



(HTBNet)Arbitrary Shape Scene Text Detection with Binarization of Hyperbolic Tangent and Cross-Entropy

Abstract
1. Introduction
- We propose the Binarization of Hyperbolic Tangent (HTB), leading the convergence speed during training from 1200 epochs to 600 epochs.
- We design the cross-entropy loss function, which is differentiable, enabling the use of optimization algorithms such as gradient descent to minimize the loss function.
- We contrive the Multi-Scale Channel Attention (MSCA) and the Fused Module with Channel and Spatial (FMCS), which interfold features from different scales in channel and spatial. Our method achieves outstanding results on Total-Text and MSRA-TD500 benchmarks.
2. Related Work
2.1. Regression-Based Methods
2.2. Component-Based Methods
2.3. Segmentation-Based Methods
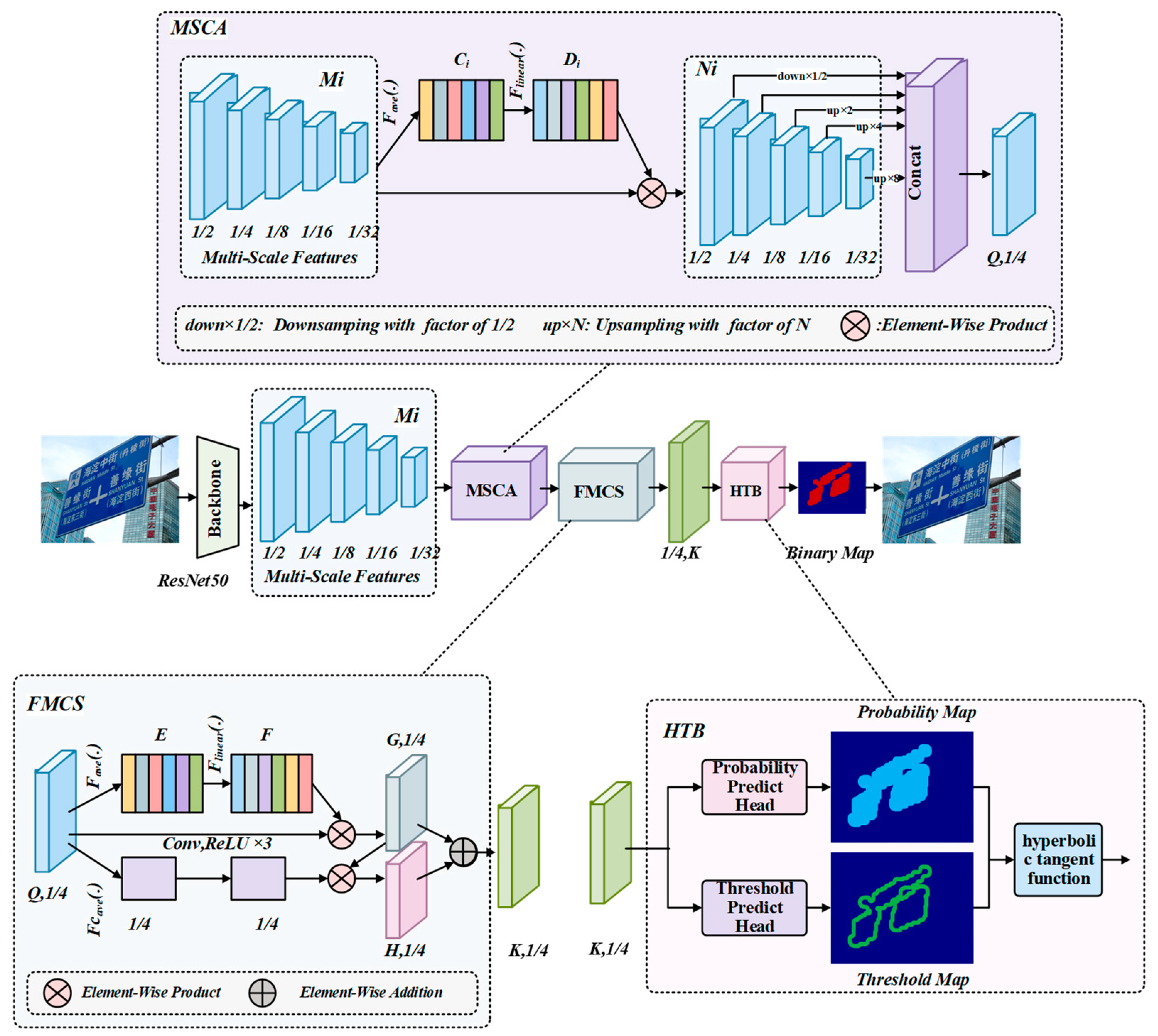
3. The Proposed Method
3.1. Overview
3.2. Multi-Scale Channel Attention (MSCA)
3.3. Fused Module with Channel and Spatial (FMCS)
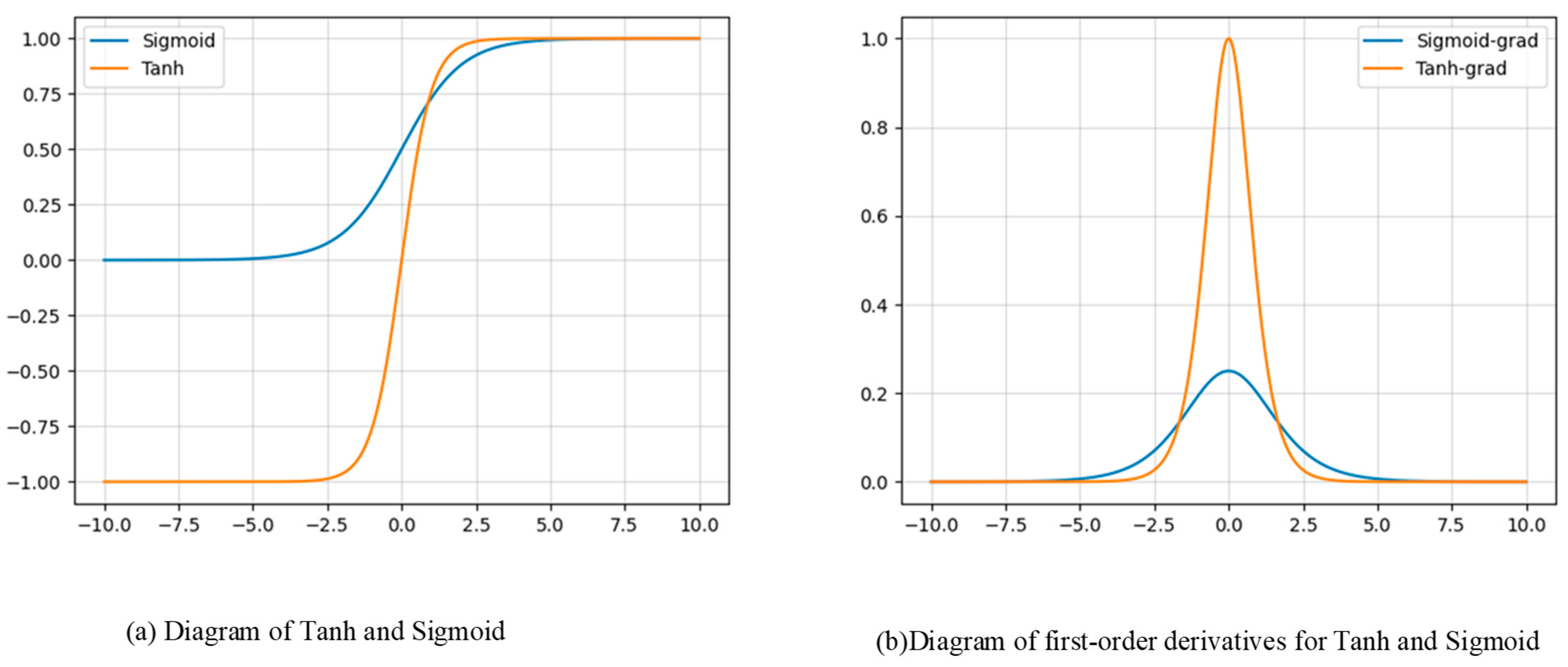
3.4. Binarization of Hyperbolic Tangent (HTB)
3.5. Cross-Entropy Loss Function
4. Experiments and Results Analysis
4.1. Datasets and Evaluation
4.2. Ablation Study
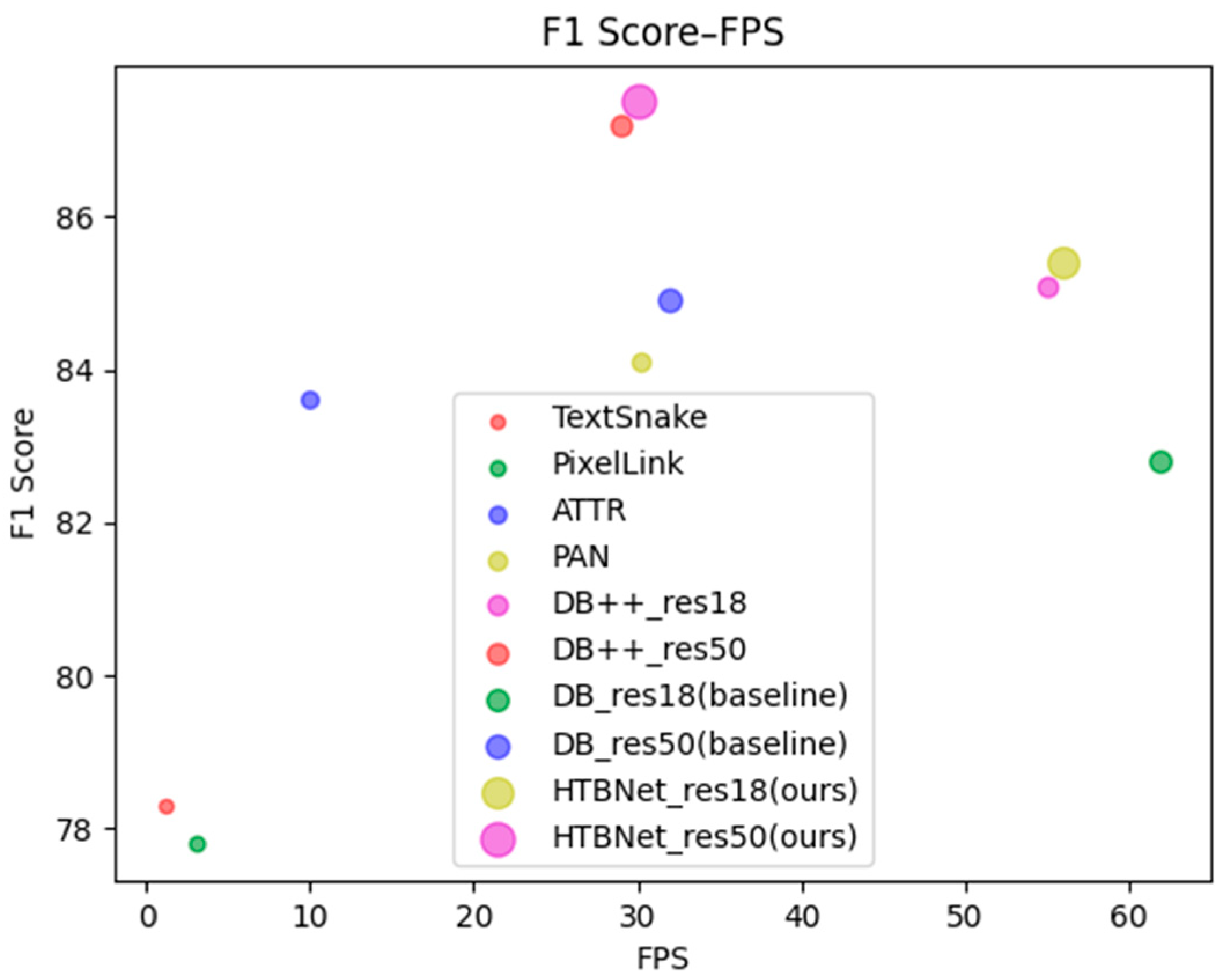
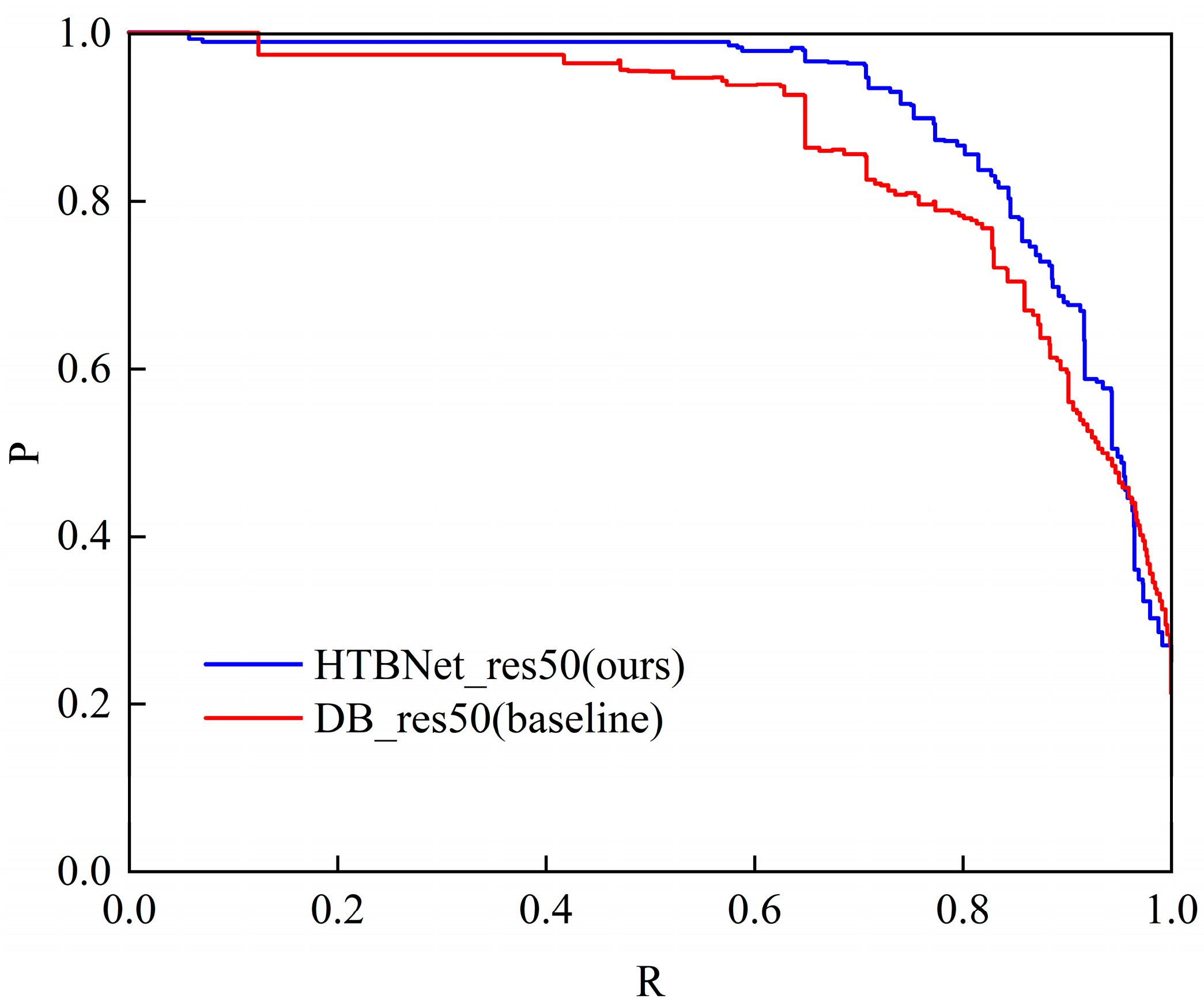
4.3. Comparisons with Other Advanced Methods
5. Conclusions
Funding
Data Availability Statement
Conflicts of Interest
References
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Sergiyenko, O.Y.; Tyrsa, V.V. 3D Optical Machine Vision Sensors With Intelligent Data Management for Robotic Swarm Navigation Improvement. IEEE Sens. J. 2021, 21, 11262–11274. [Google Scholar] [CrossRef]
- Sergiyenko, O.; Alaniz-Plataa, R.; Flores-Fuentes, W.; Rodríguez-Quiñonez, J.C.; Miranda-Vega, J.E.; Sepulveda-Valdez, C.; Núñez-López, J.A.; Kolendovska, M.; Kartashov, V.; Tyrsa, V. Multi-view 3D data fusion and patching to reduce Shannon entropy in Robotic Vision. Opt. Laser Eng. 2024, 177, 108132. [Google Scholar] [CrossRef]
- Sergiyenko, O.; Tyrsa, V.; Zhirabok, A.; Zuev, A. Sliding mode observer based fault identification in automatic vision system of robot. Control Eng. Pract. 2023, 139, 105614. [Google Scholar] [CrossRef]
- Albelwi, S. Survey on Self-Supervised Learning: Auxiliary Pretext Tasks and Contrastive Learning Methods in Imaging. Entropy 2022, 24, 551. [Google Scholar] [CrossRef]
