
Avionics Module Fault Diagnosis Algorithm Based on Hybrid Attention Adaptive Multi-Scale Temporal Convolution Network

 ,
,
Abstract
1. Introduction
- The Adaptive Multi-scale Temporal Convolution (AMTC) module is proposed, which utilizes the FFT to search for the frequency of the channel with the largest contribution, and adaptively constructs the optimal multi-scale receptive field at an extremely rapid speed, to realize the comprehensive extraction of the features of the time series data. Additionally, residual concatenation is adopted to improve the accuracy and stability of the network to enable stronger feature extraction capability for time series data.
- The Interaction Channel Attention (ICA) module is presented, which reshapes some channels into batch dimensions and groups the channel dimensions into multiple sub-features to better preserve the information of each channel and reduce the computational overhead. Meanwhile, the regulation between different channels is realized through channel interaction, enabling the model to dynamically learn and adjust the weight of different channels.
- The Hierarchical Block Temporal Attention (HBTA) module is proposed, which applies the multi-head attention mechanism to the raw feature maps in blocks to effectively extract the local information while reducing the computational complexity and simultaneously performing the downsampling operation on the raw feature maps to expand the scope of multi-head attention to obtain sufficient global information. Finally, by combining the information at different hierarchical blocks, the relationship between time steps of sequential data can be effectively captured, which enhances the expressive power of the model.
- Several fault states of the functional circuit module of the integrated modular avionics (IMA) system are simulated by using the fault injection technique, and each abnormal state can be equated to the actual situation of a certain function degradation of the electronic module; this leads to the sampling and production of the dataset of avionics module faults. This dataset can provide a database for subsequent avionics module failure analysis.
2. Related Work
2.1. Model-Based and Signal-Based Approaches
