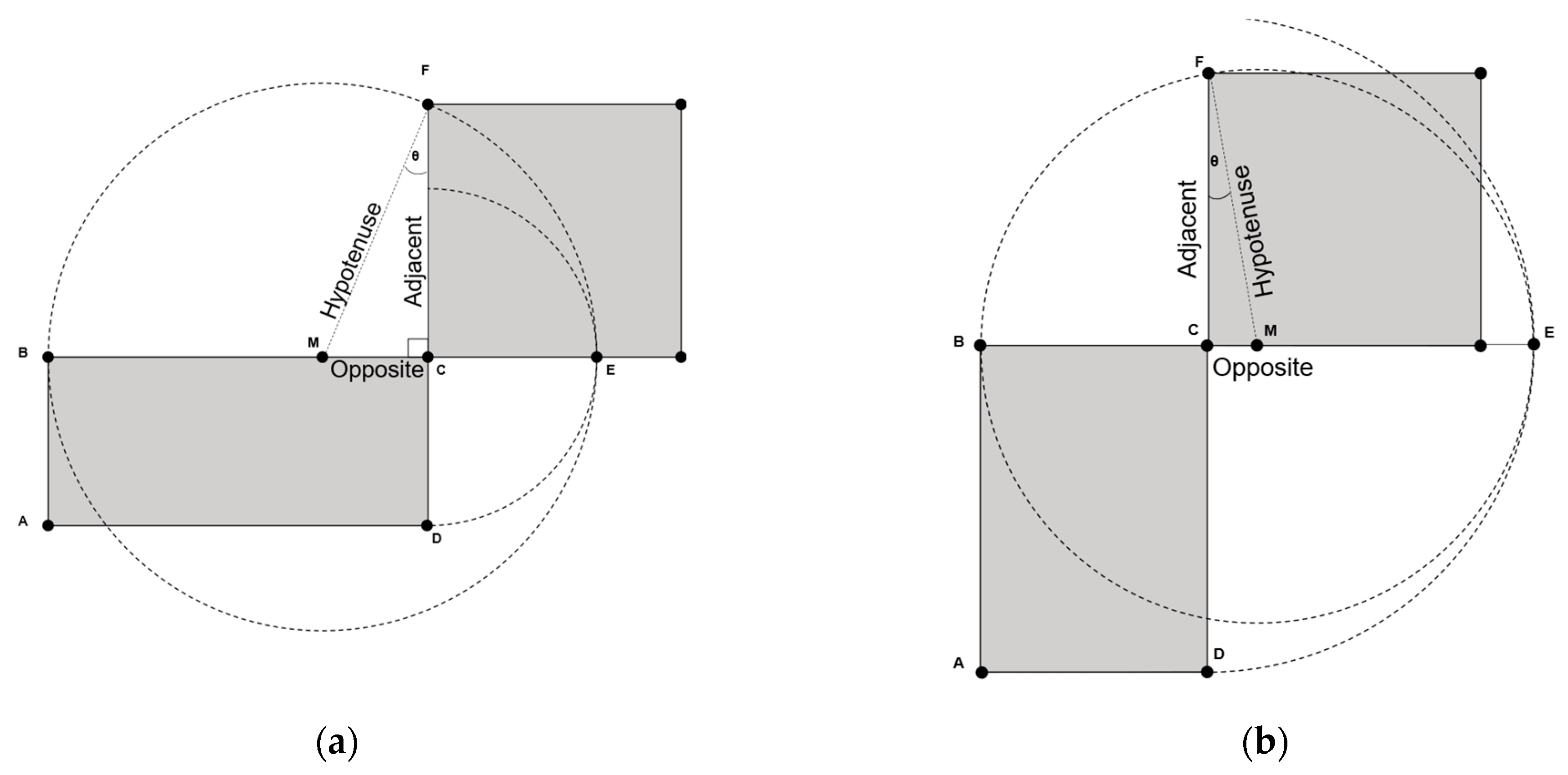
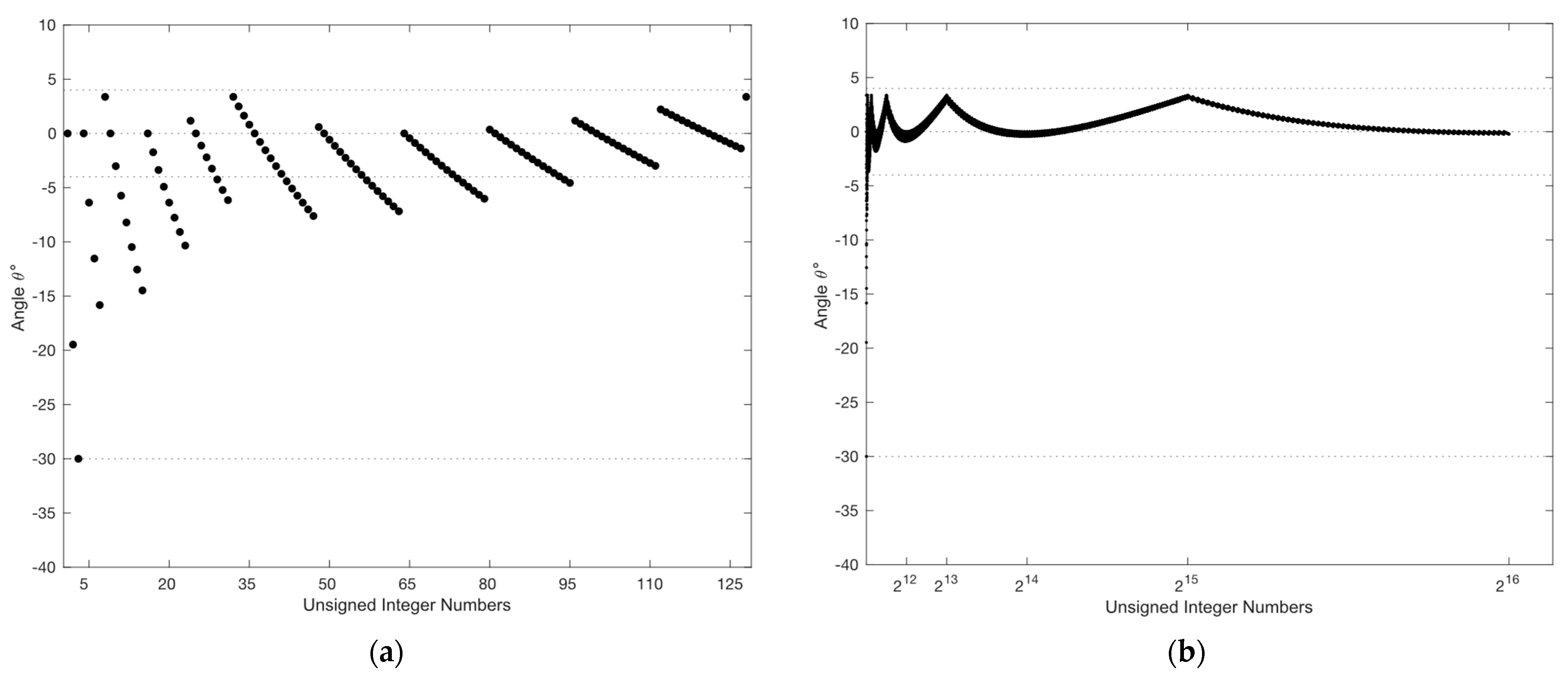
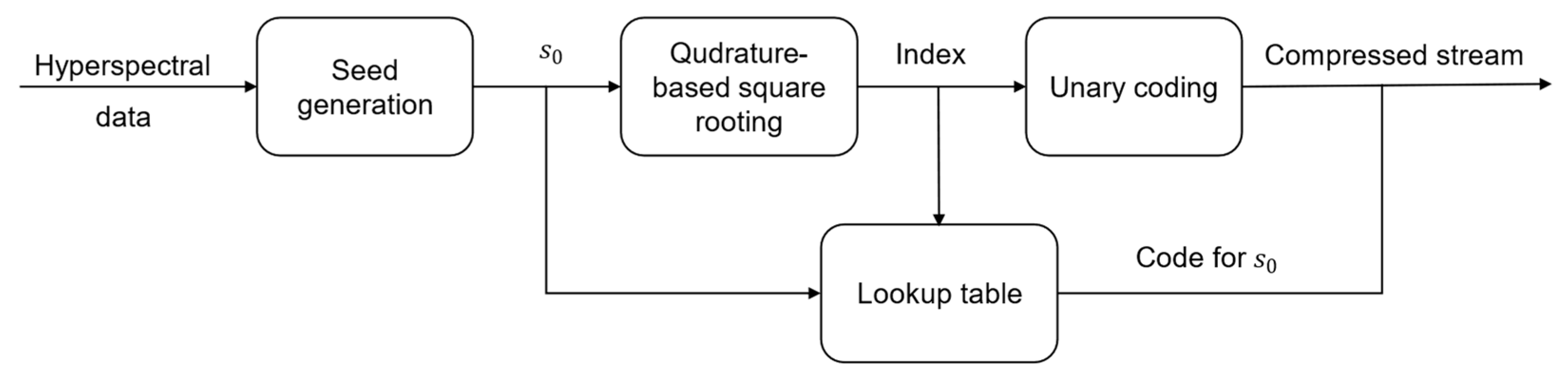
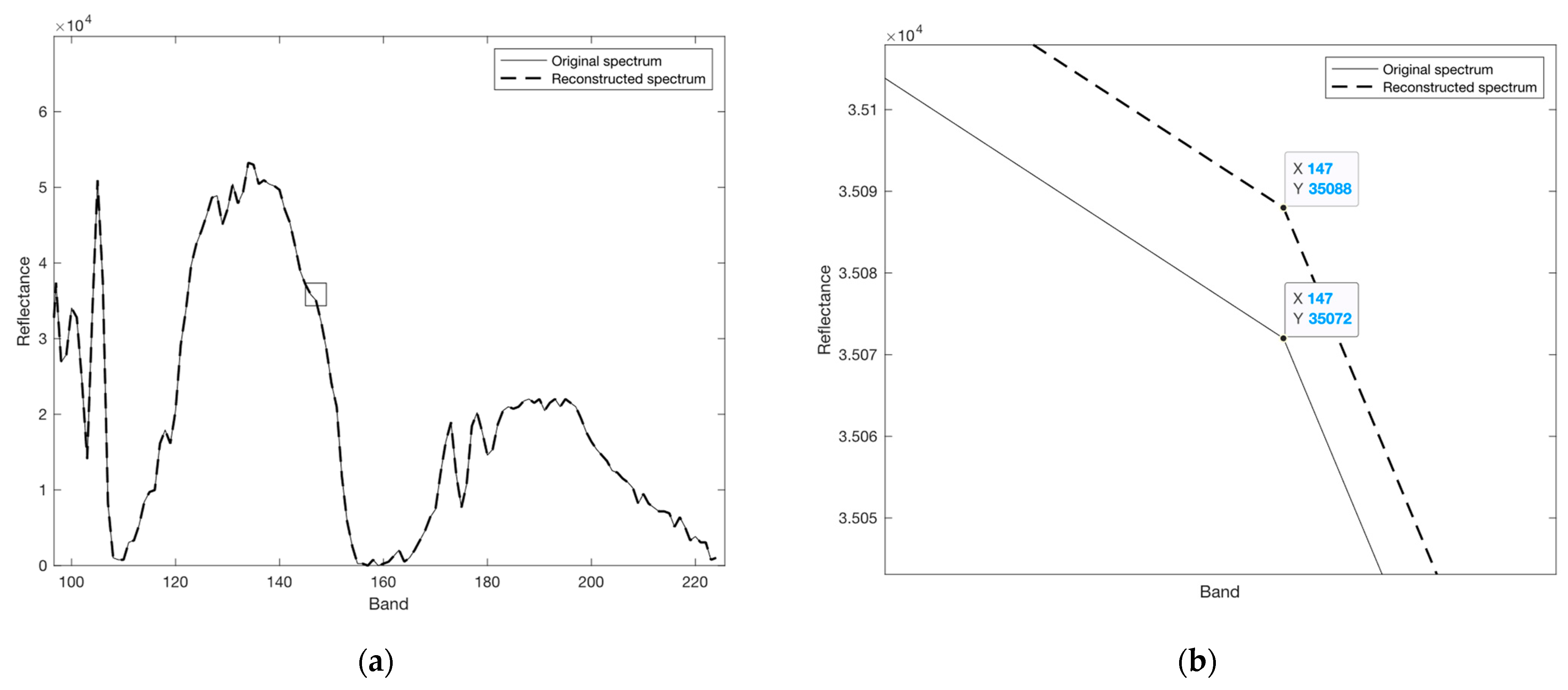
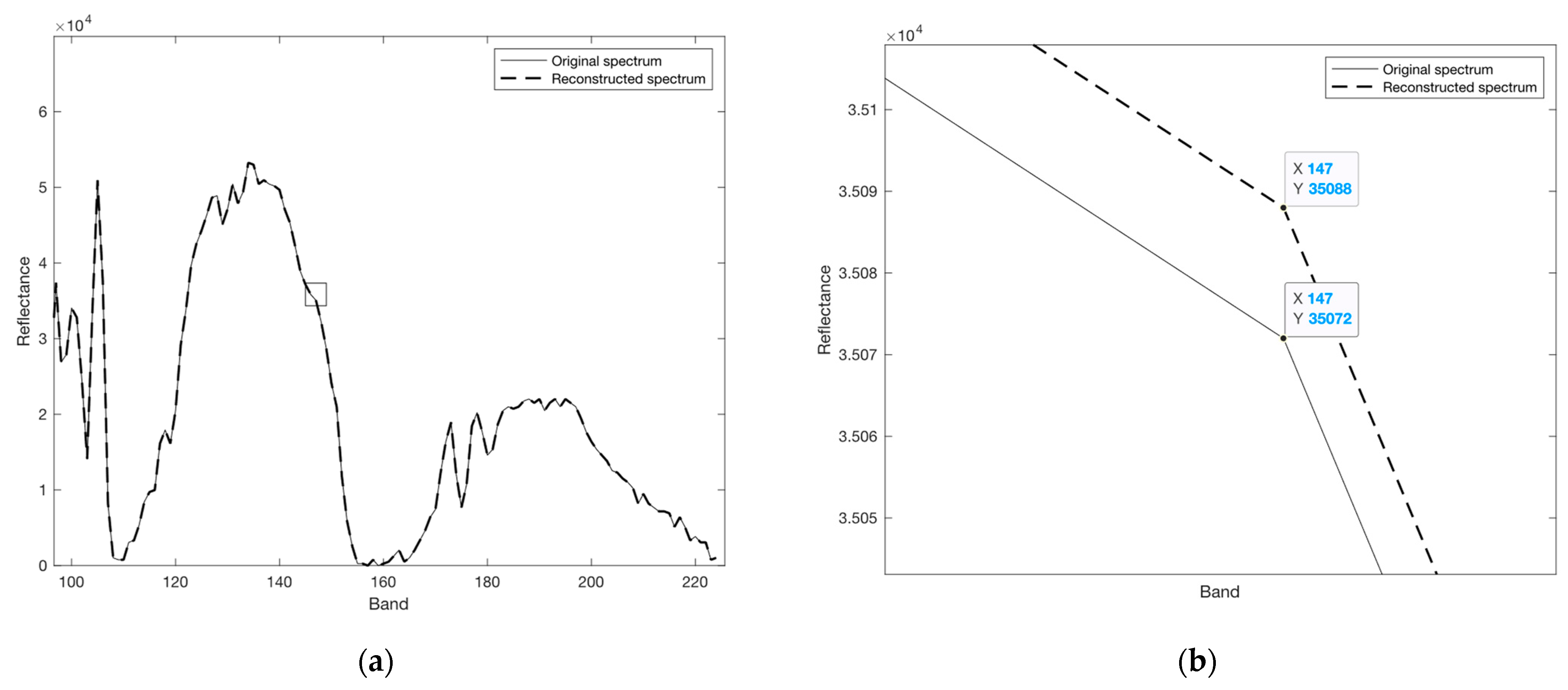
4. Near-Lossless Compression
| Algorithm 4. The quadrature-based method to compute the square root value of . |
| Inputs: Output . Initialization: |
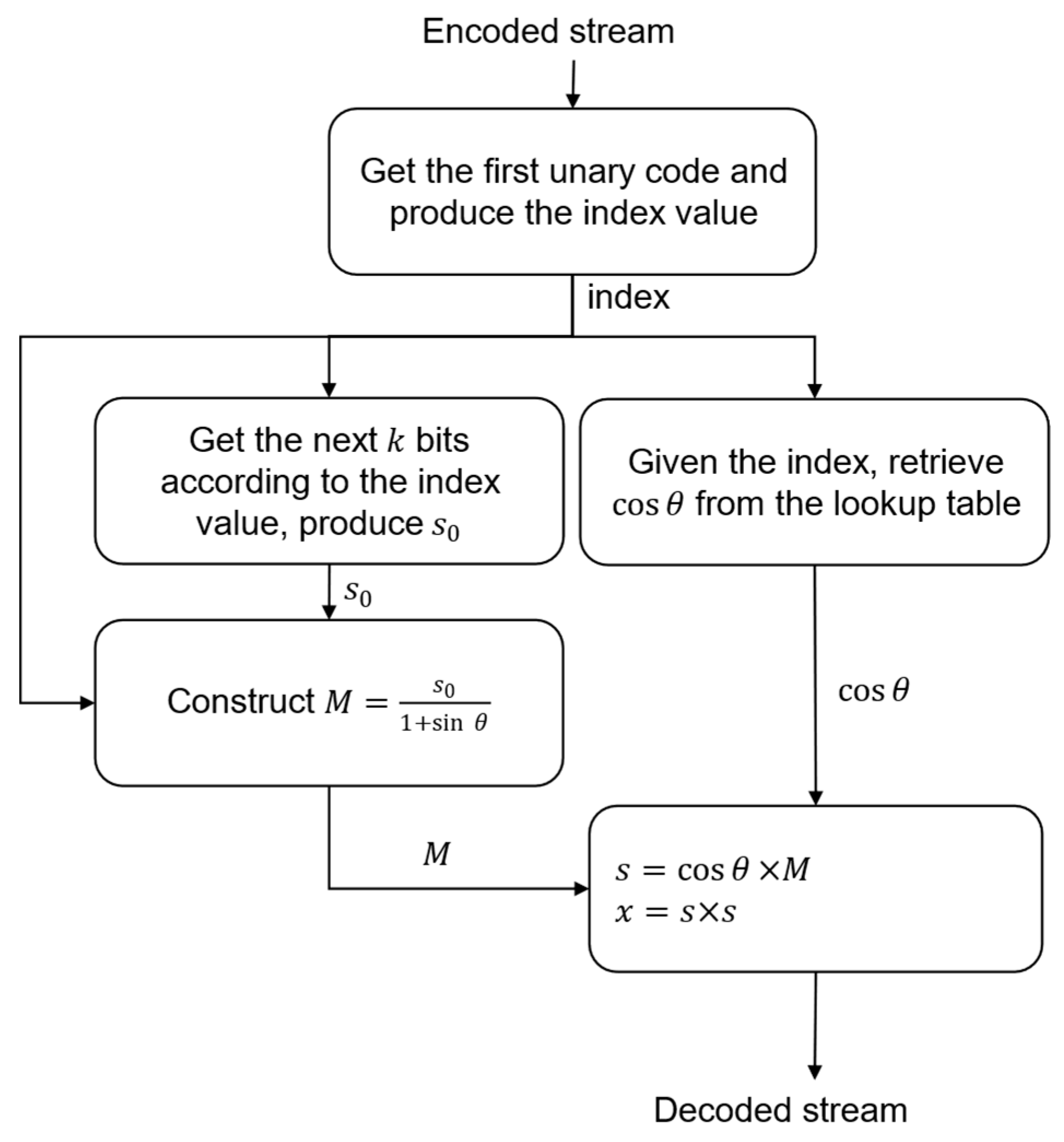
Near-Lossless Encoder/Decoder
| Algorithm 5. Pseudocode for the compressor part of the proposed near-lossless compression. |
| Input: // hyperspectral data. Outputs: vecSeed, vecUnary. Initialization: . For all Do 1. Seed generation 2. Quadrature-based square rooting 3. Preparing the compressed stream the corresponding order of the seed value within the lookup table of the index (Table A1). the number of bits that correspond to index (Table 4). . ) // add the encoded seed to vecSeed vector. the corresponding unary code of the index value. ) // add unary code to vecUnary vector. End Do |
| Algorithm 6. Pseudocode for the decompressor part of the proposed near-lossless compression. |
| Inputs: vecSeed, vecUnary Output: // reconstructed hyperspectral data Initialization: the index value obtained by interpreting the next unary code in vecUnary For all Do the number bits to be read from vecSeed based on index value (Table 4). bits from vecSeed. get the seed value given the index (Table A1). value), retrieve the cosine value from the lookup table. End Do |
5. Experimental Results and Discussion
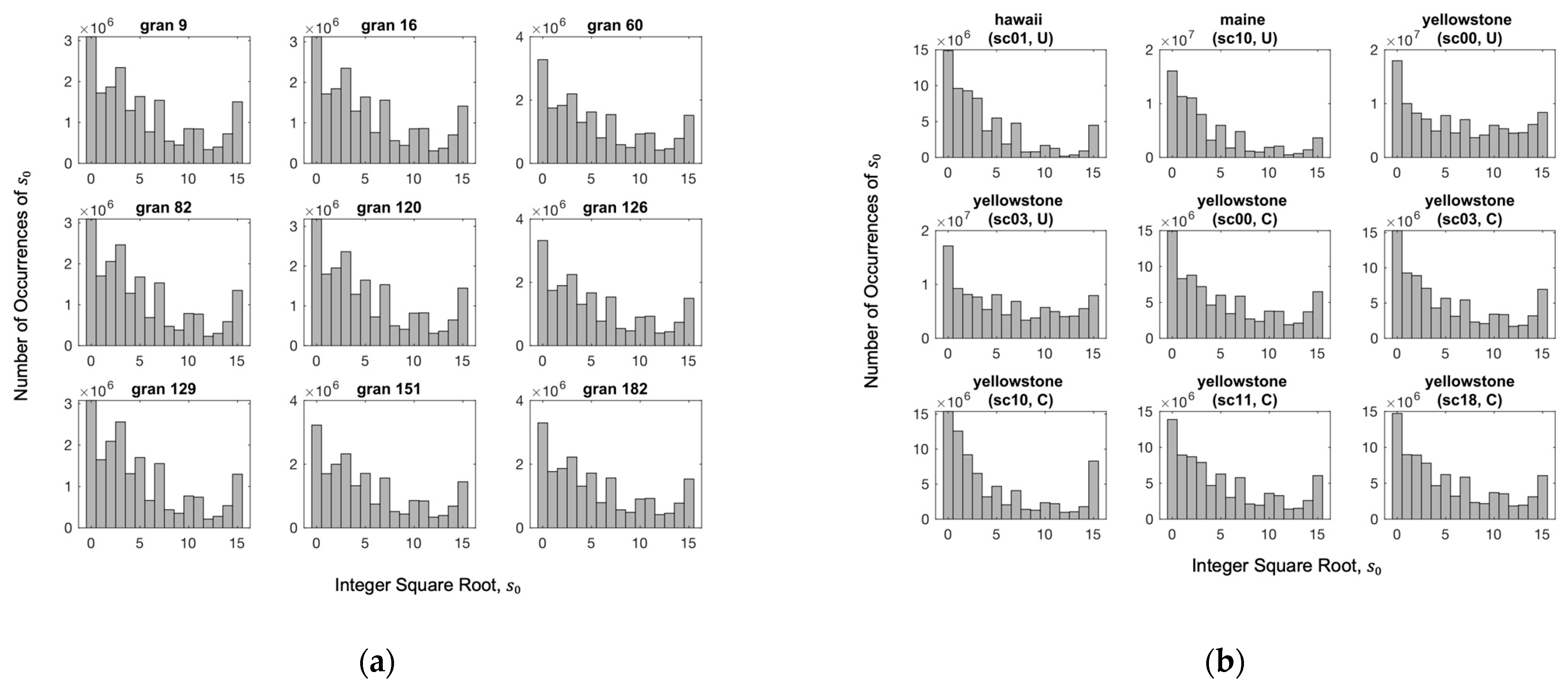
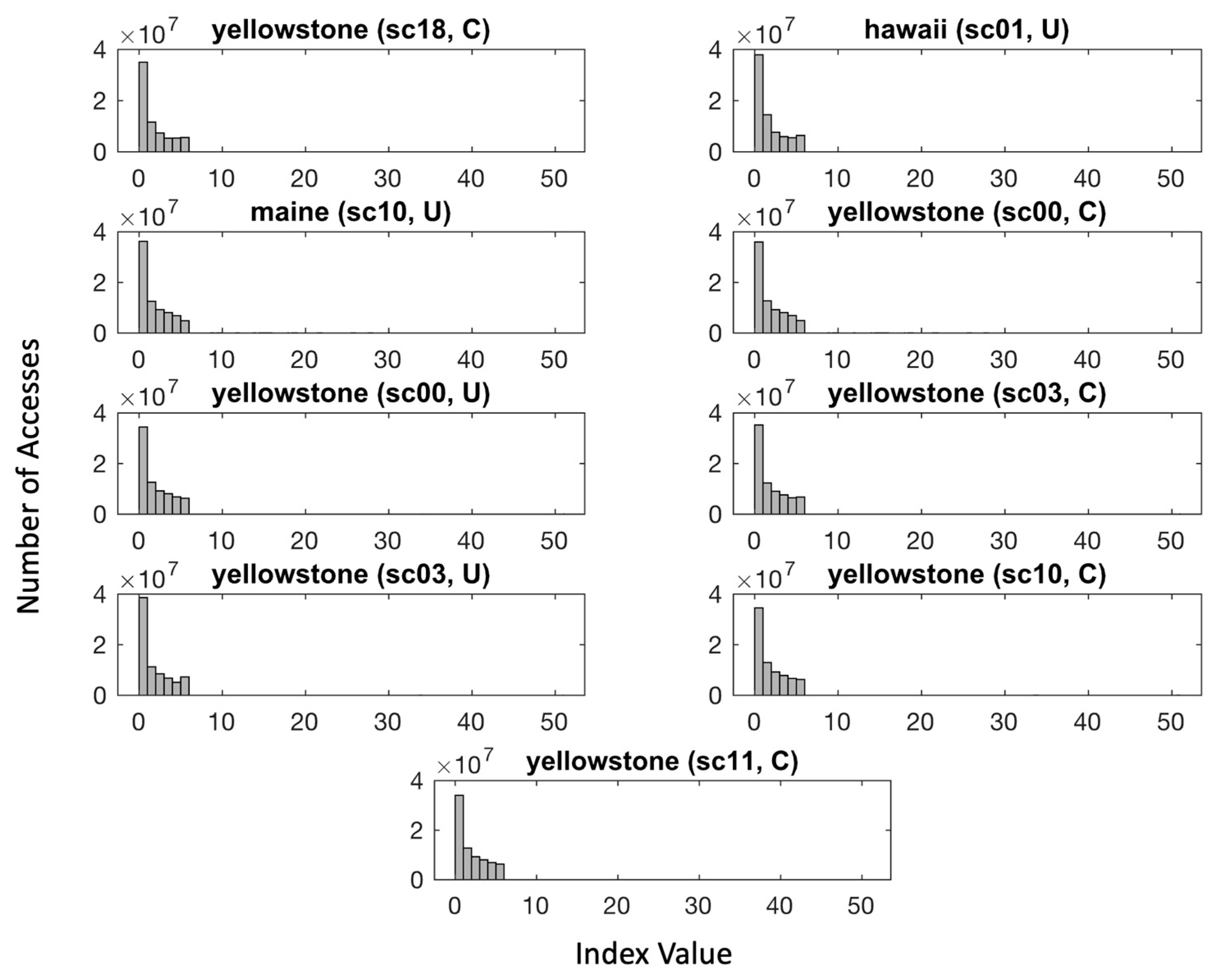
5.1. Dataset Description
5.2. Results of Lossless Compression
Comparison with Other Lossless Methods
5.3. Results of Near-Lossless Compression
Comparison with Other Near-Lossless Methods
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Index | |
|---|---|
| 0 | 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 107, 108, 109, 110, 111, 112, 113, 114, 115, 116, 117, 118, 119, 120, 121, 122, 123, 124, 125, 126, 127, 128, 129, 130, 131, 132, 133, 134, 135, 136, 137, 138, 139, 140, 141, 142, 143, 144, 145, 146, 147, 148, 149, 150, 151, 152, 153, 154, 155, 218, 219, 220, 221, 222, 223, 224, 225, 226, 227, 228, 229, 230, 231, 232, 233, 234, 235, 236, 237, 238, 239, 240, 241, 242, 243, 244, 245, 246, 247, 248, 249, 250, 251, 252, 253, 254, 255 |
| 1 | 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 75, 76, 77, 78, 79, 80, 81, 82, 83, 84, 103, 104, 105, 106, 107, 108, 109, 110, 111, 112, 149, 150, 151, 152, 153, 154, 155, 156, 157, 158, 159, 160, 161, 162, 163, 164, 209, 210, 211, 212, 213, 214, 215, 216, 217, 218, 219, 220, 221, 222, 223, 224 |
| 2 | 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 40, 41, 42, 43, 44, 45, 48, 49, 50, 51, 52, 53, 80, 81, 82, 83, 84, 85, 86, 87, 88, 100, 101, 102, 103, 104, 105, 106, 160, 161, 162, 163, 164, 165, 166, 167, 168, 169, 170, 171, 172, 203, 204, 205, 206, 207, 208, 209, 210, 211, 212, 213 |
| 3 | 4, 5, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 22, 23, 24, 25, 29, 30, 31, 43, 44, 45, 46, 47, 48, 49, 50, 51, 85, 86, 87, 88, 89, 90, 91, 97, 98, 99, 100, 101, 102, 103, 169, 170, 171, 172, 173, 174, 175, 176, 177, 178, 179, 180, 197, 198, 199, 200, 201, 202, 203, 204, 205, 206 |
| 4 | 6, 7, 8, 9, 10, 12, 13, 14, 15, 16, 17, 18, 23, 24, 25, 45, 46, 47, 48, 49, 50, 89, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99, 100, 178, 179, 180, 181, 182, 183, 184, 185, 186, 187, 188, 193, 194, 195, 196, 197, 198, 199, 200 |
| 5 | 3, 4, 5, 6, 7, 8, 9, 10, 12, 13, 14, 15, 16, 24, 47, 48, 93, 94, 95, 96, 97, 186, 187, 188, 189, 190, 191, 192, 193, 194, 195 |