- Lu, C. Reviewing Evolution of Learning Functions and Semantic Information Measures for Understanding Deep Learning. Entropy 2023, 25, 802. [Google Scholar] [CrossRef]
- Khan, M.J.; Khan, M.A.; Turaev, S.; Malik, S.; El-Sayed, H.; Ullah, F. A Vehicle-Edge-Cloud Framework for Computational Analysis of a Fine-Tuned Deep Learning Model. Sensors 2024, 24, 2080. [Google Scholar] [CrossRef] [PubMed]
- Liu, X.Y.; Meng, G.F.; Pan, C.H. Scene text detection and recognition with advances in deep learning: A survey. Int. J. Doc. Anal. Recognit. 2019, 22, 143–162. [Google Scholar] [CrossRef]
- Bacha, J.; Ullah, F.; Khan, J.; Sardar, A.W.; Lee, S. A Deep Learning-Based Framework for Offensive Text Detection in Unstructured Data for Heterogeneous Social Media. IEEE Access 2023, 11, 124484–124498. [Google Scholar] [CrossRef]
- Wang, Q.; Lu, X.C.; Zhang, C.; Yuan, Y.; Li, X.L. LSV-LP: Large-Scale Video-Based License Plate Detection and Recognition. IEEE Trans. Pattern Anal. 2023, 45, 752–767. [Google Scholar] [CrossRef] [PubMed]
- Chen, T.Y.; Pu, F.L.; Chen, H.J.; Liu, Z.H. WHUVID: A Large-Scale Stereo-IMU Dataset for Visual-Inertial Odometry and Autonomous Driving in Chinese Urban Scenarios. Remote Sens. 2022, 14, 2033. [Google Scholar] [CrossRef]
- Pan, J.P.; Li, X.; Cai, Z.Y.; Sun, B.W.; Cui, W. A Self-Attentive Hybrid Coding Network for 3D Change Detection in High-Resolution Optical Stereo Images. Remote Sens. 2022, 14, 2046. [Google Scholar] [CrossRef]
- Yu, W.; Yin, Q.; Yin, H.; Xiao, W.; Chang, T.; He, L.; Ni, L.; Ji, Q. A Systematic Review on Password Guessing Tasks. Entropy 2023, 25, 1303. [Google Scholar] [CrossRef] [PubMed]
- Gupta, N.; Jalal, A.S. Traditional to transfer learning progression on scene text detection and recognition: A survey. Artif. Intell. Rev. 2022, 55, 3457–3502. [Google Scholar] [CrossRef]
- Khan, T.; Sarkar, R.; Mollah, A.F. Deep learning approaches to scene text detection: A comprehensive review. Artif. Intell. Rev. 2021, 54, 3239–3298. [Google Scholar] [CrossRef]
- Liang, T.; Li, B.; Wang, M.; Tan, H.; Luo, Z. A Closer Look at the Joint Training of Object Detection and Re-Identification in Multi-Object Tracking. IEEE Trans. Image Process 2023, 32, 267–280. [Google Scholar] [CrossRef] [PubMed]
