Abstract
There is much interest in the topic of partial information decomposition, both in developing new algorithms and in developing applications. An algorithm, based on standard results from information geometry, was recently proposed by Niu and Quinn (2019). They considered the case of three scalar random variables from an exponential family, including both discrete distributions and a trivariate Gaussian distribution. The purpose of this article is to extend their work to the general case of multivariate Gaussian systems having vector inputs and a vector output. By making use of standard results from information geometry, explicit expressions are derived for the components of the partial information decomposition for this system. These expressions depend on a real-valued parameter which is determined by performing a simple constrained convex optimisation. Furthermore, it is proved that the theoretical properties of non-negativity, self-redundancy, symmetry and monotonicity, which were proposed by Williams and Beer (2010), are valid for the decomposition derived herein. Application of these results to real and simulated data show that the algorithm does produce the results expected when clear expectations are available, although in some scenarios, it can overestimate the level of the synergy and shared information components of the decomposition, and correspondingly underestimate the levels of unique information. Comparisons of the and (Kay and Ince, 2018) methods show that they can both produce very similar results, but interesting differences are provided. The same may be said about comparisons between the and (Barrett, 2015) methods.
1. Introduction
Williams and Beer [1] introduced a new method for the decomposition of information in a probabilistic system termed partial information decomposition (PID). This allows the joint mutual information between a number of input sources and a target (output) to be decomposed into components which quantify different aspects of the transmitted information in the system. These are the unique information that each source conveys about the target; the shared information that all sources possess about the target; the synergistic information that the sources in combination possess regarding the target. An additional achievement was to prove that the interaction information [2] is actually the difference between the synergy and redundancy in a system. Thus, a positive value for interaction information signifies that there is more synergy than redundancy in the system, while a negative value indicates the opposite. The work by Willliams and Beer has led to many new methods for defining a PID, mainly for discrete probabilistic systems [3,4,5,6,7,8,9,10,11,12,13] spawning a variety of applications [14,15,16,17,18,19].
There has been considerable interest in PID methods for Gaussian systems. The case of static and dynamic Gaussian systems with two scalar sources and a scalar target was considered in [20], which applied the minimum mutual information PID, . Further insights were developed in [21] regarding synergy. A PID for Gaussian systems based on common surprisal was published in [7]. Barrett’s work [20] was extended to multivariate Gaussian systems with two vector sources and a vector target in [22] using the method which was introduced for discrete systems in [8]. Further work based on the concept of statistical deficiency is reported in [23]. Application of PID for Gaussian systems has been used in a range of applications [18,24,25,26,27,28,29,30]
We focus in particular here on the method proposed by Niu and Quinn [3]. They applied standard results from information geometry [31,32,33] in order to define a PID for three scalar random variables which follow an exponential family distribution, including a trivariate Gaussian distribution.
Here, we extend this work in two ways: (a) we provide general formulae for a PID involving multivariate Gaussian systems which have two vector sources and a vector target by making use of the same standard methods from information geometry as in [3] and (b) we prove that the Williams–Beer properties of non-negativity, self-redundancy, symmetry and monotonicity are valid for this PID. We also provide some illustrations of the resulting algorithm using real and simulated data. The PID developed herein is based on some of the probability models in the same partially ordered lattice on which the algorithm is based. Therefore, we also compare the results obtained with those obtained by using the method. The results are also compared with those obtained using the algorithm.
2. Methods
2.1. Notation
A generic ‘p’ will be used to denote an absolutely continuous probability density function (pdf), with the arguments of the function signifying which distribution is intended. Bold capital letters are used to denote random vectors, with their realised values appearing in bold lowercase—so that denotes the joint pdf of the random vectors, , while is the conditional pdf of given a value for .
We consider the case where random vectors , of dimensions , respectively, have partitioned mean vectors equal to zero vectors of lengths , respectively, and a conformably partitioned covariance matrix. We stack these random vectors into the random vector , so that has dimension and assume that has a positive definite multivariate Gaussian distribution with pdf , mean vector and covariance matrix given by
where the covariance matrices of , respectively, are of sizes , and are the pairwise cross-covariance matrices between the three vectors . We also denote the conformably partitioned precision (or concentration) matrix K by
where . The pdf of is
2.2. Some Information Geometry
We now describe some standard results from information geometry [32,33] as applied to zero-mean, partitioned multivariate Gaussian probability distributions. The fact that there is no loss of generality in making this zero-mean assumption will be justified by Lemma 1 in Section 3. The multivariate Gaussian pdf defined in (2) may be written in the form
which may be written in terms of the Frobenius inner product as
where
This is of exponential family form [33] (p. 34) and [34] with natural parameter
and expectation parameter , where . We note that there is something of a terminal ambiguity here, since a ‘parameter’ is usually a real number. It is convenient to use the more compact notation provided by matrices since this enables all of the elements of a matrix natural parameter to be set to zero simultaneously.
The exponential family distribution in (2) is a dually flat manifold [31], which we denote by M.
We define the following e-flat submanifolds of M:
which may be conveniently pictured as the partially ordered lattice in Figure 1. The submanifolds and are necessary for the definition of the information-geometric PID [3] and the others will be considered in the sequel. Lattices similar to that in Figure 1 appear in [8,35,36] in relation to information decomposition, and in [37] who consider dually flat manifolds on posets. See also [38], and references therein, for the use of a variety of lattices of models in statistical work.
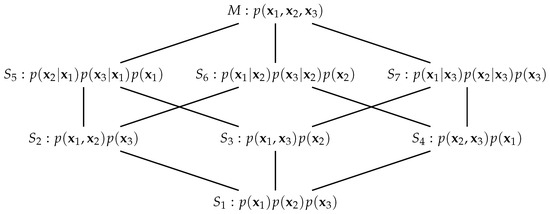
Figure 1.
A partially ordered lattice of the manifold M and submanifolds . The form of the pdf that is shown for each submanifold is that obtained by m-projection of the distribution onto the submanifold.
Hierarchical chains of submanifolds were considered in [31] but here the submanifolds are not all in a hierarchical chain due to the presence of two antichains: and There are, however, several useful chains within the lattice. Of particular relevance here are the chains , and . Application of Amari’s mixed-cut coordinates [31] and calculation of divergences produces measures of mutual information that are of direct relevance in PID (as was noted by [3] for three scalar random variables) in that the equations
are obtained—and they are standard results in information theory based on the chain rule for mutual information [39]. These are nice illustrations of Amari’s method.
