
Benefits of Zero-Phase or Linear Phase Filters to Design Multiscale Entropy: Theory and Application


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
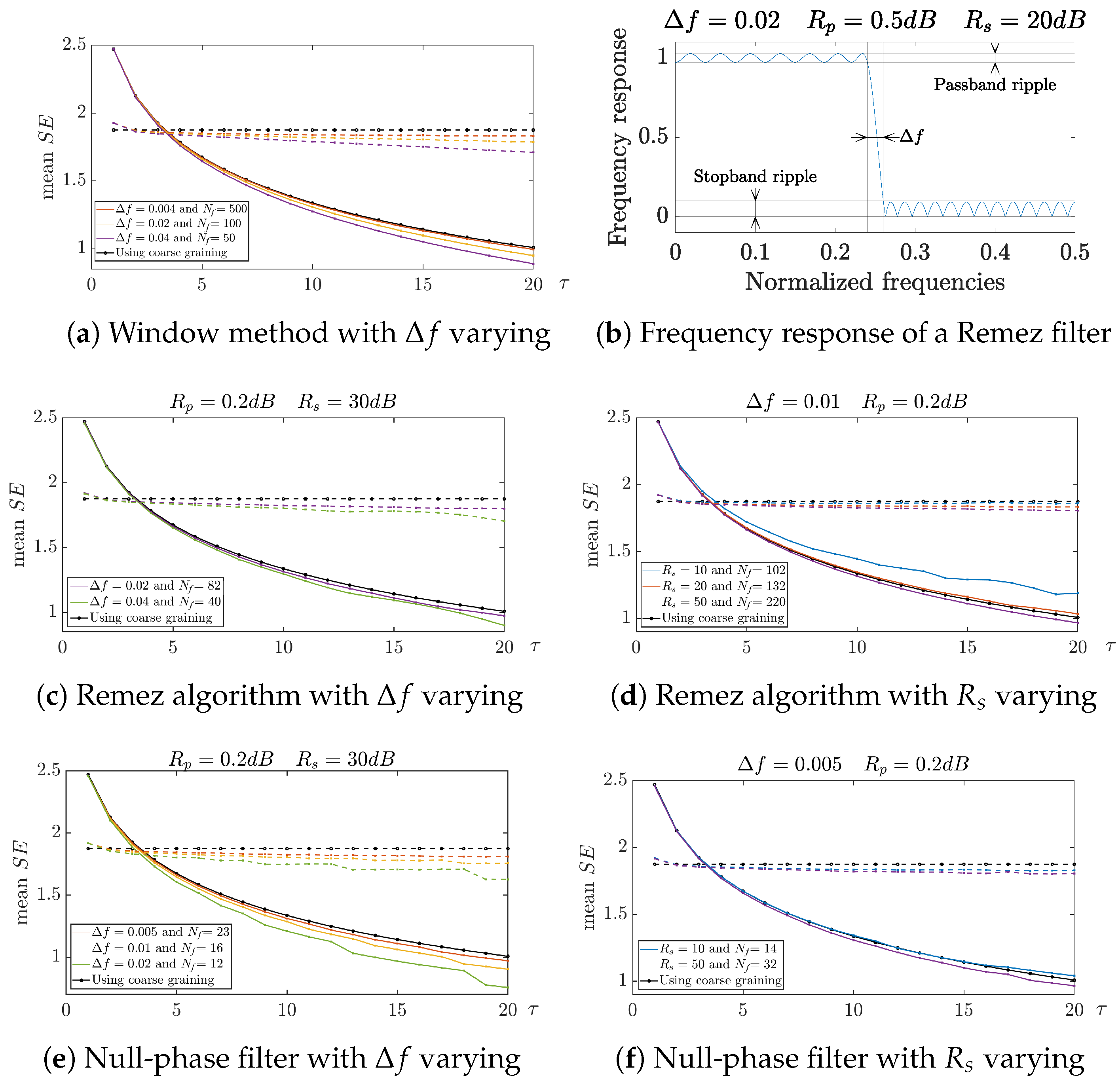
2. MSE Based on a Linear-Phase or Null-Phase Low-Pass Filter Well Suited for a Post Decimation Step
2.1. Multiscale Entropy: A Measure of Complexity
- Step 1: Applying on the signal x an averaging filter defined by a causal FIR for (with being the maximum scale) and zero elsewhere. The resulting transfer function , which is the z transform of , satisfiesConsequently, the frequency response of this causal filter for the normalized frequency is given byIt is a low-pass filter. The zeros of are equal to , with , and are located on the unit circle in the z plane. This means that the frequency response of the filter totally rejects the normalized frequencies for . Finally, due to the symmetry of the impulse filter, the filtering has the advantage of having a linear phase, thereby leading to a constant group delay and no phase distortion of the signal in the pass band. Only the steady state is considered. In other words, the first samples of the output filter are not considered.
- Step 2: Decimating by a factor the filter output: The samples whose indices are multiples of are kept for and :In the following, is the vector storing the values , with . It should be noted that in the frequency domain, due to the decimation, the normalized frequencies above will be a source of aliasing. As the frequency responses of the filters defined above have their main lobes between and and the side lobes are not necessarily much attenuated (See (6)), the filters are not well suited to be antialiasing filters. Hence, this can be a source of problems, as reported by Valencia [25], Humeau [24], or more recently Zhao [26].
- Step 3: Computing the SE for each scale and summing them: the SE is computed for each scale, and the MSE is defined by the sum . This can be rewritten asNote that only one decimated sequence, namely with , is used in the standard MSE. In addition, one of the problems of the MSE algorithm is the use of the same tolerance level r for all scales [29].
2.2. Our Theoretical Contribution
- New step 1: Applying on the signal x a linear-phase or null-phase low pass filter. For each scale , the goal is to select a low-pass causal FIR filter with a linear phase or a null phase and a normalized cutoff frequency that is smaller than .
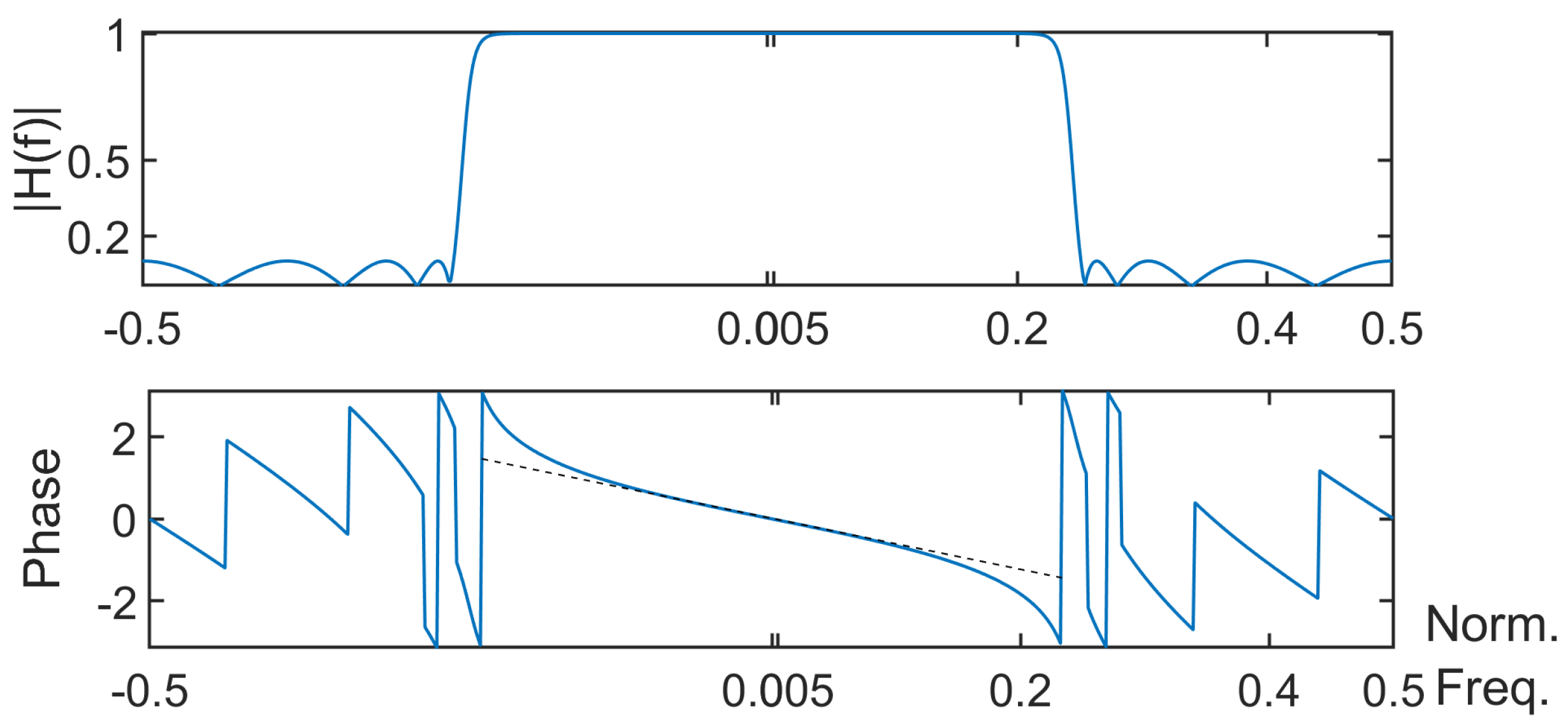
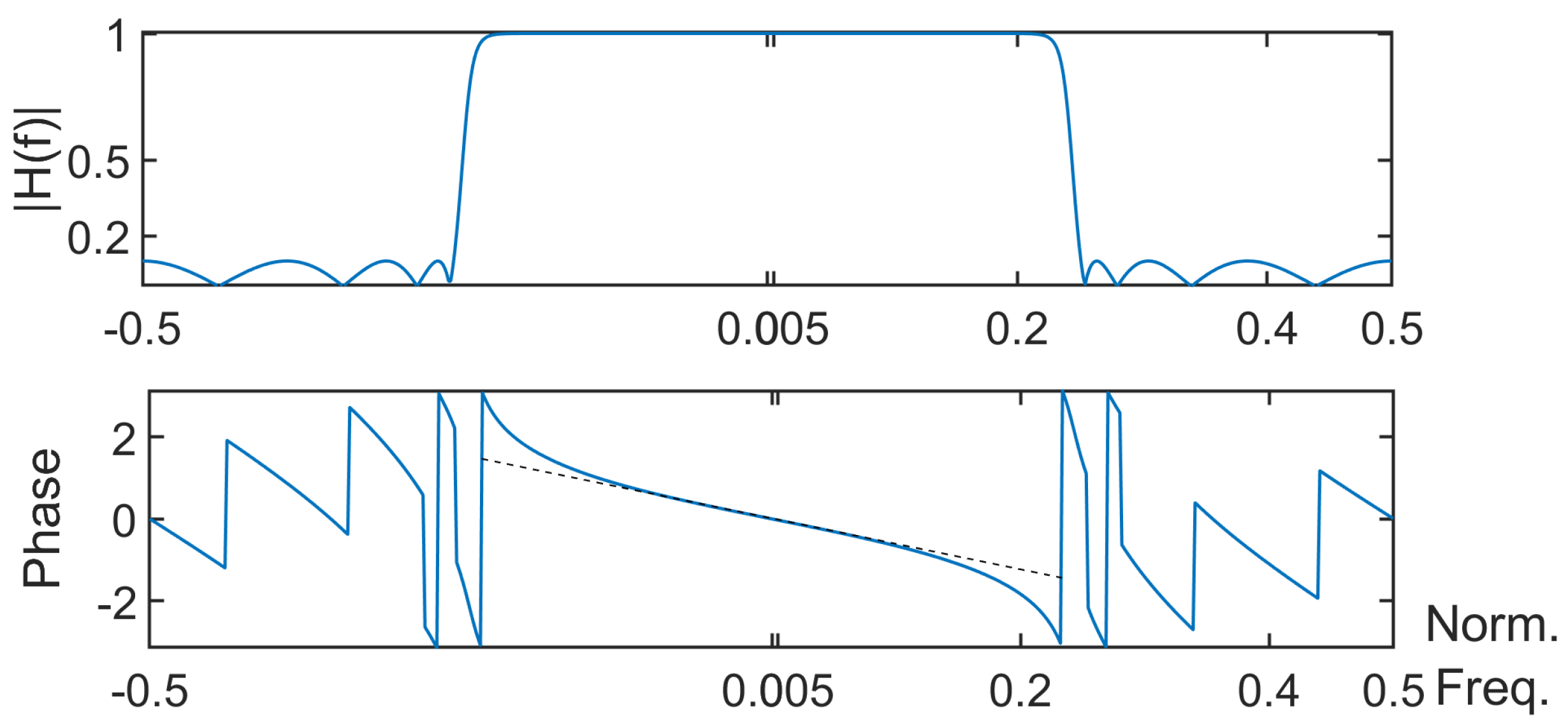
- About the window method: It operates with the following steps: defining the specifications of the low-pass digital filter , taking the inverse Fourier transform, and windowing the resulting impulse response to obtain the FIR of the low-pass filter.About the Remez algorithm: Also known as the Parks–McClellan optimal equiripple FIR filter design, the Remez algorithm is a curve fitting method proposed in the 1970s minimizing the error between the actual frequency response and the frequency response of the designed filter. The starting point of the approach is that the frequency response of a filter whose impulse response is symmetric and whose order is odd can be expressed as a linear combination of or equivalently as a linear combination of Chebyshev polynomials of the first kind in . Therefore, this frequency response can be modeled as a polynomial in . The next step is to search the coefficients of the polynomial that best approximate this frequency response so that the error between both frequency responses in the pass and stop bands are minimized. Using the alternation theorem (a polynomial fit of degree n to a set of bounded points is said to be minimax if and only if it attains its maximal error at n + 2 points with alternating signs), the normalized frequencies leading to the maximal errors and the polynomial coefficients are estimated in an iterative way. Usually less than 15 iterations are required.
