



Infrared and Harsh Light Visible Image Fusion Using an Environmental Light Perception Network


Abstract
1. Introduction
- An infrared salient target edge feature extraction module that includes high-level semantic interactive fusion (HSIF) and edge feature enhance block (EFEB) is designed, permitting the network to more precisely attend to salient semantic information at the edges, thus avoiding the blurring of the structure and edge details of salient targets in the fusion results.
- A harsh light environment aware (HLEA) module is designed. Based on the distribution of harsh light visible light image information, this module determines the feature fusion weights of the hierarchical feature fusion module to address the severe degradation of fusion performance under adverse lighting conditions due to low information entropy and high-intensity pixel value areas.
- An edge-guided hierarchical feature fusion (EGHF) module is designed. Combining target edge feature guidance with harsh light aware-weight allocation achieves efficient utilization of key semantic features under harsh light interference, avoiding the impact of blurred target boundaries and harsh light occlusion on ensuing high-level vision tasks in fusion results.
2. Related Work
2.1. Traditional Image Fusion Methods
2.2. Deep Learning Methods
2.3. Image Fusion Resilient to Interference
3. Proposed Method
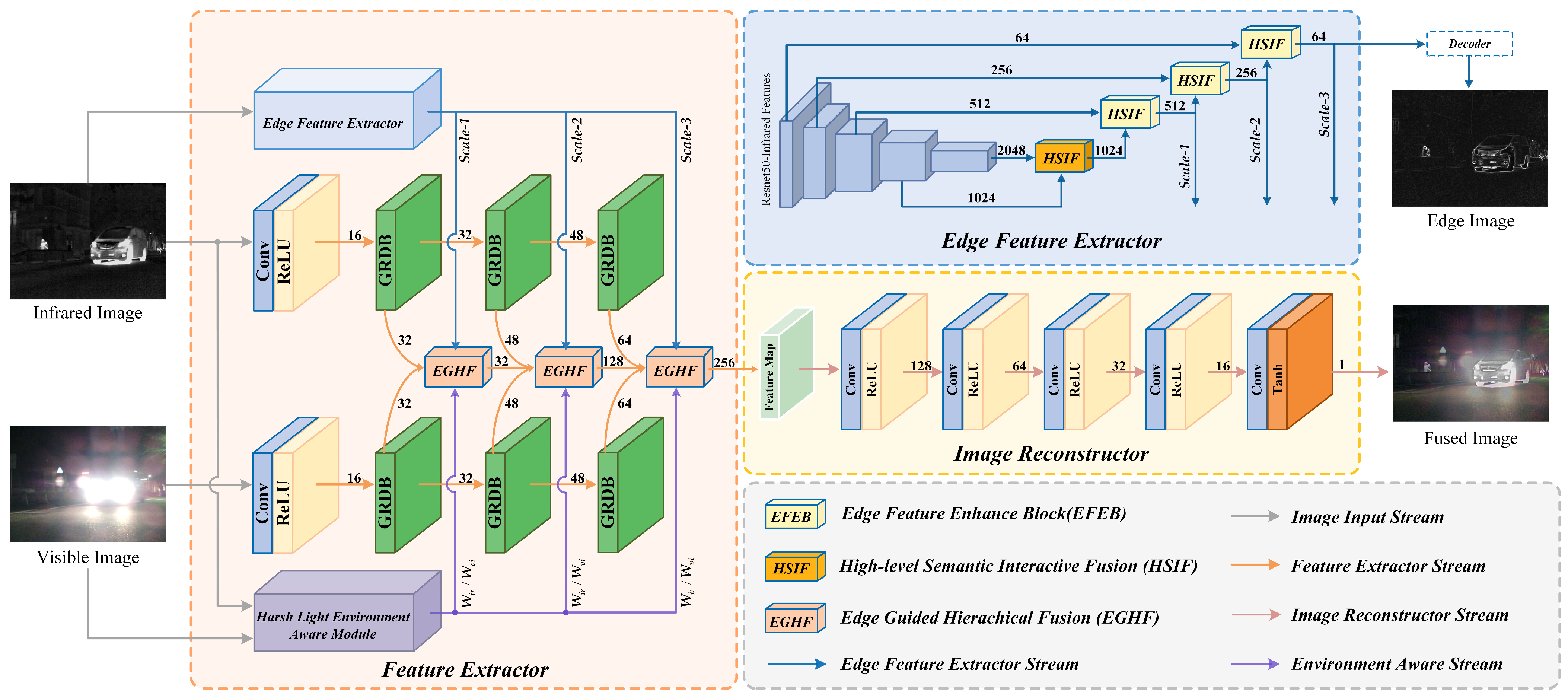
3.1. Overview of Network Architecture
3.2. Edge Feature Extraction
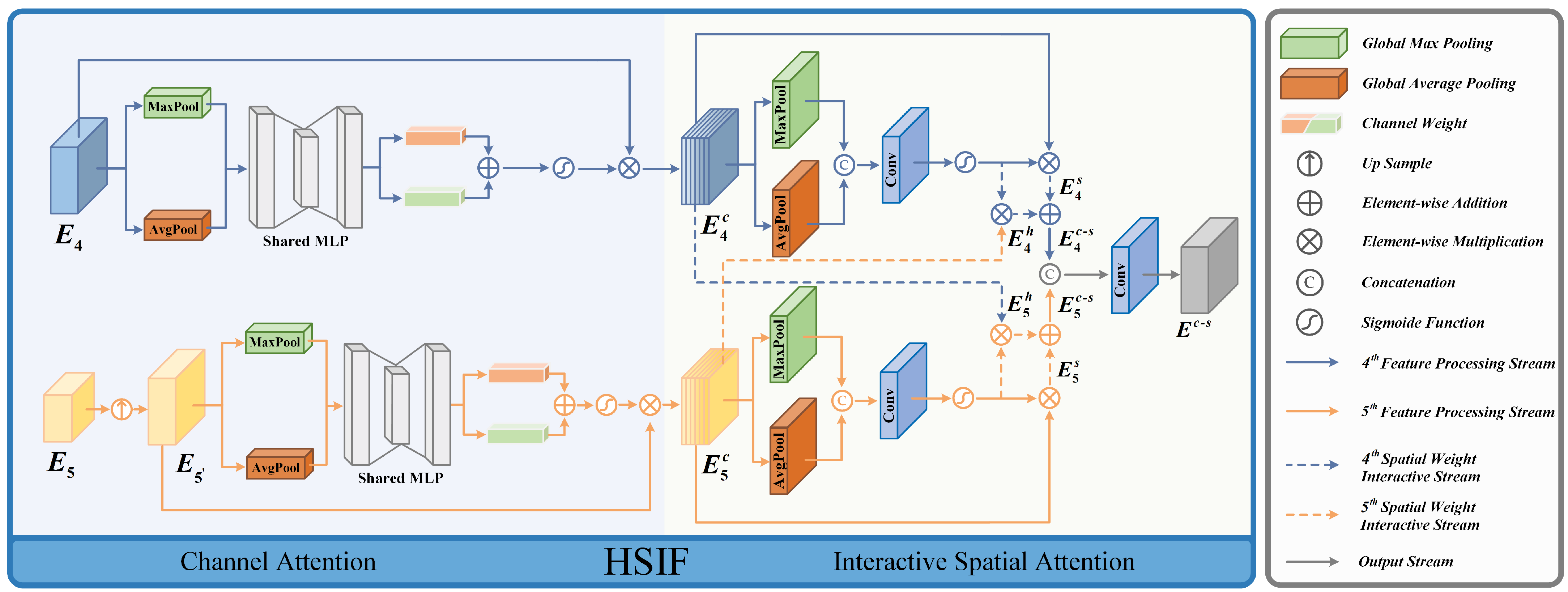
3.2.1. High-Level Semantic Feature Interactive Fusion (HSIF)
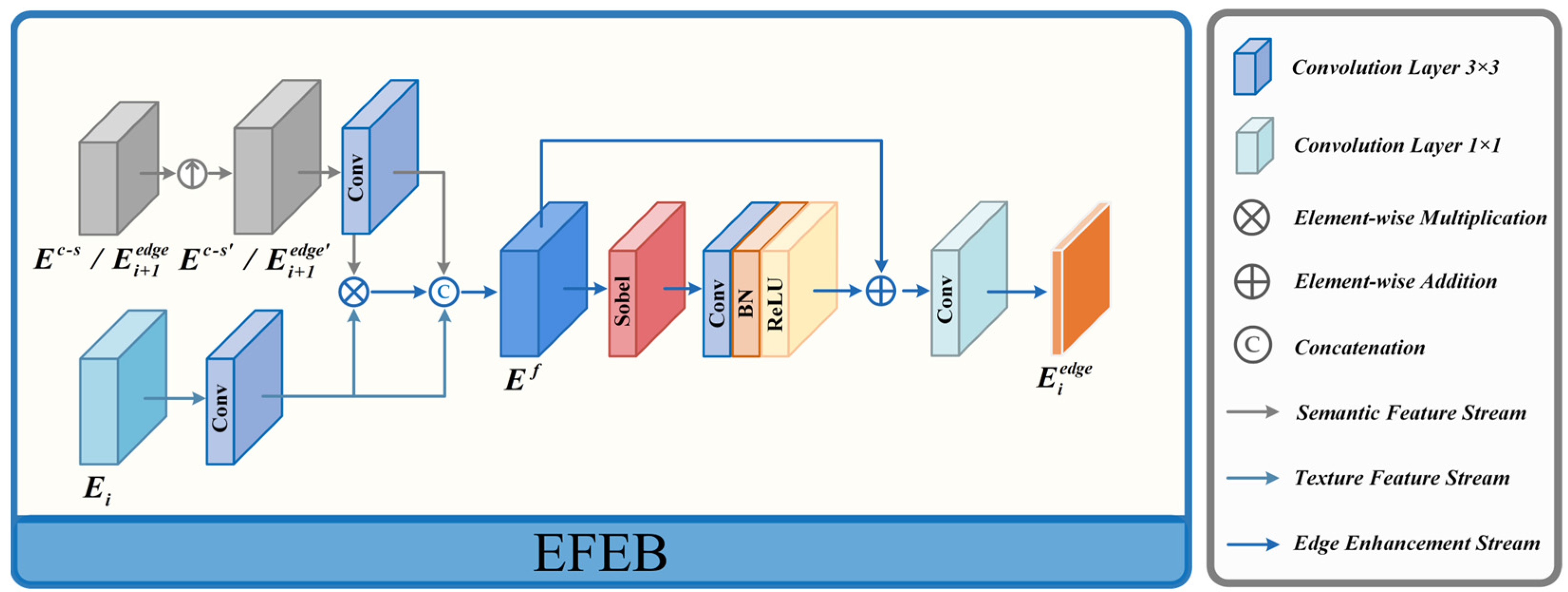
3.2.2. Edge Feature Enhance Block (EFEB)
3.3. Harsh Light Environment Awareness
3.4. Edge Guided Hierarchical Fusion
3.5. Loss Function
4. Experiments
4.1. Experimental Details
4.1.1. Cooperative Training Strategy
| Algorithm 1: Adaptive Cooperative Training Strategy |
| Network Input: Visible image and infrared image Network Output: Fused image |
| Select visible images and labels ;
Train illumination classification network with the Adam optimizer: ; Select visible images ; Train illumination decomposition network by the Adam optimizer: ; for iterations do for steps do Select visible images ; Select infrared images ; Update the balancing parameter according to Update the weight parameters of fusion network with the Adam optimizer: end Utilize the fusion network to generate fused images for the subsequent segmentation network training; for steps do Selecting fused images from the output of the fusion network; Update the weight parameters of segmentation network with the Adam optimizer: ; end |
4.1.2. Fusion Evaluation Metrics
4.1.3. Detection Evaluation Details
4.2. Comparative Experiments on the TNO Dataset
4.2.1. Qualitative Comparison
4.2.2. Quantitative Comparison
4.3. Comparative Experiments on the MFNet Dataset
4.3.1. Qualitative Comparison
- (1)
- Fusion Results Display
- (2)
- MOS Subjective Quality Evaluate
4.3.2. Quantitative Comparison
4.4. Comparative Experiments on the M3FD Dataset