We now consider m-projections from the pdf to each of the submanifolds, [31]. It is easy to find the pdf in each submanifold that is closest to the given pdf in M, p, in terms of Kullback–Leibler (KL) divergence [40], ([Ch. 4]). They are given in Figure 1. We know [34,40] that setting a block of the inverse covariance for a multivariate Gaussian distribution to zero expresses a conditional dependence between the variables involved. For example, consider . On this submanifold and so and are conditionally independent given a value for . Therefore, this pdf, which we denote by , has the form On submanifold , there are two conditional independences and so and the pair are independent and the closest pdf in to the pdf p has the form
The probability distributions defined by these information projections could also have been obtained by the method of maximum entropy, subject to constraints on model interactions [31], and they were obtained in this manner in [22] by making use of Gaussian graphical models [34,40].
We now mention important results from information geometry which are crucial for defining a PID [3]. Consider the pdfs belonging to the submanifolds , and to manifold M, and the e-geodesic passing through and . Then, any pdf on this e-geodesic path is also a zero-mean multivariate Gaussian pdf [41], ([Ch. 1]). We denote such a pdf by . It has covariance matrix , defined by
provided that is positive definite. We consider also an m-geodesic from p to . Then, by standard results [31,33], this m-geodesic meets the e-geodesic through and at a unique pdf such that generalized Pythagorean relationships hold in terms of the KL divergence:
The pdf minimizes the KL divergence between the pdf p in M and the pdf which lies on the e-geodesic which passes through pdfs and .
2.3. The Partial Information Decomposition
Williams and Beer [1] introduce a framework called the partial information decomposition (PID) which decomposes the joint mutual information between a target and a set of multiple predictor variables into a series of terms reflecting information which is shared, unique or synergistically available within and between subsets of predictors. The joint mutual information, conditional mutual information and bivariate mutual information are defined as follows.
Here, we focus on the case of two vector sources, , and a vector target . Adapting the notation of [42], we express the joint mutual information in four terms as follows:
It is possible to make deductions about a PID by using the following four equations which give a link between the components of a PID and certain classical Shannon measures of mutual information. The following are from ([42] Equations (4) and (5)), with amended notation; see also [1].
Also, the joint mutual information may be written as
| denotes the unique information that conveys about ; | |
| is the unique information that conveys about ; | |
| gives the common (or redundant or shared) information that both and have about ; | |
| is the synergy or information that the joint vector has about that cannot be obtained by observing and separately. |
The Equations (6)–(9) are of rank 3 and so it is necessary to provide a value for any one of the components, and then the remaining terms can be easily calculated. The initial formulation of [1] was based on quantifying the shared information and deriving the other quantities, but others have focussed on quantifying unique information or synergy directly [4,5,8]. Also, the following form [16] of the interaction information [2] will be useful. It was shown [1] to be equal to the difference in Syn—Shd.
3. Results
3.1. A PID for Gaussian Vector Sources and a Gaussian Vector Target
We now apply the results from the previous two sections in order to derive a partial information decomposition by making use of the method defined in [3]. The following lemma will confirm that without any loss of generality, we may assume, for all of the multivariate normal distributions considered herein, that the mean vector can be taken to be and the covariance matrix of , defined on , where , can have the form
where the matrices are of size , respectively, and are the cross-covariance (correlation) matrices between the three pairings of the three random vectors and so
The calculation of the partial information coefficients will involve the computation of KL divergences [43] between two multivariate Gaussian distributions associated with two submanifolds in the lattice, defined in Figure 1; see Lemma 1, with proof in Appendix C. These probability distributions will have two features in common: they each have the same partitioned mean vector and also the same variance–covariance matrices for the random vectors , and , but different cross covariance matrices for each pair of the random vectors , and .
Lemma 1.
Consider two multivariate Gaussian pdfs, and , which have the same partitioned mean vector, , and conformably partitioned covariance matrices
respectively, where the diagonal blocks are square.
Then, the Kullback–Liebler divergence does not depend on the mean vector μ, nor does it depend directly on the variance–covariance matrices . The divergence is equal to
where
with
which are the respective cross-correlation matrices among . The KL divergence depends only on these cross-correlation matrices.
3.2. Covariance Matrices
Table 1 gives the covariance matrices corresponding to each of the projected distributions on the submanifolds. It is known from Gaussian graphical models [34,40] that the probability distributions associated with submanifolds and are defined by setting and , respectively, in the precision matrix K. These conditions were shown in [22] to be equivalent to the equations and , respectively. From Table 1, we see that the covariance matrices for pdfs and have the following form.
The following lemma, which is proved in Appendix D, gives some useful results on determinants that will be used in the sequel.

Table 1.
Submanifold probability distributions with corresponding covariance matrices (modified from [22]).
Lemma 2.
The determinants of the matrices are given by
Also,
3.3. Feasible Values for the Parameter t
From (3), the m-projection from manifold M to the e-geodesic passing through the pdfs and meets in general at pdf which has covariance matrix defined by
and must be positive definite. Therefore, when finding the optimal pdf , we require to constrain the values of the parameter t to be such that is positive definite. We define the set of feasible values for t as
F is a closed interval in of the form , where . The interior of F—the open interval —is an open convex set. To enable the derivation of explicit results, it is useful to define the matrix by
We also require a feasible value for t when working with the matrix , and so we define the set G of feasible values as follows
It turns out that the sets of feasible values are actually the same set, as stated in the following lemma, which is proved in Appendix E, and this fact allows us to infer that is positive definite when is.
3.4. A Convex Optimisation Problem
The optimal value of the parameter t is defined by
The following lemma, with proof in Appendix F, provides details of the optimisation required to find .
Lemma 4.
We now define the PID components.For , we define the real valued function g by . Then,
and
Provided that the joint mutual information is positive, the minimization of g subject to the constraint , an open convex set, is a strictly convex problem, and the optimal value is unique.
The minimum value of g is equal to
where the determinant is defined by
Alternatively, the minimum could occur at either endpoint of F.
3.5. Definition of the PID Components
Following the proposal in [3], we define the synergy of the system to be
and by Lemma 1 and (20) the expression for the synergy is
Before defining the other PID terms, we require the following lemma, with proof in Appendix G.
Lemma 5.