- Wu, Z.; Liu, C.; Wen, J.; Xu, Y.; Yang, J.; Li, X. Selecting High-Quality Proposals for Weakly Supervised Object Detection With Bottom-Up Aggregated Attention and Phase-Aware Loss. IEEE Trans. Image Process 2023, 32, 682–693. [Google Scholar] [CrossRef] [PubMed]
- Zhang, L.Y.; Wang, H.T.; Wang, L.F.; Pan, C.H.; Liu, Q.; Wang, X.Y. Constraint Loss for Rotated Object Detection in Remote Sensing Images. Remote Sens. 2021, 13, 4291. [Google Scholar] [CrossRef]
- Deng, D.; Liu, H.; Li, X.L.; Cai, D. PixelLink: Detecting Scene Text via Instance Segmentation. In Proceedings of the Thirty-Second Aaai Conference on Artificial Intelligence / Thirtieth Innovative Applications of Artificial Intelligence Conference/Eighth Aaai Symposium on Educational Advances in Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; pp. 6773–6780. [Google Scholar]
- Long, S.B.; Ruan, J.Q.; Zhang, W.J.; He, X.; Wu, W.H.; Yao, C. TextSnake: A Flexible Representation for Detecting Text of Arbitrary Shapes. Comput. Vis.-ECCV 2018, 11206, 19–35. [Google Scholar] [CrossRef]
- Tian, Z.T.; Shu, M.; Lyu, P.Y.; Li, R.Y.; Zhou, C.; Shen, X.Y.; Jia, J.Y. Learning Shape-Aware Embedding for Scene Text Detection. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 4229–4238. [Google Scholar] [CrossRef]
- Wang, W.H.; Xie, E.Z.; Li, X.; Hou, W.B.; Lu, T.; Yu, G.; Shao, S. Shape Robust Text Detection with Progressive Scale Expansion Network. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 9328–9337. [Google Scholar] [CrossRef]
- Wang, W.H.; Xie, E.Z.; Song, X.G.; Zang, Y.H.; Wang, W.J.; Lu, T.; Yu, G.; Shen, C.H. Efficient and Accurate Arbitrary-Shaped Text Detection with Pixel Aggregation Network. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 8439–8448. [Google Scholar] [CrossRef]
- Xu, Y.; Wang, Y.; Zhou, W.; Wang, Y.; Yang, Z.; Bai, X. TextField: Learning a Deep Direction Field for Irregular Scene Text Detection. IEEE Trans. Image Process 2019, 28, 5566–5579. [Google Scholar] [CrossRef]
- Liao, M.H.; Wan, Z.Y.; Yao, C.; Chen, K.; Bai, X.; Assoc Advancement Artificial, I. Real-Time Scene Text Detection with Differentiable Binarization. In Proceedings of 34th AAAI Conference on Artificial Intelligence/32nd Innovative Applications of Artificial Intelligence Conference/10th AAAI Symposium on Educational Advances in Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 11474–11481. [Google Scholar]