4.4.1. Qualitative Comparison
4.4.2. Quantitative Comparison
4.5. High-Level Vision Task-Driven Evaluation
4.5.1. Quantitative Comparison
- (1)
- Harsh light scene detection results
- (2)
- Normal light scene detection results
4.5.2. Qualitative Presentation
4.6. Module Effectiveness Validation
4.6.1. Edge Feature Extractor Effectiveness Analysis
4.6.2. HLEA Module Effectiveness Analysis
4.6.3. Ablation Experiments
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- Cui, Y.; Chen, R.; Chu, W.; Chen, L.; Tian, D.; Li, Y.; Cao, D. Deep Learning for Image and Point Cloud Fusion in Autonomous Driving: A Review. IEEE Trans. Intell. Transp. Syst. 2022, 23, 722–739. [Google Scholar] [CrossRef]
- Han, Y.; Wang, B.; Guan, T.; Tian, D.; Yang, G.; Wei, W.; Tang, H.; Chuah, J.H. Research on Road Environmental Sense Method of Intelligent Vehicle based on Tracking check. IEEE Trans. Intell. Transp. Syst. 2023, 24, 1261–1275. [Google Scholar] [CrossRef]
- Reichstein, M.; Camps-Valls, G.; Stevens, B.; Jung, M.; Denzler, J.; Carvalhais, N.; Prabhat, N. Deep learning and process understanding for data-driven Earth system science. Nature 2019, 566, 195–204. [Google Scholar] [CrossRef] [PubMed]
- Ma, W.; Wang, K.; Li, J.; Yang, S.X.; Li, J.; Song, L.; Li, Q. Infrared and visible image fusion technology and application: A review. Sensors 2023, 23, 599. [Google Scholar] [CrossRef] [PubMed]
- Zhang, H.; Xu, H.; Tian, X.; Jiang, J.; Ma, J. Image fusion meets deep learning: A survey and perspective. Inf. Fusion 2021, 76, 323–336. [Google Scholar] [CrossRef]
- Liu, Y.; Chen, X.; Ward, R.K.; Wang, Z.J. Image fusion with convolutional sparse representation. IEEE Signal Process. Lett. 2016, 23, 1882–1886. [Google Scholar] [CrossRef]
- Luo, L.; Mei, X.; Ma, J. Infrared and visible image fusion based on target-enhanced multiscale transform decomposition. Inform. Sci. 2020, 508, 64–78. [Google Scholar]
- Kong, W.; Lei, Y.; Zhao, H. Adaptive fusion method of visible light and infrared images based on non-subsampled shearlet transform and fast non-negative matrix factorization. Infrared Phys. Technol. 2014, 67, 161–172. [Google Scholar] [CrossRef]
- Ma, J.; Chen, C.; Li, C.; Huang, J. Infrared and visible image fusion via gradient transfer and total variation minimization. Inf. Fusion 2016, 31, 100–109. [Google Scholar] [CrossRef]
- Liu, Y.; Liu, S.; Wang, Z. A general framework for image fusion based on multi-scale transform and sparse representation. Inf. Fusion 2015, 24, 147–164. [Google Scholar] [CrossRef]
- Li, H.; Wu, X.J.; Kittler, J. RFN-nest: An end-to-end residual fusion network for infrared and visible images. Inf. Fusion 2021, 73, 720–786. [Google Scholar] [CrossRef]
- Ma, J.; Yu, W.; Liang, P.; Li, C.; Jiang, J. FusionGAN: A generative adversarial network for infrared and visible image fusion. Inf. Fusion 2019, 48, 11–26. [Google Scholar] [CrossRef]
- Zhang, Y.; Liu, Y.; Sun, P.; Yan, H.; Zhao, X.; Zhang, L. IFCNN: A general image fusion framework based on convolutional neural network. Inf. Fusion 2020, 54, 99–118. [Google Scholar] [CrossRef]