The trace terms required in the definitions of the unique information are both equal to m:
From (4), we know that
and we define the unique information in the system that is due to source to be
as in [3]. By (5), we also have that
and we define the unique information in the system that is due to source to be
as in [3]. Finding the optimal point, , of minimisation of the KL divergence , and the orthogonality provided by the generalised Pythagorean theorems, define a clear connection between the geometry of the tangent space to manifold M and the definition of the information-geometric PID developed herein.
By using two of the defining equations of a PID (6) and (7), there are two possible expressions for the shared information, Shd, in the system:
Using the result in Lemma 1, we may write the unique information terms as follows. The unique information provided by is defined to be
by Lemma 5.
The unique information provided by is defined to be
by Lemma 5.
3.6. The PID
Explicit expressions for the PID components are given in Proposition 1, with proof in Appendix H.
Proposition 1.
The partial information decomposition for the zero-mean multivariate Gaussian system defined in (12) has the following components.
where the determinant is defined by
and F is the interval of real values of t for which is positive definite.
- The two possible expressions for the shared information in (31) are equal.
Theoretical properties of the PID are presented in Proposition 2, with proof in Appendix I.2.
Proposition 2.
The PID defined in Proposition 1 possesses the Williams–Beer properties of non-negativity, self-redundancy, symmetry and monotonicity.
3.7. Some Examples and Illustrations
Example 1.
Prediction of calcium contents.
This dataset was considered in [22]. The PID developed here, along with the PID [22] and PID [20], was applied using data on 73 women involving one set of predictors (Age, Weight, Height), another set of two predictors (diameter of os calcis, diameter of radius and ulna), and target (calcium content of heel and forearm). The following results were obtained.
| PID | Unq1 | Unq2 | Shd | Syn | |
| 0.2408 | 0.3581 | 0.0304 | 0.0728 | 0.1904 | |
| 0.4077 | 0.0800 | 0.0232 | 0.1408 | ||
| 0.3277 | 0 | 0.1032 | 0.2209 |
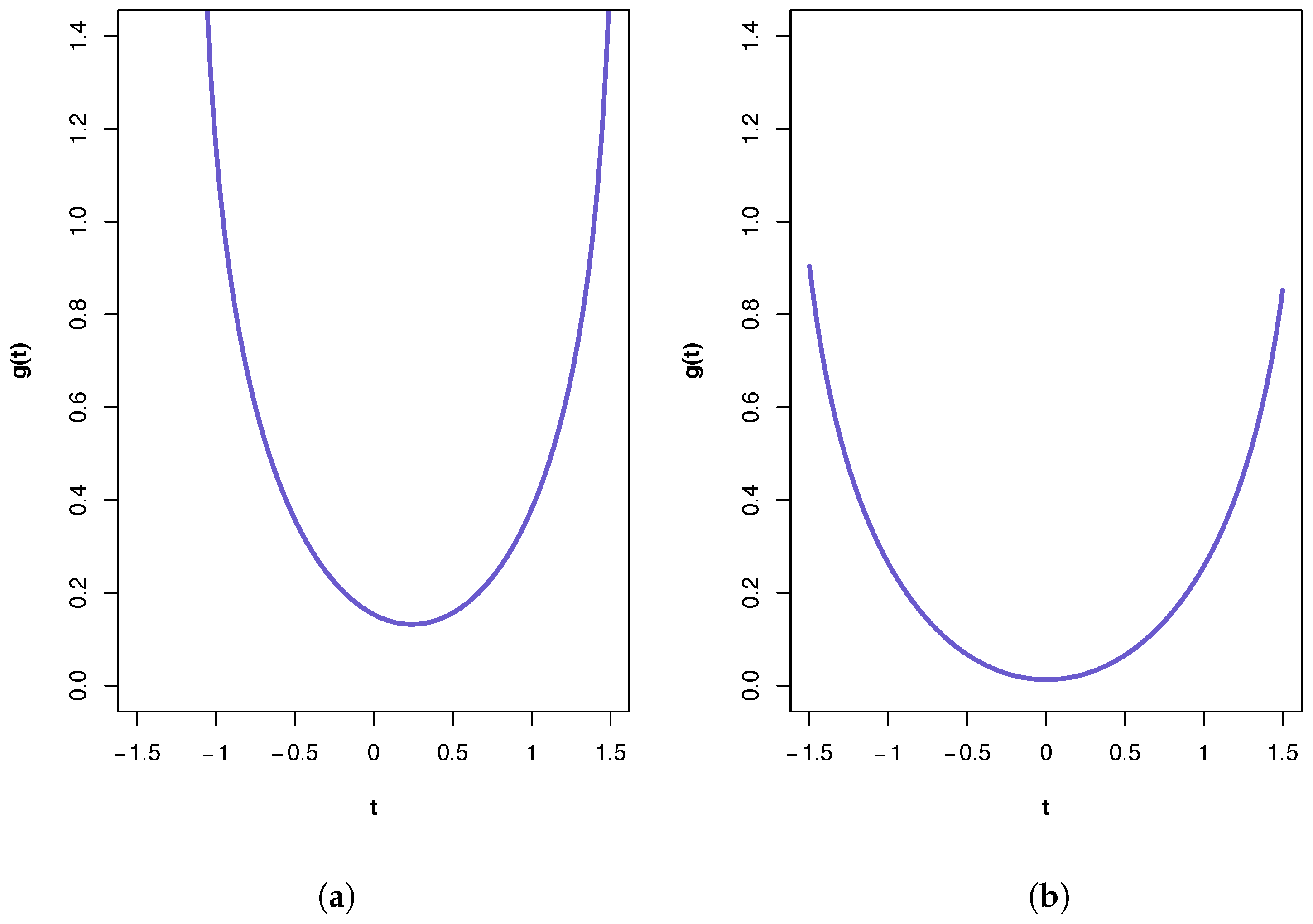
A plot of the ‘synergy’ function is shown in Figure 2a. All three PIDs indicate the presence of synergy and a large component of unique information due to the variables in . The PID suggests the transmission of more of the joint mutual information as shared and synergistic information and correspondingly less unique information due to either source vector than does the PID. This is true also for the results from the PID, but it has higher values for synergistic and shared information and a lower value for Unq1 than those produced by the PID. It was shown in [22] that pdf p in manifold M provides a better fit to these data than any of the submanifold distributions. This pdf contains pairwise cross-correlation between the vectors and , and between and . Hence, it is no surprise to find that a relatively large Unq1 component. One might also anticipate a large value for Unq2. That this is not the case is explained, at least partly, by the presence of unique information asymmetry, in that the mutual information between and (0.4309) is much larger than that between and (0.1032) and also bearing in mind the constraints imposed by (6)–(10).