| 6 | 6, 7, 8, 9, 13, 14, 15 |
| 7 | 5, 6, 7, 8, 9 |
| 8 | 4, 6, 7, 8 |
| 9 | 3, 5, 6, 7, 8 |
| 10 | 5, 7, 8 |
| 11 | 2, 4, 6, 7 |
| 12 | 6, 7 |
| 13 | 4, 6 |
| 14 | 3 |
| 15 | 4 |
| 17 | 4 |
| 18 | 3 |
| 20 | 2 |
| 21 | 3 |
| 25 | 3 |
| 27 | 2 |
| 33 | 1 |
| 50 | 1 |
References
- Lu, B.; Dao, P.D.; Liu, J.; He, Y.; Shang, J. Recent advances of hyperspectral imaging technology and applications in agriculture. Remote Sens. 2020, 12, 2659. [Google Scholar] [CrossRef]
- Dua, Y.; Kumar, V.; Singh, R.S. Comprehensive review of hyperspectral image compression algorithms. Opt. Eng. 2020, 59, 090902. [Google Scholar] [CrossRef]
- Hyperspectral Imaging: Technologies and Global Markets to 2023. 2019. Available online: https://www.bccresearch.com/market-research/instrumentation-and-sensors/hyperspectral-imaging.html (accessed on 26 October 2023).
- Lossless Multispectral and Hyperspectral Image Compression (CCSDS 120.2-G-2). Available online: https://public.ccsds.org/Pubs/120x2g2.pdf (accessed on 10 November 2023).
- Lopez, S.; Vladimirova, T.; Gonzalez, C.; Resano, J.; Mozos, D.; Plaza, A. The promise of reconfigurable computing for hyperspectral imaging onboard systems: A review and trends. Proc. IEEE 2013, 101, 698–722. [Google Scholar] [CrossRef]
- Wells, R.B. Applied Coding and Information Theory for Engineers; Prentice-Hall, Inc.: Upper Saddle River, NJ, USA, 1998. [Google Scholar]
- Hussain, A.J.; Al-Fayadh, A.; Radi, N. Image compression techniques: A survey in lossless and lossy algorithms. Neurocomputing 2018, 300, 44–69. [Google Scholar] [CrossRef]
- Dusselaar, R.; Paul, M. Hyperspectral image compression approaches: Opportunities, challenges, and future directions: Discussion. JOSA A 2017, 34, 2170–2180. [Google Scholar] [CrossRef] [PubMed]
- Altamimi, A.; Ben Youssef, B. A systematic review of hardware-accelerated compression of remotely sensed hyperspectral images. Sensors 2022, 22, 263. [Google Scholar] [CrossRef] [PubMed]
- Keymeulen, D.; Shin, S.; Riddley, J.; Klimesh, M.; Kiely, A.; Liggett, E.; Sullivan, P.; Bernas, M.; Ghossemi, H.; Flesch, G. High performance space computing with system-on-chip instrument avionics for space-based next generation imaging spectrometers (ngis). In Proceedings of the 2018 NASA/ESA Conference on Adaptive Hardware and Systems (AHS), Edinburgh, UK, 6–9 August 2018; IEEE: New York, NY, USA, 2018; pp. 33–36. [Google Scholar]
- Li, J.; Wu, J.; Jeon, G. GPU acceleration of clustered DPCM for lossless compression of hyperspectral images. IEEE Trans. Ind. Inform. 2019, 16, 2906–2916. [Google Scholar] [CrossRef]
- Dua, Y.; Kumar, V.; Singh, R.S. Parallel lossless HSI compression based on RLS filter. J. Parallel Distrib. Comput. 2021, 150, 60–68. [Google Scholar] [CrossRef]
- Ferraz, O.; Falcao, G.; Silva, V. Gbit/s throughput under 6.3-W lossless hyperspectral image compression on parallel embedded devices. IEEE Embed. Syst. Lett. 2020, 13, 13–16. [Google Scholar] [CrossRef]
- Tsigkanos, A.; Kranitis, N.; Theodorou, G.; Paschalis, A. A 3.3 Gbps CCSDS 123.0-B-1 multispectral & hyperspectral image compression hardware accelerator on a space-grade sram FPGA. IEEE Trans. Emerg. Top. Comput. 2018, 9, 90–103. [Google Scholar]
- Báscones, D.; González, C.; Mozos, D. An extremely pipelined FPGA implementation of a lossy hyperspectral image compression algorithm. IEEE Trans. Geosci. Remote Sens. 2020, 58, 7435–7447. [Google Scholar] [CrossRef]
- Báscones, D.; González, C.; Mozos, D. An FPGA accelerator for real-time lossy compression of hyperspectral images. Remote Sens. 2020, 12, 2563. [Google Scholar] [CrossRef]