- First strategy: The signal is filtered by a filter whose real impulse response is , thus leading to the signal . Then, the time-reversed version is filtered by a filter whose impulse response is still equal to . The output is denoted as . Finally, is time reversed to obtain the filtered signal of interest, which is denoted as . Let ; one hasThe Fourier transform of the impulse response of the equivalent filter is given byIt is hence a null-phase filter () characterized by .
- Second strategy: The sequences and are filtered by the same filter whose impulse response is . This leads to two sequences respectively denoted as and . The final output is equal to . In that case, the Fourier transform of the output is . It is a zero-phase filter if in the pass band.
3. Applications
3.1. Application on the Sum of Sinusoids: Interpretation and Comments
- First case: Let us first look at the case of samples of one sinusoid defined as follows:with the normalized frequency . Due to (13), the minimum and maximum values of the signal under study are obtained when k is a multiple of 100.
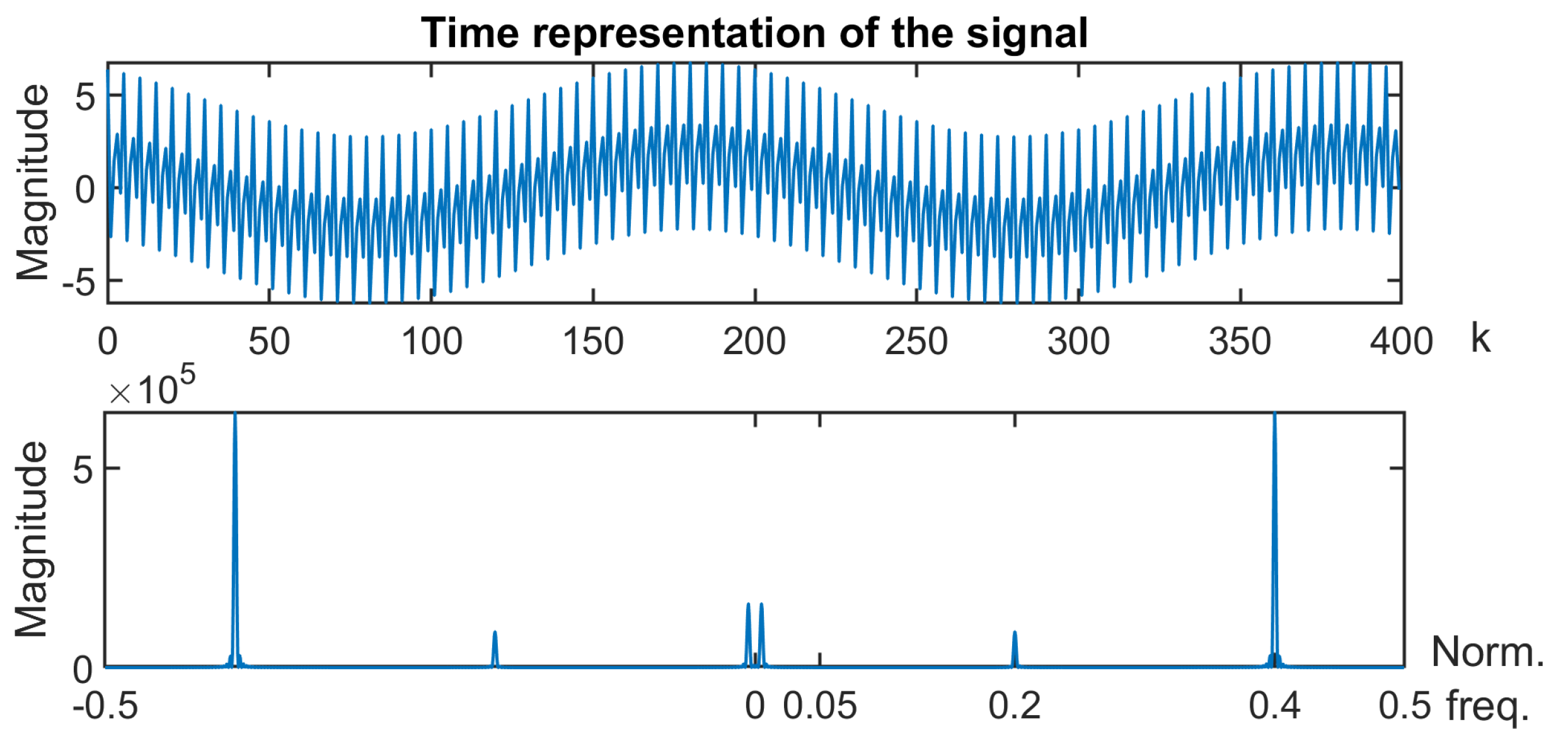
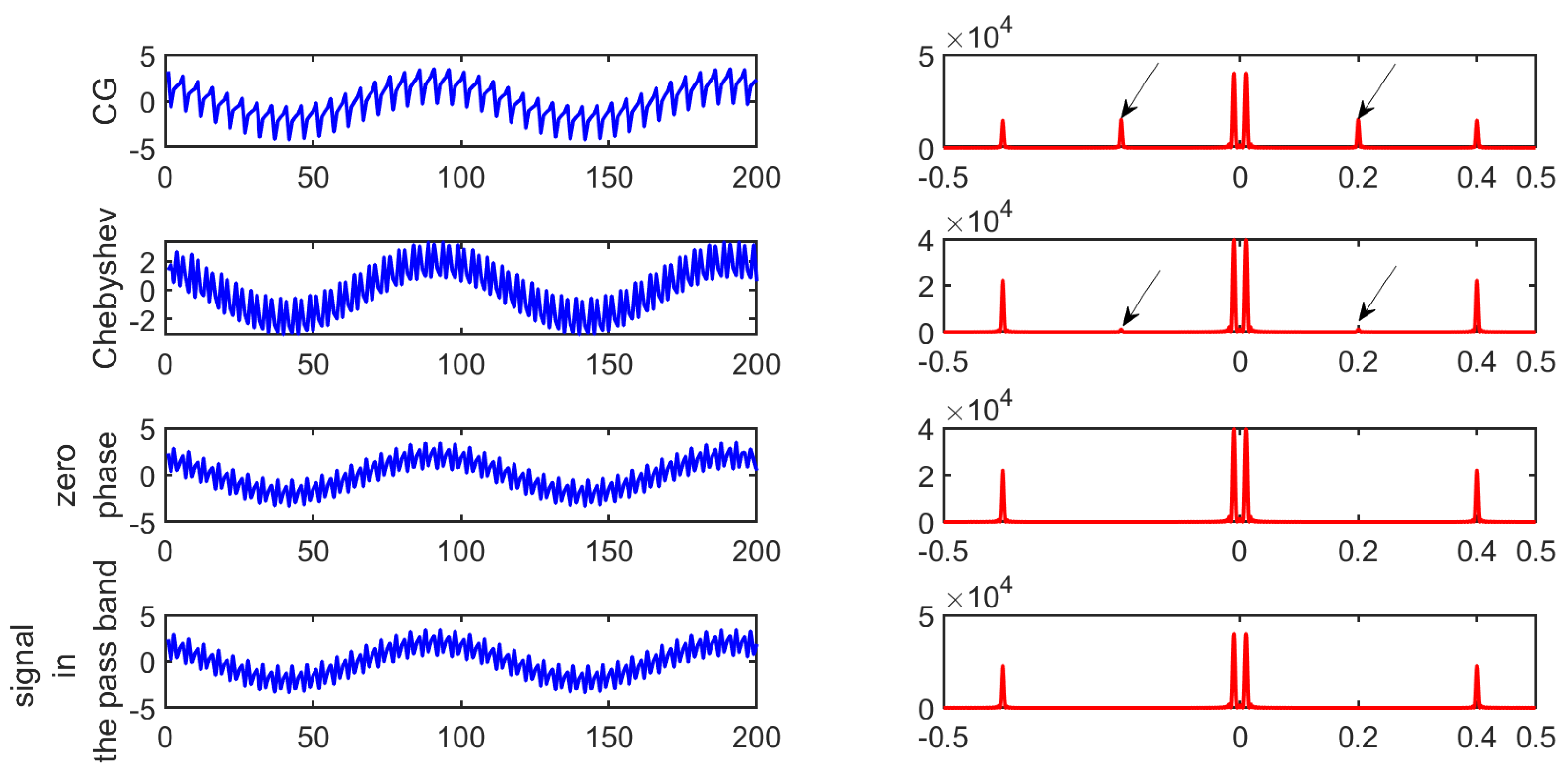
- Second case: Let us now address the case of samples of a sum of three sinusoids defined as follows:with normalized frequencies and . The time representation of the signal and its spectrum are given in Figure 4.