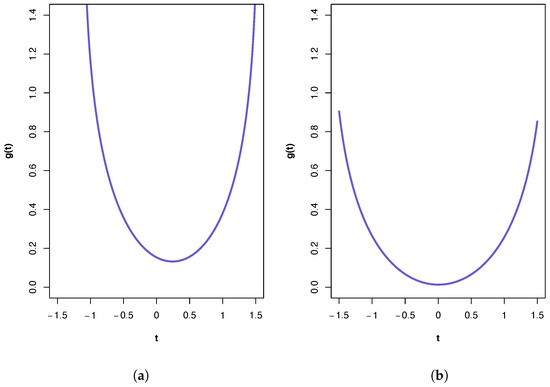
Figure 2.
Plots of the ‘synergy’ function for the two calcium datasets. (a) First calcium dataset. The feasible range for t is (−1.13, 1.56), with . (b) Second calcium dataset. The feasible range for t is (−1.67, 1.69), with .
The PIDs were also computed with the same and but taking to be another set of four predictors (surface area, strength of forearm, strength of leg, area of os calcis). The following results were obtained.
| PID | Unq1 | Unq2 | Shd | Syn | |
| 0.0027 | 0.3522 | 0.0000 | 0.0787 | 0.0186 | |
| 0.3708 | 0.0186 | 0.0601 | 0 | ||
| 0.3522 | 0 | 0.0787 | 0.0186 |
A plot of the ‘synergy’ function is shown in Figure 2b. In this case, the PIDs obtained from all three methods are very similar, with the main component being unique information due to the variables in . The PIDs indicate almost zero synergy and almost zero unique information due to the variables in . In [22], it was shown that the best of the pdfs is associated with submanifold . If this model were to hold exactly, then a PID must have Syn and Unq2 components that are equal to zero. Therefore, all three PIDs perform very well here, and the fact that the Unq1 component is much larger than the Shd component is due to unique information asymmetry, since the mutual information between and is only 0.0787. In this dataset, the PID suggests the transmission just a little more of the joint mutual information as shared and synergistic information and correspondingly less unique information due to either source vector than does the PID. The and PIDs produce identical results (to 4 d.p.).
When working with real or simulated data, it is important to use the correct covariance matrix. In order to use the results given in Proposition 1, it is essential that the input covariance matrix has the structure of , as given in (12). Further detail is provided in Appendix J.
Example 2.
PID expectations and exact results.
Since there is no way to know the true PID for any given dataset it is useful to consider situations under which some values of the PID components can be predicted, and this approach has been used in developments of the topic. Here, we consider such expectations provided by the pdfs associated with the submanifolds , defined in Figure 1. In submanifold , the source is independent of both the other source and the target . Hence, we expect only unique information due to source to be transmitted. Submanifold is similar but we expect only unique information due to source to be transmitted. In manifold , and are conditionally independent given a value for . Hence, from (9), we expect the Unq2 and Syn components to be zero. Similarly, for , we expect the Unq1 and Syn components to be equal to zero, by (8). On submanifold , the sources are conditionally independent given a value for the target (which does not mean that the sources are marginally independent). Since the target interacts with both source vectors, one might expect some shared information as well as unique information from both sources, and also perhaps some synergy. Here, from (11), the interaction information must be negative or zero, and so we can expect to see transmission of more shared information than synergy.
We will examine these expectations by using the following multivariate Gaussian distribution (which was used in [22]). The matrices are given an equi-cross-correlation structure in which all the entries are equal within each matrix:
where denote here the constant cross correlations within each matrix and denotes an n-dimensional vector whose entries are each equal to unity.
The values of are taken to be , with , . Covariance matrices for pdfs were computed using the results in Table 1. Thus, we have the exact covariance matrices which can be fed into the , and algorithms. The PID results are displayed in Table 2.
Table 2.
PID results for exact pdfs, reported as a percentage of the joint mutual information.
From Table 2, we see that all three PIDs meet the expectations exactly for pdfs , with only unique information transmitted when the pdfs , are true, respectively, and zero unique for the relevant component and zero synergy when the models are true, respectively. When model is the true model, we find that the and PIDs produce virtually identical results: the joint mutual information is transmitted almost entirely as synergistic information. The PID is slightly different, with less unique information transmitted about the variables in , and more shared and synergistic information transmitted than with the other two PIDs. The PIDs produce very different results for pdf , although, as expected, they do express more shared information than synergy. When this model is satisfied, sets the synergy to 0, even if there is no compelling reason to support this. This curiosity is mentioned and illustrated in [22]. On the other hand, the PID suggests that each of the four components contributes to the transmission of the joint mutual information, with unique information due to and shared information making more of a contribution than the other two components. The PID transmits a higher percentage of the joint information as shared and synergistic information, and a smaller percentage due to the variables in , than is found with ; these differences are much stronger when comparison is made with the corresponding components. As with model p, it appears that the setting of the Unq1 component in to zero has been translated into its percentage being subtracted from the Unq2 component and added to both the Shd and Syn components in to produce .
Example 3.
Some simulations.
Taking the same values of and as in the previous example, a small simulation study was conducted. From each of the pdfs, , a simple random sample of size 1000 was generated from the 10-dimensional distribution, a covariance matrix estimated from the data and the , and algorithms were applied. This procedure was repeated 1000 times. In order to make the PID results from the sample of 1000 datasets comparable each PID was normalized by dividing each of its components by the joint mutual information; see (10). A summary of the results is provided in Table 3. We focus here on the comparison of and , and also and , since has been compared with for Gaussian systems [22].
Table 3.
PID results for simulated datasets from the pdfs, , reported as median (in bold) and range of the sample of percentages of the joint mutual information, apart from which gives the median and range of the actual values obtained using the algorithm.
- vs.
For pdf p, the and PIDs produce very similar results in terms of both median and range, and the median results are very close indeed to the corresponding exact values in Table 2. For pdf , the differences between the PID components found in Table 2 persist here although each PID, respectively, produces median values of their components that are close to the exact results in Table 2. For the other four pdfs, there are some small but interesting differences among the results produced by the two PID methods. The method has higher median values for synergy and shared information than for the unique information, when compared against the corresponding exact values in Table 2. In particular, the values of unique information given by are much lower than expected for pdfs , and the levels of synergy are larger than expected particularly for pdfs and . On the other hand, the PID tends to have larger values for the unique information, and lower values for synergy, especially for datasets generated from pdfs , and . For models , has median values of synergy that are closer to the corresponding exact values than those produced by . The suggestion that the method can produce more synergy and shared information than the method, given the same dataset, is supported by the fact that for all the pdfs and all 6000 datasets considered, the method produced greater levels of synergy and shared information and smaller values of the unique information in every dataset. This raises a question of whether such a finding is generally the case and whether there is this type of a systematic difference between the methods. In the case of scalar variables, it is easy to derive general analytic formulae for the PID components and such a systematic difference is present in this case.