- Wang, Z.; Chen, Y.; Shao, W.; Li, H.; Zhang, L. SwinFuse: A residual swin transformer fusion network for infrared and visible images. IEEE Trans. Instrum. Meas. 2022, 71, 1–12. [Google Scholar] [CrossRef]
- Luo, Y.; Luo, Z. Infrared and visible image fusion: Methods, datasets, applications, and prospects. Appl. Sci. 2023, 13, 10891. [Google Scholar] [CrossRef]
- Feng, S.; Zhao, H.; Shi, F.; Cheng, X.; Wang, M.; Ma, Y.; Xiang, D.; Zhu, W.; Chen, X. CPFNet: Context pyramid fusion network for medical image segmentation. IEEE Trans. Med. Imaging 2020, 39, 3008–3018. [Google Scholar] [CrossRef]
- Singh, R.; Khare, A. Fusion of multimodal medical images using Daubechies complex wavelet transform—A multiresolution approach. Inf. Fusion 2014, 19, 49–60. [Google Scholar] [CrossRef]
- Burt, P.; Adelson, E. The Laplacian pyramid as a compact image code. IEEE Trans. Commun. 1983, 31, 532–540. [Google Scholar] [CrossRef]
- Jose, J.; Gautam, N.; Tiwari, M.; Tiwari, T.; Suresh, A.; Sundararaj, V.; Mr, R. An image quality enhancement scheme employing adolescent identity search algorithm in the NSST domain for multimodal medical image fusion. Biomed. Signal Process. Control 2021, 66, 102480. [Google Scholar] [CrossRef]
- Shreyamsha Kumar, B.K. Image fusion based on pixel significance using cross bilateral filter. Signal Image Video Process. 2015, 9, 1193–1204. [Google Scholar] [CrossRef]
- Zuo, Y.; Liu, J.; Bai, G.; Wang, X.; Sun, M. Airborne Infrared and Visible Image Fusion Combined with Region Segmentation. Sensors 2017, 17, 1127. [Google Scholar] [CrossRef] [PubMed]
- Vaish, A.; Patel, S. A sparse representation based compression of fused images using WDR coding. J. King. Saud. Univ.-Comput. Inf. Sci. 2022; in press. [Google Scholar]
- Li, H.; Wu, X.J.; Kittler, J. M DLatLRR: A novel decomposition method for infrared and visible image fusion. IEEE Trans. Image Process 2020, 29, 4733–4746. [Google Scholar] [CrossRef]
- Zhou, W.; Zhu, Y.; Lei, J.; Wan, J.; Yu, L. CCAFNet: Crossflow and Cross-Scale Adaptive Fusion Network for Detecting Salient Objects in RGB-D Images. IEEE Trans. Multimed. 2021, 24, 2192–2204. [Google Scholar] [CrossRef]
- Broussard, R.; Rogers, S. Physiologically motivated image fusion using pulse-coupled neural networks. In Applications and Science of Artificial Neural Networks II; SPIE: Orlando, FL, USA, 1996; pp. 372–384. [Google Scholar]
- Ram Prabhakar, K.; Sai Srikar, V.; Venkatesh Babu, R. Deepfuse: A deep unsupervised approach for exposure fusion with extreme exposure image pairs. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4714–4722. [Google Scholar]
- Li, H.; Wu, X. DenseFuse: A fusion approach to infrared and visible images. IEEE Trans. Image Process. 2019, 28, 2614–2623. [Google Scholar] [CrossRef]
- Li, H.; Wu, X.J.; Durrani, T. NestFuse: An infrared and visible image fusion architecture based on nest connection and spatial/channel attention models. IEEE Trans. Instrum. Meas. 2020, 69, 9645–9656. [Google Scholar] [CrossRef]
