
Research on Internal Damage Identification of Wire Rope Based on Improved VGG Network

Abstract
:1. Introduction
2. Spectrogram Acquisition during Internal Damage of Wire Rope
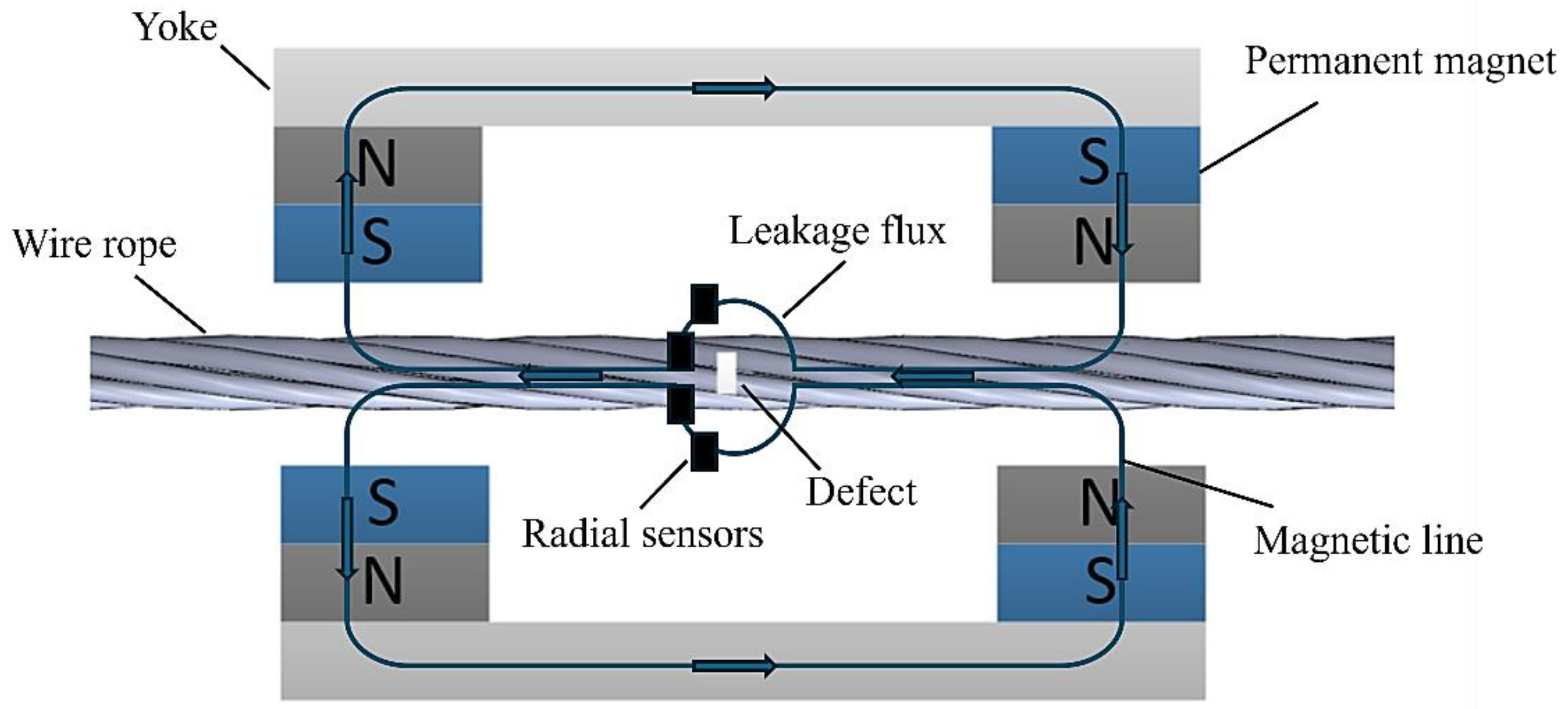
2.1. Wire Rope Internal Damage Magnetic Flux Leakage Detection Principle
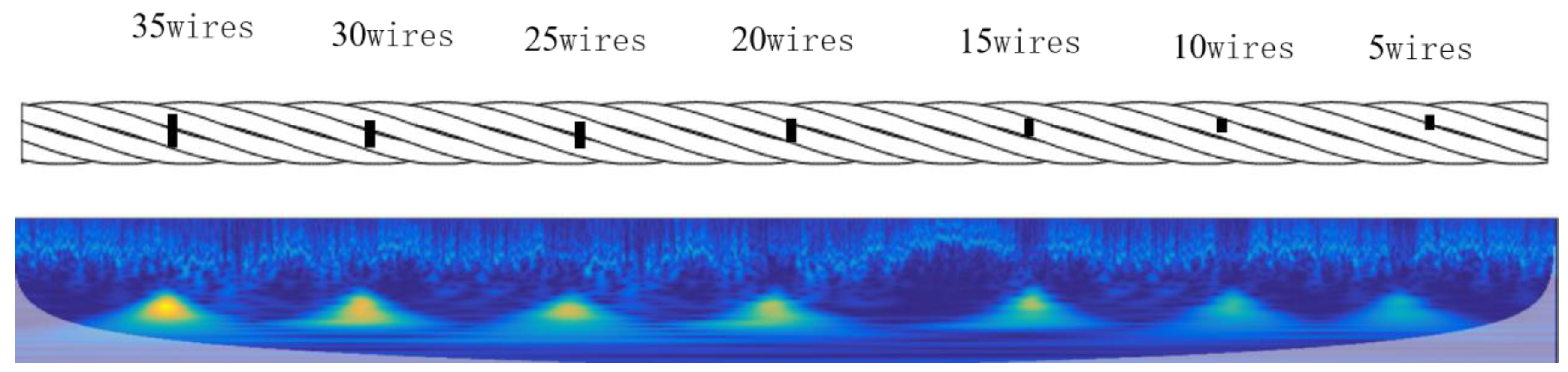
2.2. Wire Rope Damage Signal Acquisition and Time-Frequency Spectrogram Imaging
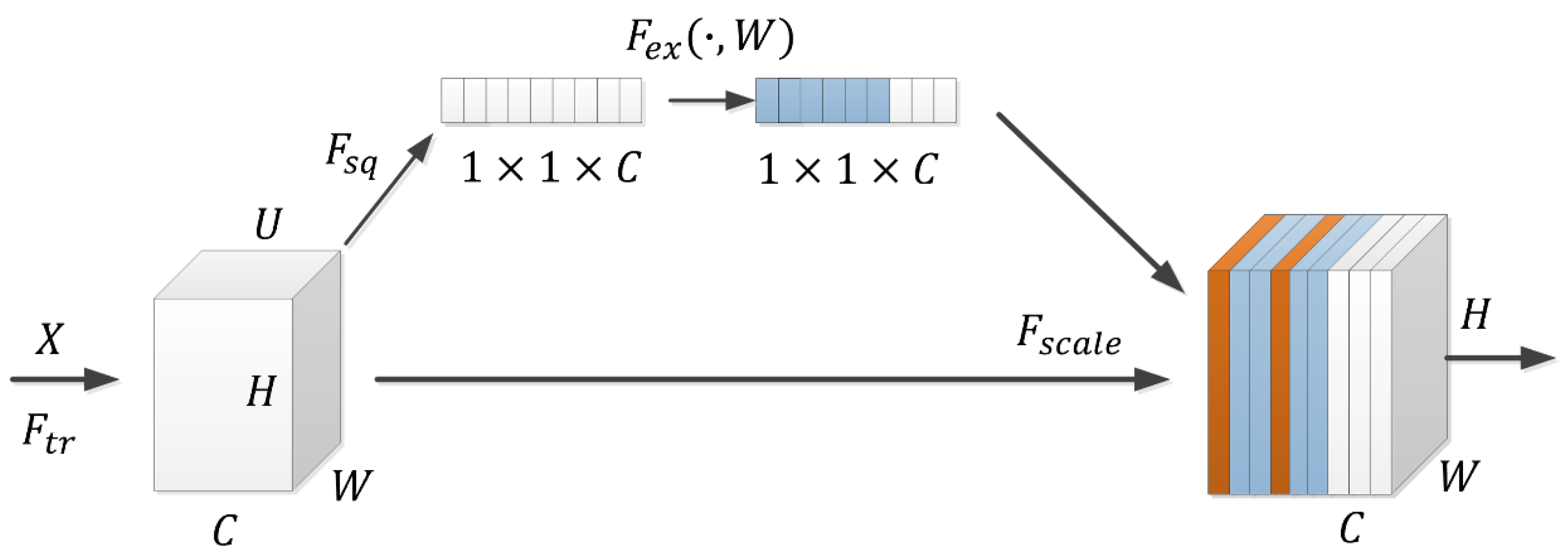
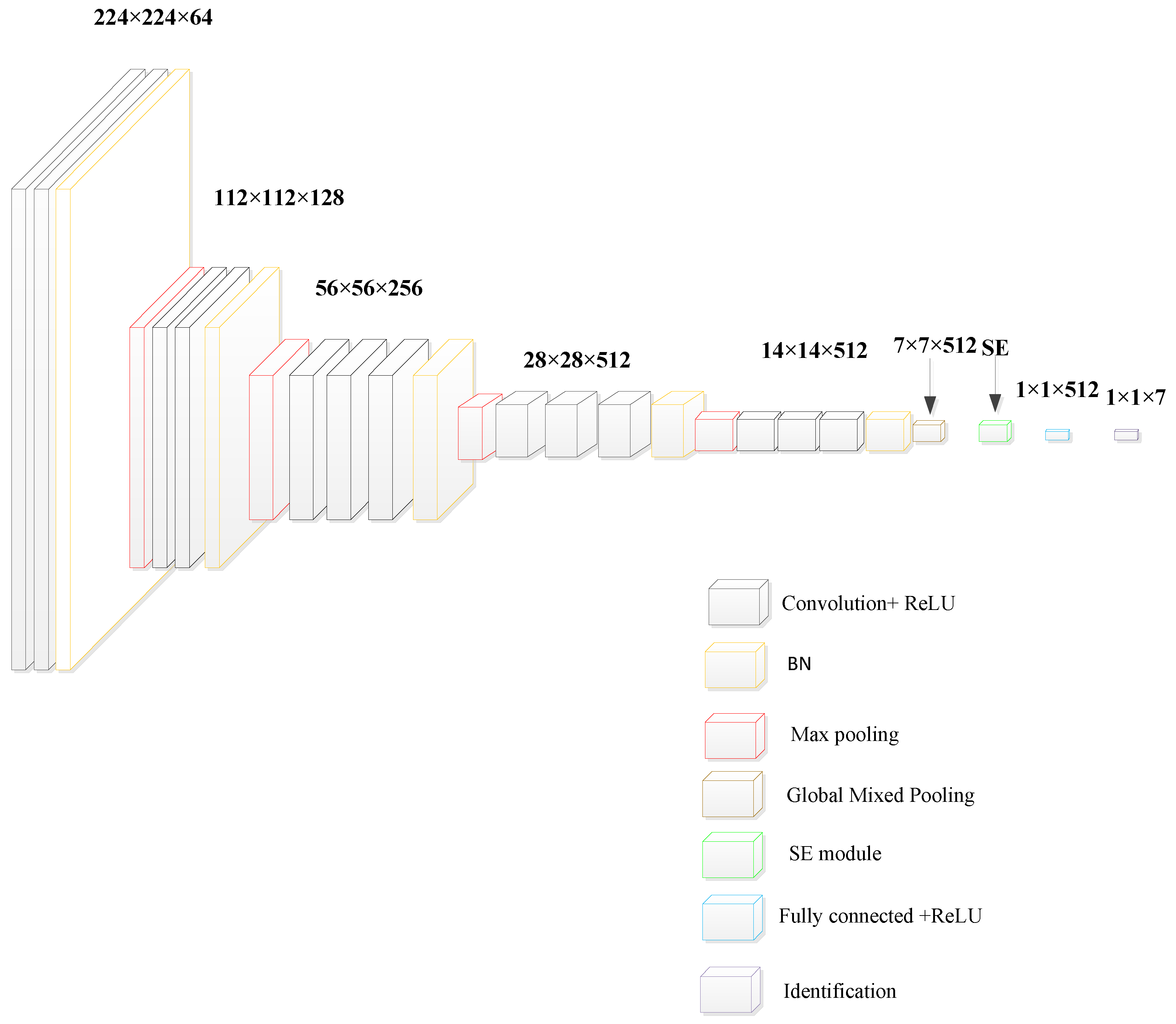
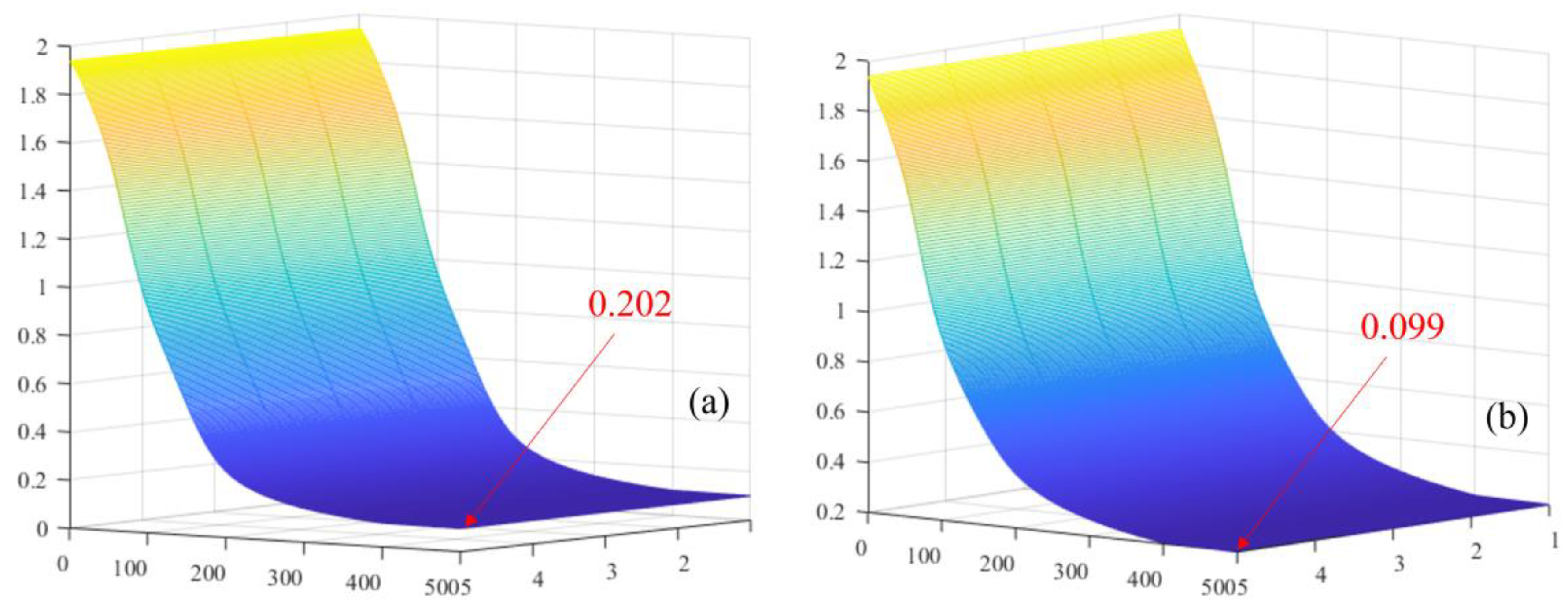
3. SE-WRVGG Model of Wire Rope Internal Damage Detection Improvement Method
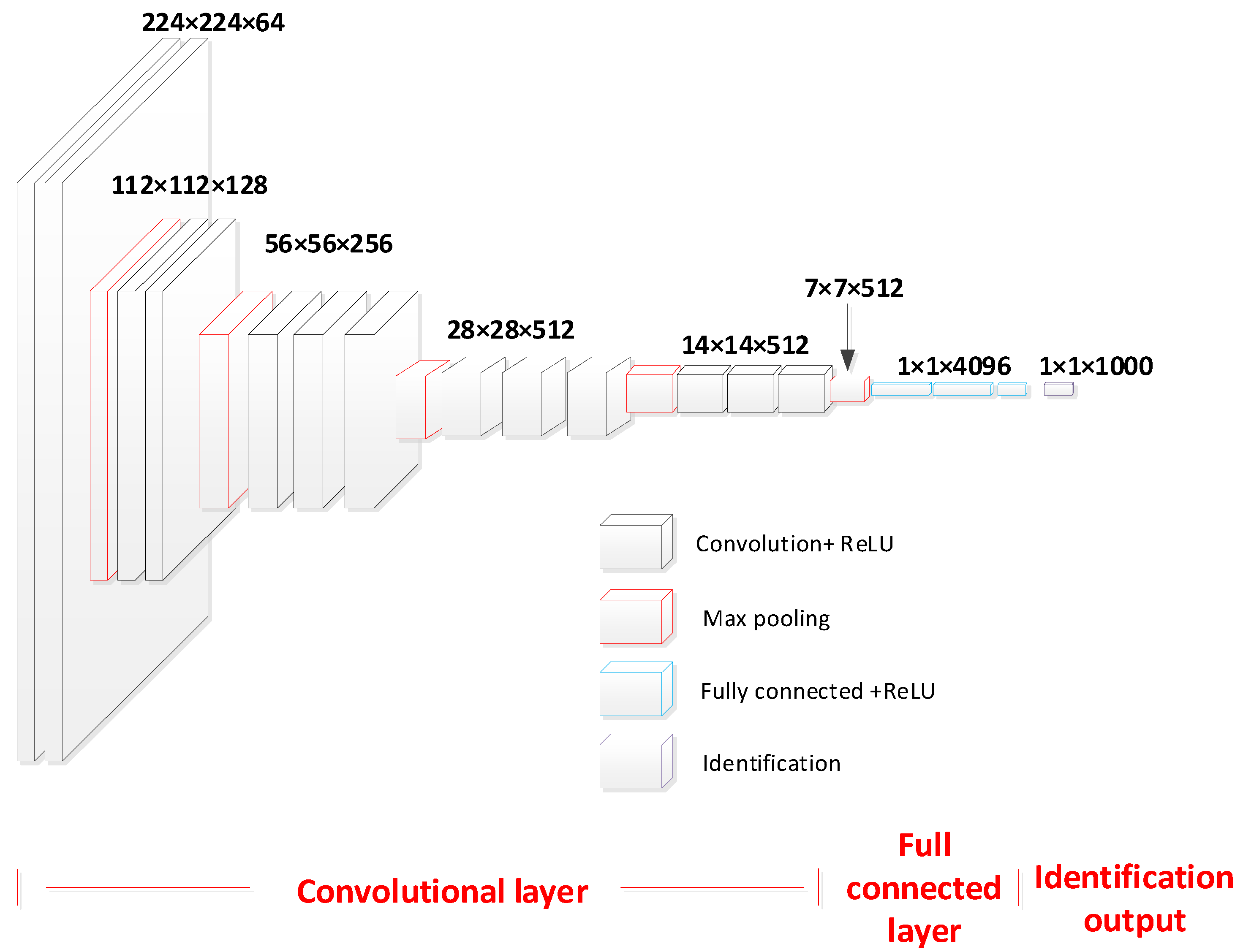
VGG Model
4. SE-WRVGG16 Model Experiments and Analysis of Results
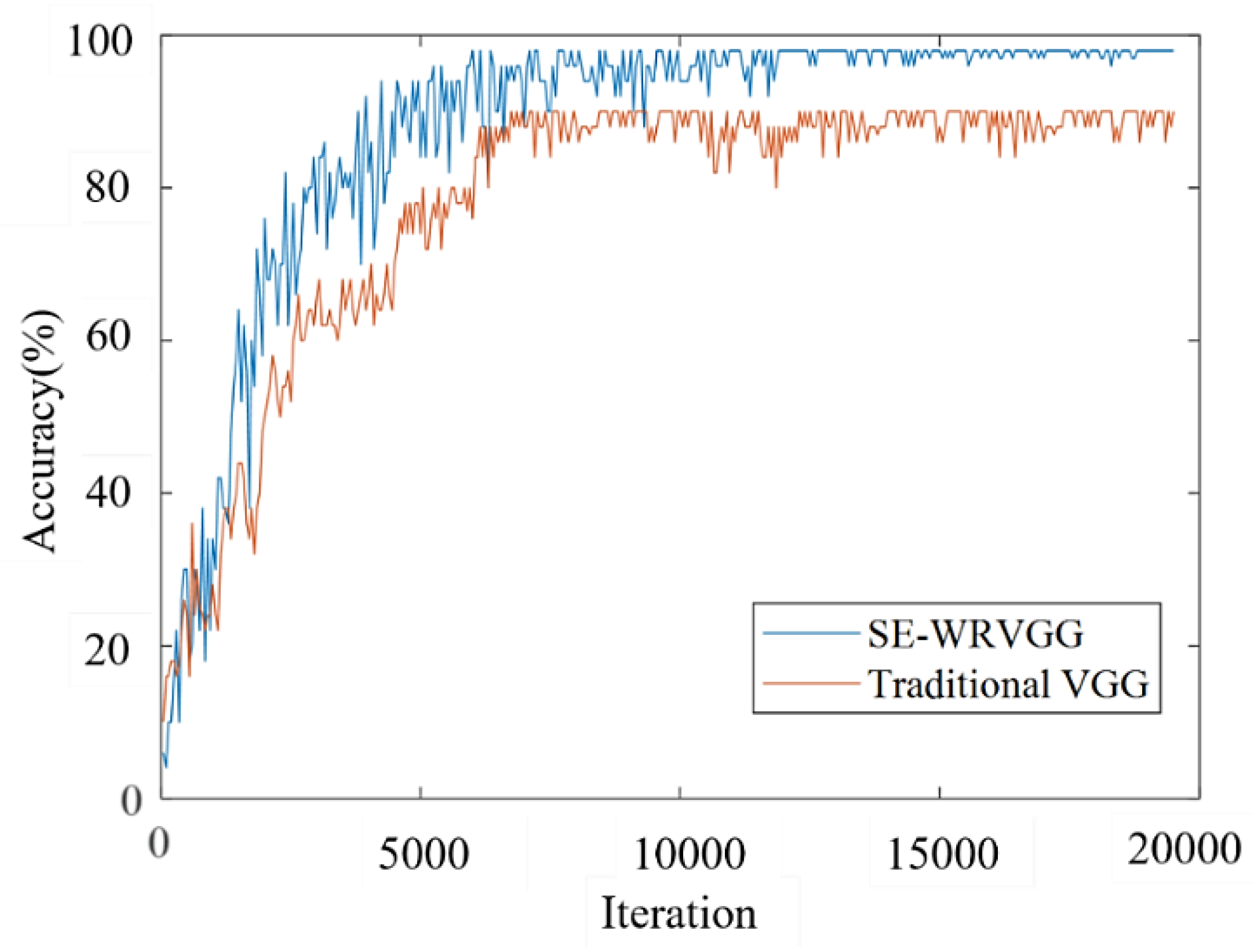
Experimental Results and Analyses of Improved Models
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| VGG model | a very deep convolutional network for large model recognition. |
| STFT method | short-time Fourier transform method. |
| SE Attention Mechanism Module | Channel Attention Module. |
| BN layer | batch normalization layer. |
