Abstract
Computer vision in sports analytics is gaining in popularity. Monitoring players’ performance using cameras is more flexible and does not interfere with player equipment compared to systems using sensors. This provides a wide set of opportunities for computer vision systems that help coaches, reporters, and audiences. This paper provides an introduction to the problem of measuring boxers’ performance, with a comprehensive survey of approaches in current science. The main goal of the paper is to provide a system to automatically detect punches in Olympic boxing using a single static camera. The authors use Euclidean distance to measure the distance between boxers and convolutional neural networks to classify footage frames. In order to improve classification performance, we provide and test three approaches to manipulating the images prior to fitting the classifier. The proposed solution achieves 95% balanced accuracy, 49% F1 score for frames with punches, and 97% for frames without punches. Finally, we present a working system for analyses of a boxing scene that marks boxers and labelled frames with detected clashes and punches.
1. Introduction
Currently, around the globe, multiple devices are installed that allow for the recording of images and sounds. The vast majority of these are surveillance cameras but, simultaneously, more and more footage is produced by bystanders. When there is an enormous amount of material, it is nearly impossible to understand a recorded scene with no automatic solutions. Extracting valuable information is becoming an important factor in making sense of such data [1,2,3]. Currently, cameras in public spaces (e.g., airports, banks, train stations, and hospitals) analyse the behaviour of individuals in order to detect dangerous situations and issue an alert to the relevant authorities [4,5]. In private spaces, cameras automatically monitor employee behaviour and equipment to improve health and security [6,7,8]. Additionally, in industry, cameras monitor the quality of manufactured products [9,10].
Recently, the use of machine learning methods is becoming more popular in the domain of combat sports [11,12,13]. The current state-of-the-art approach is to use invasive (e.g., wearable sensors) or non-invasive (e.g., cameras) approaches to detect players and analyse their movement [14,15,16,17,18,19,20,21].
The aim of this paper is to provide an automatic way of detecting punches in Olympic boxing using computer vision algorithms. The rest of the paper will discuss the other requirements and limitations, as well as the complete preliminary solution. We are using non-invasive methods and providing a solution to a problem with close co-operation with stakeholders, who validate the approach on a daily basis. The research goal of this paper is to verify the influence of multiple different approaches to image manipulation on the performance of a punch classifier.
The remainder of this article is organised as follows. Section 2 gives a broad description of the current state of the art. Section 3 presents the proposed approaches of the authors and the process of data collection and labelling. Section 4 provides the results of the experiments that describe the efficiency of three different approaches to detecting punches. Section 5 gives a statistical analysis of the results obtained. Section 6 discusses the concept of entropy in boxing punch detection, providing insights into the uncertainty and variability in the classification process. Section 7 contains the conclusions of the paper, along with ideas for future work.
2. Related Works
Detecting people in images and analysing their behaviour in videos is the current focus of many computer vision studies. In many cases, these systems are used to monitor and protect our lives [6,7,8,22]. There are many monitoring systems for potential dangerous event recognition (e.g., stroke or collapse) to protect older people using RGB and RGB-D cameras [4,5]. Additionally, cameras may be used to protect passengers at airports by automatically detecting unattended bags, which may be a direct source of danger [23].
Therefore, many systems are trying to analyse a scene in order to detect and classify people’s actions. This is a complex problem because of the many possible combinations of body postures, body parameters (such as height, weight, etc.), clothing, and environment conditions where footage is captured. Many papers [24,25,26] have been dedicated to detecting pedestrians in traffic scenes, which is an important path in the development of self-driving cars.
The recognition of human actions plays a crucial role in the analysis of athletes and players in many sports [19]. Fully automatic recognition is still an open problem; refs. [27,28,29,30] describe different approaches but are still able to classify only a tiny fraction of interesting behaviour. A similar research problem can be found in object detection, where research has focused on detecting objects that represent a particular class of objects [31,32]. The current state of these systems is far from a universal solution with the possibility of understanding the context of most scenes in real life.
Moreover, cameras are essential in sports. Because of them, all live broadcasts can be transmitted to a wider audience. Furthermore, current sophisticated computer vision systems track players, analyse their movements, and generate reports for reporters, coaches, and others for further analysis [33]. Tracking systems are used to automatically focus attention on interesting areas (e.g., a place on a pitch where the action is happening). In their current state, these systems can also be used to create databases for teams that describe their movement and behaviour on the pitch. This is the premise of the extensive analysis concluded by finding the strengths and weaknesses of both the team and each individual player [34]. The knowledge collected by vision computing is then applied using a statistical and machine learning approach.
However, cameras in many sports events play a crucial role. The current systems use several cameras in stadiums to analyse players’ movements. Camera data are used to analyse players in football [35], tennis [36], and other popular sports [37,38,39]. Some systems are very complex and use up to 10 cameras that capture 340 frames per second to generate 3D models of ball trajectories in cricket games [33].
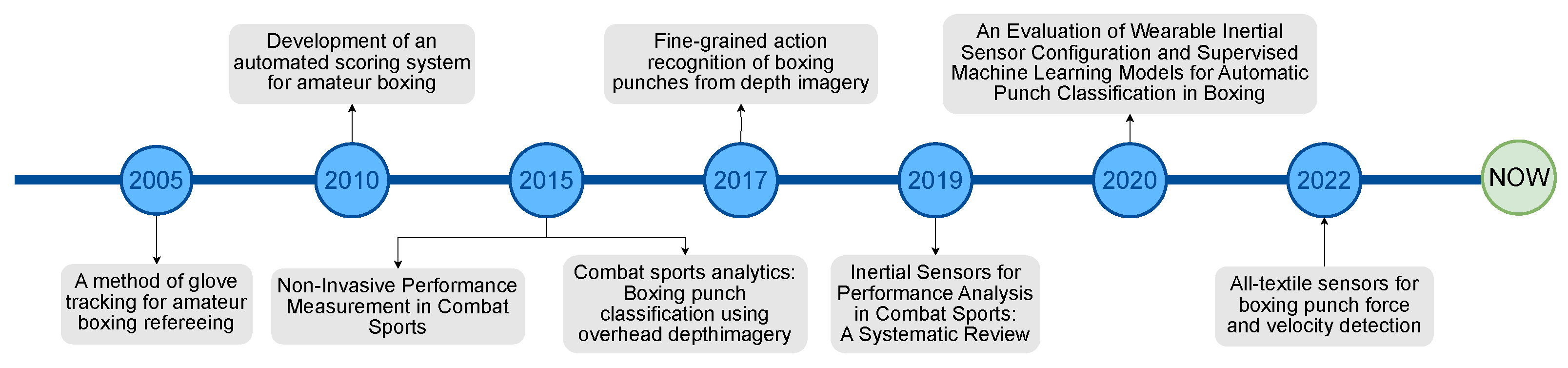
Applying similar techniques to combat sports is not as sophisticated as in the previous examples. The main reason for this is the lack of publicly available labelled data, as in other sports [40,41,42]. This is due to boxing being much less popular than football. However, current research dedicated to the analysis of boxing fights is using one of two approaches. One of them [14,15,16,17] is considered an “invasive” method, which uses wearable sensors to monitor boxer behaviour with special consideration for detecting punches. The main advantage of this approach is the accuracy and purity of the collected data, but it may be dangerous to boxers and will be banned by game regulations, as happened in NBA games [33]. The second way, which is a “non-invasive” method, uses RGB or RBG-D cameras to analyse boxers’ movement, detect events in the boxing ring, and classify punches [18,19,20,21]. In addition, all the relevant works on boxing fight analysis and the years of their publication are presented in Figure 1.
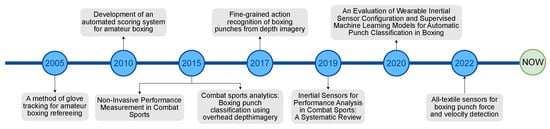
Figure 1.
Timeline chart for the most relevant works to the study.
Motivation for the Study
The motivation for our study arises from the need to improve the analysis of boxing performance using non-invasive methods. Unlike more popular sports, such as football, boxing lacks publicly available labelled data, which makes it difficult to grow robust analytical systems [40,41,42]. Traditional methods for monitoring boxer performance often rely on wearable sensors, which, despite their accuracy, pose safety risks and are sometimes prohibited in competitions [14,15,16,17]. Non-invasive methods using RGB or RGB-D cameras offer a safer alternative but are currently underdeveloped for real-time application in boxing [18,19,20,21].
Our proposed system aims to fill this gap by providing a real-time, non-invasive solution for punch detection in Olympic boxing using a single static camera. This approach is designed to be cost-effective and accessible, reducing the need for complex and expensive multi-camera setups. By leveraging advanced image manipulation techniques and convolutional neural networks, our method enhances the accuracy of punch detection while ensuring the safety and comfort of athletes.
3. Methodology
The main goal of this paper is to propose a system to detect punches in Olympic boxing. The current state of the system uses a single camera in front of the boxing ring. As will be discussed in more detail later, some of the limitations of the current approach might be overcome by using multiple cameras. The system combines the following two modules:
- Clash detecting—An approach based on boxer detection [43] and a measurement of the distance [44] between them using Euclidean distance to detect possible situations with punches.
- Punch detecting—An approach that uses neural networks to classify frames and detect the actual moment when punches hit.
The main purpose of the detection of clashes is to reduce the amount of data before the data labelling process (which was explained in Section 3.2). Reducing data also has a positive impact on processing new videos; it might be considered as a filter that reduces moments where boxers were standing far apart without any chance of punches. This reduces the processing time and computing power needed to actually detect punches, as well as decreases the number of false positives. The exact method of clash detection was previously described in the authors’ paper [44].
where A and B are points in the co-ordinate system; x and y stand for co-ordinates for values of the points.