- Graves, A.; Mohamed, A.R.; Hinton, G. Speech Recognition with Deep Recurrent Neural Networks. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Vancouver, BC, Canada, 26–31 May 2013; pp. 6645–6649. [Google Scholar]
- He, K.M.; Zhang, X.Y.; Ren, S.Q.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Ren, X.-L.; Chen, A.-X. Solving the VRP Using Transformer-Based Deep Reinforcement Learning. In Proceedings of the 2023 International Conference on Machine Learning and Cybernetics (ICMLC), Adelaide, Australia, 9–11 July 2023; pp. 365–369. [Google Scholar] [CrossRef]
- LeCun, Y.; Boser, B.; Denker, J.S.; Henderson, D.; Howard, R.E.; Hubbard, W.; Jackel, L.D. Backpropagation Applied to Handwritten Zip Code Recognition. Neural Comput. 1989, 1, 541–551. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. In Proceedings of the NIPS'17: Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Voume 30. [Google Scholar]
- Liao, M.H.; Shi, B.G.; Bai, X. TextBoxes plus plus: A Single-Shot Oriented Scene Text Detector. IEEE T Image Process 2018, 27, 3676–3690. [Google Scholar] [CrossRef]
- Liao, M.H.; Shi, B.G.; Bai, X.; Wang, X.G.; Liu, W.Y. TextBoxes: A Fast Text Detector with a Single Deep Neural Network. AAAI Conf. Artif. Intell. 2017, 31, 4161–4167. [Google Scholar] [CrossRef]
- Liu, Y.L.; Jin, L.W. Deep Matching Prior Network: Toward Tighter Multi-oriented Text Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 3454–3461. [Google Scholar] [CrossRef]
- Wang, X.B.; Jiang, Y.Y.; Luo, Z.B.; Liu, C.L.; Choi, H.; Kim, S. Arbitrary Shape Scene Text Detection with Adaptive Text Region Representation. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 6442–6451. [Google Scholar] [CrossRef]
- Xue, C.H.; Lu, S.J.; Zhang, W. MSR: Multi-Scale Shape Regression for Scene Text Detection. In Proceedings of the Twenty-Eighth International Joint Conference on Artificial Intelligence, Macao, China, 10–16 August 2019; pp. 989–995. [Google Scholar]
- Zhou, X.Y.; Yao, C.; Wen, H.; Wang, Y.Z.; Zhou, S.C.; He, W.R.; Liang, J.J. EAST: An Efficient and Accurate Scene Text Detector. In Proceedings of the 30th IEEE Conference on Computer Vision. and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2642–2651. [Google Scholar] [CrossRef]