- Fernandez, D.; Gonzalez, C.; Mozos, D.; Lopez, S. Fpga implementation of the principal component analysis algorithm for dimensionality reduction of hyperspectral images. J. Real-Time Image Process. 2019, 16, 1395–1406. [Google Scholar] [CrossRef]
- Krivenko, S.S.; Abramov, S.K.; Lukin, V.V.; Vozel, B.; Chehdi, K. Lossy DCT-based compression of remote sensing images with providing a desired visual quality. In Proceedings of the Image and Signal Processing for Remote Sensing XXV, Strasbourg, France, 9–11 September 2019; SPIE: Bellingham, WA, USA, 2019; pp. 345–356. [Google Scholar]
- Yadav, R.J.; Nagmode, M. Compression of hyperspectral image using PCA–DCT technology. In Proceedings of the Innovations in Electronics and Communication Engineering: Proceedings of the Fifth ICIECE 2016; Springer: Berlin/Heidelberg, Germany, 2017; pp. 269–277. [Google Scholar]
- Giordano, R.; Guccione, P. ROI-based on-board compression for hyperspectral remote sensing images on GPU. Sensors 2017, 17, 1160. [Google Scholar] [CrossRef] [PubMed]
- Santos, L.; Blanes, I.; García, A.; Serra-Sagristà, J.; López, J.; Sarmiento, R. On the hardware implementation of the arithmetic elements of the pairwise orthogonal transform. J. Appl. Remote Sens. 2015, 9, 097496. [Google Scholar] [CrossRef]
- Guerra, R.; Barrios, Y.; Díaz, M.; Baez, A.; López, S.; Sarmiento, R. A hardware-friendly hyperspectral lossy compressor for next-generation space-grade field programmable gate arrays. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 4813–4828. [Google Scholar] [CrossRef]
- Egho, C.; Vladimirova, T. Hardware acceleration of the integer karhunen-loeve transform algorithm for satellite image compression. In Proceedings of the 2012 IEEE International Geoscience and Remote Sensing Symposium, Munich, Germany, 22–27 July 2012; IEEE: New York, NY, USA, 2012; pp. 4062–4065. [Google Scholar]
- Ciznicki, M.; Kurowski, K.; Plaza, A. Graphics processing unit implementation of JPEG2000 for hyperspectral image compression. J. Appl. Remote Sens. 2012, 6, 061507. [Google Scholar]
- Zheng, T.; Dai, Y.; Xue, C.; Zhou, L. Recursive least squares for near-lossless hyperspectral data compression. Appl. Sci. 2022, 12, 7172. [Google Scholar] [CrossRef]
- Ansari, R.; Memon, N.D.; Ceran, E. Near-lossless image compression techniques. J. Electron. Imaging 1998, 7, 486–494. [Google Scholar]
- Beerten, J.; Blanes, I.; Serra-Sagristà, J. A fully embedded two-stage coder for hyperspectral near-lossless compression. IEEE Geosci. Remote Sens. Lett. 2015, 12, 1775–1779. [Google Scholar] [CrossRef]
- Miguel, A.; Liu, J.; Barney, D.; Ladner, R.; Riskin, E. Near-lossless compression of hyperspectral images. In Proceedings of the 2006 International Conference on Image Processing, Las Vegas, NV, USA, 26–29 June 2006; IEEE: New York, NY, USA, 2006; pp. 1153–1156. [Google Scholar]
- Aiazzi, B.; Alparone, L.; Baronti, S. Near-lossless compression of 3-D optical data. IEEE Trans. Geosci. Remote Sens. 2001, 39, 2547–2557. [Google Scholar] [CrossRef]
- Qian, S.-E.; Bergeron, M.; Cunningham, I.; Gagnon, L.; Hollinger, A. Near lossless data compression onboard a hyperspectral satellite. IEEE Trans. Aerosp. Electron. Syst. 2006, 42, 851–866. [Google Scholar] [CrossRef]
- Wu, X.; Memon, N.; Sayood, K. A Context-Based, Adaptive, Lossless/Nearly-Lossless Coding Scheme for Continuous-Tone Images. Available online: https://www.researchgate.net/publication/2822068_A_Context-based_Adaptive_LosslessNearly-Lossless_Coding_Scheme_for_Continuous-tone_Images (accessed on 20 October 2023).