- vs.
The and PIDs produce similar results for the datasets generated from pdf p, although the PID suggests the transmission of more shared and synergistic information and less unique information than does . For pdf , the differences between the PID results are much more dramatic, with the PID allocating an additional 15% of the joint mutual information to be shared and the synergistic information, and correspondingly 15% less of the unique information. Both methods produce almost identical summary statistics on the datasets generated from pdfs . Since the same patterns are present for all four distributions, we discuss the results for pdf as an exemplar and compare them with the corresponding exact values in Table 2. The results for component Unq1 show that both methods produce an underestimate of approximately 7%, on average, of the joint mutual information. The median values of Unq2 are close to those expected. The underestimates on the Unq1 component are coupled with overestimates, on average, for the shared and synergistic components; they are 2.6% and 4.3%, respectively, with the method, and 3.1% and 4.7%, respectively, with .
As to be expected with percentage data, the variation in results for each component tends to be larger for values that are not extreme and much smaller for the extreme values. Also, the optimal values of are shown in Table 3. They were all found to be in the range [0, 1], except for 202 of the datasets generated from pdf or .
4. Discussion
For the case of multivariate Gaussian systems with two vector inputs and a vector output, results have been derived using standard theorems from information geometry in order to develop simple, almost exact formulae for the PID, thus extending the scope of the work of [3] on scalar inputs and output. The formulae require one parameter to be determined by a simple, constrained convex optimisation. In addition, it has been proved that this PID algorithm satisfies the desirable theoretical properties of non-negativity, self-redundancy, symmetry and monotonicity, first postulated by Williams and Beer [1]. These results strengthen the confidence that one might have in using the method to separate the joint mutual information in a multivariate Gaussian system into shared, unique and synergistic components. The examples demonstrate that the method is simple to use and a small simulation study reveals that it is fairly robust, although in some of the scenarios considered the method produced more synergy and shared information than expected, and correspondingly less unique information; in some other scenarios, it performed as expected. Comparison of the and algorithms reveal that they can produce exactly the same, or very similar, results in some scenarios, but in other situations, it is clear that the method tends to have larger levels of shared information and synergy, and correspondingly, lower levels of unique information when compared with the results from the method.
For datasets generated from pdfs , the PIDs produced using the and methods are, on average, very similar indeed, and both methods overestimate synergy and shared information and underestimate unique information. The extent of these biases, as a percentage of the joint mutual information, is fairly small, on average, when pdf or is the true pdf, but larger, on average, when or is the true pdf. When pdf or p is the true pdf, the algorithm produces even more shared and synergistic information than obtained with the method. This effect is particularly dramatic in the case of , where on average with 82% of the joint mutual information is transmitted as shared or synergistic information, as compared with 51.5% for . It appears that the fact that the method forces one of the unique informations to be zero leads to an underestimation of the other unique information and an overestimate of both the shared and synergistic information, especially when or p is the true pdf and both unique information are expected to be non-zero.
While some numerical support is presented here for the hypothesis that there might be a systematic difference in this type between the and methods further research would be required to investigate this possibility. Also, the developed here is a bivariate PID and it would be of interest to explore whether the method could be extended to deal with more than two source vectors.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Data Availability Statement
The data used in Example 1 is available from https://github.com/JWKay/PID (accessed on 17 June 2024).
Conflicts of Interest
The author declares no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| d.p. | decimal places |
| Idep PID for Gaussian systems | |
| Information-geometric PID | |
| Immi for Gaussian systems | |
| KL | Kullback–Leibler |
| probability density function | |
| PID | Partial information decomposition |
Appendix A. Two Matrix Lemmas from [22]
Lemma A1.
Suppose that a symmetric matrix M is partitioned as
where A and C are symmetric and square. Then,
- (i)
- The matrix M is positive definite if and only if A and are positive definite.
- (ii)
- The matrix M is positive definite if and only if C and are positive definite.
- (iii)
Lemma A2.
When the covariance matrix Σ in (12) is positive definite then the following matrices are also positive definite, and hence nonsingular:
Also, the determinant of each of these matrices is positive and bounded above by unity, and it is equal to unity if, and only if, the matrix involved is the zero matrix. Furthermore,
Appendix B. Some Formulae from [22]
The following equations provide the relevant information-theoretic terms with a slight change of notation: is now , the indices on the vectors run from 1 to 3 rather than from 0 to 2, and is replaced by .
Appendix C. Proof of Lemma 1
From [43] (p. 189), the KL divergence is
since the mean vectors are equal. Each of the diagonal blocks in (13) is positive definite, by Lemma A1, and so possesses a positive definite square root [44] (p. 472). We define the positive definite block diagonal matrix
Hence, we may write
where
and
Therefore, using standard properties of determinants, we have from
Use of a similar argument provides a similar expression for the determinant of :
It follows that
We now consider the trace term. We have from (A8) that
and so
Since , for any three conformable matrices, the required result follows.
Appendix D. Proof of Lemma 2
Making use of Lemma A1(iii), we may write the determinant of the covariance matrix as
where
Since
it can be shown that
From Lemma A1(iii), we have that
and putting these results together gives
We now apply this result to obtain expressions for the determinants of and , which are defined in Table 1. In , R is replaced by and making this substitution in (A13) gives
Similarly, replacing Q by in (A13), gives the determinant of , after some manipulation, as
For the final result, we have that
from which it is clear that implies that . Conversely,
by Lemma A2. For the last equivalence, we note by (A13) that and implies that . Conversely, by (A4) and (A13) and the non-negativity of mutual information, implies that and , which imply from (A1) and (A2) and Lemma A2 that and .
Appendix E. Proof of Lemma 3
and are each positive definite if and only their inverses are positive definite. We work with the inverses. When or clearly both inverses are positive definite, since the inverses of and are positive definite. Suppose that and consider for , and for any , the quadratic form
This term is non-negative for every since the inverses of and are positive definite and . Clearly, for the same reasons, this quadratic form is equal to zero if and only if is the zero vector in , hence the result. A similar argument shows that is positive definite when .