- Neubeck, A.; Van Gool, L. Efficient non-maximum suppression. In Proceedings of the 18th International Conference on Pattern Recognition, Hong Kong, China, 20–24 August 2006; Volume 3, p. 850. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. Comput. Vis.-ECCV 2016, 9905, 21–37. [Google Scholar] [CrossRef]
- Baek, Y.; Lee, B.; Han, D.; Yun, S.; Lee, H. Character Region Awareness for Text Detection. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2019), Long Beach, CA, USA, 15–20 June 2019; pp. 9357–9366. [Google Scholar] [CrossRef]
- Shi, B.G.; Bai, X.; Belongie, S. Detecting Oriented Text in Natural Images by Linking Segments. In Proceedings of the 30th Ieee Conference on Computer Vision. and Pattern Recognition (CVPR 2017), Honolulu, HI, USA, 21–26 July 2017; pp. 3482–3490. [Google Scholar] [CrossRef]
- Tang, J.; Yang, Z.B.; Wang, Y.P.; Zheng, Q.; Xu, Y.C.; Bai, X. SegLink plus plus: Detecting Dense and Arbitrary-shaped Scene Text by Instance-aware Component Grouping. Pattern Recogn. 2019, 96, 106954. [Google Scholar] [CrossRef]
- Tian, Z.; Huang, W.L.; He, T.; He, P.; Qiao, Y. Detecting Text in Natural Image with Connectionist Text Proposal Network. Comput. Vis.-ECCV 2016, 9912, 56–72. [Google Scholar] [CrossRef]
- Zhang, S.X.; Zhu, X.; Hou, J.B.; Liu, C.; Yang, C.; Wang, H.; Yin, X.C. Deep Relational Reasoning Graph Network for Arbitrary Shape Text Detection. In Proceedings of 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 9696–9705. [Google Scholar]
- Liao, M.H.; Zou, Z.S.; Wan, Z.Y.; Yao, C.; Bai, X. Real-Time Scene Text Detection With Differentiable Binarization and Adaptive Scale Fusion. IEEE Trans. Pattern Anal. 2023, 45, 919–931. [Google Scholar] [CrossRef]
- Lian, Z.; Yin, Y.; Zhi, M.; Xu, Q. PCBSNet: A Pure Convolutional Bilateral Segmentation Network for Real-Time Natural Scene Text Detection. Electronics 2023, 12, 3055. [Google Scholar] [CrossRef]
- Zhang, S.; Zhou, C.; Li, Y.; Zhang, X.; Ye, L.; Wei, Y. Irregular Scene Text Detection Based on a Graph Convolutional Network. Sensors 2023, 23, 1070. [Google Scholar] [CrossRef]
- Dinh, M.-T.; Choi, D.-J.; Lee, G.-S. DenseTextPVT: Pyramid Vision Transformer with Deep Multi-Scale Feature Refinement Network for Dense Text Detection. Sensors 2023, 23, 5889. [Google Scholar] [CrossRef]