- Wu, X.; Memon, N. Context-based lossless interband compression-extending CALIC. IEEE Trans. Image Process. 2000, 9, 994–1001. [Google Scholar] [PubMed]
- Magli, E.; Olmo, G.; Quacchio, E. Optimized onboard lossless and near-lossless compression of hyperspectral data using calic. IEEE Geosci. Remote Sens. Lett. 2004, 1, 21–25. [Google Scholar] [CrossRef]
- Blanes, I.; Magli, E.; Serra-Sagrista, J. A tutorial on image compression for optical space imaging systems. IEEE Geosci. Remote Sens. Mag. 2014, 2, 8–26. [Google Scholar] [CrossRef]
- Bartrina-Rapesta, J.; Blanes, I.; Aulí-Llinàs, F.; Serra-Sagristà, J.; Sanchez, V.; Marcellin, M.W. A lightweight contextual arithmetic coder for on-board remote sensing data compression. IEEE Trans. Geosci. Remote Sens. 2017, 55, 4825–4835. [Google Scholar] [CrossRef]
- Tai, S.-C.; Kuo, T.-M.; Ho, C.-H.; Liao, T.-W. A near-lossless compression method based on CCSDS for satellite images. In Proceedings of the 2012 International Symposium on Computer, Consumer and Control, Taichung, Taiwan, 4–6 June 2012; IEEE: New York, NY, USA, 2012; pp. 706–709. [Google Scholar]
- Wu, X.; Bao, P. Near-lossless image compression by combining wavelets and CALIC. In Proceedings of the Conference Record of the Thirty-First Asilomar Conference on Signals, Systems and Computers (Cat. No. 97CB36136), Pacific Grove, CA, USA, 2–5 November 1997; IEEE: New York, NY, USA, 1997; pp. 1427–1431. [Google Scholar]
- Carvajal, G.; Penna, B.; Magli, E. Unified lossy and near-lossless hyperspectral image compression based on JPEG 2000. IEEE Geosci. Remote Sens. Lett. 2008, 5, 593–597. [Google Scholar] [CrossRef]
- Altamimi, A.; Ben Youssef, B. Novel seed generation and quadrature-based square rooting algorithms. Sci. Rep. 2022, 12, 20540. [Google Scholar] [CrossRef] [PubMed]
- Chow, K.; Tzamarias, D.E.O.; Hernández-Cabronero, M.; Blanes, I.; Serra-Sagristà, J. Analysis of Variable-Length Codes for Integer Encoding in Hyperspectral Data Compression with the k2-Raster Compact Data Structure. Remote Sens. 2020, 12, 1983. [Google Scholar] [CrossRef]
- Valsesia, D.; Magli, E. High-throughput onboard hyperspectral image compression with ground-based CNN reconstruction. IEEE Trans. Geosci. Remote Sens. 2019, 57, 9544–9553. [Google Scholar] [CrossRef]
- Luo, J.; Wu, J.; Zhao, S.; Wang, L.; Xu, T. Lossless compression for hyperspectral image using deep recurrent neural networks. Int. J. Mach. Learn. Cybern. 2019, 10, 2619–2629. [Google Scholar] [CrossRef]
- Zikiou, N.; Lahdir, M.; Helbert, D. Support vector regression-based 3D-wavelet texture learning for hyperspectral image compression. Vis. Comput. 2020, 36, 1473–1490. [Google Scholar] [CrossRef]
- Dua, Y.; Singh, R.S.; Parwani, K.; Lunagariya, S.; Kumar, V. Convolution neural network based lossy compression of hyperspectral images. Signal Process. Image Commun. 2021, 95, 116255. [Google Scholar] [CrossRef]
- Guo, Y.; Chong, Y.; Pan, S. Hyperspectral image compression via cross-channel contrastive learning. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5513918. [Google Scholar] [CrossRef]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Patel, A.A. Hands-On Unsupervised Learning Using Python: How to Build Applied Machine Learning Solutions from Unlabeled Data; O’Reilly Media: Sebastopol, CA, USA, 2019. [Google Scholar]
- Melián, J.; Díaz, M.; Morales, A.; Guerra, R.; López, S.; López, J.F. A Novel Data Reutilization Strategy for Real-Time Hyperspectral Image Compression. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Bajpai, S.; Kidwai, N.R.; Singh, H.V.; Singh, A.K. Low memory block tree coding for hyperspectral images. Multimed. Tools Appl. 2019, 78, 27193–27209. [Google Scholar] [CrossRef]