2.2. Data-Driven Approach
3. Methodology
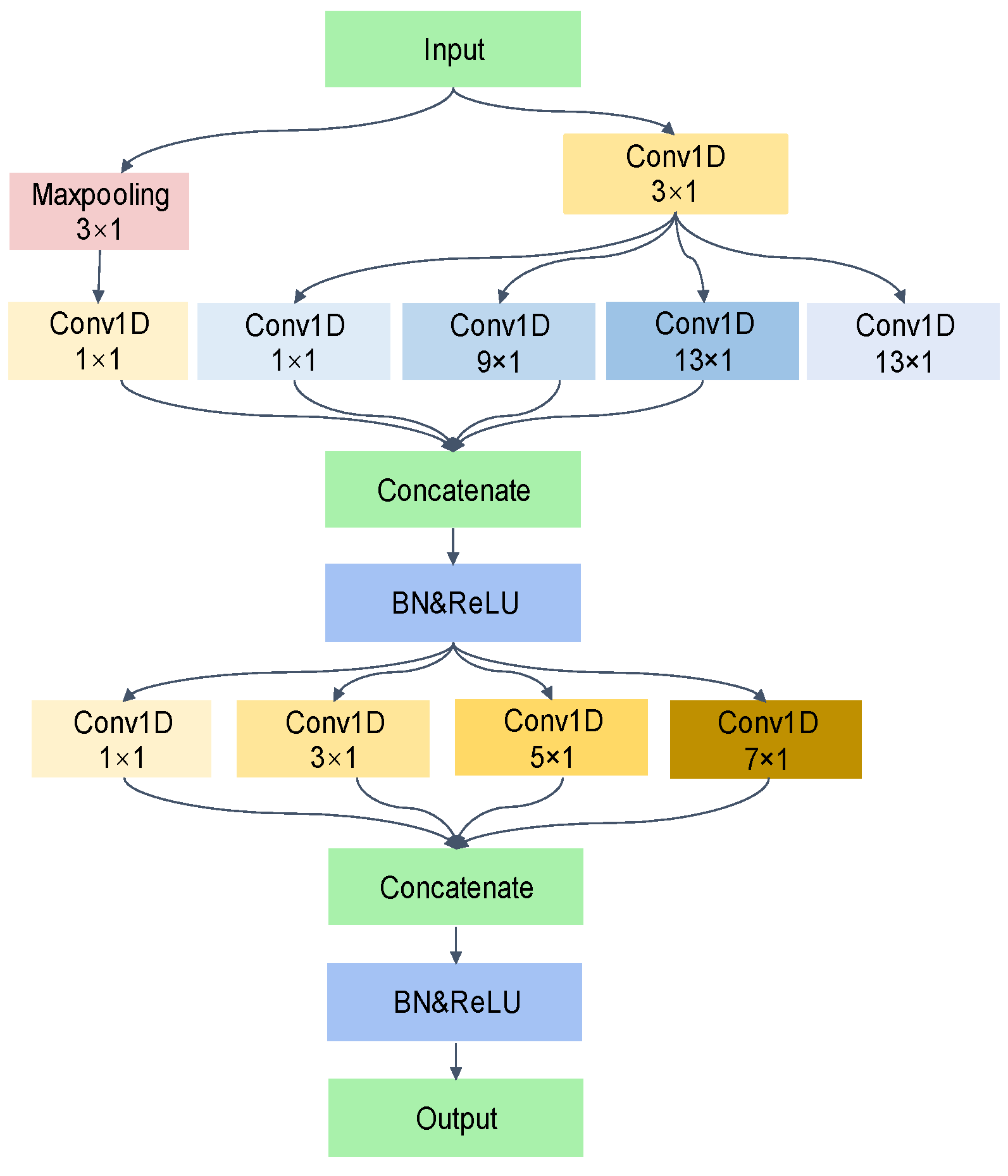
3.1. HAAMTCN Structure
3.2. Adaptive Multi-Scale Temporal Convolution Module
3.3. Interaction Channel Attention Module
3.4. Hierarchical Block Temporal Attention Module
4. Experiment
4.1. Evaluation Metrics
4.2. Data Preprocessing
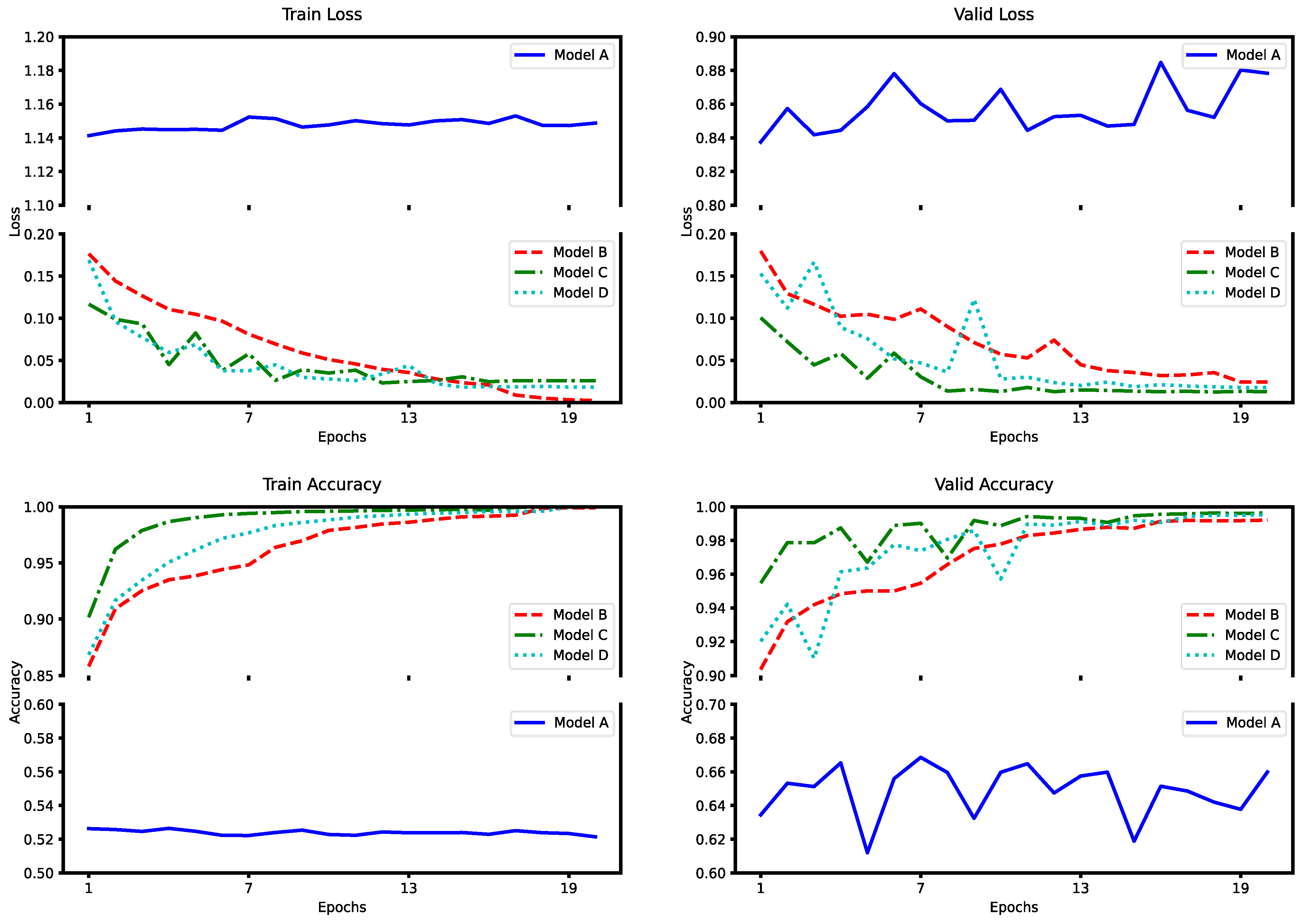
4.3. Ablation and Alternative Experiment
4.3.1. AMTC Module Ablation Experiment
4.3.2. Network Structure Ablation Experiment
4.3.3. Network Module Replacement Experiment
4.4. Comparison Experiment
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Xu, Q.; Chen, J.; Wu, B. Preprocessing of massive flight data based on noise and dimension reduction. In Proceedings of the 6th International Conference on Computer and Communications (ICCC), Chengdu, China, 11–14 December 2020; IEEE Publications: New York, NY, USA, 2020; pp. 1706–1710. [Google Scholar]
- Wu, Z.; Huang, N.; Zheng, X.; Li, X. Cyber-physical avionics systems and its reliability evaluation. In Proceedings of the 4th Annual IEEE International Conference on Cyber Technology in Automation, Control and Intelligent, Hong Kong, China, 4–7 June 2014; pp. 429–433. [Google Scholar]
- Zhang, J.; Li, T.; Chi, C.; Lv, Y. A TFPG-based method of fault modeling and diagnosis for IMA systems. In Proceedings of the Prognostics and Health Management Conference (PHM-Besançon), Besancon, France, 4–7 May 2020; pp. 167–175. [Google Scholar]
- Liu, Y.; Li, K.; Zhang, Y.; Song, S. MRD-NETS: Multi-scale Residual Networks with Dilated Convolutions for Classification and Clustering Analysis of Spacecraft Electrical Signal. IEEE Access 2019, 7, 171584–171597. [Google Scholar] [CrossRef]
- Li, T.; Zhao, Z.; Sun, C.; Cheng, L.; Chen, X.; Yan, R.; Gao, R.X. WaveletKernelNet: An Interpretable Deep Neural Network for Industrial Intelligent Diagnosis. IEEE Trans. Syst. Man Cybern. Syst. 2021, 52, 2302–2312. [Google Scholar] [CrossRef]
- Chattopadhyay, S.; Chowdhuri, D.R.; Bhattacharjee, S.; Chaudhuri, P.P. Board level fault diagnosis using cellular automata array. In Proceedings of the 8th International Conference on VLSI Design, New Delhi, India, 4–7 January 1995; pp. 343–348. [Google Scholar]