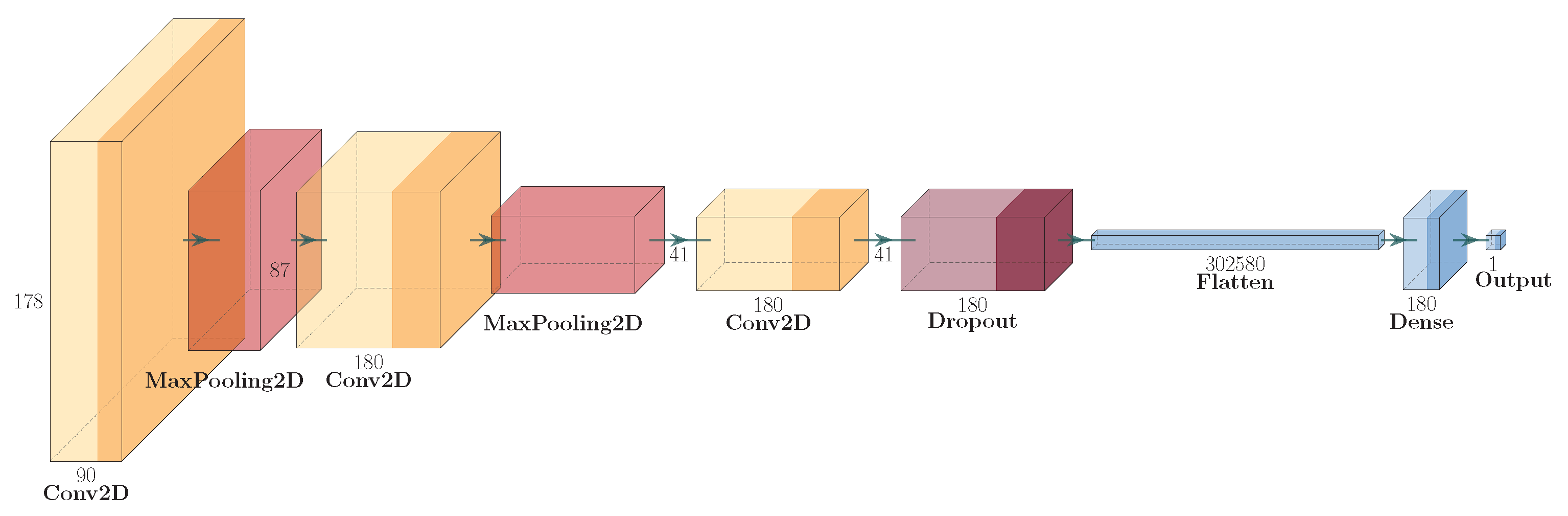
In the second step of the presented approach, only frames with boxers in close proximity to each other are used. Punch detection is a binary classification with two classes (punch and not punch). In order to classify this, an approach using neural networks was used. The authors used the CNN neural network, which was inspired by natural biological visual recognition mechanisms [45] and is popular in the domain of image classification. Furthermore, the authors suspect that convolutions allow one to emphasise small details which are vital for clash detection. In order to train classifiers, the novel neural network structure was created with fewer layers compared to popular network structures such as ResNet, Inception, etc. The main reason is to speed up the training process and to overcome the limitations with computing power. The structure of the convolutional neural network used is presented in Figure 2.
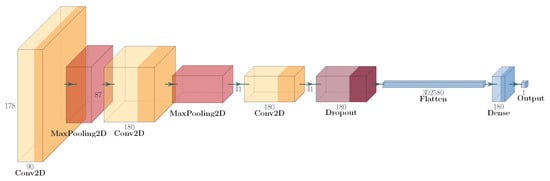
Figure 2.
Structure of convolutional neural network used.
The input frames were resized to 180 × 180 pixels to balance computational efficiency and model performance. While the original video frames were recorded in full HD resolution, processing such high-resolution images would significantly increase the computational load and training time, especially given the extensive dataset. Resizing to 180 × 180 pixels ensures that the model can be trained more rapidly without requiring prohibitively high computing power. This dimension was selected as it is sufficiently large to capture the essential features necessary for punch detection while being small enough to allow for faster processing and iteration during model training. Additionally, this resizing step helps standardise the input data, which is crucial for the stability and performance of the convolutional neural network used for classification. By reducing the resolution, we ensure that the model focuses on the most relevant parts of the image, thereby maintaining the ability to emphasise small but vital details for accurate punch detection.
Punch detection is one of the computer vision problems in which algorithms must learn how to detect very small objects in an image. It is our assumption that classification without preprocessing will not work properly. The basis of this was covered by previous works [1,2,3,46], where adapting the input image resulted in better classification results. The confirmation of this hypothesis applied to punch detection will be verified by the performance of classification. We propose different methods for manipulating the images prior to fitting the classifier to check the performance of the classification over the same dataset but preprocessed using different methods.
The authors proposed and tested four approaches, three of which were created in order to extract ROIs (regions of interest). The following approaches are the subject of this research.
- Original image (Approach 1)—The algorithm receives the original image without any transformations.
- Colour extraction (Approach 2)—Based on the representation of the HSV [47] image model, we extract the blue and red colours of the boxers’ outfits. The outfit colours are regulated by the rules of Olympic boxing and are constant in every fight. According to these rules, a boxer must wear red or blue gloves, a head guard, and a singlet corresponding to their respective corner.
- Background subtraction (Approach 3)—The algorithm, which is based on the work in [48], removes static objects and elements from the video, leaving only objects in motion.
- Hybrid method (Approach 4)—Combining in sequence the previous two approaches: removing colours other than blue or red followed by the removal of static elements such as the floor or corners of the boxing ring.
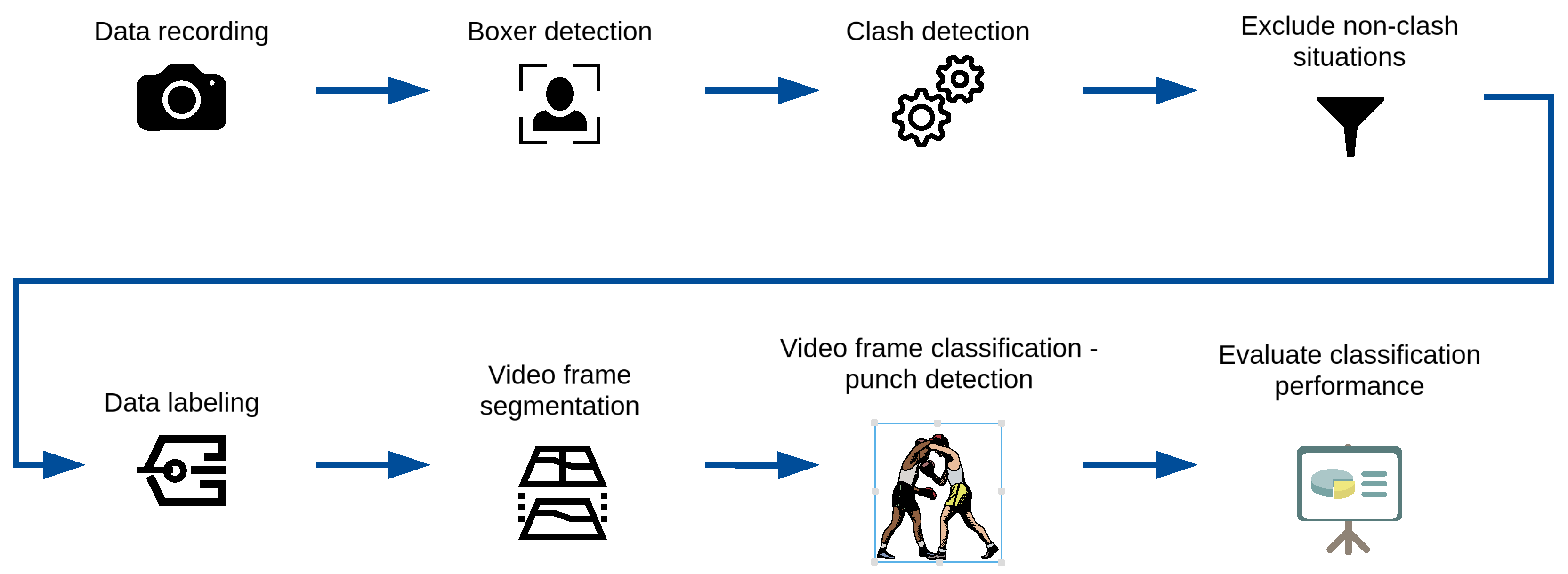
Example results of video frame segmentation using all four proposed approaches are presented in Figure 3. In addition, we provided a flowchart of the entire processing pipeline proposed in this study in Figure 4. The pipeline starts with the data recording step (which is described in Section 3.1) and ends with the evaluation classification performance step (which is described in Section 4).

Figure 3.
Visualisation of the original image along with the proposed approach of image manipulation. (A)—Original frame from the camera. (B)—Binary mask after segmentation based on colour extraction approach. (C)—Binary mask after segmentation based on background subtraction approach. (D)—Binary mask after segmentation based on hybrid approach.
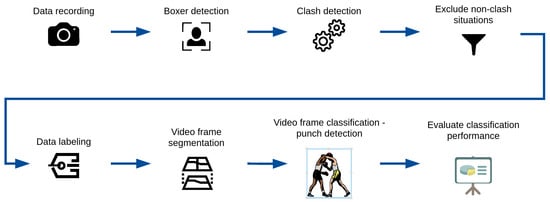
Figure 4.
Methodology flowchart of the entire processing pipeline proposed in this study.
3.1. Data Collection
For sports image classification problems, it is difficult to find good quality and valuable datasets. This is even more difficult for boxing fight footage, especially for videos verified and labelled by experts (e.g., boxing referees with a licence). Therefore, we need to record, collect, and label the relevant sets of data.
The necessary footage of the boxing fights was recorded in Poland in the Silesian league for juniors, cadets, and seniors. For this purpose, four GoPro Hero8 cameras with power banks and 128 GB memory cards were used. Due to the dynamic nature of fights and the occlusions of clashes, each piece of camera footage can provide a unique opportunity to detect punches. The cameras were mounted behind each corner on 1.8 m high tripods and recorded video in full HD resolution at 50 frames per second. After the competition, which lasted four hours, each memory card was nearly full, totalling just under 500 GB of recorded footage [44].