- Can, E.; Karaca, A.C.; Danışman, M.; Urhan, O.; Güllü, M.K. Compression of hyperspectral images using luminance transform and 3D-DCT. In Proceedings of the IGARSS 2018-2018 IEEE International Geoscience and Remote Sensing Symposium, Valencia, Spain, 22–27 July 2018; IEEE: New York, NY, USA, 2018; pp. 5073–5076. [Google Scholar]
- Tzamarias, D.E.O.; Chow, K.; Blanes, I.; Serra-Sagristà, J. Compression of hyperspectral scenes through integer-to-integer spectral graph transforms. Remote Sens. 2019, 11, 2290. [Google Scholar] [CrossRef]
- Salut, M.M.; Anderson, D.V. Tensor Robust CUR for Compression and Denoising of Hyperspectral Data. IEEE Access 2023, 11, 77492–77505. [Google Scholar] [CrossRef]
- Mahoney, M.W.; Drineas, P. CUR matrix decompositions for improved data analysis. Proc. Natl. Acad. Sci. USA 2009, 106, 697–702. [Google Scholar] [CrossRef]
- Das, S. Hyperspectral image, video compression using sparse tucker tensor decomposition. IET Image Process. 2021, 15, 964–973. [Google Scholar] [CrossRef]
- Chang, C.I. Advances in Hyperspectral Image Processing Techniques; Wiley: Hoboken, NJ, USA, 2022. [Google Scholar]
- Chong, Y.; Zheng, W.; Li, H.; Qiao, Z.; Pan, S. Hyperspectral image compression and reconstruction based on block-sparse dictionary learning. J. Indian Soc. Remote Sens. 2018, 46, 1171–1186. [Google Scholar] [CrossRef]
- Gunasheela, K.; Prasantha, H. Compressive sensing approach to satellite hyperspectral image compression. In Information and Communication Technology for Intelligent Systems: Proceedings of Ictis 2018; Springer: Berlin/Heidelberg, Germany, 2018; Volume 1, pp. 495–503. [Google Scholar]
- Fu, W.; Lu, T.; Li, S. Context-aware compressed sensing of hyperspectral image. IEEE Trans. Geosci. Remote Sens. 2019, 58, 268–280. [Google Scholar] [CrossRef]
- Luo, J.; Xu, T.; Pan, T.; Han, X.; Sun, W. An efficient compression method of hyperspectral images based on compressed sensing and joint optimization. Integr. Ferroelectr. 2020, 208, 194–205. [Google Scholar] [CrossRef]
- Karaca, A.C.; Güllü, M.K. Lossless hyperspectral image compression using bimodal conventional recursive least-squares. Remote Sens. Lett. 2018, 9, 31–40. [Google Scholar] [CrossRef]
- Karaca, A.C.; Güllü, M.K. Superpixel based recursive least-squares method for lossless compression of hyperspectral images. Multidimens. Syst. Signal Process. 2019, 30, 903–919. [Google Scholar] [CrossRef]
- Chow, K.; Tzamarias, D.E.O.; Blanes, I.; Serra-Sagristà, J. Using predictive and differential methods with k2-raster compact data structure for hyperspectral image lossless compression. Remote Sens. 2019, 11, 2461. [Google Scholar] [CrossRef]
- Brisaboa, N.R.; Ladra, S.; Navarro, G. k2-trees for compact web graph representation. In Proceedings of the International Symposium on String Processing and Information Retrieval, Pisa, Italy, 26–28 September 2009; Springer: Berlin/Heidelberg, Germany, 2009; pp. 18–30. [Google Scholar]
- Steiner, C. The 8051/8052 Microcontroller: Architecture, Assembly Language, and Hardware Interfacing; Universal-Publishers: Boca Raton, FL, USA, 2005. [Google Scholar]
- Chaudhuri, S.; Kotwal, K. Hyperspectral Image Fusion; Springer: New York, NY, USA, 2013. [Google Scholar]
- Fog, A. Instruction Tables: Lists of Instruction Latencies, Throughputs and Micro-Operation Breakdowns for Intel, AMD and VIA CPUs; Copenhagen University College of Engineering: Ballerup, Denmark, 2011; Volume 93, p. 110. [Google Scholar]