| GWO-SVM algorithm | grey wolf optimization algorithm optimized support vector machine algorithm. |
| HOG algorithm | an algorithm for extracting histogram features of directional gradients. |
| DCNN networks | dynamic convolutional neural networks. |
| AUTO-CNN network | autonomous convolutional neural network. |
| ALEXNET network model | deep convolutional neural network. |
| GOOGLENET network model | a deep network structure developed by Google. |
| RESNET50 model | deep residual network. |
| CNN-LSTM network model | convolutional neural network combined with long-short-term memory network. |
References
- Mazurek, P. A Comprehensive Review of Steel Wire Rope Degradation Mechanisms and Recent Damage Detection Methods. Sustainability 2023, 42, 77–83. [Google Scholar] [CrossRef]
- Liu, S.; Sun, Y.; Jiang, X.; Kang, Y. A Review of Wire Rope Detection Methods, Sensors and Signal Processing Techniques. J. Nondestruct. Eval. 2020, 39, 85. [Google Scholar] [CrossRef]
- Zhou, P.; Zhou, G.; Zhu, Z.; He, Z.; Ding, X.; Tang, C. A Review of Non-Destructive Damage Detection Methods for Steel Wire Ropes. Appl. Sci. 2019, 9, 2771. [Google Scholar] [CrossRef]