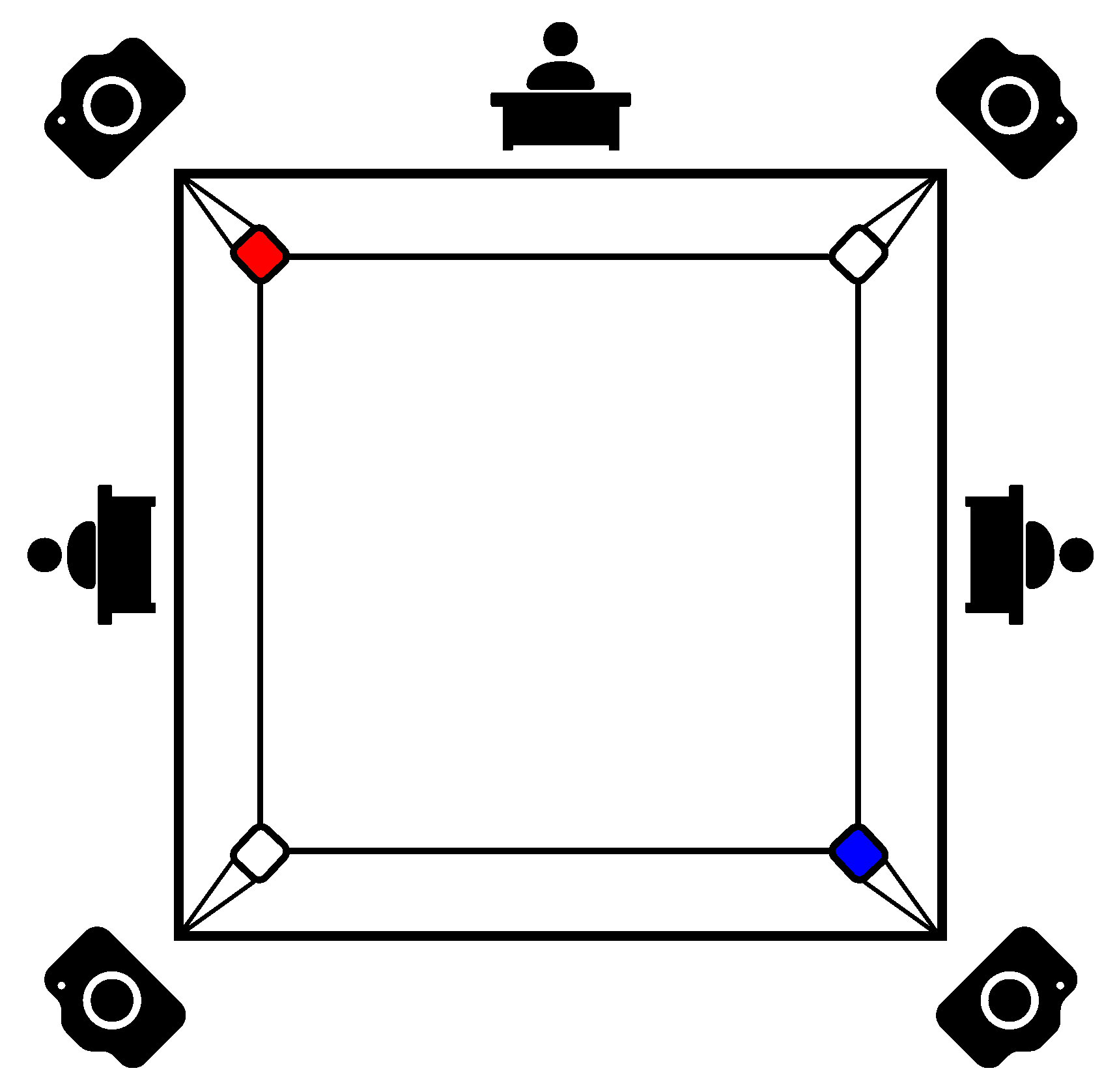
The proposed recording setup is presented in Figure 5 and is inspired by the positions of three referees behind the boxing ring. Four cameras were used in order to avoid occlusions between boxers and referees in the boxing ring. The combined footage allows for observing the fight and capturing more details than the three referees can capture on their own. In this paper, the authors have only used footage from one camera but, in the future, it will be combined and used for ensemble voting in the classification process.
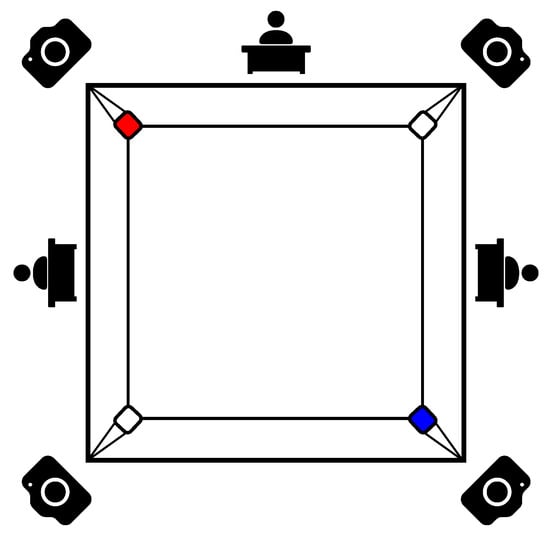
Figure 5.
Diagram of the location of cameras and referees around the boxing ring.
3.2. Data Labelling
The labelling process was difficult due to the huge amount of data. In order to prepare the videos for image classification, one has to treat each frame individually. Because a punch happens rather quickly, precision in labelling is crucial. Four hours of recording with four cameras in 50 frames per second gives about three million frames to label; thus, reducing the amount of data to a more practical volume is imperative. Clash detection provides good results and filters out about 70% of the footage where the boxers were standing far apart without any chance of punches.
The filtered footage was loaded into a labelling tool (CVAT—https://github.com/opencv/cvat (accessed on 15 May 2024)) and passed through the labelling process commenced by a licensed boxing referee. The referee provided information on images from two cameras. The whole fight was divided into 14 videos for each camera, totalling 28 video clips. Each video contains about 12 min (before the filtering process) of recording. As a result, the referee looked at 312,774 frames, where 11,345 (roughly 3.62%) were considered as punches and 301,429 were not. This shows that the number of frames with a punch is significantly disproportional to the number of frames without a punch. An example of a labelled video frame is presented in Figure 6, where the referee labelled the frame as the “punch” class and also drew a bounding box around the punch area.

Figure 6.
Example of a frame labelled as a punch by the referee.
In order to address reproducibility, we made our dataset publicly available. The dataset, which includes the labelled boxing footage used in this study, is accessible on Kaggle (https://www.kaggle.com/datasets/piotrstefaskiue/olympic-boxing-punch-classification-video-dataset (accessed on 15 May 2024)).
3.3. Public Release of Data
The collected and prepared data were made available for noncommercial use: in academic institutions for teaching and research purposes and in non-profit research organisations. Along with the release, a detailed description related to the data was prepared, such as recording methodology, labelling methodology, and privacy and data protection [49].
The entire competition (the inaugural boxing league of youngsters, cadets, and juniors organised in 2021 in Szczyrk) lasted approximately four hours and the recorded material took up almost 500 GB of disk space. As interpreted by the legal department of the University of Economics in Katowice, in order to ethically and legally make the constructed database public, care was taken to reliably blur the faces of those appearing in the footage to protect personal data, using available algorithms.
4. Experiments
The results of the experiments were obtained on a computer using an Intel Core i9-11900K@3.50 GHz 16-core processor, 64 GB of RAM (from Polish company GOODRAM, Łaziska Górne, Poland), and an Nvidia Geforce GTX 1080Ti graphic card, using the Ubuntu 22.04.4 operating system.
In order to test our hypothesis, a binary classification machine learning model using a neural network was created. In order to confirm the statistical performance of the classification, each approach was trained and evaluated 30 times using a random sub-sample from the whole dataset. Therefore, in Section 4, the authors presented medians of the computed performance metrics: computed accuracy (Equation (2)), balanced accuracy (Equation (5)), precision (Equation (4)), and recall (Equation (3)). As the number of video frames with punches is in the order of several magnitudes lower than the frames without punches (the data is highly imbalanced), balanced accuracy should give a better perspective for performance evaluation.
where
- is the true positive, which denotes the number of frames correctly classified as a punch;
- is the true negative, which denotes the number of frames correctly classified as no punch;
- is the false positive, which denotes the incorrectly classified frames as a punch;
- is the false negative, which denotes the incorrectly classified frames as no punch;
- is the true negative ratio, defined as , also known as specificity or selectivity.
In total, we trained four classifiers using transformed datasets according to our methodology (Section 3). Each model in the input layer obtains images at a 180 × 180 resolution with a colour channel; in addition, the classifiers were trained with an Adam optimiser and cross-entropy loss function. The entire dataset was divided into two subsets: 80% of the samples were used for training and the remaining 20% were used for testing purposes. The model for each approach was trained and evaluated 30 times using a random subsample from the whole dataset to statistically confirm the classification performance. Therefore, Table 1 and Table 2 contain the medians of the computed metrics.

Table 1.
Medians of classification performance metrics for all approaches.
Table 2.
Medians of confusion matrix for all approaches.
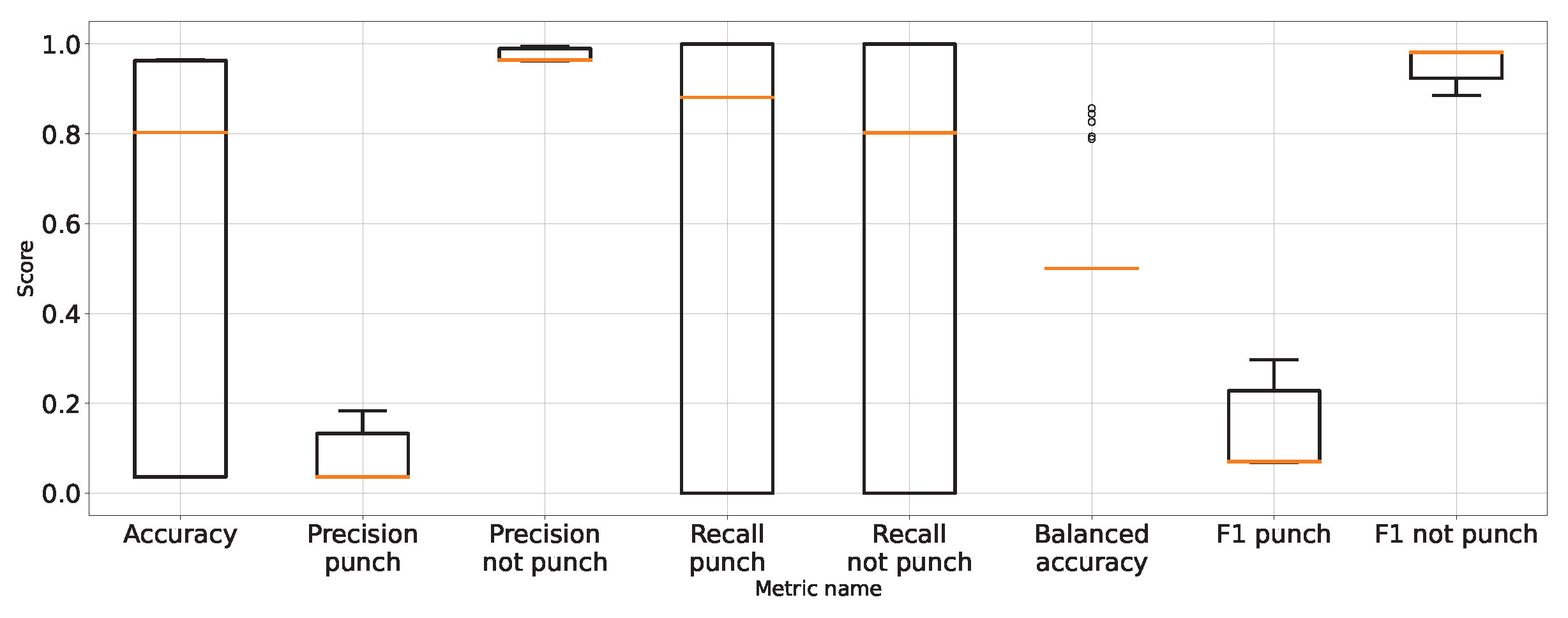
As expected, Table 1 and Table 2 and Figure 7 show that the approach to detect punches in the original image without any preprocessing steps is not optimal. The model is very unstable, and the classifier repeatedly produces a constant, single-class output. This is also confirmed by the recall results presented in Figure 7 and the FN metric in Table 2 for this approach. The problem of the classifier bias to output a single class is the main challenge in working with imbalanced data. In the case of our problem, this is, therefore, convergent with most real-world computer vision problems. This is why we also use balanced accuracy in the analysis and maintained diligence in minimising imbalance during data preparation.