- Zhao, Z.; Xu, S.; Zhang, C.; Liu, J.; Zhang, J.; Li, P. DIDFuse: Deep image decomposition for infrared and visible image fusion. In Proceedings of the IJCAI, Yokohama, Japan, 11–17 July 2020; pp. 970–976. [Google Scholar]
- Li, H.; Wu, X.; Kittler, J. Infrared and visible image fusion using a deep learning framework. In Proceedings of the 2018 24th International Conference on Pattern Recognition (ICPR), Beijing, China, 20–24 August 2018; pp. 2705–2710. [Google Scholar]
- Li, H.; Wu, X.; Durrani, T. Infrared and visible image fusion with ResNet and zero-phase component analysis. Infrared Phys. Technol. 2019, 102, 103039. [Google Scholar] [CrossRef]
- Yang, Y.; Gao, C.; Ming, Z.; Guo, J.; Leopold, E.; Cheng, J.; Zuo, J.; Zhu, M. LatLRR-CNN: An infrared and visible image fusion method combining latent low-rank representation and CNN. Multimed. Tools Appl. 2023, 82, 36303–36323. [Google Scholar] [CrossRef]
- Xu, H.; Wang, X.; Ma, J. DRF: Disentangled representation for visible and infrared image fusion. IEEE Trans. Instrum. Meas. 2021, 70, 5006713. [Google Scholar] [CrossRef]
- Ma, J.; Zhang, H.; Shao, Z.; Liang, P.; Xu, H. GANMcC: A generative adversarial network with multiclassification constraints for infrared and visible image fusion. IEEE Trans. Instrum. Meas. 2021, 70, 1–14. [Google Scholar] [CrossRef]
- Li, X.; Chen, L.; Wang, L.; Wu, P.; Tong, W. SCGAN: Disentangled Representation Learning by Adding Similarity Constraint on Generative Adversarial Nets. IEEE Access 2019, 7, 147928–147938. [Google Scholar] [CrossRef]
- Xu, H.; Ma, J.; Le, Z.; Jiang, J.; Guo, X. Fusiondn: A unified densely connected network for image fusion. In Proceedings of the AAAI Conference on Artificial Intelligence, Washington, DC, USA, 3 April 2020; Volume 34, pp. 12484–12491. [Google Scholar]
- Zhao, H.; Nie, R. DNDT: Infrared and visible image fusion via DenseNet and dual-transformer. In Proceedings of the 2021 International Conference on Information Technology and Biomedical Engineering (ICITBE), Nanchang, China, 24–26 December 2021; pp. 71–75. [Google Scholar]
- Zhang, X.; Wang, X.; Yan, C.; Sun, Q. EV-Fusion: A Novel Infrared and Low-Light Color Visible Image Fusion Network Integrating Unsupervised Visible Image Enhancement. IEEE Sens. 2024, 24, 4920–4934. [Google Scholar] [CrossRef]
- Tang, L.; Yuan, J.; Zhang, H.; Jiang, X.; Ma, J. PIAFusion: A progressive infrared and visible image fusion network based on illumination aware. Inf. Fusion 2022, 83, 79–92. [Google Scholar] [CrossRef]
- Luo, X.; Gao, Y.; Wang, A.; Zhang, Z.; Wu, X. IFSepR: A General Framework for Image Fusion Based on Separate Representation Learning. IEEE Trans. Multimed. 2023, 25, 608–623. [Google Scholar] [CrossRef]
- Rao, Y.; Wu, D.; Han, M.; Wang, T.; Yang, Y.; Lei, T.; Zhou, C.; Bai, H.; Xing, L. AT-GAN: A generative adversarial network with attention and transition for infrared and visible image fusion. Inf. Fusion 2023, 92, 336–349. [Google Scholar] [CrossRef]