- Han, R.; Wang, S.; Liu, B.; Zhao, T.; Ye, Z. A novel model-based dynamic analysis method for state correlation with IMA fault recovery. IEEE Access 2018, 6, 22094–22107. [Google Scholar] [CrossRef]
- Wang, B.; Zhang, J.K.; Yan, J. Aircraft avionics system fault diagnosis based on directed graph model. Aviat. Electron. Technol. 2021, 52, 9–15. [Google Scholar]
- Zhou, Z.; Li, T.; Liu, T.; Wang, K.; Huang, Y.; Shi, L. Fault diagnosis method for complex electronic system. In Proceedings of the Prognostics and Health Management Conference (PHM-2022 London), London, UK, 27–29 May 2022; pp. 17–21. [Google Scholar]
- Bechhoefer, E.; Fang, A. Algorithms for embedded PHM. In Proceedings of the IEEE Conference on Prognostics and Health Management, Denver, CO, USA, 23–27 September 2012; pp. 1–8. [Google Scholar]
- Shi, L.; Zhou, Z.; Jia, H.; Cheng, L.; Yu, P.; Huang, Y.; En, Y. Evaluation of health condition for IMA module based on Mahalanobis distance. In Proceedings of the Prognostics and System Health Management Conference (PHM-Chongqing), Chongqing, China, 26–28 October 2018; pp. 303–307. [Google Scholar]
- Ali, M.Z.; Shabbir, M.N.S.K.; Liang, X.; Zhang, Y.; Hu, T. Machine learning-based fault diagnosis for single- and multi-faults in induction motors using measured stator currents and vibration signals. IEEE Trans. Ind. Appl. 2019, 55, 2378–2391. [Google Scholar] [CrossRef]
- Shi, L.; Zhou, Z.; Jia, H.; Yu, P.; He, S.; Cheng, L.; Huang, Y. Fault diagnosis of functional circuit in avionics system based on BPNN. In Proceedings of the Prognostics and System Health Management Conference (PHM-Qingdao), Qingdao, China, 25–27 October 2019; pp. 1–5. [Google Scholar]
- Huang, Y.; Shi, L.; Lu, Y. Research on module-level fault diagnosis of avionics system based on residual convolutional neural network. In Proceedings of the 4th International Conference on Algorithms, Computing and Artificial Intelligence, New York, NY, USA, 22–24 December 2021; pp. 1–7. [Google Scholar]
- Wen, L.; Li, X.; Gao, L.; Zhang, Y. A new convolutional neural network-based data-driven fault diagnosis method. IEEE Trans. Ind. Electron. 2017, 65, 5990–5998. [Google Scholar] [CrossRef]