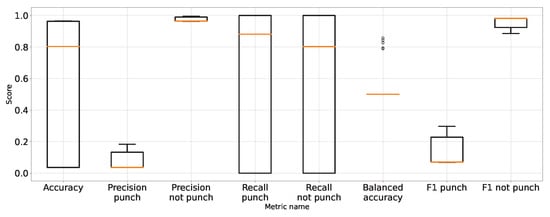
Figure 7.
Performance of classification on original images.
The performance metrics for the classifier using the unprocessed images are presented in Figure 7. We treat them as the reference point for other performance metrics presented separately in Figure 8, Figure 9, Figure 10, Figure 11, Figure 12, Figure 13, Figure 14 and Figure 15. Additionally, to improve readability, the outliers were filtered using the three-sigma rule [50] shown in Equation (6). The number of removed observations was noted in each figure caption.
where a is the arithmetic mean and is the standard deviation.
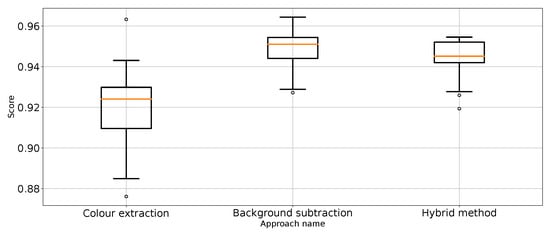
Figure 8.
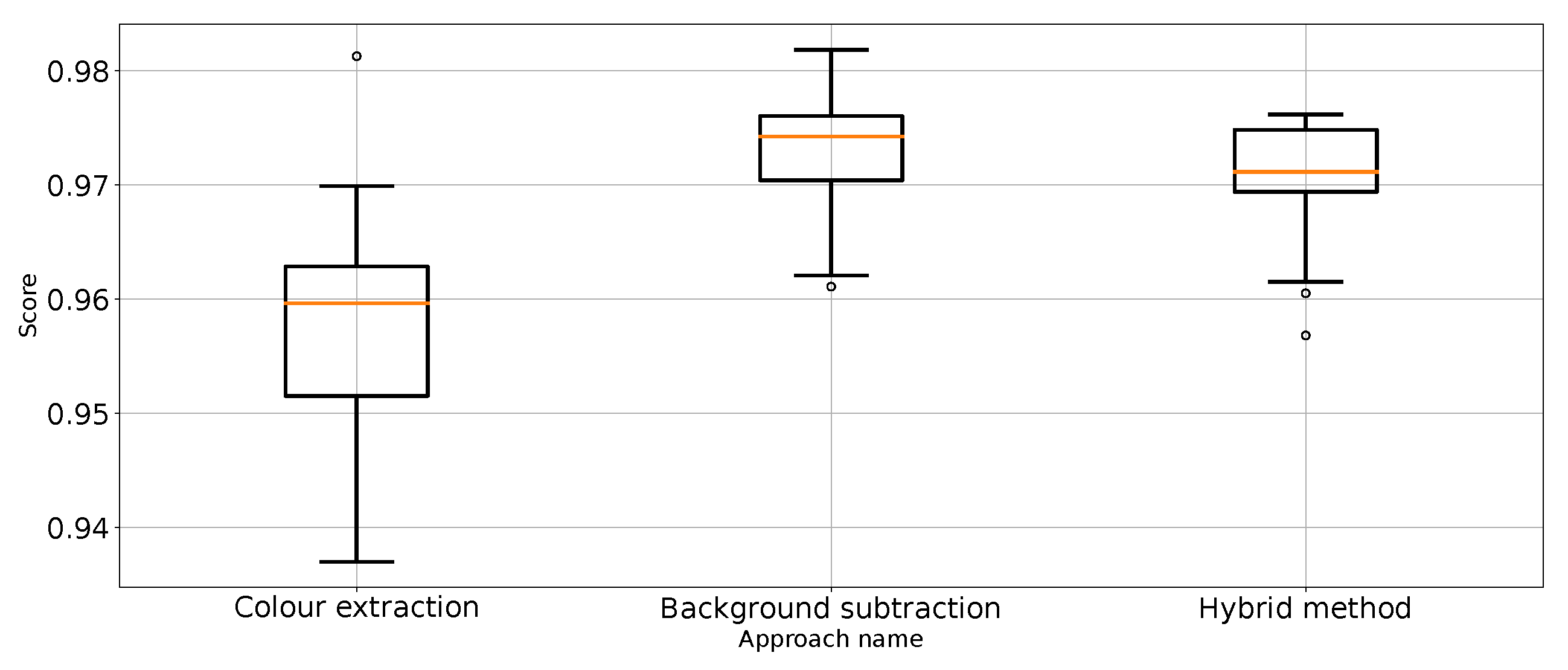
Accuracy for the three proposed approaches (one outlier was removed).
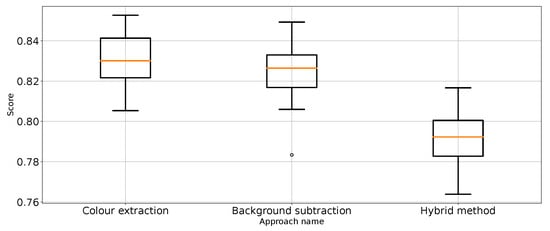
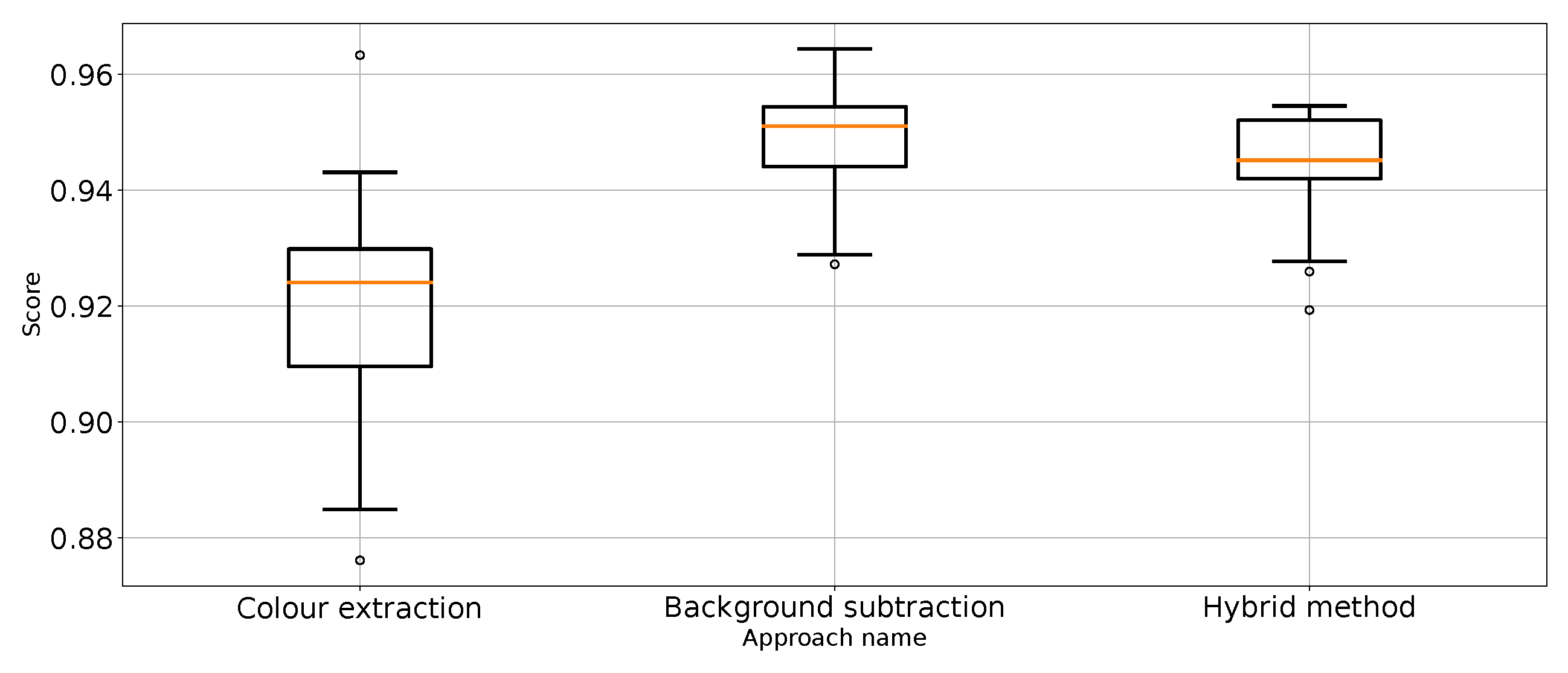
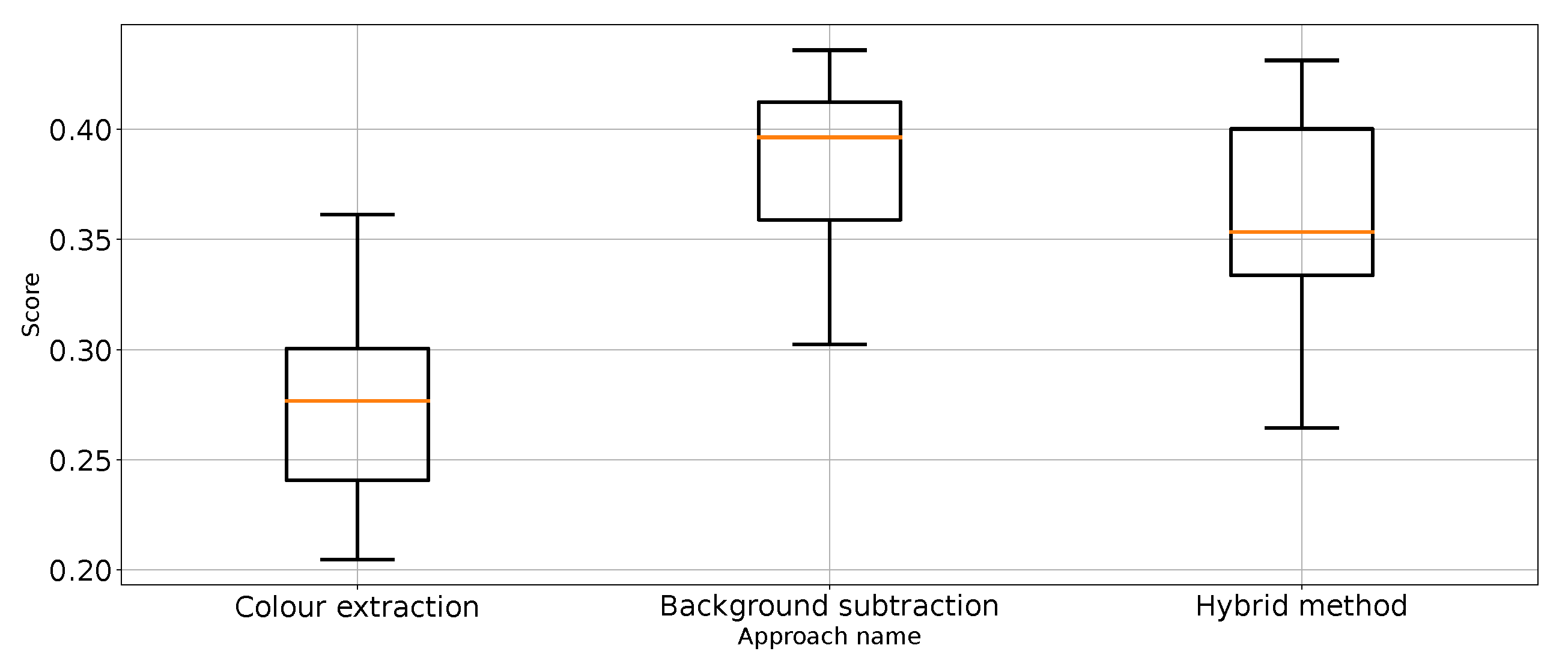
Figure 9.