- Liu, X.; Yang, L.; Zhang, X.; Duan, X. MA-ResNet50: A General Encoder Network for Video Segmentation. In Proceedings of the 17th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications (VISIGRAPP 2022), Online, 6–8 February 2022; Volume 4, pp. 79–86. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. arXiv 2014, arXiv:1409.0575. [Google Scholar] [CrossRef]
- Mittal, A.; Moorthy, A.K.; Bovik, A.C. No-reference image quality assessment in the spatial domain. IEEE Trans. Image Process 2012, 21, 4695–4708. [Google Scholar] [CrossRef]
- Tang, L.; Yuan, J.; Ma, J. Image fusion in the loop of high-level vision tasks: A semantic-aware real-time infrared and visible image fusion network. Inf. Fusion 2022, 82, 28–42. [Google Scholar] [CrossRef]
- Zhang, K.; Sun, M.; Han, T.X.; Yuan, X.; Guo, L.; Liu, T. Residual Networks of Residual Networks: Multilevel Residual Networks. IEEE Trans. Circuits Syst. Video Technol. 2018, 28, 1303–1314. [Google Scholar] [CrossRef]
- Ma, L.; Ma, T.; Liu, R.; Fan, X.; Luo, Z. Toward fast, flexible, and robust low-light image enhancement. In Proceedings of the 2022 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 19–24 June 2022; pp. 5637–5646. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16 × 16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Han, D.; Ye, T.; Ha Han, D.; Ye, T.; Han, Y.; Xia, Z.; Song, S.; Huang, G. Agent attention: On the integration of softmax and linear attention. arXiv 2023, arXiv:2312.08874. [Google Scholar]
- Lu, M.; Chen, Z.; Liu, C.; Ma, S.; Cai, L.; Qin, H. MFNet: Multi-feature fusion network for real-time semantic segmentation in road scenes. IEEE Trans. Intell. Transp. Syst. 2022, 23, 20991–21003. [Google Scholar] [CrossRef]
- Roberts, W.J.; Van, J.A.A.; Ahmed, F. Assessment of image fusion procedures using entropy, image quality, and multispectral classification. J. Appl. Remote Sens. 2008, 2, 1–28. [Google Scholar]
- Qu, G.; Zhang, D.; Yan, P. Information measure for performance of image fusion. Electron. Lett. 2002, 38, 313–315. [Google Scholar] [CrossRef]
- Hanna, M.H.; Kaiser, A.M. Update on the management of sigmoid diverticulitis. World J. Gastroenterol. 2021, 27, 760. [Google Scholar] [CrossRef]
- Han, Y.; Cai, Y.; Cao, Y.; Xu, X. A new image fusion performance metric based on visual information fidelity. Inf. Fusion 2013, 14, 127–135. [Google Scholar] [CrossRef]
- Eskicioglu, A.M.; Fisher, P.S. Image quality measures and their performance. IEEE Trans. Commun. 1995, 43, 2959–2965. [Google Scholar] [CrossRef]
- Wang, E.; Yu, Q.; Chen, Y.; Slamu, W.; Luo, X. Multi-modal knowledge graphs representation learning via multi-headed self-attention. Inf. Fusion 2022, 88, 78–85. [Google Scholar] [CrossRef]
- Zhao, W.; Wang, D.; Lu, H. Multi-focus image fusion with a natural enhancement via a joint multi-level deeply supervised convolutional neural network. IEEE Trans. Circuits Syst. Video Technol. 2018, 29, 1102–1115. [Google Scholar] [CrossRef]
- Toet, A. TNO Image Fusion Dataset. 2014. Available online: https://figshare.com/articles/dataset/TNO_Image_Fusion_Dataset/1008029 (accessed on 27 June 2024).