3.2. Application on White Noises and Process
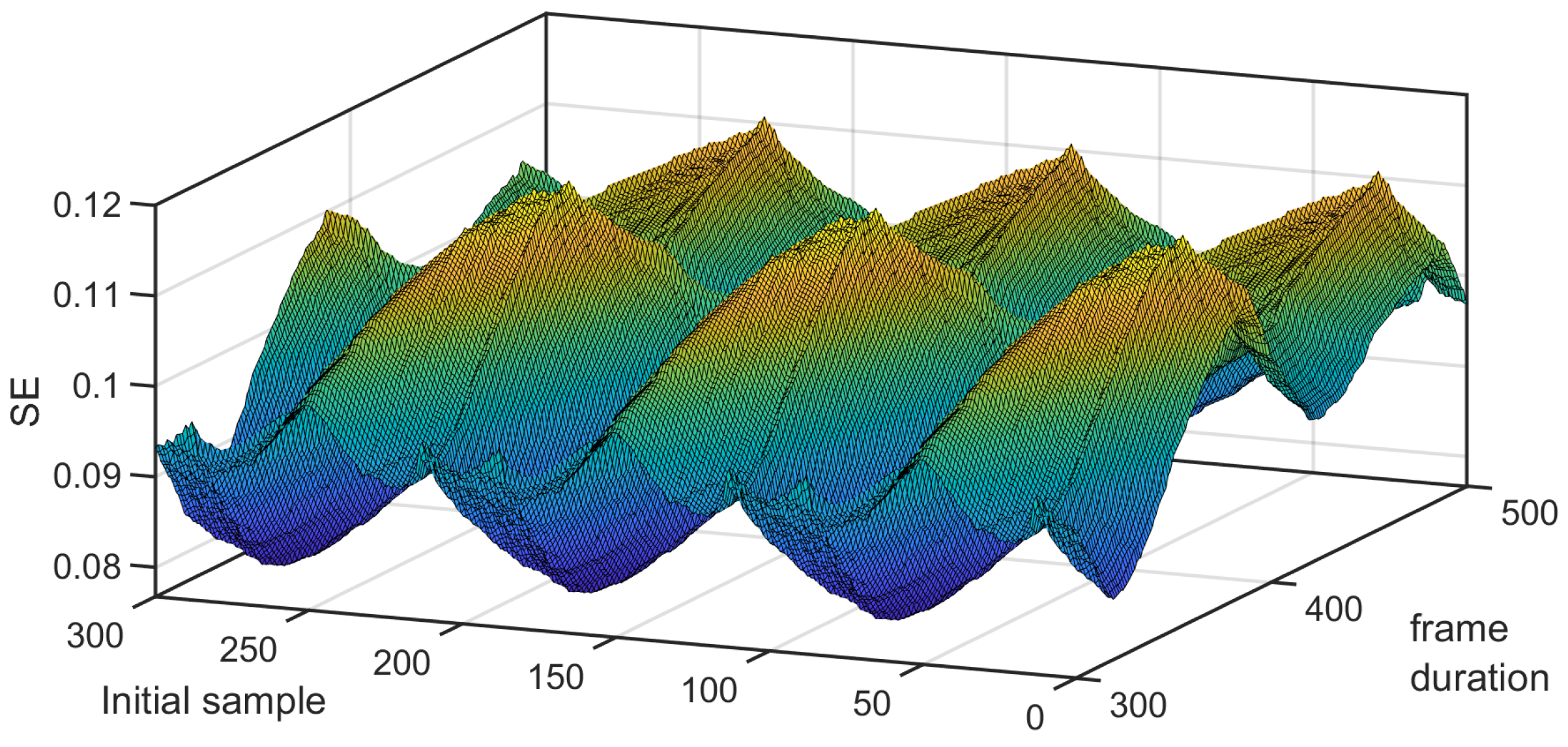
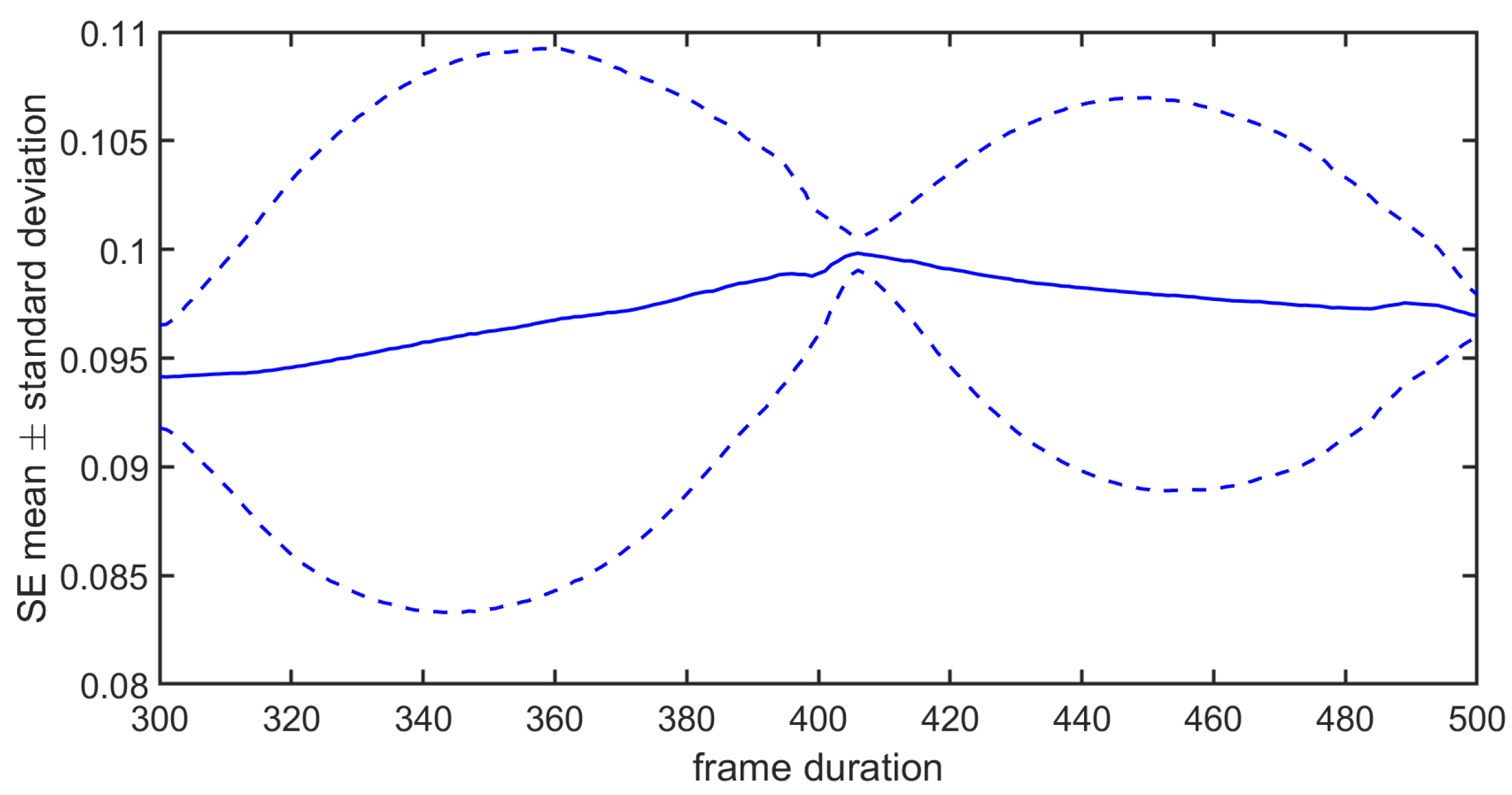
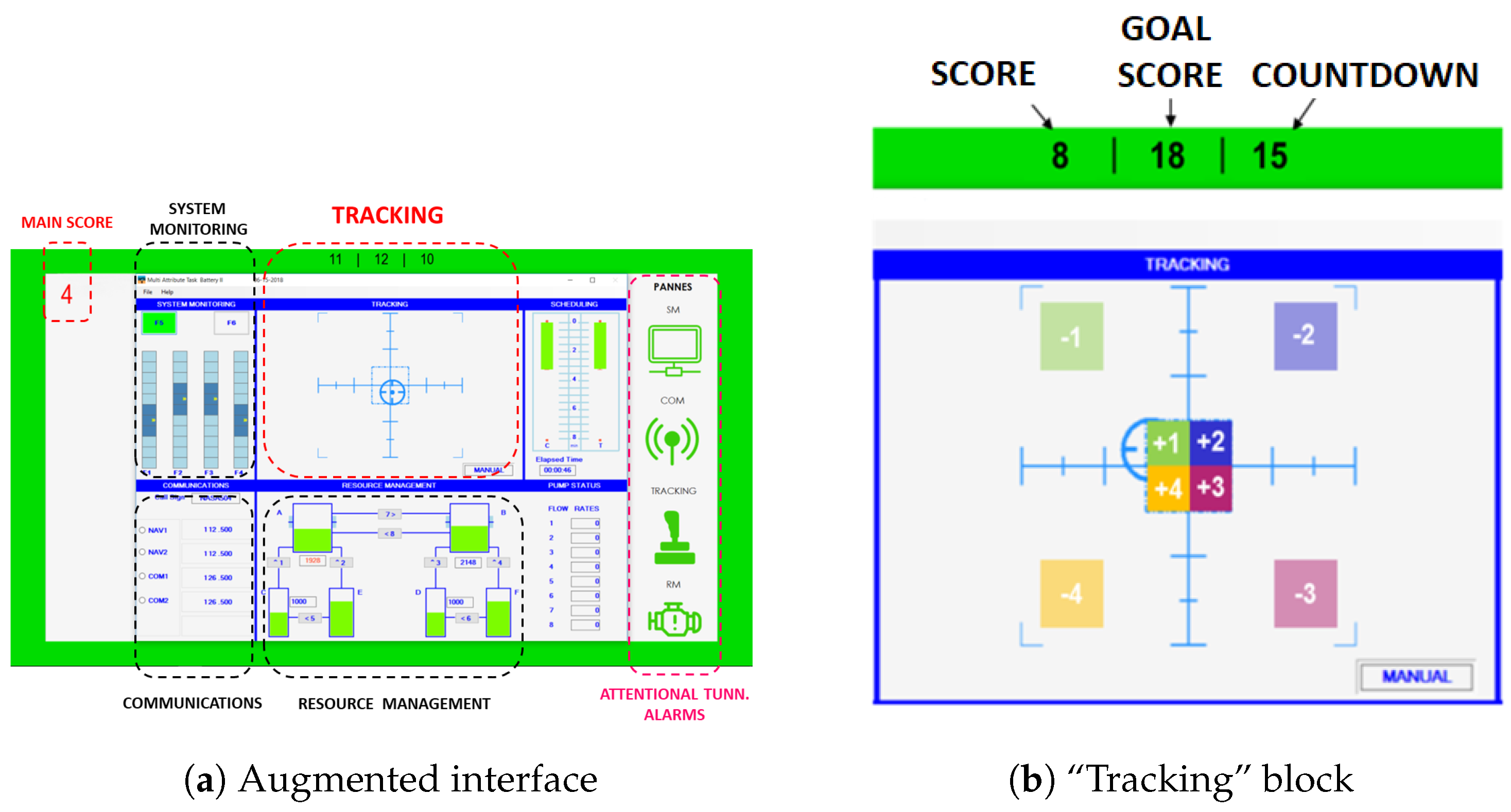
3.3. Application on Real Data to Detect Attentional Tunneling
- Ocular data have proven to be relevant to characterize tunneling [42]. It has been shown that this state is correlated with a reduction in the number of eye movements (saccades) and an increase in fixation duration.
- Ocular data are collected from cameras or eyetrackers, which are sensors that can be accepted by a user in ecological conditions, unlike electrodes for example. This facilitates the integration of a visual tunneling monitoring solution.
3.3.1. Information about the Protocol
- During the 30-min training phase, the subject becomes familiar with each task that can be done with the simulator. Then, the subject faces a situation combining several tasks during 4 min.
- During the reference phase, subjects are first asked to relax and do nothing during two minutes. Then, a two-minute scenario leading to a “Low” mental workload is launched.
- During the experimental phase, there are two parts with a short break in between. Each part is composed of a task of “Low” mental workload lasting four minutes, a four-minute scenario corresponding to “Medium” mental workload, and a final task of “High” mental workload. The order of the three tasks is randomly set.