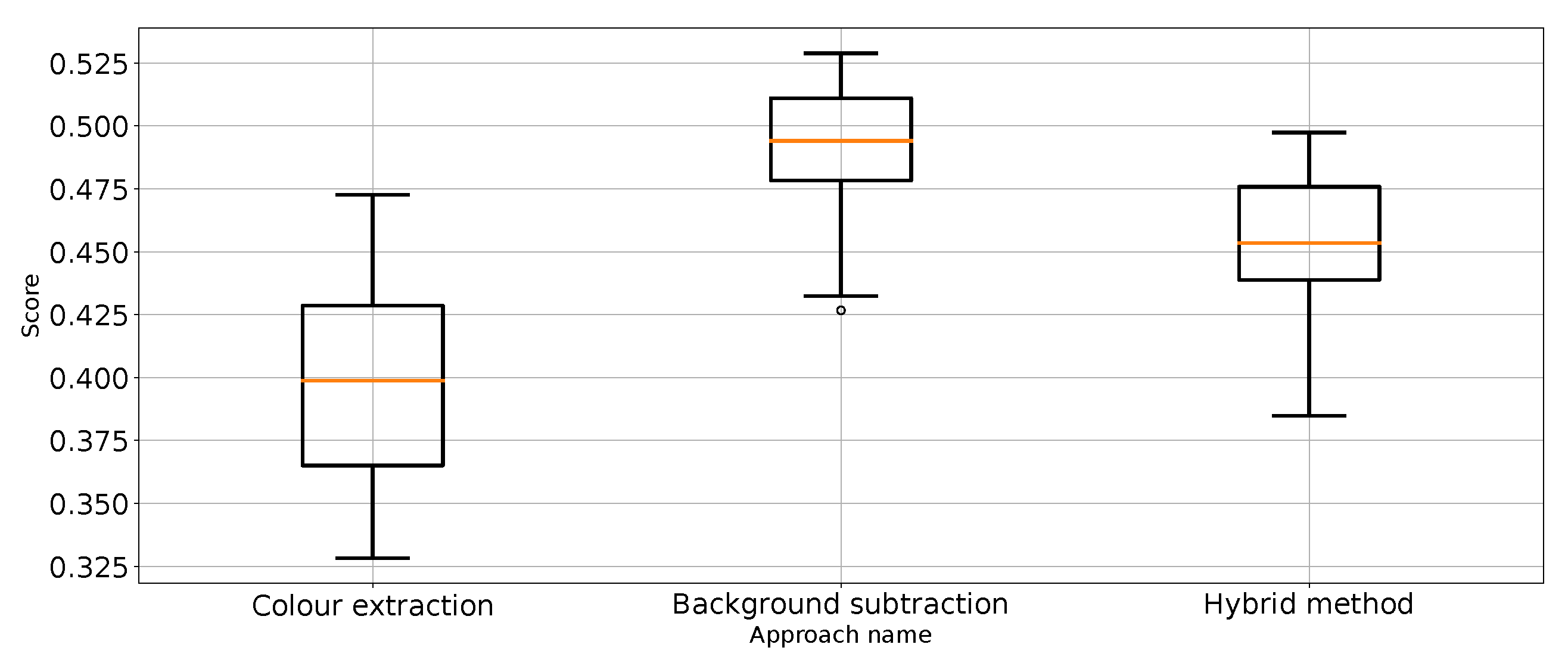
Balanced accuracy the for three proposed approaches (four outliers were removed).
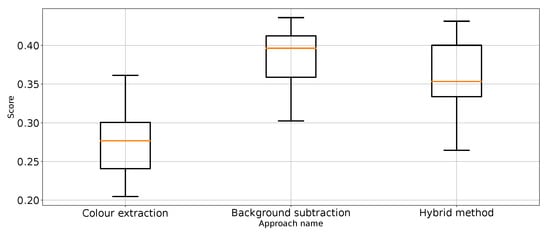
Figure 10.
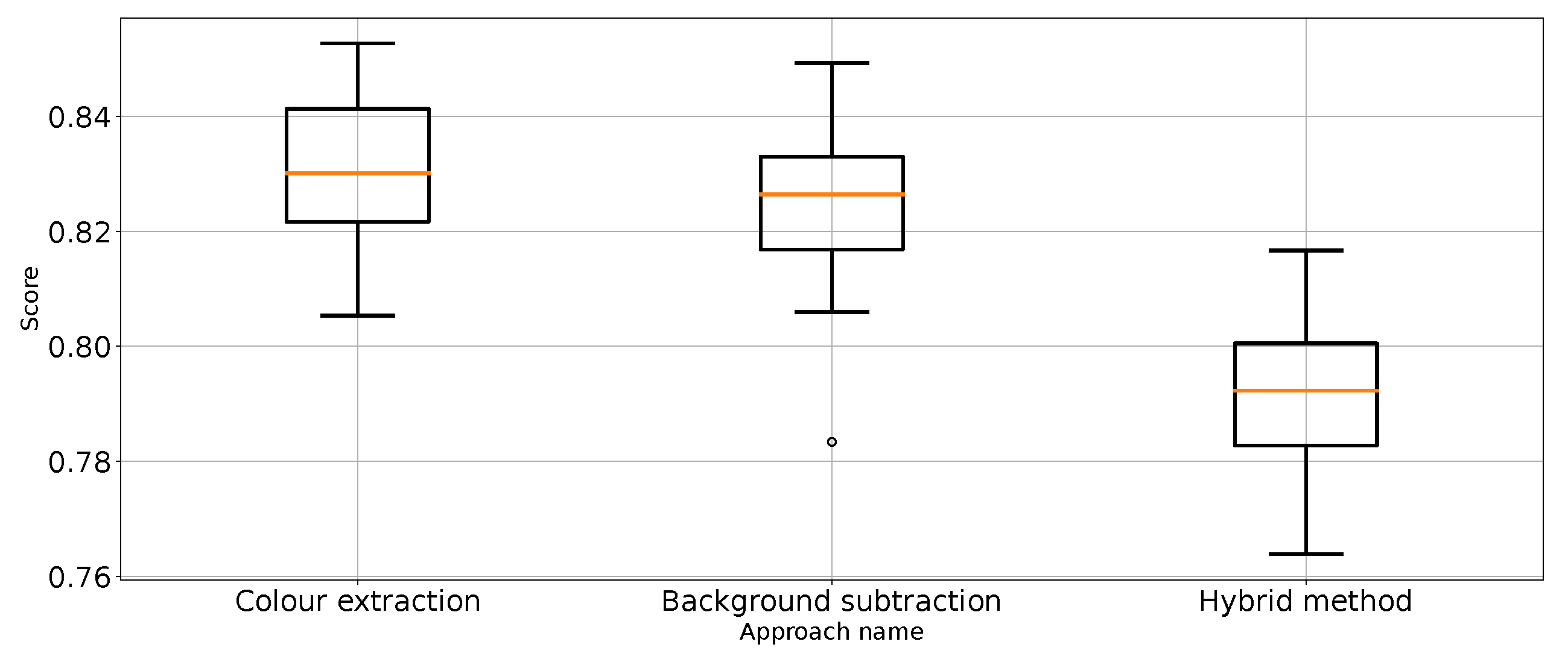
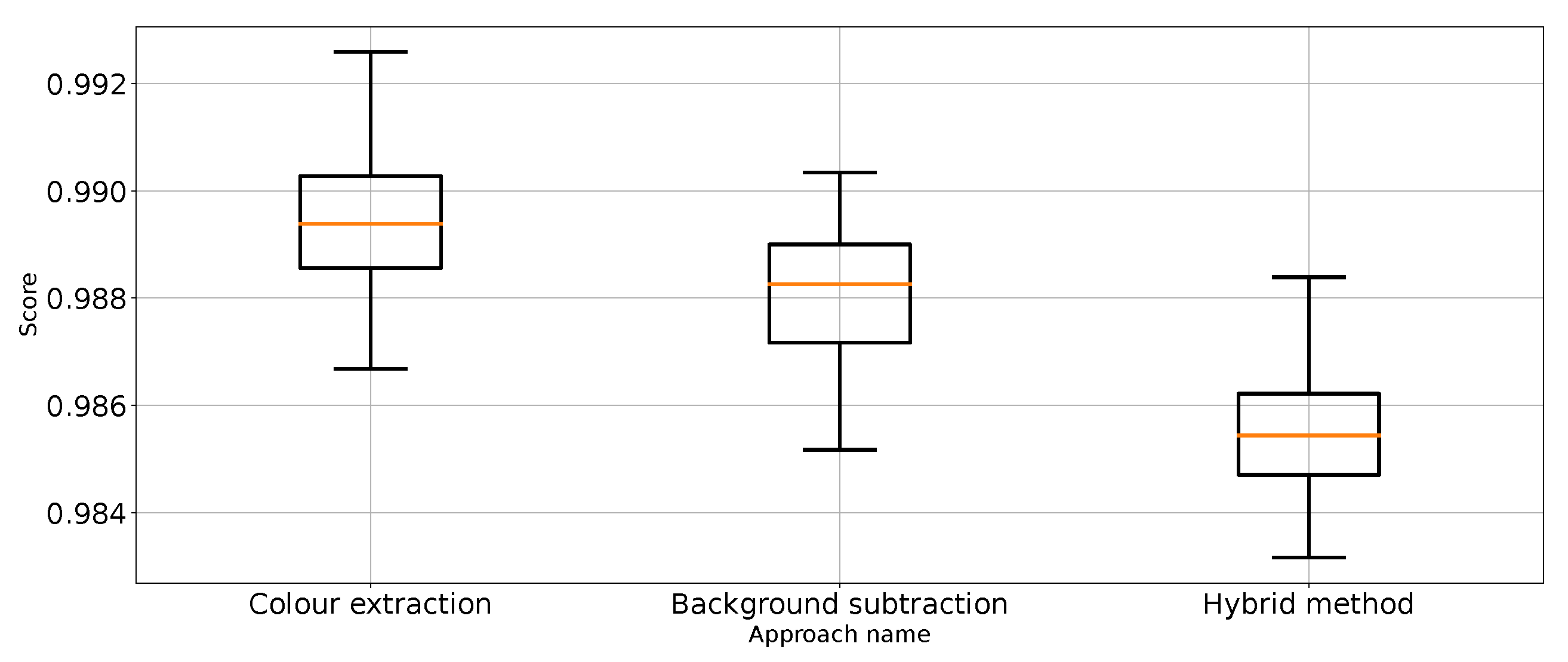
Precision for “punch” class for the three proposed approaches (one outlier was removed).