- Yan, D.; Wu, T.; Liu, Y.; Gao, Y. An efficient sparse-dense matrix multiplication on a multicore system. In Proceedings of the 2017 IEEE 17th International Conference on Communication Technology (ICCT), Chengdu, China, 27–30 October 2017; IEEE: New York, NY, USA, 2017; pp. 1880–1883. [Google Scholar]
- Huang, B. Satellite Data Compression; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2011. [Google Scholar]
- Qian, S.-E. Optical Satellite Data Compression and Implementation; SPIE: Bellingham, WA, USA, 2013. [Google Scholar]
- Joshi, V.; Rani, J.S. A Simple Lossless Algorithm (SLA) for on-board Satellite Hyperspectral Data Compression. IEEE Geosci. Remote Sens. Lett. 2023, 20, 5504305. [Google Scholar] [CrossRef]
- Shen, H.; Jiang, Z.; Pan, W.D. Efficient lossless compression of multitemporal hyperspectral image data. J. Imaging 2018, 4, 142. [Google Scholar] [CrossRef]
- Xu, P.; Chen, B.; Xue, L.; Zhang, J.; Zhu, L. A prediction-based spatial-spectral adaptive hyperspectral compressive sensing algorithm. Sensors 2018, 18, 3289. [Google Scholar] [CrossRef]
- Blanes, I.; Serra-Sagristà, J. Pairwise orthogonal transform for spectral image coding. IEEE Trans. Geosci. Remote Sens. 2010, 49, 961–972. [Google Scholar] [CrossRef]
- Amrani, N.; Serra-Sagristà, J.; Laparra, V.; Marcellin, M.W.; Malo, J. Regression wavelet analysis for lossless coding of remote-sensing data. IEEE Trans. Geosci. Remote Sens. 2016, 54, 5616–5627. [Google Scholar] [CrossRef]
- Guerra, R.; Barrios, Y.; Díaz, M.; Santos, L.; López, S.; Sarmiento, R. A new algorithm for the on-board compression of hyperspectral images. Remote Sens. 2018, 10, 428. [Google Scholar] [CrossRef]
- Hernández-Cabronero, M.; Portell, J.; Blanes, I.; Serra-Sagristà, J. High-performance lossless compression of hyperspectral remote sensing scenes based on spectral decorrelation. Remote Sens. 2020, 12, 2955. [Google Scholar] [CrossRef]
- Cooper, T.K. Exclusive-or Preprocessing and Dictionary Coding of Continuous-Tone Images. Doctoral Dissertation, University of Louisville, St, Louisville, KY, USA, 2015. [Google Scholar]
- Huo, F.; Gong, G. Xor encryption versus phase encryption, an in-depth analysis. IEEE Trans. Electromagn. Compat. 2015, 57, 903–911. [Google Scholar] [CrossRef]
- Li, R.; Pan, Z.; Wang, Y. The linear prediction vector quantization for hyperspectral image compression. Multimed. Tools Appl. 2019, 78, 11701–11718. [Google Scholar] [CrossRef]
- Rice, R.; Plaunt, J. Adaptive variable-length coding for efficient compression of spacecraft television data. IEEE Trans. Commun. Technol. 1971, 19, 889–897. [Google Scholar] [CrossRef]
- Bhaskaran, V.; Konstantinides, K. Image and Video Compression Standards: Algorithms and Architectures; Springer: New York, NY, USA, 2012. [Google Scholar]
- Dunham, W. Journey through Genius: Great Theorems of Mathematics; John Wiley & Sons: Hoboken, NJ, USA, 1991. [Google Scholar]
- Consultative Committee for Space Data Systems (CCSDS). Corpus Datasets. Available online: https://cwe.ccsds.org/sls/docs/SLS-DC/123.0-B-Info/TestData/ (accessed on 4 July 2023).
- Consultative Committee for Space Data Systems (CCSDS). Low-Complexity Lossless and Near-Lossless Multispectral and Hyperspectral Image Compression.Blue Book. Issue 2. 2019. Available online: https://public.ccsds.org/Pubs/123x0b2e1c3.pdf (accessed on 10 August 2023).
- Consultative Committee for Space Data Systems (CCSDS). The Corpus Dataset Info. 21 May 2015. Available online: https://cwe.ccsds.org/sls/docs/SLS-DC/123.0-B-Info/TestData/README.txt (accessed on 4 July 2023).