- Serrà, J.; Pascual, S.; Karatzoglou, A. Towards a Universal Neural Network Encoder for Time Series; CCIA: Washington, DC, USA, 2018; pp. 120–129. [Google Scholar]
- Karim, F.; Majumdar, S.; Darabi, H.; Harford, S. Multivariate LSTM-FCNs for time series classification. Neural Netw. 2019, 116, 237–245. [Google Scholar] [CrossRef]
- Yan, X.; Liu, Y.; Zhang, C.-A. Multiresolution hypergraph neural network for intelligent fault diagnosis. IEEE Trans. Instrum. Meas. 2022, 71, 3525910. [Google Scholar] [CrossRef]
- Pan, Y.; Bi, Y.; Zhang, C.; Yu, C.; Li, Z.; Chen, X. Feeding material identification for a crusher based on deep learning for status monitoring and fault diagnosis. Minerals 2022, 12, 380. [Google Scholar] [CrossRef]
- An, B.T.; Wang, S.B.; Zhao, Z.B.; Qin, F.; Yan, R.; Chen, X. Interpretable neural network via algorithm unrolling for mechanical fault diagnosis. IEEE Trans. Instrum. Meas. 2022, 71, 3517011. [Google Scholar] [CrossRef]
- Zhao, Z.; Li, T.; An, B.; Wang, S.; Ding, B.; Yan, R.; Chen, X. Model-driven deep unrolling: Towards interpretable deep learning against noise attacks for intelligent fault diagnosis. ISA Trans. 2022, 129, 644–662. [Google Scholar] [CrossRef] [PubMed]
- An, B.T.; Wang, S.B.; Qin, F.H.; Zhao, Z.; Yan, R.; Chen, X. Adversarial algorithm unrolling network for interpretable mechanical anomaly detection. IEEE Trans. Neural Netw. Learn. Syst. 2023, 35, 6007–6020. [Google Scholar] [CrossRef] [PubMed]
- Bai, S.; Kolter, J.Z.; Koltun, V. An empirical evaluation of generic convolutional and recurrent networks for sequence modeling. arXiv 2018, arXiv:1803.01271. [Google Scholar]
- Zhang, Y.W.; Wang, Z.H.; Liu, H.Y. A time series classification algorithm based on multi-scale residual FCN. J. Softw. 2022, 33, 555–570. [Google Scholar]
- Chen, W.; Shi, K. Multi-scale attention convolutional neural network for time series classification. Neural Netw. 2021, 136, 126–140. [Google Scholar] [CrossRef] [PubMed]
- Ronald, M.; Poulose, A.; Han, D.S. iSPLInception: An inception-ResNet deep learning architecture for human activity recognition. IEEE Access 2021, 9, 68985–69001. [Google Scholar] [CrossRef]