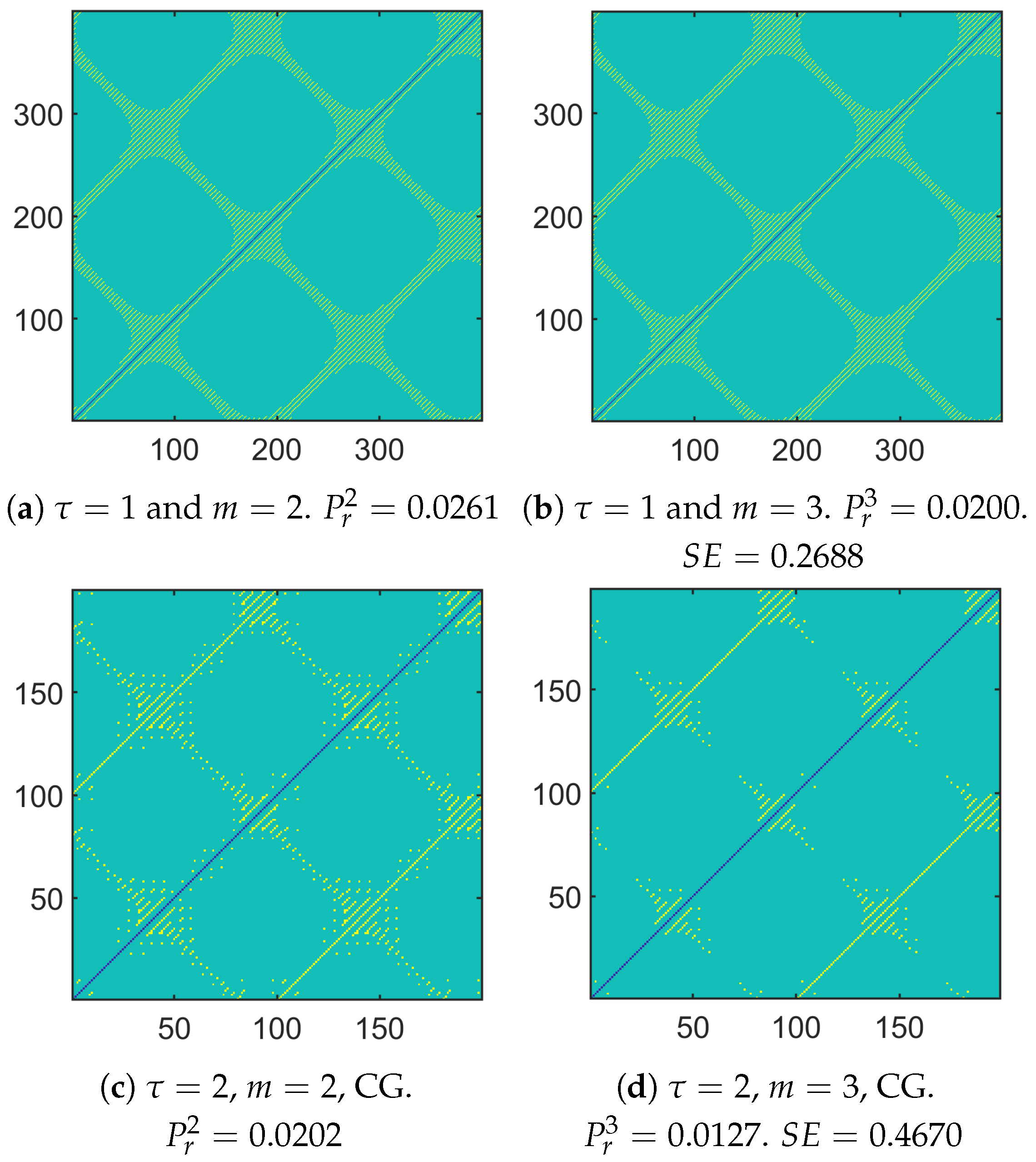
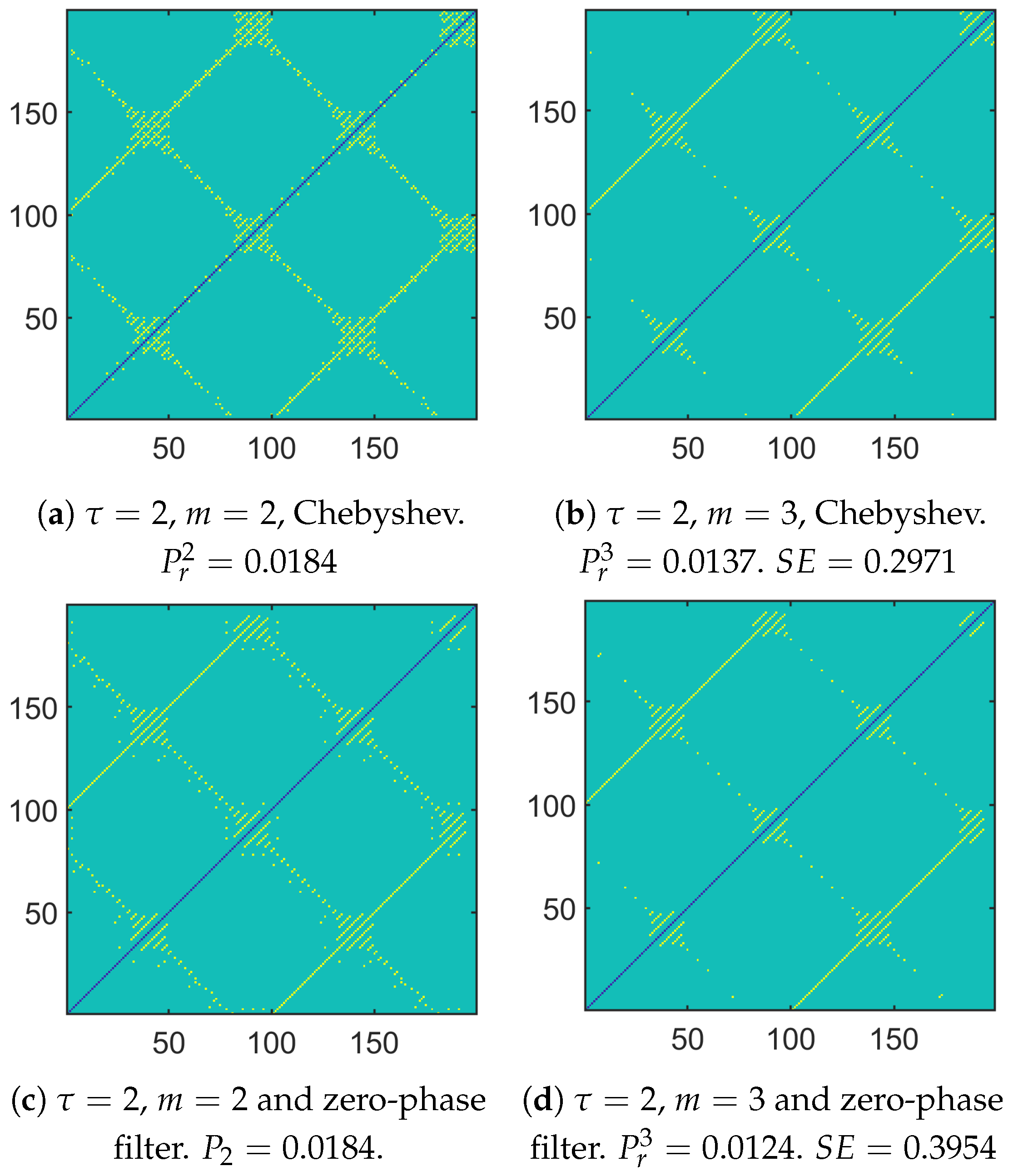
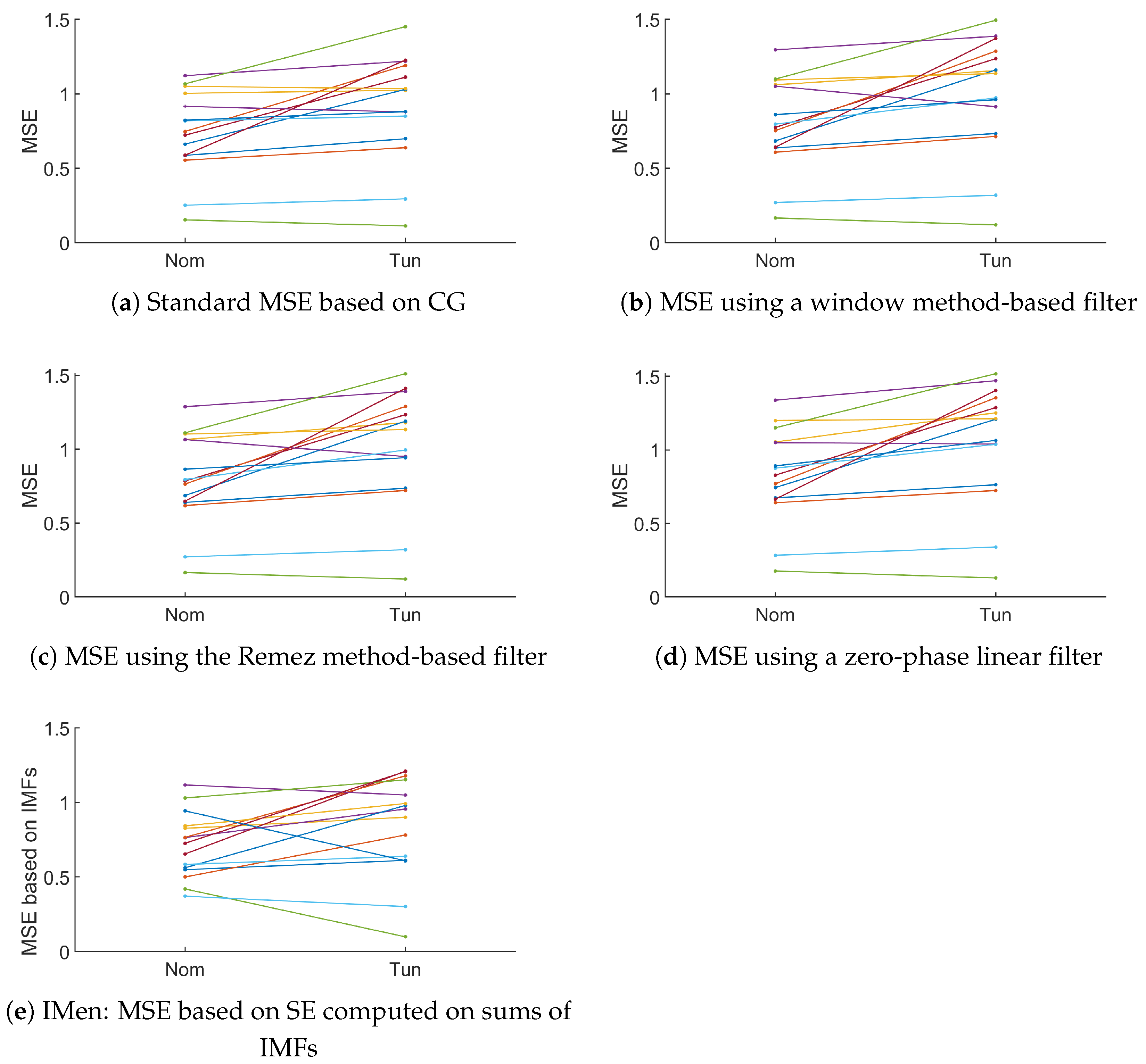
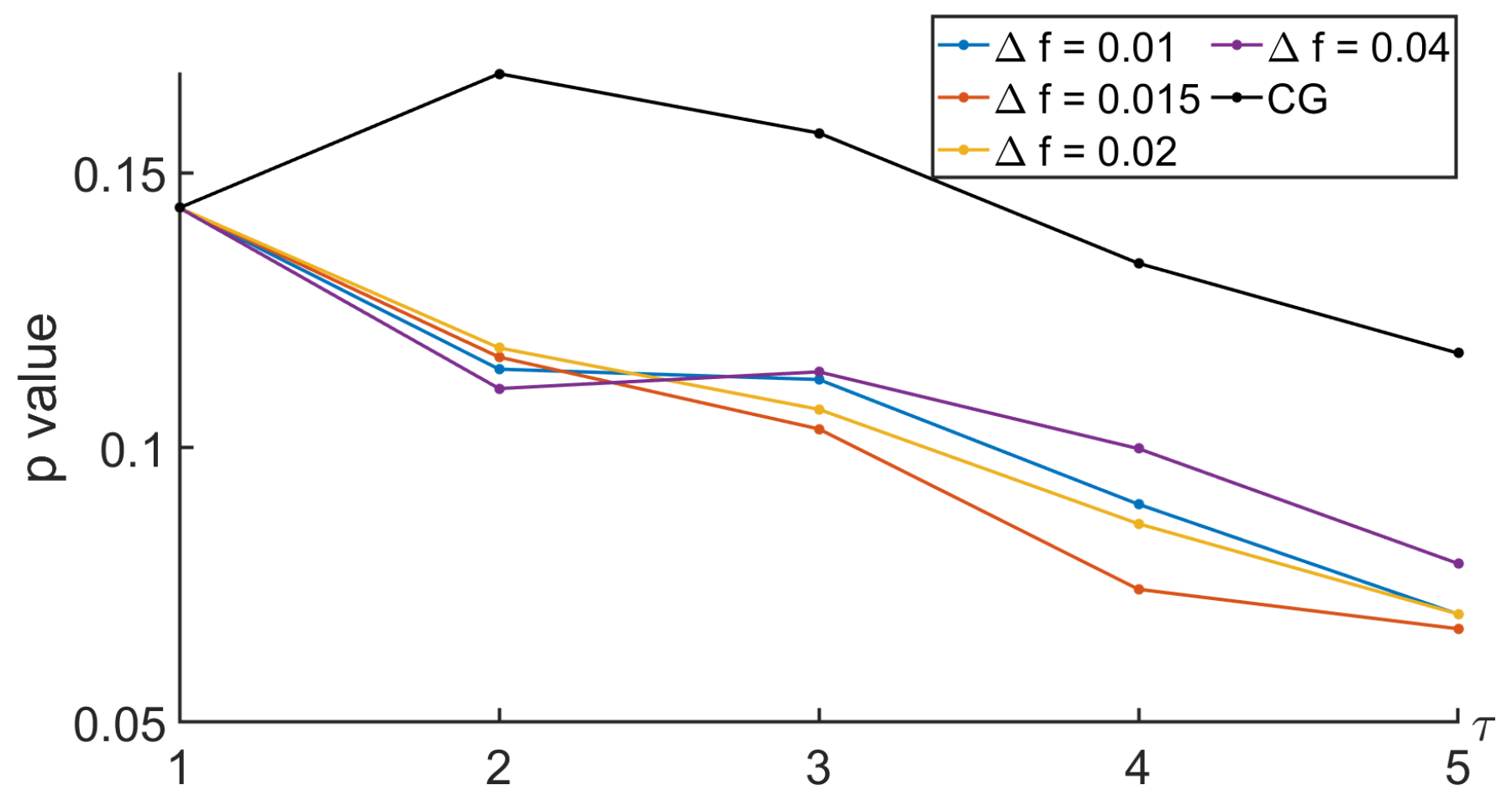
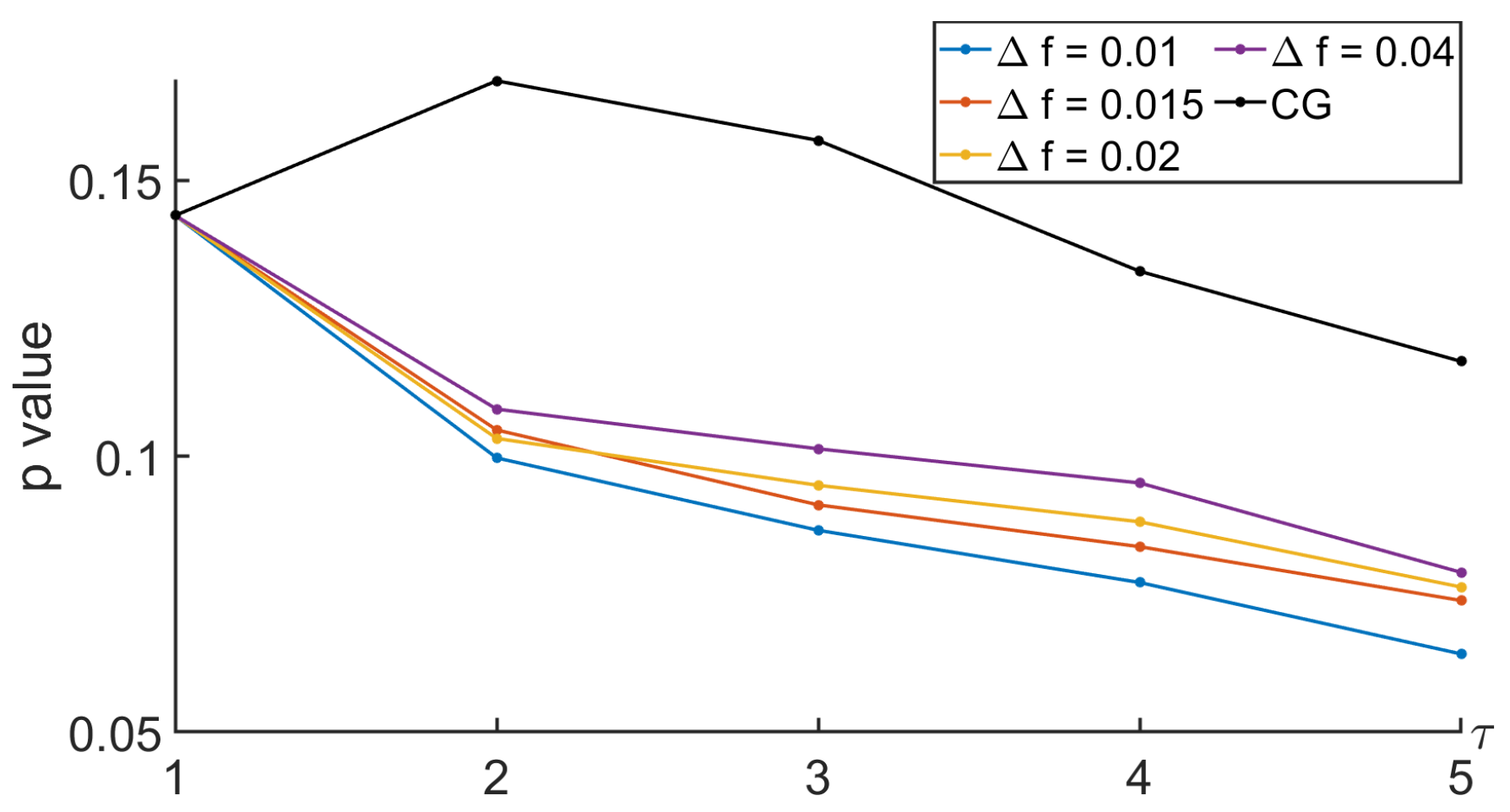
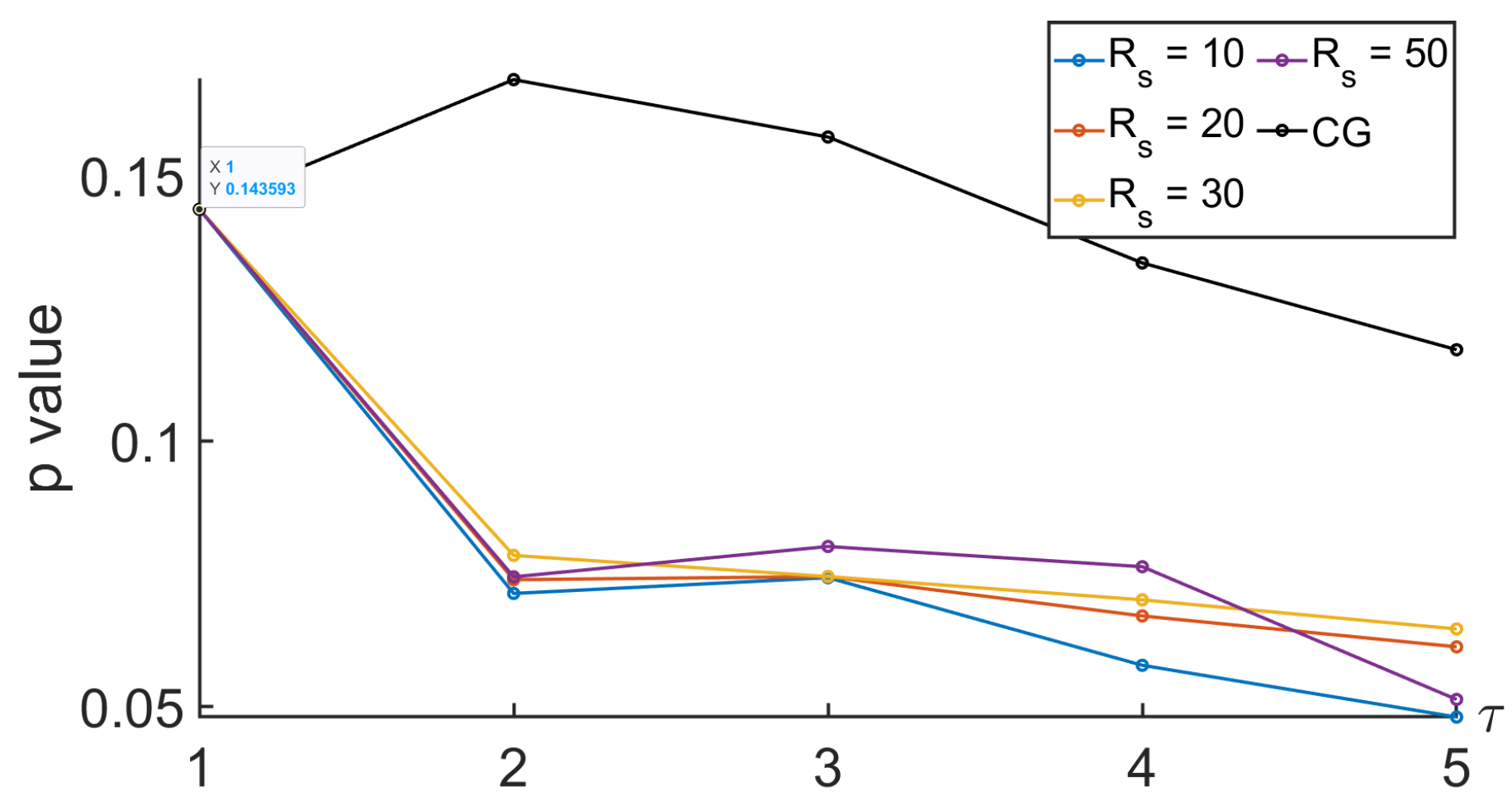
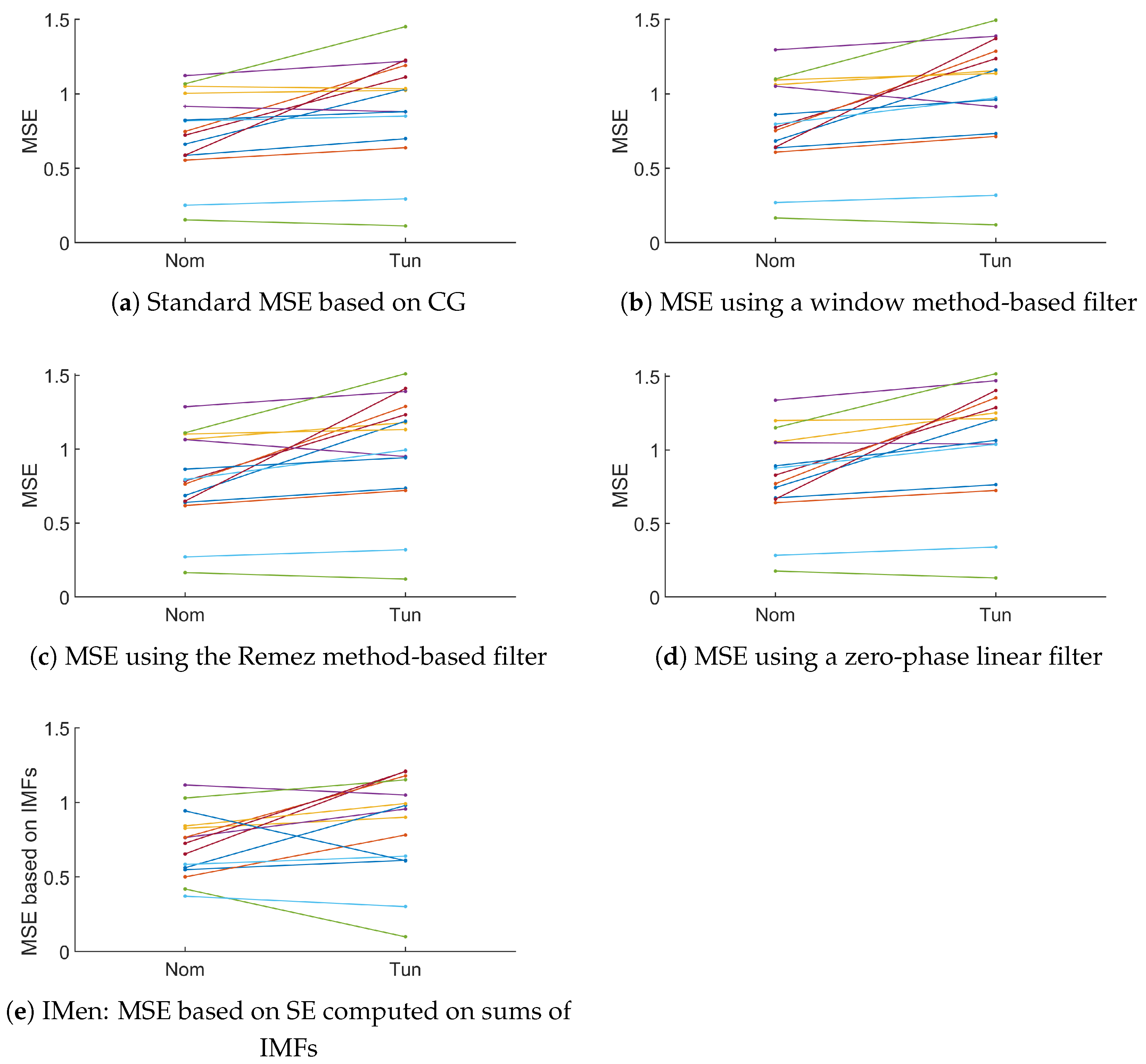
3.3.2. Using CG-Based MSE or Its New Variant
4. Conclusions and Perspectives
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| AME | adaptive MSE |
| ApEN | approximate entropy |
| AR | autoregressive |
| ARFIMA | autoregressive fractionnaly integrated moving average |
| ARMA | autoregressive with moving average |
| CFIT | controlled flight into terrain |
| CG | coarse-graining |
| CMSE | composite MSE |
| COSEn | coefficient of the sample entropy |
| dfBm | discrete fractional Brownian motion |
| dfGn | discrete fractional Gaussian noise |
| DE | dispersion entropy |
| EMD | empirical mode decomposition |
| ECG | electrocardiogram |
| EEG | electroencephalogram |
| ER | Eckmann–Ruelle |
| FI | fractionally integrated |
| FIR | finite impulse response |
| FuzEn | fuzzy entropy |
| HE | hierarchical Entropy |
| IIR | infinite impulse response |
| IMEn | intrinsic mode entropy |
| IMFs | intrinsic mode functions |
| IMPE | improved multiscale PE |
| KS | Kolmogorov–Sinai |
| LZ | Lempel–Ziv |
| MEMD | multivariate EMD |
| MFE | multiscale fuzzy sample entropy |
| MFPE | multiscale fractional-order PE |
| MGMSE | multivariate generalized MSE |
| MGrcMSE | multivariate generalized rcMSE |
| MMSE | modified MSE |
| MrcMSE | multivariate |
| MSampEn | multivariate sample entropy |
| MSE | multiscale entropy |
| MSSE | multiscale symbolic entropy analysis |
| mv | multivariate |
| mvMPE | mv multiscale PE |
| PE | permutation entropy |
| PSD | power spectral density |
| rcMFE | refined composite multiscale fuzzy entropy |
| rcMPE | refined composite multiscale permutation entropy |
| rcMSE | refined composite MSE |
| rMSE | refined MSE |
| SE | sample entropy |
| SV | singular value |
| SVD | singular value decomposition |
| TSMBE | time shift multiscale bubble entropy |
| WPE | weighted permutation entropy |
| WMFPE | weighted multiscale fractional-order PE |
Appendix A
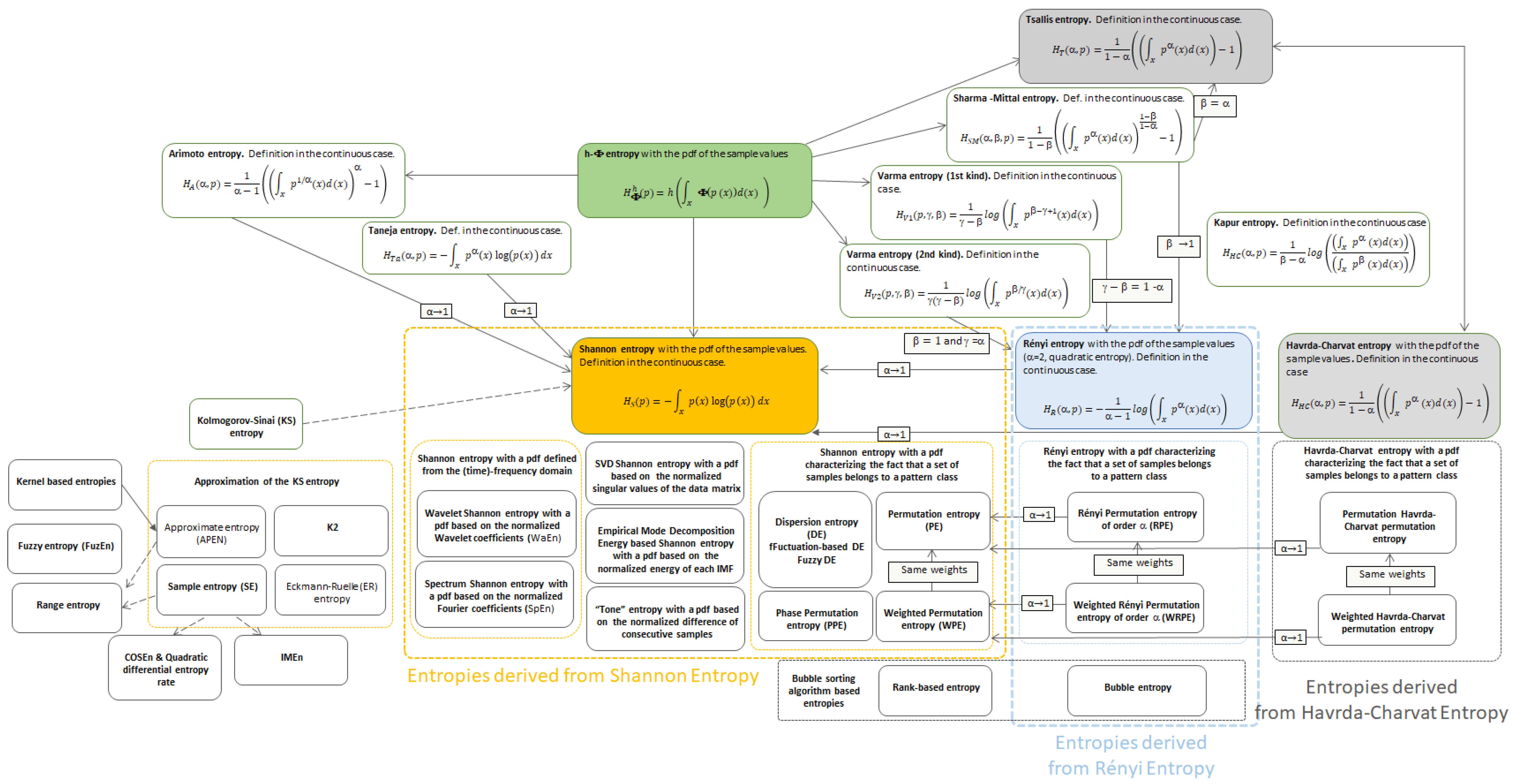
Appendix A.1. About Entropies
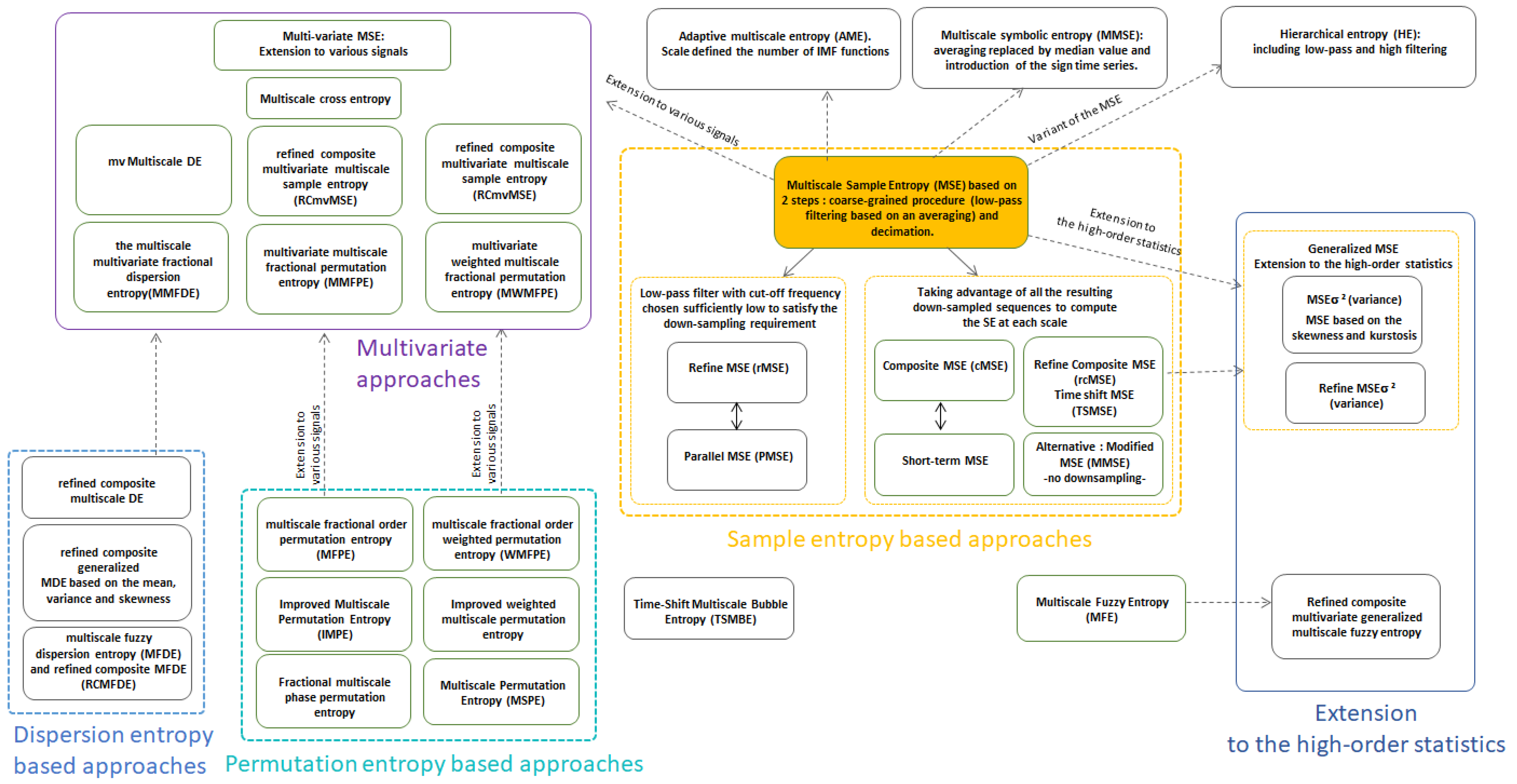
Appendix A.2. Some Variants of the MSE


References
- Berthelot, B.; Grivel, E.; Legrand, P.; André, J.-M.; Mazoyer, P. Alternative ways to compare the detendred fluctuation analysis and its variants. application to visual tunneling detection. Digit. Signal Process. 2020, 108, 102865. [Google Scholar] [CrossRef]