- Kwok, W.; Haghighi, K.; Kang, E. An efficient data structure for the advancing-front triangular mesh generation technique. Commun. Numer. Methods Eng. 1995, 11, 465–473. [Google Scholar] [CrossRef]
- Bairagi, V.K.; Sapkal, A.M.; Gaikwad, M. The role of transforms in image compression. J. Inst. Eng. (INDIA) Ser. B 2013, 94, 135–140. [Google Scholar] [CrossRef]
- Elisei-Iliescu, C.; Stanciu, C.; Paleologu, C.; Benesty, J.; Anghel, C.; Ciochină, S. Efficient recursive least-squares algorithms for the identification of bilinear forms. Digit. Signal Process. 2018, 83, 280–296. [Google Scholar] [CrossRef]
- Jiang, J.; Zhang, Y. A revisit to block and recursive least squares for parameter estimation. Comput. Electr. Eng. 2004, 30, 403–416. [Google Scholar] [CrossRef]












| Reference | Method | Category | Type | Year |
|---|---|---|---|---|
| [40] | -raster | Compact Data Structure | Lossless | 2020 |
| [45] | HCCNet | Deep Learning | Lossy | 2023 |
| [44] | Autoencoders | Deep Learning | Lossy | 2021 |
| [43] | SVR | Machine Learning | Lossy | 2020 |
| [42] | RNN | Deep Learning | Lossless | 2019 |
| [41] | CNN | Deep Learning | Lossy | 2019 |
| [48] | HyperLCA | Transform-Based | Lossy | 2022 |
| [22] | HW-HyperLCA | Transform-Based | Lossy | 2019 |
| [49] | 3D-WBTC | Transform-Based | Lossy | 2019 |
| [51] | Spectral Graph Transform | Transform-Based | Lossless | 2019 |
| [50] | 3D-DCT | Transform-Based | Lossy | 2018 |
| [52] | Tensor-Robust CUR | Tensor-Based | Lossy | 2023 |
| [54] | Tucker Decomposition | Tensor-Based | Lossy | 2021 |
| [59] | Optimized CS | Compressed Sensing | Lossy | 2020 |
| [58] | CACS | Compressed Sensing | Lossy | 2019 |
| [57] | SHSIR | Compressed Sensing | Lossy | 2019 |
| [56] | BlockSparse Dictionary | Compressed Sensing | Lossy | 2018 |
| [60] | B-CRLS | Recursive Least-Squares | Lossless | 2018 |
| [61] | SuperRLS | Recursive Least-Squares | Lossless | 2018 |
| [61] | BSuperRLS | Recursive Least-Squares | Lossless | 2018 |
| Fractional Bits | |
|---|---|
| 1 | |
| 2 | |
| 3 | |
| 4 | |
| 5 | |
| 6 | |
| 7 | |
| 8 | |
| 9 |
| Integer Bits | Fractional Bits | ||
|---|---|---|---|
| 1 | 1 | 0000 | 0 (unary) |
| 2 | 1 | 0001 | 0 |
| 3 | 1 | 0001 | 1 |
| 4 | 2 | 0000 | 10 (unary) |
| 5 | 2 | 0010 | 00 |
| 6 | 2 | 0010 | 01 |
| 7 | 2 | 0010 | 10 |
| 8 | 2 | 0010 | 11 |
| 9 | 3 | 0011 | 00 |
| ... | ... | ... | ... |
| 16 | 4 | 0000 | 110 (unary) |
| 17 | 4 | 0100 | 000 |
| 18 | 4 | 0100 | 001 |
| 19 | 4 | 0100 | 010 |
| 20 | 4 | 0100 | 011 |
| 21 | 4 | 0100 | 100 |
| 22 | 4 | 0100 | 101 |
| 23 | 4 | 0100 | 110 |
| 24 | 4 | 0100 | 111 |
| 25 | 5 | 0101 | 0000 |
| ... | ... | ... | ... |
| Index | Number of Bits | |
|---|---|---|
| 0 | 157 | 8 |
| 1 | 111 | 7 |
| 2 | 83 | 7 |
| 3 | 66 | 7 |
| 4 | 52 | 6 |
| 5 | 31 | 5 |
| 6 | 7 | 3 |
| 7 | 5 | 3 |
| 8 | 4 | 2 |
| 9 | 5 | 3 |
| 10 | 3 | 2 |
| 11 | 4 | 2 |
| 12 | 2 | 1 |
| 13 | 2 | 1 |
| 14 | 1 | 0 |
| 15 | 1 | 0 |
| 17 | 1 | 0 |
| 18 | 1 | 0 |
| 20 | 1 | 0 |
| 21 | 1 | 0 |
| 25 | 1 | 0 |
| 27 | 1 | 0 |
| 33 | 1 | 0 |
| 50 | 1 | 0 |
| Index | ||
|---|---|---|
| 29 | 5 | 7 |
| 12,317 | 112 | 0 |
| 22,556 | 152 | 1 |
| 31,003 | 185 | 4 |
| 5403 | 74 | 0 |
| 1818 | 44 | 3 |
| 21,017 | 146 | 0 |
| 61,974 | 249 | 0 |
| 15,125 | 123 | 0 |
| 10,260 | 104 | 2 |
| Imager | Scene | Data Type | Dimensions | C\U * | Bit Rate |
|---|---|---|---|---|---|
| AIRS | gran9 | u16 | 1501 × 135 × 90 | U | 12 |
| gran16 | 1501 × 135 × 90 | ||||
| gran60 | 1501 × 135 × 90 | ||||
| gran82 | 1501 × 135 × 90 | ||||
| gran120 | 1501 × 135 × 90 | ||||
| gran126 | 1501 × 135 × 90 | ||||
| gran129 | 1501 × 135 × 90 | ||||
| gran151 | 1501 × 135 × 90 | ||||
| gran182 | 1501 × 135 × 90 | ||||
| AVIRIS | Hawaii | u16 | 224 × 512 × 614 | U | 16 |
| Maine | 224 × 512 × 680 | ||||
| Yellowstone (sc00) | 224 × 512 × 680 | ||||
| Yellowstone (sc03) | 224 × 512 × 680 | ||||
| AVIRIS | Yellowstone (sc00) | s16 | 224 × 512 × 677 | C | 16 |
| Yellowstone (sc03) | 224 × 512 × 677 | ||||
| Yellowstone (sc10) | 224 × 512 × 677 | ||||
| Yellowstone (sc11) | 224 × 512 × 677 | ||||
| Yellowstone (sc18) | 224 × 512 × 677 | ||||
| CRISM | sc182 | u16 | 545 × 450 × 320 | U | 12 |
| sc214 | 74 × 2700 × 64 | ||||
| CASI | t0477f06 | u16 | 72 × 1225 × 406 | U | 12 |
| t0180f07 | 72 × 2852 × 405 | ||||
| Hyperion | Cuprite | u16 | 242 × 1024 × 256 | U | 12 |
| ErtaAle | 242 × 3187 × 256 | ||||
| LakeMonona | 242 × 3176 × 256 | ||||
| MtStHelens | 242 × 3242 × 256 | ||||
| M3 | globalA | u16 | 86 × 512 × 320 | U | 12 |
| globalB | 86 × 512 × 320 | ||||
| targetA | 260 × 512 × 640 | ||||
| targetB | 260 × 512 × 640 | ||||
| targetC | 260 × 512 × 640 | ||||
| SFSI | Mantar | u16 | 240 × 140 × 496 | U | 12 |
| Scene | Original Sparsity | Sparsity after Decorrelation | Average Bit Rate | CR |
|---|---|---|---|---|
| Hawaii (U) | 01.45% | 25.84% | 12.87 | 1.2 |
| Maine (U) | 0% | 25.90% | 12.86 | 1.2 |
| Yellowstone (sc00, C) | 0% | 30.80% | 12.07 | 1.3 |
| Yellowstone (sc00, U) | 01.19% | 19.86% | 13.82 | 1.2 |
| Yellowstone (sc03, C) | 0% | 00.19% | 16.97 | 0.9 |
| Yellowstone (sc03, U) | 02.65% | 24.69% | 13.05 | 1.2 |
| Yellowstone (sc10, C) | 0% | 00.18% | 16.97 | 0.9 |
| Yellowstone (sc11, C) | 07.68% | 35.58% | 11.31 | 1.4 |
| Yellowstone (sc18, C) | 02.03% | 27.12% | 12.66 | 1.3 |
| Scene | Original Sparsity | Sparsity after Decorrelation | Average Bit Rate | CR |
|---|---|---|---|---|
| Hawaii (U) | 04.74% | 43.05% | 5.56 | 1.4 |
| Maine (U) | 11.77% | 53.51% | 4.72 | 1.7 |
| Yellowstone (sc00, C) | 14.28% | 54.23% | 4.66 | 1.7 |
| Yellowstone (sc00, U) | 04.43% | 43.82% | 5.49 | 1.5 |
| Yellowstone (sc03, C) | 00.96% | 27.52% | 6.80 | 1.2 |
| Yellowstone (sc03, U) | 06.53% | 44.91% | 5.41 | 1.5 |
| Yellowstone (sc10, C) | 01.33% | 28.85% | 6.69 | 1.2 |