- Saulig, N.; Milovanovic, M.; Milicic, S.; Lerga, J. Signal Useful Information Recovery by Overlapping Supports of Time-Frequency Representations. IEEE Trans. Signal Process 2022, 70, 5504–5517. [Google Scholar] [CrossRef]
- Ch'ng, C.K.; Chan, C.S. Total-Text: A Comprehensive Dataset for Scene Text Detection and Recognition. In Proceedings of the 2017 14th Iapr International Conference on Document Analysis and Recognition (ICDAR), Kyoto, Japan, 9–15 November 2017; Volume 1, pp. 935–942. [Google Scholar] [CrossRef]
- Yao, C.; Bai, X.; Liu, W.Y.; Ma, Y.; Tu, Z.W. Detecting Texts of Arbitrary Orientations in Natural Images. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012; pp. 1083–1090. [Google Scholar]
- Gupta, A.; Vedaldi, A.; Zisserman, A. Synthetic Data for Text Localisation in Natural Images. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2315–2324. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Module | HTB | MSCA | FMCS | Total-Text | ||
|---|---|---|---|---|---|---|
| P | R | F | ||||
| DB_res18 (baseline) | ✕ | ✕ | ✕ | 88.3 | 77.9 | 82.8 |
| res18 | ✓ | ✕ | ✕ | 90.9 | 77.1 | 83.5 |
| res18 | ✕ | ✓ | ✕ | 89 | 78.9 | 83.7 |
| res18 | ✕ | ✕ | ✓ | 88.5 | 79 | 83.5 |
| HTBNet_res18 (ours) | ✓ | ✓ | ✓ | 86.8 | 81.6 | 84.1 |
| Module | HTB | MSCA | FMCS | Total-Text | ||
|---|---|---|---|---|---|---|
| P | R | F | ||||
| DB_res50 (baseline) | ✕ | ✕ | ✕ | 87.1 | 82.5 | 84.7 |
| res50 | ✓ | ✕ | ✕ | 94.9 | 76.8 | 84.9 |
| res50 | ✕ | ✓ | ✕ | 87.9 | 82.8 | 85.3 |
| res50 | ✕ | ✕ | ✓ | 90.5 | 81.3 | 86 |
| HTBNet_res50 (ours) | ✓ | ✓ | ✓ | 91.3 | 81.3 | 86 |
| Module | HTB | MSCA | FMCS | MSRA-TD500 | ||
|---|---|---|---|---|---|---|
| P | R | F | ||||
| DB_res18 (baseline) | ✕ | ✕ | ✕ | 90.4 | 76.3 | 82.8 |
| res18 | ✓ | ✕ | ✕ | 89.3 | 77.7 | 83.1 |
| res18 | ✕ | ✓ | ✕ | 92.3 | 75.9 | 83.3 |
| res18 | ✕ | ✕ | ✓ | 88.8 | 82 | 85.3 |
| HTBNet_res18 (ours) | ✓ | ✓ | ✓ | 89.8 | 81.4 | 85.4 |
| Module | HTB | MSCA | FMCS | MSRA-TD500 | ||
|---|---|---|---|---|---|---|
| P | R | F | ||||
| DB_res50 (baseline) | ✕ | ✕ | ✕ | 91.5 | 79.2 | 84.9 |
| res50 | ✓ | ✕ | ✕ | 90.3 | 81.4 | 85.6 |
| res50 | ✕ | ✓ | ✕ | 89.7 | 82.3 | 85.8 |
| res50 | ✕ | ✕ | ✓ | 91.9 | 83.3 | 87.4 |