- Usmankhujaev, S.; Ibrokhimov, B.; Baydadaev, S.; Kwon, J. Time series classification with InceptionFCN. Sensors 2021, 22, 157. [Google Scholar] [CrossRef] [PubMed]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Corresponding Failure Modes | Fault Injection Point | Injected Fault Signal Type |
|---|---|---|
| Normal | None | None |
| CPU processing power decreases | P2020_GND | Inject 0−0.2 V noise signal |
| P2020_CLK | Inject 0−0.3 V 1 KHz square wave signal | |
| Parallel connection of 200 ohm resistors | ||
| Parallel connection of 470 nF capacitors | ||
| Memory performance degradation | DDR3_GND | Inject 0−0.2 V noise signal |
| DDR3_CLK | Inject 0−0.3 V 5 KHz square wave signal | |
| Parallel connection of 470 nF capacitors | ||
| Parallel connection of 200 ohm resistors | ||
| DDR3_CK2 | Inject 0−0.3 V 5 KHz square wave signal | |
| Parallel connection of 200 ohm resistors | ||
| Parallel connection of 470 nF capacitors | ||
| NAND Flash_GND | Inject 0−0.2 V noise signal | |
| NOR Flash_GND | Inject 0−0.2 V noise signal |
| Sample Size | Total Number of Samples | Number of Samples for Adjusting Hyperparameters (Datatset1) | Number of Samples for k-Fold Cross-Validation (Datatset2) | Fault Category |
|---|---|---|---|---|
| 256 × 16 | 280,000 | 140,000 | 140,000 | 14 |
| Model | Number of AMTC Modules | Validation Set Accuracy (Dataset1) | Test Set Accuracy (Dataset2) | Test Set Precision (Dataset2) | Test Set Recall (Dataset2) | Test Set F1-Score (Dataset2) |
|---|---|---|---|---|---|---|
| A | 0 | 65.99% | 66.22% | 66.10% | 66.18% | 66.14% |
| B | 1 | 99.21% | 99.32% | 99.30% | 99.30% | 99.30% |
| C | 3 | 99.59% | 99.65% | 99.62% | 99.61% | 99.62% |
| D | 5 | 99.52% | 99.44% | 99.47% | 99.44% | 99.45% |
| Model | Validation Set Accuracy (Dataset1) | Test Set Accuracy (Dataset2) | Test Set Precision (Dataset2) | Test Set Recall (Dataset2) | Test Set F1-Score (Dataset2) |
|---|---|---|---|---|---|
| AMTC | 99.30% | 99.32% | 99.36 | 99.36 | 99.36 |
| AMTC-ICA | 99.42% | 99.44% | 99.43 | 99.44 | 99.43 |
| AMTC-HBTA | 99.44% | 99.54% | 99.52 | 99.50 | 99.51 |
| HAAMTCN | 99.59% | 99.65% | 99.62% | 99.61% | 99.62% |
| Attention Mechanism | Validation Set Accuracy (Dataset1) | Test Set Accuracy (Dataset2) | Test Set Precision (Dataset2) | Test Set Recall (Dataset2) | Test Set F1-Score (Dataset2) |