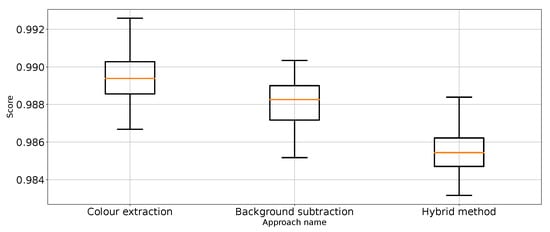
Figure 11.
Precision for “no punch” class for the three proposed approaches (three outliers were removed).
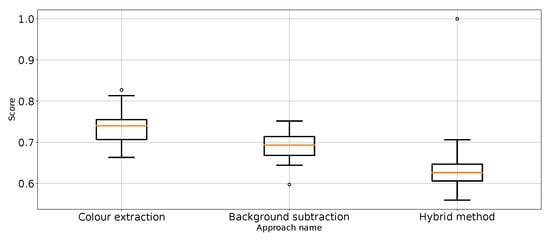
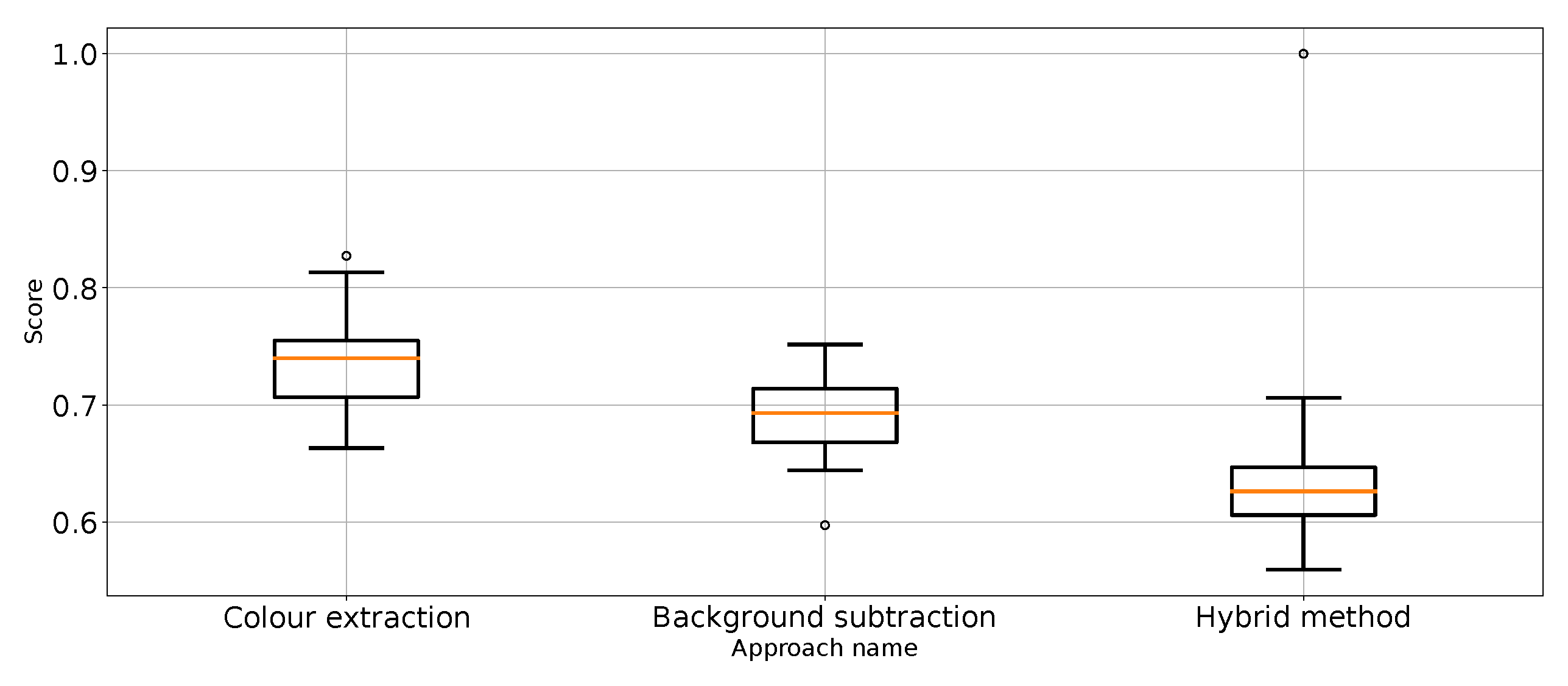
Figure 12.
Recall for “punch” class for the three proposed approaches (three outliers were removed).
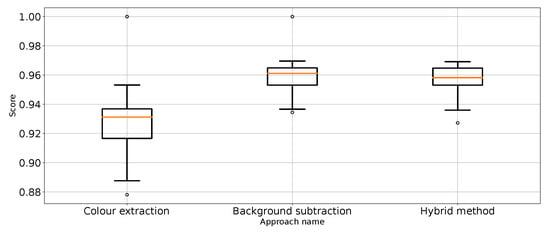
Figure 13.
Recall for “no punch” class for the three proposed approaches (one outlier was removed).
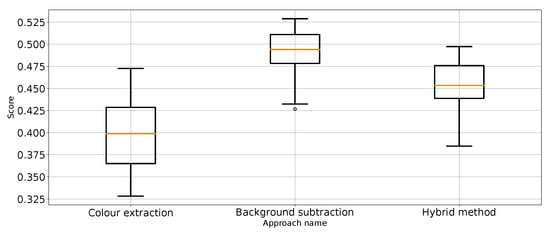
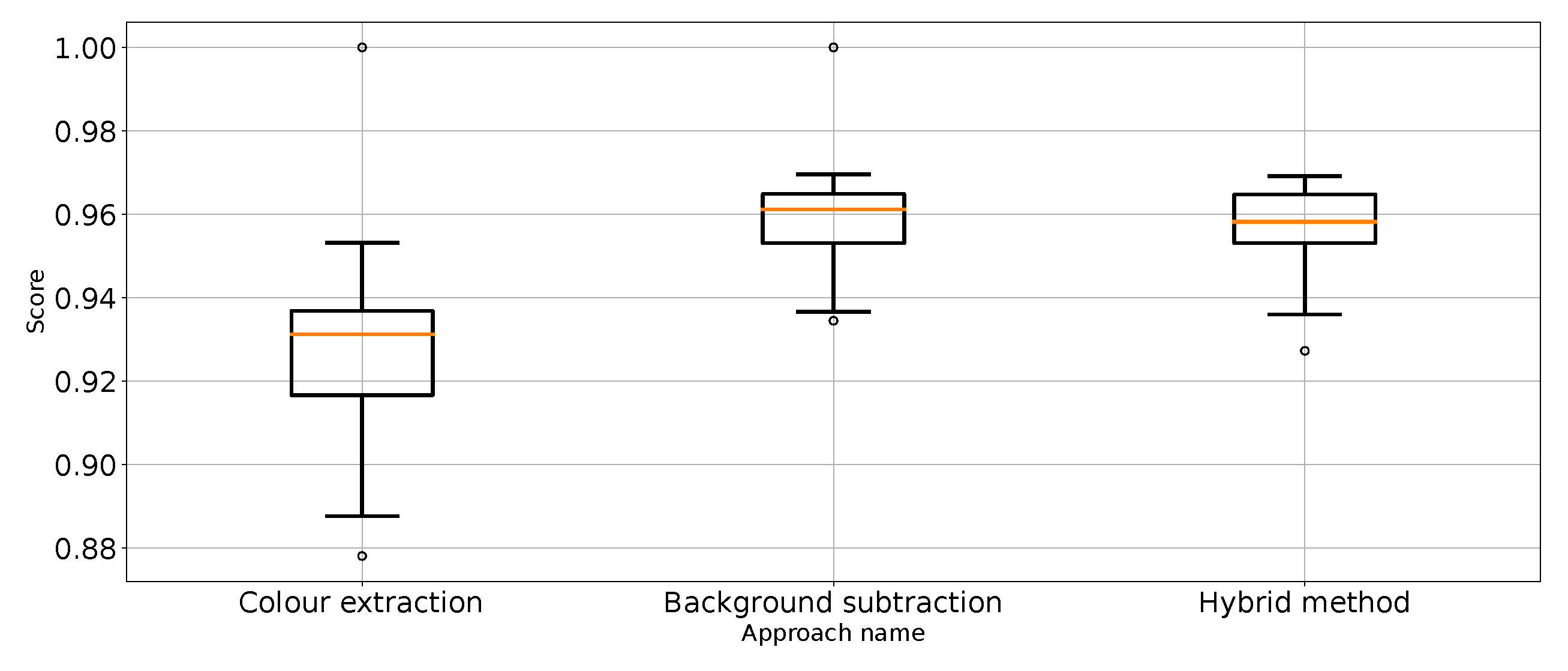
Figure 14.
value for “punch” class for the three proposed approaches (one outlier was removed).
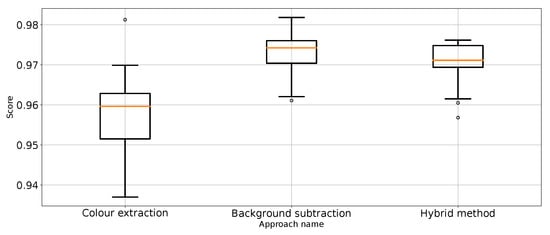
Figure 15.
value for “no punch” class for the three approaches (one outlier was removed).
In addition, each proposed method of segmentation was tested for processing performance on a subset that contained 14,331 frames. The results are presented in Table 3. The approach based on colour extraction (Apr. 2) proved to be the fastest and most computationally efficient. The hybrid approach (Apr. 4), which combines the two following approaches—colour extraction (Apr. 2) followed by the removal of static elements (Apr. 3)—proved to be the slowest, as expected.
Table 3.
Average processing time and resource utilisation for the tested approaches.