- Liu, J.; Fan, X.; Huang, Z.; Wu, G.; Liu, R.; Zhong, W.; Luo, Z. Target-aware dual adversarial learning and a multi-scenario multi-modality benchmark to fuse infrared and visible for object detection. In Proceedings of the 2022 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 19–24 June 2022; pp. 5792–5801. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition(CVPR), Seattle, WA, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Marr, D.; Hildreth, E. Theory of edge detection. Proc. R. Soc. Lond. Ser. B Biol. Sci. 1980, 207, 187–217. [Google Scholar]
- Canny, J. A computational approach to edge detection. IEEE Trans. Pattern Anal. Mach. Intell. 1986, PAMI-8, 679–698. [Google Scholar] [CrossRef]
- Liu, Y.; Cheng, M.M.; Hu, X.; Wang, K.; Bai, X. Richer convolutional features for edge detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 3000–3009. [Google Scholar]
- Kang, H.; Lee, S.; Chui, C.K. Coherent line drawing. In Proceedings of the 5th International Symposium on Non-Photorealistic Animation and Rendering, Stuttgart, Germany, 4–5 August 2007; pp. 43–50. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| EN | SD | MS-SSIM | VIF | PSNR | FMIpixel | Qabf | |
|---|---|---|---|---|---|---|---|
| CBF | 7.1291 | 40.4001 | 0.7084 | 0.5895 | 62.9445 | 0.8646 | 0.4200 |
| NSST | 6.8753 | 42.4164 | 0.8237 | 0.6565 | 61.7691 | 0.8921 | 0.2986 |
| GTF | 6.8811 | 42.7918 | 0.8238 | 0.6527 | 61.7706 | 0.8897 | 0.4202 |
| DIDFuse | 7.2034 | 52.4016 | 0.8796 | 0.8140 | 61.9209 | 0.8645 | 0.3419 |
| NestFuse | 7.1964 | 44.6529 | 0.8825 | 0.9437 | 62.6227 | 0.8911 | 0.5273 |
| FusionGAN | 6.5960 | 30.9010 | 0.7392 | 0.6125 | 60.9479 | 0.8709 | 0.2252 |
| GANMcC | 6.8340 | 34.1770 | 0.8375 | 0.6736 | 61.7864 | 0.8816 | 0.2646 |
| PIAFusion | 6.9998 | 44.5875 | 0.8655 | 0.9345 | 61.6819 | 0.8949 | 0.4854 |
| DRF | 6.7745 | 33.8643 | 0.7115 | 0.5633 | 61.3385 | 0.8766 | 0.1977 |
| Ours | 7.2156 | 44.8749 | 0.9418 | 0.8696 | 62.9953 | 0.8954 | 0.5467 |
| Image Clarity | Color Fidelity | Light Resistance | Artifact Noise | Overall Impression | Average Score | |
|---|---|---|---|---|---|---|
| CBF | 2.0567 | 1.9917 | 3.0733 | 1.6833 | 2.1033 | 2.1817 |
| NSST | 1.6483 | 1.8933 | 3.3917 | 2.5183 | 2.0950 | 2.3093 |
| GTF | 2.0133 | 2.4983 | 3.2833 | 2.2317 | 2.1450 | 2.4343 |
| DIDFuse | 2.4717 | 2.2650 | 3.0267 | 2.5833 | 2.3283 | 2.5350 |
| NestFuse | 3.1967 | 3.2783 | 2.5433 | 3.4917 | 3.0367 | 3.1093 |
| FusionGAN | 1.7517 | 2.3583 | 3.6433 | 2.0250 | 2.1433 | 2.3843 |
| GANMcC | 2.8683 | 2.8417 | 3.4017 | 2.9200 | 2.9917 | 3.0047 |
| PIAFusion | 2.7567 | 2.5933 | 2.2239 | 3.0733 | 2.4217 | 2.6138 |
| DRF | 1.7567 | 2.0967 | 3.1983 | 1.7533 | 1.8833 | 2.1377 |
| Ours | 3.3233 | 3.3275 | 3.5200 | 3.3833 | 3.4317 | 3.3918 |
| EN | SD | MS-SSIM | VIF | PSNR | FMIpixel | Qabf | |
|---|---|---|---|---|---|---|---|
| CBF | 6.5949 | 36.8343 | 0.7942 | 0.7370 | 64.4616 | 0.9031 | 0.5697 |
| NSST | 5.8504 | 23.7295 | 0.6489 | 0.6522 | 63.7954 | 0.9224 | 0.2350 |
| GTF | 5.8667 | 23.7152 | 0.8471 | 0.5788 | 64.1360 | 0.9101 | 0.4076 |
| DIDFuse | 4.8717 | 39.6267 | 0.8087 | 0.4136 | 63.6994 | 0.9075 | 0.2305 |