| HTBNet_res50 (ours) | ✓ | ✓ | ✓ | 92.2 | 83.3 | 87.5 |
| Module | Mean Square Error | Cross-Entropy | MSRA-TD500 | Total-Text | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| P | R | F | Convergence Epochs | P | R | F | Convergence Epochs | |||
| HTBNet_res18 | ✓ | ✕ | 87.9 | 82.5 | 85.1 | 1200 | 87.5 | 80.7 | 84 | 1200 |
| HTBNet_res18 (Ours) | ✕ | ✓ | 89.8 | 81.4 | 85.4 | 600 | 86.8 | 81.6 | 84.1 | 600 |
| HTBNet_res50 | ✓ | ✕ | 91.5 | 83.5 | 87.3 | 1200 | 90.5 | 81.5 | 85.8 | 1200 |
| HTBNet_res50 (Ours) | ✕ | ✓ | 92.2 | 83.3 | 87.5 | 600 | 91.3 | 81.3 | 86 | 600 |
| Module | K | Multiplication Factor | MSRA-TD500 | Total-Text | ||||
|---|---|---|---|---|---|---|---|---|
| P | R | F | P | R | F | |||
| HTBNet_res18 (Ours) | 10 | 3 | 89.3 | 81.2 | 85.1 | 86.6 | 81.1 | 83.8 |
| HTBNet_res18 (Ours) | 10 | 89.5 | 81.3 | 85.2 | 86.8 | 81.4 | 84.0 | |
| HTBNet_res18 (Ours) | 30 | 89.6 | 81.0 | 85.1 | 87.0 | 79.7 | 83.2 | |
| HTBNet_res18 (Ours) | 50 | 3 | 89.5 | 81.2 | 85.1 | 86.6 | 81.5 | 84.0 |
| HTBNet_res18 (Ours) | 10 | 89.8 | 81.4 | 85.4 | 86.8 | 81.6 | 84.1 | |
| HTBNet_res18 (Ours) | 30 | 90.1 | 80.9 | 85.3 | 87.0 | 81.1 | 83.9 | |
| HTBNet_res18 (Ours) | 250 | 3 | 89.5 | 81.0 | 85.0 | 86.4 | 81.6 | 83.9 |
| HTBNet_res18 (Ours) | 10 | 89.7 | 81.2 | 85.2 | 86.6 | 81.6 | 84.0 | |
| HTBNet_res18 (Ours) | 30 | 90.1 | 80.5 | 85.0 | 86.9 | 81.0 | 83.8 | |
| Module | K | Multiplication Factor | MSRA-TD500 | Total-Text | ||||
|---|---|---|---|---|---|---|---|---|
| P | R | F | P | R | F | |||
| HTBNet_res50 (Ours) | 10 | 3 | 91.8 | 83.1 | 87.2 | 91.0 | 80.8 | 85.6 |
| HTBNet_res50 (Ours) | 10 | 92.0 | 83.3 | 87.4 | 91.2 | 81.0 | 85.8 | |
| HTBNet_res50 (Ours) | 30 | 92.2 | 82.8 | 87.2 | 91.5 | 80.5 | 85.6 | |
| HTBNet_res50 (Ours) | 50 | 3 | 92.0 | 83.2 | 87.4 | 91.1 | 81.0 | 85.8 |
| HTBNet_res50 (Ours) | 10 | 92.2 | 83.3 | 87.5 | 91.3 | 81.3 | 86.0 | |
| HTBNet_res50 (Ours) | 30 | 92.5 | 82.8 | 87.4 | 91.6 | 80.7 | 85.8 | |
| HTBNet_res50 (Ours) | 250 | 3 | 92.0 | 82.5 | 87.0 | 90.5 | 81.2 | 85.6 |
| HTBNet_res50 (Ours) | 10 | 92.1 | 83.1 | 87.4 | 90.8 | 81.4 | 85.8 | |
| HTBNet_res50 (Ours) | 30 | 92.3 | 82.6 | 87.2 | 91.2 | 80.6 | 85.6 | |
| Methods | P (%) | R (%) | F (%) | Params (M) | FPS |
|---|---|---|---|---|---|
| TextSnake [21] | 82.7 | 74.5 | 78.4 | 218.9 | * |