Figure 16 and Figure 17 present a complete visualisation of the individual steps during punch detection. The former shows the close-combat situation with no punches, while the latter clearly informs about the hit. Each subframe on these figures corresponds to a single step in the proposed system, from the original image through the detection mask (obtained based on Approach 3, as described in Section 3), up to the final visualisation with labels applied directly to the frame. The label “NEAR” printed in yellow means that the boxers are close together, while the label “PUNCHES” denotes the detected punches between the boxers in the current scene.

Figure 16.
An overview of the whole processing pipeline for a punch event. (A): Original image; (B): original image with detected information; (C): mask of proposed Approach 3; (D): original image with detection mask applied.

Figure 17.
An overview of the whole processing pipeline for the close-combat situation without punches. (A): Original image; (B): original image with detected information; (C): mask of proposed Approach 3; (D): original image with detection mask applied.
Figure 17 and Figure 18 show the state of the fight when there is no contact between the boxers. In one of them, the boxers are only close together without any active fight with punches; therefore, only the “NEAR” label was printed. In the second situation, the boxers move to their own corners at the end of the round and stand far apart; therefore, no label is written on them.

Figure 18.
An overview of the whole processing pipeline for the no-contact situation. (A): Original image; (B): original image with detected information; (C): mask of proposed Approach 3; (D): original image with detection mask applied.
The results (Table 1) have shown that Approach 3 (background subtraction) achieved the best scores using half of the metrics. Approach 3 achieved nearly the same balanced accuracy and precision for “no punch”, whereas Approach 1 provided slightly better recall for “punch” and score for “not punch”. What is surprising is that the best medians of the results in these categories are achieved by the classifier using unprocessed images. That leads to the conclusion that further research on image processing might result in even better images. At the same time, the numerical stability of the unprocessed image classifier is far from optimal and, thus, not suitable for general use.
Therefore, it can be considered that Approach 3 has the best impact on classification performance. This is quite surprising because Approach 4 was the most sophisticated. In order to remove the referee from the scene, which is proven to work (Figure 3), extra processing steps are taken, which should make the scores better. Based on the results from Table 1, Approach 4 (hybrid method) is slightly worse and sometimes as good as the best method: Approach 3. It is good to note that Approach 4 is an extension of Approach 2, which effectively improves the metrics score. Therefore, one might come to the conclusion that colour extraction does remove too much valuable information from the scene.
5. Statistical Analysis
The experimental results of the proposed approaches were compared using a non-parametric statistical hypothesis test, i.e., the Friedman test [51,52] for . The parameters of the Friedman test are presented in Table 4. The same table shows the mean rank values for the compared approaches. The results for each of the classification quality measures analysed were used for statistical tests.
Table 4.
The Friedman test results and mean ranks.
The highest rank (1.625) was obtained for Approach 3 and it is, at the same time, critically better than Approach 1 (rank difference of 1.6250, with a 5% critical difference of 1.2274). At the same time, this is the only critical difference between all approaches. Because no approach was critically worse than all the other approaches, we did not perform a second round of statistical analysis.
Very similar ranks were obtained for Approach 2 and Approach 4: 2.5000 and 2.6250, respectively. These are lower ranks than Approach 3 (by 0.875 and 1.000), but there is no critical difference between the approaches in this case.
In summary, as a result of the statistical analysis, Approach 3 turns out to be statistically the best, is better (but not critically better) than Approaches 2 and 4, and is critically better than Approach 1. In contrast, Approaches 2 and 4 are better than Approach 1.
6. Entropy in Boxing Punch Detection
Entropy, a concept rooted in thermodynamics and information theory, measures the degree of disorder or uncertainty in a system. In the context of data analysis, entropy quantifies the amount of unpredictability or randomness in a dataset. For a machine learning model, particularly in classification tasks, understanding and managing entropy can provide valuable insights into ensuring accurate and reliable predictions.
When analysing video frames for punch detection in boxing, each frame can be considered a discrete data point. The goal is to classify each frame accurately as either containing a punch or not. In this context, entropy can be useful for evaluating the uncertainty in the classification process and improving the model’s robustness.
Entropy H can be calculated using formula (7).
where is the probability of occurrence of class i in the dataset. In our case, we have two classes: ”punch” and ”no punch”. The probabilities are derived from the frequency of these classes in the training data.
Given the initial data
the initial entropy can be calculated as
This low entropy indicates a high imbalance in the data, reflecting low uncertainty in predicting the dominant class (“not punch”) but potentially high misclassification rates for the minority class (“punch”).
Monitoring entropy during the training phase can help in understanding how well the model is learning the distinguishing features of punches. A decrease in entropy over successive epochs indicates that the model is becoming more confident in its predictions. For instance, if the model starts with an entropy of 0.2244 (initial low uncertainty due to imbalance) and reduces to 0.1 (even lower uncertainty), it signifies that the model is learning effectively. However, if the entropy remains high, it suggests that the model is struggling to learn, possibly due to insufficient or poor-quality data.
Incorporating entropy into the analysis of boxing punch detection with a single static camera provides a deeper understanding of the data’s variability and the model’s performance. By managing and reducing entropy through various techniques, we can potentially improve the model’s ability to accurately classify frames, thereby enhancing the overall effectiveness of the punch detection system. This approach can boost the model’s reliability and ensure a more robust analysis suitable for real-world applications in sports analytics.
7. Conclusions
The analysis of the obtained results proved that punch detecting using one static RGB camera is possible. In order to achieve this, two techniques were combined: The first was to measure the distances between boxers in order to detect any clashes between them. The second one was more complex and was used to detect hit punches between boxers in clashes.
As the experiments showed, detecting punches using a classifier trained on unprocessed images yields subpar results. We propose three novel approaches to make recorded scenes easier for classification. The approach of removing static elements from the footage has the best scores in almost all calculated metrics.
We have also presented a working system for analyses of a boxing scene that marks the boxers, labels the frames with detected clashes and punches, and counts all situations with punches between the boxers. It is worth noting that the system is ready to automatically label recorded footage, for example, to auto-generate short clips from fights or for the need of broadcasting.
Despite these promising results, several significant shortcomings and open research directions were identified. One notable limitation was the reliance on a single static camera, which might not capture all relevant angles and details of the boxers’ movements. Future work could explore the integration of multiple camera channels to provide a more comprehensive view of the boxing ring, potentially enhancing the accuracy and robustness of the punch detection system.
Another limitation related to the classifier’s performance on unprocessed images underscores the need for more advanced image preprocessing techniques. Future research could investigate alternative preprocessing methods or the use of data augmentation to improve the classifier’s performance.
Future plans included synchronising data from all four cameras and preparing an ensemble voting framework to improve classification performance. There was also an aim to create a sophisticated neural network structure for punch classification. Further exploration into the use of temporal information, such as analyzing sequences of frames rather than individual frames, could enhance the system’s ability to detect punches more accurately.
In conclusion, while this study demonstrated the feasibility of using a single static camera for punch detection in boxing, numerous avenues for future research remain. Addressing these limitations and following these directions could lead to the development of more robust and accurate systems for sports analytics, ultimately benefiting athletes, coaches, and broadcasters.
Author Contributions
Conceptualization, P.S. and J.K.; methodology, P.S., J.K. and T.J.; software, P.S.; validation, P.S., J.K. and T.J.; formal analysis, P.S. and J.K.; investigation, P.S., J.K. and T.J.; resources, P.S.; data curation, P.S.; writing—original draft preparation, P.S., J.K. and T.J.; writing—review and editing, P.S. and J.K.; visualization, P.S.; supervision, J.K.; project administration, J.K.; funding acquisition, J.K. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Data Availability Statement
The original data presented in the study are openly available on Kaggle at https://www.kaggle.com/datasets/piotrstefaskiue/olympic-boxing-punch-classification-video-dataset (accessed on 15 May 2024).