For , we know that the matrix is positive definite. The matrix may be written in two ways as
which is a product of three positive definite matrices. Since the last two expressions are transposes of each other it follows that this product is symmetric. Hence, from a result by E. P. Wigner [45], we deduce that is positive definite, so that . A similar argument shows that . Thus, we have proved that the feasible sets F and G are equal.
Appendix F. Proof of Lemma 4
For the first part, we consider (3):
and apply the trace operator, which is linear, to obtain
Consider We may write this as
Now, from (12) and the form of in Table 1, we have that
The pdf is defined by the constraint in the inverse covariance matrix K. Hence, has the form
Performing the multiplication of these block matrices shows that the diagonal blocks of are all equal to a zero matrix, and so have trace equal to zero. Hence, the trace of this matrix is equal to zero. Since , it follows from (A18) that this matrix has trace equal to m.
Now consider the trace of . From (12) and the form of in Table 1, we have that
The pdf is defined by the constraint in the inverse covariance matrix K. Hence, has the form
By adopting a similar argument to that given above for , it follows that . The required result follows from (A17). Now for the second part of the proof, we use Lemma 1 and the trace result just derived to write
may be written as
and so, by Lemma 2, we have
Hence
We wish to minimize with respect to t under the constraint that . We set , which is positive definite by Lemma 3, and apply Jacobi’s formula and the chain rule. Differentiating (A22) with respect to t we obtain
Further differentiation yields
where the are the eigenvalues of the matrix . Since is positive definite it possesses a positive definite square root , say. Since the eigenvalues of are the same as those of , which is symmetric and so has real eigenvalues, and since the joint mutual information is positive (and so by Lemma 2 ), it follows that at least one of the eigenvalues must be non-zero. Hence, . Therefore, is strictly convex on the convex set and the minimum is unique, and given by the value which satisfies the necessary condition . (This turns out to be exactly the value of t that is required for the two forms of shared information to be equal.) Of course, the minimum could occur at an endpoint of the interval F, in which case the minimum value of is the value taken at the endpoint.
Finally, we write
where A is defined in (A10), with inverse given by (A11), and
Some matrix calculation then gives
and also
Now from (A12) and (A23) it follows that is equal to
Making use of this equation and also (A22), and replacing t by the optimal , we have that the minimum of , when , is
where
Appendix G. Proof of Lemma 5
From (4) we know that
Then, by Lemmas 1 and 4,
Also,
and
by (20) with . By substituting these expressions into (A28) it follows that . The proof that is obtained by using a very similar argument, starting with (5).
Appendix H. Proof of Proposition 1
The formula for synergy is the minimum value of as provided in (A26). From (30), Lemmas 1 and 5, we have that
By making use of a similar calculation we find that
The two expressions for the shared information are
By using (6), (7), (A29) and (A30) it is easy to see that both expressions for the shared information, Shd, are equal to
Appendix I. Proof of Proposition 2
Appendix I.1. Non-Negativity
Since the Syn, Unq1 and Unq2 components in the PID have been defined to be KL divergences they are non-negative. It remains to show that Shd is non-negative. From Appendix H, we see that this is the case if and only if . From (A23), (A24) and (A27) we have, with , that
and that
Since , we know by Lemma 3 that , and so this matrix is positive definite. It follows from Lemma A1(iii) that is positive definite and from Lemma A1(i) that A is positive definite, as is . Therefore, possesses a (symmetric) positive definite square root, C say, and we may write
Then the matrix is positive semi-definite and so has non-negative eigenvalues, . We denote the eigenvalues of as . Since is positive definite we know that for It follows that for Since the determinant of a square matrix is the product of its eigenvalues we have that
and so , hence the result.
Appendix I.2. Self-Redundancy
The property of self-redundancy considers the case of , i.e., both sources are the same, and it requires us to show that
When the sources are the same we have and , which results in a singular covariance matrix. Therefore, we take , for very small such that , and let . Using this information in (A27) we have that
Therefore , which is equal to by (A1).
Out of interest, it seems worthwhile to check the limits for the classical information measures given in (A3)–(A7). From (A3) and (A13), after some cancellation, we have that
Also, since ,
Similarly, for the joint mutual information and the interaction information:
and
as expected, since .
Appendix I.3. Symmetry
To validate the symmetry property we require to prove that is equal to . Swapping and means that the sources are now in order and the covariance matrix in (12) becomes
The switching of and means also that the probability distributions on and swap, since
and the corresponding covariance matrices are
We now apply a similar argument to that used in the proof of Lemma 4.
where and are
and
Some matrix calculation then gives
and also
Hence,
which is identical to the expression of obtained in (A27). It follows that and that the shared information is unchanged by swapping and .
Appendix I.4. Monotonicity on the Redundancy Lattice
We use the term ‘redundancy’ here for convenience rather than ‘shared information’, since both terms mean exactly the same thing. A redundancy lattice is defined in [1]. When there are two sources and a target, there are four terms of interest that are usually denoted by , which are the terms in the redundancy lattice. For monotonicity it is required that the redundancy values for these four terms satisfy the inequalities and that .
The redundancy value for term is the self-redundancy which is, by the self-redundancy property, equal to the joint mutual information . Similarly, the redundancy values for the terms and are, by self-redundancy, the mutual information and , respectively. The final term is equal to the shared information defined in Proposition 1.
Since the PID defined in Proposition 1 possesses the non-negativity property it follows from (6)–(10) that the redundancy measure is monotonic on the redundancy lattice.
Appendix J. Computation
Code was written using R [46] in RStudio [46] to compute the PID. This code together with R code to compute the and PIDs is available from https://github.com/JWKay/PID (accessed on 17 June 2024). The code first checks whether the input covariance matrix is positive-definite. If so, the feasible region F is computed by defining a function whose value indicates whether or not the matrix is positive definite, and then applying the uniroot root-finding algorithm. The constrained optimisation is performed by using the base R function optim. The code produces a plot of and returns the numerical results. Details of the pre-processing employed to make use of the formulae presented in Proposition 1 are the same as used with the PID and are available from Appendix D [22].