- Park, S.H.; Kim, J.W.; Nam, M.J.; Lee, J.J. Magnetic Flux Leakage Sensing-Based Steel Cable NDE Technique. Shock Vib. 2014, 83, 217–222. [Google Scholar] [CrossRef]
- Yan, X.; Zhang, D.; Wang, H. Increasing Detection Resolution of Wire Rope Metallic Cross-Sectional Area Damage Based on Magnetic Aggregation Structure. IEEE Trans. Instrum. Meas. 2019, 69, 4487–4495. [Google Scholar] [CrossRef]
- Tian, J.; Zhao, C.; Wang, W.; Sun, G. Detection Technology of Mine Wire Rope Based on Radial Magnetic Vector With Flexible Printed Circuit. IEEE Trans. Instrum. Meas. 2021, 70, 3521810. [Google Scholar] [CrossRef]
- Wang, H.; Li, Q.; Han, S.; Li, P.; Tian, J.; Zhang, S. Wire Rope Damage Detection Signal Processing Using K-Singular Value Decomposition and Optimized Double-Tree Complex Wavelet Transform. IEEE Trans. Instrum. Meas. 2022, 71, 3528212. [Google Scholar] [CrossRef]
- Zheng, P.; Zhang, J. Application of Variational Mode Decomposition and k-Nearest Neighbor Algorithm in the Quantitative Nondestructive Testing of Wire Ropes. Shock Vib. 2019, 2019, 9828536. [Google Scholar] [CrossRef]