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Garcia-Garcia, B.; Bouwmans, T.; Silva, A.J.R. Background subtraction in real applications: Challenges, current models and future directions. Comput. Sci. Rev. 2020, 35, 100204. [Google Scholar] [CrossRef]
- Barnich, O.; Droogenbroeck, M.V. ViBe: A Universal Background Subtraction Algorithm for Video Sequences. IEEE Trans. Image Process. 2011, 20, 1709–1724. [Google Scholar] [CrossRef] [PubMed]
- Wu, Y.J.; Tsai, C.M.; Shih, F. Improving Leaf Classification Rate via Background Removal and ROI Extraction. J. Image Graph. 2016, 4, 93–98. [Google Scholar] [CrossRef]
- Ni, B.; Nguyen, C.D.; Moulin, P. RGBD-camera based get-up event detection for hospital fall prevention. In Proceedings of the 2012 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Kyoto, Japan, 25–30 March 2012. [Google Scholar] [CrossRef]
- Crispim, C.F.; Bathrinarayanan, V.; Fosty, B.; Konig, A.; Romdhane, R.; Thonnat, M.; Bremond, F. Evaluation of a monitoring system for event recognition of older people. In Proceedings of the 2013 10th IEEE International Conference on Advanced Video and Signal Based Surveillance, Krakow, Poland, 27–30 August 2013. [Google Scholar] [CrossRef]
- Zhou, F.; Zhao, H.; Nie, Z. Safety Helmet Detection Based on YOLOv5. In Proceedings of the 2021 IEEE International Conference on Power Electronics, Computer Applications (ICPECA), Shenyang, China, 22–24 January 2021. [Google Scholar] [CrossRef]
- Seo, J.; Han, S.; Lee, S.; Kim, H. Computer vision techniques for construction safety and health monitoring. Adv. Eng. Inform. 2015, 29, 239–251. [Google Scholar] [CrossRef]
- Li, J.; Liu, H.; Wang, T.; Jiang, M.; Wang, S.; Li, K.; Zhao, X. Safety helmet wearing detection based on image processing and machine learning. In Proceedings of the 2017 Ninth International Conference on Advanced Computational Intelligence (ICACI), Doha, Qatar, 4–6 February 2017. [Google Scholar] [CrossRef]
- Elbehiery, H.; Hefnawy, A.; Elewa, M. Surface Defects Detection for Ceramic Tiles Usingimage Processing and Morphological Techniques. 2007. Available online: https://zenodo.org/records/1084534 (accessed on 15 May 2024). [CrossRef]
- Baygin, M.; Karakose, M.; Sarimaden, A.; Erhan, A. Machine vision based defect detection approach using image processing. In Proceedings of the 2017 International Artificial Intelligence and Data Processing Symposium (IDAP), Malatya, Turkey, 16–17 September 2017. [Google Scholar] [CrossRef]
- Khasanshin, I. Application of an Artificial Neural Network to Automate the Measurement of Kinematic Characteristics of Punches in Boxing. Appl. Sci. 2021, 11, 1223. [Google Scholar] [CrossRef]
- Quinn, E.; Corcoran, N. Automation of Computer Vision Applications for Real-time Combat Sports Video Analysis. Eur. Conf. Impact Artif. Intell. Robot. 2022, 4, 162–171. [Google Scholar] [CrossRef]
- Kato, S.; Yamagiwa, S. Predicting Successful Throwing Technique in Judo from Factors of Kumite Posture Based on a Machine-Learning Approach. Computation 2022, 10, 175. [Google Scholar] [CrossRef]
- Ye, X.; Shi, B.; Li, M.; Fan, Q.; Qi, X.; Liu, X.; Zhao, S.; Jiang, L.; Zhang, X.; Fu, K.; et al. All-textile sensors for boxing punch force and velocity detection. Nano Energy 2022, 97, 107114. [Google Scholar] [CrossRef]
- Hahn, A.; Helmer, R.; Kelly, T.; Partridge, K.; Krajewski, A.; Blanchonette, I.; Barker, J.; Bruch, H.; Brydon, M.; Hooke, N.; et al. Development of an automated scoring system for amateur boxing. Procedia Eng. 2010, 2, 3095–3101. [Google Scholar] [CrossRef]
- Worsey, M.T.O.; Espinosa, H.G.; Shepherd, J.B.; Thiel, D.V. An Evaluation of Wearable Inertial Sensor Configuration and Supervised Machine Learning Models for Automatic Punch Classification in Boxing. IoT 2020, 1, 360–381. [Google Scholar] [CrossRef]
- Worsey, M.; Espinosa, H.; Shepherd, J.; Thiel, D. Inertial Sensors for Performance Analysis in Combat Sports: A Systematic Review. Sports 2019, 7, 28. [Google Scholar] [CrossRef] [PubMed]
- Kasiri-Bidhendi, S.; Fookes, C.; Morgan, S.; Martin, D.T.; Sridharan, S. Combat sports analytics: Boxing punch classification using overhead depthimagery. In Proceedings of the 2015 IEEE International Conference on Image Processing (ICIP), Quebec City, QC, Canada, 27–30 September 2015. [Google Scholar] [CrossRef]
- Kasiri, S.; Fookes, C.; Sridharan, S.; Morgan, S. Fine-grained action recognition of boxing punches from depth imagery. Comput. Vis. Image Underst. 2017, 159, 143–153. [Google Scholar] [CrossRef]
- Behendi, S.K.; Morgan, S.; Fookes, C.B. Non-Invasive Performance Measurement in Combat Sports. In Proceedings of the 10th International Symposium on Computer Science in Sports (ISCSS); Springer International Publishing: Cham, Switzerland, 2015; pp. 3–10. [Google Scholar] [CrossRef]
- Wattanamongkhol, N.; Kumhom, P.; Chamnongthai, K. A method of glove tracking for amateur boxing refereeing. In Proceedings of the IEEE International Symposium on Communications and Information Technology, ISCIT 2005, Beijing, China, 12–14 October 2005. [Google Scholar] [CrossRef]
- Jia, W.; Xu, S.; Liang, Z.; Zhao, Y.; Min, H.; Li, S.; Yu, Y. Real-time automatic helmet detection of motorcyclists in urban traffic using improved YOLOv5 detector. IET Image Process. 2021, 15, 3623–3637. [Google Scholar] [CrossRef]
- Wu, Z.; Radke, R.J. Real-time airport security checkpoint surveillance using a camera network. In Proceedings of the CVPR 2011 WORKSHOPS, Colorado Springs, CO, USA, 20–25 June 2011. [Google Scholar] [CrossRef]
- Braun, M.; Krebs, S.; Flohr, F.; Gavrila, D.M. EuroCity Persons: A Novel Benchmark for Person Detection in Traffic Scenes. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 41, 1844–1861. [Google Scholar] [CrossRef]
- Dollar, P.; Wojek, C.; Schiele, B.; Perona, P. Pedestrian Detection: An Evaluation of the State of the Art. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 743–761. [Google Scholar] [CrossRef] [PubMed]
- Ragesh, N.K.; Rajesh, R. Pedestrian Detection in Automotive Safety: Understanding State-of-the-Art. IEEE Access 2019, 7, 47864–47890. [Google Scholar] [CrossRef]
- Wu, J.; Chen, F.; Hu, D. Human Interaction Recognition by Spatial Structure Models. In Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2013; pp. 216–222. [Google Scholar] [CrossRef]
- Malgireddy, M.R.; Inwogu, I.; Govindaraju, V. A temporal Bayesian model for classifying, detecting and localizing activities in video sequences. In Proceedings of the 2012 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Providence, RI, USA, 16–21 June 2012. [Google Scholar] [CrossRef]
- Alfaro, A.; Mery, D.; Soto, A. Human Action Recognition from Inter-temporal Dictionaries of Key-Sequences. In Image and Video Technology; Springer: Berlin/Heidelberg, Germany, 2014; pp. 419–430. [Google Scholar] [CrossRef]
- Patron-Perez, A.; Marszalek, M.; Reid, I.; Zisserman, A. Structured Learning of Human Interactions in TV Shows. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 2441–2453. [Google Scholar] [CrossRef] [PubMed]
- Chen, C.; Liu, M.Y.; Tuzel, O.; Xiao, J. R-CNN for Small Object Detection. In Computer Vision—ACCV 2016; Springer International Publishing: Berlin/Heidelberg, Germany, 2017; pp. 214–230. [Google Scholar] [CrossRef]
- Kisantal, M.; Wojna, Z.; Murawski, J.; Naruniec, J.; Cho, K. Augmentation for small object detection. arXiv 2019, arXiv:1902.07296. [Google Scholar] [CrossRef]
- Thomas, G.; Gade, R.; Moeslund, T.B.; Carr, P.; Hilton, A. Computer vision for sports: Current applications and research topics. Comput. Vis. Image Underst. 2017, 159, 3–18. [Google Scholar] [CrossRef]
- Leo, M.; D’Orazio, T.; Trivedi, M. A multi camera system for soccer player performance evaluation. In Proceedings of the 2009 Third ACM/IEEE International Conference on Distributed Smart Cameras (ICDSC), Como, Italy, 30 August 2009–2 September 2009. [Google Scholar] [CrossRef]
- Setterwall, D. Computerised Video Analysis of Football—Technical and Commercial Possibilitiesfor Football Coaching. Master’s Thesis, Stockholms Universitet, Stockholm, Sweden, 2003, unpublished. [Google Scholar]
- Sudhir, G.; Lee, J.; Jain, A. Automatic classification of tennis video for high-level content-based retrieval. In Proceedings of the Proceedings 1998 IEEE International Workshop on Content-Based Access of Image and Video Database, Bombay, India, 3 January 1998. [Google Scholar] [CrossRef]
- Stein, M.; Janetzko, H.; Lamprecht, A.; Breitkreutz, T.; Zimmermann, P.; Goldlucke, B.; Schreck, T.; Andrienko, G.; Grossniklaus, M.; Keim, D.A. Bring It to the Pitch: Combining Video and Movement Data to Enhance Team Sport Analysis. IEEE Trans. Vis. Comput. Graph. 2018, 24, 13–22. [Google Scholar] [CrossRef]
- Buric, M.; Pobar, M.; Ivasic-Kos, M. Object detection in sports videos. In Proceedings of the 2018 41st International Convention on Information and Communication Technology, Electronics and Microelectronics (MIPRO), Opatija, Croatia, 21–25 May 2018. [Google Scholar] [CrossRef]
- Jeffries, C.T. Sports Analytics with Computer Vision. Senior Independent Study Theses. Paper 8103. 2018. Available online: https://openworks.wooster.edu/independentstudy/8103 (accessed on 15 May 2024).
- Pettersen, S.A.; Halvorsen, P.; Johansen, D.; Johansen, H.; Berg-Johansen, V.; Gaddam, V.R.; Mortensen, A.; Langseth, R.; Griwodz, C.; Stensland, H.K. Soccer video and player position dataset. In Proceedings of the 5th ACM Multimedia Systems Conference on—MMSys ’14, Singapore, 19 March 2014; ACM Press: New York, NY, USA, 2014. [Google Scholar] [CrossRef]
- Johnson, S.; Everingham, M. Clustered Pose and Nonlinear Appearance Models for Human Pose Estimation. In Proceedings of the British Machine Vision Conference 2010, Aberystwyth, UK, 31 August–3 September 2010; British Machine Vision Association: Durham, UK, 2010. [Google Scholar]
- Leo, M.; Mosca, N.; Spagnolo, P.; Mazzeo, P.L.; D’Orazio, T.; Distante, A. Real-time multiview analysis of soccer matches for understanding interactions between ball and players. In Proceedings of the 2008 International Conference on Content-Based Image and Video Retrieval—CIVR’08, New York, NY, USA, 7–9 July 2008; ACM Press: New York, NY, USA, 2008. [Google Scholar] [CrossRef]
- Stefański, P.; Kozak, J.; Jach, T. The Problem of Detecting Boxers in the Boxing Ring. In Proceedings of the Recent Challenges in Intelligent Information and Database Systems: 14th Asian Conference, ACIIDS 2022, Ho Chi Minh City, Vietnam, 28–30 November 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 592–603. [Google Scholar] [CrossRef]
- Stefański, P. Detecting Clashes in Boxing. In Proceedings of the 3rd Polish Conference on Artificial Intelligence, Gdynia, Poland, 25–27 April 2022; pp. 29–32. [Google Scholar]
- Fang, W.; Ding, Y.; Zhang, F.; Sheng, V.S. DOG: A new background removal for object recognition from images. Neurocomputing 2019, 361, 85–91. [Google Scholar] [CrossRef]
- Kim, C.; Lee, J.; Han, T.; Kim, Y.M. A hybrid framework combining background subtraction and deep neural networks for rapid person detection. J. Big Data 2018, 5, 22. [Google Scholar] [CrossRef]
- Kolkur, S.; Kalbande, D.; Shimpi, P.; Bapat, C.; Jatakia, J. Human Skin Detection Using RGB, HSV and YCbCr Color Models. arXiv 2017, arXiv:1708.02694. [Google Scholar] [CrossRef]
- Zivkovic, Z. Improved adaptive Gaussian mixture model for background subtraction. In Proceedings of the 17th International Conference on Pattern Recognition, 2004, ICPR 2004, Cambridge, UK, 26 August 2004. [Google Scholar] [CrossRef]
- Stefański, P.; Kozak, J. Olympic Boxing Punch Classification Video Dataset. 2024. Available online: https://www.kaggle.com/datasets/piotrstefaskiue/olympic-boxing-punch-classification-video-dataset (accessed on 17 June 2024).
- Leonard, J.K. Theory and Problems of Business Statstics; McGraw-Hill: New York, NY, USA, 2004. [Google Scholar]
- Friedman, M. The use of ranks to avoid the assumption of normality implicit in the analysis of variance. J. Am. Stat. Assoc. 1937, 32, 675–701. [Google Scholar] [CrossRef]
- Kanji, G.K. 100 Statistical Tests; Sage: Newcastle upon Tyne, UK, 2006. [Google Scholar]





Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).