- Berthelot, B.; Grivel, E.; Legrand, P. New Variants of DFA based on LOESS and LOWESS methods: Generalization of the detrended moving average. In Proceedings of the ICASSP 2021 IEEE International Conference on Acoustics, Speech and Signal Processing, Toronto, ON, Canada, 6–11 June 2021. [Google Scholar]
- Grivel, E.; Berthelot, B.; Legrand, P.; Giremus, A. Dfa-based abacuses providing the hurst exponent estimate for short-memory processes. Digit. Signal Process. 2021, 116, 103102. [Google Scholar] [CrossRef]
- Peng, C.K.; Buldyrev, S.V.; Goldberger, A.L.; Havlin, S.; Sciortino, F.; Simons, M.; Stanley, H.E. Long-range correlations in nucleotide sequences. Nature 1992, 356, 168–170. [Google Scholar] [CrossRef] [PubMed]
- Peng, C.K.; Havlin, S.; Hausdorf, J.M.; Mietus, J.E.; Stanley, H.E.; Goldberger, A.L. Fractal mechanisms and heart rate dynamics. J. Electrocardiol. 1996, 28, 59–64. [Google Scholar] [CrossRef] [PubMed]
- Pincus, S.M. Approximate entropy as a measure of system complexity. Proc. Natl. Acad. Sci. USA 1991, 88, 2297–2301. [Google Scholar] [CrossRef] [PubMed]
- Costa, M.; Goldberger, A.L.; Peng, C.K. Multiscale entropy analysis of complex physiologic time series. Phys. Rev. Lett. 2002, 89, 068102. [Google Scholar] [CrossRef] [PubMed]
- Jiang, Y.; Peng, C.K.; Xu, Y. Hierarchical entropy analysis for biological signals. J. Comput. Appl. Math. 2011, 236, 728–742. [Google Scholar] [CrossRef]
- Chen, Z.; Gómez, A.I.; Gómez-Pérez, D.; Tirkeld, A. Correlation measure, linear complexity and maximum order complexity for families of binary sequences. Finite Fields Their Appl. 2022, 78, 101977. [Google Scholar] [CrossRef]
- Xiong, H.; Qu, L.; Li, C. A New Method to Compute the 2-adic Complexity of Binary Sequences. IEEE Trans. Inf. Theory 2014, 60, 2399–2406. [Google Scholar] [CrossRef]
- Lempel, A.; Ziv, J. On the complexity of finite sequences. IEEE Trans. Inf. Theory 1976, 22, 75–81. [Google Scholar] [CrossRef]
- Ziv, J.; Lempel, A. A universal algorithm for sequential data compression. IEEE Trans. Inf. Theory 1977, 23, 337–343. [Google Scholar] [CrossRef]
- Yan, X.; She, D.; Xu, Y.; Jia, M. Application of Generalized Composite Multiscale Lempel–Ziv Complexity in Identifying Wind Turbine Gearbox Faults. Entropy 2021, 23, 1372. [Google Scholar] [CrossRef] [PubMed]
- Bai, Y.; Liang, Z.; Li, X. A permutation Lempel-Ziv complexity measure for EEG analysis. Biomed. Signal Process. Control 2015, 19, 102–114. [Google Scholar] [CrossRef]
- Borowska, M. Multiscale Permutation Lempel–Ziv Complexity Measure for Biomedical Signal Analysis: Interpretation and Application to Focal EEG Signals. Entropy 2021, 23, 832. [Google Scholar] [CrossRef] [PubMed]
- Ibáñez-Molina, A.J.; Iglesias-Parro, S.; Soriano, M.F.; Aznarte, J.I. Multiscale Lempel–Ziv complexity for EEG measures. Clin. Neurophysiol. 2015, 126, 541–548. [Google Scholar] [CrossRef] [PubMed]