References
- Williams, P.L.; Beer, R.D. Nonnegative Decomposition of Multivariate Information. arXiv 2010, arXiv:1004.2515. [Google Scholar]
- McGill, W.J. Multivariate Information Transmission. Psychometrika 1954, 19, 97–116. [Google Scholar] [CrossRef]
- Niu, X.; Quinn, C.J. A measure of Synergy, Redundancy, and Unique Information using Information Geometry. In Proceedings of the 2019 IEEE International Symposium on Information Theory (ISIT), Paris, France, 7–12 July 2019. [Google Scholar]
- Griffith, V.; Koch, C. Quantifying synergistic mutual information. In Guided Self-Organization: Inception. Emergence, Complexity and Computation; Springer: Berlin/Heidelberg, Germany, 2014; Volume 9, pp. 159–190. [Google Scholar]
- Bertschinger, N.; Rauh, J.; Olbrich, E.; Jost, J.; Ay, N. Quantifying Unique Information. Entropy 2014, 16, 2161–2183. [Google Scholar] [CrossRef]
- Harder, M.; Salge, C.; Polani, D. Bivariate measure of redundant information. Phys. Rev. E 2013, 87, 012130. [Google Scholar] [CrossRef] [PubMed]
- Ince, R.A.A. Measuring multivariate redundant information with pointwise common change in surprisal. Entropy 2017, 19, 318. [Google Scholar] [CrossRef]
- James, R.G.; Emenheiser, J.; Crutchfield, J.P. Unique Information via Dependency Constraints. J. Phys. Math. Theor. 2018, 52, 014002. [Google Scholar] [CrossRef]
- Finn, C.; Lizier, J.T. Pointwise Information Decomposition using the Specificity and Ambiguity Lattices. arXiv 2018, arXiv:1801.09010. [Google Scholar]
- Lizier, J.T.; Bertschinger, N.; Jost, J.; Wibral, M. Information Decomposition of Target Effects from Multi-Source Interactions: Perspectives on Previous, Current and Future Work. Entropy 2018, 20, 307. [Google Scholar] [CrossRef]
- Makkeh, A.; Gutknecht, A.J.; Wibral, M. Introducing a differentiable measure of pointwise shared information. Phys. Rev. 2021, 103, 032149. [Google Scholar] [CrossRef]
- Gutknecht, A.J.; Wibral, M.; Makkeh, A. Bits and pieces: Understanding information decomposition from part-whole relationships and formal logic. Proc. R. Soc. A 2021, 477, 0110. [Google Scholar] [CrossRef]
- Kolchinsky, A. A Novel Approach to the Partial Information Decomposition. Entropy 2022, 24, 403. [Google Scholar] [CrossRef] [PubMed]
- Wibral, M.; Finn, C.; Wollstadt, P.; Lizier, J.T.; Priesemann, V. Quantifying Information Modification in Developing Neural Networks via Partial Information Decomposition. Entropy 2017, 19, 494. [Google Scholar] [CrossRef]
- Finn, C.; Lizier, J.T. Quantifying Information Modification in Cellular Automata Using Pointwise Partial Information Decomposition. In Artificial Life Conference Proceedings; MIT Press: Cambridge, MA, USA, 2018; pp. 386–387. [Google Scholar]
- Timme, N.; Alford, W.; Flecker, B.; Beggs, J.M. Synergy, redundancy, and multivariate information measures: An experimentalist’s perspective. J. Comput. Neurosci. 2014, 36, 119–140. [Google Scholar] [CrossRef] [PubMed]
- Sherrill, S.P.; Timme, N.M.; Beggs, J.M.; Newman, E.L. Partial information decomposition reveals that synergistic neural integration is greater downstream of recurrent information flow in organotypic cortical cultures. PLoS Comput. Biol. 2021, 17, e1009196. [Google Scholar] [CrossRef] [PubMed]
- Pinto, H.; Pernice, R.; Silva, M.E.; Javorka, M.; Faes, L.; Rocha, A.P. Multiscale partial information decomposition of dynamical processes with short and long-range correlations: Theory and application to cardiovascular control. Physiol. Meas. 2022, 43, 085004. [Google Scholar] [CrossRef]
- Ince, R.A.A.; Giordano, B.L.; Kayser, C.; Rousselet, G.A.; Gross, J.; Schyns, P.G. A Statistical Framework for Neuroimaging Data Analysis Based on Mutual Information Estimated via a Gaussian Copula. Hum. Brain Mapp. 2017, 38, 1541–1573. [Google Scholar] [CrossRef] [PubMed]
- Barrett, A.B. An exploration of synergistic and redundant information sharing in static and dynamical Gaussian systems. Phys. Rev. E 2015, 91, 052802. [Google Scholar] [CrossRef] [PubMed]
- Olbrich, E.; Bertschinger, N.; Rauh, J. Information decomposition and synergy. Entropy 2015, 17, 3501–3517. [Google Scholar] [CrossRef]
- Kay, J.W.; Ince, R.A.A. Exact partial information decompositions for Gaussian systems based on dependency constraints. Entropy 2018, 20, 240. [Google Scholar] [CrossRef]