| NestFuse | 6.6019 | 44.1226 | 0.9533 | 0.9247 | 65.0529 | 0.9241 | 0.6275 |
| FusionGAN | 5.6645 | 20.4431 | 0.7226 | 0.5559 | 64.3055 | 0.9056 | 0.1476 |
| GANMcC | 6.1798 | 29.4363 | 0.8767 | 0.6752 | 66.0370 | 0.9088 | 0.2923 |
| PIAFusion | 6.6460 | 49.8703 | 0.9549 | 1.0224 | 63.6291 | 0.9255 | 0.6550 |
| DRF | 5.9020 | 22.6209 | 0.7820 | 0.5675 | 65.2373 | 0.9060 | 0.1532 |
| Ours | 6.6945 | 45.2648 | 0.9697 | 0.9380 | 64.3400 | 0.9259 | 0.6750 |
| EN | SD | MS-SSIM | VIF | PSNR | FMIpixel | Qabf | |
|---|---|---|---|---|---|---|---|
| CBF | 7.0005 | 35.4986 | 0.7125 | 0.7448 | 64.8020 | 0.8804 | 0.5605 |
| NSST | 7.1781 | 46.2808 | 0.7434 | 0.6730 | 63.0551 | 0.9050 | 0.1706 |
| GTF | 7.1995 | 45.8126 | 0.9080 | 0.7047 | 63.5330 | 0.8990 | 0.5161 |
| DIDFuse | 6.8437 | 46.5106 | 0.9270 | 0.8562 | 62.3610 | 0.8846 | 0.4565 |
| NestFuse | 6.8604 | 36.4310 | 0.9157 | 0.9030 | 64.3610 | 0.8969 | 0.4943 |
| FusionGAN | 6.4800 | 27.3050 | 0.8293 | 0.5518 | 63.8132 | 0.8842 | 0.2826 |
| GANMcC | 6.6894 | 32.2526 | 0.8978 | 0.7379 | 64.3309 | 0.8930 | 0.3318 |
| PIAFusion | 6.8480 | 36.0857 | 0.9242 | 0.9506 | 63.5715 | 0.9081 | 0.6104 |
| DRF | 6.8879 | 39.2190 | 0.7959 | 0.7132 | 62.6709 | 0.8824 | 0.1857 |
| Ours | 6.8937 | 36.5702 | 0.9611 | 0.9047 | 64.3942 | 0.9055 | 0.6364 |
| Metrics | IR | VI | CBF | NSST | GTF | DIDFuse | NestFuse | FusionGAN | GANMcC | PIAFusion | DRF | Ours | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| F1_Score | people | 0.811 | 0.372 | 0.695 | 0.770 | 0.554 | 0.678 | 0.643 | 0.709 | 0.857 | 0.729 | 0.724 | 0.811 |
| car | 0.753 | 0.207 | 0.555 | 0.738 | 0.466 | 0.600 | 0.381 | 0.675 | 0.622 | 0.328 | 0.568 | 0.723 | |
| all | 0.782 | 0.290 | 0.625 | 0.754 | 0.510 | 0.639 | 0.512 | 0.692 | 0.739 | 0.528 | 0.646 | 0.767 | |
| AP@50 | people | 0.878 | 0.594 | 0.753 | 0.818 | 0.696 | 0.732 | 0.713 | 0.770 | 0.869 | 0.772 | 0.770 | 0.864 |
| car | 0.791 | 0.493 | 0.682 | 0.781 | 0.580 | 0.663 | 0.618 | 0.743 | 0.725 | 0.598 | 0.678 | 0.778 | |
| all | 0.835 | 0.544 | 0.718 | 0.800 | 0.638 | 0.698 | 0.666 | 0.757 | 0.797 | 0.685 | 0.724 | 0.821 | |
| AP@70 | people | 0.770 | 0.488 | 0.721 | 0.776 | 0.654 | 0.708 | 0.700 | 0.697 | 0.779 | 0.705 | 0.695 | 0.808 |
| car | 0.751 | 0.332 | 0.623 | 0.706 | 0.550 | 0.663 | 0.618 | 0.689 | 0.697 | 0.598 | 0.647 | 0.757 | |
| all | 0.761 | 0.410 | 0.672 | 0.741 | 0.602 | 0.686 | 0.659 | 0.693 | 0.738 | 0.652 | 0.671 | 0.783 | |
| AP@90 | people | 0.108 | 0.037 | 0.133 | 0.083 | 0.085 | 0.133 | 0.118 | 0.093 | 0.223 | 0.107 | 0.104 | 0.211 |
| car | 0.221 | 0.000 | 0.257 | 0.068 | 0.056 | 0.352 | 0.383 | 0.078 | 0.383 | 0.363 | 0.233 | 0.453 | |
| all | 0.165 | 0.019 | 0.195 | 0.076 | 0.071 | 0.243 | 0.251 | 0.086 | 0.303 | 0.235 | 0.169 | 0.332 | |
| AP@[50–90] | people | 0.599 | 0.351 | 0.536 | 0.562 | 0.480 | 0.516 | 0.510 | 0.515 | 0.610 | 0.515 | 0.539 | 0.631 |
| car | 0.606 | 0.247 | 0.527 | 0.547 | 0.424 | 0.599 | 0.533 | 0.535 | 0.595 | 0.487 | 0.511 | 0.688 | |
| all | 0.603 | 0.299 | 0.532 | 0.555 | 0.452 | 0.558 | 0.522 | 0.525 | 0.603 | 0.501 | 0.525 | 0.660 |