|---|---|---|---|---|---|
| SE | 99.32% | 99.30% | 99.30% | 99.32% | 99.31% |
| MulAtt | 99.33% | 99.37% | 99.35% | 99.36% | 99.35% |
| Gate | 99.35% | 99.28% | 99.30% | 99.28% | 99.29% |
| GCnet | 99.40% | 99.40% | 99.38% | 99.38% | 99.38% |
| FFT-CrossAttention | 99.40% | 99.42% | 99.42% | 99.45% | 99.43% |
| ICA-HBTA | 99.59% | 99.65% | 99.62% | 99.61% | 99.62% |
| Module | Validation Set Accuracy (Dataset1) | Test Set Accuracy (Dataset2) | Test Set Precision (Dataset2) | Test Set Recall (Dataset2) | Test Set F1-Score (Dataset2) |
|---|---|---|---|---|---|
| DTW-KNN | 73.10% | 71.36% | 71.32% | 70.55% | 70.93% |
| TCN | 78.96% | 78.55% | 77.88% | 78.70% | 78.29% |
| SVM | 85.36% | 84.20% | 83.22% | 82.85% | 83.03% |
| 1D-CNN | 93.81% | 93.65% | 93.58% | 93.58% | 93.58% |
| MRes-FCN | 97.19% | 97.10% | 96.81% | 96.60% | 96.70% |
| MACNN | 97.40% | 97.62% | 97.55% | 97.54% | 97.53% |
| MLSTM-FCN | 98.07% | 98.26% | 98.23% | 98.04% | 98.03% |
| Inception-Resnet | 98.34% | 98.50% | 98.58% | 98.58% | 98.58% |
| Inception-FCN | 99.33% | 99.38% | 99.39% | 99.39% | 99.39% |
| HAAMTCN | 99.59% | 99.65% | 99.62% | 99.61% | 99.62% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Du, Q.; Sheng, M.; Yu, L.; Zhou, Z.; Tian, L.; He, S. Avionics Module Fault Diagnosis Algorithm Based on Hybrid Attention Adaptive Multi-Scale Temporal Convolution Network. Entropy 2024, 26, 550. https://doi.org/10.3390/e26070550
Du Q, Sheng M, Yu L, Zhou Z, Tian L, He S. Avionics Module Fault Diagnosis Algorithm Based on Hybrid Attention Adaptive Multi-Scale Temporal Convolution Network. Entropy. 2024; 26(7):550. https://doi.org/10.3390/e26070550
Chicago/Turabian StyleDu, Qiliang, Mingde Sheng, Lubin Yu, Zhenwei Zhou, Lianfang Tian, and Shilie He. 2024. "Avionics Module Fault Diagnosis Algorithm Based on Hybrid Attention Adaptive Multi-Scale Temporal Convolution Network" Entropy 26, no. 7: 550. https://doi.org/10.3390/e26070550
APA StyleDu, Q., Sheng, M., Yu, L., Zhou, Z., Tian, L., & He, S. (2024). Avionics Module Fault Diagnosis Algorithm Based on Hybrid Attention Adaptive Multi-Scale Temporal Convolution Network. Entropy, 26(7), 550. https://doi.org/10.3390/e26070550