- Zhou, P.; Zhou, G.; Li, Y.; He, Z.; Liu, Y. A Hybrid Data-Driven Method for Wire Rope Surface Defect Detection. IEEE Sens. J. 2020, 20, 8297–8306. [Google Scholar] [CrossRef]
- Zhang, J.; Peng, F.; Chen, J. Quantitative Detection of Wire Rope Based on Three-Dimensional Magnetic Flux Leakage Color Imaging Technology. IEEE Access 2020, 8, 104165–104174. [Google Scholar] [CrossRef]
- Lu, S.; Zhang, J. Quantitative Nondestructive Testing of Wire Ropes Based on Features Fusion of Magnetic Image and Infrared Image. Shock Vib. 2019, 2019, 2041401. [Google Scholar] [CrossRef]
- Li, X.; Zhang, J.; Shi, J. Quantitative Nondestructive Testing of Broken Wires for Wire Rope Based on Magnetic and Infrared Information. J. Sens. 2020, 2020, 6419371. [Google Scholar] [CrossRef]
- Zhang, J.; Zhang, Z.; Liu, B. Non-destructive Testing of Steel Wire Ropes Incorporating Magnetic Memory Information. Insight-Non-Destr. Test. Cond. Monit. 2023, 65, 87–94. [Google Scholar] [CrossRef]
- Zhang, J.; Wang, S. Nondestructive Testing of Wire Ropes Based on Image Fusion of Leakage Flux and Visible Light. J. Fail. Anal. Prev. 2019, 19, 551–560. [Google Scholar] [CrossRef]