- Mao, X.; Shang, P.; Xu, M.; Peng, C.-K. Measuring time series based on multiscale dispersion Lempel–Ziv complexity and dispersion entropy plane. Chaos Solitons Fractals 2020, 37, 109868. [Google Scholar] [CrossRef]
- Liu, L.; Miao, S.; Hu, H.; Deng, Y. On the Eigenvalue and Shannon’s Entropy of Finite Length Random Sequences. Complexity 2015, 21, 154–161. [Google Scholar] [CrossRef]
- Liu, L.; Xiang, H.; Li, R.; Hu, H. The Eigenvalue Complexity of Sequences in the Real Domain. Entropy 2019, 21, 1194. [Google Scholar] [CrossRef]
- Jauregui, M.; Zunino, L.; Lenzi, E.K.; Mendes, R.S.; Ribeiro, H.V. Characterization of time series via Rényi complexity–entropy curves. Physica A 2018, 498, 74–85. [Google Scholar] [CrossRef]
- Pham, T.D. Time-Shift Multiscale Entropy Analysis of Physiological Signals. Entropy 2017, 19, 257. [Google Scholar] [CrossRef]
- Wu, S.D.; Wu, C.W.; Lin, S.G.; Wang, C.C.; Lee, K.Y. Time series analysis using composite multiscale entropy. Entropy 2013, 15, 1069–1084. [Google Scholar] [CrossRef]
- Zhang, Y.-C. Complexity and 1/f noise. A phase space approach. J. Phys. I 1991, 1, 971–977. [Google Scholar] [CrossRef]
- Humeau-Heurtier, A. The multiscale entropy algorithm and its variants: A review. Entropy 2015, 17, 3110–3123. [Google Scholar] [CrossRef]
- Valencia, J.F.; Porta, A.; Vallverdu, M.; Claria, F.; Baranowski, R.; Orlowska-Baranowska, E.; Caminal, P. Refined multiscale entropy: Application to 24-h holter recordings of heart periodvariability in healthy and aortic stenosis subjects. IEEE Trans. Biomed. Eng. 2009, 56, 2202–2213. [Google Scholar] [CrossRef] [PubMed]
- Zhao, D.; Liu, S.; Cheng, S.; Sun, X.; Wang, L.; Wei, Y.; Zhang, H. Parallel multi-scale entropy and its application in rolling bearing fault diagnosis. Measurement 2021, 168, 108333. [Google Scholar] [CrossRef]
- Azami, H.; Escudero, J. Coarse-Graining Approaches in Univariate Multiscale Sample and Dispersion Entropy. Entropy 2018, 20, 138. [Google Scholar] [CrossRef] [PubMed]
- Grivel, E.; Berthelot, B.; Legrand, P.; Colin, G. Null or linear-phase filters for the derivation of a new variant of the MSE. In Proceedings of the 2023 31st European Signal Processing Conference (EUSIPCO), Helsinki, Finland, 4–8 September 2023. [Google Scholar]
- Nikulin, V.V.; Brismar, T. Comment on multiscale entropy analysis of complex physiologic time series. Phys. Rev. Lett. 2004, 92, 089803. [Google Scholar] [CrossRef] [PubMed]
- D’avalos, A.; Jabloun, M.; Ravier, P.; Buttelli, O. Theoretical study of multiscale permutation entropy on finite-length fractional gaussian noise. In Proceedings of the 2018 26th European Signal Processing Conference (EUSIPCO), Rome, Italy, 3–7 September 2018. [Google Scholar]