| Metrics | IR | VI | CBF | NSST | GTF | DIDFuse | NestFuse | FusionGAN | GANMcC | PIAFusion | DRF | Ours | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| F1_Score | people | 0.920 | 0.648 | 0.892 | 0.858 | 0.706 | 0.639 | 0.898 | 0.836 | 0.912 | 0.882 | 0.894 | 0.912 |
| car | 0.693 | 0.886 | 0.847 | 0.681 | 0.857 | 0.826 | 0.888 | 0.857 | 0.903 | 0.874 | 0.807 | 0.890 | |
| all | 0.806 | 0.767 | 0.870 | 0.769 | 0.781 | 0.733 | 0.893 | 0.847 | 0.907 | 0.878 | 0.851 | 0.901 | |
| AP@50 | people | 0.964 | 0.717 | 0.917 | 0.890 | 0.752 | 0.707 | 0.936 | 0.871 | 0.935 | 0.916 | 0.936 | 0.956 |
| car | 0.723 | 0.945 | 0.866 | 0.735 | 0.896 | 0.874 | 0.924 | 0.859 | 0.921 | 0.907 | 0.840 | 0.927 | |
| all | 0.844 | 0.831 | 0.892 | 0.813 | 0.824 | 0.791 | 0.930 | 0.865 | 0.928 | 0.912 | 0.888 | 0.942 | |
| AP@70 | people | 0.786 | 0.634 | 0.840 | 0.812 | 0.690 | 0.673 | 0.884 | 0.731 | 0.879 | 0.867 | 0.856 | 0.896 |
| car | 0.723 | 0.903 | 0.866 | 0.735 | 0.844 | 0.874 | 0.885 | 0.859 | 0.861 | 0.871 | 0.840 | 0.891 | |
| all | 0.755 | 0.769 | 0.853 | 0.774 | 0.767 | 0.774 | 0.885 | 0.795 | 0.870 | 0.869 | 0.848 | 0.894 | |
| AP@90 | people | 0.070 | 0.095 | 0.183 | 0.122 | 0.148 | 0.119 | 0.134 | 0.122 | 0.139 | 0.157 | 0.109 | 0.159 |
| car | 0.293 | 0.434 | 0.473 | 0.116 | 0.402 | 0.239 | 0.523 | 0.464 | 0.498 | 0.441 | 0.420 | 0.517 | |
| all | 0.182 | 0.264 | 0.328 | 0.119 | 0.275 | 0.179 | 0.329 | 0.293 | 0.319 | 0.299 | 0.265 | 0.338 | |
| AP@[50–90] | people | 0.604 | 0.481 | 0.656 | 0.609 | 0.537 | 0.511 | 0.662 | 0.583 | 0.652 | 0.651 | 0.635 | 0.681 |
| car | 0.556 | 0.750 | 0.727 | 0.557 | 0.708 | 0.695 | 0.760 | 0.711 | 0.743 | 0.741 | 0.682 | 0.767 | |
| all | 0.580 | 0.616 | 0.692 | 0.583 | 0.623 | 0.603 | 0.711 | 0.647 | 0.698 | 0.696 | 0.659 | 0.724 |
| Module | M1 | M2 | M3 | M4 | |
|---|---|---|---|---|---|
| EFEB+HSIF+EGHF | ✗ | ✓ | ✗ | ✓ | |
| HLEA | ✓ | ✗ | ✗ | ✓ | |
| F1_Score | harsh light scenes | 0.784 | 0.668 | 0.638 | 0.767 |
| normal light scenes | 0.880 | 0.900 | 0.866 | 0.901 | |
| mAP@50 | harsh light scenes | 0.834 | 0.735 | 0.733 | 0.821 |
| normal light scenes | 0.929 | 0.928 | 0.905 | 0.942 | |
| mAP@[50:95] | harsh light scenes | 0.641 | 0.560 | 0.559 | 0.660 |
| normal light scenes | 0.694 | 0.699 | 0.699 | 0.724 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yan, A.; Gao, S.; Lu, Z.; Jin, S.; Chen, J. Infrared and Harsh Light Visible Image Fusion Using an Environmental Light Perception Network. Entropy 2024, 26, 696. https://doi.org/10.3390/e26080696
Yan A, Gao S, Lu Z, Jin S, Chen J. Infrared and Harsh Light Visible Image Fusion Using an Environmental Light Perception Network. Entropy. 2024; 26(8):696. https://doi.org/10.3390/e26080696
Chicago/Turabian StyleYan, Aiyun, Shang Gao, Zhenlin Lu, Shuowei Jin, and Jingrong Chen. 2024. "Infrared and Harsh Light Visible Image Fusion Using an Environmental Light Perception Network" Entropy 26, no. 8: 696. https://doi.org/10.3390/e26080696
APA StyleYan, A., Gao, S., Lu, Z., Jin, S., & Chen, J. (2024). Infrared and Harsh Light Visible Image Fusion Using an Environmental Light Perception Network. Entropy, 26(8), 696. https://doi.org/10.3390/e26080696