| PixelLink [20] | 53.5 | 52.7 | 53.1 | 218 | * |
| ATTR [36] | 76.2 | 80.9 | 78.5 | * | * |
| SAE [22] | 82.7 | 77.8 | 80.1 | * | * |
| PAN [24] | 89.3 | 81 | 85 | 46.8 | 39.6 |
| MSR [37] | 73 | 85.2 | 78.6 | * | * |
| DRRG [45] | 84.9 | 86.5 | 85.7 | 198.6 | * |
| DenseTextPVT [49] | 89.4 | 80.1 | 84.7 | * | * |
| DB++_res18 [46] | 87.4 | 79.6 | 83.3 | 55.9 | 48 |
| DB++_res50 [46] | 88.9 | 83.2 | 86 | 116.3 | 28 |
| DB_res18 (baseline) [26] | 88.3 | 77.9 | 82.8 | 55.3 | 50 |
| DB_res50 (baseline) [26] | 87.1 | 82.5 | 84.7 | 115.7 | 32 |
| HTBNet_res18 (ours) | 86.8 | 81.6 | 84.1 | 55.5 | 49 |
| HTBNet_res50 (ours) | 91.3 | 81.3 | 86 | 115.8 | 30 |
| Methods | P (%) | R (%) | F (%) | Params (M) | FPS |
|---|---|---|---|---|---|
| TextSnake [21] | 83.2 | 73.9 | 78.3 | 218.9 | 1.1 |
| PixelLink [20] | 83 | 73.2 | 77.8 | 218 | 3 |
| ATTR [36] | 82.1 | 85.2 | 83.6 | * | 10 |
| SAE [22] | 84.2 | 81.7 | 82.9 | * | * |
| PAN [24] | 84.4 | 83.8 | 84.1 | 46.8 | 30.2 |
| MSR [37] | 76.7 | 87.4 | 81.7 | * | * |
| DRRG [45] | 82.3 | 88.1 | 85.1 | 198.6 | * |
| PCBSNet [47] | 90 | 76.7 | 82.8 | * | * |
| TDGCN [48] | 89.7 | 85.1 | 87.4 | * | * |
| DB++_res18 [46] | 87.9 | 82.5 | 85.1 | 55.9 | 55 |
| DB++_res50 [46] | 91.5 | 83.3 | 87.2 | 116.3 | 29 |
| DB_res18 (baseline) [26] | 90.4 | 76.3 | 82.8 | 55.3 | 62 |
| DB_res50 (baseline) [26] | 91.5 | 79.2 | 84.9 | 115.7 | 32 |
| HTBNet_res18 (ours) | 89.8 | 81.4 | 85.4 | 55.5 | 56 |
| HTBNet_res50 (ours) | 92.2 | 83.3 | 87.5 | 115.8 | 30 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, Z. (HTBNet)Arbitrary Shape Scene Text Detection with Binarization of Hyperbolic Tangent and Cross-Entropy. Entropy 2024, 26, 560. https://doi.org/10.3390/e26070560
Chen Z. (HTBNet)Arbitrary Shape Scene Text Detection with Binarization of Hyperbolic Tangent and Cross-Entropy. Entropy. 2024; 26(7):560. https://doi.org/10.3390/e26070560
Chicago/Turabian StyleChen, Zhao. 2024. "(HTBNet)Arbitrary Shape Scene Text Detection with Binarization of Hyperbolic Tangent and Cross-Entropy" Entropy 26, no. 7: 560. https://doi.org/10.3390/e26070560
APA StyleChen, Z. (2024). (HTBNet)Arbitrary Shape Scene Text Detection with Binarization of Hyperbolic Tangent and Cross-Entropy. Entropy, 26(7), 560. https://doi.org/10.3390/e26070560