- Gao, J.; Hu, J.; Liu, F.; Cao, Y. Multiscale entropy analysis of biological signals: A fundamental bi-scaling law. Front. Comput. Neurosci. 2015, 9, 1–9. [Google Scholar] [CrossRef] [PubMed]
- Wickens, C. Attentional Tunneling and Task Management; International Symposium on Aviation Psychology: Dayton, OH, USA, 2005; pp. 812–817. [Google Scholar]
- Shappell, S.A.; Wiegman, D.A. Definition and Computation of Oculomotor Measures in the Study of Cognitive Processes; Elsevier Science Ltd.: Amsterdam, The Netherlands, 2003. [Google Scholar]
- Dehais, F.; Roy, R.; Scannella, S. Inattentional deafness to auditory alarms: Inter-individual differences, electrophysiological signature and single trial classification. Behav. Brain Res. 2018, 360, 51–59. [Google Scholar] [CrossRef]
- Rock, I.; Linnett, C.; Grant, P.; Mack, A. Perception without attention: Results of a new method. Cogn. Psychol. 1992, 24, 502–534. [Google Scholar] [CrossRef]
- McAtee, A.; Feltman, K.; Swanberg, D.; Russell, D.; Statz, J.; Harding, T.; Ramiccio, J. Pilot Cueing Synergies for Degraded Visual Environments; Society of Photo-Optical Instrumentation Engineers, SPIE Defense + Security: Anaheim, CA, USA, 2017. [Google Scholar]
- Simons, D.; Chabris, C. Gorillas in our midst: Sustained inattentional blindness for dynamic events. Perception 1999, 28, 1059–1074. [Google Scholar] [CrossRef] [PubMed]
- Wilson, G.; Eggemeier, F. Psychophysiological assessment of workload in multi-task environments. In Multiple-Task Performance; CRC Press: Boca Raton, FL, USA, 1991; pp. 329–360. [Google Scholar]
- Posner, M.I.; Dehaene, S. Attentional networks. Trends Neurosci. 1994, 17, 75–79. [Google Scholar] [CrossRef] [PubMed]
- Gaume, A.; Dreyfus, G.; Vialatte, F.B. A cognitive brain–computer interface monitoring sustained attentional variations during a continuous task. Cogn. Neurodyn. 2019, 13, 257–269. [Google Scholar] [CrossRef] [PubMed]
- Chanel, P.C.C.; Wilson, M.D.; Scannella, S. Online ECG-based features for cognitive load assessment. In Proceedings of the 2019 IEEE International Conference on Systems, Man and Cybernetics (SMC), Bari, Italy, 6–9 October 2019; pp. 3710–3717. [Google Scholar]
- Regis, N.; Dehais, F.; Rachelson, E.; Thooris, C.; Pizziol, S.; Causse, M.; Tessier, C. Formal detection of attentional tunneling in human operator– automation interactions. IEEE Trans. Hum. Mach. Syst. 2014, 44, 326–336. [Google Scholar]
- Santiago-Espada, Y.; Myer, R.R.; Latorella, K.A.; Comstock, J.R., Jr. The Multi-Attribute Task Battery II (Matb-II) Software for Human Performance and Workload Research: A User’s Guide; NASA/TM–2011-217164; 2011. Available online: https://ntrs.nasa.gov/api/citations/20110014456/downloads/20110014456.pdf (accessed on 5 April 2024).