- Yea, Q.; Zhang, J.; Chen, Q. Quantitative detection of wire rope damage based on local structural characteristics. J. Intell. Fuzzy Syst. 2023, 45, 4337–4347. [Google Scholar] [CrossRef]
- Zhou, Z.; Zhang, J.; Gong, C. Hybrid semantic segmentation for tunnel lining cracks based on Swin Transformer and convolutional neural network. Comput.-Aided Civ. Infrastruct. Eng. 2023, 38, 2491–2510. [Google Scholar] [CrossRef]
- Chuma, E.L.; Iano, Y. A Movement Detection System Using Continuous-Wave Doppler Radar Sensor and Convolutional Neural Network to Detect Cough and Other Gestures. IEEE Sens. J. 2020, 21, 2921–2928. [Google Scholar] [CrossRef]
- Yu, Y.; Cheng, X.; Wang, L.; Wang, C. Convolutional Neural Network-Based Quantitative Evaluation for Corrosion Cracks in Oil/Gas Pipeline by Millimeter-Wave Imaging. IEEE Trans. Instrum. Meas. 2022, 71, 8006109. [Google Scholar] [CrossRef]
- Akter, R.; Golam, M.; Doan, V.S.; Lee, J.M.; Kim, D.S. IoMT-Net: Blockchain Integrated Unauthorized UAV Localization Using Lightweight Convolution Neural Network for Internet of Military Things. IEEE Internet Things J. 2022, 10, 6634–6651. [Google Scholar] [CrossRef]