| Yellowstone (sc11, C) | 14.12% | 52.40% | 4.81 | 1.7 |
| Yellowstone (sc18, C) | 05.80% | 47.85% | 5.17 | 1.5 |
| Rice Code | AIRS-1D | AIRS-2D | AVIRIS-1D | AVIRIS-2D |
|---|---|---|---|---|
| 0.0 | 0 | 0 | 0 | 0 |
| 0.1 | 3 | 3 | 1 | 1 |
| 10.0 | 2 | 2 | 2 | 2 |
| 10.1 | 1 | 1 | 15 | 3 |
| 110.0 | 5 | 5 | 3 | 5 |
| 110.1 | 7 | 7 | 7 | 15 |
| 1110.0 | 15 | 15 | 5 | 7 |
| 1110.1 | 4 | 4 | 14 | 4 |
| 11110.0 | 10 | 11 | 10 | 10 |
| 11110.1 | 14 | 10 | 4 | 11 |
| 111110.0 | 6 | 6 | 6 | 6 |
| 111110.1 | 11 | 14 | 11 | 14 |
| 1111110.0 | 9 | 8 | 9 | 8 |
| 1111110.1 | 13 | 9 | 13 | 9 |
| 11111110.0 | 8 | 13 | 8 | 13 |
| 11111110.1 | 12 | 12 | 12 | 12 |
| Imager | Scene | Entropy (Bits) | -Raster | Proposed (1D XOR, Rice) | Proposed (2D XOR, Rice) | Proposed (1D XOR, Mapped Rice) | Proposed (2D XOR, Mapped Rice) |
|---|---|---|---|---|---|---|---|
| AIRS | gran9 | 11.2 | 21% | 22% | 23% | 25% | 26% |
| gran16 | 11.1 | 24% | 24% | 24% | 26% | 26% | |
| gran60 | 11.5 | 19% | 18% | 20% | 20% | 22% | |
| gran82 | 11.0 | - | 29% | 27% | 32% | 30% | |
| gran120 | 11.2 | - | 25% | 25% | 27% | 27% | |
| gran126 | 11.5 | 20% | 20% | 21% | 22% | 24% | |
| gran129 | 11.1 | 28% | 31% | 29% | 34% | 31% | |
| gran151 | 11.6 | 21% | 23% | 23% | 26% | 25% | |
| gran182 | 11.6 | 19% | 19% | 20% | 22% | 22% | |
| AVIRIS | Hawaii | 8.6 | - | 58% | 57% | 59% | 57% |
| Maine | 9.1 | - | 58% | 57% | 58% | 57% | |
| Yellowstone (sc00, U) | 12.6 | 25% | 19% | 22% | 22% | 25% | |
| Yellowstone (sc03, U) | 12.3 | 27% | 22% | 25% | 24% | 27% | |
| AVIRIS | Yellowstone (sc00, C) | 10.3 | 40% | 39% | 43% | 41% | 44% |
| Yellowstone (sc03, C) | 9.9 | 41% | 40% | 44% | 43% | 46% | |
| Yellowstone (sc10) | 8.6 | 52% | 53% | 52% | 55% | 55% | |
| Yellowstone (sc11) | 9.8 | 45% | 46% | 48% | 47% | 49% | |
| Yellowstone (sc18) | 10.2 | 39% | 39% | 44% | 41% | 46% | |
| CRISM | sc182 | 11.2 | 16% | 35% | 27% | 37% | 29% |
| sc214 | 9.9 | - | 60% | 52% | 61% | 53% | |
| CASI | t0477f06 | 10.4 | - | 24% | 23% | 27% | 25% |
| t0180f07 | 10.7 | - | 15% | 17% | 18% | 19% | |
| Hyperion | Cuprite | 9.4 | - | 44% | 37% | 46% | 40% |
| ErtaAle | 9.5 | 35% | 43% | 36% | 45% | 38% | |
| LakeMonona | 9.9 | 35% | 43% | 36% | 45% | 38% | |
| MtStHelens | 9.3 | 34% | 40% | 33% | 42% | 36% | |
| M3 | globalA | 9.4 | - | 44% | 37% | 46% | 43% |
| globalB | 9.3 | - | 45% | 38% | 47% | 45% | |
| targetA | 8.7 | - | 55% | 48% | 56% | 51% | |
| targetB | 9.7 | - | 52% | 45% | 53% | 48% | |
| targetC | 8.8 | - | 61% | 54% | 62% | 56% | |
| SFSI | mantar | 7.2 | - | 47% | 40% | 50% | 45% |
| Geometric Mean | 28.40% | 34.45% | 33.13% | 36.89% | 35.72% | ||
| Reduction Enhancement | NA | 21.30% | 16.65% | 29.89% | 25.77% | ||
| Imager | Scene | Proposed (1D XOR, Rice) | Proposed (2D XOR, Rice) | Proposed (1D XOR, Mapped Rice) | Proposed (2D XOR, Mapped Rice) | -Raster (DACs) | gzip | bzip2 | xz |
|---|---|---|---|---|---|---|---|---|---|
| AIRS | gran9 | 9.37 | 9.23 | 9.03 | 8.92 | 9.49 | 10.16 | 7.42 | 7.90 |
| gran16 | 9.16 | 9.13 | 8.82 | 8.83 | 9.12 | 9.82 | 7.15 | 7.66 | |
| gran60 | 9.89 | 9.63 | 9.56 | 9.33 | 9.72 | 10.53 | 7.71 | 8.23 | |
| gran126 | 9.65 | 9.47 | 9.33 | 9.16 | 9.61 | 10.33 | 7.64 | 8.10 | |
| gran129 | 8.25 | 8.57 | 7.94 | 8.26 | 8.65 | 9.50 | 6.68 | 7.22 | |
| gran151 | 9.23 | 9.24 | 8.91 | 8.93 | 9.53 | 10.31 | 7.43 | 7.97 | |
| gran182 | 9.72 | 9.60 | 9.39 | 9.29 | 9.68 | 10.64 | 7.79 | 8.33 | |
| AVIRIS | Yellowstone (sc00, U) | 12.94 | 12.41 | 12.51 | 12.07 | 11.92 | 12.39 | 9.99 | 10.61 |
| Yellowstone (sc03, U) | 12.46 | 11.95 | 12.11 | 11.63 | 11.74 | 11.98 | 9.54 | 10.23 | |
| AVIRIS | Yellowstone (sc00, C) | 9.83 | 9.18 | 9.47 | 8.90 | 9.61 | 10.12 | 7.51 | 8.04 |
| Yellowstone (sc03, C) | 9.53 | 8.89 | 9.15 | 8.57 | 9.42 | 9.59 | 7.10 | 7.62 | |
| Yellowstone (sc10) | 7.55 | 7.62 | 7.15 | 7.18 | 7.62 | 7.41 | 5.30 | 5.73 | |
| Yellowstone (sc11) | 8.72 | 8.38 | 8.45 | 8.11 | 8.81 | 9.04 | 6.65 | 7.07 | |
| Yellowstone (sc18) | 9.80 | 8.91 | 9.48 | 8.65 | 9.78 | 10.00 | 7.45 | 7.95 | |
| CRISM | sc182 | 7.83 | 8.81 | 7.57 | 8.53 | 10.11 | 10.90 | 8.53 | 7.90 |
| Hyperion | ErtaAle | 6.82 | 7.67 | 6.57 | 7.40 | 7.76 | 8.69 | 6.41 | 6.73 |
| LakeMonona | 6.84 | 7.73 | 6.56 | 7.43 | 7.82 | 8.69 | 6.46 | 6.74 | |
| MtStHelens | 7.18 | 7.95 | 6.93 | 7.69 | 7.91 | 8.26 | 6.28 | 6.48 |
| Imager | Scene | Data Reduction (%) | MRE | MAE |
|---|---|---|---|---|
| AIRS | gran9 | 39.4242 | 0.0667 | 30 |
| gran16 | 39.7075 | 0.0038 | 30 | |
| gran60 | 39.5578 | 0.3333 | 30 | |
| gran82 | 39.6562 | 0.0038 | 30 | |
| gran120 | 39.5115 | 0.0667 | 30 | |
| gran126 | 39.5593 | 0.0667 | 30 | |
| gran129 | 39.6236 | 0.0038 | 30 | |
| gran151 | 39.5363 | 0.3333 | 30 | |
| gran182 | 39.5240 | 0.0667 | 30 | |
| AVIRIS | Yellowstone (sc00, U) | 39.7314 | 0.0667 | 30 |
| Yellowstone (sc03, U) | 39.7106 | 0.0667 | 30 | |
| CRISM | sc182 | 39.4889 | 0.3333 | 30 |
| CASI | t0477f06 | 39.6337 | 0.3333 | 30 |
| t0180f07 | 38.9011 | 0.3333 | 30 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Altamimi, A.; Ben Youssef, B. Lossless and Near-Lossless Compression Algorithms for Remotely Sensed Hyperspectral Images. Entropy 2024, 26, 316. https://doi.org/10.3390/e26040316
Altamimi A, Ben Youssef B. Lossless and Near-Lossless Compression Algorithms for Remotely Sensed Hyperspectral Images. Entropy. 2024; 26(4):316. https://doi.org/10.3390/e26040316
Chicago/Turabian StyleAltamimi, Amal, and Belgacem Ben Youssef. 2024. "Lossless and Near-Lossless Compression Algorithms for Remotely Sensed Hyperspectral Images" Entropy 26, no. 4: 316. https://doi.org/10.3390/e26040316
APA StyleAltamimi, A., & Ben Youssef, B. (2024). Lossless and Near-Lossless Compression Algorithms for Remotely Sensed Hyperspectral Images. Entropy, 26(4), 316. https://doi.org/10.3390/e26040316