- Hart, S.; Staveland, L. Development of nasa-tlx (task load index): Results of empirical and theoretical research. Adv. Psychol. 1988, 52, 139–183. [Google Scholar]
- Menendez, M.L.; Morales, D.; Pardo, L.; Salicru, M. (h;ϕ)-entropy differential metric. Appl. Math. 1997, 42, 81–98. [Google Scholar] [CrossRef]
- Xu, L.S.; Wang, K.Q.; Wang, L. Gaussian kernel approximate entropy algorithm for analyzing irregularity of time-series. Int. Conf. Mach. Learn. Cybern. 2005, 9, 5605–5608. [Google Scholar]
- Richman, J.S.; Moorman, J.R. Physiological time-series analysis using approximate entropy and sample entropy. Am. J. Physiol. Heart Circ. Physiol. 2000, 278, H2039–H2049. [Google Scholar] [CrossRef] [PubMed]
- Lake, D.E.; Moorman, J.R. Accurate estimation of entropy in very short physiological time series: The problem of atrial fibrillation detection in implanted ventricular devices. Am. J. Physiol. Heart Circ. Physiol. 2011, 300, H319–H325. [Google Scholar] [CrossRef]
- Amoud, H.; Snoussi, H.; Hewson, D.; Doussot, M.; Duchêne, J. Intrinsic mode entropy for nonlinear discriminant analysis. IEEE Signal Process. Lett. 2014, 14, 297–300. [Google Scholar] [CrossRef]
- Chen, W.; Wang, Z.; Xie, H.; Yu, W. Characterization of surface emg signal based on fuzzy entropy. IEEE Trans. Neural Syst. Rehabil. Eng. 2007, 15, 266–272. [Google Scholar] [CrossRef] [PubMed]
- Chen, W.; Zhuang, J.; Yu, W.; Wang, Z. Measuring complexity using fuzzyen, apen, and sampen. Med. Eng. Phys. 2009, 15, 61–68. [Google Scholar] [CrossRef] [PubMed]
- Omidvarnia, A.; Mesbah, M.; Pedersen, M.; Jackson, G. Range entropy: A bridge between signal complexity and self-similarity. Entropy 2018, 20, 962. [Google Scholar] [CrossRef] [PubMed]
- Citi, L.; Guffanti, G.; Mainardi, L. Rank-based multi-scale entropy analysis of heart rate variability. Comput. Cardiol. 2014, 41, 597–600. [Google Scholar]
- Manis, G.; Bodini, M.W.; Rivolta, M.; Sassi, R. A two-steps-ahead estimator for bubble entropy. Entropy 2021, 23, 761. [Google Scholar] [CrossRef] [PubMed]
- Roberts, S.J.; Penny, W.; Rezek, I. Temporal and spatial complexity measures for electroencephalogram based brain-computer interfacing. Med Biol. Eng. Comput. 1999, 37, 93–98. [Google Scholar] [CrossRef] [PubMed]
- Yu, Y.; Junsheng, C. A roller bearing fault diagnosis method based on emd energy entropy and ANN. J. Sound Vib. 2006, 294, 269–277. [Google Scholar] [CrossRef]
- Oida, E.; Moritani, T.; Yamori, Y. Tone-entropy analysis on cardiac recoveryafter dynamic exercise. J. Appl. Physiol. 1997, 82, 1794–1801. [Google Scholar] [CrossRef]
- Powell, G.E.; Percival, I.C. A spectral entropy method for distinguishing regular and irregular motion of hamiltonian systems. J. Phys. A: Math. Gen. 1979, 12, 2053. [Google Scholar] [CrossRef]
- Rosso, O.A.; Blanco, S.; Yordanova, J.; Kolev, V.; Figliola, A.; Schürmann, M.; Başar, E. Wavelet entropy: A new tool for analysis of short duration brain electrical signals. J. Neurosci. Methods 2001, 105, 65–75. [Google Scholar] [CrossRef]
- Bandt, C.; Pompe, B. Permutation entropy: A natural complexity measure for time series. Phys. Rev. Lett. 2002, 88, 174102. [Google Scholar] [CrossRef]
- Kang, H.; Zhang, X.; Zhang, G. Phase permutation entropy: A complexity measure for nonlinear time series incorporating phase information. Physica A 2021, 568, 9125686. [Google Scholar] [CrossRef]
- Zhao, X.; Shang, P.; Huang, J. Permutation complexity and dependence measures of time series. Europhys. Lett. 2013, 102, 40005. [Google Scholar] [CrossRef]
- Shi, Y.; Shang, Y.; Wu, P. Research on weighted havrda–charvat’s entropy in financial time series. Physica A 2021, 572, 125914. [Google Scholar] [CrossRef]
- Rostaghi, M.; Azami, H. Dispersion entropy: A measure for time series analysis. IEEE Signal Process. Lett. 2016, 23, 610–614. [Google Scholar] [CrossRef]
- Azami, H.; Escudero, J. Amplitude and Fluctuation-Based Dispersion Entropy. Entropy 2018, 20, 210. [Google Scholar] [CrossRef]
- Rostaghi, R.M.; Khatibi, M.M.; Ashory, M.R.; Azami, H. Fuzzy Dispersion Entropy: A Nonlinear Measure for Signal Analysis. IEEE Trans. Fuzzy Syst. 2021, 30, 3785–3796. [Google Scholar] [CrossRef]
- Ahmed, M.U.; Mandic, D.P. Multivariate multiscale entropy: A tool for complexity analysis of multichannel data. Phys. Rev. E 2011, 84, 061918. [Google Scholar] [CrossRef] [PubMed]
- Chang, Y.C.; Wu, H.T.; Chen, H.R.; Liu, A.B.; Yeh, J.J.; Lo, M.T.; Tsao, J.H.; Tang, C.J.; Tsai, I.T.; Sun, C.K. Application of a modified entropy computational method in assessing the complexity of pulse wave velocity signals in healthy and diabetic subjects. Entropy 2014, 16, 4032–4043. [Google Scholar] [CrossRef]
- Wu, S.D.; Wu, P.H.; Wu, C.W.; Ding, J.J.; Wang, C.C. Bearing fault diagnosis based on multiscale permutation entropy and support vector machine. Entropy 2012, 14, 1343–1356. [Google Scholar] [CrossRef]
- Wu, S.D.; Wu, C.W.; Lee, K.Y.; Lin, S.G. Modified multiscale entropy for short-term time series analysis. Physica A 2013, 392, 5865–5873. [Google Scholar] [CrossRef]
- Shi, W.; Feng, H.; Zhang, X.; Yeh, C.-H. Amplitude modulation multiscale entropy characterizes complexity and brain states. Chaos Solitons Fractals 2023, 173, 113646. [Google Scholar] [CrossRef]
- Vakharia, V.; Gupta, V.K.; Kankar, P.K. A multiscale permutation entropy based approach to select wavelet for fault diagnosis of ball bearings. J. Vib. Control. 2015, 21, 3123–3131. [Google Scholar] [CrossRef]
- Humeau-Heurtier, A.; Wu, C.-W.; Wu, S.-D. Refined composite multiscale permutation entropy to overcome multiscale permutation entropy length dependence. IEEE Signal Process. Lett. 2015, 22, 2364–2367. [Google Scholar] [CrossRef]
- Azami, H.; Escudero, J. Improved multiscale permutation entropy for biomedical signal analysis:interpretation and application to electroencephalogram recordings. Biomed. Signal Process. Control 2016, 23, 28–41. [Google Scholar] [CrossRef]
- Chen, S.; Shang, P.; Wu, Y. Multivariate multiscale fractional order weighted permutation entropy of nonlinear time series. Physica A 2019, 515, 217–231. [Google Scholar] [CrossRef]
- Wan, L.; Ling, G.; Guan, Z.-H.; Fan, Q.; Tong, Y.-H. Fractional multiscale phase permutation entropy for quantifying the complexity of nonlinear time series. Physica A 2022, 600, 127506. [Google Scholar] [CrossRef]
- Zheng, J.; Pan, H.; Cheng, J. Rolling bearing fault detection and diagnosis based on composite multiscale fuzzy entropy and ensemble support vector machines. Mech. Syst. Signal Process. 2017, 85, 746–759. [Google Scholar] [CrossRef]
- Costa, M.D.; Goldberger, A.L. Generalized multiscale entropy analysis: Application to quantifying thecomplex volatility of human heartbeat time series. Entropy 2015, 17, 1197–1203. [Google Scholar] [CrossRef]
- Liu, Y.; Lin, Y.; Wanga, J.; Shang, P. Refined generalized multiscale entropy analysis for physiological signals. Physica A 2018, 490, 975–985. [Google Scholar] [CrossRef]
- Xu, M.; Shang, P. Analysis of financial time series using multiscale entropy based on skewness and kurtosis. Physica A 2018, 490, 1543–1550. [Google Scholar] [CrossRef]
- Hu, M.; Liang, H. Adaptive multiscale entropy analysis of multivariate neural data. IEEE Trans. Biomed. Eng. 2012, 59, 12–15. [Google Scholar]
- Lo, M.T.; Chang, Y.C.; Lin, C.; Young, H.W.V.; Lin, Y.H.; Ho, Y.L.; Peng, C.K.; Hu, K. Outlier-resilient complexity analysis of heartbeat dynamics. Sci. Rep. 2015, 5, 8836. [Google Scholar] [CrossRef] [PubMed]
- Chen, F.; Tian, W.; Zhang, L.; Li, J.; Ding, C.; Chen, D.; Wang, W.; Wu, F.; Wang, B. Fault diagnosis of power transformer based on time-shift multiscale bubble entropy and stochastic configuration network. Entropy 2022, 24, 1135. [Google Scholar] [CrossRef] [PubMed]
- Azami, H.; Rostaghi, M.; Abasolo, D.; Escudero, J. Refined Composite Multiscale Dispersion Entropy and its Application to Biomedical Signals. IEEE Trans. Biomed. Eng. 2017, 64, 2872–2879. [Google Scholar]
- Rostaghi, M.; Khatibi, M.M.; Ashory, M.R.; Azami, H. Bearing Fault Diagnosis Using Refined Composite Generalized Multiscale Dispersion Entropy-Based Skewness and Variance and Multiclass FCM-ANFIS. Entropy 2021, 23, 1510. [Google Scholar] [CrossRef] [PubMed]
- Rostaghi, R.M.; Khatibi, M.M.; Ashory, M.R.; Azami, H. Refined Composite Multiscale Fuzzy Dispersion Entropy and Its Applications to Bearing Fault Diagnosis. Entropy 2023, 25, 1494. [Google Scholar] [CrossRef] [PubMed]
- Humeau-Heurtier, A. Multivariate generalized multiscale entropy analysis. Entropy 2016, 18, 411. [Google Scholar] [CrossRef]
- Minhasa, A.S.; Kankarb, P.K.; Kumarc, N.; Singh, S. Bearing fault detection and recognition methodology based on weighted multiscale entropy approach. Mech. Syst. Signal Process. 2021, 147, 107073. [Google Scholar] [CrossRef]
- Azami, H.; Fernández, A.; Escudero, J. Multivariate Multiscale Dispersion Entropy of Biomedical Times Series. Entropy 2019, 21, 913. [Google Scholar] [CrossRef]
- Zhang, B.; Shang, P.; Zhou, Q. The identification of fractional order systems by multiscale multivariate analysis. Chaos Solitons Fractals Nonlinear Sci. Nonequilibrium Complex Phenom. 2021, 144, 110735. [Google Scholar] [CrossRef]
- Jamin, A.; Humeau-Heurtier, A. (Multiscale) Cross-Entropy Methods: A Review. Entropy 2020, 22, 45. [Google Scholar] [CrossRef] [PubMed]














Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Grivel, E.; Berthelot, B.; Colin, G.; Legrand, P.; Ibanez, V. Benefits of Zero-Phase or Linear Phase Filters to Design Multiscale Entropy: Theory and Application. Entropy 2024, 26, 332. https://doi.org/10.3390/e26040332
Grivel E, Berthelot B, Colin G, Legrand P, Ibanez V. Benefits of Zero-Phase or Linear Phase Filters to Design Multiscale Entropy: Theory and Application. Entropy. 2024; 26(4):332. https://doi.org/10.3390/e26040332
Chicago/Turabian StyleGrivel, Eric, Bastien Berthelot, Gaetan Colin, Pierrick Legrand, and Vincent Ibanez. 2024. "Benefits of Zero-Phase or Linear Phase Filters to Design Multiscale Entropy: Theory and Application" Entropy 26, no. 4: 332. https://doi.org/10.3390/e26040332
APA StyleGrivel, E., Berthelot, B., Colin, G., Legrand, P., & Ibanez, V. (2024). Benefits of Zero-Phase or Linear Phase Filters to Design Multiscale Entropy: Theory and Application. Entropy, 26(4), 332. https://doi.org/10.3390/e26040332