- Yuan, Y.; Xu, Z.; Lu, G. SPEDCCNN: Spatial Pyramid-Oriented Encoder-Decoder Cascade Convolution Neural Network for Crop Disease Leaf Segmentation. IEEE Access 2021, 9, 14849–14866. [Google Scholar] [CrossRef]
- He, Y.; Song, K.; Meng, Q.; Yan, Y. An End-to-End Steel Surface Defect Detection Approach via Fusing Multiple Hierarchical Features. IEEE Trans. Instrum. Meas. 2020, 69, 1493–1504. [Google Scholar] [CrossRef]
- Wen, W.; Bai, Y.; Hu, F.; Cheng, W. Intelligent Fault Diagnosis Based on Receptive Field of DCNN for Rotary Machine under Variable Conditions. Procedia Manuf. 2020, 49, 119–125. [Google Scholar] [CrossRef]
- Wang, Z.; Lu, H.; Shi, Y.; Wang, X. Lightweight CNN Architecture Design Based on Spatial–Temporal Tensor and Its Application in Bearing Fault Diagnosis. IEEE Trans. Instrum. Meas. 2024, 73, 3504112. [Google Scholar] [CrossRef]
- Wang, J.; Zhang, Y.; Luo, C.; Miao, Q. Deep Learning Domain Adaptation for Electro-mechanical Actuator Fault Diagnosis under Variable Driving Waveforms. IEEE Sens. J. 2022, 22, 10783–10793. [Google Scholar] [CrossRef]