- Venkatesh, P.; Schamberg, G. Partial Information Decomposition via Deficiency for Multivariate Gaussians. In Proceedings of the IEEE International Symposium on Information Theory (ISIT), Espoo, Finland, 26 June–1 July 2022; pp. 2892–2897. [Google Scholar]
- Niu, X.; Quinn, C.J. Synergy and Redundancy Duality Between Gaussian Multiple Access and Broadcast Channels. In Proceedings of the 2020 International Symposium on Information Theory and Its Applications (ISITA), Kapolei, HI, USA, 24–27 October 2020; pp. 6–10. [Google Scholar]
- Faes, F.; Marinazzo, D.; Stramaglia, S. Multiscale Information Decomposition: Exact Computation for Multivariate Gaussian Processes. Entropy 2017, 19, 408. [Google Scholar] [CrossRef]
- Stramaglia, S.; Wu, G.-R.; Pellicoro, M.; Marinazzo, D. Expanding the transfer entropy to identify information circuits in complex systems. Phys. Rev. E 2012, 86, 066211. [Google Scholar] [CrossRef] [PubMed]
- Daube, C.; Ince, R.A.A.; Gross, J. Simple acoustic features can explain phoneme-based predictions of cortical responses to speech. Curr. Biol. 2019, 29, 1924–1937. [Google Scholar] [CrossRef] [PubMed]
- Park, H.; Ince, R.A.A.; Schyns, P.G.; Thut, G.; Gross, J. Representational interactions during audiovisual speech entrainment: Redundancy in left posterior superior temporal gyrus and synergy in left motor cortex. PLoS Biol. 2018, 16, e2006558. [Google Scholar] [CrossRef]
- Schulz, J.M.; Kay, J.W.; Bischofberger, J.; Larkum, M.E. GABAB Receptor-Mediated Regulation of Dendro-Somatic Synergy in Layer 5 Pyramidal Neurons. Front. Cell. Neurosci. 2021, 15, 718413. [Google Scholar] [CrossRef] [PubMed]
- Newman, E.L.; Varley, T.F.; Parakkattu, V.K.; Sherrill, S.P.; Beggs, J.M. Revealing the Dynamics of Neural Information Processing with Multivariate Information Decomposition. Entropy 2022, 24, 930. [Google Scholar] [CrossRef] [PubMed]
- Amari, S.-I. Information geometry on hierarchy of probability distributions. IEEE Trans. Inf. Theory 2001, 47, 1701–1711. [Google Scholar] [CrossRef]
- Amari, S.-I. Information Geometry and Its Applications; Springer: Tokyo, Japan, 2020. [Google Scholar]
- Amari, S.-I.; Nagaoka, H. Methods of Information Geometry; American Mathematical Society: Providence, Rhode Island, 2000. [Google Scholar]
- Lauritzen, S.L. Graphical Models; Oxford University Press: Oxford, UK, 1996. [Google Scholar]
- Zwick, M. An overview of reconstructability analysis. Kybernetes 2004, 33, 877–905. [Google Scholar] [CrossRef]
- Ay, N.; Polani, D.; Virgo, N. Information Decomposition Based on Cooperative Game Theory. Kybernetika 2020, 56, 979–1014. [Google Scholar] [CrossRef]
- Sugiyama, M.; Nakahara, H.; Tsuda, K. Information Decomposition on Structured Space. In Proceedings of the IEEE International Symposium on Information Theory (ISIT), Barcelona, Spain, 10–15 July 2016; pp. 575–579. [Google Scholar]
- Bailey, R.A. Hasse diagrams as a visual aid for linear models and analysis of variance. Commun. Stat. Theory Methods 2021, 50, 5034–5067. [Google Scholar] [CrossRef]
- Cover, T.M.; Thomas, J.A. Elements of Information Theory; Wiley-Interscience: New York, NY, USA, 1991. [Google Scholar]
- Whittaker, J. Graphical Models in Applied Multivariate Statistics; Wiley: Chichester, UK, 2008. [Google Scholar]
- Eguchi, E.; Komori, O. Minimum Divergence Methods in Statistical Machine Learning; Springer: Tokyo, Japan, 2022. [Google Scholar]
- Wibral, M.; Priesemann, V.; Kay, J.W.; Lizier, J.T.; Phillips, W.A. Partial information decomposition as a unified approach to the specification of neural goal functions. Brain Cogn. 2017, 112, 25–38. [Google Scholar] [CrossRef]
- Kullback, S. Information Theory and Statistics; Courier Corporation: Gloucester, MA, USA, 1978. [Google Scholar]
- Horn, R.A.; Johnson, C.R. Matrix Analysis; Cambridge University Press: New York, NY, USA, 1985. [Google Scholar]
- Wigner, E.P. On weakly positive matrices. Can. J. Math. 1963, 15, 313–318. [Google Scholar] [CrossRef]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2021; Available online: https://www.R-project.org/ (accessed on 20 May 2024).
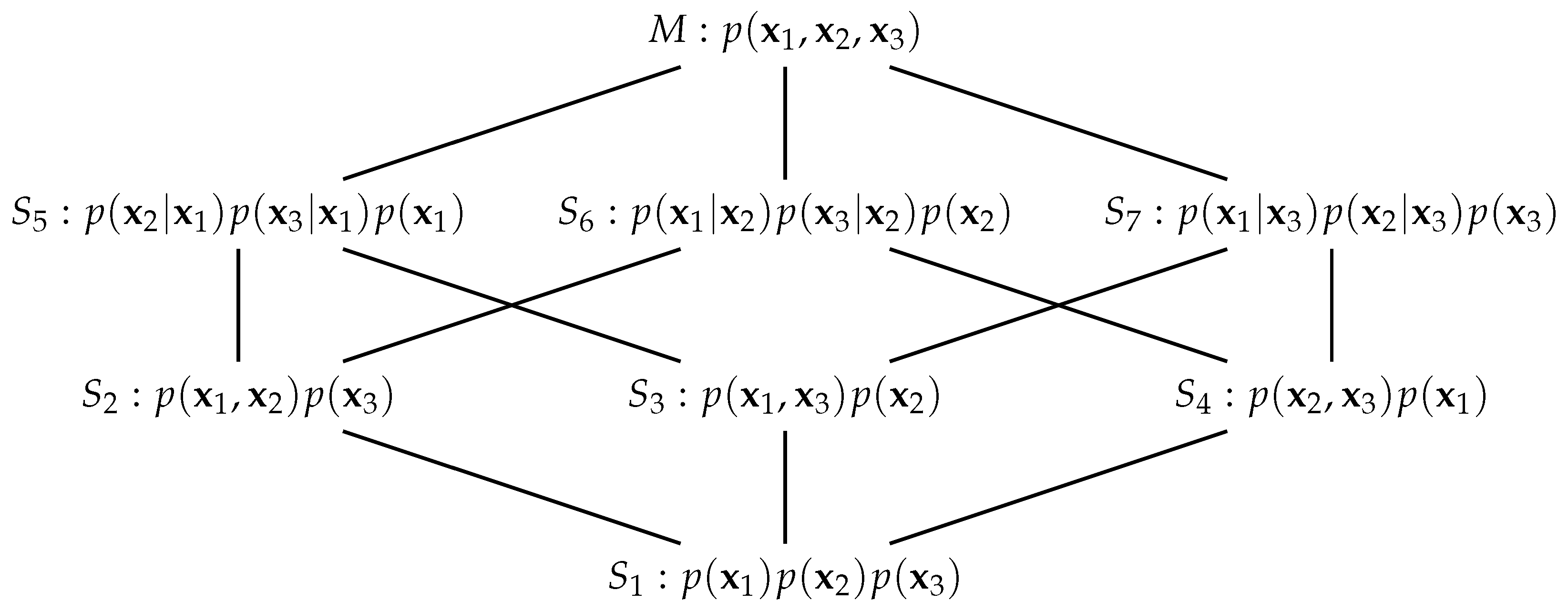
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).