- Long, X.; Ding, X.; Li, J.; Dong, R.; Su, Y.; Chang, C. Indentation Reverse Algorithm of Mechanical Response for Elastoplastic Coatings Based on LSTM Deep Learning. Materials 2023, 16, 2617. [Google Scholar] [CrossRef] [PubMed]
- Chen, Z.; Xu, Y.Q.; Wang, H.; Guo, D. Deep STFT-CNN for Spectrum Sensing in Cognitive Radio. IEEE Commun. Lett. 2020, 25, 864–868. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Identification Methods | Identification Accuracy (%) | Average Identification Accuracy (%) | ||||
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| WRVGG | 89.63 | 89.63 | 88.91 | 89.63 | 89.63 | 89.49 |
| SE-WRVGG | 98.65 | 99.12 | 98.65 | 98.65 | 99.12 | 98.84 |
| Identification Methods | Training Time (s) | Average Training Time (s) | ||||
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| VGG | 8258.45 | 8467.31 | 8321.73 | 8351.62 | 8243.86 | 8328.59 |
| SE-WRVGG | 6021.54 | 6186.11 | 6092.36 | 6113.27 | 6033.64 | 6089.38 |
| Identification Methods | Identification Accuracy (%) | Average Identification Accuracy (%) | ||||
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| SE-VGG | 92.72 | 92.69 | 92.69 | 92.69 | 92.72 | 92.7 |
| SE-WRVGG | 98.65 | 99.12 | 98.65 | 98.65 | 99.12 | 98.84 |
| Serial Number | Identification Methods | Acc (%) | Pre (%) | Rec (%) | F1 (%) |
|---|---|---|---|---|---|
| 1 | SE-WRVGG | 98.84 | 98.25 | 97.91 | 98.08 |
| 2 | ALEXNET | 91.5 | 91.17 | 91.23 | 91.19 |
| 3 | GOOGLENET | 90.27 | 90.16 | 91.15 | 90.65 |
| 4 | RESNET50 | 88.79 | 87.64 | 88.05 | 87.84 |
| 5 | CNN-LSTM | 91.73 | 91.35 | 91.82 | 91.58 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, P.; Tian, J. Research on Internal Damage Identification of Wire Rope Based on Improved VGG Network. Entropy 2024, 26, 531. https://doi.org/10.3390/e26070531
Li P, Tian J. Research on Internal Damage Identification of Wire Rope Based on Improved VGG Network. Entropy. 2024; 26(7):531. https://doi.org/10.3390/e26070531
Chicago/Turabian StyleLi, Pengbo, and Jie Tian. 2024. "Research on Internal Damage Identification of Wire Rope Based on Improved VGG Network" Entropy 26, no. 7: 531. https://doi.org/10.3390/e26070531